1. Introduction
In a binary classification problem, such as anomaly-based detection, where the dataset contains two sets of examples (normal and anomalous), it is common to encounter class imbalance. Class imbalance generally occurs when the normal set contains significantly more examples or samples than the anomalous set, thus dividing the dataset into minority and majority class samples. While both classes exist in binary classification datasets, the minority class is the one that is often of interest to many binary classification problems [
1]. For example, training an AN-Intel-IDS model often involves imbalanced data where the normal samples are typically more frequent than the anomalous. Even when considering realistic conditions, the normal class contains numerous samples compared to the abnormal or anomalous class, which is often poorly sampled or not well-defined [
2]. Inevitably, the training dataset influences the machine learning models’ predictability and performance. Hence, an imbalanced dataset can lead to classification issues, such as over classification. For example, data imbalance or uneven class distribution can cause an AN-Intel-IDS model to over classify the normal class due to its high probability in the dataset compared to the anomalous one. Thus, data imbalance directly impacts the trained model’s prediction accuracy and overall performance. Further, the class imbalance has an adverse impact on many machine learning (ML) algorithms [
3]. It can lead to biased predictive models, misclassification, and performance degradation. For instance, an anomaly-based detection model is usually biased towards the majority class (i.e., the normal or non-malicious class). In addition to data imbalance, training ML models using insufficient data can also lead to misclassification and performance degradation issues. In general, the expensiveness of data collection and gathering often creates a situation where data for training learning models becomes insufficiently large to train these models effectively. Invariably, insufficient data and imbalanced data adversely affect ML and deep learning (DL) models, where the models’ performance typically degrades when learning from severely imbalanced data, insufficient data, or both [
3,
4,
5,
6,
7,
8,
9]. Therefore, training effective AN-Intel-IDS models require considerable data [
3]. However, sufficient data for training learning models may not be readily available due to data sparsity, data limitation, data privacy, and data sensitivity. Invariably, data privacy, concealment, and sensitivity limit data sharing and accessibility, leading to the use of synthetic data to train the predictive models instead of actual or ground truth data.
Using synthetic data to train, test, or evaluate AN-Intel-IDS models is problematic when the training of predictive models typically involves imbalanced data. In addition, synthetic data can be unrealistic and potentially bias. On the other hand, ground-truth datasets are highly desirable when training AN-Intel-IDS models. However, the ground truth data usually has a skewed distribution, thus, leading to biased predictive models. Another critical issue to consider when training AN-Intel-IDS models is the ability of the learning model to detect both known and unknown attacks, which indicates the need to train learning models in an adversarial setting by generating novel adversarial examples containing unforeseen attacks. Hence, adversarial learning is as equally crucial as imbalanced learning. Nonetheless, adversarial learning still suffers from data imbalance. In general, anomaly-based detection models use a one-class approach, typically the normal class, to detect intrusions even when the abnormal class is of interest. Further, even when using adversarial learning approaches, such as unsupervised generative adversarial networks (GAN), the underlying assumption is that the training data are anomaly-free [
4]. As a result, anomaly-based models suffer from false positives due to the model’s bias towards the normal examples.
Traditional approaches to solving the data imbalance problem had primarily focused on data augmentation, data generation, and data imputation. Data augmentation aims at increasing the data by creating additional training samples either by transforming the data in the data space or creating additional examples in the feature space [
5]. Data generation aims to increase the data by creating new synthetic data to preserve the privacy and confidentiality of the actual data. Data imputation, which targets missing data, increases data samples by replacing missing values using substitution methods, such as regression and matching methods, to name a few [
6,
7]. While data augmentation, data generation, and data imputation are the intuitive approaches to consider, generating sufficient data or obtaining a balanced class distribution from ground truth data using traditional ML or DL is invariably tortuous. Hence, a better approach is to use non-traditional ML and DL methods to address data imbalance for normal learning and adversarial learning. For example, non-traditional ML and DL methods for data augmentation, data generation, or both include but not limited to IoT Sequential GAN, Wasserstein GAN plus Gradient Penalty (WGAN-GP), and GAN plus Synthetic Minority Oversampling Techniques (GAN-SMOTE) [
10,
11,
12].
This paper surveys the most recent data augmentation and generation methods, we refer to as data-driven learning (DDL) methods, for imbalanced and adversarial learning using rapid review, structured reporting, and subgroup analysis. It focuses on methods that employ non-traditional approaches to data augmentation and generation, such as generative models, and whose domain of application is one or more of the following domains: Internet of Things (IoT), cyber-physical systems (CPS), smart homes, intrusion detection systems, traditional communication networks, and cybersecurity. In general, this paper aims to present a rapid review of data augmentation and generation methods proposed, particularly in the last three to four years using a qualitative approach. Its main goal is to enable researchers, who are interested in using data-driven learning to address data scarcity and data restriction present to build AN-Intel IDS, to get a general idea of the latest proposed methods using non-traditional ML and DL approaches, as well as a general understanding of the challenges and knowledge of open issues. Hence, the main contribution of this paper is a classification scheme based on the method class of learning, type of the generative model, the specific domain of application, publication year, and subgroup analysis. Subgroup analysis uses the type of approach to subgroup the methods, to show the evaluation results based on the following: data quality, prediction accuracy using f-score, and performance compared to other methods. In addition, it highlights the advantages and disadvantages of DDL methods. The remainder of this paper’s organization is as follows: In
Section 2, we provide background preliminaries. Then, we review the related work in
Section 3 and describe our research design and methodology in
Section 4. Next, in
Section 5,
Section 6 and
Section 7, we describe and summarize the DDL methods for imbalanced and adversarial learning, respectively. Then, we present the results of our findings in
Section 8. Finally, we highlight challenges, discuss open research issues in
Section 9 and conclude in
Section 10.
3. Related Work
The thesis in [
17], which focused on network security for IoT, provided an overview of generative deep learning models for generating network traffic. The author broadly categorized the surveyed models into network flow-level and network packet-level. Further, they classified the models based on the type of the generated network traffic, the employed algorithm, and used features of the generated traffic. In addition, the author highlighted the limitations of these models based on IoT traffic generation and the level of generated traffic and proposed a hybrid model that generated a combination of flow-level and packet-level network traffic.
The authors in [
18] focused on GAN-based anomaly detection (AnoGAN) methods by highlighting their pros and cons. The authors suggested that the GAN-based methods for anomaly detection’s approach built on the adversarial feature learning approach for detecting anomaly used by the bidirectional GAN, known as BiGAN. Further, they empirically validated the main GAN-based models for anomaly detection by re-implementing all models and evaluating their performance using the commonly known datasets for training and testing the models.
The study in [
19] focused on adversarial examples for deceiving deep learning models for image recognition and surveyed AEs generation methods and their defense techniques. The authors suggested that one notable aspect of AEs was that the same set of AEs could attack different models with different architecture and training data. Further, they explained the cause of AEs, described their characteristics, and discussed their evaluation metrics. Additionally, the authors listed AEs’ adversarial abilities and goals and introduced AEs’ construction methods, highlighting their advantages and disadvantages. The authors compared their attributes, success rate, and transfer rate based on different attack methods. Moreover, they described the primary goals of defending against AEs, detailed current defense techniques and their limitations, and summarized several challenges.
Focusing on the creation of synthetic data through deep generative models, the authors in [
3] provided a comprehensive survey of GAN-based approaches for generating or transforming synthetic network data for network applications such as IoT and mobile networks and presented an overall taxonomy of generative models where they broadly divided them into explicit density and implicit density models. Further, they provided a detailed overview of GAN variations and architectures and their applications in computer and communication networks. They proposed an evaluation framework for comparing the performance of different GAN-based approaches using publicly known network datasets. Most notably, they provided a taxonomic categorization of generative approaches based on their application, problem solved, and model used over the various classes of mobile network, network analysis, IoT, physical layer, and cybersecurity, In addition, they introduced parameters for evaluating GANs such as loss, optimizer, learning rate, latent dimension, batch size, and epochs.
The paper in [
20] reviewed GANs and discussed their strength compared to other generative models and how they operate. The authors noted problems related to the training, testing, and evaluation of GANs and further classified the GANs based on the used approach into two categories: GANs to protect cybersecurity systems from attacks and GANs used to attack cybersecurity systems. In addition, they highlighted four GAN properties and discussed variant GAN architectures and GANs limitations in cybersecurity applications.
