1. Introduction
The camera module is an important component of digital products such as smartphones and personal computers [
1]. In order to produce high quality and high resolution cameras, defect detection on the lens surface of camera modules is an essential process in the production process. Due to the large gap between the camera module lens surface defect features and the target features of the mainstream dataset, which are small target features, the detection accuracy of traditional machine vision algorithms on the camera module lens surface defect detection is not high. In the actual production process, the camera module factory needs to go through a series of processing procedures, such as FPC board cleaning, baking FPC board, wafer fixing, baking wafers, binding, focusing and other processes [
2]. As the industrial production workshop is not the ideal dust-free environment, resulting in the module in the processing and installation process, there are often dust, lint and other foreign objects falling on the surface of the camera lens, resulting in the camera module lens surface white spots, white dots, scratches, hair filaments, foreign objects and dirt and other defects, seriously affecting the imaging quality. At present, in the actual production of enterprise, camera module defect detection mainly relies on manual inspection or traditional machine vision inspection technology [
3]. For manual inspection, it often produces low efficiency, low detection accuracy and high labor cost. The manual inspection facilities commonly used are shown as
Figure 1, where
Figure 1a shows an eight times magnifying glass and
Figure 1b shows a chromaticity meter. As for the traditional machine vision inspection technology, it can meet the requirements of industrial reality in terms of accuracy and real-time. However, its adaptability to different features is less than satisfactory, and the feature extraction ability for deep features is limited, which makes it difficult to adapt to the complex and diverse defect requirements on the surface of camera module lenses [
4]. Therefore, how to quickly and accurately detect the defects on the lens surface of camera modules is an urgent problem in the camera module production line.
From the above analysis, it can be seen that camera module lens surface defect detection has high engineering significance and has become an important research topic in the field of defect detection. Traditional machine vision detection algorithms can only extract shallow features of the image, resulting in limited detection accuracy. Deep learning technology has excellent feature learning and feature expression capabilities, and can extract features layer by layer, taking the strengths of the other to complement the weaknesses of the other, effectively improving the accuracy of defect detection [
5,
6,
7]. From the perspective of scientific research, there is still no universal automatic detection algorithm for camera module lens surface defect detection based on deep learning. Therefore, it is of high practical significance to study an algorithm for camera module lens surface defect detection both in the engineering field and in the academic field of research. In view of this, this paper carries out a study of a deep learning-based surface defect detection method for camera module lenses.
2. Related Works
Defect Detection based on Machine Learning: Chang, C.F. [
4] proposed an automatic detection method for compact camera lenses using circular Hough transform, weighted Sobel filter and polar transform, and used a machine learning support vector machine method to obtain accurate detection results. To improve the accuracy and speed of optical lens image thresholding segmentation in optical lens defect detection, Cao Yu et al. [
8] proposed a new particle swarm algorithm (PSO) and Otsu thresholding segmentation algorithm, which improves the PSO weight factor update strategy and the global search capability, and assigns the optimal position calculated to the Otsu algorithm, and finally achieves the threshold segmentation of optical lens images. In order to improve the defect detection accuracy of small size curved optical lenses, Pan, J.D. et al. [
9] proposed a comprehensive defect detection system based on transmission streak deflection method, dark field illumination and light transmission, and the experimental results show that the proposed system can be applied to the actual mass production of small size curved optical lenses. For defect detection in electronic screens, Gao Yan et al. [
10] designed an image processing-based screen defect detection algorithm. Based on the new edge detection algorithm, the defective part is detected by comparing the grayscale difference between the normal and defective regions, thus different types of defects in the screen can be located efficiently and accurately. Although the method basically meets the requirements of industrial sites in terms of detection speed and accuracy, the setting of many parameters in the algorithm is highly dependent on manual experience, so it is difficult to be widely promoted in the industrial inspection field. To improve the detection of fabric defects, Deng Chao et al. [
11] proposed a new algorithm based on edge detection. Fabric defects are detected as the edges of normal texture by using the texture edges generated by the defects and normal texture in the fabric image. Using the directionality of the Sobel operator, the horizontal and vertical gradients of the fabric defects are enhanced, respectively, and the horizontal and vertical gradients of the RGB image are computed for edge detection, and the final detection is performed by image fusion and binarization. However, when the fabric is wrinkled or the sample is not placed correctly, the detection accuracy will be greatly decreased.
The above analysis shows that most of the traditional machine vision algorithms have the following common problems: (1) the setting of parameters is highly dependent on manual definition, and the detection algorithm cannot extract deep semantic information of the image, which in turn limits the improvement of detection accuracy. (2) Traditional machine vision algorithms lack a common, unified detection framework, and it is often needed to combine multiple image processing algorithms to achieve accurate detection of the target. (3) If the defect type is changed, the detection algorithm needs to be redesigned, and the algorithm is poorly reusable, consuming too much manpower and material resources.
Defect Detection based on Deep Learning: With the industry’s increasingly stringent requirements for defect detection accuracy and speed, more and more deep learning algorithms are being applied to the field of industrial product surface defect detection. Daniel W. et al. [
12] conducted an earlier study on the use of convolutional neural networks for defect classification and recognition. This method passes the acquired image feature information into the backbone feature extraction network for processing to determine whether the image to be detected contains defects. To improve the surface quality of tiles, Xie, L.F. et al. [
13] proposed an end-to-end CNN architecture called fused feature CNN (FFCNN). In addition, an attention mechanism is introduced to focus on the more representative parts and suppress the less important information. Experimental results show that the developed system is effective and efficient for magnetic tile surface defect detection. Aiming at the problems of low recognition rate and inaccurate localization of small defects on the surface of industrial aluminum products with traditional detection algorithms, Xiang Kuan et al. [
14] proposed an improved deep learning network, Faster RCNN, to detect surface defects on 10 types of aluminum products. Experiments show that the average accuracy (mAP50) of the improved network for detecting surface defects of aluminum products is 91.20%, which is 16% better than the original Faster RCNN network, and its detection ability of small defects of aluminum products is stronger. However, it needs to be further improved in the detection’s real-time performance.
