
A Hybrid Driver Fatigue and Distraction Detection Model Using AlexNet Based on Facial Features


Abstract
:1. Introduction
2. Related Work
2.1. Rule-Based
2.2. Machine Learning
2.3. Deep Learning
2.4. Pre-Trained CNN
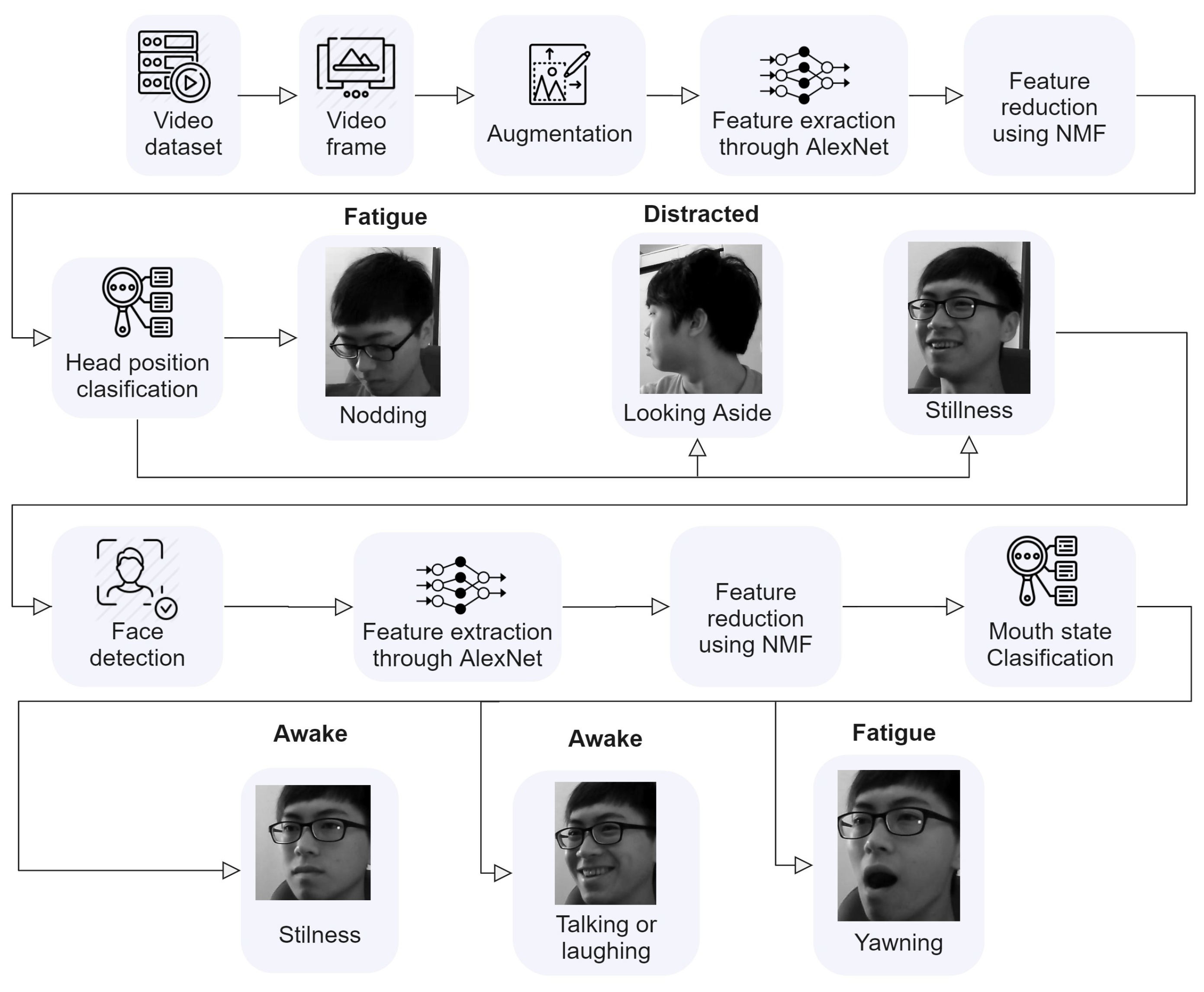
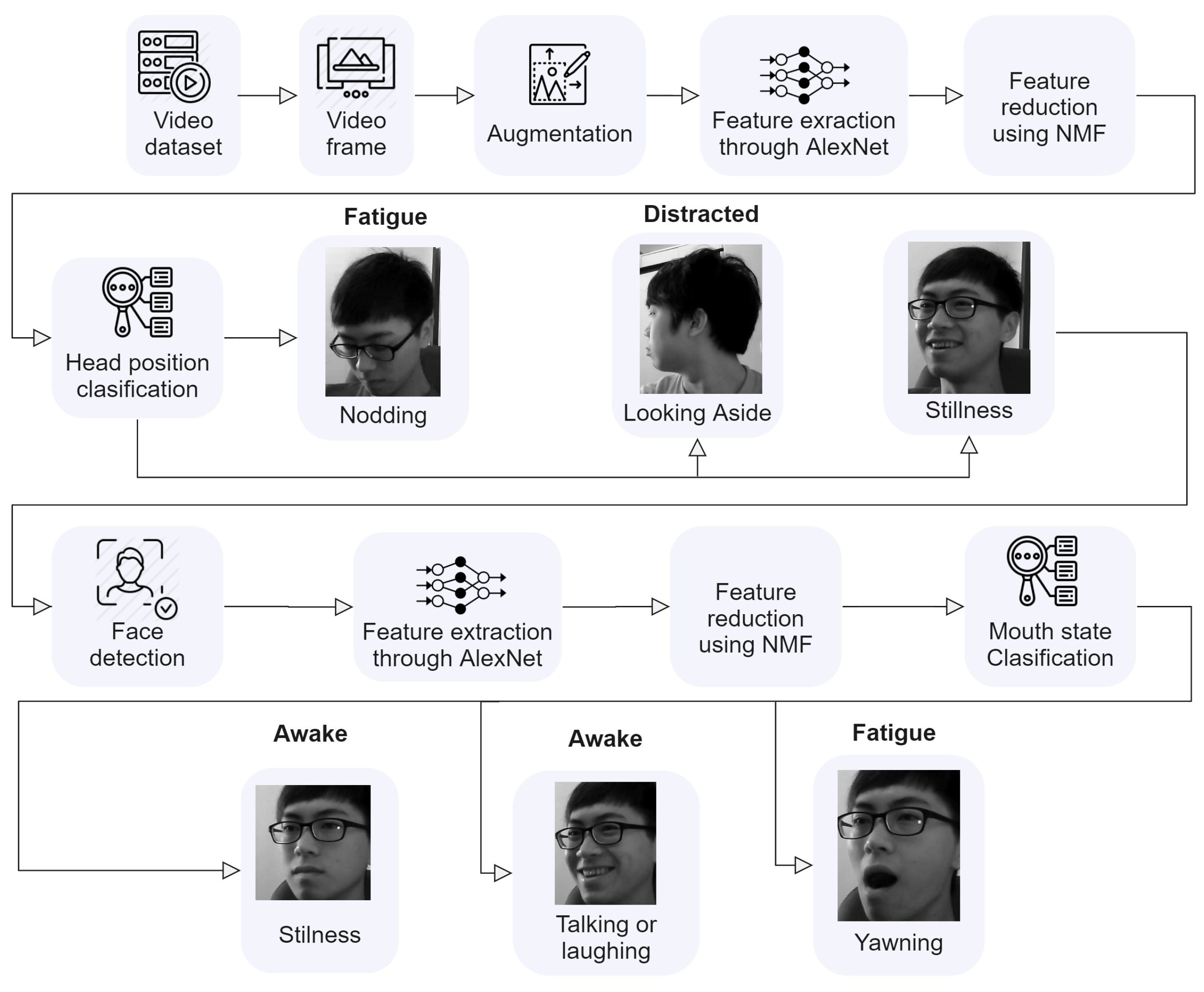
3. Methodology
4. Background Knowledge
4.1. Convolutional Neural Networks
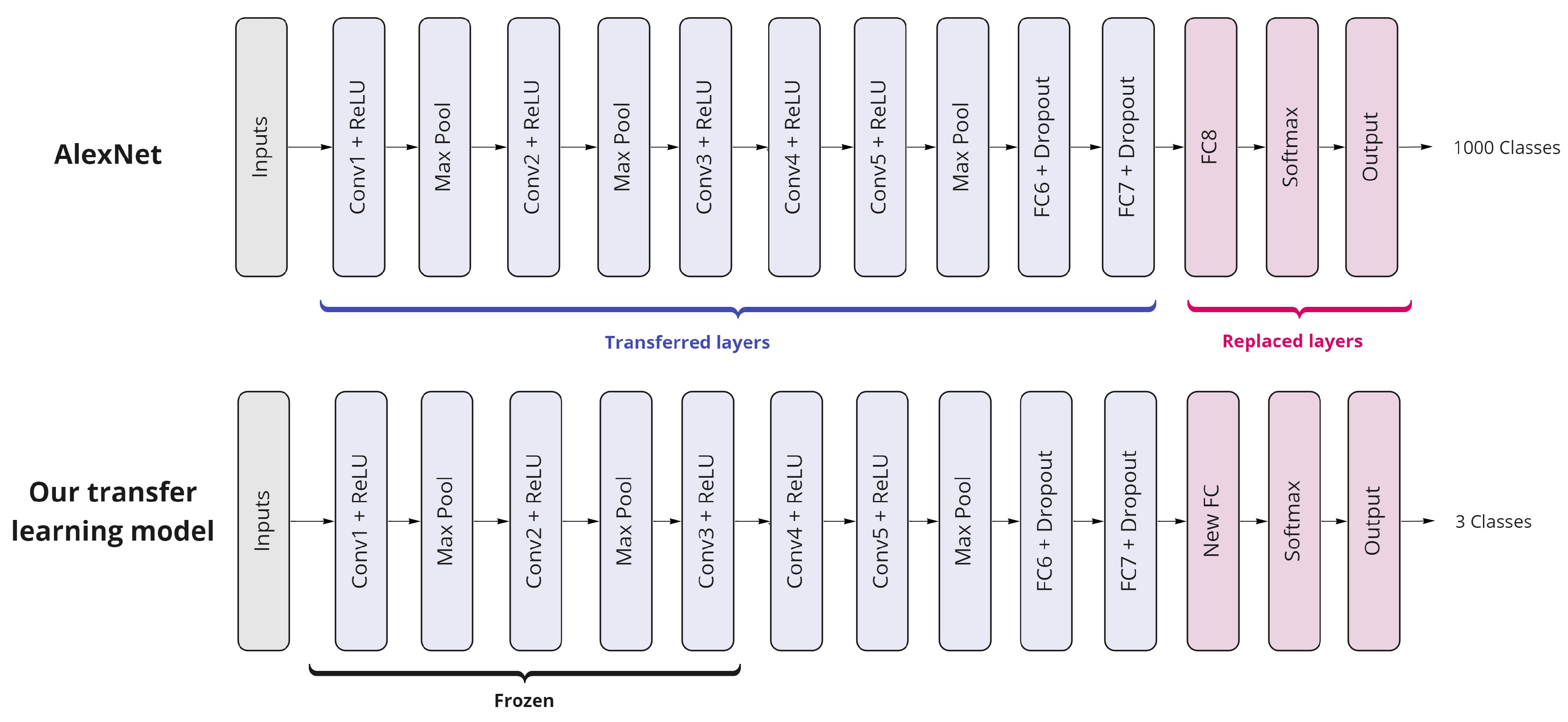
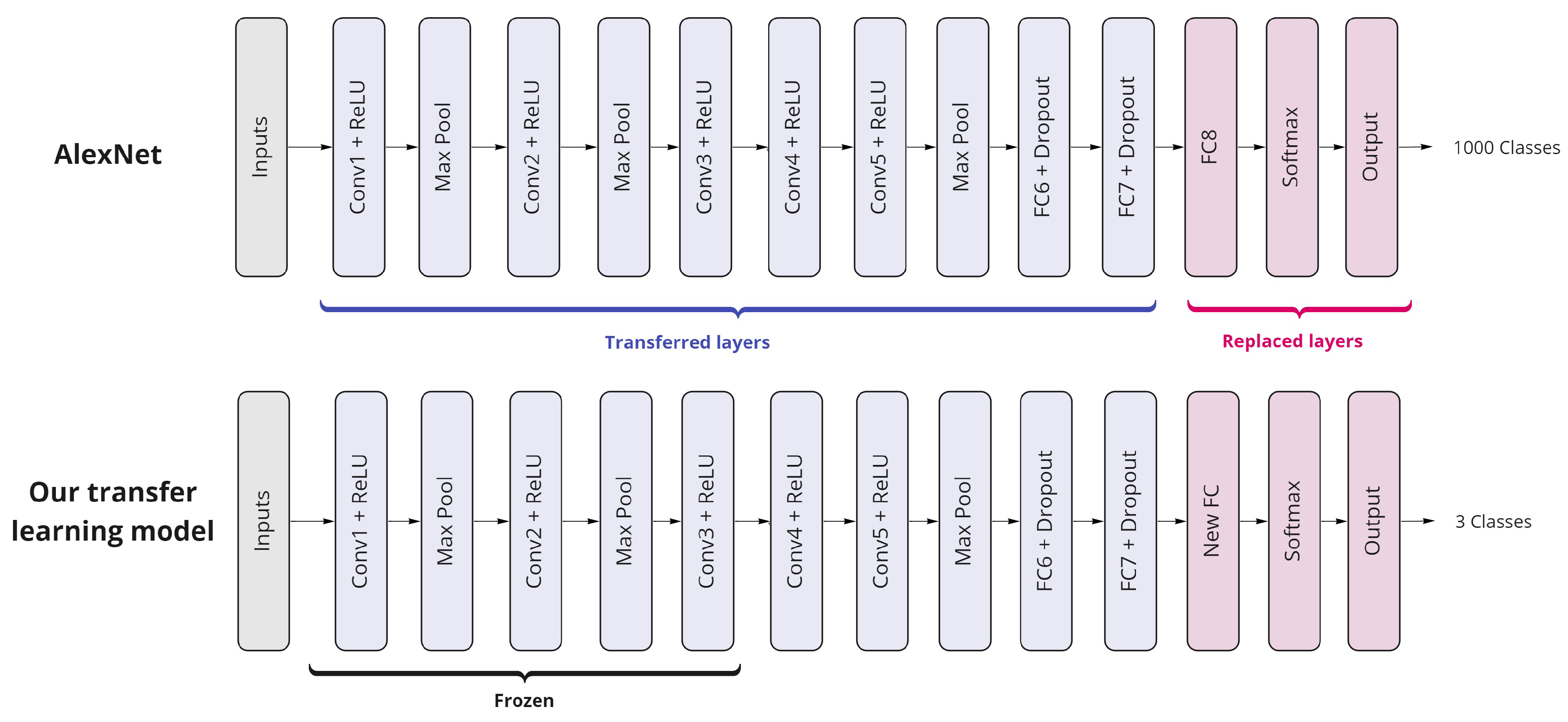
4.2. Pre-Trained Networks and Transfer Learning
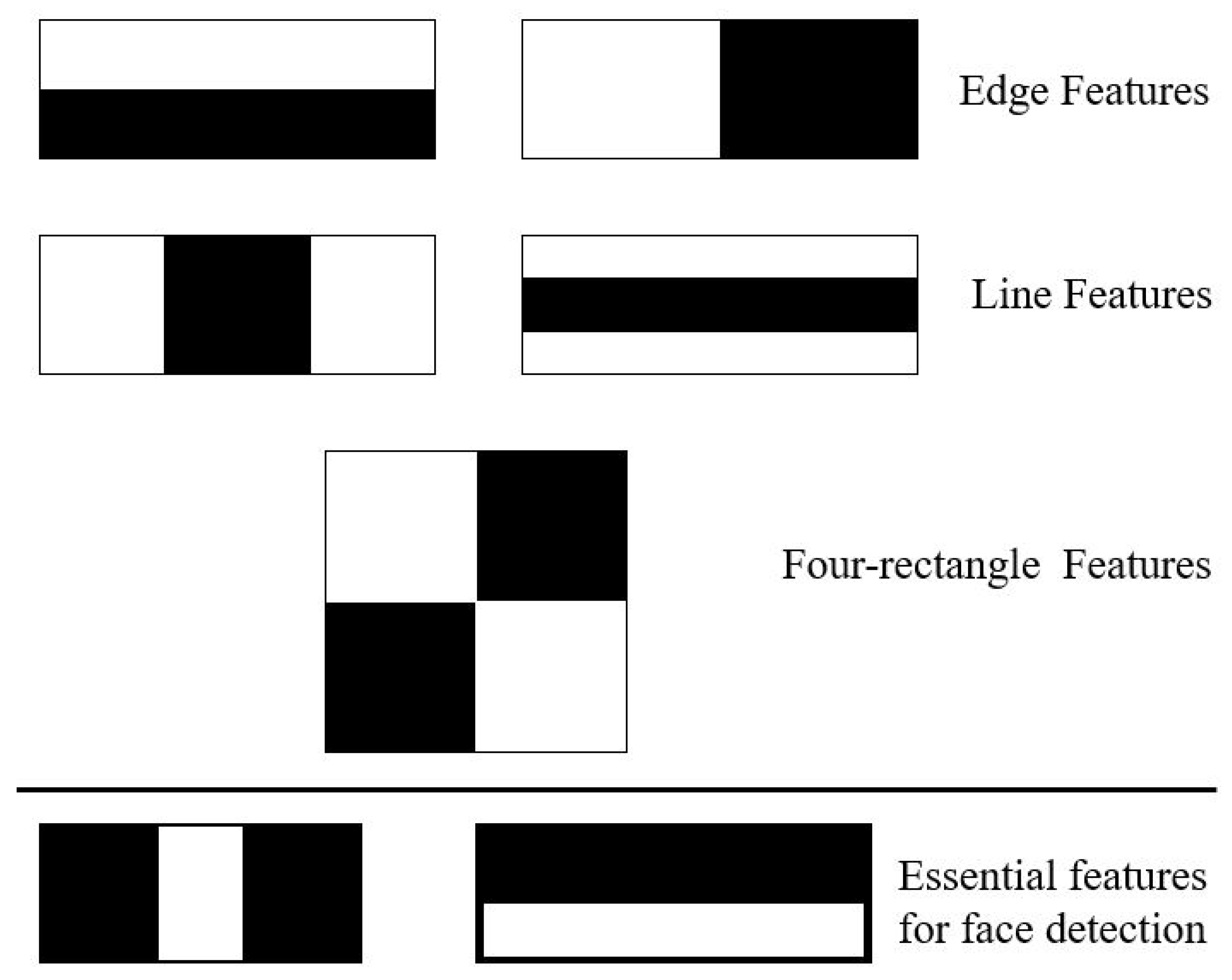
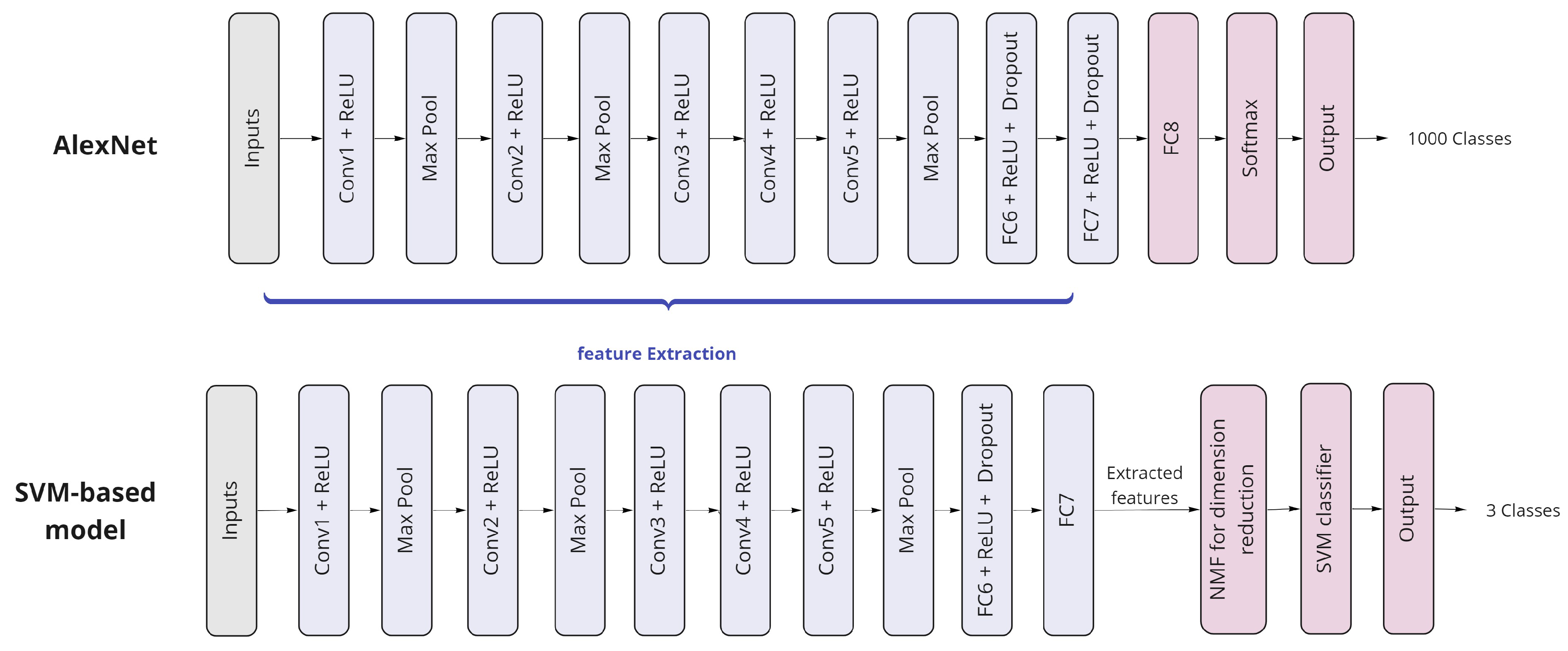
4.3. AlexNet
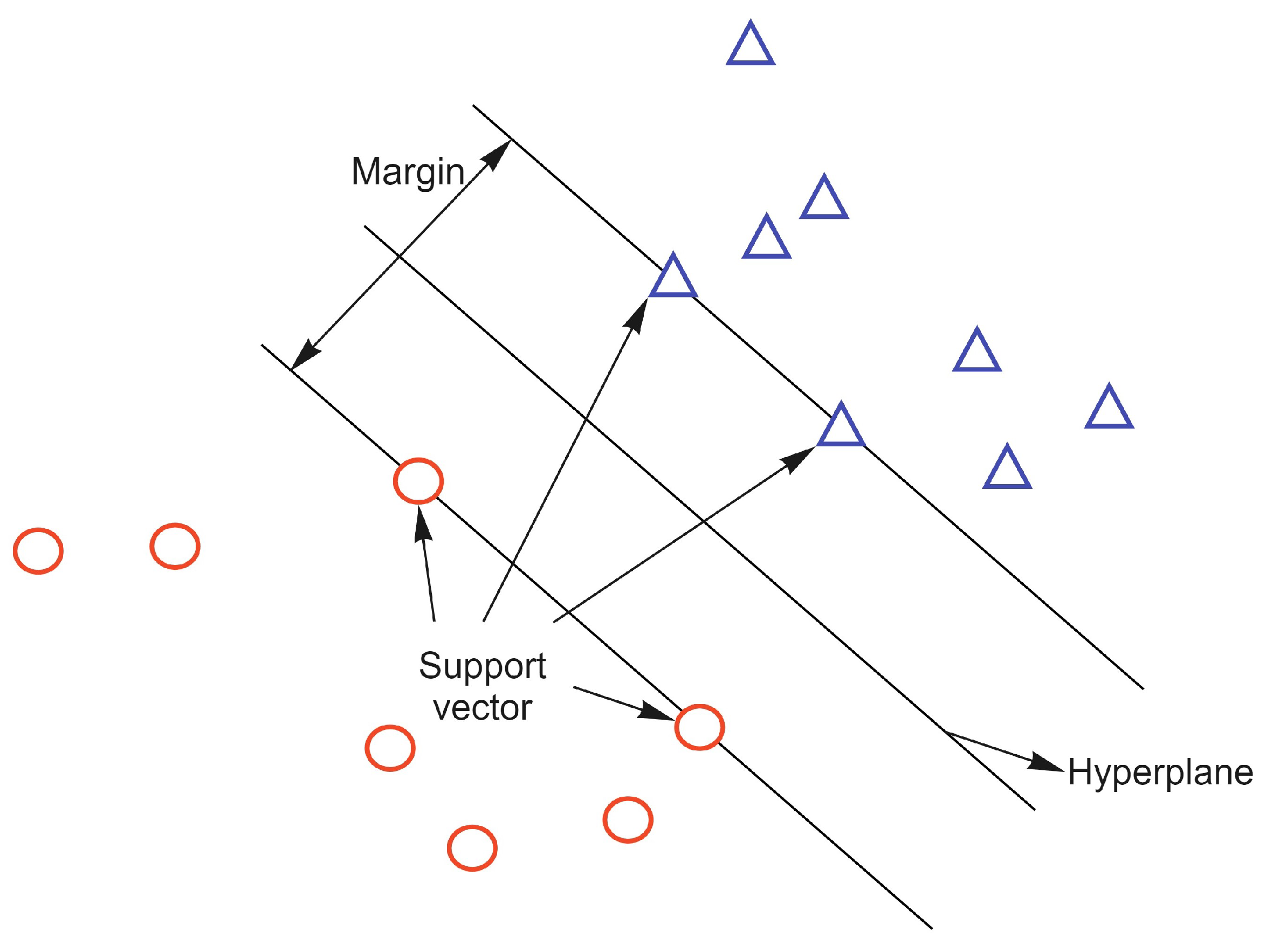
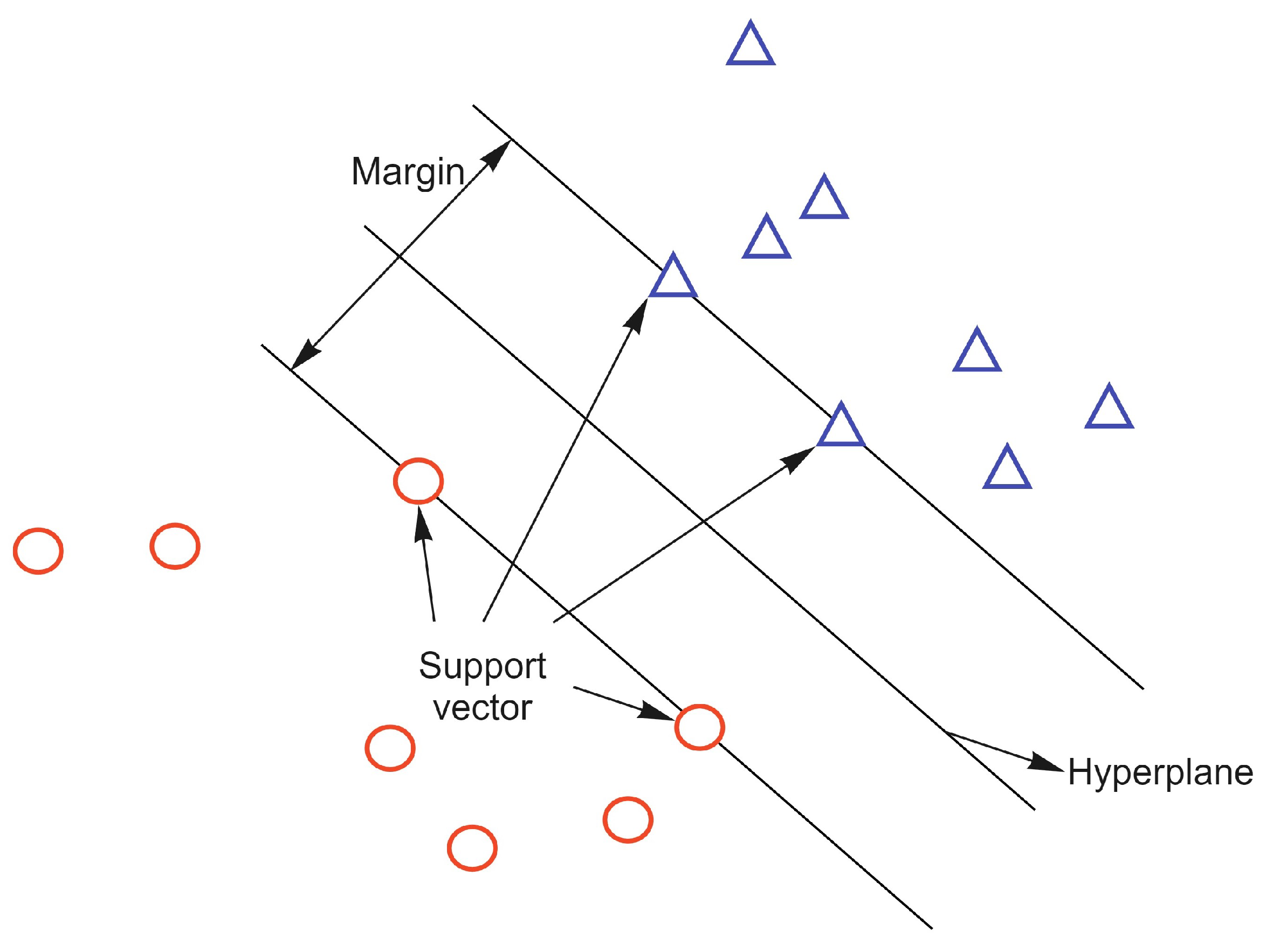
4.4. Support Vector Machine
5. Implementation
5.1. Dataset Description
5.2. Dataset Preprocessing and Augmentation
5.3. AlexNet as a Deep Transfer Learning Model
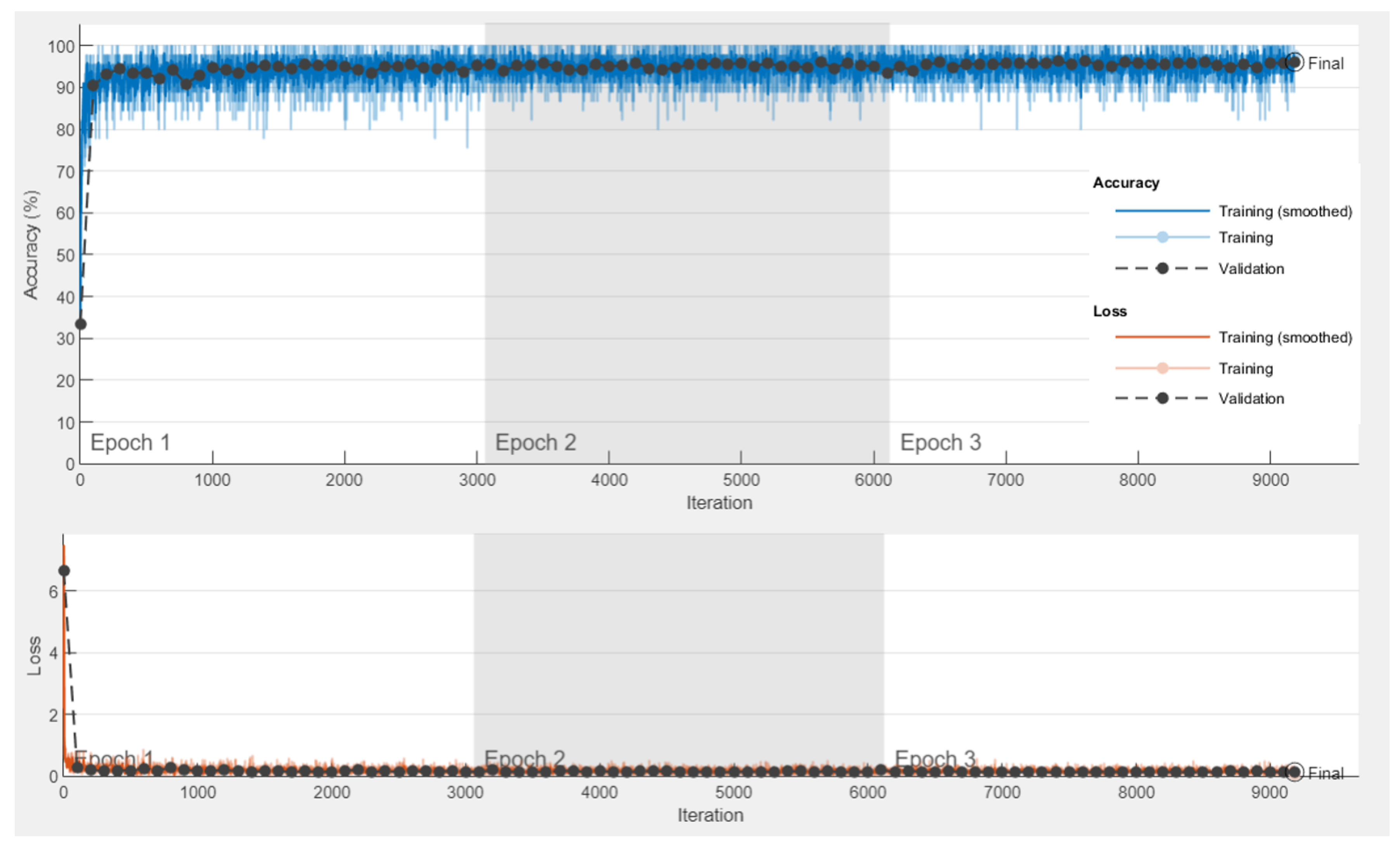
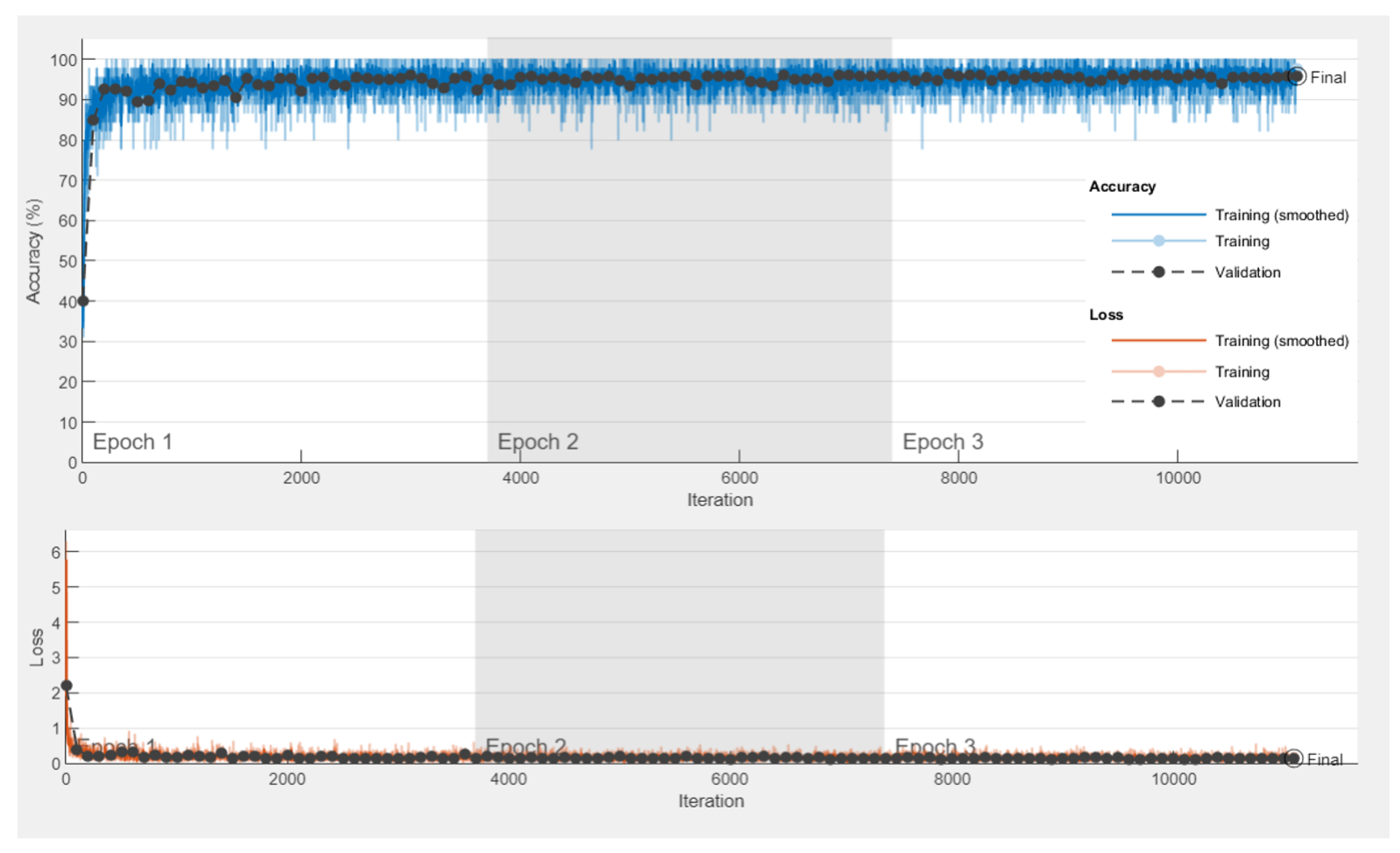
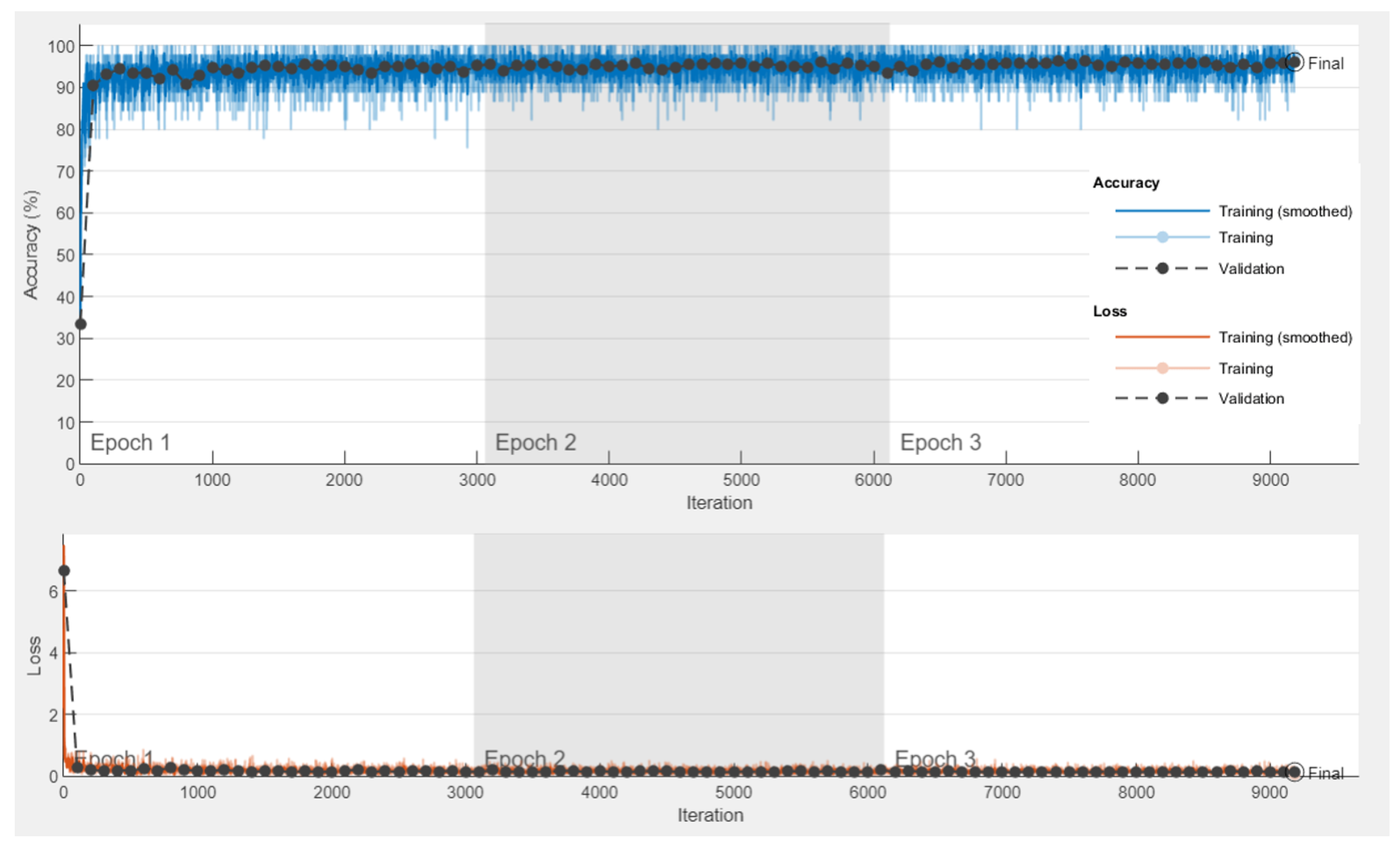
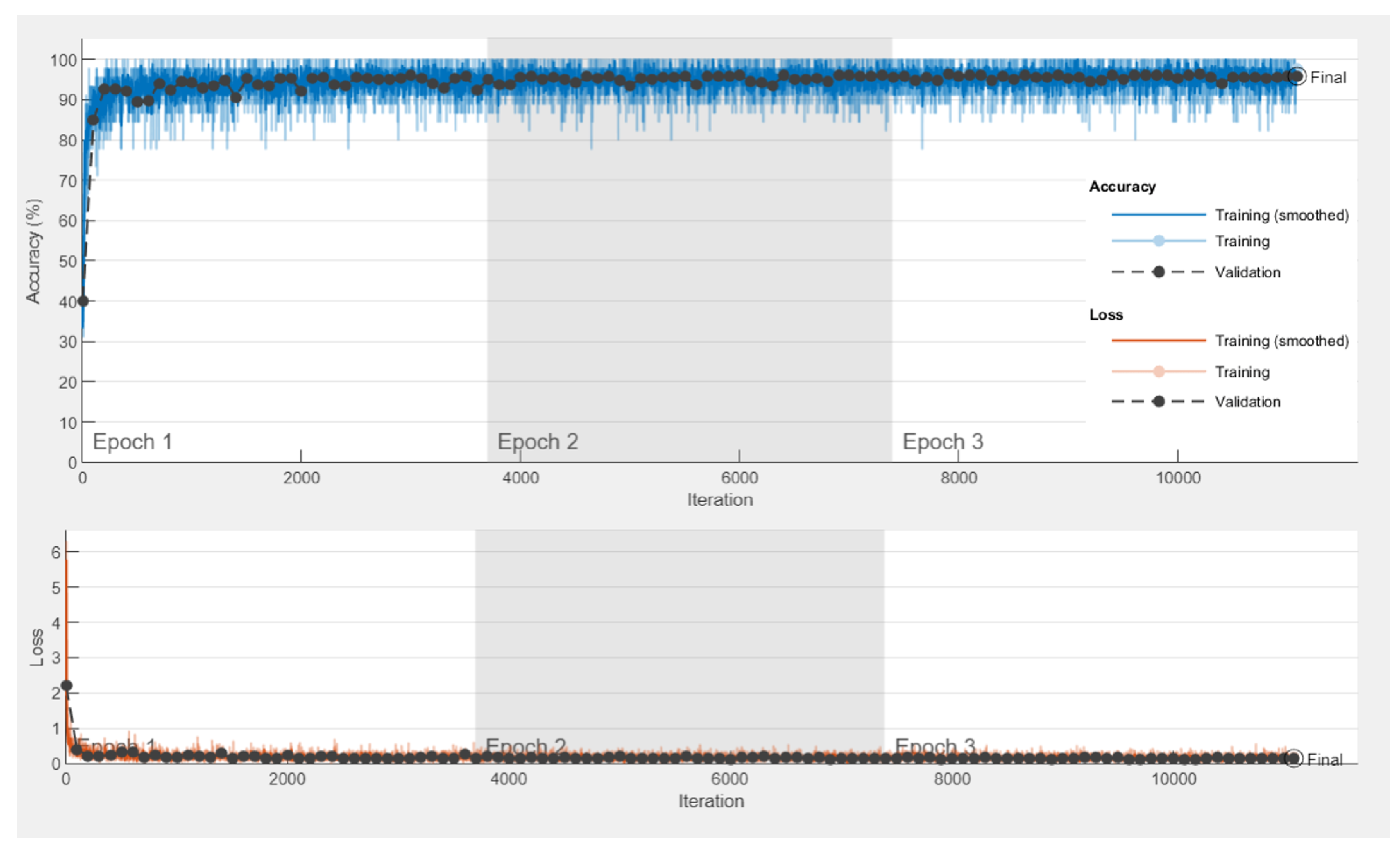
5.3.1. The Experiment of the Transfer Learning-Based Model
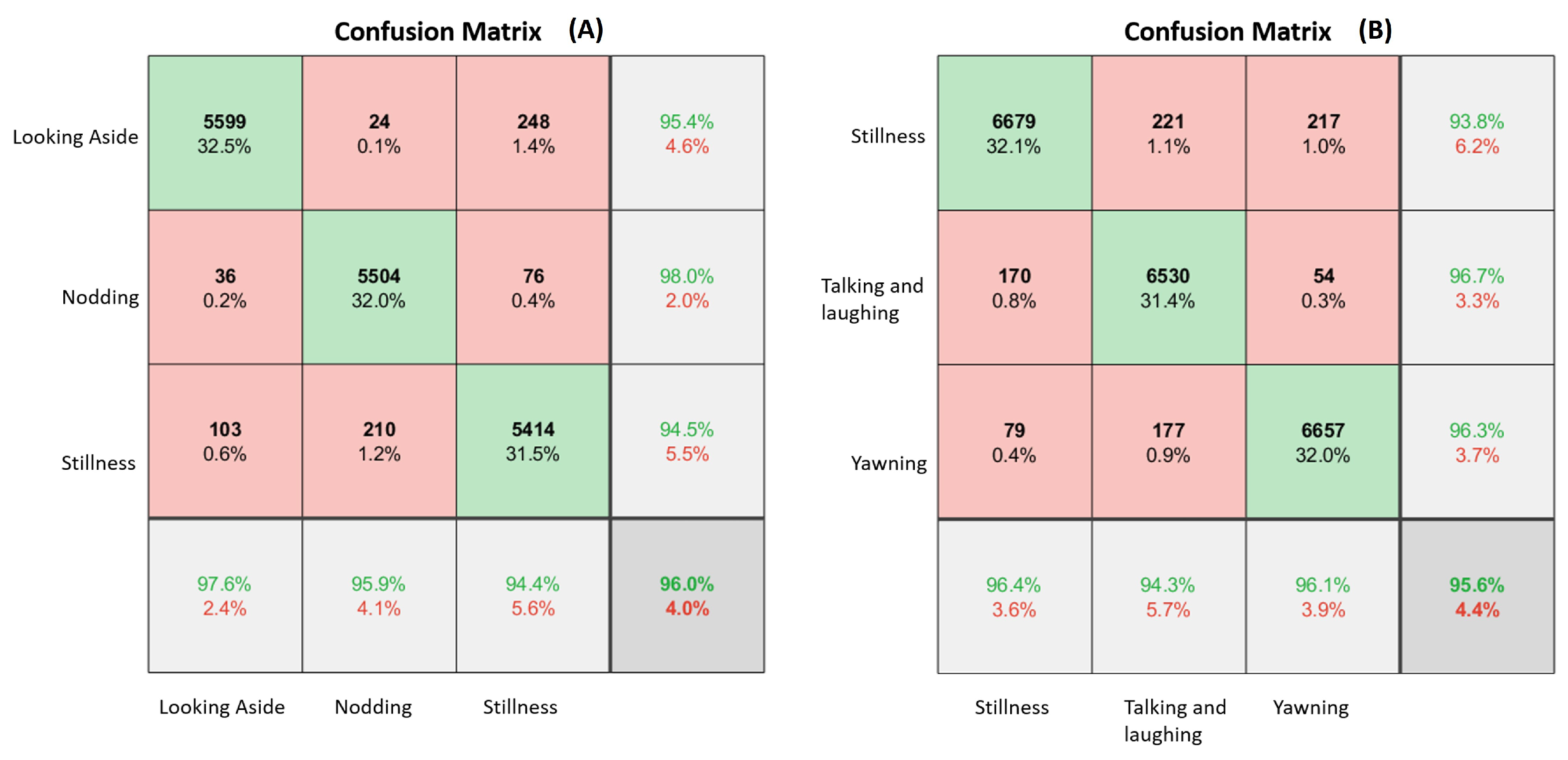
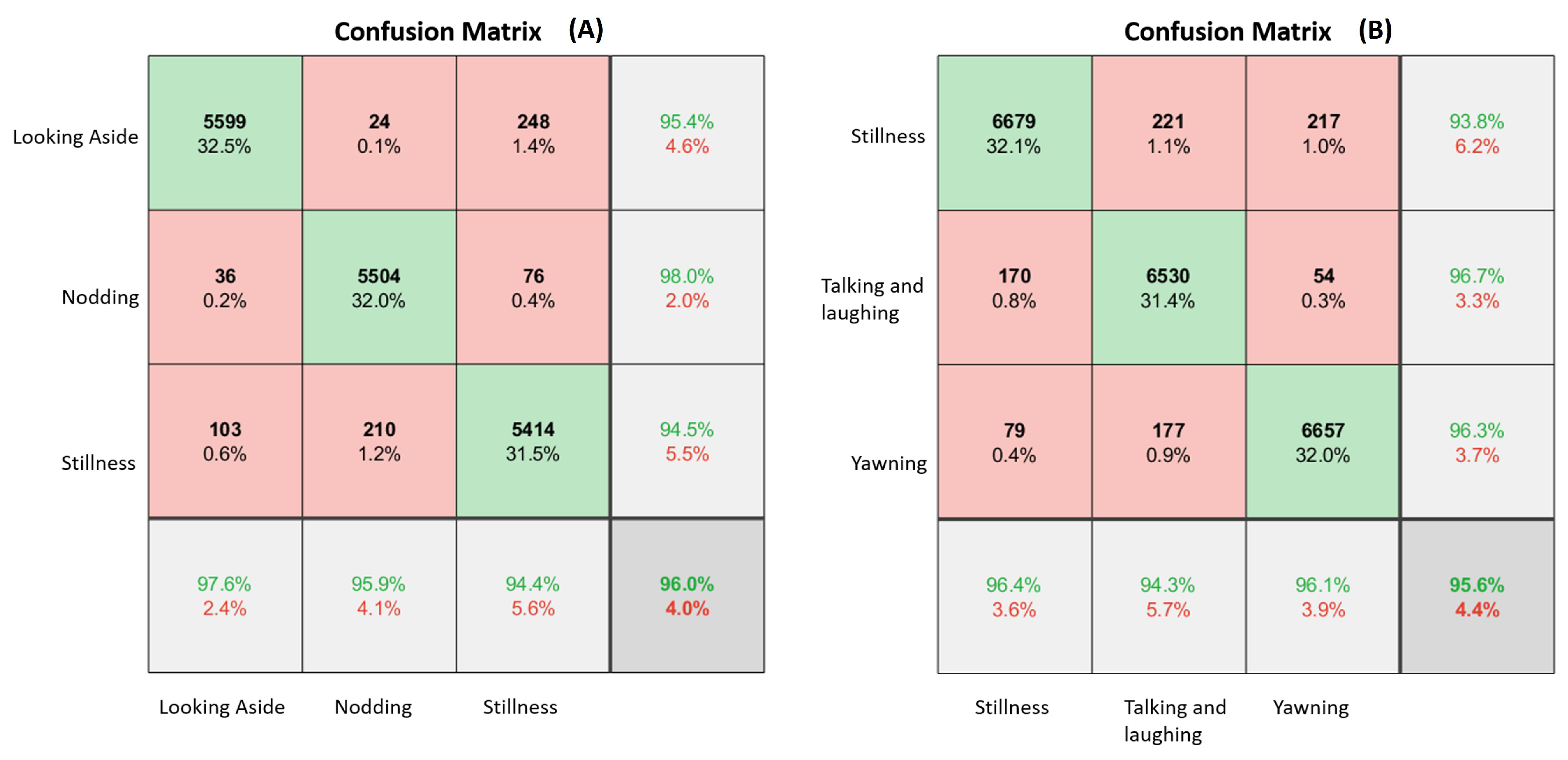
5.3.2. Experimental Results
5.3.3. Performance Metrics
5.4. AlexNet as a Feature Extractor with SVM Classifier Model
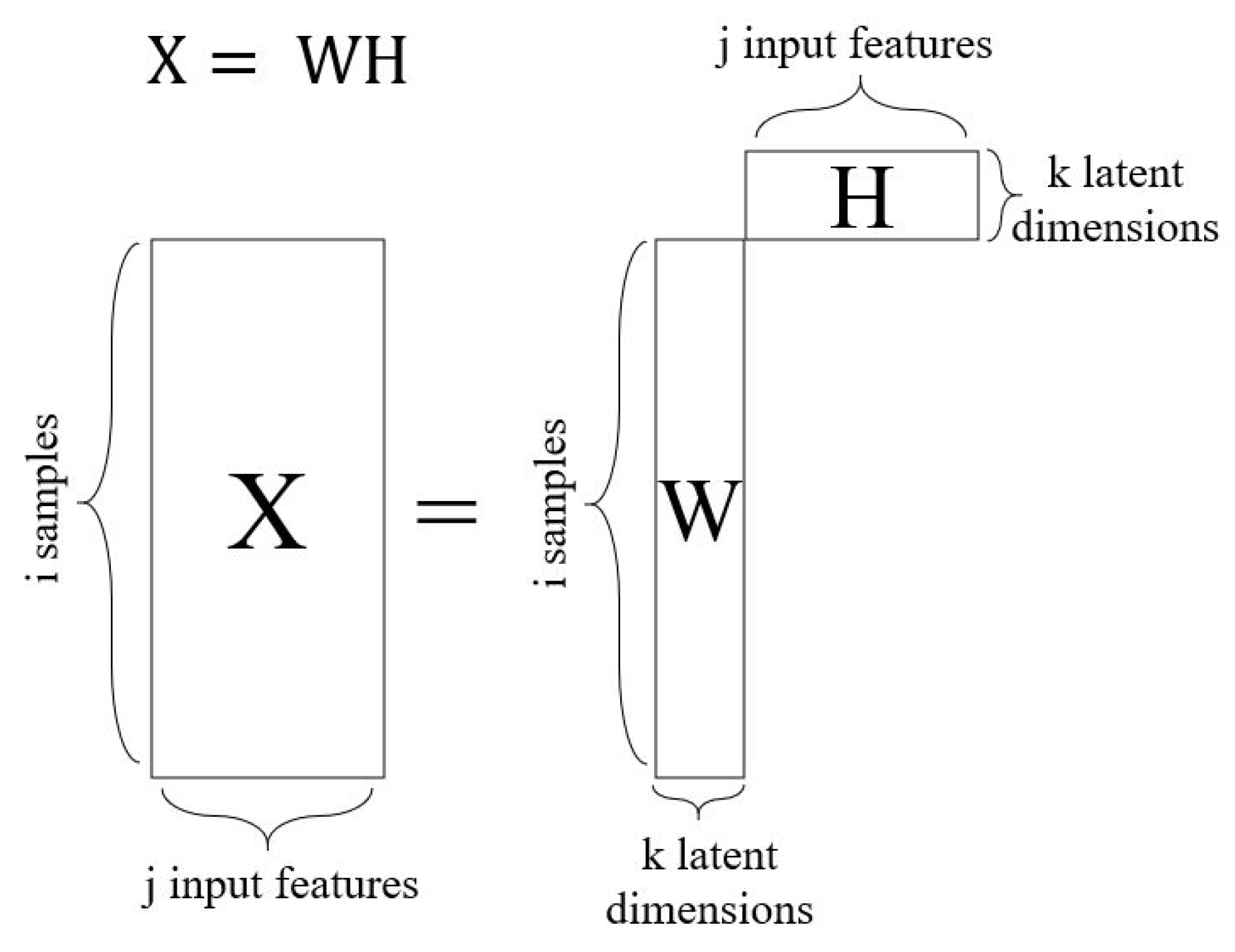
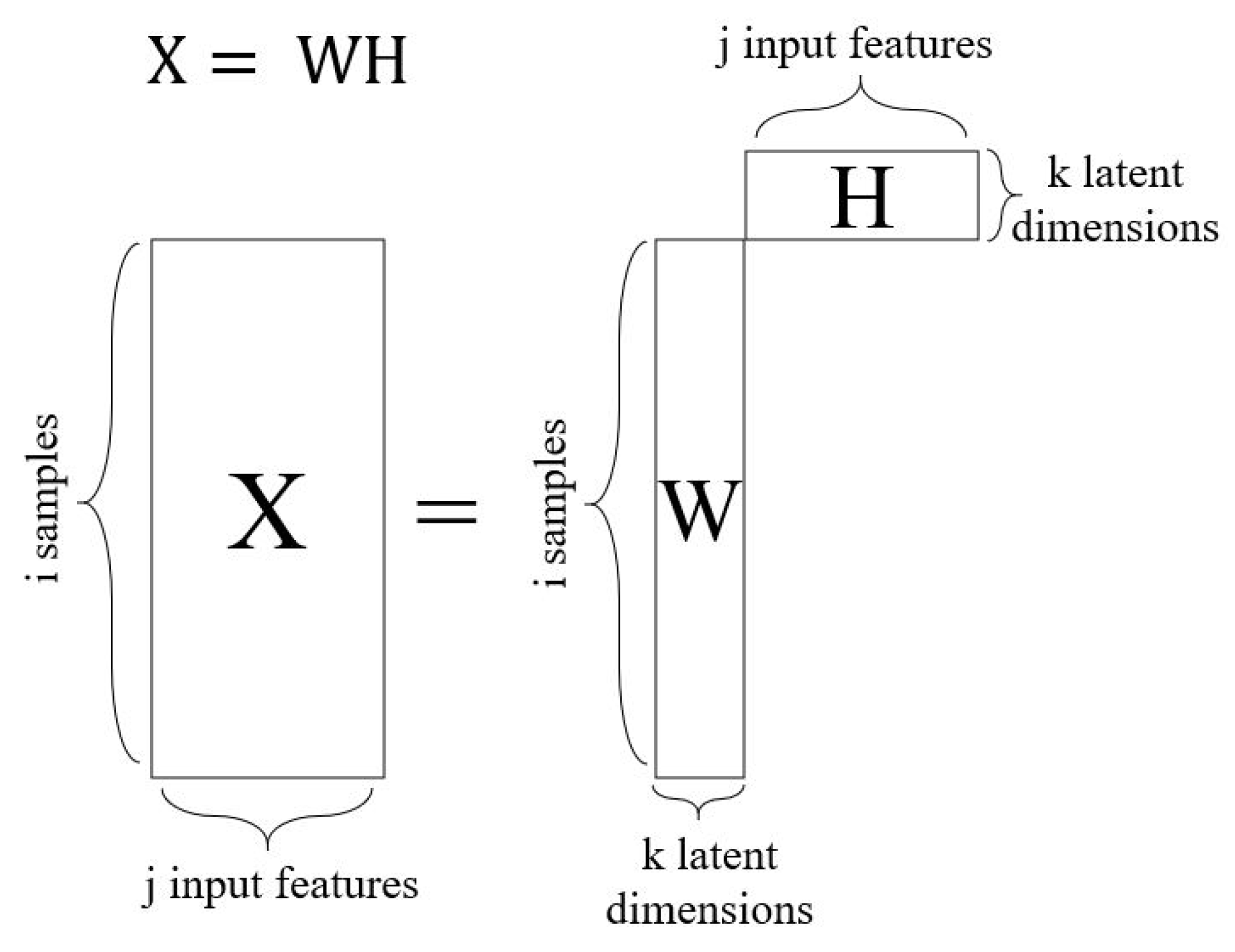
5.4.1. Non-Negative Matrix Factorization
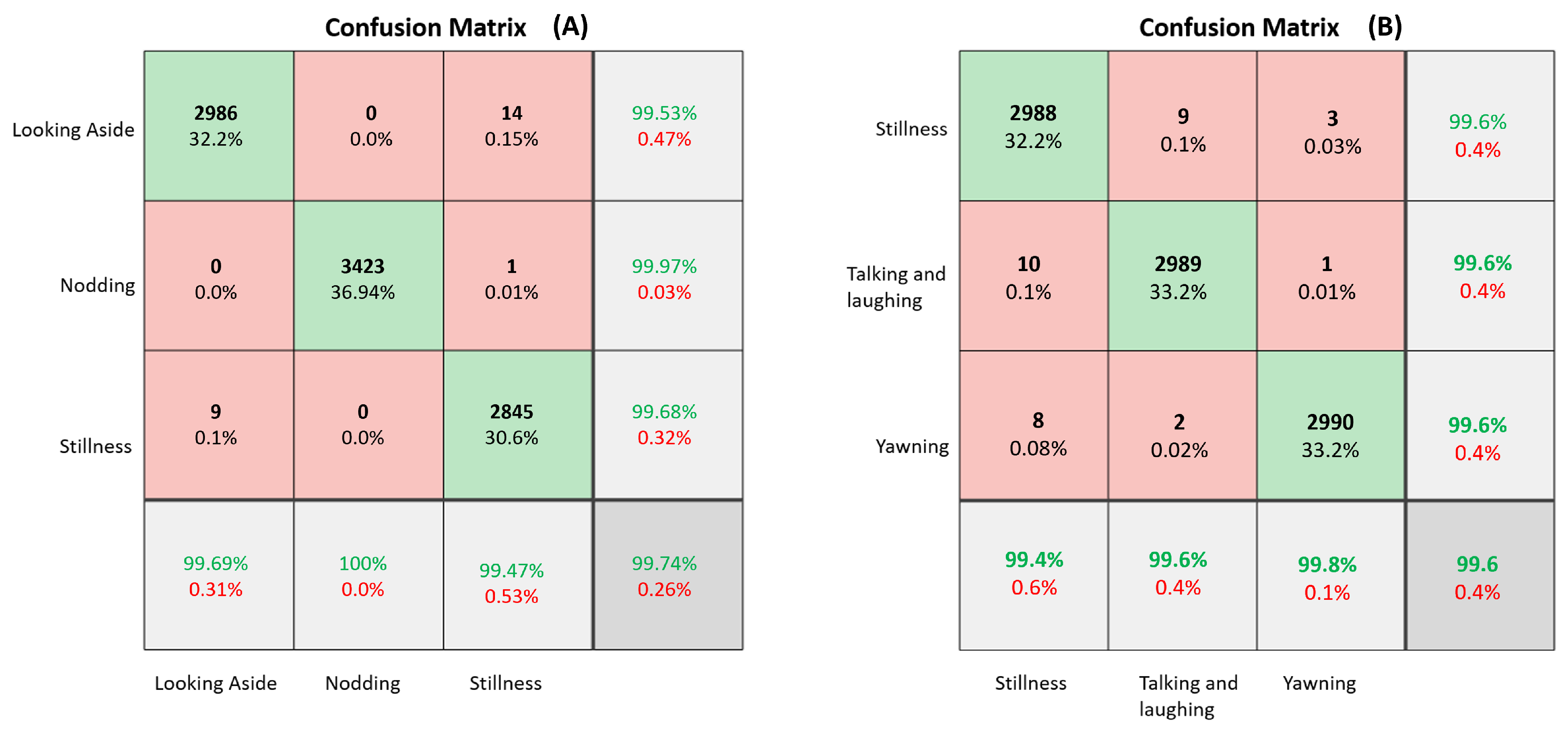
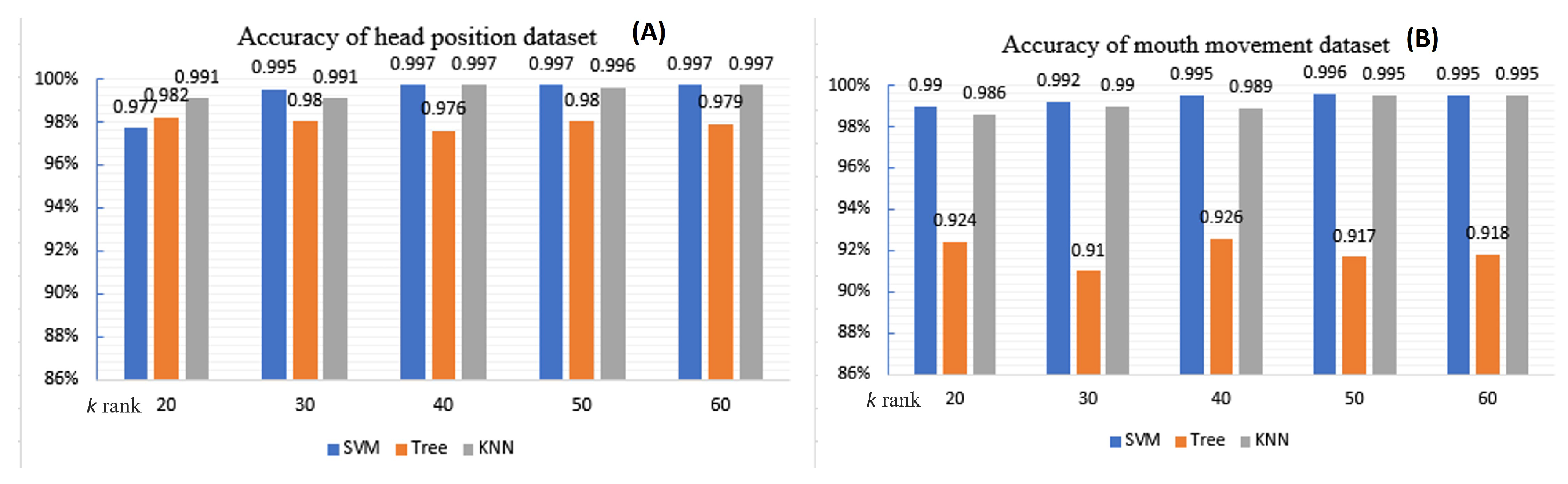
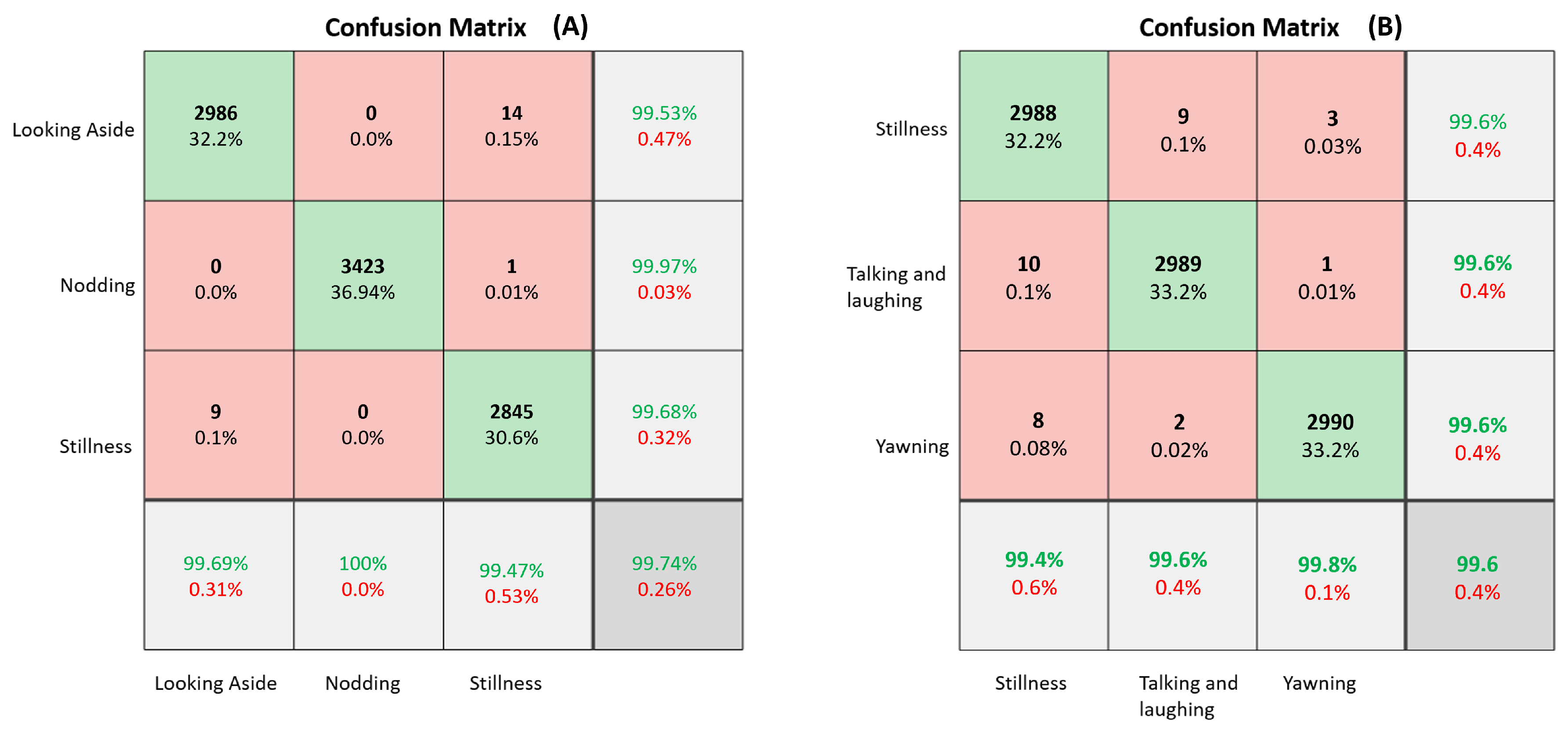
5.4.2. Experimental Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- W.H.O. Global Status Report on Road Safety 2018; World Health Organization: Geneva, Switzerland, 2019; OCLC: 1084537103. [Google Scholar]
- Tefft, B.C. Prevalence of motor vehicle crashes involving drowsy drivers, United States, 1999–2008. Accid. Anal. Prev. 2012, 45, 180–186. [Google Scholar] [CrossRef]
- Gao, Z.; Wang, X.; Yang, Y.; Mu, C.; Cai, Q.; Dang, W.; Zuo, S. EEG-Based Spatio-Temporal Convolutional Neural Network for Driver Fatigue Evaluation. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1–9. [Google Scholar] [CrossRef]
- Zhang, C.; Sun, L.; Cong, F.; Kujala, T.; Ristaniemi, T.; Parviainen, T. Optimal imaging of multi-channel EEG features based on a novel clustering technique for driver fatigue detection. Biomed. Signal Process. Control 2020, 62, 102103. [Google Scholar] [CrossRef]
- Tuncer, T.; Dogan, S.; Ertam, F.; Subasi, A. A dynamic center and multi threshold point based stable feature extraction network for driver fatigue detection utilizing EEG signals. Cogn. Neurodyn. 2021, 15, 223–237. [Google Scholar] [CrossRef]
