1. Introduction
In recent years, Unmanned Aerial Vehicles (UAV) have played an increasingly important role in many fields due to their high flexibility, low cost, and easy operation [
1]. In the military, they are often utilized to perform reconnaissance, battlefield situation monitoring, and other tasks. Since infrared images have thermal radiation properties and visible images have light reflection properties, if the two are accurately registered and fused, the result not only preserves the clear details and edges of the visible image but also preserves the brightness information in the infrared image, making the target easier to identify [
2]. As these two sensors are more common, at present, small UAVs are usually equipped with infrared and visible sensors for target detection or tracking. Using the above principles can make it easier for small UAVs to lock the target [
3]. However, due to differences in the time period, distance, shooting angle, etc., of UAV aerial photography, the images obtained by multi-source sensors may not be strictly aligned due to the existence of translation, rotation, scaling, and other spatial transformation relationships. Therefore, registration needs to be carried out before fusion [
4]. However, the information has a low overlap in the reconnaissance area, so the inconsistence of the information amplitude and resolution, large differences in viewing angles, etc., due to the constraints of terrain, time, climate, UAV flight trajectory, and other conditions, as well as the mutual constraints between the various loads when the infrared and visible sensors work simultaneously, mean that image registration is still a difficult task.
Existing image registration technology can be roughly divided into three categories: calibration-based registration technology [
5], region-based registration technology [
6], and feature-based registration technology [
7]. Calibration-based methods are fixed at a specific distance, so they are not suitable for UAV image registration applications. Region-based methods usually use the whole image information to establish a similarity measure of two images. They directly judge the intensity differences between images without extracting salient features. Under the condition that the image has a certain deformation in the local area or the heterogeneous image, the region-based registration methods usually fail to match successfully, so they are not suitable for the research in this paper. The feature-based methods are the most commonly used registration methods at present, and they are also a class of methods that have been widely improved by scholars. The algorithm in this paper is also an image registration algorithm based on feature point design. The detailed research process of image registration will be described in
Section 2.
The above methods have been widely discussed in the past; however, registration of infrared and visible images for UAVs is still a difficult task. First, the spectra of infrared images is different from visible images, resulting in large differences in the corresponding regions and difficult registration implementation. Second, the resolutions of infrared images are different from visible images, resulting in a point in an infrared image that may not have matching areas in a visible image. Third, the low resolution of infrared images will lead to difficulty in feature point extraction. Fourth, there are viewpoint differences between infrared images and visible images, which will lead to difficulty in image matching.
In response to the above problems, a new feature point-based deep convolution automatic robust registration algorithm, named the deep convolutional network–rough to fine registration algorithm, was proposed for infrared and visible images. First, the feature points are fully extracted by the improved convolutional neural network, which solves the problem of feature point location between images; secondly, the problem of resolution difference is solved by the rough to fine feature matching method, which obtains an accurate image transformation matrix and solves the problem of inaccurate matching. The proposed registration algorithm fully utilizes image features and combines deep convolutional networks and the R2F method, which achieves accurate registration of infrared and visible images on UAVs. The main contributions of this paper are:
(1) A multi-scale feature descriptor is generated by utilizing a pre-trained deep convolutional network to obtain the feature points of the images. The advantages of convolutional neural network are effectively utilized in feature extraction to obtain accurately positioned feature points.
(2) A rough-to-fine feature point matching method is designed, which introduces the concept of location orientation scale transform Euclidean distance and fine matching, based on update global optimization, to obtain high-precision registration images.
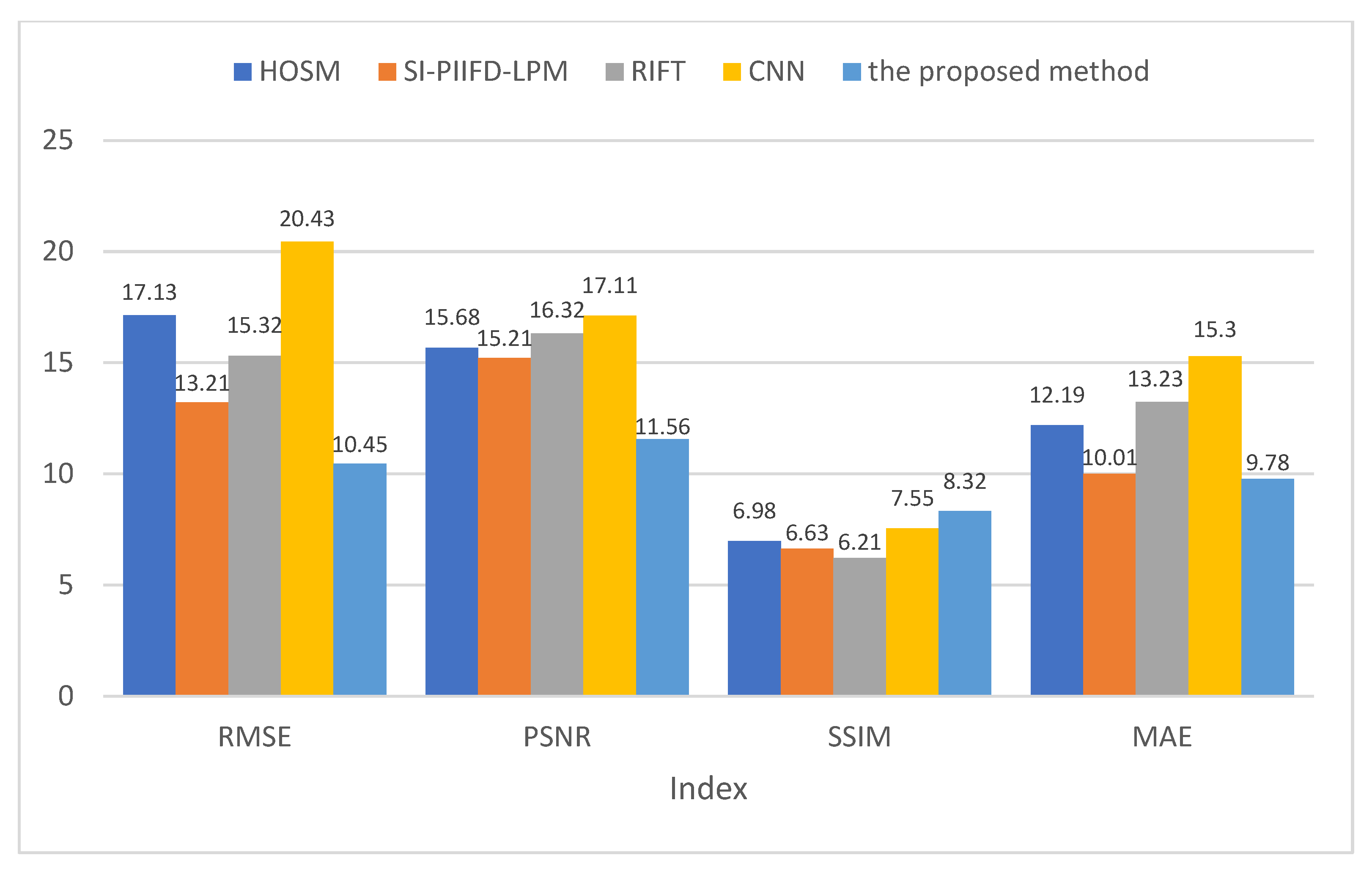
(3) The feature point extraction comparison experiment and the image registration comparison experiment, respectively, prove that the proposed algorithm has a good performance in the feature point extraction and the overall image registration effect, which verifies the effectiveness and robustness of the proposed algorithm.
