
Evaluating Intelligent Methods for Detecting COVID-19 Fake News on Social Media Platforms

 , , ,
, , , 
Abstract
:1. Introduction
2. Related Work
3. Description of Classifiers
3.1. Naïve Bayes
3.2. Logistic Regression
3.3. Support Vector Machines
3.4. Decision Tree
3.5. Random Forests
3.6. K-Nearest Neighbor
3.7. Convolutional Neural Network (CNN or ConvNet)
3.8. Long Short-Term Memory (LSTM)
4. Experiments
4.1. Description of the Datasets
4.2. Data Preprocessing
- Tokenization: Tokenization of the textual data is performed to break long sentences into individual words or numbers called tokens, and delimited by spaces.
- Noise Removal: Noise is unwanted data like punctuation marks, special symbols and hyperlinks that need to be removed from the text, as they do not carry any meaning to the model.
- Removal of Stop words: The most frequently used words in any language that do not contribute much information to the data are called stop words. The stop words in English are is, am, are, of, the, etc. The removal of stop words from the text decreases the dimensionality of the feature space and may also help in enhancing the performance of the classification model.
4.3. Feature Representation
4.4. Evaluation Metrics
4.4.1. Accuracy
4.4.2. Precision
4.4.3. Recall
4.4.4. False Positive Rate (FPR)
