1. Introduction
Skin cancer is a widespread disease, and a particularly lethal instance of this disease is melanoma. According to statistics, if melanoma patients are not diagnosed at an early stage, the survival rate is only 24% [
1]. However, if they are diagnosed soon enough, the survival rate can exceed 95% [
2]. Although melanoma usually occurs on the skin surface, the accuracy of its clinical diagnosis with unaided eyes is only approximately 60% [
3], which means that many potentially curable melanomas are not detected until a terminal stage is reached. Fortunately, the invention of dermoscopy effectively alleviates the above problems. Dermoscopy is a non-invasive imaging technique that eliminates surface reflection from the skin, allowing for deeper visual enhancement. Still, without the guidance of professional doctors, dermoscopic images provide little help to the diagnosis [
4]. In addition, artificially analyzing whether a skin lesion belongs to melanoma is costly in terms of time and energy, further leading to misdiagnoses and missed diagnoses.
In the past few years, computer-aided diagnosis (CAD) has brought vitality into the diagnosis of melanoma. CAD in dermatology involves five fundamental steps: image acquisition, data processing, lesion segmentation, feature extraction, and lesion recognition. Each step is essential inside a CAD system. Among them, lesion segmentation is a crucial step concerning subsequent treatments because the segmentation results can provide rich morphological information of the lesion area to reduce the probability of misdiagnosis. Owing to the variety of sizes and shapes, fuzzy boundaries, unclear textures, hairs, bubbles occlusion, etc. [
5], segmentation results based on traditional methods such as histogram threshold processing and support vector machine have not been satisfactory.
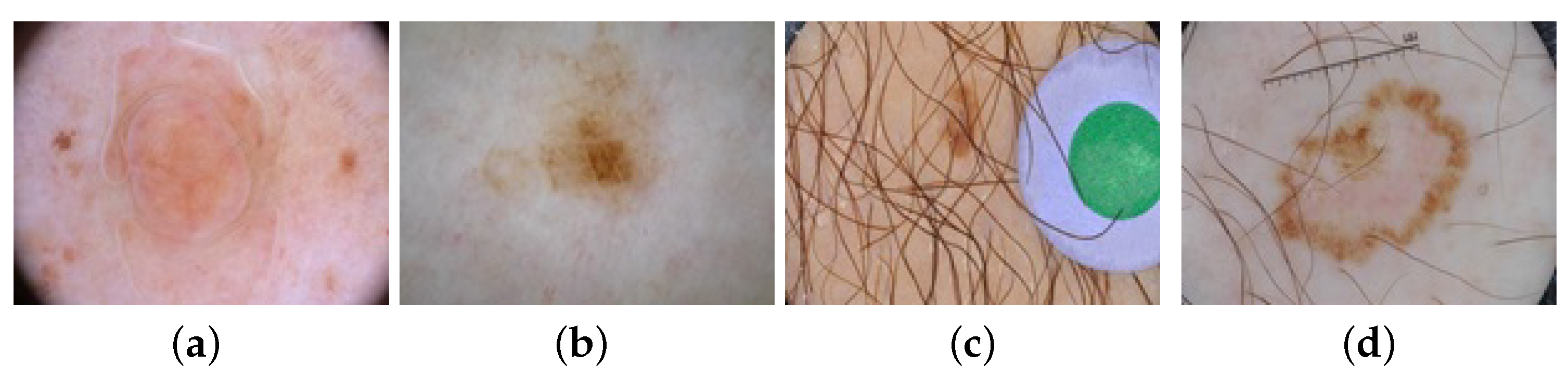
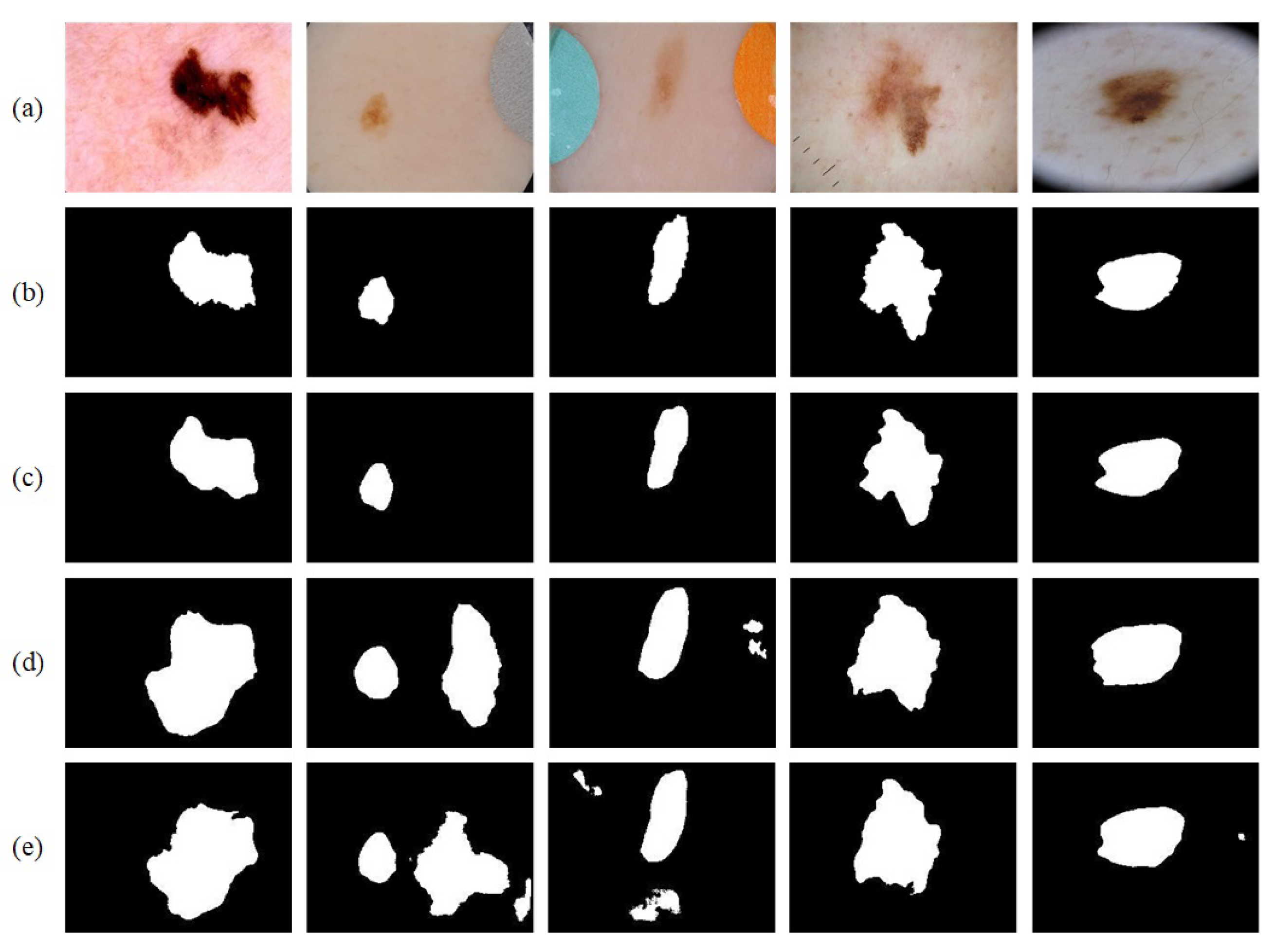
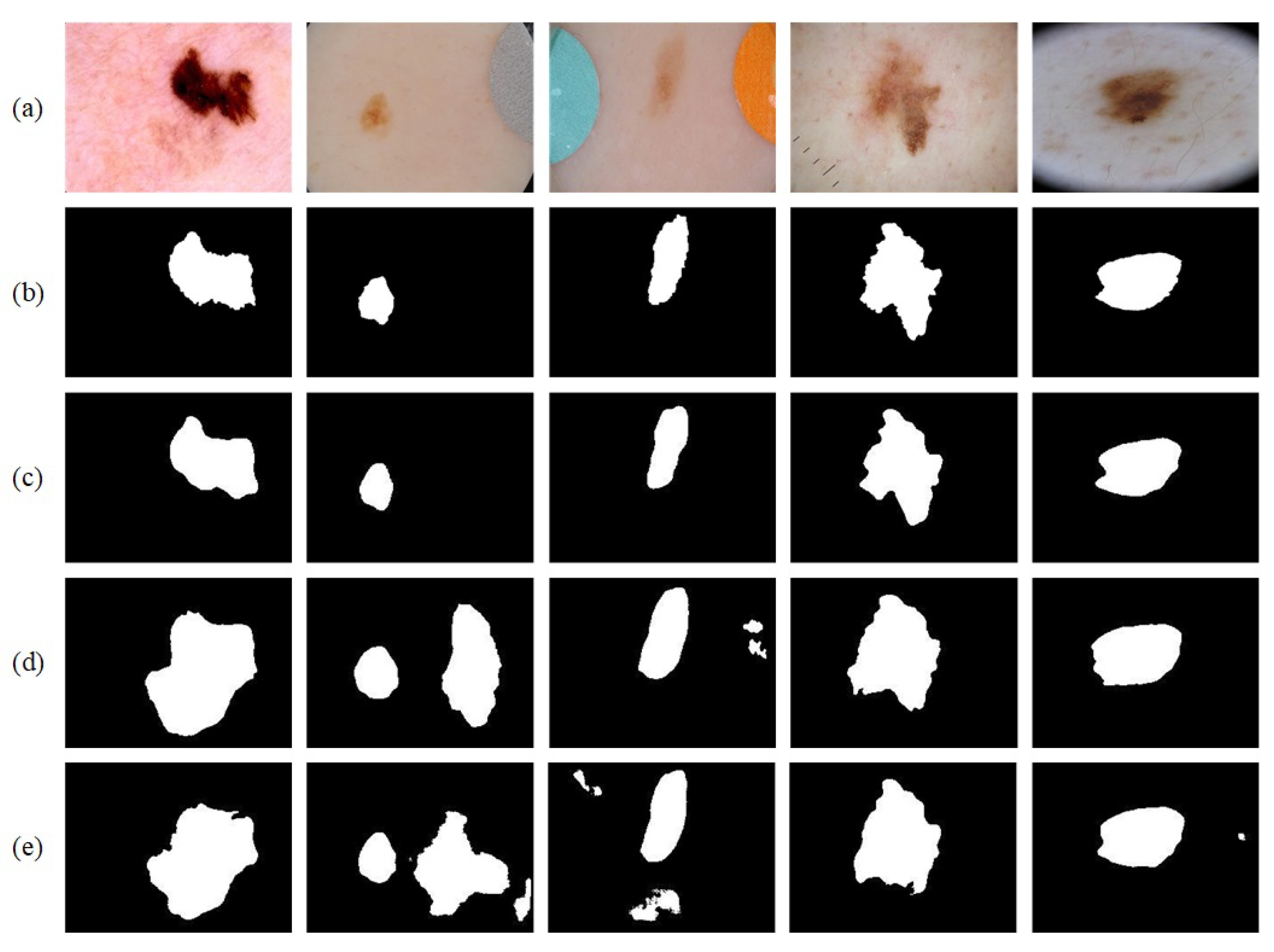
Figure 1 shows several difficult-segment dermoscopic images with external interferences.
In previous years, non-iterative artificial neural networks were popular in the field of image processing, including medical image processing. Izonin et al. [
