
Hemerocallis citrina Baroni Maturity Detection Method Integrating Lightweight Neural Network and Dual Attention Mechanism




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Computer vision technology and deep learning algorithms are applied to the maturity detection of Hemerocallis citrina Baroni, and highly accurate maturity detection of whether the Hemerocallis citrina Baroni are mature and meet the picking standards, providing ideas for improving the picking method and reducing the cost of picking labor.
- The lightweight neural network is introduced to reduce the number of network layers and model complexity, compress the model volume, and lay the foundation for the embedded development of picking robots.
- Combined with the dual attention mechanism, it improves the tendency of feature extraction and enhances the detection precision and real-time detection efficiency.
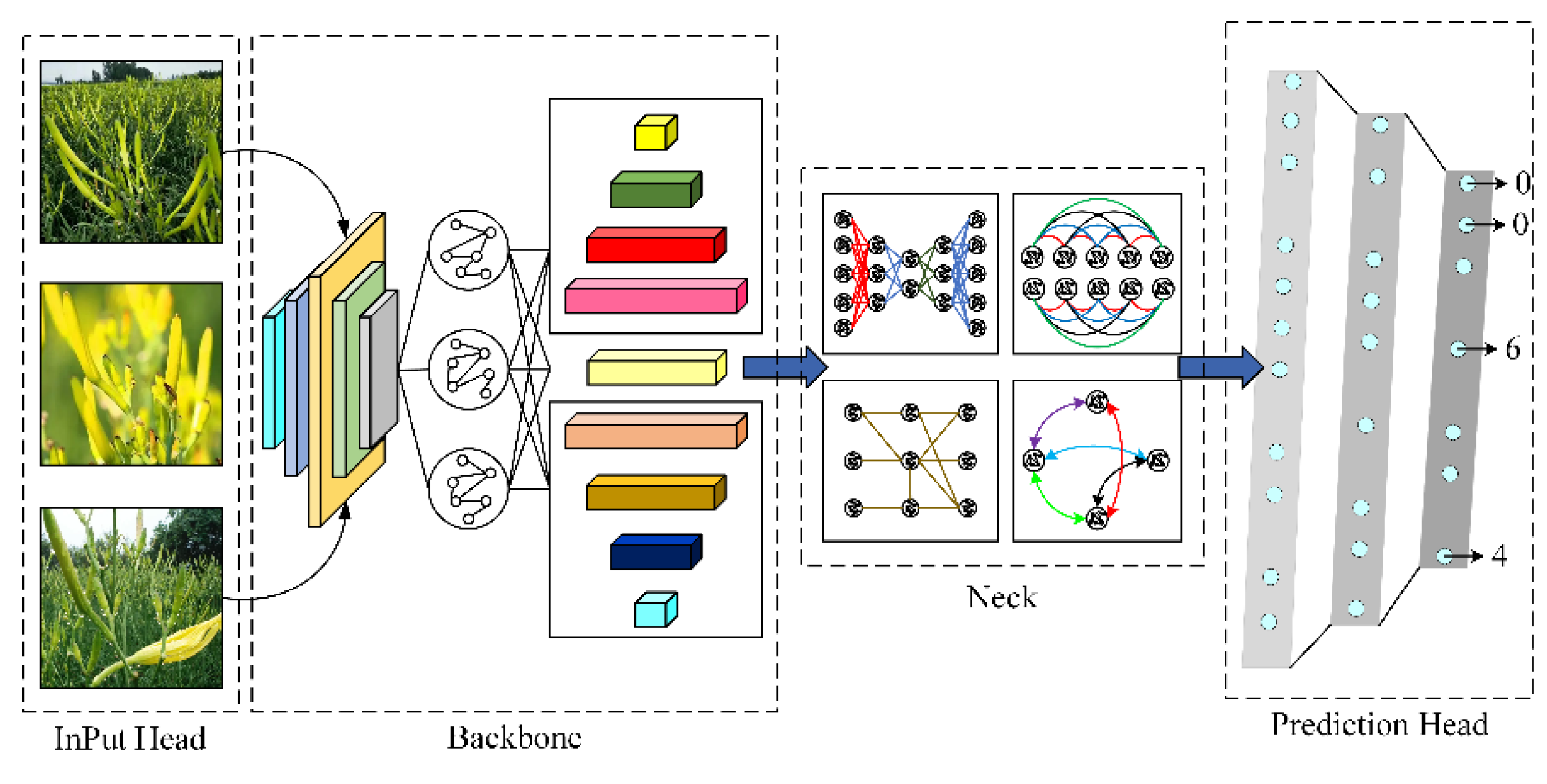
2. YOLOv5 Object Detection Algorithms
3. Deep Learning Detection Algorithm GGSC YOLOv5
3.1. Ghost Lightweight Convolution
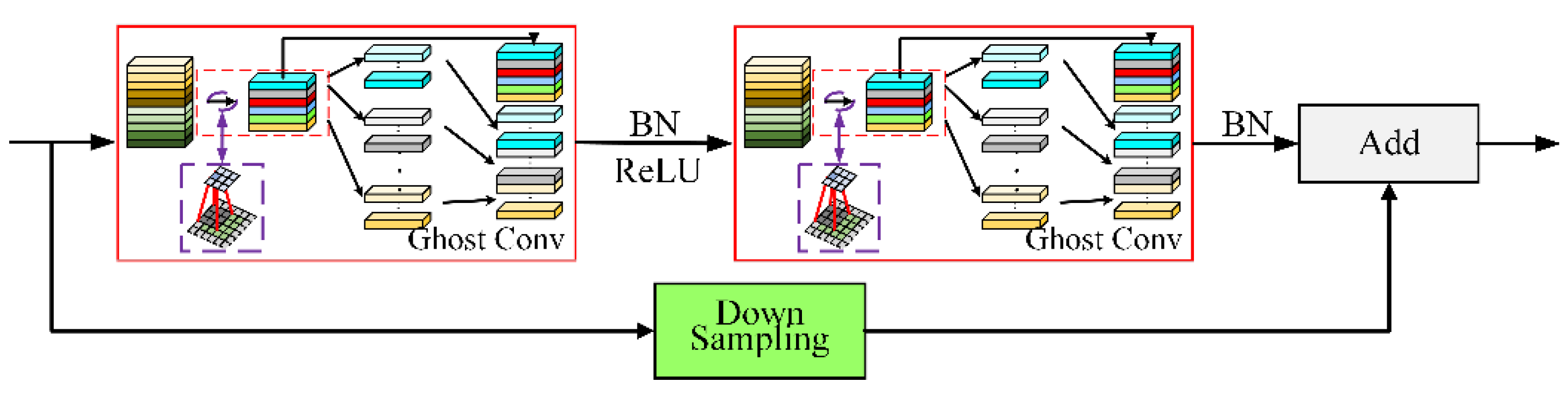
3.2. Ghost Lightweight Bottleneck
3.3. SE Attentional Mechanisms
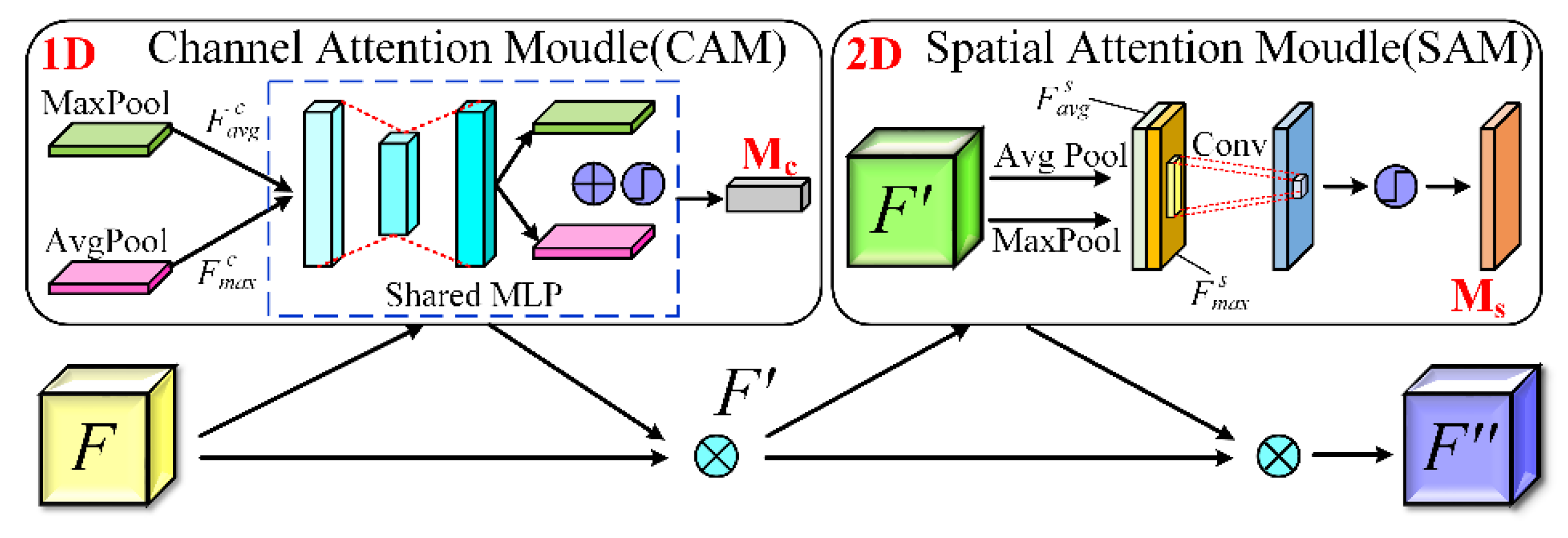
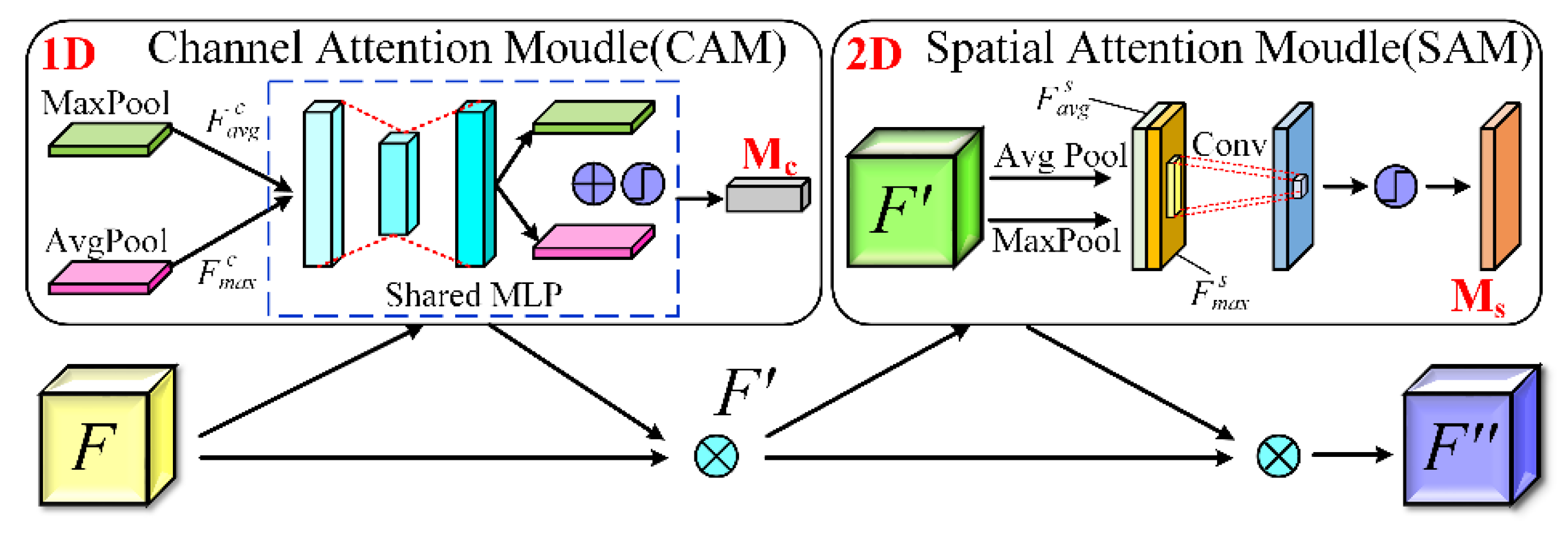
3.4. CBAM Attentional Mechanisms
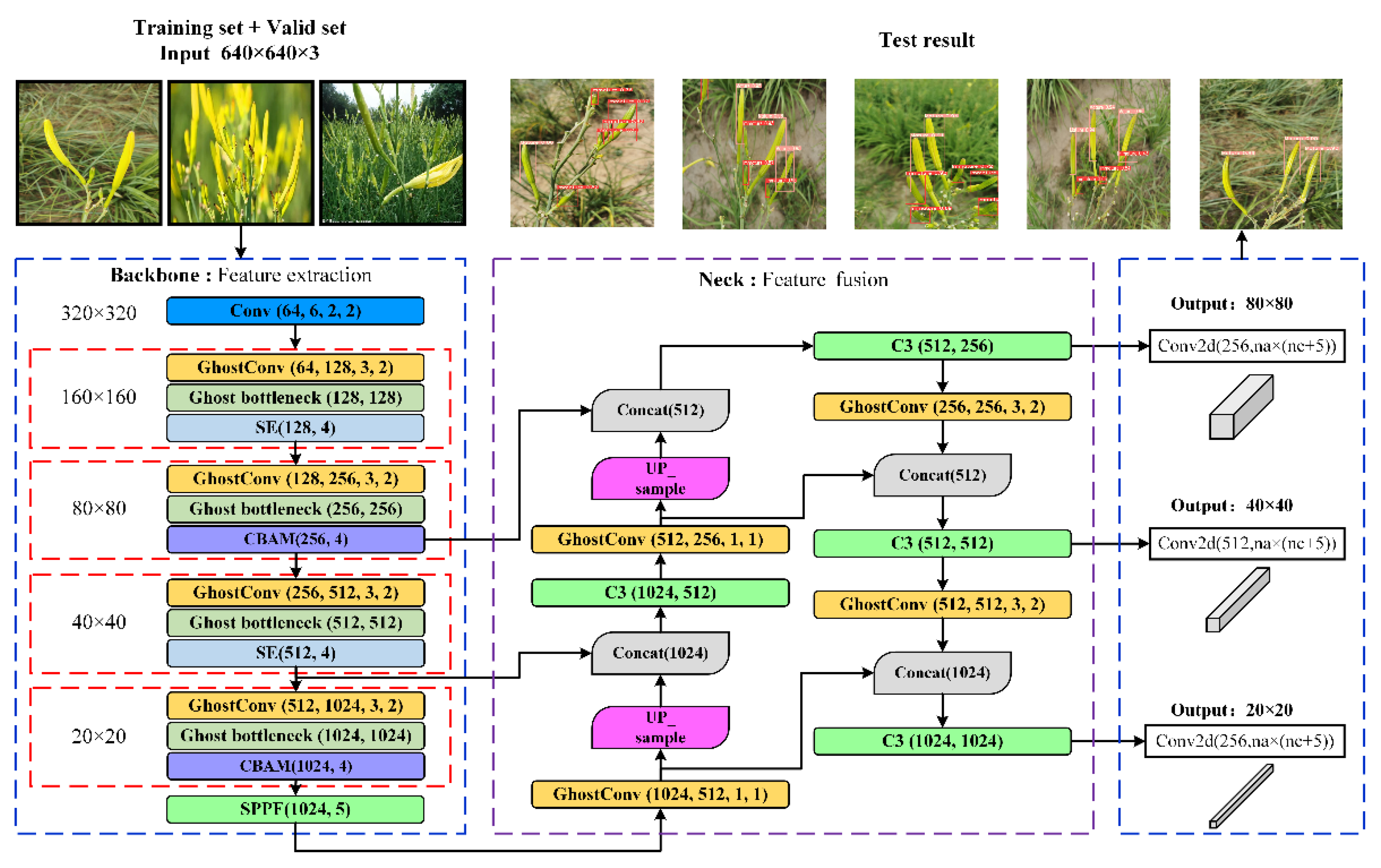
