
A Lightweight Military Target Detection Algorithm Based on Improved YOLOv5



Abstract
1. Introduction
- The Stem block is used to replace the Focus module, and the multi-channel information fusion improves the feature expression ability, reducing the model’s parameters and computation complexity.
- The coordinate attention module is embedded in the MobileNetV3 block structure to redesign the backbone network of YOLOv5. This strategy reduces the network’s parameters and computation complexity and improves its detection performance.
- Considering the defects of CIOU loss, we propose a power parameter loss opti-mized by combining the EIOU loss and Focal loss. The experiments show that the convergence speed is faster and the regression error is lower.
2. Datasets
2.1. Source of Data
2.2. Label Format and Data Size
3. Related Work
3.1. YOLOv5 Algorithm
- Input: The Input preprocesses the original image data, mainly including Mosaic data enhancement, random cropping, and adaptive image filling. In order to adapt to different target data sets, adaptive frame calculation is integrated into the input.
- Backbone: The Backbone network extracts the feature information at different levels of the image through the deep residual structure. The main structures are Cross Stage Partial (CSP) [30] and Spatial Pyramid Pooling (SPP) [31]. The former aims to reduce the amount of calculation and improve the inference speed. The latter aims to perform feature extraction at different scales for the same feature map, which helps to improve detection performance.
- Neck: The Neck network layer includes Feature Pyramid Networks (FPN) and Path Aggregation Network (PAN). FPN transmits semantic information from top to bottom in the network, and PAN transmits positioning information from top to bottom. The information is fused to improve the detection performance further.
- Head: The head output uses the feature information extracted from the Neck end to filter the best detection frame through non-maximum suppression, and generates a detection frame to predict the target category.
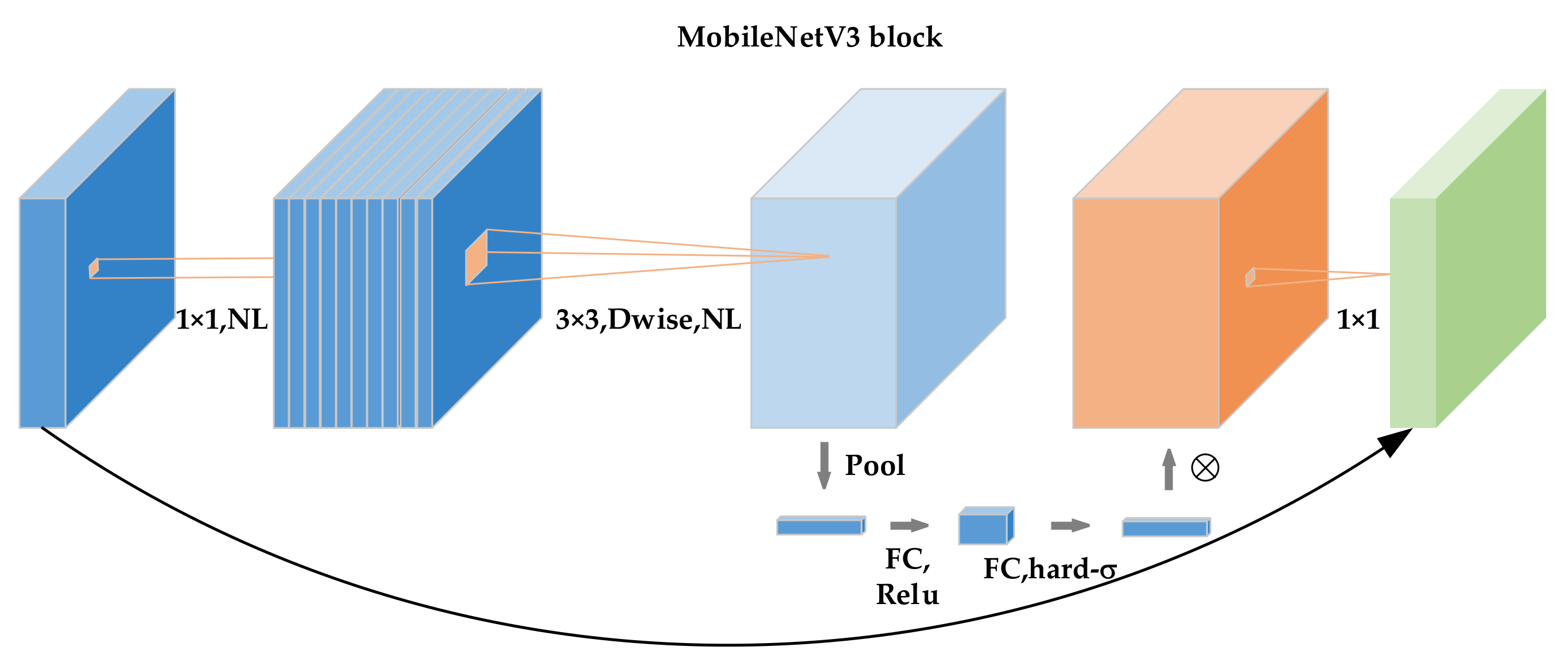
3.2. MobileNetV3 Block
3.3. Coordinate Attention
3.4. Loss Metrics in Object detection
4. Approach
