
Deep Learning-Based Context-Aware Video Content Analysis on IoT Devices




Abstract
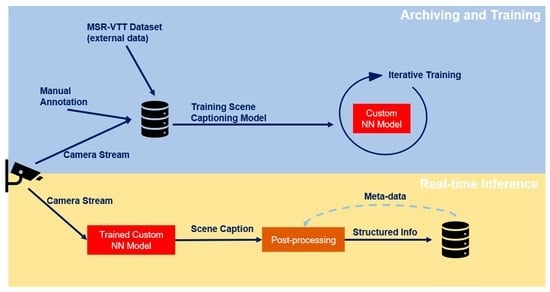
:
1. Introduction
2. Related Work
- Restricting the captions’ language model to simple sentence templates to decrease the complexity and size of the model that is required to achieve a certain accuracy.
- Developing two lightweight video captioning models, optimizing their parameters with hyperparameter tuning and evaluating their performance in terms of accuracy and inference time.
- Predicting captions that have predefined sentence structures to make post processing of these captions easier relative to processing natural language-based captions.
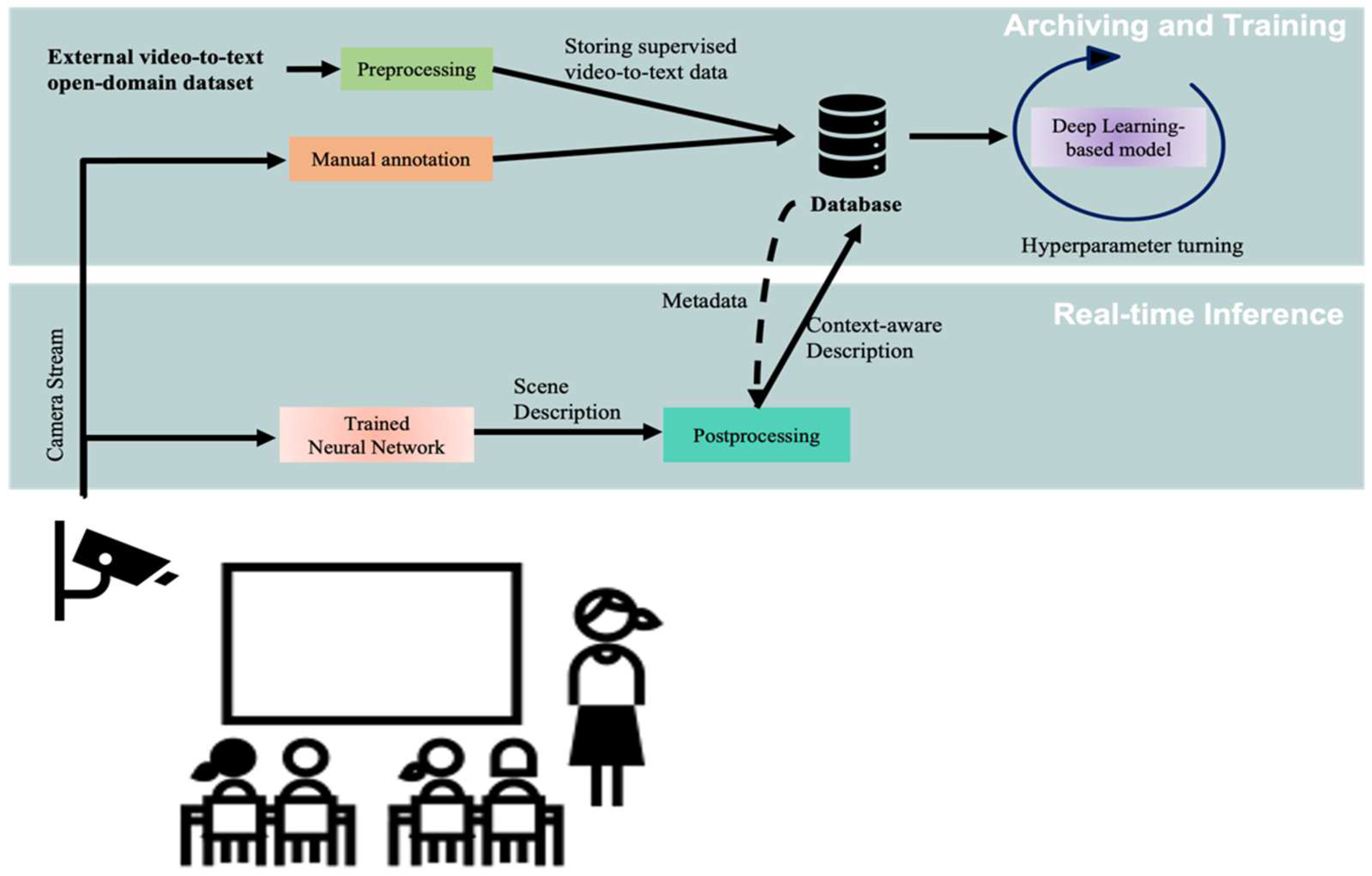
3. Methodology
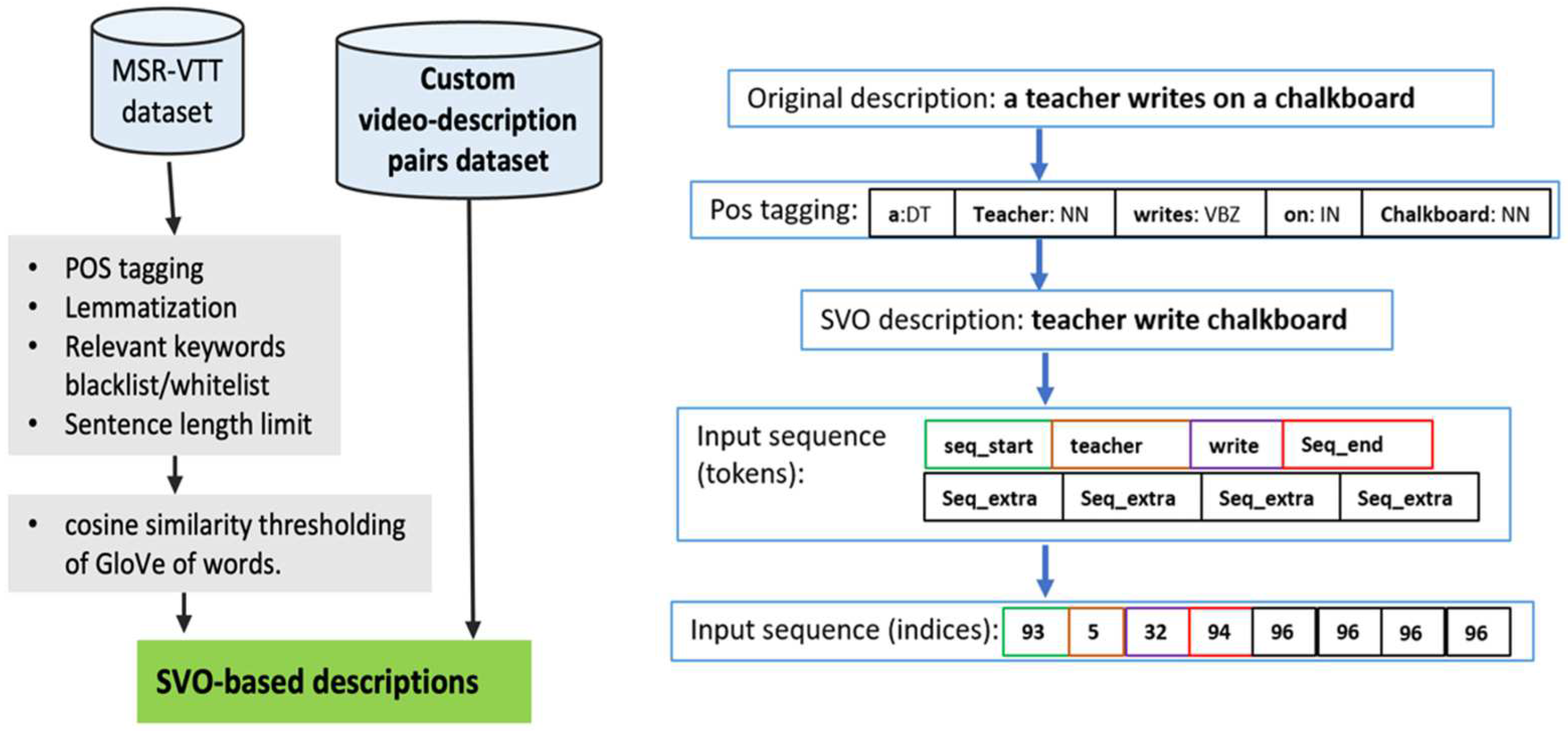
3.1. Dataset
3.2. Deep Learning-Based Models
3.2.1. Transformer-Based Model
3.2.2. LSTM-Based Model
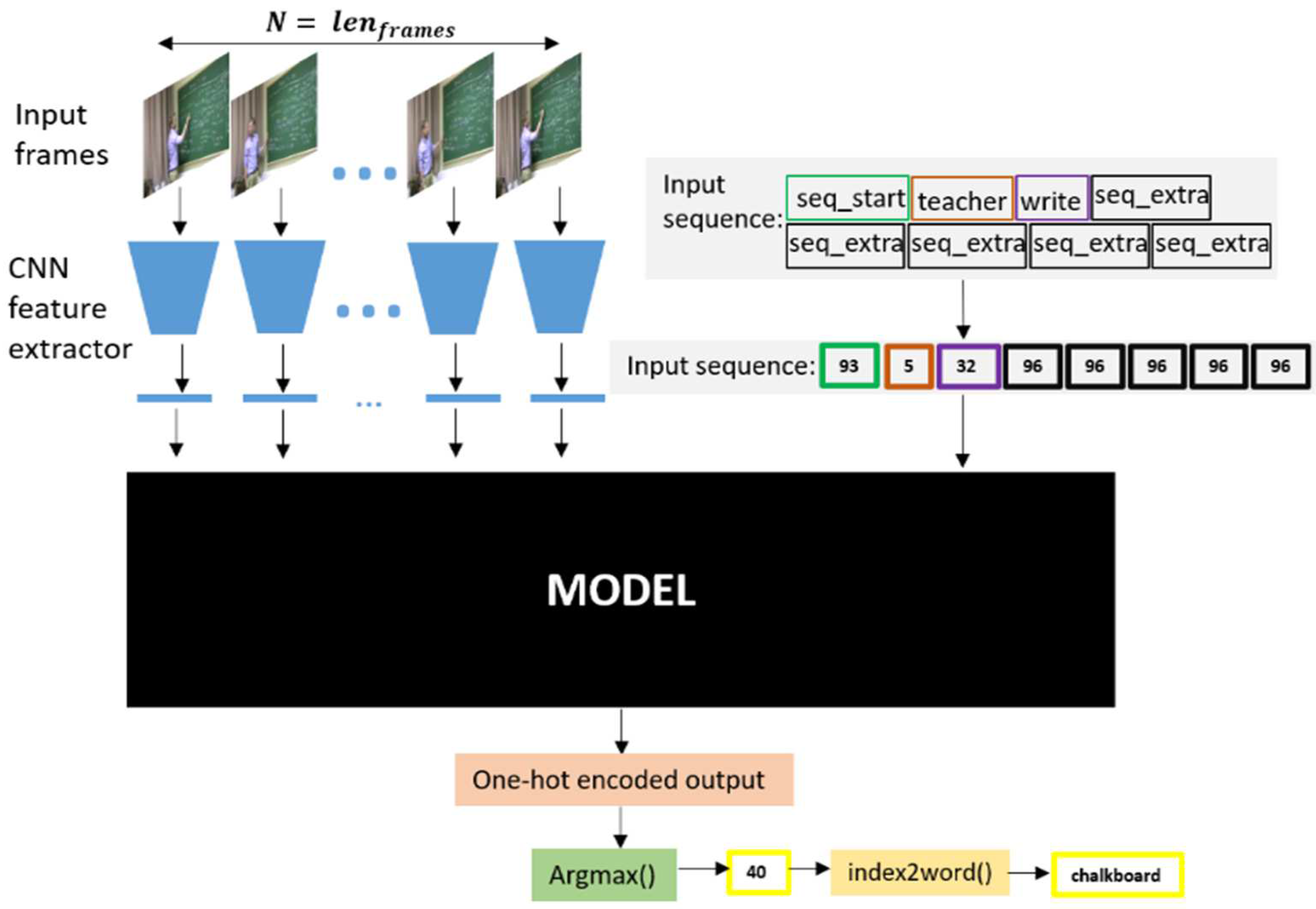
3.2.3. CNN Feature Extractor
3.3. Generating Captions
| Algorithm 1. Sequential Caption Generation |
| Input: frames (list of frames), (Maximum length of the generated description sentence), word2ix (a dictionary mapping each token to index), ix2word (a dictionary mapping each generated index to token), model (trained model) Output: caption (generated sentence) |
|
| Algorithm 2. Padding Captions |
| Input: word_tokens (list of tokens to pad), word2ix (a dictionary mapping each token to index), (maximum length of the caption), Output: ix_tokens (list of padded indices tokens) |
|
4. Results
- The length of SVO-captions is relatively small and fixed, therefore, comparing the corresponding words of the predicted and the ground truth captions makes more sense than machine translation (MT) quality metrics like BLEU [33] which is more suitable for assessing natural language-based captions.
