
IoT Anomaly Detection Based on Autoencoder and Bayesian Gaussian Mixture Model


Abstract

1. Introduction
- Higher dimensionality of data, which is more complex to process;
- A certain degree of randomness and uncertainty in the selection of features using feature selection methods;
- Clustering algorithms are often used to classify normal and abnormal data. However, traditional clustering algorithms, such as K-means, need to manually specify clusters and have certain limitations. Their clustering results are easily disturbed by noise points and easily fall into local optima.
- We use an autoencoder for feature selection, which effectively solves the problem that high-dimensional data is difficult to handle, and the autoencoder feature selection method improves the uncertainty and randomness of other feature selection methods.
- We propose a Bayesian Gaussian mixture model based on autoencoder, which uses posterior probability for parameter estimation and dynamically adjusts the cluster class division to solve the problem that the model tends to fall into local optima; and the Bayesian Gaussian mixture model is useful for both the data class imbalance problem and the data complex hard-to-fit problem.
- We compare different methods used for anomaly detection, and the results show that the autoencoder-based Bayesian Gaussian mixture model achieves over 99% accuracy for anomaly detection.
2. Related Work
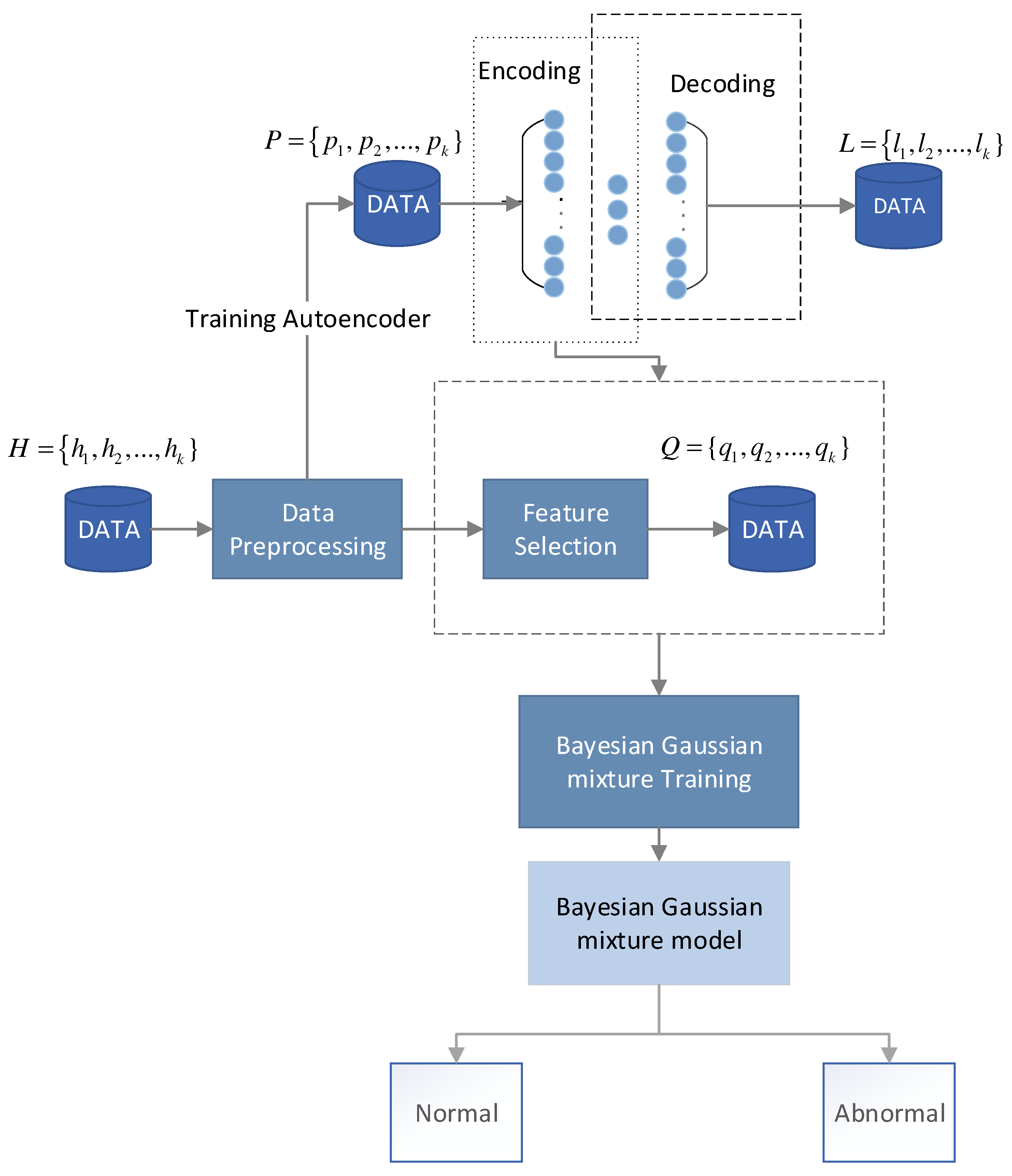
3. Bayesian Gaussian Mixture Model Based on Autoencoder
3.1. Methodology Model Overview
3.2. Data Preprocessing
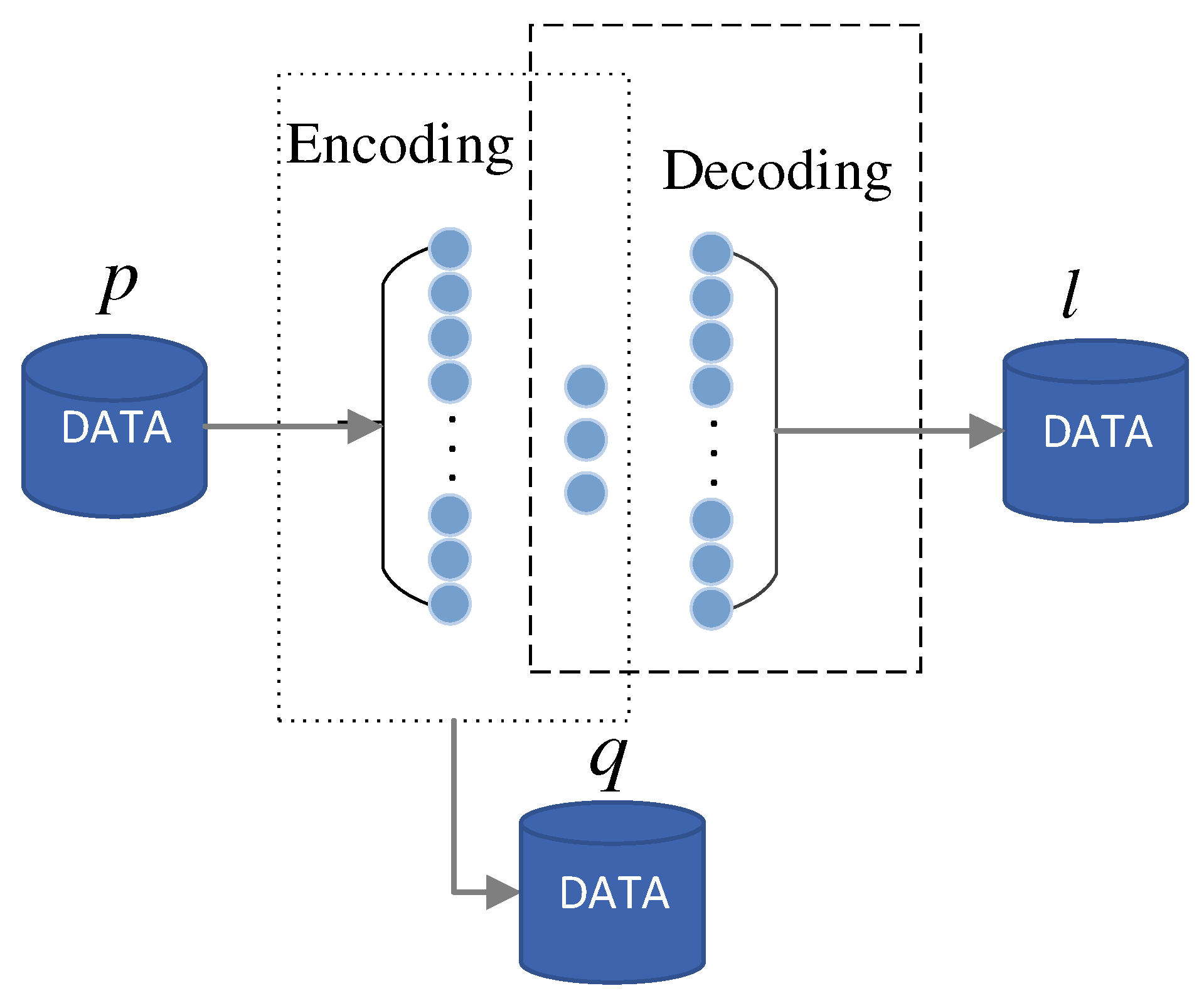
3.3. Autoencoder Network-Based Feature Processing
3.4. Bayesian Gaussian Mixture Model
4. Experiment and Analysis
4.1. Dataset Introduction
4.2. Feature Processing Using Autoencoder
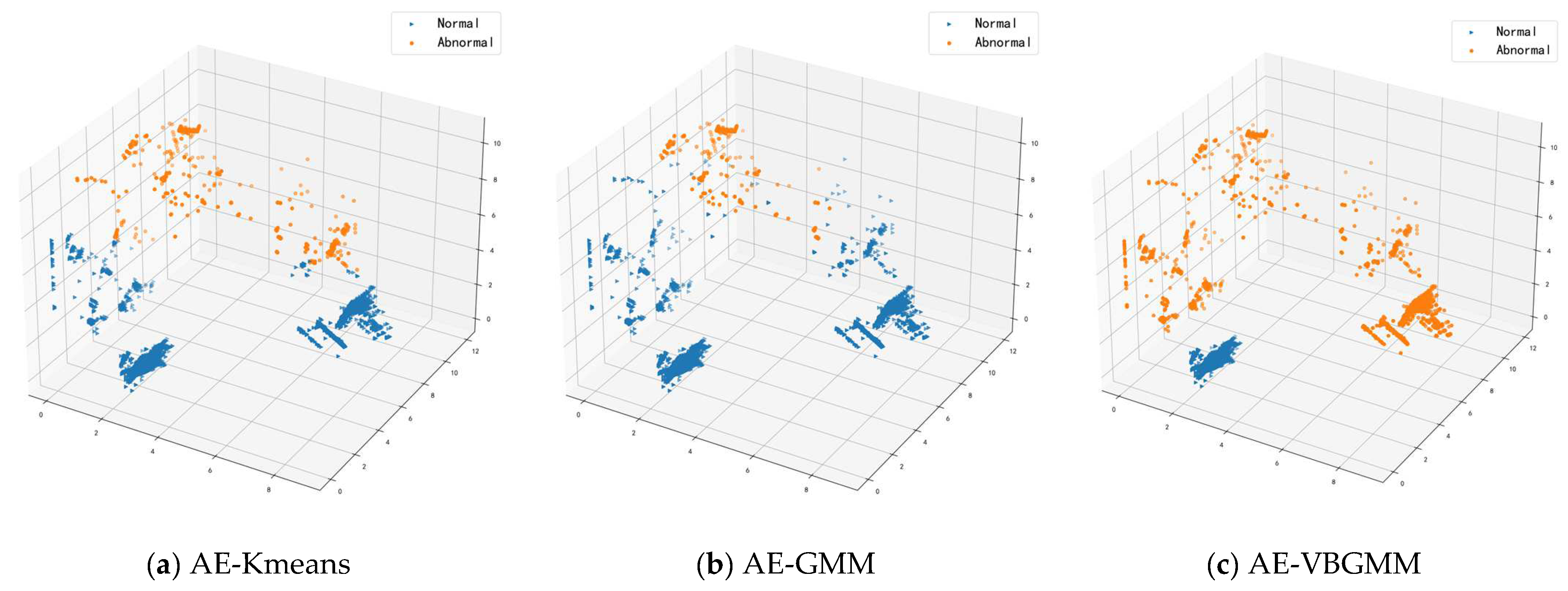
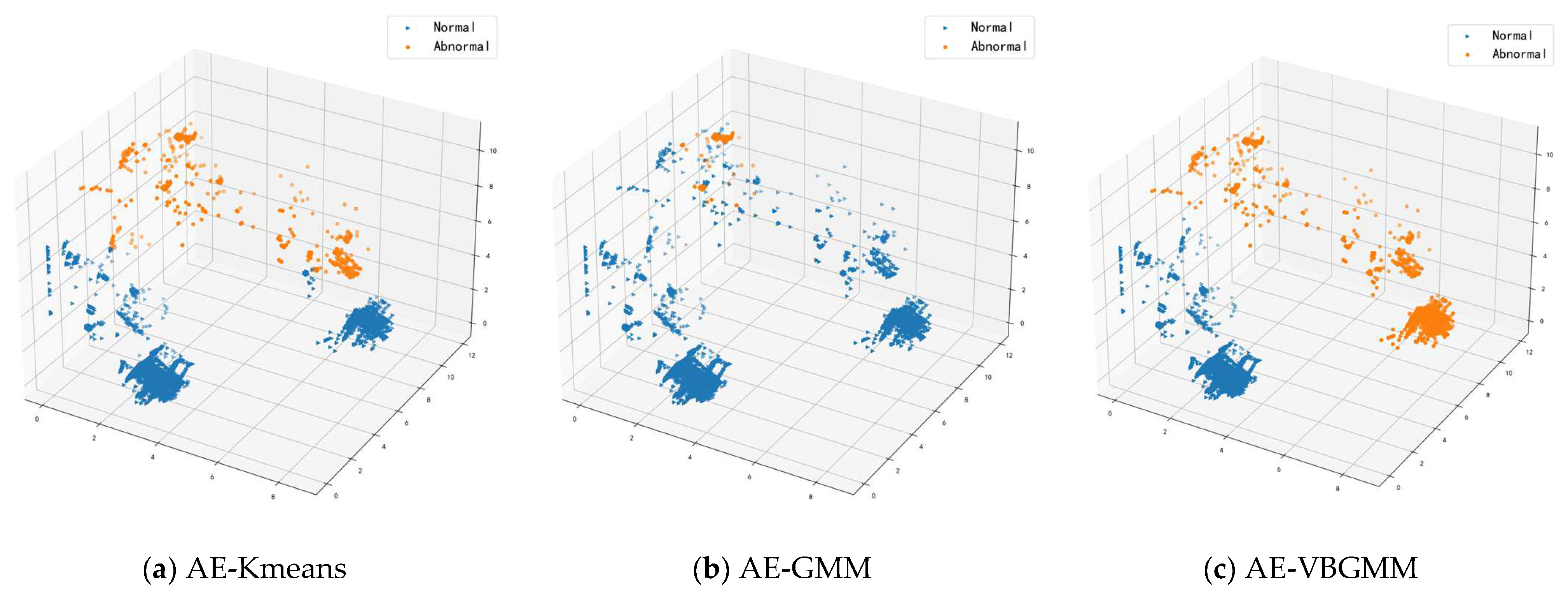
4.3. Cluster Analysis
4.3.1. Evaluation Indicators
- 1.
- P. Purity P is the most intuitive criterion to show how good the evaluation results are. Its calculation formula is as follows:where denotes the total number of samples; denotes a cluster after clustering; denotes the correct category; denotes all samples in the th cluster after clustering; and denotes the number of true samples in the th category after clustering. The value of P is in the range of [0,1], and the larger the value, the better the clustering effect.
