
ARET-IQA: An Aspect-Ratio-Embedded Transformer for Image Quality Assessment


Abstract
:1. Introduction
- We adaptively embed the original aspect ratios of input images into the self-attention module of the Swin Transformer [26], which can alleviate the quality change caused by warping the input images to a fixed size and improve the evaluation performance of the proposed IQA model.
- We employ the shifted window-based self-attention module to effectively reduce the computational overhead of our Transformer-based IQA model, which can not only capture features that measure image quality as a whole but also combine the output features of multistage Transformer blocks to jointly infer the perceptual quality of images.
- We propose an aspect-ratio-embedded Transformer for image quality assessment (ARET-IQA), whose experimental results on multiple IQA databases demonstrate that the proposed ARET-IQA model is superior to the state-of-the-art IQA models.
2. Related Works
2.1. Image Quality Assessment
2.2. Aspect-Ratio-Preserving
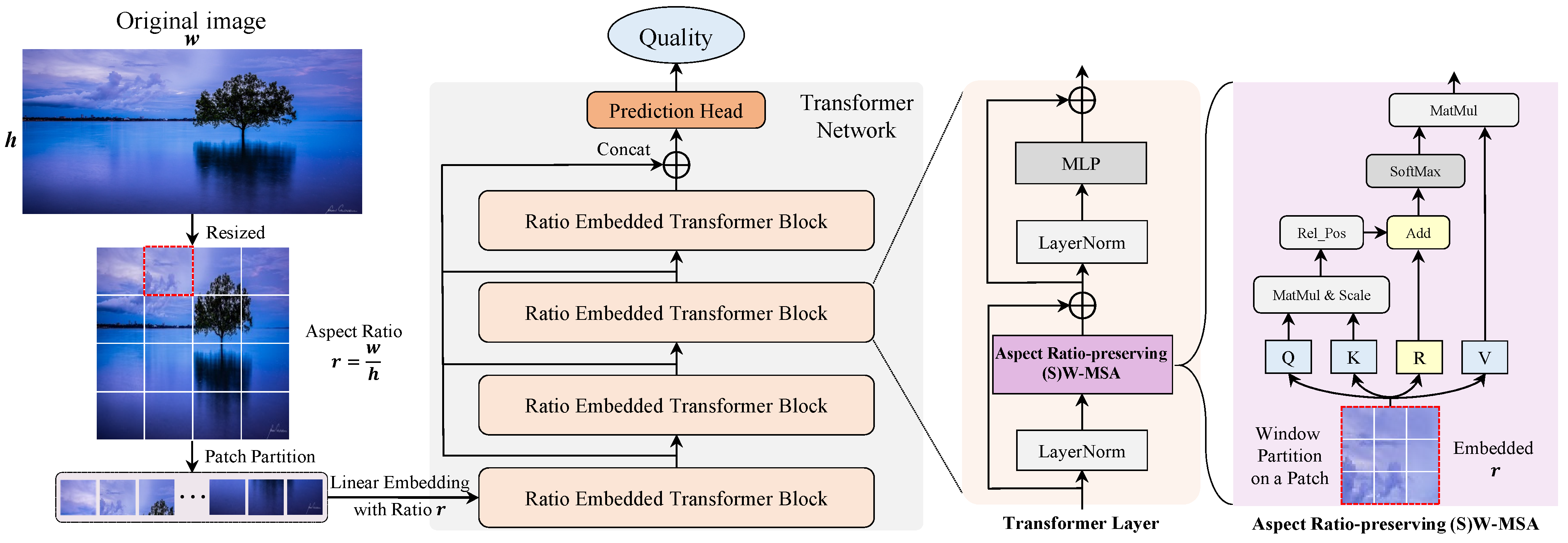
3. Proposed Method
3.1. Patch and Aspect Ratio Embedding
3.2. Aspect-Ratio-Preserving Multihead Self-Attention
3.3. Quality Prediction
4. Experimental Results
4.1. Databases
4.2. Experimental Settings
4.3. Comparing with the State-of-the-Art IQA Methods
4.3.1. Performance on TQA Databases
4.3.2. Performance on AQA Database
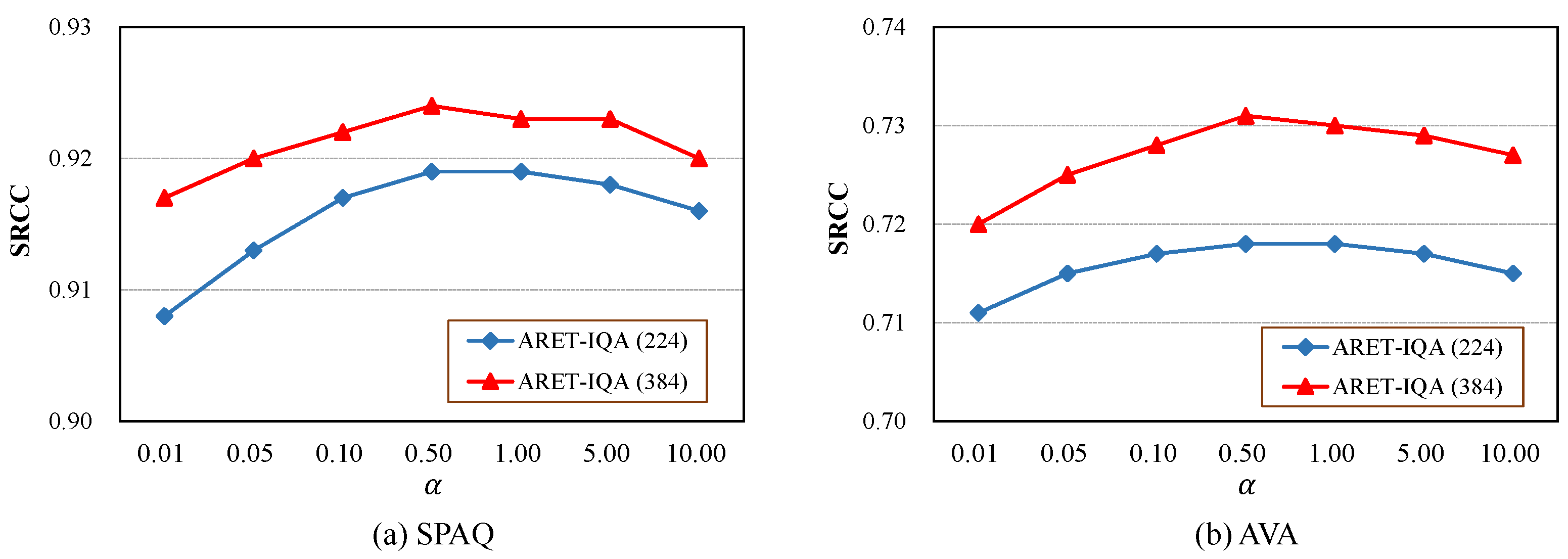
4.4. Ablation Study
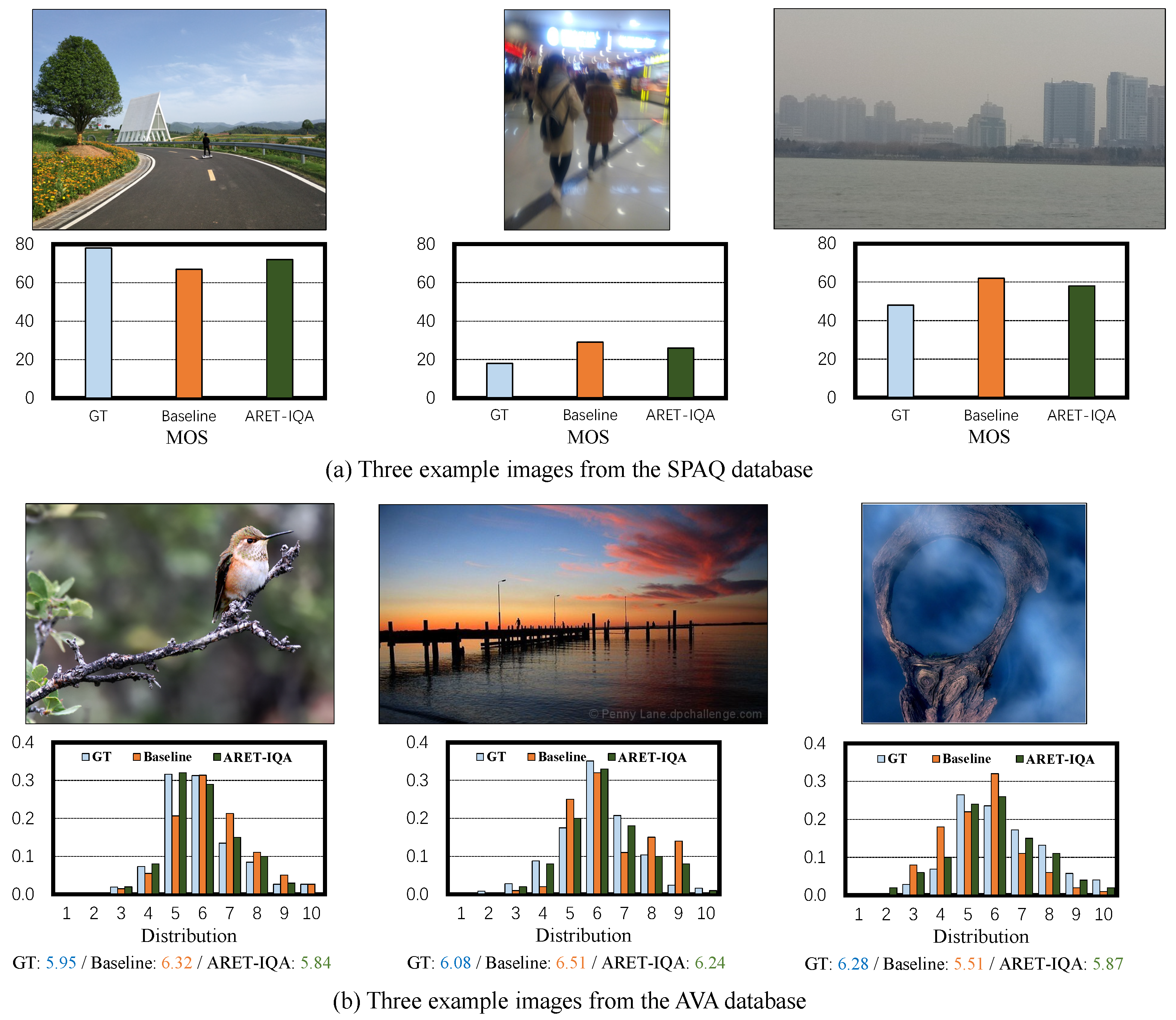
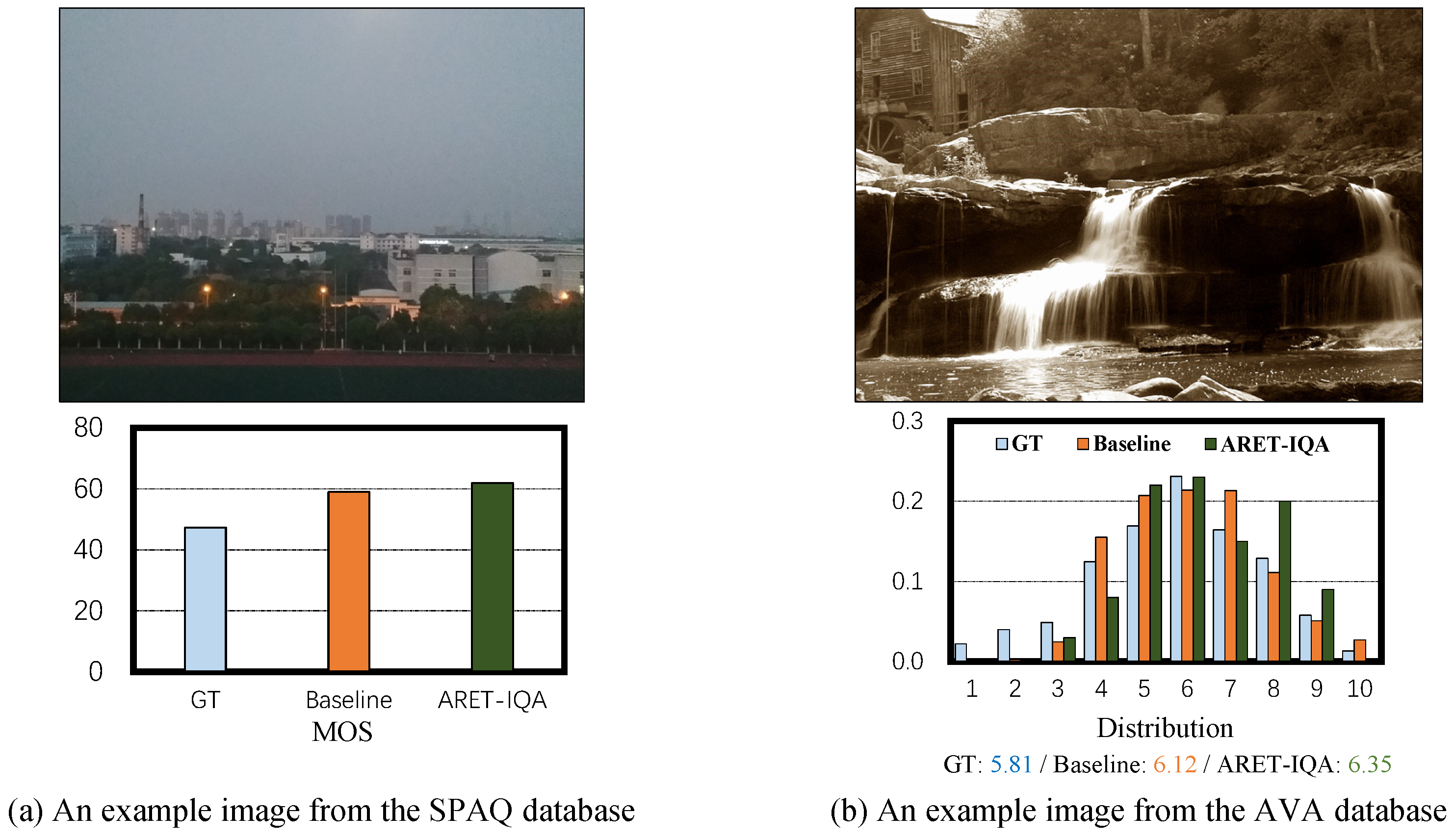
4.5. Visual Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kim, J.; Zeng, H.; Ghadiyaram, D.; Lee, S.; Zhang, L.; Bovik, A.C. Deep Convolutional Neural Models for Picture-Quality Prediction: Challenges and Solutions to Data-Driven Image Quality Assessment. IEEE Signal Process. Mag. 2017, 34, 130–141. [Google Scholar] [CrossRef]
- Deng, Y.; Chen, C.L.; Tang, X. Image Aesthetic Assessment: An Experimental Survey. IEEE Signal Process. Mag. 2017, 34, 80–106. [Google Scholar] [CrossRef] [Green Version]
