
Topology-Aware Mapping of Spiking Neural Network to Neuromorphic Processor


Abstract
:1. Introduction
- We exploit the global topology of SNNs, divide the SNNs into multiple groups, and use the strategy to partition SNNs into multiple clusters. The strategy reduces the destination cores for a group of neurons simultaneously, which significantly reduces the spike messages on NoC.
- To map the partitioned clusters onto the multicore neuromorphic processor, we propose a heuristic mapping algorithm that minimizes the average hop of spike messages and balances the NoC workload.
- To obtain the NoC workload, we propose to use the spike firing rates of all spiking neurons to approximate the workload of physical links.
2. Background and Related Work
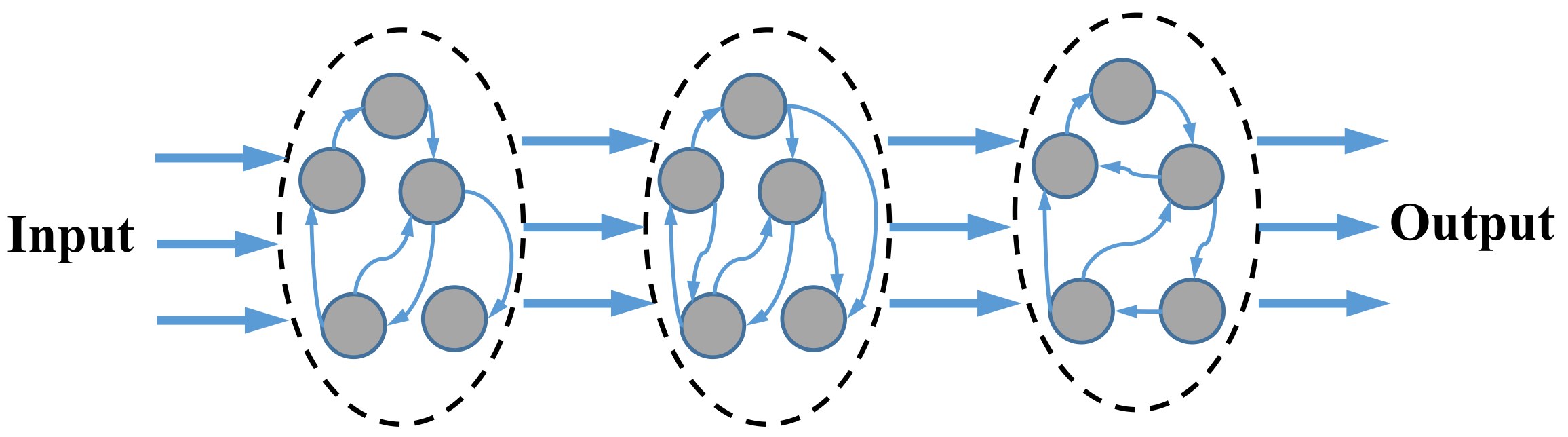
2.1. Spiking Neural Network
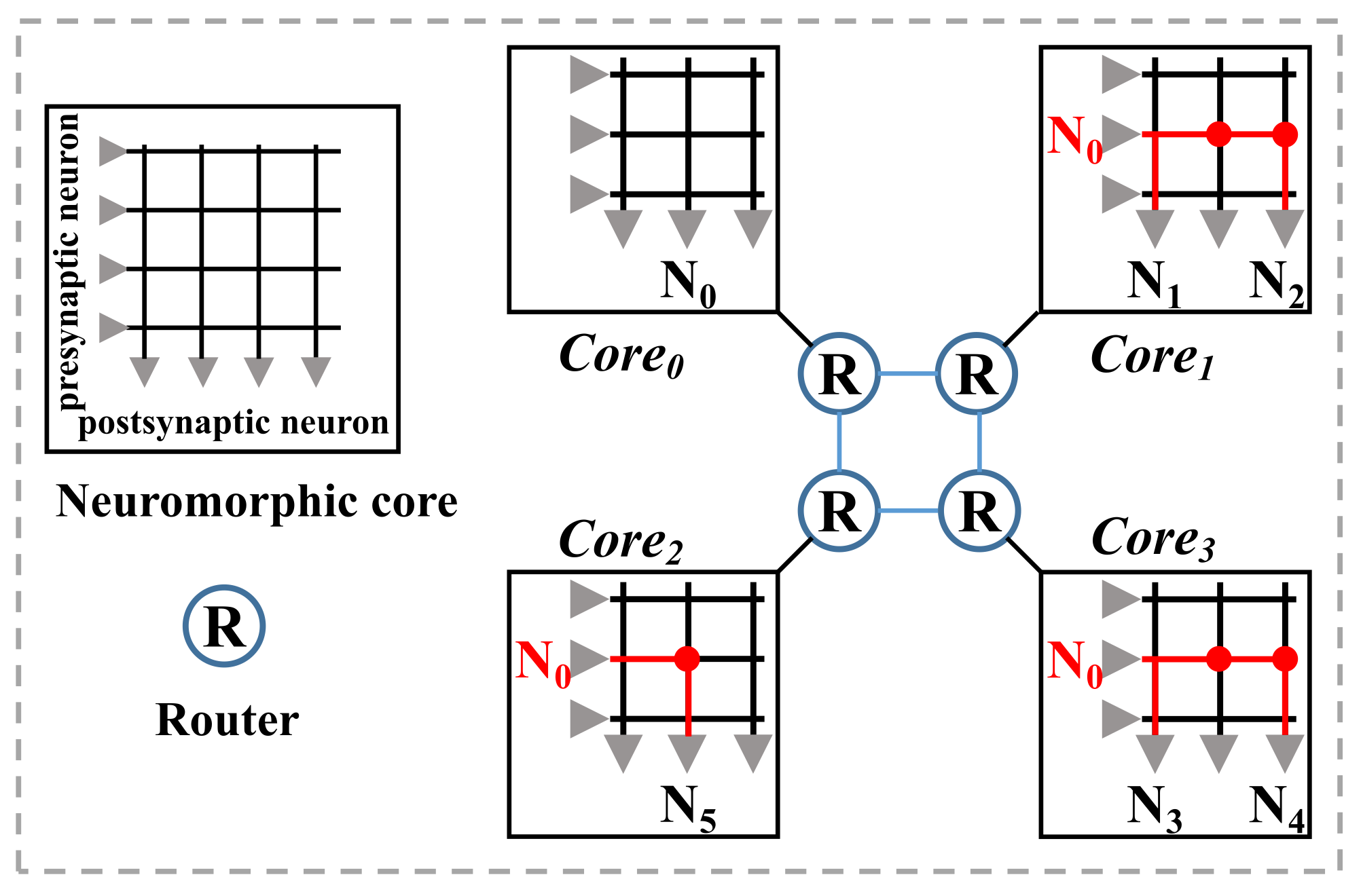
2.2. Spike Communication in Neuromorphic Processor
2.3. Related Work
3. NeuToMa
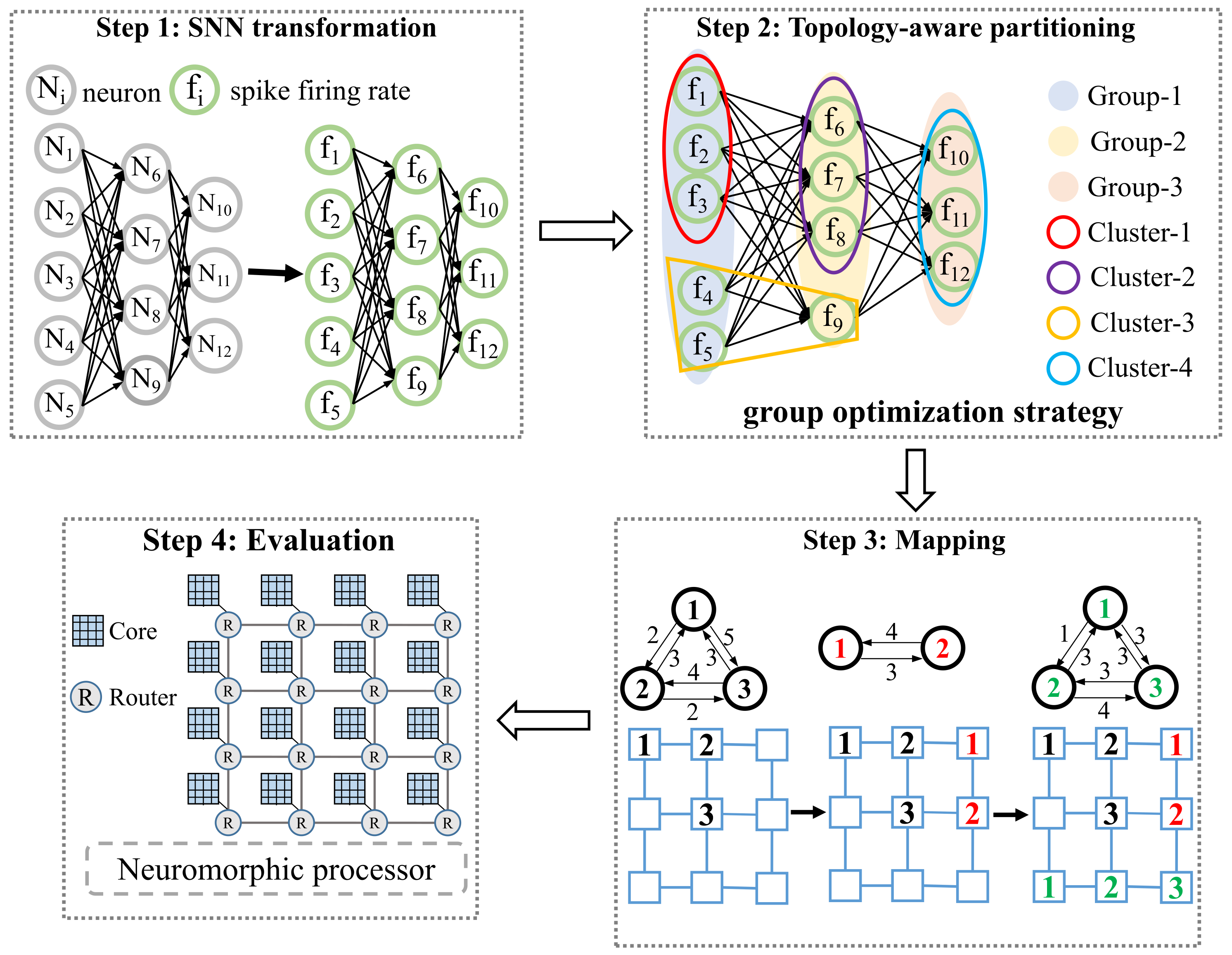
3.1. Overview
3.2. SNN Transformation
3.3. Topology-Aware Partitioning
3.3.1. Division