- 2.
- RI. The Rand Index (RI) is a common criterion for evaluating the effect of clustering and is calculated as follows:where denotes the number of data point pairs that group similar samples into the same cluster, is the number of data point pairs that group different samples into the same cluster, is the number of data point pairs that group similar samples into different clusters, and denotes the number of data point pairs that group dissimilar samples into different clusters. The value of the RI is between [0, 1], and the RI is 1 when the clustering results are perfectly matched.
- 3.
- F-score. Similar to the F1 score in the classification index, it is calculated as follows:where is a parameter, and in this paper, we set .
- 4.
- ARI. Adjusted Rand Index (ARI) is an improved version of the Rand Index (RI) to remove the influence of random labels on the RI assessment criteria. The API takes values in the range [−1,1], with larger values representing better results.
4.3.2. Analysis of Clustering Results
- Autoencoder K-means model (AE-Kmeans). Refer to Section 4.2 for the parameter setting of the autoencoder; cluster class of K-means is set to 2.
- Autoencoder Gaussian Mixture Model (AE-GMM). The autoencoder parameter settings are referred to in Section 4.2, the number of cluster classes is set to 2 for GMM, and the number of iterations is set to 10.
- Bayesian Gaussian Mixture Model for Autoencoder (AE-VBGMM). The parameter setting of the autoencoder is described in Section 4.2. VBGMM sets the initial cluster class to 2, calculates the weight of each cluster, dynamically adjusts the number of cluster classes according to the weight, and sets the number of iterations to 10.
4.4. Discussion
- The model adopts an autoencoder for feature processing of high-dimensional data, and its non-linear dimensionality reduction feature well preserves the effective features of the data, solves the problem of the high dimensionality of data which is difficult to process, and circumvents the randomness and uncertainty of traditional feature processing methods.