- Yang, Y.X.; Gao, Z.K. A Multivariate Weighted Ordinal Pattern Transition Network for Characterizing Driver Fatigue Behavior from EEG Signals. Int. J. Bifurc. Chaos 2020, 30, 2050118. [Google Scholar] [CrossRef]
- Wang, F.; Wu, S.; Zhang, W.; Xu, Z.; Zhang, Y.; Chu, H. Multiple nonlinear features fusion based driving fatigue detection. Biomed. Signal Process. Control 2020, 62, 102075. [Google Scholar] [CrossRef]
- Shalash, W.M. A Deep Learning CNN Model for Driver Fatigue Detection Using Single Eeg Channel. In Proceedings of the IEEE International Conference on Imaging Systems and Techniques, New York, NY, USA, 24–26 August 2021. [Google Scholar]
- Gu, X.; Zhang, L.; Xiao, Y.; Zhang, H.; Hong, H.; Zhu, X. Non-contact Fatigue Driving Detection Using CW Doppler Radar. In Proceedings of the 2018 IEEE MTT-S International Wireless Symposium (IWS), Chengdu, China, 6–10 May 2018; pp. 1–3. [Google Scholar] [CrossRef]
- Murugan, S.; Selvaraj, J.; Sahayadhas, A. Detection and analysis: Driver state with electrocardiogram (ECG). Phys. Eng. Sci. Med. 2020, 43, 525–537. [Google Scholar] [CrossRef]
- Cherian, V.A.; Bhardwaj, R.; Balasubramanian, V. Real-Time Driver Fatigue Detection from ECG Using Deep Learning Algorithm. In Ergonomics for Improved Productivity; Muzammil, M., Khan, A.A., Hasan, F., Eds.; Springer: Singapore, 2021; pp. 615–621. [Google Scholar]
- Chieh, T.C.; Mustafa, M.M.; Hussain, A.; Hendi, S.F.; Majlis, B.Y. Development of vehicle driver drowsiness detection system using electrooculogram (EOG). In Proceedings of the 2005 1st International Conference on Computers, Communications, & Signal Processing with Special Track on Biomedical Engineering, Kuala Lumpur, Malaysia, 14–16 November 2005; pp. 165–168. [Google Scholar] [CrossRef]
- Jiao, Y.; Deng, Y.; Luo, Y.; Lu, B.L. Driver sleepiness detection from EEG and EOG signals using GAN and LSTM networks. Neurocomputing 2020, 408, 100–111. [Google Scholar] [CrossRef]
- Boon-Leng, L.; Dae-Seok, L.; Boon-Giin, L. Mobile-based wearable-type of driver fatigue detection by GSR and EMG. In Proceedings of the TENCON 2015—2015 IEEE Region 10 Conference, Macao, China, 1–4 November 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Satti, A.T.; Kim, J.; Yi, E.; Cho, H.Y.; Cho, S. Microneedle Array Electrode-Based Wearable EMG System for Detection of Driver Drowsiness through Steering Wheel Grip. Sensors 2021, 21, 5091. [Google Scholar] [CrossRef] [PubMed]
- Wali, M.K. Ffbpnn-based high drowsiness classification using EMG and WPT. Biomed. Eng. Appl. Basis Commun. 2020, 32, 2050023. [Google Scholar] [CrossRef]
- Chen, P. Research on driver fatigue detection strategy based on human eye state. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 619–623. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, R.; Guo, L. Eye gaze pattern analysis for fatigue detection based on GP-BCNN with ESM. Pattern Recognit. Lett. 2019, 123, 61–74. [Google Scholar] [CrossRef]