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Advances in Neural Information Processing Systems. June 2017, Volume 2017-December, pp. 5999–6009. Available online: https://arxiv.org/abs/1706.03762v5 (accessed on 17 March 2021).
- Rohrbach, A.; Rohrbach, M.; Tandon, N.; Schiele, B. A dataset for Movie Description. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef] [Green Version]
- Chen, D.L.; Dolan, W.B. Collecting highly parallel data for paraphrase evaluation. In ACL-HLT 2011, Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, Oregon, 19–24 June 2011; IEEE: Manhattan, NY, USA, 2011; Volume 1. [Google Scholar]
- Torabi, A.; Pal, C.; Larochelle, H.; Courville, A. Using Descriptive Video Services to Create a Large Data Source for Video Annotation Research. March 2015. Available online: http://arxiv.org/abs/1503.01070 (accessed on 13 March 2021).
- Xu, J.; Mei, T.; Yao, T.; Rui, Y. MSR-VTT: A large video description dataset for bridging video and language. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 2016-December. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar] [CrossRef]
- Bahdanau, D.; Chorowski, J.; Serdyuk, D.; Brakel, P.; Bengio, Y. End-to-end attention-based large vocabulary speech recognition. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Shanghai, China, 20–25 March 2016; Volume 2016-May. [Google Scholar] [CrossRef] [Green Version]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef] [Green Version]
- Donahue, J.; Saenko, K.; Darrell, T.; Austin, U.T.; Lowell, U.; Berkeley, U.C. Long-term Recurrent Convolution Networks for Visual Recognition and Description. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2625–2634. [Google Scholar] [CrossRef] [PubMed]
- Venugopalan, S.; Rohrbach, M.; Donahue, J.; Mooney, R.; Darrell, T.; Saenko, K. Sequence to sequence—Video to text. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; Volume 2015, pp. 4534–4542. [Google Scholar] [CrossRef] [Green Version]
- Hessel, J.; Pang, B.; Zhu, Z.; Soricut, R. A case study on combining ASR and visual features for generating instructional video captions. arXiv 2019, arXiv:1910.02930. [Google Scholar] [CrossRef] [Green Version]
- Venugopalan, S.; Xu, H.; Donahue, J.; Rohrbach, M.; Mooney, R.; Saenko, K. Translating videos to natural language using deep recurrent neural networks. arXiv 2015, arXiv:1412.4729. [Google Scholar] [CrossRef]
- Wang, X.; Chen, W.; Wu, J.; Wang, Y.F.; Wang, W.Y. Video captioning via hierarchical reinforcement learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4213–4222. [Google Scholar]
- Mun, J.; Yang, L.; Ren, Z.; Xu, N.; Han, B. Streamlined dense video captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6588–6597. [Google Scholar]
- Xin, X.; Tu, Y.; Stojanovic, V.; Wang, H.; Shi, K.; He, S.; Pan, T. Online reinforcement learning multiplayer non-zero sum games of continuous-time Markov jump linear systems. Appl. Math. Comput. 2022, 412, 126537. [Google Scholar] [CrossRef]
- Zhou, L.; Zhou, Y.; Corso, J.J.; Socher, R.; Xiong, C. End-to-End Dense Video Captioning with Masked Transformer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Girdhar, R.; Carreira, J.J.; Doersch, C.; Zisserman, A. Video action transformer network. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; Volume 2019-June. [Google Scholar] [CrossRef] [Green Version]
- Rahman, T.; Xu, B.; Sigal, L. Watch, listen and tell: Multi-modal weakly supervised dense event captioning. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; Volume 2019-October. [Google Scholar] [CrossRef] [Green Version]
- Iashin, V.; Rahtu, E. Multi-modal dense video captioning. arXiv 2020, arXiv:2003.07758. [Google Scholar]
- Namjoshi, M.; Khurana, K. A Mask-RCNN based object detection and captioning framework for industrial videos. Int. J. Adv. Technol. Eng. Explor. 2021, 8, 1466. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cheng, Y.; Dai, Z.; Ji, Y.; Li, S.; Jia, Z.; Hirota, K.; Dai, Y. Student Action Recognition Based on Deep Convolutional Generative Adversarial Network. In Proceedings of the 32nd Chinese Control and Decision Conference, CCDC 2020, Hefei, China, 22–24 August 2020; pp. 128–133. [Google Scholar] [CrossRef]
- Rashmi, M.; Ashwin, T.S.; Guddeti, R.M.R. Surveillance video analysis for student action recognition and localization inside computer laboratories of a smart campus. Multimed. Tools Appl. 2021, 80, 2907–2929. [Google Scholar] [CrossRef]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. April 2018. Available online: http://arxiv.org/abs/1804.02767 (accessed on 2 July 2021).
