
Chinese Spam Detection Using a Hybrid BiGRU-CNN Network with Joint Textual and Phonetic Embedding


Abstract
:1. Introduction
2. Related Work
2.1. Traditional Detection Methods
2.2. Detection Methods Based on Machine Learning
2.3. Detection Methods Based on Deep Learning
3. Methods
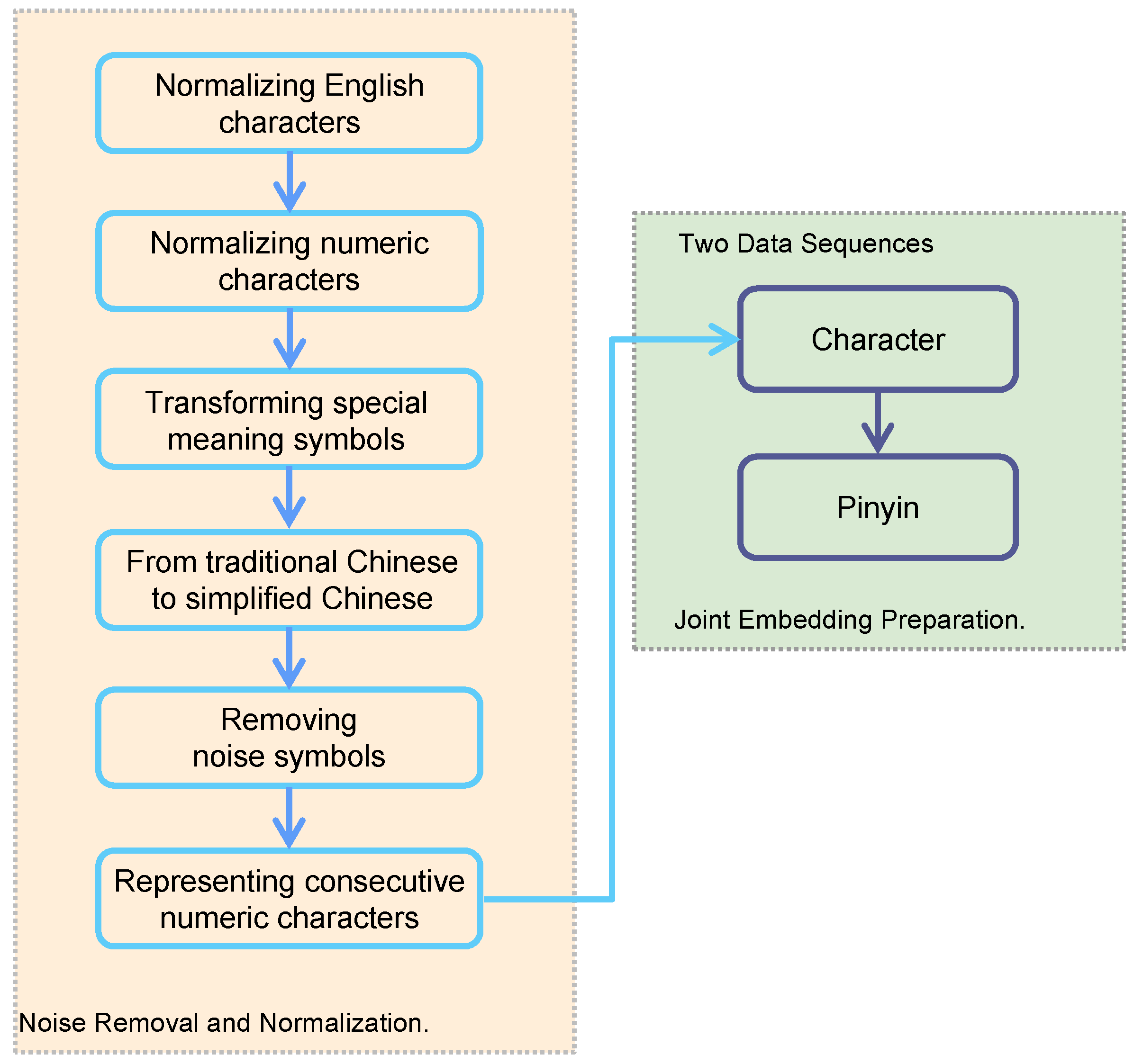
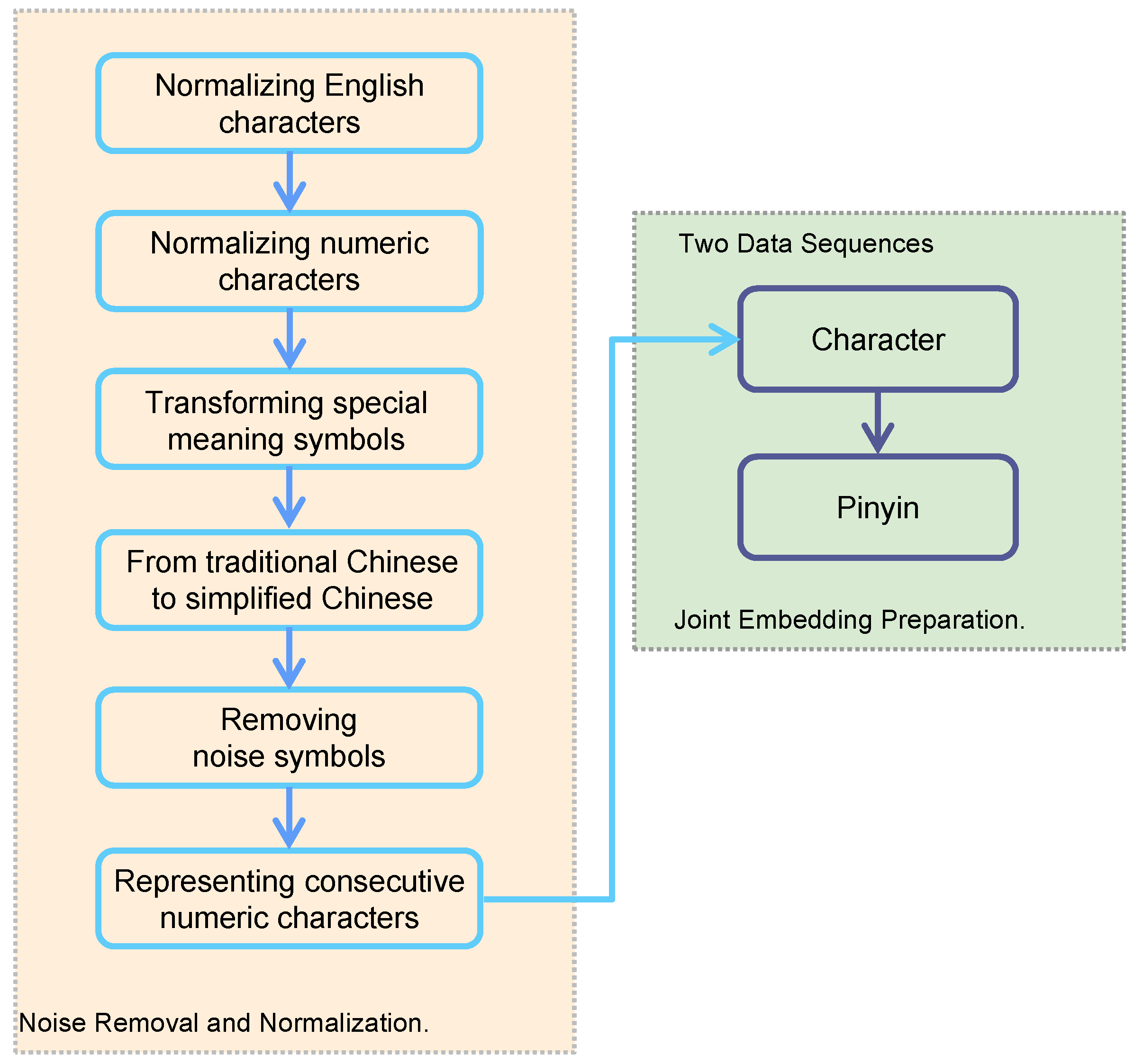
3.1. Data Preprocessing
- Normalizing English characters: converting all differently encoded alphabet symbols with similar shapes to standard lowercase English characters;
- Normalizing numeric characters: converting all coded symbols with numeric meaning in Unicode encoding to standard numeric character encoding;
- Transforming special-meaning symbols: converting some symbols with special meanings into corresponding special-meaning symbols. For instance, ‘†’ and other symbols similar to ‘+’ are converted into the Chinese character ‘加’, which means “add”;
- Converting traditional Chinese to simplified Chinese characters;
- Removing noise symbols to filter out all symbols of non-Chinese characters, non-English characters, and non-numeric characters;
- Representing consecutive numeric characters: constructing a new consecutive numeric character form in the text that has undergone the previous processing. In this step, a sequence of numeric characters is expressed as “<num_n>” according to the number of numeric characters, where n represents the number of consecutive numeric characters. For instance, “QQ2517645947” is expressed as “QQ<num_10>”.
