
Few-Shot Learning with a Novel Voronoi Tessellation-Based Image Augmentation Method for Facial Palsy Detection

 , and
, and
Abstract
1. Introduction
- A new method for face palsy recognition based on the principles of data augmentation and few-shot (one-shot and two-shot) learning;
- A novel image augmentation method, called Voronoi decomposition-based random region erasing (VDRRE), for generating new artificial images with randomly covered regions of irregular shape and augmenting the original dataset for more efficient neural network training;
- A hybrid face palsy detector that combines the pre-trained SqueezeNet network [42] as feature extractor and error-correcting output codes (ECOC)-based SVM (ECOC-SVM) as a classifier.
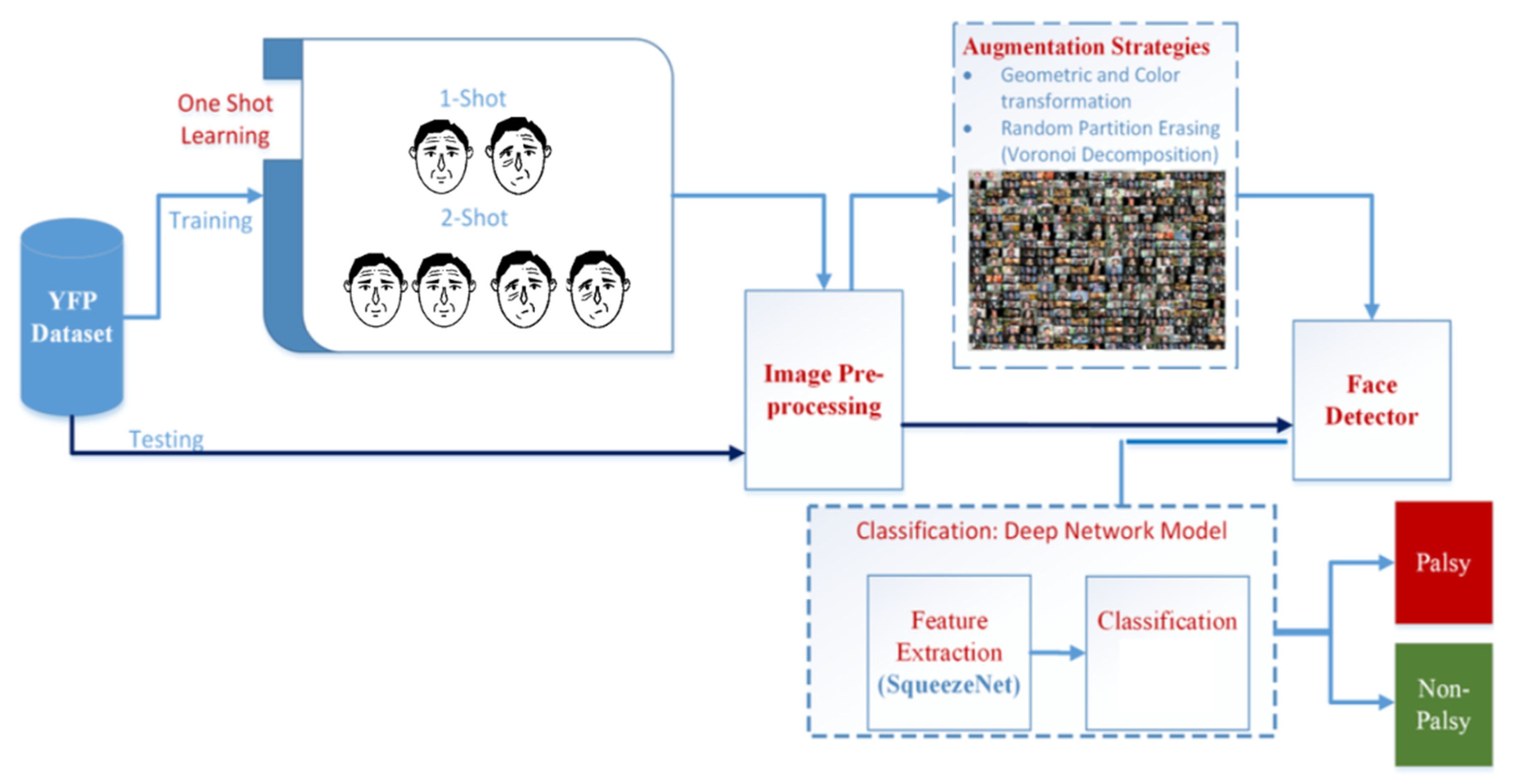
2. Methods
- Data collection: The first stage is the original face image dataset consisting of 1555 data samples (1105 of palsy face dataset and 450 of normal face dataset).
- Data preprocessing: This stage includes the removal of noise and improvement of image contrast using contrast limited adaptive histogram equalization (CLAHE).
- Few-shot learning: This stage tries to mimic human intelligence using only a few samples (one or two images, for each class) for supervised training.
- Face detector: We adopted the improved classical Viola–Jones face detection algorithm, which depends on the Haar-like rectangle feature expansion [43].
- Augmentation strategy stage: we use the proposed Voronoi decomposition-based random region erasing (VDRRE) image augmentation method as well as adopted other data augmentation techniques to improve neural network training and generalization and solve class imbalance, thus addressing the problem of overfitting.