- The Gaussian mixture model often uses the EM algorithm, and the Bayesian Gaussian mixture model uses variational inference to estimate the parameters. Using variational inference to estimate the parameters can effectively circumvent the disadvantage that the EM algorithm can easily lead to local optima.
- The Bayesian Gaussian mixture model can dynamically implement cluster partitioning according to the weights assigned to each cluster class in the clustering process. In contrast, the traditional clustering algorithm K-means requires manual specification of the number of clusters. Still, in the realistic anomaly detection environment, the number of abnormal attacks cannot be predicted in advance, so K-means is unsuitable for anomaly detection.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jayalaxmi, P.; Saha, R.; Kumar, G.; Kumar, N.; Kim, T.-H. A Taxonomy of Security Issues in Industrial Internet-of-Things: Scoping Review for Existing Solutions, Future Implications, and Research Challenges. IEEE Access 2021, 9, 25344–25359. [Google Scholar] [CrossRef]
- Sisinni, E.; Saifullah, A.; Han, S.; Jennehag, U.; Gidlund, M. Industrial Internet of Things: Challenges, Opportunities, and Directions. IEEE Trans. Ind. Inform. 2018, 14, 4724–4734. [Google Scholar] [CrossRef]
- Tange, K.; De Donno, M.; Fafoutis, X.; Dragoni, N. A Systematic Survey of Industrial Internet of Things Security: Requirements and Fog Computing Opportunities. IEEE Commun. Surv. Tutor. 2020, 22, 2489–2520. [Google Scholar] [CrossRef]
- Yan, X.; Xu, Y.; Xing, X.; Cui, B.; Guo, Z.; Guo, T. Trustworthy Network Anomaly Detection Based on an Adaptive Learning Rate and Momentum in IIoT. IEEE Trans. Ind. Inform. 2020, 16, 6182–6192. [Google Scholar] [CrossRef]
- Bhuyan, M.H.; Bhattacharyya, D.K.; Kalita, J.K. Network Anomaly Detection: Methods, Systems and Tools. IEEE Commun. Surv. Tutor. 2013, 16, 303–336. [Google Scholar] [CrossRef]
- Doshi, R.; Apthorpe, N.; Feamster, N. Machine Learning DDoS Detection for Consumer Internet of Things Devices. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; pp. 29–35. [Google Scholar] [CrossRef]
- Joglar, J.A. Electrical abnormalities with St. Jude Medical/Abbott pacing leads: Let’s not call it lead failure yet. Heart Rhythm. 2021, 18, 2070–2071. [Google Scholar] [CrossRef] [PubMed]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–22. [Google Scholar] [CrossRef]
- Song, Q. Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Jolliffe, I.T. Principal Component Analysis and Factor Analysis; Principal Component Analysis; Springer: New York, NY, USA, 1986. [Google Scholar]
- Yang, J.; Frangi, A.; Yang, J.-Y.; Zhang, D.; Jin, Z. KPCA plus LDA: A complete kernel Fisher discriminant framework for feature extraction and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 230–244. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Miranda-Moreno, L.; Sun, L. Hankel-structured Tensor Robust PCA for Multivariate Traffic Time Series Anomaly Detection. arXiv 2021, arXiv:2110.04352. [Google Scholar]
- Chang, C.-P.; Hsu, W.-C.; Liao, I.-E. Anomaly Detection for Industrial Control Systems Using K-Means and Convolutional Autoencoder. In Proceedings of the 2019 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 19–21 September 2019. [Google Scholar] [CrossRef]
- Kravchik, M.; Shabtai, A. Detecting Cyber Attacks in Industrial Control Systems using Convolutional Neural Networks. In Proceedings of the 2018 Workshop on Cyber-Physical Systems Security and PrivaCy, Toronto, ON, Canada, 15–19 October 2018; pp. 72–83. [Google Scholar]
- Ferrag, M.A.; Maglaras, L.; Moschoyiannis, S.; Janicke, H. Deep learning for cyber security intrusion detection: Approaches, datasets, and comparative study. J. Inf. Secur. Appl. 2019, 50, 102419. [Google Scholar] [CrossRef]
