Abstract
With the development of network technology, the number of gambling websites has grown dramatically, causing a threat to social stability. There are many machine learning-based methods are proposed to identify gambling websites by analyzing the URL, the text, and the images of the websites. Nevertheless, most of the existing methods ignore one important piece of information, i.e., the text within the website images. Only the visual features of images are extracted for detection, while the semantic features of texts on the images are ignored. However, these texts have key information clearly pointing to gambling websites, which can help us identify such websites more accurately. Therefore, how to fuse image and text multimodal data is a challenge that should be met.Motivated by this, in this paper, we propose a hybrid multimodal data fusion-based method for identifying gambling websites by extracting and fusing visual and semantic features of the website screenshots. First, we fine tune the pretrained ResNet34 model to train an image classifier and to extract visual features of webpage screenshots. Second, we extract textual content from webpage screenshots through the optical character recognition (OCR) technique. We use pretrained Word2Vec word vectors as the initial embedding layer and use Bi-LSTM to train a text classifier and extract semantic features of textual content on the screenshots. Third, we use self-attention to fuse the visual and semantic features and train a multimodal classifier. The prediction results of image, text, and multimodal classifiers are fused by the late fusion method to obtain the final prediction result. To demonstrate the effectiveness of the proposed method, we conduct experiments on the webpage screenshot dataset we collected. The experimental results indicate that OCR text on the webpage screenshots has strong semantic features and the proposed hybrid multimodal data fusion based method can effectively improve the performance in identifying gambling websites, with accuracy, precision, recall, and F1-score all over 99%.
1. Introduction
Nowadays, the Internet is a major way for people to obtain information. However, online websites not only have useful information but also contain malicious content, especially gambling websites, which are on the edge of network crime and do great harm to society. Due to the huge number and continuous updating of gambling websites, it is difficult to identify them manually. Therefore, it is necessary to design an automatic, efficient, and accurate method to identify gambling websites.
To reduce cybercrime and purify cyberspace, a variety of methods have been proposed to identify gambling websites [1,2,3]. Malicious website identification methods can be classified into blacklist-based, URL-based, single-feature-based, and mixed-feature-based. Early researchers built black uniform resource locators (URLs) or domain lists to filter malicious webpages [4,5]. The blacklist-based method takes a lot of time to build and maintain, and the identification accuracy is slow because it cannot detect illegal URLs or domains that are not on the blacklist. URL-based methods [6,7,8] extract features from URLs and use machine learning algorithms to identify gambling websites. However, the information in a URL is insufficient and cannot achieve high accuracy. Single-feature-based methods [9,10,11,12,13,14,15] extract a single feature from the content of webpages. The texts in Hyper Text Markup Language (HTML) or images of the webpage are usually used to learn a machine learning algorithm for identifying malicious websites. There is also much other information utilized by researchers, such as links, JavaScript code, cascading style sheets (CSS), HTML tags, etc. However, when malicious websites disguise themselves by disguising, misleading, and bypassing, these single-feature-based methods cannot work well. Mixed-feature-based methods [16,17,18,19,20] extract and combine different features to promote the accuracy in identifying malicious websites. However, improper feature combinations cannot effectively improve the performance of model recognition but will lead to more consumption of computing resources.
Furthermore, in our study, we find that there is some text content in webpage screenshots that has not been utilized in the existing single-feature-based and mixed-feature-based methods. Figure 1 shows a webpage screenshot of a gambling website. From Figure 1b, we can see that the screenshot has the text “QT老虎机,疯狂送豪礼” (translated to English, the text means “QT one-arm bandit, crazy gift-giving”). The word “老虎机” (“one-arm bandit”) refers to a gambling machine. Most gambling websites have some text content in webpage screenshots, and these key texts can be utilized to effectively promote identification accuracy. In conclusion, there are still two issues that need to be solved: (i) The textual information in the images of the website is not being utilized, and this textual information often has obvious semantic features. One challenge is how to extract this textual information. (ii) Another challenge is how to combine the visual features of the images and the semantic features of the text contained in the images.
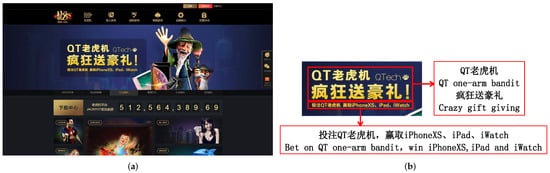
Figure 1.
A webpage screenshot of a gambling website. (a) The webpage screenshot. (b) The text content in the screenshot.
Motivated by the above two issues, in this paper, we propose a hybrid multimodal data fusion based method for identifying gambling websites, which extracts and fuses both visual features and semantic features of webpage screenshots to improve the identification accuracy. First, we fine tune the pretrained ResNet34 [21] model to train an image classifier and extract visual features of webpage screenshots. Second, we extract text information from webpage screenshots by OCR [22] technique. Then we use pretrained Word2Vec [23] word vectors as the initial embedding layer and use Bi-LSTM [24] to train a text classifier and extract semantic features. Third, we design a hybrid multimodal data fusion method to fuse image data and OCR text data. This study makes the following contributions:
- We propose a hybrid multimodal data fusion-based method for identifying gambling websites. Compared with existing single-feature-based and mixed-feature-based methods that extract only visual features of website images, the proposed method extracts text information in the images and fuses image data and text data to improve the identification performance.
- We design a hybrid multimodal data fusion algorithm, which fuses multimodal data at both the feature level and decision level. At the feature level, we use a self-attention network to fuse image features and semantic features and map them into the same feature space. At the decision level, we use the late fusion approach to fuse the prediction results of image, text, and multimodal classifiers.
