
Transformer-Based Disease Identification for Small-Scale Imbalanced Capsule Endoscopy Dataset



Abstract
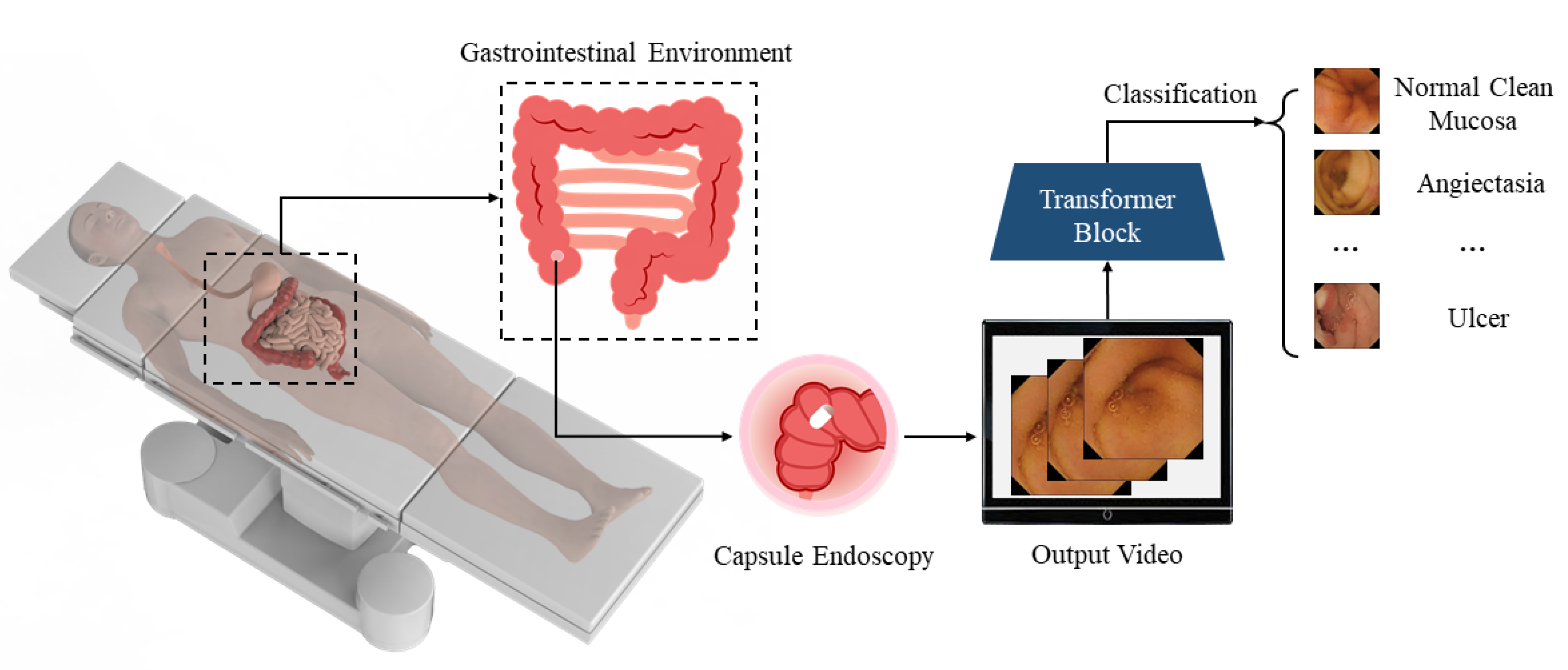
:1. Introduction
- 1.
- The amount of data is small;
- 2.
- The images of the dataset lack distinguishable features;
- 3.
- The data representing different diseases are not balanced. Common diseases may be represented in a large number of images, while for some rare diseases, there are only a few images for training.
