
Two Advanced Models of the Function of MRT Public Transportation in Taipei



Abstract
1. Introduction
2. Literature Review
2.1. Passenger Traffic Forecasts and Application
2.2. Variable Selection
- Y1: The training samples are from the passenger traffic data of the Muzha Line from 1996 to 2015, and the artificial neural network and regression analysis are adopted to forecast the Taipei MRT passenger traffic.
- X1: The “nominal market value” of “final products and services” produced by “all people in a specific region” within a “certain period”. A prosperous economy will lead the passenger traffic.
- X2: The total market value of all the “services” and “final products” produced by a country within a certain period. In general, a higher number means higher productivity in the country, which means it is more prosperous and helpful in relation to passenger traffic.
- X3: The most important economic indicator to determine the macroeconomic situation, which may reflect the change in the scale of the total economic output, and the most physical symbol of economic prosperity, which may affect the capacity of public transportation tools.
- X4: The higher the density of a financial industry, the more prosperous the business development, which may increase the demand for MRT.
- X5: The tourism business is an important service industry that contributes much to the national income, employment, and foreign exchange earnings. Meanwhile, the number of tourists is also helpful in evaluating the increase in passenger traffic.
- X6: The good operation of listed companies with sufficient working capital may promote business activities and increase the demand for transportation.
- X7: A local employee population may reflect the level of local economic prosperity. The people of a country with greater employment opportunities may have a certain consumption ability and will affect the public transportation volume.
- X8: The price variation indicator, calculated based on the prices of products and services relating to living in a residence, is one of the major indicators for measuring inflation. The increase in price will affect the public transportation volume.
- X9: The total population density of Taipei and New Taipei City, obtained using the land area of Taipei and New Taipei City divided by the population, is adopted as the variable. The population will affect the consumption ability of the public. The consumption ability will automatically increase with an increasing population. Therefore, the population may affect the demand for transportation in a certain area.
- X10: Personal income affects the consumption ability of the public. The higher the income, the greater the consumption ability. Therefore, personal income may affect the transportation demand.
- X11: This factor measures the change in prices of imported and exported products. The higher the consumption amount of the public, the stronger the consumption ability of the nationals in the country, which may affect the passenger traffic.
- X12: The consumption of the public in the country could be observed from the total amount imported to Taiwan. A higher amount means a stronger consumption ability of the people in the country, which may affect the passenger traffic.
- X13: The density of the total MRT train trips and time spent waiting for mass transportation are important factors affecting the willingness of commuters to take public transportation. The shorter the waiting time, the higher the willingness of commuters to take public transportation.
- X14: The accessibility of the transportation network to administrative regions may likely affect the willingness of the public to take public transportation. If different mass transportation tools can be effectively integrated, commuters will be more willing to take public transportation.
- X15: The total travel mileage of all MRT trains within a specific time and period. The higher the passenger traffic is, the more train trips and travel mileage of trains there will be.
- X16: Operation income status is critical for the sustainable operation of a transportation organization. If the organization has operation losses, its transportation supply efficiency must be affected.
- X17: The actual number of stops in all the routes of the MRT operation and the expansion of the transportation network will increase the accessibility of the expected destinations. If different mass transportation tools can be effectively integrated, commuters will be more willing to take public transportation.
- X18: Shorter distances of transportation routes will increase the accessibility of the planned destinations. If different mass transportation tools can be effectively integrated, commuters will be more willing to take public transportation.
- X19: The total number of passengers multiplied by the mileage traveled. The mileage for the calculation of passenger kilometers will be based on the mileage for the freight calculation.
- X20: The changes in MRT, bus transportation, and transfer volume are used to analyze the effects of decreases in transfers. The time spent waiting for public transportation tools is an important factor affecting the willingness of commuters to take public transportation. The shorter the waiting time, the higher the willingness of the commuters to take public transportation.
2.3. Artificial Neural Network
2.4. Regression Analysis Method
2.5. Mean Absolute Percentage Error
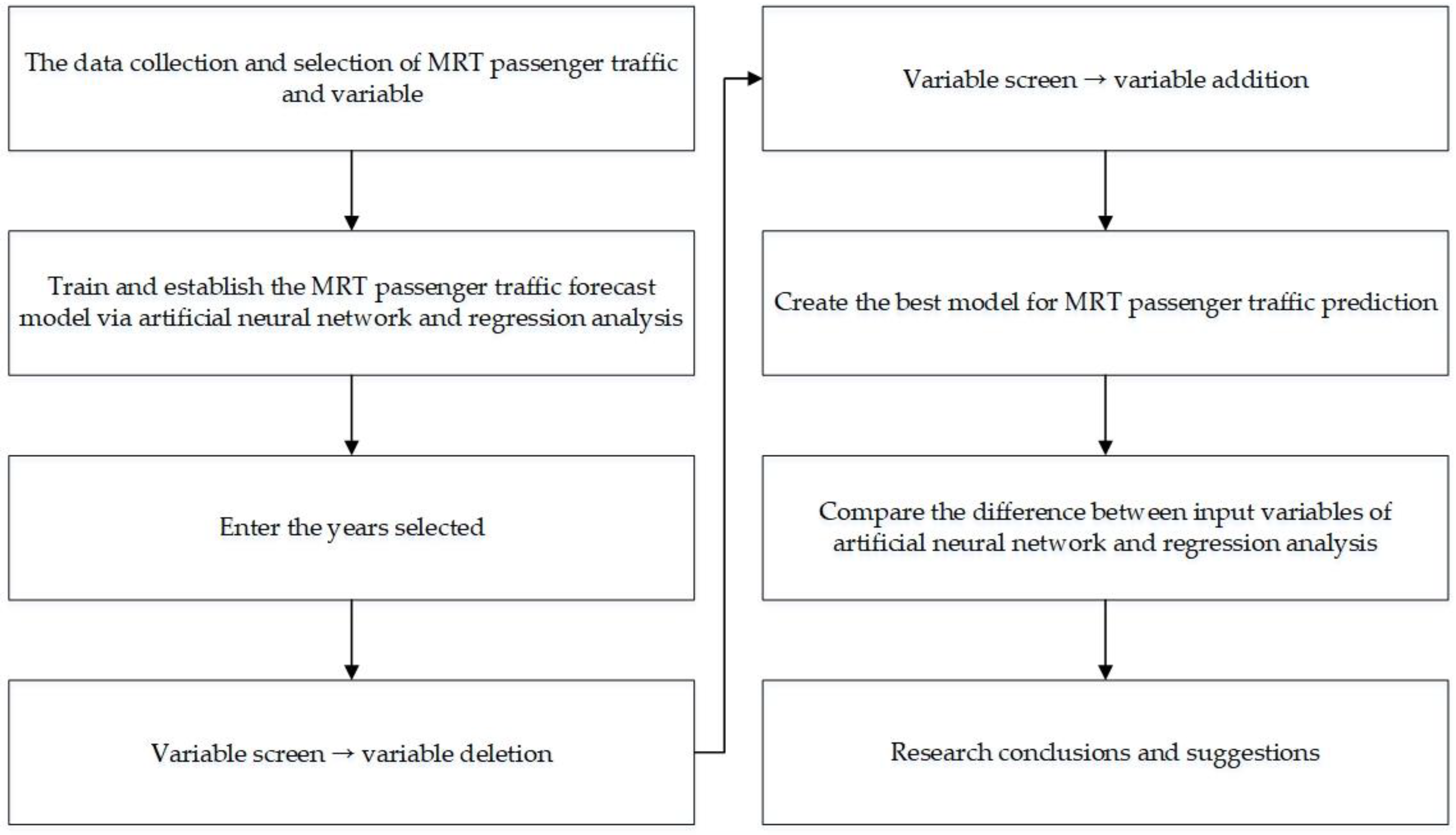
3. Materials and Methods
3.1. Research Structure
- The literature and selected variables that may affect the MRT passenger traffic are collected via a literature review.
