
Reputation System for Increased Engagement in Public Transport Oriented-Applications

 , ,
, ,
Abstract
1. Introduction
2. Background
2.1. Academic Proposals
- PageRank [13]: Advantages: This algorithm converges in about 45 iterations. Its scaling factor is roughly linear in . It uses graph theory to link the pages. An important component of PageRank is that its calculation can be personalized. PageRank can estimate web traffic and can predict backlinks. Disadvantages: PageRank is based on random walks on graphs. This algorithm assumes the behaviour of a “random surfer”, but if a real Web surfer ever gets into small loops of web pages, the PageRank will have false positives. This method of random surfer assumes that periodically the surfer “gets bored” and jumps to another random page;
- EigenTrust [14]: Advantages: This reputation system is among the most well-known and successful reputation systems. It satisfactorily solves different problems existing in P2P systems, which is the context in which the algorithm was designed. Disadvantages: The main drawback of this system is its reliance on a set of pre-trusted peers, which causes nodes to centre around them. As a consequence, other peers are ranked low despite being honest, marginalizing their role in the system [15];
- PathTrust [10]: Advantages: This model of reputation (using the trust relationships amongst the participants) is resistant against the attack of faking positive feedback. A group of attackers collaborates to boost their reputation rating by leaving false, positive feedback for each other. In this model of reputation, this will only strengthen the trust relationship among the attackers, but will not necessarily strengthen the path of the attacker to an honest inquirer, such that their reputation does not affect the honest inquirer. Another benefit of exploiting established relationships in member selection is the formation of long-term relationships. Disadvantages: The trust relationship between two participants is formed on the basis of past experience with each other. A participant leaves a feedback rating after each transaction, and these ratings are accumulated to a relationship value. Therefore, one user can boost a positive or negative feedback.
2.2. Commercial Proposals
3. Proposal for User and Users’ Choices Reputation Algorithm
3.1. Mathematical Description of the Reputation System
3.1.1. User Reputation Mathematical Model
- refers to the current date.
- refers to the registration date.
- refers to the number of valuations of the user.
- refers to the number of times the user opened the app.
- refers to the number of routes the user has chosen to travel.
- is the initial score of days registered.
- is the initial score of the list of valuations.
- is the initial score of the number of uses of the application.
- is the initial score of number of chosen routes.
| Algorithm 1 User Reputation Calculation. |
|
3.1.2. Users’ Choices Reputation Mathematical Model
- is the rating of the k-th user on the i-th activity. The number of users who rated this activity is defined as n.
- is the reputation of the k-th user who rated the activity. The number of users who rated this activity is defined as n.
- is the number of days since the activity was created.
- is the number of views of the activity.
- is the initial score of N-star ratings weighted average.
- is the initial score of the number of views of the activity.
| Algorithm 2 Activity Reputation Calculation. |
|
3.2. Updating the Parameters and Their Weights
- Manually: when an expert administrator/developer decides that it should be changed for some reason.
- Automatically: depending on the evolution of the information on the platform. For example, the rating an activity has in the system will not remain the same; it is going to change over time and, according to its evolution, the maximum weight of this parameter in the system can increase or decrease (if it receives many ratings, its weight will decrease).
4. Evaluation and Results
- 1.
- Gender of users (i.e., male, female).
- 2.
- Age group: Three age groups were considered (i.e., 16–30, 31–50, 51–90).
- 3.
- Volume of performed actions. Two possibilities: users that performs a small number of actions and users that performs many actions.
- 4.
- Type or category of the performed actions. Six major categories of actions were defined for the generated dataset: sports, eating, history, dancing, cinema, shopping.
