
An Optimized Algorithm for Dangerous Driving Behavior Identification Based on Unbalanced Data


Abstract
:1. Introduction
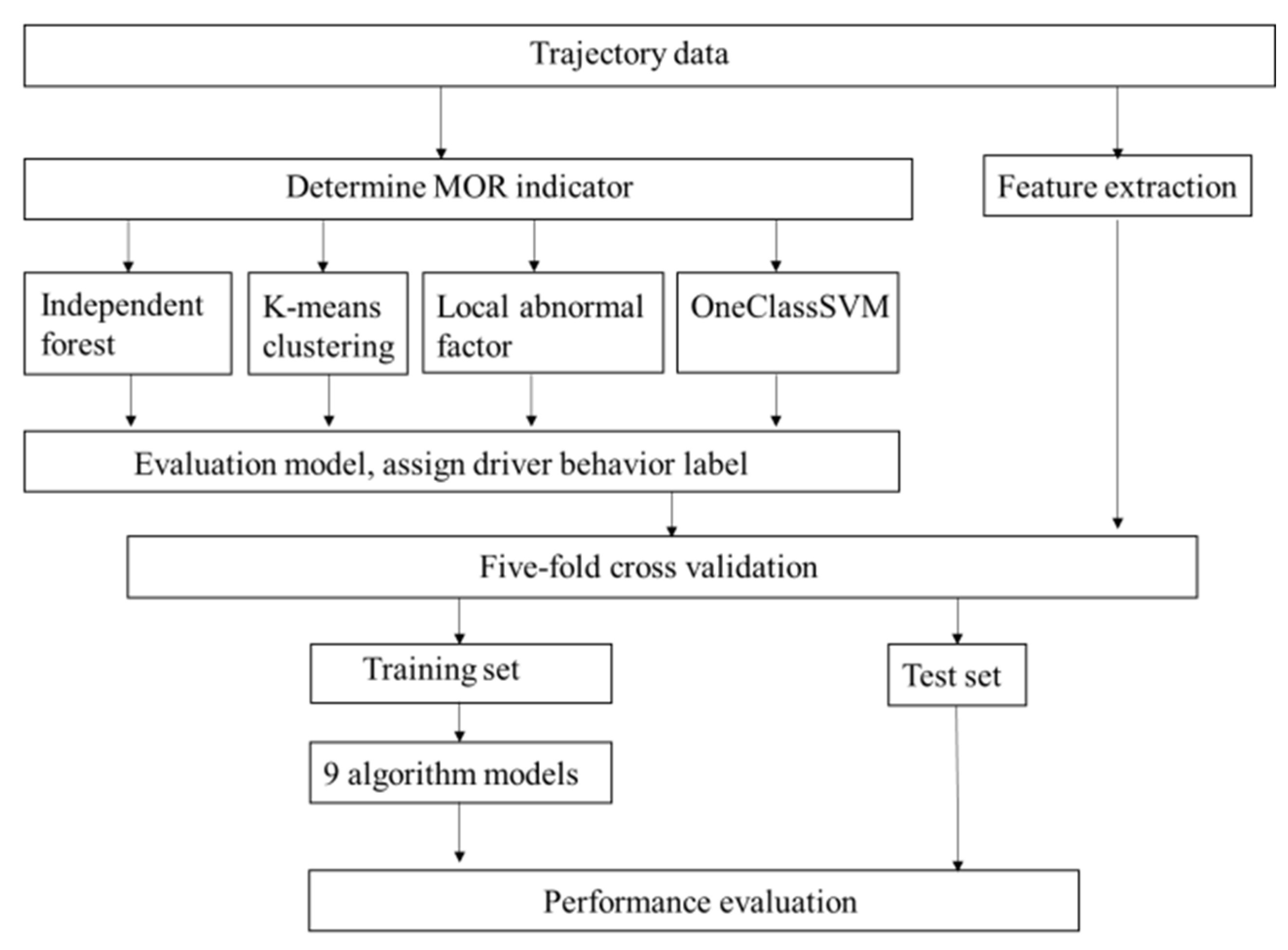
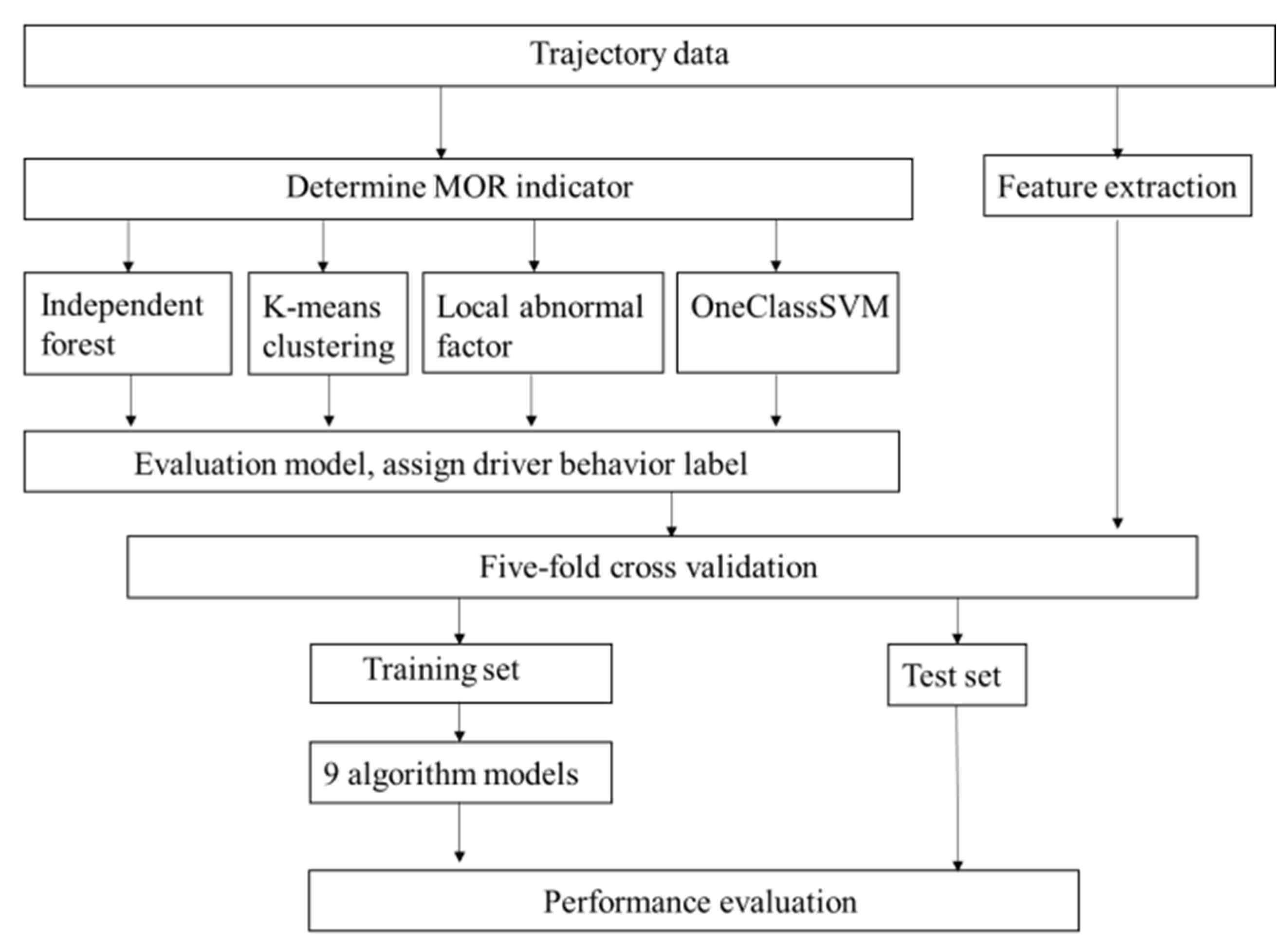
2. Methodology
2.1. Dangerous Driving Behavior Indicators
2.2. Classification of Dangerous Driving Behaviors
2.2.1. Anomaly Detection Method
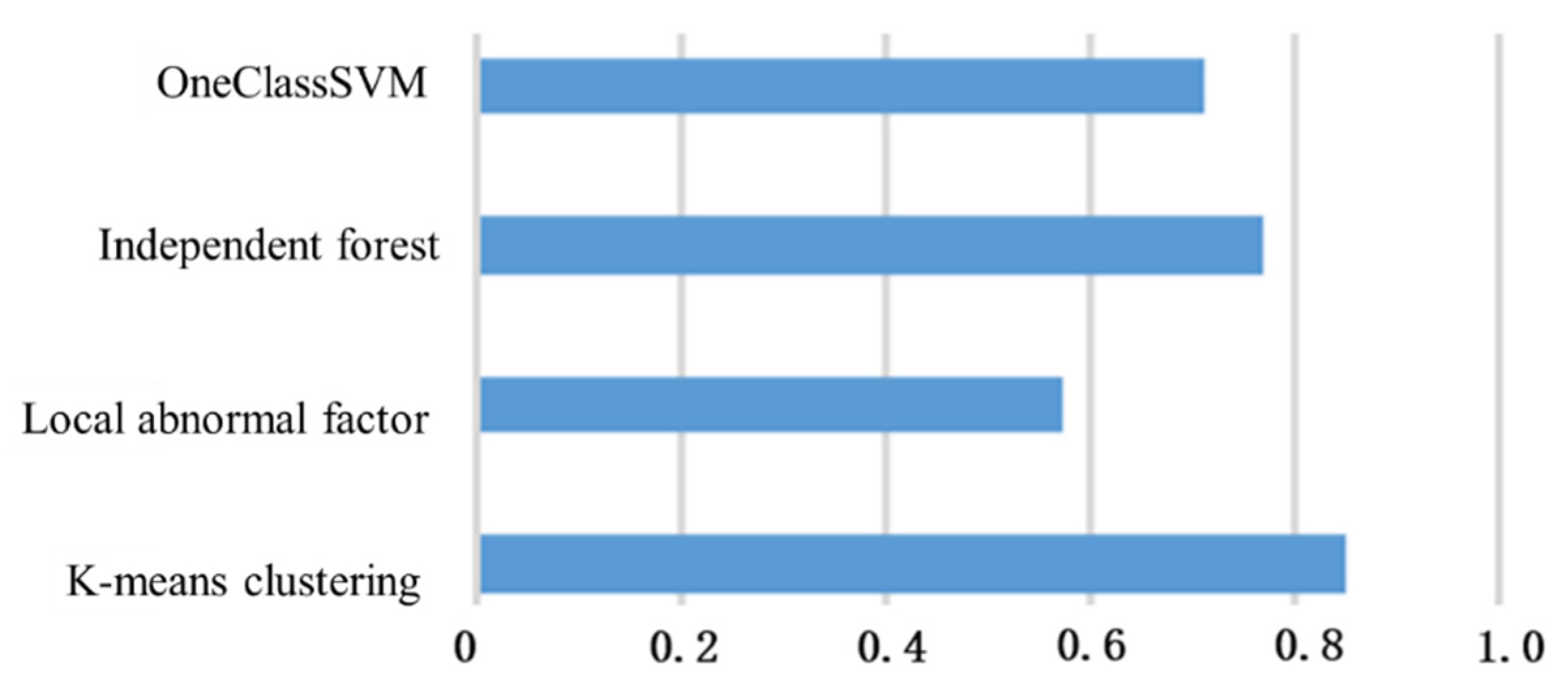
2.2.2. Evaluation of Classification Method
- Contour factor
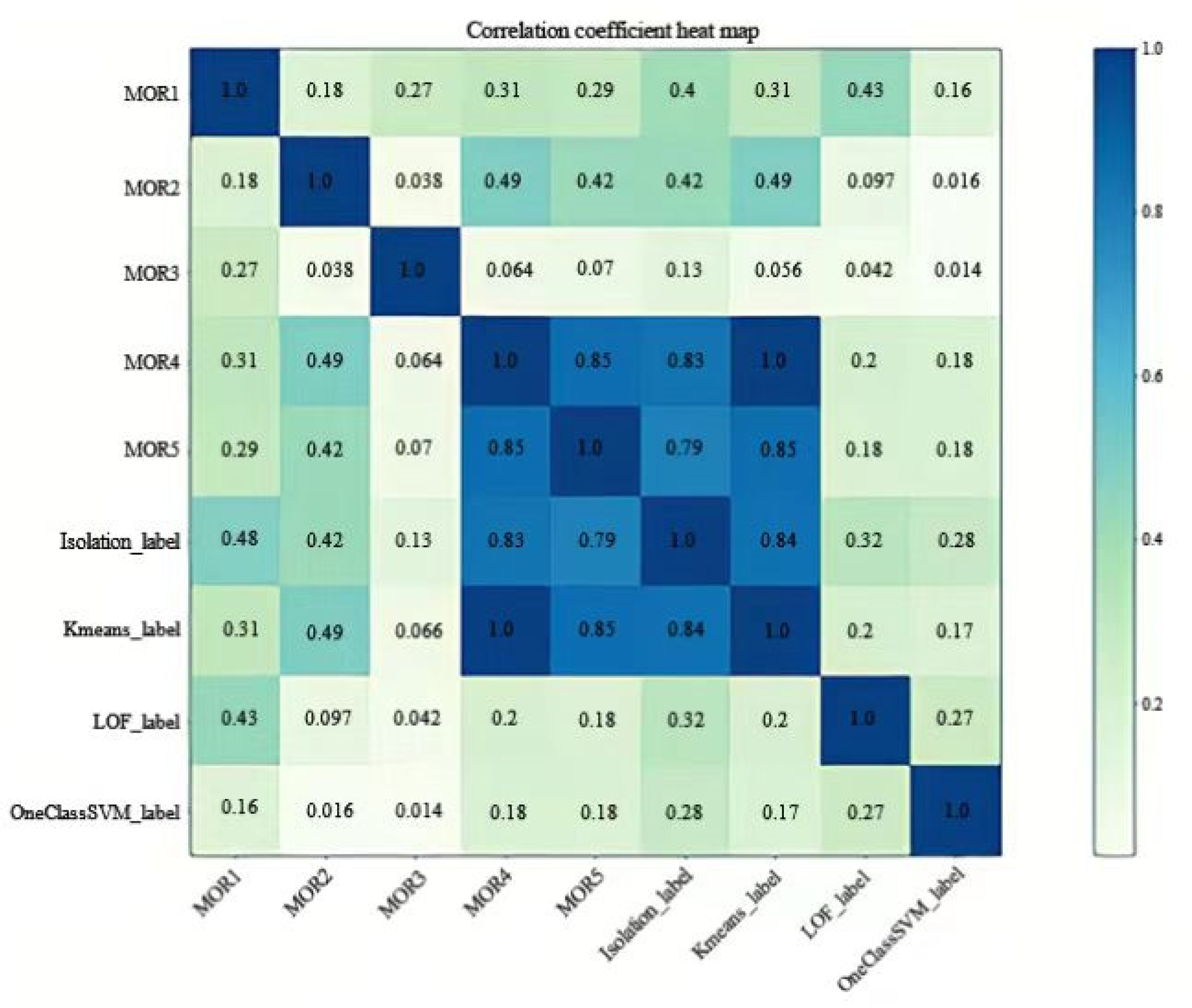
- Correlation coefficient
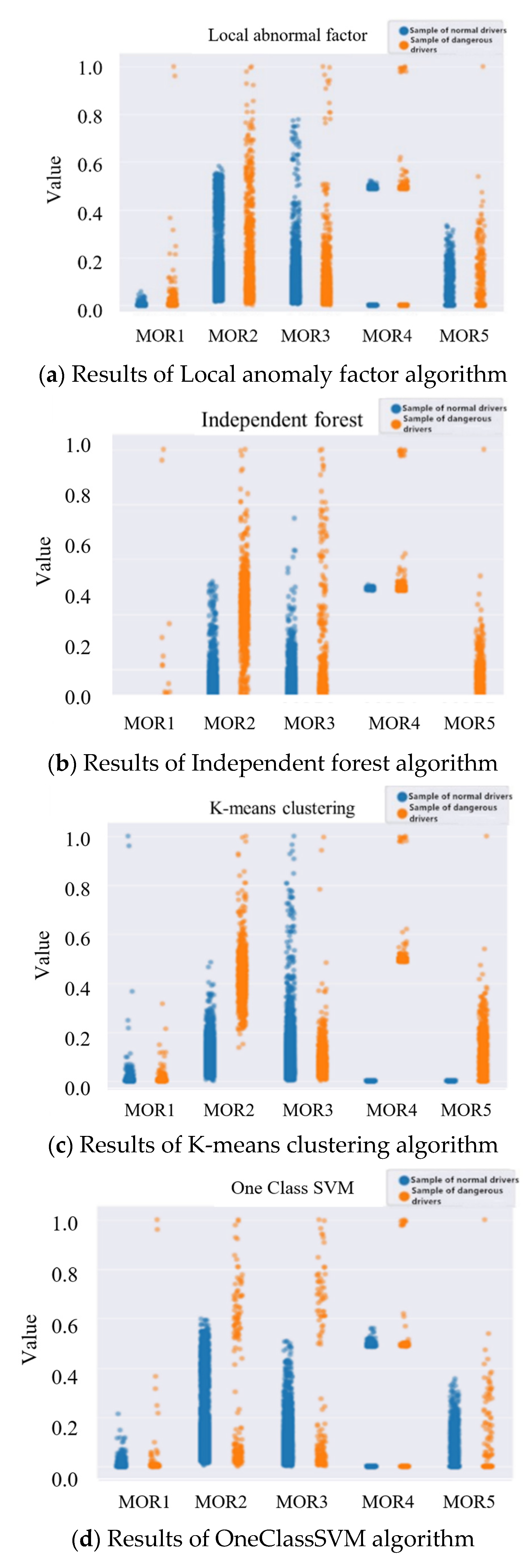
- Category feature analysis
2.3. Extraction of Characteristics of Driving Behavior
2.4. Recognition Model
2.4.1. Model Description
2.4.2. Evaluation Index of Identification Model
3. Data Description
4. Results
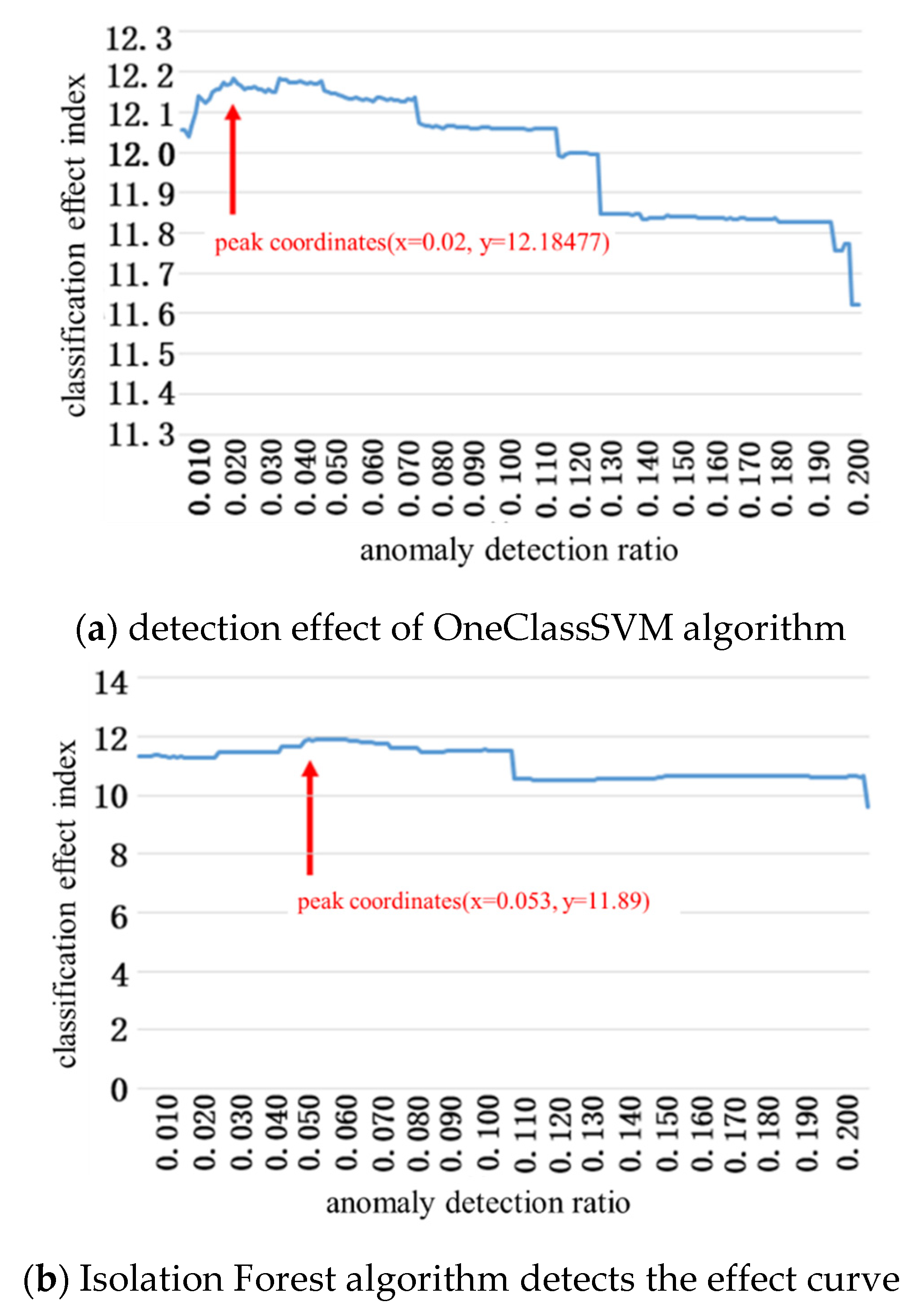
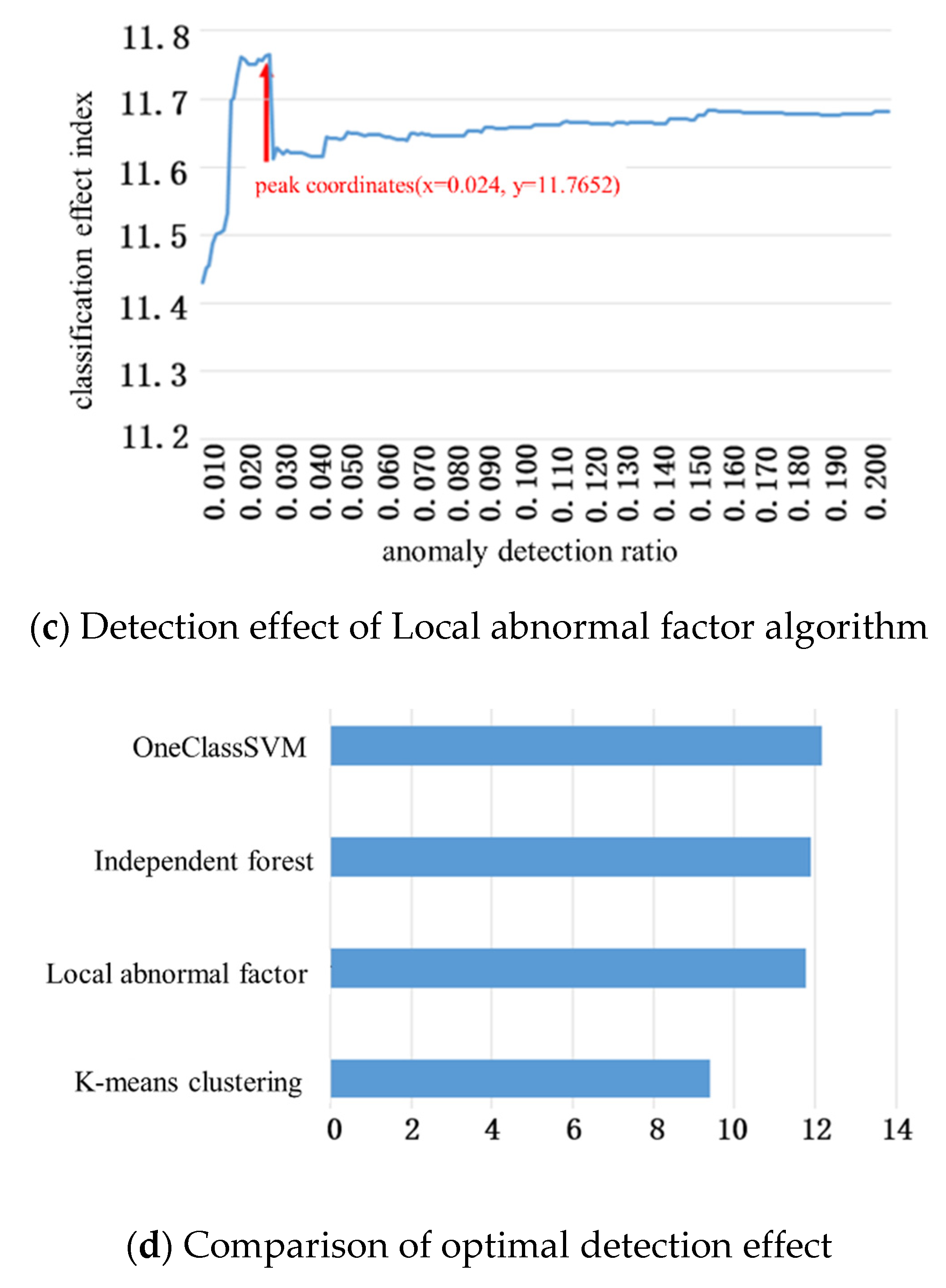
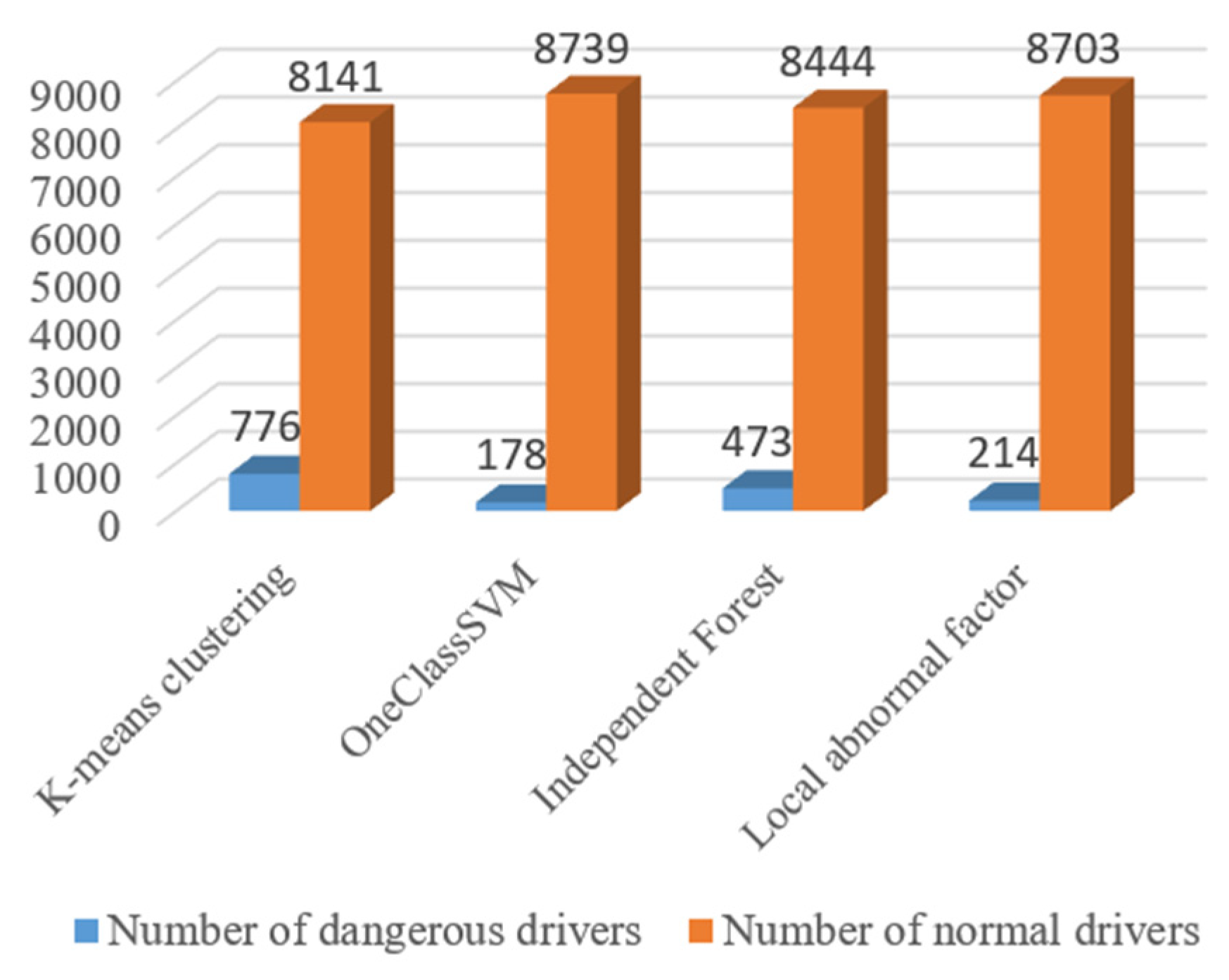
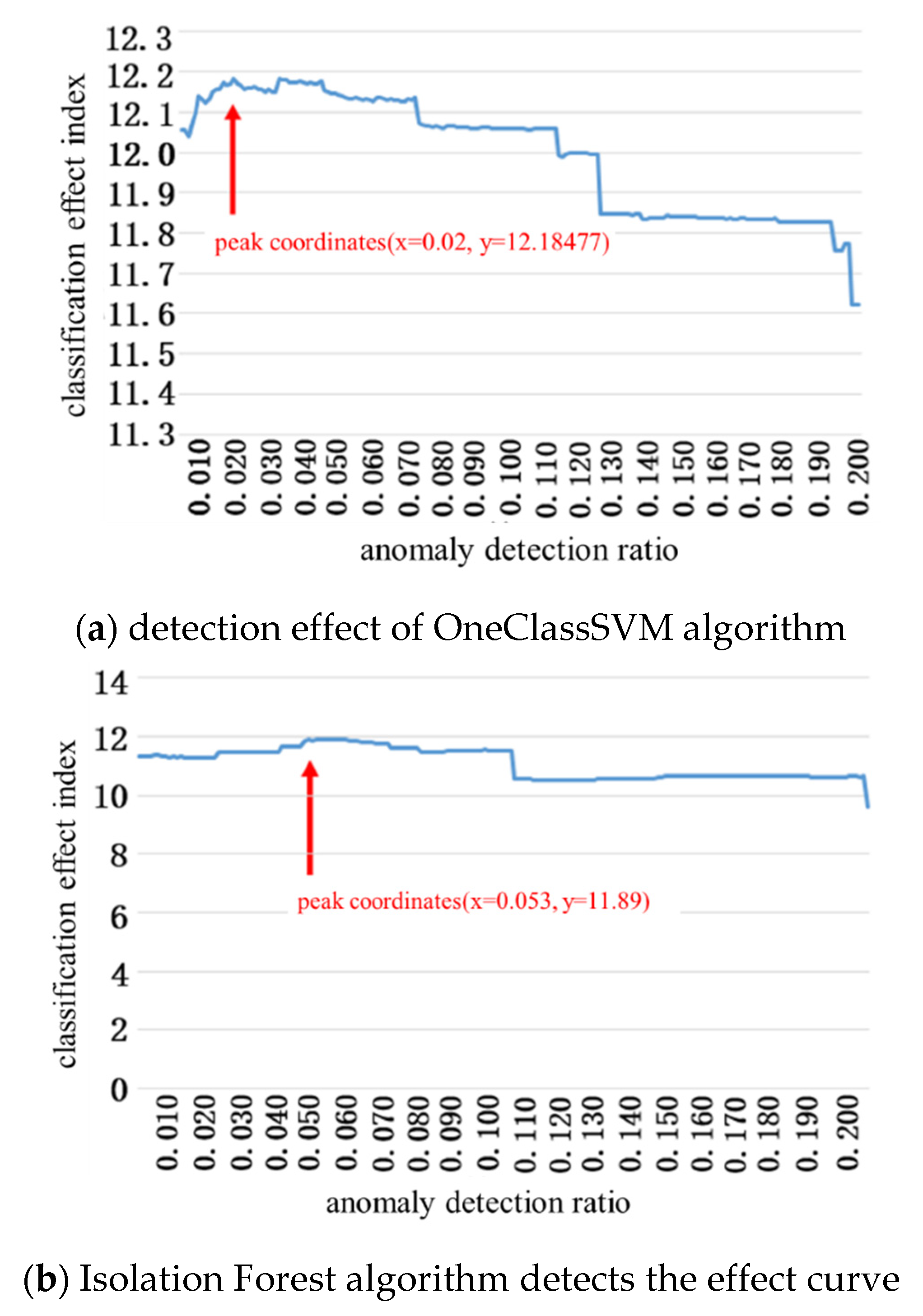
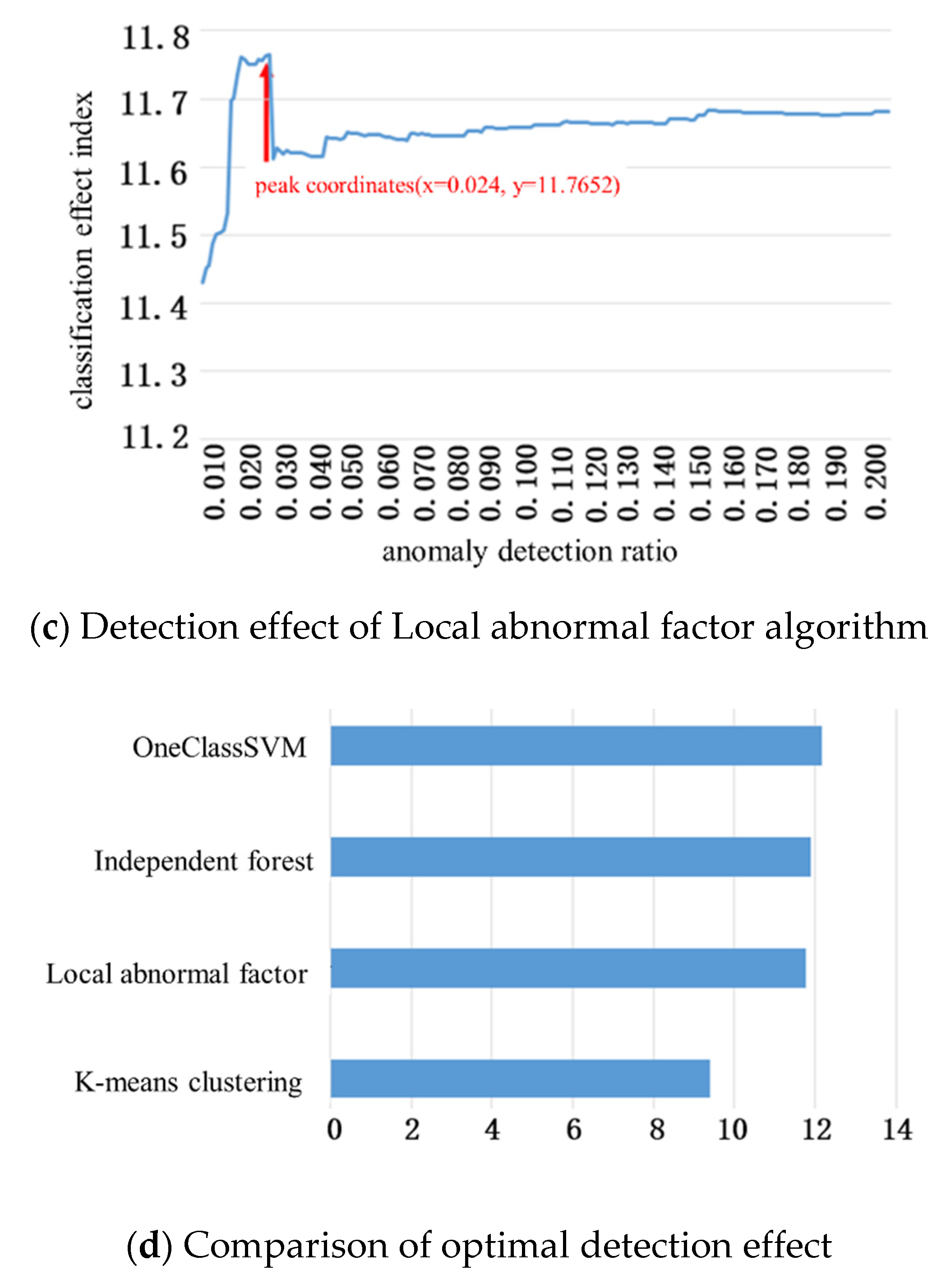
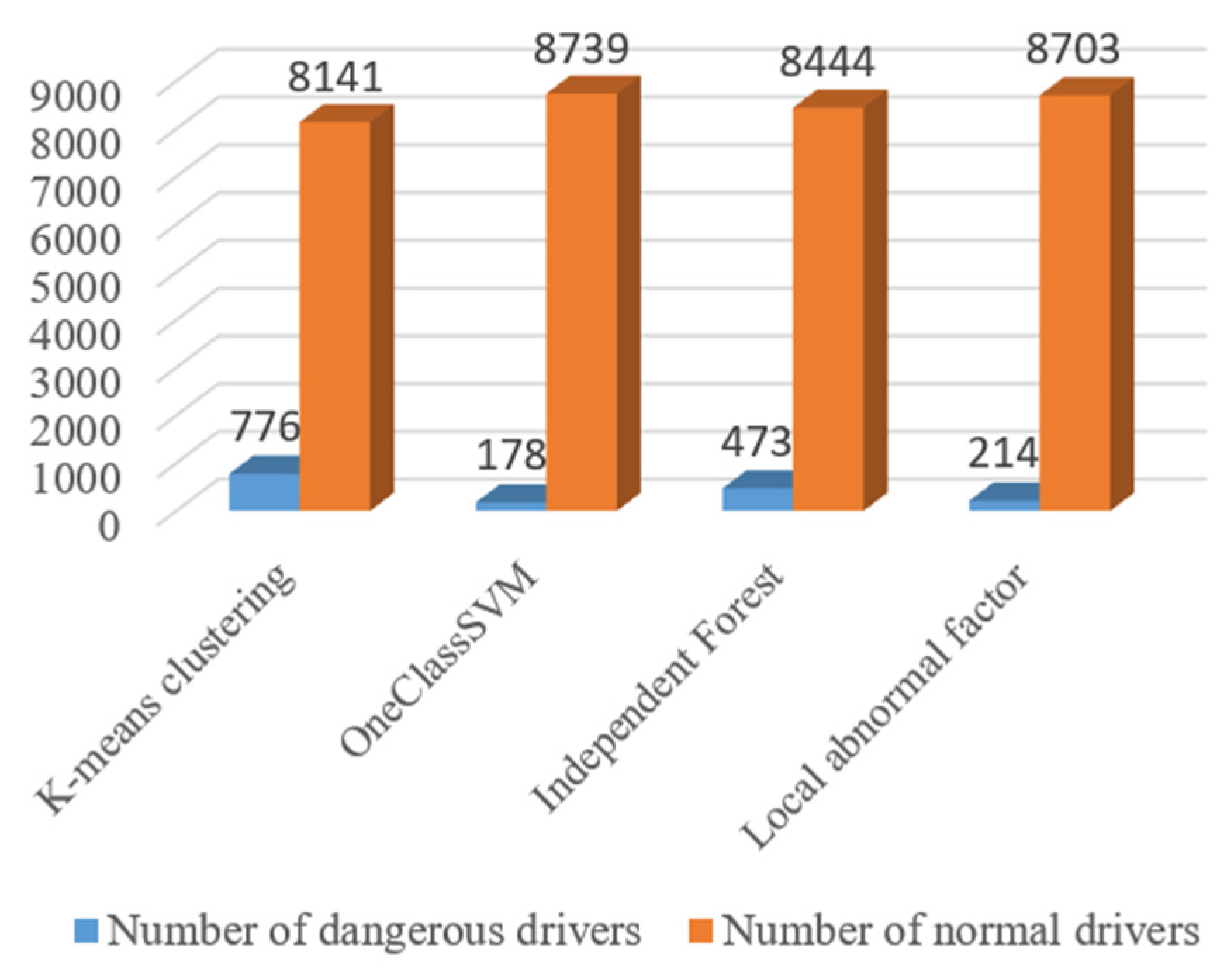
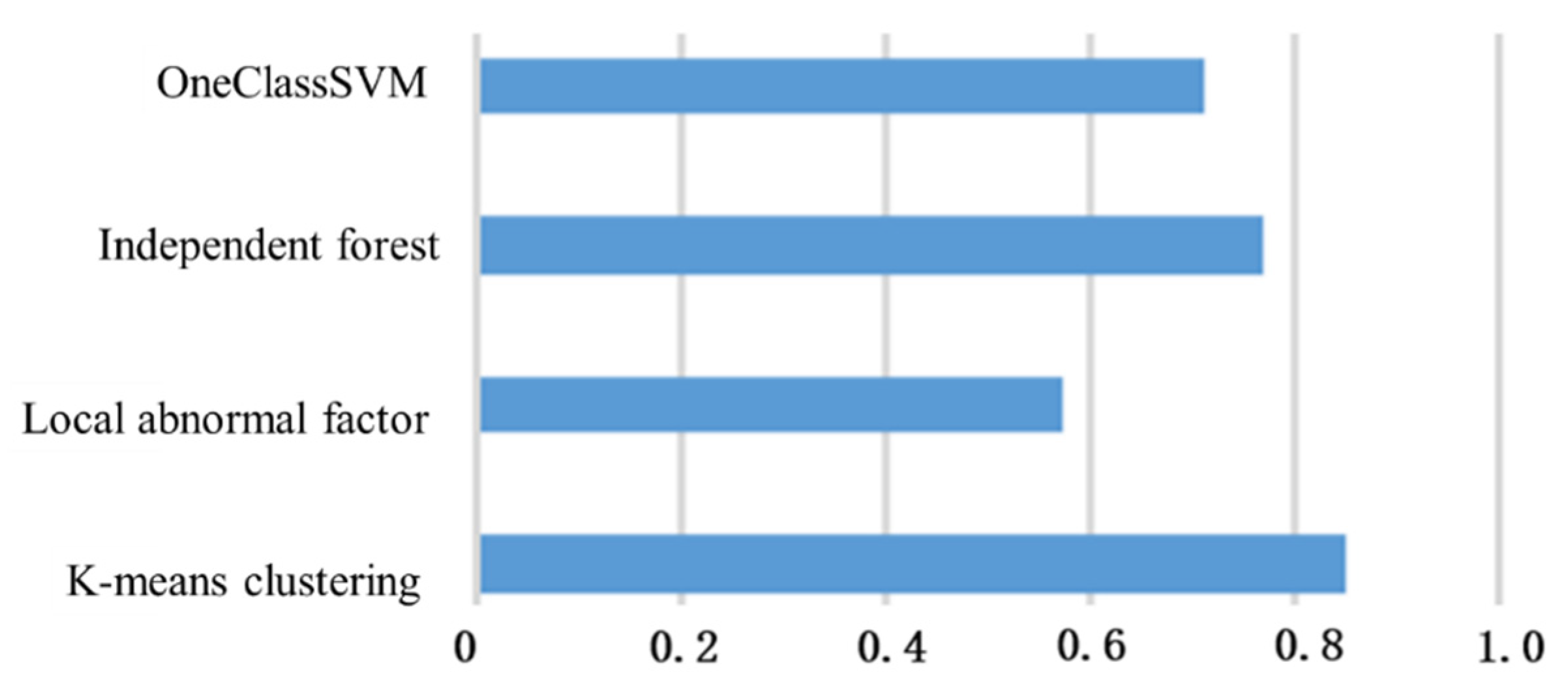
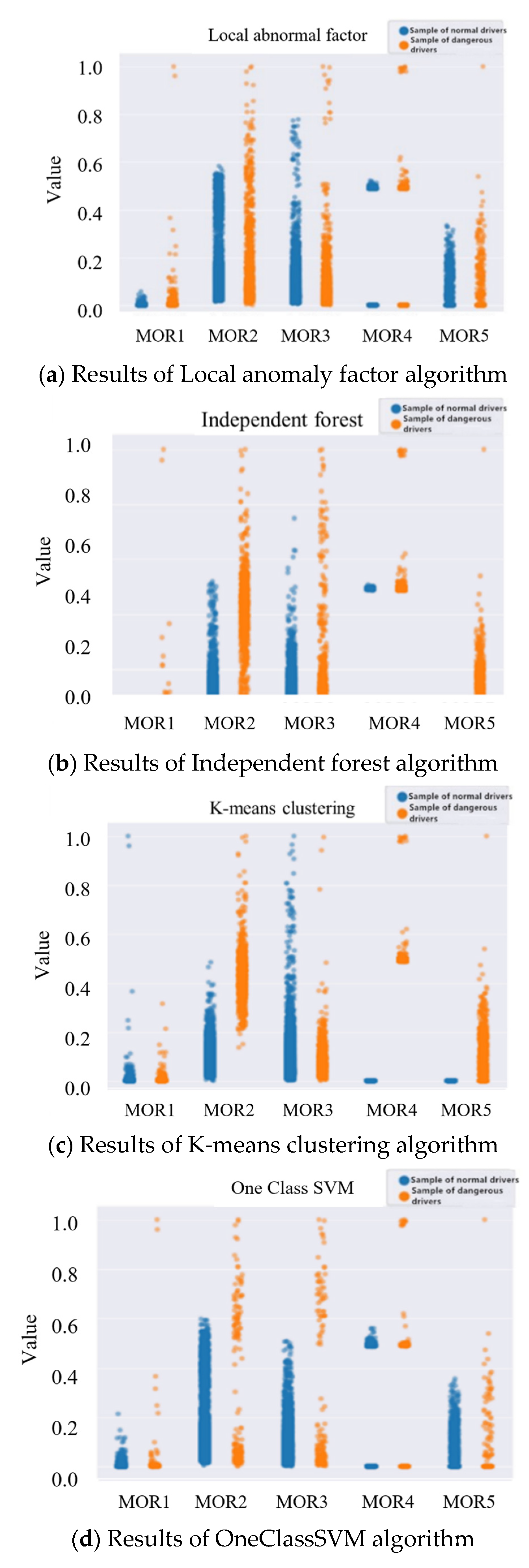
4.1. Test Results of Dangerous Driving Behavior
4.2. Results of Dangerous Driving Behavior Recognition