- The artificial neural network and regression analysis are adopted as research methods for training and establishing a prediction model of the MRT passenger traffic: (1) the years of training are selected; (2) the input variables of the MRT passenger traffic are deleted one by one, and the best variable is found; (3) the possible input variables that are likely to affect the MRT passenger traffic in the training are added, and the best variable is found; and (4) the MRT passenger traffic forecast model is established via an artificial neural network and regression analysis.
- The MRT passenger traffic forecast model is established.
- The advantages and disadvantages of the input variables selected are compared and analyzed, considering the results of the artificial neural network and regression analysis.
- The research conclusions and suggestions based on the research results are provided.
3.2. Research Design and Steps
3.2.1. Line Chart and Scatter Chart
3.2.2. Correlation Analysis
3.2.3. Enter Method
3.2.4. Stepwise Regression
4. Empirical Analysis
4.1. Regression Analysis
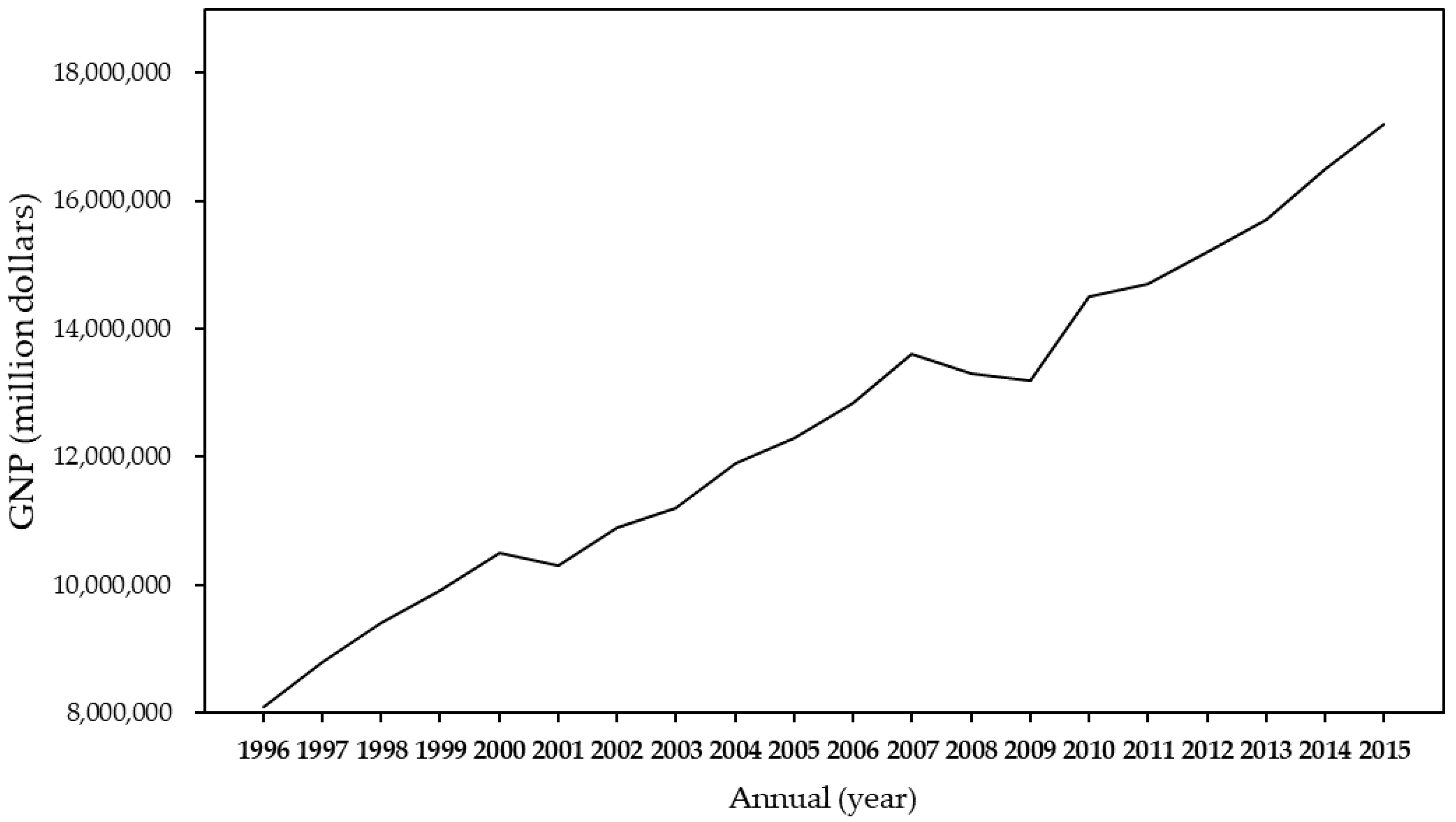
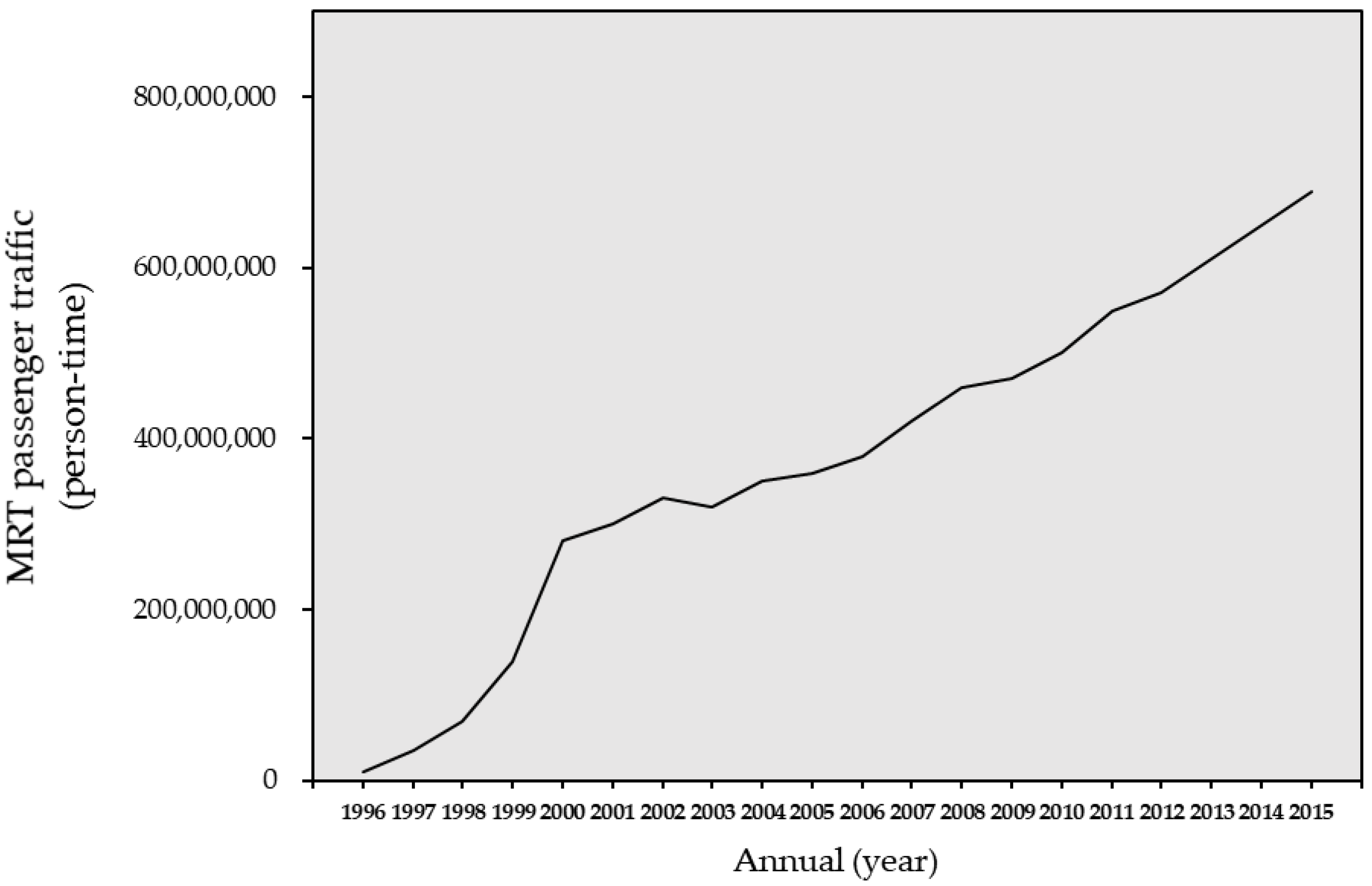
4.1.1. Line Chart
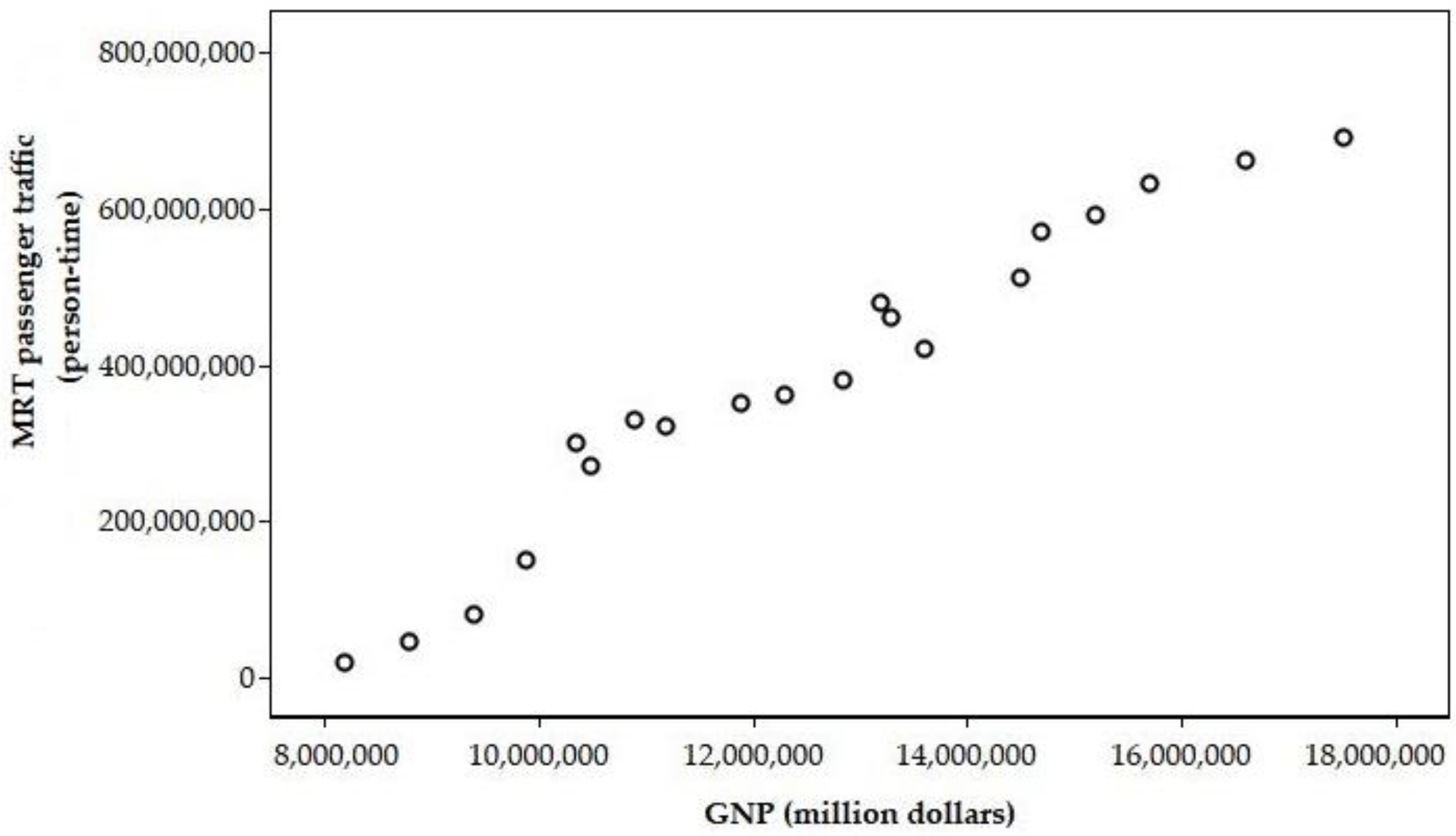
4.1.2. Scatter Chart
4.1.3. Correlation Analysis
4.1.4. Entry Method
4.1.5. Stepwise Method
4.2. Artificial Neural Network
4.2.1. Year of Selection
4.2.2. Deleted Variables
4.2.3. The Output Results of the Artificial Neural Network
4.3. Comparison of Regression Analysis and Artificial Neural Networks
4.3.1. Deletion of the Forced Entry Method of Regression Analysis to Exclude Four Variables
4.3.2. Deletion of Four Variables with High MAPE Values in Artificial Neural Networks
4.3.3. Collinearity Verification
4.3.4. Monthly Passenger Traffic Experiment
4.4. Summary of the Empirical Results
5. Analysis of Empirical Results
5.1. Analysis of Results