- Gad, G.; Gad, E.; Mokhtar, B. Towards Optimized IoT-based Context-aware Video Content Analysis Framework. In Proceedings of the 2021 IEEE 7th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 14 June–31 July 2021; pp. 46–50. [Google Scholar] [CrossRef]
- Motwani, T.S.; Mooney, R.J. Improving video activity recognition using object recognition and text mining. In ECAI 2012; IOS Press: Amsterdam, The Netherlands, 2012; pp. 600–605. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar] [CrossRef]
- Ayeldeen, H.; Hassanien, A.E.; Fahmy, A.A. Lexical similarity using fuzzy Euclidean distance. In Proceedings of the 2014 International Conference on Engineering and Technology (ICET), Cairo, Egypt, 19–20 April 2014; pp. 1–6. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 2016-December. [Google Scholar] [CrossRef] [Green Version]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Methods | Advantages | Disadvantages |
|---|---|---|---|
| Natural language-based video captioning | Uni-modal (visual features): [9,10]: LSTM-based seq-to-seq model. [16]: Transformer-based model to generate captions and event proposals. [13,14]: Reinforcement learning (RL)-based dense captioning methods Multi-modal (visual features + audio + other features): [11]: Automatic speech recognition ASR and transformer-based model. [18]: Weakly supervised trained model. [19]: Dense video captioning (Localize and caption one event or more). |
|
|
| Template-based video captioning | [26]: Preliminary results of this work using custom model. [27]: Language processing to estimate activity–object correlation to improve activity recognition systems. [20]: Mask R-CNN [21] and template-based captioning. The proposed method trains a transformer model on SVO templates converted from natural language-based captions. |
|
|
| Classification-based video description | [17]: 3DCNN for object detection and transformer-based for action classification. [22]: A generative adversarial network (GAN) [24] is used to recognize activities. [23]: Uses YOLOV3 [25] to classify students’ behavior. |
|
|
| Model | Selected Hyperparameters | Accuracy (%) | ||
|---|---|---|---|---|
| # of Attention Heads | Learning Rate | Word Embeddings | ||
| Transformer | 1 | 0.001 | 100 | 69.8 |
| 1 | 0.005 | 100 | 80.2 | |
| 1 | 0.0005 | 100 | 95.6 | |
| 2 | 0.001 | 100 | 83.3 | |
| 4 | 0.001 | 100 | 81.2 | |
| 4 | 0.0005 | 100 | 97 | |
| LSTM-based model | N/A | 0.005 | 20 | 52.1 |
| N/A | 0.005 | 100 | 52.1 | |
| N/A | 0.001 | 80 | 54.2 | |
| N/A | 0.001 | 256 | 65.6 | |
| N/A | 0.0005 | 20 | 25 | |
| N/A | 0.0005 | 256 | 59.4 | |
| Category | Model | Power Mode | |
|---|---|---|---|
| MAXN | 5 W | ||
| CNN feature extractor | GoogLeNet | s | s |
| RESNET-18 | s | s | |
| RESNET-50 | s | s | |
| Token generation | LSTM-based | 0.21 s | 0.3 s |
| Transformer | 2.8 s | 3.2 s | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gad, G.; Gad, E.; Cengiz, K.; Fadlullah, Z.; Mokhtar, B. Deep Learning-Based Context-Aware Video Content Analysis on IoT Devices. Electronics 2022, 11, 1785. https://doi.org/10.3390/electronics11111785
Gad G, Gad E, Cengiz K, Fadlullah Z, Mokhtar B. Deep Learning-Based Context-Aware Video Content Analysis on IoT Devices. Electronics. 2022; 11(11):1785. https://doi.org/10.3390/electronics11111785
Chicago/Turabian StyleGad, Gad, Eyad Gad, Korhan Cengiz, Zubair Fadlullah, and Bassem Mokhtar. 2022. "Deep Learning-Based Context-Aware Video Content Analysis on IoT Devices" Electronics 11, no. 11: 1785. https://doi.org/10.3390/electronics11111785
APA StyleGad, G., Gad, E., Cengiz, K., Fadlullah, Z., & Mokhtar, B. (2022). Deep Learning-Based Context-Aware Video Content Analysis on IoT Devices. Electronics, 11(11), 1785. https://doi.org/10.3390/electronics11111785