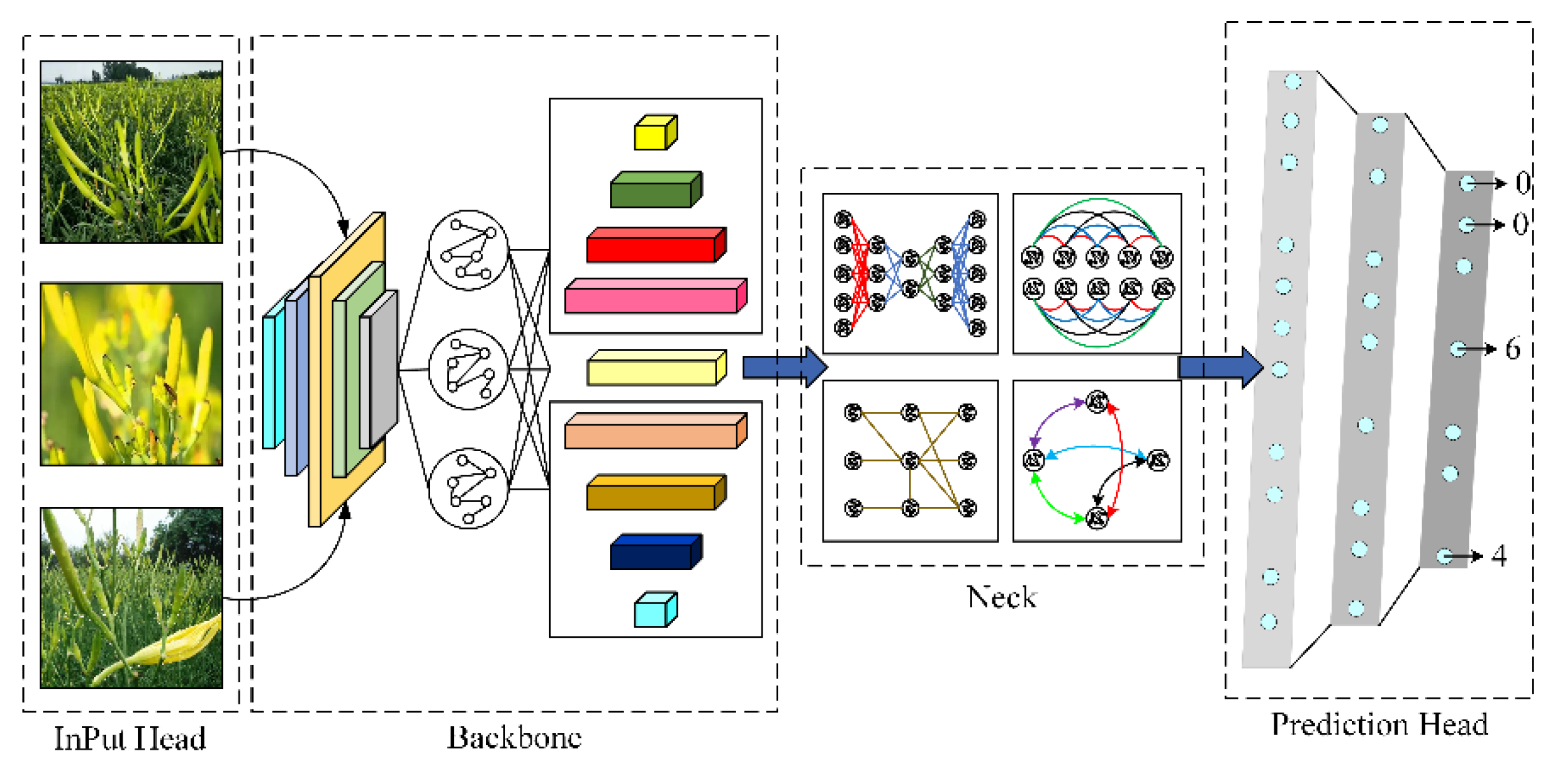
3.5. GGSC YOLOv5 Model Structure
4. Experiments and Results Analysis
4.1. Model Training
| Algorithm 1: Training process of GGSC YOLOv5. |
| Determine: Parameters, Anchor, . |
| InPut: Training dataset, Valid dataset, Label set. |
| Loading: Train models, Valid models. |
| Ensure: In Put, Backbone, Neck, OutPut. Algorithm environment. |
| iterations of training. i-th iteration training(): |
| Feature extraction Net: |
| a: Rectangular convolution |
| b: i-th iteration(): |
| Ghost Conv-Ghost Bottleneck-SE, feature extraction. |
| Ghost Conv-Ghost Bottleneck-CBAM, feature extraction. |
| c: Feature fusion. |
| d: Predicted Head: classification , confidence . |
| e: Positioning error, category error, confidence error. |
| f: . |
| Val Net: |
| a: Test effect of model . |
| b: Calculate and . |
| c: Adjust and update strategy. |
| Save results of the i-th training: weight , and model . |
| Update: Weight: , Model: . |
| Temporary storage model . |
| Plot: Result curve, Save best model , Output. |
| End Train |
4.2. Model Lightweight Analysis
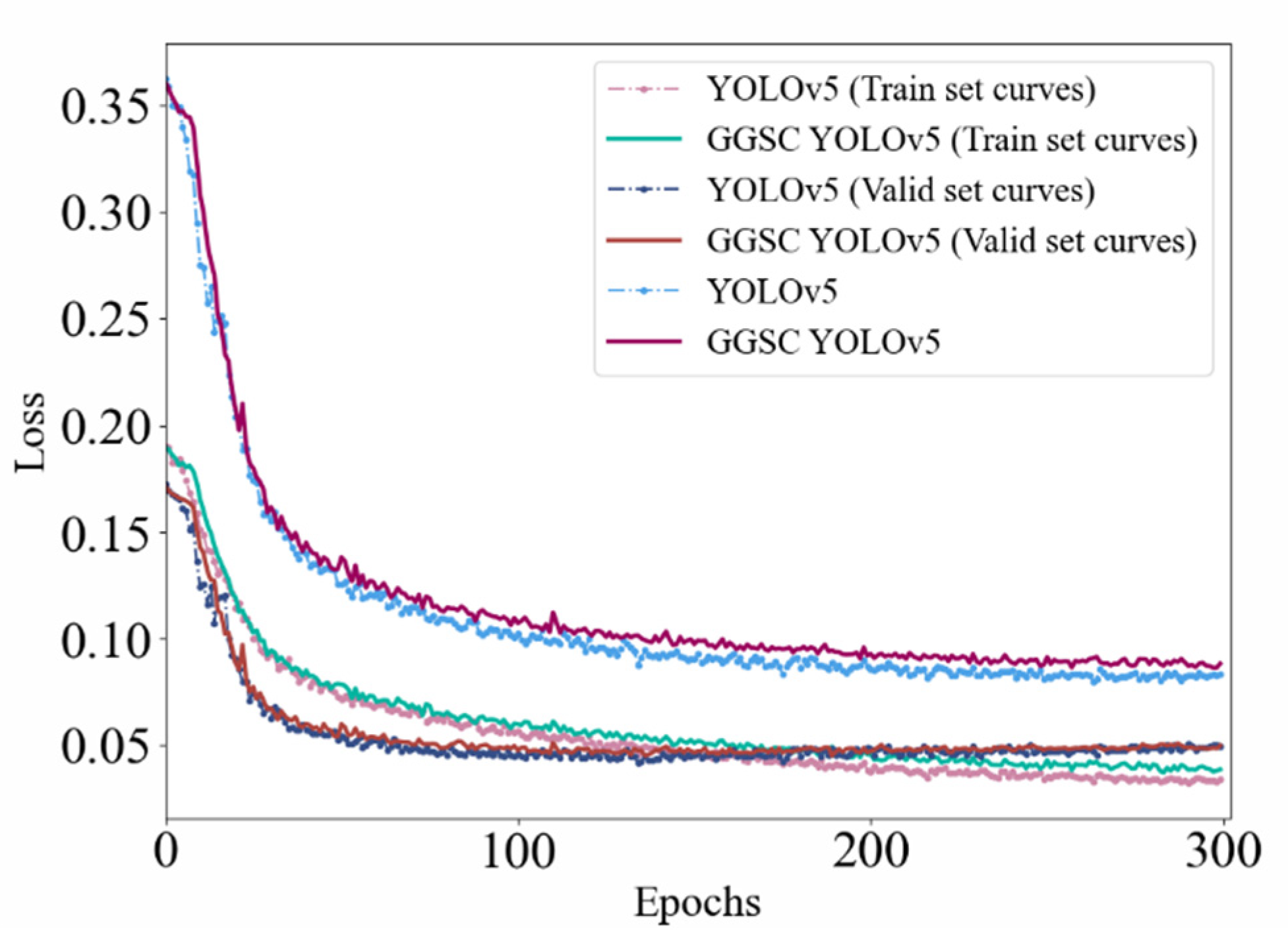
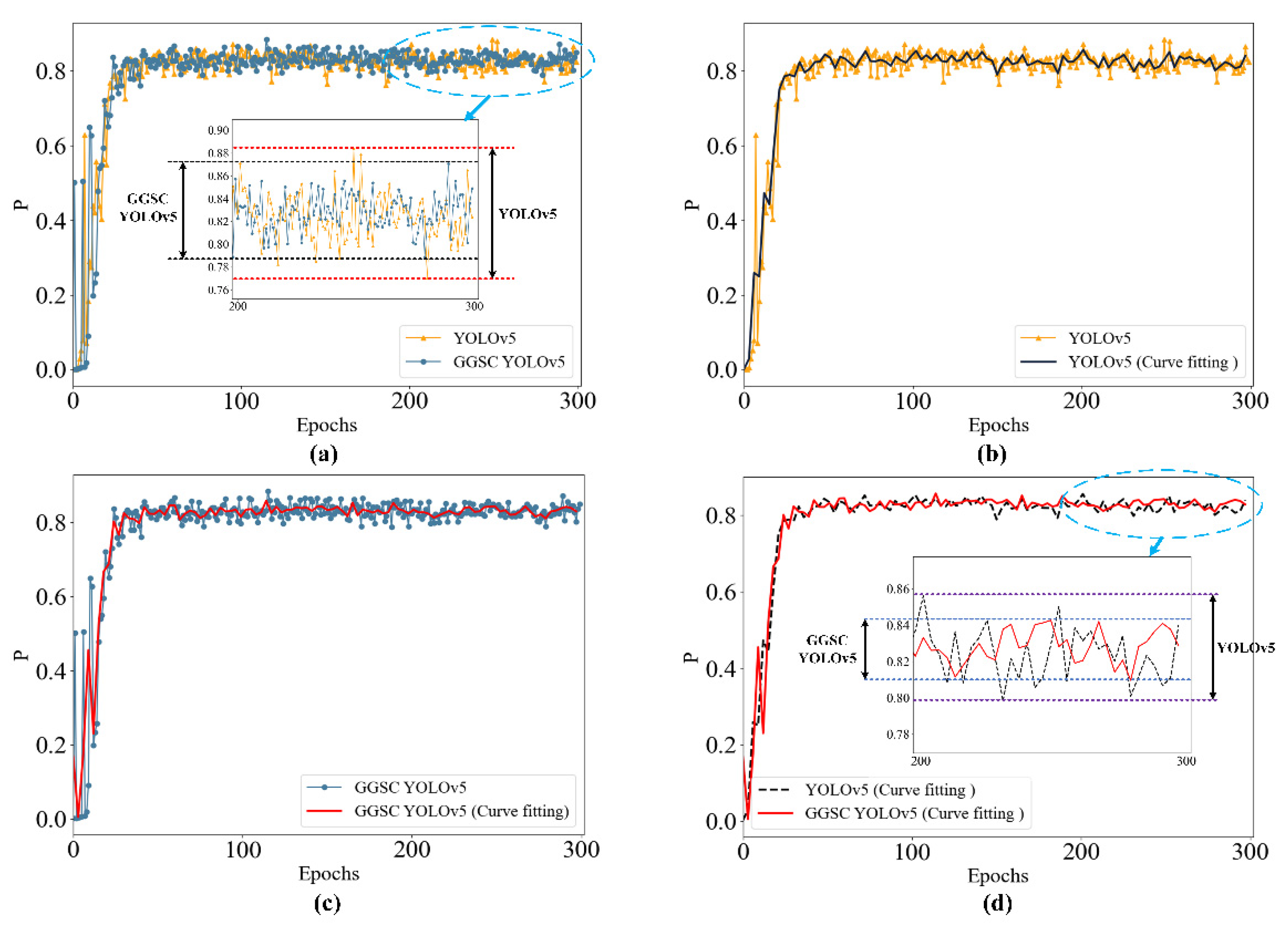
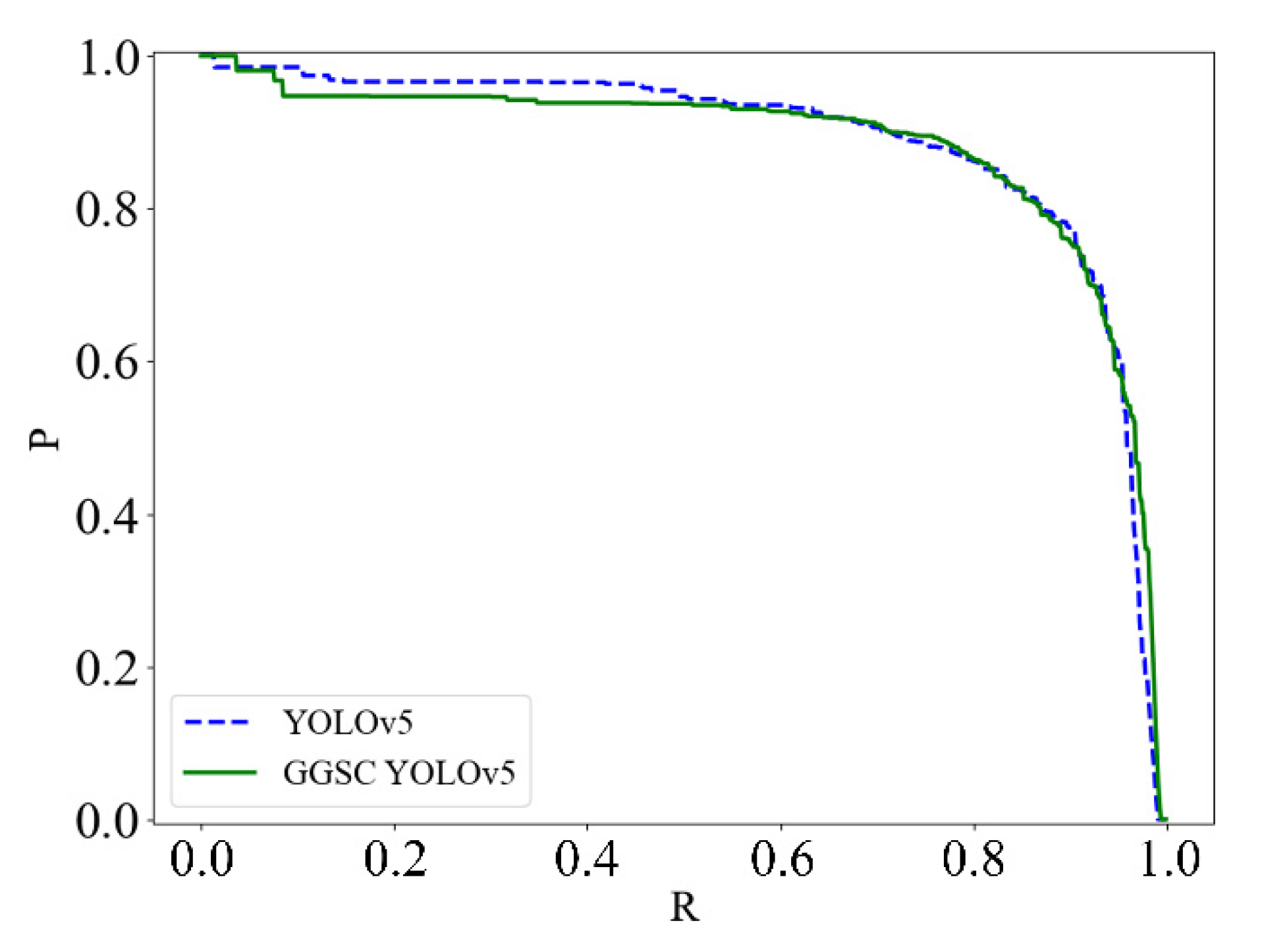