- Fatima, B.; Shahid, A.R.; Ziauddin, S.; Safi, A.A.; Ramzan, H. Driver Fatigue Detection Using Viola Jones and Principal Component Analysis. Appl. Artif. Intell. 2020, 34, 456–483. [Google Scholar] [CrossRef]
- Savas, B.K.; Becerikli, Y. Real Time Driver Fatigue Detection System Based on Multi-Task ConNN. IEEE Access 2020, 8, 12491–12498. [Google Scholar] [CrossRef]
- Zhang, W.; Su, J. Driver yawning detection based on long short term memory networks. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Yang, H.; Liu, L.; Min, W.; Yang, X.; Xiong, X. Driver Yawning Detection Based on Subtle Facial Action Recognition. IEEE Trans. Multimed. 2021, 23, 572–583. [Google Scholar] [CrossRef]
- Hari, C.; Sankaran, P. Driver distraction analysis using face pose cues. Expert Syst. Appl. 2021, 179, 115036. [Google Scholar] [CrossRef]
- Ansari, S.; Naghdy, F.; Du, H.; Pahnwar, Y.N. Driver Mental Fatigue Detection Based on Head Posture Using New Modified reLU-BiLSTM Deep Neural Network. IEEE Trans. Intell. Transp. Syst. 2021, 1–13. [Google Scholar] [CrossRef]
- Xu, X.; Rong, H.; Li, S. Internet-of-Vehicle-Oriented Fatigue Driving State. In Proceedings of the 2016 IEEE International Conference on Ubiquitous Wireless Broadband (ICUWB), Nanjing, China, 16–19 October 2016; p. 4. [Google Scholar]
- Xi, J.; Wang, S.; Ding, T.; Tian, J.; Shao, H.; Miao, X. Detection Model on Fatigue Driving Behaviors Based on the Operating Parameters of Freight Vehicles. Appl. Sci. 2021, 11, 7132. [Google Scholar] [CrossRef]
- Li, R.; Chen, Y.V.; Zhang, L. A method for fatigue detection based on Driver’s steering wheel grip. Int. J. Ind. Ergon. 2021, 82, 103083. [Google Scholar] [CrossRef]
- Bakker, B.; Zabłocki, B.; Baker, A.; Riethmeister, V.; Marx, B.; Iyer, G.; Anund, A.; Ahlström, C. A Multi-Stage, Multi-Feature Machine Learning Approach to Detect Driver Sleepiness in Naturalistic Road Driving Conditions. IEEE Trans. Intell. Transp. Syst. 2021, 1–10. [Google Scholar] [CrossRef]
- Liu, Z.; Peng, Y.; Hu, W. Driver fatigue detection based on deeply-learned facial expression representation. J. Vis. Commun. Image Represent. 2020, 71, 102723. [Google Scholar] [CrossRef]
- Teyeb, I.; Jemai, O.; Zaied, M.; Ben Amar, C. A Drowsy Driver Detection System Based on a New Method of Head Posture Estimation. In Intelligent Data Engineering and Automated Learning–IDEAL 2014; Corchado, E., Lozano, J.A., Quintián, H., Yin, H., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Germany, 2014; Volume 8669, pp. 362–369. [Google Scholar]
