
High-Level Design Optimizations for Implementing Data Stream Sketch Frequency Estimators on FPGAs


Abstract
:1. Introduction
- (1)
- A simple item weight accumulation circuit that is entirely specified at the C language level to remove dependencies associated with memory updates in frequency estimation sketches.
- (2)
- A scheme for scaling the performance of an HLS-generated sketch through fine-tuning the dependance distance in the memory blocks of a sketch.
- (3)
- A scheme for scaling performance through partitioning the sketch into separate update/query hardware tasks that can be constrained separately.
- (4)
- A power-optimized sketch design that takes advantage of the natural skew in typical data streams to reduce memory accesses, and consequently reduce the overall dynamic power consumption.
- (5)
- The fastest and most well-rounded FPGA implementation of the popular Count-Min sketch compared to previous work.
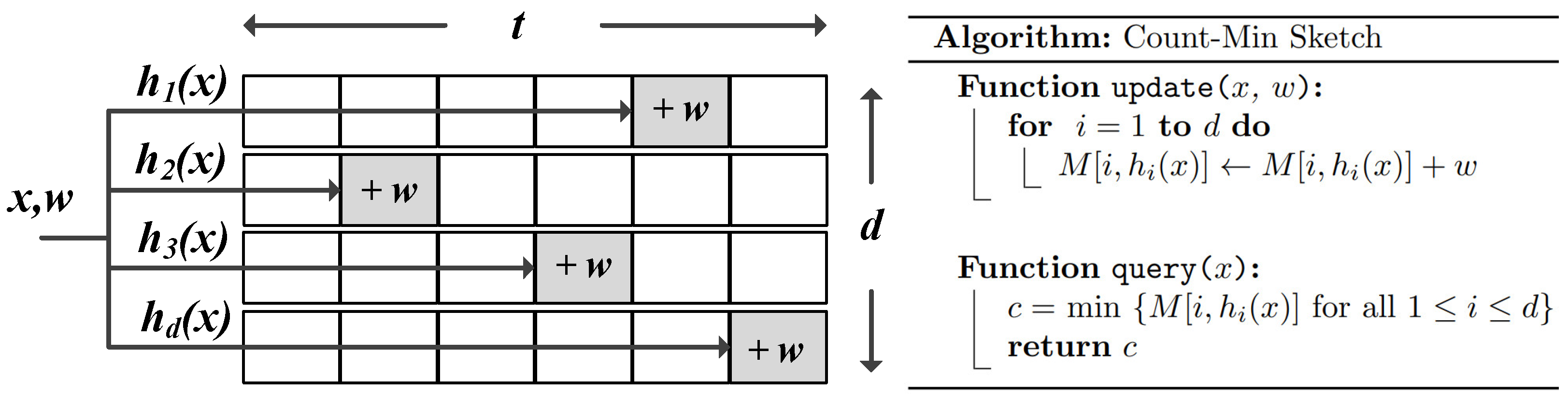
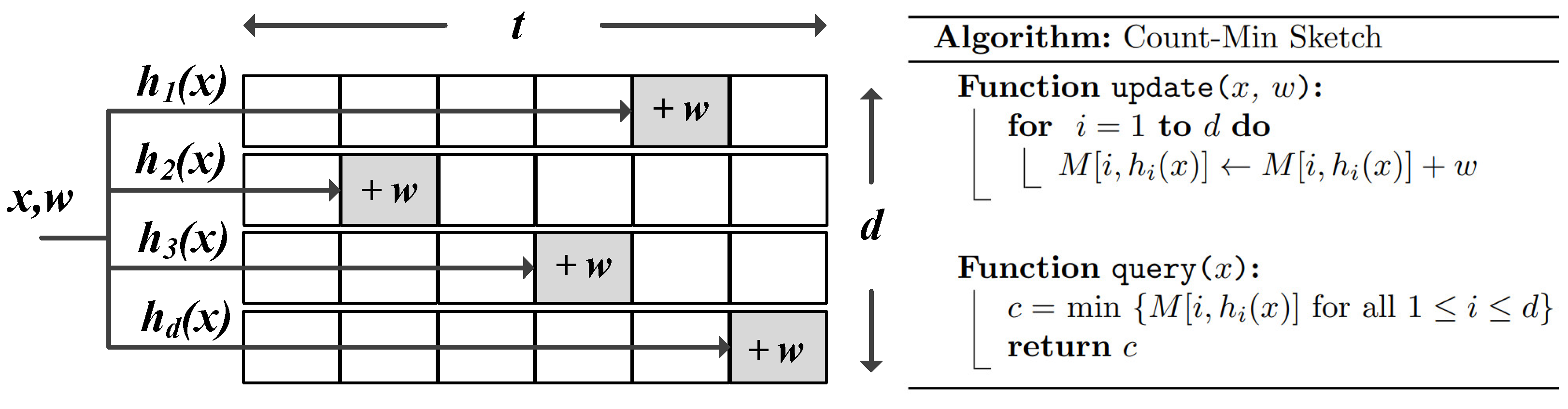
2. Background: Count-Min Sketch
3. Related Work: FPGA-Based Data Stream Frequency Estimators
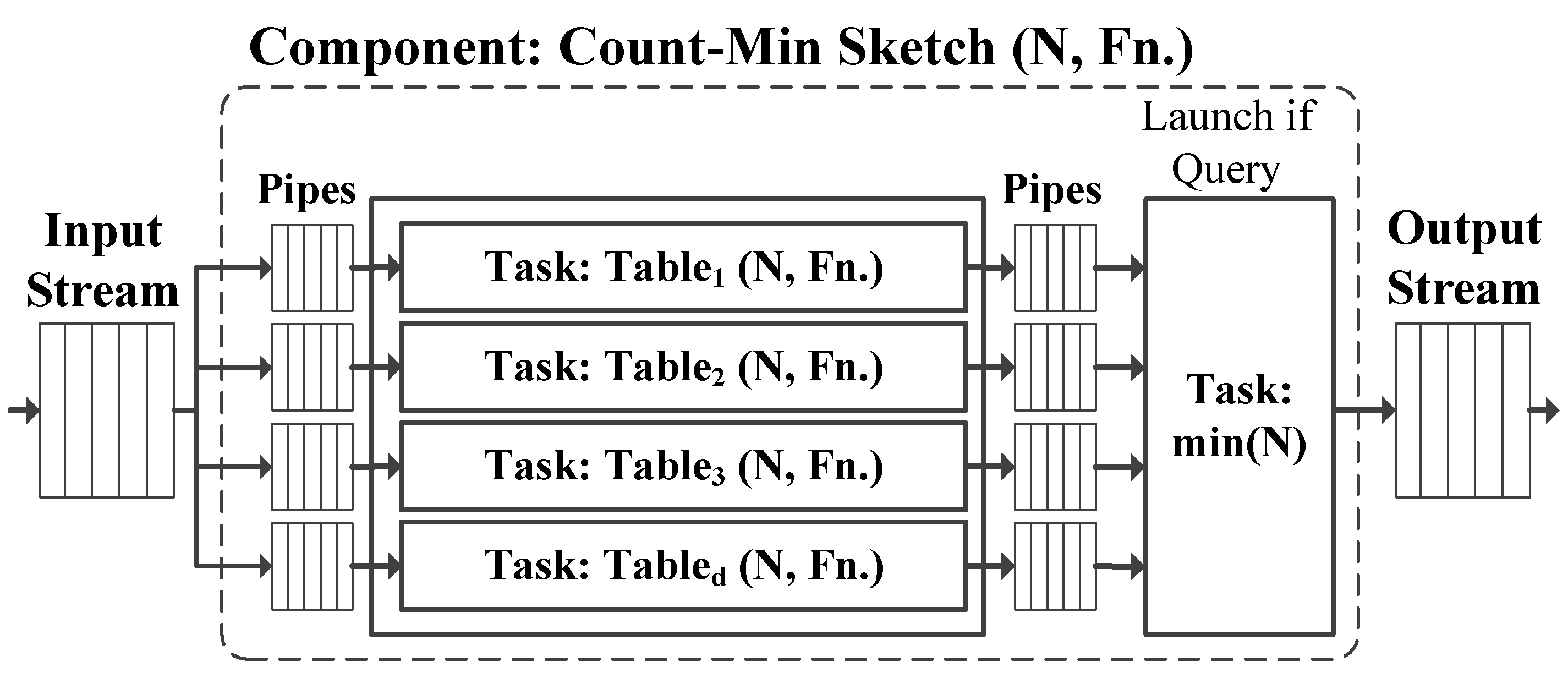
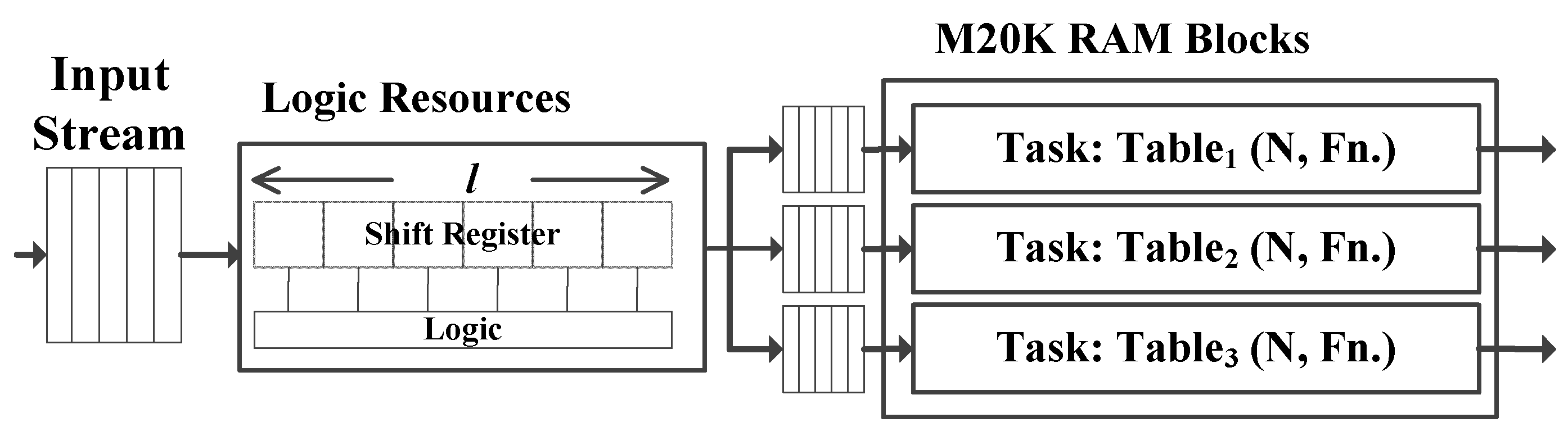
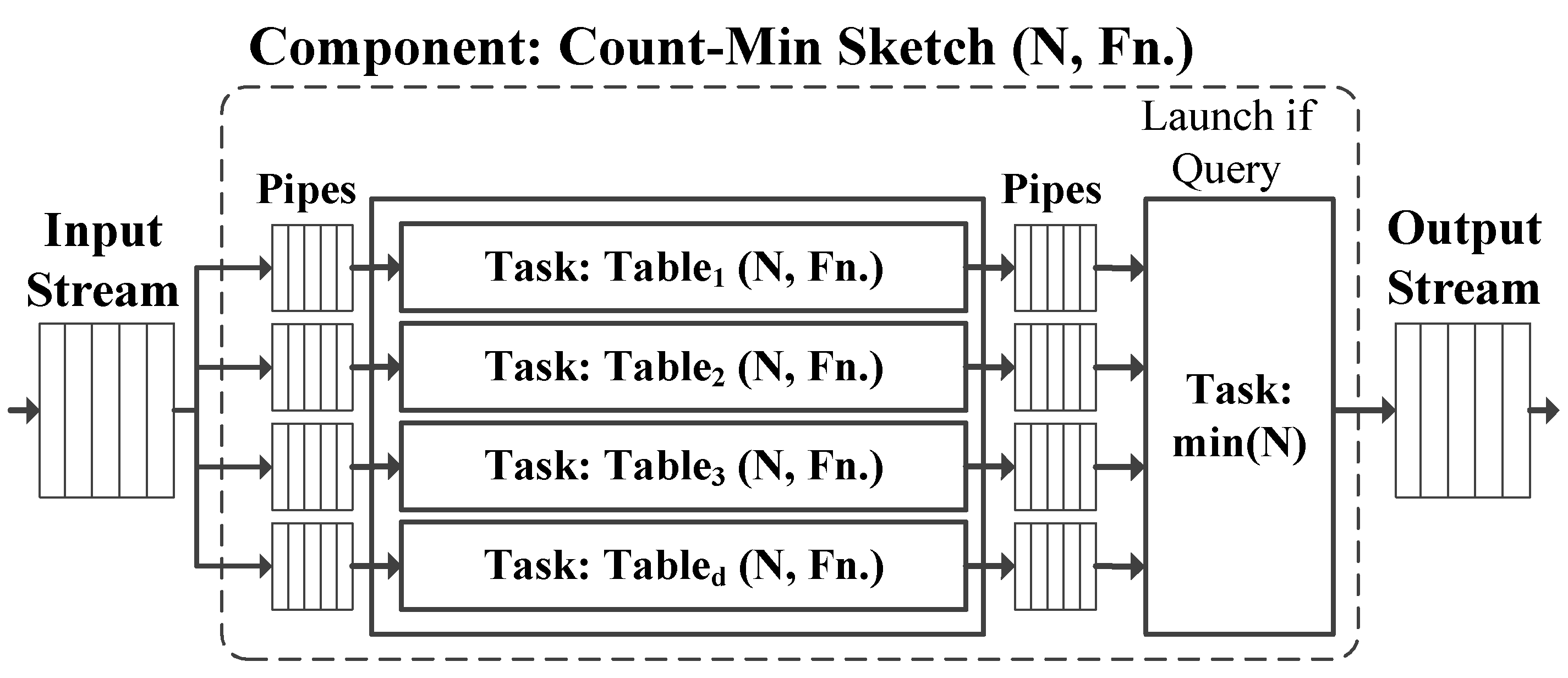
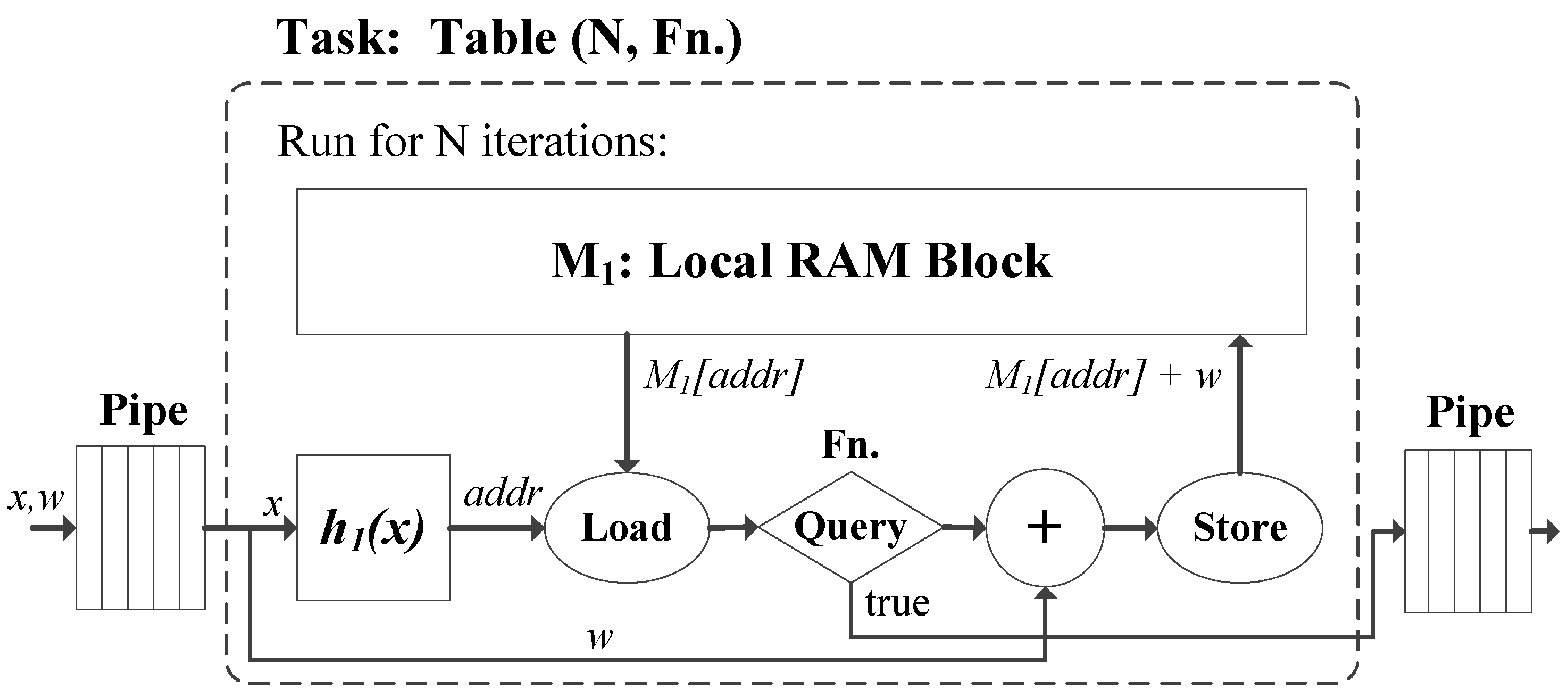
4. Baseline FPGA Implementation
5. Optimizing for High Throughput
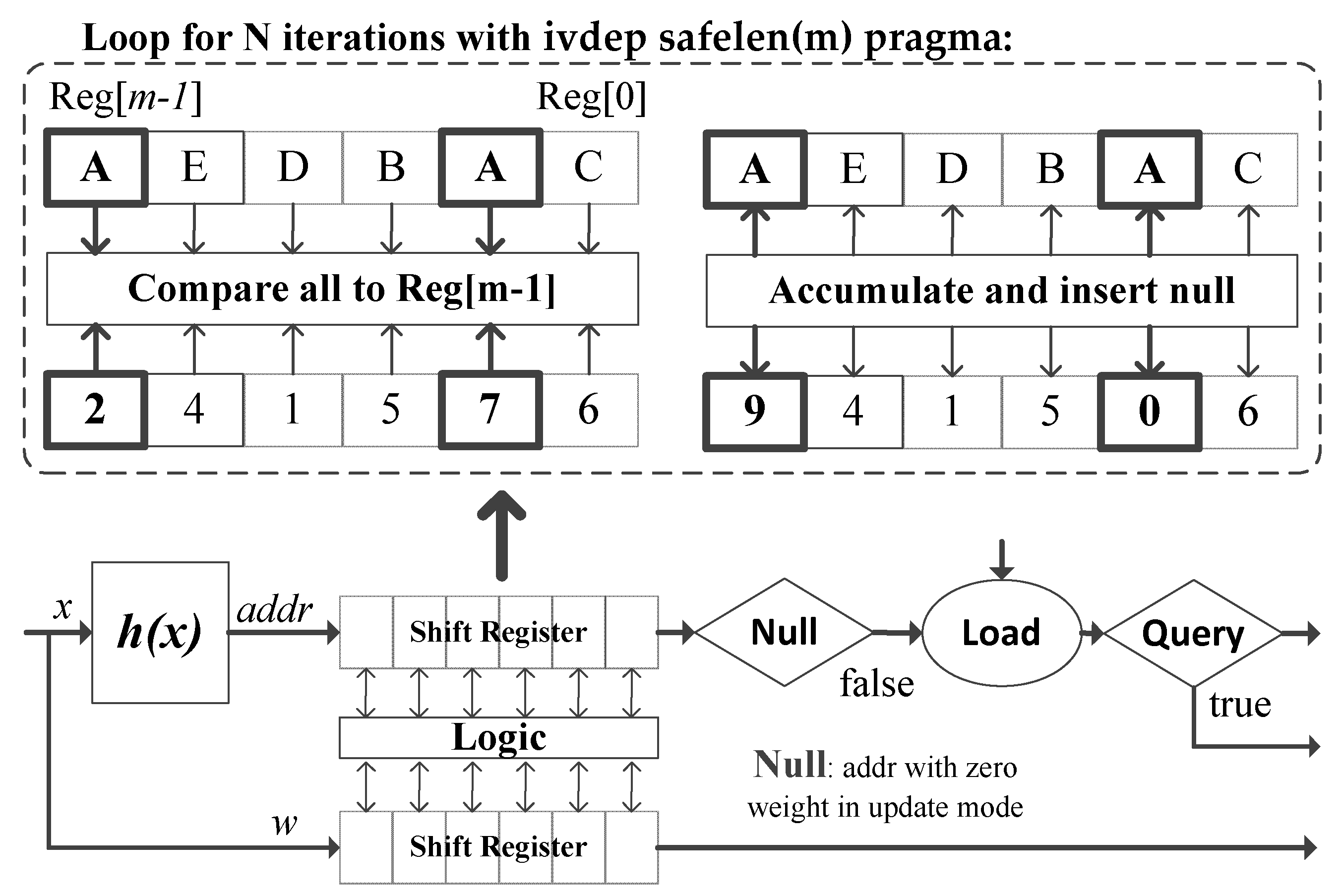
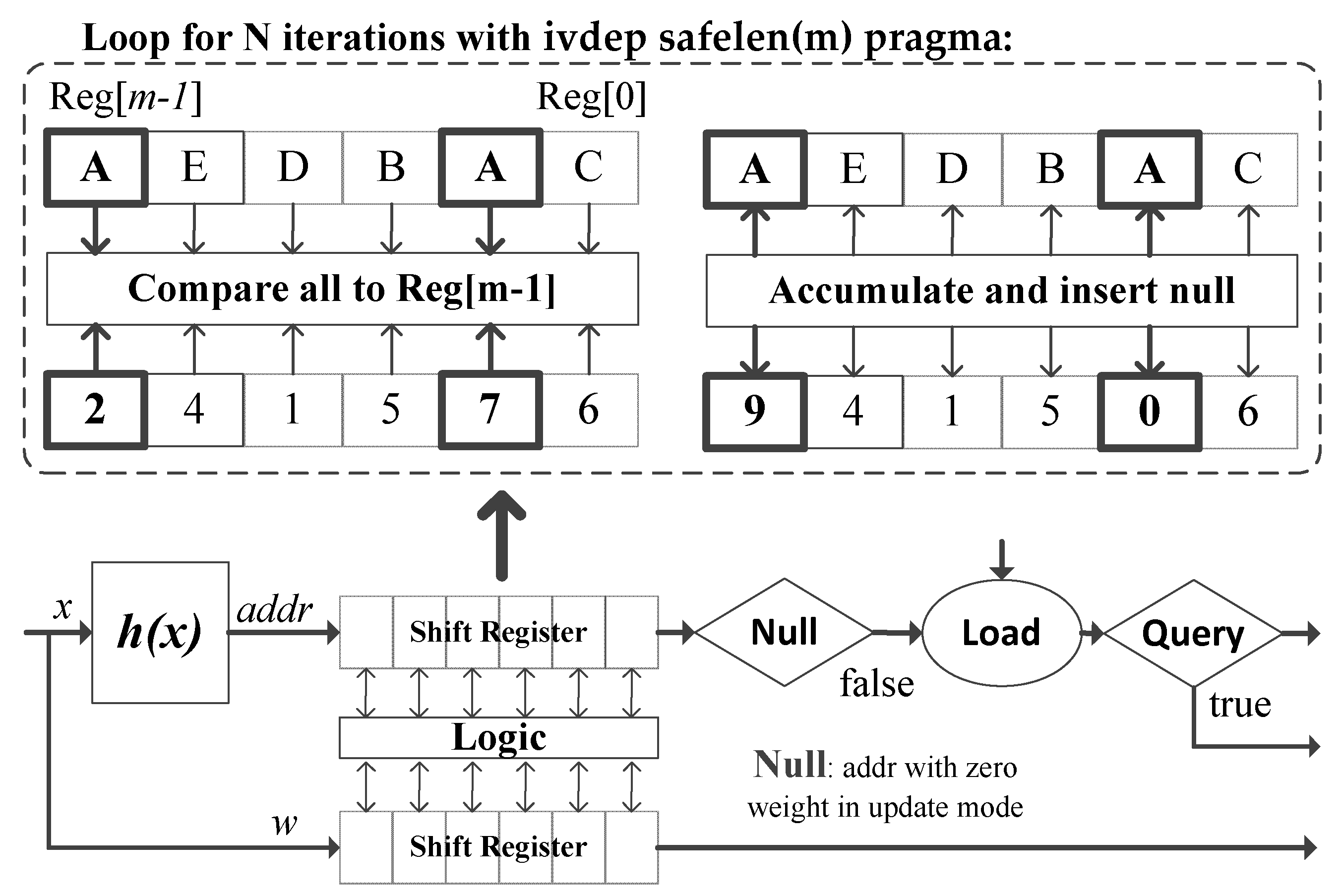
5.1. Effect of Relaxing Memory Dependency