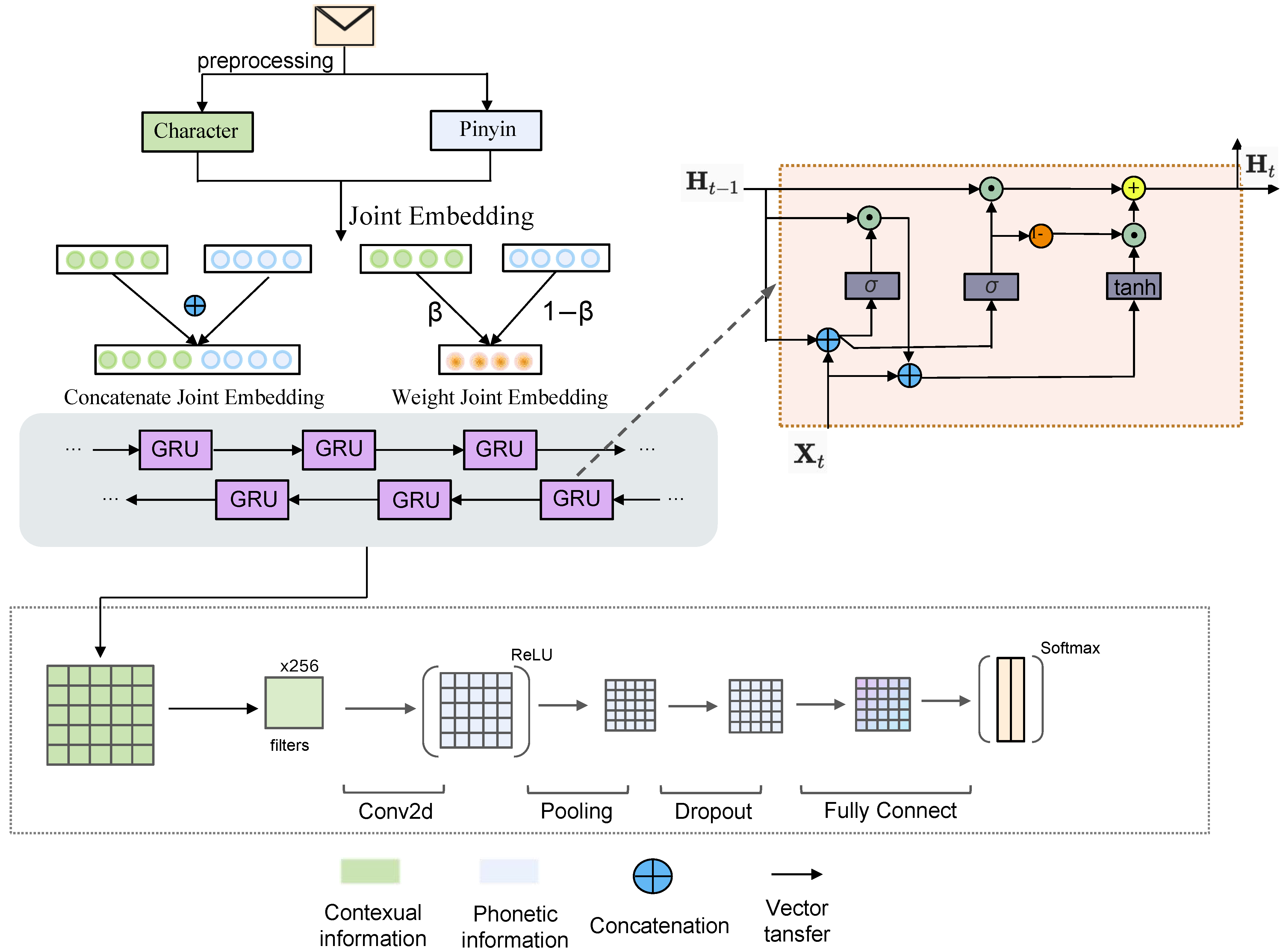
3.2. BiGRU-CNN-JE Model
3.2.1. Joint Embedding Module
- •
- Concatenate Joint Embedding (CJE):CJE denotes the direct concatenation of Chinese character embedding and Pinyin embedding, and the dimensions of the joint embedding are their sum. Formally, we denote by the Chinese character embedding vector and by the Pinyin embedding vector; the joint embedding vector E is obtained byObviously, this is the most straightforward to use and requires the fewest model parameters.