3.3.2. Partitioning and Merging
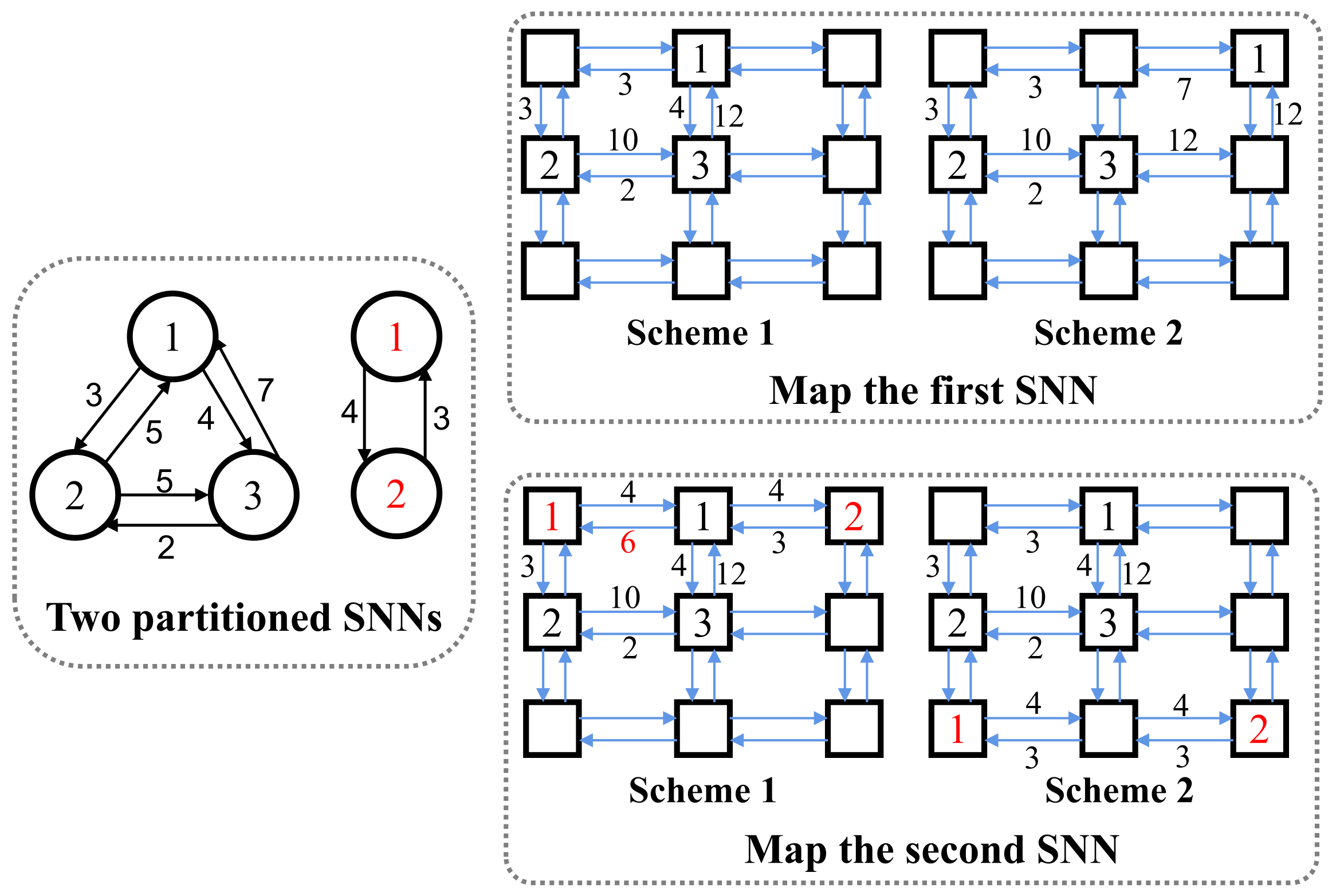
3.4. Mapping
| Algorithm 1: Mapping algorithm |
 |
4. Experiment Setup
4.1. Experiment Platform
4.2. Evaluated SNNs
- Group 1: MLP-MNIST, MLP-FaMNIST;
- Group 2: LSM-FSDD, SFC-FSDD;
- Group 3: MLP-MNIST, MLP-FaMNIST, CNN-FaMNIST.
5. Results
5.1. Partitioning and Mapping Performance
5.1.1. Partitioning Performance
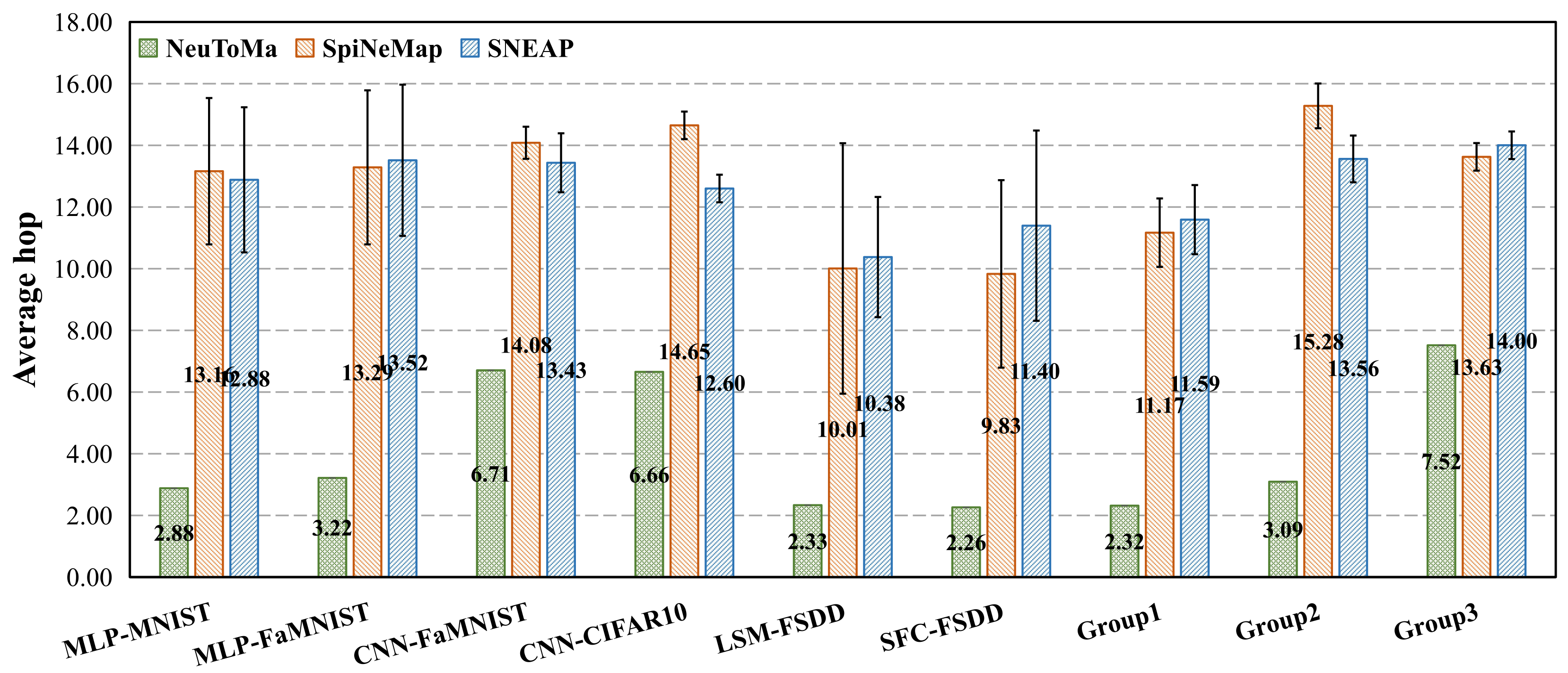
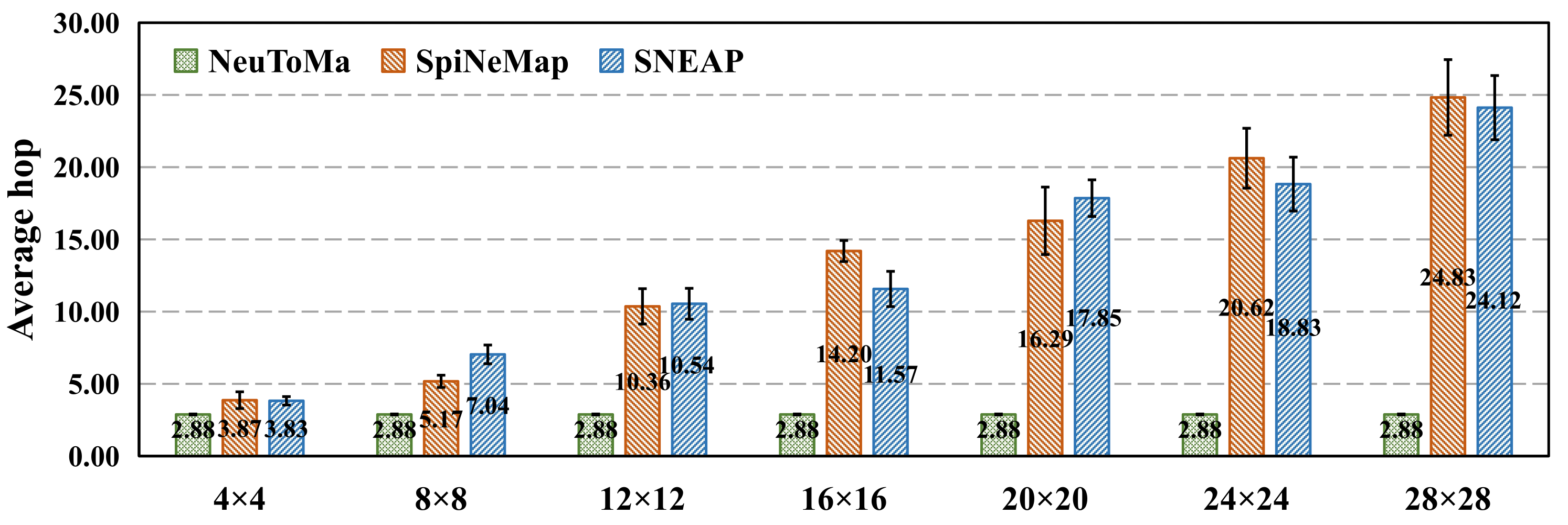
5.1.2. Mapping Performance
5.2. NoC Performance
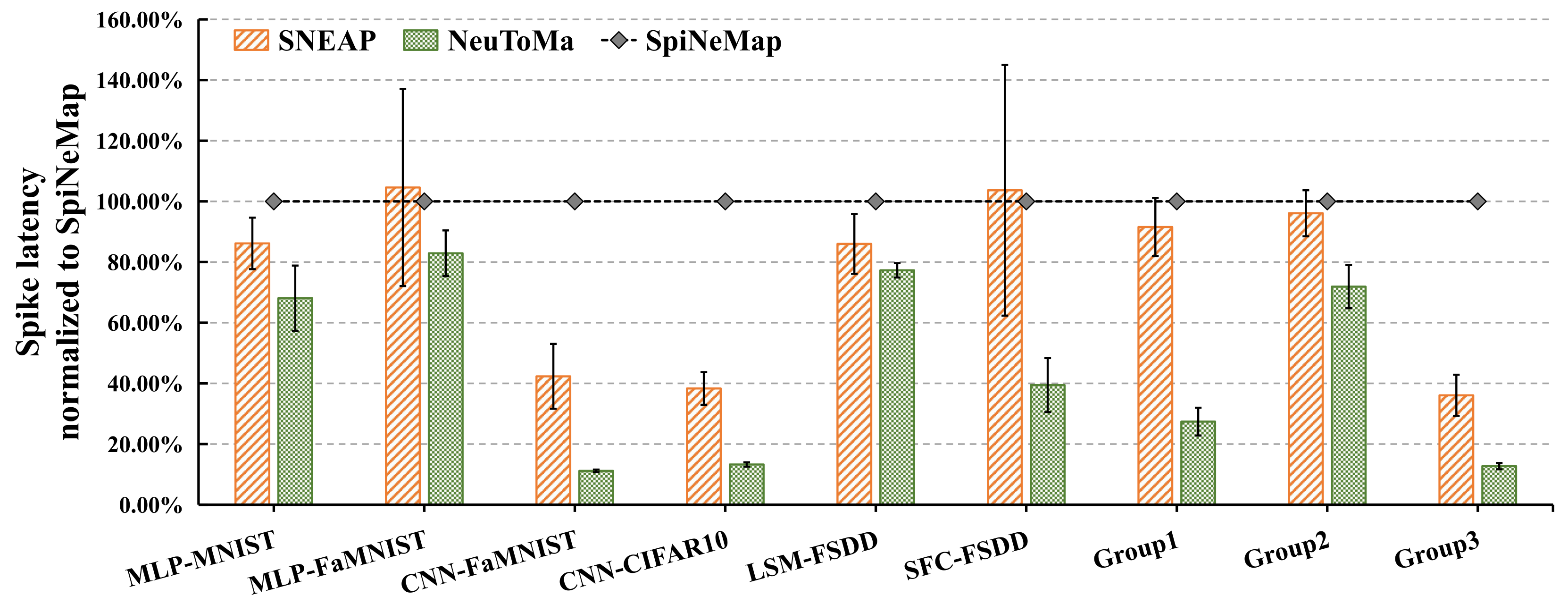
5.2.1. Spike Latency
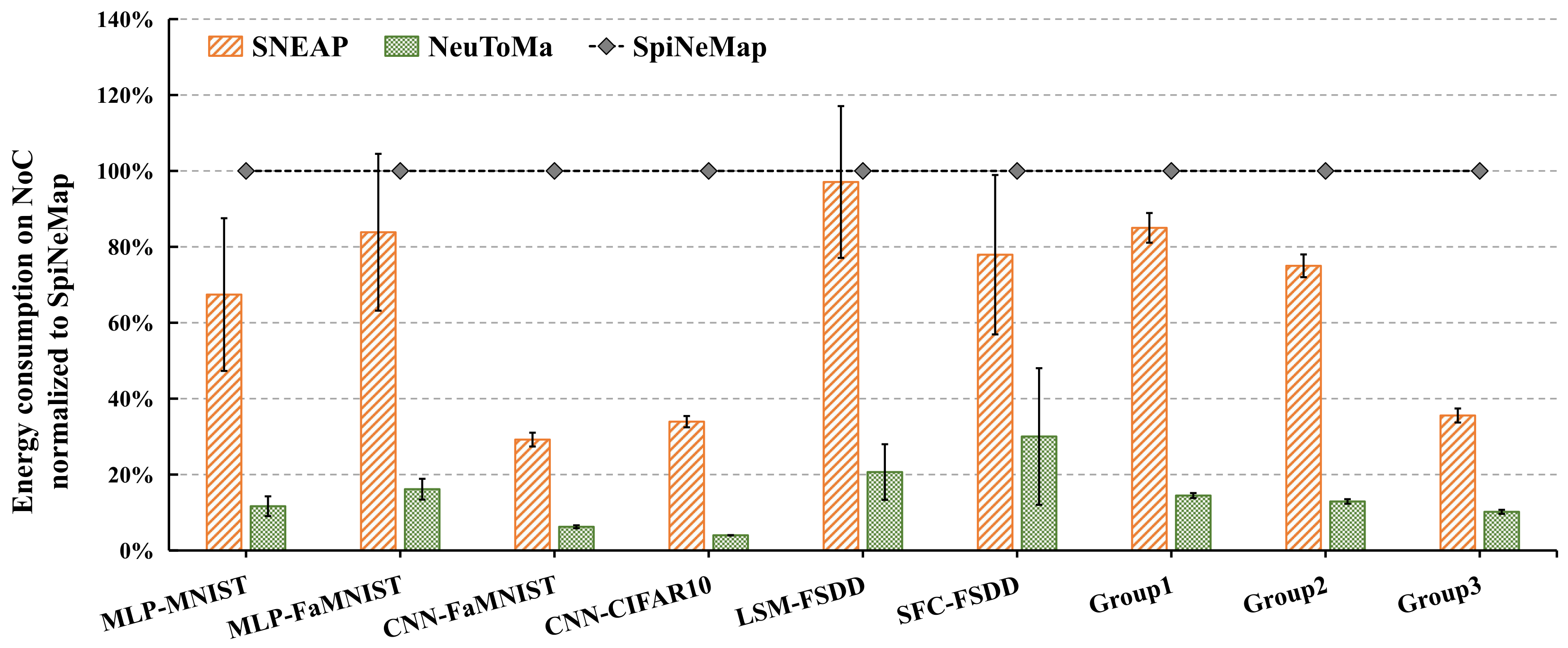
5.2.2. Energy Consumption on NoC
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Merolla, P.A.; Arthur, J.V.; Alvarez-Icaza, R.; Cassidy, A.S.; Sawada, J.; Akopyan, F.; Jackson, B.L.; Imam, N.; Chen, G.; Yutaka, N.; et al. A million spiking-neuron integrated circuit with a scalable communication network and interface. Science 2014, 345, 668–673. [Google Scholar] [CrossRef] [PubMed]