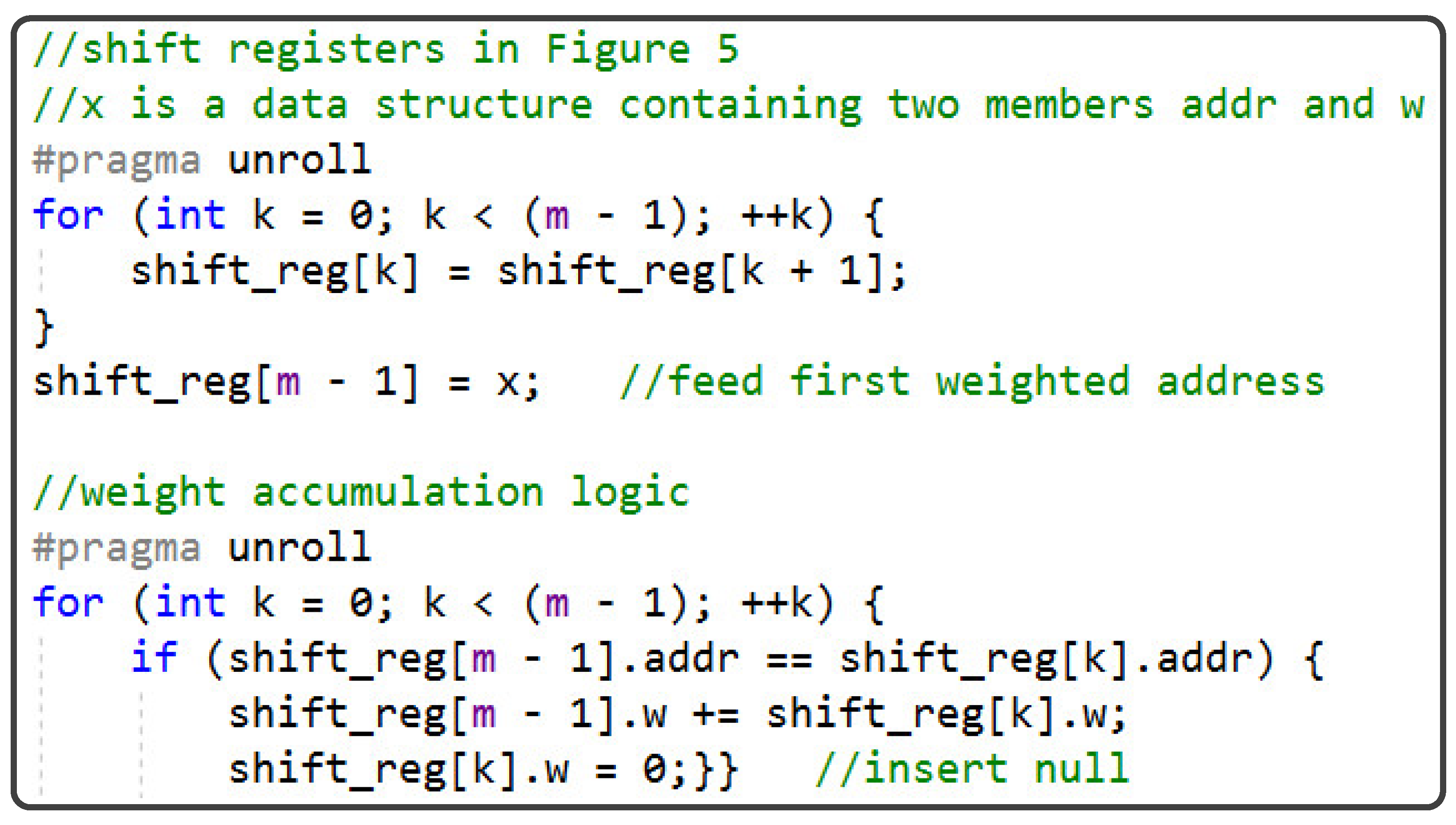
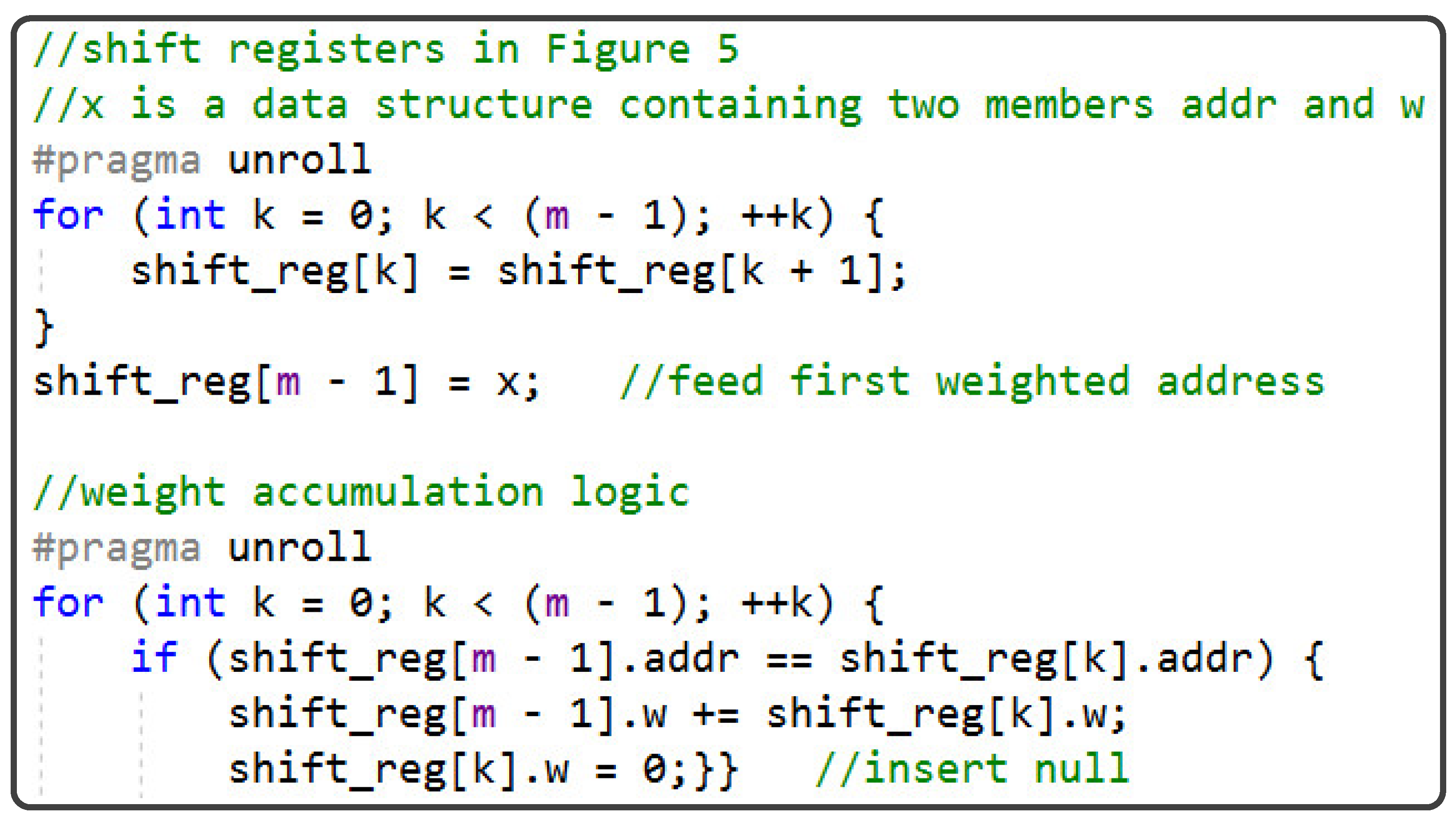
5.2. Pre-Update Weight Accumulation
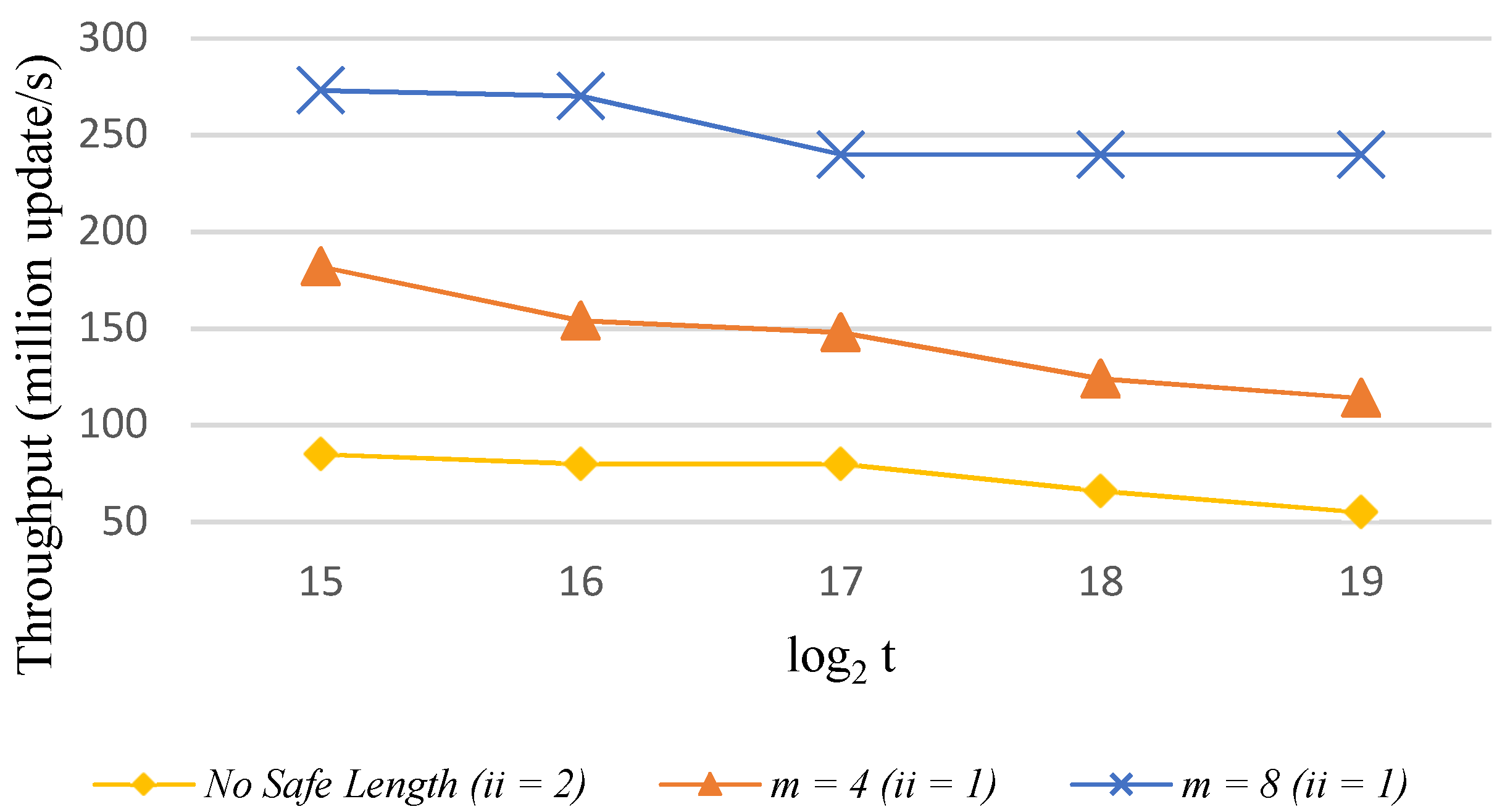
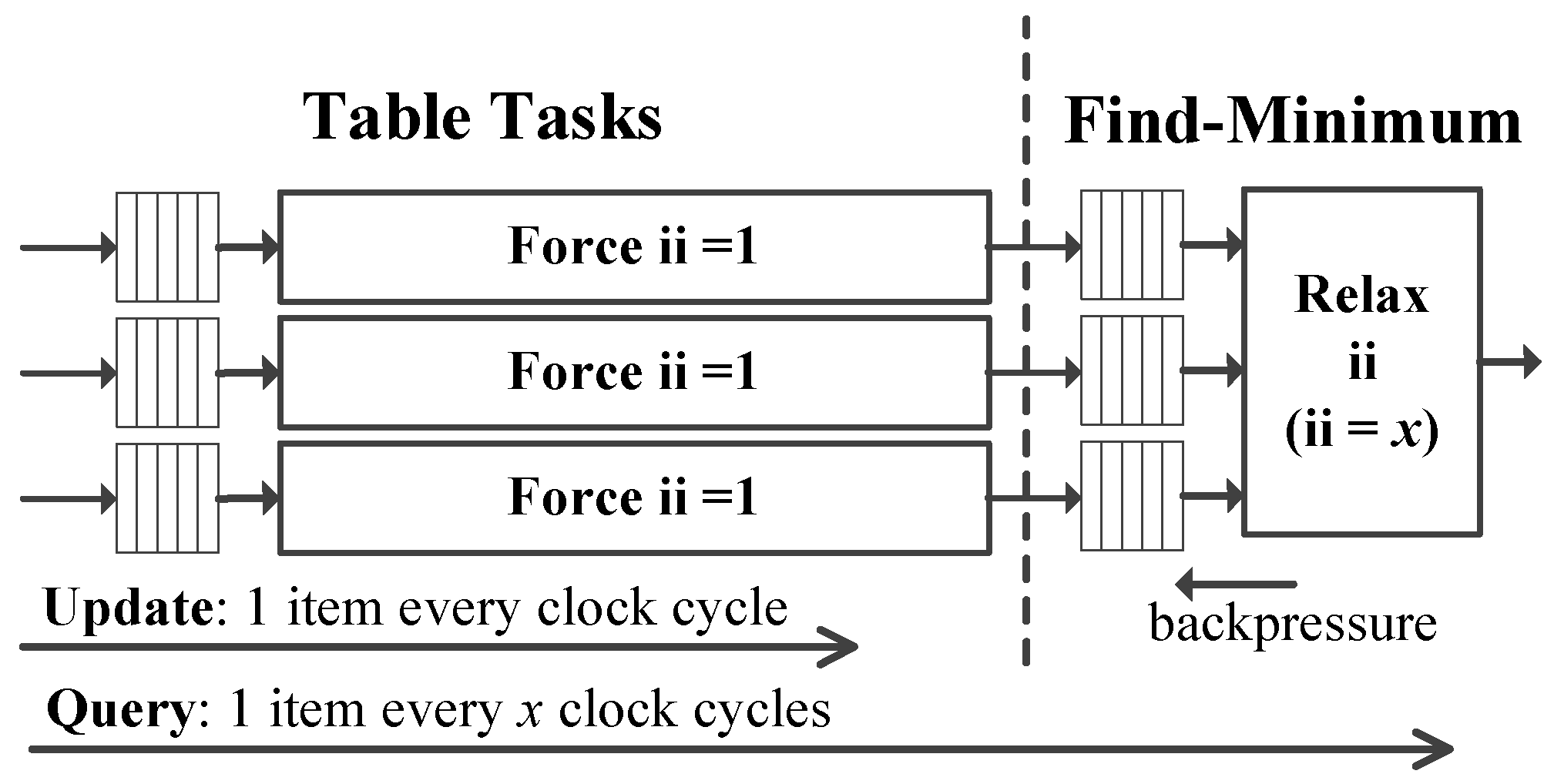
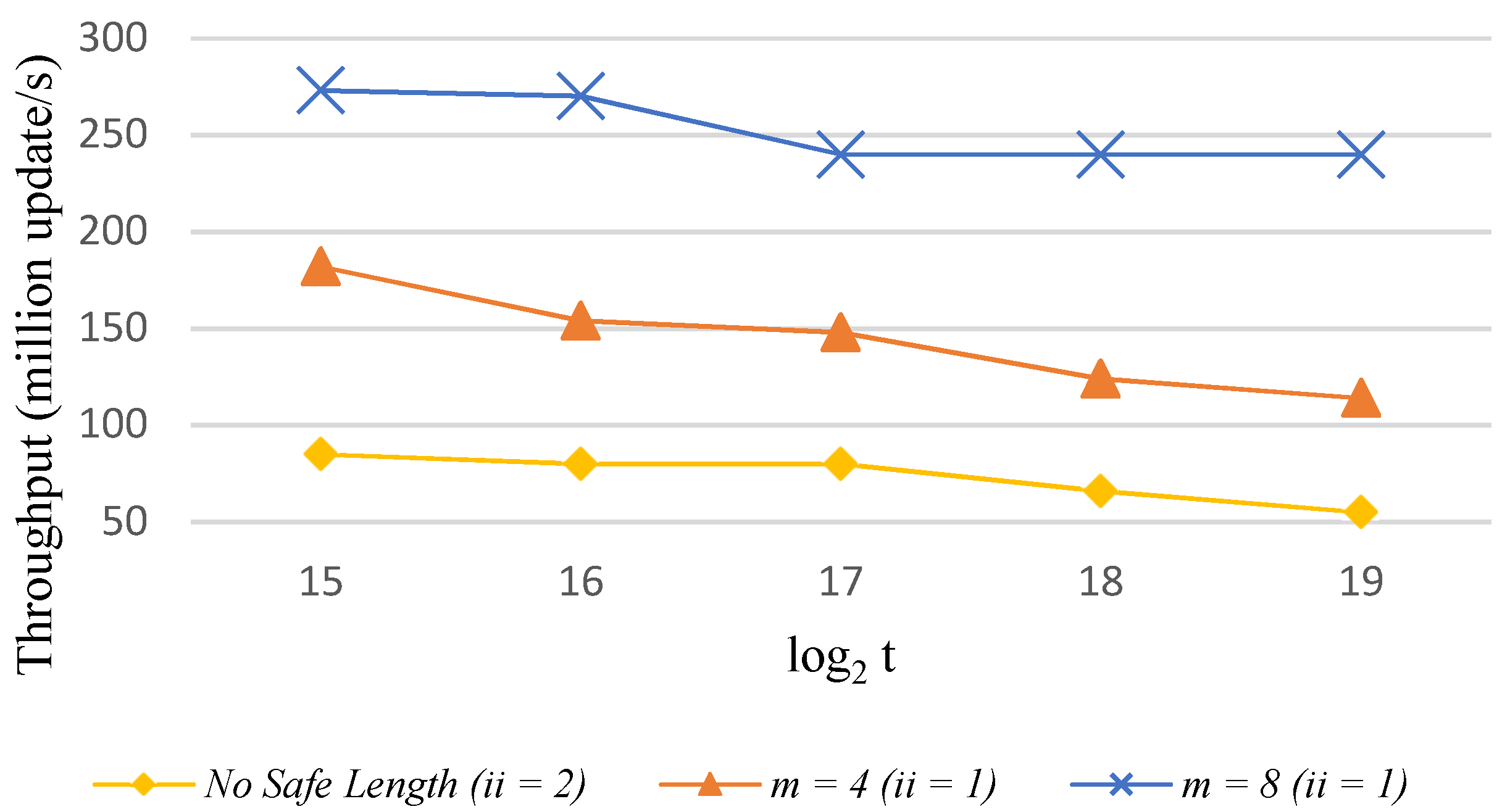
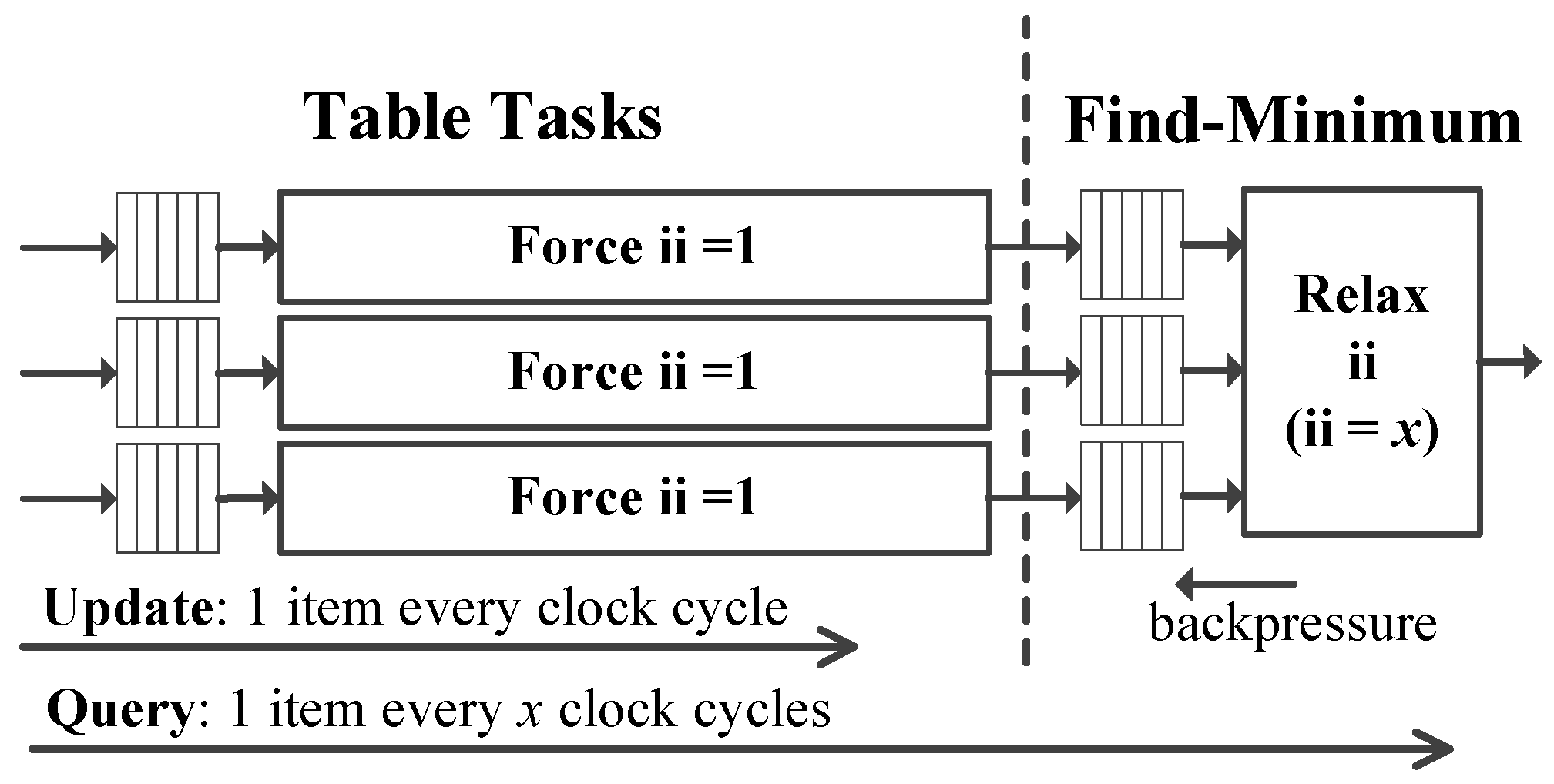
5.3. Mixed Intiation Interval Design
5.4. Evaluation
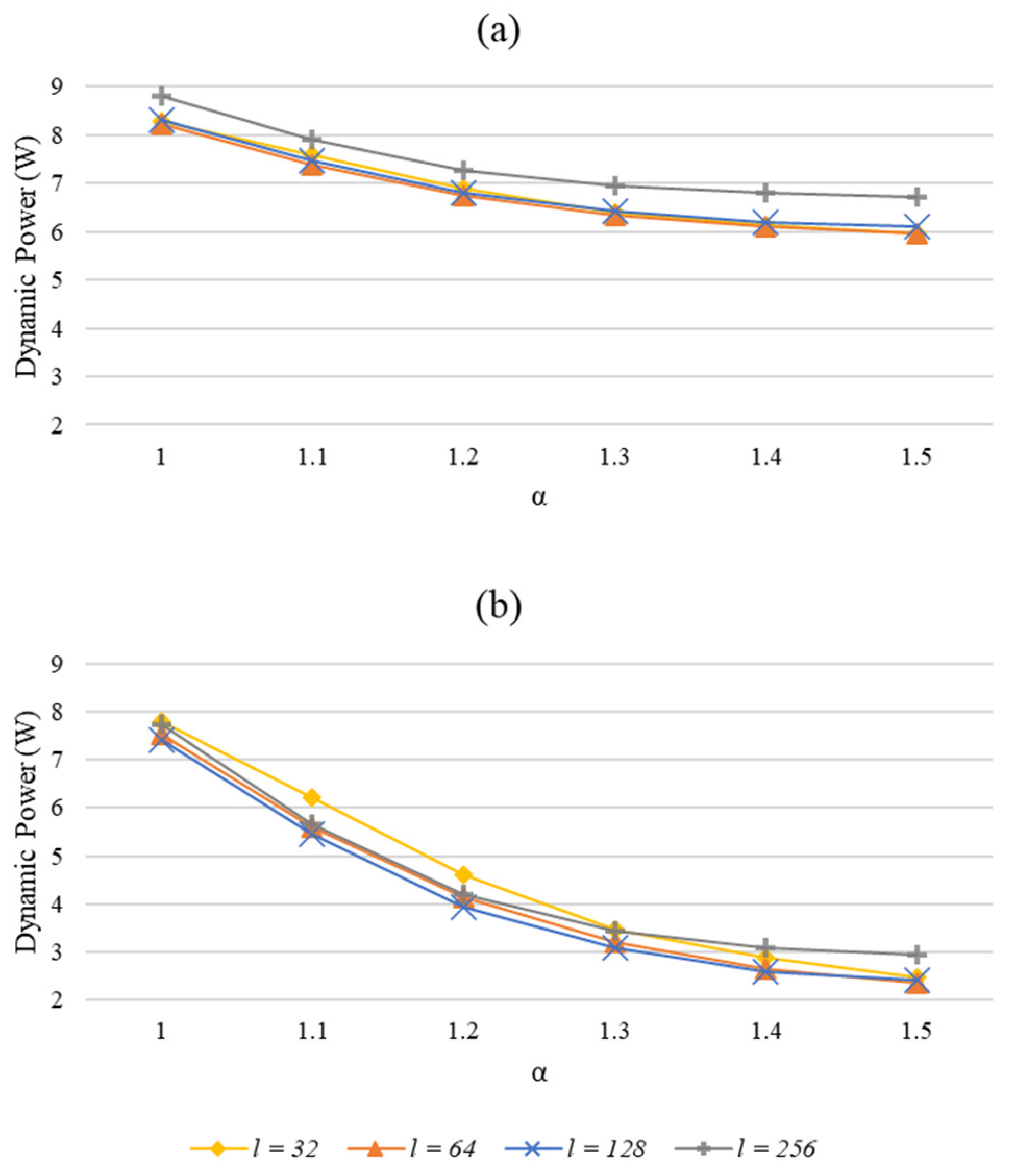
6. Optimizing for Low Power
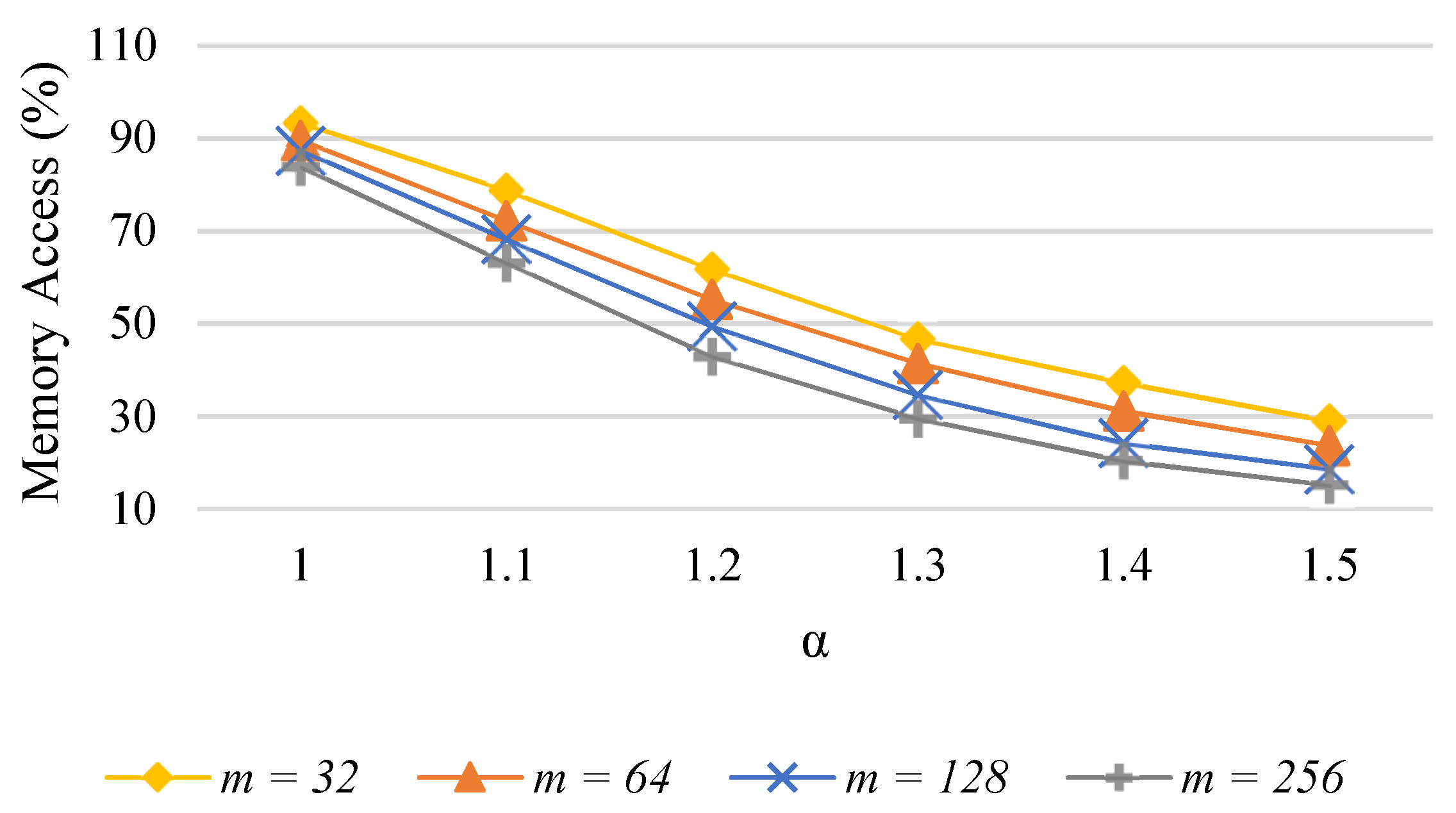
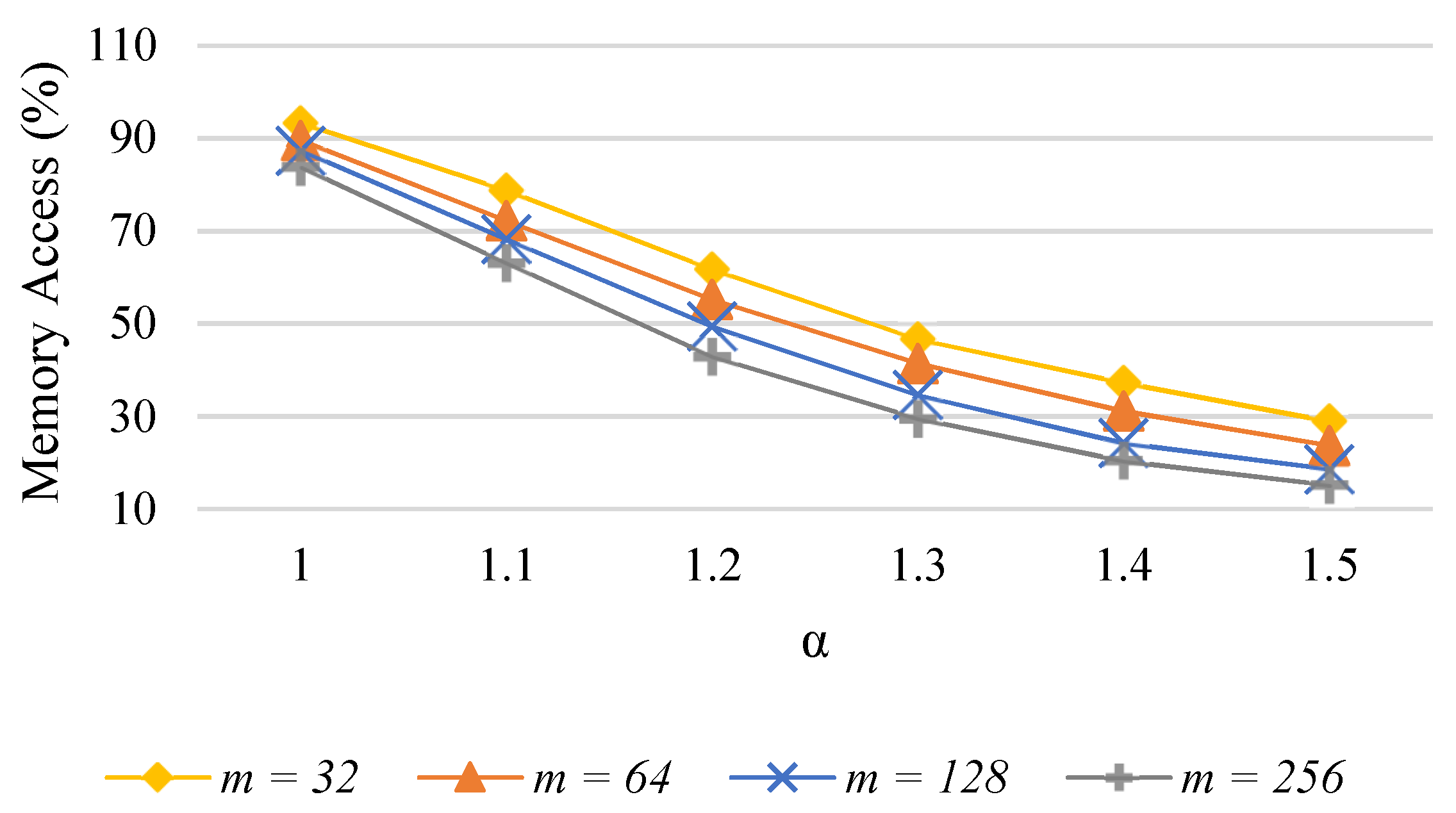
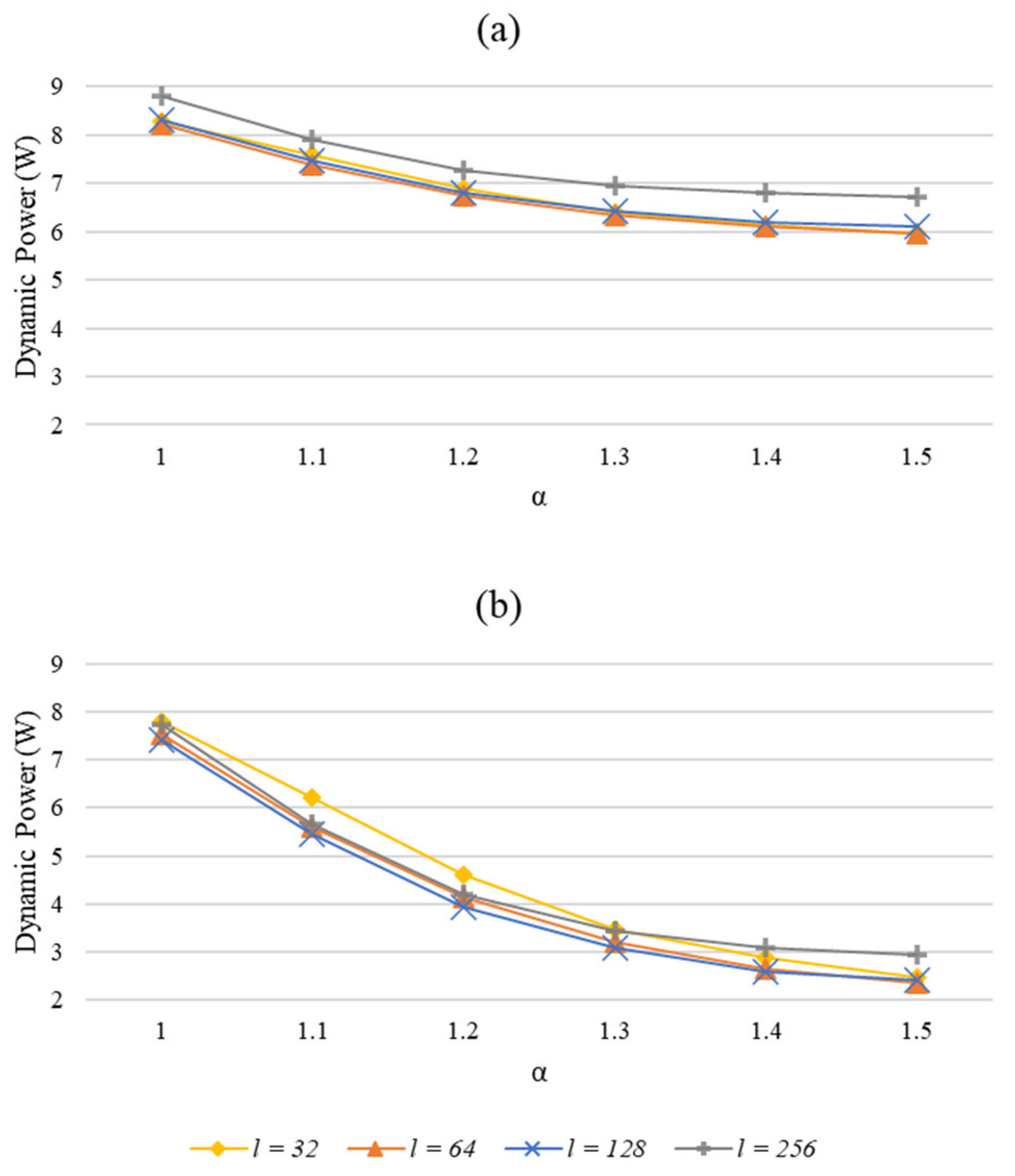
6.1. Reduced Memory Accesses in Skewed Streams
6.2. Power Optimized Sketch
6.3. Evaluation
7. Comparison with the State-of-the-Art
8. Conclusions and Further Research
- (1)