Single-stage target detection algorithms are gradually being applied to the field of industrial product inspection to improve production efficiency even further. For example, Wu Tao et al. [
15] used the K-means++ algorithm to determine the prior frame, and then built an improved lightweight network based on the YOLOV3 detection architecture to address the problems of low accuracy and slow detection rate of transmission line insulator defects. The experimental results show that the method improves the image detection speed of high-definition insulators and can complete insulator localization and defect detection. Fan, CS et al. [
16] proposed a real-time detection algorithm based on improved YOLOv4 to address the problems of low detection accuracy and slow detection rate speed in cell phone lens surface defect detection. YOLOv4′s cross-stage partial block and convolutional block attention modules are combined to introduce channel attention and spatial attention to learn the discriminative features of defects. Meanwhile, a new feature fusion network is being designed to combine shallow details with deep semantics. Finally, the proposed model is refined using a structural clipping strategy to improve detection speed without sacrificing accuracy. In comparison to the YOLOv4, this algorithm significantly improves the accuracy of defect detection and achieves real-time performance for industrial production. Guo Lei et al. [
17] proposed a small target detection algorithm based on improved YOLOv5 to address the problems of false detection, missed detection and insufficient feature extraction capability of small targets in target detection. The algorithm applies the Mosaic-8 data augmentation technique, which increases the network’s capacity for small target detection by introducing a shallow feature map and modifying the loss function. In comparison to the original YOLOv5 method, the experimental results demonstrate that the algorithm has greater feature extraction ability and higher detection accuracy in small target detection. Zhang, R. [