4.4.5. Misclassification Rate
4.4.6. F-Score
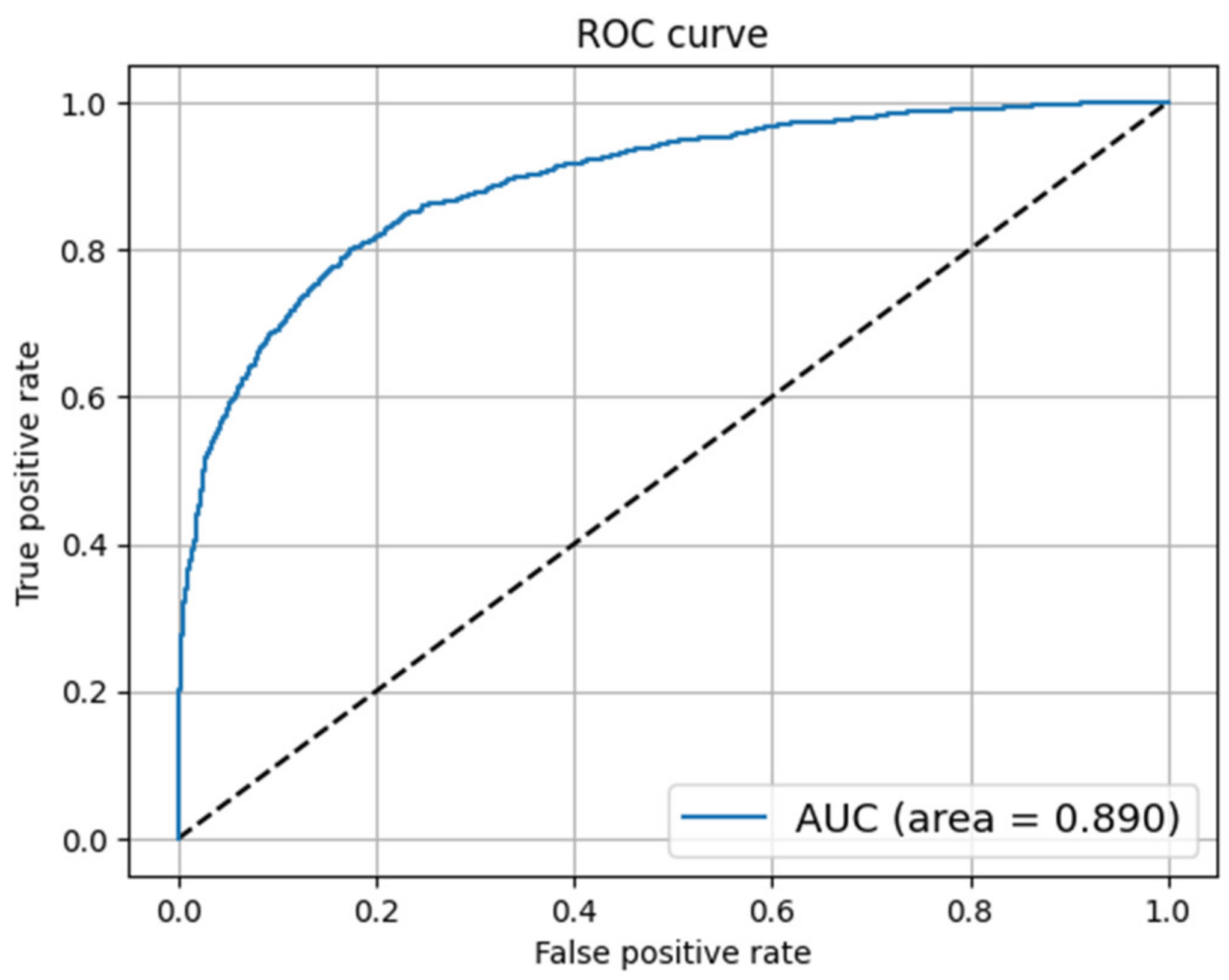
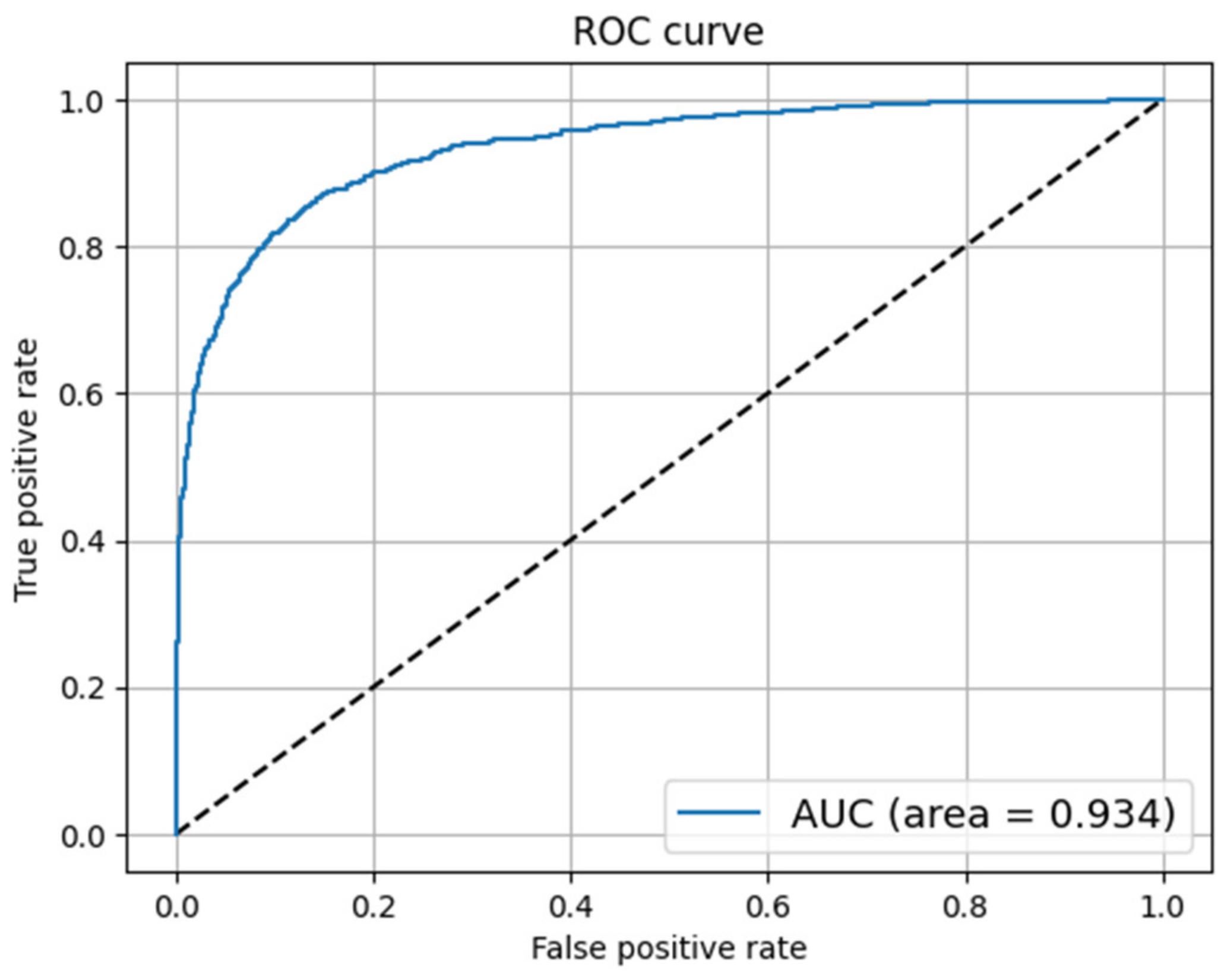
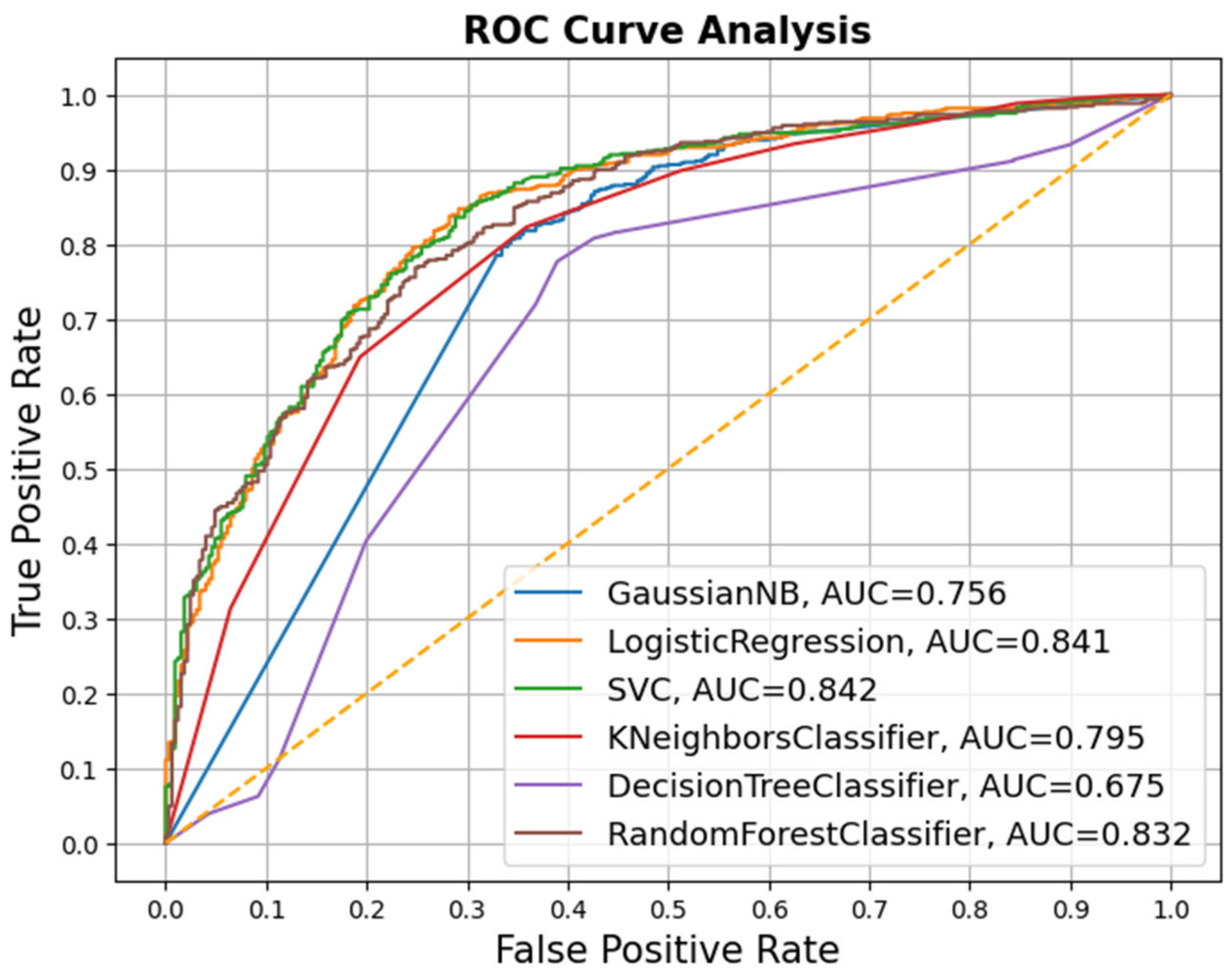
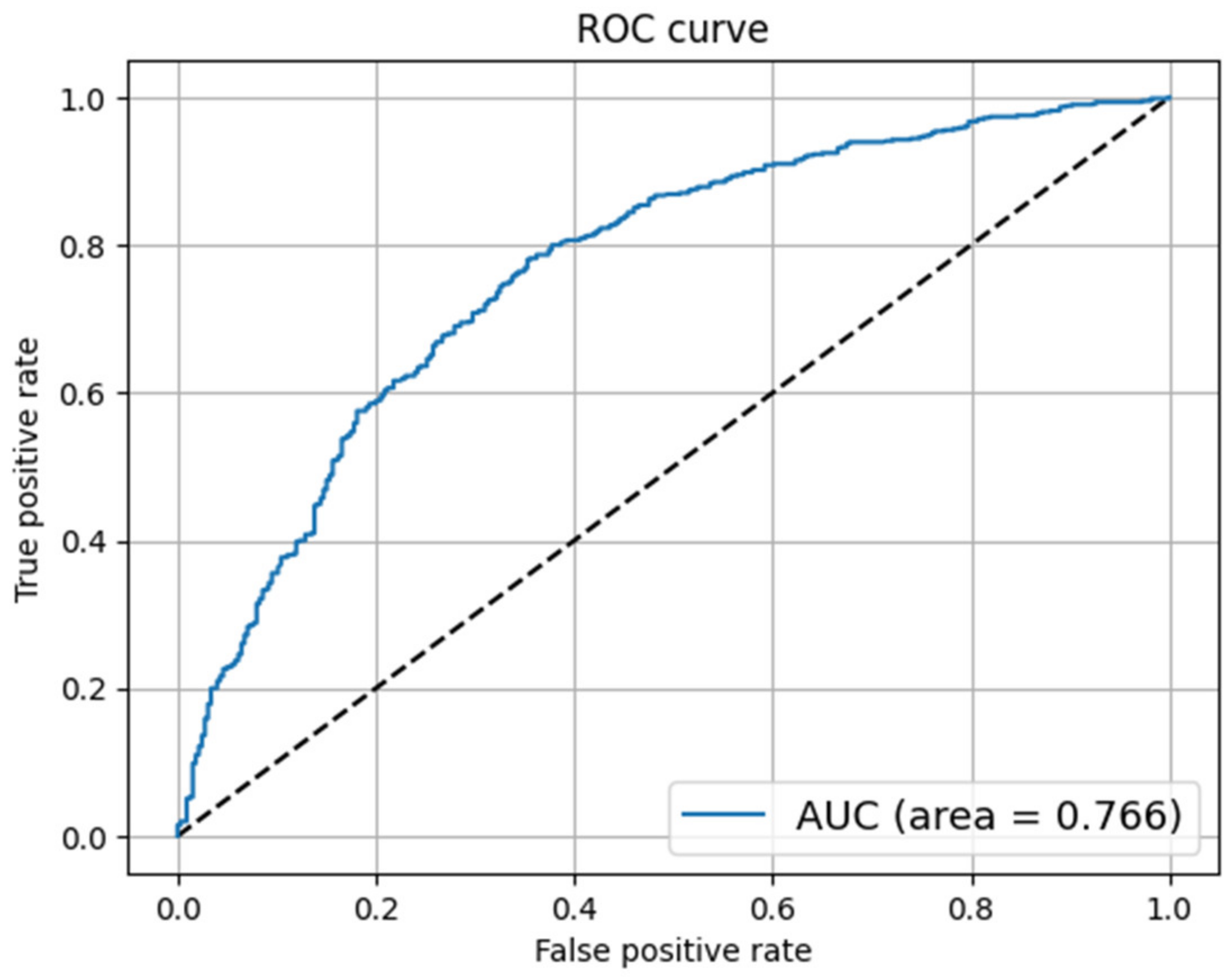
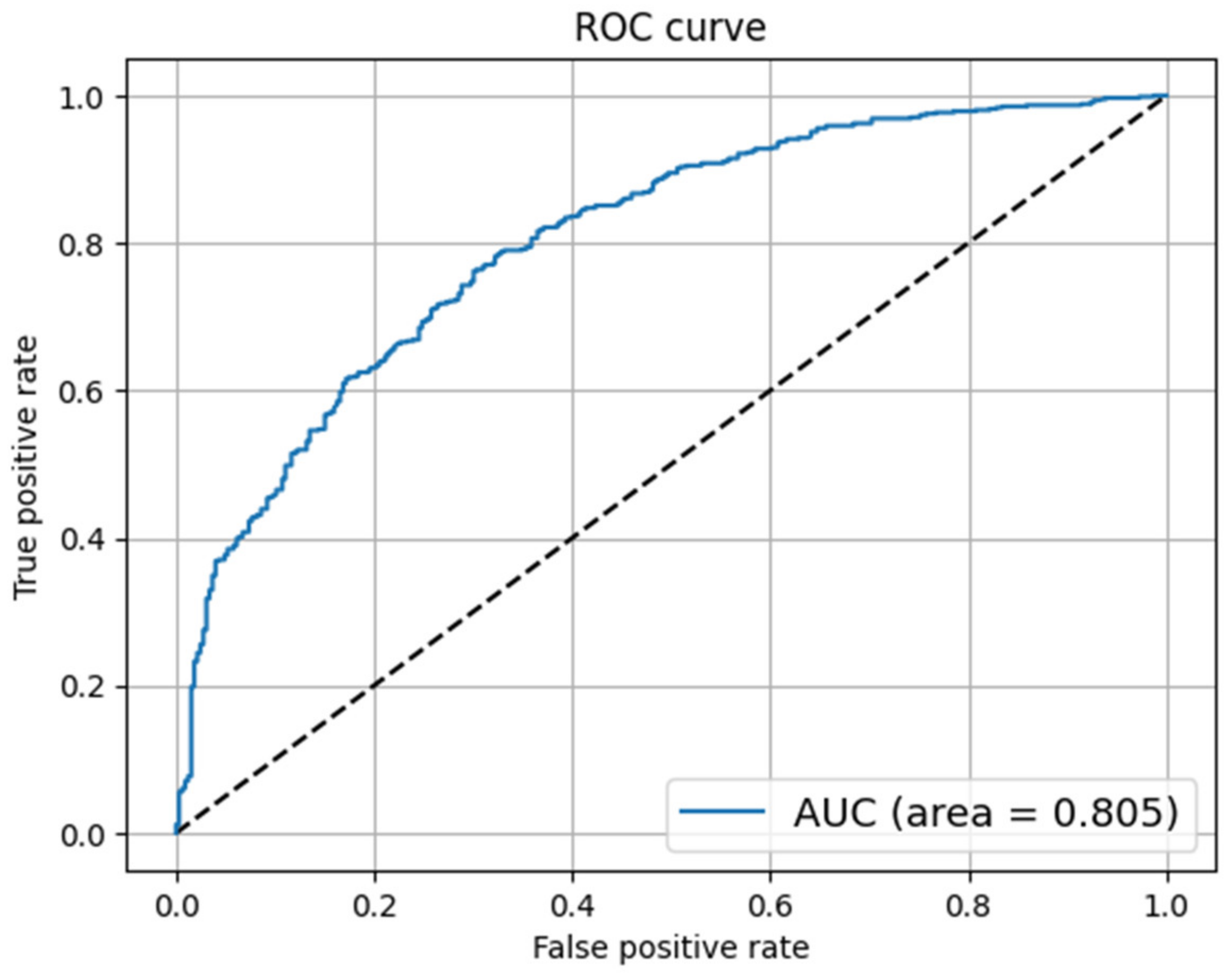
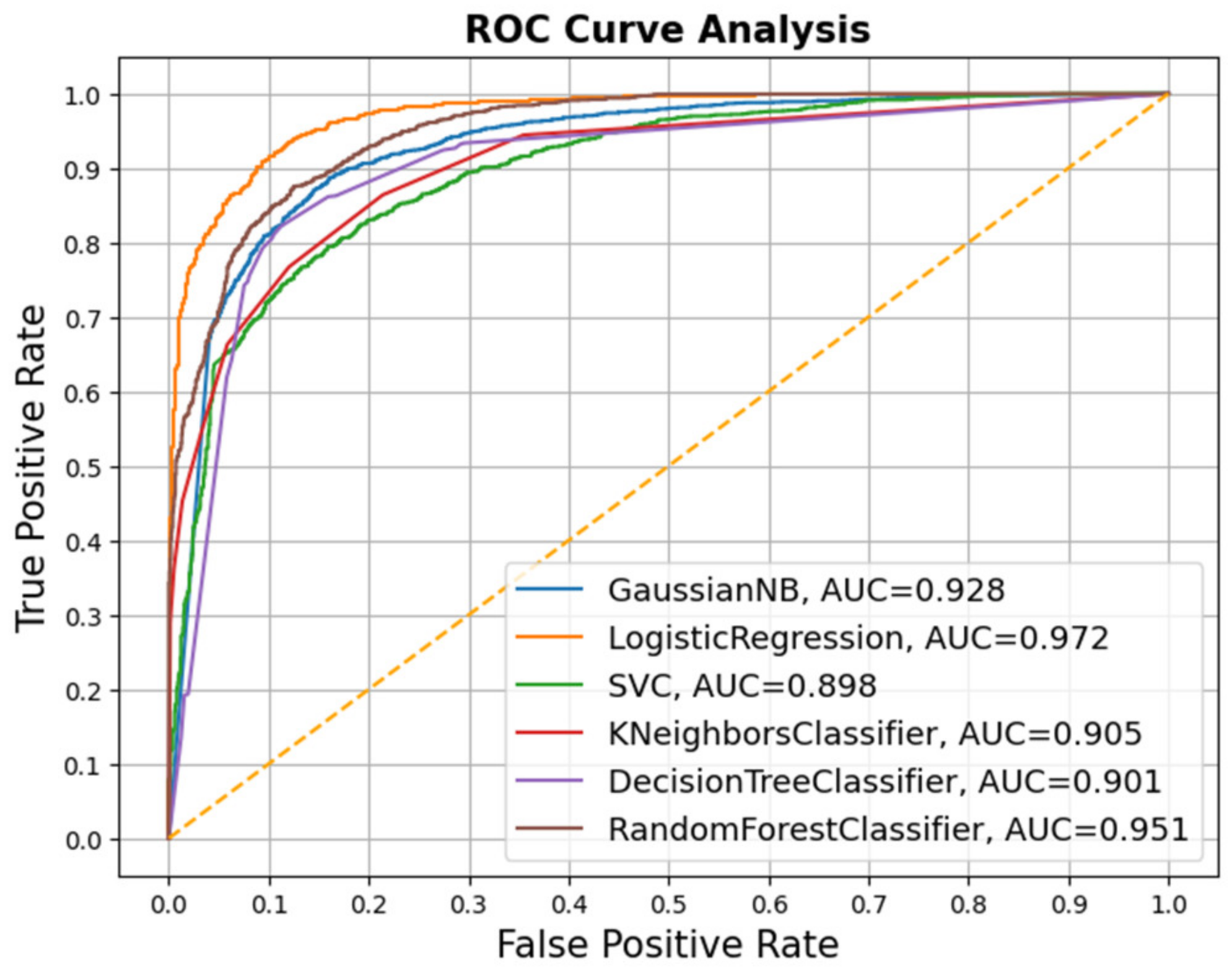
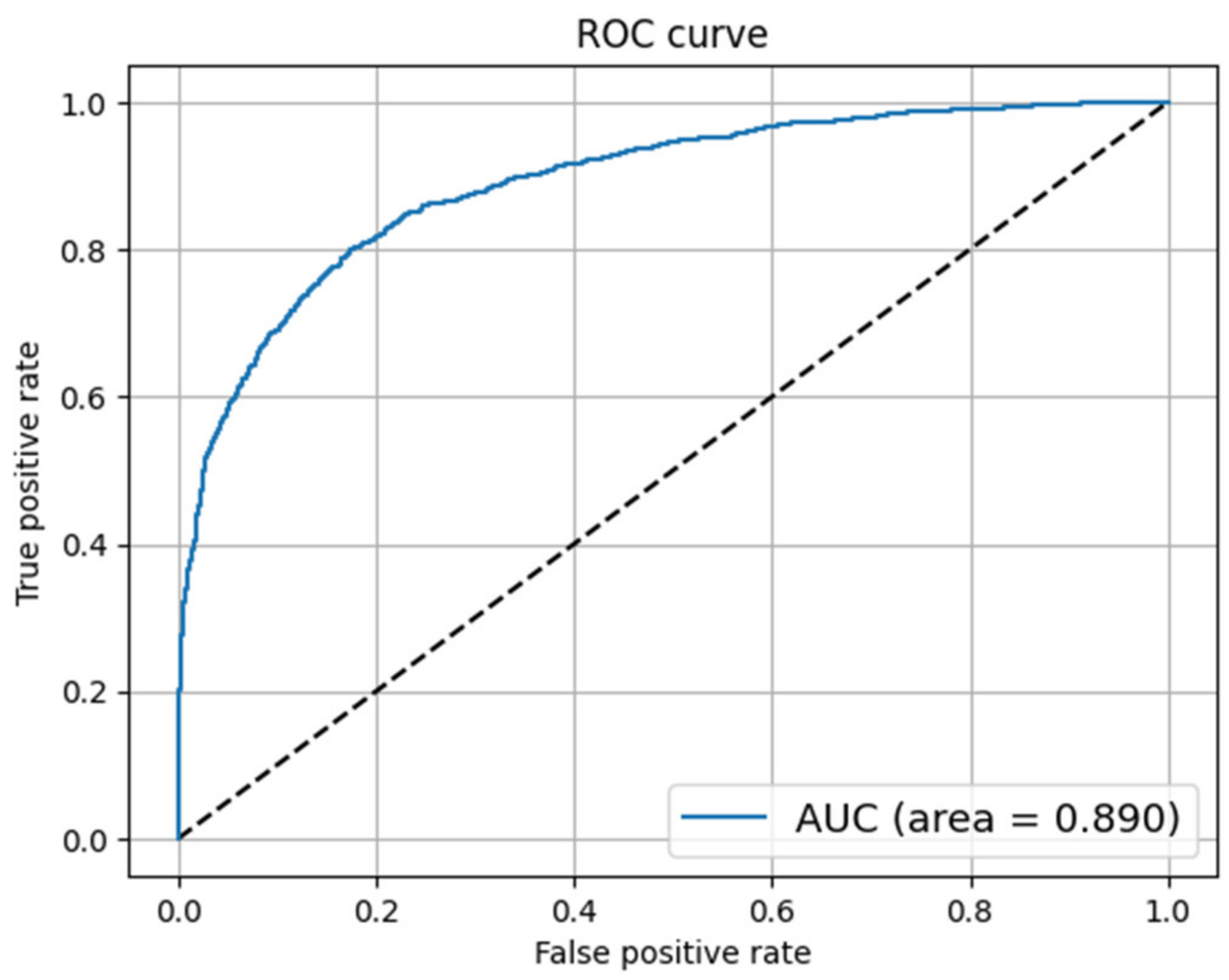
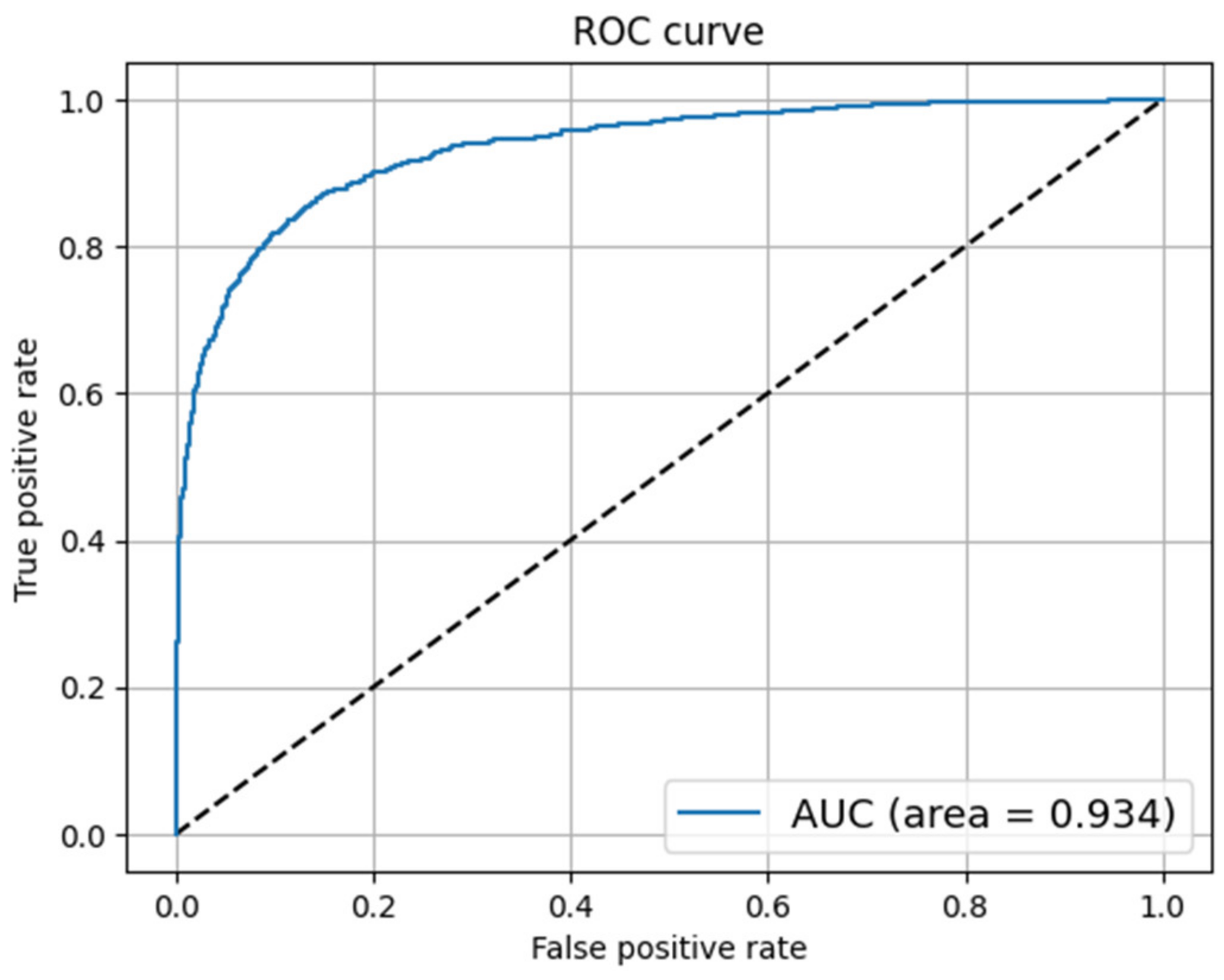
4.4.7. Receiver Operating Characteristic (ROC) Curve
4.5. Parameter Settings
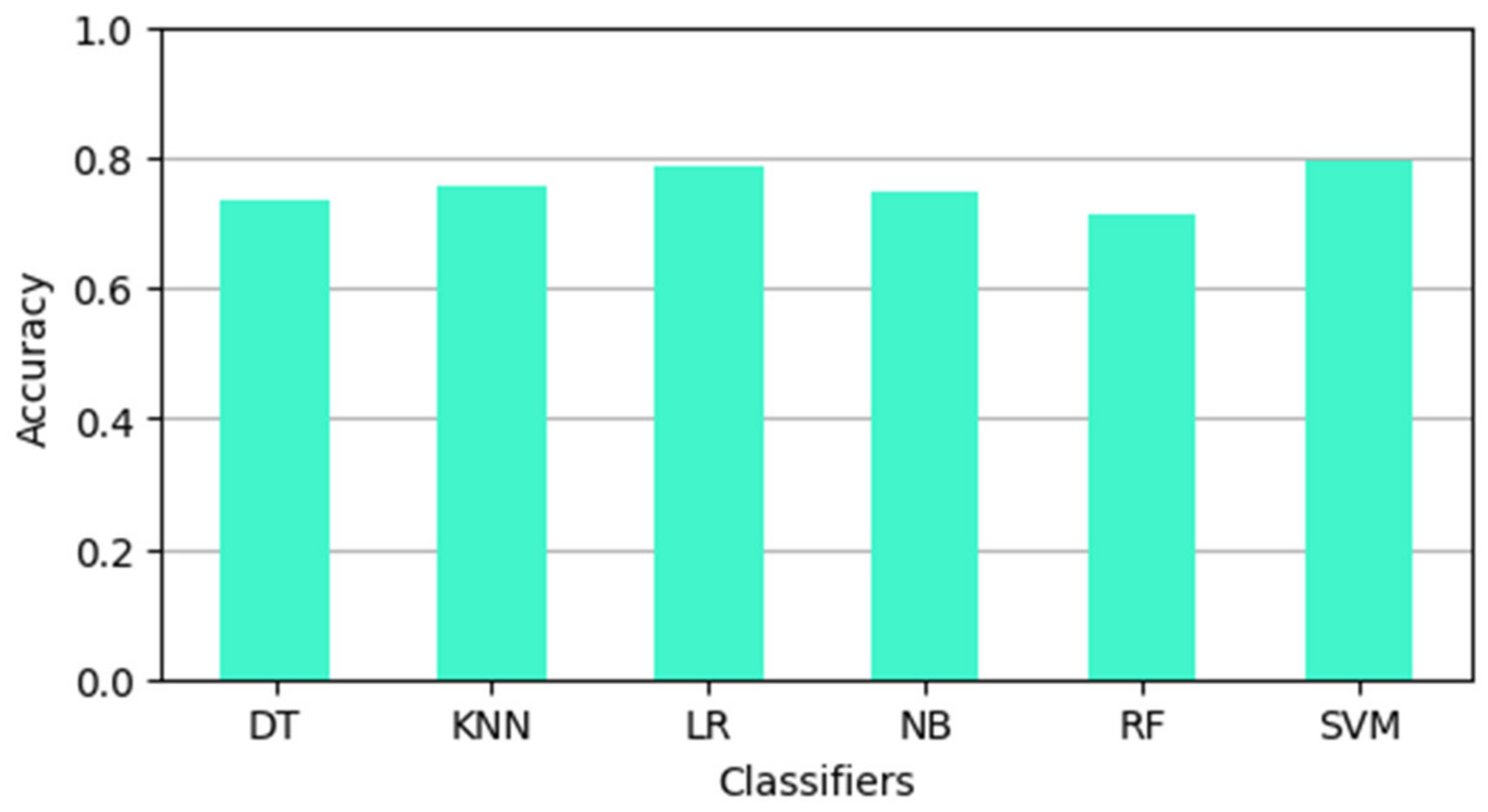
5. Results and Discussion
5.1. COVID-19 Fake News Dataset
5.2. Constraint@AAAI 2021 Dataset
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef] [PubMed]
- Zaryan, S. Truth and Trust: How Audiences are Making Sense of Fake News. Master’s Thesis, Lund University, Stockholm, Sweden, June 2017. [Google Scholar]
- Nicola, M.; Alsafi, Z.; Sohrabi, C.; Kerwan, A.; Al-Jabir, A.; Iosifidis, C.; Agha, M.; Agha, R. The socio-economic implications of the coronavirus pandemic (COVID-19): A review. Int. J. Surg. 2020, 78, 185–193. [Google Scholar] [CrossRef] [PubMed]
- Fake News in India—Wikipedia. Available online: https://en.wikipedia.org/wiki/FakenewsinIndia (accessed on 12 May 2022).