- Easier design entry for a range of frequency estimation sketches compared to RTL (the main optimization only requires the addition of a small circuit specified with two simple unrolled loops).
- (2)
- Achieving significant throughput and latency advantages compared to unoptimized sketches designed with HLS (more than threefold increase in throughput is achieved).
- (3)
- Extracting the best possible accuracy from a given chip with error guarantee that can be tailored to specific streams with minimal effort at the design level (sketches utilizing 80% of the FPGA were easily synthesized).
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Babcock, B.; Babu, S.; Datar, M.; Motwani, R.; Widom, J. Models and issues in data stream systems. In Proceedings of the Twenty-First ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Madison, WI, USA, 3–5 June 2002; pp. 1–16. [Google Scholar]
- Kfoury, E.F.; Crichigno, J.; Bou-Harb, E. An exhaustive survey on p4 programmable data plane switches: Taxonomy, applications, challenges, and future trends. IEEE Access 2021, 9, 87094–87155. [Google Scholar] [CrossRef]
- Muthukrishnan, S. Data streams: Algorithms and applications. Found. Trends Theor. Comput. Sci. 2005, 1, 117–236. [Google Scholar] [CrossRef]
- Gribonval, R.; Chatalic, A.; Keriven, N.; Schellekens, V.; Jacques, L.; Schniter, P. Sketching data sets for large-scale learning: Keeping only what you need. IEEE Signal Processing Mag. 2021, 38, 12–36. [Google Scholar] [CrossRef]