- Classification: We adopted the SqueezeNet architecture, which has comparatively low computational demands, for feature extraction and ECOC-SVM as a classifier.
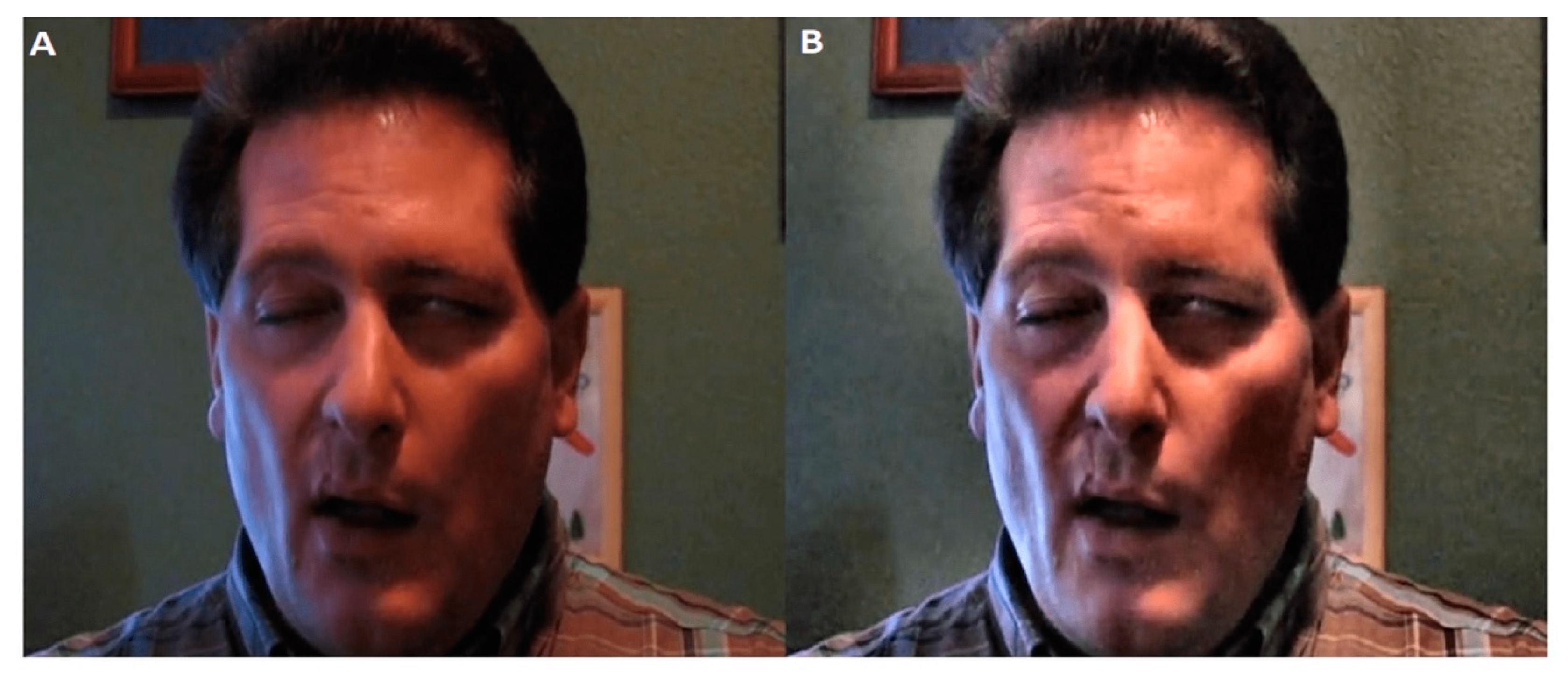
2.1. Dataset
2.2. Few-Shot Learning
- Take a subset of labels, T ⊂.
- Take a training set and a training set . Both contain only data with labels from the subset from item 1:
- The set of is fed to the input of the classifier model.