- Zheng, B.; Zhang, J.; Sun, G.; Ren, X. EnGe-CSNet: A Trainable Image Compressed Sensing Model Based on Variational Encoder and Generative Networks. Electronics 2021, 10, 1089. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, L.; Yan, C.; Ji, X.; Dai, Q. Adaptive Residual Networks for High-Quality Image Restoration. IEEE Trans. Image Process. 2018, 27, 3150–3163. [Google Scholar] [CrossRef]
- Fan, R.; Li, X.; Lee, S.; Li, T.; Zhang, H.L. Smart Image Enhancement Using CLAHE Based on an F-Shift Transformation during Decompression. Electronics 2020, 9, 1374. [Google Scholar] [CrossRef]
- Wang, R.; Qin, Y.; Wang, Z.; Zheng, H. Group-Based Sparse Representation for Compressed Sensing Image Reconstruction with Joint Regularization. Electronics 2022, 11, 182. [Google Scholar] [CrossRef]
- Varga, D. Analysis of Benford’s Law for No-Reference Quality Assessment of Natural, Screen-Content, and Synthetic Images. Electronics 2021, 10, 2378. [Google Scholar] [CrossRef]
- Guha, T.; Hosu, V.; Saupe, D.; Goldlücke, B.; Kumar, N.; Lin, W.; Martinez, V.; Somandepalli, K.; Narayanan, S.; Cheng, W.H.; et al. ATQAM/MAST’20: Joint Workshop on Aesthetic and Technical Quality Assessment of Multimedia and Media Analytics for Societal Trends. In Proceedings of the ACM International Conference on Multimedia, Virtual Event, 12–16 October 2020; pp. 4758–4760. [Google Scholar] [CrossRef]
- Talebi, H.; Milanfar, P. NIMA: Neural Image Assessment. IEEE Trans. Image Process. 2018, 27, 3998–4011. [Google Scholar] [CrossRef] [Green Version]
- Ke, J.; Wang, Q.; Wang, Y.; Milanfar, P.; Yang, F. MUSIQ: Multi-scale Image Quality Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 5128–5137. [Google Scholar] [CrossRef]