- •
- Weight Joint Embedding (WJE):WJE refers to weighing the contextual and phonetic information and then combining the two embedding vectors. The joint embedding vector E is as follows:where β is a trainable parameter. WJE is not a coarse-grained joint scheme, and it is capable of dynamically capturing more complex correlations across contextual and phonetic information.
3.2.2. BiGRU Module
3.2.3. CNN Module
4. Experiment
4.1. Dataset
4.2. Experimental Configuration
4.3. Performance Metrics
- Accuracy is the proportion of correctly classified samples to total samples for a given datum;
- Precision is the percentage of samples predicted to be positive as true classes;
- Recall is the percentage of positive samples that are predicted to be positive;
- F1 score is the weighted average of precision and recall.
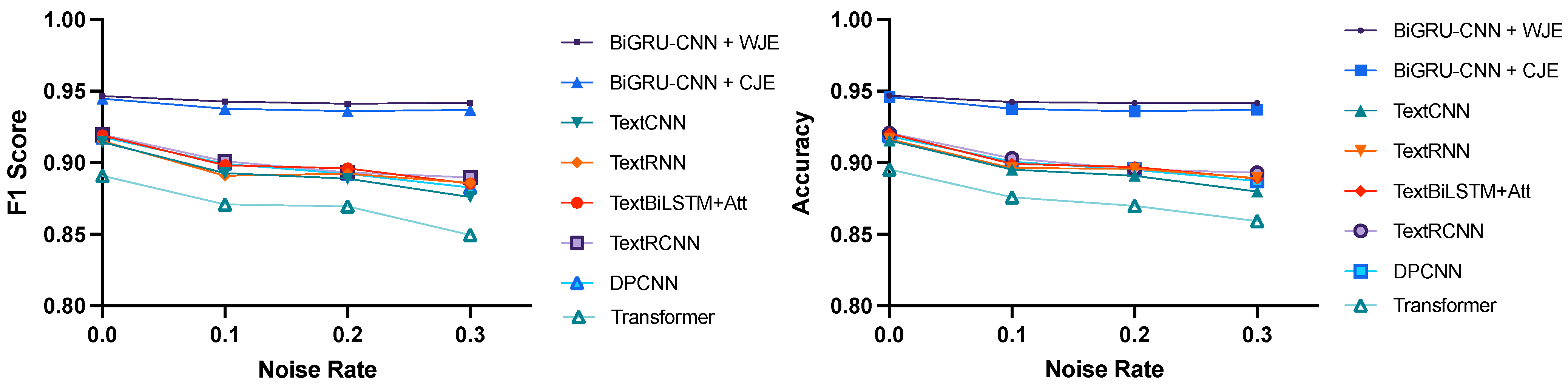
4.4. Experimental Results and Analyses
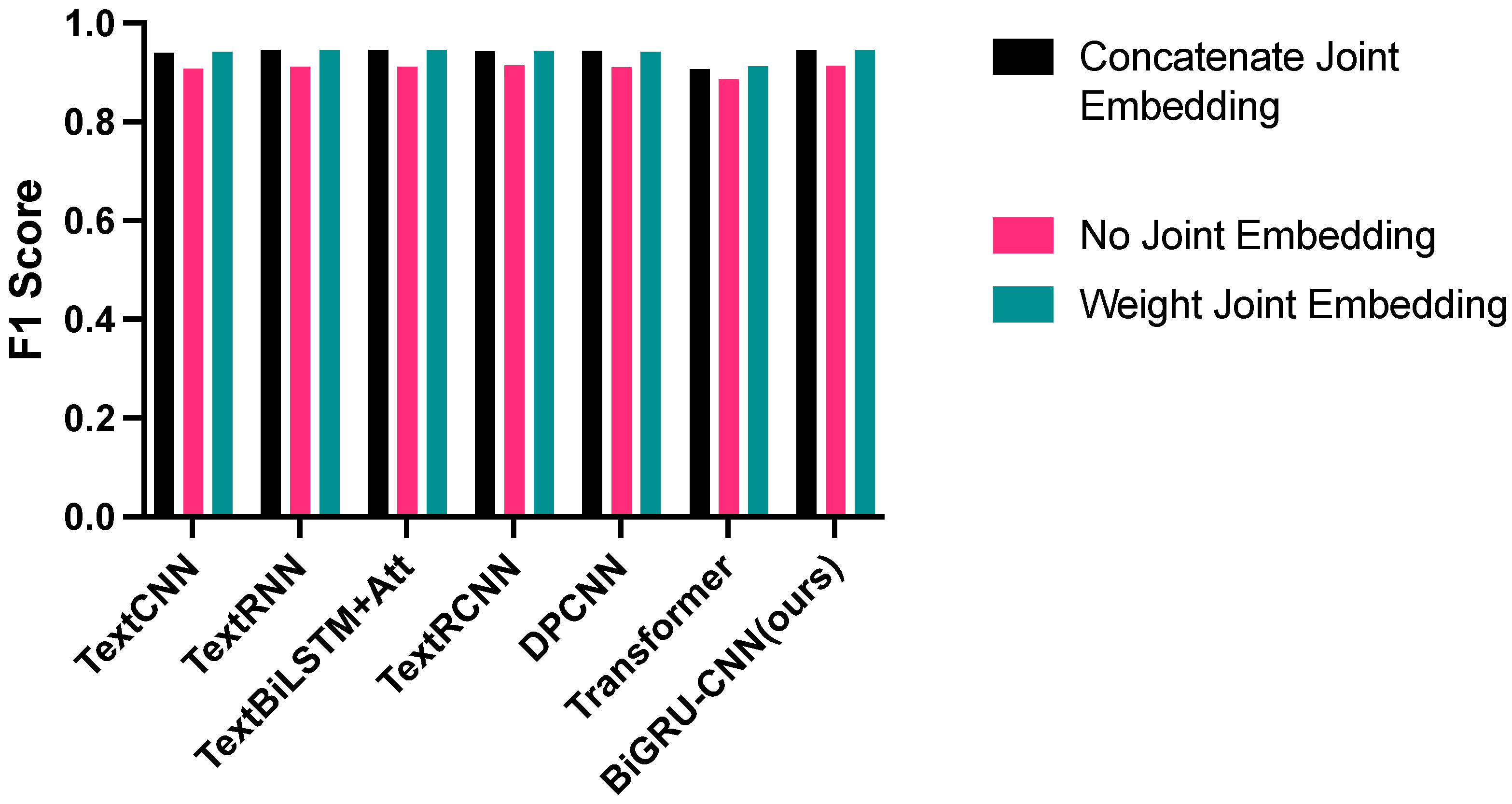
4.5. Ablation Experiment
5. Discussion and Limitations
- The proposed method primarily focuses on improving the ability to deal with Chinese homophonic noise. It is incapable of dealing with other types of textual noise. We believe that spammers will improve their technology to create adversarial spam to evade spam detection systems. The problem of managing the new noise-adding method is always a vital issue. Other common types of noise are the substitution of Chinese characters with similar shapes, the addition of good words, etc. We would like to find a new way to detect other noise in Chinese spam text in the future.
