
Towards Low-Cost Classification for Novel Fine-Grained Datasets



Abstract
:1. Introduction
2. Related Work
- In addition to the four traditional-based image representations, we evaluate 21 CNN-based image representations that use the pre-trained models and are the most comprehensive evaluation of CNN-based image representations on the datasets of butterflies and reef fish on two different data settings in a single publication to the best of our knowledge.
- Similarly, the reef fish image dataset collected from the internet and used in this work is also the most diverse dataset to date, containing images of 50 species, most of which are obtained in their natural habitat.
3. Datasets
3.1. Butterflies Dataset
3.2. ReefFish Dataset
4. Methodology
4.1. Traditional Algorithms
- Visual Vocabulary Construction: In the BoVWs model, features are collected from a set of images and quantized using a clustering strategy such as the k-means to form the visual vocabulary. Since the value of k defined the number of the clusters, the visual vocabulary consists of k or M visual words.
- Image representation: An image consists of image patches, and these patches are represented by local descriptors such SIFT; the given image is first represented as a set of descriptorswhere N is the total number of descriptors. A visual word from the vocabulary is then assigned to any given descriptor using a similarity measure such as the Euclidean distance as follows:where is the kth descriptor in the image and is the visual word assigned to this descriptor based on the distance . In the given image, all the descriptors are mapped to the visual words. The frequency of these visual words is then aggregated in a histogram where the number of bins in this histogram is equal to the size of the visual vocabulary, that is, M. Such a histogram-based representation of the image is called the bag-of-visual-words (BoVWs).
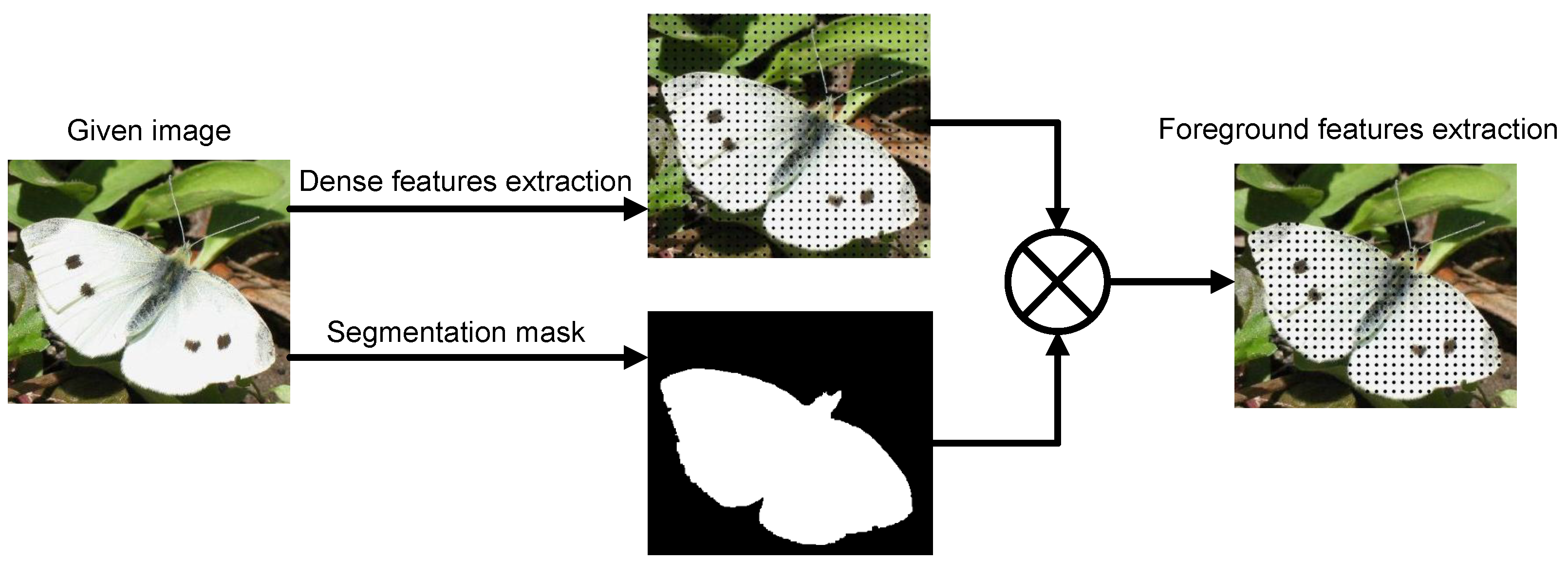
4.1.1. The Background Clutter Minimization
4.1.2. Scale and Rotation Invariance
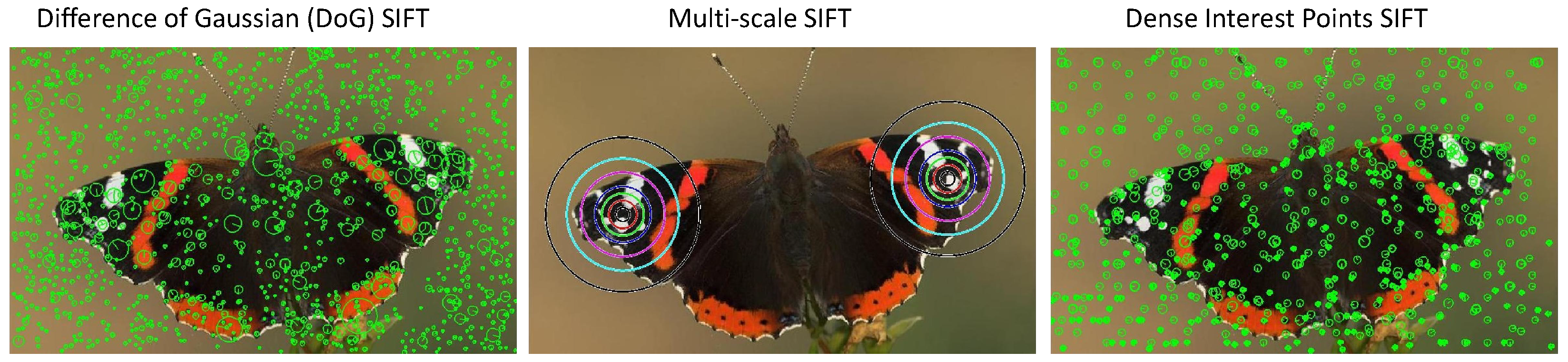