- Davies, M.; Srinivasa, N.; Lin, T.H.; Chinya, G.; Joshi, P.; Lines, A.; Wild, A.; Wang, H. Loihi: A Neuromorphic Manycore Processor with On-Chip Learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Furber, S.B.; Lester, D.R.; Plana, L.A.; Garside, J.D.; Painkras, E.; Temple, S.; Brown, A.D. Overview of the SpiNNaker System Architecture. IEEE Trans. Comput. 2013, 62, 2454–2467. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, L.; Wang, Y.; Peng, L.; Chen, X.; Xiao, X.; Wang, Y.; Xu, W. Unicorn: A Multicore Neuromorphic Processor with Flexible Fan-In and Unconstrained Fan-Out for Neurons. In Proceedings of the 59th ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 10–14 July 2022. [Google Scholar] [CrossRef]
- Wang, L.; Yang, Z.; Guo, S.; Qu, L.; Zhang, X.; Kang, Z.; Xu, W. LSMCore: A 69k-Synapse/mm2 Single-Core Digital Neuromorphic Processor for Liquid State Machine. IEEE Trans. Circuits Syst. I Regul. Pap. 2022, 69, 1976–1989. [Google Scholar] [CrossRef]
- Benini, L.; Micheli, G.D. Networks on chip: A new paradigm for systems on chip design. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition, Antwerp, Belgium, 14–23 March 2002. [Google Scholar]