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine learning and deep learning. Electron. Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Data Classification: Algorithms and Applications; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Lai, C.-M.; Chen, M.-H.; Kristiani, E.; Verma, V.K.; Yang, C.-T. Fake News Classification Based on Content Level Features. Appl. Sci. 2022, 12, 1116. [Google Scholar] [CrossRef]
- Oshikawa, R.; Qian, J.; Wang, W.Y. A survey on natural language processing for fake news detection. arXiv 2018, arXiv:1811.00770. [Google Scholar]
- Minaee, S.; Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning—Based Text Classification: A Comprehensive Review. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Chen, Y.; Conroy, N.J.; Rubin, V.L. Misleading online content: Recognizing clickbait as ‘false news’. In Proceedings of the ACM Workshop on Multimodal Deception Detection, Seattle, WA, USA, 13 November 2015. [Google Scholar]
- Bourgonje, P.; Schneider, J.M.; Rehm, G. From clickbait to fake news detection: An approach based on detecting the stance of headlines to articles. In Proceedings of the EMNLP Workshop, Natural Language Processing Meets Journalism; Association for Computational Linguistics: Copenhagen, Denmark, 2017. [Google Scholar]
- Alrubaian, M.; Al-Qurishi, M.; Mehedi Hassan, M.; Alamri, A. A credibility analysis system for assessing information on Twitter. IEEE Trans. Depend. Sec. Comput. 2018, 15, 661–674. [Google Scholar] [CrossRef]