4.1. Reputation Models Evaluation—Synthetic Data
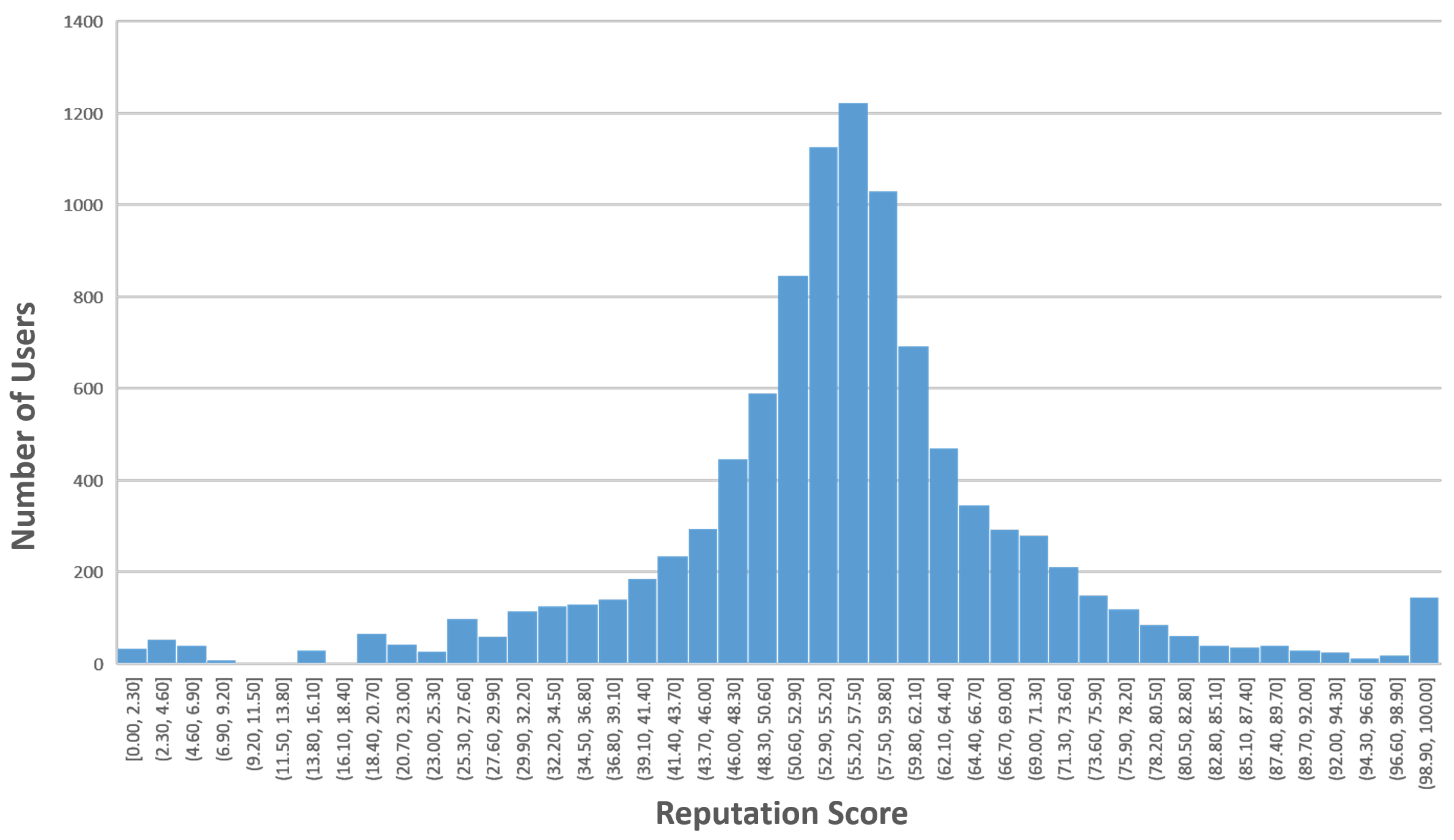
4.1.1. Users’ Reputation Evaluation
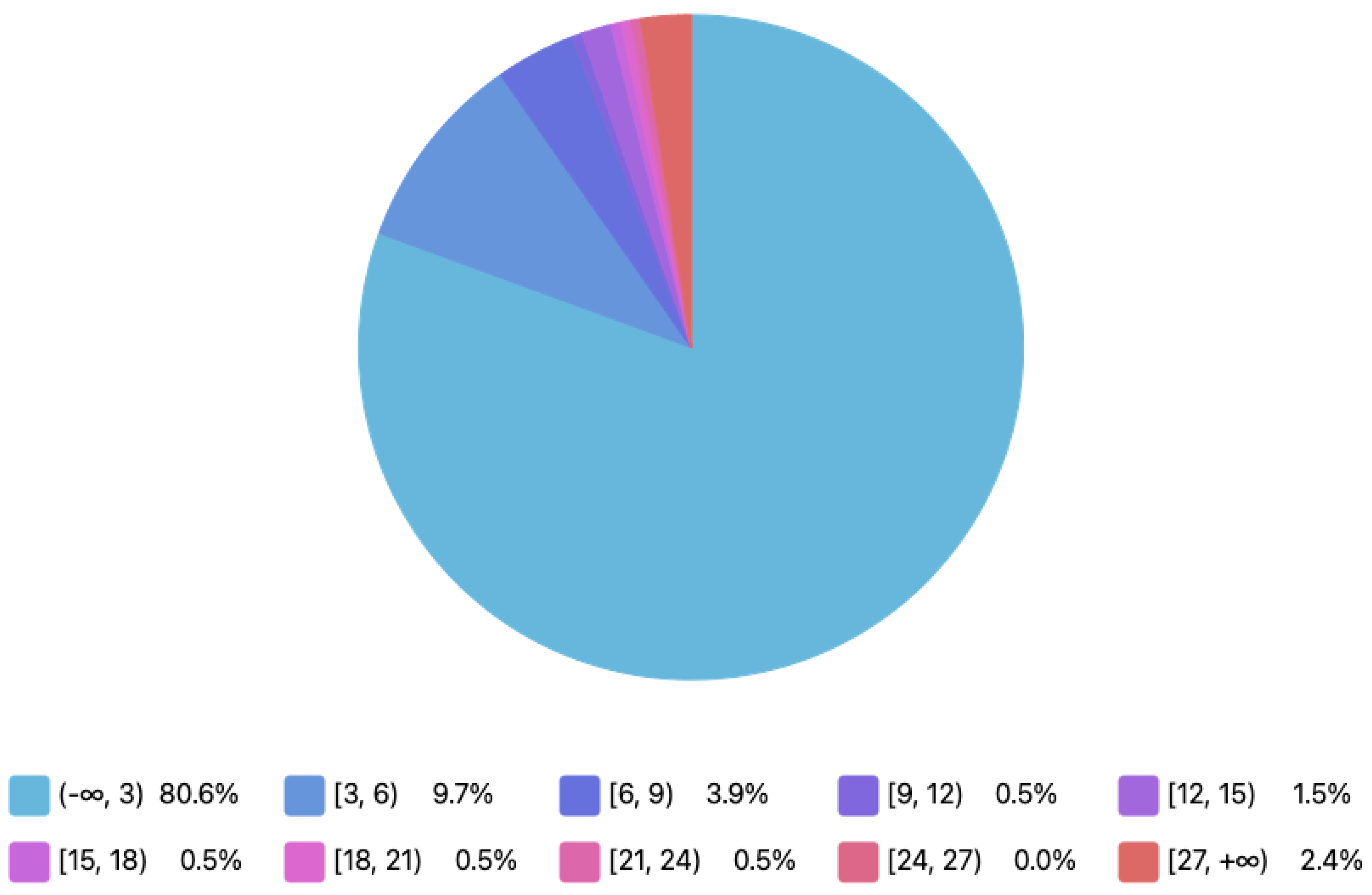
4.1.2. Users’ Choices Reputation Evaluation
- The identifier is a unique integer from 1 to 1000.
- The inclusion date is between 1 September 2017 (start of the project) and 18 December 2018 (the date on which the evaluation was carried out).
- The number of views of an activity is higher than its number of ratings.
4.2. Reputation Models Evaluation—Pilot Study
- 1.
- The duration of the pilots is the same for all users and if a user has used the application more times than another user, they should get a higher reward, independently of the date of registration.
- 2.
- If the date has a negative effect on the user’s reputation, i.e., the more time passes, the less reputation the user will have if they do not participate. This would cause the user’s points on the Social Market to decrease even though the user has not spent them. This is an undesirable situation for the evaluation of the model.
