
Service Discovery Method Based on Knowledge Graph and Word2vec

 ,
,
Abstract
:1. Introduction
- We propose a service discovery method based on the knowledge graph and word2vec [18]. This method effectively improves the accuracy of service discovery and can mine deeper relationships between services.
- We obtained all the real services from ProgrammableWeb. Then, the ten categories of services with the largest number of services were selected from the constructed service set as the test set, and a total of 5565 requirement statements were constructed. The results show that our method outperforms existing related methods. To facilitate the reproducibility of our work, we provide an online reproduction package, which is publicly available via https://github.com/zhoujunkai/Service_Axioms (accessed on 11 June 2022).
2. Related Work
2.1. Service Discovery Method Based on Information Retrieval Model Matching
2.2. Semantic-Based Service Discovery Approach
2.3. Cluster-Based Service Discovery Method
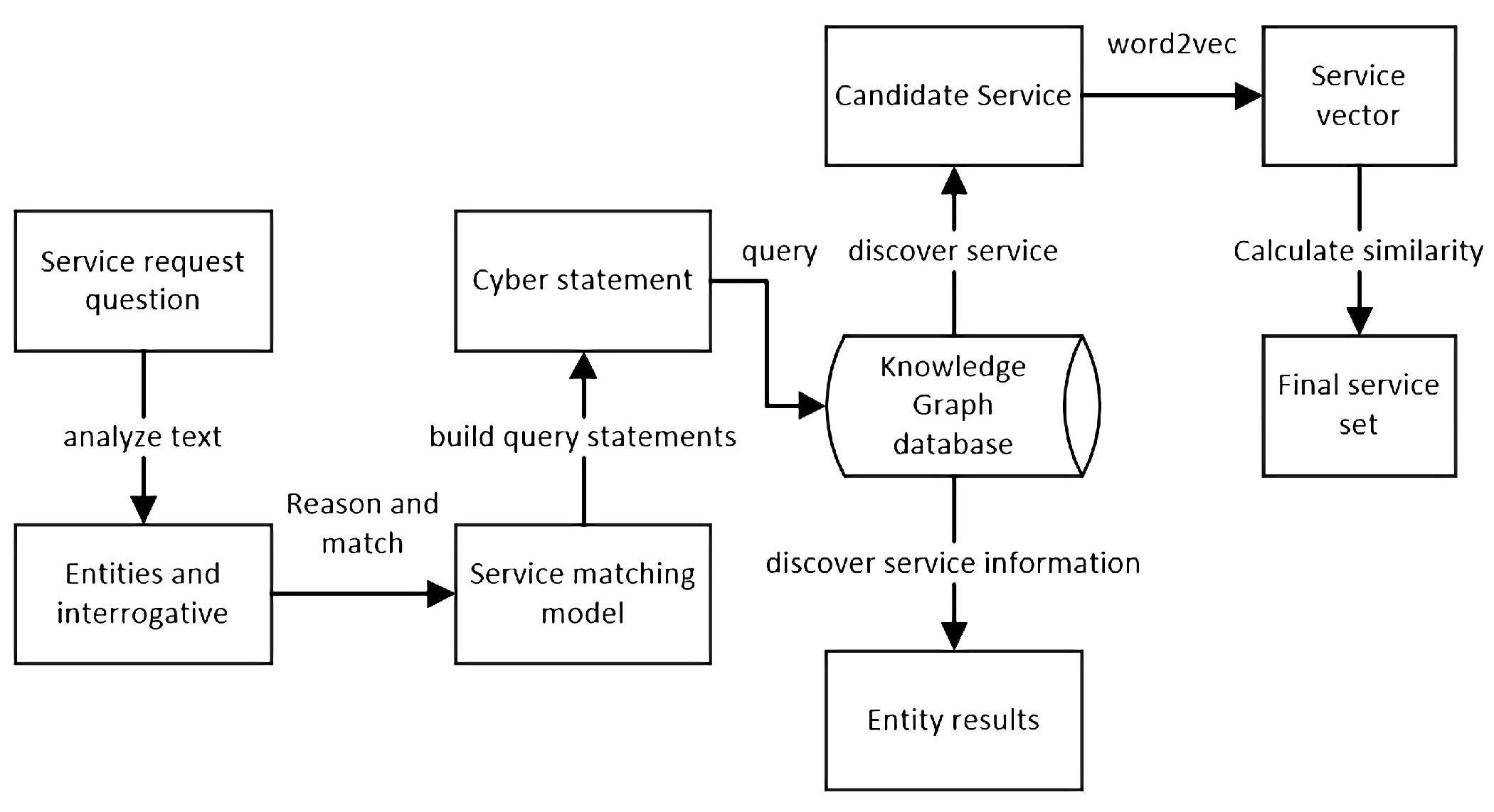
3. SDKG Method
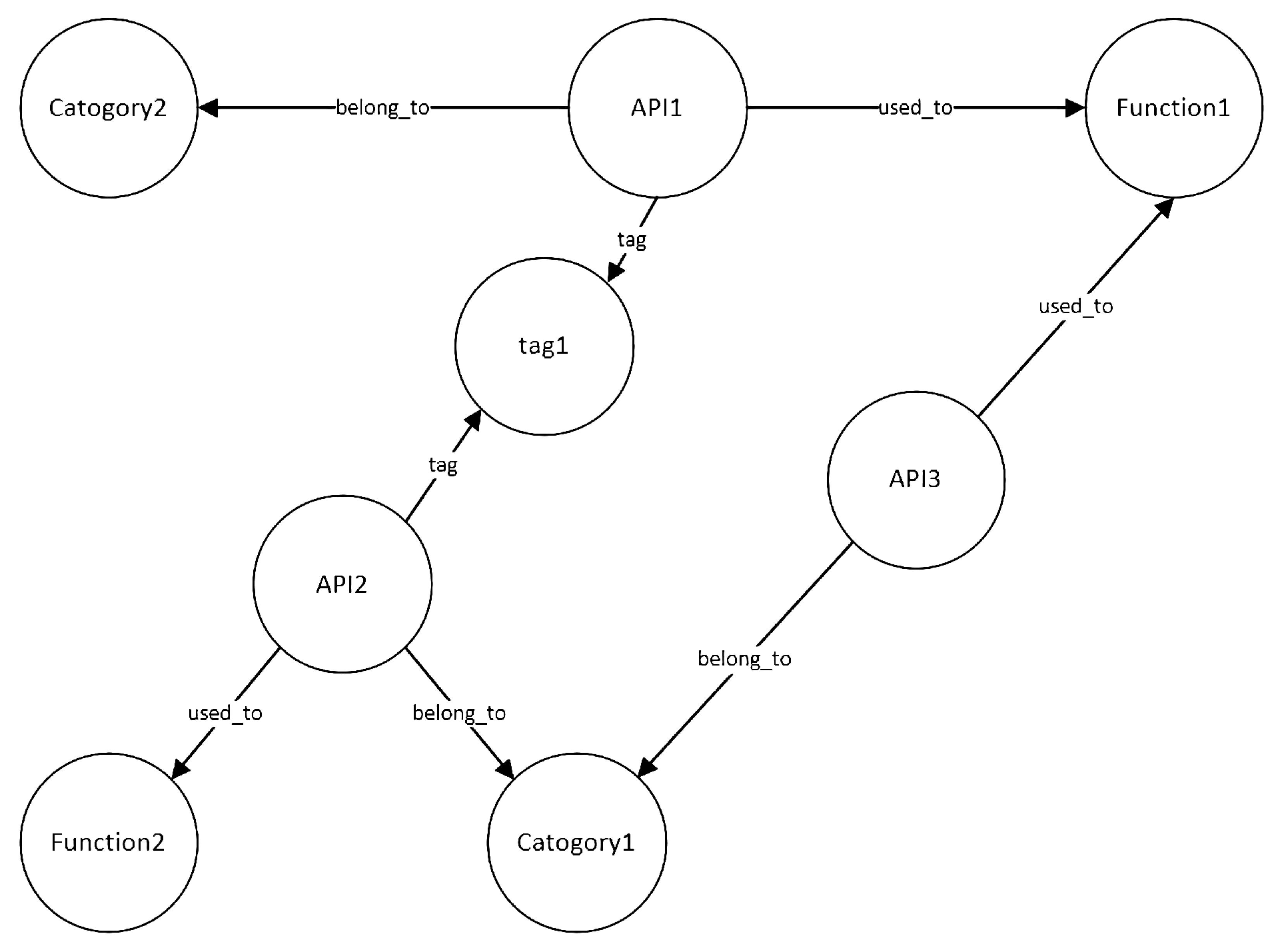
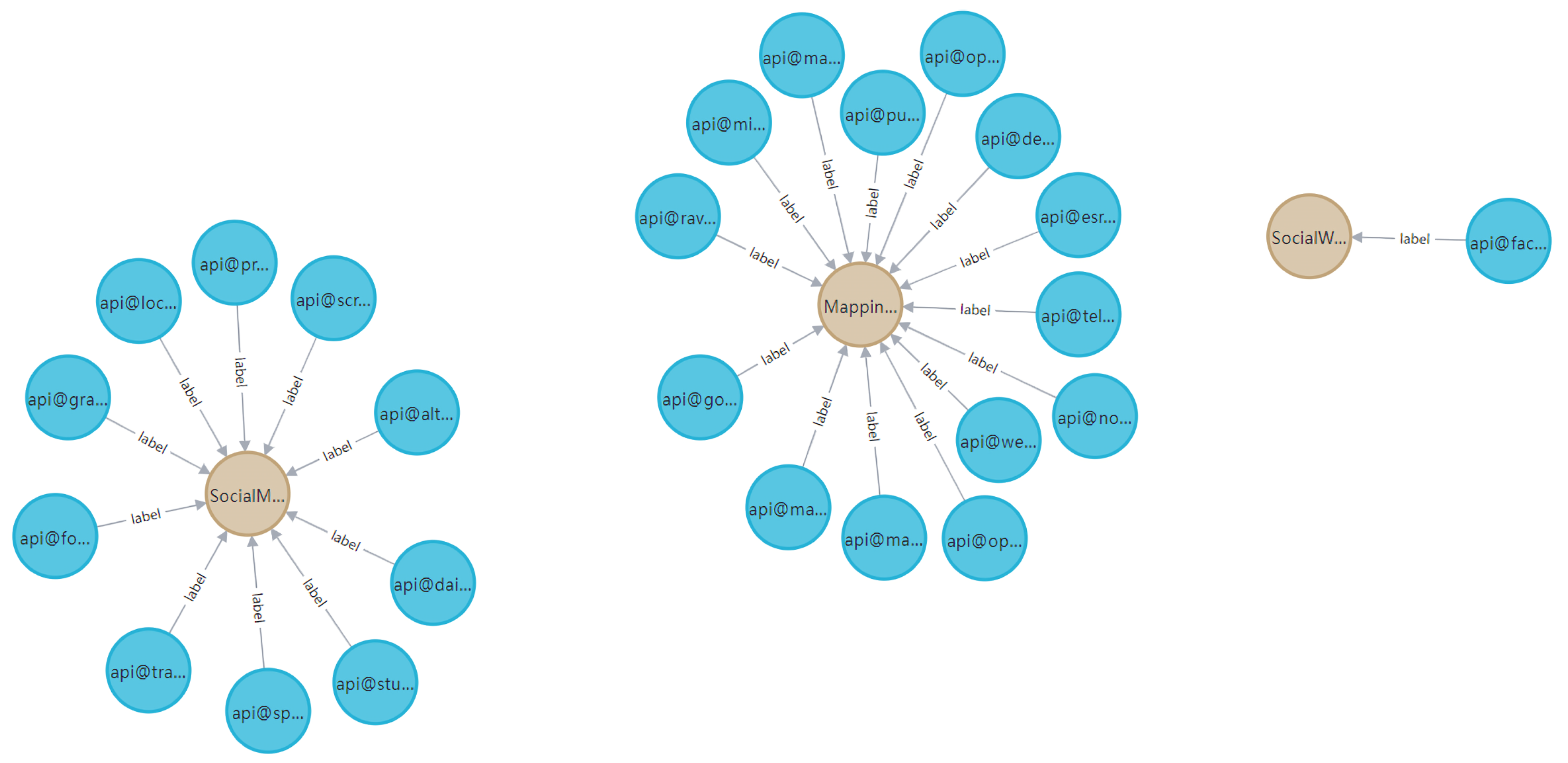
3.1. The Construction of the Service Knowledge Graph
3.2. Dictionary Building
3.3. Service Inference Matching
3.4. Query Based on Knowledge Graph
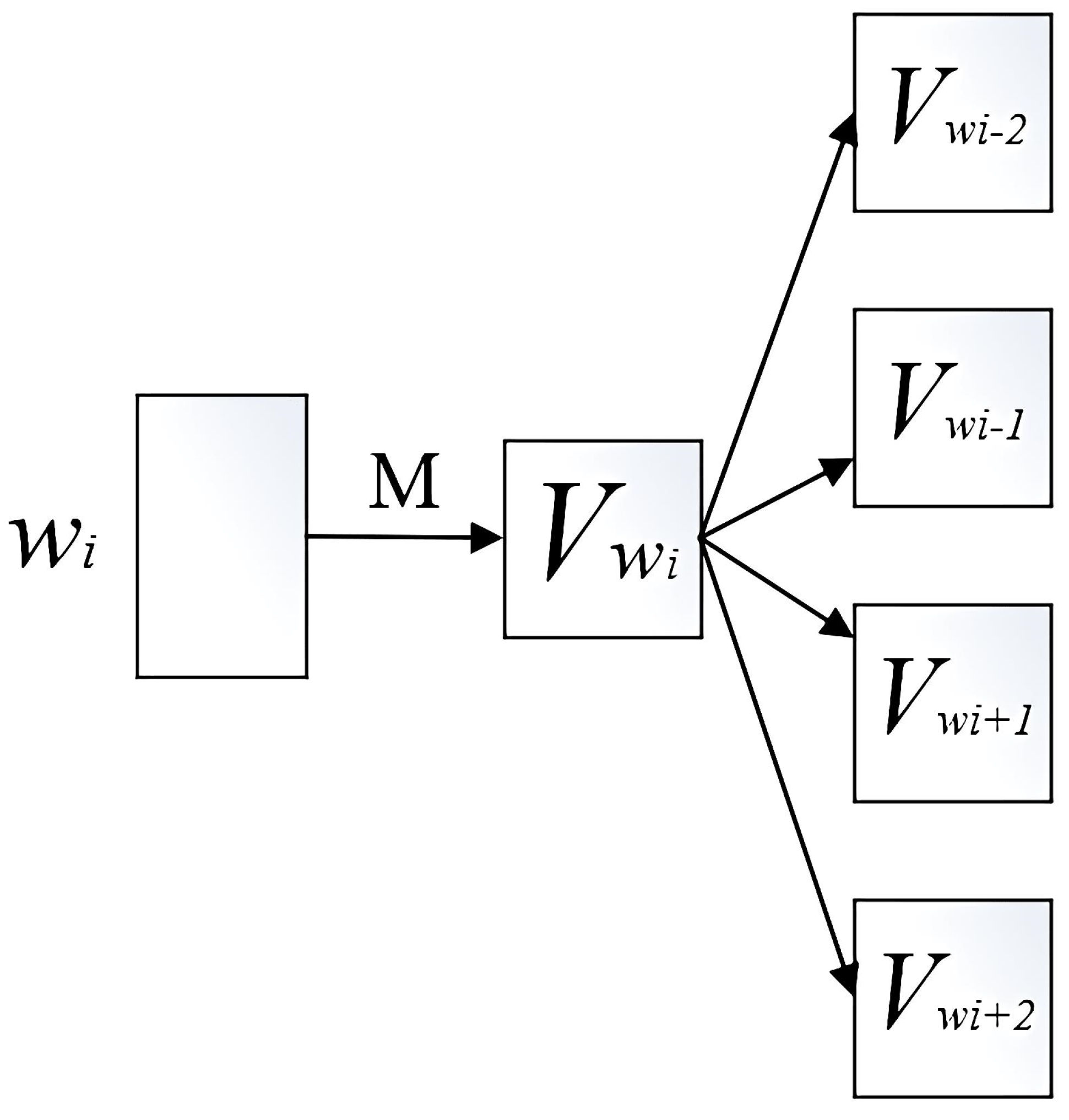
3.5. Text Similarity Matching Based on Word2vec Model
4. Empirical Evaluation
4.1. Dataset
4.2. Baseline Approaches
4.3. Evaluation Metrics
4.4. Results and Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pan, W.; Chai, C. Structure-aware Mashup service Clustering for cloud-based Internet of Things using genetic algorithm based clustering algorithm. Future Gener. Comput. Syst. 2018, 87, 267–277. [Google Scholar] [CrossRef]