- Park, S.H.; Park, H.J.; Choi, Y.-J. RNN-based Prediction for Network Intrusion Detection. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 19–21 February 2020; pp. 572–574. [Google Scholar] [CrossRef]
- Goh, J.; Adepu, S.; Tan, M.; Lee, Z.S. Anomaly Detection in Cyber Physical Systems Using Recurrent Neural Networks. In Proceedings of the 2017 IEEE 18th International Symposium on High Assurance Systems Engineering (HASE), Singapore, 12–14 January 2017; pp. 140–145. [Google Scholar] [CrossRef]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the Development of Realistic Botnet Dataset in the Internet of Things for Network Forensic Analytics: Bot-IoT Dataset. Future Gener. Comput. Syst. 2018, 100, 779–796. [Google Scholar] [CrossRef]
- De Araujo-Filho, P.F.; Kaddoum, G.; Campelo, D.R.; Santos, A.G.; Macedo, D.; Zanchettin, C. Intrusion Detection for Cyber–Physical Systems Using Generative Adversarial Networks in Fog Environment. IEEE Internet Things J. 2020, 8, 6247–6256. [Google Scholar] [CrossRef]
- Zhou, P. Payload-based Anomaly Detection for Industrial Internet Using Encoder Assisted GAN. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020; pp. 669–673. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, Z.; Zhang, M. Application of Optimized Bidirectional Generative Adversarial Network in ICS Intrusion Detection. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 3009–3014. [Google Scholar] [CrossRef]
- Zhou, X.; Hu, Y.; Liang, W.; Ma, J.; Jin, Q. Variational LSTM Enhanced Anomaly Detection for Industrial Big Data. IEEE Trans. Ind. Inform. 2020, 17, 3469–3477. [Google Scholar] [CrossRef]
- Al-Hawawreh, M.; Sitnikova, E. Industrial Internet of Things Based Ransomware Detection using Stacked Variational Neural Network. In Proceedings of the BDIOT 2019: Proceedings of the 3rd International Conference on Big Data and Internet of Things, Melbourn, VIC, Australia, 22–24 August 2019; pp. 126–130. [Google Scholar] [CrossRef]
- Sumathi, S.; Karthikeyan, N. Search for Effective Data Mining Algorithm for Network Based Intrusion Detection (NIDS)-DDOS Attacks. In Proceedings of the 2018 International Conference on Intelligent Computing and Communication for Smart World (I2C2SW), Erode, India, 14–15 December 2018; pp. 41–45. [Google Scholar] [CrossRef]
- Lukashevich, H.; Nowak, S.; Dunker, P. Using one-class SVM Outliers Detection for Verification of Collaboratively Tagged Image Training Sets. In Proceedings of the IEEE International Conference on Multimedia and Expo, New York, NY, USA, 28 June–3 July 2009; pp. 682–685. [Google Scholar] [CrossRef]
- Gajera, V.; Shubham; Gupta, R.; Jana, P.K. An effective Multi-Objective task scheduling algorithm using Min-Max normalization in cloud computing. In Proceedings of the 2016 2nd International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT), Bangalore, India, 21–23 July 2016; pp. 812–816. [Google Scholar] [CrossRef]
- Yuan, F.N.; Zhang, L.; Shi, J.T.; Xia, X.; Li, G. Theories and applications of auto-encoder neural networks: A literature survey. Chin. J. Comput. 2019, 42, 203–230. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: New York, NY, USA, 2006. [Google Scholar]
- Zimek, A.; Schubert, E.; Kriegel, H.-P. A survey on unsupervised outlier detection in high-dimensional numerical data. Stat. Anal. Data Min. ASA Data Sci. J. 2012, 5, 363–387. [Google Scholar] [CrossRef]
- Zhang, Y.Y.; Zhong, Y.W. Image Segmentation via Variational Mixture of Gaussions. J. Ningbo Univ. 2014, 27. [Google Scholar]
- Mnih, A.; Gregor, K. Neural Variational Inference and Learning in Belief Networks. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1791–1799. [Google Scholar] [CrossRef]
- Kang, H.; Ahn, D.H.; Lee, G.M.; Yoo, J.D.; Park, K.H.; Kim, H.K. IoT Network Intrusion Dataset. IEEE Dataport. Available online: https://dx.doi.org/10.21227/q70p-q449 (accessed on 27 September 2019).