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhao, L.; Jia, Y. Intelligent transportation system for sustainable environment in smart cities. Int. J. Electr. Eng. Educ. 2021. [Google Scholar] [CrossRef]
- Borsos, A.; Birth, S.; Vollpracht, H.J. The Role of Human Factors in Road Design. In Proceedings of the IEEE International Conference on Cognitive Infocommunications, Wrocław, Poland, 16–18 October 2016; pp. 363–367. [Google Scholar]
- Amarasinghe, M.; Muramudalige, S.R.; Kottegoda, S.; Arachchi, A.L.; Muramudalige, S.; Bandara, H.D.; Azeez, A. Cloud-based driver monitoring and vehicle diagnostic with OBD2 telematics. Int. J. Handheld Comput. Res. 2015, 6, 57–74. [Google Scholar] [CrossRef]
- Wu, M.; Zhang, S.; Dong, Y. A novel model-based driving behavior recognition system using motion sensors. Sensors 2016, 16, 1746. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dula, C.S.; Martin, B.A.; Fox, R.T.; Leonard, R.L. Differing types of cellular phone conversations and dangerous driving. Accid. Anal. Prev. 2011, 43, 187–193. [Google Scholar] [CrossRef]
- Xu, X. Identification of dangerous driving behaviors based on neural network and Bayesian filter. Adv. Mater. Res. 2013, 846–847, 1343–1346. [Google Scholar] [CrossRef]
- Chiabaut, N.; Leclercq, L.; Buisson, C. From heterogeneous drivers to macroscopic patterns in congestion. Transp. Res. Part B Methodol. 2010, 44, 308. [Google Scholar] [CrossRef] [Green Version]
- Hammit, B.E.; Ghasemzadeh, A.; James, R.M.; Ahmed, M.M.; Young, R.K. Evaluation of weather-related freeway car-following behavior using the SHRP2 naturalistic driving study database. Transp. Res. Part F Traffic Psychol. Behav. 2018, 59, 244–259. [Google Scholar] [CrossRef]
- Xue, Q.W.; Wang, K.; Lu, J.; Liu, Y. Rapid driving style recognition in car-following using machine learning and vehicle trajectory data. J. Adv. Transp. 2019, 2019, 209–219. [Google Scholar] [CrossRef] [Green Version]
- Agamennoni, G.; Ward, J.R.; Worrall, S.; Nebot, E.M. Anomaly Detection in Driving Behaviour by Road Profiling. In Proceedings of the IEEE Intelligent Vehicles Symposium Workshops, Gold Coast City, Australia, 23–26 June 2013. [Google Scholar]
- Chen, X.; Xu, X.; Yang, Y.; Wu, H.; Tang, J.; Zhao, J. Augmented ship tracking under occlusion conditions from maritime surveillance videos. IEEE Access 2020, 8, 42884–42897. [Google Scholar] [CrossRef]