- Since the BiGRU-CNN-JE model increases the total number of model parameters, it may slightly reduce efficiency and increase the overall time complexity. We argue that this would not be a barrier to real-world use in areas where network security needs to be guaranteed because spam is both annoying and harmful. To reduce the model’s time complexity, we will consider addressing the following directions in the future. First, we will attempt to reduce model parameters through model compression via knowledge distillation [35,36] or improve the convolution operation via depthwise separable convolutions [37]. Next, we will try to use a simple autoencoder and deep neural network in a combined network structure [38] that can perform fast training and prediction. In addition, in an effort to reduce overall computation time, distributed computing [39] will be used in Chinese spam detection tasks.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bakshy, E.; Rosenn, I.; Marlow, C.; Adamic, L. The role of social networks in information diffusion. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 519–528. [Google Scholar]
- Luo, Y.; Xu, X. Comparative study of deep learning models for analyzing online restaurant reviews in the era of the COVID-19 pandemic. Int. J. Hosp. Manag. 2021, 94, 102849. [Google Scholar] [CrossRef] [PubMed]
- Rao, S.; Verma, A.K.; Bhatia, T. A review on social spam detection: Challenges, open issues, and future directions. Expert Syst. Appl. 2021, 186, 115742. [Google Scholar] [CrossRef]
- Nalarubiga, E.; Sindhuja, M. Efficient Classifier for Detecting Spam in Social Networks through Sentiment Analysis. Asian J. Res. Soc. Sci. Humanit. 2016, 6, 1066. [Google Scholar] [CrossRef]
- Bindu, P.; Mishra, R.; Thilagam, P.S. Discovering spammer communities in twitter. J. Intell. Inf. Syst. 2018, 51, 503–527. [Google Scholar] [CrossRef]
- Alom, Z.; Carminati, B.; Ferrari, E. Detecting spam accounts on Twitter. In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Barcelona, Spain, 28–31 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1191–1198. [Google Scholar]
- Karan, M.; Šnajder, J. Cross-domain detection of abusive language online. In Proceedings of the 2nd Workshop on Abusive Language Online (ALW2), Brussels, Belgium, 31 October 2018; pp. 132–137. [Google Scholar]
- Yaseen, Q.; AbdulNabi, I. Spam email detection using deep learning techniques. Procedia Comput. Sci. 2021, 184, 853–858. [Google Scholar]
- Deshmukh, R.; Bhalerao, V. Performance comparison for spam detection in social media using deep learning algorithms. Turk. J. Comput. Math. Educ. (TURCOMAT) 2021, 12, 193–201. [Google Scholar]
- Papernot, N.; McDaniel, P.; Swami, A.; Harang, R. Crafting adversarial input sequences for recurrent neural networks. In Proceedings of the MILCOM 2016–2016 IEEE Military Communications Conference, Baltimore, MD, USA, 1–3 November 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 49–54. [Google Scholar]
- Gao, J.; Lanchantin, J.; Soffa, M.L.; Qi, Y. Black-box generation of adversarial text sequences to evade deep learning classifiers. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 50–56. [Google Scholar]
- Behjati, M.; Moosavi-Dezfooli, S.M.; Baghshah, M.S.; Frossard, P. Universal adversarial attacks on text classifiers. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 7345–7349. [Google Scholar]
- Jáñez-Martino, F.; Alaiz-Rodríguez, R.; González-Castro, V.; Fidalgo, E.; Alegre, E. A review of spam email detection: Analysis of spammer strategies and the dataset shift problem. Artif. Intell. Rev. 2022, 1–29. [Google Scholar] [CrossRef]