- A total of 20 parameters from 1996 to 2013 were used as the input variables of the regression analysis, and the output value was the passenger traffic prediction value of the Taipei MRT. The stepwise regression of the regression analysis, predicting the MAPE value of the Taipei MRT passenger traffic, is 6.47%, which demonstrates an excellent predictive performance.
- Using the training data from 1996 to 2015 as artificial neural network training materials and the data from 2013 to 2015 as the sample data, a total of 20 parameters were used as the input variables of the artificial neural network; the output value was the passenger traffic prediction value of the Taipei MRT. Using an artificial neural network to predict the MAPE value of the Taipei MRT passenger traffic, the result was 4.82%, which demonstrates an excellent predictive performance.
- We used the 5-year training for 2 years (2009–2013/2014–2015) model and deleted the already eliminated four variables of regression analysis, which were the GNP, GDP, MRT mileage, and MRT extended passenger mileage. In total, 16 parameters were used as the input variables for regression analysis and artificial neural network comparison. The MAPE value predicted by regression analysis was found to be 0.94%, and the MAPE value of the artificial neural network was 0.54%. Both methods had the best prediction results.
- We used the model of 5-year training for 2 years (2009–2013/2014–2015) and deleted the four variables with the highest MAPE values in the artificial neural network, including the economic growth rate, personal income, total amount of goods imported into Taiwan, and number of MRT stations. In total, 16 parameters were used as the input variables for regression analysis and artificial neural network comparison. The MAPE value predicted by regression analysis was 0.62%, and the MAPE value of artificial neural networks was 0.31%. Both methods had the best prediction results.