The study in [
21] focused on the field of imbalanced learning development by discussing data imbalance open issues and challenges related to various forms of learning and new methods for managing data imbalance for recent applications. The author analyzed different aspects of imbalanced learning such as classification, clustering, and regression and highlighted challenges in several critical areas, including imbalanced classification and semi-supervised and unsupervised handling of imbalanced datasets.
The authors in [
13] focused on high-class imbalance, where the majority to minority class ratio is 100:1 and 10,000:1, in big data. Further, they discussed data-level and algorithm-level techniques and reviewed methods addressing the class imbalance in regular and big data. The authors noted that data sampling methods with random over-sampling methods showed overall better results concerning the class imbalance. However, algorithm-level methods performance reported in the literature showed inconsistent and conflicting results and evaluation methods with limited scope. As a result, the authors suggested the need for comprehensive, comparative studies.
This study focuses on data scarcity, unequal data distribution, lack of adversarial examples and survey generative approaches, data generation, data augmentation, imputation methods for training, testing, and validating intelligent network intrusion detection systems using non-adversarial and adversarial settings. While it expands on the scope of DDL methods, it is not exhaustive and does not comparatively analyze and evaluate the performance of the surveyed methods. However, it provides a subgroup analysis, where the type of the approach indicates the method’s subgroup membership, to enable comparing studies based on their evaluation results, such as standard measures to assess the augmented or generated data’s quality, and the trained models’ prediction accuracy and performance compared to other methods, algorithms, or approaches.
4. Research Design and Methodology
This section describes the design method and research methodology we used conducting the survey, extracting the existing research work on DDL methods for imbalanced and adversarial learning, synthesizing information, and reporting findings.
For our methodological approach, we used a rapid review method to survey the literature on non-traditional or generative-based data augmentation and generation methods for imbalanced and adversarial learning. Precluding meta-analysis, we used structured reporting and subgroup analysis to synthesize DDL methods published in the last three to four years. Hence, the study is qualitative in nature. By undertaking the review and analysis approach mentioned earlier, our main objective is to enable researchers to get a general idea of the state of the DDL methods and their application in certain domains without increasing the needed time to synthesize and analyze the gathered information and report on findings. Furthermore, to offset the shortcoming of rapid review, we use an alternative synthesis method. While meta-analysis is highly desirable for comparing studies and driving new findings, acceptable synthesis methods, such as structured reporting with tabulation and visual displays and subgroup analysis, are better alternatives to the precluded meta-analysis when there is a concern about missing studies and statistical heterogeneity or simply heterogeneity of studies, i.e., variability among studies [
22]. Additionally, our search strategy increased search specificity at the expense of search comprehensibility. We are limiting the search scope to include a relatively small set of publications while excluding others, which may result in excluding other relevant studies and selection bias. However, using a systematic review later to verify the critical outcomes of this survey can help address these issues [
23].
To gather relevant and specific studies, we searched three repositories, including Howard University Libraries (accessed on 5 December 2021) (
https://founders.howard.edu/using-the-libraries/), IEEEXplore (accessed on 5 December 2021) (
https://ieeexplore.ieee.org/Xplore/home.jsp), and Google Scholar (accessed on 31 December 2021) (
https://scholar.google.com/). We used the following search strings: data augmentation for imbalanced learning, data generation for adversarial learning, data augmentation using generative models, and data generation using generative models. In addition, we used the publication date and domain of application as our selection criteria to increase the specificity of the search. In particular, we filtered the results by publication date to consider only publications from 2021–2018. In addition, we sorted the publications by relevance using the IoT, CPS, IDS, network, and security domains of applications while excluding other domains. Finally, we conducted our analysis using structured reporting, which we augmented with tabulation and visual display methods and subgroup analysis to compare methods based on their evaluation results using the type of the approach, for example, data augmentation, data generation, or both. In summary, we conducted the following for data analysis and information synthesis:
First, we broadly classified the surveyed DDL methods based on the class of learning into imbalanced, adversarial, and non-adversarial (normal) learning.
Second, we considered methods employing more than one class of learning and those using more than one level of traffic (i.e., flow-level and packet-level), which we classified as hybrid data-generation methods.
Third, we considered the type of approach (e.g., data generation, data augmentation, and data imputation), application domain, and publication year.
Fourth, we used the type of approach to create subgroups (e.g., data augmentation and data generation), for further analysis and comparison
Finally, we compared the methods for each subgroup based on data quality, prediction accuracy, and performance.
In addition to imbalanced learning, non-adversarial or normal learning, and adversarial learning, we further considered other forms of learning to classify the DDL methods into conditional adversarial learning, transfer learning, statistical learning, exploiting learning, and deceptive learning. Finally, we defined the learning forms mentioned above in
Table 1 and detailed our findings using the classification scheme in
Table 2 and subgroup analysis based on the type of approach to reporting on the results of the evaluations in
Table 3. Finally, we summarized the advantages and disadvantages of these methods in
Table 4.
5. DDL Methods for Imbalanced Learning
The study in [
8] suggested that most approaches that employ methods other than GAN suffered from data loss or overfitting and proposed the use of GAN to solve the data imbalance instead of resampling and SMOTE techniques to avoid overfitting caused by resampling and class overlapping or noise caused by SMOTE. The GAN generated virtual data similar to the minority class of the imbalanced data. The authors used the balanced data generated by the GAN, which solved the problem of overfitting and overlapping by specifying the desired resampling rate, to train an anomaly-based detection model based on the random forest (RF) method by increasing the weight of the minority attack class in the intrusion detection evaluation dataset (CICIDS). The GAN-based data augmentation method using resampling boosted the rare classes of the CICIDS 2017 dataset, which constituted less than 0.1% of the dataset, by generating 10,000 data of Bot, infiltration, and heartbleed. The batch size or the number of data learned at a time is 10 for Bot, 1 for the remaining two classes due to tiny data size (less than 30), and 20 for the epoch. The study compared the performance of the GAN-RF model, Single-RF model, and SMOTE-RF model using accuracy, precision, recall, and f-score. The GAN with Random Forest algorithm (GAN-RF) model used GAN for data resampling and RF for classification, standalone Random Forest algorithm (Single-RF) used RF for classification only, and SMOTE with Random Forest algorithm (SMOTE-RF) used SMOTE for data resampling and RF for classification. The GAN-RF performed better than the Single-RF and SMOTE-RF. Using the average score, GAN-RF had an accuracy of 99.83% and f-score of 95.04% compared to 99.19% accuracy and 87.79% f-score for the Single-RF model and 99.51% accuracy and 88.16% f-score for SMOTE-RF.