- Ko, H.; Lee, S.; Park, Y.; Choi, A. A survey of recommendation systems: Recommendation models, techniques, and application fields. Electronics 2022, 11, 141. [Google Scholar] [CrossRef]
- Wang, X.; Liu, X.; Liu, J.; Chen, X.; Wu, H. A novel knowledge graph embedding based API recommendation method for Mashup development. World Wide Web 2021, 24, 869–894. [Google Scholar] [CrossRef]
- Botangen, K.A.; Yu, J.; Sheng, Q.Z.; Han, Y.; Yongchareon, S. Geographic-aware collaborative filtering for Web service recommendation. Expert Syst. Appl. 2020, 151, 113347. [Google Scholar] [CrossRef]
- Zhang, Y.; Yin, C.; Wu, Q.; He, Q.; Zhu, H. Location-aware deep collaborative filtering for service recommendation. IEEE Trans. Syst. Man Cybern. Syst. 2019, 51, 3796–3807. [Google Scholar] [CrossRef]
- Chen, C.; Peng, X.; Xing, Z.; Sun, J.; Wang, X.; Zhao, Y.; Zhao, W. Holistic combination of structural and textual code information for context based api recommendation. In IEEE Transactions on Software Engineering; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Almarimi, N.; Ouni, A.; Bouktif, S.; Mkaouer, M.W.; Kula, R.G.; Saied, M.A. Web service API recommendation for automated mashup creation using multi-objective evolutionary search. Appl. Soft Comput. 2019, 85, 105830. [Google Scholar] [CrossRef]
- Duan, L.; Tian, H.; Liu, K. A novel approach for Web service recommendation based on advanced trust relationships. Information 2019, 10, 233. [Google Scholar] [CrossRef] [Green Version]
- Pan, W.; Dong, J.; Liu, K.; Wang, J. Topology and topic-aware service clustering. Int. J. Web Serv. Res. 2018, 15, 18–37. [Google Scholar] [CrossRef]