- Chen, X.; Wang, S.; Shi, C.; Wu, H.; Zhao, J.; Fu, J. Robust ship tracking via multi-view learning and sparse representation. J. Navig. 2019, 72, 176–192. [Google Scholar] [CrossRef]
- Zou, Y.; Lin, B.; Yang, X.; Wu, L.; Muneeb Abid, M.; Tang, J. Application of the Bayesian model averaging in analyzing freeway traffic incident clearance time for emergency management. J. Adv. Transp. 2021, 2021, 6671983. [Google Scholar] [CrossRef]
- Chen, X.; Chen, H.; Yang, Y.; Wu, H.; Zhang, W.; Zhao, J.; Xiong, Y. Traffic flow prediction by an ensemble framework with data denoising and deep learning model. Phys. A Stat. Mech. Appl. 2021, 565, 125574. [Google Scholar] [CrossRef]
- Chen, X.; Li, Z.; Yang, Y.; Qi, L.; Ke, R. High-resolution vehicle trajectory extraction and denoising from aerial videos. IEEE Trans. Intell. Transp. Syst. 2020, 22, 3190–3202. [Google Scholar] [CrossRef]
- Ramyar, S.; Homaifar, A.; Karimoddini, A.; Tunstel, E. Identification of Anomalies in Lane Change Behavior Using One-Class SVM. In Proceedings of the IEEE International Conference on Systems, Budapest, Hungary, 9–12 October 2016. [Google Scholar]