6] designed a new learning-based image super-resolution method. In their study, the process of increasing the resolution of video frames or images from a set according is based on the weight coefficients of synaptic connections. These coefficients are obtained by the learning neural-like structure on a pair of images of low and high resolution. Tkachenko et al. [
7] proposed the solutions of a problem of changing image resolution based on the use of computational intelligence means, which were constructed using the new neuro-paradigm—Geometric Transformations Model.
Nowadays, convolutional neural networks (CNNs) have become the dominant trend for skin lesion segmentation. The commonly used CNN has a U-shaped encoder–decoder structure. In this structure, an encoder is used to extract image features, while a decoder is often applied to restore extracted features to the original image size and output the final segmentation results. To achieve more satisfactory skin lesion segmentation, the researchers have introduced a considerable amount of effective mechanisms that can enhance the feature learning into the encoder–decoder structure. In 2016, Yu et al. [
8] first segmented skin lesion images with a deep residual network. Inspired by PSPNet [
9], Sarker et al. [
10] proposed SLSDeep. They adopted ResNet50 as the encoding path, and a pyramid pooling module was placed at the bottom to extract multi-scale semantic information. Tong et al. [
11] developed ASCU-Net, a network integrating a triple attention mechanism, including a new attention gate, a spatial attention module, and a channel attention module. They were put into the decoding path of U-shaped network. Qu et al. [
12] designed ResDense U-Net by integrating ResNet [
13] and DenseNet [
14]. Inspired by ACNet [
15], traditional 3 × 3 convolution kernels were all replaced by asymmetric convolution kernels. Simultaneously, residual modules were introduced at the skip connection to alleviate the semantic gap between the two feature maps from the encoding and decoding paths. Dai et al. [
16] proposed a novel multi-scale residual encoding–decoding network called Ms RED. In Ms RED, a multi-scale residual encoding fusion module was employed as the encoder, and a multi-scale residual decoding fusion module was applied as the decoder to adaptively fuse multi-scale features.