- Multi-Scale SIFT: In this setting, we densely extract the rotation-invariant SIFT features from multiple predefined scales. The descriptors extracted from all the scales are concatenated for a given feature. Several empirically defined scales are evaluated on the dataset for multi-scale SIFT. The one with the best performance is selected.
- Scale-Less SIFT (SL-SIFT): Hassner et al. [35] propose to extract SIFT descriptors from multiple scales and then combine them into a single descriptor called the Scale-Less SIFT (SLS). They represent each pixel as a set of descriptors extracted at several predefined scales. The subspace to point mapping technique is then used to combine all those descriptors into a single SLS descriptor.
- Difference of Gaussian (DoG-SIFT): Regions of images with high information content that can be localized are called interesting regions [36]. These regions are detected in images using the interest point detectors [37]. The difference-of-Gaussian (DoG) is one of the interest point detectors used by Lowe [34] to extract interesting regions for SIFT features. Among these regions, the low contrast regions on edges are then neglected by performing a non-maximal suppression. The rest of the interest points are then assigned orientation, followed by calculating a 128-dimensional SIFT descriptor for each interest point.
- Dense Interest Points (DIP-SIFT): This hybrid approach proposed aims at combining the best of both worlds, i.e., interest points and dense sampling [36]. Image patches are densely sampled on a regular grid and at multiple scales. The amount of the pixel stride on the dense grid is adjusted according to the patch’s scale to minimize the adjacent patches’ overlap. An “interestingness” measure such as the Laplacian is used to refine the patch for scale and position. If an actual maximum is found within the patch limits, it is considered the patch center. Otherwise, the center point of the patch is considered its center. The SIFT descriptor for this patch is then calculated centered on the center.
