
A Piece-Wise Linear Model-Based Algorithm for the Identification of Nonlinear Models in Real-World Applications



Abstract
:1. Introduction
2. Methodology
- is the output of the model at time t;
- is the input vector of the model at time t, including both the autoregressive and the exogenous parts;
- , …, are the regions into which the input space is divided and are used to select the parameters to compute the output of the model at time t;
- , …, are the parameter vectors to be estimated during the identification phase, with each vector associated with region .
- -
- K is the number of regions;
- -
- N is the number of considered time instants (tuples in the identification dataset);
- -
- is the measured data of the output model at time t;
- -
- is the value of the exogenous input l at time t;
- -
- is the autoregressive order of the linear systems;
- -
- is the exogenous order of the l-th input of the linear systems;
- -
- L is the number of the exogenous inputs of the different models;
- -
- , , , are the lower and upper bound for the decision variables;
- -
- is the output at time t;
- -
- is the input vector of the model, including both the previous output values () and the measured input values ();
- -
- are the parameters of the i-th model to be estimated;
- -
- are the centroids of the different clusters (to be optimized during the identification);
- -
- is a check function that determines if belongs to region i, based on a distance measure.
| Algorithm 1 Objective function |
|
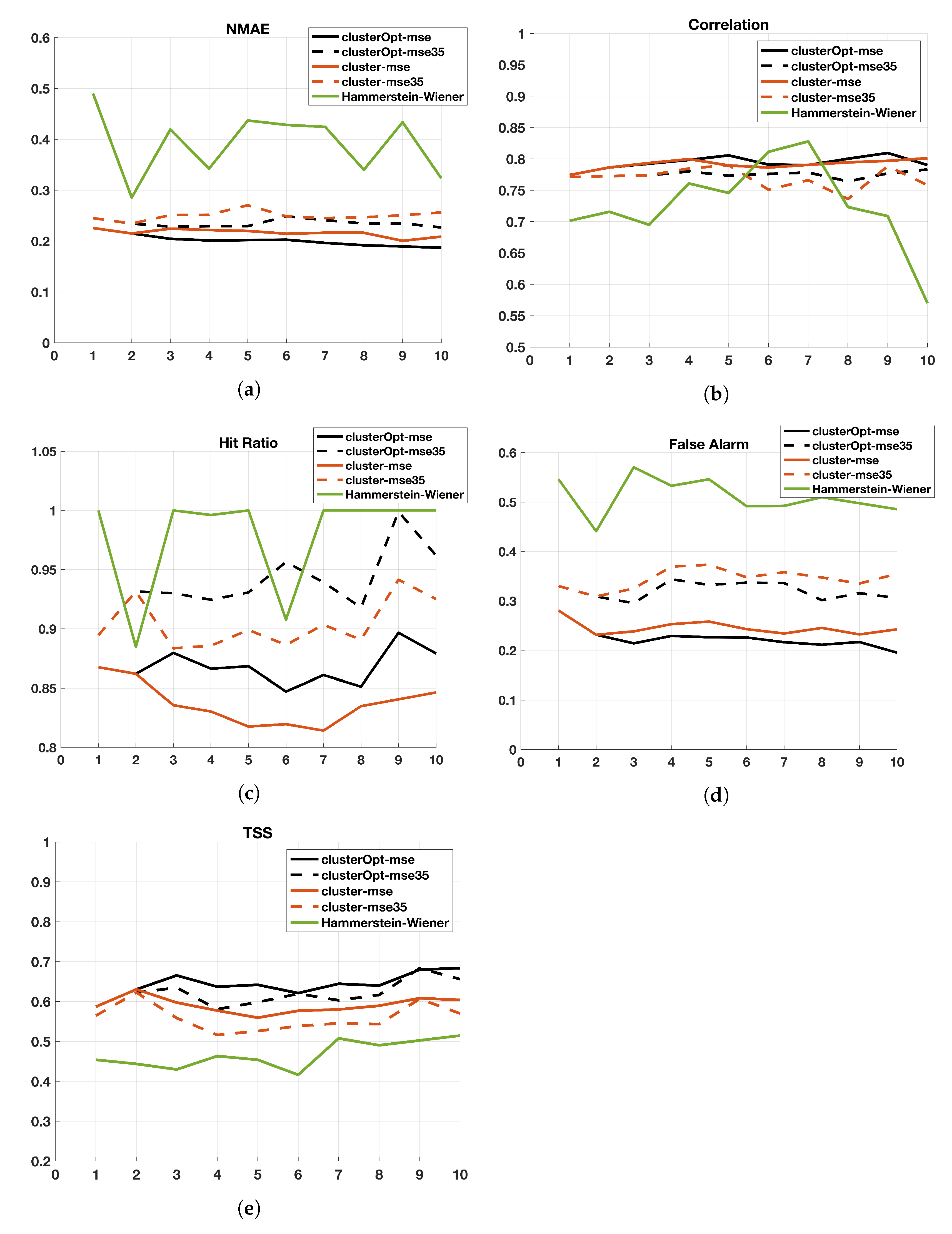
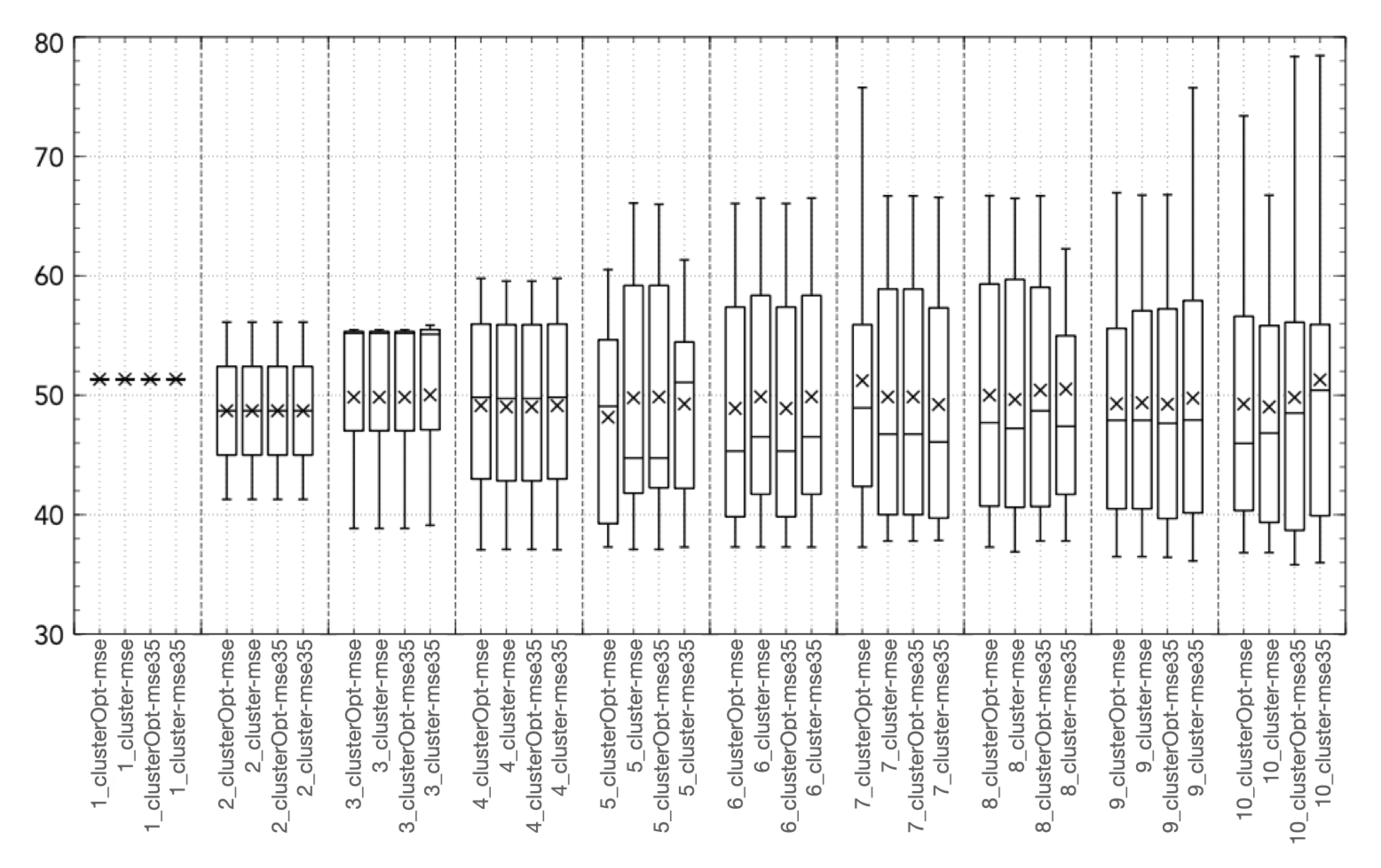
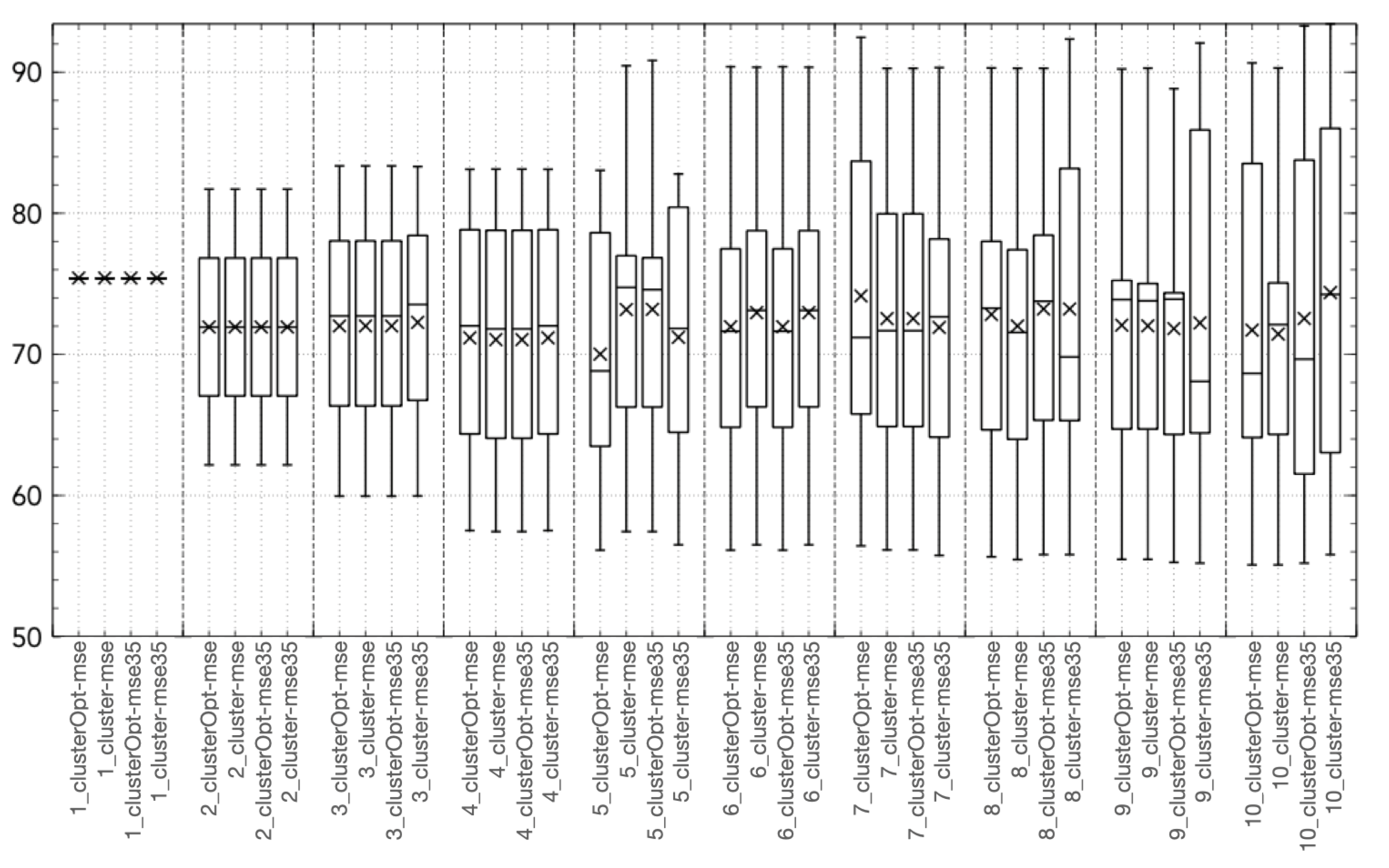
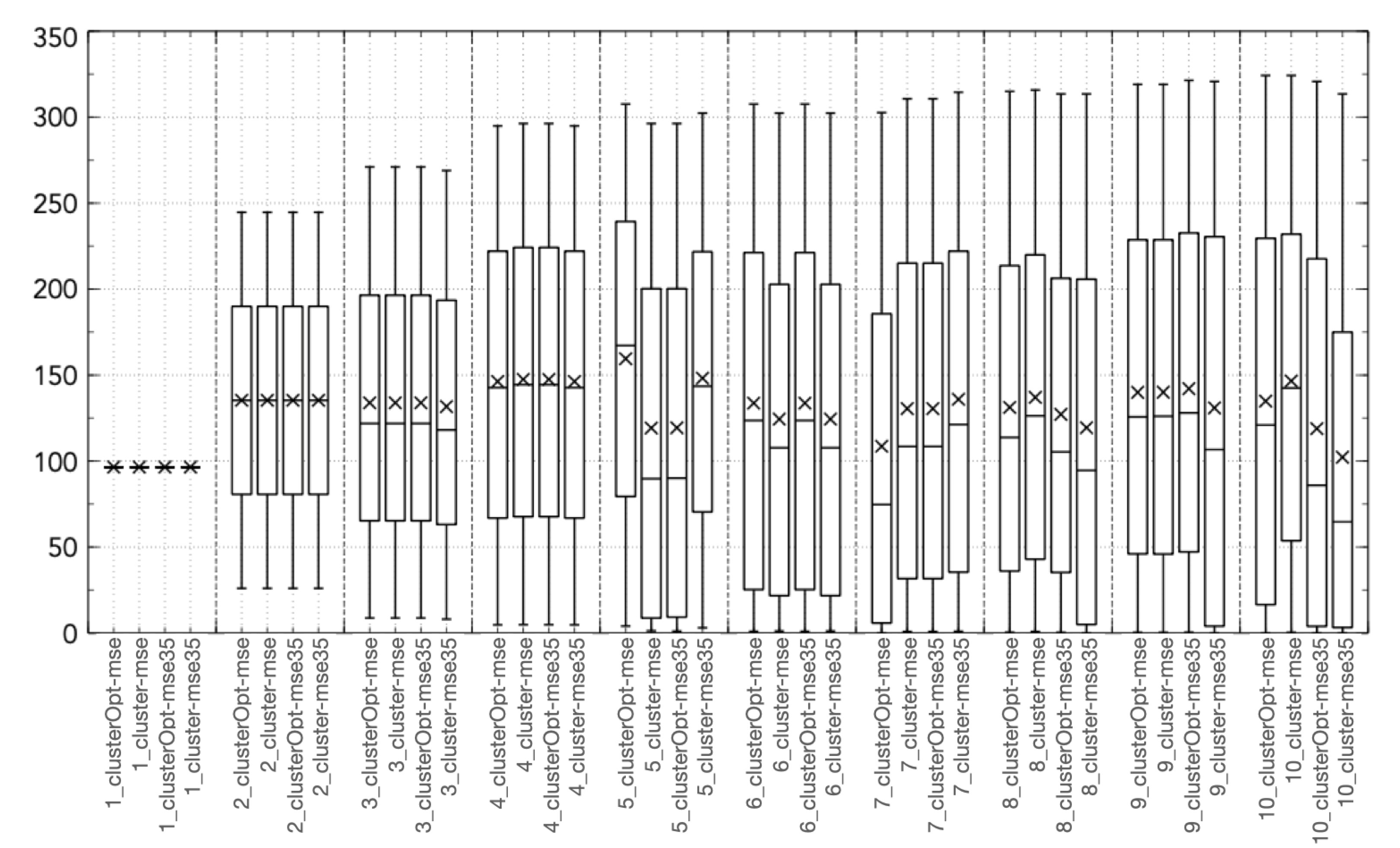
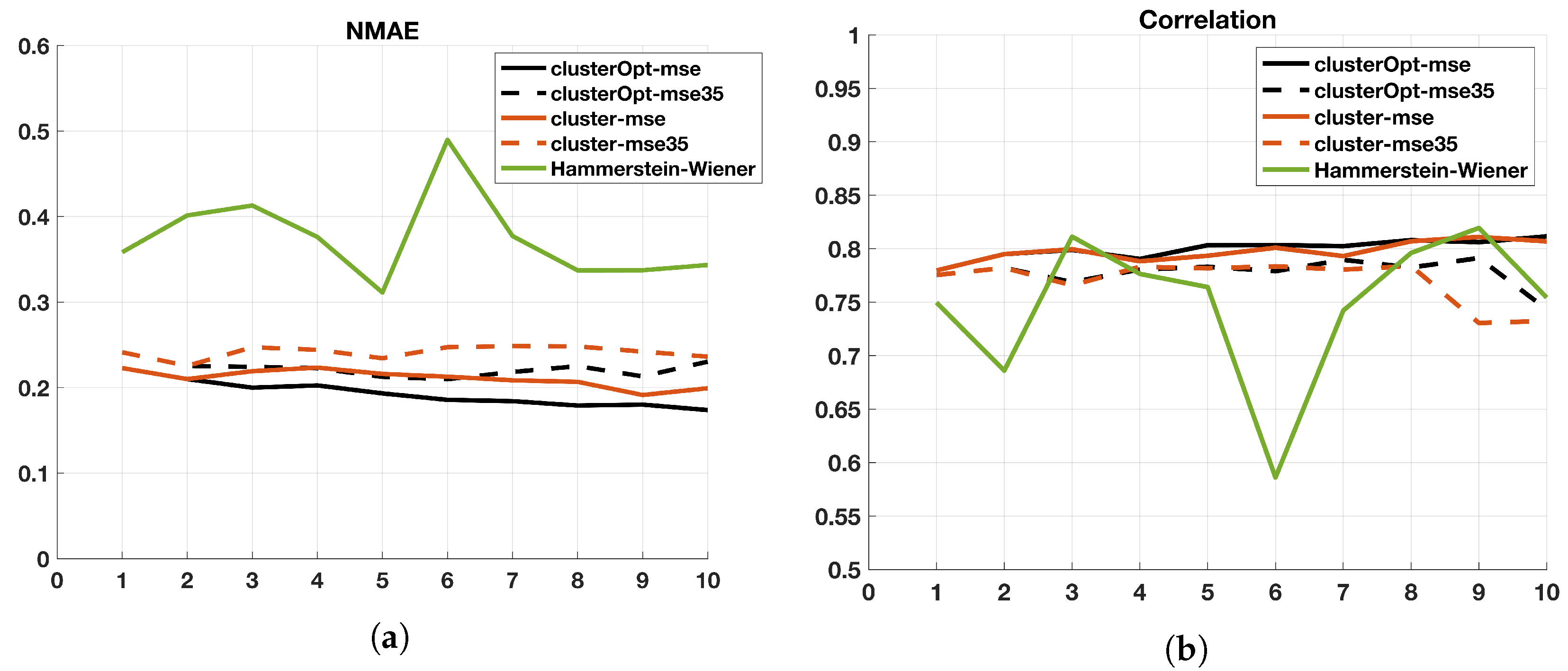
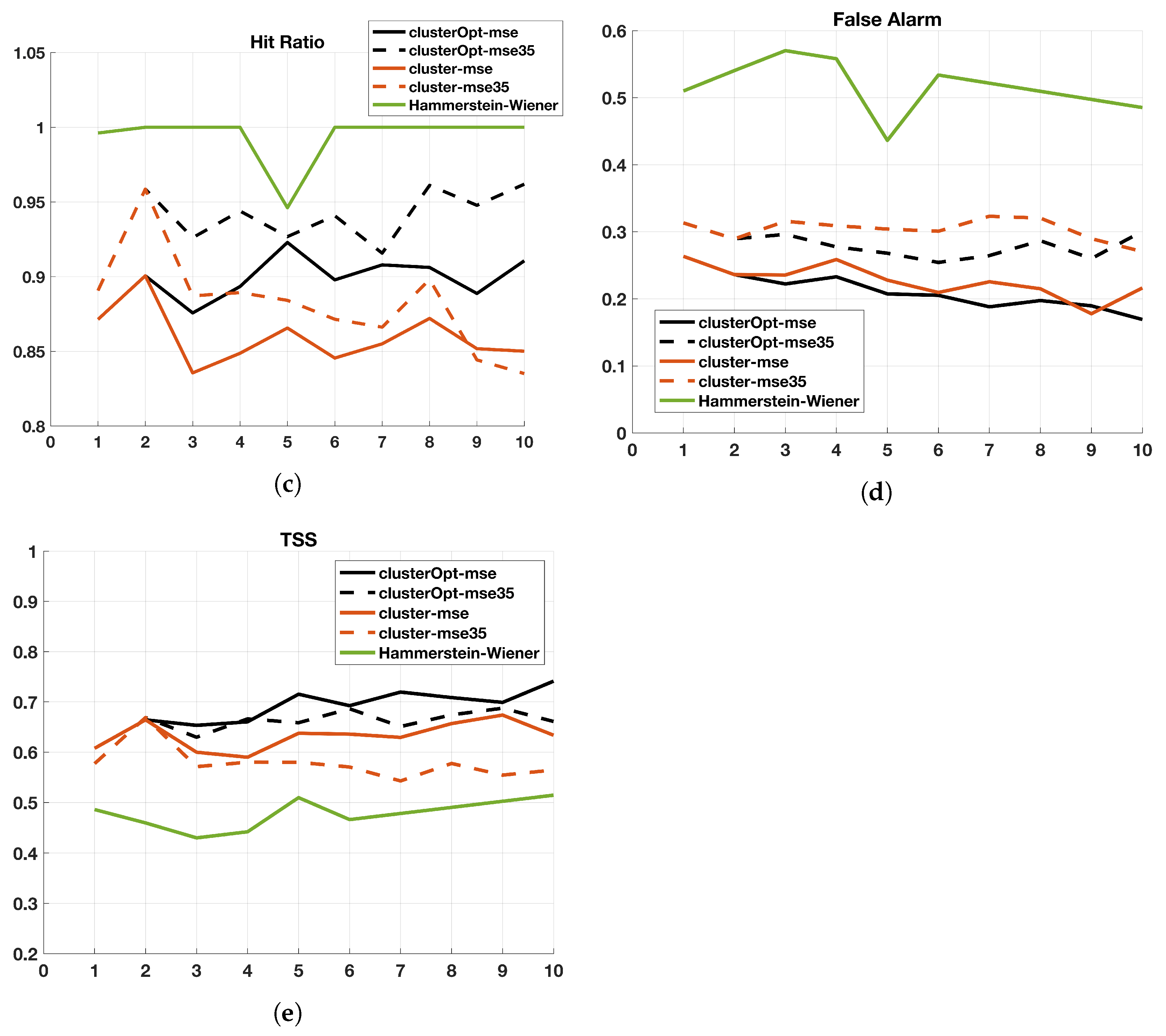
3. Experimental Results
- cluster-mse: the model parameters are computed firstly applying the cluster analysis to the model input, then splitting the data on the basis of the different clusters and finally computing a model for each cluster minimizing the mean square error;
- cluster-mse35: is a variant of cluster-mse, where only the tuples with NO concentrations higher than 35 g/m are considered in the objective function. The idea is to focus only on the highest (most critical) concentration values;
- clusterOpt-mse: the model parameters are computed by the proposed methodology, thus, jointly optimizing the centroid positions and the model parameters and dynamically splitting the dataset on the basis of the distance of the input data from the optimized centroids;
- clusterOpt-mse35: is a variant of clusterOpt-mse considering only the tuples with NO concentrations higher than 35 g/m in the objective function.
- Normalized Mean Absolute Error
- Correlation Coefficient
- Hit Ratio:
- False alarm fraction:
- True Skill Score:
3.1. ARX Model Validation
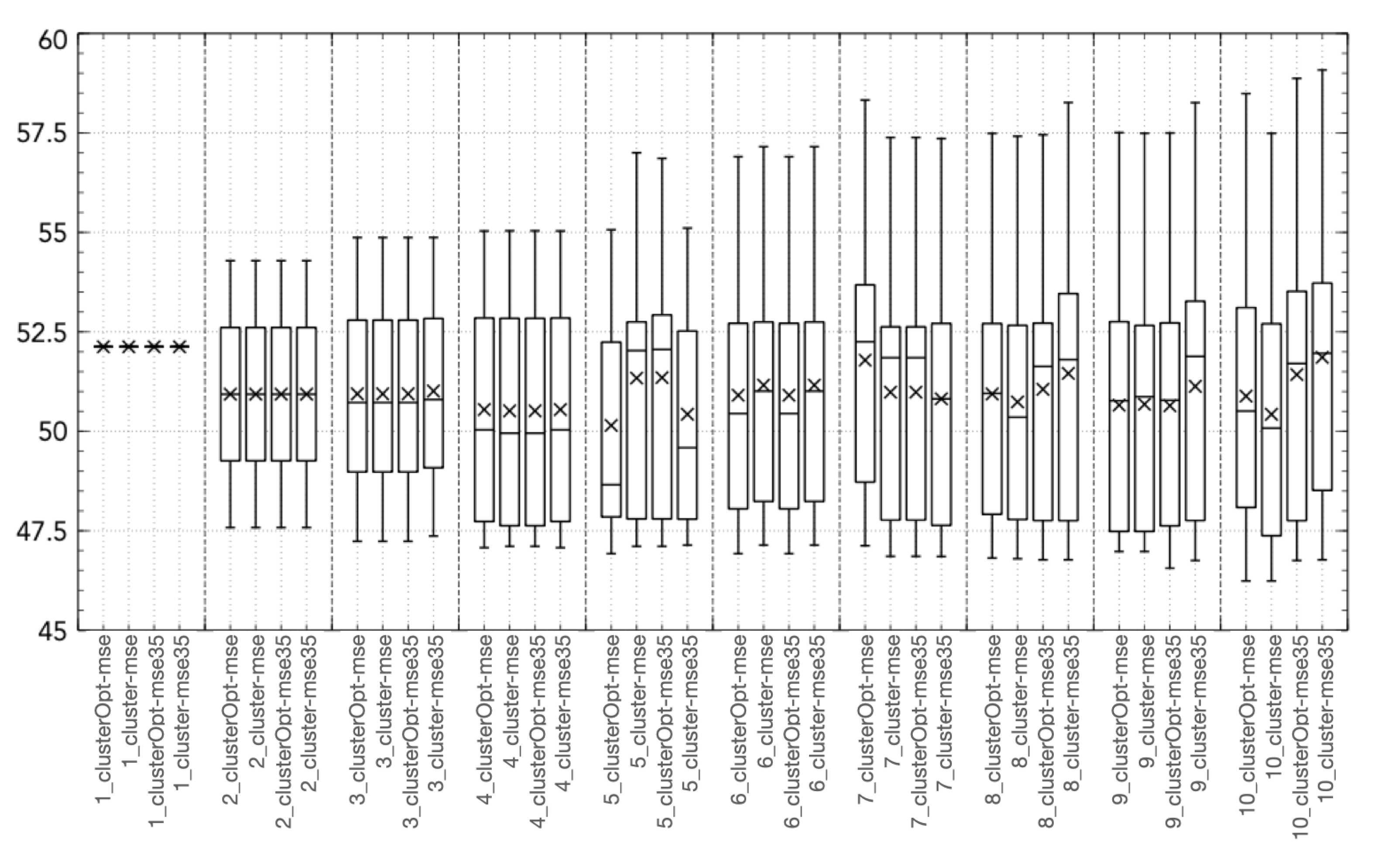
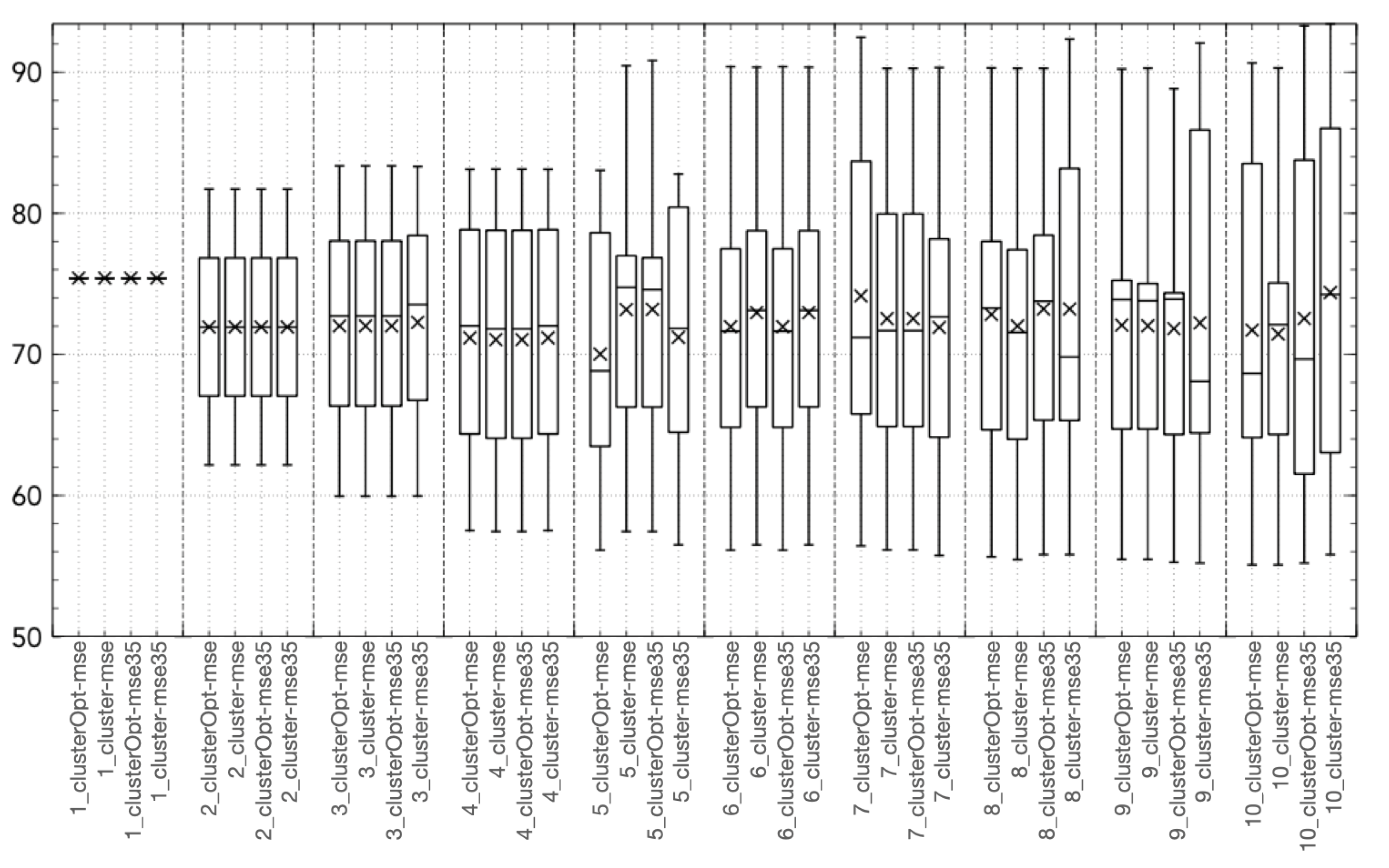
3.2. Validation and Comparison of Solution Methods
4. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ARX | AutoRegressive model with eXogenous input |