- Matousek, M.; Yassin, M.; Al-Momani, A.; Heijden, R.; Kargl, F. Robust Detection of Anomalous Driving Behavior. In Proceedings of the 2018 IEEE 87th Vehicular Technology Conference (VTC Spring), Porto, Portugal, 3–6 June 2018; pp. 1–5. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Chawla, N.V.; Lazarevic, A.; Hall, L.O.; Bowyer, K.W. SMOTEBoost: Improving Prediction of the Minority Class in Boosting. In Proceedings of the Seventh European Conference Principles and Practice of Knowledge Discovery in Databases, Cavtat-Dubrovnik, Croatia, 22–26 September 2003; pp. 107–119. [Google Scholar]
- Seiffert, C.; Khoshgoftaar, T.; Van Hulse, J.; Napolitano, A. Rusboost: A Hybrid Approach to Alleviating Class Imbalance. In IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans; IEEE: New York, NY, USA, 2010; Volume 40, pp. 185–197. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Volume 1, pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 2999–3007. [Google Scholar]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. ACM Sigmod Rec. 2000, 29, 93–104. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.; Zhou, Z. Isolation-based anomaly detection. ACM Trans. Knowl. Discov. Data 2012, 6, 3. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef]
- Zhu, J.; Zou, H.; Rosset, S.; Hastie, T. Multi-class adaboost. Stat. Terface 2009, 2, 349–360. [Google Scholar]
- Zhang, J.; Hu, Z.B.; Zhu, X.S. Real-time traffic accident prediction based on Adaboost classifier. J. Comput. Appl. 2017, 37, 284–288. [Google Scholar] [CrossRef]
- Ma, W.Y.; Chang, R.S. Revision and reliability and validity test of prosocial and aggressive driving behavior scale. Ergonomics 2016, 22, 7–10. [Google Scholar]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the roc plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, 0118432. [Google Scholar] [CrossRef] [PubMed] [Green Version]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Category of Dangerous Driving Behaviour | Related Parameters | MOR |
|---|---|---|---|
| 1 | Dangerous car following | Front and rear car speed vf, vp, front and rear workshop interval D(t) | |
| 2 | Lateral deviation | Travel offset center line cumulative distance X, travel distance D | |
| 3 | Frequent acceleration and deceleration | The vehicle speed v, STD: Standard deviation | |