- Moujahid, A.; Dornaika, F.; Arganda-Carreras, I.; Reta, J. Efficient and compact face descriptor for driver drowsiness detection. Expert Syst. Appl. 2021, 168, 114334. [Google Scholar] [CrossRef]
- Bakheet, S.; Al-Hamadi, A. A Framework for Instantaneous Driver Drowsiness Detection Based on Improved HOG Features and Naïve Bayesian Classification. Brain Sci. 2021, 11, 240. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Xia, J.; Cao, L.; Zhang, G.; Feng, X. Driver fatigue detection based on convolutional neural network and face alignment for edge computing device. Proc. Inst. Mech. Eng. Part J. Automob. Eng. 2021, 235, 2699–2711. [Google Scholar] [CrossRef]
- Jabbar, R.; Al-Khalifa, K.; Kharbeche, M.; Alhajyaseen, W.; Jafari, M.; Jiang, S. Real-time Driver Drowsiness Detection for Android Application Using Deep Neural Networks Techniques. Procedia Comput. Sci. 2018, 130, 400–407. [Google Scholar] [CrossRef]
- Quddus, A.; Shahidi Zandi, A.; Prest, L.; Comeau, F.J. Using long short term memory and convolutional neural networks for driver drowsiness detection. Accid. Anal. Prev. 2021, 156, 106107. [Google Scholar] [CrossRef]
- Jacobé de Naurois, C.; Bourdin, C.; Bougard, C.; Vercher, J.L. Adapting artificial neural networks to a specific driver enhances detection and prediction of drowsiness. Accid. Anal. Prev. 2018, 121, 118–128. [Google Scholar] [CrossRef]
- He, H.; Zhang, X.; Jiang, F.; Wang, C.; Yang, Y.; Liu, W.; Peng, J. A Real-time Driver Fatigue Detection Method Based on Two-Stage Convolutional Neural Network. IFAC-PapersOnLine 2020, 53, 15374–15379. [Google Scholar] [CrossRef]
- Pinto, A.; Bhasi, M.; Bhalekar, D.; Hegde, P.; Koolagudi, S.G. A Deep Learning Approach to Detect Drowsy Drivers in Real Time. In Proceedings of the 2019 IEEE 16th India Council International Conference (INDICON), Rajkot, India, 13–15 December 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Xing, Y.; Lv, C.; Cao, D. Application of Deep Learning Methods in Driver Behavior Recognition. In Advanced Driver Intention Inference; Elsevier: Amsterdam, The Netherlands, 2020; pp. 135–156. [Google Scholar] [CrossRef]
- Masood, S.; Rai, A.; Aggarwal, A.; Doja, M.; Ahmad, M. Detecting distraction of drivers using Convolutional Neural Network. Pattern Recognit. Lett. 2020, 139, 79–85. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, Y.; Gao, C. Deep unsupervised multi-modal fusion network for detecting driver distraction. Neurocomputing 2021, 421, 26–38. [Google Scholar] [CrossRef]