- Castillo, C.; Mendoza, M.; Poblete, B. Information credibility on Twitter. In Proceedings of the 20th International Conference on World Wide Web (WWW); Association for Computing Machinery: New York, NY, USA, 2011. [Google Scholar]
- Kaliyar, R.K.; Goswami, A.; Narang, P.; Sinha, S. FNDNet—A deep convolutional neural network for fake news detection. Cognit. Syst. Res. 2020, 61, 32–44. [Google Scholar] [CrossRef]
- Burgoon, J.K.; Blair, J.; Qin, T.; Nunamaker, J. Detecting deception through linguistic analysis. In Proceedings of the 1st NSF/NIJ Conference on Intelligence and Security Informatics, Berlin, Germany, 2–3 June 2003. [Google Scholar]
- Vicario, M.D.; Quattrociocchi, W.; Scala, A.; Zollo, F. Polarization and fake news: Early warning of potential misinformation targets. ACM Trans. Web. 2019, 13, 1–22. [Google Scholar] [CrossRef]
- Buntain, C.; Golbeck, J. Automatically identifying fake news in popular Twitter threads. In Proceedings of the 2017 IEEE International Conference on Smart Cloud (SmartCloud), New York, NY, USA, 3–5 November 2017. [Google Scholar]
- Newman, M.L.; Pennebaker, J.W.; Berry, D.S.; Richards, J.M. Lying words: Predicting deception from linguistic styles. Personal. Soc. Psychol. Bull. 2003, 29, 665–675. [Google Scholar] [CrossRef]