| FA | False Alarm |
| HR | Hit Ratio |
| NO | Nitrogen Oxides |
| PLM | Piecewise Linear Model |
| TSS | True Skill Score (index) |
References
- Pope, C., III; Dockery, D.; Spengler, J.; Raizenne, M. Respiratory health and PM10 pollution: A daily time series analysis. Am. Rev. Respir. Dis. 1991, 144, 668–674. [Google Scholar] [CrossRef] [PubMed]
- Pope, C., III; Dockery, D. Acute health effects of PM10 pollution on symptomatic and asymptomatic children. Am. Rev. Respir. Dis. 1992, 145, 1123–1128. [Google Scholar] [CrossRef] [PubMed]
- Manerba, D.; Mansini, R.; Zanotti, R. Attended Home Delivery: Reducing last-mile environmental impact by changing customer habits. IFAC-PapersOnLine 2018, 51, 55–60. [Google Scholar] [CrossRef]
- Bonomi, V.; Mansini, R.; Zanotti, R. Last Mile Delivery with Parcel Lockers: Evaluating the environmental impact of eco-conscious consumer behavior. IFAC-PapersOnLine 2022, 55, 72–77. [Google Scholar] [CrossRef]
- Miranda, A.; Silveira, C.; Ferreira, J.; Monteiro, A.; Lopes, D.; Relvas, H.; Borrego, C.; Roebeling, P. Current air quality plans in Europe designed to support air quality management policies. Atmos. Pollut. Res. 2015, 6, 434–443. [Google Scholar] [CrossRef]
- Carnevale, C.; Sangiorgi, L.; De Angelis, E.; Mansini, R.; Volta, M. A System of Systems for the Optimal Allocation of Pollutant Monitoring Sensors. IEEE Syst. J. 2021, 1–8. [Google Scholar] [CrossRef]