- Maass, W. Networks of spiking neurons: The third generation of neural network models. Neural Netw. 1997, 10, 1659–1671. [Google Scholar] [CrossRef]
- Xiang, S.; Jiang, S.; Liu, X.; Zhang, T.; Yu, L. Spiking VGG7: Deep Convolutional Spiking Neural Network with Direct Training for Object Recognition. Electronics 2022, 11, 2097. [Google Scholar] [CrossRef]
- Xing, Y.; Zhang, L.; Hou, Z.; Li, X.; Shi, Y.; Yuan, Y.; Zhang, F.; Liang, S.; Li, Z.; Yan, L. Accurate ECG Classification Based on Spiking Neural Network and Attentional Mechanism for Real-Time Implementation on Personal Portable Devices. Electronics 2022, 11, 1889. [Google Scholar] [CrossRef]
- Rueckauer, B.; Liu, S.C. Conversion of analog to spiking neural networks using sparse temporal coding. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar]
- Galluppi, F.; Davies, S.; Rast, A.; Sharp, T.; Plana, L.A.; Furber, S. A hierachical configuration system for a massively parallel neural hardware platform. In Proceedings of the 9th conference on Computing Frontiers, Caligari, Italy, 22–23 September 2012; p. 183. [Google Scholar]
- Das, A.; Wu, Y.; Huynh, K.; Dell’Anna, F.; Catthoor, F.; Schaafsma, S. Mapping of Local and Global Synapses on Spiking Neuromorphic Hardware. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018. [Google Scholar]
- Balaji, A.; Das, A.; Wu, Y.; Huynh, K.; Dell’Anna, F.; Indiveri, G.; Krichmar, J.L.; Dutt, N.; Schaafsma, S.; Catthoor, F. Mapping Spiking Neural Networks to Neuromorphic Hardware. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 28, 76–86. [Google Scholar] [CrossRef]
- Li, S.; Guo, S.; Zhang, L. SNEAP: A Fast and Efficient Toolchain for Mapping Large-Scale Spiking Neural Network onto NoC-based Neuromorphic Platform. In Proceedings of the 30th Great Lakes Symposium on VLSI (GLSVLSI 2020), Beijing, China, 27–29 May 2020. [Google Scholar]
- Kernighan, B.W.; Lin, S. An efficient heuristic procedure for partitioning graphs. Bell Syst. Tech. J. 1970, 49, 291–307. [Google Scholar] [CrossRef]