- Murray, N.; Marchesotti, L.; Perronnin, F. AVA: A large-scale database for aesthetic visual analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2408–2415. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A Feature Similarity Index for Image Quality Assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [Green Version]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-Reference Image Quality Assessment in the Spatial Domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Tang, L.; Sun, K.; Huang, S.; Wang, G.; Jiang, K. Quality Assessment of View Synthesis Based on Visual Saliency and Texture Naturalness. Electronics 2022, 11, 1384. [Google Scholar] [CrossRef]
- Datta, R.; Joshi, D.; Li, J.; Wang, J.Z. Studying Aesthetics in Photographic Images Using a Computational Approach. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 288–301. [Google Scholar] [CrossRef]
- Ma, K.; Liu, W.; Zhang, K.; Duanmu, Z.; Wang, Z.; Zuo, W. End-to-End Blind Image Quality Assessment Using Deep Neural Networks. IEEE Trans. Image Process. 2018, 27, 1202–1213. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Ma, J.; Liang, F.; Dong, W.; Shi, G.; Lin, W. End-to-End Blind Image Quality Prediction With Cascaded Deep Neural Network. IEEE Trans. Image Process. 2020, 29, 7414–7426. [Google Scholar] [CrossRef]
- Bosse, S.; Maniry, D.; Müller, K.R.; Wiegand, T.; Samek, W. Deep Neural Networks for No-Reference and Full-Reference Image Quality Assessment. IEEE Trans. Image Process. 2018, 27, 206–219. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, H.; Li, L.; Wu, J.; Dong, W.; Shi, G. MetaIQA: Deep Meta-Learning for No-Reference Image Quality Assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14131–14140. [Google Scholar] [CrossRef]
- Guan, X.; Li, F.; He, L. Quality Assessment on Authentically Distorted Images by Expanding Proxy Labels. Electronics 2020, 9, 252. [Google Scholar] [CrossRef] [Green Version]
- Kong, S.; Shen, X.; Lin, Z.; Mech, R.; Fowlkes, C. Photo Aesthetics Ranking Network with Attributes and Content Adaptation. In Proceedings of the European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 662–679. [Google Scholar] [CrossRef] [Green Version]
