
Deep LSTM Model for Diabetes Prediction with Class Balancing by SMOTE

 ,
,  , , and
, , and
Abstract
:1. Introduction
2. Related Works
- Designing a deep-learning classifier for diabetic recognition;
- Incorporating SMOTE to treat the class-imbalance problem and improve the accuracy of the deep-learning classifier.
3. Diabetes Prediction
3.1. Data Set
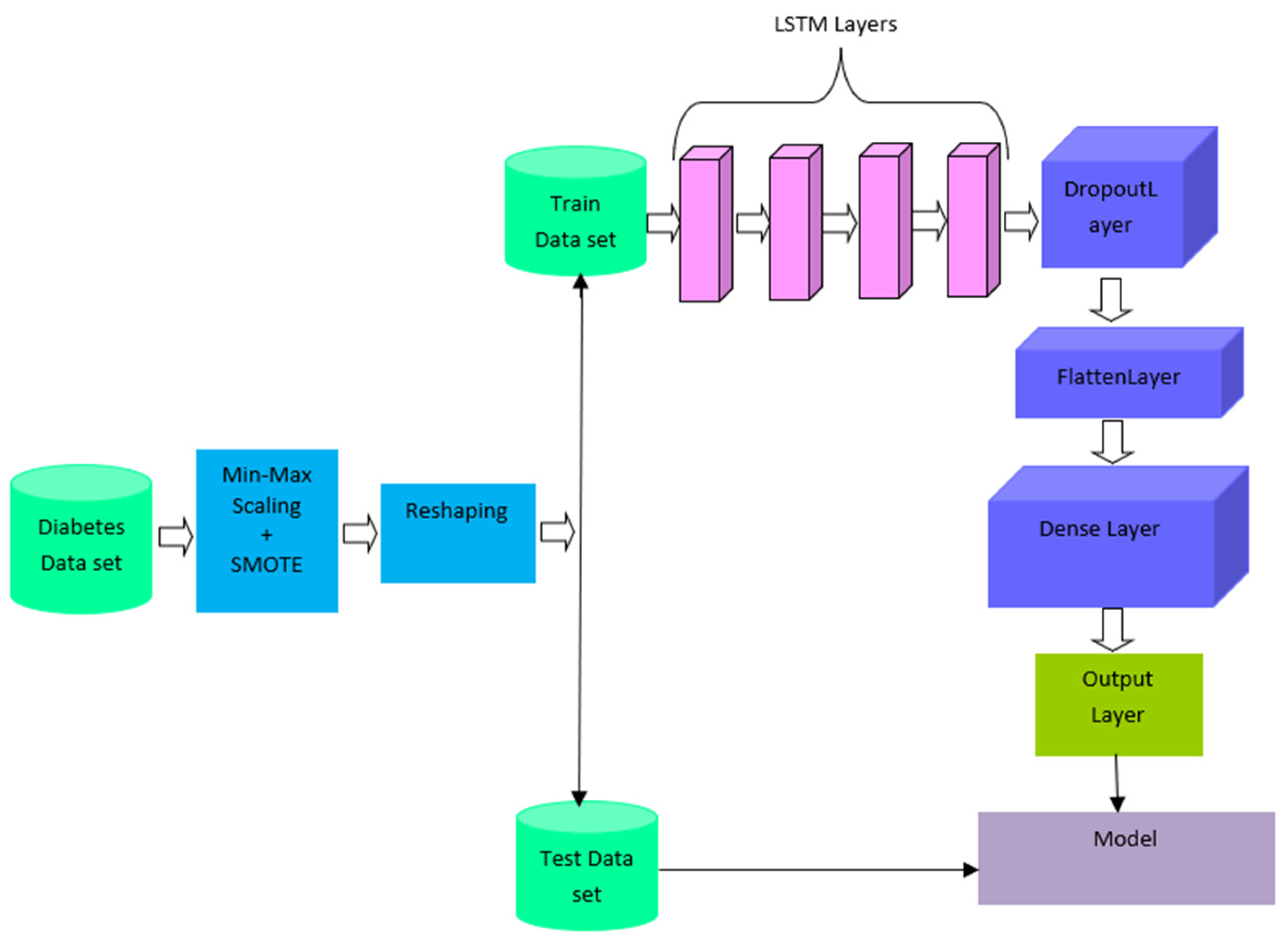
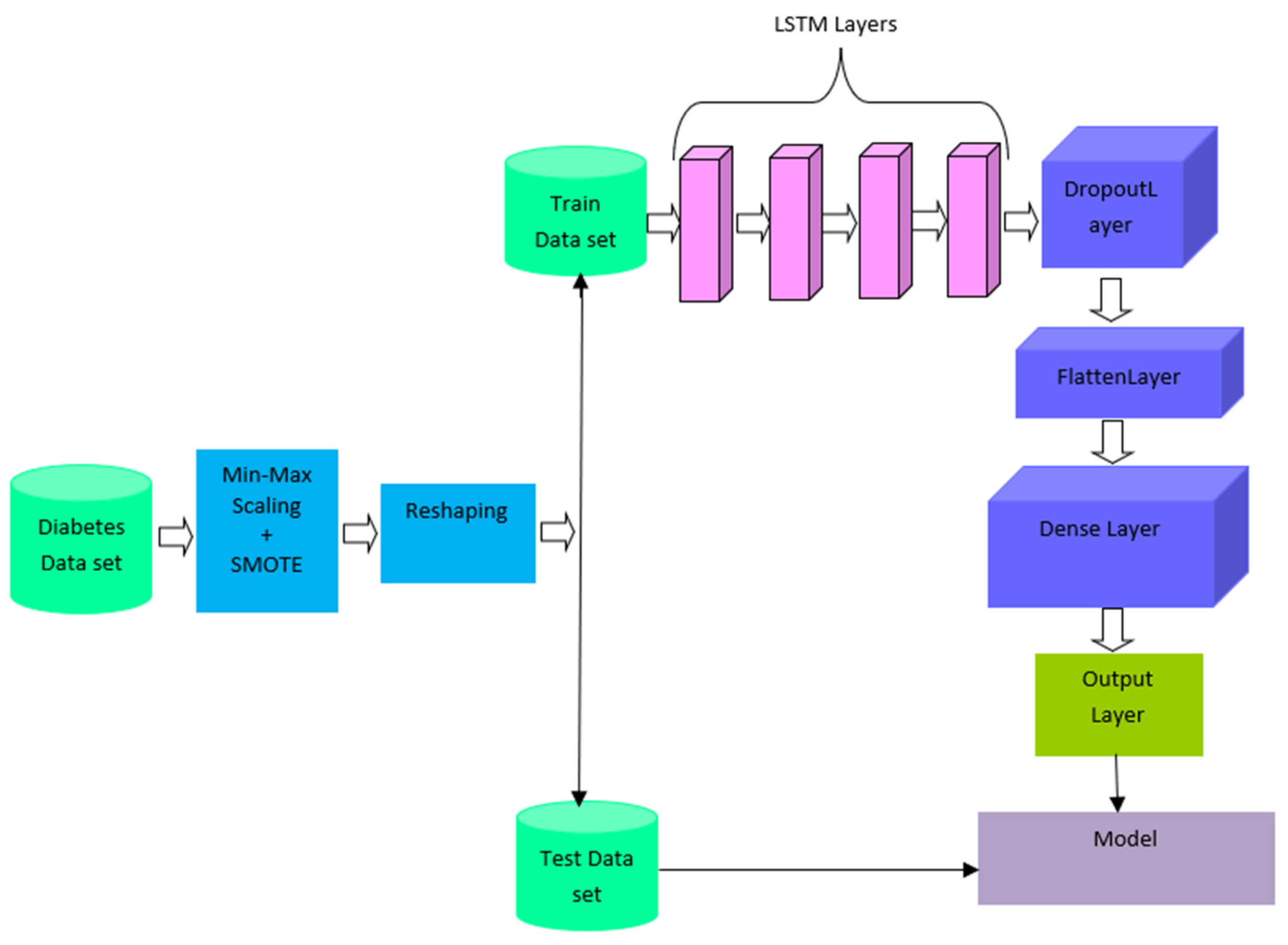