- Zhou, X.; Jain, A.; Phoha, V.V.; Zafarani, R. Fake news early detection: A theory-driven model. Digit. Threat. Res. Pract. 2020, 1, 1–25. [Google Scholar] [CrossRef]
- Gravanis, G.; Vakali, A.; Diamantaras, K.; Karadais, P. Behind the cues: A benchmarking study for fake news detection. Expert Syst. Appl. 2019, 128, 201–213. [Google Scholar] [CrossRef]
- Krešňáková, V.; Sarnovský, M.; Butka, P. Deep learning methods for Fake News detection. In Proceedings of the IEEE 19th International Symposium on Computational Intelligence and Informatics and 7th IEEE International Conference on Recent Achievements in Mechatronics, Automation, Computer Sciences and Robotics, Szeged, Hungary, 14–16 November 2019. [Google Scholar]
- Nassif, A.B.; Elnagar, A.; Elgendy, O.; Afadar, Y. Arabic fake news detection based on deep contextualized embedding models. Neural Comput. Appl. 2022; in press. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2009. [Google Scholar]
- Joachims, T. Text Categorization with Support Vector Machines: Learning with Many Relevant Features. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Koirala, A. COVID-19 Fake News Dataset; Mendeley Data, V1. 2021. Available online: https://data.mendeley.com/datasets/zwfdmp5syg/1 (accessed on 28 June 2022).