- Czerwinski, S.E.; Zhao, B.Y.; Hodes, T.D.; Joseph, A.D.; Katz, R.H. An architecture for a secure service discovery service. In Proceedings of the 5th Annual ACM/IEEE International Conference on Mobile Computing and Networking, Seattle, DC, USA, 15–19 August 1999; pp. 24–35. [Google Scholar]
- Palathingal, P.; Chandra, S. Agent approach for service discovery and utilization. In Proceedings of the 37th Annual Hawaii International Conference on System Sciences, Big Island, HI, USA, 5–8 January 2004; IEEE: Piscataway, NJ, USA, 2004; p. 9. [Google Scholar]
- Lee, K.H.; Lee, M.y.; Hwang, Y.Y.; Lee, K.C. A framework for xml Web services retrieval with ranking. In Proceedings of the 2007 International Conference on Multimedia and Ubiquitous Engineering (MUE’07), Seoul, Korea, 26–28 April 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 773–778. [Google Scholar]
- Li, C.; Zhang, R.; Huai, J.; Guo, X.; Sun, H. A probabilistic approach for Web service discovery. In Proceedings of the 2013 IEEE International Conference on Services Computing, Santa Clara, CA, USA, 28 June–3 July 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 49–56. [Google Scholar]
- Bianchini, D.; De Antonellis, V.; Pernici, B.; Plebani, P. Ontology-based methodology for e-service discovery. Inf. Syst. 2006, 31, 361–380. [Google Scholar] [CrossRef]
- Corley, C.D.; Mihalcea, R. Measuring the semantic similarity of texts. In Proceedings of the ACL Workshop on Empirical Modeling of Semantic Equivalence and Entailment, Ann Arbor, MI, USA, 13–18 June 2005; pp. 13–18. [Google Scholar]