18] suggested a high-precision WTB surface defect detection model SOD-YOLO based on the UAV image analysis of YOLOv5 to address the problems of low accuracy of wind turbine blade surface defect detection and long model inference time. The original YOLOv5 was enhanced with a micro-scale detection layer, and the anchor was re-clustered. In order to reduce the loss of feature information for defects such as small target defects, the K-means algorithm and the CBAM attention mechanism are applied to each feature fusion layer. The experimental results demonstrate that the improved algorithm SOD-YOLO can detect the wind turbine blade surface defects quickly and effectively.
At present, the research of applying deep learning detection algorithm to the field of camera module lens surface defect detection has not been carried out deeply enough, and there are mainly problems in the following aspects.
- (1)
The problem of limited number of training samples and uneven distribution of sample data.
To obtain detection models with excellent performance, we need sufficient sample data as a driver [
19]. However, in engineering practice, the acquisition of defective samples is not easy. In the actual production line, the images acquired by the inspection cameras are mostly qualified products, while the proportion of defective images valid for training is small, and the number of various types of sample data is unevenly distributed.
- (2)
Small target detection accuracy problem.
Current deep learning models perform well in mainstream datasets such as MS COCO dataset, Pascal VOC, ImageNet, [
20] etc., but often fail to meet detection standards in industrial applications. Because most of the objects to be detected in mainstream datasets are large and medium targets, official network models can detect them more easily and achieve high detection accuracy. In practical industrial applications, the targets to be detected are mostly small objects, and the detection accuracy of the official network model is not ideal, so the network needs to be improved and optimized in a targeted way.
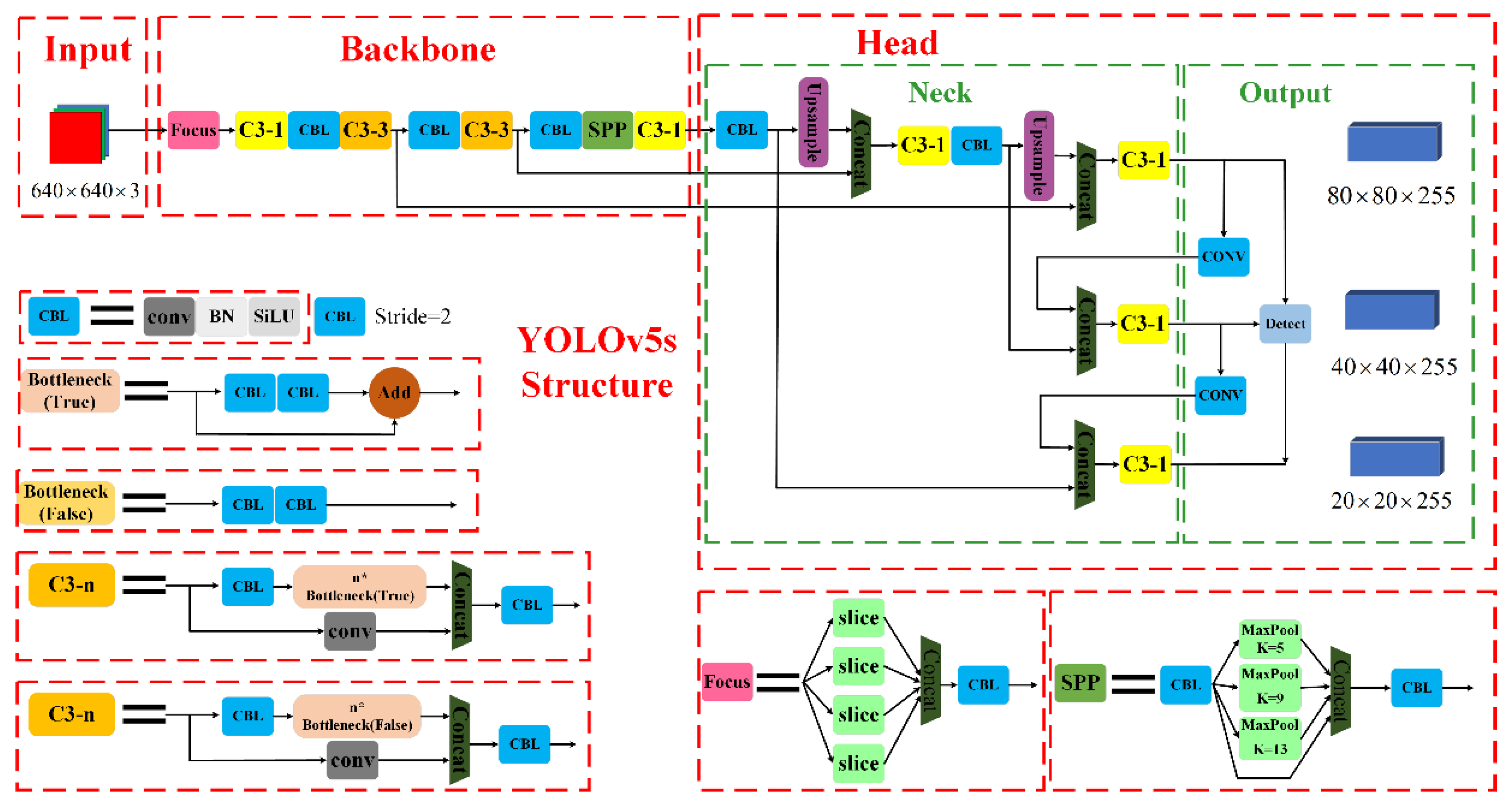
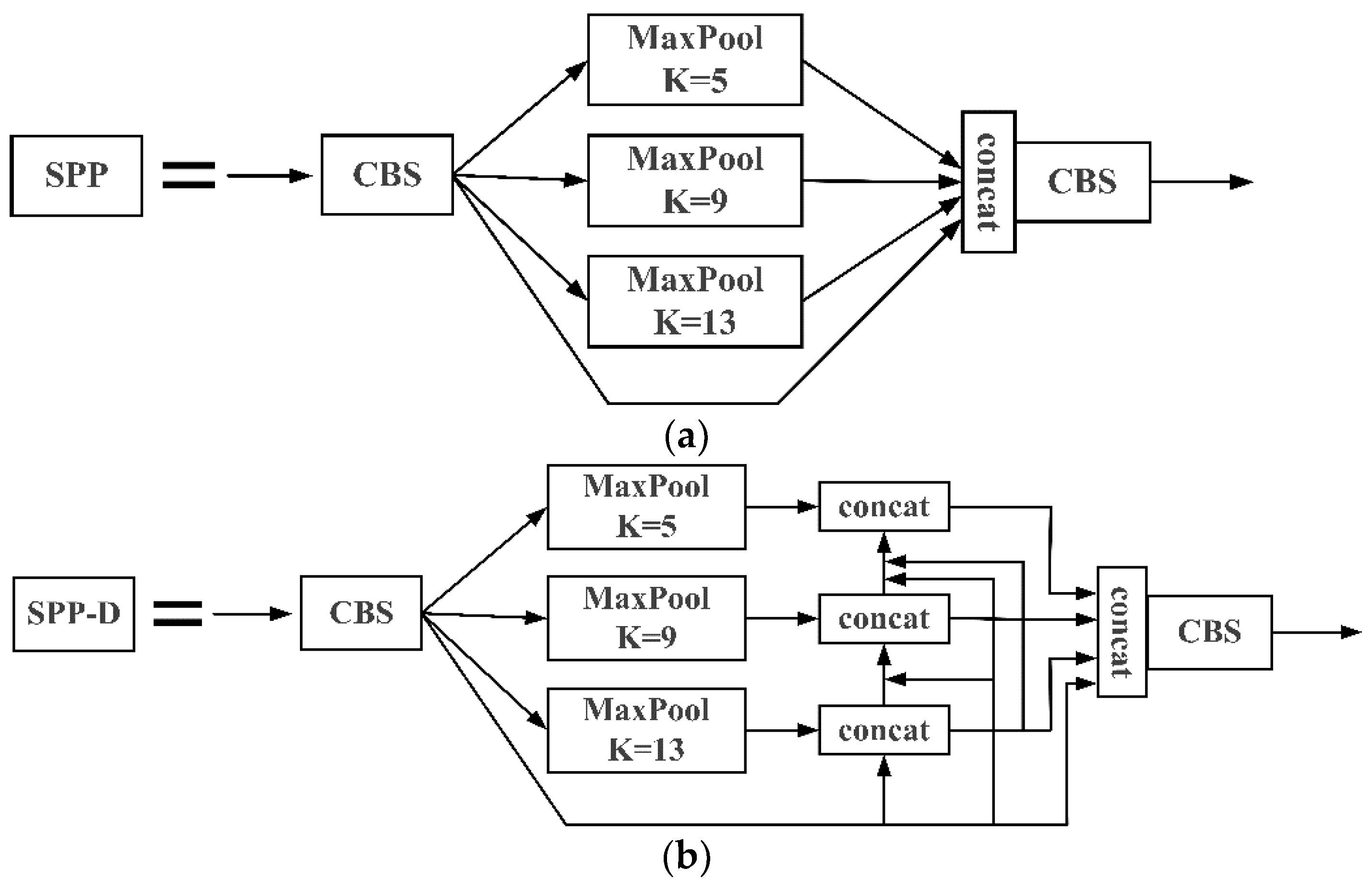
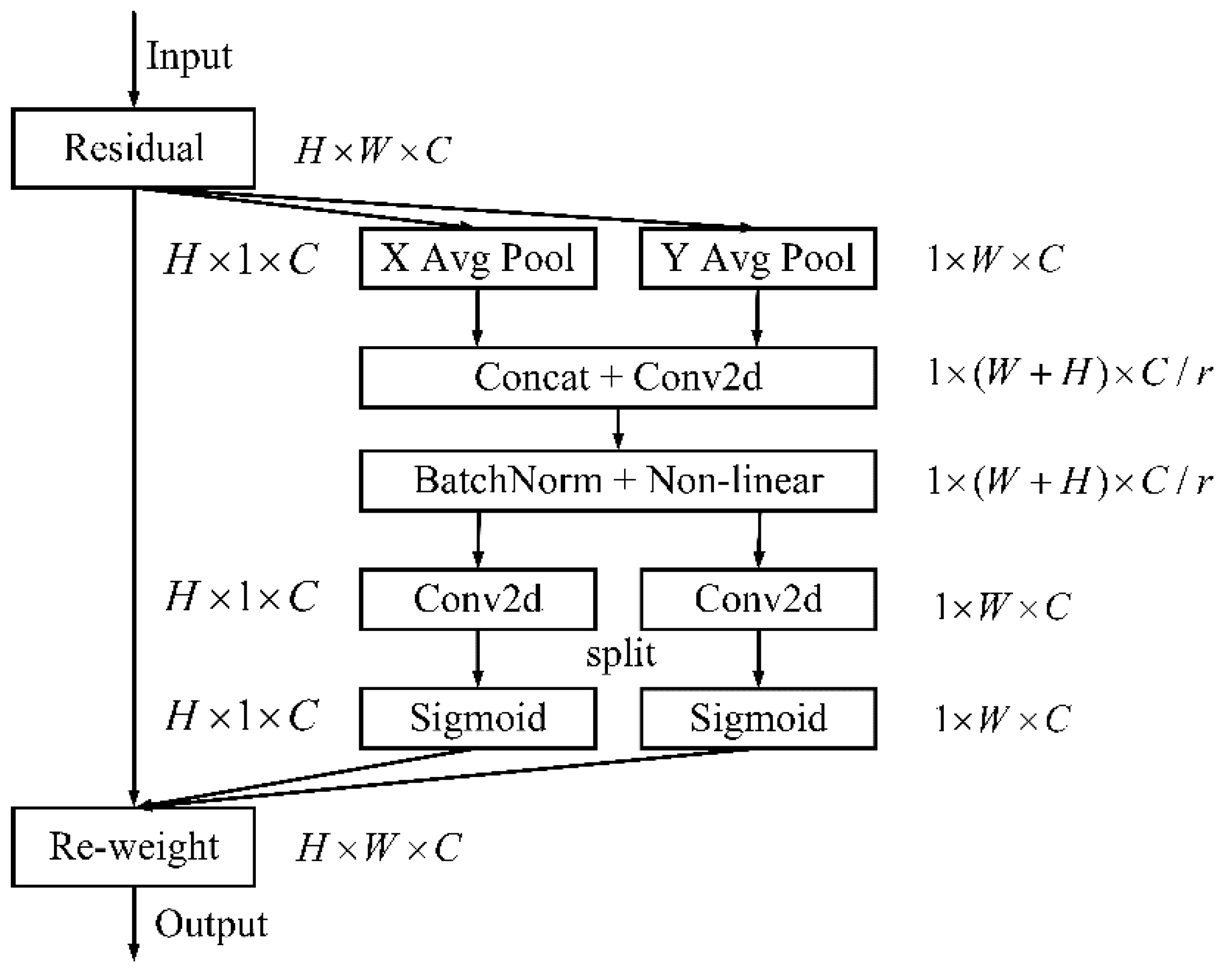
Since the detection targets of this topic are all small targets, which have certain requirements on detection accuracy, speed and industrial site deployment, this paper adopts YOLOv5s network model as the base network model. By improving and optimizing it, the algorithm improves the detection and recognition ability of small target defects.
