
An Adaptive Modeling Framework for Bearing Failure Prediction



Abstract
:1. Introduction
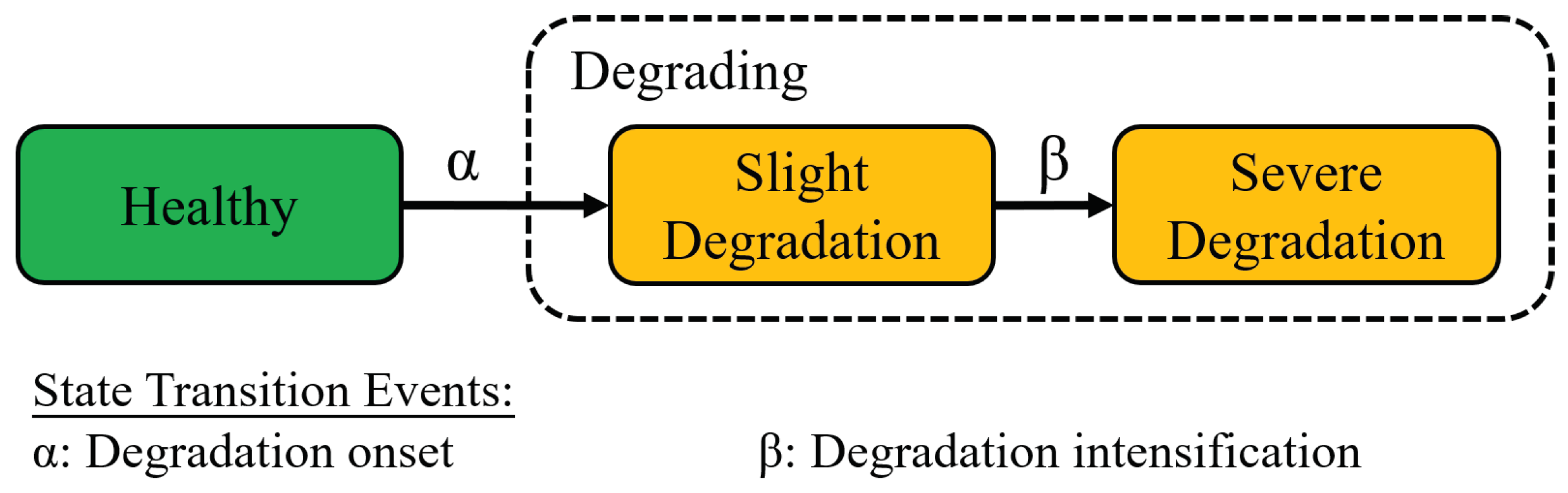
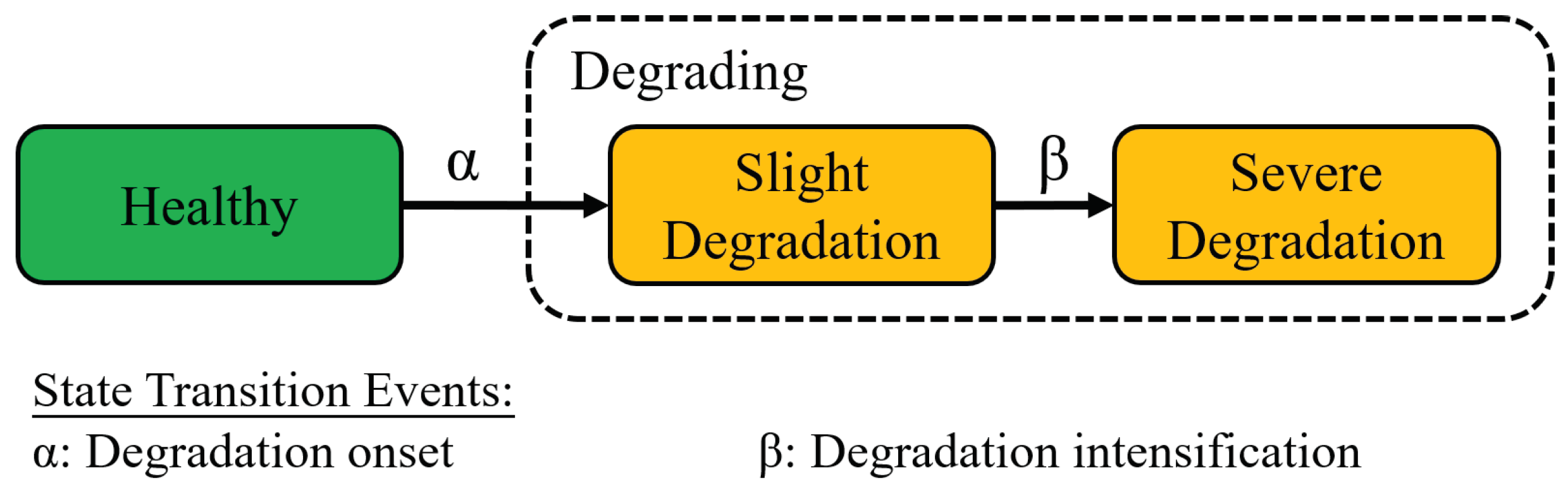
2. Multi-State Health Model
2.1. Health Model Structure
2.2. Detection of Degradation Onset
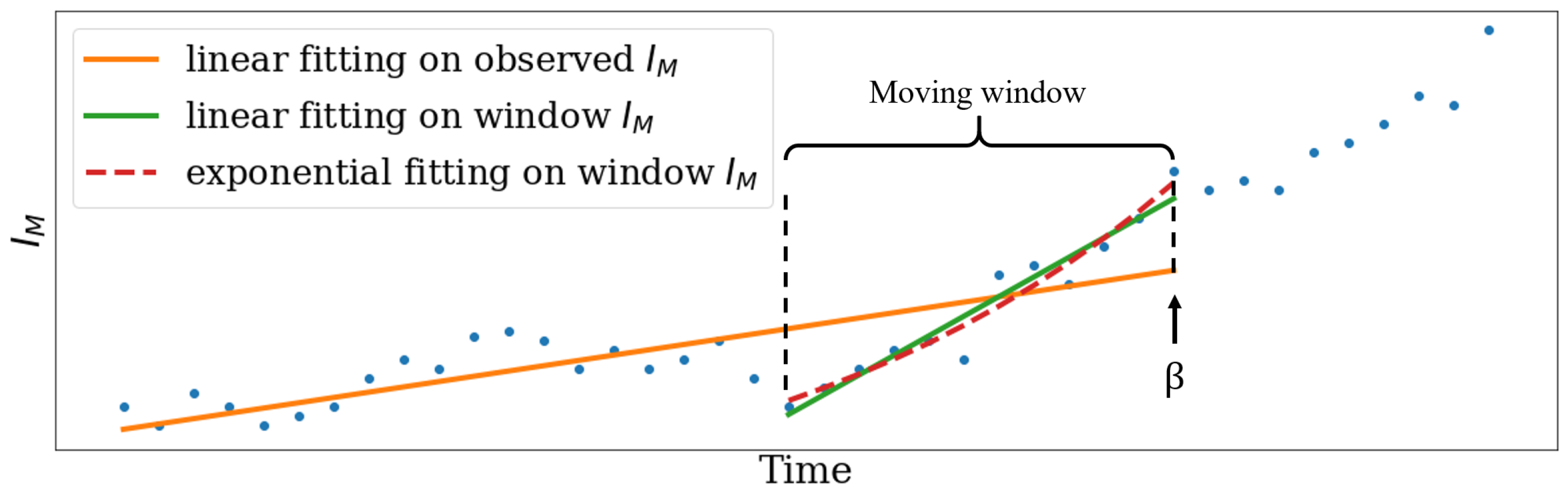
2.3. Detection of Degradation Intensification
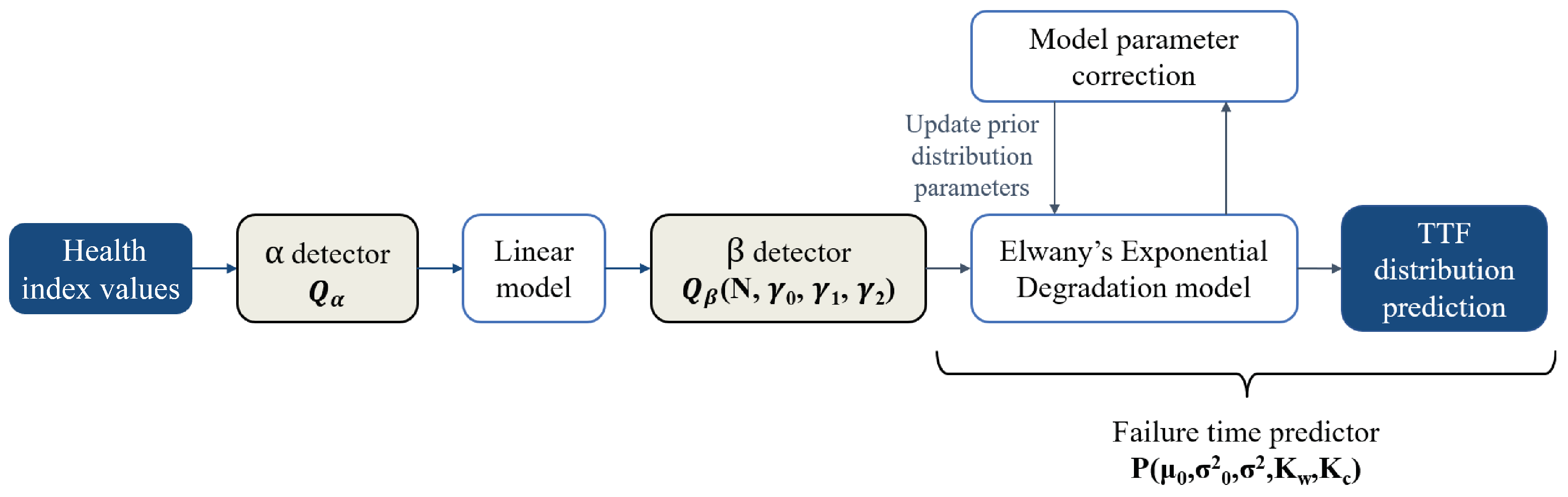
2.4. Prediction of TTF Distribution with Bayesian Updating Method
2.4.1. Exponential Random Coefficient Model
2.4.2. Bayesian Updating of the Distribution Parameters
2.4.3. Computing the TTF Distribution
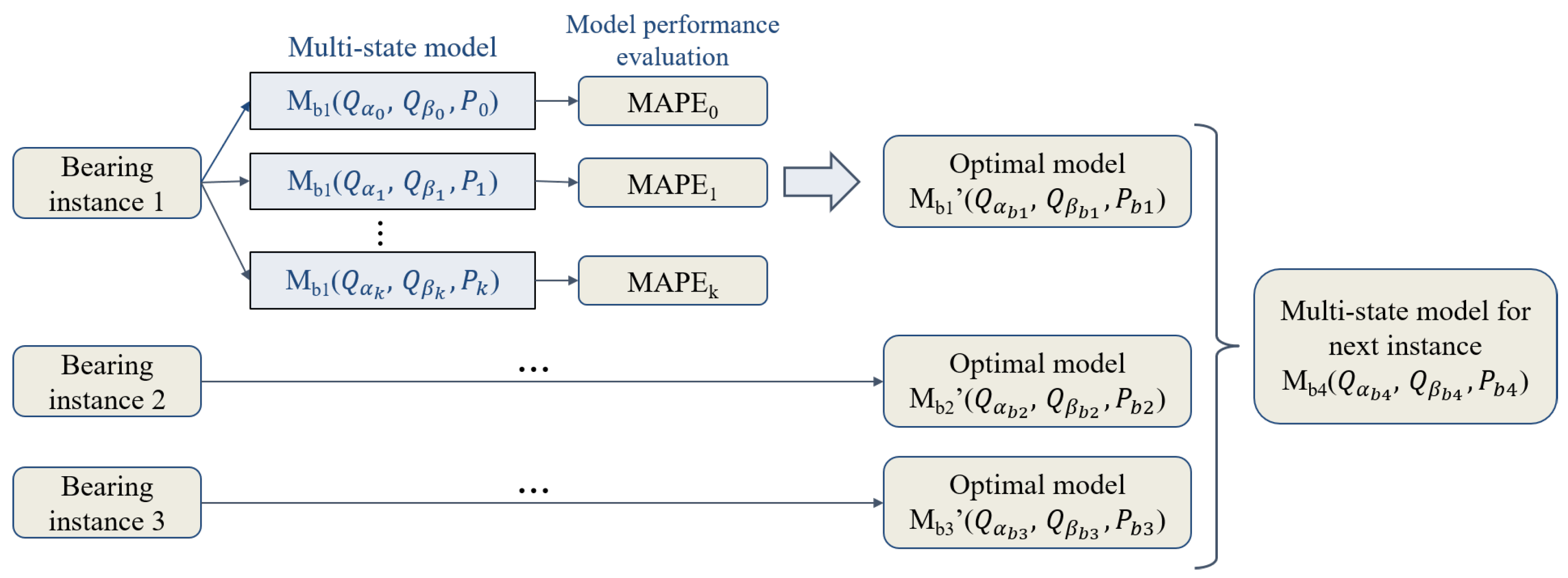
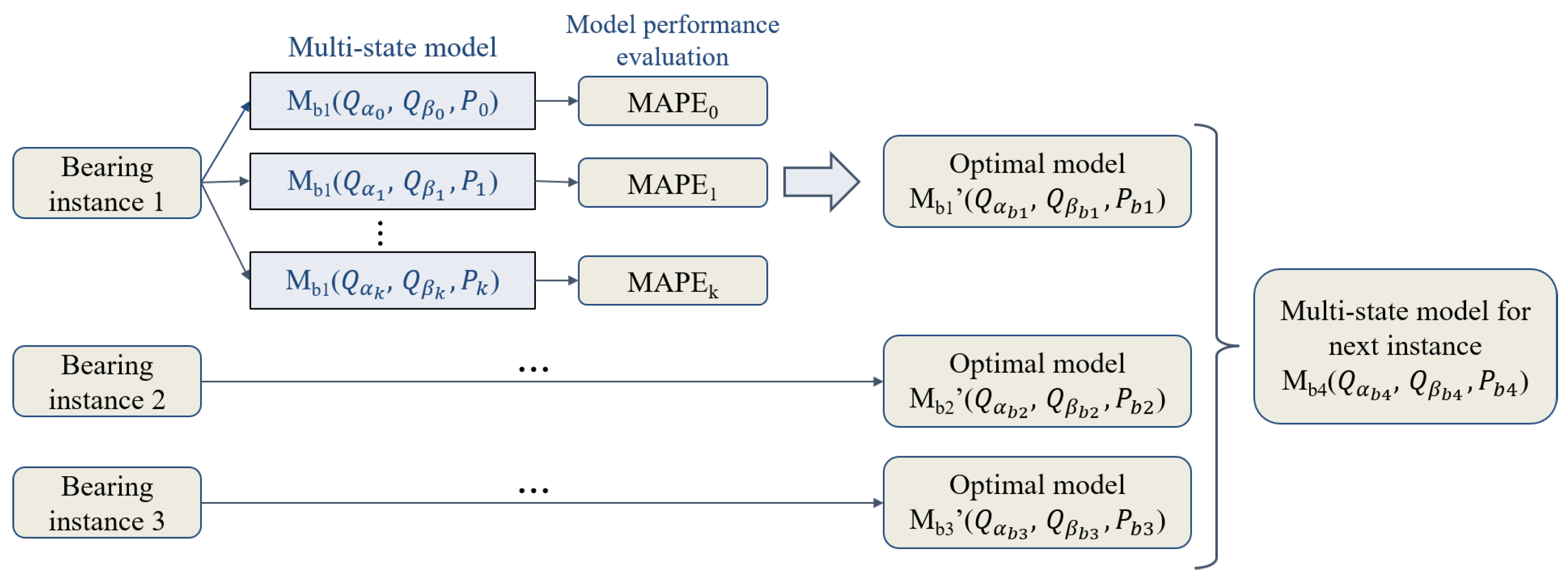
3. Model Training Process
3.1. Evaluation Metrics
3.2. Training Method
4. Case Study
4.1. IMS Dataset
4.2. Model Implementation
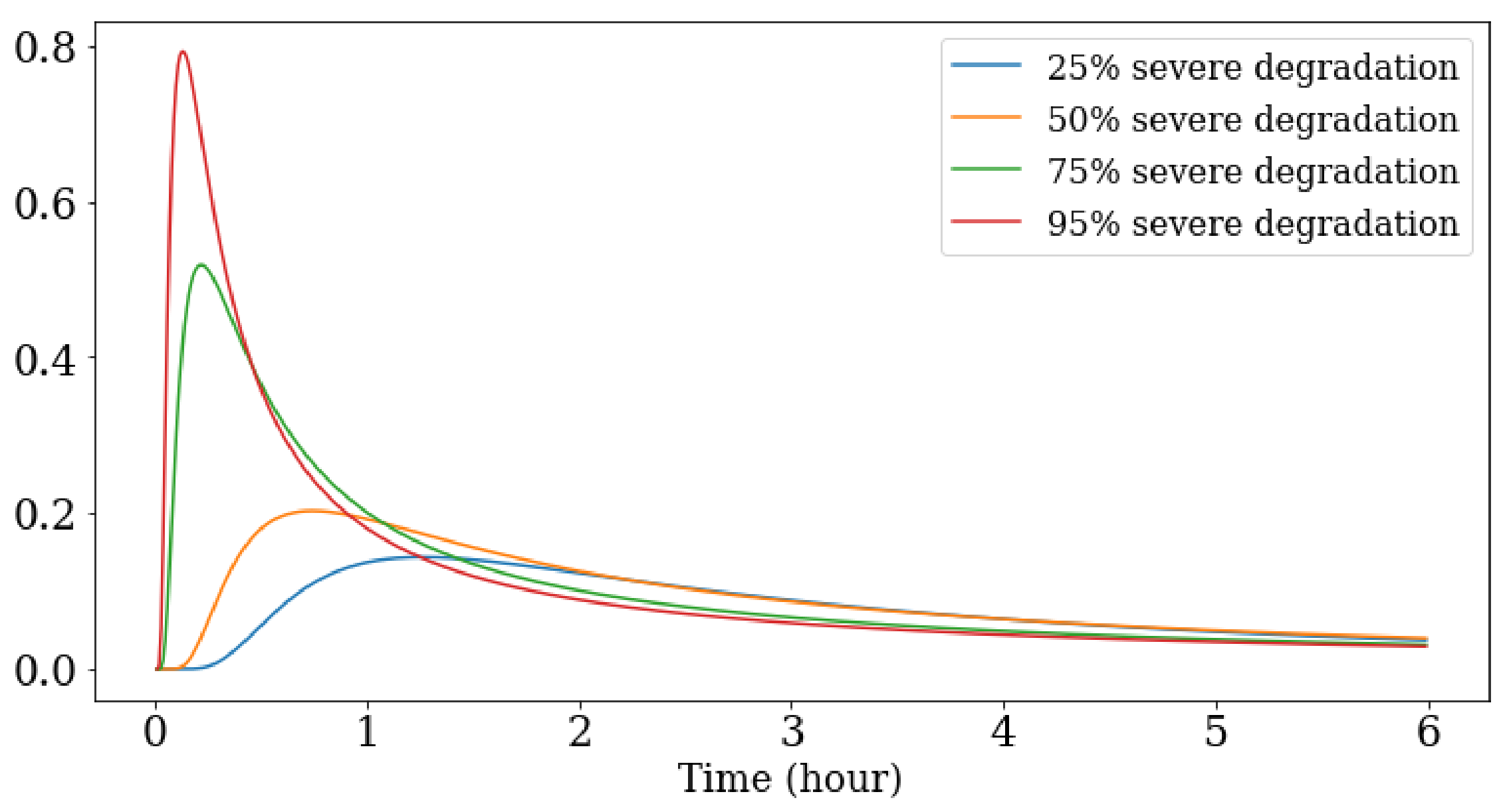
4.3. Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jiang, J.; Zhang, B. Rolling element bearing vibration modeling with applications to health monitoring. J. Vib. Control 2012, 18, 1768–1776. [Google Scholar] [CrossRef]
- Nandi, S.; Toliyat, H.A.; Li, X. Condition Monitoring and Fault Diagnosis of Electrical Motors, A Review. IEEE Trans. Energy Convers. 2005, 20, 719–729. [Google Scholar] [CrossRef]