- Ram, S.; Hwang, Y.; Zhao, H. A clustering based approach for facilitating semantic Web service discovery. In Proceedings of the 15th Annual Workshop on Information Technolgies & Systems (WITS) Paper, Dallas, TX, USA, 9–10 December 2006. [Google Scholar]
- Wang, X.; Wu, H.; Hsu, C.H. Mashup-oriented API recommendation via random walk on knowledge graph. IEEE Access 2018, 7, 7651–7662. [Google Scholar] [CrossRef]
- Rong, X. word2vec parameter learning explained. arXiv 2014, arXiv:1411.2738. [Google Scholar]
- Francis, N.; Green, A.; Guagliardo, P.; Libkin, L.; Lindaaker, T.; Marsault, V.; Plantikow, S.; Rydberg, M.; Selmer, P.; Taylor, A. Cypher: An evolving query language for property graphs. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 1433–1445. [Google Scholar]
- Webber, J. A programmatic introduction to neo4j. In Proceedings of the 3rd Annual Conference on Systems, Programming, and Applications: Software for Humanity, Tucson, AZ, USA, 19–26 October 2012; pp. 217–218. [Google Scholar]
- Sangers, J.; Frasincar, F.; Hogenboom, F.; Chepegin, V. Semantic Web service discovery using natural language processing techniques. Expert Syst. Appl. 2013, 40, 4660–4671. [Google Scholar] [CrossRef]
- Paolucci, M.; Kawamura, T.; Payne, T.R.; Sycara, K. Semantic matching of Web services capabilities. In Proceedings of the International Semantic Web Conference, Sardinia, Italy, 9–12 June 2022; Springer: Berlin/Heidelberg, Germany, 2002; pp. 333–347. [Google Scholar]
- Bener, A.B.; Ozadali, V.; Ilhan, E.S. Semantic matchmaker with precondition and effect matching using SWRL. Expert Syst. Appl. 2009, 36, 9371–9377. [Google Scholar] [CrossRef]