2. Related Work
2.1. WCE Pathological Diagnosis
2.2. Vit Training from Scratch
3. Methodology
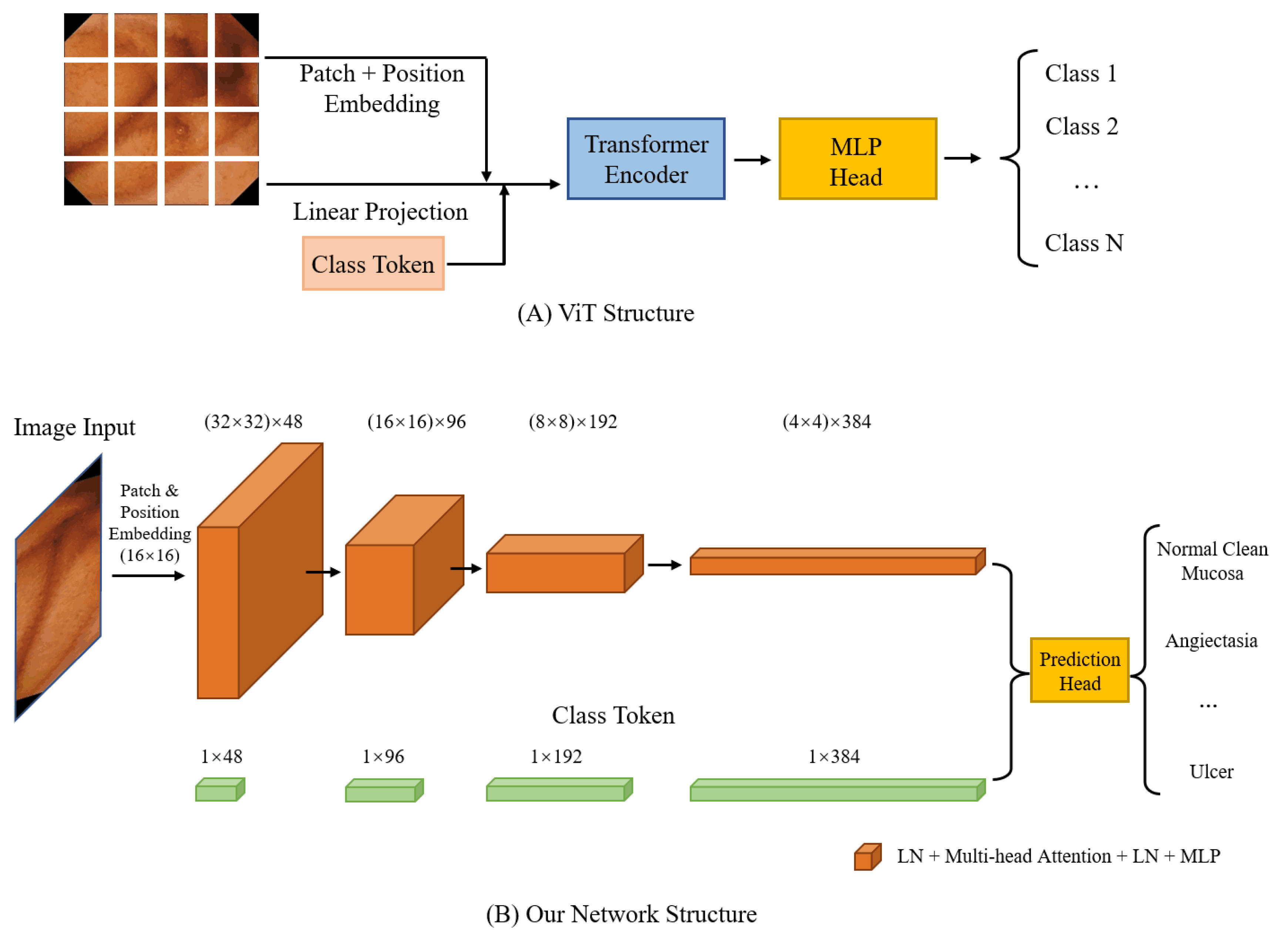
3.1. Vision Transformer
3.2. Pooling in CNN
3.3. Pooling in ViT
4. Experiment Validation
4.1. Datasets
4.2. Model Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BIR | Bleedy Image Recognition |
| CaiT | Class-Attention in Image Transformer |
| CvT | Convolutional vision Transformer |
| DeiT | Data-efficient Image Transformer |
| DL | Deep Learning |
| GI | Gastrointestinal |
| GIANA | Gastrointestinal Image ANAlysis |
| LN | LayerNorm |
| MLP | Multilayer Perceptron |
| RLE | Red Lesion Endoscopy |
| SSD | Single-shot MultiBox Detector |
| SVM | Support Vector Machine |
| T2T | Tokens-To-Token |
| ViT | Vision Transformer |
| WCE | Wireless Capsule Endoscopy |
Appendix A
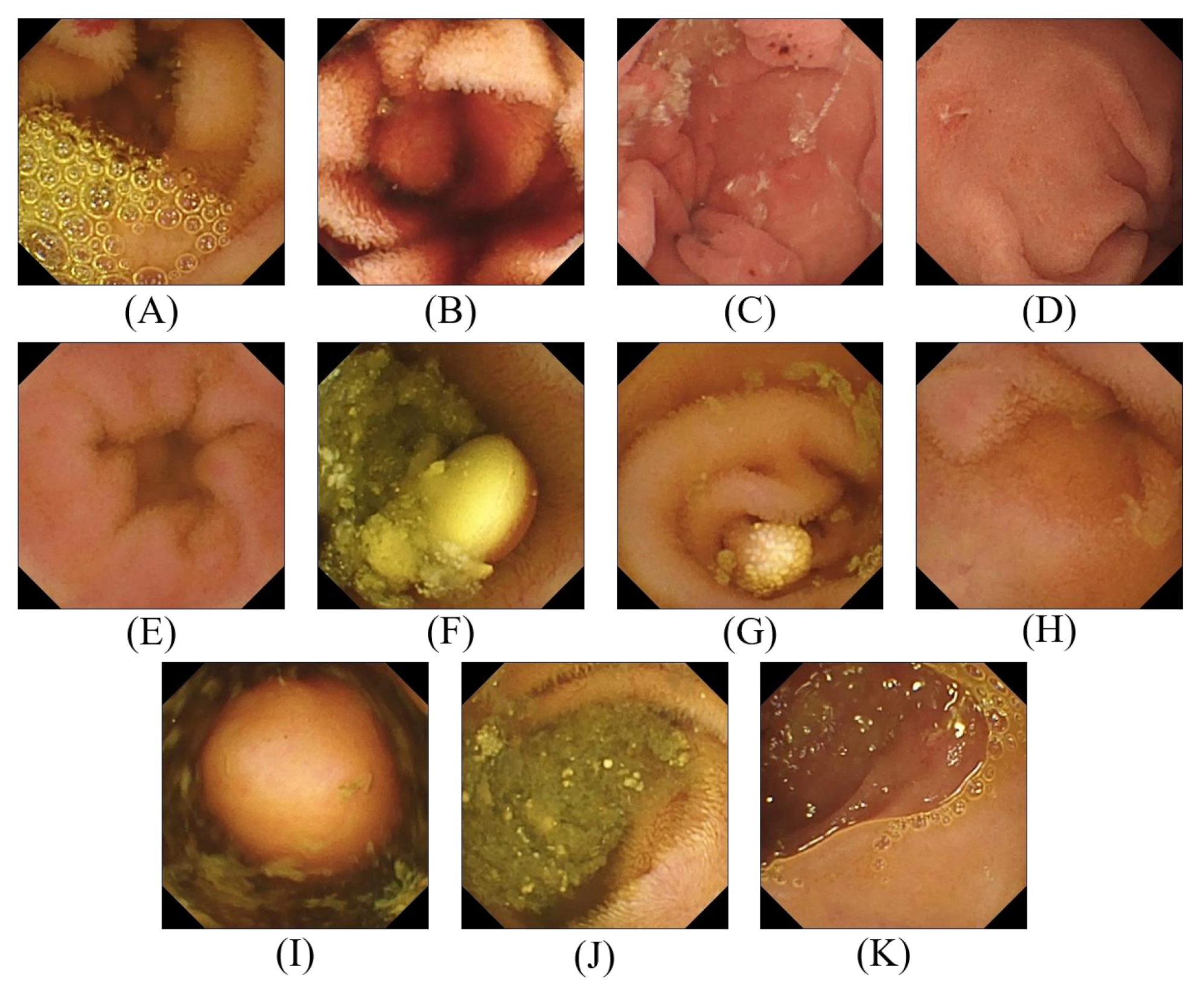

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Number of Images |
|---|---|
| Normal Clean Mucosa | 34,338 |
| Reduced Mucosal View | 2906 |
| Lymphangiectasia | 592 |
| Erythema | 159 |
| Angiectasia | 866 |
| Blood—fresh | 446 |
| Blood—Hematin | 12 |
| Erosion | 506 |
| Ulcer | 854 |
| Polyp | 55 |
| Foreign Body | 776 |
| Category | Number of Images |
|---|---|
| Normal | 2160 |
| Bleeding | 1125 |
References