4.1. Introduction of Stem Block
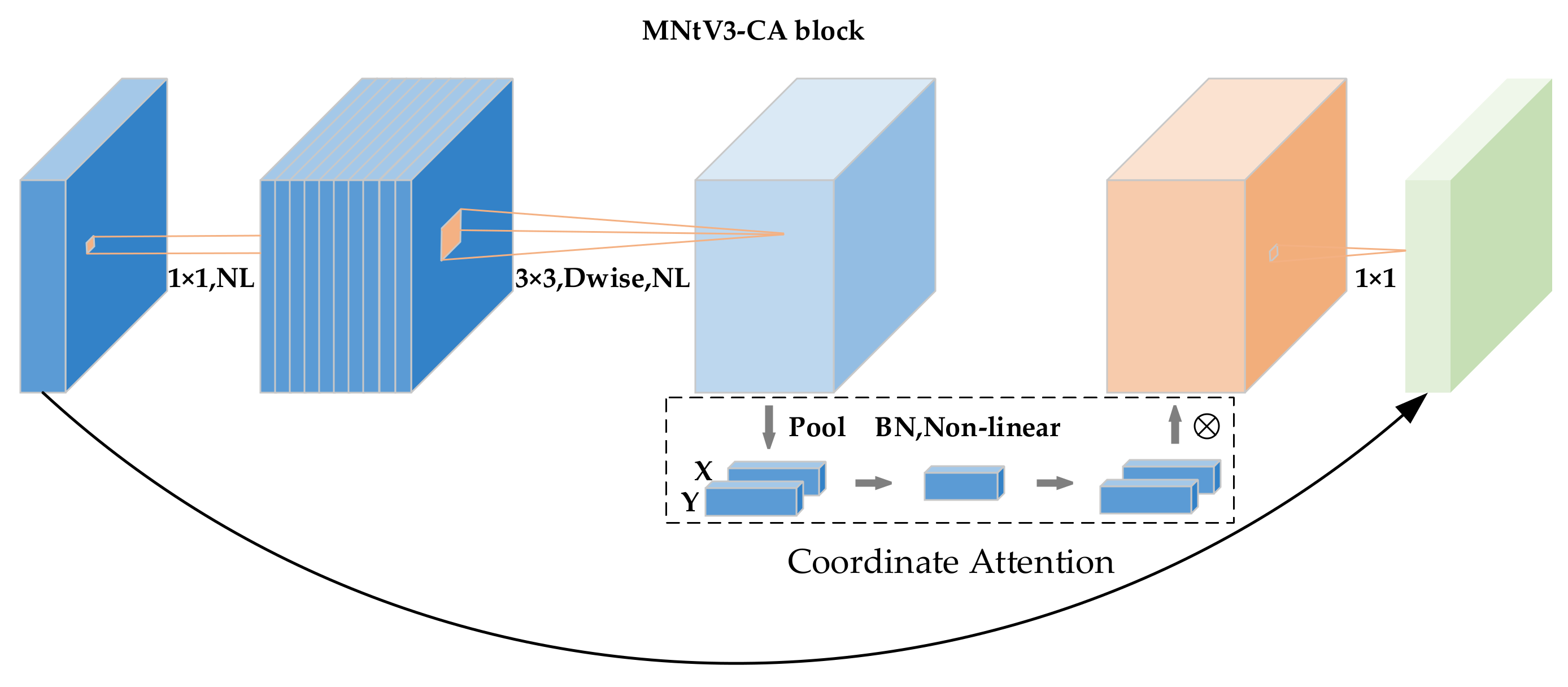
4.2. MNtV3-CA Block Structure
4.3. Optimization of Loss Function
4.4. Network Structure of SMCA-α-YOLOv5
5. Experiments and Results
5.1. Experiment Platform
5.2. Evaluation Indicators
5.3. Analysis of Ablation Experiments
5.3.1. Ablation Experiment of Backbone Network
5.3.2. Ablation Experiment of Loss Function
5.4. Compare with Other Algorithms
5.5. Analysis of Detection Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, W.; Liu, H.; Lin, W.; Chen, Y.; Yang, J. Investigation on works and military applications of artificial intelligence. IEEE Access 2020, 8, 131614–131625. [Google Scholar] [CrossRef]
- Bi, J.; Zhang, G.; Yang, C.; Jin, L.; Zhang, W. Architecture Design of Typical Target Detection and Tracking System in Battlefield Environment. In Proceedings of the 2021 3rd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Brisbane, Australia, 26–27 June 2021; pp. 473–477. [Google Scholar]
- Mittal, V.; Davidson, A. Combining wargaming with modeling and simulation to project future military technology requirements. IEEE Trans. Eng. Manag. 2020, 68, 1195–1207. [Google Scholar] [CrossRef]
- Lai, K.; Zhang, L. Sizing and siting of energy storage systems in a military-based vehicle-to-grid microgrid. IEEE Trans. Ind. Appl. 2021, 57, 1909–1919. [Google Scholar] [CrossRef]
- Genereux, S.J.; Lai, A.K.; Fowles, C.O.; Roberge, V.R.; Vigeant, G.P.; Paquet, J.R. Maidens: Mil-std-1553 anomaly-based intrusion detection system using time-based histogram comparison. IEEE Trans. Aerosp. Electron. Syst. 2019, 56, 276–284. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 21–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature fusion single shot multibox detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Neagoe, V.E.; Carata, S.V.; Ciotec, A.D. An advanced neural network-based approach for military ground vehicle recognition in sar aerial imagery. Int. Sci. Commun. 2016, 41, 4321–4327. [Google Scholar] [CrossRef]
- Wang, Q.; Chang, T.; Zhang, L.; Dai, W. Automatic detection and tracking system of tank armored targets based on deep learning algorithm. Syst. Eng. Electron. 2017, 40, 2143–2156. [Google Scholar]