- Carnevale, C.; Finzi, G.; Pederzoli, A.; Pisoni, E.; Thunis, P.; Turrini, E.; Volta, M. A methodology for the evaluation of re-analyzed PM10 concentration fields: A case study over the PO Valley. Air Qual. Atmos. Health 2015, 8, 533–544. [Google Scholar] [CrossRef]
- Candiani, G.; Carnevale, C.; Finzi, G.; Pison, E.; Volta, M. A comparison of reanalysis techniques: Applying optimal interpolation and Ensemble Kalman Filtering to improve air quality monitoring at mesoscale. Sci. Total. Environ. 2013, 458–460, 7–14. [Google Scholar] [CrossRef]
- San José, R.; Pérez, J.L.; Morant, J.L.; González, R.M. European operational air quality forecasting system by using MM5–CMAQ–EMIMO tool. Simul. Model. Pract. Theory 2008, 16, 1534–1540. [Google Scholar] [CrossRef]
- Manders, A.; Schaap, M.; Hoogerbrugge, R. Testing the capability of the chemistry transport model LOTOS-EUROS to forecast PM10 levels in the Netherlands. Atmos. Environ. 2009, 43, 4050–4059. [Google Scholar] [CrossRef]
- Samaké, A.; Mahamane, A.; Alassane, M.; Diallo, O. A Mathematical and Numerical Framework for Traffic-Induced Air Pollution Simulation in Bamako. Computation 2022, 10, 76. [Google Scholar] [CrossRef]
- Carnevale, C.; Finzi, G.; Guariso, G.; Pisoni, E.; Volta, M. Surrogate models to compute optimal air quality planning policies at a regional scale. Environ. Model. Softw. 2012, 34, 44–50. [Google Scholar] [CrossRef]
- Carnevale, C.; Finzi, G.; Pederzoli, A.; Turrini, E.; Volta, M. Lazy Learning based surrogate models for air quality planning. Environ. Model. Softw. 2016, 83, 47–57. [Google Scholar] [CrossRef]