- In order to verify whether the independent variable MRT passenger revenue is collinear with the dependent variable MRT passenger traffic, we applied statistical software to analyze the inputting of 19 parameter variables from 1996 to 2013 and outputting of the passenger traffic prediction value of the Taipei MRT. Again, we used the training data from 1996 to 2015 as the artificial neural network training materials and the data from 2013 to 2015 as the sample data. We used a total of 19 parameters as the input variables of the artificial neural network and the passenger traffic prediction value of the Taipei MRT as the output value in order to compare the predictive values of the regression analysis and artificial neural network. The result showed that the MAPE value of the regression analysis was 5.19%, and the MAPE value of the artificial neural network was 4.63%. Twenty variables and 19 parameter variables were used to compare the predictive values of the regression analysis and artificial neural network after removing the independent variable, the MRT revenue. The results showed that the MAPE residual value of regression analysis was 1.28%, and the MAPE residual value of the artificial neural network was 0.19%. No significant difference was observed between them, which proves that there is no collinearity problem after deleting the independent variable, the MRT passenger revenue.
- We collected data on the passenger traffic (month) and related variables (month); however, because some data were recorded at different times, 167 regression analyses were conducted from January 2000 to December 2015 (excluding the incomplete data on Cyclone Nari in September 2001). The neural network used the mode of 2000–2013 training 2014–2015 and the following seven parameter variables: the MRT operation mileage, MRT station number, MRT train number, MRT extended vehicle mileage, MRT extended passenger mileage, MRT passenger revenue, and two-way transit preferential volume. The output value is the passenger traffic prediction value of the Taipei MRT. The results show that the MAPE value of regression analysis was 1.45%, and the MAPE value of the artificial neural network was 0.42%. Both methods had the best prediction results.