- We evaluate the performance of the proposed method by conducting experiments on the webpage screenshot dataset we collected. The experimental results demonstrate that the proposed hybrid multimodal data fusion method can effectively improve the performance in identifying gambling websites, with accuracy, precision, recall, and F1-score all over 99%.
The remainder of this paper is organized as follows: In Section 2, we introduce the related work of illegal website identification and multimodal data fusion. In Section 3, we introduce the proposed hybrid multimodal data fusion method for identifying gambling websites. In Section 4, we conduct experiments to verify the effectiveness of the proposed method. In Section 5, we summarize the paper.
2. Related Work
2.1. Illegal Websites Identification
Illegal websites (phishing, gambling, pornography websites, etc.) identification methods can be classified into four categories: blacklist-based methods, URL-based methods, single-feature-based methods, and mixed-feature-based methods. The performance of the blacklist-based method suffers due to the constantly changing URLs of illegal websites. Thus, we introduce some related works of URL-based methods, single-feature-based methods, and mixed-feature-based methods in the following section.
URL-based methods. URL-based methods extract features from URLs for classification. Fan et al. [6] use the Fast Unfolding algorithm to achieve websites clustering and extract URL features of illegal websites. They detect whether an unknown website has the URL features of an illegal website to identify illegal websites. Garera et al. [7] identify several fine-grained heuristics that can be used to distinguish between a phishing URL and a benign URL. They use these heuristics to model a logistic regression classifier. Ma et al. [8] propose an automated URL classification method, which uses statistical approaches to discover lexical features and host-based properties of malicious Web site URLs. The URL-based methods cannot achieve high identification accuracy because URLs contain insufficient information.
Single-feature-based methods. Single-feature-based methods extract a single feature from the content of a webpage for classification. Web pages contain a lot of information, such as images, text, links, JS code, CSS, etc. Single-feature-based methods extract a single feature from one of these information to identify illegal websites. Liu et al. [12] propose a CNN-based method, which extracts visual features from web snapshots for detecting malicious websites. Zhang et al. [9] extract Chinese text content from webpages, and combine bloom filter and TF-IDF algorithm to classify webpages into different themes. Sun et al. [10] propose a Bert fine-tuning based text classification method to identify online gambling websites. Li et al. [11] develop a website screenshot tool to collect screenshots of gambling and porn websites. They extract Speeded-Up Robust Features (SURF) from webpage screenshots based on the bag of words (BoW) model and use the support vector machine (SVM) classifier to distinguish gambling websites and porn websites from normal websites. Jain et al. [13] propose a phishing website detection method by analyzing the hyperlinks in the webpage. However, it is difficult to represent a website and achieve excellent performance using a single feature, especially when malicious websites disguise themselves by disguising, misleading, and bypassing.
Mixed-feature-based methods. Mixed-feature-based methods extract and combine several different features to improve the identification accuracy. Cernica et al. [16] combine the Computer Vision technique with other techniques to detect phishing webpages. Zhang et al. [17] propose a two-stage extreme learning machine technique based on the mixed features of URL, web, and text content for phishing website detection. Chen et al. [18] use the Doc2Vec model to extract textual features and use the local spatial improved bag-of-visual-words (Spa-BoVW) model to extract visual features of website screenshots. They use a data fusion algorithm based on logistic regression (LR) to obtain the final prediction result. Zuhair et al. [19] propose a hybrid feature-based classifier, which hybridized two machine learning algorithms for phishing website detection. Yang et al. [20] combine URL statistical features, webpage code features, webpage text features, and use a deep learning method for classification. However, improper feature combinations cannot effectively improve the performance of model recognition. For example, simple concatenation of visual and semantic feature vectors is often insufficient to achieve good results because visual features and semantic features are not in the same feature space and there are great differences between them. In addition, deep neural networks extract features layer by layer, and early features and late features contain different information, so how to fully fuse early and late features of multimodal data is a challenge. Thus, it is still difficult to fuse different features well.
In conclusion, URL-based methods cannot achieve a high identification accuracy because URLs contain insufficient information. The performance of single-feature-based methods still has a high false positive rate because a single feature is insufficient to represent a website. The existing mixed-feature-based illegal website identification methods extract features from the multi-source data of websites, which improves the identification performance. However, the collection and processing of multi-source data also increase the complexity of the algorithm. In addition, among these methods, they ignore one important piece of information, that is, the text information in the image. The text information in the image often has obvious semantic features and clearly points to gambling websites, which is very helpful to improve the identification performance. Furthermore, we can extract multimodal data simply from webpage screenshots, without the additional processing of other data such as HTML, links, CSS, etc., reducing the complexity. Therefore, it is necessary to study how to extract these texts in the images and fuse the visual feature and semantic features of website screenshots to improve the performance in identifying gambling websites.
2.2. Multimodal Data Fusion
Multimodal data fusion [25,26,27] integrates information from multiple modalities effectively and takes advantage of different modalities. Multimodal data fusion methods can be roughly divided into two categories: model-independent fusion methods and model-based fusion methods. In this paper, we focus on model-independent fusion methods. Model-independent fusion methods can be classified into three categories: early fusion, late fusion, and hybrid fusion. Early fusion methods fuse the features extracted from multimodal data. Because the representation, distribution, and density of various modalities may be different, simply connecting the attributes may ignore the unique attributes and correlations of each modality, and may cause redundancy between data. Late fusion methods fuse the prediction results of different modality classifiers. Compared with early fusion, this method can ignore the difference in features. However, the late fusion lacks the low-level interaction between multiple modalities. Hybrid fusion combines the advantages of early fusion and late fusion. This method can fuse multimodal data both at the feature level and decision level.