4.3. Model Training Process Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lin, Y.D.; Chen, T.T.; Liu, S.Y.; Cai, Y.L.; Shi, H.W.; Zheng, D.; Lan, Y.B.; Yue, X.J.; Zhang, L. Quick and accurate monitoring peanut seedlings emergence rate through UAV video and deep learning. Comput. Electron. Agric. 2022, 197, 106938. [Google Scholar] [CrossRef]
- Perugachi-Diaz, Y.; Tomczak, J.M.; Bhulai, S. Deep learning for white cabbage seedling prediction. Comput. Electron. Agric. 2021, 184, 106059. [Google Scholar] [CrossRef]
- Feng, A.; Zhou, J.; Vories, E.; Sudduth, K.A. Evaluation of cotton emergence using UAV-based imagery and deep learning. Comput. Electron. Agric. 2020, 177, 105711. [Google Scholar] [CrossRef]
- Azimi, S.; Wadhawan, R.; Gandhi, T.K. Intelligent Monitoring of Stress Induced by Water Deficiency in Plants Using Deep Learning. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Patel, A.; Lee, W.S.; Peres, N.A.; Fraisse, C.W. Strawberry plant wetness detection using computer vision and deep learning. Smart Agric. Technol. 2021, 1, 100013. [Google Scholar] [CrossRef]
- Liu, W.; Wu, G.; Ren, F.; Kang, X. DFF-ResNet: An insect pest recognition model based on residual networks. Big Data Min. Anal. 2020, 3, 300–310. [Google Scholar] [CrossRef]