- Budiharto, W.; Andreas, V.; Suroso, J.S.; Gunawan, A.A.S.; Irwansyah, E. Development of tank-based military robot and object tracker. In Proceedings of the 2019 4th Asia-Pacific Conference on Intelligent Robot Systems (ACIRS), Nagoya, Japan, 13–15 July 2019; pp. 221–224. [Google Scholar]
- Yin, S.; Li, H. Hot region selection based on selective search and modified fuzzy C-means in remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5862–5871. [Google Scholar] [CrossRef]
- Shen, Y.; Lin, W.; Wang, Z.; Li, J.; Sun, X.; Wu, X.; Wang, S.; Huang, F. Rapid Detection of Camouflaged Artificial Target Based on Polarization Imaging and Deep Learning. IEEE Photonics J. 2021, 13, 1–9. [Google Scholar] [CrossRef]
- Kong, L.; Wang, J.; Zhao, P. YOLO-G: A Lightweight Network Model for Improving the Performance of Military Targets Detection. IEEE Access 2022, 10, 55546–55564. [Google Scholar] [CrossRef]
- Ravi, N.; EI-Sharkawy, M. Real-Time Embedded Implementation of Improved Object Detector for Resource-Constrained Devices. J. Low Power Electron. Appl. 2022, 12, 21. [Google Scholar] [CrossRef]
- Dai, J.; Zhao, X.; Li, L.P.; Ma, X.F. GCD-YOLOv5: An Armored Target Recognition Algorithm in Complex Environments Based on Array Lidar. IEEE Photonics J. 2022, 14, 1–11. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Guo, S.; Li, L.; Guo, T.; Cao, Y.; Li, Y. Research on Mask-Wearing Detection Algorithm Based on Improved YOLOv5. Sensors 2022, 22, 4933. [Google Scholar] [CrossRef]
- Liu, Y.; He, G.; Wang, Z.; Li, W.; Huang, H. NRT-YOLO: Improved YOLOv5 Based on Nested Residual Transformer for Tiny Remote Sensing Object Detection. Sensors 2022, 22, 4953. [Google Scholar] [CrossRef]
- Li, Z.; Xie, W.; Zhang, L.; Lu, S.; Xie, L.; Su, H.; Du, W.; Hou, W. Toward Efficient Safety Helmet Detection Based on YoloV5 With Hierarchical Positive Sample Selection and Box Density Filtering. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Zhang, H.; Tian, M.; Shao, G.; Cheng, J.; Liu, J. Target Detection of Forward-Looking Sonar Image Based on Improved YOLOv5. IEEE Access 2022, 10, 18023–18034. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 16–18 July 2020; pp. 390–391. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. arXiv 2018, arXiv:1801.04381. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Long Beach, CA, USA, 16–20 June 2019; pp. 1314–1324. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Yu, J.H.; Jiang, Y.N.; Wang, Z.Y.; Cao, Z.M.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.H.; Wang, P.; Liu, W.; Li, J.Z.; Ye, R.G.; Ren, D.W. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Zhang, Y.F.; Ren, W.Q.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T.N. Focal and efficient IOU loss for accurate bounding box re-gression. arXiv 2021, arXiv:2101.08158. [Google Scholar]
- He, J.; Erfani, S.; Ma, X.; Bailey, J.; Chi, Y.; Hua, X.S. Alpha-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression. Adv. Neural Inf. Processing Syst. 2021, 34, 20230–20242. [Google Scholar]
- Zhou, D.; Fang, J.; Song, X.; Guan, C.; Yin, J.; Dai, Y.; Yang, R. Iou loss for 2d/3d object detection. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Quebec City, QC, Canada, 16–19 September 2019; pp. 85–94. [Google Scholar]
- Chen, Z.; Chen, K.; Lin, W.; See, J.; Yu, H.; Ke, Y.; Yang, C. Piou loss: Towards accurate oriented object detection in complex environments. In Proceedings of the European Conference on Computer Vision, Cham, Switzerland, 23–28 August 2020; pp. 195–211. [Google Scholar]
- Zheng, Y.; Zhang, D.; Xie, S.; Lu, J.; Zhou, J. Rotation-robust intersection over union for 3d object detection. In Proceedings of the European Conference on Computer Vision, Cham, Switzerland, 23–28 August 2020; pp. 464–480. [Google Scholar]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking rotated object detection with gaussian wasserstein distance loss. In Proceedings of the International Conference on Machine Learning, Jeju Island, Korea, 23–25 April 2021; pp. 11830–11841. [Google Scholar]
- Wang, R.J.; Li, X.; Ling, C.X. Pelee: A real-time object detection system on mobile devices. Adv. Neural Inf. Processing Syst. 2018, 31, 104–116. [Google Scholar]
- Cui, C.; Gao, T.; Wei, S.; Du, Y.; Guo, R.; Dong, S.; Lu, B.; Zhou, Y.; Lv, X.; Liu, Q.; et al. PP-LCNet: A Lightweight CPU Convolutional Neural Network. arXiv 2021, arXiv:2109.15099. [Google Scholar]
- Qi, D.; Tan, W.; Yao, Q.; Liu, J. YOLO5Face: Why reinventing a face detector. arXiv 2021, arXiv:2105.12931. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Military Target Name | Image | Target Box | ||