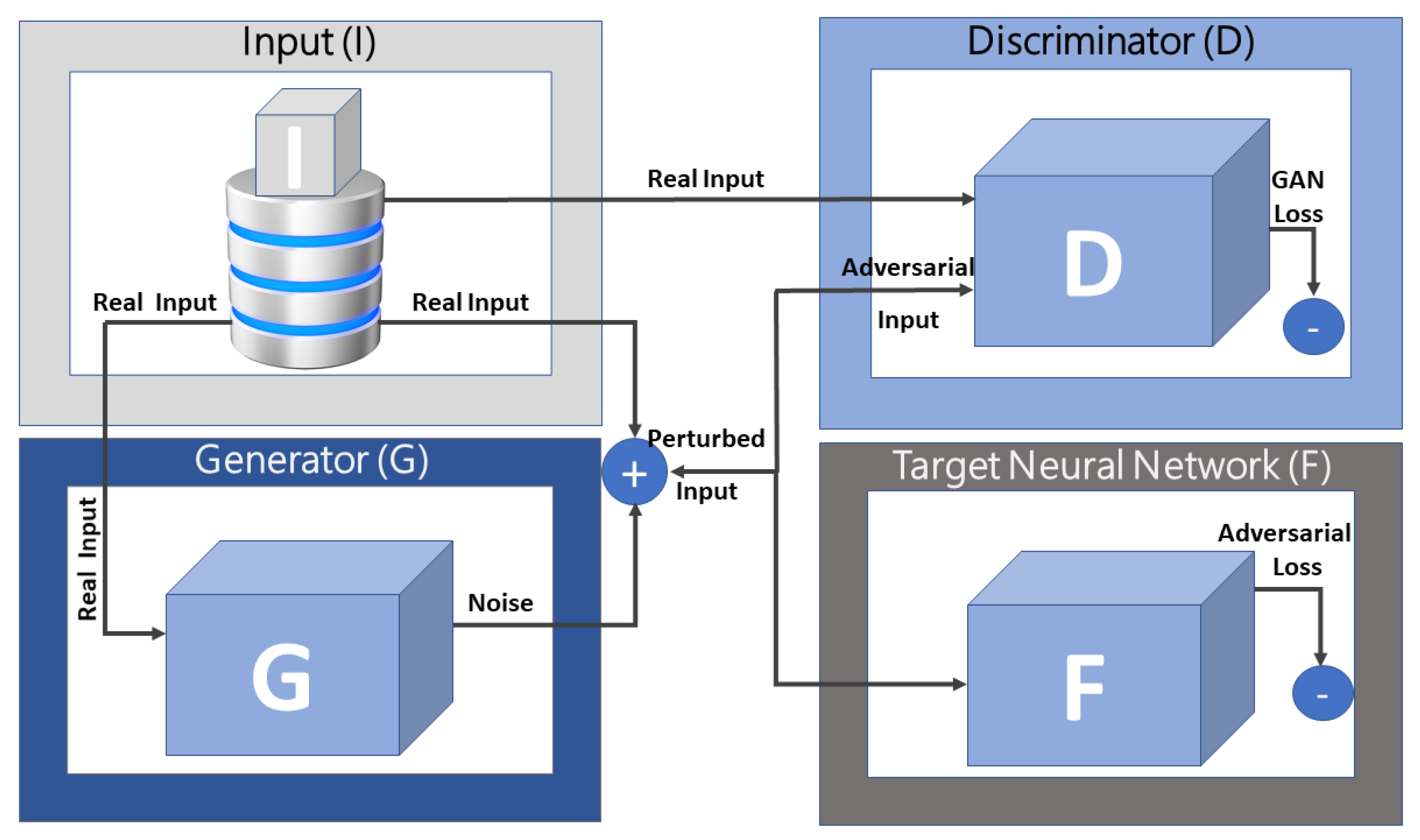
In addition to augmenting data by producing more examples to balance the minority class examples in the dataset, the GAN can simulate new unforeseen attacks. For example, the authors in [
26] used GAN to augment network traffic represented using imagery to train a Convolutional Neural Network (CNN)-based intrusion detection model, and to simulate unforeseen attacks, we refer to this method as GAN 2D imagery CNN or GAN-2CNN for simplicity. However, the two-dimensional image of network flow, produced using two-dimensional mapping techniques, suffered from the unequal representation of normal and abnormal examples. The GAN addressed the imbalanced imagery issue by generating new images of unforeseen attacks, and the CNN classified the 2-D imagery, leading to better predictive accuracy for the GAN-2CNN model. The GAN-based imagery data augmentation method trained the auxiliary classifier GAN (AC-GAN), where it used the generator of the AC-GAN to create new synthetic attacks’ images and balance the training dataset. A variant of GAN, AC-GAN, takes a class label and noise as input and generates images [
35]. The employed AC-GAN’s generator created fake images from a 100-dimensional input random noise vector of a uniform distribution and a two-dimensional one-hot label. The study analyzed the performance of the GAN-based imagery data augmentation using CICIDS17 and AAGM17 datasets with imbalanced traffic data and the full implementation of the model (referred to by the authors as MAGNETO, a supervised