4. Experimental Results and Analysis
The camera module lens surface defect detection dataset produced in this paper contains 12,000 defect sample images, and these defect sample images are randomly divided into training set, validation set and test set in the ratio of 7:2:1, including 8400 images in the training set, 2400 images in the validation set and 1200 images in the test set. In order to comprehensively verify the testing effectiveness of the three YOLOv5 improvement strategies used in this paper, ablation experiments are conducted on the produced camera module lens surface defect dataset to judge the actual effectiveness of each improvement point.
In order to make the model converge as much as possible, the number of iterations was set to 2000. In order to increase the training speed as much as possible and also combine with the computer hardware configuration, after several attempts, the batch size was set to 8. In order to balance the training speed and the quality of the training sample images, the input image size was set to 640 × 640. After repeated debugging with several training sessions, the initial learning rate lr was set to 0.01 and the momentum was set to 0.937 in order to obtain the optimal network model. The results of the ablation experiments are shown in
Table 1.
Row 1 of
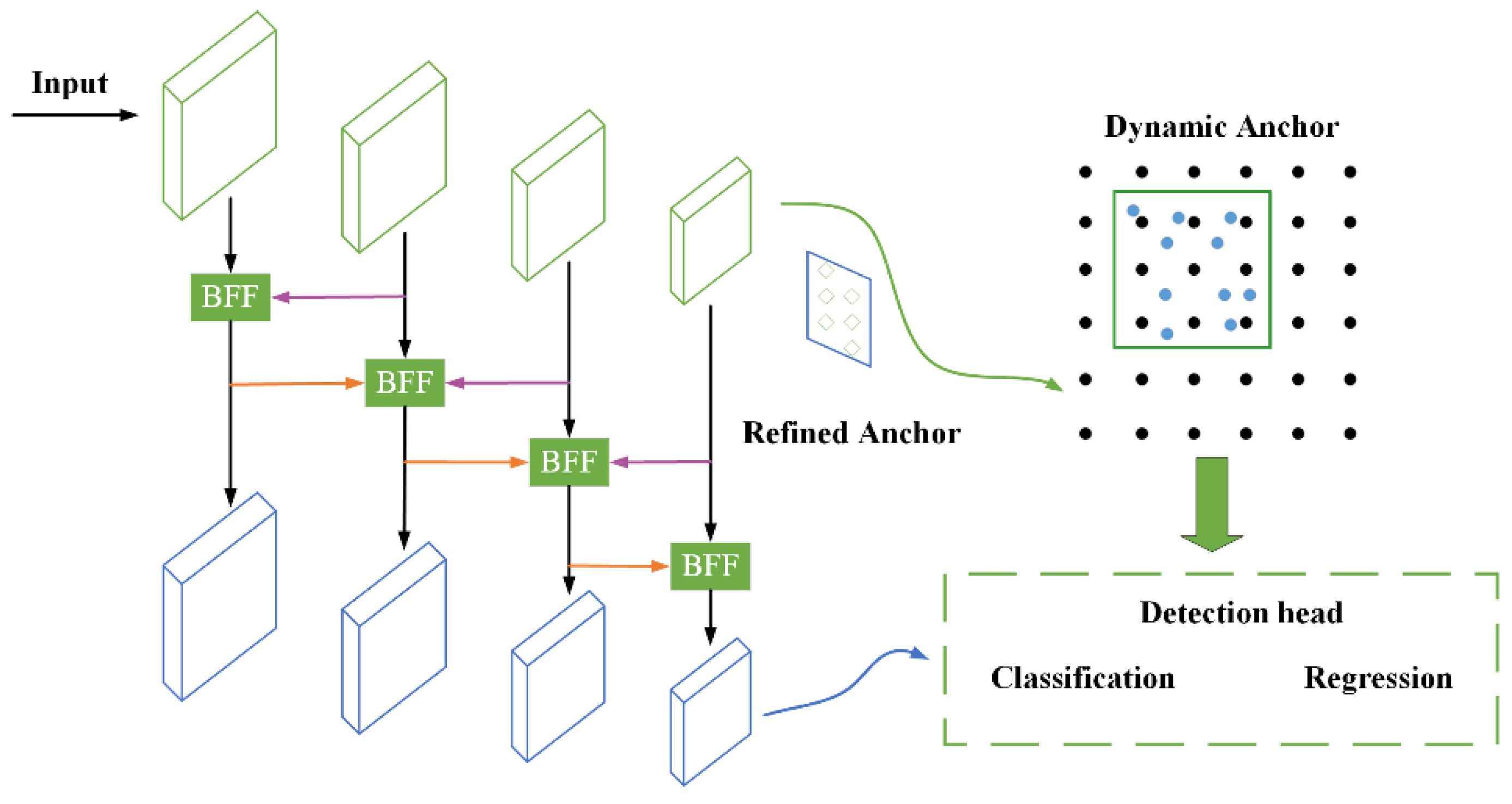
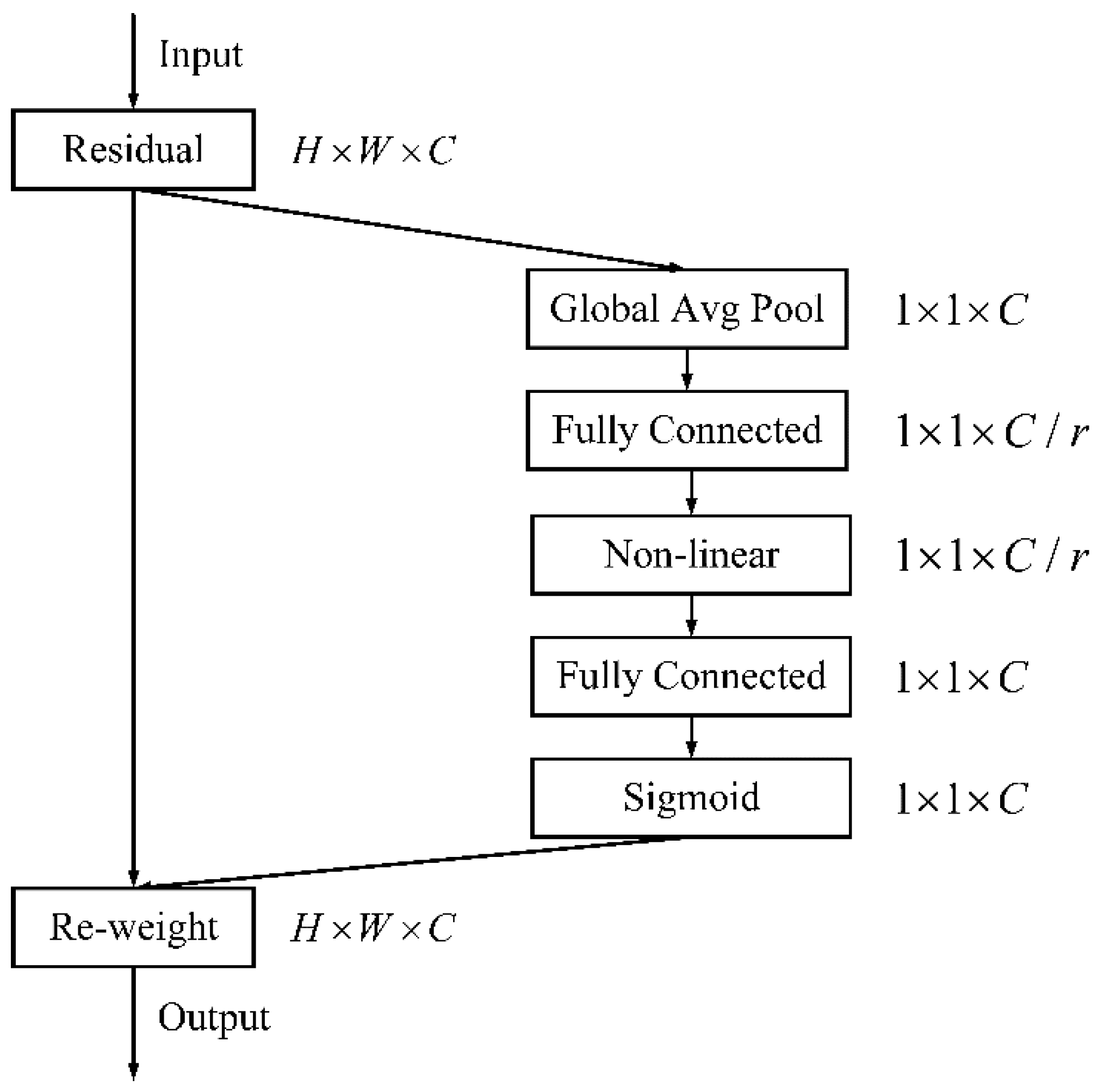
Table 1 indicates the base performance of the original YOLOv5s on the dataset, and the average detection accuracy is 91.5%. After the introduction of CBAM and DAFS, respectively, it can be seen that CBAM improves the detection results more significantly, with significant improvements in Precision, Recall, and AP, while the improvement performance of DAFS is slightly weaker. The analysis suggests that this is related to the different functions of the two modules. The attention mechanism aims to improve the network’s ability to extract important features, which is expressed in the improvement of accuracy, while the DAFS dynamic anchor frame module speeds up the regression of the prediction frame and improves the regression accuracy, so there is only a small improvement in the detection accuracy. After introducing both CBAM and DAFS modules, the detection network achieves the best results, with an average accuracy mAP improvement of 4.7% compared to the original network.