The paper is organized as follows.
Section 2 outlines the research progress of image registration algorithms.
Section 3 introduces the proposed registration algorithm, which mainly consists of deep convolutional feature extraction and the rough to fine method. The experiment results and analysis are presented in
Section 4. Finally, the conclusion is given in
Section 5.
2. Related Works
Image registration technology was developed in the 1970s, and it was generally used in military fields, such as missile guidance and aircraft navigation systems, in the early stage of development. With the advancement of software and hardware technology, image registration technology is applied in more and more fields. After years of development and accumulation, many excellent research results have been produced in the field of image registration. Initially, image registration algorithms were mostly based on image grayscale. Barnea et al. [
8], in 1972, proposed the use of similarity metric functions to match images. In 1995, Viola et al. [
9] introduced the concept of mutual information, which opened a new door for image registration, and scholars have performed a great deal of research on this basis. For example, the multi-source medical image matching method, based on mutual information proposed by Maes et al. [
10] in 1997, still inspires the processing of medical images. In 2005, Fan et al. [
11] combined the advantages of wavelet transform and the mutual information method to propose an image registration method, which had gained extensive attention in the field of multi-source remote sensing registration images. The advantage of the grayscale-based image registration algorithm is that it is relatively simple to implement and has strong robustness; the disadvantage is that it requires significant computation and requires a strong grayscale correlation between images. It is difficult to obtain the best registration effect for grayscale information.
With the continuous development of technology, a large number of new image registration schemes continue to emerge, multi-source image registration research has been vigorously developed, and the image registration accuracy has also been greatly improved. At present, the research of image registration technology can be roughly divided into three categories: calibration-based image registration technology, region-based image registration technology, and feature-based image registration technology.
Calibration-based methods rely on calibrated cameras and can simply align images taken at the same time and view. The registration error of these methods is fixed at a certain distance, so it is not suitable for registration applications of UAV images. Unlike calibration-based methods, region-based registration methods and feature-based registration methods are automatic. However, region-based methods usually use the whole image information to establish a similarity measure of two images, directly compare and match the intensity difference between the images, and do not extract salient features. There are generally three region-based methods: the cross-correlation methods, the mutual information methods, and the Fourier methods. The registration accuracy of such methods can reach the pixel level, but there are occlusion and affine transformations. The region-based registration methods usually fail to match successfully under the conditions of local deformation of the images or with heterogeneous images.
Feature-based image registration methods are important tools for solving image registration problems due to their good invariant properties. In 1981, Moravec [
12] proposed a method to detect the corners of image contours. In 1988, Harris [
13] was inspired by it and developed a corner detection method that is not affected by image rotation, which is known as the famous Harris operator. Then, Lindeberg et al. [
14] proposed scale space theory to solve the problem of scale invariance, and they designed operators, such as Hessian-Laplace and Harris-Affine, to perform affine transformation on images. After summarizing the previous research results and learning from each other’s strengths, Lowe proposed the SIFT operator [
15], with trans-epoch significance, in 2004. This operator can solve the problem of image registration in most complex situations, and it has been influential to this day. At the ECCV conference in 2006, Bay first proposed another famous operator: the SURF operator [
16]. The SURF operator is an improvement of the SIFT algorithm, which greatly reduces the computational complexity in the feature extraction process, and it has higher robustness. After years of development, scholars have also proposed many excellent algorithms, such as BRISK [
17], ORB [
18], and multiple phase congruency directional patterns [
19], which make the feature-based image registration methods more widely used.
With the widespread development of deep learning, convolutional neural networks (CNNs) have been utilized for image registration tasks [
20]. In 2017, Ma et al. [
21] proposed a feature registration method for full image representation based on CNN features. The features of the CNN were used to find keyframes with a similar appearance from the topological map. Then, the geometric features were checked by the consistency of the vector field to obtain the most similar key features and achieve the matching performance. DeTone et al. [
22] used an end-to-end neural network to learn the homography between images, showing the superiority that is difficult to achieve by traditional image registration. The algorithm learned the homography between network parameters and images at the same time, and it obtained the homography between images by outputting the offset of four coordinate points. Japkowicz et al. [
23] proposed a dual convolutional neural network for image registration. Four of the convolutional layers are used to process two images simultaneously, and the other four are used to concatenate the feature maps to generate homography estimates, resulting in superior accuracy. However, because the network processes a pair of images in parallel and is trained hierarchically, the amount of parameters and computation of the network is greatly increased. Ty Nguyen et al. [
24] proposed an unsupervised learning neural network, which achieved more robustness by computing the loss by exploiting the similarity between images. Li et al. [
25] proposed a multiple vector (VLAD) encoding method, with local classification descriptors and CNN features, for image classification. Wen et al. [
26] proposed a depth-guided color-coarse-to-fine image processing method based on convolutional neural networks, which solves the phenomenon of texture duplication and can effectively reserve the edge details of super-resolution images.
In summary, the image registration algorithm based on feature points is suitable for the research in this paper. Through the analysis of the literature, it is found that the above algorithm still has some shortcomings for the registration of infrared and visible images of UAVs. In this paper, the feature point-based image registration algorithm is used, and the feature point extraction is realized by using the advantages of the convolutional neural network for feature point location. Then, the traditional algorithm is used for subsequent matching and transformation.