deep learning methodology for learning a robust intrusions model that deals with data imbalance). In addition, it measured the effectiveness of the data augmentation method compared to the SMOTE and adaptive synthetic (ADASYN), proposed by [
36] data augmentation methods, and the effectiveness of training the 2D CNN using GAN-augmented data of varying balance sizes. Using a Variant of MAGNETO, i.e., MAGNETO with SMOTE (SMOTE-MAGNETO) and MAGNETO with ADASYN (ADASYN-MAGNETO), the MAGNETO with GAN (GAN-MAGNETO) outperformed the other variants on both datasets in terms of f-score and precision. However, GAN-MAGNETO exhibited a drop in recall, though negligible, using CICIDS17 compared to its performance using the AAGM17 dataset.
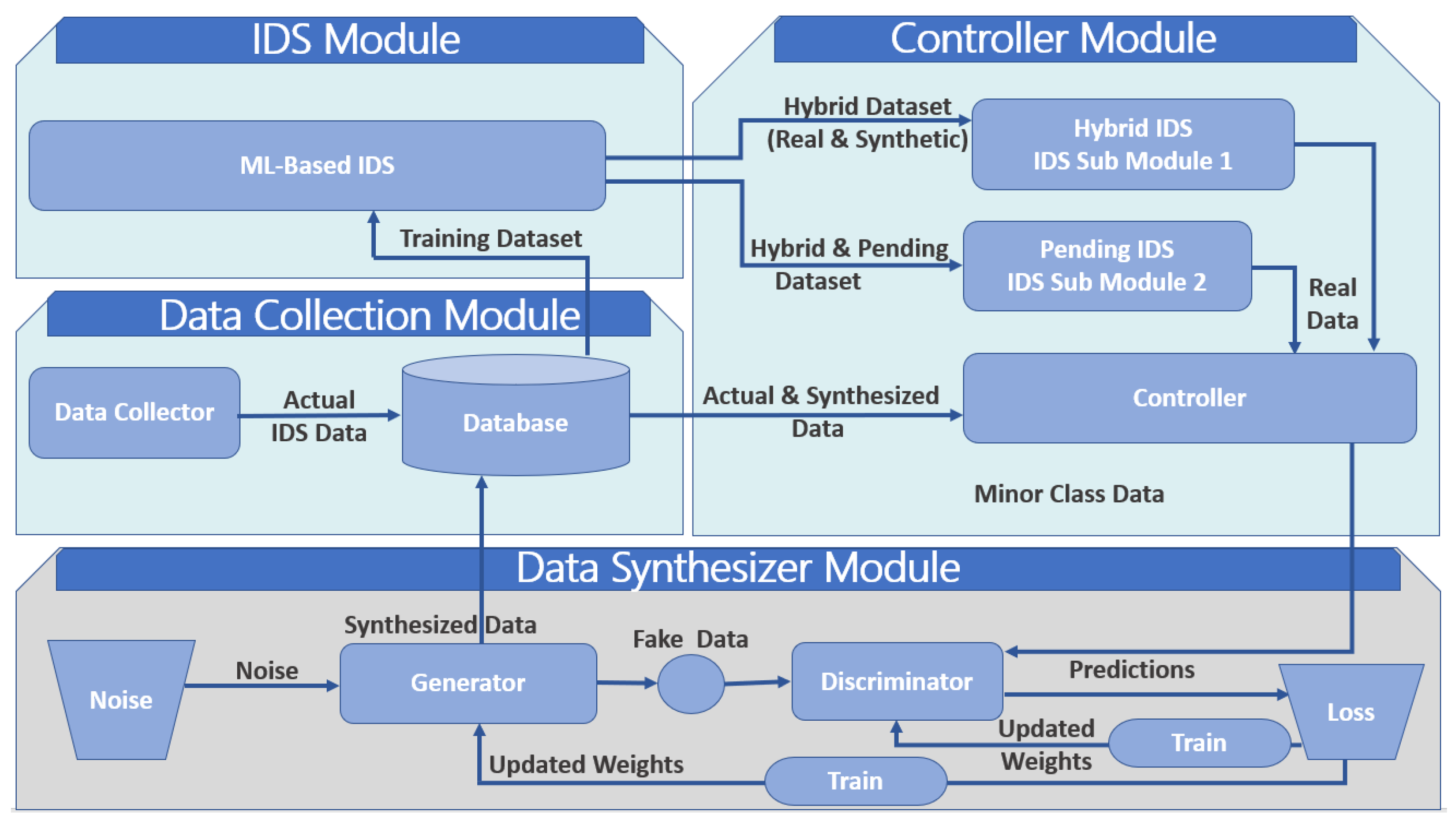
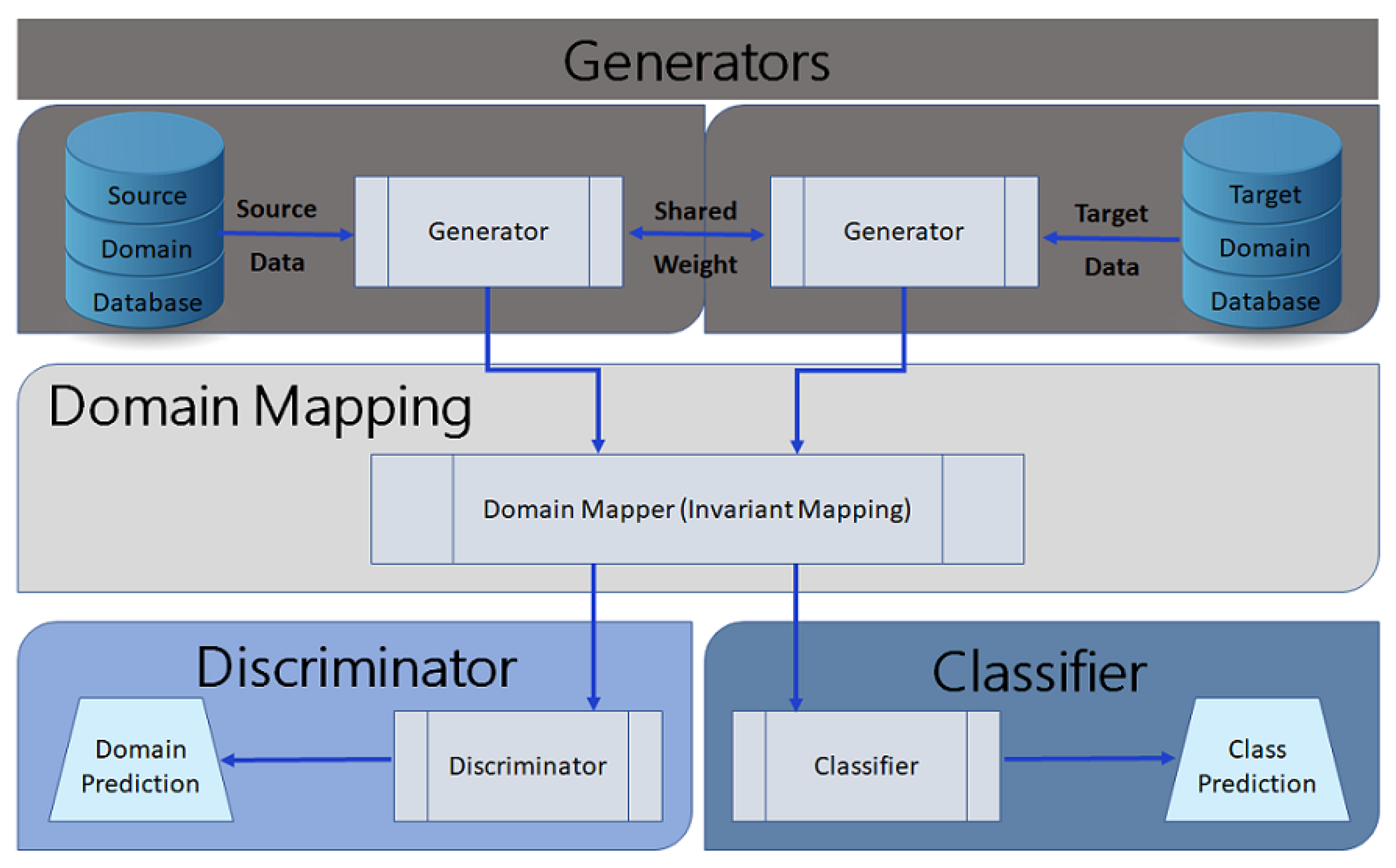
Imbalanced data can hinder the proper training of an AN-Intel-IDS and thus its performance. Publicly available datasets, such as the KDD-99 and CIDDS-001, are mostly imbalanced and often contain more ’normal’ examples than anomalous examples. The GAN-based IDS (G-IDS) in [
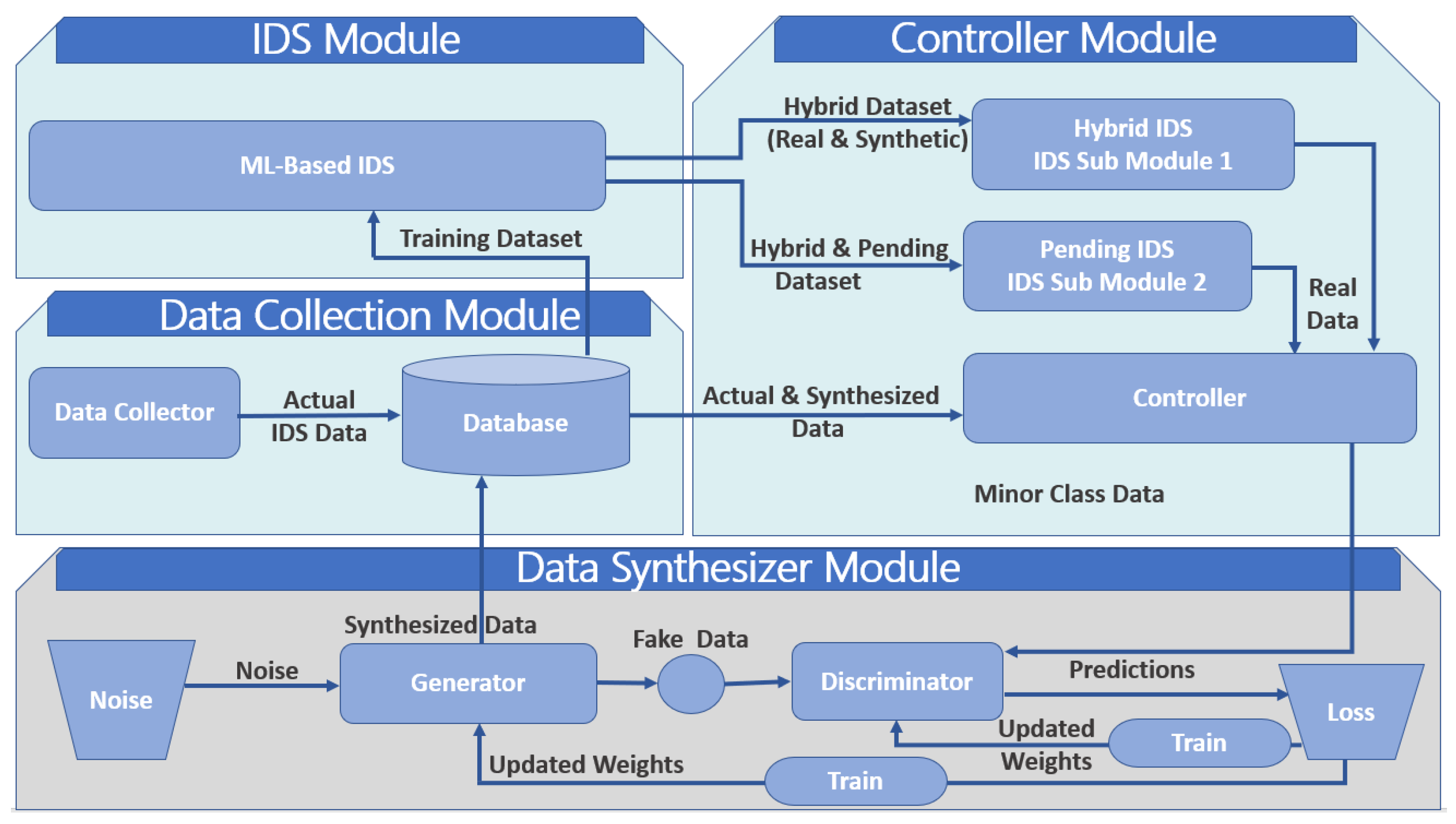
28] for securing cyber-physical systems (CPS) addressed the issue of imbalanced data by generating more data to train the IDS, which is a multi-layer artificial neural network. It used the NSL KDD-99 to generate synthetic data that augmented the original data, thus, increasing the distribution of attack examples in the dataset. The proposed G-IDS framework consisted of four modules: database, IDS, controller, and synthesizer.