- Rahman, Z.A.S.A.; Jasim, B.H.; Al-Yasir, Y.I.A.; Abd-Alhameed, R.A.; Alhasnawi, B.N. A New No Equilibrium Fractional Order Chaotic System, Dynamical Investigation, Synchronization, and Its Digital Implementation. Inventions 2021, 6, 49. [Google Scholar] [CrossRef]
- Rahman, Z.A.S.A.; Jasim, B.H.; Al-Yasir, Y.I.A.; Hu, Y.F.; Abd-Alhameed, R.A.; Alhasnawi, B.N. A New Fractional-Order Chaotic System with Its Analysis, Synchronization, and Circuit Realization for Secure Communication Applications. Mathematics 2021, 9, 2593. [Google Scholar] [CrossRef]
- Carnevale, C.; Finzi, G.; Pisoni, E.; Singh, V.; Volta, M. An integrated air quality forecast system for a metropolitan area. J. Environ. Monit. 2011, 13, 3437–3447. [Google Scholar] [CrossRef]
- Wu, Y.; Ding, Y.; Feng, J. SMOTE-Boost-based sparse Bayesian model for flood prediction. EURASIP J. Wirel. Commun. Netw. 2020, 2020, 78. [Google Scholar] [CrossRef]
- Wu, Y.; Han, P.; Zheng, Z. Instant water body variation detection via analysis on remote sensing imagery. J. Real-Time Image Process. 2021, 18, 1577–1590. [Google Scholar] [CrossRef]
- Carnevale, C.; Turrini, E.; Zeziola, R.; De Angelis, E.; Volta, M. A Wavenet-Based Virtual Sensor for PM10 Monitoring. Electronics 2021, 10, 2111. [Google Scholar] [CrossRef]
- Dolanc, G.; Strmčnik, S. Identification of nonlinear systems using a piecewise-linear Hammerstein model. Syst. Control Lett. 2005, 54, 145–158. [Google Scholar] [CrossRef]