3. Materials and Methods
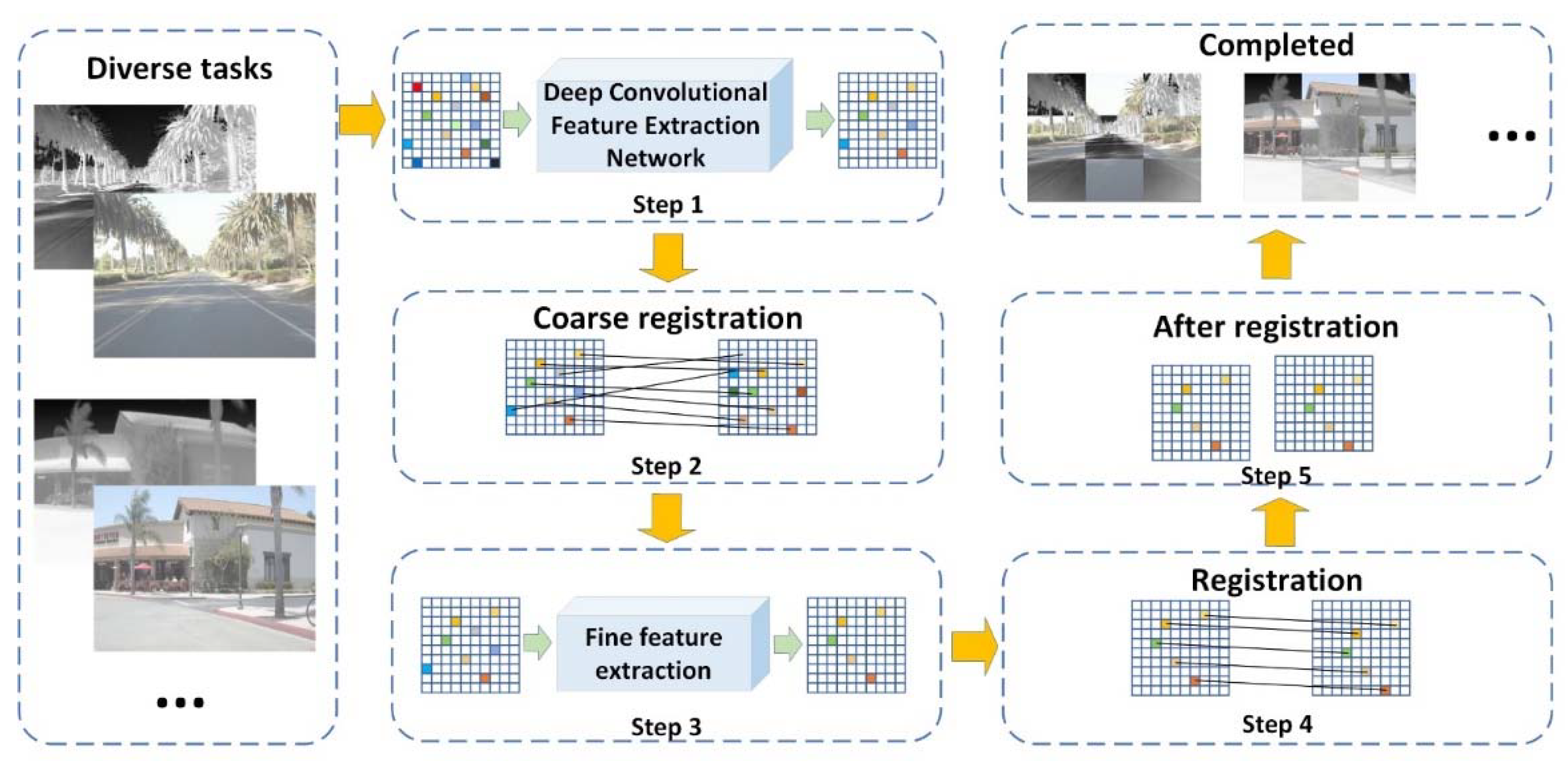
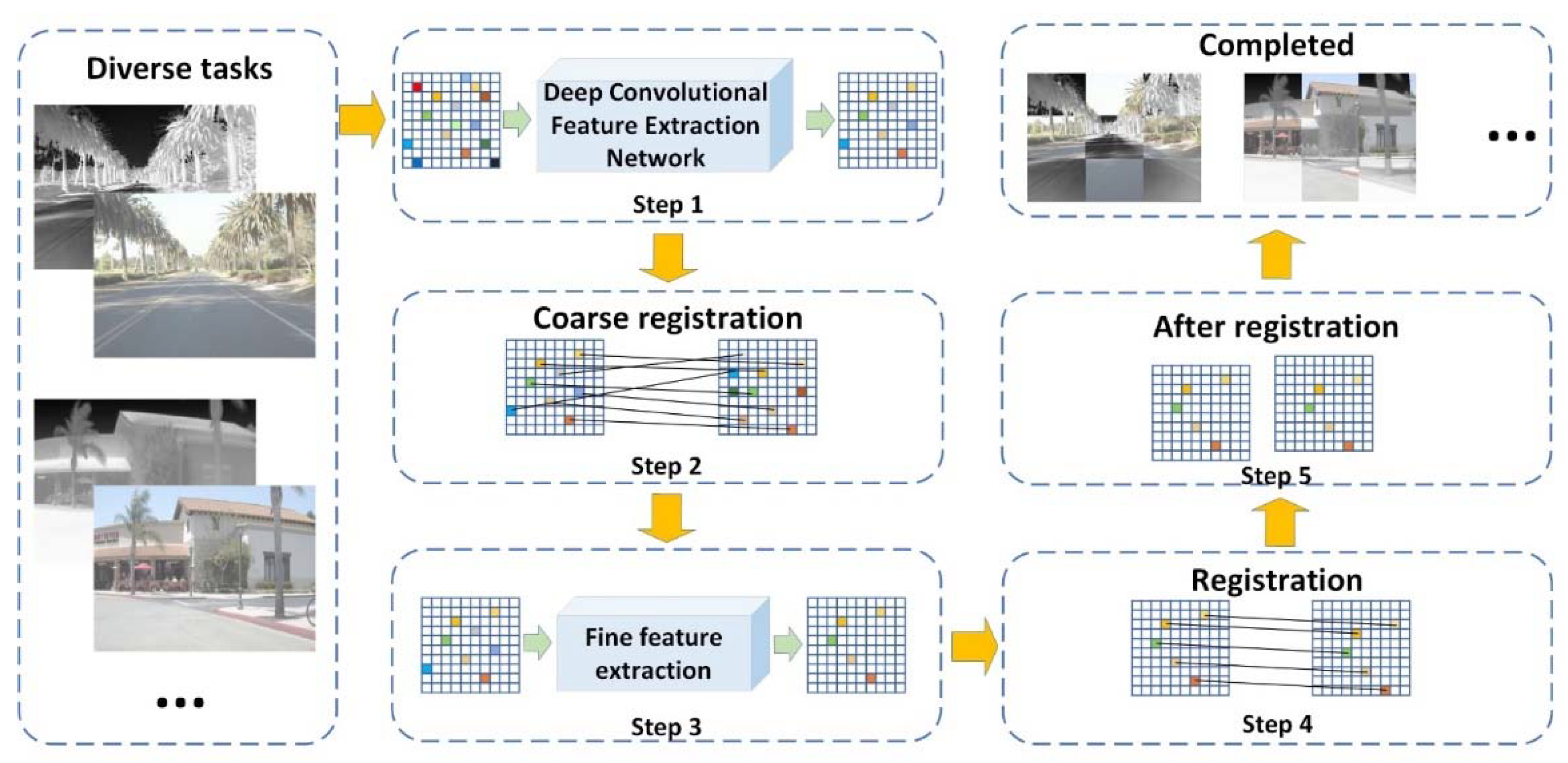
In order to improve the problem of poor registration performance, a new image registration model is framed, as shown in the
Figure 1. Different from the traditional image registration algorithm, in order to better extract feature points and perform correct matching, firstly, the deep convolution feature extraction network model is utilized to extract feature points from the image (i.e., step 1 in
Figure 1), and then, the concept of location orientation scale transform Euclidean distance is introduced. The extracted feature points are roughly matched (i.e., step 2 in
Figure 1); finally, a fine matching, based on update global optimization, is introduced to reduce the positional deviation of the feature points (i.e., step 3 in
Figure 1). After the above operations, all the feature points corresponding to the infrared and visible images are correctly matched, and the final registered image pair is obtained by corresponding to the images.
