
Deep Reinforcement Learning for Intelligent Dual-UAV Reconnaissance Mission Planning


Abstract
:1. Introduction
- First, the task planning problem of dual-UAV coordinated reconnaissance is described, and the action space and environment space are analyzed to meet MDP.
- Second, the principle of the DRL algorithm is introduced. According to the requirements of UAV reconnaissance for HVT missions, the clip reward function is set to reduce the influence of sparse reward, improving the algorithm convergence.
- Finally, based on the PPO algorithm, a dual-UAV collaborative reconnaissance with multi-radar detection threaten environment mission platform is established. The experiments evaluate the reconnaissance capability and decision-making essence and analyze the superiority and potential value of this method.
2. Problem Formulation
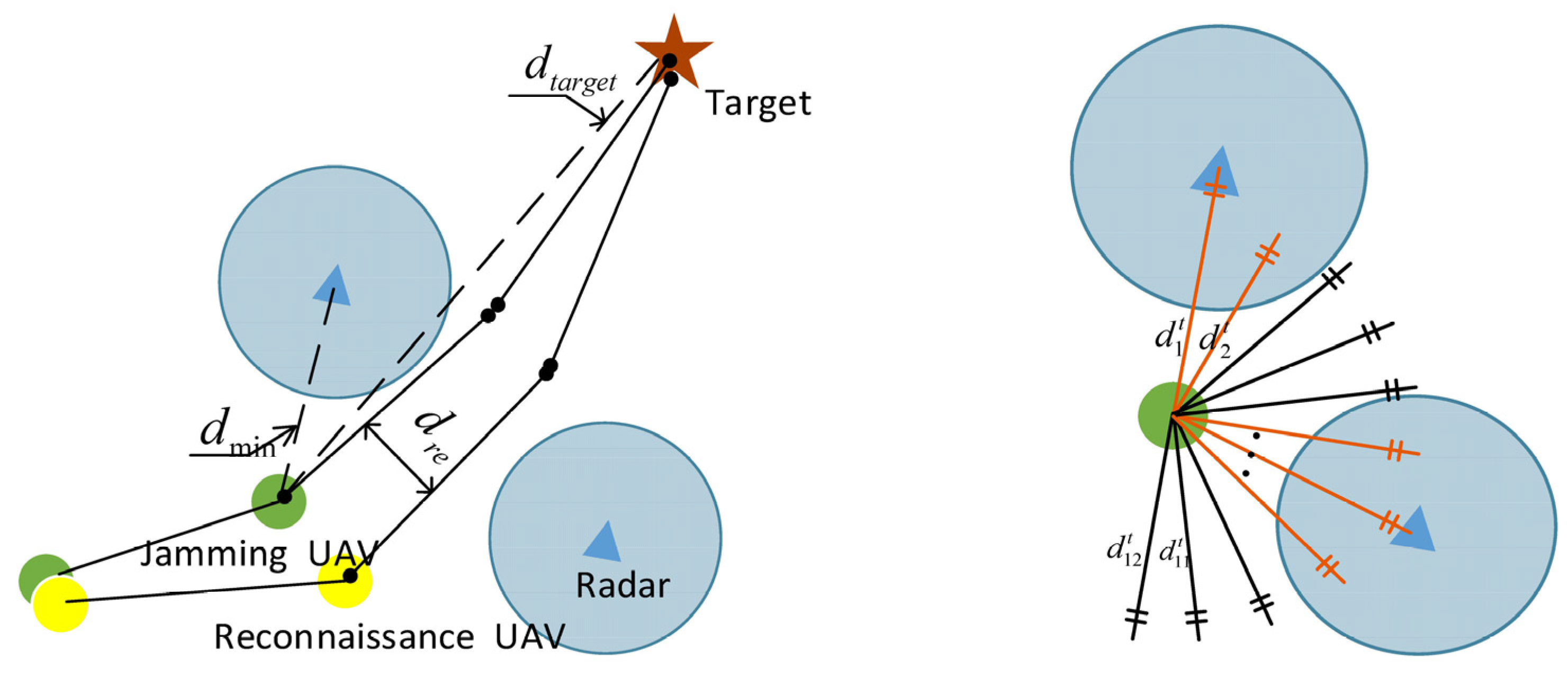
2.1. Map Description
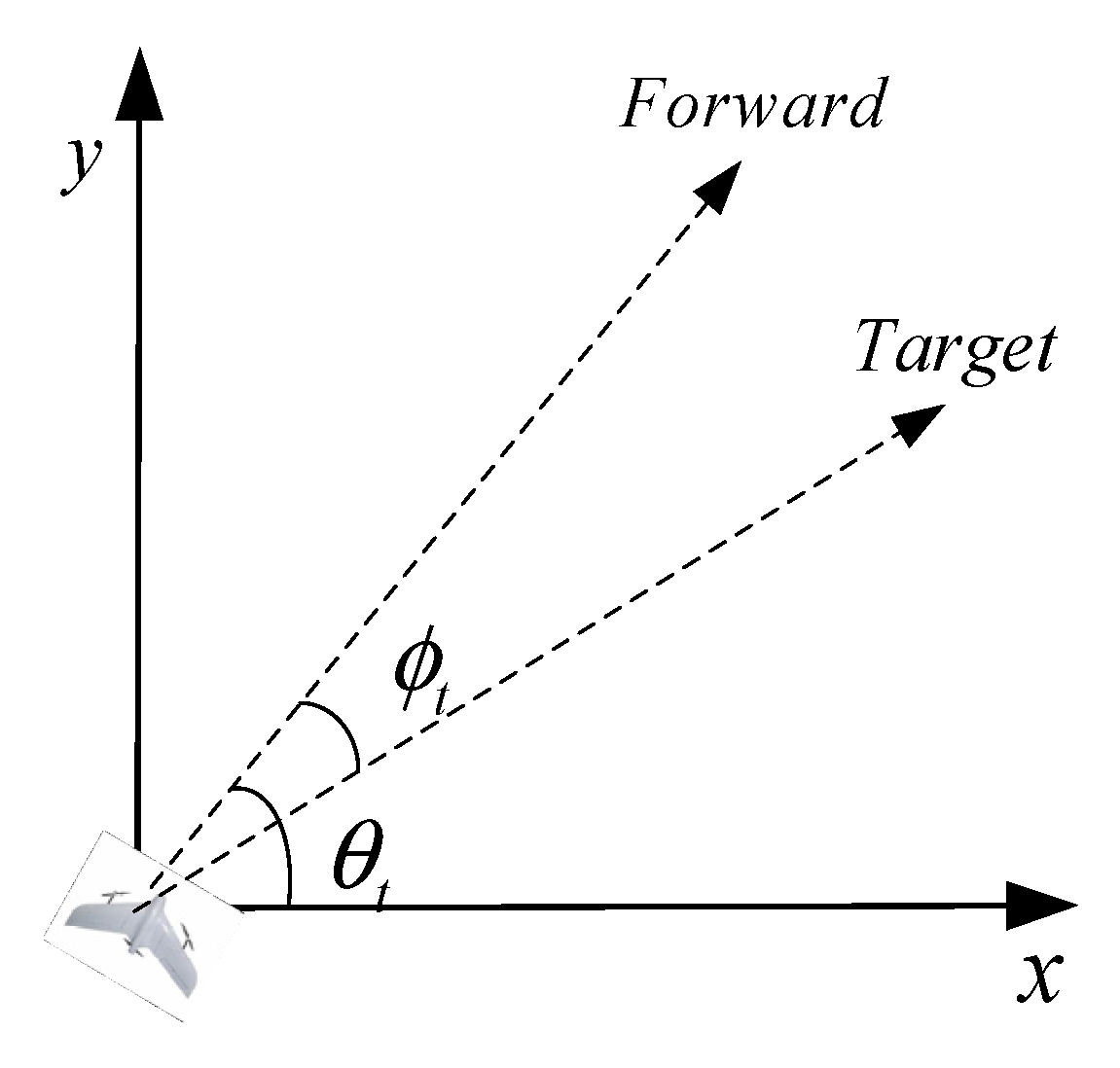
2.2. Kinematics of UAV
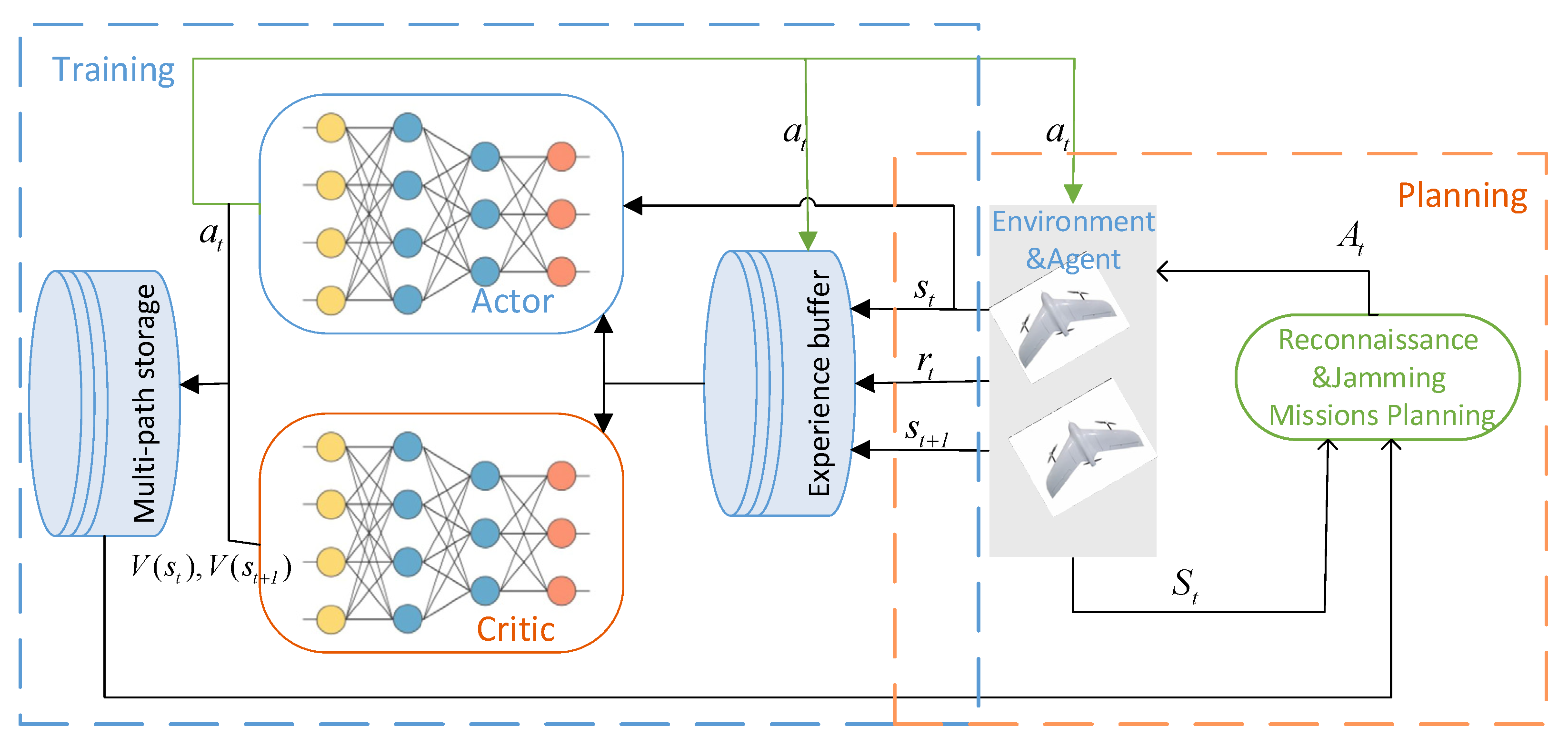
3. Deep Reinforcement Learning in Reconnaissance Mission Planning
3.1. Basic Principle
3.2. Proximal Policy Optimization Introduction
| Algorithm 1 Proximal Policy Optimization Algorithm (CLIP) [30]. |
| 1.for do |
| 2. Run policy for timesteps, collecting |
| 3. Estimate advantages |
| 4. Given policy parameters |
| 5. for do |
| 6. Sampled from the generated trajectory |
| 7. Estimate policy loss function and value loss function |
| 8. Optimized objective function |
| 9. Update based on |
| 10. |
| 11. end for |
| 12.end for |
3.3. Environment and Reward Settings
3.3.1. State Representation
3.3.2. Reward Shaping
- Closing to target. The reward needs to be set to conduct the UAV to gradually approach the target in the environment exploration. Under the security distance, the closer the UAV is to target, the higher the rewards as . To speed up reaching the target, assign a penalty function to urge the agent to avoid meaningless wandering:where are constants, and can be obtained with a rangefinder device. The first-reword function is defined as .