- Wang, K.; Chen, K.; Du, H.; Liu, S.; Xu, J.; Zhao, J.; Chen, H.; Liu, Y.; Liu, Y. New image dataset and new negative sample judgment method for crop pest recognition based on deep learning models. Ecol. Inf. 2022, 69, 101620. [Google Scholar] [CrossRef]
- Jiang, H.; Li, X.; Safara, F. IoT-based Agriculture: Deep Learning in Detecting Apple Fruit Diseases. Microprocess. Microsyst. 2021, 91, 104321. [Google Scholar] [CrossRef]
- Orano, J.F.V.; Maravillas, E.A.; Aliac, C.J.G. Jackfruit Fruit Damage Classification using Convolutional Neural Network. In Proceedings of the 2019 IEEE 11th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment, and Management (HNICEM), Laoag, Philippines, 29 November–1 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Herman, H.; Cenggoro, T.W.; Susanto, A.; Pardamean, B. Deep Learning for Oil Palm Fruit Ripeness Classification with DenseNet. In Proceedings of the 2021 International Conference on Information Management and Technology (ICIMTech), Jakarta, Indonesia, 19–20 August 2021; pp. 116–119. [Google Scholar] [CrossRef]
- Gayathri, S.; Ujwala, T.U.; Vinusha, C.V.; Pauline, N.R.; Tharunika, D.B. Detection of Papaya Ripeness Using Deep Learning Approach. In Proceedings of the 2021 3rd International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 2–4 September 2021; pp. 1755–1758. [Google Scholar] [CrossRef]