- Arnold, M.; Abnet, C.C.; Neale, R.E.; Vignat, J.; Giovannucci, E.L.; McGlynn, K.A.; Bray, F. Global burden of 5 major types of gastrointestinal cancer. Gastroenterology 2020, 159, 335–349. [Google Scholar] [CrossRef] [PubMed]
- Center, M.; Siegel, R.; Jemal, A. Global Cancer Facts & Figures; American Cancer Society: Atlanta, GA, USA, 2011; Volume 3, p. 52. [Google Scholar]
- Flemming, J.; Cameron, S. Small bowel capsule endoscopy: Indications, results, and clinical benefit in a University environment. Medicine 2018, 97, e0148. [Google Scholar] [CrossRef] [PubMed]
- Aktas, H.; Mensink, P.B. Small bowel diagnostics: Current place of small bowel endoscopy. Best Pract. Res. Clin. Gastroenterol. 2012, 26, 209–220. [Google Scholar] [CrossRef] [PubMed]
- McLaughlin, P.D.; Maher, M.M. Primary malignant diseases of the small intestine. Am. J. Roentgenol. 2013, 201, W9–W14. [Google Scholar] [CrossRef] [PubMed]
- Thomson, A.; Keelan, M.; Thiesen, A.; Clandinin, M.; Ropeleski, M.; Wild, G. Small bowel review: Diseases of the small intestine. Dig. Dis. Sci. 2001, 46, 2555–2566. [Google Scholar] [CrossRef]
- Zheng, Y.; Hawkins, L.; Wolff, J.; Goloubeva, O.; Goldberg, E. Detection of lesions during capsule endoscopy: Physician performance is disappointing. Off. J. Am. Coll. Gastroenterol. ACG 2012, 107, 554–560. [Google Scholar] [CrossRef]