- Avoiding radar detection. When approaching the target, UAVs need to avoid the threat of radar detection so as to plan a reasonable flight trajectory. The closer the distance to the radar, the greater the penalty:Considering the detection radius of radar, is obtained based on the distance defined in Section 2.1.
- Wandering reward. When the jammer approaches the target detectable airspace, the searchable radius of the ground-to-air missile force is suppressed. Simultaneously, the reconnaissance aircraft implements reconnaissance, depending on its own stealth performance, under the premise of safety, the maximum distance to the target and wandering. For the aircraft performing reconnaissance missions, the radar cross section (RCS) can be reduced by relying on their own stealth coatings to reduce the probability of discovery; generally indicates the RCS [21]:where represents the dynamic detection distance of the UAV by radar and denotes the maximum radar range. Considering the non-idealization of the actual stealth efficiency, is set as an attenuation value to ensure the safety of the detection unmanned air vehicle.
- Collision avoidance. During the cooperative of two UAVs, a safe distance is set to establish avoidance penalty function:where indicate the safe and the relative distance between dual UAVs.
4. Experiment
4.1. Experiment Establishment
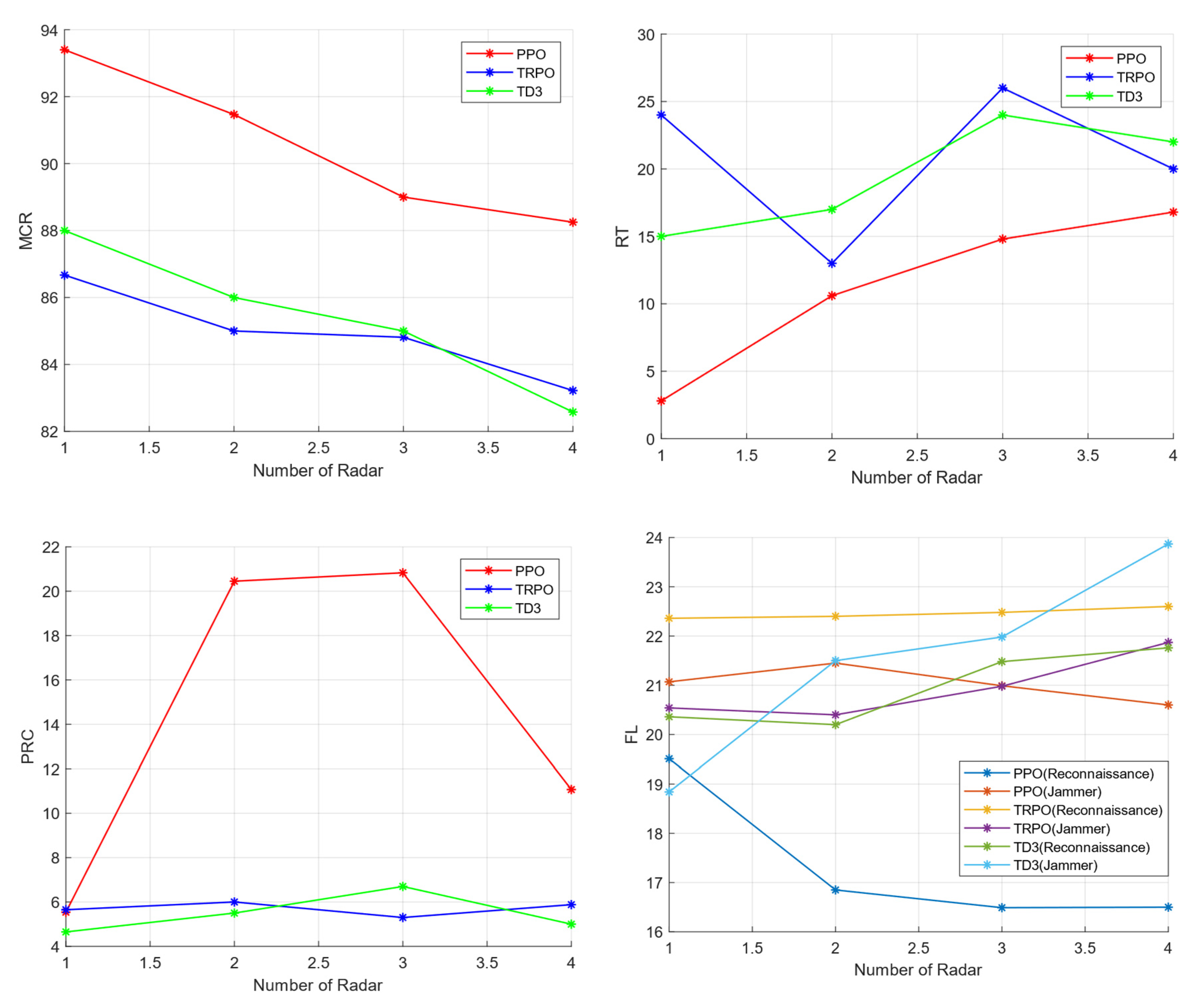
4.2. Evaluation Indicators
- Mission Complete Rate (MCR): Refers to the percentage of episodes in which the reconnaissance UAV finishes by successfully evading the search and completing a reconnaissance mission. The value can be reported after offline training episodes have been run. This indicator can evaluate the learning efficiency of the evaluation environment and reward settings in the algorithm;