- This study investigated the passenger traffic prediction of the Taipei MRT and analyzed and constructed the prediction model based on two prediction methods: regression analysis and artificial neural networks. The results are presented to allow transportation organizations to maximize their profits by making plans and decisions relating to future operations based on past passenger traffic trends.
5.2. Research Contributions
- 1.
- Choosing the right forecasting tools for business planning and decision making.
- 2.
- Construction and planning of transport systems.
- 3.
- Curbing the growth of private vehicles.
- 4.
- Public transportation leads to urban development.
- 5.
- Improvement of the efficiency of all public transport vehicles.
6. Conclusions
- The forecasting of passenger traffic has a great influence on the transportation industry, and transportation organizations can make plans and decisions for future operations based on past passenger traffic trends. Therefore, it is very important for transportation organizations to have a clear and objective forecasting method.
- Based on past research data and a literature review, we determined the variable that affects the forecasting of passenger traffic demand the most. The forecasting of the MRT passenger traffic affects the future economic development of Taipei City and New Taipei City, so it is necessary to select the appropriate passenger traffic forecasting tool.
- The data on passenger traffic forecasting in this study not only allow for the planning of traffic dispatching, operation management, manpower allocation, shift distance, transportation demand, etc., but also serve as an essential basis for transportation organizations, enabling them to put forward requirements for the construction and expansion of transportation equipment.
Author Contributions
Funding
Conflicts of Interest
References
- Verbavatz, V.; Barthelemy, M. Access to mass rapid transit in OECD urban areas. Sci. Data 2020, 7, 1–6. [Google Scholar] [CrossRef]
- Wiseman, Y. Autonomous vehicles. In Encyclopedia of Information Science and Technology, 5th ed.; IGI Global: Hershey, PA, USA, 2021; pp. 1–11. [Google Scholar]
- Wiseman, Y. Driverless cars will make passenger rail obsolete [Opinion]. IEEE Technol. Soc. Mag. 2019, 38, 22–27. [Google Scholar] [CrossRef]
- Yang, Z.; Li, C.; Jiao, J.; Liu, W.; Zhang, F. On the joint impact of high-speed rail and megalopolis policy on regional economic growth in China. Transp. Policy 2020, 99, 20–30. [Google Scholar] [CrossRef]
- Lio, W.; Liu, B. Uncertain maximum likelihood estimation with application to uncertain regression analysis. Soft Comput. 2020, 24, 9351–9360. [Google Scholar] [CrossRef]
- Toraman, S.; Alakus, T.B.; Turkoglu, I. Convolutional capsnet: A novel artificial neural network approach to detect COVID-19 disease from X-ray images using capsule networks. Chaos Solitons Fractals 2020, 140, 110122. [Google Scholar] [CrossRef]
- Mazanec, J.A. Classifying tourists into market segments: A neural network approach. J. Travel Tour. Mark. 1992, 1, 39–60. [Google Scholar] [CrossRef]
- Law, R.; Au, N. A neural network model to forecast Japanese demand for travel to Hong Kong. Tour. Manag. 1999, 20, 89–97. [Google Scholar] [CrossRef]
- Kulendran, N.; Witt, S.F. Leading indicator tourism forecasts. Tour. Manag. 2003, 24, 503–510. [Google Scholar] [CrossRef]
- Grosche, T.; Rothlauf, F.; Heinzl, A. Gravity models for airline passenger volume estimation. J. Air Transp. Manag. 2007, 13, 175–183. [Google Scholar] [CrossRef]
- Shams, S.R.; Jahani, A.; Moeinaddini, M.; Khorasani, N. Air carbon monoxide forecasting using an artificial neural network in comparison with multiple regression. Model. Earth Syst. Environ. 2020, 6, 1467–1475. [Google Scholar] [CrossRef]
- Liu, S.; Mocanu, D.C.; Matavalam, A.R.R.; Pei, Y.; Pechenizkiy, M. Sparse evolutionary deep learning with over one million artificial neurons on commodity hardware. Neural Comput. Appl. 2020, 1–16. [Google Scholar] [CrossRef]
- Sun, W.; Huang, C. A carbon price prediction model based on secondary decomposition algorithm and optimized back propagation neural network. J. Clean. Prod. 2020, 243, 118671. [Google Scholar] [CrossRef]
- Liu, R.; Mancuso, C.A.; Yannakopoulos, A.; Johnson, K.A.; Krishnan, A. Supervised learning is an accurate method for network-based gene classification. Bioinformatics 2020, 36, 3457–3465. [Google Scholar] [CrossRef] [PubMed]
- Shirokanev, A.S.; Kirsh, D.V.; Kupriyanov, A.V. Research of an algorithm for crystal lattice parameter identification based on the gradient steepest descent method. Comput. Opt. 2017, 41, 453–460. [Google Scholar] [CrossRef]