- Chetcuti Zammit, S.; Sidhu, R. Capsule endoscopy–recent developments and future directions. Expert Rev. Gastroenterol. Hepatol. 2021, 15, 127–137. [Google Scholar] [CrossRef]
- Rondonotti, E.; Soncini, M.; Girelli, C.M.; Russo, A.; Ballardini, G.; Bianchi, G.; Cantù, P.; Centenara, L.; Cesari, P.; Cortelezzi, C.C.; et al. Can we improve the detection rate and interobserver agreement in capsule endoscopy? Dig. Liver Dis. 2012, 44, 1006–1011. [Google Scholar] [CrossRef]
- Kaminski, M.F.; Regula, J.; Kraszewska, E.; Polkowski, M.; Wojciechowska, U.; Didkowska, J.; Zwierko, M.; Rupinski, M.; Nowacki, M.P.; Butruk, E. Quality indicators for colonoscopy and the risk of interval cancer. N. Engl. J. Med. 2010, 362, 1795–1803. [Google Scholar] [CrossRef]
- Shen, D.; Wu, G.; Suk, H.I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221. [Google Scholar] [CrossRef] [Green Version]
- Wang, A.; Islam, M.; Xu, M.; Ren, H. Rethinking Surgical Instrument Segmentation: A Background Image Can Be All You Need. arXiv 2022, arXiv:2206.11804. [Google Scholar]
- Bai, L.; Chen, S.; Gao, M.; Abdelrahman, L.; Al Ghamdi, M.; Abdel-Mottaleb, M. The Influence of Age and Gender Information on the Diagnosis of Diabetic Retinopathy: Based on Neural Networks. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Guadalajara, Mexico, 1–5 November 2021; pp. 3514–3517. Available online: https://embc.embs.org/2021/ (accessed on 30 November 2021).