- Risk Times (RT): RT represents the total number of UAVs under radar detection. The indicator value is calculated by statistically online-test planning the UAVs trajectory;
- Proportion of Reconnaissance Completed (PRC): PRC is the maneuver response period of the aircraft successfully approaching the target, revealing the agent’s understanding of task completion;
- Flight Length (FL): The whole flight path length from the starting to the target airspace.
4.3. Experiment I: Convergence
4.4. Experiment II: Effectiveness
4.5. Experiment III: Generalization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shen, L.; Chen, J.; Wang, N. Overview of Air Vehicle Mission Planning Techniques. Acta Aeronaut. Astronaut. Sin. 2014, 35, 593–606. (In Chinese) [Google Scholar]
- Nelder, J.A.; Mead, R. A simplex method for function miniimzation. Comput. J. 1965, 7, 6. [Google Scholar] [CrossRef]
- Yao, M.; Wang, X.-Z.; Zhao, M. Cooperative Combat Task Assignment Optimization Design for Unmanned Aerial Vehicle Cluster. J. Univ. Electron. Sci. Technol. China 2013, 42, 723–727. (In Chinese) [Google Scholar]
- Xin, C.; Luo, Q.; Wang, C.; Yan, Z.; Wang, H. Research on Route Planning based on improved Ant Colony Algorithm. J. Phys. Conf. Ser. 2021, 1820, 012180–012187. [Google Scholar] [CrossRef]
- Darrah, M.; Niland, W.; Stolarik, B.; Walp, L. UAV Cooperative Task Assignments for a SEAD Mission Using Genetic Algorithms; In Proceedings of the AIAA Guidance, Navigation & Control Conference & Exhibit, Keystone, CO, USA, 21–24 August 2006.