- Paliwal, A.V.; Bornhovd, C.; Adam, N.R. Web Service Discovery: Adding Semantics through Service Request Expansion and Latent Semantic Indexing. In Proceedings of the 2007 IEEE International Conference on Services Computing, Salt Lake City, UT, USA, 9–13 July 2007; IEEE Computer Society: Los Alamitos, CA, USA, 2007; pp. 106–113. [Google Scholar] [CrossRef]
- Amorim, R.; Claro, D.B.; Lopes, D.; Albers, P.; Andrade, A. Improving Web service discovery by a functional and structural approach. In Proceedings of the 2011 IEEE International Conference on Web Services, Washington, DC, USA, 4–9 July 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 411–418. [Google Scholar]
- Pop, C.B.; Chifu, V.R.; Salomie, I.; Dinsoreanu, M.; David, T.; Acretoaie, V. Semantic Web service clustering for efficient discovery using an ant-based method. In Intelligent Distributed Computing IV; Springer: Berlin/Heidelberg, Germany, 2010; pp. 23–33. [Google Scholar]
- Liu, W.; Wong, W. Discovering homogenous service communities through Web service clustering. In Proceedings of the International Workshop on Service-Oriented Computing: Agents, Semantics, and Engineering, Estoril, Portugal, 12 May 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 69–82. [Google Scholar]
- Elgazzar, K.; Hassan, A.E.; Martin, P. Clustering wsdl documents to bootstrap the discovery of Web services. In Proceedings of the 2010 IEEE International Conference on Web Services, Miami, FL, USA, 5–10 July 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 147–154. [Google Scholar]
- Liu, F.; Shi, Y.; Yu, J.; Wang, T.; Wu, J. Measuring similarity of Web services based on wsdl. In Proceedings of the 2010 IEEE International Conference on Web Services, Miami, FL, USA, 5–10 July 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 155–162. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 1421. [Google Scholar]