4.2. CNN Algorithms
5. Experiments and Results
5.1. Experimental Protocols
5.2. Results and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wiemers, M.; Fiedler, K. Does the DNA barcoding gap exist?—A case study in blue butterflies (Lepidoptera: Lycaenidae). Front. Zool. 2007, 4, 8. [Google Scholar] [CrossRef] [PubMed]
- Scoble, M.J. Geometrid Moths of the World: A Catalogue; Apollo Books; CSIRO Publishing: Collingwood, VIC, Australia, 1999; ISBN 8788757293. [Google Scholar]
- Lieske, E.; Robert, M. Coral Reef Fishes: Indo-Pacific and Caribbean; Princeton University Press: Princeton, NJ, USA, 2001; ISBN 9780691089959. [Google Scholar]
- Melvin, S.D.; Wilson, S.P. The effects of environmental pollutants on complex fish behaviour: Integrating behavioural and physiological indicators of toxicity. Aquat. Toxicol. 2004, 68, 369–392. [Google Scholar]
- Borenstein, E.; Ullman, S. Learning to Segment. In Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; pp. 315–328. [Google Scholar]
- Magee, D.; Boyle, R. Detecting Lameness in Livestock using Re-sampling Condensation and Multi-stream Cyclic Hidden Markov Models. Image Vis. Comput. 2002, 20, 581–594. [Google Scholar] [CrossRef]
- Lazebnik, S.; Schmid, C.; Ponce, J. Semi-local Affine Parts for Object Recognition. In British Machine Vision Conference (BMVC’04); The British Machine Vision Association: Durham, UK, 2004; pp. 779–788. [Google Scholar]
- Wang, J.; Markert, K.; Everingham, M. Learning Models for Object Recognition from Natural Language Descriptions. In British Machine Vision Conference (BMVC’04); The British Machine Vision Association: Durham, UK, 2009; pp. 2.1–2.11. [Google Scholar]
- Zambanini, S.; Kavelar, A.; Kampel, M. Classifying Ancient Coins by Local Feature Matching and Pairwise Geometric Consistency Evaluation. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 3032–3037. [Google Scholar]
- Parikh, D. Discovering Localized Attributes for Fine-grained Recognition. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3474–3481. [Google Scholar]
- Khamis, S.; Lampert, C. CoConut: Co-Classification with Output Space Regularization. In Proceedings of the British Machine Vision Conference 2014, Nottingham, UK, 1 September 2014. [Google Scholar]
- Anwar, H.; Zambanini, S.; Kampel, M. Encoding Spatial Arrangements of Visual Words for Rotation-invariant Image Classification. In Proceedings of the German Conference on Pattern Recognition, Munich, Germany, 12–14 September 2014; pp. 407–416. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Zhao, R.; Li, C.; Ye, S.; Fang, X. Butterfly recognition based on faster R-CNN. J. Phys. Conf. Ser. 2019, 1176, 032048. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 630–645. [Google Scholar]
- Almryad, A.S.; Kutucu, H. Automatic identification for field butterflies by convolutional neural networks. Eng. Sci. Technol. Int. J. 2020, 23, 189–195. [Google Scholar] [CrossRef]
- Lin, Z.; Jia, J.; Gao, W.; Huang, F. Fine-grained visual categorization of butterfly specimens at sub-species level via a convolutional neural network with skip-connections. Neurocomputing 2020, 384, 295–313. [Google Scholar] [CrossRef]
- Nie, L.; Wang, K.; Fan, X.; Gao, Y. Fine-grained butterfly recognition with deep residual networks: A new baseline and benchmark. In Proceedings of the 2017 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Sydney, NSW, Australia, 29 November–1 December 2017; pp. 1–7. [Google Scholar]
- Carvajal, J.A.; Romero, D.G.; Sappa, A.D. Fine-tuning based deep convolutional networks for lepidopterous genus recognition. In Proceedings of the Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2016; pp. 467–475. [Google Scholar]