To analyze the impact of two improvement points of DAFS and DIoU-NMS on the detection results, some of the test results are visualized as shown in
Figure 14.
Figure 14a shows some of the detection results of the original YOLOv5s+DAFS, and it can be seen that the network has missed detection when the target is too small, and some of the detection frames are not very accurate.
Figure 14b is the DIoU-NMS post-processing method obtained by improving the non-extremely suppressed post-processing method on the basis of (a), and the regression accuracy of the detection frame is significantly improved in the same image compared with
Figure 14a, but the same problem of missed detection exists.
Figure 14c shows the detection results with the CBAM module, and compared to
Figure 14b, the missed white point defects are detected while maintaining a high detection accuracy.
In this paper, we use YOLOv5s as the basic defect detection algorithm. In order to solve the problem of low accuracy of small target defect detection, we add the CBAM convolutional attention mechanism module to the original YOLOv5s to improve it. The evaluation results of the improved YOLOv5s-Small-Target network model are shown in
Figure 15a–e.
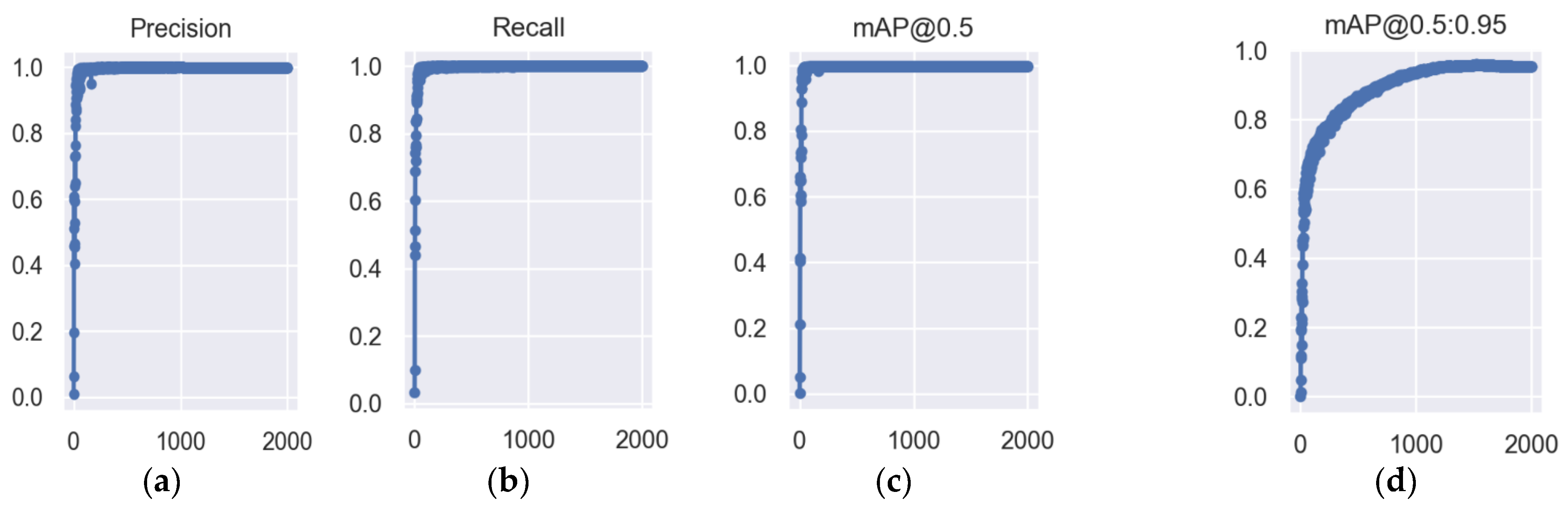
Figure 16 shows the results of each evaluation of the improved YOLOv5 model. After 2000 epochs, the model reaches the convergence state. During the training of the model, the precision and recall rate are improved very steadily. After the model reaches saturation, its precision rate, which is shown in
Figure 16a, can be maintained steadily around 99%; the recall rate, shown in
Figure 16b, can be maintained steadily around 100%. The mean average precision and the reconciled mean average precision also remain at a high level, and the mean average precision, as shown in
Figure 16c, can be stably maintained around 99%; the reconciled mean average precision, as shown in
Figure 16d, can be stably maintained around 0.96.