- Perfetti, C.A.; Tan, L.H. The time course of graphic, phonological, and semantic activation in Chinese character identification. J. Exp. Psychol. Learn. Mem. Cogn. 1998, 24, 101. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Chen, Y. Convolutional Neural Network for Sentence Classification. Master’s Thesis, University of Waterloo, Waterloo, ON, Canada, 2015. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Recurrent neural network for text classification with multi-task learning. arXiv 2016, arXiv:1605.05101. [Google Scholar]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 7–12 August 2016; pp. 207–212. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Johnson, R.; Zhang, T. Deep pyramid convolutional neural networks for text categorization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 562–570. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 3058. [Google Scholar]
- Qiu, Y.; Xu, Y.; Li, D.; Li, H. A keyword based strategy for spam topic discovery from the Internet. In Proceedings of the 2010 Fourth International Conference on Genetic and Evolutionary Computing, Shenzhen, China, 13–15 December 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 260–263. [Google Scholar]
- Zhou, Y.; Jiang, J.Y.; Chang, K.W.; Wang, W. Learning to discriminate perturbations for blocking adversarial attacks in text classification. arXiv 2019, arXiv:1909.03084. [Google Scholar]
- Li, J.; Ji, S.; Du, T.; Li, B.; Wang, T. Textbugger: Generating adversarial text against real-world applications. arXiv 2018, arXiv:1812.05271. [Google Scholar]
- Oak, R. Poster: Adversarial Examples for Hate Speech Classifiers. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 2621–2623. [Google Scholar]
- Chan, P.P.; Yang, C.; Yeung, D.S.; Ng, W.W. Spam filtering for short messages in adversarial environment. Neurocomputing 2015, 155, 167–176. [Google Scholar] [CrossRef]
- Almeida, T.A.; Hidalgo, J.M.G.; Yamakami, A. Contributions to the study of SMS spam filtering: New collection and results. In Proceedings of the 11th ACM Symposium on Document Engineering, Mountain View, CA, USA, 19–22 September 2011; pp. 259–262. [Google Scholar]
- Hassanpour, R.; Dogdu, E.; Choupani, R.; Goker, O.; Nazli, N. Phishing e-mail detection by using deep learning algorithms. In Proceedings of the ACMSE 2018 Conference, Richmond, KY, USA, 29–31 March 2018; p. 1. [Google Scholar]
- Srinivasan, S.; Ravi, V.; Alazab, M.; Ketha, S.; Al-Zoubi, A.; Kotti Padannayil, S. Spam emails detection based on distributed word embedding with deep learning. In Machine Intelligence and Big Data Analytics for Cybersecurity Applications; Springer: Berlin/Heidelberg, Germany, 2021; pp. 161–189. [Google Scholar]
- Barushka, A.; Hajek, P. Spam filtering using integrated distribution-based balancing approach and regularized deep neural networks. Appl. Intell. 2018, 48, 3538–3556. [Google Scholar] [CrossRef] [Green Version]
- Tong, X.; Wang, J.; Zhang, C.; Wang, R.; Ge, Z.; Liu, W.; Zhao, Z. A content-based chinese spam detection method using a capsule network with long-short attention. IEEE Sens. J. 2021, 21, 25409–25420. [Google Scholar] [CrossRef]
- Liu, H.; Ma, M.; Huang, L.; Xiong, H.; He, Z. Robust neural machine translation with joint textual and phonetic embedding. arXiv 2018, arXiv:1810.06729. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1746–1751. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Chia, Y.K.; Witteveen, S.; Andrews, M. Transformer to CNN: Label-scarce distillation for efficient text classification. arXiv 2019, arXiv:1909.03508. [Google Scholar]
- Kaiser, L.; Gomez, A.N.; Chollet, F. Depthwise separable convolutions for neural machine translation. arXiv 2017, arXiv:1706.03059. [Google Scholar]
- Dong, S.; Xia, Y.; Peng, T. Network abnormal traffic detection model based on semi-supervised deep reinforcement learning. IEEE Trans. Netw. Serv. Manag. 2021, 18, 4197–4212. [Google Scholar] [CrossRef]
- Ding, T.; Yang, W.; Wei, F.; Ding, C.; Kang, P.; Bu, W. Chinese keyword extraction model with distributed computing. Comput. Electr. Eng. 2022, 97, 107639. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Part | All | Spam | Normal |