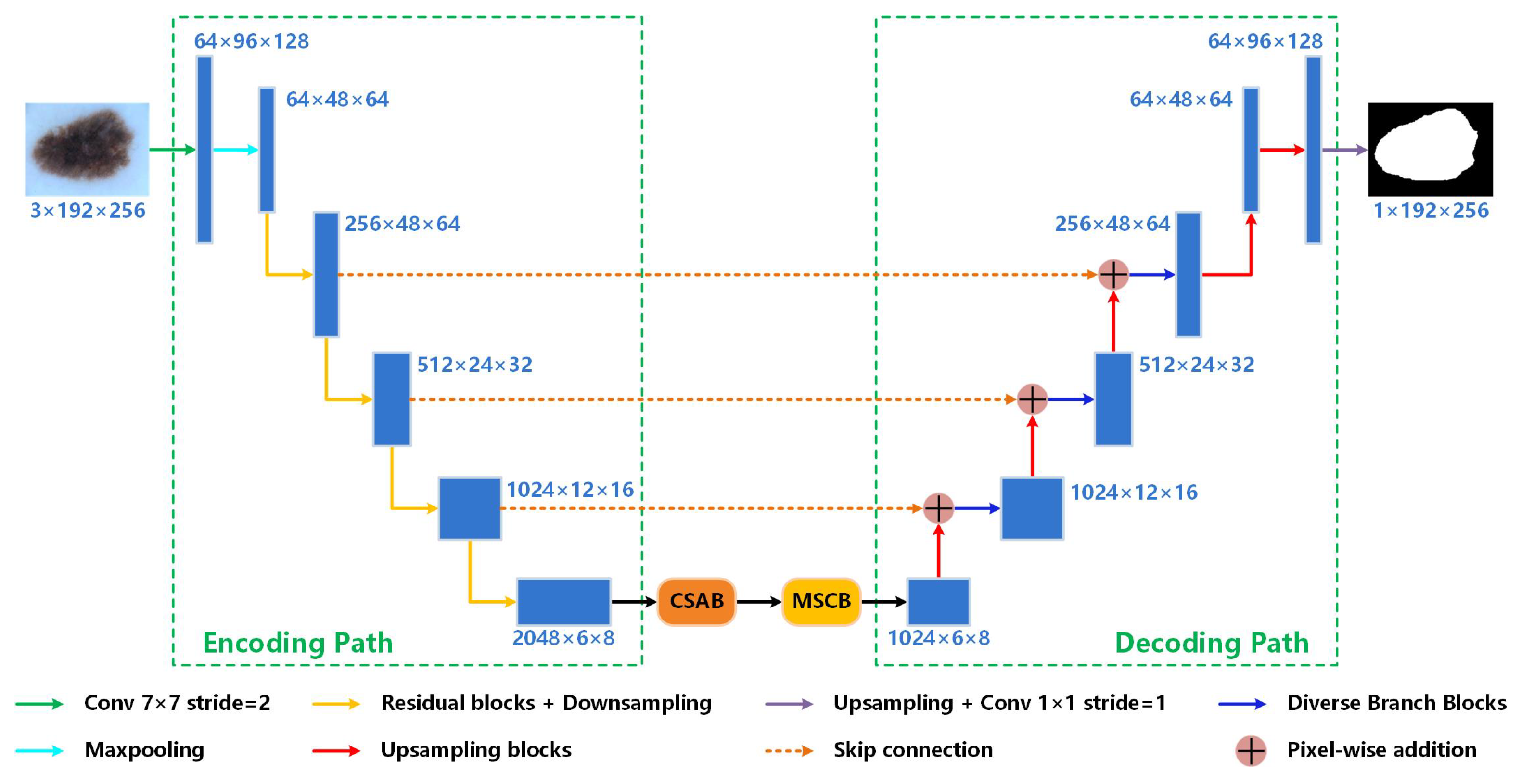
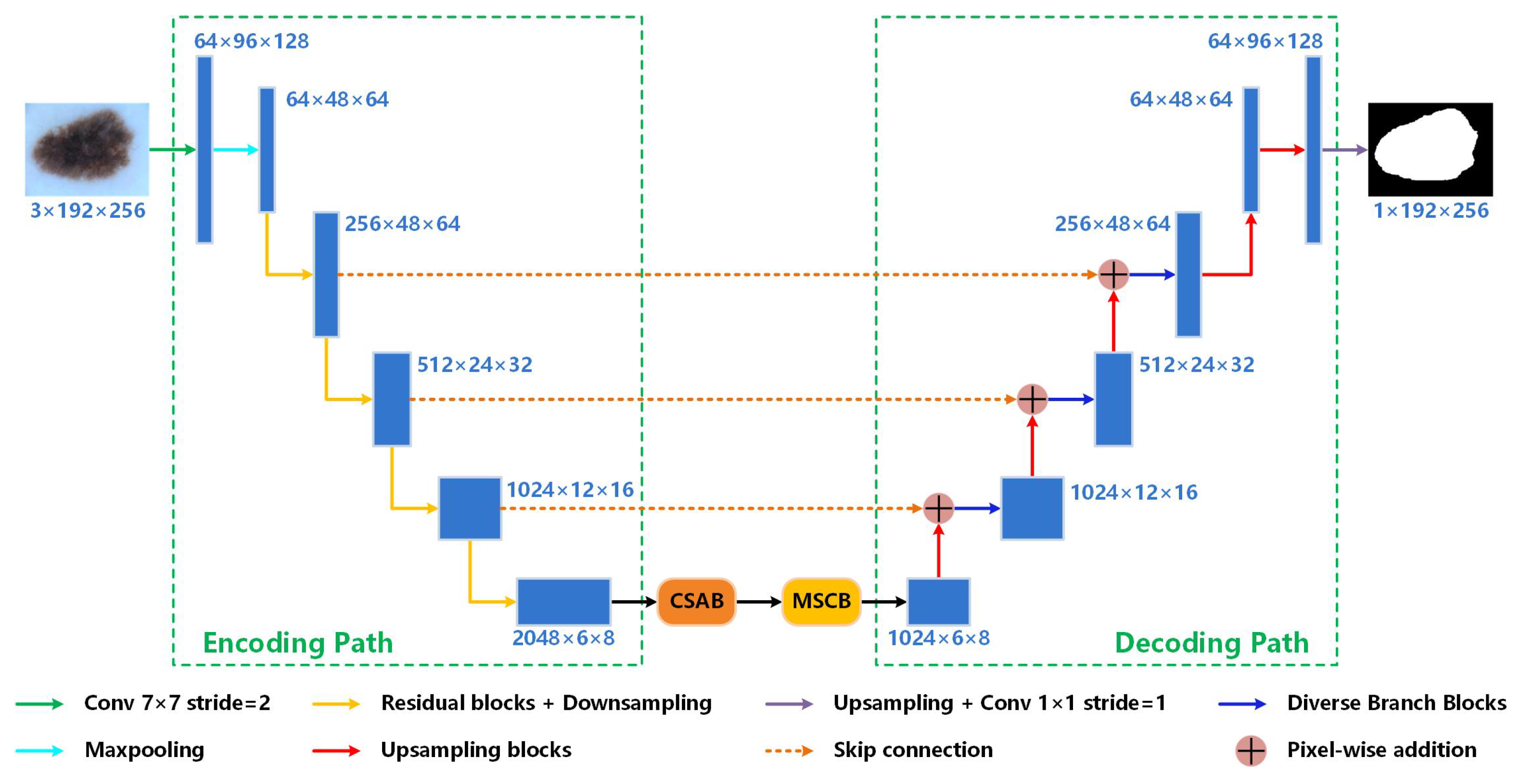
Previous methods have greatly contributed to skin lesion segmentation. However, challenges such as irregular shapes, hair covering, and low contrast in the surrounding can be better tackled. To efficiently acquire more accurate segmentation results, we propose Res-CDD-Net for skin lesion segmentation. The network is designed based on U-shaped encoder–decoder structure and we introduce some novel mechanisms to further enhance the performance and save training time.
For the encoding path, we adopt ResNeXt50 [
17] pre-trained on the ImageNet dataset to capture more feature information and make the whole network more efficient. For skin lesion datasets containing a small number of images, pre-loading weights trained on a general dataset is helpful to improve the segmentation accuracy. The feature extraction capacity of ResNeXt50 is enhanced compared to ResNet50 [
13] (the error rates are reduced by 2–3% in ImageNet1-K and ImageNet5-K classification tasks). In addition, the topology of ResNeXt is more consistent with GPU-hardware design principles. This can accelerate the reasoning speed during training.