3.2. SMOTE-Based Deep LSTM for Diabetes Prediction
3.2.1. Data Preprocessing
3.2.2. Class-Imbalance Processing
3.2.3. Reshaping
3.2.4. Deep LSTM
3.2.5. Parameter Setting
4. Experimental Methods and Results
4.1. Experimental Setup
4.2. Performance Measures
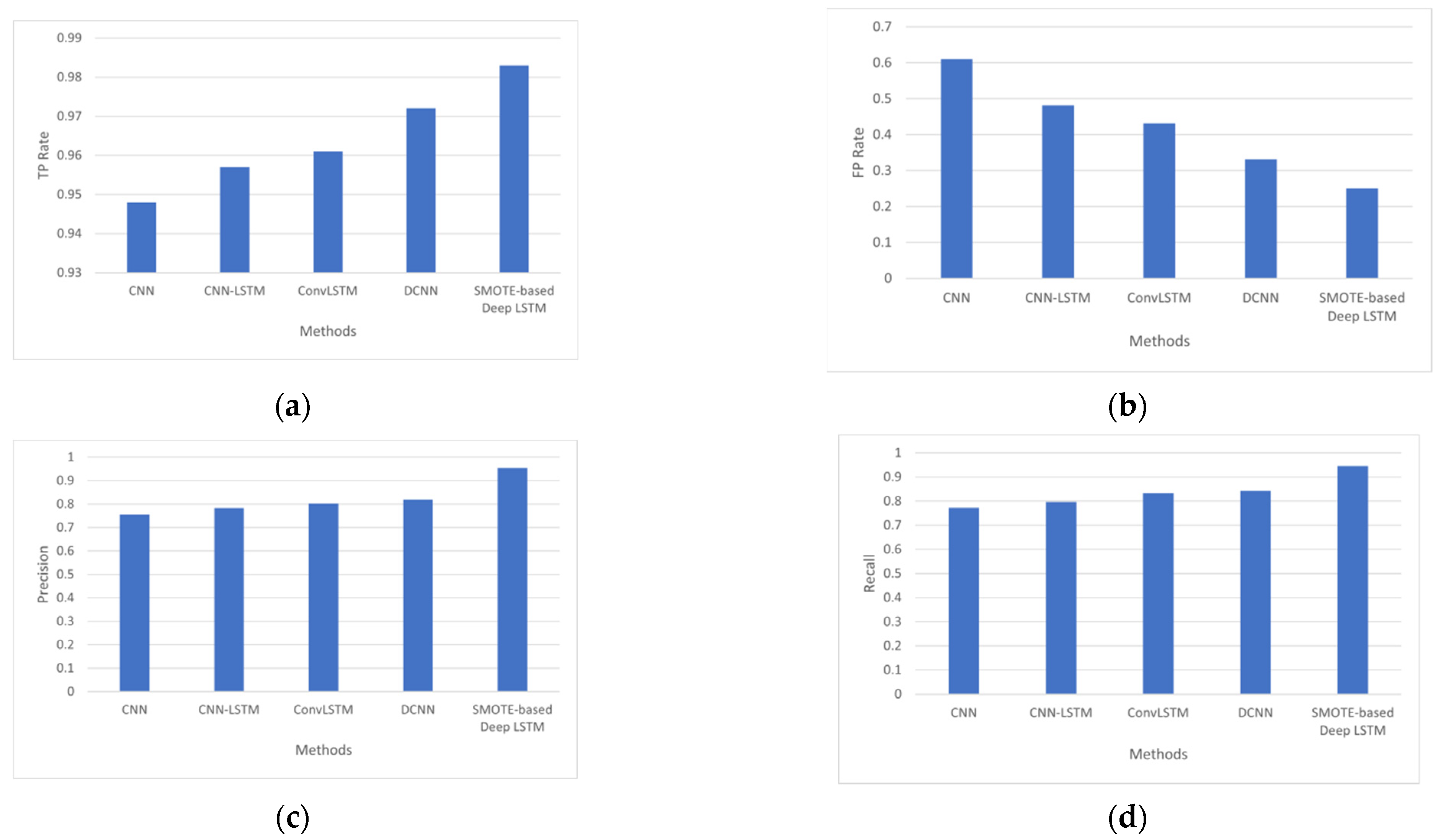
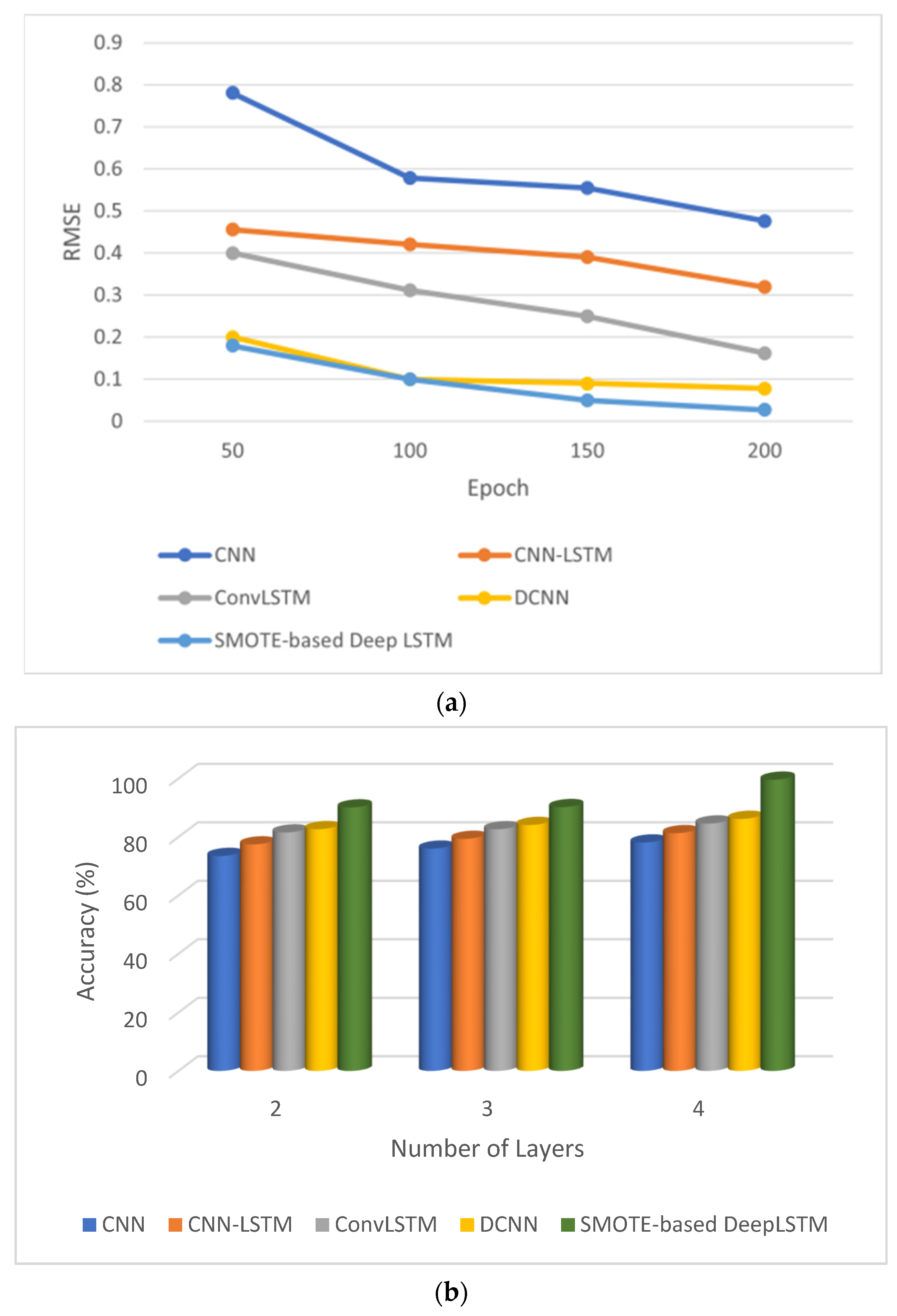
4.3. Results Analysis
- The SMOTE-based deep LSTM model was introduced to diagnose type-2 diabetes using the PIDD as input.
- Class imbalance learning is also handled by SMOTE-based deep LSTM.
- The accuracy of automated diabetes prediction method is higher than that of other diabetes-prediction methods.
5. Conclusions
- The proposed method does not focus on treating intra-class imbalance;
- SMOTE-based Deep LSTM is not designed for the multiclass classification problem;
- The classification ability of the proposed method was evaluated only on the Pima Indian Diabetes Dataset.
- Inter-class imbalance commonly exists in binary-class datasets. The proposed method solves inter-class imbalance.
- In future, the proposed method can be extended to focus on intra-class imbalance. The proposed method performed binary classification on the Pima Indian Diabetes Dataset. It can be extended to work on multiclass datasets.