- Ji, X. Research on Web service discovery based on domain ontology. In Proceedings of the 2009 2nd IEEE International Conference on Computer Science and Information Technology, Beijing, China, 8–11 August 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 65–68. [Google Scholar]
- Pakari, S.; Kheirkhah, E.; Jalali, M. Web service discovery methods and techniques: A review. Int. J. Comput. Sci. Eng. Inf. Technol. 2014, 4, 1–14. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Du, X.; Wang, T.; Wang, L.; Pan, W.; Chai, C.; Xu, X.; Jiang, B.; Wang, J. CoreBug: Improving Effort-Aware Bug Prediction in Software Systems Using Generalized k-Core Decomposition in Class Dependency Networks. Axioms 2022, 11, 205. [Google Scholar] [CrossRef]
- Pan, W.; Ming, H.; Kim, D.K.; Yang, Z. PRIDE: Prioritizing documentation effort based on a PageRank-like algorithm and simple filtering rules. In IEEE Transactions on Software Engineering; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Pan, W.; Ming, H.; Yang, Z.; Wang, T. Comments on “Using k-core Decomposition on Class Dependency Networks to Improve Bug Prediction Model’s Practical Performance”. In IEEE Transactions on Software Engineering; IEEE: Piscataway, NJ, USA, 2022; p. 1. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Element Name | Element Type | Number of Elements | Element Example |
|---|---|---|---|
| Service name | entity | 5580 | Google Map, Twitter, Google Earth, GitHub, etc. |
| Service type | entity | 1197 | Travel, E-commerce, government, technology, music, video, etc. |
| Service tag | entity | 1389 | America, shopping, software, electronics, women, etc. |