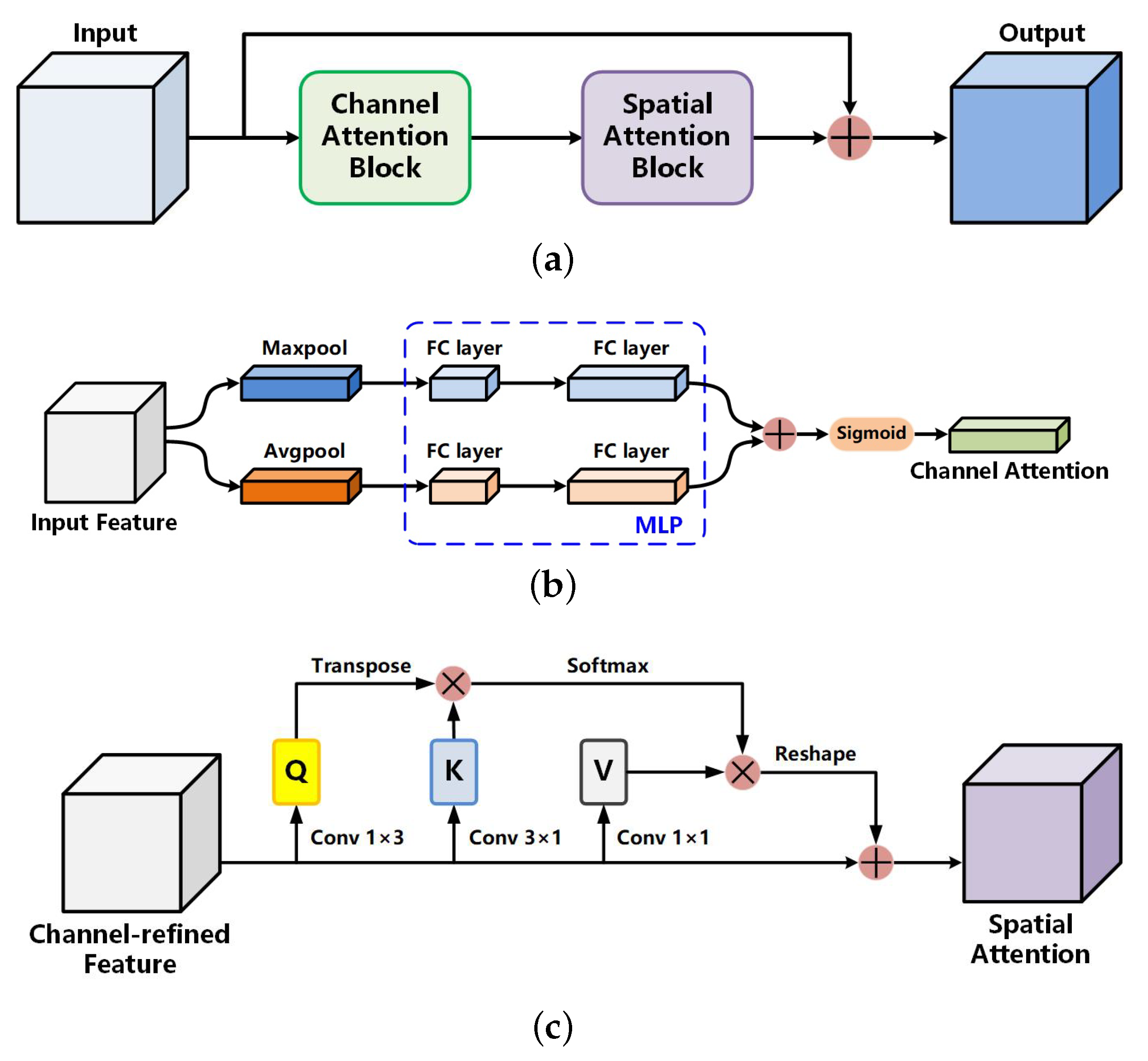
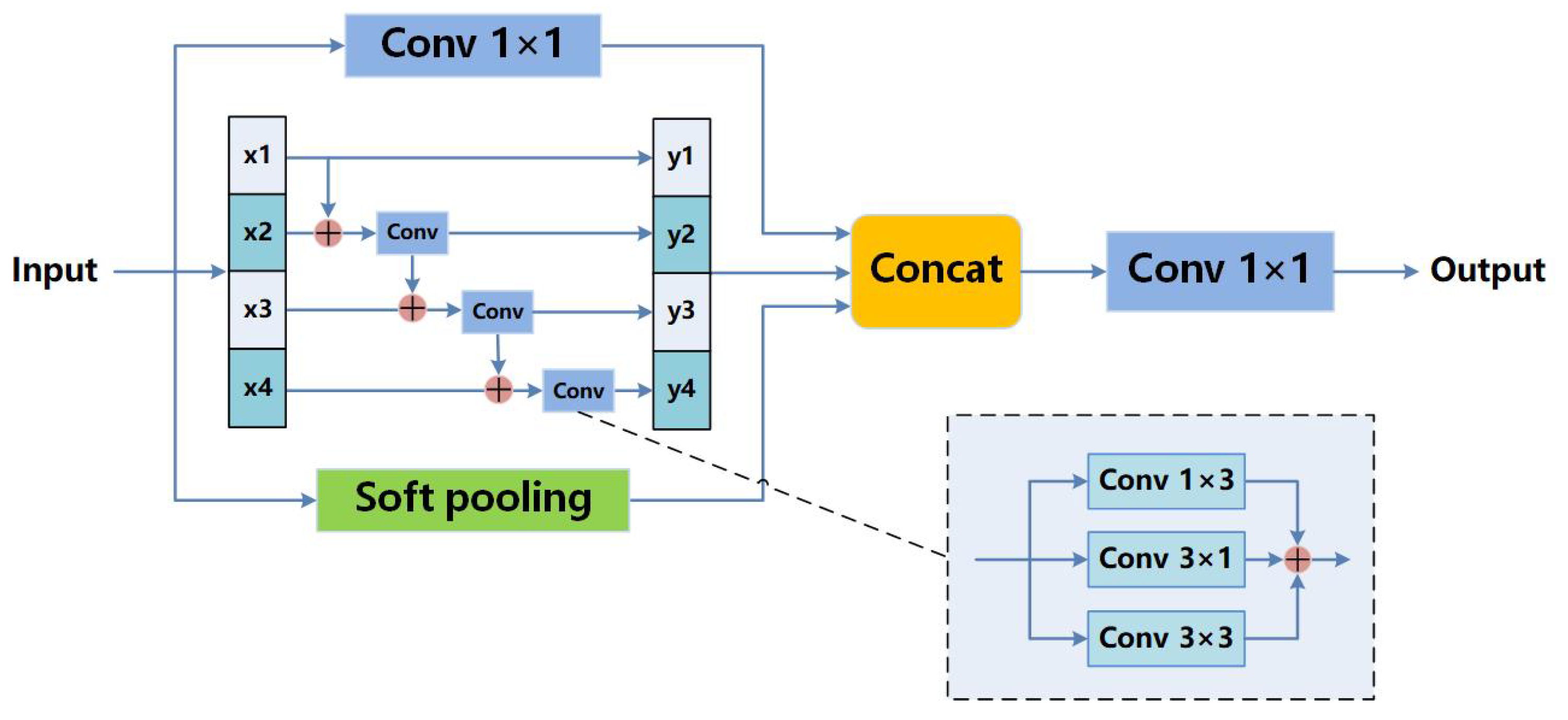
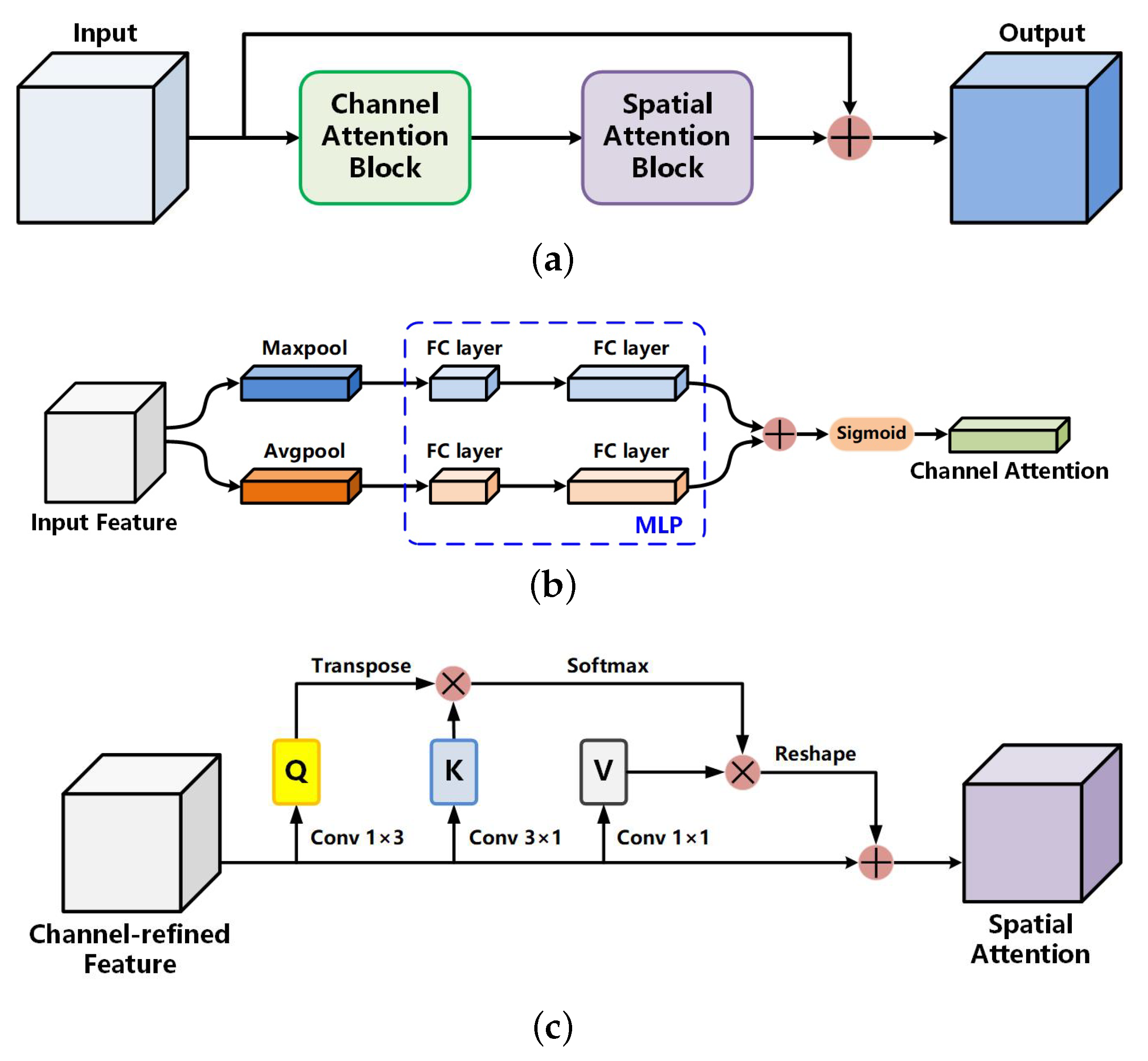
Between the encoding and decoding paths, we use a channel and spatial attention block (CSAB) and a multi-scale capture block (MSCB). The CSAB combines channel and spatial attention to enhance the lesion area and compress irrelevant features from hairs and bubbles while maintaining a small overhead. In addition, the CSAB makes the network more sensitive to the edge of the lesion. The boundary with weak contrast can be recognized more accurately. The MSCB captures the image features in a multi-scale way to extract the global and local information of skin lesions. Instead of using atrous convolution to increase the receptive field, we adopt hierarchical residual-like connections within a single residual block. Multi-scale features flows at a granular level and the range of receptive fields will be increased through the residual block. In this way, the MSCB solves the problem of information loss in the atrous convolution. We also introduce soft pooling as a branch of MSCB. Soft pooling combines the advantages of max pooling and average pooling. Compared with traditional average pooling branch in widely used ASPP, the softpooling branch can retain more semantic information. The serial placement of the two modules can effectively extract features of skin lesions with different sizes, shapes, edges, and colors.
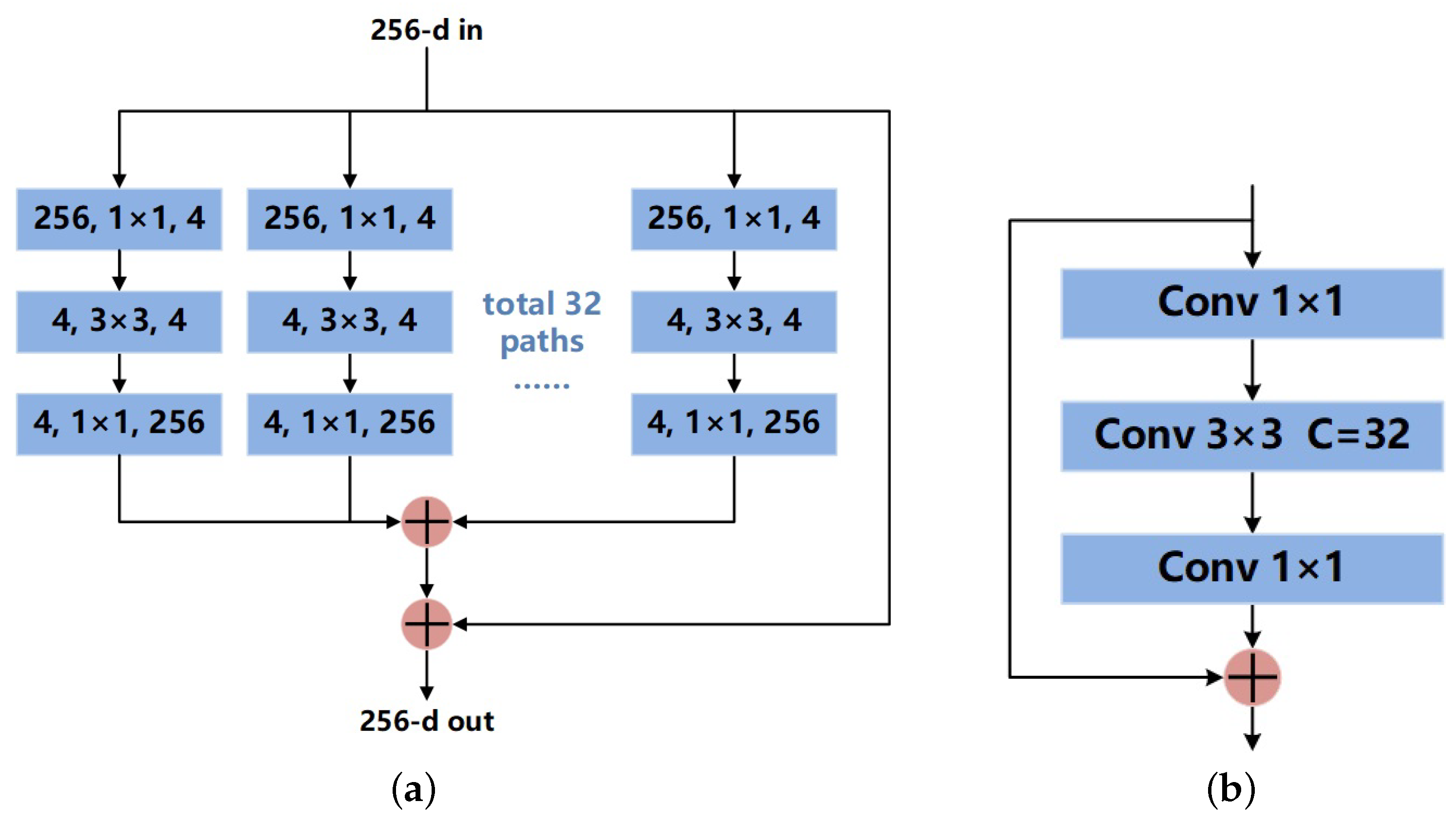
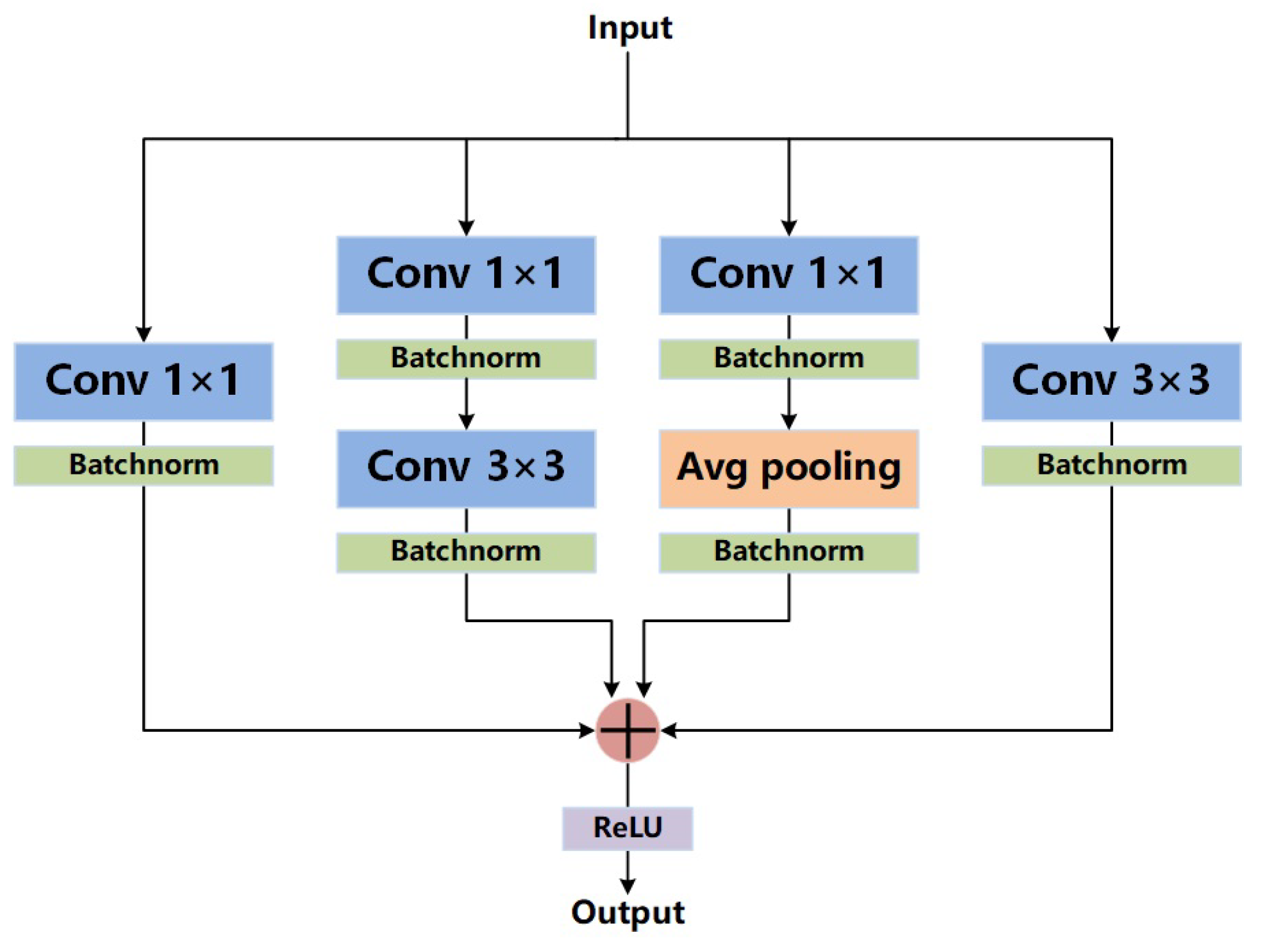
We optimize the decoding path with diverse branch blocks (DBBs) [
18] to enhance the feature restoration capacity. Many previous studies focused on improving the encoding path, skip connections, and the bottom of the network. Only a few improvements were made to the decoding path. In our study, we replace every traditional 3 × 3 convolution by a DBB. Inspired by the Inception [