- SMOTE was used in this work as a data augmentation technique for class balancing. In the future, a generative adversarial network can be used for data augmentation.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mishra, S.; Tripathy, H.K.; Mallick, P.K.; Bhoi, A.K.; Barsocchi, P. EAGA-MLP—An enhanced and adaptive hybrid classification model for diabetes diagnosis. Sensors 2020, 20, 4036. [Google Scholar] [CrossRef] [PubMed]
- Swapna, G.; Vinayakumar, R.; Soman, K.P. Diabetes detection using deep learning algorithms. ICT Express 2018, 4, 243–246. [Google Scholar]
- Sisodia, D.; Sisodia, D.S. Prediction of diabetes using classification algorithms. Procedia Comput. Sci. 2018, 132, 1578–1585. [Google Scholar] [CrossRef]
- Learning, U.M. Pima Indians Diabetes Database. 2016. Available online: https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database (accessed on 5 May 2022).
- Rakshit, S.; Manna, S.; Biswas, S.; Kundu, R.; Gupta, P.; Maitra, S.; Barman, S. Prediction of diabetes type-II using a two-class neural network. In Proceedings of the International Conference on Computational Intelligence, Communications, and Business Analytics, Kolkata, India, 24–25 March 2017; Springer: Singapore, 2017; pp. 65–71. [Google Scholar]
- Alex, S.A.; Nayahi, J.; Shine, H.; Gopirekha, V. Deep convolutional neural network for diabetes mellitus prediction. Neural Comput. Appl. 2022, 34, 1319–1327. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Singh, A.; Ranjan, R.K.; Tiwari, A.; Naveena, S. Credit card fraud detection under extreme imbalanced data: A comparative study of data-level algorithms. J. Exp. Theor. Artif. Intell. 2022, 34, 571–598. [Google Scholar]
- Han, W.; Huang, Z.; Li, S.; Jia, Y. Distribution-sensitive unbalanced data oversampling method for medical diagnosis. J. Med. Syst. 2019, 43, 39. [Google Scholar] [CrossRef]
- Luukka, P.; Leppälampi, T. Similarity classifier with generalized mean applied to medical data. Comput. Biol. Med. 2006, 36, 1026–1040. [Google Scholar] [CrossRef]
- Ahmad, F.; Mat Isa, N.A.; Hussain, Z.; Osman, M.K. Intelligent medical disease diagnosis using improved hybrid genetic algorithm-multilayer perceptron network. J. Med. Syst. 2013, 37, 9934. [Google Scholar] [CrossRef]
- Christobel, Y.A.; Sivaprakasam, P. A new classwise k nearest neighbor (CKNN) method for the classification of diabetes dataset. Int. J. Eng. Adv. Technol. 2013, 2, 396–400. [Google Scholar]
- Polat, K.; Güneş, S.; Arslan, A. A cascade learning system for classification of diabetes disease: Generalized discriminant analysis and least square support vector machine. Expert Syst. Appl. 2008, 34, 482–487. [Google Scholar] [CrossRef]
- Abiodun,, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar]
- Kahramanli, H.; Allahverdi, N. Design of a hybrid system for the diabetes and heart diseases. Expert Syst. Appl. 2008, 35, 82–89. [Google Scholar] [CrossRef]
- Kayaer, K.; Yildirim, T. Medical diagnosis on Pima Indian diabetes using general regression neural networks. In Proceedings of the International Conference on Artificial Neural Networks and Neural Information Processing, Istanbul, Turkey, 26–29 June 2003; pp. 181–184. [Google Scholar]
- Pokharel, M.; Alsadoon, A.; Nguyen, T.Q.V.; Al-Dala’in, T.; Pham, D.T.H.; Prasad, P.W.C.; Mai, H.T. Deep learning for predicting the onset of type 2 diabetes: Enhanced ensemble classifier using modified t-SNE. Multimed. Tools Appl. 2022, 81, 27837–27852. [Google Scholar] [CrossRef]
- Vidhya, K.; Shanmugalakshmi, R. Deep learning based big medical data analytic model for diabetes complication prediction. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 5691–5702. [Google Scholar] [CrossRef]