- Koirala, A. COVID-19 Fake News Classification with Deep Learning. 2020. Available online: https://www.researchgate.net/profile/Abhishek-Koirala/publication/344966237_COVID-19_Fake_News_Classification_with_Deep_Learning/links/5f9b6ba5299bf1b53e5130b8/COVID-19-Fake-News-Classification-with-Deep-Learning.pdf(accessed on 28 June 2022).
- Patwa, P. Fighting an infodemic: COVID-19 fake news dataset. arXiv 2020, arXiv:2011.03327. [Google Scholar]
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Zhao, R.; Kezhi, M. Fuzzy bag-of-words model for document representation. IEEE Trans. Fuzzy Syst. 2017, 26, 794–804. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems; Association for Computing Machinery: New York, NY, USA, 2012. [Google Scholar]
- Mikolov, T.; Deoras, A.; Povey, D.; Burget, L.; Cernocky, J. Strategies for training large scale neural network language models. In Proceedings of the Automatic Speech Recognition and Understanding, Waikoloa, HI, USA, 11–15 December 2011. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Cham, Germany, 2014. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2013. [Google Scholar]
- Naseem, U.; Razzak, I.; Khan, S.K.; Prasad, M. A Comprehensive Survey on Word Representation Models: From Classical to State-Of-The-Art Word Representation Language Models. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 20, 1–35. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics: Stroudsburg, PA, USA, 2014. [Google Scholar]
- Bhoir, S.; Ghorpade, T.; Mane, V. Comparative analysis of different word embedding models. In Proceedings of the International Conference on Advances in Computing, Communication and Control (ICAC3), Mumbai, India, 1–2 December 2017. [Google Scholar]