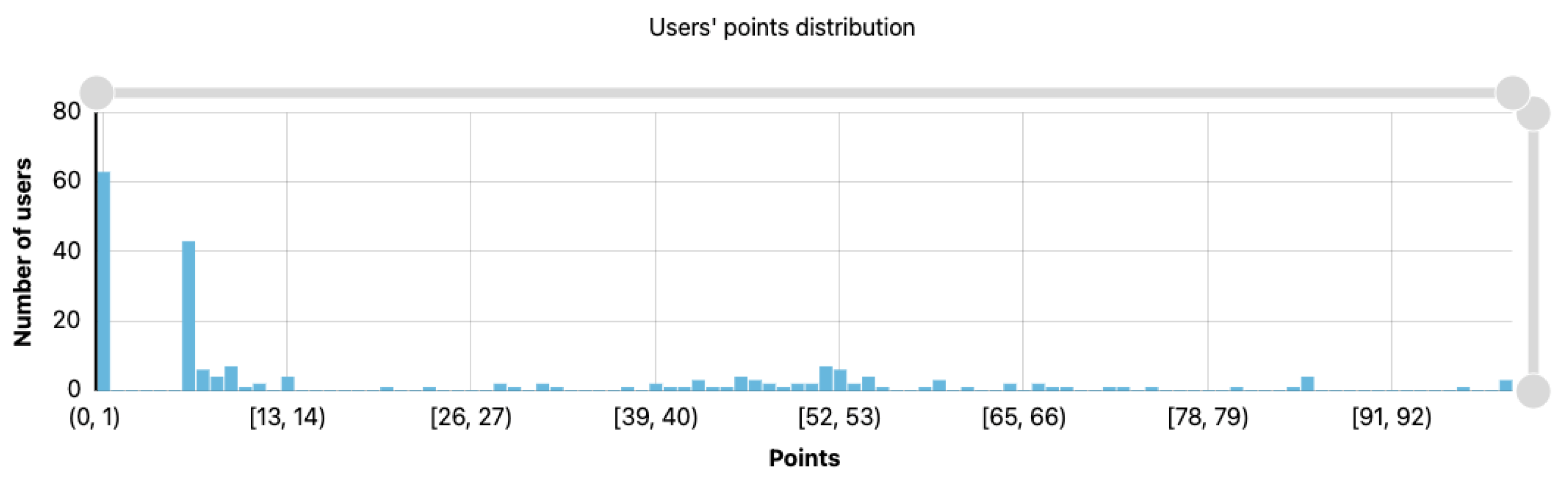
4.2.1. User Points (Social Market Version)
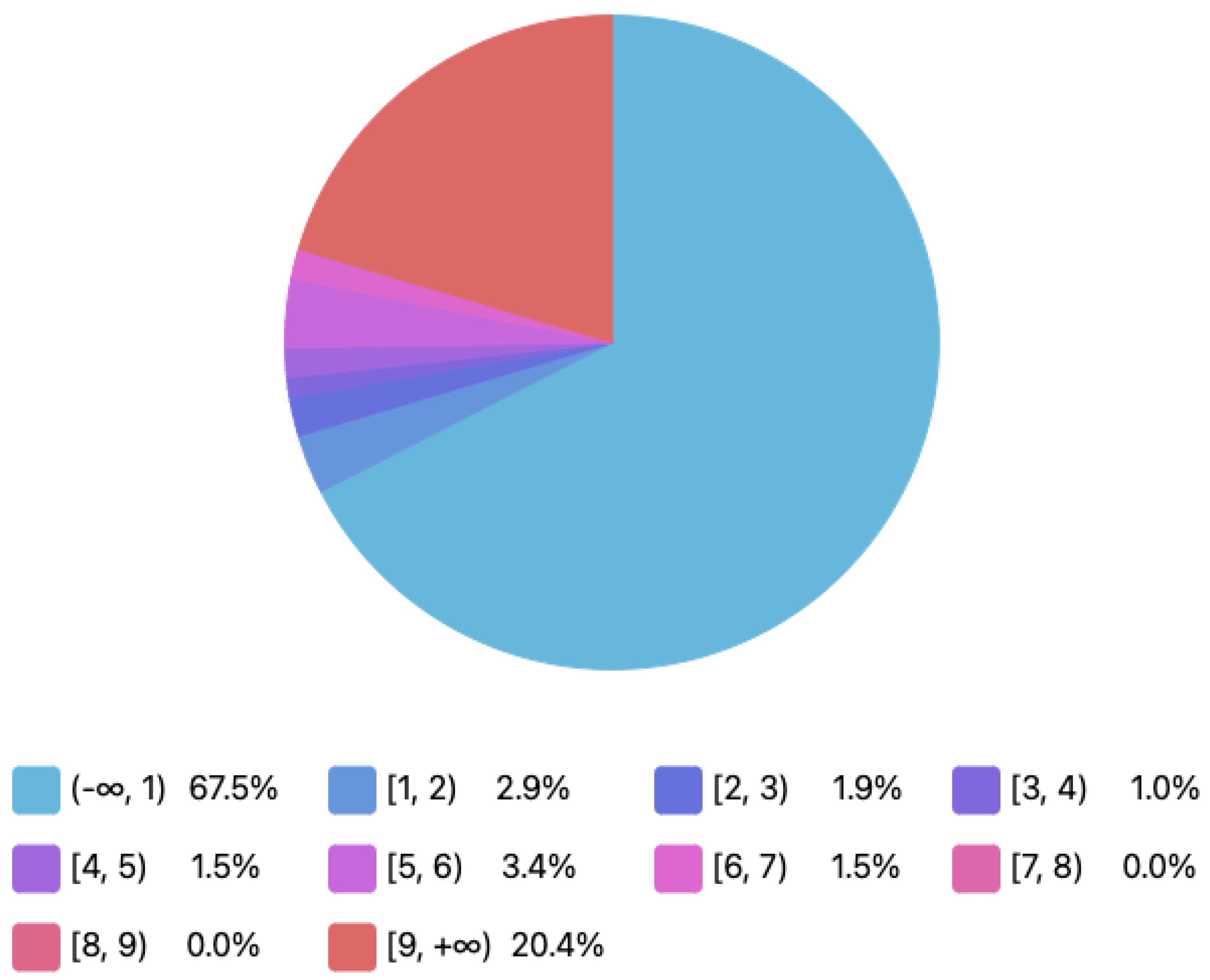
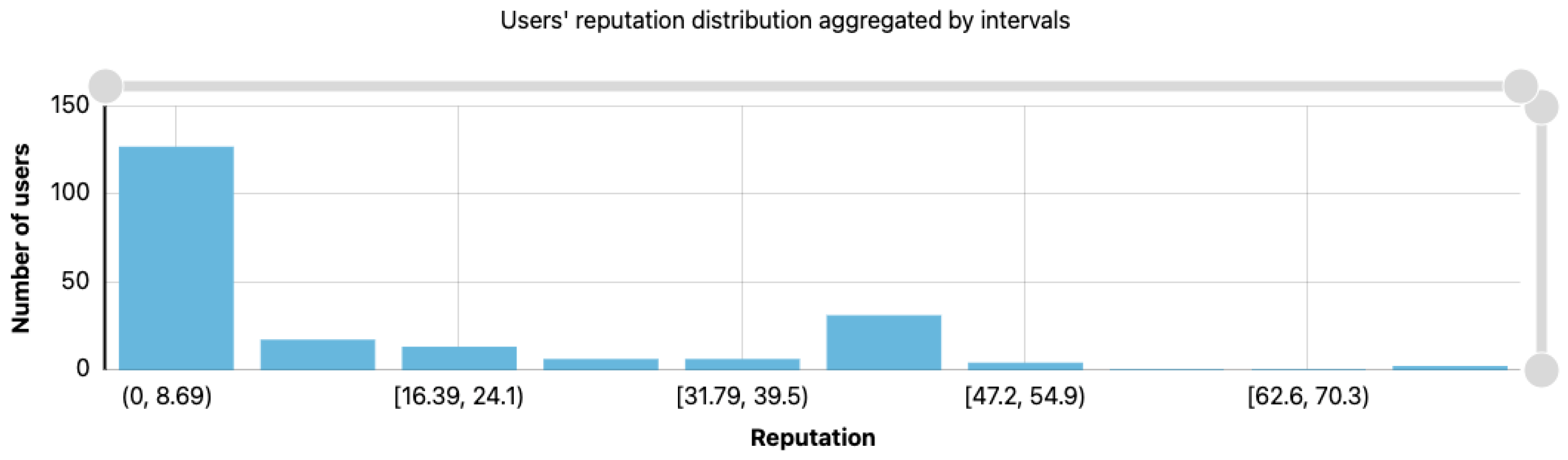
4.2.2. Users’ Reputation
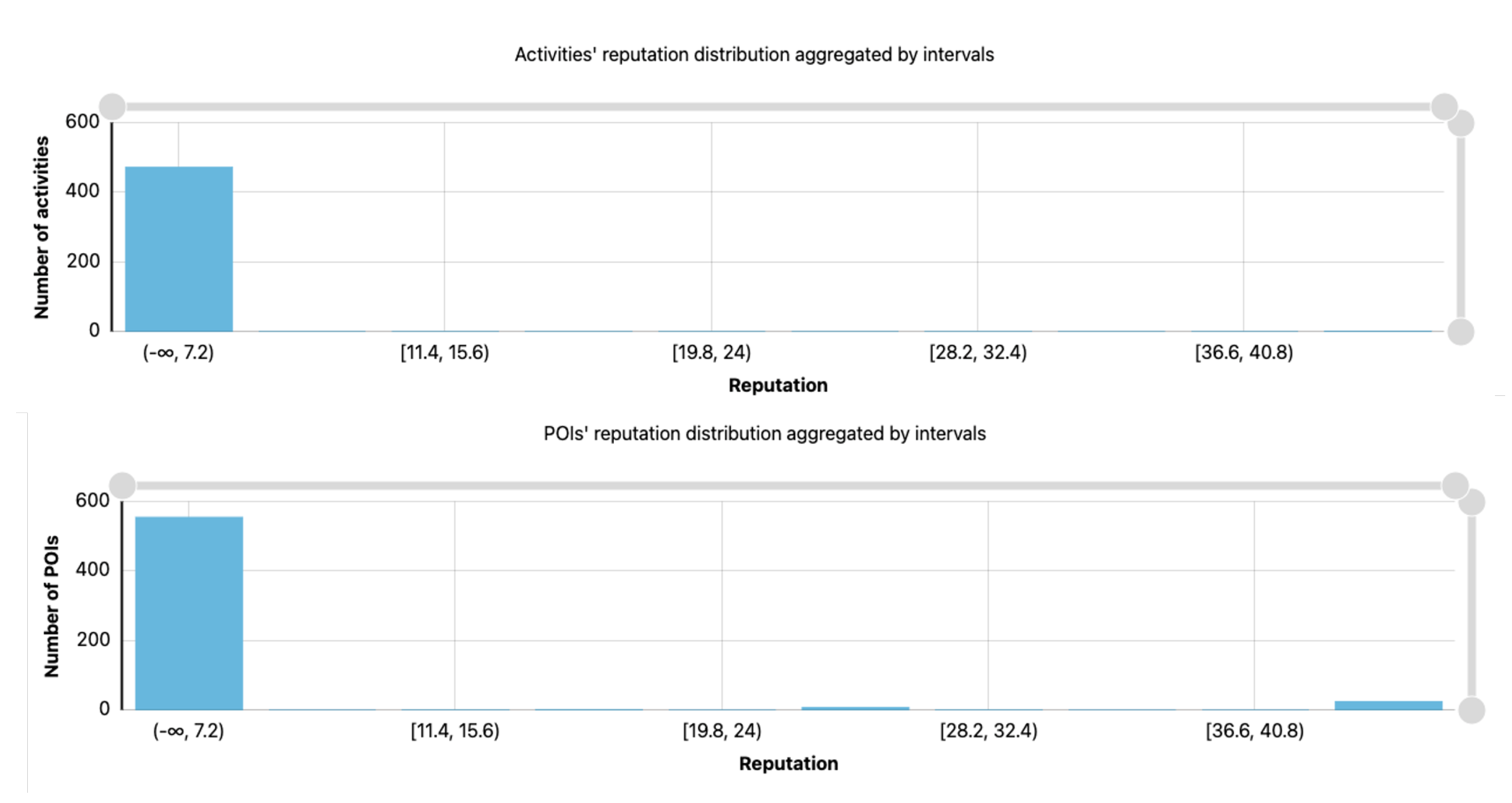
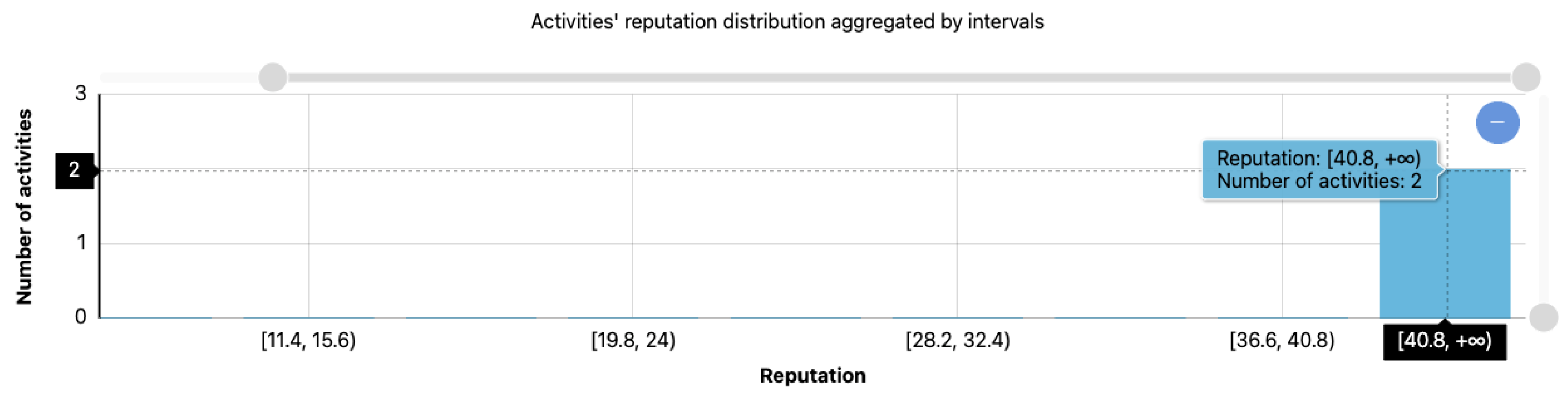
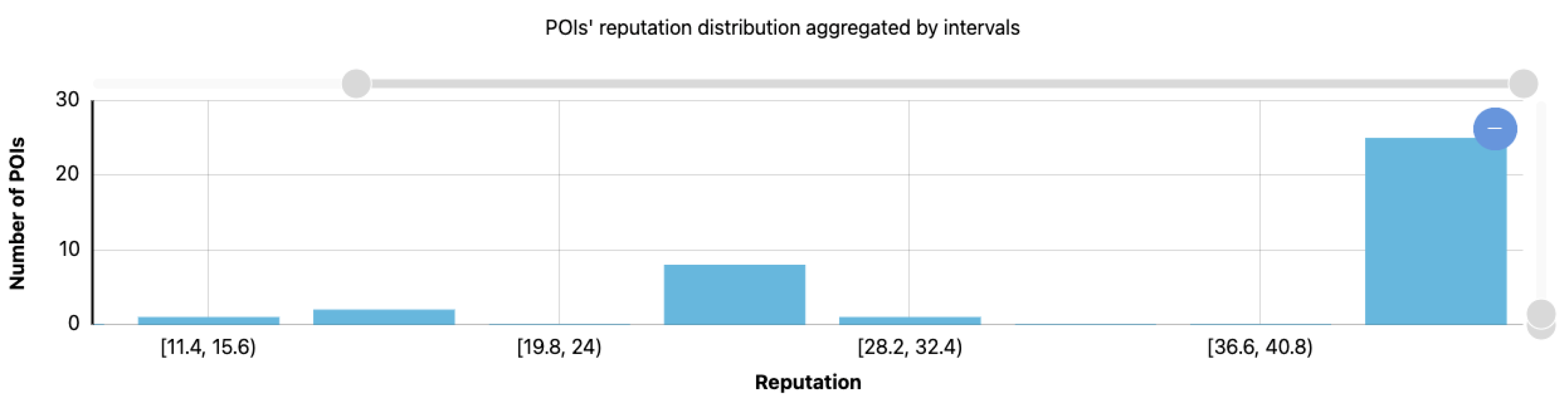
4.2.3. POIs and Activities’ Reputation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kamargianni, M.; Li, W.; Matyas, M.; Schäfer, A. A critical review of new mobility services for urban transport. Transp. Res. Procedia 2016, 14, 3294–3303. [Google Scholar] [CrossRef]
- Dickinson, J.E.; Ghali, K.; Cherrett, T.; Speed, C.; Davies, N.; Norgate, S. Tourism and the smartphone app: Capabilities, emerging practice and scope in the travel domain. Curr. Issues Tour. 2014, 17, 84–101. [Google Scholar] [CrossRef]
- Chun, B.N.; Bavier, A. Decentralized trust management and accountability in federated systems. In Proceedings of the 37th Annual Hawaii International Conference on System Sciences, Big Island, HI, USA, 5–8 January 2004; p. 9. [Google Scholar]