3.1. Feature Point Extraction by Deep Convolutional Network
The VGG-16 [
27] network is an image classification network that can classify a large number of categories. It is often utilized in various computer vision feature extraction links. Its advantages are: (1) it has excellent image resolution ability; (2) it relies on connecting convolutional layers, pooling layers, and fully connected layers to build a network model. The structure is very simple and concise, so the network can be used for a variety of image processing tasks. (3) Its network structure is deep and can be trained with a large amount of diverse image data. Therefore, partial convolutional layers of VGG-16 were adopted, in this paper, to construct a deep convolutional network for feature descriptor extraction. The VGG-16 network is frequently utilized for feature detection in the field of image processing, such as the automatic detection of corn kernels from UAV images using the VGG-16 network [
28] and Super-Resolution Generative Adversarial Networks (SRGAN) [
29].
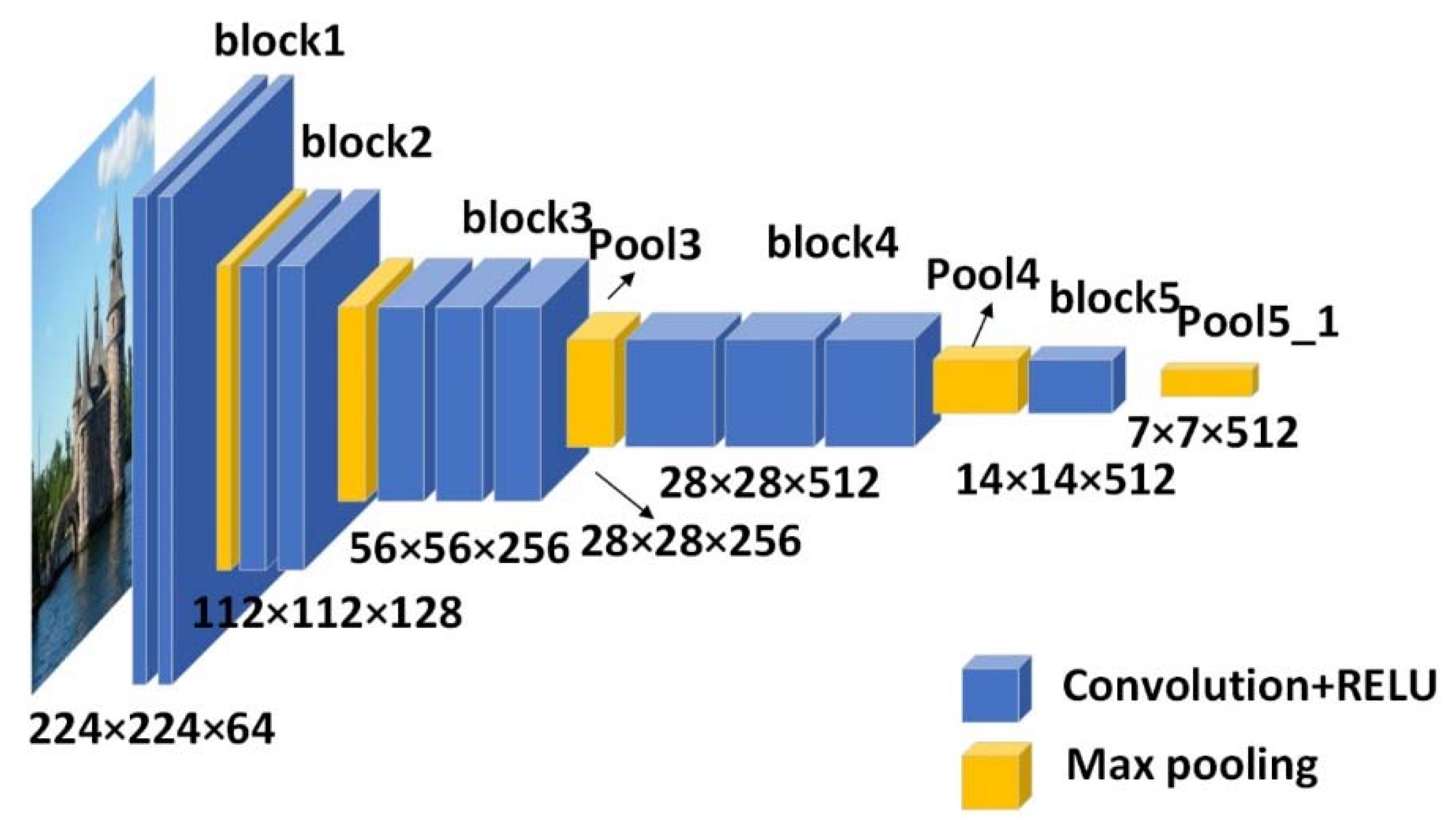
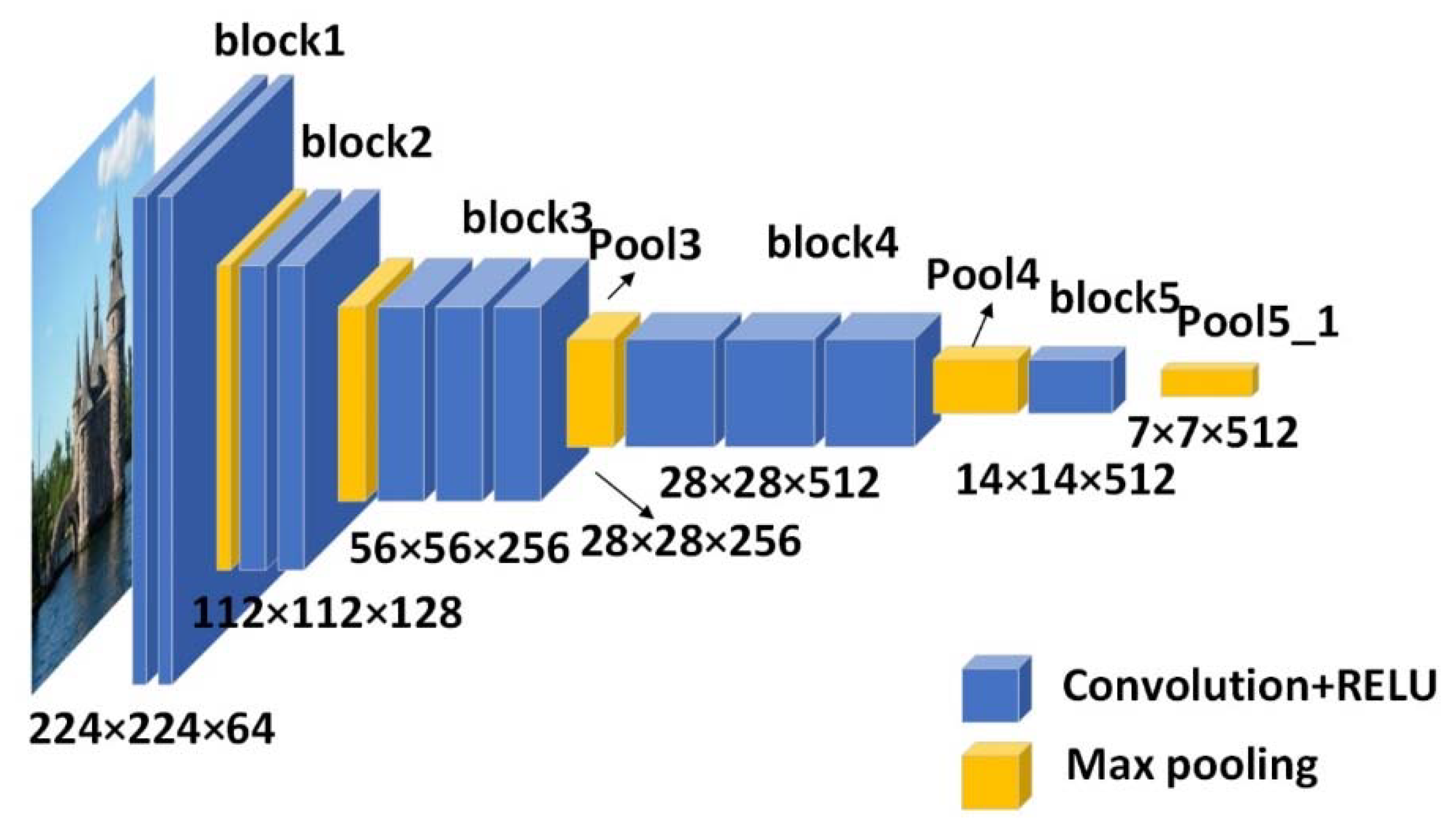
In order to obtain a single feature descriptor output, while taking into account the universality of the convolution filter and the size of the receptive field, multiple network layers are selected to construct the experimental model. The size of the input image can be arbitrarily set to a multiple of 32, but it may affect the computational efficiency, make the receptive fields of each feature point different, and even influence the performance