- Bai, L.; Yang, J.; Wang, J.; Lu, M. An Overspeed Capture System Based on Radar Speed Measurement and Vehicle Recognition. In Proceedings of the International Conference on International Conference on Artificial Intelligence for Communications and Networks, Virtual Event, 19–20 December 2020; pp. 447–456. [Google Scholar]
- Kim, H.; Park, J.; Lee, H.; Im, G.; Lee, J.; Lee, K.B.; Lee, H.J. Classification for Breast Ultrasound Using Convolutional Neural Network with Multiple Time-Domain Feature Maps. Appl. Sci. 2021, 11, 10216. [Google Scholar] [CrossRef]
- Jang, Y.; Jeong, I.; Cho, Y.K. Identifying impact of variables in deep learning models on bankruptcy prediction of construction contractors. In Engineering, Construction and Architectural Management; Emerald Publishing Limited: Bradford, UK, 2021. [Google Scholar]
- Kang, S.H.; Han, J.H. Video captioning based on both egocentric and exocentric views of robot vision for human-robot interaction. Int. J. Soc. Robot. 2021, 1–11. [Google Scholar] [CrossRef]
- Che, H.; Jin, H.; Chen, H. Learning Robust Representation for Joint Grading of Ophthalmic Diseases via Adaptive Curriculum and Feature Disentanglement. arXiv 2022, arXiv:2207.04183. [Google Scholar]
- Yuan, Y.; Meng, M.Q.H. Deep learning for polyp recognition in wireless capsule endoscopy images. Med. Phys. 2017, 44, 1379–1389. [Google Scholar] [CrossRef]
- Karargyris, A.; Bourbakis, N. Detection of small bowel polyps and ulcers in wireless capsule endoscopy videos. IEEE Trans. Biomed. Eng. 2011, 58, 2777–2786. [Google Scholar] [CrossRef]
- Li, L.; Li, X.; Yang, S.; Ding, S.; Jolfaei, A.; Zheng, X. Unsupervised-learning-based continuous depth and motion estimation with monocular endoscopy for virtual reality minimally invasive surgery. IEEE Trans. Ind. Inform. 2020, 17, 3920–3928. [Google Scholar] [CrossRef]
- Ozyoruk, K.B.; Gokceler, G.I.; Bobrow, T.L.; Coskun, G.; Incetan, K.; Almalioglu, Y.; Mahmood, F.; Curto, E.; Perdigoto, L.; Oliveira, M.; et al. EndoSLAM dataset and an unsupervised monocular visual odometry and depth estimation approach for endoscopic videos. Med. Image Anal. 2021, 71, 102058. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Neyshabur, B. Towards learning convolutions from scratch. Adv. Neural Inf. Process. Syst. 2020, 33, 8078–8088. [Google Scholar]
- Smedsrud, P.H.; Thambawita, V.; Hicks, S.A.; Gjestang, H.; Nedrejord, O.O.; Næss, E.; Borgli, H.; Jha, D.; Berstad, T.J.D.; Eskeland, S.L.; et al. Kvasir-Capsule, a video capsule endoscopy dataset. Sci. Data 2021, 8, 142. [Google Scholar] [CrossRef] [PubMed]
- Coelho, P.; Pereira, A.; Salgado, M.; Cunha, A. A deep learning approach for red lesions detection in video capsule endoscopies. In Proceedings of the International Conference Image Analysis and Recognition, Póvoa de Varzim, Portugal, 27–29 June 2018; pp. 553–561. [Google Scholar]
- Koulaouzidis, A.; Iakovidis, D.K.; Yung, D.E.; Rondonotti, E.; Kopylov, U.; Plevris, J.N.; Toth, E.; Eliakim, A.; Johansson, G.W.; Marlicz, W.; et al. KID Project: An internet-based digital video atlas of capsule endoscopy for research purposes. Endosc. Int. Open 2017, 5, E477–E483. [Google Scholar] [CrossRef] [PubMed]
- Bernal, J.; Aymeric, H.; Gastrointestinal Image Analysis (GIANA) Angiodysplasia d&l Challenge. Web-page of the 2017 Endoscopic Vision Challenge. 2017. Available online: https://endovissub2017-giana.grand-challenge.org/ (accessed on 20 May 2018).
