
High-Performance and Robust Binarized Neural Network Accelerator Based on Modified Content-Addressable Memory

Abstract
:1. Introduction
2. CAM-Based BNN Accelerator Design
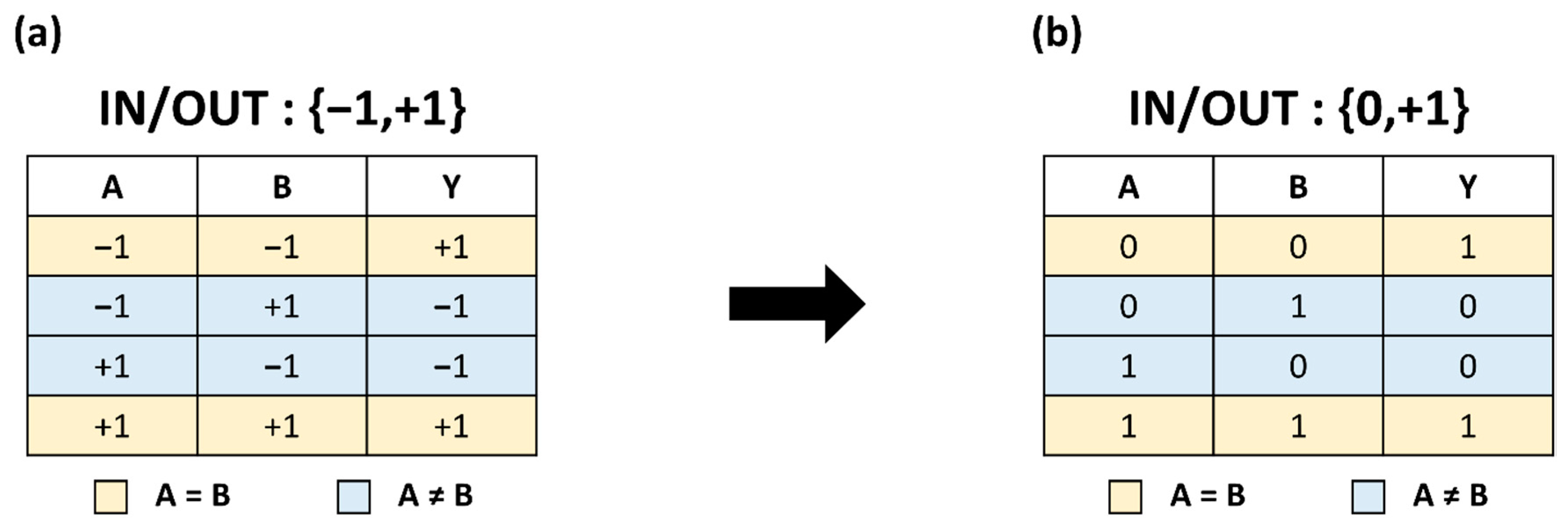
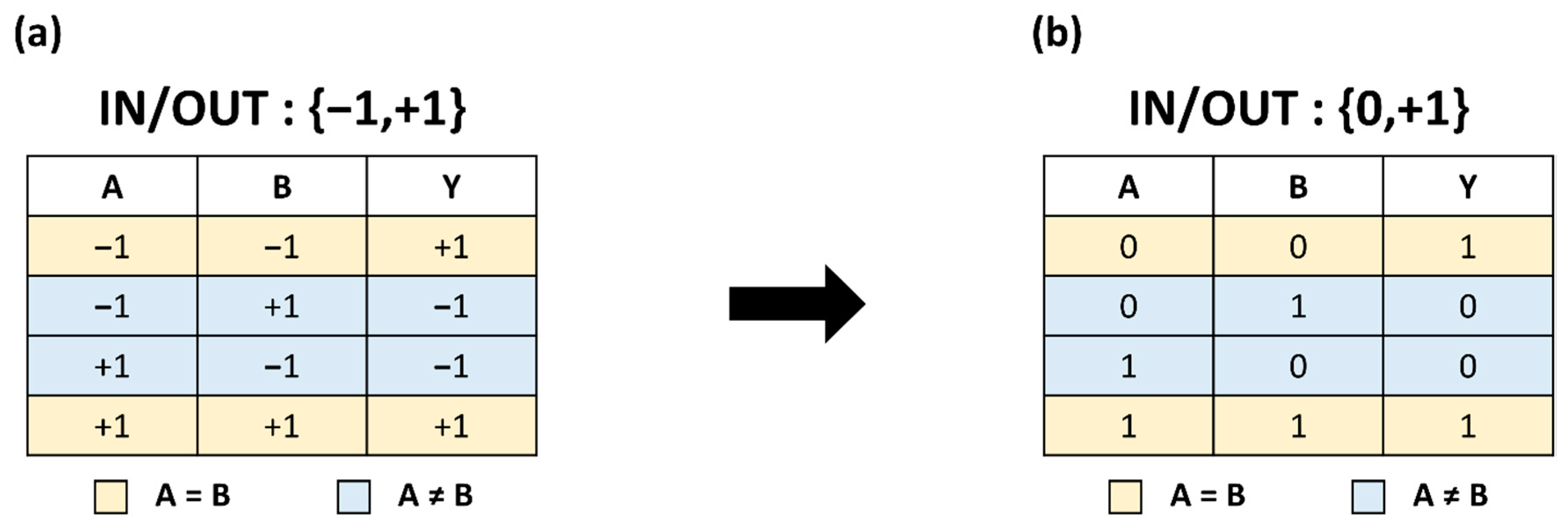
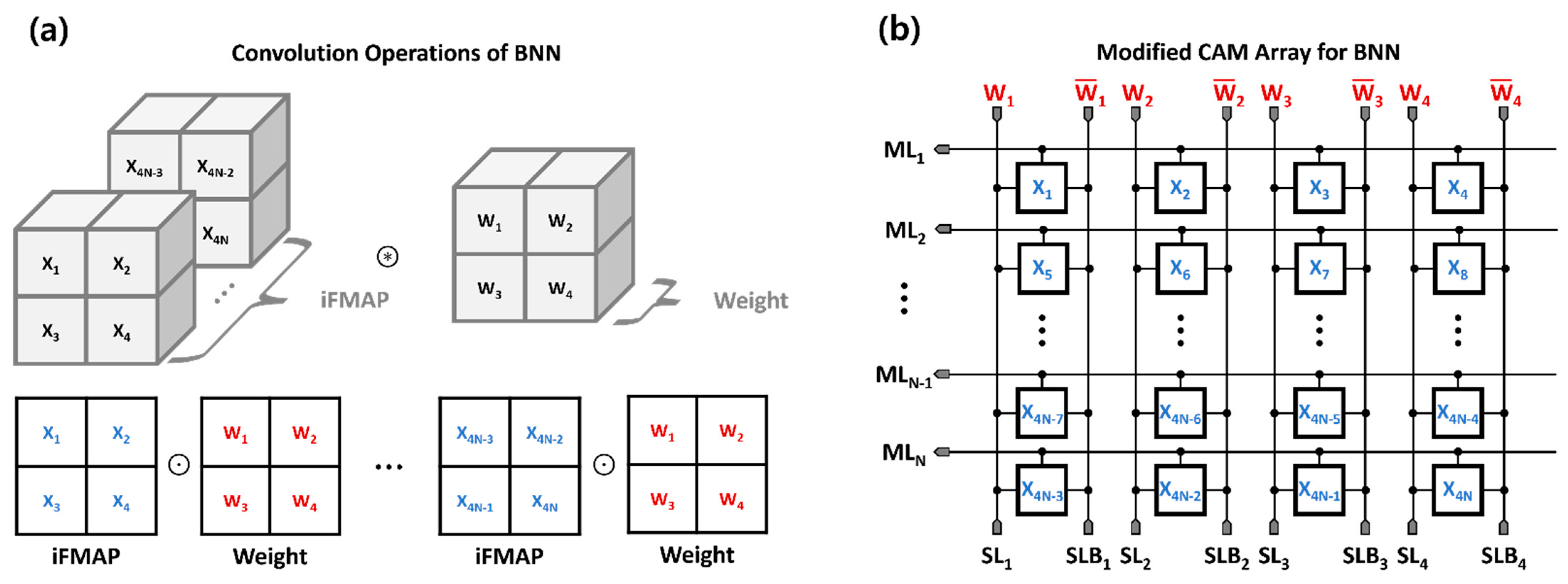
2.1. XNOR Bit-Counting Operation
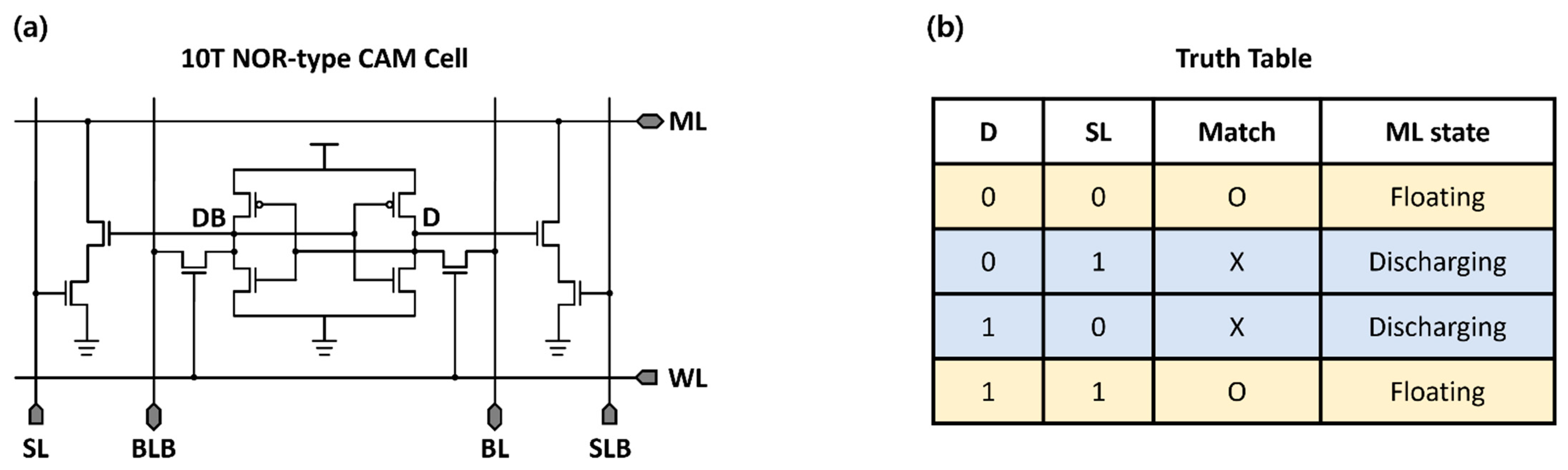
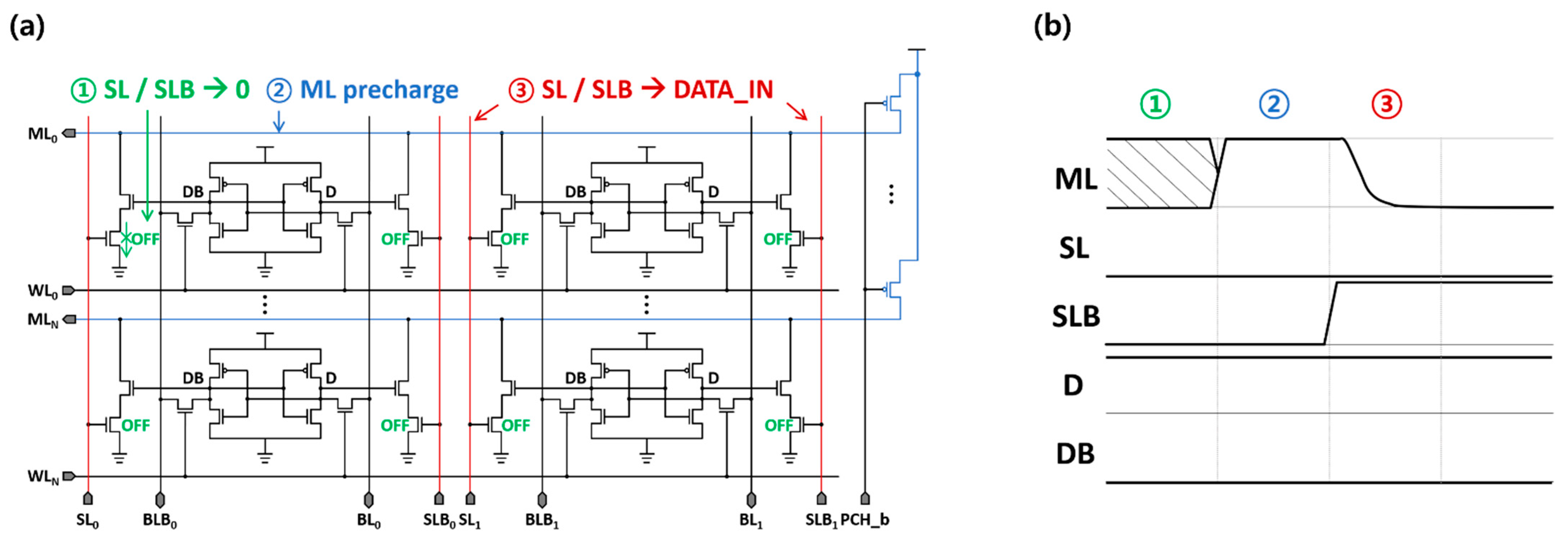
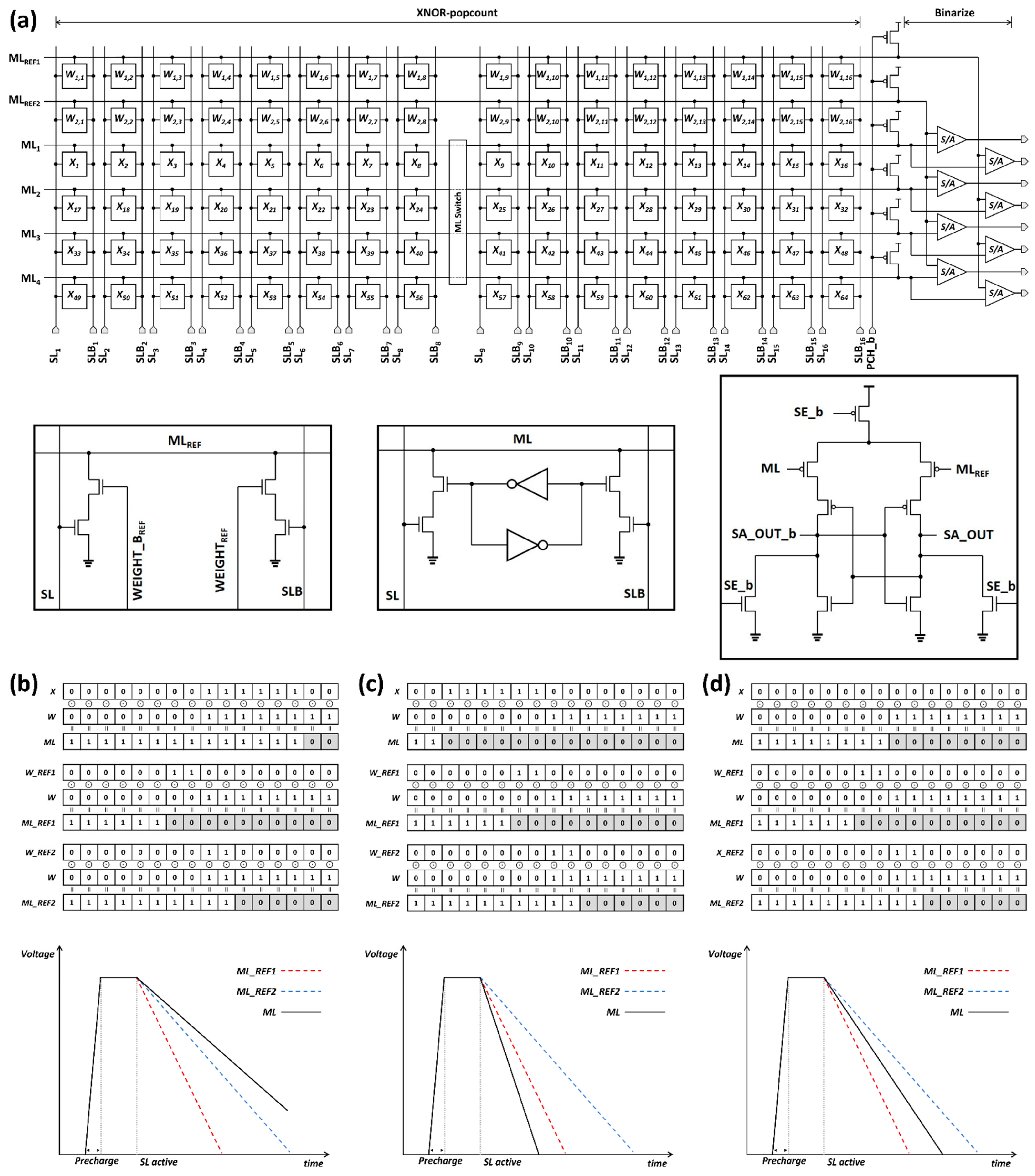
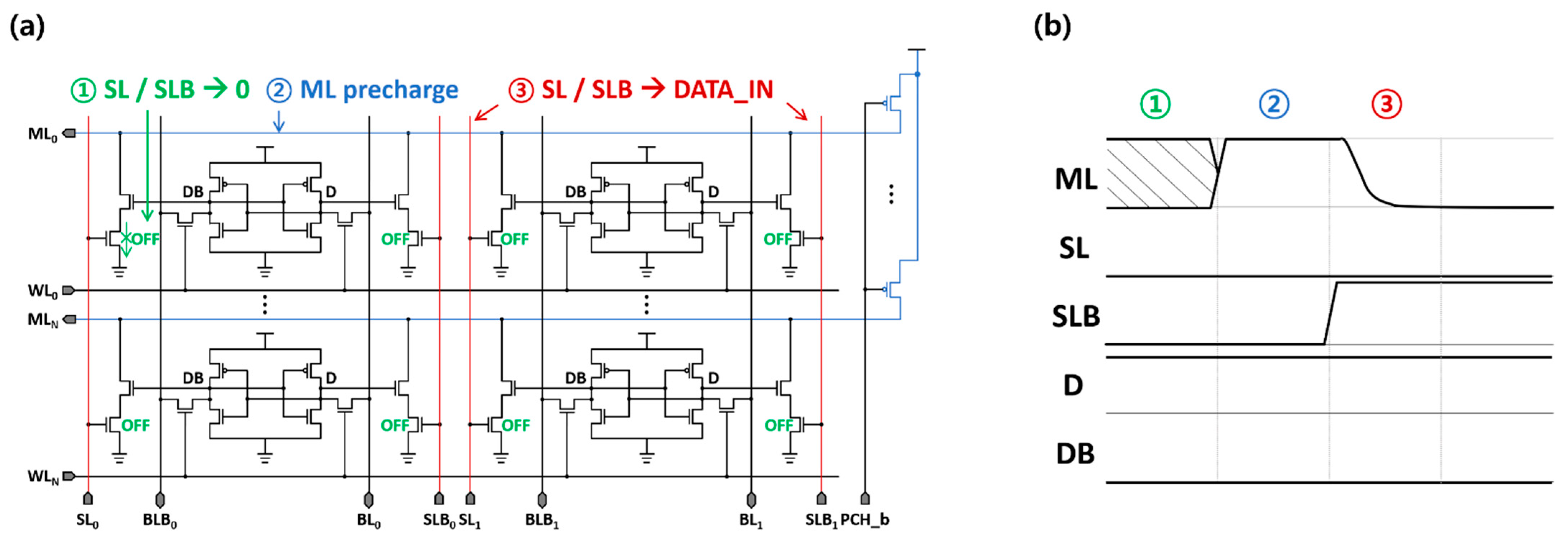
2.2. CAM-Based BNN Accelerator
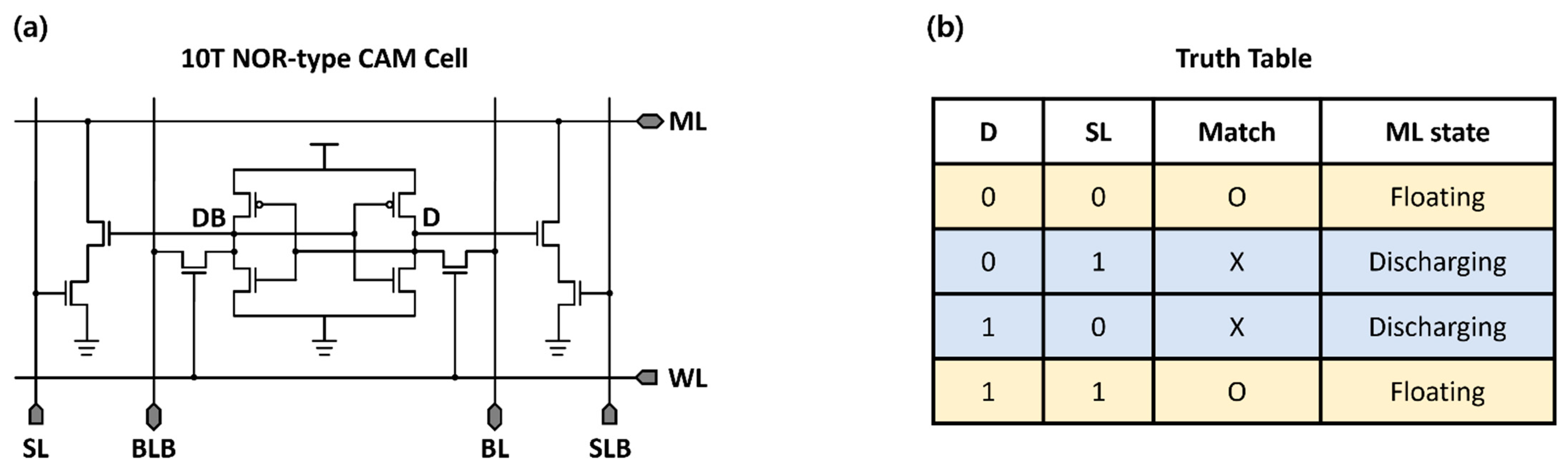
- Prior to the ML pre-charge phase, the search-line (SL) pairs are deactivated to prevent unintentional ML discharges.
- During the ML pre-charge phase, all MLs in the array are pre-charged to the supply voltage.
- When SL pairs are set to search for data, the two stacked NMOS transistors compared the search and stored data.