| Service function | entity | 17,851 | Compare prices, search for locations, send mail, and more |
| Ask for the service name | question words | 26 | “What are the services”, etc. |
| Ask for the service category | question words | 24 | “What is the category”, “Which category does it belong to”, etc. |
| Ask for service tag | question words | 15 | “What is the label”, “Which field”, etc. |
| Ask for service function | question words | 42 | “What’s the function”, “What can it be used for”, etc. |
| Template Number | Entity Type | Question Word Type | Query Statement Structure |
|---|---|---|---|
| Template 1 | service name | ask for the service name | Discover services based on already used services |
| Template 2 | service type | ask for the service name | Discover services by service class. |
| Template 3 | service tag | ask for the service name | Discover services based on service tags |
| Template 4 | service function | ask for the service name | Discover services based on service capabilities |
| Template 5 | service name | ask for service type | Obtain a service class based on a service name |
| Template 6 | service name | ask for service tag | Obtain a service tag based on a service name |
| Template 7 | service name | ask for service function | Function to obtained service based on a service name |
| N = 5 | N = 10 | N = 15 | N = 20 | |
|---|---|---|---|---|
| Precision | ||||
| WSD-VSM | 0.86% | 0.72% | 0.59% | 0.53% |
| FBWSD | 4.49% | 2.88% | 2.4% | 2.11% |
| SRMWSD-LDA | 2.62% | 1.7% | 1.32% | 1.16% |
| SDKG | 51.33% | 28.92% | 20.41% | 15.90% |
| Recall | ||||
| WSD-VSM | 4.31% | 7.19% | 8.81% | 10.6% |
| FBWSD | 22.46% | 28.75% | 35.94% | 42.23% |
| SRMWSD-LDA | 13.12% | 17% | 19.78% | 23.16% |