- Kůrková, V.; Manolopoulos, Y.; Hammer, B.; Iliadis, L.; Maglogiannis, I. (Eds.) Artificial Neural Networks and Machine Learning. In Proceedings of the ICANN 2018: 27th International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Lecture Notes in Computer Science. Springer International Publishing: Berlin/Heidelberg, Germany, 2018. Part II. Volume 11140. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Abbas, Q. HybridFatigue: A Real-time Driver Drowsiness Detection using Hybrid Features and Transfer Learning. Int. J. Adv. Comput. Sci. Appl. (IJACSA) 2020, 11. [Google Scholar] [CrossRef] [Green Version]
- Kunze, J.; Kirsch, L.; Kurenkov, I.; Krug, A.; Johannsmeier, J.; Stober, S. Transfer Learning for Speech Recognition on a Budget. arXiv 2017, arXiv:1706.00290. [Google Scholar]
- Alyoubi, W.L.; Abulkhair, M.F.; Shalash, W.M. Diabetic Retinopathy Fundus Image Classification and Lesions Localization System Using Deep Learning. Sensors 2021, 21, 3704. [Google Scholar] [CrossRef] [PubMed]
- Sargano, A.B.; Wang, X.; Angelov, P.; Habib, Z. Human action recognition using transfer learning with deep representations. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Vancouver, QC, Canada, 24–29 July 2017; pp. 463–469. [Google Scholar] [CrossRef] [Green Version]
- Kaya, H.; Gürpınar, F.; Salah, A.A. Video-based emotion recognition in the wild using deep transfer learning and score fusion. Image Vis. Comput. 2017, 65, 66–75. [Google Scholar] [CrossRef]
- Manzo, M.; Pellino, S. Voting in Transfer Learning System for Ground-Based Cloud Classification. Mach. Learn. Knowl. Extr. 2021, 3, 542–553. [Google Scholar] [CrossRef]
- Shalash, W.M. Driver Fatigue Detection with Single EEG Channel Using Transfer Learning. In Proceedings of the 2019 IEEE International Conference on Imaging Systems and Techniques (IST), Abu Dhabi, United Arab Emirates, 9–10 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Weng, C.H.; Lai, Y.H.; Lai, S.H. Driver Drowsiness Detection via a Hierarchical Temporal Deep Belief Network. In Proceedings of the Asian Conference on Computer Vision—ACCV 2016 Workshops, Taipei, Taiwan, 20–24 November 2016; Chen, C.S., Lu, J., Ma, K.K., Eds.; Lecture Notes in Computer Science. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; Volume 10118, pp. 117–133. [Google Scholar]
- Viola, P.; Jones, M. Robust Real-time Object Detection. Int. J. Comput. Vis. 2001, 4, 4. [Google Scholar]
- Michelucci, U. Applied Deep Learning: A Case-Based Approach to Understanding Deep Neural Networks; Apress: Berkeley, CA, USA, 2018. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef]
- Gillis, N. Nonnegative Matrix Factorization: Complexity, Algorithms and Applications. Ph.D. Thesis, Université Catholique de Louvain, Ottignies-Louvain-la-Neuve, Belgique, 2011. Available online: https://dial.uclouvain.be/downloader/downloader.php?pid=boreal:70744&datastream=PDF_01 (accessed on 5 November 2020).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Citation | Goal | Used Measures | Method | Dataset | Performance |