|---|---|---|---|---|
| Number | Range of Heights | Range of Width | Number | |
| tank | 1448 | [233, 2560] | [180, 1600] | 1667 |
| missile | 1441 | [273, 4096] | [180, 2800] | 1911 |
| helicopter | 986 | [267, 3000] | [230, 2000] | 1126 |
| air early warning | 1456 | [400, 3100] | [260, 2063] | 1591 |
| submarine | 1717 | [399, 2500] | [262, 2437] | 1754 |
| warship | 1394 | [240, 4960] | [240, 2802] | 1901 |
| soldier | 927 | [266, 2048] | [167, 1360] | 3249 |
| total/range | 9369 | [233, 4960] | [167, 2802] | 13,199 |
| No | Model | mAP@0.5 | Parameters/106 | GFLOPs | Inference Time | FPS |
|---|---|---|---|---|---|---|
| 0 | YOLOv5s | 96.5 | 7.070 | 16.4 | 0.019 | 52.6 |
| 1 | YOLOv5s+Stem | 95.9 | 4.502 | 5.8 | 0.022 | 45.5 |
| 2 | YOLOv5s+MNtV3 | 96.8 | 3.558 | 6.3 | 0.025 | 40 |
| 3 | YOLOv5s+Stem+MNtV3 | 96.6 | 1.384 | 0.7 | 0.023 | 43.5 |
| 4 | YOLOv5s+Stem+MNtV3-CBAM | 97.3 | 1.016 | 0.71 | 0.024 | 41.7 |
| 5 | SMCA-YOLOv5 | 97.8 | 1.024 | 0.69 | 0.022 | 45.5 |
| Loss | YOLOv5s Algorithm (mAP/%) | SMCA-YOLOv5 Algorithm (mAP/%) |
|---|---|---|
| LCIOU | 96.5 | 97.8 |
| LEIOU | 96.6 | 98.0 |
| Lα-EIOU | 96.8 | 97.9 |
| LFocal-EIOU | 97.0 | 98.2 |
| LFocal-α-EIOU | 97.3 | 98.4 |
| Loss Method | AP50 | AP55 | AP60 | AP65 | AP70 | AP75 | AP80 | AP85 | AP90 | AP95 | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|
| LIOU * | 78.6 | 76.1 | 73.2 | 69.2 | 64 | 57.5 | 48.5 | 36.4 | 20.1 | 2.8 | 52.64 |
| LGIOU * | 78.5 | 76.3 | 73.2 | 68.6 | 63.7 | 57 | 48.9 | 36.4 | 21.1 | 3.4 | 52.71 |
| LDIOU * | 78.6 | 76.3 | 73.2 | 69.1 | 63.6 | 57.3 | 49.5 | 37.4 | 21.6 | 3.3 | 52.99 |
| LIIOU * | 78.7 | 76.5 | 73.5 | 69.3 | 64.1 | 57.8 | 50.2 | 37.5 | 21.4 | 3.2 | 53.22 |
| LCIOU | 78.9 | 76.3 | 73.4 | 69.1 | 63.8 | 57.6 | 50.3 | 37.4 | 21.2 | 3.1 | 53.11 |
| LEIOU | 78.7 | 76.5 | 73.3 | 68.9 | 63.9 | 57.7 | 50.5 | 36.7 | 21.4 | 3.2 | 53.08 |
| Lα-EIOU | 78.5 | 76.4 | 73.3 | 69.7 | 64.3 | 58.3 | 49.9 | 37.7 | 21.9 | 3.1 | 53.31 |
| LFocal-EIOU | 78.6 | 76.8 | 73.5 | 69.4 | 64.3 | 58.2 | 50.8 | 37.5 | 21.6 | 3.3 | 53.40 |
| LFocal-α-EIOU | 78.8 | 76.9 | 73.6 | 69.6 | 64.6 | 58.6 | 50.7 | 38.2 | 21.8 | 3.6 | 53.64 |