- Karypis, G.; Kumar, V. Multilevelk-way Partitioning Scheme for Irregular Graphs. J. Parallel Distrib. Comput. 1998, 48, 96–129. [Google Scholar] [CrossRef]
- Dayan, P.; Abbott, L. Theoretical Neuroscience : Computational and Mathematical Modeling of neural systems. Philos. Psychol. 2001, 15, 154–155. [Google Scholar]
- Maass, W.; Natschläger, T.; Markram, H. Real-Time Computing Without Stable States: A New Framework for Neural Computation Based on Perturbations. Neural Comput. 2002, 14, 2531–2560. [Google Scholar] [CrossRef] [PubMed]
- Bienenstock, E. A model of neocortex. Netw. Comput. Neural Syst. 1995, 6, 179–224. [Google Scholar] [CrossRef]
- Shen, J.; Liu, J.K.; Wang, Y. Dynamic Spatiotemporal Pattern Recognition with Recurrent Spiking Neural Network. Neural Comput. 2021, 33, 2971–2995. [Google Scholar] [CrossRef] [PubMed]
- Sinha, D.B.; Ledbetter, N.M.; Barbour, D.L. Spike-timing computation properties of a feed-forward neural network model. Front. Comput. Neurosci. 2014, 8, 5. [Google Scholar] [CrossRef] [PubMed]
- Stimberg, M.; Brette, R.; Dan, G. Brian 2, an intuitive and efficient neural simulator. eLife 2019, 8, e47314. [Google Scholar] [CrossRef] [PubMed]