- Wu, D.; Wu, C. Research on the Time-Dependent Split Delivery Green Vehicle Routing Problem for Fresh Agricultural Products with Multiple Time Windows. Agriculture 2022, 12, 793. [Google Scholar] [CrossRef]
- An, Z.; Wang, X.; Li, B.; Xiang, Z.; Zhang, B. Robust visual tracking for UAVs with dynamic feature weight selection. Appl. Intell. 2022, 14, 392–407. [Google Scholar] [CrossRef]
- Kumar, A.; Joshi, R.C.; Dutta, M.K.; Jonak, M.; Burget, R. Fruit-CNN: An Efficient Deep learning-based Fruit Classification and Quality Assessment for Precision Agriculture. In Proceedings of the 2021 13th International Congress on Ultra-Modern Telecommunications and Control Systems and Workshops (ICUMT), Brno, Czech Republic, 25–27 October 2021; pp. 60–65. [Google Scholar] [CrossRef]
- Widiyanto, S.; Wardani, D.T.; Wisnu Pranata, S. Image-Based Tomato Maturity Classification and Detection Using Faster R-CNN Method. In Proceedings of the 2021 5th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkey, 21–23 October 2021; pp. 130–134. [Google Scholar] [CrossRef]
- Wu, H.; Cheng, Y.; Zeng, R.; Li, L. Strawberry Image Segmentation Based on U^ 2-Net and Maturity Calculation. In Proceedings of the 2022 14th International Conference on Advanced Computational Intelligence (ICACI), Wuhan, China, 15–17 July 2022; pp. 74–78. [Google Scholar] [CrossRef]