- Amiri, Z.; Hassanpour, H.; Beghdadi, A. A Computer-Aided Method for Digestive System Abnormality Detection in WCE Images. J. Healthc. Eng. 2021, 2021, 7863113. [Google Scholar] [CrossRef] [PubMed]
- Saito, H.; Aoki, T.; Aoyama, K.; Kato, Y.; Tsuboi, A.; Yamada, A.; Fujishiro, M.; Oka, S.; Ishihara, S.; Matsuda, T.; et al. Automatic detection and classification of protruding lesions in wireless capsule endoscopy images based on a deep convolutional neural network. Gastrointest. Endosc. 2020, 92, 144–151. [Google Scholar] [CrossRef]
- Gjestang, H.L.; Hicks, S.A.; Thambawita, V.; Halvorsen, P.; Riegler, M.A. A self-learning teacher-student framework for gastrointestinal image classification. In Proceedings of the 2021 IEEE 34th International Symposium on Computer-Based Medical Systems (CBMS), Aveiro, Portugal, 7–9 June 2021; pp. 539–544. [Google Scholar]
- Muruganantham, P.; Balakrishnan, S.M. Attention aware deep learning model for wireless capsule endoscopy lesion classification and localization. J. Med Biol. Eng. 2022, 42, 157–168. [Google Scholar] [CrossRef]
- Khadka, R.; Jha, D.; Hicks, S.; Thambawita, V.; Riegler, M.A.; Ali, S.; Halvorsen, P. Meta-learning with implicit gradients in a few-shot setting for medical image segmentation. Comput. Biol. Med. 2022, 143, 105227. [Google Scholar] [CrossRef] [PubMed]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.H.; Tay, F.E.; Feng, J.; Yan, S. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 558–567. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Touvron, H.; Cord, M.; Sablayrolles, A.; Synnaeve, G.; Jégou, H. Going deeper with image transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 32–42. [Google Scholar]
- Liu, Y.; Sangineto, E.; Bi, W.; Sebe, N.; Lepri, B.; Nadai, M. Efficient training of visual transformers with small datasets. Adv. Neural Inf. Process. Syst. 2021, 34, 23818–23830. [Google Scholar]
- Lee, S.H.; Lee, S.; Song, B.C. Vision transformer for small-size datasets. arXiv 2021, arXiv:2112.13492. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Wang, J.; Li, J.; Ding, L.; Wang, Y.; Xu, T. PAPooling: Graph-based Position Adaptive Aggregation of Local Geometry in Point Clouds. arXiv 2021, arXiv:2111.14067. [Google Scholar]