- Li, Y.; Billington, S.; Zhang, C.; Kurfess, T.; Danyluk, S.; Liang, S. Adaptive prognostics for rolling element bearing condition. Mech. Syst. Signal Process. 1999, 13, 103–113. [Google Scholar] [CrossRef]
- Qiu, J.; Zhang, C.; Seth, B.B.; Liang, S.Y. Damage mechanics approach for bearing lifetime prognostics. Mech. Syst. Signal Process. 2002, 16, 817–829. [Google Scholar] [CrossRef]
- Cubillo, A.; Perinpanayagam, S.; Esperon-Miguez, M. A review of physics-based models in prognostics: Application to gears and bearings of rotating machinery. Adv. Mech. Eng. 2016, 8, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Cerrada, M.; Sánchez, R.V.; Li, C.; Pacheco, F.; Cabrera, D.; Valente de Oliveira, J.; Vásquez, R.E. A review on data-driven fault severity assessment in rolling bearings. Mech. Syst. Signal Process. 2018, 99, 169–196. [Google Scholar] [CrossRef]
- Neupane, D.; Seok, J. Bearing Fault Detection and Diagnosis Using Case Western Reserve University Dataset With Deep Learning Approaches: A Review. IEEE Access 2020, 8, 93155–93178. [Google Scholar] [CrossRef]