2.3. Image Pre-Processing
2.4. Face Detection
2.5. Data Augmentation
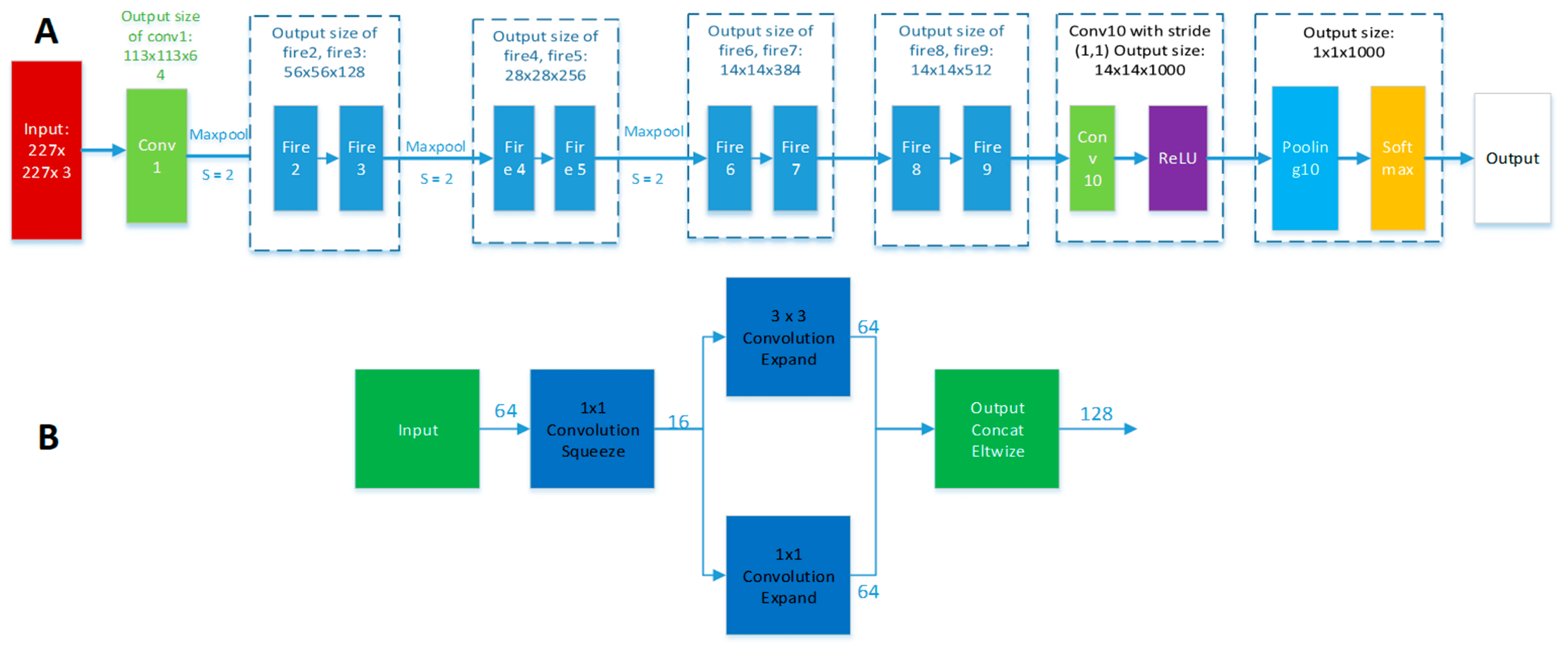
2.6. Feature Extraction
2.7. Classification
2.8. Performance Metrics
- Accuracy is the measure of correctness of predicted classes:
- Precision is the proportion of predicted positive class that comes from the correctly real positive (palsy) class:
- Recall is the proportion of real positive class (palsy class) that are correctly predicted:
- F1-score is the weighted harmonic average of precision and recall:
2.9. Experimental Settings
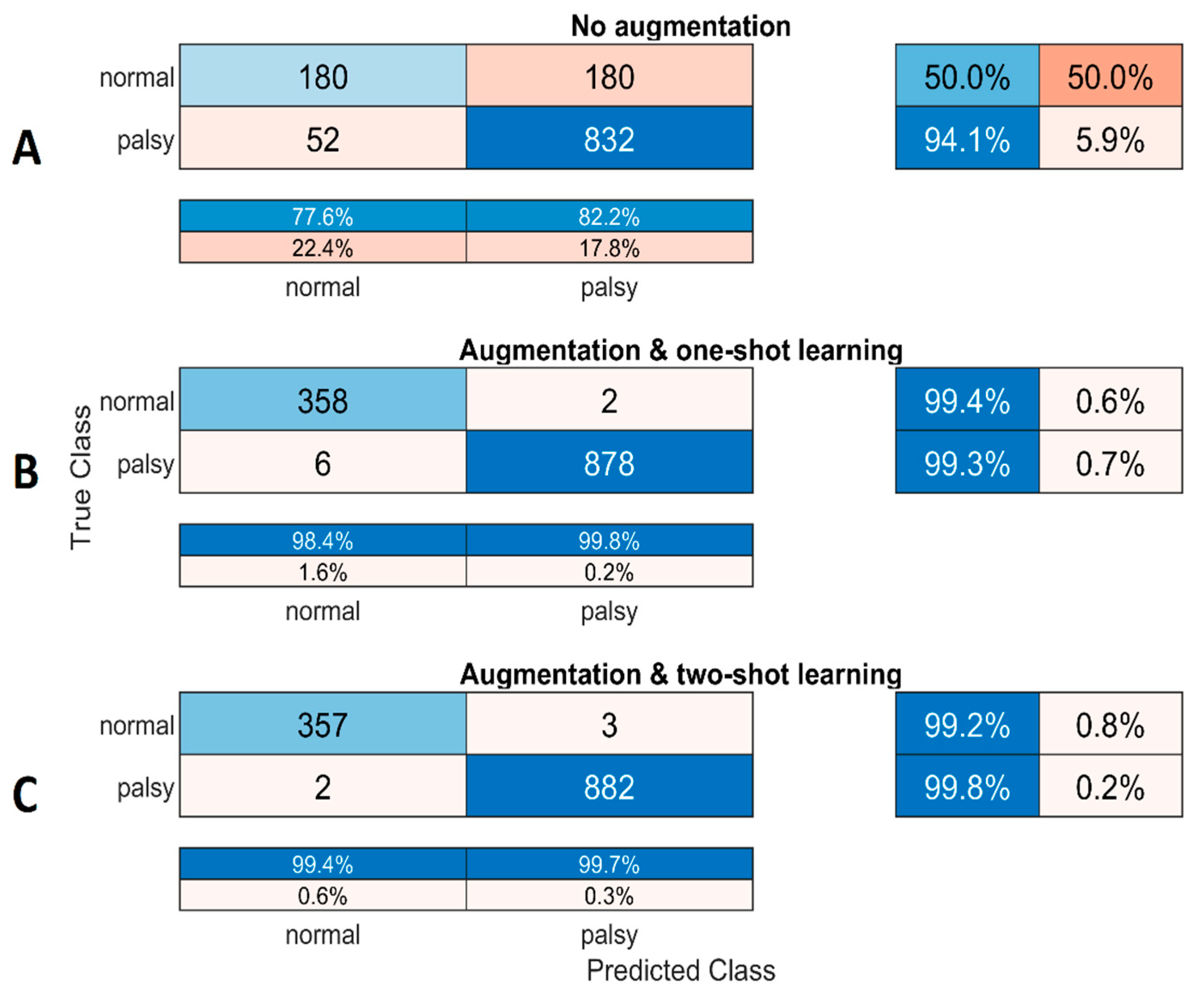
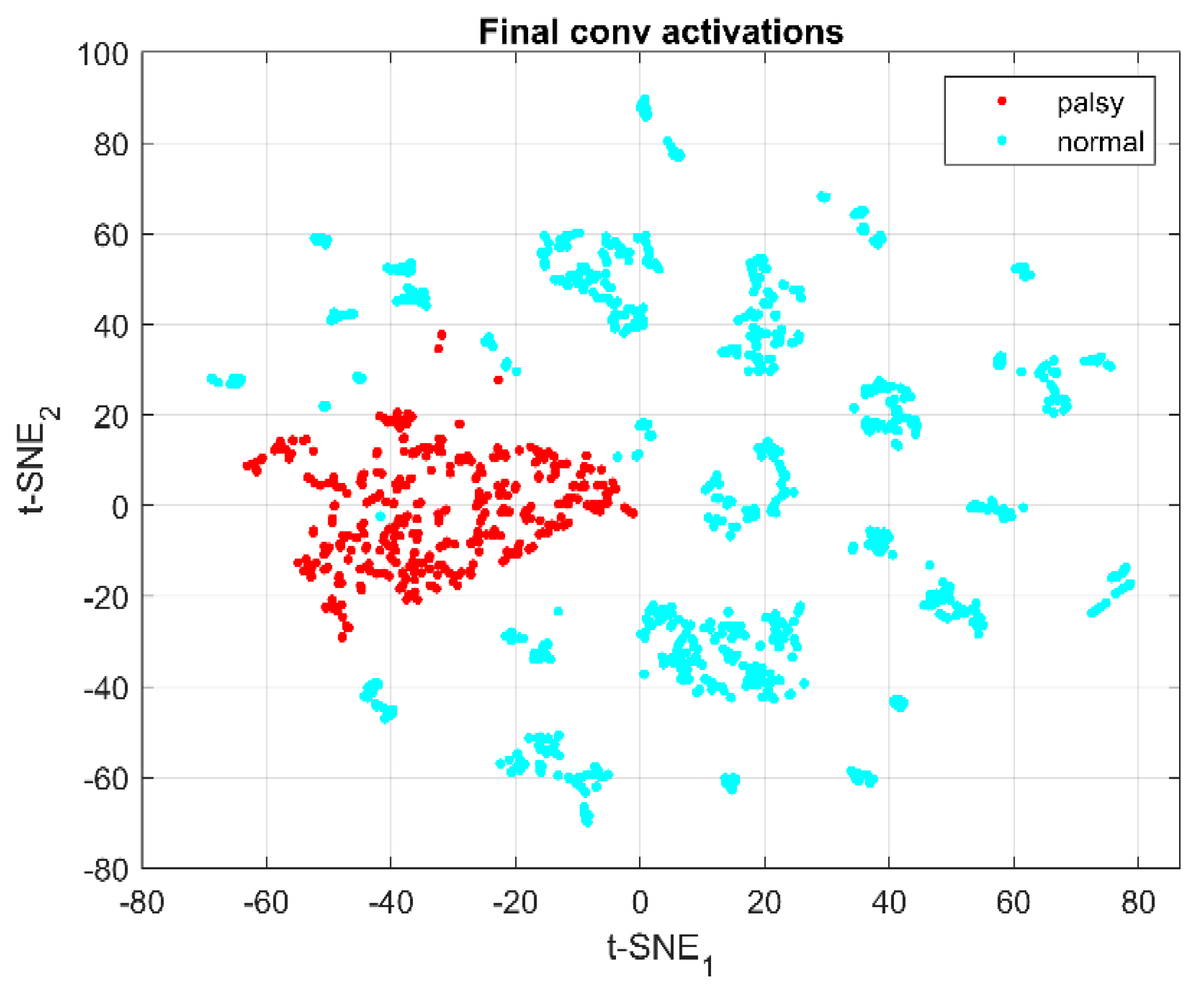
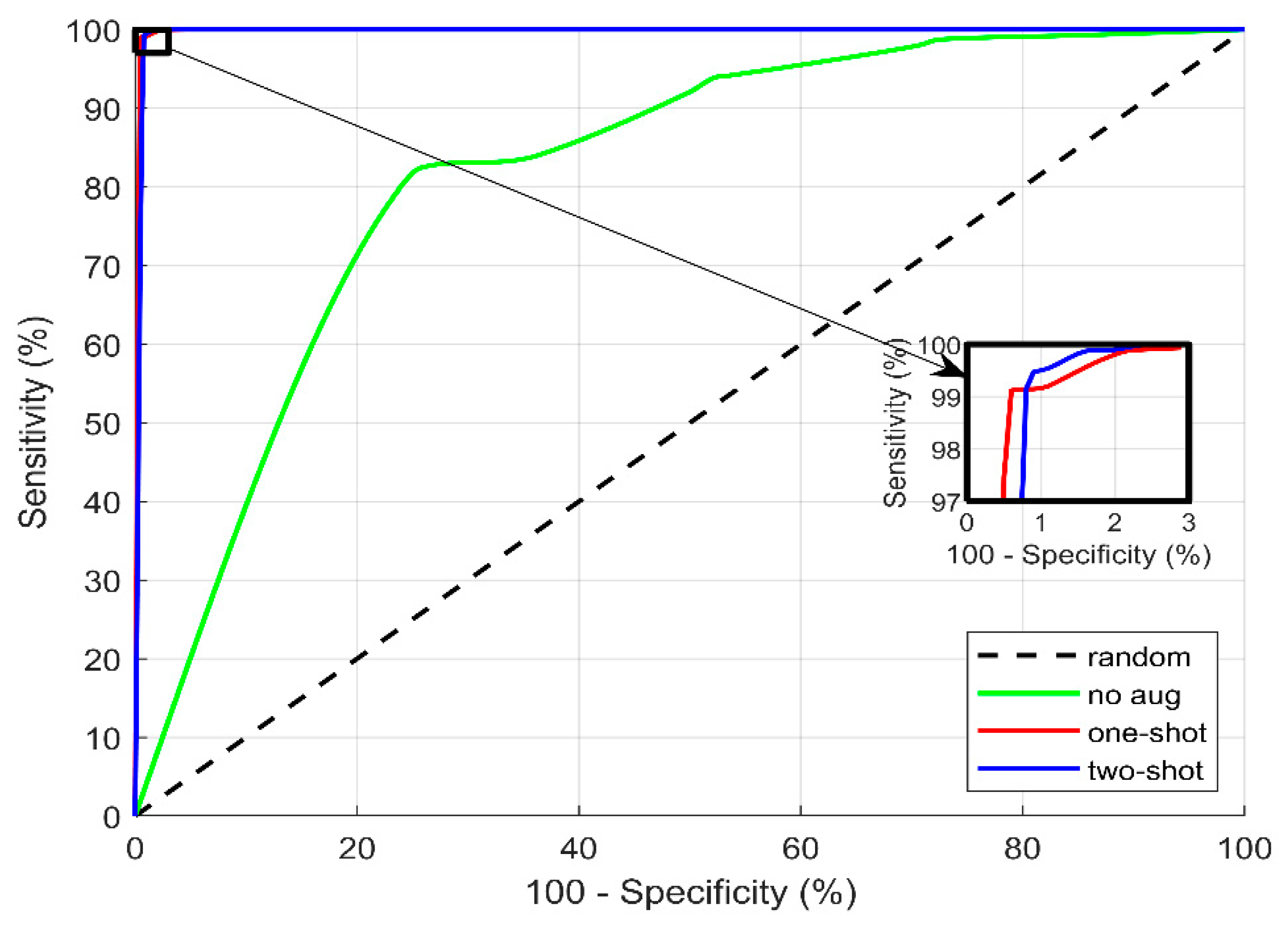
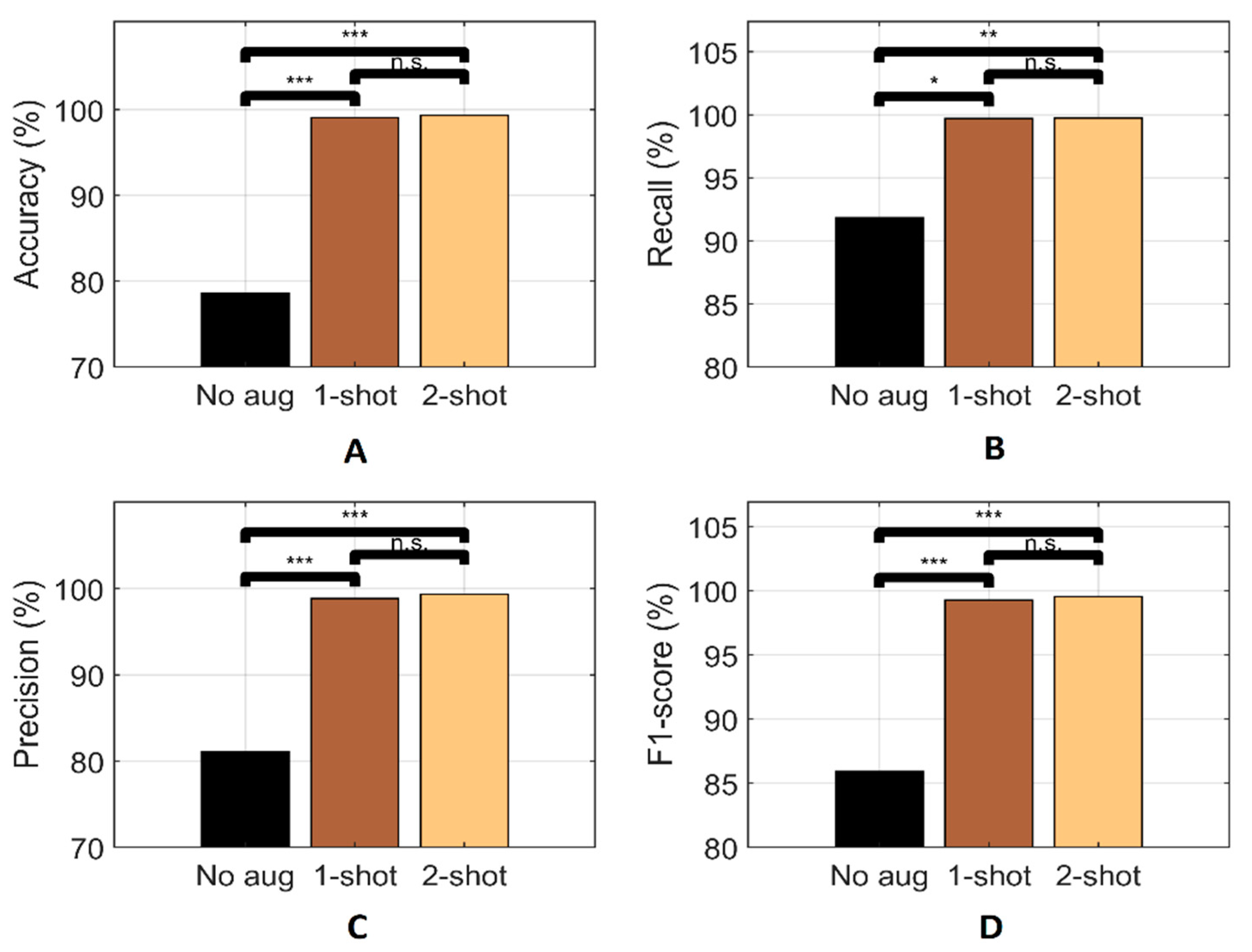
3. Experimental Results
Comparison with Related Work and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gilden, D.H. Bell’s palsy. N. Engl. J. Med. 2004, 351, 1323–1331. [Google Scholar] [CrossRef]
- Nellis, J.C.; Ishii, M.; Byrne, P.J.; Boahene, K.; Dey, J.K.; Ishii, L.E. Association Among Facial Paralysis, Depression, and Quality of Life in Facial Plastic Surgery Patients. JAMA Facial Plast. Surg. 2017, 19, 190–196. [Google Scholar] [CrossRef]
- Lou, J.; Yu, H.; Wang, F. A review on automated facial nerve function assessment from visual face capture. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 488–497. [Google Scholar] [CrossRef]