of the network construction. Therefore, in order to maximize the network performance and be computationally efficient enough, the size of the input image is set to 224 × 224. The maximum pooling layer pool5_1, added after the three output layers pool3, pool4, and pool5, is utilized to construct the deep convolutional output network in this paper. Compared with the original VGG-16 model, our model removes the fully connected layer and adds a pool5_1 layer after the pool5 layer that can detect more general features.
As shown in
Figure 2, the network structure model of this paper contains five convolution blocks, the first two blocks contain two convolutional layers, the third and fourth convolutional blocks contain three convolutional layers, and the last convolutional block contains one convolutional layer, each with a max-pooling layer at the end of them. A
Pool5_1 layer, as a max pooling layer, is added to the end. A 28 × 28 grid is utilized to divide the input image into blocks, where each block corresponds to a 256-dimensional vector in the output of
pool3, which is also the feature descriptor of
pool3, and a central feature descriptor is produced by each 8 × 8 square. The feature map
is directly obtained from the output of
pool3. Different from how the
pool3 output layer is processed, the feature map
output by the
pool4 layer (with a size of 14 × 14 × 512) is shared by four feature points in each 16 × 16 region, obtained by Kronecker (denoted by
):
where
represents the output of the
pool4 layer,
represents the tensor subscript shape and fills it with 1s.