|---|---|---|---|---|
| Chat | Training | 208,240 | 104,242 | 103,998 |
| Dev | 69,413 | 34,509 | 34,904 | |
| Test | 69,415 | 34,783 | 34,632 |
| Layers/Item | Hyperparameter | Value |
|---|---|---|
| Embedding | Embedding_size | 300 |
| Sequence_length | 32 | |
| BiGRU | Bidirectional | 2 |
| Hidden_size | 256 | |
| Layer_number | 2 | |
| Conv2d | Channel | 1 |
| Filters_size | (2, 3, 4) | |
| Num_filters | 256 | |
| Others | Learning_rate | 1 |
| Batch_size | 128 | |
| Drop_out | 0.5 |
| Model | Precision | Recall | F1 Score | Accuracy | Classification Time |
|---|---|---|---|---|---|
| TextCNN | 0.9298 | 0.8996 | 0.9144 | 0.9156 | 1 s |
| TextRNN | 0.9328 | 0.8981 | 0.9151 | 0.9165 | 1 s |
| TextBiLSTM+Att | 0.9378 | 0.9009 | 0.9190 | 0.9204 | 1 s |
| TextRCNN | 0.9362 | 0.9036 | 0.9196 | 0.9208 | 1 s |
| DPCNN | 0.9280 | 0.9081 | 0.9179 | 0.9186 | 1 s |
| Transformer | 0.9321 | 0.8534 | 0.8910 | 0.8954 | 2 s |
| BiGRU-CNN + CJE(ours) | 0.9513 | 0.9382 | 0.9447 | 0.9459 | 3 s |
| BiGRU-CNN + WJE(ours) | 0.9566 | 0.9367 | 0.9465 | 0.9470 | 3 s |
| Model | Noise Rate | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|---|
| TextCNN | 0 | 0.9298 | 0.8996 | 0.9144 | 0.9156 |
| 0.1 | 0.9178 | 0.8689 | 0.8927 | 0.8953 | |
| 0.2 | 0.9089 | 0.8697 | 0.8889 | 0.8910 | |
| 0.3 | 0.9078 | 0.8466 | 0.8761 | 0.8800 | |
| TextRNN | 0 | 0.9328 | 0.8981 | 0.9151 | 0.9165 |
| 0.1 | 0.9421 | 0.8451 | 0.8910 | 0.8963 | |
| 0.2 | 0.9247 | 0.8624 | 0.8925 | 0.8959 | |
| 0.3 | 0.9156 | 0.8582 | 0.8859 | 0.8893 | |
| TextBiLSTM+Att | 0 | 0.9378 | 0.9009 | 0.9190 | 0.9204 |
| 0.1 | 0.9084 | 0.8885 | 0.8983 | 0.8992 | |
| 0.2 | 0.9073 | 0.8851 | 0.8961 | 0.8971 | |
| 0.3 | 0.9164 | 0.8566 | 0.8855 | 0.8890 | |
| TextRCNN | 0 | 0.9362 | 0.9036 | 0.9196 | 0.9208 |
| 0.1 | 0.9223 | 0.8806 | 0.9010 | 0.9030 | |
| 0.2 | 0.9151 | 0.8723 | 0.8932 | 0.8955 | |
| 0.3 | 0.9208 | 0.8607 | 0.8897 | 0.8931 | |
| DPCNN | 0 | 0.9280 | 0.9081 | 0.9179 | 0.9186 |
| 0.1 | 0.9161 | 0.8828 | 0.8992 | 0.9008 | |
| 0.2 | 0.9179 | 0.8681 | 0.8923 | 0.8950 | |
| 0.3 | 0.9218 | 0.8468 | 0.8827 | 0.8872 | |
| Transformer | 0 | 0.9321 | 0.8534 | 0.8910 | 0.8954 |
| 0.1 | 0.9095 | 0.8357 | 0.8710 | 0.8760 | |
| 0.2 | 0.9121 | 0.8699 | 0.8696 | 0.8699 | |
| 0.3 | 0.9158 | 0.7921 | 0.8495 | 0.8593 | |
| BiGRU-CNN + CJE(ours) | 0 | 0.9513 | 0.9382 | 0.9447 | 0.9459 |
| 0.1 | 0.9396 | 0.9359 | 0.9378 | 0.9378 | |
| 0.2 | 0.9353 | 0.9369 | 0.9361 | 0.9359 | |
| 0.3 | 0.9406 | 0.9332 | 0.9369 | 0.9370 | |
| BiGRU-CNN + WJE(ours) | 0 | 0.9566 | 0.9367 | 0.9465 | 0.9470 |
| 0.1 | 0.9405 | 0.9451 | 0.9428 | 0.9425 | |
| 0.2 | 0.9511 | 0.9317 | 0.9413 | 0.9417 | |
| 0.3 | 0.9410 | 0.9430 | 0.9420 | 0.9418 |
| Model | Change | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|---|
| BiGRU-CNN-JE | 0.9566 | 0.9367 | 0.9465 | 0.9470 | |
| Embedding | No Joint Embedding | 0.9309 | 0.9037 | 0.9171 | 0.9181 |
| BiGRU Layer | No BiGRU | 0.9498 | 0.9342 | 0.9419 | 0.9422 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, J.; Wang, C.; Hu, C.; Huang, X. Chinese Spam Detection Using a Hybrid BiGRU-CNN Network with Joint Textual and Phonetic Embedding. Electronics 2022, 11, 2418. https://doi.org/10.3390/electronics11152418
Yao J, Wang C, Hu C, Huang X. Chinese Spam Detection Using a Hybrid BiGRU-CNN Network with Joint Textual and Phonetic Embedding. Electronics. 2022; 11(15):2418. https://doi.org/10.3390/electronics11152418
Chicago/Turabian StyleYao, Jinliang, Chenrui Wang, Chuang Hu, and Xiaoxi Huang. 2022. "Chinese Spam Detection Using a Hybrid BiGRU-CNN Network with Joint Textual and Phonetic Embedding" Electronics 11, no. 15: 2418. https://doi.org/10.3390/electronics11152418
APA StyleYao, J., Wang, C., Hu, C., & Huang, X. (2022). Chinese Spam Detection Using a Hybrid BiGRU-CNN Network with Joint Textual and Phonetic Embedding. Electronics, 11(15), 2418. https://doi.org/10.3390/electronics11152418