- Mohebbi, A.; Aradottir, T.B.; Johansen, A.R.; Bengtsson, H.; Fraccaro, M.; Mørup, M. A deep learning approach to adherence detection for type 2 diabetics. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Jeju, Korea, 11–15 July 2017; pp. 2896–2899. [Google Scholar]
- Caliskan, A.; Yuksel, M.E.; Badem, H.; Basturk, A. Performance improvement of deep neural network classifiers by a simple training strategy. Eng. Appl. Artif. Intell. 2018, 67, 14–23. [Google Scholar] [CrossRef]
- Pham, T.; Tran, T.; Phung, D.; Venkatesh, S. Predicting healthcare trajectories from medical records: A deep learning approach. J. Biomed. Inform. 2017, 69, 218–229. [Google Scholar] [CrossRef]
- Sun, J.; Li, H.; Fujita, H.; Fu, B.; Ai, W. Class-imbalanced dynamic financial distress prediction based on Adaboost-SVM ensemble combined with SMOTE and time weighting. Inf. Fusion 2020, 54, 128–144. [Google Scholar] [CrossRef]
- Temurtas, H.; Yumusak, N.; Temurtas, F. A comparative study on diabetes disease diagnosis using neural networks. Expert Syst. Appl. 2009, 36, 8610–8615. [Google Scholar] [CrossRef]
- Dwivedi, A.K. Analysis of computational intelligence techniques for diabetes mellitus prediction. Neural Comput. Appl. 2018, 30, 3837–3845. [Google Scholar] [CrossRef]
- Swapna, G.; Kp, S.; Vinayakumar, R. Automated detection of diabetes using CNN and CNN-LSTM network and heart rate signals. Procedia Comput. Sci. 2018, 132, 1253–1262. [Google Scholar]
- Rabby, M.F.; Tu, Y.; Hossen, M.I.; Lee, I.; Maida, A.S.; Hei, X. Stacked LSTM based deep recurrent neural network with kalman smoothing for blood glucose prediction. BMC Med. Inform. Decis. Mak. 2021, 21, 101. [Google Scholar] [CrossRef] [PubMed]
- Kutlu, H.; Avcı, E. A novel method for classifying liver and brain tumors using convolutional neural networks, discrete wavelet transform and long short-term memory networks. Sensors 2019, 19, 1992. [Google Scholar] [CrossRef] [PubMed]
- Rahman, M.; Islam, D.; Mukti, R.J.; Saha, I. A deep learning approach based on convolutional LSTM for detecting diabetes. Comput. Biol. Chem. 2020, 88, 107329. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S. Ja1 4 rgen schmidhuber. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chang, V.; Bailey, J.; Xu, Q.A.; Sun, Z. Pima Indians diabetes mellitus classification based on machine learning (ML) algorithms. Neural Comput. Appl. 2022, 1–17. [Google Scholar] [CrossRef]
- Chang, P.; Grinband, J.; Weinberg, B.D.; Bardis, M.; Khy, M.; Cadena, G.; Chow, D. Deep-learning convolutional neural networks accurately classify genetic mutations in gliomas. Am. J. Neuroradiol. 2018, 39, 1201–1207. [Google Scholar] [CrossRef]
- Dorffner, G. Neural networks for time series processing. In Proceedings of the Neural Network World; 1996. Available online: https://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=02C8586DF982ABE36E5775BF3E86642E?doi=10.1.1.45.5697&rep=rep1&type=pdf (accessed on 10 January 2022).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhao, H.; Hou, C.; Alrobassy, H.; Zeng, X. Recognition of transportation state by smartphone sensors using deep bi-LSTM neural network. J. Comput. Netw. Commun. 2019, 2019, 4967261. [Google Scholar] [CrossRef]
- Sunny, M.A.I.; Maswood, M.M.S.; Alharbi, A.G. Deep learning-based stock price prediction using LSTM and bi-directional LSTM model. In Proceedings of the 2020 2nd Novel Intelligent and Leading Emerging Sciences Conference (NILES), Giza, Egypt, 24–26 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 87–92. [Google Scholar]