The feature map
of the
pool5_1 layer is possessed by 16 feature points, which are represented as:
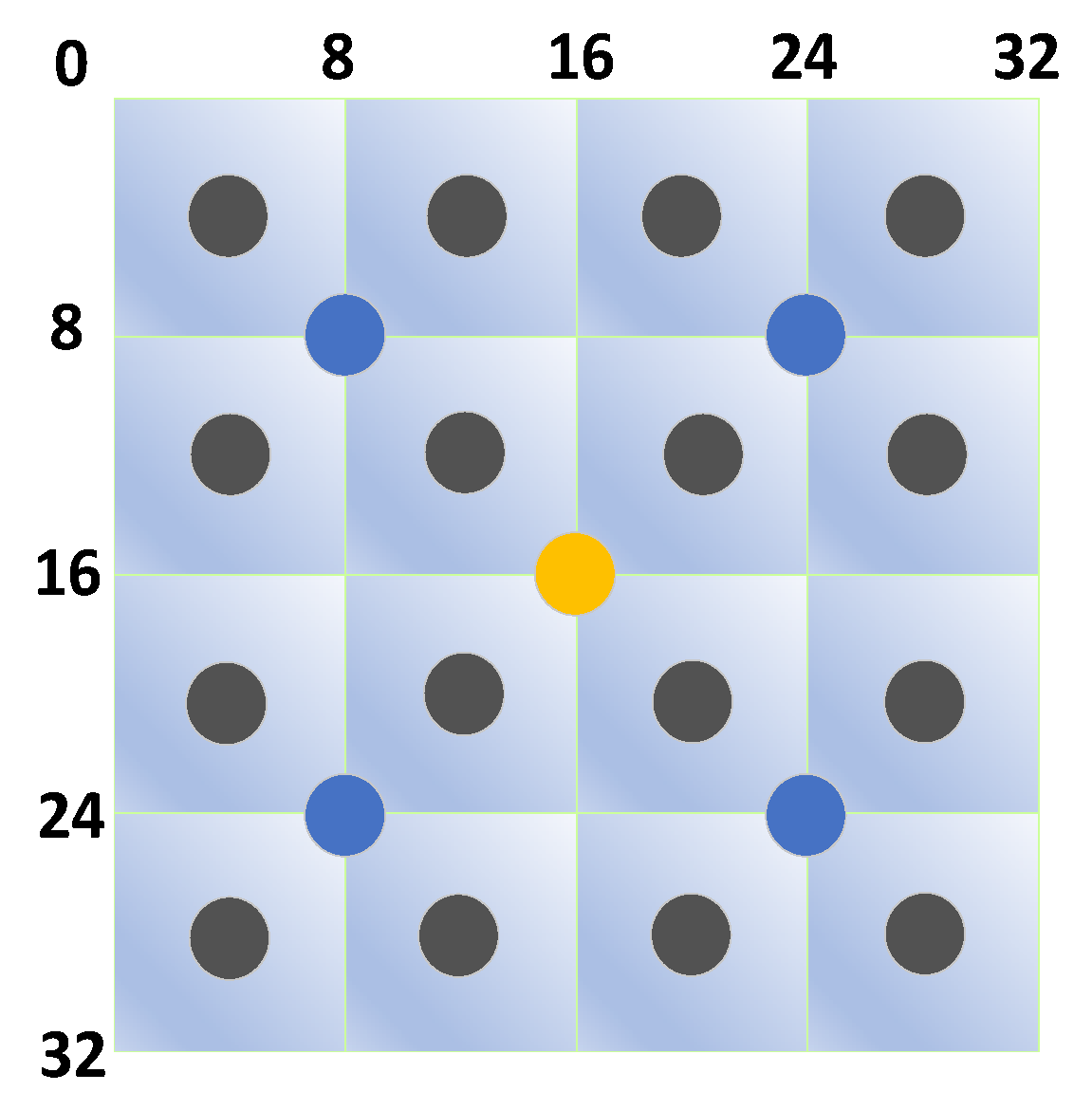
Figure 3 shows the distribution of the above key points-descriptors. The gray circles represent
, which are produced in each 8 × 8 region. The blue circles represent
, which are generated in each 16 × 16 region. The yellow circle represents
, which are generated in the 32 × 32 region. Additionally, the shared relationship between them can be clearly seen in the figure.
After obtaining
,
, and
, the feature maps are normalized to unit variance.
where
represents the standard deviation of each element in the matrix. The descriptors,
pool3,
pool4, and
pool5_1, of point
are represented by
,
, and
, respectively.
3.2. Rough-to-Fine Feature Point Matching
3.2.1. Rough Matching
The spatial transformation of images usually includes translation, rotation, and scaling. Under the spatial transformation model, the correct feature point matching has the same position, main orientation, and scale in most cases. Therefore, correct matching can be performed by judging the spatial transformation information of each feature point in the two images.
Two feature point sets,
and
, are extracted from the visible and infrared reference images, respectively.
,
, and
, respectively, represent the position, main direction, and zoom scale of the key point
in the visible reference image.
, and
, respectively, represent the position, main direction, and scale of the key point
in the infrared images. The position transformation error
of
and
, of the corresponding feature points, is represented:
where
is the spatial transformation model, and
is the transformation variable. The main direction transformation error and scaling transformation error of feature points are expressed as
where
and
represent the main direction difference and scaling transformation between the visible and infrared reference images, respectively, and
represents the difference of main direction between
and
. These parameters can be obtained from the histograms. In addition,
and
represent the scale of the key point
and scale of the key point
, respectively, and they can be obtained from the algorithm commands. Next, a robust connection distance called location orientation scale transform Euclidean distance (LOSTED) is defined as:
where
represents the Euclidean distance of the descriptors in the feature points
and
. Additionally,
,
, and
represent the position transformation error, main direction transformation error, and scaling transformation error of the corresponding feature points mentioned above, respectively. LOSTED is minimal in most scenarios, as point pairs are matched accurately. The rough matching process in this paper is as follows:
(1) Initial matching: A ratio threshold is set as T, and the ratio of the nearest neighbor Euclidean distance to the next nearest neighbor Euclidean distance of the corresponding feature point is calculated. Then, we compare the calculated ratio with T and match the feature points that meet the threshold to obtain the key point pair set
. To build histograms of horizontal displacement, vertical displacement, scaling scale, and principal direction difference, the image transformations
,
,
, and
are obtained from the histograms, as shown in
Figure 4. According to the description in [
30], the FSC algorithm can find the largest consistent sample set from the extracted sample set by setting the threshold relationship, and then finding the corresponding relationship through the transformation error, so the transformation parameters can be obtained. Therefore, we use this algorithm to calculate the initial transformation parameter
from the feature point pair set
.