Multimodal data fusion has many application scenarios, such as image classification, document classification, emotion recognition, etc. Choi et al. [28] propose a deep learning architecture called “EmbraceNet” for multimodal information-based classification tasks, which combines the representations of multiple modalities in a probabilistic approach. Gallo et al. [29] propose a multimodal approach that fuses images and text descriptions to improve classification performance in real-world scenarios. Audebert et al. [30] propose a multimodal deep network that learns from both a document image and its textual content extracted by OCR to perform document classification. Jain et al. [31] experimentally demonstrate that combining both text and visual modalities of the document can improve the accuracy of document classification. Huang et al. [32] propose an image–text multimodal attentive fusion method to exploit the discriminative features and the internal correlation between visual and semantic contents for sentiment analysis. Nemati [33] proposes a feature-level and decision-level hybrid multimodal fusion method for emotion recognition. In conclusion, multimodal data fusion methods can integrate multimodal information to improve the performance of tasks in the real world.
In webpage screenshots, the image and the text content extracted from screenshots are different modalities of data, even if they come from the same source. In addition, the text content can be used as an effective supplement to image features and improve the performance in identifying gambling websites. Therefore, it is necessary to study an appropriate multimodal data fusion method to fuse the image data and OCR text data from webpage screenshots in identifying gambling websites.
3. Method
Figure 2 shows the proposed hybrid multimodal data fusion method for identifying gambling websites. The image data are webpage screenshots of websites. We fine-tune the pretrained ResNet34 model on these image data and use ResNet34 to extract visual features. Visual features are input into a multilayer perceptron (MLP) for classification, and the prediction from the image modality is obtained. Then, we use the OCR technique to extract text from webpage screenshots. We train a word2vec model as the initial embedding layer and obtain the word embedding vectors of the text. The Bi-LSTM is used to extract semantic features. Semantic features are input into an MLP for classification, and the prediction from text modality is obtained. Next, visual and semantic features are concatenated and input into a self-attention network to obtain fused features. The fused features are input into an MLP for classification, and the prediction is obtained. Finally, the late fusion approach is adopted to fuse the predictions , , and and obtain the final prediction, which is either normal or gambling. We implement the hybrid fusion approach by fusing multimodal data at both the feature level and decision level.
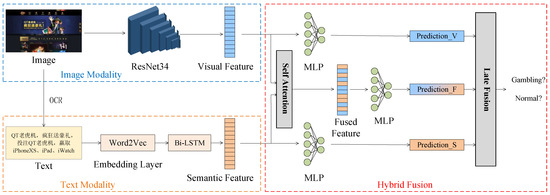
Figure 2.
Overview framework of the proposed method.
In the following subsections, we first introduce the image classifier based on ResNet34 and the text classifier based on Bi-LSTM. Then we introduce the multimodal classifier based on the self-attention network and how to fuse visual and semantic features by self-attention. Finally, we introduce the late fusion method which fuses the prediction results of three classifiers.
3.1. Image Classifier Based on ResNet34
3.1.1. The Structure of ResNet34
With the rapid development of Computer Vision, Deep Convolutional Neural Network (DCNN) [34] has achieved great success in the field of digital image processing. DCNN uses the superposition structure of multiple convolutional layers and pooling layers as the feature extraction module. The weight sharing approach of DCNN can greatly reduce the number of training parameters of the network and multiple convolutional kernels in each layer can obtain different features of the image, which has a great advantage in processing image data.
Residual Network (ResNet) is a typical network of DCNN, which is proposed to alleviate the gradient disappearance problem. The ResNet consists of multiple residual blocks. The detail of the residual block is shown in Figure 3. The residual block consists of several convolutional layers (Conv), a rectified linear unit (ReLU) activation function, and a shortcut connection. The input of the residual block is x, the residual function is F, and the output of the block can be calculated as follows:
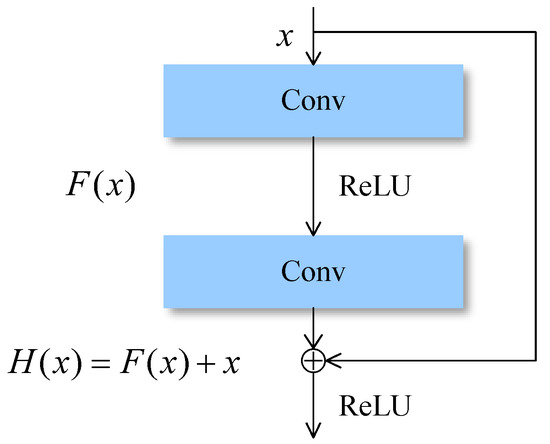
Figure 3.
A residual block in ResNet34.
The ResNet34 model consists of 16 residual blocks (33 convolutional layers), a max-pooling layer, an average pooling layer, and a fully connected network. The image classifier in this paper is built based on ResNet34, and the details of the image classifier are shown in Figure 4. In the ResNet34 model structure, there are four types of residual blocks: , , , and . After one convolutional layer with a kernel size of , one BatchNorm layer (BN), the ReLU activation, and one Maxpooling layer, there are three blocks. A block contains two convolutional layers with 64 kernels, a ReLU activation function, and two BatchNorm layers (Conv-BN-ReLU-Conv-BN). After three blocks, there are four blocks with 128 kernels in convolutional layers, six blocks with 256 kernels in convolutional layers and three blocks with 512 kernels in convolutional layers. One average pooling layer and a fully connected network are after these residual blocks.
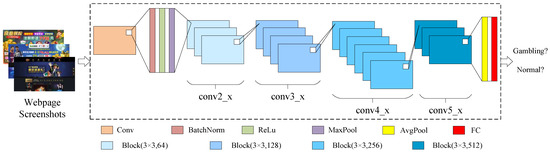
Figure 4.
The structure of the image classifier.