- Peng, B.; Wan, S.; Bi, Y.; Xue, B.; Zhang, M. Automatic Feature Extraction and Construction Using Genetic Programming for Rotating Machinery Fault Diagnosis. IEEE Trans. Cybern. 2020, 51, 4909–4923. [Google Scholar] [CrossRef] [PubMed]
- Qiu, H.; Lee, J.; Lin, J.; Yu, G. Wavelet filter-based weak signature detection and its application on rolling element bearing prognosis. J. Sound Vib. 2006, 289, 1066–1090. [Google Scholar] [CrossRef]
- Ahmad, W.; Khan, S.A.; Kim, J.M. A Hybrid Prognostics Technique for Rolling Element Bearings Using Adaptive Predictive Models. IEEE Trans. Ind. Electron. 2018, 65, 1577–1584. [Google Scholar] [CrossRef]
- Ali, J.B.; Chebel-Morello, B.; Saidi, L.; Malinowski, S.; Fnaiech, F. Accurate bearing remaining useful life prediction based on Weibull distribution and artificial neural network. Mech. Syst. Signal Process. 2015, 56–57, 150–172. [Google Scholar]
- Mahamad, A.K.; Saon, S.; Hiyama, T. Predicting remaining useful life of rotating machinery based artificial neural network. Comput. Math. Appl. 2010, 60, 1078–1087. [Google Scholar] [CrossRef] [Green Version]
- Cui, L.; Wang, X.; Xu, Y.; Jiang, H.; Zhou, J. A novel Switching Unscented Kalman Filter method for remaining useful life prediction of rolling bearing. Measurement 2019, 135, 678–684. [Google Scholar] [CrossRef]