In addition to the generated synthetic data by the synthesizer module generator, the database module contained real-world intrusion detection data. The controller module decided whether to accept or reject pending data, i.e., synthetic data was data that had not been accepted or rejected by the controller. The GAN, which is part of the synthesizer module, generated the synthetic data. The synthesizer labeled the generated data as pending, due to the uncertainty of the GAN, before sending it to the database module. The authors used the controller module to evaluate the IDS module twice. First, they trained the IDS module on a hybrid dataset only, i.e., the combined original and synthetic data already accepted by the controller. Then, they trained the IDS module using a combination of the hybrid and pending datasets. The controller accepted or rejected the pending data based on the IDS performance. By measuring the detection rate for each data class (normal or attack) and comparing it to a pre-established performance threshold, the controller identified the weakly detected classes and sent the data examples to the synthesizer module to generate more examples. The process repeated until a satisfactory IDS performance was obtainable.
Figure 1 shows the G-IDS framework, where
and
denoted IDS performance using hybrid and pending data, respectively. Comparing the performance of the G-IDS to a standalone IDS (S-IDS) or an IDS without a GAN using precision, recall, and F1 score as metrics, G-IDS performed better than S-IDS in terms of detection accuracy and stability on both the original and boosted datasets. The f-score of S-IDS was 70% to 78% using a 20% and 40% data increase, respectively, compared to G-IDS, which was 90% to 96% for a 20% and 40% data increase, respectively. However, G-IDS f-score dropped significantly to 60% for a 60% data decrease due to the G-IDS taking random noise as input. In terms of prediction accuracy, S-IDS performance suffered due to insufficient data. G-IDS generally had better performance and prediction accuracy; however, it is centralized and computationally expensive.
Unbalanced distribution of normal and attack examples in a dataset can lead to detection inaccuracies. Further, the detection accuracy of an IDS may vary based on the degree of class imbalance. The method in [
12] addressed the issue of imbalanced learning using GAN-augmented data to train a supervised and unsupervised host-based intrusion detection system (HIDS), i.e., Support Vector Machines (SVM) and CNN, respectively. In addition to data augmentation using GAN, the author considered data oversampling using SMOTE to evaluate the performance of the GAN-based approach. The SMOTE-based approach over-sampled minority classes from unbalanced data, whereas the GAN-based approach generated the data (similar to the training dataset) itself. The dataset contained system-call trace data represented as a series of integer numbers mappable to system calls made on a Linux OS. Both approaches augmented the abnormal examples by creating new data that was invariably synthetic. The author applied both approaches to the pre-processed ADFA-LD dataset and then used SVM and CNN to classify process operation based on system call trace data into normal or malicious behavior. The GAN-based approach to data augmentation was slightly reliable compared to the SMOTE-based approach. In addition, models trained using augmented data had better classification accuracy than models trained using original data. In both cases, models that used GAN-based augmented data performed better. As the number of minority class examples increased by 30%, 50%, 70% and 100%, the classification accuracy and classification performance increased as well. In general, when using data augmentation, CNN performed better than SVM for largedata sizes, whereas SVM showed a better performance for moderate data sizes.
The number of attack examples in the smart home environment, is often smaller than the normal examples, thus creating data imbalance. Therefore, detecting intrusions in a smart home environment requires designing intelligent anomaly-based IDS capable of handling disproportions in the datasets. The authors in [
9] proposed an embedded intrusion detection scheme on the smart homes edge nodes that exploited GAN to reduce the impact of disproportionate datasets, where normal examples are more frequent than attack examples, on the performance of the classifier. The authors used AC-GAN to generate synthetic data to balance the proportion of normal and attack examples in the UNSW-NB15 training dataset. The authors converted the network data into images prior to feeding the pre-processed data to the AC-GAN generator. In addition to a noise, the AC-GAN generator took the class label as input to generate synthesized data for the minority attack class. The authors then combined the synthesized data with the original data to train the classifier. The evaluation results showed that the proposed scheme, which included GAN-based data augmentation, improved the classifier precision for the minor attack class; the precision and recall of the anomaly detection was about 96% and 98%. However, when comparing the precision given the different categories of attacks, the precision of some of the attacks belonging to the majority class declined due to the low quality of the generated synthetic data.
7. Hybrid DDL Methods
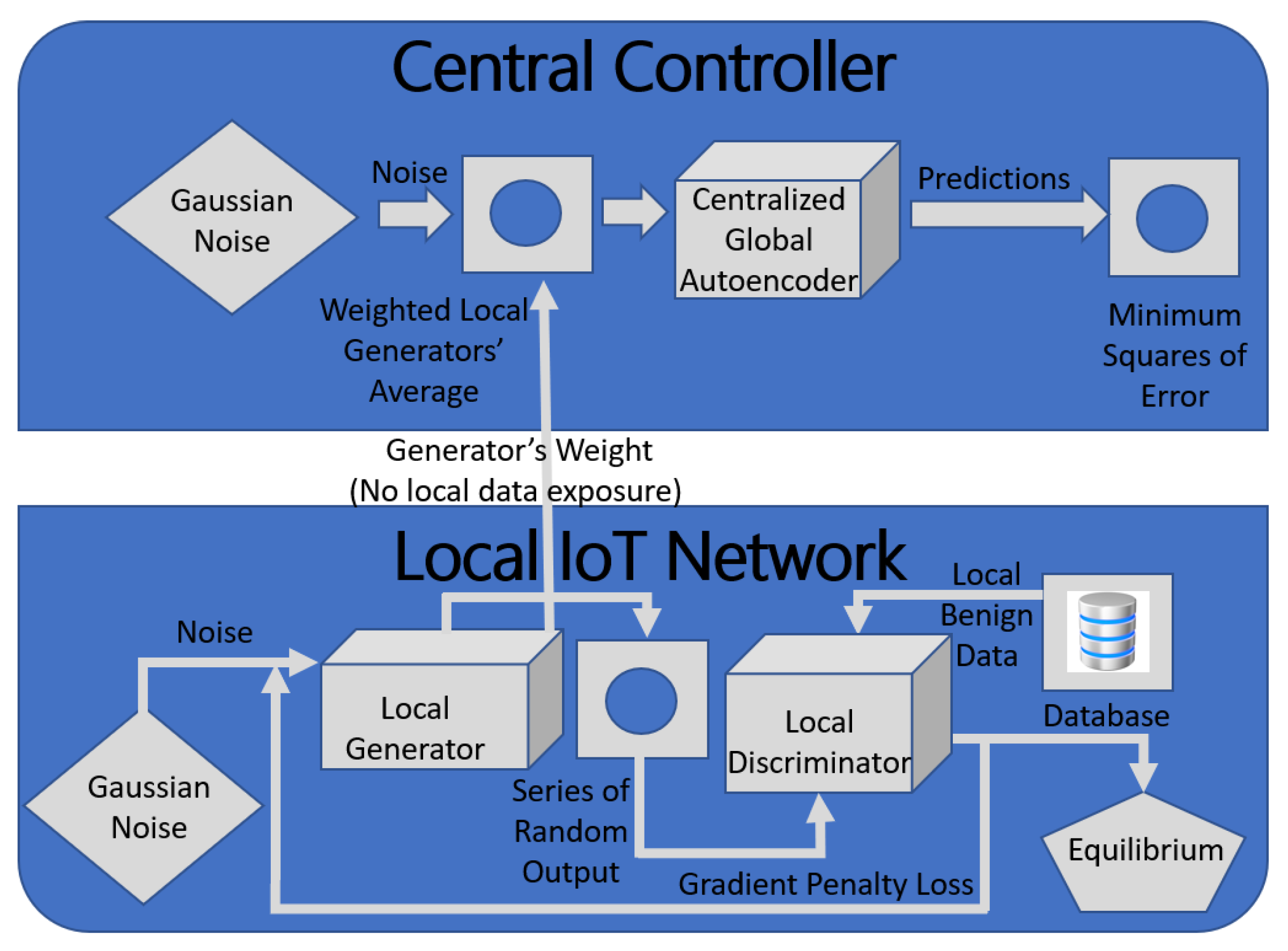
IoT traffic flow is bidirectional; therefore, methods for generating IoT synthetic data for training IoT intelligent IDS must consider bidirectional flow generation and the relationship between packet-level and flow-level features. The flow is composed of individual packets; thus, the packets’ sizes are closely related to the flow duration. To this purpose, the author in [
17] leveraged GAN to generate bidirectional flow that mimicked the bidirectional flow generated by actual IoT devices to train and test intelligent IoT IDS that used a set of sparse autoencoders; unsupervised neural networks. Unlike most of the surveyed synthetic data generation methods, which generated either packet-level features or flow-level features, the proposed generator created packet-level features while implicitly learning to comply with the flow-level characteristics to generate synthetic data that looks realistic. The flow-level features included packets’ ordering, the total number of packets, and the total duration of the flow (total number of bytes). In contrast, features related to the packet-level included the packets’ sizes. In general, packet-level features are describable using different fields of the network layer and the transport layer headers. The generated synthetic bidirectional flow consisted of a sequence of packets and their duration value. The trained generators using Autoencoder/WGAN with weight clipping(WGAN-C) model generated the sequence of packets. The trained mixture density networks (MDN), which took the generated packets sequence as input, determined their duration. The author used the WGAN to overcome the issues of GAN generating a sequence of categorical data, i.e., a sequence of packet sizes. The WGAN first converted the sequence of categorical data into a latent vector in a continuous space using the autoencoder and then trained the WGAN on the generated latent space to decode latent vectors into realistic sequences. Further, the author assessed the quality of the synthetic bidirectional flow by comparing the distribution of the duration of the synthetic bidirectional flow with that of the actual bidirectional flow and the sequence of packets sizes by using a Google Home Mini Show. The generated data are of quality if their duration is close to the duration of the real bidirectional flow. In both cases, the generated flow had a duration close to the real flow indicating the generated synthetic bidirectional flow was of high quality.