- Hemilä, H.; Chalker, E. Vitamin C may reduce the duration of mechanical ventilation in critically ill patients: A meta-regression analysis. J. Intensive Care 2020, 8, 15. [Google Scholar] [CrossRef]
- Şahin, U.; Şahin, T. Forecasting the cumulative number of confirmed cases of COVID-19 in Italy, UK and USA using fractional nonlinear grey Bernoulli model. Chaos Solitons Fractals 2020, 138, 109948. [Google Scholar] [CrossRef]
- Prado, F.; Minutolo, M.C.; Kristjanpoller, W. Forecasting based on an ensemble autoregressive moving average-adaptive neuro-fuzzy inference system–neural network-genetic algorithm framework. Energy 2020, 197, 117159. [Google Scholar] [CrossRef]
- Longo, G.A.; Righetti, G.; Zilio, C.; Ortombina, L.; Zigliotto, M.; Brown, J.S. Application of an Artificial Neural Network (ANN) for predicting low-GWP refrigerant condensation heat transfer inside herringbone-type Brazed Plate Heat Exchangers (BPHE). Int. J. Heat Mass Transf. 2020, 156, 119824. [Google Scholar] [CrossRef]
- Feng, Y.; Yang, T.; Niu, Y. Subpixel computer vision detection based on wavelet transform. IEEE Access 2020, 8, 88273–88281. [Google Scholar] [CrossRef]
- Sohn, C.; Choi, H.; Kim, K.; Park, J.; Noh, J. Line Chart understanding with convolutional neural network. Electronics 2021, 10, 749. [Google Scholar] [CrossRef]
- Shibzukhov, Z.M. Robust method for finding the center and the scatter matrix of the cluster. J. Phys. Conf. Ser. 2020, 1479, 012045. [Google Scholar] [CrossRef]
- Peng, Q.; Wen, F.; Gong, X. Time-dependent intrinsic correlation analysis of crude oil and the US dollar based on CEEMDAN. Int. J. Financ. Econ. 2021, 26, 834–848. [Google Scholar] [CrossRef]
- Shi, J.; Liu, B.; Qin, J.; Jiang, J.; Wu, X.; Tan, J. Experimental study of performance of repair mortar: Evaluation of in-situ tests and correlation analysis. J. Build. Eng. 2020, 31, 101325. [Google Scholar] [CrossRef]
- Ibrahim, M.S.; Sidiropoulos, N.D. Reliable detection of unknown cell-edge users via canonical correlation analysis. IEEE Trans. Wirel. Commun. 2020, 19, 4170–4182. [Google Scholar] [CrossRef]
- Di Tella, M.; Romeo, A.; Benfante, A.; Castelli, L. Mental health of healthcare workers during the COVID-19 pandemic in Italy. J. Eval. Clin. Pract. 2020, 26, 1583–1587. [Google Scholar] [CrossRef]
- Moskowitz, S.; Dewaele, J.M. Is teacher happiness contagious? A study of the link between perceptions of language teacher happiness and student attitudes. Innov. Lang. Learn. Teach. 2021, 15, 117–130. [Google Scholar] [CrossRef]
- Liu, B.; Zhao, Q.; Jin, Y.; Shen, J.; Li, C. Application of combined model of stepwise regression analysis and artificial neural network in data calibration of miniature air quality detector. Sci. Rep. 2021, 11, 1–12. [Google Scholar]
- Hornby, T.G.; Henderson, C.E.; Holleran, C.L.; Lovell, L.; Roth, E.J.; Jang, J.H. Stepwise regression and latent profile analyses of locomotor outcomes poststroke. Stroke 2020, 51, 3074–3082. [Google Scholar] [CrossRef]
- Żogała-Siudem, B.; Jaroszewicz, S. Fast stepwise regression based on multidimensional indexes. Inf. Sci. 2021, 549, 288–309. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Name of Variable | Variable Code |
|---|---|---|
| Y1 | MRT passenger traffic | Passengers |
| X1 | Gross National Product | GNP |
| X2 | Gross Domestic Product | GDP |
| X3 | Economic growth rate | Economic |
| X4 | Number and density of registered financial businesses | InFinanden |
| X5 | Number of major tourists | Visitors |
| X6 | Number of listed companies | Companies |
| X7 | Employment population | Employed |
| X8 | Consumer Price Index | CPI |
| X9 | Population density | InPopden |
| X10 | Personal income | PCI |
| X11 | Import Price Index | IPI |
| X12 | Total cargo input amount | CargoInput |
| X13 | MRT train trips | Trains |
| X14 | Number of administrative regions | Administrative |
| X15 | MRT train kilometers | TrainsKM |
| X16 | MRT passenger traffic income | Income |
| X17 | Number of MRT stations | Stations |
| X18 | MRT operation kilometers | OperationsKM |
| X19 | MRT passenger kilometers | PassengersKM |
| X20 | Round trip transfer discount volume | Transfers |
| MAPE Value | Standard |
|---|---|
| MAPE < 10% | Excellent prediction power (the closer to 0, the better) |
| 10% < MAPE < 20% | Good prediction power |
| 20% < MAPE < 50% | Reasonable prediction power |
| 50% < MAPE | Poor prediction power |
| Variable | X1 | X2 | X3 | X4 | ... | X17 | X18 | X19 | X20 | Y1 |
|---|---|---|---|---|---|---|---|---|---|---|
| Unit/Year | Million | Million | % | Km2 (Train) | ... | Station | Km | Persons/Km | Persons (Thousand) | Total Persons |
| 1996 | 8,146,092 | 8,036,590 | 6.18 | 500 | ... | 12 | 10.5 | 57,226,810 | 102 | 11,174,359 |