| SDKG | 64.16% | 72.3% | 76.54% | 79.52% |
| F1 | ||||
| WSD-VSM | 1.43% | 1.31% | 1.11% | 1.01% |
| FBWSD | 7.48% | 5.24% | 4.5% | 4.02% |
| SRMWSD-LDA | 4.37% | 3.09% | 2.47% | 2.21% |
| SDKG | 57.03% | 41.31% | 32.23% | 26.50% |
| Algorithm | Ranking |
|---|---|
| WSD-VSM | 4.0 |
| FBWSD | 2.0 |
| SRMWSD-LDA | 3.0 |
| SDKG | 4.0 |
| z = (R0 − Ri)/SE | p | Holm | Shaffe | |
|---|---|---|---|---|
| = 0.05 | ||||
| WSD-VSM vs. SDKG | 3.2863 | 0.0010 | 0.0083 | 0.0083 |
| SRMWSD-LDA vs. SDKG | 2.1908 | 0.02845 | 0.0125 | 0.0166 |
| FBWSD vs. SDKG | 1.0954 | 0.2733 | 0.0500 | 0.0500 |
| = 0.10 | ||||
| WSD-VSM vs. SDKG | 3.2863 | 0.0010 | 0.0166 | 0.0166 |
| SRMWSD-LDA vs. SDKG | 2.1908 | 0.02845 | 0.0250 | 0.0333 |
| FBWSD vs. SDKG | 1.0954 | 0.2733 | 0.1000 | 0.1000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, J.; Jiang, B.; Yang, J.; Yang, J.; Li, H.; Wang, N.; Wang, J. Service Discovery Method Based on Knowledge Graph and Word2vec. Electronics 2022, 11, 2500. https://doi.org/10.3390/electronics11162500
Zhou J, Jiang B, Yang J, Yang J, Li H, Wang N, Wang J. Service Discovery Method Based on Knowledge Graph and Word2vec. Electronics. 2022; 11(16):2500. https://doi.org/10.3390/electronics11162500
Chicago/Turabian StyleZhou, Junkai, Bo Jiang, Jie Yang, Junchen Yang, Hang Li, Ning Wang, and Jiale Wang. 2022. "Service Discovery Method Based on Knowledge Graph and Word2vec" Electronics 11, no. 16: 2500. https://doi.org/10.3390/electronics11162500
APA StyleZhou, J., Jiang, B., Yang, J., Yang, J., Li, H., Wang, N., & Wang, J. (2022). Service Discovery Method Based on Knowledge Graph and Word2vec. Electronics, 11(16), 2500. https://doi.org/10.3390/electronics11162500