3.1.2. Transfer Learning
Due to a large number of parameters (63.5 million) in the ResNet34 model, a large number of labeled samples are required to train the ResNet34-based image classifier to achieve high performance in classification. However, it is difficult to collect a large number of webpage screenshots of gambling websites and it takes a lot of time to label images. Therefore, in this paper, we train the image classifier based on the transfer learning method. Transfer learning [35] can update the trained model adaptively according to the new samples, and transfer the model to new tasks. The pretrained ResNet34 model trained on the ImageNet dataset has a very strong visual feature extraction ability for images. Therefore, based on the transfer learning method, fine tuning the parameters of the pretrained model with a small-scale image dataset can avoid overfitting and greatly reduce the training time. The output dimension of the fully connected layer in original ResNet34 is 1000, which is cannot be used for our mission. Because there are two labels, gambling or normal, we modify the output dimension of the fully connected layer to 2 to fit our label category. In addition, the weight of the pretrained ResNet34 model has been smoothed, as we do not want to distort them too fast. Thus, we set a much smaller learning rate when fine tuning the ResNet34 model, so that the model can adapt to new data on the basis of the original excellent feature extraction ability. The input is webpage screenshots, and the output of the average pooling layer is flattened to m dimensional visual features:
The visual features are input into the fully connected network for classification.
3.2. Text Classifier Based on Bi-LSTM
A Recurrent Neural network (RNN) is suitable to deal with sequence data and is widely used in the Natural Language Process field. In this paper, we construct a text classifier based on Bi-LSTM. Figure 5 shows the structure of the text classifier. First, we tokenize the input sentence into n words and map these words to ids according to the word vocabulary. Second, the word ids are embedded into vectors through the embedding layer. Third, the Bi-LSTM network is used to learn context semantics and the concatenation of the forward LSTM and backward LSTM outputs at the last moment is used as the semantic features of the sentence. Finally, the semantic features are input into the fully connected network for classification.
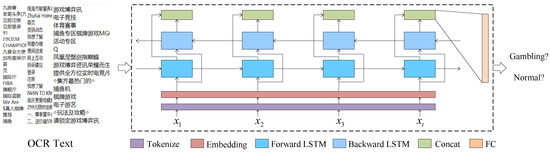
Figure 5.
The structure of the text classifier.
3.2.1. Incremental Training of the Embedding Layer
Similar to the transfer learning method of the image classifier, when training the embedding layer, we adopt the incremental training method. The reasons are as follows: (i) The quality of embedding affects the semantic features extraction. An excellent embedding needs a large-scale high-quality corpus to train. However, it is difficult to collect and extract texts from webpage screenshots of gambling websites. (ii) The parameters of the embedded layer greatly exceed those of the LSTM model and this may lead to the overfitting of the embedding layer. Therefore, we need to train a good word-embedding layer in advance and then fix the parameters of the embedding layer when training the Bi-LSTM-based text classifier. We use gensim [36], a free open-source Python library that is designed to process raw, unstructured digital texts (“plain text”) using unsupervised machine learning algorithms to train a Word2Vec model on Chinese Sogou News Corpus. We train the Word2Vec with Skip-gram mode, the window size is set to 5 and the dimension of each word vector is set to 300. Then the pretrained Word2Vec model is trained on OCR texts extracted from webpage screenshots based on an incremental training algorithm to obtain word vectors of OCR text. The word vectors of the Word2Vec model are fixed and used as the weights of the embedding layer. The ids of the sentence are input into the pretrained embedding layer and get the words embedding .
3.2.2. Bi-LSTM
LSTM can effectively solve the problem of a long-term dependence on texts and avoid the disappearance or explosion of gradients. Therefore, we use LSTM as the semantic feature extraction module instead of the traditional simple RNN. To obtain the forward and backward information of texts, we construct a bidirectional recurrent neural network with Bi-LSTM. Each LSTM unit has the following vectors at the moment t: An input gate , an output gate , a forgetting gate , a memory unit , and a hidden layer state . Figure 6 shows the calculation process of a LSTM unit at moment t.
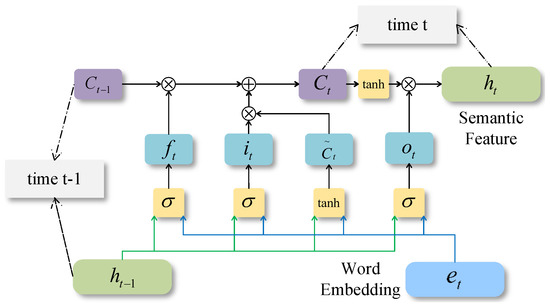
Figure 6.
The calculation of a LSTM unit.
There are three inputs to LSTM unit at moment t: word embedding , the hidden layer state at moment , and the conveyor vector at moment . The calculations of , , , , and are as follows.
The input gate decides what information to store in the cell state:
where is the word embedding at moment t, is the hidden state at moment t, and are concatenated and and multiplied by the weight of the input gate, and the product is input into the sigmoid function.
A candidate vector is calculated as:
and are concatenated and and multiplied by the weight , and the product is input into the tanh function. is the candidate vector added to the input gate at moment t.
The forgetting gate decides what information to discard:
and are concatenated and and multiplied by the weight of the forget gate, and the product is input into the sigmoid function. The output is a number between 0 and 1, “1” means that the information is fully retained and “0” means the information is completely forgotten.
The conveyor vector is updated from and is calculated as:
The conveyor vector at moment multiplied by the forgetting gate to forget part of the previous information. The candidate vector multiplied by the input gate to obtain the candidate input information. The sum of these two products is the conveyor vector at moment t.
The output gate decides what information to output:
and are concatenated and and multiplied by the weight of the output gate, and the product is input into the sigmoid function.
Then, the hidden layer state is updated and is calculated as:
The conveyor vector is input into the tanh function and multiplied by the output gate to obtain the hidden state at moment t. and are input to the LSTM cell at the next moment.