- Zhang, R.; Li, X.; Zhu, L.; Zhong, M.; Gao, Y. Target detection of banana string and fruit stalk based on YOLOv3 deep learning network. In Proceedings of the 2021 IEEE 2nd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Nanchang, China, 26–28 March 2021; pp. 346–349. [Google Scholar] [CrossRef]
- Mohd Basir Selvam, N.A.; Ahmad, Z.; Mohtar, I.A. Real Time Ripe Palm Oil Bunch Detection using YOLO V3 Algorithm. In Proceedings of the 2021 IEEE 19th Student Conference on Research and Development (SCOReD), Kota Kinabalu, Malaysia, 23–25 November 2021; pp. 323–328. [Google Scholar] [CrossRef]
- Wu, Y.J.; Yi, Y.; Wang, X.F.; Jian, C. Fig Fruit Recognition Method Based on YOLO v4 Deep Learning. In Proceedings of the 2021 18th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Chiang Mai, Thailand, 19–22 May 2021; pp. 303–306. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, P.; Dai, G.; Yan, J.; Yang, Z. Tomato Fruit Maturity Detection Method Based on YOLOV4 and Statistical Color Model. In Proceedings of the 2021 IEEE 11th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), Jiaxing, China, 27–31 July 2021; pp. 904–908. [Google Scholar] [CrossRef]
- Jose, N.T.; Marco, M.; Claudio, F.; Andres, V. Disease and Defect Detection System for Raspberries Based on Convolutional Neural Networks. Electronics 2021, 11, 11868. [Google Scholar] [CrossRef]