- Li, N.; Mitchell, J.C.; Winsborough, W.H. Design of a role-based trust-management framework. In Proceedings of the Proceedings 2002 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 12–15 May 2002; pp. 114–130. [Google Scholar]
- Kim, Y.H.; Kim, D.J.; Wachter, K. A study of mobile user engagement (MoEN): Engagement motivations, perceived value, satisfaction, and continued engagement intention. Decis. Support Syst. 2013, 56, 361–370. [Google Scholar] [CrossRef]
- Lalmas, M.; O’Brien, H.; Yom-Tov, E. Measuring user engagement. Synth. Lect. Inf. Concepts Retr. Serv. 2014, 6, 1–132. [Google Scholar] [CrossRef]
- Bruns, A. Blogs, Wikipedia, Second Life, and beyond: From Production to Produsage; Peter Lang: New York, NY, USA, 2008; Volume 45. [Google Scholar]
- Forslund, G. Toward cooperative advice-giving systems: A case study in knowledge-based decision support. IEEE Expert 1995, 10, 56–62. [Google Scholar] [CrossRef]
- Josang, A.; Ismail, R. The beta reputation system. In Proceedings of the 15th Bled Electronic Commerce Conference, Bled, Slovenia, 17–19 June 2002; Volume 5, pp. 2502–2511. [Google Scholar]