- Heo, B.; Yun, S.; Han, D.; Chun, S.; Choe, J.; Oh, S.J. Rethinking spatial dimensions of vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11936–11945. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Sharif, M.; Attique Khan, M.; Rashid, M.; Yasmin, M.; Afza, F.; Tanik, U.J. Deep CNN and geometric features-based gastrointestinal tract diseases detection and classification from wireless capsule endoscopy images. J. Exp. Theor. Artif. Intell. 2021, 33, 577–599. [Google Scholar] [CrossRef]
- Rustam, F.; Siddique, M.A.; Siddiqui, H.U.R.; Ullah, S.; Mehmood, A.; Ashraf, I.; Choi, G.S. Wireless capsule endoscopy bleeding images classification using CNN based model. IEEE Access 2021, 9, 33675–33688. [Google Scholar] [CrossRef]
- Zhao, X.; Fang, C.; Gao, F.; De-Jun, F.; Lin, X.; Li, G. Deep Transformers for Fast Small Intestine Grounding in Capsule Endoscope Video. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 150–154. [Google Scholar]
- Borgli, H.; Thambawita, V.; Smedsrud, P.H.; Hicks, S.; Jha, D.; Eskeland, S.L.; Randel, K.R.; Pogorelov, K.; Lux, M.; Nguyen, D.T.D.; et al. HyperKvasir, a comprehensive multi-class image and video dataset for gastrointestinal endoscopy. Sci. Data 2020, 7, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Biradher, S.; Aparna, P. Classification of Wireless Capsule Endoscopy Bleeding Images using Deep Neural Network. In Proceedings of the 2022 IEEE Delhi Section Conference (DELCON), Delhi, India, 11–13 February 2022; pp. 1–4. [Google Scholar]
- Bajhaiya, D.; Unni, S.N. Deep learning-enabled classification of gastric ulcers from wireless-capsule endoscopic images. In Medical Imaging 2022: Digital and Computational Pathology; SPIE: San Diego, CA, USA, 2022; Volume 12039, pp. 352–356. [Google Scholar]
- Goel, N.; Kaur, S.; Gunjan, D.; Mahapatra, S. Dilated CNN for abnormality detection in wireless capsule endoscopy images. Soft Comput. 2022, 26, 1231–1247. [Google Scholar] [CrossRef]
- Srivastava, A.; Tomar, N.K.; Bagci, U.; Jha, D. Video Capsule Endoscopy Classification using Focal Modulation Guided Convolutional Neural Network. arXiv 2022, arXiv:2206.08298. [Google Scholar]
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do vision transformers see like convolutional neural networks? Adv. Neural Inf. Process. Syst. 2021, 34, 12116–12128. [Google Scholar]
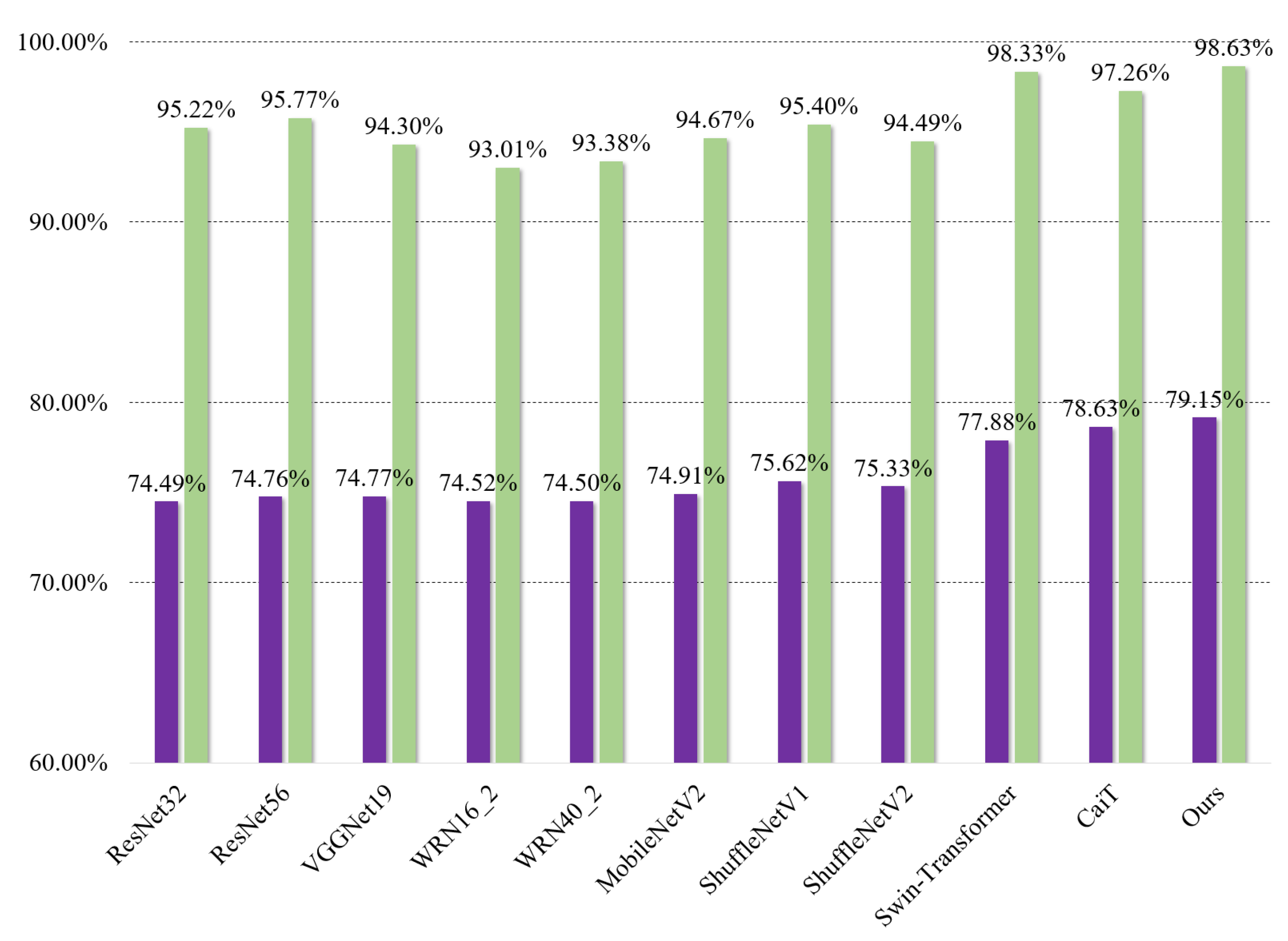
| Models | Kvasir-Capsule | RLE | Inference Time/Per Image |
|---|---|---|---|
| ResNet32 [43] | 74.49% | 95.22% | 0.41 ms |
| ResNet56 [43] | 74.76% | 95.77% | 0.42 ms |