| 1997 | 8,806,852 | 8,717,241 | 6.11 | 509 | ... | 32 | 32.4 | 243,676,517 | 3282 | 31,081,395 |
| 1998 | 9,449,692 | 9,381,141 | 4.21 | 501 | ... | 39 | 40.3 | 512,282,678 | 12,229 | 60,737,782 |
| 1999 | 9,906,113 | 9,815,595 | 6.72 | 495 | ... | 56 | 56.4 | 1,031,342,472 | 21,203 | 126,952,122 |
| 2000 | 10,490,818 | 10,351,260 | 6.42 | 491 | ... | 62 | 65.1 | 2,042,303,171 | 38,138 | 268,716,740 |
| 2001 | 10,350,233 | 10,158,209 | −1.26 | 448 | ... | 62 | 65.1 | 2,223,486,596 | 44,368 | 289,642,714 |
| 2002 | 10,923,385 | 10,680,883 | 5.57 | 437 | ... | 62 | 65.1 | 2,469,037,312 | 53,093 | 324,433,557 |
| 2003 | 11,294,739 | 10,965,866 | 4.12 | 433 | ... | 62 | 65.1 | 2,440,488,934 | 72,399 | 316,189,128 |
| 2004 | 12,021,744 | 11,649,645 | 6.51 | 428 | ... | 63 | 67 | 2,680,355,529 | 125,350 | 350,141,956 |
| 2005 | 12,383,120 | 12,092,254 | 5.42 | 422 | ... | 63 | 67 | 2,742,372,258 | 127,424 | 360,729,803 |
| 2006 | 12,952,502 | 12,640,803 | 5.62 | 415 | ... | 69 | 74.4 | 3,002,988,957 | 130,916 | 384,003,220 |
| 2007 | 13,739,828 | 13,407,062 | 6.52 | 417 | ... | 69 | 74.4 | 3,298,870,463 | 140,044 | 416,229,685 |
| 2008 | 13,465,596 | 13,150,950 | 0.70 | 418 | ... | 70 | 75.8 | 3,513,969,060 | 152,643 | 450,024,415 |
| 2009 | 13,375,650 | 12,961,656 | −1.57 | 428 | ... | 82 | 90.6 | 3,720,991,244 | 153,679 | 462,472,351 |
| 2010 | 14,548,852 | 14,119,213 | 10.63 | 425 | ... | 93 | 100.8 | 4,123,189,518 | 162,098 | 505,466,450 |
| 2011 | 14,700,572 | 14,312,200 | 3.80 | 425 | ... | 94 | 101.9 | 4,607,801,411 | 170,963 | 566,404,489 |
| 2012 | 15,141,108 | 14,686,917 | 2.06 | 427 | ... | 102 | 112.8 | 4,973,666,983 | 177,918 | 594,864,715 |
| 2013 | 15,646,211 | 15,221,201 | 2.23 | 428 | ... | 109 | 121.3 | 5,234,160,050 | 182,193 | 634,961,083 |
| 2014 | 16,621,378 | 16,081,798 | 3.74 | 428 | ... | 116 | 129.2 | 5,589,414,250 | 180,133 | 679,506,401 |
| 2015 | 17,485,375 | 16,881,614 | 3.78 | 429 | ... | 117 | 131.1 | 5,880,980,257 | 173,877 | 717,511,809 |
| Model | Variable Inputted | Variable Removed | Method |
|---|---|---|---|
| 1 | X3, X4, X5, X6, X7, X8, X9, X10, X11, X12, X13, X14, X15, X16, X17, X20 | Entry |
| Collinearity Statistical Material | |||||
|---|---|---|---|---|---|
| Model | T | Significance | Permissible Deviation | VIF | |
| 1 | (Constant) | −2.374 | 0.098 | ||
| X1 | 0.685 | 0.543 | 0.094 | 10.601 | |
| X3 | 2.787 | 0.069 | 0.004 | 263.957 | |
| X4 | 1.500 | 0.231 | 0.002 | 457.889 | |
| X5 | 1.429 | 0.248 | 0.001 | 1047.998 | |
| X6 | 3.584 | 0.037 | 0.000 | 4167.205 | |
| X8 | −1.309 | 0.282 | 0.001 | 835.575 | |
| X9 | −3.509 | 0.039 | 0.001 | 1728.353 | |
| X10 | −1.115 | 0.346 | 0.007 | 143.916 | |
| X11 | 2.919 | 0.062 | 0.005 | 206.473 | |
| X12 | 1.151 | 0.333 | 0.007 | 142.958 | |
| X13 | −3.006 | 0.057 | 0.003 | 293.111 | |
| X14 | −1.913 | 0.152 | 0.003 | 313.741 | |
| X15 | 0.030 | 0.978 | 0.002 | 617.120 | |
| X16 | 11.990 | 0.001 | 0.003 | 374.019 | |
| X17 | −0.098 | 0.928 | 0.002 | 656.926 | |
| X20 | −2.325 | 0.103 | 0.003 | 348.165 | |
| Model | Variable Inputted | Method |
|---|---|---|
| 1 | X16 | Step by step (criteria: F-to-enter probability ≤ 0.050, F-to-remove probability ≥ 0.100) |
| 2 | X20 | Step by step (criteria: F-to-enter probability ≤ 0.050, F-to-remove probability ≥ 0.100) |
| Model | Unstandardized Coefficients | Standardized Coefficients | T | Significance | ||
|---|---|---|---|---|---|---|
| B | Standard Error | Beta | ||||
| 1 | (Constant) | −12,082,965.667 | 3,520,486 | −3.432 | 0.003 | |
| X16 | 0.047 | 0 | 0.999 | 124.893 | 0 | |
| 2 | (Constant) | −9,989,402.575 | 2,818,390 | −3.544 | 0.002 | |
| X16 | 0.044 | 0.001 | 0.942 | 53.482 | 0 | |
| X20 | 193.099 | 54.85 | 0.062 | 3.52 | 0.003 | |
| Model | Beta | T | Significance | Partial Correlation | |
|---|---|---|---|---|---|
| 1 | X1 | 0.031 | 0.799 | 0.436 | 0.190 |
| X2 | 0.024 | 0.641 | 0.530 | 0.154 | |
| X3 | 0.007 | 0.780 | 0.446 | 0.186 | |
| X4 | −0.031 | −2.705 | 0.015 | −0.549 | |
| X5 | −0.020 | −1.234 | 0.234 | −0.287 | |
| X6 | 0.100 | 2.949 | 0.009 | 0.582 | |
| X7 | 0.085 | 2.668 | 0.016 | 0.543 | |
| X8 | 0.009 | 0.371 | 0.715 | 0.090 | |
| X9 | 0.080 | 1.411 | 0.176 | 0.324 | |
| X10 | 0.002 | 0.071 | 0.944 | 0.017 | |
| X11 | 0.025 | 1.981 | 0.064 | 0.433 | |
| X12 | 0.016 | 0.782 | 0.445 | 0.186 | |
| X13 | −0.008 | −0.204 | 0.841 | −0.049 | |
| X14 | 0.012 | 0.481 | 0.637 | 0.116 | |
| X15 | −0.039 | −0.831 | 0.418 | −0.197 | |
| X17 | −0.058 | −1.788 | 0.092 | −0.398 | |
| X18 | −0.063 | −1.873 | 0.078 | −0.414 | |
| X19 | 0.220 | 1.473 | 0.159 | 0.336 | |
| X20 | 0.062 | 3.520 | 0.003 | 0.649 | |
| 2 | X1 | −0.026 | −0.750 | 0.464 | −0.184 |
| X2 | −0.030 | −0.900 | 0.382 | −0.219 | |