- Zeng, H.; Cao, Z.; Zhang, L.; Bovik, A.C. A Unified Probabilistic Formulation of Image Aesthetic Assessment. IEEE Trans. Image Process. 2020, 29, 1548–1561. [Google Scholar] [CrossRef]
- Fang, Y.; Zhu, H.; Zeng, Y.; Ma, K.; Wang, Z. Perceptual Quality Assessment of Smartphone Photography. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3674–3683. [Google Scholar] [CrossRef]
- Hosu, V.; Goldlucke, B.; Saupe, D. Effective Aesthetics Prediction With Multi-Level Spatially Pooled Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9375–9383. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Zhang, W.; Zhou, N.; Lei, P.; Xu, Y.; Zheng, Y.; Fan, J. Adaptive Fractional Dilated Convolution Network for Image Aesthetics Assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14102–14111. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Hosu, V.; Lin, H.; Sziranyi, T.; Saupe, D. KonIQ-10k: An Ecologically Valid Database for Deep Learning of Blind Image Quality Assessment. IEEE Trans. Image Process. 2020, 29, 4041–4056. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saad, M.A.; Bovik, A.C.; Charrier, C. Blind Image Quality Assessment: A Natural Scene Statistics Approach in the DCT Domain. IEEE Trans. Image Process. 2012, 21, 3339–3352. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Bovik, A.C. A Feature-Enriched Completely Blind Image Quality Evaluator. IEEE Trans. Image Process. 2015, 24, 2579–2591. [Google Scholar] [CrossRef] [Green Version]
- Ye, P.; Kumar, J.; Kang, L.; Doermann, D. Unsupervised feature learning framework for no-reference image quality assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1098–1105. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Ye, P.; Li, Q.; Du, H.; Liu, Y.; Doermann, D. Blind Image Quality Assessment Based on High Order Statistics Aggregation. IEEE Trans. Image Process. 2016, 25, 4444–4457. [Google Scholar] [CrossRef]