19] module, a DBB contains four branches, including average pooling and multi-scale convolution. Each branch contains different receptive fields and computational complexity, which can greatly enrich the feature space of the whole decoding path.
Compared with state-of-the-art medical image segmentation networks and skin lesion segmentation methods, Res-CDD-Net achieves superior performance on ISIC-2016 [
20], ISIC-2017 [
21], and PH2 [
22] skin lesion datasets. Moreover, its training is much faster than other approaches. Only 2 h are approximately required on ISIC-2017. Overall, the main contributions of this study can be summarized as follows:
(1) We propose a U-shaped network combined attention and multi-scale mechanisms to enhance the skin lesion segmentation accuracy. These two modules overcome the challenges in dermoscopic imaging.
(2) The decoding path of the network is optimized by DBBs to make the network robust and effective.
(3) A new loss function is adopted to alleviate the affect of the uneven proportion between positive and negative samples.
(4) Comprehensive experiments show that our network achieves outstanding performance and fast training process compared with state-of-art methods.
The remainder of the paper is structured as follows:
Section 2 reviews previous studies related to the methods we adopted.
Section 3 provides detailed information about the proposed Res-CDD-Net.
Section 4 focuses on the experiments with Res-CDD-Net by comparing this network with other state-of-the-art methods.
Section 5 is devoted to discussion, and
Section 6 concludes the paper.
5. Discussion