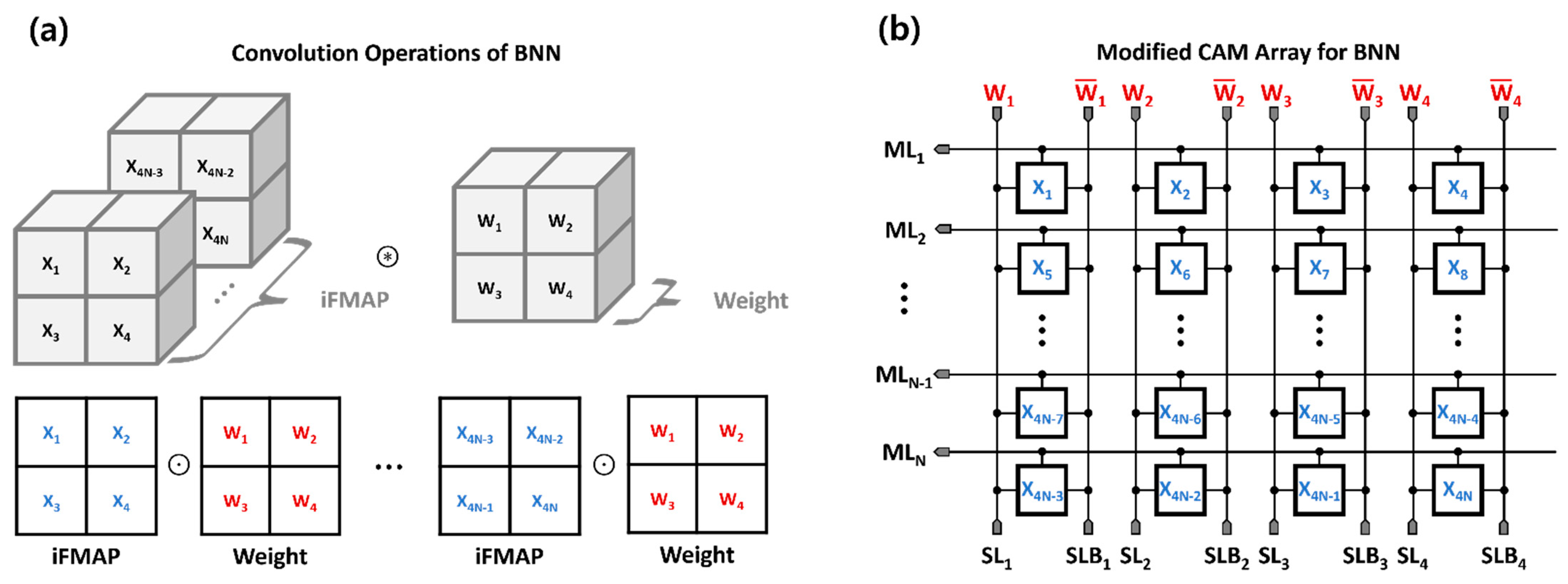
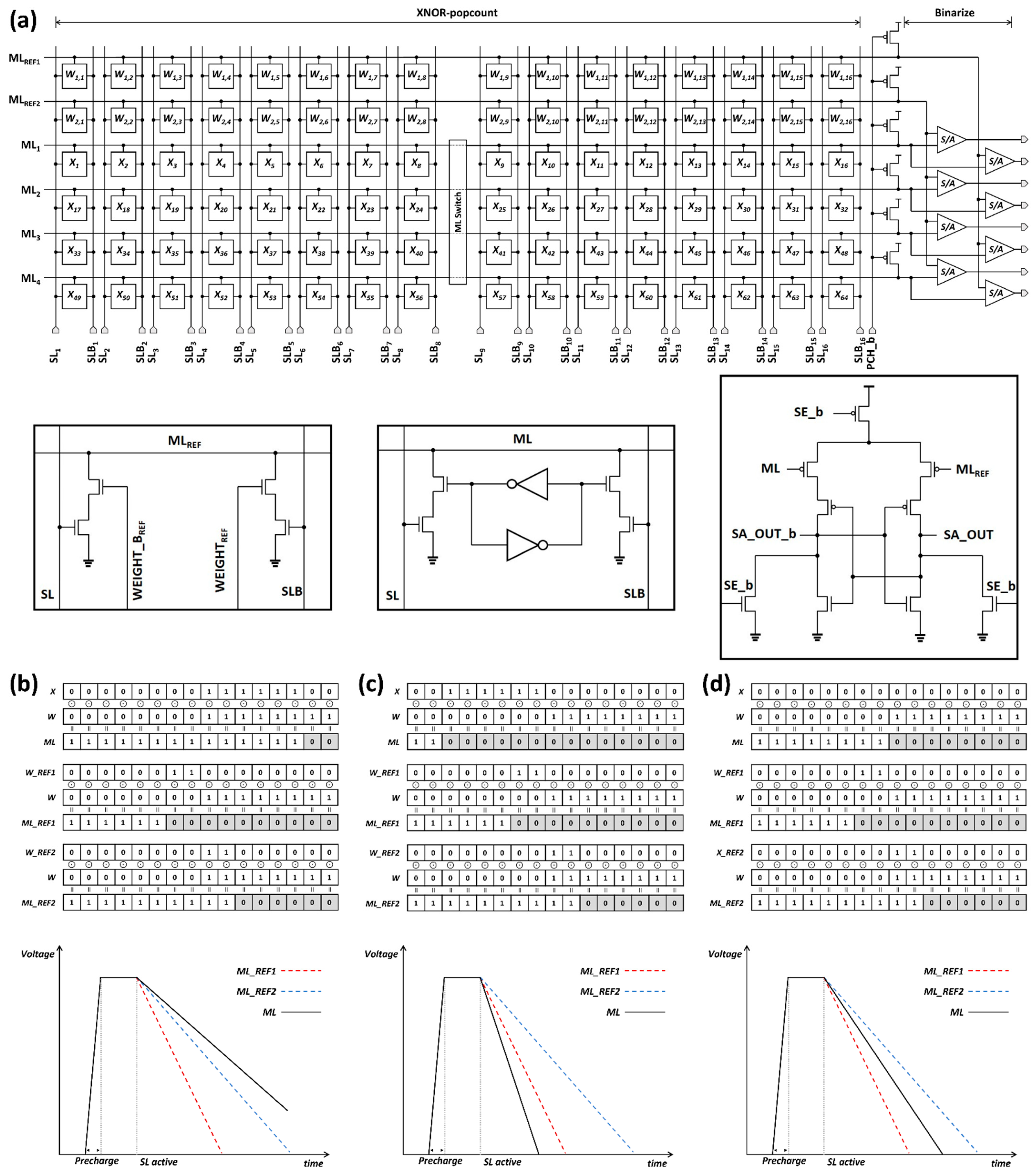
3. Proposed BNN Accelerator Design
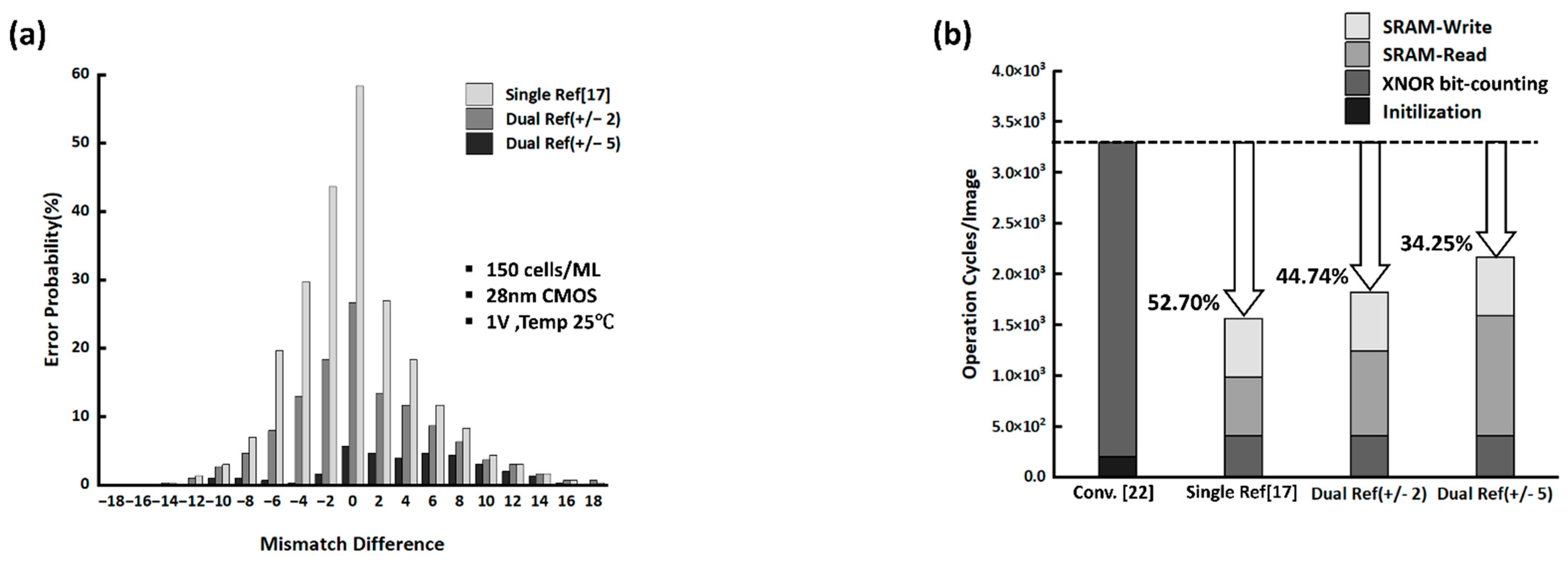
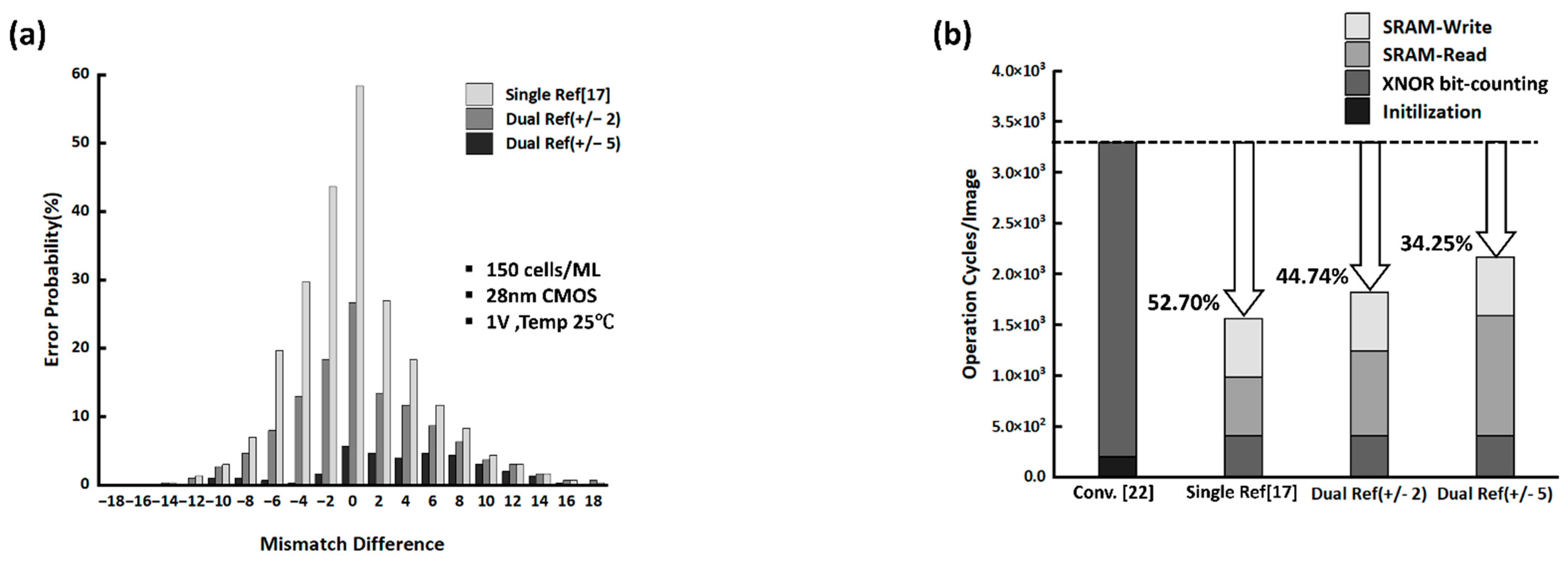
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2013. [Google Scholar] [CrossRef]
- Ciresan, D.C.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. arXiv 2012. [Google Scholar] [CrossRef]
- Deng, L.; Hinton, G.; Kingsbury, B. New types of deep neural network learning for speech recognition and related applications: An overview. In Proceedings of the IEEE Int. Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar] [CrossRef]
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F.-Y. Traffic Flow Prediction With Big Data: A Deep Learning Approach. IEEE Trans. Intell. Transp. Syst. 2015, 16, 865–873. [Google Scholar] [CrossRef]