- Kim, J.; Lee, S. Fully Deep Blind Image Quality Predictor. IEEE J. Sel. Topics Signal Process. 2017, 11, 206–220. [Google Scholar] [CrossRef]
- Kim, J.; Nguyen, A.D.; Lee, S. Deep CNN-Based Blind Image Quality Predictor. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 11–24. [Google Scholar] [CrossRef] [PubMed]
- Lu, X.; Lin, Z.; Jin, H.; Yang, J.; Wang, J.Z. RAPID: Rating Pictorial Aesthetics using Deep Learning. In Proceedings of the ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 457–466. [Google Scholar] [CrossRef]
- She, D.; Lai, Y.K.; Yi, G.; Xu, K. Hierarchical Layout-Aware Graph Convolutional Network for Unified Aesthetics Assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 8471–8480. [Google Scholar] [CrossRef]
- Zhu, H.; Zhou, Y.; Yao, R.; Wang, G.; Yang, Y. Learning image aesthetic subjectivity from attribute-aware relational reasoning network. Pattern Recogn. Lett. 2022, 155, 84–91. [Google Scholar] [CrossRef]
- Zhang, W.; Ma, K.; Yan, J.; Deng, D.; Wang, Z. Blind Image Quality Assessment Using a Deep Bilinear Convolutional Neural Network. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 36–47. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Zhu, H.; Zhao, S.; Ding, G.; Lin, W. Personality-Assisted Multi-Task Learning for Generic and Personalized Image Aesthetics Assessment. IEEE Trans. Image Process. 2020, 29, 3898–3910. [Google Scholar] [CrossRef]
- Ma, S.; Liu, J.; Chen, C.W. A-Lamp: Adaptive Layout-Aware Multi-patch Deep Convolutional Neural Network for Photo Aesthetic Assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 722–731. [Google Scholar] [CrossRef] [Green Version]
- Su, S.; Yan, Q.; Zhu, Y.; Zhang, C.; Ge, X.; Sun, J.; Zhang, Y. Blindly Assess Image Quality in the Wild Guided by a Self-Adaptive Hyper Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3664–3673. [Google Scholar] [CrossRef]