- Zhang, H.; Yang, R.; Wu, J.; Li, Q.; Fu, X.; Sun, C. Research on multi-aircraft cooperative suppressing jamming embattling in electronic warfare planning. Syst. Eng. Electron. 2017, 39, 542–548. (In Chinese) [Google Scholar]
- Moraes, R.; Pignaton de Freitas, E. Multi-UAV Based Crowd Monitoring System. IEEE Trans. Aerosp. Electron. Syst. 2019, 56, 1332–1345. [Google Scholar] [CrossRef]
- Wang, B.; Sun, Y.; Sun, Z.; Long, N.; Duong, T. UAV-assisted Emergency Communications in Social IoT: A Dynamic Hypergraph Coloring Approach. IEEE Internet Things J. 2020, 7, 7663–7677. [Google Scholar] [CrossRef]
- Fu, C.; Carrio, A.; Campoy, P. Efficient visual odometry and mapping for Unmanned Aerial Vehicle using ARM-based stereo vision pre-processing system. In Proceedings of the 2015 International Conference on Unmanned Aircraft Systems, ICUAS, Denver, CO, USA, 9–12 June 2015; pp. 957–962. [Google Scholar]
- Kabamba, P.T.; Meerkov, S.M.; Zeitz, F.H., III. Optimal Path Planning for Unmanned Combat Aerial Vehicles to Defeat Radar Tracking. Am. Inst. Aeronaut. Astronaut. 2006, 29, 279–288. [Google Scholar] [CrossRef]
- Hu, C.-F.; Yang, N.; Wang, N. Fuzzy multi-objective distributed cooperative tracking of ground target for multiple unmanned aerial vehicles. Control. Theory Appl. 2018, 35, 1101–1110. (In Chinese) [Google Scholar]
- Zhou, D.; Wang, P.; Li, X.; Zhang, K. Cooperative path planning of multi-UAV based on multi-objective optimization algorithm. Syst. Eng. Electron. 2017, 39, 782–787. (In Chinese) [Google Scholar]
- Shah, M.A.; Aouf, N. 3D Cooperative Pythagorean Hodograph path planning and obstacle avoidance for multiple UAVs. In Proceedings of the 2010 IEEE 9th International Conference on Cyberntic Intelligent Systems, Reading, UK, 1–2 September 2010. [Google Scholar]
- Wang, Y.; Bai, P.; Liang, X.; Wang, W.; Zhang, J.; Fu, Q. Reconnaissance Mission Conducted by UAV Swarms Based on Distributed PSO Path Planning Algorithms. IEEE Access 2019, 7, 105086–105099. [Google Scholar] [CrossRef]
- Hwangbo, J.; Lee, J.; Dosovitskiy, A.; Bellicoso, D.; Tsounis, V.; Koltun, V.; Hutter, M. Learning agile and dynamic motor skills for legged robots. Sci. Robot. 2019, 4, eaau5872. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, Y.; Steinweg, M.; Kaufmann, E.; Scaramuzza, D. Autonomous Drone Racing with Deep Reinforcement Learning. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021. [Google Scholar]
- Kendall, A.; Hawke, J.; Janz, D.; Mazur, P.; Reda, D.; Allen, J.M.; Lam, V.D.; Bewley, A.; Shah, A. Learning to Drive in a Day. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Ye, D.; Liu, Z.; Sun, M.; Shi, B.; Zhao, P.; Wu, H.; Yu, H.; Yang, S.; Wu, X.; Guo, Q.; et al. Mastering Complex Control in MOBA Games with Deep Reinforcement Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Imanberdiyev, N.; Fu, C.; Kayacan, E.; Chen, I.M. Autonomous navigation of UAV by using real-time model-based reinforcement learning. In Proceedings of the 2016 14th International Conference on Control, Automation, Robotics and Vision (ICARCV), Phuket, Thailand, 13–15 November 2016. [Google Scholar]
- Hu, J.; Wang, L.; Hu, T.; Guo, C.; Wang, Y. Autonomous Maneuver Decision Making of Dual-UAV Cooperative Air Combat Based on Deep Reinforcement Learning. Electronics 2022, 11, 467. [Google Scholar] [CrossRef]