- Sun, B.; Liu, M.; Zheng, R.; Zhang, S. Attention-based LSTM network for wearable human activity recognition. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8677–8682. [Google Scholar]
- Rajagukguk, R.A.; Kamil, R.; Lee, H.J. A Deep Learning Model to Forecast Solar Irradiance Using a Sky Camera. Appl. Sci. 2021, 11, 5049. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, H.; Liu, Z.; Meng, S. Fault diagnosis of wheelset bearings using deep bidirectional long short-term memory network. In Proceedings of the 2019 Prognostics and System Health Management Conference (PHM-Qingdao), Qingdao, China, 25–27 October 2019; pp. 1–7. [Google Scholar]
- Zhang, T.; Song, S.; Li, S.; Ma, L.; Pan, S.; Han, L. Research on gas concentration prediction models based on LSTM multidimensional time series. Energies 2019, 12, 161. [Google Scholar] [CrossRef]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1110–1118. [Google Scholar]
- Majhi, B.; Naidu, D.; Mishra, A.P.; Satapathy, S.C. Improved prediction of daily pan evaporation using Deep-LSTM model. Neural Comput. Appl. 2020, 32, 7823–7838. [Google Scholar] [CrossRef]
- Phan, H.; Andreotti, F.; Cooray, N.; Chén, O.Y.; De Vos, M. DNN filter bank improves 1-max pooling CNN for single-channel EEG automatic sleep stage classification. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 453–456. [Google Scholar]
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Range | Average |
|---|---|---|
| Age | 21 to 81 | 33 |
| Pregnancies | 0 to 17 | 4 |
| Glucose (2 h) | 0 to 199 | 121 |
| Blood pressure (mm Hg) | 0 to 122 | 69 |
| Skin thickness (mm) | 0 to 99 | 21 |
| Insulin (mu U/mL) | 0 to 846 | 80 |
| BMI (Kg/m2) | 0 to 67.1 | 32 |
| Diabetes pedigree function | 0.078 to 2.42 | 0.47 |
| Outcome | either 0 or 1 | - |
| Layer | Input | Output | Parameter |
|---|---|---|---|
| SMOTE | #Minority instances = 268 # Majority instances = 500 | # Minority instances = 500 # Majority instances = 500 | K = 5 |
| LSTM1 | # Training data = 700 [20 × 35] | (20 × 30) | Hidden units = 96 Learning rate = 0.005 Batch size = 20 Loss = MSE Optimizer = Adam Dropout = 0.5 # Epochs = 417 Return Sequences = true |
| LSTM2 | # Training data = 600 (20 × 30) | (20 × 25) | Hidden units = 96 Learning rate = 0.005 Batch size = 20 Loss = MSE Optimizer = Adam Dropout = 0.5 # Epochs = 351 Return Sequences = true |
| LSTM3 | # Training data = 500 (20 × 25) | (20 × 20) | Hidden units = 96 Learning rate = 0.005 Batch size = 20 Loss = MSE Optimizer = Adam Dropout = 0.5 # Epochs = 325 Return Sequences = true |
| LSTM4 | # Training data = 400 (20 × 20) | (20 × 15) | Hidden units = 96 Learning rate = 0.005 Batch size = 20 Loss = MSE Optimizer = Adam Dropout = 0.5 # Epochs = 200 Return Sequences = true |
| Flatten | (20 × 15) | 300 | - |
| FC | 300 | - | Number of neurons = 15 Activation = sigmoid |
| Output | - | - | Activation = sigmoid |
| Hyperparameter | Range | Value |
|---|---|---|
| Learning Rate [35] | 0.1, 0.01, 0.005, 0.001, 0.0005 | 0.005 |
| Optimizer [34] | Adam, sgdm, rmsprop | Adam |
| Number of LSTM layers [36] | 1, 3, 5, 7 | 4 |
| Hidden units per LSTM layer [37] | 12, 24, 48, 96, 192 | 96 |
| Number of epochs [30] | 50, 100, 200, 300, 400, 500 | 200 |
| Dropout rate [38] | 0.3, 0.4, 0.5, 0.6, 0.7, 0.8 | 0.5 |
| Batch size [39] | 1, 5, 10, 20 | 20 |
| Number of neurons in fully connected (FC) layer [40] | 10, 12, 15, 20, 25, 30 | 15 Activation = sigmoid |
| Number of neurons in output layer [41] | - | 1 Activation = sigmoid |
| Model | Configuration | Parameter Detail |
|---|---|---|