- Hadid, B.; Duviella, E.; Lecoeuche, S. Data-driven modeling for river flood forecasting based on a piecewise linear ARX system identification. J. Process Control 2020, 86, 44–56. [Google Scholar] [CrossRef]
- Ipanaqué, W.; Manrique, J. Identification and Control of pH using Optimal Piecewise Linear Wiener Model. IFAC Proc. Vol. 2011, 44, 12301–12306. [Google Scholar] [CrossRef]
- Westra, R.L.; Ralf, M.P.; Peeters, L. Identification of Piecewise Linear Models of Complex Dynamical Systems. IFAC Proc. Vol. 2011, 44, 14863–14868. [Google Scholar] [CrossRef]
- Yang, X.; Yang, H.; Zhang, F.; Zhang, L.; Fan, X.; Ye, Q.; Fu, L. Piecewise Linear Regression Based on Plane Clustering. IEEE Access 2019, 7, 29845–29855. [Google Scholar] [CrossRef]
- Liu, J.; Xu, Z.; Zhao, J.; Shao, Z. Identification of piecewise affine model for batch processes based on constrained clustering technique. Chem. Eng. Res. Des. 2022, 181, 278–286. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S.J. Numerical Optimization, 2nd ed.; Springer: New York, NY, USA, 2006. [Google Scholar]
- Li, Y.; Wu, H. A Clustering Method Based on K-Means Algorithm. Phys. Procedia 2012, 25, 1104–1109. [Google Scholar] [CrossRef]
- Zhang, J.; Chin, K.S.; awryńczuk, M. Nonlinear model predictive control based on piecewise linear Hammerstein models. Nonlinear Dyn. 2018, 92, 1001–1021. [Google Scholar] [CrossRef]
- Lassoued, Z.; Abderrahim, K. Identification and control of nonlinear systems using PieceWise Auto-Regressive eXogenous models. Trans. Inst. Meas. Control 2019, 41, 4050–4062. [Google Scholar] [CrossRef]