- You, S.; Diao, M.; Gao, L. Deep Reinforcement Learning for Target Searching in Cognitive Electronic Warfare. IEEE Access 2019, 7, 37432–37447. [Google Scholar] [CrossRef]
- Guo, T.; Jiang, N.; Li, B.; Zhu, X.; Wang, Y.; Du, W. UAV navigation in high dynamic environments: A deep reinforcement learning approach. Chin. J. Aeronaut. 2021, 34, 479–489. [Google Scholar] [CrossRef]
- Yue, L.; Yang, R.; Zhang, Y.; Yu, L.; Wang, Z. Deep Reinforcement Learning for UAV Intelligent Mission Planning. Complexity 2022, 2022, 3551508. [Google Scholar] [CrossRef]
- Li, B.; Yang, Z.-P.; Chen, D.-Q.; Liang, S.-Y.; Ma, H. Maneuvering target tracking of UAV based on MN-DDPG and transfer learning. Def. Technol. 2021, 17, 457–466. [Google Scholar]
- You, S.; Diao, M.; Gao, L. Implementation of a combinatorial-optimisation-based threat evaluation and jamming allocation system. IET Radar Sonar Navig. 2019, 13, 1636–1645. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.P.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. arXiv 2016, arXiv:1602.01783. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithm. arXiv 2017, arXiv:1707.06347v2. [Google Scholar]
- Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Dębiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; Hesse, C.; et al. Dota 2 with Large Scale Deep Reinforcement Learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]
- Ye, D.; Chen, G.; Zhang, W.; Chen, S.; Yuan, B.; Liu, B.; Chen, J.; Liu, Z.; Qiu, F.; Yu, H.; et al. Towards Playing Full MOBA Games with Deep Reinforcement Learning. arXiv 2020, arXiv:2011.12692. [Google Scholar]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.I.; Abbeel, P.J.C. High-Dimensional Continuous Control Using Generalized Advantage Estimation. arXiv 2016, arXiv:1506.02438. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. arXiv 2015, arXiv:1502.05477. [Google Scholar]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing Function Approximation Erronr in Actor-Critic Methods. arXiv 2018, arXiv:1802.09477. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Neural Network | torch.nn.init.orthogonal_() |
| Optimizer | Adam |
| Num_episode | 600 |
| Learning Rate | 0.0003 |
| Clip | 0.2 |
| Minibatch Size | 64 |
| Num_seed | 3 |
| Step Per Round | 500 |
| Bunch Size | 2048 |
| 4 | |
| 2 | |
| 0.01 | |
| 0.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Yang, R.; Zhang, Y.; Yan, M.; Yue, L. Deep Reinforcement Learning for Intelligent Dual-UAV Reconnaissance Mission Planning. Electronics 2022, 11, 2031. https://doi.org/10.3390/electronics11132031
Zhao X, Yang R, Zhang Y, Yan M, Yue L. Deep Reinforcement Learning for Intelligent Dual-UAV Reconnaissance Mission Planning. Electronics. 2022; 11(13):2031. https://doi.org/10.3390/electronics11132031
Chicago/Turabian StyleZhao, Xiaoru, Rennong Yang, Ying Zhang, Mengda Yan, and Longfei Yue. 2022. "Deep Reinforcement Learning for Intelligent Dual-UAV Reconnaissance Mission Planning" Electronics 11, no. 13: 2031. https://doi.org/10.3390/electronics11132031
APA StyleZhao, X., Yang, R., Zhang, Y., Yan, M., & Yue, L. (2022). Deep Reinforcement Learning for Intelligent Dual-UAV Reconnaissance Mission Planning. Electronics, 11(13), 2031. https://doi.org/10.3390/electronics11132031