The best detection model obtained from the training have been used for the defect detection of camera module lens, and some of the detection results are shown in
Figure 17. The detection accuracy of white spot defects is basically maintained at about 93%, and the detection accuracy of white spots, scratches and dirty defects is as high as 96%, and there is no leakage and false detection. Therefore, the test experiment has achieved relatively satisfactory results.
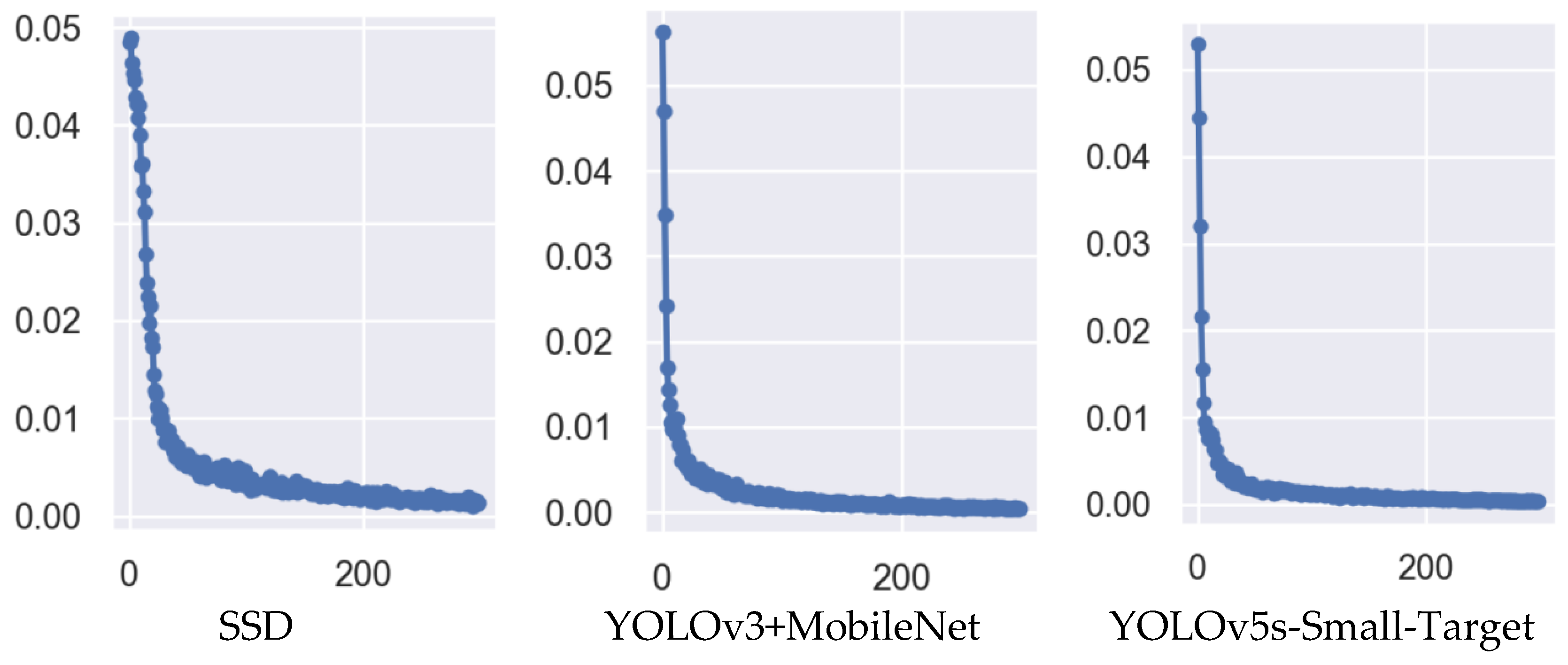
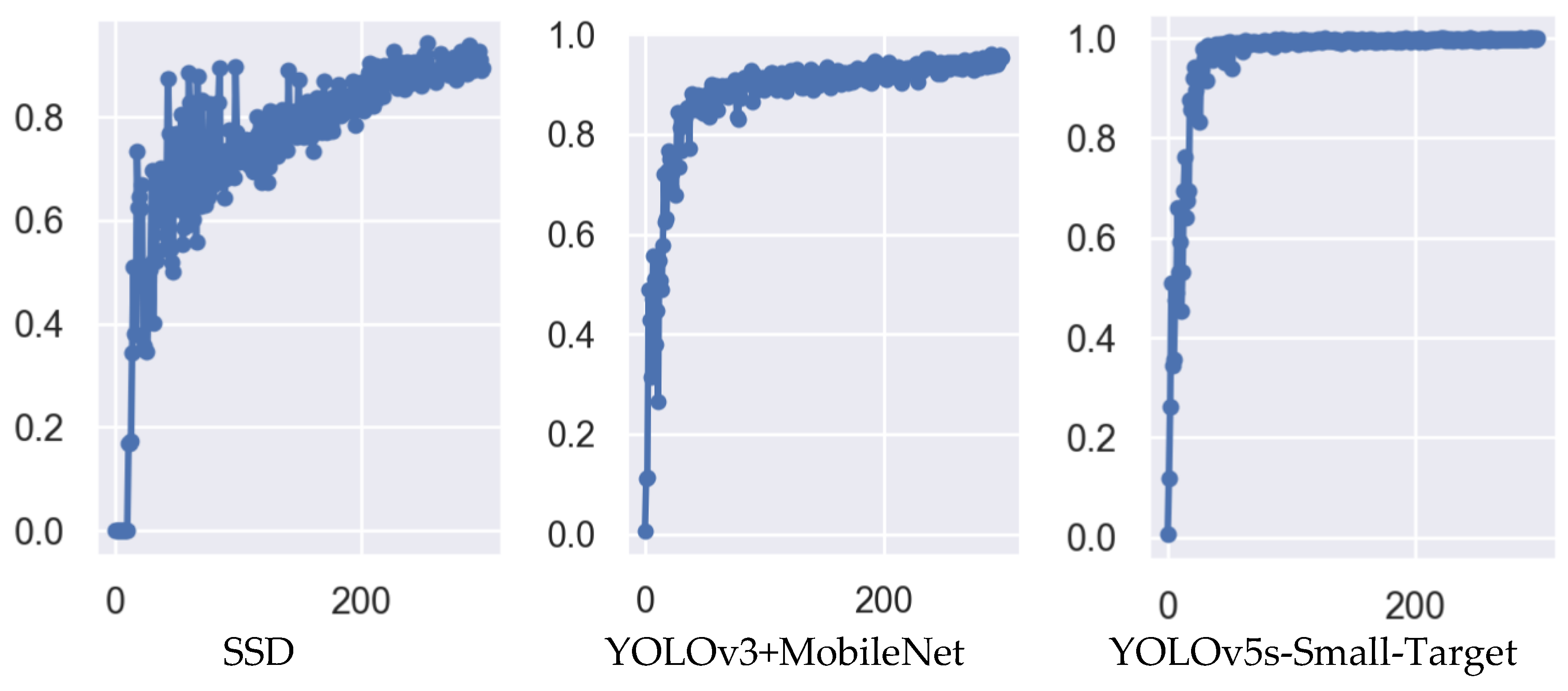
To further validate the testing effectiveness of the YOLOv5s-Small-Target algorithm used in this paper on camera module lens surface defect detection, it is compared with the single-stage SSD algorithm and the YOLOv3+MobileNet lightweight network. The number of model training is set to 300, the batch size is set to 8, and all three algorithms do not use pre-trained models. The specific experimental results are shown in
Figure 18,
Figure 19,
Figure 20 and
Figure 21.
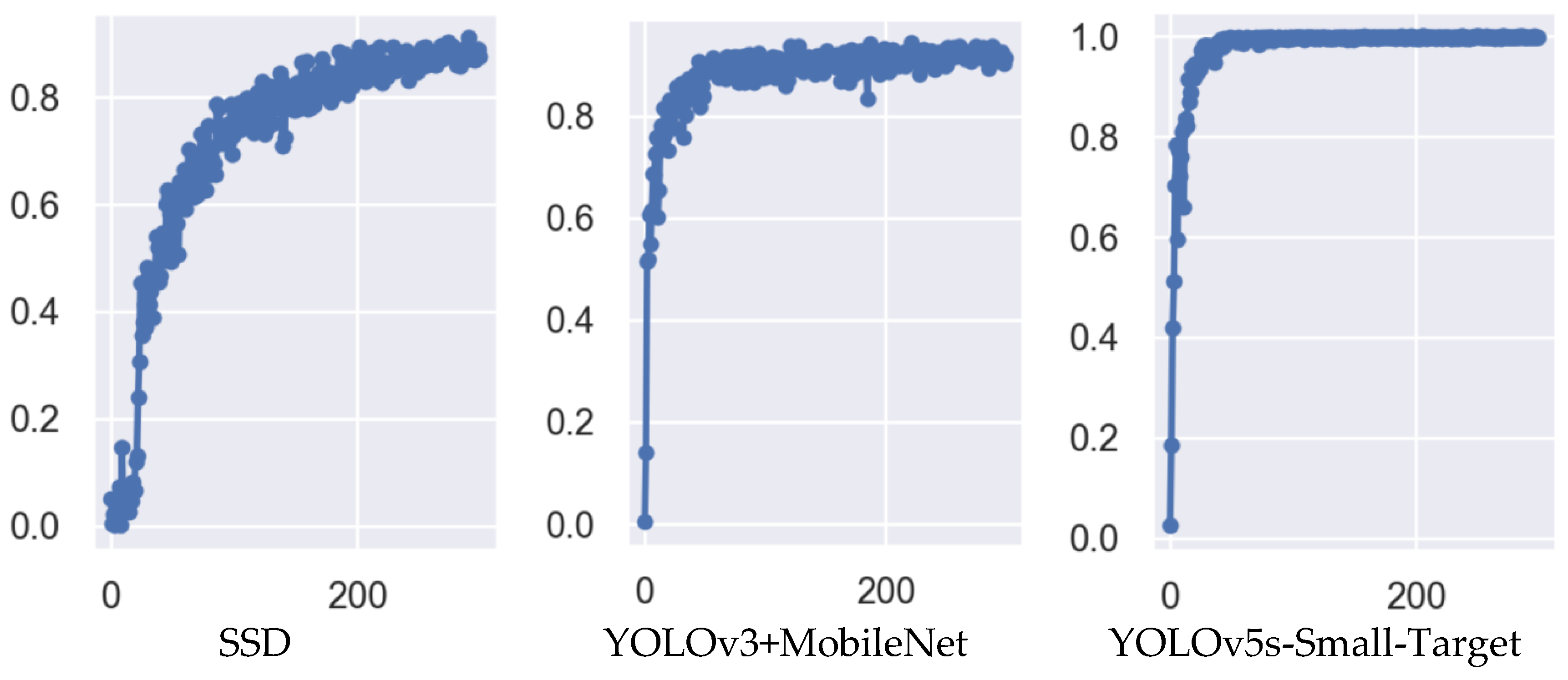
From the experimental results in
Figure 18,
Figure 19,
Figure 20 and
Figure 21, we can see that the accuracy P of the YOLOv5s-Small-Target algorithm designed in this paper is as high as 99%, which is better than the SSD and YOLOv3 algorithms in terms of model fitting speed and accuracy. The main reason for this result is that the detection objects in this paper are mostly small targets, and the improved algorithm contains a CBAM attention module, which improves the ability to detect small targets, so the comprehensive performance of the improved algorithm is improved.
In order to further analyze the defect detection performance of the improved YOLOv5s-Small-Target algorithm in this paper, a longitudinal comparison test and a cross-sectional comparison test are conducted for the camera module lens surface defect dataset.
- (i)
Longitudinal comparison experiment
The test results of YOLOv5s-Small-Target algorithm were compared with Faster R-CNN, SSD 300 (VGG16), SSD 512 (VGG16), and RetinaNet algorithms in terms of accuracy P, recall R, average precision and inference time while keeping all parameters set consistently, and the specific experimental data are shown in
Table 2.