| VGGNet19 [47] | 74.77% | 94.30% | 0.41 ms |
| WRN16_2 [48] | 74.52% | 93.01% | 0.41 ms |
| WRN40_2 [48] | 74.50% | 93.38% | 0.42 ms |
| MobileNetV2 [49] | 74.91% | 94.67% | 0.41 ms |
| ShuffleNetV1 [50] | 75.62% | 95.40% | 0.42 ms |
| ShuffleNetV2 [51] | 75.33% | 94.49% | 0.41 ms |
| Swin [39] | 77.88% | 98.33% | 0.47 ms |
| CaiT [40] | 78.63% | 97.26% | 0.48 ms |
| Ours | 79.15% | 98.63% | 0.47 ms |
| Authors | Methodology | Dataset | Accuracy |
|---|---|---|---|
| M. Sharif et al. [52] | Geometric Features, CNN | 10 WCE videos | 99.1% |
| F. Rustam et al. [53] | MobileNet, BIR | Bleeding Detection, Binary Classification | 99.3% |
| X. Zhao et al. [54] | CNN Backbone, LSTM, Transformer | 113 WCE videos | 93.0% |
| H. L. Gjestang et al. [33] | Teacher–student Framework | Kvasir-Capsule [27] | 69.5% |
| H. L. Gjestang et al. [33] | Teacher–student Framework | HyperKvasir [55] | 89.3% |
| P. Muruganantham et al. [34] | Self-attention CNN | Processed Kvasir-Capsule [27] | 95.4% |
| P. Muruganantham et al. [34] | Self-attention CNN | Processed RLE [28] | 95.1% |
| S. Biradher et al. [56] | CNN | Processed RLE | 98.5% |
| D. Bajhaiya et al. [57] | DenseNet121 | Ulcer Classification [27] | 99.9% |
| N. Goel et al. [58] | Dilated Input Context Retention CNN | 8 WCE videos | 96.0% |
| N. Goel et al. [58] | Dilated Input Context Retention CNN | KID [29] | 93.0% |
| A. Srivastava et al. [59] | FocalConvNet | Processed Kvasir-Capsule [27] | 63.7% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, L.; Wang, L.; Chen, T.; Zhao, Y.; Ren, H. Transformer-Based Disease Identification for Small-Scale Imbalanced Capsule Endoscopy Dataset. Electronics 2022, 11, 2747. https://doi.org/10.3390/electronics11172747
Bai L, Wang L, Chen T, Zhao Y, Ren H. Transformer-Based Disease Identification for Small-Scale Imbalanced Capsule Endoscopy Dataset. Electronics. 2022; 11(17):2747. https://doi.org/10.3390/electronics11172747
Chicago/Turabian StyleBai, Long, Liangyu Wang, Tong Chen, Yuanhao Zhao, and Hongliang Ren. 2022. "Transformer-Based Disease Identification for Small-Scale Imbalanced Capsule Endoscopy Dataset" Electronics 11, no. 17: 2747. https://doi.org/10.3390/electronics11172747
APA StyleBai, L., Wang, L., Chen, T., Zhao, Y., & Ren, H. (2022). Transformer-Based Disease Identification for Small-Scale Imbalanced Capsule Endoscopy Dataset. Electronics, 11(17), 2747. https://doi.org/10.3390/electronics11172747