| X3 | 0.004 | 0.562 | 0.582 | 0.139 | |
| X4 | −0.015 | −1.232 | 0.236 | −0.294 | |
| X5 | −0.007 | −0.519 | 0.611 | −0.129 | |
| X6 | 0.050 | 1.239 | 0.233 | 0.296 | |
| X7 | 0.021 | 0.471 | 0.644 | 0.117 | |
| X8 | −0.017 | −0.804 | 0.433 | −0.197 | |
| X9 | −0.076 | −1.158 | 0.264 | −0.278 | |
| X10 | −0.018 | −0.708 | 0.489 | −0.174 | |
| X11 | −0.007 | −0.447 | 0.661 | −0.111 | |
| X12 | −0.026 | −1.306 | 0.210 | −0.310 | |
| X13 | −0.032 | −1.015 | 0.325 | −0.246 | |
| X14 | −0.011 | −0.519 | 0.611 | −0.129 | |
| X15 | −0.024 | −0.637 | 0.533 | −0.157 | |
| X17 | −0.027 | −0.945 | 0.359 | −0.230 | |
| X18 | −0.033 | −1.093 | 0.290 | −0.264 | |
| X19 | 0.090 | 0.698 | 0.495 | 0.172 | |
| Year of Observation | Actual Number of MRT Passengers | Predictive Value of Regression Analysis | Residual Value |
|---|---|---|---|
| 1996 | 11,174,359 | 3,305,117 | 7,869,242 |
| 1997 | 31,081,395 | 36,987,970 | −5,906,575 |
| 1998 | 60,737,782 | 68,054,760 | −7,316,978 |
| 1999 | 126,952,122 | 129,264,711 | −2,312,589 |
| 2000 | 268,716,740 | 270,052,789 | −1,336,049 |
| 2001 | 289,642,714 | 287,079,395 | 2,563,319 |
| 2002 | 324,433,557 | 319,060,611 | 5,372,946 |
| 2003 | 316,189,128 | 312,874,254 | 3,314,874 |
| 2004 | 350,141,956 | 351,632,592 | −1,490,636 |
| 2005 | 360,729,803 | 359,697,272 | 1,032,531 |
| 2006 | 384,003,220 | 385,978,346 | −1,975,126 |
| 2007 | 416,229,685 | 421,166,927 | −4,937,242 |
| 2008 | 450,024,415 | 449,687,066 | 337,349 |
| 2009 | 462,472,351 | 457,533,201 | 4,939,150 |
| 2010 | 505,466,450 | 495,603,126 | 9,863,324 |
| 2011 | 566,404,489 | 560,822,898 | 5,581,591 |
| 2012 | 594,864,715 | 607,214,292 | −12,349,577 |
| 2013 | 634,961,083 | 638,210,638 | −3,249,555 |
| Evaluation Indicators | 7 Years/2 Years of Training (1996–2002/2003–2004) | 6 Years/2 Years of Training (2003–2008/2009–2010) | 5 Years/2 Years of Training (2009–2013/2014–2015) |
|---|---|---|---|
| MAPE | 8.26% | 4.35% | 2.45% |
| Year of Observation | Actual Number of MRT Passengers | Predictive Values of the Artificial Neural Network | Residual Value |
|---|---|---|---|
| 1996 | 11,174,359 | 15,320,813 | 4,146,454 |
| 1997 | 31,081,395 | 30,226,981 | −854,414 |
| 1998 | 60,737,782 | 60,188,236 | −549,546 |
| 1999 | 126,952,122 | 126,305,437 | −646,685 |
| 2000 | 268,716,740 | 267,922,813 | −793,927 |
| 2001 | 289,642,714 | 289,012,656 | −630,058 |
| 2002 | 324,433,557 | 324,181,085 | −252,472 |
| 2003 | 316,189,128 | 327,612,737 | 11,423,609 |
| 2004 | 350,141,956 | 349,893,508 | −248,448 |
| 2005 | 360,729,803 | 360,534,282 | −195,521 |
| 2006 | 384,003,220 | 383,858,990 | −144,230 |
| 2007 | 416,229,685 | 415,952,914 | −276,771 |
| 2008 | 450,024,415 | 285,870,926 | −164,153,489 |
| 2009 | 462,472,351 | 462,125,697 | −346,654 |
| 2010 | 505,466,450 | 505,270,408 | −196,042 |
| 2011 | 566,404,489 | 565,977,673 | −426,816 |
| 2012 | 594,864,715 | 616,442,418 | 21,577,703 |
| 2013 | 634,961,083 | 630,207,775 | −4,753,308 |
| Experiment Module | Regression Analysis MAPE Value | Artificial Neural Network MAPE Value | Results |
|---|---|---|---|
| 20 variables | 6.47% | 4.82% | The artificial neural network is better. |
| The four variables excluded in the regression analysis were deleted: the GNP, GDP, MRT mileage, and MRT extended passenger mileage. | 0.94% | 0.54% | Both had the best prediction results. |
| The four variables with the highest MAPE values were deleted: the economic growth rate, personal income, total amount of goods imported into Taiwan, and number of MRT stations. | 0.62% | 0.31% | Both had the best prediction results. |
| 19-variable collinearity verification (deletion of the MRT passenger revenue). | 5.19% | 4.63% | There is no collinearity problem. |
| Monthly passenger traffic experiment. | 1.45% | 0.42% | Both had the best prediction results. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.-S.; Lin, C.-K.; Chen, S.-F.; Chen, S.-H. Two Advanced Models of the Function of MRT Public Transportation in Taipei. Electronics 2021, 10, 1048. https://doi.org/10.3390/electronics10091048
Chen Y-S, Lin C-K, Chen S-F, Chen S-H. Two Advanced Models of the Function of MRT Public Transportation in Taipei. Electronics. 2021; 10(9):1048. https://doi.org/10.3390/electronics10091048
Chicago/Turabian StyleChen, You-Shyang, Chien-Ku Lin, Su-Fen Chen, and Shang-Hung Chen. 2021. "Two Advanced Models of the Function of MRT Public Transportation in Taipei" Electronics 10, no. 9: 1048. https://doi.org/10.3390/electronics10091048
APA StyleChen, Y.-S., Lin, C.-K., Chen, S.-F., & Chen, S.-H. (2021). Two Advanced Models of the Function of MRT Public Transportation in Taipei. Electronics, 10(9), 1048. https://doi.org/10.3390/electronics10091048