- Dundar, A.; Jin, J.; Gokhale, V.; Martini, B.; Culurciello, E. Memory access optimized routing scheme for deep networks on a mobile coprocessor. In Proceedings of the IEEE High Performance Extreme Computing Conference, Waltham, MA, USA, 9–11 September 2014. [Google Scholar] [CrossRef]
- Gong, Y.; Liu, L.; Yang, M.; Bourdev, L. Compressing deep convolutional networks using vector quantization. arXiv 2014. [Google Scholar] [CrossRef]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or −1. arXiv 2016. [Google Scholar] [CrossRef]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar] [CrossRef]
- Simons, T.; Lee, D.-J. A Review of Binarized Neural Networks. Electronics 2019, 8, 661. [Google Scholar] [CrossRef] [Green Version]
- Gao, J.; Liu, Q.; Lai, J. An Approach of Binary Neural Network Energy-Efficient Implementation. Electronics 2021, 10, 1830. [Google Scholar] [CrossRef]
- Choi, J.H.; Gong, Y.-H.; Chung, S.W. A System-Level Exploration of Binary Neural Network Accelerators with Monolithic 3D Based Compute-in-Memory SRAM. Electronics 2021, 10, 623. [Google Scholar] [CrossRef]
- Chen, J.; Wang, J.; Shu, T.; de Silva, C.W. WSN optimization for sampling-based signal estimation using semi-binarized variational autoencoder. Inf. Sci. 2022, 587, 188–205. [Google Scholar] [CrossRef]
- Austin, J. High speed image segmentation using a binary neural network. In Neurocomputation in Remote Sensing Data Analysis; Springer: Berlin/Heidelberg, Germany, 1997. [Google Scholar] [CrossRef]
- Kung, J.; Zhang, D.; van der Wal, G.; Chai, S.; Mukhopadhyay, S. Efficient Object Detection Using Embedded Binarized Neural Networks. J. Signal Processing 2018, 90, 877–890. [Google Scholar] [CrossRef]