| 4 | Frequently change lanes | D: Multi-lane lane change distance; T: lane change times | |
| 5 | Forced insertion | x0: Lane change vehicle insertion position; v0: lane change vehicle speed; x1: front vehicle position; v1: front vehicle speed; x2: rear vehicle position; v2: rear vehicle speed |
| Recognition Model | Pretreatment Method | Algorithm Improvement |
|---|---|---|
| Adaboost [26,27] | None | None |
| Rus + Adaboost | Random under-sampling | None |
| Smote + Adaboost | Smote Oversampling | None |
| Rusboost [20] | None | Iterative combination Under-sampling |
| Smoteboost [19] | None | Iterative combination Smote |
| Xgboost [28] | None | None |
| Smote + Xgboost | Smote Oversampling | None |
| Rus + Xgboost | Random under-sampling | None |
| Imbalance-Xgboost [21] | None | Loss function improvement |
| Algorithm | Correct Rate | Recall Rate | F1 | Auprc |
|---|---|---|---|---|
| Adaboost | 0.799 | 0.597 | 0.683 | 0.783 |
| Rus + Adaboost | 0.482 | 0.888 | 0.624 | 0.722 |
| Smote + Adaboost | 0.544 | 0.839 | 0.66 | 0.758 |
| Rusboost | 0.51 | 0.946 | 0.663 | 0.83 |
| Smoteboost | 0.531 | 0.888 | 0.664 | 0.791 |
| Xgboost | 0.84 | 0.651 | 0.733 | 0.839 |