- Kihara, Y.; Duan, G.; Nishida, T.; Matsushiro, N.; Chen, Y.-W. A dynamic facial expression database for quantitative analysis of facial paralysis. In Proceedings of the 2011 6th International Conference on Computer Sciences and Convergence Information Technology (ICCIT), Seogwipo, Korea, 29 November–1 December 2011; pp. 949–952. [Google Scholar]
- Banks, C.A.; Bhama, P.K.; Park, J.; Hadlock, C.R.; Hadlock, T.A. Clinician-graded electronic facial paralysis assessment: The eFACE. Plast. Reconstr. Surg. 2015, 136, 223–230. [Google Scholar] [CrossRef]
- Linstrom, C.J. Objective facial motion analysis in patients with facial nerve dysfunction. Laryngoscope 2002, 112, 1129–1147. [Google Scholar] [CrossRef] [PubMed]
- He, S.; Soraghan, J.J.; O’Reilly, B.F.; Xing, D. Quantitative analysis of facial paralysis using local binary patterns in biomedical videos. IEEE Trans. Biomed. Eng. 2009, 56, 1864–1870. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Dong, J.; Sun, X.; Zhang, S.; Wang, S. Automatic recognition of facial movement for paralyzed face. Bio-Med. Mater. Eng. 2014, 24, 2751–2760. [Google Scholar] [CrossRef]
- Ngo, T.H.; Seo, M.; Matsushiro, N.; Xiong, W.; Chen, Y.-W. Quantitative analysis of facial paralysis based on limited-orientation modified circular Gabor filters. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancún, Mexico, 4–8 December 2016; pp. 349–354. [Google Scholar] [CrossRef]
- Kim, H.S.; Kim, S.Y.; Kim, Y.H.; Park, K.S. A smartphone-based automatic diagnosis system for facial nerve palsy. Sensors 2015, 15, 26756–26768. [Google Scholar] [CrossRef] [PubMed]