- Liu, R.; Peng, X.; Sun, X.; Khwa, W.S.; Si, X.; Chen, J.J.; Li, J.F.; Chang, M.F.; Yu, S. Parallelizing SRAM Arrays with Customized Bit-Cell for Binary Neural Networks. In Proceedings of the ACM/ESDA/IEEE Design Automation Conference, San Francisco, CA, USA, 24–28 June 2018. [Google Scholar] [CrossRef]
- Choi, W.; Jeong, K.; Choi, K.; Lee, K.; Park, J. Content Addressable Memory Based Binarized Neural Network Accelerator Using Time-Domain Signal Processing. In Proceedings of the ACM/ESDA/IEEE Design Automation Conference, San Francisco, CA, USA, 24–28 June 2018. [Google Scholar] [CrossRef]
- Guo, P.; Ma, H.; Chen, R.; Li, P.; Xie, S.; Wang, D. FBNA: A Fully Binarized Neural Network Accelerator. In Proceedings of the International Conference on Field Programmable Logic and Applications, Dublin, Ireland, 27–31 August 2018. [Google Scholar] [CrossRef]
- Kim, J.H.; Lee, J.; Anderson, J.H. FPGA Architecture Enhancements for Efficient BNN Implementation. In Proceedings of the International Conference on Field-Programmable Technology, Naha, Japan, 10–14 December 2018. [Google Scholar] [CrossRef]
- Pagiamtzis, K.; Sheikholeslami, A. Content-addressable memory (CAM) circuits and architectures: A tutorial and survey. IEEE J. Solid-State Circuits 2006, 41, 712–727. [Google Scholar] [CrossRef]
- Huang, P.-T.; Chang, W.-K.; Hwang, W. Low Power Pre-Comparison Scheme for NOR-Type 10T Content Addressable Memory. In Proceedings of the IEEE Asia Pacific Conference on Circuits and Systems, Singapore, 4–7 December 2006. [Google Scholar] [CrossRef]
- Yonekawa, H.; Nakahara, H. On-chip Memory Based Binarized Convolutional Deep Neural Network Applying Batch Normalization Free Technique on an FPGA. In Proceedings of the IEEE International Parallel and Distributed Processing Symposium Work, Lake Buena Vista, FL, USA, 29 May–2 June 2017. [Google Scholar] [CrossRef]