In the above formulas, , , , , , , , and are parameters that can be learned from samples. The hidden state vector of the forward LSTM and the hidden state vector of the backward LSTM at the last moment are concatenated as the n dimensional semantic features:
The semantic features are input into the fully connected network for classification.
3.3. Hybrid Fusion
We propose a hybrid multimodal data fusion method, which fuses visual and semantic features of webpage screenshots by a self-attention network and fuses prediction results by the late fusion method.
3.3.1. Feature Fusion Based on Self-Attention
A simple concatenation of visual and semantic features may ignore the unique attributes and correlations of each modality and lead to data redundancy. To address the issue, we fuse visual and semantic features based on self-attention. The attention mechanism makes the model pay more attention to the effective area and suppress other irrelevant areas. In the fields of image processing and text processing, the effect of attention is reflected in the distribution of weights. Self-attention is a special case of the attention mechanism, which makes a part of the input calculate attention with each part of the input itself to learn internal correlation and enhance effective areas. Self-attention can learn the relationship between features well and assign more weight to effective features. Therefore, we use self-attention to fuse visual and semantic features and construct a multimodal classifier. Figure 7 shows the detail of the self-attention based multimodal classifier.
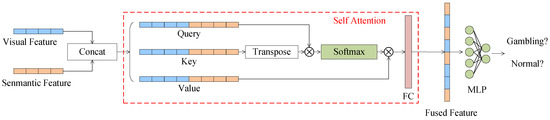
Figure 7.
The self-attention based multimodal classifier.
We concat the visual features and the semantic features to obtain the dimensional vector :
In attention mechanism, there are three vectors participate in the calculation: , , and . is the input vector, is the product of input and the weight , and is the product of input and the weight . Specially, in self-attention, the , , and are the same:
, , and come from the same input: the concatenation of visual feature vectors and semantic feature vectors .
We can calculate the weights of each part of the input and other parts:
where is the transpose of and is the dimension of . First, we calculate the dot product between and . Second, we divide this product by a scale . Third, the softmax function is used to normalize the calculation results to a probability distribution .
Then we can calculate the output by multiplying and the weight :
The output of the self-attention network is input into a fully connected layer to obtain the fused feature :
where W and b are the parameters of the fully connected layer. Finally, the fused feature is input into a fully connected network for classification.
3.3.2. Late Fusion
Different modalities and multimodal decision processes are relatively independent, so we assign different weights to the prediction results of image, text, and multimodal classifiers through late fusion to obtain the final prediction result. The late fusion process is shown in Figure 8.
where , , and are prediction results of the image, text, and multimodal classifiers. , , and are the weights of the three classifiers. y is the final prediction result.
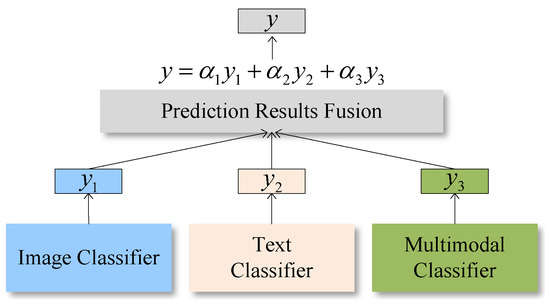
Figure 8.
The late fusion of prediction results.
In order to maximize the performance of late fusion, we need to find the optimal parameter assignment strategy of , , and . The grid search algorithm is a method for optimizing model performance by traversing a given combination of parameters. The process of the grid search algorithm is to find the best performing parameter combination on the validation set from all the parameter combinations by sequentially adjusting the parameters in steps within the parameter range. This algorithm is suitable for cases with few parameters. Therefore, we adopt the grid search method to search for the optimal parameter assignment strategy. If the step size of the grid search method is set too small, it will lead to a significant increase in computational complexity. Thus, in this paper, we set 0.1 as the step size between 0 and 1.
4. Experiments and Analysis
In this section, we conduct experiments to evaluate the performance of the proposed hybrid multimodal data fusion method for identifying gambling websites. Our experiments are conducted on a server with Intel(R) Xeon(R) Gold 6139 CPU, 377 GB memory, and TITAN RTX2080Ti GPU, 24GB video memory. The frequency of the processor is 1000 MHz and the frequency of the RAM memory is 1333 MHz. Webpage sceenshots are stored as Portable Network Graphics (.png) format data and text is stored as .txt format data.
Datasets. We used web crawlers to obtain gambling webpage screenshots of gambling websites on the internet from a gambling URL list. Since there are duplicate screenshots and domain name changes, we removed duplicate data and noise data, and then selected 800 gambling webpage screenshots for training. We also crawled 800 normal webpage screenshots (the types are education, movie, shopping, medical, science, traffic, etc.) for training. We extracted text data from these webpage screenshots by OCR technique for training. We also crawled a total of 300 gambling and 300 normal webpage screenshots and extracted text data for testing.
Evaluation metrics. In this paper, we use four evaluation metrics to evaluate the method, including Accuracy, Precision, Recall, and F1-score. The confusion matrix of our experiments is shown in Table 1. The confusion matrix consists of four values: true positive (), true negative (), false positive (), and false negative (). Among them, is the number of gambling websites correctly predicted as gambling websites, is the number of normal websites correctly predicted as normal websites, is the number of normal websites incorrectly predicted as gambling websites, and is the number of gambling websites incorrectly predicted as normal websites.

Table 1.
The confusion matrix.
Accuracy measures the percentage of gambling and normal websites that were correctly predicted across all sites. The Accuracy is calculated as:
Precision represents the classification accuracy effect of the classifier. Precision_g is the rate of websites correctly predicted as gambling websites in all predictions and Precision_n is the rate of websites correctly predicted as normal websites in all predictions. The calculation is as follows:
Recall_g is the rate of websites correctly predicted as gambling websites in all actual gambling websites and Recall_n is the rate of websites correctly predicted as normal websites in all actual normal websites. The calculation is as follows:
F1-score is the harmonic mean of the Precision and the Recall:
The values of Accuracy, Precision, Recall, and F1-score are all between 0 and 1. The closer the value of the four evaluation metrics is to 1, the better the performance of the model.