- Jiang, C.; Wu, J.; Zhong, W.; Wei, M.; Tong, J.; Yu, H.; Wang, L. Automatic facial paralysis assessment via computational image analysis. J. Healthc. Eng. 2020. [Google Scholar] [CrossRef]
- Hsu, G.J.; Kang, J.; Huang, W. Deep hierarchical network with line segment learning for quantitative analysis of facial palsy. IEEE Access 2019, 7, 4833–4842. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Guo, Z.; Dan, G.; Xiang, J. An unobtrusive computerized assessment framework for unilateral peripheral facial paralysis. IEEE J. Biomed. Health Inform. 2018, 22, 835–841. [Google Scholar] [CrossRef]
- Sajid, M.; Shafique, T.; Baig, M.J.A.; Riaz, I.; Amin, S.; Manzoor, S. Automatic grading of palsy using asymmetrical facial features: A study complemented by new solutions. Symmetry 2018, 10, 242. [Google Scholar] [CrossRef]
- Storey, G.; Jiang, R. Face symmetry analysis using a unified multi-task cnn for medical applications. In Proceedings of the SAI Intelligent Systems Conference, IntelliSys 2018: Intelligent Systems and Applications, London, UK, 5–6 September 2018; pp. 451–463. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, S.; Liu, L.; Wu, G.; Dong, J. Automatic Facial Paralysis Evaluation Augmented by a Cascaded Encoder Network Structure. IEEE Access 2019, 7, 135621–135631. [Google Scholar] [CrossRef]
- Storey, G.; Jiang, R.; Keogh, S.; Bouridane, A.; Li, C. 3DPalsyNet: A facial palsy grading and motion recognition framework using fully 3D convolutional neural networks. IEEE Access 2019, 7, 121655–121664. [Google Scholar] [CrossRef]