- Kayed, M.; Anter, A.; Mohamed, H. Classification of Garments from Fashion MNIST Dataset Using CNN LeNet-5 Architecture. In Proceedings of the International Conference on Innovative Trends in Communication and Computer Engineering, Aswan, Egypt, 8–9 February 2020. [Google Scholar] [CrossRef]
- Chen, Y.; Rouhsedaghat, M.; You, S.; Rao, R.; Kuo, C.-C.J. Pixelhop++: A Small Successive-Subspace-Learning-Based (Ssl-Based) Model For Image Classification. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| XNOR-Bitcounting Error Probability | Fashion MNIST Classification Accuracy | |
|---|---|---|
| TOP-1 Accuracy | - | 84.4% |
| Single Ref. [17] | 8.83% | 81.5% |
| Dual Ref. (±2) | 4.42% | 82.5% |
| Dual Ref. (±5) | 1.00% | 83.9% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, S.; Jeon, Y.; Seo, Y. High-Performance and Robust Binarized Neural Network Accelerator Based on Modified Content-Addressable Memory. Electronics 2022, 11, 2780. https://doi.org/10.3390/electronics11172780
Choi S, Jeon Y, Seo Y. High-Performance and Robust Binarized Neural Network Accelerator Based on Modified Content-Addressable Memory. Electronics. 2022; 11(17):2780. https://doi.org/10.3390/electronics11172780
Chicago/Turabian StyleChoi, Sureum, Youngjun Jeon, and Yeongkyo Seo. 2022. "High-Performance and Robust Binarized Neural Network Accelerator Based on Modified Content-Addressable Memory" Electronics 11, no. 17: 2780. https://doi.org/10.3390/electronics11172780
APA StyleChoi, S., Jeon, Y., & Seo, Y. (2022). High-Performance and Robust Binarized Neural Network Accelerator Based on Modified Content-Addressable Memory. Electronics, 11(17), 2780. https://doi.org/10.3390/electronics11172780