- Tobon-Mejia, D.A.; Medjaher, K.; Zerhouni, N.; Tripot, G. A Data-Driven Failure Prognostics Method Based on Mixture of Gaussians Hidden Markov Models. IEEE Trans. Reliab. 2012, 61, 491–503. [Google Scholar] [CrossRef] [Green Version]
- Ren, L.; Sun, Y.; Cui, J.; Zhang, L. Bearing remaining useful life prediction based on deep autoencoder and deep neural networks. J. Manuf. Syst. 2018, 48, 71–77. [Google Scholar] [CrossRef]
- Huang, C.G.; Huang, H.Z.; Li, Y.F.; Peng, W. A novel deep convolutional neural network-bootstrap integrated method for RUL prediction of rolling bearing. J. Manuf. Syst. 2021, 61, 757–772. [Google Scholar] [CrossRef]
- Gebraeel, N.Z.; Lawley, M.A.; Li, R.; Ryan, J.K. Residual-life distributions from component degradation signals: A Bayesian approach. IIE Trans. 2005, 37, 543–557. [Google Scholar] [CrossRef]
- Elwany, A.; Gebraeel, N. Real-Time Estimation of Mean Remaining Life Using Sensor-Based Degradation Models. J. Manuf. Sci. Eng. 2009, 131, 051005. [Google Scholar] [CrossRef]
- Ginart, A.; Barlas, I.; Goldin, J.; Dorrity, J.L. Automated Feature Selection for Embeddable Prognostic and Health Monitoring (PHM) Architectures. In Proceedings of the 2006 IEEE Autotestcon, Anaheim, CA, USA, 18–21 September 2006; pp. 195–201. [Google Scholar]