| 1-CNN [42] | # Convolution layers = 1 # Max-pooling layer = 1 # Flatten layer = 1 # Fully connected layer = 1 # Output layer = 1 | Input layer = 1000 neurons # Filters = 32 Kernel size = 3 × 3 Stride = 1 × 1 Pooling size = 2 Dropout = 0.5 |
| 2-CNN [42] | # Convolution layers = 2 # Max-pooling layer = 2 # Flatten layer = 1 # Fully connected layer = 1 # Output layer = 1 | Input layer = 1000 neurons # Filters = 32 Kernel size = 3 × 3 Stride = 1 × 1 Pooling size = 2 Dropout = 0.5 |
| 3-CNN [28] | # Convolution layers = 3 # Max-pooling layer = 3 # Flatten layer = 1 # Fully connected layer = 1 # Output layer = 1 | Input layer = 1000 neurons # Filters = 32 kernel size = 3 × 3 Stride = 1 × 1 Pooling size = 2 Dropout = 0.5 |
| 4-CNN [28] | # Convolution layers = 4 # Max-pooling layer = 4 # Flatten layer = 1 # Fully connected layer = 1 # Output layer = 1 | Input layer = 1000 neurons # Filters = 32 Kernel size = 3 × 3 Stride = 1 × 1 Pooling size = 2 Dropout = 0.5 |
| CNN-LSTM [29] | # Convolution layers = {1,2,3,4,5} # LSTM layers = {1,2,3,4,5} # Flatten layer = 1 # Fully connected layer = 1 # Output layer = 1 | First convolution layer’s kernel size = 11 × 11 Second convolution layer’s kernel size = 5 × 5 Third convolution layer’s kernel size = 3 × 3 Fourth convolution layer’s kernel size = 2 × 2 Fifth convolution layer’s kernel size = 2 × 2 Stride = 2 × 2 Learning rate = 10−3 Epoch = 100 |
| ConvLSTM [30] | # ConvLSTM layers = 3 # Flatten layer = 1 # Fully connected layer = 2 # Output layer = 1 | Learning rate = 0.05 Number of filters = 28 Kernel Size = 5 Dropout = 15% Epoch = 100 Number of hidden units = 50 |
| DCNN [6] | # 1D convolution layers = 4 # Max pooling layer = 1 # Flatten layer = 1 # Fully connected layer = 2 # Output layer = 1 | Learning rate = 0.01 Number of filters = 32 Kernel size = 5 Dropout = 20% Epoch = 200 Number of hidden units = 100 |
| Models | Precision | Recall | Accuracy | AUC |
|---|---|---|---|---|
| CNN | 0.756 | 0.772 | 0.781 | 0.81 |
| CNN-LSTM | 0.783 | 0.797 | 0.813 | 0.836 |
| ConvLSTM | 0.802 | 0.833 | 0.846 | 0.858 |
| DCNN | 0.819 | 0.842 | 0.862 | 0.912 |
| SMOTE-based Deep LSTM | 0.954 | 0.946 | 0.996 | 0.983 |
| Predicted Class | |||
| Actual Class | 1 | 0 | |
| 1 | 430 | 68 | |
| 0 | 100 | 170 | |
| Predicted Class | |||
| Actual Class | 1 | 0 | |
| 1 | 445 | 43 | |
| 0 | 100 | 180 | |
| Predicted Class | |||
| Actual Class | 1 | 0 | |
| 1 | 522 | 31 | |
| 0 | 87 | 128 | |
| Predicted Class | |||
| Actual Class | 1 | 0 | |
| 1 | 582 | 25 | |
| 0 | 81 | 80 | |
| Predicted Class | |||
| Actual Class | 1 | 0 | |
| 1 | 665 | 2 | |
| 0 | 1 | 100 | |
| Models | MAE |
|---|---|
| CNN | 0.396 |
| CNN-LSTM | 0.239 |
| ConvLSTM | 0.082 |
| DCNN | 0.032 |
| SMOTE-based Deep LSTM | 0.013 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alex, S.A.; Jhanjhi, N.; Humayun, M.; Ibrahim, A.O.; Abulfaraj, A.W. Deep LSTM Model for Diabetes Prediction with Class Balancing by SMOTE. Electronics 2022, 11, 2737. https://doi.org/10.3390/electronics11172737
Alex SA, Jhanjhi N, Humayun M, Ibrahim AO, Abulfaraj AW. Deep LSTM Model for Diabetes Prediction with Class Balancing by SMOTE. Electronics. 2022; 11(17):2737. https://doi.org/10.3390/electronics11172737
Chicago/Turabian StyleAlex, Suja A., NZ Jhanjhi, Mamoona Humayun, Ashraf Osman Ibrahim, and Anas W. Abulfaraj. 2022. "Deep LSTM Model for Diabetes Prediction with Class Balancing by SMOTE" Electronics 11, no. 17: 2737. https://doi.org/10.3390/electronics11172737
APA StyleAlex, S. A., Jhanjhi, N., Humayun, M., Ibrahim, A. O., & Abulfaraj, A. W. (2022). Deep LSTM Model for Diabetes Prediction with Class Balancing by SMOTE. Electronics, 11(17), 2737. https://doi.org/10.3390/electronics11172737