- Zhu, H.; Li, L.; Wu, J.; Dong, W.; Shi, G. Generalizable No-Reference Image Quality Assessment via Deep Meta-Learning. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1048–1060. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 5754–5764. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations, Virtual, Austria, 3–7 May 2021. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ghadiyaram, D.; Bovik, A.C. Massive Online Crowdsourced Study of Subjective and Objective Picture Quality. IEEE Trans. Image Process. 2016, 25, 372–387. [Google Scholar] [CrossRef] [Green Version]
- You, J.; Korhonen, J. Transformer For Image Quality Assessment. In Proceedings of the IEEE International Conference on Image Processing, Anchorage, AK, USA, 19–22 September 2021; pp. 1389–1393. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | LIVE Challenge | KonIQ-10k | ||
|---|---|---|---|---|
| PLCC ↑ | SRCC ↑ | PLCC ↑ | SRCC ↑ | |
| BLIINDS-II [28] | 0.507 | 0.463 | 0.615 | 0.529 |
| BRISQUE [13] | 0.645 | 0.607 | 0.681 | 0.665 |
| ILNIQE [29] | 0.508 | 0.432 | 0.537 | 0.501 |
| CORNIA [30] | 0.662 | 0.618 | 0.795 | 0.780 |
| HOSA [31] | 0.678 | 0.659 | 0.813 | 0.805 |
| BIECON [32] | 0.613 | 0.595 | 0.651 | 0.618 |
| WaDIQaM-NR [18] | 0.680 | 0.671 | 0.761 | 0.739 |
| DB-CNN [37] | 0.869 | 0.851 | 0.869 | 0.856 |
| MetaIQA [19] | 0.835 | 0.802 | 0.887 | 0.850 |
| HyperNet [40] | 0.882 | 0.859 | 0.917 | 0.906 |
| MetaIQA+ [41] | 0.872 | 0.852 | 0.921 | 0.909 |
| MUSIQ [10] | - | - | 0.926 | 0.918 |
| TRIQ [47] | 0.826 | 0.812 | 0.925 | 0.907 |
| ARET-IQA (224) | 0.891 | 0.874 | 0.937 | 0.925 |
| ARET-IQA (384) | 0.899 | 0.882 | 0.945 | 0.932 |
| Methods | PLCC ↑ | SRCC ↑ |
|---|---|---|
| BRISQUE [13] | 0.817 | 0.809 |
| ILNIQE [29] | 0.721 | 0.713 |
| CORNIA [30] | 0.725 | 0.709 |
| HOSA [31] | 0.873 | 0.866 |
| DB-CNN [37] | 0.915 | 0.911 |
| MetaIQA [19] | 0.871 | 0.870 |
| HyperNet [40] | 0.914 | 0.909 |
| Baseline (Fang et al.) [41] | 0.909 | 0.908 |
| MUSIQ [10] | 0.921 | 0.917 |
| TRIQ [47] | 0.848 | 0.857 |
| ARET-IQA (224) | 0.925 | 0.919 |