- Alon, N.; Matias, Y.; Szegedy, M. The space complexity of approximating the frequency moments. J. Comput. Syst. Sci. 1999, 58, 137–147. [Google Scholar] [CrossRef] [Green Version]
- Charikar, M.; Chen, K.; Farach-Colton, M. Finding frequent items in data streams. In Proceedings of the International Colloquium on Automata, Languages, and Programming, Eindhoven, The Netherlands, 30 June–4 July 2002; pp. 693–703. [Google Scholar]
- Cormode, G.; Muthukrishnan, S. An improved data stream summary: The count-min sketch and its applications. J. Algorithms 2005, 55, 58–75. [Google Scholar] [CrossRef] [Green Version]
- Intel® High Level Synthesis Compiler Pro Edition: User Guide. Available online: https://www.intel.com/content/www/us/en/docs/programmable/683456/21–4/pro-edition-user-guide.html (accessed on 26 June 2022).
- Bledaite, L. Count-Min Sketch in Real Data Applications. Available online: https://skillsmatter.com/skillscasts/6844-count-min-sketch-in-real-data-applications (accessed on 18 July 2022).
- Team, D.P. Learning with Privacy at Scale. Apple Mach. Learn. J. 2017, 1, 1–25. [Google Scholar]
- Apache Spark: CountMin Data Structure. Available online: https://spark.apache.org/docs/2.0.1/api/java/org/apache/spark/util/sketch/CountMinSketch.html (accessed on 18 July 2022).
- RedisBloom: Bloom Filters and Other Probabilistic Data Structures for Redis. Available online: https://github.com/RedisBloom/RedisBloom/ (accessed on 18 July 2022).