- Wang, J.; Wang, L.Q.; Han, Y.L.; Zhang, Y.; Zhou, R.Y. On Combining Deep Snake and Global Saliency for Detection of Orchard Apples. Electronics 2021, 11, 6269. [Google Scholar] [CrossRef]
- Zhou, X.; Ma, H.; Gu, J.; Chen, H.; Deng, W. Parameter adaptation-based ant colony optimization with dynamic hybrid mechanism. Eng. Appl. Artif. Intell. 2022, 114, 105139. [Google Scholar] [CrossRef]
- Chen, H.Y.; Miao, F.; Chen, Y.J.; Xiong, Y.J.; Chen, T. A Hyperspectral Image Classification Method Using Multifeature Vectors and Optimized KELM. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2781–2795. [Google Scholar] [CrossRef]
- Wang, C.Y.; Mark Liao, H.Y.; Wu, Y.H.; Chen, Y.H.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 346–361. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Liu, J.; Chen, H.; Li, Y.; Xu, J.; Deng, W. Intelligent diagnosis using continuous wavelet transform and gauss convolutional deep belief network. IEEE Trans. Reliab. 2022, 2022, 1–11. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1577–1586. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Yao, R.; Guo, C.; Deng, W.; Zhao, H. A novel mathematical morphology spectrum entropy based on scale-adaptive techniques. ISA Trans. 