4.1. Evaluation of Image Classification
We train a ResNet34-based image classifier on image data of webpage screenshots. To compare with simple CNNs, we do the same experiment on five-layers CNN (CNN-5) and seven-layers CNN (CNN-7) we constructed. The CNN-5 and CNN-7 are composed of convolutional layers, batch normalization layers, and ReLU activation functions. The test results of ResNet34, CNN-5, and CNN-7 are shown in Table 2.
Table 2.
Results of ResNet34, CNN-5, and CNN-7.
From Table 2 we can observe that the test result on the accuracy, precision, recall and F1-score of ResNet34 is better than that of CNN-5 and CNN-7. With the increase of convolutional network layers, the performance of the model becomes better.
Due to the large number of parameters in the ResNet network and the small amount of data in the training dataset, we use the transfer learning method to train ResNet34. We use the official weight of ResNet34 trained on the ImageNet dataset as the pretrained model and fine tune the pretrained model on the webpage screenshot dataset we collected. There are two approaches to fine tune the pretrained model: one is to freeze the convolutional network and fine tune the fully connected network, and the other is to fine tune both the convolutional network and fully connected network. When fine tuning the pretrained network, we set a much smaller learning rate so that the parameters of the model will not change much. Through transfer learning, we can avoid the problem of overfitting in the training of models on a small dataset and significantly reduce training time. The test results of different transfer learning approaches are shown in Table 3.
Table 3.
Results of different fine tuning approaches.
It can be seen from Table 3 that when the pretrained weight is not used, that is, initializing the weights of ResNet34 and training on webpage screenshot dataset, the macro avg of accuracy, precision, recall, and F1-score are 0.9200, 0.9219, 0.9200, and 0.9199. When freezing the convolutional network (33 convolutional layers and two pooling layers) and fine tuning the fully connected network, the macro average of accuracy, precision, recall, and F1-score are 0.8700, 0.8299, 0.8167, and 0.8148, respectively. When fine tuning both the convolutional network and the fully connected network of ResNet34, the test results on the four evaluation metrics are 0.9300, 0.9328, 0.9300, and 0.9299, respectively.
Fine tuning the entire network gives better test results than fine tuning parts of the network and not using the pretrained model. It indicates that the transfer learning method can effectively improve the performance of the model. When fine tuning the pretrained network, fine tuning the entire network is better than fine tuning only the fully connected network. Because the source dataset is often very different from the target dataset, it is difficult to extract features of the target data well without updating the weights of the pretrained model. Therefore, fine tuning the entire network allows the model to learn the distribution of the target data during the training process and allows the model to transfer adaptively from the source task to the target task.
4.2. Evaluation of Text Classification
We train a Bi-LSTM-based text classifier on OCR text extracted from webpage screenshots by the OCR technique. We use gensim to train a word2vec model on the Chinese Sougou News corpus. The word vectors of the trained word2vec model are fixed and used as the weights of the embedding layer, the output dimension of the embedding layer is 300. The number of layers of the Bi-LSTM network is 2, the hidden size is 128, and the max sentence length is 200. We also carry out the same experiment on the simple Bi-RNN model and Transformer model for comparison. The test results of Bi-RNN, Transformer, and Bi-LSTM on the four evaluation metrics are shown in Table 4.
Table 4.
Results of Bi-RNN, Transformer, and Bi-LSTM.
We can observe from Table 4 that Bi-LSTM performs better than Bi-RNN and Transformer, with macro averages of 0.9769, 0.9770, 0.9769, and 0.9769 for accuracy, precision, recall, and F1-score, respectively. Comparing the test results of image classification and text classification, we can see that the Bi-LSTM-based text classifier performs better than ResNet34 based image classifier. This may be because the visual feature of the webpage screenshots is more complex than the semantic feature of OCR text.
In order to illustrate the effectiveness of the semantic features of OCR texts, we extract texts from HTML for text classification experiments and compare them with OCR text classification. The test results of Bi-RNN, Transformer, and Bi-LSTM on OCR text and HTML text are shown in Figure 9.
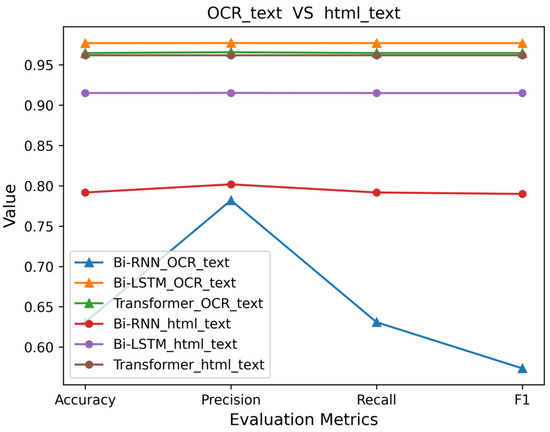
Figure 9.
Results on OCR text and html text.
We can observe from Figure 9 that except for Bi-RNN, both Transformer and Bi-LSTM perform better on OCR text than on HTML text. It indicates that OCR text has stronger semantic features than HTML text and is useful for identifying gambling websites. In the HTML text, there may be some text irrelevant to the identification of gambling websites. In addition, to avoid the keyword matching detection method, some gambling websites do not have obvious gambling-related text in HTML, and such gambling-related text is contained in website images. In this case, OCR text is more helpful for classification than HTML text. However, Transformer-based classifier gives good performance on HTML text classification, with accuracy, precision, recall, and F1-score all over 0.95. This is probably because the attention network used by Transformer makes the model focus more on classification-related information.