Rapid and accurate skin lesion segmentation greatly contributes to subsequent treatments of melanoma. Traditional methods cost time and energy. They are heavily reliant on tuning a large number of parameters. Based on this fact, we designed a U-shaped encoder–decoder network named Res-CDD-Net. First, the pre-trained ResNeXt50 network was adopted as the encoding path to provide abundant image features for the network. Thus, higher evaluation indexes can be achieved at the beginning of training and the inference of the network can be accelerated. Second, the CSAB was adopted to provide attention information in both channel and space dimensions to make the features cover the lesion itself, instead of focusing on irrelevant information such as hairs, bubbles, blood vessels, and measurement scales. In addition, the SAB in the module is more sensitive to the blurry edges. It can capture long range dependencies to gain a global contextual view to help the network achieve accurate segmentation for skin lesion boundaries. Third, the MSCB was inserted between the encoding and decoding paths to provide multi-scale semantic information for the network, which is of great help to identify lesions of different sizes. Unlike using large dilation rates in ASPP, the MSCB has a hierarchical residual-like structure to finely extract multi-scale information and avoid extracting excessive useless information. The soft pooling in MSCB can retain more information in the reduced activation maps. Finally, we optimized the decoding path. Traditional 3 × 3 convolutions in the decoding path were equivalently substituted by DBBs, which utilize the associative and distributive laws of convolution. Multi-branch and serial convolutions are thus fused together to greatly advance the feature space of the decoding path. It also enhances the robustness of the network.