|---|---|---|---|---|---|
| [29] | Detecting driver fatigue | PERCLOS Yawning | Rule-based | Caltech10k Web Faces dataset, FDDB dataset | Success rate under normal conditions: 96.5% |
| [30] | Detecting driver fatigue | Head position | Rule-based | Self-built dataset | Success rate: 88.33% |
| [23] | Detecting driver distraction | Head position | Two-layer clustered approach with Gabor features and SVM classifier | Self-built dataset | Accuracy: 95.8% |
| [32] | Detecting driver fatigue | Eye state | Improved HOG features and NB classifier | NTHU Drowsy Driver Detection dataset | Accuracy: 85.62% |
| [31] | Detecting driver fatigue | Facial features | Feature extraction through multiple face descriptors followed by PCA and SVM | NTHU Drowsy Driver Detection dataset | Accuracy: 79.84% |
| [34] | Detecting driver fatigue | Facial features | Multi-layer perceptron | NTHU Drowsy Driver Detection dataset | Accuracy: 81% |
| [33] | Detecting driver fatigue and distraction | Eye aspect ratio, mouth aspect ratio, head poses | CNN-based face detection network, speed-optimized SDM face alignment algorithm | AFLW, Pointing’04, 300W, 300W-LP, Menpo2D, self-built dataset (DriverEyes), YawDD dataset | Accuracy: 89.55% |
| [35] | Detecting driver fatigue | Eye movement | LSTM-CNN | Self-built dataset | Accuracy: 97.87% |
| [36] | Detecting driver fatigue | Eye movement, head position, head rotation, heart rate, respiration rate, car data | Adaptive ANN | Self-built dataset | 80% performance improvement after adaptation of AdANN |
| [37] | Detecting driver fatigue | Eye state, mouth state | CNN | YawDD dataset, Self-built dataset | Accuracy: 94.7% |
| [18] | Detecting driver fatigue | Eye gaze | Dual-stream bidirectional CNN with projection vectors and Gabor filters | Closed Eyes in the Wild dataset, Eyeblink dataset, self-built dataset | Accuracy: 97.9% |
| [20] | Detecting driver fatigue | PERCLOS, Yawning | CNN | YawdDD dataset, NTHU Drowsy Driver Detection dataset | Accuracy: 98.81% |
| [38] | Detecting driver fatigue | Eye state | Pre-trained VGG-16 CNN | Closed Eyes in the Wild dataset, self-built dataset | Accuracy: 93.3% |
| [39] | Detecting driver distraction | Upper body behaviors | Pre-trained AlexNet CNN | Self-built dataset | Accuracy: 94.2% |
| [40] | Detecting driver distraction | Upper body behaviors | Pre-trained VGG-16 CNN | State Farm Distracted Drivers Dataset | Accuracy: 99.5% |
| [41] | Detecting driver distraction | Head orientation, eye behavior, skin sensor to detect emotions, car signals, EMG | Deep multi-modal fusion based on Conv-LSTM MobileNet CNN is used for images data type | Self-built dataset | Accuracy: 97.47% |