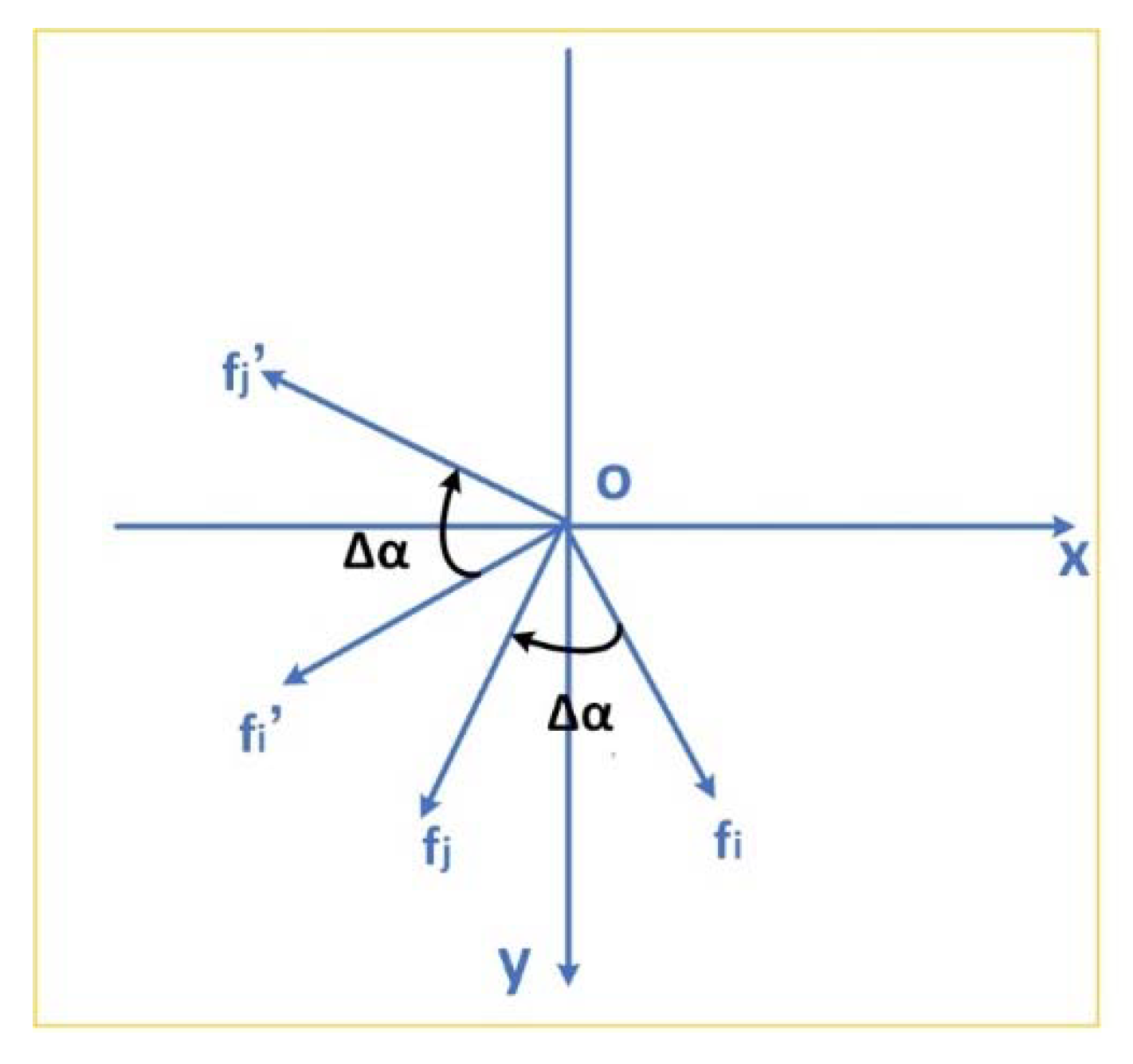
(2) Rematch: Since the circumferential angles at
and
are not continuous [see
Figure 5], there are two main situations of the main direction difference. Actually, there should only be one main modal for the rotation angle. Once one of the two models is known, the other can be calculated as:
and
represent the two angles in the main direction difference histogram, respectively.
Figure 5 presents the two angles of the principal direction difference and the single mode of the rotation angle.
Based on the above, there are two combinations of , , , and . For each combination, the distance metric is performed by LOSTED, and keypoints are matched by the ratio of the nearest Euclidean neighbor distance to the next nearest Euclidean neighbor distance. The ratio threshold is set as . Since two matchings are done, the feature points of one image may be matched more than once in the other image, so the point pair with the smallest LOSTED is selected as the candidate matching pair to obtain a relatively accurate key point pair set .
3.2.2. Fine Matching
After rough matching, the set of key point pairs is obtained, but due to the difference in resolution and viewpoint between infrared and visible images, there are still positional deviations in many matches. Aiming at this problem, a fine matching, based on update global optimization, is introduced to lower the positional deviation of key points.
The projection matrix is calculated by the least squares method:
The least squares solution of
is called:
Then, the fitting point corresponding to
is expressed as:
The residuals of
and
are expressed as:
where
is correct matching numbers.
Extensive experiments show that the point closest to the correct position is usually the fitted point with a large residual. Therefore,
is used to find the 1/4 element of the whole, with a large residual, by descending order. Then, replace the 1/4 element in
with the fitted points.
where
and
are the points with large residuals.
Then, all points in are updated by repeating (9)–(12) until the residual summation equals 0 (considering the storage of floating-point numbers in the computer, 0 is replaced by a threshold of ).
After updating the position of through global optimization, the matching items with obvious position errors are corrected, and finally, the final image registration is obtained by calculating the position transformation matrix of infrared and visible images.