- Schittkowski, K. NLQPL: A FORTRAN-Subroutine Solving Constrained Nonlinear Programming Problems. Ann. Oper. Res. 1985, 5, 485–500. [Google Scholar] [CrossRef]
- INEMAR—Arpa Lombardia. INEMAR. Emission Inventory: 2014 Emission in Region Lombardy—Public Review; Technical Report; ARPA Lombardia Settore Aria: Milano, Italy, 2017. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Approach | Model Type | Minimized | MIMO | Real World |
|---|---|---|---|---|---|
| Error | Applicability | Applications | |||
| Dolanc and Strmcnik, 2005 [20] | Fixed Intervals + RLS with forgetting factor | Hammerstein | Forecasting | - | - |
| Ipanaque and Manrique, 2011 [22] | 2 step: interval definition + Recursive Least Square | Wiener | Forecasting | - | PH control |
| Westra et al., 2011 [23] | Fixed intervals + model parameter estimation based on optimization algorithm | State Space + discrete state | Forecasting | MIMO | - |
| Zhang et al., 2018 [28] | Online clustering + Least Square | Hammerstein | Forecasting | MIMO | Stirred track control |
| Lassoued and Abderrahim, 2019 [29] | Static Clustering based on SVM reconstruction of regions + least square | PWARX | Forecasting | MISO | - |
| Yang et al., 2019 [24] | Plane clustering (number of plane selected through optimization algorithm) | Non dynamical regression | Regression error | - | UCI data |
| Hadid et al., 2020 [21] | Static Clustering + Least Square | PWARX | Forecasting | MISO | River flood |