While the G-IDS framework in [
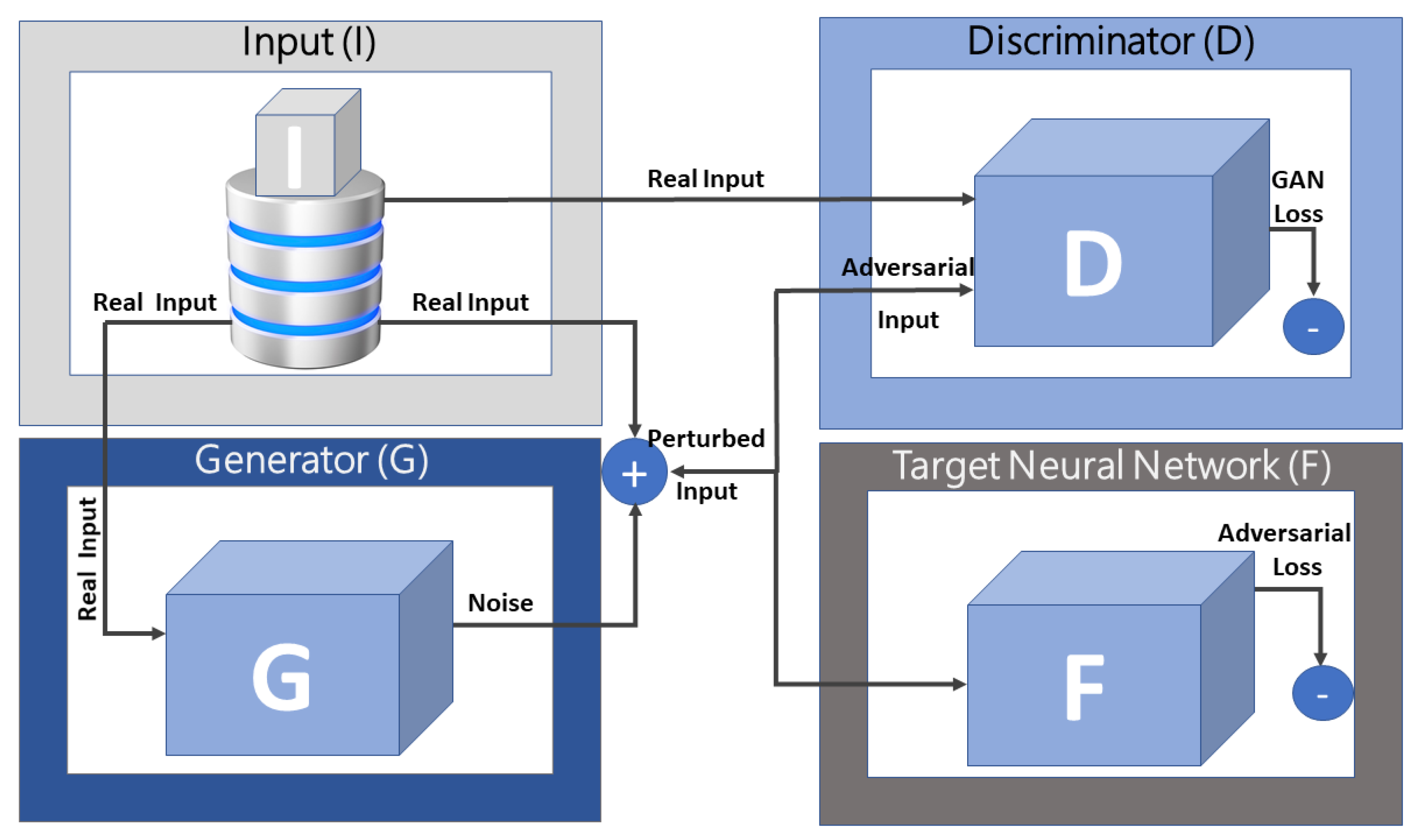
28] focused on solving the imbalanced or missing data using adversarial learning, the network intrusion detection (NID) framework in [
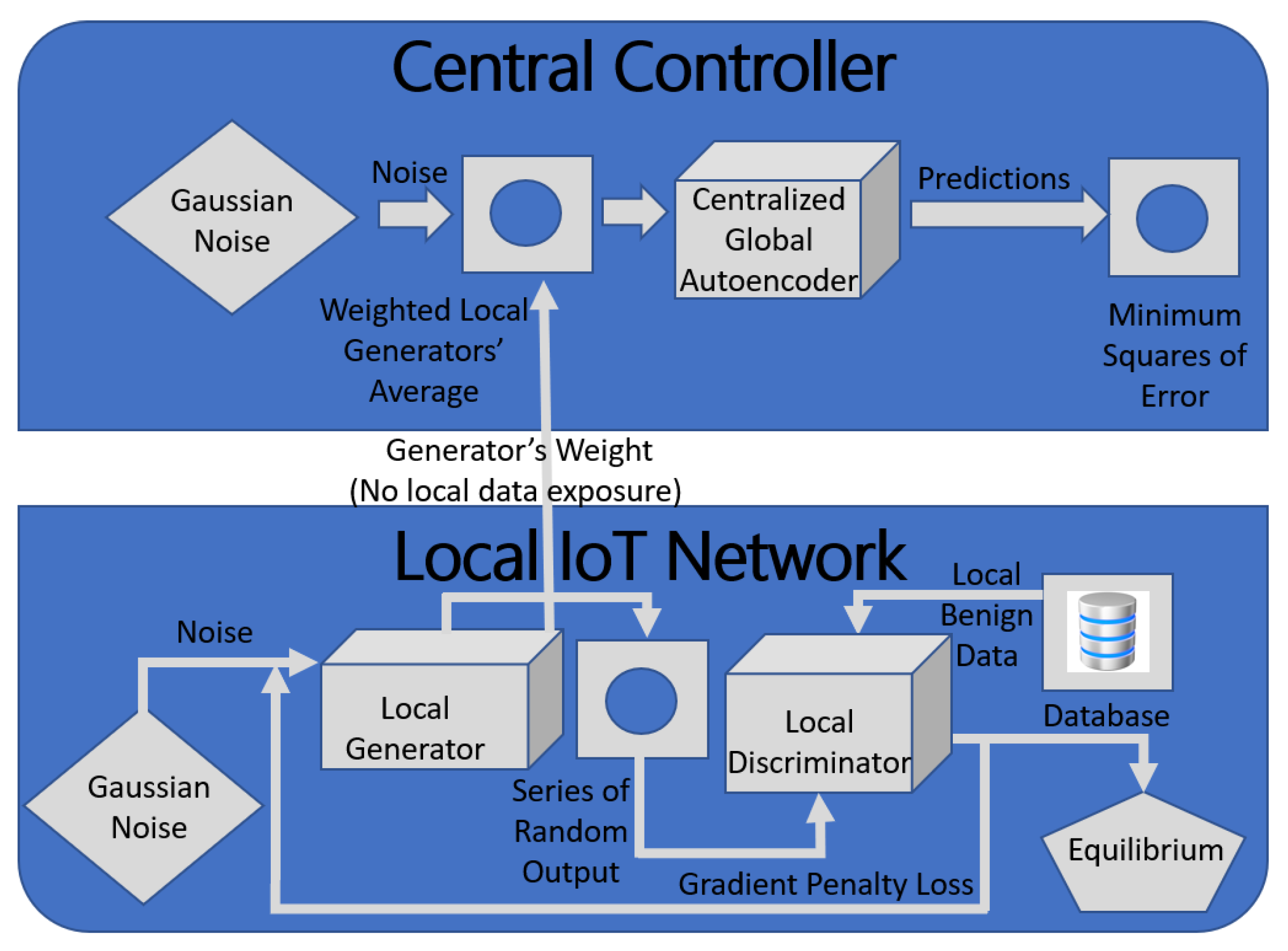
33] focused on solving the small and imbalanced dataset challenges using statistical learning and adversarial learning. The NID framework tackled both data scarcity and data imbalance by incorporating adversarial learning with statistical learning and exploiting learning using a data augmentation module (DA) consisting of a probabilistic generative model (PGM) and GAN. While the probabilistic model estimated the data feature distribution and generated synthesized intrusions using Monte Carlo methods, the deep generative neural network (DGNN) created high-quality intrusions by augmenting the synthesized data with actual data to provide high-quality training data. In addition, the PGM model initialized the DGNN, thus enabling it to converge on limited intrusion data.