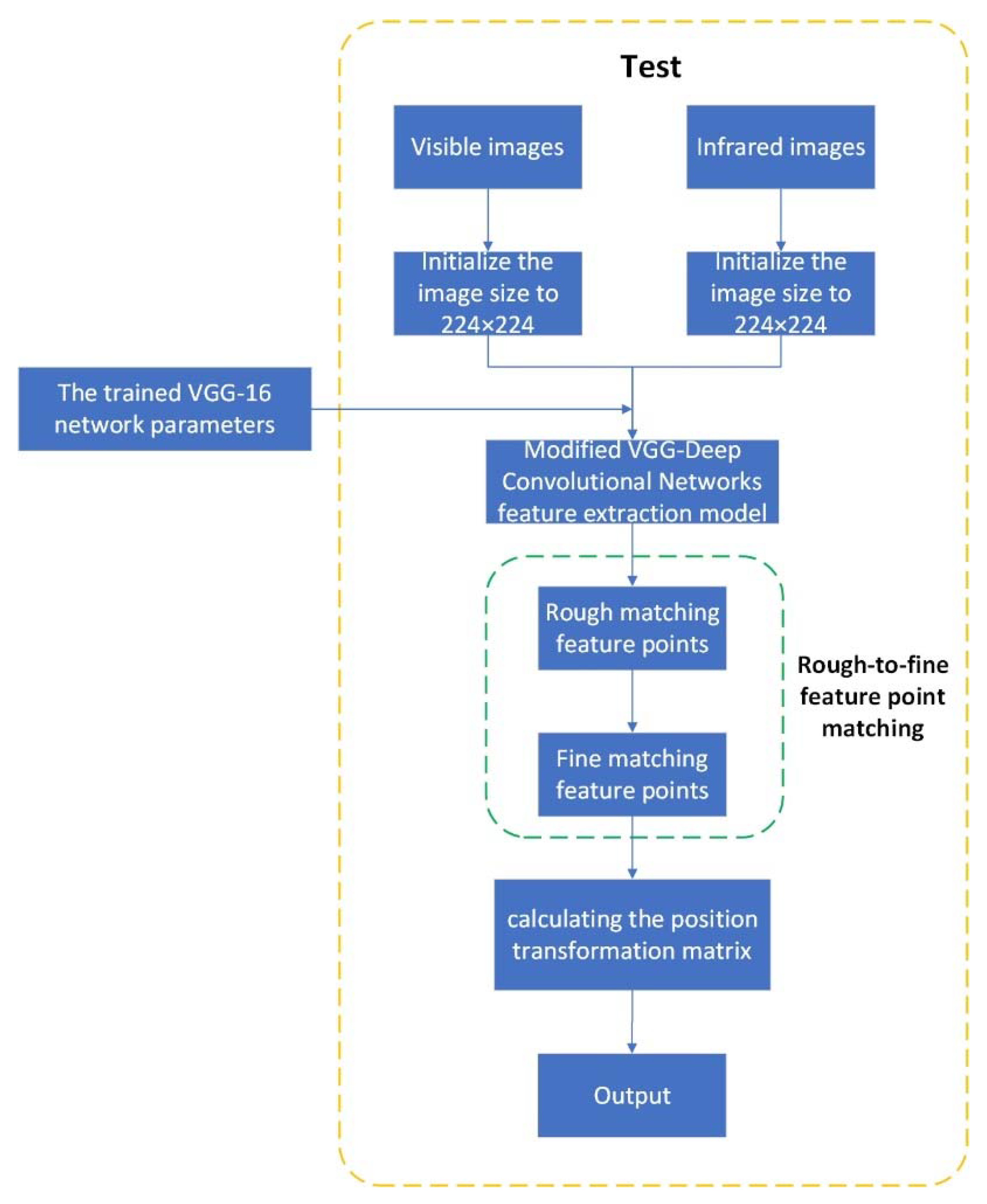
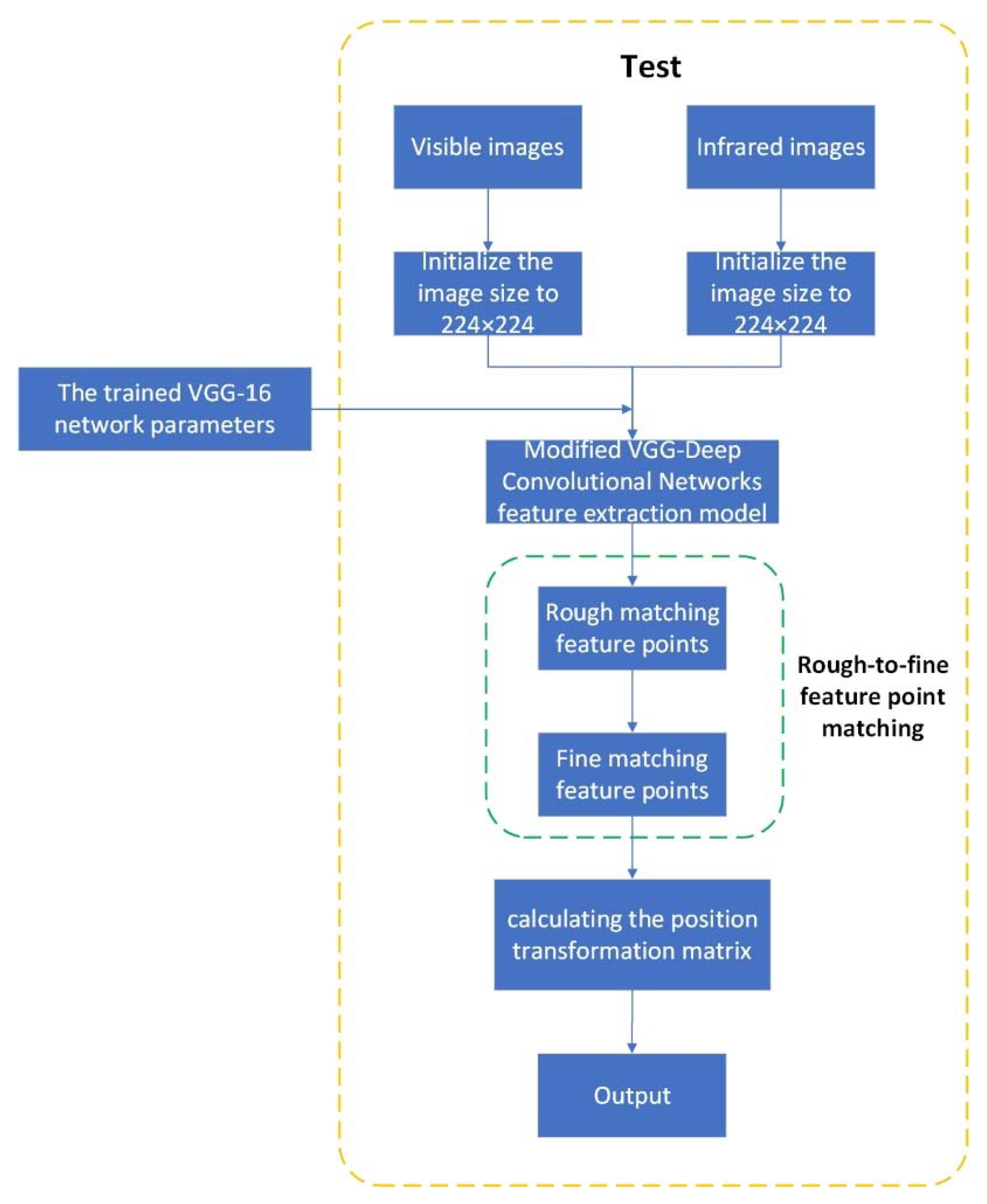
To summarize, the flow of the proposed registration method is shown in
Figure 6. First, the infrared images and visible images are initialized to 224 × 224, respectively, and then, the trained VGG-16 model parameters are called. The images are passed through the modified deep convolution feature extraction network in this paper, and the obtained output goes through the process of rough matching feature points and fine matching feature points. Finally, the final image registration is obtained by calculating the position transformation matrix of infrared and visible images.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}