- Shapol, M.; Jacksi, K.; Zeebaree, S. A state-of-the-art survey on semantic similarity for document clustering using GloVe and density-based algorithms. Indones. J. Electr. Eng. Comput. Sci. 2021, 22, 552–562. [Google Scholar]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Shami, A. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Cervantes, J.; Li, X.; Yu, W.; Li, K. Support vector machine classification for large data sets via minimum enclosing ball clustering. Neurocomputing 2008, 71, 611–619. [Google Scholar] [CrossRef]
- Fabio, J.; Bezerra, R. Content-based fake news classification through modified voting ensemble. J. Inf. Telecommun. 2021, 5, 499–513. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Actual Class Label | Predicted Class Label |
|---|---|---|
| True Positive (TP) | True | True |
| True Negative (TN) | Fake | Fake |
| False Positive (FP) | Fake | True |
| False Negative (FN) | True | Fake |
| Model | Hyperparameter | Value |
|---|---|---|
| SVM | C | 1 |
| gamma | 1 | |
| kernel | rbf | |
| KNN | n_neighbors | 8 |
| DT | criterion | gini |
| max_depth | 8 | |
| LR | C | 1 |
| RF | criterion | gini |
| max_depth | 8 | |
| max_features | sqrt | |
| n_estimators | 200 | |
| CNN | Conv1D Layers | 1 |
| Filters | 32 | |
| Kernel size | 2,3,4 | |
| global avgpool layer | 3 | |
| activation function | relu | |
| optimizer | Adam | |
| loss function | binary cross entropy | |
| LSTM | hidden layers | 6 |
| learning rate | 0.001 | |
| batch size | 64 | |
| gate activation function | sigmoid | |
| state activation function | tanh |
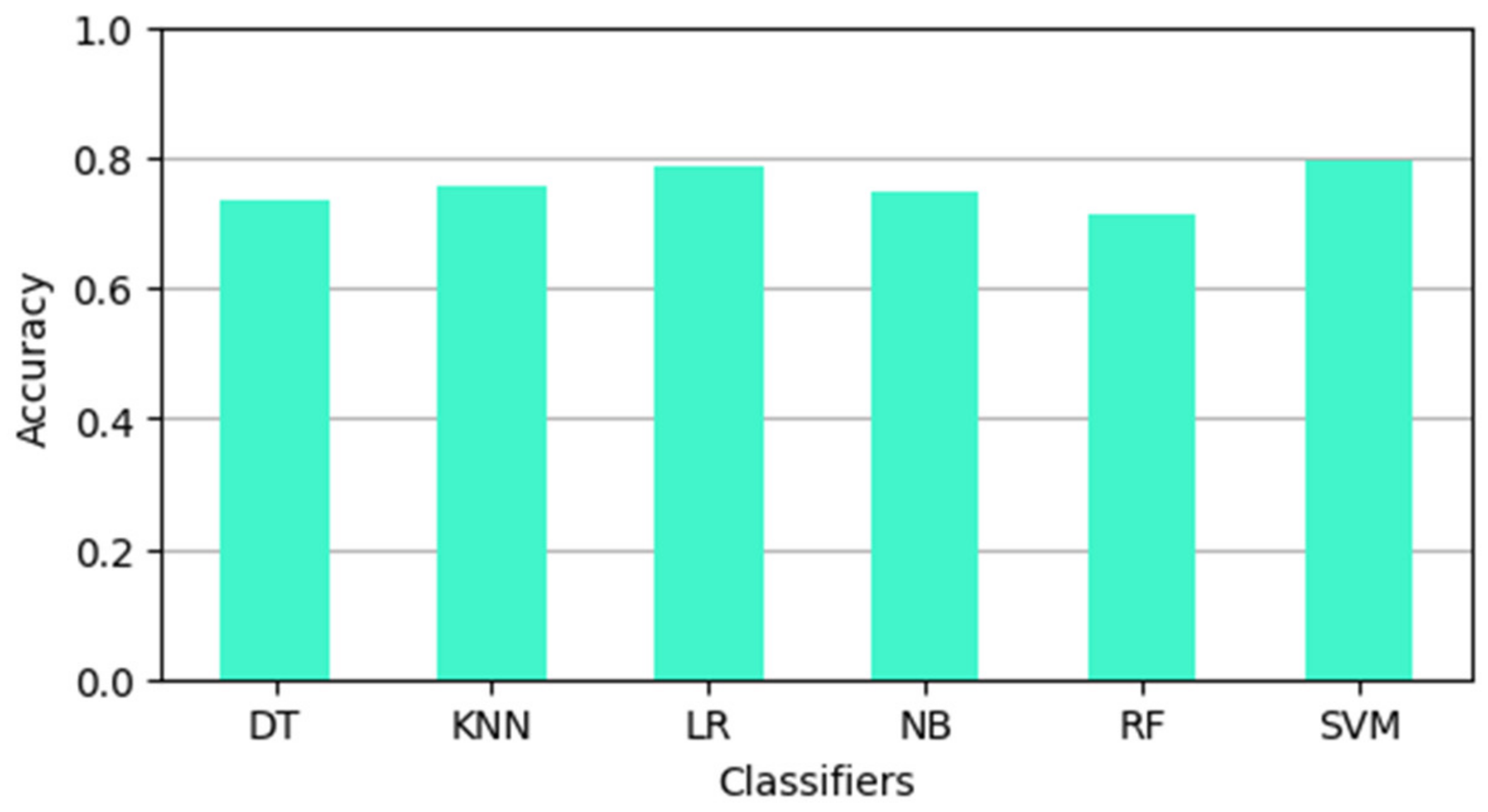
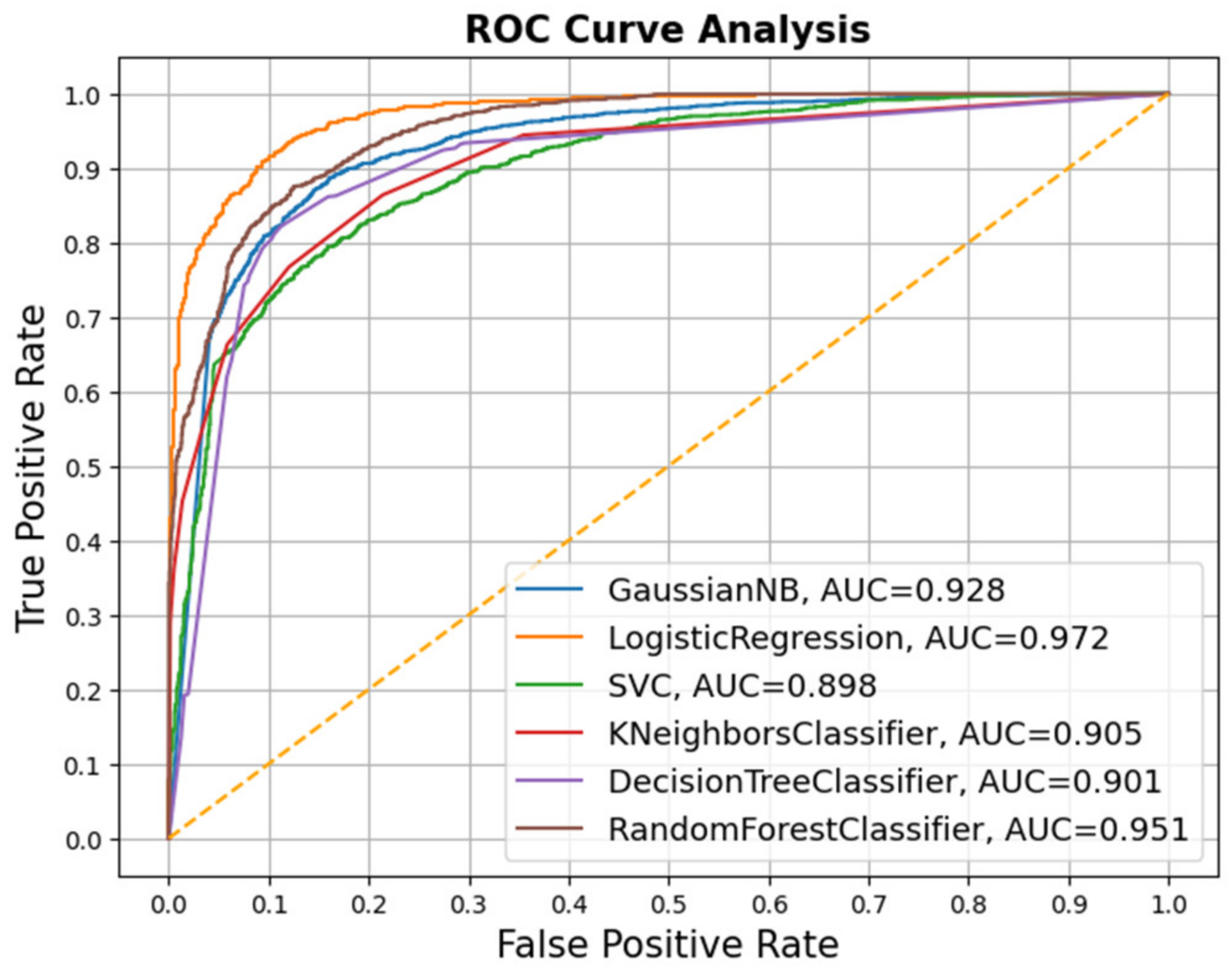
| Classifier | DT | KNN | LR | NB | RF | SVM |
|---|---|---|---|---|---|---|
| Accuracy | 0.74 | 0.76 | 0.79 | 0.75 | 0.71 | 0.80 |
| Precision | 0.78 | 0.77 | 0.79 | 0.82 | 0.70 | 0.81 |
| Recall | 0.82 | 0.90 | 0.91 | 0.79 | 0.97 | 0.90 |
| FPR | 0.43 | 0.51 | 0.45 | 0.33 | 0.78 | 0.40 |
| Rate of Misclassification | 0.26 | 0.24 | 0.21 | 0.25 | 0.29 | 0.20 |
| F-score | 0.79 | 0.83 | 0.85 | 0.80 | 0.81 | 0.85 |
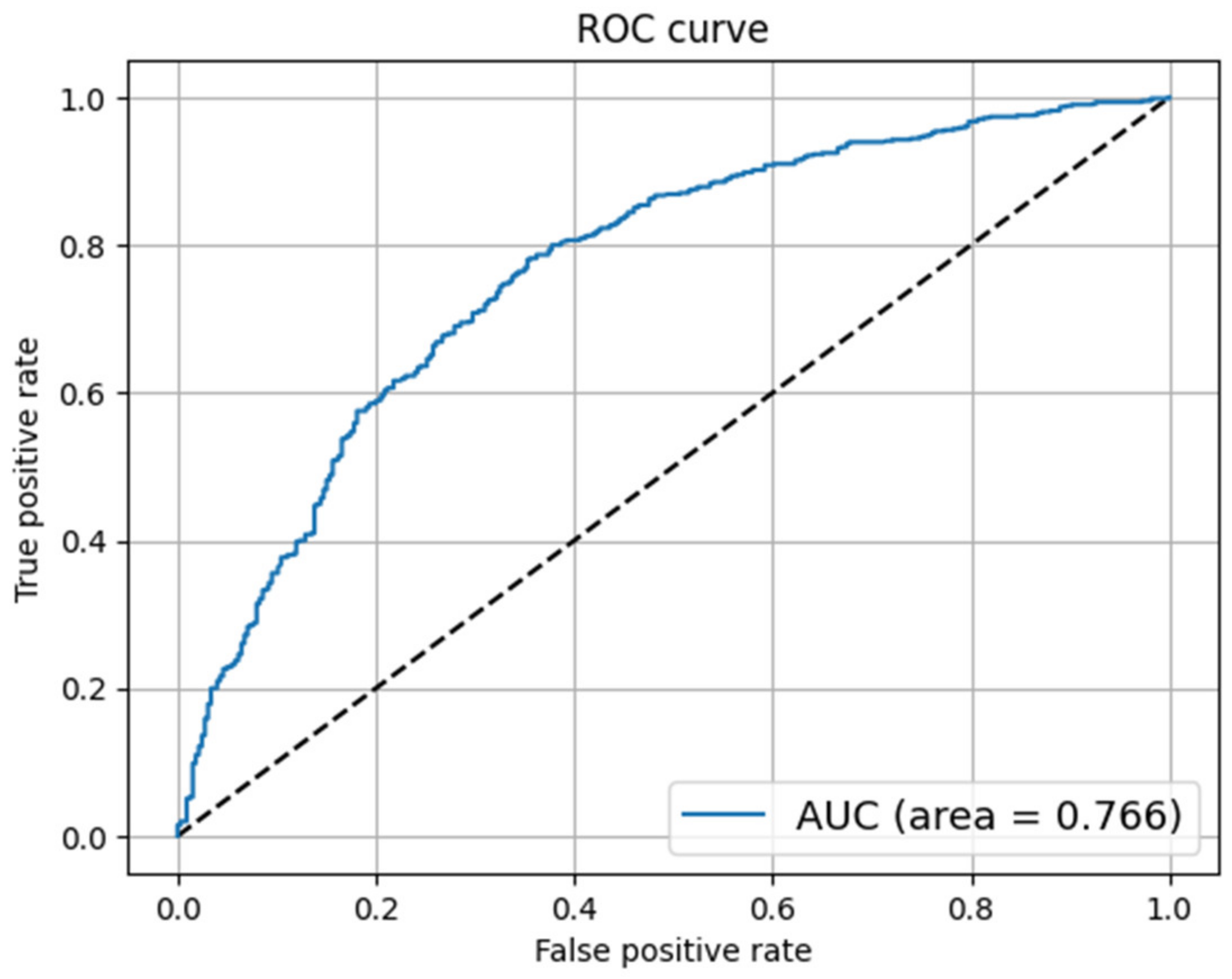