- Chang, Q.; Qu, H.; Wu, P.; Yi, J. Fine-Grained Butterfly and Moth Classification Using Deep Convolutional Neural Networks; Rutgers University: New Brunswick, NJ, USA, 2017. [Google Scholar]
- Xin, D.; Chen, Y.W.; Li, J. Fine-Grained Butterfly Classification in Ecological Images Using Squeeze-And-Excitation and Spatial Attention Modules. Appl. Sci. 2020, 10, 1681. [Google Scholar] [CrossRef]
- Joly, A.; Goëau, H.; Glotin, H.; Spampinato, C.; Bonnet, P.; Vellinga, W.; Planque, R.; Rauber, A.; Fisher, R.; Müller, H. LifeCLEF 2014: Multimedia life species identification challenges. In Proceedings of the International Conference of the Cross-Language Evaluation Forum for European Languages 2014, Sheffield, UK, 15–18 September 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Huang, P.X.; Boom, B.J.; Fisher, R.B. GMM improves the reject option in hierarchical classification for fish recognition. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014; pp. 371–376. [Google Scholar]
- Siddiqui, S.A.; Salman, A.; Malik, M.I.; Shafait, F.; Mian, A.; Shortis, M.R.; Harvey, E.S. Automatic fish species classification in underwater videos: Exploiting pre-trained deep neural network models to compensate for limited labelled data. ICES J. Mar. Sci. 2018, 75, 374–389. [Google Scholar] [CrossRef]
- Villon, S.; Mouillot, D.; Chaumont, M.; Darling, E.S.; Subsol, G.; Claverie, T.; Villéger, S. A deep learning method for accurate and fast identification of coral reef fishes in underwater images. Ecol. Inform. 2018, 48, 238–244. [Google Scholar] [CrossRef]
- Iqbal, M.A.; Wang, Z.; Ali, Z.A.; Riaz, S. Automatic Fish Species Classification Using Deep Convolutional Neural Networks. Wirel. Pers. Commun. 2019, 116, 1043–1053. [Google Scholar] [CrossRef]
- Zheng, H.; Fu, J.; Zha, Z.J.; Luo, J. Looking for the devil in the details: Learning trilinear attention sampling network for fine-grained image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5012–5021. [Google Scholar]
- Beuth, F.; Schlosser, T.; Friedrich, M.; Kowerko, D. Improving automated visual fault detection by combining a biologically plausible model of visual attention with deep learning. In Proceedings of the IECON 2020 The 46th Annual Conference of the IEEE Industrial Electronics Society, Singapore, 18–21 October 2020; pp. 5323–5330. [Google Scholar]
- Beuth, F. Visual Attention in Primates and for Machines-Neuronal Mechanisms. Ph.D. Thesis, Technische Universität Chemnitz, Chemnitz, Germany, 2019. [Google Scholar]
- Anwar, H.; Zambanini, S.; Kampel, M. Invariant image-based species classification of butterflies and reef fish. In Proceedings of the Machine Vision of Animals and their Behaviour (MVAB), Swansea, UK, 7–10 September 2015; pp. 5.1–5.8. [Google Scholar]
- Mikulík, A.; Perdoch, M.; Chum, O.; Matas, J. Learning a Fine Vocabulary. In Proceedings of the 11th European Conference on Computer Vision (ECCV), Part III, Heraklion, Greece, 5–11 September 2010; pp. 1–14. [Google Scholar]
- Mikulík, A.; Perdoch, M.; Chum, O.; Matas, J. Learning Vocabularies over a Fine Quantization. Int. J. Comput. Vision 2013, 103, 163–175. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vision 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Hassner, T.; Mayzels, V.; Zelnik-Manor, L. On SIFTs and their Scales. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Tuytelaars, T. Dense Interest Points. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2281–2288. [Google Scholar]