- Kim, J.; Lee, H.R.; Jeong, J.H.; Lee, W.S. Features of facial asymmetry following incomplete recovery from facial paralysis. Yonsei Med. J. 2010, 51, 943–948. [Google Scholar] [CrossRef]
- Wei, W.; Ho, E.S.L.; McCay, K.D.; Damaševičius, R.; Maskeliūnas, R.; Esposito, A. Assessing facial symmetry and attractiveness using augmented reality. Pattern Anal. Appl. 2021. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Song, A.; Wu, Z.; Ding, X.; Hu, Q.; Di, X. Neurologist Standard Classification of Facial Nerve Paralysis with Deep Neural Networks. Future Internet 2018, 10, 111. [Google Scholar] [CrossRef]
- Wang, X.; Wang, K.; Lian, S. A survey on face data augmentation for the training of deep neural networks. Neural Comput. Appl. 2020, 32, 15503–15531. [Google Scholar] [CrossRef]
- Kitchin, R.; Lauriault, T.P. Small data in the era of big data. GeoJournal 2015, 80, 463–475. [Google Scholar] [CrossRef]
- Porcu, S.; Floris, A.; Atzori, L. Evaluation of Data Augmentation Techniques for Facial Expression Recognition Systems. Electronics 2020, 9, 1892. [Google Scholar] [CrossRef]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI-20), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Jiang, W.; Zhang, K.; Wang, N.; Yu, M. MeshCut data augmentation for deep learning in computer vision. PLoS ONE 2020, 15, e0243613. [Google Scholar] [CrossRef] [PubMed]
- Singh, K.K.; Yu, H.; Sarmasi, A.; Pradeep, G.; Lee, Y.J. Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization and Beyond. arXiv 2018, arXiv:1811.02545. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. arXiv 2019, arXiv:1905.04899. [Google Scholar]