| ARET-IQA (384) | 0.932 | 0.924 |
| Methods | Binary Classification | Score Regression | Distribution Prediction | |
|---|---|---|---|---|
| ACC (%)↑ | PLCC ↑ | SRCC ↑ | EMD ↓ | |
| Murray et al. [11] | 68.0 | - | - | - |
| RAPID [34] | 74.5 | - | - | - |
| A-Lamp [39] | 82.5 | - | - | - |
| Kong et al. [21] | 77.3 | - | 0.558 | - |
| NIMA [9] | 81.5 | 0.636 | 0.612 | 0.050 |
| PA_IAA [38] | 83.7 | 0.678 | 0.677 | 0.047 |
| Zeng et al. [22] | 80.8 | 0.720 | 0.719 | 0.0650 |
| AFDC [25] | 83.0 | 0.671 | 0.649 | 0.045 |
| MUSIQ [10] | 81.5 | 0.738 | 0.726 | - |
| HLA-GCN [35] | 84.6 | 0.687 | 0.665 | 0.043 |
| Zhu et al. [36] | 85.1 | 0.702 | 0.683 | 0.041 |
| ARET-IQA (224) | 82.9 | 0.729 | 0.718 | 0.043 |
| ARET-IQA (384) | 83.6 | 0.744 | 0.731 | 0.040 |
| Models | SPAQ | AVA | ||
|---|---|---|---|---|
| PLCC ↑ | SRCC ↑ | PLCC ↑ | SRCC ↑ | |
| Baseline | 0.910 | 0.906 | 0.725 | 0.712 |
| ARET-IQA w/o ratio | 0.919 | 0.914 | 0.733 | 0.719 |
| ARET-IQA w/o multi | 0.927 | 0.921 | 0.741 | 0.726 |
| ARET-IQA | 0.932 | 0.924 | 0.744 | 0.731 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, H.; Zhou, Y.; Shao, Z.; Du, W.-L.; Zhao, J.; Yao, R. ARET-IQA: An Aspect-Ratio-Embedded Transformer for Image Quality Assessment. Electronics 2022, 11, 2132. https://doi.org/10.3390/electronics11142132
Zhu H, Zhou Y, Shao Z, Du W-L, Zhao J, Yao R. ARET-IQA: An Aspect-Ratio-Embedded Transformer for Image Quality Assessment. Electronics. 2022; 11(14):2132. https://doi.org/10.3390/electronics11142132
Chicago/Turabian StyleZhu, Hancheng, Yong Zhou, Zhiwen Shao, Wen-Liang Du, Jiaqi Zhao, and Rui Yao. 2022. "ARET-IQA: An Aspect-Ratio-Embedded Transformer for Image Quality Assessment" Electronics 11, no. 14: 2132. https://doi.org/10.3390/electronics11142132
APA StyleZhu, H., Zhou, Y., Shao, Z., Du, W.-L., Zhao, J., & Yao, R. (2022). ARET-IQA: An Aspect-Ratio-Embedded Transformer for Image Quality Assessment. Electronics, 11(14), 2132. https://doi.org/10.3390/electronics11142132