- Mikolajczyk, K.; Tuytelaars, T.; Schmid, C.; Zisserman, A.; Matas, J.; Schaffalitzky, F.; Kadir, T.; Gool, L.V. A Comparison of Affine Region Detectors. Int. J. Comput. Vision 2005, 65, 43–72. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Chen, Y.; Li, J.; Xiao, H.; Jin, X.; Yan, S.; Feng, J. Dual path networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4467–4475. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Vedaldi, A.; Fulkerson, B. VLFeat: An Open and Portable Library of Computer Vision Algorithms. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1469–1472. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CNN Methods | Versions | No. of Features | CNN Methods | Versions | No. of Features |
|---|---|---|---|---|---|
| AlexNet [39] | - | 4096 | ResNet [40] | 152 | 2048 |
| DenseNet [41] | 201 | 1920 | 101 | 2048 | |
| 169 | 1664 | 50 | 2048 | ||
| 161 | 2208 | 34 | 512 | ||
| 121 | 1024 | 18 | 512 | ||
| DPN [42] | 131 | 2688 | VGG [15] | 19 | 4096 |
| 98 | 2688 | 16 | 4096 | ||
| 68 | 832 | 13 | 4096 | ||
| Inception [43] | v4 | 1536 | SqueezeNet [44] | 1_1 | 512 |
| v3 | 2048 | 1_0 | 512 |
| Datasets | ||||
|---|---|---|---|---|
| Butterflies | ReefFish | |||
| Algorithms | Accuracy (90–10) | Accuracy (80–20) | Accuracy (90–10) | Accuracy (80–20) |
| DoG | 82.12 ± 0.83 | 80.64 ± 1.43 | 60.04 ± 2.04 | 58.74 ± 1.75 |
| DIP | 81.75 ± 1.87 | 80.15 ± 1.28 | 81.40 ± 1.10 | 79.43 ± 0.70 |
| Mutiscale | 86.25 ± 1.25 | 84.72 ± 1.52 | 88.75 ± 1.80 | 86.72 ± 1.37 |
| SLS | 84.02 ± 1.37 | 82.75 ± 1.82 | 87.80 ± 1.60 | 84.81 ± 1.25 |
| Butterflies Dataset | ReefFish Dataset | |||
|---|---|---|---|---|
| Architectures | Accuracy (90–10) | Accuracy (80–20) | Accuracy (90–10) | Accuracy (80–20) |
| AlexNet | 90.54 ± 1.11 | 89.94 ± 1.74 | 89.99 ± 0.95 | 91.44 ± 0.75 |
| DenseNet201 | 95.27 ± 0.90 | 95.80 ± 0.66 | 96.08 ± 0.55 | 96.34 ± 0.40 |
| DenseNet169 | 95.81 ± 1.24 | 95.22 ± 0.36 | 95.14 ± 1.66 | 95.46 ± 1.07 |
| DenseNet161 | 95.66 ± 0.86 | 96.27 ± 0.90 | 94.93 ± 0.93 | 95.98 ± 0.55 |
| DenseNet121 | 95.89 ± 1.09 | 96.08 ± 0.99 | 94.36 ± 0.88 | 95.33 ± 0.56 |
| DPN131 | 89.53 ± 1.32 | 89.59 ± 0.83 | 88.98 ± 1.06 | 90.37 ± 0.15 |
| DPN98 | 90.08 ± 1.06 | 89.94 ± 1.00 | 89.77 ± 1.04 | 90.65 ± 0.45 |
| DPN68 | 91.86 ± 2.51 | 91.73 ± 0.82 | 91.85 ± 1.11 | 93.29 ± 0.67 |
| Inceptionv4 | 92.25 ± 1.57 | 92.04 ± 0.73 | 90.81 ± 1.65 | 92.17 ± 0.83 |
| Inceptionv3 | 93.02 ± 1.10 | 93.05 ± 0.91 | 94.24 ± 0.47 | 94.33 ± 0.67 |
| ResNet152 | 94.96 ± 1.30 | 94.91 ± 0.23 | 95.56 ± 1.48 | 95.43 ± 0.32 |
| ResNet101 | 94.88 ± 0.62 | 94.95 ± 0.94 | 94.36 ± 1.75 | 94.73 ± 0.66 |
| ResNet50 | 93.95 ± 1.40 | 94.64 ± 0.38 | 94.36 ± 1.03 | 94.62 ± 0.32 |
| ResNet34 | 93.57 ± 1.03 | 93.71 ± 0.99 | 92.79 ± 2.12 | 93.73 ± 0.38 |
| ResNet18 | 93.88 ± 0.62 | 94.45 ± 1.00 | 93.16 ± 1.31 | 93.55 ± 0.83 |
| SqueezeNet1_1 | 94.34 ± 1.17 | 93.98 ± 0.79 | 94.10 ± 1.01 | 94.02 ± 0.71 |
| SqueezeNet1_0 | 94.26 ± 0.62 | 93.83 ± 1.17 | 94.26 ± 0.72 | 94.57 ± 1.02 |
| VGG19 | 89.46 ± 1.82 | 90.21 ± 1.00 | 88.67 ± 1.54 | 89.61 ± 0.91 |
| VGG16 | 92.09 ± 1.64 | 93.20 ± 0.86 | 89.30 ± 1.29 | 90.16 ± 0.73 |
| VGG13 | 92.17 ± 2.21 | 93.13 ± 0.78 | 91.07 ± 0.10 | 91.33 ± 0.44 |
| VGG11 | 92.95 ± 0.90 | 92.86 ± 1.19 | 92.48 ± 0.53 | 92.04 ± 0.66 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anwar, A.; Anwar, H.; Anwar, S. Towards Low-Cost Classification for Novel Fine-Grained Datasets. Electronics 2022, 11, 2701. https://doi.org/10.3390/electronics11172701
Anwar A, Anwar H, Anwar S. Towards Low-Cost Classification for Novel Fine-Grained Datasets. Electronics. 2022; 11(17):2701. https://doi.org/10.3390/electronics11172701
Chicago/Turabian StyleAnwar, Abbas, Hafeez Anwar, and Saeed Anwar. 2022. "Towards Low-Cost Classification for Novel Fine-Grained Datasets" Electronics 11, no. 17: 2701. https://doi.org/10.3390/electronics11172701
APA StyleAnwar, A., Anwar, H., & Anwar, S. (2022). Towards Low-Cost Classification for Novel Fine-Grained Datasets. Electronics, 11(17), 2701. https://doi.org/10.3390/electronics11172701