- Chen, P.; Liu, S.; Zhao, H.; Jia, J. GridMask Data Augmentation. ArXiv 2020, arXiv:2001.04086. CoRR abs/2001.04086. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Fei-Fei, L.; Fergus, R.; Perona, P. One-shot learning of object categories. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 594–611. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a Few Examples: A Survey on Few-shot Learning. ACM Comput. Surv. 2020, 53, 63. [Google Scholar] [CrossRef]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Krpalkova, L.; Hernandez, G.V.; Harapanahalli, S.; Riordan, D.; Walsh, J. One-Shot Learning for Custom Identification Tasks: A Review. Procedia Manuf. 2019, 38, 186–193. [Google Scholar] [CrossRef]
- Jiang, W.; Huang, K.; Geng, J.; Deng, X. Multi-Scale Metric Learning for Few-Shot Learning. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1091–1102. [Google Scholar] [CrossRef]
- Gu, K.; Zhang, Y.; Qiao, J. Ensemble Meta-Learning for Few-Shot Soot Density Recognition. IEEE Trans. Ind. Inform. 2020, 17, 2261–2270. [Google Scholar] [CrossRef]
- Li, Y.; Yang, J. Meta-learning baselines and database for few-shot classification in agriculture. Comput. Electron. Agric. 2021, 182, 106055. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001. [Google Scholar] [CrossRef]
- Caltech Face Database. 1999. Available online: http://www.vision.caltech.edu/archive.html (accessed on 3 March 2021).