| Type | Number of Filters | Filter Size | Stride | Padding | Size of the Feature Map | Activation Function |
|---|---|---|---|---|---|---|
| Input | - | - | - | - | 227 × 227 × 3 | - |
| Convolution l | 96 | 11 × 11 | 4 | - | 55 × 55 × 96 | ReLU |
| Max Pool 1 | - | 3 × 3 | 2 | - | 27 × 27 × 96 | - |
| Convolution 2 | 256 | 5 × 5 | 1 | 2 | 27 × 27 × 256 | ReLU |
| Max Pool 2 | - | 3 × 3 | 2 | - | 13 × 13 × 256 | - |
| Convolution 3 | 384 | 3 × 3 | 1 | 1 | 13 × 13 × 384 | ReLU |
| Convolution 4 | 384 | 3 × 3 | 1 | 1 | 13 × 13 × 384 | ReLU |
| Convolution 5 | 256 | 3 × 3 | 1 | 1 | 13 × 13 × 256 | ReLU |
| Max Pool 3 | - | 3 × 3 | 2 | - | 6 × 6 × 256 | - |
| Fully Connected 1 | - | - | - | - | 4096 | ReLU |
| Dropout 1 | Rate = 0.5 | - | - | - | 4096 | - |
| Fully Connected 2 | - | - | - | - | 4096 | ReLU |
| Dropout 2 | Rate = 0.5 | - | - | - | 4096 | - |
| Fully Connected 3 | - | - | - | - | 1000 | Softmax |
| Driver’s Behavior | Description |
|---|---|
| Yawning | The participant yawns as an indication of tiredness |
| Nodding | The participant’s head falls as an indication of feeling sleepy |
| Looking aside | The participant looks right or left as an indication of distraction |
| Talking or laughing | The participant makes conversation as an indication of being vigilant |
| Sleepy eyes | The participant’s eye blinking rate is increasing as an indication of drowsiness |
| Drowsy | The participant performs a collection of the above behaviors as an indication of drowsiness |
| Stillness | The participant is still and drives normally |
| Dataset | Classes | Dataset Annotation | Number of Subjects | Scenarios |
|---|---|---|---|---|
| Head Position | Stillness | 0 | 36 | Day—without glasses |
| Nodding | 1 | Day—glasses | ||
| Looking to the side | 2 | Day—sunglasses | ||
| Mouth Movements | Stillness | 0 | 36 | Night—without glasses |
| Yawning | 1 | Night—glasses | ||
| Talking and laughing | 2 |
| Configuration | Value |
|---|---|
| Optimizer | Adam optimizer |
| Mini-batches | 45 |
| Initial learning rate | 0.0003 |
| Maximum epochs | 3 |
| Validation frequency | Every 100 iterations |
| L2 regularization | 0.1 |
| Squared gradient decay factor | 0.8 |
| Execution environment | multi-GPU |
| Head Position Dataset | Mouth Movement Dataset | |
|---|---|---|
| Training | 45,600 images | 55,200 images |
| Evaluation | 5700 images | 6900 images |
| Testing | 5700 images | 6900 images |
| Image Size | 640 × 480 | 640 × 480 |
| Total | 57,000 images | 69,000 images |
| Transfer Learning Model | PPV | Recall | Specificity | FDR | F1-Score | Accuracy |
|---|---|---|---|---|---|---|
| Transfer learning model | PPV | Recall | Specificity | FDR | F1-score | Accuracy |