In order to obtain the best performance of the Bi-LSTM-based text classifier, we conduct OCR text classification experiments on different parameters of the Bi-LSTM net structure. The test results of different Bi-LSTM net structures on the four evaluation metrics are shown in Table 5. We can observe from Table 5 that the Bi-LSTM with the net structure of 2 layers and 128 hidden size (Bi-LSTM(2-128)) performs best.
Table 5.
Different parameters of Bi-LSTM.
4.3. Evaluation of Hybrid Multimodal Data Fusion
In this subsection, we discuss the performance of single modal, multimodal, and different data fusion approaches. The experiments we conduct are as follows:
- I: Image classification based on ResNet34 model.
- T: Text classification based on Bi-LSTM model.
- IT: Late fusion of image prediction results and text prediction results.
- SA: Visual and semantic features fusion based on self-attention for multimodal classification.
- ISA: Late fusion of image predictions and multimodal predictions (self-attention).
- TSA: Late fusion of text predictions and multimodal predictions (self-attention).
- ITSA: The hybrid multimodal data fusion method proposed in this paper.
I and T are single modal data classification methods, IT is a late fusion (decision fusion) method, SA is an early fusion (feature fusion) method, ISA and TSA are hybrid fusion methods, and ITSA is the hybrid fusion method proposed in this paper. The test results of the seven above methods are shown in Table 6.
Table 6.
Results of different data fusion methods.
From Table 6 we can observe that in single modal data classification methods, the performance of the text classifier is better than that of the image classifier. This is because the visual features of webpage screenshots are more complex than the semantic features of OCR text, and this shows the necessity of extracting textual information from webpage screenshots for identifying gambling websites. The performance of the late fusion of image and text classifiers is better than that of the single modal classifier. The self-attention based feature fusion method performs better than the image classifier but performs worse than the text classifier. This may be due to the fact that the visual and semantic features are quite different and the self-attention does not fuse the two features very well. The ISA method has a higher performance than the I method and the TSA method has a higher performance than the T method and SA method. This indicates that hybrid fusion methods perform better than single modal classification, early fusion, and late fusion methods in identifying gambling websites. The proposed method ITSA performs best among the seven above methods, with accuracy, precision, recall, and F1-score all over 0.99. The test results in Table 6 demonstrate the effectiveness of the proposed method.
5. Conclusions
In this paper, we propose a hybrid multimodal data fusion-based method for identifying gambling websites, which extracts and fuses both visual features and semantic features of webpage screenshots. We make full use of the text information in the images of gambling websites to improve identification accuracy. We experimentally demonstrate that the text information in images has stronger semantics than HTML and is more useful for gambling website identification. In particular, we propose a hybrid multimodal data fusion approach to fuse the visual and semantic features at both the feature level and decision level. The experimental results demonstrate the effectiveness of the proposed method, with all the evaluation metrics achieving satisfactory standards.
Despite the effective performance of the proposed method, it still has some limitations that need to be improved in the future. First, the model can be improved by being incorporated with more features. In this paper, we mainly use visual and semantic features of webpage screenshots. In the future, we will explore fusing more features and investigate better multimodal data fusion methods to fuse more modalities of data. Another limitation is that the accuracy of OCR extraction of text will directly affect the accuracy of text classification and multimodal data fusion. If there are some errors in the text information extracted by OCR, the performance of text classification and multimodal classification will suffer. Therefore, we will explore the impact of OCR errors on model performance and how to reduce such errors in future work.
Author Contributions
Conceptualization, C.W. and M.Z.; methodology, C.W. and M.Z.; software, C.W.; validation, C.W. and F.S.; formal analysis, M.Z. and P.X.; investigation C.W. and M.Z.; resources, F.S.; data curation, Y.L.; writing—original draft preparation C.W.; writing—review and editing M.Z. and F.S.; visualization, P.X.; supervision, Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key R&D Program of China under Grant 2021YFB3100500.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
This work is supported by the National Key R&D Program of China under Grant 2021YFB3100500.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gao, Y.; Wang, H.; Li, L.; Luo, X.; Xu, G.; Liu, X. Demystifying illegal mobile gambling apps. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 1447–1458. [Google Scholar]
- Min, M.; Lee, J.J.; Park, H.; Lee, K. Honeypot system for automatic reporting of illegal online gambling sites utilizing SMS spam. In Proceedings of the 2021 IEEE World Automation Congress (WAC), Taipei, Taiwan, 1–5 August 2021; pp. 180–185. [Google Scholar]
- Min, M.; Lee, J.J.; Lee, K. Detecting Illegal Online Gambling (IOG) Services in the Mobile Environment. Secur. Commun. Netw. 2022, 2022, 3286623. [Google Scholar] [CrossRef]
- Prakash, P.; Kumar, M.; Kompella, R.R.; Gupta, M. Phishnet: Predictive blacklisting to detect phishing attacks. In Proceedings of the 2010 Proceedings IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010; pp. 1–5. [Google Scholar]