- Li, T.; Hong, Z.; Yu, L. Machine Learning-based Intrusion Detection for IoT Devices in Smart Home. In Proceedings of the 2020 IEEE 16th International Conference on Control & Automation (ICCA), Singapore, 9–11 October 2020; pp. 277–282. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Flow Types | Description |
|---|---|
| benign | Data |
| arpspoofing | Traffic data of MITM (arp spoofing) |
| udpflooding | UDP attack traffic data from bot computers compromised by Mirai malware |
| udpflooding | ACK attack traffic data for bot computers compromised by Mirai malware |
| httpflooding | HTTP Flooding attack traffic data for bot computers compromised by Mirai malware |
| hostbrute | Initial stages of Mirai malware, including host discovery and Telnet exhaustive method |
| Index | Feature Name | Index | Feature Name |
|---|---|---|---|
| 1 | frame.time_epoch | 23 | tcp.flags |
| 2 | frame.time_delta | 24 | tcp.flags.ack |
| 3 | frame.time_delta_displayed | 25 | tcp.flags.push |
| 4 | frame.time_relative | 26 | tcp.flags.reset |
| 5 | frame.number | 27 | tcp.flags.syn |
| 6 | frame.len | 28 | tcp.window_size |
| 7 | frame.cap_len | 29 | tcp.window_size_scalefactor |
| 8 | eth.lg | 30 | tcp.checksum.status |
| 9 | ip.version | 31 | tcp.analysis.bytes_in_flight |
| 10 | ip.hdr_len | 32 | tcp.analysis.push_bytes_sent |
| 11 | ip.len | 33 | tcp.time_relative |
| 12 | ip.flags | 34 | icmp.ident |
| 13 | ip.flags.df | 35 | icmp.seq |
| 14 | ip.ttl | 36 | icmp.seq_le |
| 15 | ip.proto | 37 | data.len |
| 16 | ip.checksum.status | 38 | udp.srcport |
| 17 | tcp.stream | 39 | udp.dstport |
| 18 | tcp.len | 40 | udp.length |
| 19 | tcp.seq | 41 | udp.checksum.status |
| 20 | tcp.nxtseq | 42 | udp.stream |
| 21 | tcp.ack | 43 | dns.count.queries |
| 22 | tcp.hdr_len |
| Hyperparameter | Content |
|---|---|
| LR | 0.001 |
| Epoch | 15 |
| Batch size | 500 |
| Loss function | mse |
| Optimization algorithm | Adam |
| Activation function (Encoding) | Relu |
| Activation function (Decoding) | Sigmoid |
| Attack | AE-GMM | AE-Kmeans | AE-VBGMM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | RI | ARI | F | P | RI | ARI | F | P | RI | ARI | F | |
| hostbrute | 1.000 | 1.000 | 1.000 | 1.000 | 0.999 | 0.998 | 0.997 | 0.998 | 1.000 | 1.000 | 1.000 | 1.000 |
| ackflooding | 0.885 | 0.797 | 0.579 | 0.833 | 0.887 | 0.799 | 0.585 | 0.834 | 0.995 | 0.991 | 0.981 | 0.991 |
| arpspoofing | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| httpflooding | 0.896 | 0.814 | 0.616 | 0.845 | 0.896 | 0.814 | 0.615 | 0.845 | 1.000 | 1.000 | 1.000 | 1.000 |
| udpflooding | 0.899 | 0.821 | 0.630 | 0.850 | 0.901 | 0.820 | 0.630 | 0.850 | 0.999 | 0.999 | 0.999 | 0.999 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, Y.; He, R.; Dong, J.; Yang, Y.; Ma, W. IoT Anomaly Detection Based on Autoencoder and Bayesian Gaussian Mixture Model. Electronics 2022, 11, 3287. https://doi.org/10.3390/electronics11203287
Hou Y, He R, Dong J, Yang Y, Ma W. IoT Anomaly Detection Based on Autoencoder and Bayesian Gaussian Mixture Model. Electronics. 2022; 11(20):3287. https://doi.org/10.3390/electronics11203287
Chicago/Turabian StyleHou, Yunyun, Ruiyu He, Jie Dong, Yangrui Yang, and Wei Ma. 2022. "IoT Anomaly Detection Based on Autoencoder and Bayesian Gaussian Mixture Model" Electronics 11, no. 20: 3287. https://doi.org/10.3390/electronics11203287
APA StyleHou, Y., He, R., Dong, J., Yang, Y., & Ma, W. (2022). IoT Anomaly Detection Based on Autoencoder and Bayesian Gaussian Mixture Model. Electronics, 11(20), 3287. https://doi.org/10.3390/electronics11203287