| Head dataset | 0.959 | 0.959 | 0.97 | 0.04 | 0.959 | 95.9% |
| Mouth dataset | 0.955 | 0.958 | 0.977 | 0.04 | 0.957 | 95.5% |
| Combined model | 0.957 | 0.958 | 0.97 | 0.04 | 0.958 | 95.7% |
| Head Position Dataset | Mouth Movement Dataset |
|---|---|
| 3000 looking aside images | 3000 yawning images |
| 3425 nodding images | 3000 talking and laughing images |
| 2854 stillness images | 3000 stillness images |
| 9279 images | 9000 images |
| Configuration | Value |
|---|---|
| Classifier | Optimizable SVM, optimizable tree and optimizable KNN |
| Kernel function | Gaussian |
| Optimizer | Bayesian optimization |
| K rank | 20–60 |
| Validation | Five-fold cross-validation technique |
| Transfer Learning Model | K Rank | PPV | Recall | Specificity | FDR | F1-Score | Accuracy |
|---|---|---|---|---|---|---|---|
| Head dataset | 40 | 0.997 | 0.997 | 0.998 | 0.02 | 0.997 | 99.7% |
| Mouth dataset | 50 | 0.996 | 0.996 | 0.998 | 0.003 | 0.996 | 99.6% |
| Combined model | - | 0.9965 | 0.9965 | 0.998 | 0.01 | 0.9965 | 99.65% |
| Citation | Used Measures | Method | Dataset | Performance |
|---|---|---|---|---|
| [31] | Facial features | Feature extraction through multiple face descriptors followed by PCA and SVM | NTHU Drowsy Driver Detection dataset | Accuracy: 79.84% |
| [32] | Eye state | Improved HOG features and NB classifier | NTHU Drowsy Driver Detection dataset | Accuracy: 85.62% |
| [34] | Facial features | Multi-layer perceptron | NTHU Drowsy Driver Detection dataset | Accuracy: 81% |
| [20] | PERCLOS, yawning | CNN | NTHU Drowsy Driver Detection dataset | Accuracy: 98.89% |
| Our model | Head position, mouth movements | AlexNet feature extraction based on NMF and SVM | NTHU Drowsy Driver Detection dataset | Accuracy: 99.65% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anber, S.; Alsaggaf, W.; Shalash, W. A Hybrid Driver Fatigue and Distraction Detection Model Using AlexNet Based on Facial Features. Electronics 2022, 11, 285. https://doi.org/10.3390/electronics11020285
Anber S, Alsaggaf W, Shalash W. A Hybrid Driver Fatigue and Distraction Detection Model Using AlexNet Based on Facial Features. Electronics. 2022; 11(2):285. https://doi.org/10.3390/electronics11020285
Chicago/Turabian StyleAnber, Salma, Wafaa Alsaggaf, and Wafaa Shalash. 2022. "A Hybrid Driver Fatigue and Distraction Detection Model Using AlexNet Based on Facial Features" Electronics 11, no. 2: 285. https://doi.org/10.3390/electronics11020285
APA StyleAnber, S., Alsaggaf, W., & Shalash, W. (2022). A Hybrid Driver Fatigue and Distraction Detection Model Using AlexNet Based on Facial Features. Electronics, 11(2), 285. https://doi.org/10.3390/electronics11020285