- Jin, X.; Sun, Y.; Que, Z.; Wang, Y.; Chow, T.W.S. Anomaly Detection and Fault Prognosis for Bearings. IEEE Trans. Instrum. Meas. 2016, 65, 2046–2054. [Google Scholar] [CrossRef]
- Toothman, M.; Braun, B.; Bury, S.J.; Dessauer, M.; Henderson, K.; Wright, R.; Tilbury, D.M.; Moyne, J.; Barton, K. Trend-based repair quality assessment for industrial rotating equipment. IEEE Control Syst. Lett. 2020, 5, 1675–1680. [Google Scholar] [CrossRef]
- Shao, Y.; Nezu, K. Prognosis of remaining bearing life using neural networks. Proc. Inst. Mech. Eng. Part I J. Syst. Control. Eng. 2000, 214, 217–230. [Google Scholar] [CrossRef]
- Yang, F.; Habibullah, M.S.; Zhang, T.; Xu, Z.; Lim, P.; Nadarajan, S. Health Index-Based Prognostics for Remaining Useful Life Predictions in Electrical Machines. IEEE Trans. Ind. Electron. 2016, 63, 2633–2644. [Google Scholar] [CrossRef]
- Liu, K.; Chehade, A.; Song, C. Optimize the Signal Quality of the Composite Health Index via Data Fusion for Degradation Modeling and Prognostic Analysis. IEEE Trans. Autom. Sci. Eng. 2017, 14, 1504–1514. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.; Guo, L.; Li, N.; Yan, T.; Lin, J. Machinery health prognostics: A systematic review from data acquisition to RUL prediction. Mech. Syst. Signal Process. 2018, 104, 799–834. [Google Scholar] [CrossRef]
- Coble, J.; Hines, J.W. Incorporating prior belief in the general path model: A comparison of information sources. Nucl. Eng. Technol. 2014, 46, 773–782. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Qiu, H.; Yu, G.; Lin, J.; Services, R.T. Bearing Data Set. Available online: https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/ (accessed on 19 November 2021).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Expression |
|---|---|
| Kurtosis | |
| Skewness | |
| Peak Frequency | |
| Peak-to-peak | |
| Root Mean Square (RMS) |
| Time (Hour) | % Severe Degradation Time | Actual Failure Time (Hour) | Predicted Failure Time (Hour) | 5th Percentile | 95th Percentile | % Error D |
|---|---|---|---|---|---|---|
| 26.0 | 25% | 30.5 | 33.02 | 25.60 | >100 | 8.25% |
| 27.5 | 50% | 30.5 | 31.31 | 25.25 | >100 | 2.64% |
| 29.0 | 75% | 30.5 | 30.96 | 24.86 | 76.06 | 1.50% |
| 30.2 | 95% | 30.5 | 31.02 | 24.79 | 63.69 | 1.69% |
| Model | Bearing | MAPE 1 |