Figure 6 shows the structure of the DA module. The DA module enabled the NID framework to detect intrusions in small datasets. The authors used a GAN, which augmented the limited intrusion data, to adversarially train the DGNN and then evaluated the DA-enhanced NID using the KDD Cup 99 dataset against existing learning-based IDS, which included support vector machine (SVM), classical logistic regression (LR), and advanced DNN. The proposed NID framework outperformed the existing IDS, given accuracy, precision, recall, and f-score as metrics.
8. Analysis and Discussion
In this section, we summarize our analysis and provide a classification of the surveyed methods and techniques. Our initial focus was to categorize the surveyed DDL methods and techniques into data augmentation and data generation based on the class of problem they are attempting to solve and into adversarial and non-adversarial learning based on their learning approach (see
Table 2 for data-driven learning classification scheme). However, some techniques or methods tackle more than one problem, e.g., data augmentation and data generation, and employ two or more learning approaches, e.g., adversarial learning and non-adversarial learning.
Table 2 lists several examples of these methods, such as the GAN-2CNN, G-IDS, GAN-SMOTE, GAN-based DA, PAV-GAN, and NID Framework, which address two classes of data problems, and the GAN-AE method, which considers solving three classes of data problems. The NID framework address two data problems and employ four different learning approaches: imbalanced learning, adversarial learning, statistical learning, and exploiting learning.
Table 1 lists and describes these learning approaches and others mentioned in this study. In addition to data generation and data augmentation problems, some methods consider preserving data privacy, such as GAN-AE, and data adaptation, such as the GAN-based DA. Most of the methods have applications in network-based intrusion detection and fewer in IoT-based intrusion detection. Other methods have applications in cyber-physical systems security, defensive security, offensive security, and predictive maintenance of smart systems. While most of the methods focus on generating uni-directional flow-level or packet-level network traffic, the bidirectional GAN can generate bidirectional flow.
Table 3 provides a subgroup analysis based on the evaluation results of the DDL methods and
Table 4 summarizes the advantages and disadvantages of these methods.
Most of the studies presented in this paper focused on evaluating the data augmentation and generation methods using models trained on data augmented or generated by these methods compared to other state-of-the-art data augmentation and generation methods, ML and DL algorithms, or both. Further, most studies noted that the generated data, which resembled real data, is of good quality. However, few studies like the study in [
11] assessed the quality and realism of the generated data using derived properties. Inevitably, there is a need to create standard metrics or develop a standard methodology to evaluate the quality of augmented and generated data. Furthermore, most studies evaluated the DDL methods using standard machine learning metrics, such as accuracy, precision, recall, and f-score.
On the other hand, few studies reported on the ROC metric, and others used specific metrics such as capacity, generality, detection rate, evasion increase rate, and percentage of unblocking actions. While these standard and specific metrics are essential to assess the performance of the proposed methods or approaches, there is a need to assess the sensitivity (true-positive rate) and specificity (false-positive rate) to indicate whether there was a significant improvement in the detection rate. In general, accuracy, precision, and recall metrics are not always a good indication of the models’ performance.
Further, except for the study in [
34], most of the studies assumed that the improvement in the performance of the proposed method was due to data augmentation or generation as opposed to the amount of training and model parameters. Data generation and augmentation methods invariably increase the computational cost. Nonetheless, some studies did not consider evaluating the proposed methods based on their execution time and computational overhead. Finally, most studies used static training, where models trained using publicly available data. Since public data are often static and prone to obsolesce, it is essential to consider dynamic learning and train models that consider the dynamic aspect of the data to augment or generate new data for imbalanced and adversarial learning.
9. Challenges and Open Research Issues