- Kerschbaum, F.; Haller, J.; Karabulut, Y.; Robinson, P. Pathtrust: A trust-based reputation service for virtual organization formation. In Proceedings of the International Conference on Trust Management, Pisa, Italy, 16–19 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 193–205. [Google Scholar]
- Corchado, J.M.; Chamoso, P.; Hernández, G.; Gutierrez, A.S.R.; Camacho, A.R.; González-Briones, A.; Pinto-Santos, F.; Goyenechea, E.; Garcia-Retuerta, D.; Alonso-Miguel, M.; et al. Deepint. net: A Rapid Deployment Platform for Smart Territories. Sensors 2021, 21, 236. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Retuerta, D.; Chamoso, P.; Hernández, G.; Guzmán, A.S.R.; Yigitcanlar, T.; Corchado, J.M. An Efficient Management Platform for Developing Smart Cities: Solution for Real-Time and Future Crowd Detection. Electronics 2021, 10, 765. [Google Scholar] [CrossRef]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Technical Report; Stanford InfoLab: Stanford, CA, USA, 1999. [Google Scholar]
- Kamvar, S.D.; Schlosser, M.T.; Garcia-Molina, H. The eigentrust algorithm for reputation management in p2p networks. In Proceedings of the 12th international conference on World Wide Web, Budapest, Hungary, 20–24 May 2003; pp. 640–651. [Google Scholar]
- Kurdi, H.A. HonestPeer: An enhanced EigenTrust algorithm for reputation management in P2P systems. J. King Saud Univ. Comput. Inf. Sci. 2015, 27, 315–322. [Google Scholar] [CrossRef]
- Adler, B.T.; De Alfaro, L. A content-driven reputation system for the Wikipedia. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 261–270. [Google Scholar]
- Zacharia, G.; Maes, P. Trust management through reputation mechanisms. Appl. Artif. Intell. 2000, 14, 881–907. [Google Scholar] [CrossRef]
- Waze. Your Rank and Points—Connected Citizens Program. 2019. Available online: https://wiki.waze.com/wiki/Your_Rank_and_Points (accessed on 12 January 2019).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor | Metrics (Equations) | Inputs | Outputs |
|---|---|---|---|
| Days registered | |||
| List of valuations | |||
| Number of uses of the application | |||
| Number of chosen routes |
| Factor | Metrics (Equations) | Inputs | Outputs |
|---|---|---|---|
| n-star ratings weighted average | |||
| Number of views of the activity |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
García-Retuerta, D.; Rivas, A.; Guisado-Gámez, J.; Antoniou, E.; Chamoso, P. Reputation System for Increased Engagement in Public Transport Oriented-Applications. Electronics 2021, 10, 1070. https://doi.org/10.3390/electronics10091070
García-Retuerta D, Rivas A, Guisado-Gámez J, Antoniou E, Chamoso P. Reputation System for Increased Engagement in Public Transport Oriented-Applications. Electronics. 2021; 10(9):1070. https://doi.org/10.3390/electronics10091070
Chicago/Turabian StyleGarcía-Retuerta, David, Alberto Rivas, Joan Guisado-Gámez, Eleni Antoniou, and Pablo Chamoso. 2021. "Reputation System for Increased Engagement in Public Transport Oriented-Applications" Electronics 10, no. 9: 1070. https://doi.org/10.3390/electronics10091070
APA StyleGarcía-Retuerta, D., Rivas, A., Guisado-Gámez, J., Antoniou, E., & Chamoso, P. (2021). Reputation System for Increased Engagement in Public Transport Oriented-Applications. Electronics, 10(9), 1070. https://doi.org/10.3390/electronics10091070