| Classifier | CNN | LSTM |
|---|---|---|
| Accuracy | 0.76 | 0.75 |
| Precision | 0.77 | 0.77 |
| Recall | 0.89 | 0.88 |
| FPR | 0.50 | 0.50 |
| Rate of Misclassification | 0.24 | 0.25 |
| F-score | 0.83 | 0.82 |
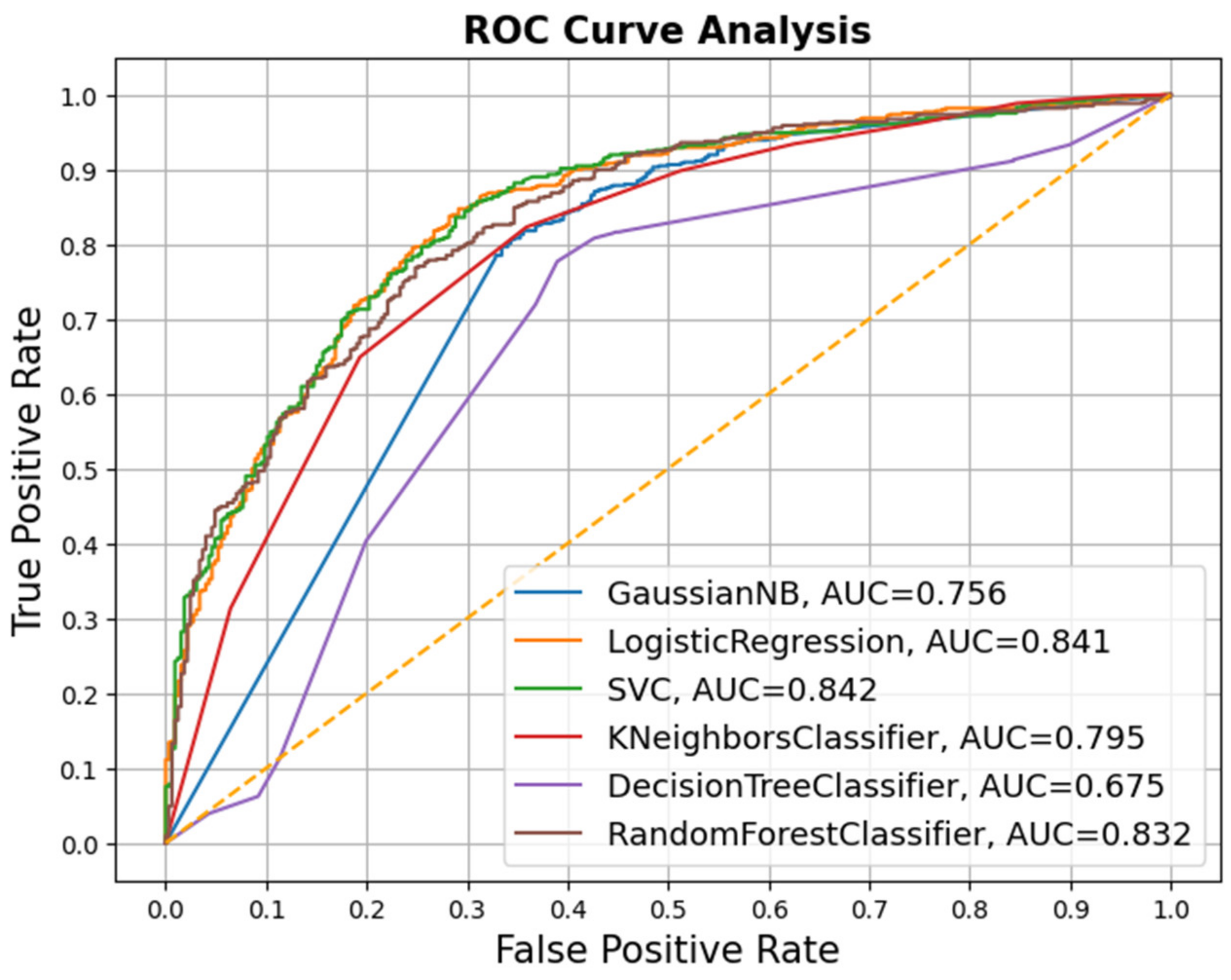
| Classifier | DT | KNN | LR | NB | RF | SVM |
|---|---|---|---|---|---|---|
| Accuracy | 0.87 | 0.76 | 0.91 | 0.81 | 0.88 | 0.65 |
| Precision | 0.91 | 0.96 | 0.93 | 0.95 | 0.88 | 0.60 |
| Recall | 0.84 | 0.58 | 0.90 | 0.68 | 0.88 | 0.99 |
| FPR | 0.09 | 0.03 | 0.08 | 0.04 | 0.13 | 0.72 |
| Rate of Misclassification | 0.13 | 0.24 | 0.09 | 0.19 | 0.12 | 0.35 |
| F-score | 0.87 | 0.72 | 0.92 | 0.80 | 0.88 | 0.75 |
| Classifier | CNN | LSTM |
|---|---|---|
| Accuracy | 0.81 | 0.84 |
| Precision | 0.83 | 0.93 |
| Recall | 0.77 | 0.72 |
| FPR | 0.17 | 0.07 |
| Rate of Misclassification | 0.19 | 0.16 |
| F-score | 0.80 | 0.81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alhakami, H.; Alhakami, W.; Baz, A.; Faizan, M.; Khan, M.W.; Agrawal, A. Evaluating Intelligent Methods for Detecting COVID-19 Fake News on Social Media Platforms. Electronics 2022, 11, 2417. https://doi.org/10.3390/electronics11152417
Alhakami H, Alhakami W, Baz A, Faizan M, Khan MW, Agrawal A. Evaluating Intelligent Methods for Detecting COVID-19 Fake News on Social Media Platforms. Electronics. 2022; 11(15):2417. https://doi.org/10.3390/electronics11152417
Chicago/Turabian StyleAlhakami, Hosam, Wajdi Alhakami, Abdullah Baz, Mohd Faizan, Mohd Waris Khan, and Alka Agrawal. 2022. "Evaluating Intelligent Methods for Detecting COVID-19 Fake News on Social Media Platforms" Electronics 11, no. 15: 2417. https://doi.org/10.3390/electronics11152417
APA StyleAlhakami, H., Alhakami, W., Baz, A., Faizan, M., Khan, M. W., & Agrawal, A. (2022). Evaluating Intelligent Methods for Detecting COVID-19 Fake News on Social Media Platforms. Electronics, 11(15), 2417. https://doi.org/10.3390/electronics11152417