Generative models such as GANs are predominant in the field of image recognition. As such, they are more suited for discrete data generation. However, to extend their use beyond image recognition to other fields such as networking, GANs must have the capability to deal with categorical data such as IP addresses in addition to continuous data. Therefore, transforming network flow that contains categorical data into continuous value must occur before adversarial learning or imbalanced learning using generative models occurs. The authors in [
11] proposed the use of three different prepossessing approaches for generating network flow. Others, such as the authors in [
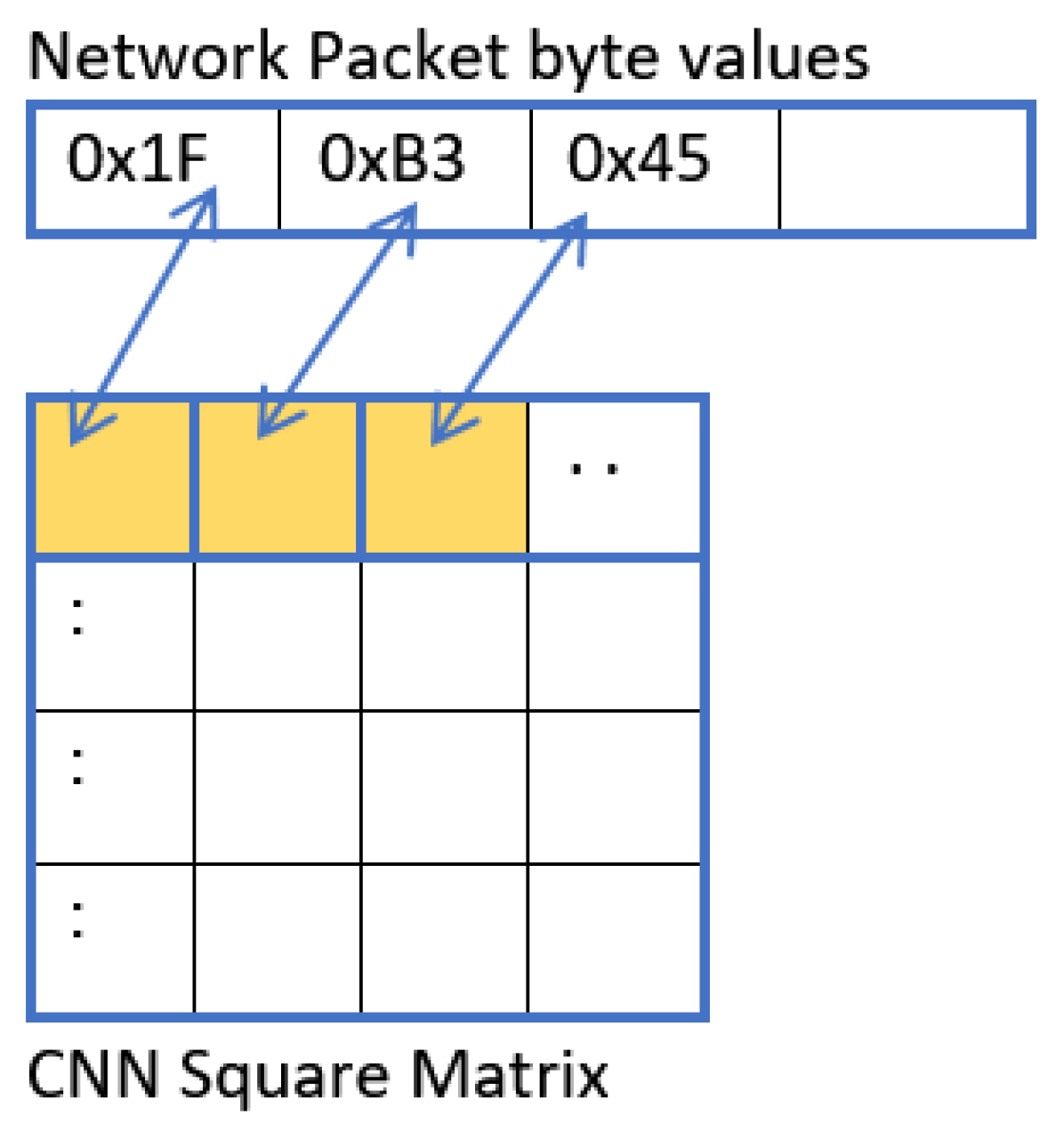
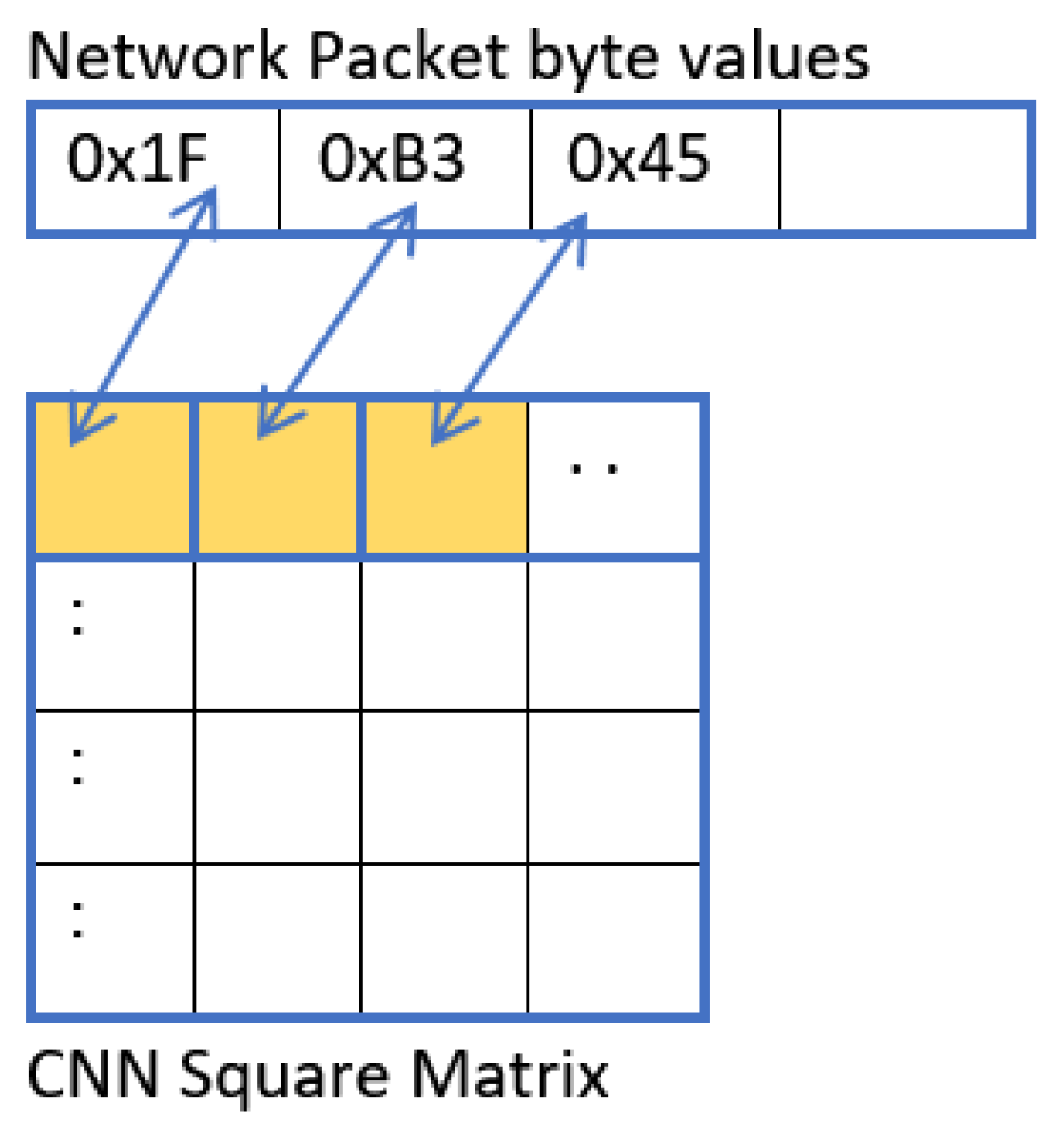
14], proposed a network encoding scheme to map network traffic from categorical format to image-based matrix representation.
Despite these transformation and mapping efforts, generating significant and realistic network traffic using cost-effective means remains challenging. When generating network traffic, it is essential to consider the traffic level. While some approaches generate network traffic at the flow level, others generate network traffic at the packet level. A better approach is to generate flow-based and packet-based traffic. To that extent, very few approaches, such as the Bidirectional GAN in [
17], generated packet-level traffic and ensured that the generated traffic complies with the flow-level characteristics. Therefore, developing generative models that can exploit the relationship between flow-level and packet-level is an open research issue. Likewise, generating a sequence of flows instead of a single flow and generating bidirectional traffic for training IoT-based IDS is equally essential.
Evaluating GANs and assessing their data realism is challenging. However, the majority of GANs evaluation methods, both quantitative and qualitative, apply to image data [
3]. Hence, developing methods for evaluating the performance of GANs and their variants for network data or non-imagery data are open for research. Another open issue to consider is defining metrics to evaluate GANs and their variants and assessing the authenticity and realism of the generated data. Current metrics exist at the individual GAN level, which makes it difficult to compare and assess different GANs [
17]. Hence, there is a need to define standard metrics to assess the realism of the generated data. Furthermore, when considering generative models in networking, assessing data realism at a granular level, i.e., packet-level and flow-level, and assessing the generated data quality using comprehensive metrics are open questions. The generalization of generative models is an open research question. The initial intuition is to develop GANs that can adapt and transfer their knowledge from one domain of application to another similar yet different domain, e.g., from network-based intrusion detection to IoT-based intrusion detection. Moreover, developing generative models that consider bidirectional traffic generation is equally important.
10. Conclusions and Future Work
This paper presented an overview of various data augmentation and data generation methods for imbalanced and adversarial learning. The reason for augmenting data include but are not limited to small ground truth data, lack of attack data, preventive maintenance data, sensitive data, and data privacy. On the other hand, data generation is essential for adversarial learning, transfer learning, and deceptive learning. Further, the paper focused on the most recent research work published in the last three to four years and analyzed the findings using qualitative analysis. It used rapid review, structured reporting, and subgroup analysis, which narrowed the pool of selected publications to those which covered non-traditional ML/DL data augmentation and generation methods for training anomaly-based intelligent intrusion detection systems for detecting intrusions in traditional network and emerging fields of IoT, cybersecurity, and smart homes. Hence, it is limited in scope. This paper provided classification and a comparison of the reviewed methods and their implementing models and discussed their advantages and disadvantages to report findings. In addition, it introduced open issues and research challenges with a specific focus on categorical data mapping and transformation, evaluating and assessing generative models, generating packet-level and flow-level traffic, and bidirectional traffic. Most studies used standard machine learning metrics or domain-specific metrics to assess the augmented or generated data quality; there is a lack of standard data quality metrics and methodologies to assess the quality of the data. In addition, some studies were missing analysis on time and computational complexity, and communication overhead. In the future, we are planning to verify the outcome of this study using a systematic review and meta-analysis. Additionally, we plan to increase the scope of the systematic review to include network traffic transformation and mapping methods, and GANs variants for generating adversarial non-imagery examples.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}