In terms of the loss function, we introduced a weighted sum between the commonly adopted binary cross-entropy loss function and the Dice loss function to generate a new loss function so as to solve the problems resulting from an extremely uneven number of positive and negative samples. The performance resulting from using the new loss function is greater than that resulting from using the binary cross-entropy loss function when other configurations remain unaltered.
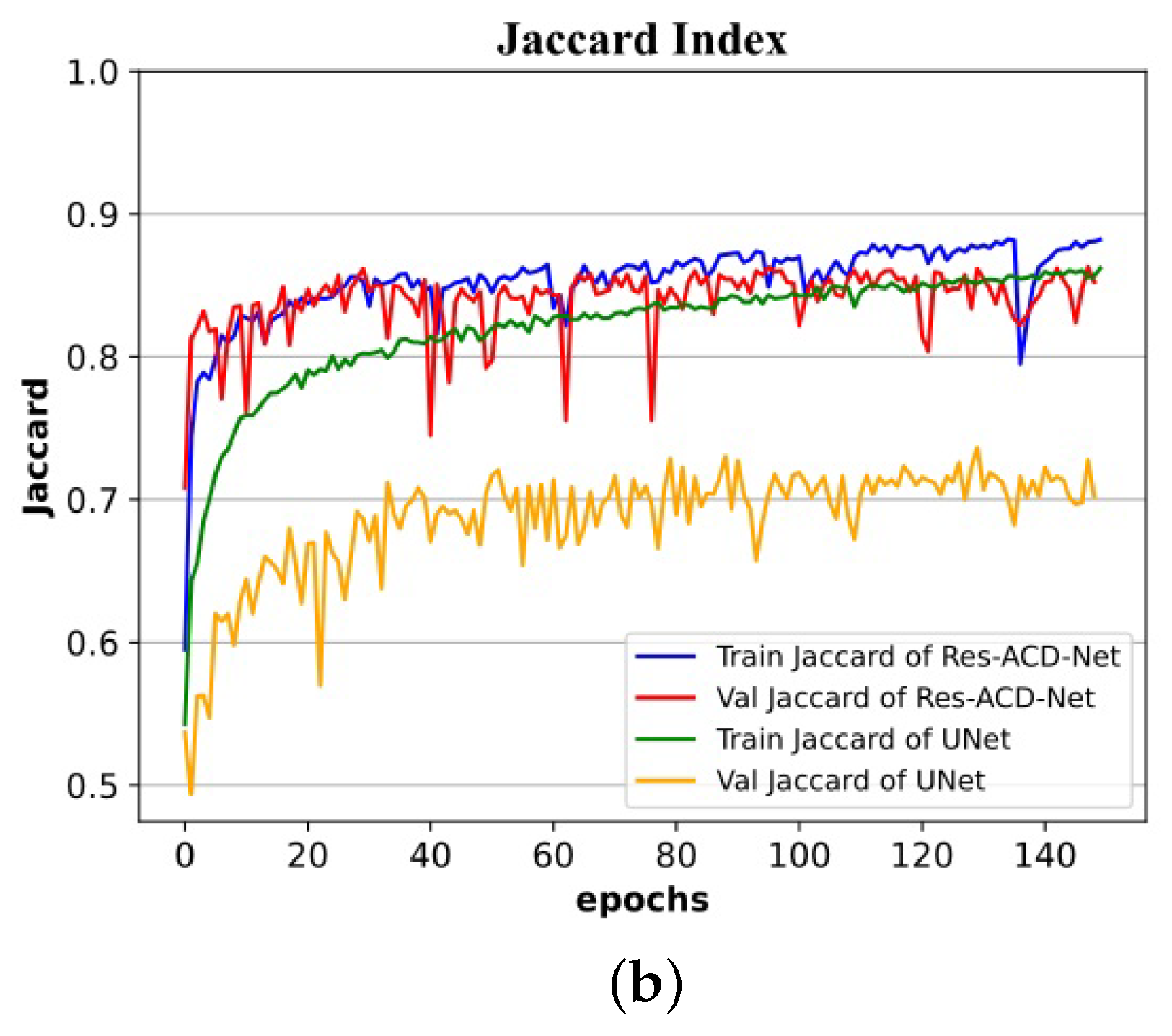
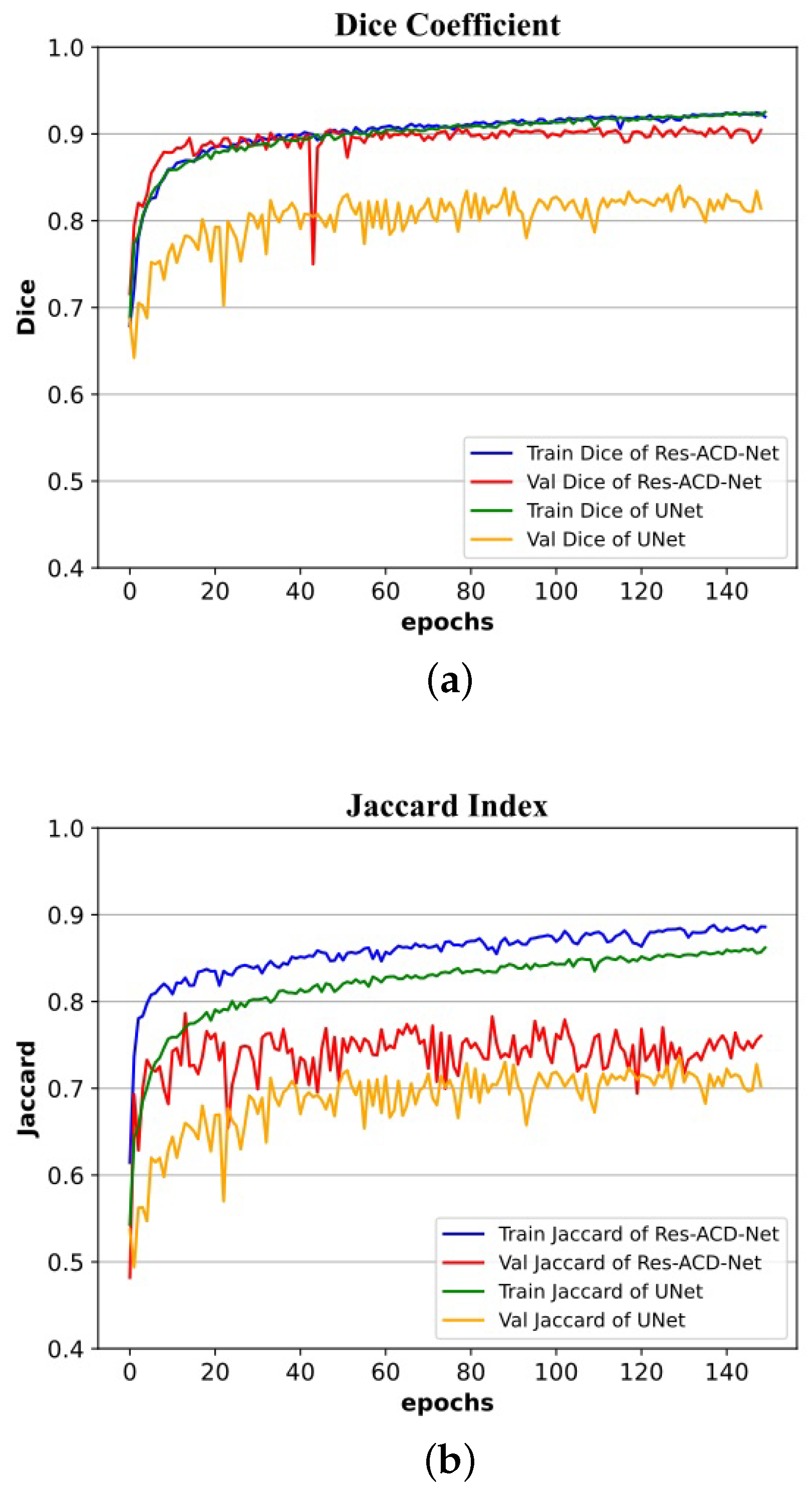
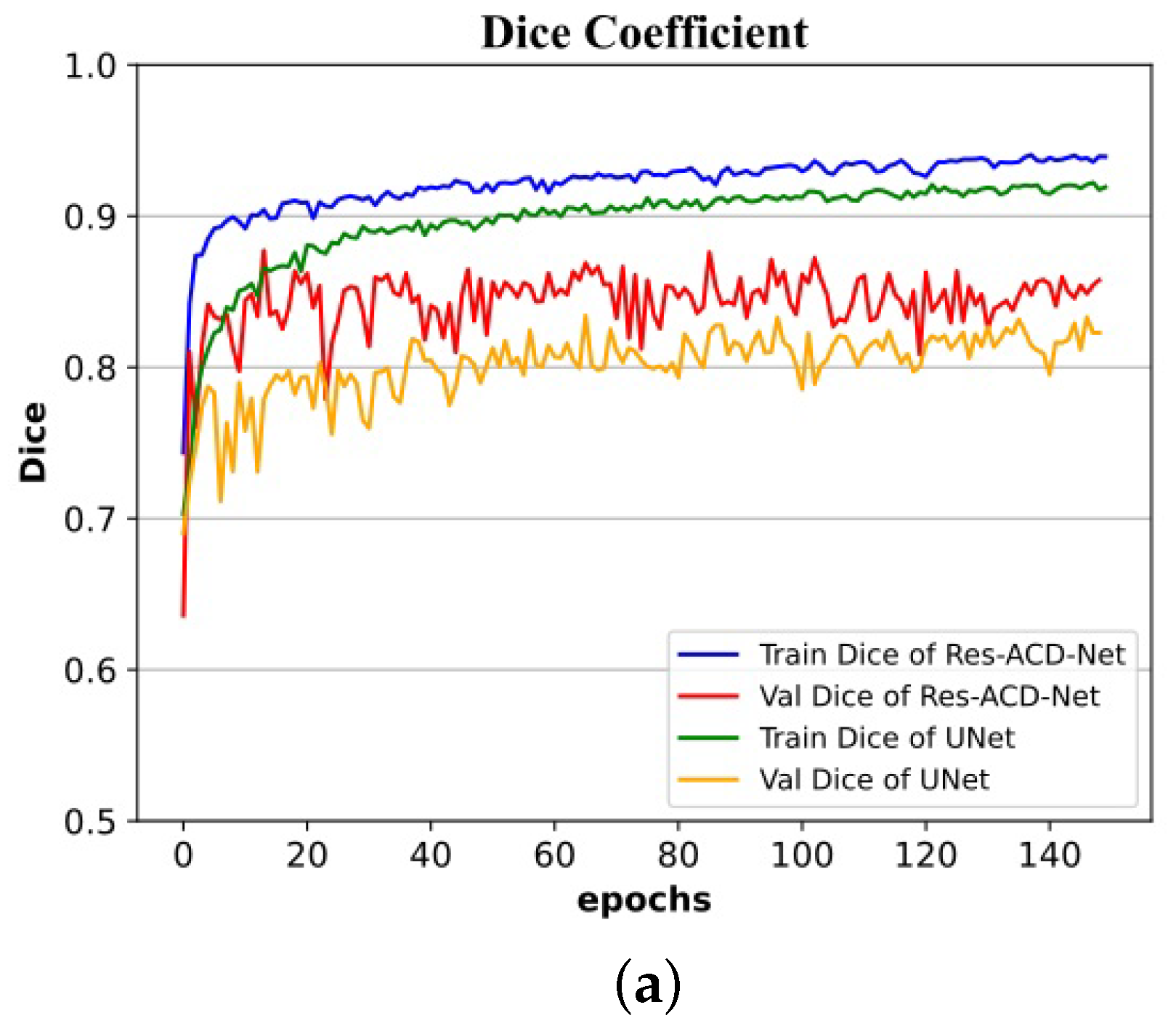
Experiments on the ISIC-2016, ISIC-2017, and PH2 authoritative datasets of skin lesion images present convincing results. Res-CDD-Net exhibits high reliability, high robustness, and strong adaptability to images with more interference. Its performance exceeds most of the mainstream open-source networks, such as CE-Net, BiO-Net, and UTNet. Compared with U-Net, the Dice coefficient is improved by 6.90%, 3.90%, and 4.01% in ISIC-2017, ISIC-2016, and PH2, respectively. The Jaccard index is improved by 10.84%, 5.16%, and 5.54% in ISIC-2017, ISIC-2016, and PH2, respectively. Compared with state-of-the-art skin lesion segmentation approaches reported in recent years, the proposed method is competitive. Above all, Res-CDD-Net has an easy-to-understand structure and the shortest training time while achieving remarkable performance. This jointly constitutes its most remarkable advantage in practical applications.