From
Table 2, the improved YOLOv5 algorithm has the highest average precision and the fastest inference speed among the single-stage detection algorithms. Compared with the two-stage Faster R-CNN, the improved recall and average precision are not much different from them, but in terms of inference speed, the improved YOLOv5 algorithm inferred each image 95.6 ms faster than the Faster R-CNN, which also meets the requirement in terms of speed.
- (ii)
Cross-sectional comparison experiment
In order to further verify the performance of the improved algorithm for lens surface defect detection in this paper, it is compared and analyzed with the mainstream YOLO series target detection algorithm, and the specific experimental results are shown in
Table 3.
As can be seen from
Table 3, the improved YOLOv5s-Small-Target has the best overall performance, with an accuracy of 96.0%, 1.8% higher than YOLOv5m; a recall rate of 100%, 5.1% higher than YOLOv5m; an average precision of 99.6%, 5.1% higher than YOLOv5m, maintaining a high detection accuracy; and an average inference time per image is 10.5 ms, which is 7.0 ms, 5.5 ms, 3.9 ms, and 0.8 ms faster than YOLOv3, YOLOv3+SPP, YOLOv5m, and YOLOv3+MobileNetV2, respectively. In terms of model size, YOLOv5s model has the smallest size, but its accuracy, recall, and average precision values are lower. The improved model after incorporating the attention mechanism has an increase in model size and inference time, but the accuracy, recall, and average precision have increased by 3.8%, 7.2%, and 8.1%, respectively.
Figure 22 shows the comparison of YOLOv5s-Small-Target model with other YOLO models in terms of number of parameters. The number of parameters of the improved algorithm has increased, but the detection accuracy has been improved substantially. Therefore, in comprehensive industrial field camera module lens surface defect detection accuracy and detection of real-time requirements, while considering the mobile deployment of the algorithm at a later stage, the YOLOv5s-Small-Target improved algorithm performs better.
Overall, although the YOLOv5s-Small-Target model shows some growth in volume and inference time, the accuracy, recall and mean average precision mAP values of the YOLOv5s-Small-Target algorithm are 3.8%, 7.2% and 8.1% higher than the original YOLOv5s algorithm. Therefore, the YOLOv5s-Small-Target algorithm has the best overall performance compared to other algorithms when considering the requirements of camera module lens surface defect detection accuracy and real-time, as well as the difficulty of mobile deployment of the model.
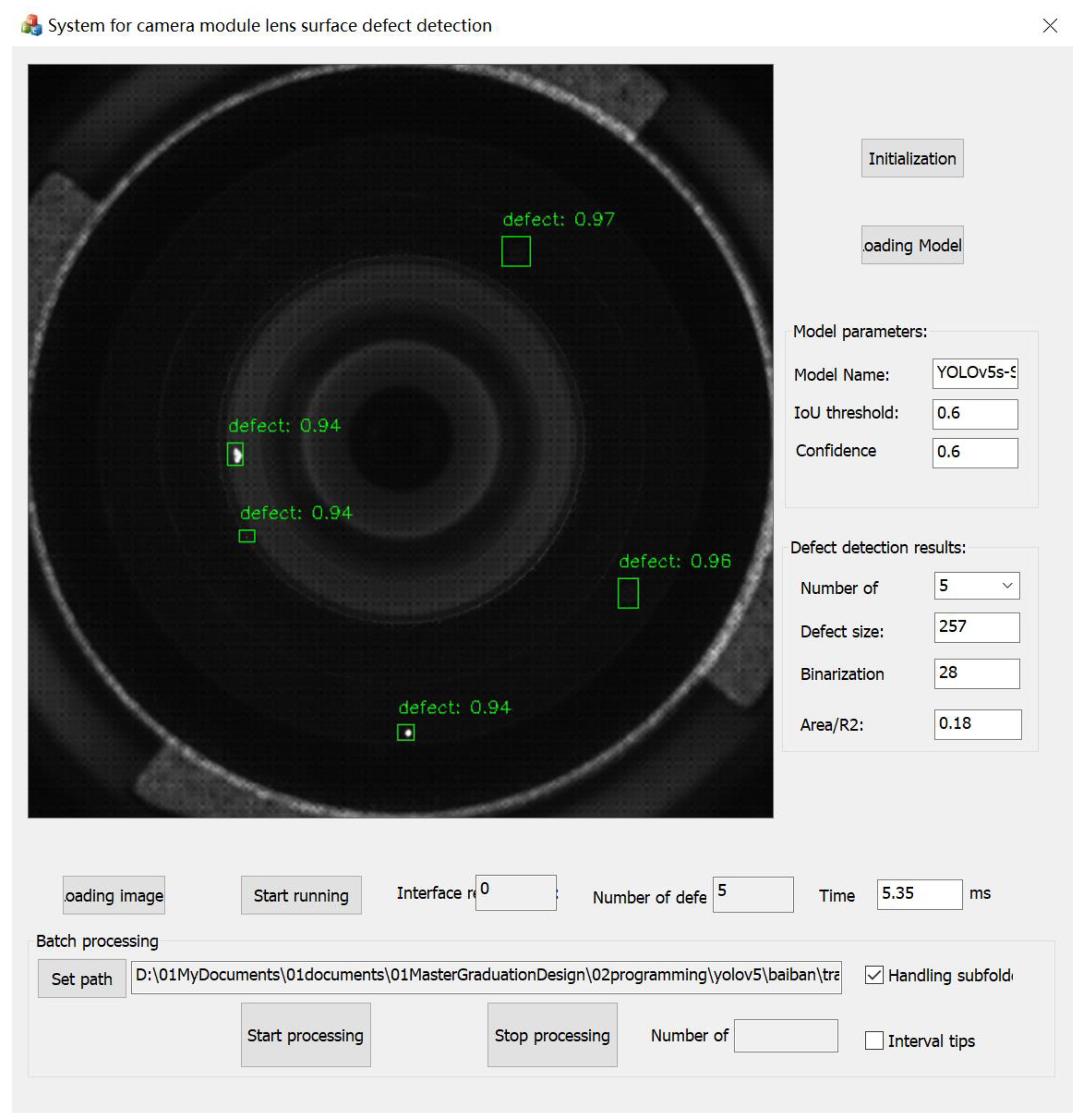
A camera module lens surface defect detection visualization system is designed and implemented, in which the YOLOv5s-Small-Target network model based on the LibTorch framework is deployed. An example graph of the operation results of the camera module lens surface defect detection system under the GPU RTX 3070 configuration is shown in
Figure 23.




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}