- Sheng, S.; Wardman, B.; Warner, G.; Cranor, L.; Hong, J.; Zhang, C. An empirical analysis of phishing blacklists. In Proceedings of the CEAS 2009 Sixth Conference on Email and Anti-Spam, Mountain View, CA, USA, 16–17 July 2009. [Google Scholar]
- Fan, Y.; Yang, T.; Wang, Y.; Jiang, G. Illegal Website Identification Method Based on URL Feature Detection. Comput. Eng. 2018. [Google Scholar]
- Garera, S.; Provos, N.; Chew, M.; Rubin, A.D. A framework for detection and measurement of phishing attacks. In Proceedings of the 2007 ACM workshop on Recurring malcode, Alexandria, VA, USA, 2 November 2007; pp. 1–8. [Google Scholar]
- Ma, J.; Saul, L.K.; Savage, S.; Voelker, G.M. Beyond blacklists: Learning to detect malicious web sites from suspicious URLs. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 1245–1254. [Google Scholar]
- Zhang, D. Research and Implementation of Content-Oriented Web page Classification; Nanjing University of Posts and Telecommunications: Nanjing, China, 2017. [Google Scholar]
- Sun, G.; Ye, F.; Chai, T.; Zhang, Z.; Tong, X.; Prasad, S. Gambling Domain Name Recognition via Certificate and Textual Analysis. Comput. J. 2022, bxac043. [Google Scholar] [CrossRef]
- Li, L.; Gou, G.; Xiong, G.; Cao, Z.; Li, Z. Identifying Gambling and Porn Websites with Image Recognition. In Pacific Rim Conference on Multimedia; Springer: Berlin/Heidelberg, Germany, 2017; pp. 488–497. [Google Scholar]
- Liu, D.; Lee, J.H.; Wang, W.; Wang, Y. Malicious websites detection via cnn based screenshot recognition. In Proceedings of the 2019 IEEE International Conference on Intelligent Computing and its Emerging Applications (ICEA), Tainan, Taiwan, 30 August–1 September 2019; pp. 115–119. [Google Scholar]
- Jain, A.K.; Gupta, B.B. A machine learning based approach for phishing detection using hyperlinks information. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 2015–2028. [Google Scholar] [CrossRef]
- Gupta, J.; Pathak, S.; Kumar, G. Aquila coyote-tuned deep convolutional neural network for the classification of bare skinned images in websites. Int. J. Mach. Learn. Cybern. 2022, 1–16. [Google Scholar] [CrossRef]
- Zhao, J.; Shao, M.; Peng, H.; Wang, H.; Li, B.; Liu, X. Porn2Vec: A robust framework for detecting pornographic websites based on contrastive learning. Knowl.-Based Syst. 2021, 228, 107296. [Google Scholar] [CrossRef]
- Cernica, I.; Popescu, N. Computer Vision Based Framework For Detecting Phishing Webpages. In Proceedings of the 2020 IEEE 19th RoEduNet Conference: Networking in Education and Research (RoEduNet), Bucharest, Romania, 11–12 December 2020; pp. 1–4. [Google Scholar]
- Zhang, W.; Jiang, Q.; Chen, L.; Li, C. Two-stage ELM for phishing Web pages detection using hybrid features. World Wide Web 2017, 20, 797–813. [Google Scholar] [CrossRef]
- Chen, Y.; Zheng, R.; Zhou, A.; Liao, S.; Liu, L. Automatic detection of pornographic and gambling websites based on visual and textual content using a decision mechanism. Sensors 2020, 20, 3989. [Google Scholar] [CrossRef] [PubMed]
- Zuhair, H.; Selamat, A. Phishing hybrid feature-based classifier by using recursive features subset selection and machine learning algorithms. In International Conference of Reliable Information and Communication Technology; Springer: Berlin/Heidelberg, Germany, 2018; pp. 267–277. [Google Scholar]
- Yang, P.; Zhao, G.; Zeng, P. Phishing website detection based on multidimensional features driven by deep learning. IEEE Access 2019, 7, 15196–15209. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Mori, S.; Suen, C.Y.; Yamamoto, K. Historical Review of OCR Research and Development; IEEE Computer Society Press: Piscataway, NJ, USA, 1992. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems 26 (NIPS 2013), Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Gao, J.; Li, P.; Chen, Z.; Zhang, J. A survey on deep learning for multimodal data fusion. Neural Comput. 2020, 32, 829–864. [Google Scholar] [CrossRef] [PubMed]
- Gaw, N.; Yousefi, S.; Gahrooei, M.R. Multimodal data fusion for systems improvement: A review. IISE Trans. 2021, 1–19. [Google Scholar] [CrossRef]
- Gupta, J.; Pathak, S.; Kumar, G. A hybrid optimization-tuned deep convolutional neural network for bare skinned image classification in websites. Multimed. Tools Appl. 2022, 81, 26283–26305. [Google Scholar] [CrossRef]
- Choi, J.H.; Lee, J.S. EmbraceNet: A robust deep learning architecture for multimodal classification. Inf. Fusion 2019, 51, 259–270. [Google Scholar] [CrossRef]
- Gallo, I.; Calefati, A.; Nawaz, S.; Janjua, M.K. Image and encoded text fusion for multi-modal classification. In Proceedings of the 2018 IEEE Digital Image Computing: Techniques and Applications (DICTA), Canberra, Australia, 10–13 December 2018; pp. 1–7. [Google Scholar]
- Audebert, N.; Herold, C.; Slimani, K.; Vidal, C. Multimodal deep networks for text and image-based document classification. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2019; pp. 427–443. [Google Scholar]
- Jain, R.; Wigington, C. Multimodal document image classification. In Proceedings of the 2019 IEEE International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 71–77. [Google Scholar]
- Huang, F.; Zhang, X.; Zhao, Z.; Xu, J.; Li, Z. Image–text sentiment analysis via deep multimodal attentive fusion. Knowl.-Based Syst. 2019, 167, 26–37. [Google Scholar] [CrossRef]
- Nemati, S. Canonical correlation analysis for data fusion in multimodal emotion recognition. In Proceedings of the 2018 IEEE 9th International Symposium on Telecommunications (IST), Tehran, Iran, 17–19 December 2018; pp. 676–681. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012; Volume 25. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Řehůřek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 22 May 2010; ELRA: Valletta, Malta, 2010; pp. 45–50. Available online: http://is.muni.cz/publication/884893/en (accessed on 14 July 2022).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).