In future research, we will conduct the following improvement schemes. First, we will fine-tune hyperparameters, such as dropout rate, to further improve the segmentation accuracy through experiments. Second, additional pre-processing techniques such as hair removal and calibration color normalization will be adopted. Third, simple post-processing methods will be explored. These methods will also help to improve the network performance.
6. Conclusions
We propose an advanced end-to-end skin lesion segmentation network called Res-CDD-Net. It combines the pre-trained ResNeXt50 network, CSAB, MSCB, and a decoding path with DBBs. Experimental results on three authoritative skin lesion datasets (ISIC 2017, ISIC 2016, and PH2) show that, compared with most open-source state-of-the-art networks, the proposed network requires less training time to achieve more accurate segmentation results. The Dice coefficient has reached 86.55%, 92.89%, and 92.62% on ISIC 2017, ISIC 2016, and PH2, respectively. The Jaccard index has reached 78.63%, 86.54%, and 85.76% on ISIC 2017, ISIC 2016, and PH2, respectively. The training time on the ISIC2017 dataset is about 2 h, which is significantly lower than the other methods. However, some limitations of the proposed approach should not be neglected. The network is relatively large and computationally expensive. In addition, we only focused on the segmentation task of skin lesion datasets in this study. We can try to apply the proposed approach to other tasks related to medical imaging, such as lung segmentation, brain tumor segmentation, retinal blood vessel segmentation, and nerve optic disc segmentation. We believe that the use of the proposed network for these medical image segmentation tasks, combined with appropriate pre-processing and post-processing operations, can give rise to more advanced segmentation methods.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}