| Loss Method | AP50 | AP55 | AP60 | AP65 | AP70 | AP75 | AP80 | AP85 | AP90 | AP95 | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|
| LIOU * | 48.8 | 45.8 | 42.4 | 38.3 | 32.3 | 27.7 | 20.7 | 13.6 | 6.2 | 0.8 | 27.66 |
| LGIOU * | 49.6 | 46.0 | 42.9 | 38.6 | 34.2 | 28.5 | 22.1 | 14.7 | 5.6 | 1.0 | 28.32 |
| LDIOU * | 49.5 | 46.5 | 43.1 | 39.0 | 33.2 | 28.3 | 22.2 | 13.2 | 6.4 | 1.2 | 28.26 |
| LIIOU * | 52.1 | 48.6 | 44.6 | 40.5 | 35.5 | 28.0 | 18.5 | 11.6 | 4.6 | 0.6 | 28.46 |
| LCIOU | 50.9 | 47.2 | 43.4 | 40.3 | 34.6 | 27.9 | 21.4 | 13.4 | 6.0 | 1.3 | 28.64 |
| LEIOU | 49.9 | 48.2 | 43.7 | 39.6 | 35.2 | 29.5 | 21.8 | 14.1 | 5.6 | 1.2 | 28.88 |
| Lα-EIOU | 50.7 | 48.5 | 43.4 | 40.1 | 36.3 | 28.1 | 22.2 | 14.4 | 5.9 | 1.0 | 29.06 |
| LFocal-EIOU | 51.4 | 49.1 | 43.6 | 40.7 | 35.4 | 27.1 | 21.5 | 13.6 | 6.9 | 1.1 | 29.04 |
| LFocal-α-EIOU | 51.3 | 49.5 | 44.8 | 40.8 | 36.2 | 28.2 | 22.7 | 14.1 | 6.1 | 1.3 | 29.50 |
| Model | Image size | mAP@0.5 | Parameters | GFLOPs | Inference Time | FPS |
|---|---|---|---|---|---|---|
| SSD | 640*640 | 90.1 | 26.79 | 31.4 | 0.015 | 66.7 |
| Faster R-CNN | 640*640 | 88.5 | 60.61 | 284.1 | 0.173 | 5.7 |
| YOLOv3 | 640*640 | 96.3 | 61.53 | 154.8 | 0.035 | 28.6 |
| YOLOv4 | 640*640 | 96.8 | 52.53 | 128.5 | 0.040 | 25 |
| YOLOv5 | 640*640 | 96.5 | 7.070 | 16.4 | 0.019 | 52.6 |
| SMCA-α-YOLOv5 | 640*640 | 98.4 | 1.014 | 0.67 | 0.021 | 47.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, X.; Song, L.; Lv, Y.; Qiu, S. A Lightweight Military Target Detection Algorithm Based on Improved YOLOv5. Electronics 2022, 11, 3263. https://doi.org/10.3390/electronics11203263
Du X, Song L, Lv Y, Qiu S. A Lightweight Military Target Detection Algorithm Based on Improved YOLOv5. Electronics. 2022; 11(20):3263. https://doi.org/10.3390/electronics11203263
Chicago/Turabian StyleDu, Xiuli, Linkai Song, Yana Lv, and Shaoming Qiu. 2022. "A Lightweight Military Target Detection Algorithm Based on Improved YOLOv5" Electronics 11, no. 20: 3263. https://doi.org/10.3390/electronics11203263
APA StyleDu, X., Song, L., Lv, Y., & Qiu, S. (2022). A Lightweight Military Target Detection Algorithm Based on Improved YOLOv5. Electronics, 11(20), 3263. https://doi.org/10.3390/electronics11203263