| Smote + Xgboost | 0.621 | 0.893 | 0.732 | 0.811 |
| Rus + Xgboost | 0.541 | 0.918 | 0.681 | 0.777 |
| Imblance-Xgboost | 0.835 | 0.691 | 0.755 | 0.852 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, S.; Li, C.; Fang, K.; Peng, Y.; Jiang, Y.; Zou, Y. An Optimized Algorithm for Dangerous Driving Behavior Identification Based on Unbalanced Data. Electronics 2022, 11, 1557. https://doi.org/10.3390/electronics11101557
Zhu S, Li C, Fang K, Peng Y, Jiang Y, Zou Y. An Optimized Algorithm for Dangerous Driving Behavior Identification Based on Unbalanced Data. Electronics. 2022; 11(10):1557. https://doi.org/10.3390/electronics11101557
Chicago/Turabian StyleZhu, Shengxue, Chongyi Li, Kexin Fang, Yichuan Peng, Yuming Jiang, and Yajie Zou. 2022. "An Optimized Algorithm for Dangerous Driving Behavior Identification Based on Unbalanced Data" Electronics 11, no. 10: 1557. https://doi.org/10.3390/electronics11101557
APA StyleZhu, S., Li, C., Fang, K., Peng, Y., Jiang, Y., & Zou, Y. (2022). An Optimized Algorithm for Dangerous Driving Behavior Identification Based on Unbalanced Data. Electronics, 11(10), 1557. https://doi.org/10.3390/electronics11101557