- Zuiderveld, K. Contrast limited adaptive histogram equalization. Graph. Gems 1994, IV, 474–485. [Google Scholar]
- Liu, C.; Sui, X.; Kuang, X.; Liu, Y.; Gu, G.; Chen, Q. Adaptive Contrast Enhancement for Infrared Images Based on the Neighborhood Conditional Histogram. Remote Sens. 2019, 11, 1381. [Google Scholar] [CrossRef]
- Huang, J.; Shang, Y.; Chen, H. Improved Viola-Jones face detection algorithm based on HoloLens. Eurasip J. Image Video Process. 2019, 41. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision theoretic generalization of online learning and an application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Takahashi, R.; Matsubara, T.; Uehara, K. RICAP: Random Image Cropping and Patching Data Augmentation for Deep CNNs. In Proceedings of the 10th Asian Conference on Machine Learning, Beijing, China, 14–16 November 2018; pp. 786–798. [Google Scholar]
- Du, Q.; Faber, V.; Gunzburger, M. Centroidal Voronoi tessellations: Applications and algorithms. Siam Rev. 1999, 41, 637–676. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2017, 25, 1097–1105. [Google Scholar] [CrossRef]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Nie, J.; Chao, X. Do we really need deep CNN for plant diseases identification? Comput. Electron. Agric. 2020, 178, 105803. [Google Scholar] [CrossRef]
- Alhichri, H.; Bazi, Y.; Alajlan, N.; Bin Jdira, B. Helping the Visually Impaired See via Image Multi-labeling Based on SqueezeNet CNN. Appl. Sci. 2019, 9, 4656. [Google Scholar] [CrossRef]
- House, J.W.; Brackmann, D.E. Facial nerve grading system. Otolaryngol. Head Neck Surg. 1985, 93, 146–147. [Google Scholar] [CrossRef] [PubMed]
- Fürnkranz, J. Round Robin Classification. J. Mach. Learn. Res. 2002, 2, 721–747. [Google Scholar]
- Nalepa, J.; Kawulok, M. Selecting training sets for support vector machines: A review. Artif. Intell. Rev. 2019, 52, 857–900. [Google Scholar] [CrossRef]
- Finnoff, W.; Hergert, F.; Zimmermann, H.G. Improving model selection by nonconvergent methods. Neural Netw. 1993, 6, 771–783. [Google Scholar] [CrossRef]
- Van Der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Liu, X.; Xia, Y.; Yu, H.; Dong, J.; Jian, M.; Pham, T.D. Region Based Parallel Hierarchy Convolutional Neural Network for Automatic Facial Nerve Paralysis Evaluation. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 2325. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Statistics | without Augmentation | with Augmentation | |
|---|---|---|---|---|
| One-Shot | Two Shot | |||
| Accuracy (%) | Mean | 78.62 | 99.07 | 99.34 |
| Min | 63.59 | 97.35 | 98.87 | |
| Max | 91.16 | 99.7 | 99.80 | |
| STD | 7.89 | 0.72 | 0.34 | |
| Precision (%) | Mean | 81.06 | 98.85 | 99.35 |
| Min | 72.61 | 95.45 | 98.66 | |
| Max | 90.31 | 99.77 | 99.66 | |
| STD | 6.29 | 1.40 | 0.33 | |
| Recall (%) | Mean | 91.85 | 99.71 | 99.74 |
| Min | 78.28 | 99.09 | 99.43 | |
| Max | 99.32 | 100 | 100 | |
| STD | 7.57 | 0.36 | 0.25 | |
| F1-Score (%) | Mean | 85.91 | 99.28 | 99.54 |
| Min | 75.34 | 97.67 | 99.21 | |
| Max | 94.03 | 99.77 | 99.83 | |
| STD | 5.28 | 0.66 | 0.23 | |
| Methods | Average Performance with 95% Confidence Limits | |||
|---|---|---|---|---|
| Accuracy (%) | Recall (%) | Precision (%) | F1-Score (%) | |
| Without augmentation | 78.62 ± 5.65 | 91.85 ± 5.41 | 81.06 ± 4.50 | 85.59 ± 3.78 |
| With random erase augmentation | 92.91 ± 1.12 | 96.14 ± 0.83 | 93.96 ± 1.87 | 95.04 ± 1.42 |
| With VDRRE augmentation (one-shot learning) | 99.07 ± 0.60 | 99.72 ± 0.28 | 98.85 ± 1.15 | 99.28 ± 0.55 |
| With VDRRE augmentation (two-shot learning) | 99.35 ± 0.24 | 99.74 ± 0.17 | 99.35 ± 0.24 | 99.54 ± 0.16 |
| Methodology | Performance Metrics | References | |||
|---|---|---|---|---|---|
| Classifier | Data Augmentation | Accuracy (%) | Precision (%) | Recall (%) | |
| Deep Hierarchical Network | NA | 91.2 | - | - | [12] |
| Parallel Hierarchy CNN + LSTM | GAN, translation and rotation transformation | 94.81 | 95.6 | 94.8 | [59] |
| Our proposed model | Geometric and color transformation | 99.07 | 98.85 | 99.72 | Our paper |
| VDRRE (proposed) | 99.34 | 99.43 | 99.35 | ||
| No augmentation | 89.25 | 95.43 | 89.13 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abayomi-Alli, O.O.; Damaševičius, R.; Maskeliūnas, R.; Misra, S. Few-Shot Learning with a Novel Voronoi Tessellation-Based Image Augmentation Method for Facial Palsy Detection. Electronics 2021, 10, 978. https://doi.org/10.3390/electronics10080978
Abayomi-Alli OO, Damaševičius R, Maskeliūnas R, Misra S. Few-Shot Learning with a Novel Voronoi Tessellation-Based Image Augmentation Method for Facial Palsy Detection. Electronics. 2021; 10(8):978. https://doi.org/10.3390/electronics10080978
Chicago/Turabian StyleAbayomi-Alli, Olusola Oluwakemi, Robertas Damaševičius, Rytis Maskeliūnas, and Sanjay Misra. 2021. "Few-Shot Learning with a Novel Voronoi Tessellation-Based Image Augmentation Method for Facial Palsy Detection" Electronics 10, no. 8: 978. https://doi.org/10.3390/electronics10080978
APA StyleAbayomi-Alli, O. O., Damaševičius, R., Maskeliūnas, R., & Misra, S. (2021). Few-Shot Learning with a Novel Voronoi Tessellation-Based Image Augmentation Method for Facial Palsy Detection. Electronics, 10(8), 978. https://doi.org/10.3390/electronics10080978