- Haykin, S.; Kosko, B. Gradient-Based Learning Applied to Document Recognition. In Intelligent Signal Processing; IEEE: Piscataway, NJ, USA, 2001; pp. 306–351. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Hinton, A.K. Learning multiple layers of features from tiny images. In Handbook of Systemic Autoimmune Diseases; Elsevier: Amsterdam, The Netherlands, 2009. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Partitioning | Cluster-to-Core Mapping | Consistent Results after Multiple Tests? | |
|---|---|---|---|
| PSOPART [12] | particle swarm optimization | not optimized | × |
| SpiNeMap [13] | Kernighan–Lin graph partitioning algorithm | particle swarm optimization | × |
| SNEAP [14] | multi-level graph partitioning algorithm | simulated annealing algorithm | × |
| NeuToMa | topology-aware partitioning algorithm | a traversal algorithm with two optimization objectives | ✓ |
| SNNs | Topology | Neurons | Synapses |
|---|---|---|---|
| MLP-MNIST | Feed-foward | 738 | 548,480 |
| MLP-FaMNIST | Feed-foward | 738 | 548,480 |
| CNN-FaMNIST | CNN | 16,714 | 1,948,288 |
| CNN-CIFAR10 | CNN | 19,894 | 2,343,464 |
| LSM-FSDD | LSM(E_800,I_200) | 1000 | 399,970 |
| SFC-FSDD | SFC(400,300,300) | 1000 | 27,097 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, C.; Wang, Y.; Chen, J.; Wang, L. Topology-Aware Mapping of Spiking Neural Network to Neuromorphic Processor. Electronics 2022, 11, 2867. https://doi.org/10.3390/electronics11182867
Xiao C, Wang Y, Chen J, Wang L. Topology-Aware Mapping of Spiking Neural Network to Neuromorphic Processor. Electronics. 2022; 11(18):2867. https://doi.org/10.3390/electronics11182867
Chicago/Turabian StyleXiao, Chao, Yao Wang, Jihua Chen, and Lei Wang. 2022. "Topology-Aware Mapping of Spiking Neural Network to Neuromorphic Processor" Electronics 11, no. 18: 2867. https://doi.org/10.3390/electronics11182867
APA StyleXiao, C., Wang, Y., Chen, J., & Wang, L. (2022). Topology-Aware Mapping of Spiking Neural Network to Neuromorphic Processor. Electronics, 11(18), 2867. https://doi.org/10.3390/electronics11182867