|---|---|---|
| Randomly generated | Test 3 Bearing 3 | 16.637% |
| Optimal model among 50 randomly generated models | Test 3 Bearing 3 | 4.594% |
| Randomly generated | Test 2 Bearing 1 | 5.962% |
| Model trained with Test 3 Bearing 3 | 3.792% | |
| Model trained with Test 3 Bearing 3 and Test 1 Bearing 3 | 5.483% | |
| Model trained with Test 3 Bearing 3, Test 1 Bearings 3 & 4 | 5.156% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Toothman, M.; Moyne, J.; Barton, K. An Adaptive Modeling Framework for Bearing Failure Prediction. Electronics 2022, 11, 257. https://doi.org/10.3390/electronics11020257
Zhao Y, Toothman M, Moyne J, Barton K. An Adaptive Modeling Framework for Bearing Failure Prediction. Electronics. 2022; 11(2):257. https://doi.org/10.3390/electronics11020257
Chicago/Turabian StyleZhao, Yuntian, Maxwell Toothman, James Moyne, and Kira Barton. 2022. "An Adaptive Modeling Framework for Bearing Failure Prediction" Electronics 11, no. 2: 257. https://doi.org/10.3390/electronics11020257
APA StyleZhao, Y., Toothman, M., Moyne, J., & Barton, K. (2022). An Adaptive Modeling Framework for Bearing Failure Prediction. Electronics, 11(2), 257. https://doi.org/10.3390/electronics11020257