2022, 126, 691–702. [Google Scholar] [CrossRef] [PubMed]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Deng, W.; Ni, H.; Liu, Y.; Chen, H.; Zhao, H. An adaptive differential evolution algorithm based on belief space and generalized opposition-based learning for resource allocation. Appl. Soft Comput. 2022, 127, 109419. [Google Scholar] [CrossRef]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Wu, L.; Liu, Y. Hemerocallis citrina Baroni Maturity Detection Method Integrating Lightweight Neural Network and Dual Attention Mechanism. Electronics 2022, 11, 2743. https://doi.org/10.3390/electronics11172743
Zhang L, Wu L, Liu Y. Hemerocallis citrina Baroni Maturity Detection Method Integrating Lightweight Neural Network and Dual Attention Mechanism. Electronics. 2022; 11(17):2743. https://doi.org/10.3390/electronics11172743
Chicago/Turabian StyleZhang, Liang, Ligang Wu, and Yaqing Liu. 2022. "Hemerocallis citrina Baroni Maturity Detection Method Integrating Lightweight Neural Network and Dual Attention Mechanism" Electronics 11, no. 17: 2743. https://doi.org/10.3390/electronics11172743
APA StyleZhang, L., Wu, L., & Liu, Y. (2022). Hemerocallis citrina Baroni Maturity Detection Method Integrating Lightweight Neural Network and Dual Attention Mechanism. Electronics, 11(17), 2743. https://doi.org/10.3390/electronics11172743