- Bustio-Martínez, L.; Cumplido, R.; Letras, M.; Hernández-León, R.; Feregrino-Uribe, C.; Hernández-Palancar, J. FPGA/GPU-based acceleration for frequent itemsets mining: A comprehensive review. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Ebrahim, A.; Khalifat, J. Fast Approximation of the Top-k Items in Data Streams Using a Reconfigurable Accelerator. In Proceedings of the International Symposium on Applied Reconfigurable Computing, Virtual Conference, 29–30 June 2021; pp. 3–17. [Google Scholar]
- Ebrahim, A.; Khlaifat, J. An Efficient Hardware Architecture for Finding Frequent Items in Data Streams. In Proceedings of the IEEE International Conference on Computer Design (ICCD), Lake Tahoe, NV, USA, 23–26 October 2020; pp. 113–119. [Google Scholar]
- Sun, Y.; Wang, Z.; Huang, S.; Wang, L.; Wang, Y.; Luo, R.; Yang, H. Accelerating frequent item counting with FPGA. In Proceedings of the ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 26–28 February 2014; pp. 109–112. [Google Scholar]
- Gololo, M.G.D.; Zhao, Q.; Amagasaki, M.; Iida, M.; Kuga, M.; Sueyoshi, T. Low-cost Hardware that Accelerates Frequent Item Counting with an FPGA. IEIE Trans. Smart Processing Comput. 2017, 6, 347–354. [Google Scholar] [CrossRef]
- Sha, M.; Guo, Z.; Wang, K.; Zeng, X. A High-Performance and Accurate FPGA-Based Flow Monitor for 100 Gbps Networks. Electronics 2022, 11, 1976. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Z.; Wang, R.; Yang, T.; Li, J.; Miao, R.; Liu, P.; Zhang, R.; Jiang, J. CocoSketch: High-performance sketch-based measurement over arbitrary partial key query. In Proceedings of the ACM SIGCOMM 2021 Conference, Virtual Conference, 23–27 August 2021; pp. 207–222. [Google Scholar]
- Tong, D.; Prasanna, V.K. Sketch acceleration on FPGA and its applications in network anomaly detection. IEEE Trans. Parallel Distrib. Syst. 2017, 29, 929–942. [Google Scholar] [CrossRef]
- Kiefer, M.; Poulakis, I.; Breß, S.; Markl, V. Scotch: Generating fpga-accelerators for sketching at line rate. Proc. VLDB Endow. 2020, 14, 281–293. [Google Scholar] [CrossRef]
- Soto, J.E.; Ubisse, P.; Fernández, Y.; Hernández, C.; Figueroa, M. A high-throughput hardware accelerator for network entropy estimation using sketches. IEEE Access 2021, 9, 85823–85838. [Google Scholar] [CrossRef]
- Soto, J.E.; Ubisse, P.; Hernández, C.; Figueroa, M. A hardware accelerator for entropy estimation using the top-k most frequent elements. In Proceedings of the Euromicro Conference on Digital System Design (DSD), Virtual Conference, 26–28 August 2020; pp. 141–148. [Google Scholar]
- Saavedra, A.; Hernández, C.; Figueroa, M. Heavy-hitter detection using a hardware sketch with the countmin-cu algorithm. In Proceedings of the 2018 21st Euromicro Conference on Digital System Design (DSD), Prague, Czech Republic, 29–31 August 2018; pp. 38–45. [Google Scholar]
- Sateesan, A.; Vliegen, J.; Scherrer, S.; Hsiao, H.-C.; Perrig, A.; Mentens, N. Speed records in network flow measurement on FPGA. In Proceedings of the 2021 31st International Conference on Field-Programmable Logic and Applications (FPL), Dresden, Germany, 30 August–3 September 2021; pp. 219–224. [Google Scholar]
- Tang, M.; Wen, M.; Shen, J.; Zhao, X.; Zhang, C. Towards memory-efficient streaming processing with counter-cascading sketching on FPGA. In Proceedings of the ACM/IEEE Design Automation Conference (DAC), Virtual Conference, 20–24 July 2020; pp. 1–6. [Google Scholar]
- Chiosa, M.; Preußer, T.B.; Alonso, G. SKT: A One-Pass Multi-Sketch Data Analytics Accelerator. Proc. VLDB Endow. 2021, 14, 2369–2382. [Google Scholar] [CrossRef]
- Singla, P.; Goodchild, C.; Sarangi, S.R. EHDSktch: A Generic Low Power Architecture for Sketching in Energy Harvesting Devices. In Proceedings of the 26th Asia and South Pacific Design Automation Conference, Virtual Conference, 18–21 January 2021; pp. 615–620. [Google Scholar]
- Kulkarni, A.; Chiosa, M.; Preußer, T.B.; Kara, K.; Sidler, D.; Alonso, G. Hyperloglog sketch acceleration on fpga. In Proceedings of the 2020 30th International Conference on Field-Programmable Logic and Applications (FPL), Gothenburg, Sweden, 31 August–4 September 2020; pp. 47–56. [Google Scholar]
- Preußer, T.B.; Chiosa, M.; Weiss, A.; Alonso, G. Using DSP Slices as Content-Addressable Update Queues. In Proceedings of the 2020 30th International Conference on Field-Programmable Logic and Applications (FPL), Gothenburg, Sweden, 31 August–4 September 2020; pp. 121–126. [Google Scholar]
- FPGA. Optimization Guide for Intel® oneAPI Toolkits. Available online: https://www.intel.com/content/www/us/en/develop/documentation/oneapi-fpga-optimization-guide/top.html (accessed on 26 June 2022).
- Intel Acquires eASIC—Why? Strategic Moves in the FPGA World. Available online: https://www.eejournal.com/article/intel-acquires-easic-why/ (accessed on 20 July 2022).
- Cormode, G.; Muthukrishnan, S. Summarizing and mining skewed data streams. In Proceedings of the 2005 SIAM International Conference on Data Mining, Newport Beach, CA, USA, 21–23 April 2005; pp. 44–55. [Google Scholar]
- Zipf, G.K. Human Behavior and the Principle of Least Effort; Addison-Wesley Press: Boston, MA, USA, 1949. [Google Scholar]
- Early Power Estimator for Intel® Arria® 10 FPGAs User Guide. Available online: https://www.intel.com/content/www/us/en/docs/programmable/683688/18–0-1/overview-of-the-early-power-estimator.html (accessed on 26 June 2022).
- Designing for Stratix 10 Devices with Power in Mind. Available online: https://www.intel.com/content/www/us/en/docs/programmable/683058/current/designing-for-stratix-10-devices-with.html (accessed on 26 June 2022).
- Goyal, A.; Daumé III, H.; Cormode, G. Sketch algorithms for estimating point queries in nlp. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; pp. 1093–1103. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Optimization | Device | Drop in fmax |
|---|---|---|
| ivdep safelen(8) pragma | Intel Arria 10 | 11% |
| RTL 64-stage pipeline [20] | Xilinx Virtex UltraScale | 17% |
| RTL 32-stage pipeline [20] | Xilinx Virtex UltraScale | 26% |
| RTL 16-stage pipeline [20] | Xilinx Virtex UltraScale | 56% |
| Sketch Feature | Chip Utilization (%) | |||||
|---|---|---|---|---|---|---|
| t | d | ɛ | (1 − δ) | ALMs | DSPs | M20K |
| 216 | 16 | 0.00003 | 0.99998 | 18 | 2 | 80 |
| 217 | 8 | 0.000015 | 0.996 | 10 | 1 | 80 |
| 218 | 4 | 0.0000076 | 0.94 | 5 | 0.5 | 80 |
| t | d | Optimized? | ii | fmax (MHz) | Latency (ns) 1 | Throughput (M Updates/s) |
|---|---|---|---|---|---|---|
| 216 | 16 | No | 2 | 153 | 712 | 77 |
| 217 | 8 | No | 2 | 139 | 790 | 70 |
| 218 | 4 | No | 2 | 123 | 886 | 62 |
| 216 | 16 | Yes (m = 8) | 1 | 255 | 459 | 255 |
| 217 | 8 | Yes (m = 8) | 1 | 232 | 466 | 232 |
| 218 | 4 | Yes (m = 8) | 1 | 234 | 462 | 234 |
| t | d | Optimization | ii | fmax (MHz) | Query Throughput (M Updates/s) | Update Throughput (M Updates/s) |
|---|---|---|---|---|---|---|
| 216 | 16 | m = 8, mixed ii | 1,2 | 264 | 132 | 264 |
| 217 | 8 | m = 8, mixed ii | 1,2 | 330 | 165 | 330 |
| 218 | 4 | m = 8, mixed ii | 1,2 | 312 | 156 | 312 |
| Accumulation Window Length (l) | Dynamic Power (W) | |||
|---|---|---|---|---|
| RAM | Logic | Others | Total | |
| 32 | 7.03 | 0.70 | 0.94 | 8.67 |
| 64 | 7.03 | 0.74 | 1.00 | 8.77 |
| 128 | 7.03 | 0.88 | 1.10 | 9.01 |
| 256 | 7.03 | 1.32 | 1.30 | 9.65 |
| Sketch | Hash Function | Weighted Updates? | Error Guarantee? | Memory Access (%) |
|---|---|---|---|---|
| Proposed | Equation (1) | Yes | Yes | various |
| [20] | H3 | No | Yes | 100% |
| [21] | H3 | No | Yes | 100% |
| [23] | MurmurHash | No | No | various |
| [25] | Xoodoo-NC | No | No | 100% |
| [27] | MurmurHash | No | No | 100% |
| Sketch | Device | Sketch Size | Accuracy Parameters | Throughput (M Updates/s) | ||
|---|---|---|---|---|---|---|
| t | d | ɛ | (1 − δ) | |||
| Proposed | Stratix 10 | 217 | 14 | 0.000015 | 0.99994 | 494 |
| Proposed | Stratix 10 | 217 | 5 | 0.000015 | 0.97 | 513 |
| [20] | Virtex UltraScale | 217 | 14 | 0.000015 | 0.99994 | 325 |
| [21] | Stratix 10 | 217 | 5 | 0.000015 | 0.97 | 503 |
| [23] | UltraScale+ MPSoC | 214 | 4 | 0.00012 | 0.94 | 354 |
| [25] | Virtex UltraScale+ | 216 | 4 | 0.00003 | 0.94 | 415 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ebrahim, A. High-Level Design Optimizations for Implementing Data Stream Sketch Frequency Estimators on FPGAs. Electronics 2022, 11, 2399. https://doi.org/10.3390/electronics11152399
Ebrahim A. High-Level Design Optimizations for Implementing Data Stream Sketch Frequency Estimators on FPGAs. Electronics. 2022; 11(15):2399. https://doi.org/10.3390/electronics11152399
Chicago/Turabian StyleEbrahim, Ali. 2022. "High-Level Design Optimizations for Implementing Data Stream Sketch Frequency Estimators on FPGAs" Electronics 11, no. 15: 2399. https://doi.org/10.3390/electronics11152399
APA StyleEbrahim, A. (2022). High-Level Design Optimizations for Implementing Data Stream Sketch Frequency Estimators on FPGAs. Electronics, 11(15), 2399. https://doi.org/10.3390/electronics11152399