| Liu et al., 2022 [25] | Time partitioning + optimal identification | PWARX | Forecasting | MISO | Injection Molding |
| Carnevale et al., this work | Full dynamical selection of cluster centroids + constrained optimization | PWARX | Simulation | MISO | Air quality simulation |
| Observed Values | |||
|---|---|---|---|
| ≥35 g/m | <35 g/m | ||
| Model | ≥35 g/m | ||
| <35 g/m | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carnevale, C.; Sangiorgi, L.; Mansini, R.; Zanotti, R. A Piece-Wise Linear Model-Based Algorithm for the Identification of Nonlinear Models in Real-World Applications. Electronics 2022, 11, 2770. https://doi.org/10.3390/electronics11172770
Carnevale C, Sangiorgi L, Mansini R, Zanotti R. A Piece-Wise Linear Model-Based Algorithm for the Identification of Nonlinear Models in Real-World Applications. Electronics. 2022; 11(17):2770. https://doi.org/10.3390/electronics11172770
Chicago/Turabian StyleCarnevale, Claudio, Lucia Sangiorgi, Renata Mansini, and Roberto Zanotti. 2022. "A Piece-Wise Linear Model-Based Algorithm for the Identification of Nonlinear Models in Real-World Applications" Electronics 11, no. 17: 2770. https://doi.org/10.3390/electronics11172770
APA StyleCarnevale, C., Sangiorgi, L., Mansini, R., & Zanotti, R. (2022). A Piece-Wise Linear Model-Based Algorithm for the Identification of Nonlinear Models in Real-World Applications. Electronics, 11(17), 2770. https://doi.org/10.3390/electronics11172770