
GPU-Based Embedded Intelligence Architectures and Applications


Abstract
1. Introduction
2. Overview and Classifications of EI Research on GPU Architecture
3. Deep Learning on GPU Architecture
3.1. Architecture Framework and Strategy
3.2. Scheduling and Communication
3.3. Image Processing and Computer Vision
3.4. Medical or Health
3.5. Modeling, Prediction and Memory
3.6. Convolution and Performance Analysis
3.7. VLSI Placement
4. Machine Learning in GPU Architecture
4.1. Architecture/Platform/Framework and Strategy
4.2. Applications
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Aluru, S.; Jammula, N. A Review of Hardware Acceleration for Computational Genomics. IEEE Des. Test 2014, 31, 19–30. [Google Scholar] [CrossRef]
- Belletti, F.; King, D.; Yang, K.; Nelet, R.; Shafi, Y.; Shen, Y.-F.; Anderson, J. Tensor Processing Units for Financial Monte Carlo. In Proceedings of the 2020 SIAM Conference on Parallel Processing for Scientific Computing, Seattle, WA, USA, 12–15 February 2020; pp. 12–23. [Google Scholar]
- Gauen, K.; Rangan, R.; Mohan, A.; Lu, Y.H.; Liu, W.; Berg, A.C. Low-power image recognition challenge. In Proceedings of the 2017 22nd Asia and South Pacific Design Automation Conference (ASP-DAC), Chiba, Japan, 16–19 January 2017; pp. 99–104. [Google Scholar]
- Park, H.; Kim, D.; Ahn, J.; Yoo, S. Zero and data reuse-aware fast convolution for deep neural networks on GPU. In Proceedings of the Eleventh IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis, Pittsburgh, PA, USA, 2–7 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1–10. [Google Scholar]
- Meng, W.; Cheng, Y.G.; Wu, J.; Yang, Z.; Zhu, Y.; Shang, S. GPU Acceleration of Hydraulic Transient Simulations of Large-Scale Water Supply Systems. Appl. Sci. 2018, 9, 91. [Google Scholar] [CrossRef]
- Liu, Q.; Qin, Y.; Li, G. Fast Simulation of Large-Scale Floods Based on GPU Parallel Computing. Water 2018, 10, 589. [Google Scholar] [CrossRef]
- Černý, D.; Dobeš, J. GPU Accelerated Nonlinear Electronic Circuits Solver for Transient Simulation of Systems with Large Number of Components. Electronics 2020, 9, 1819. [Google Scholar] [CrossRef]
- Kim, S.; Cho, J.; Park, D. Accelerated DEVS Simulation Using Collaborative Computation on Multi-Cores and GPUs for Fire-Spreading IoT Sensing Applications. Appl. Sci. 2018, 8, 1466. [Google Scholar] [CrossRef]
- Guo, J.; Liu, W.; Wang, W.; Yao, C.; Han, J.; Li, R.; Lu, Y.; Hu, S. AccUDNN: A GPU Memory Efficient Accelerator for Training Ultra-Deep Neural Networks. In Proceedings of the 2019 IEEE 37th International Conference on Computer Design (ICCD), Abu Dhabi, United Arab Emirates, 17–20 November 2019; pp. 65–72. [Google Scholar]
- Lee, K.; Son, M. DeepSpotCloud: Leveraging Cross-Region GPU Spot Instances for Deep Learning. In Proceedings of the 2017 IEEE 10th International Conference on Cloud Computing (CLOUD), Honolulu, HI, USA, 25–30 June 2017; pp. 98–105. [Google Scholar]
- Del Monte, B.; Prodan, R. A scalable GPU-enabled framework for training deep neural networks. In Proceedings of the 2016 2nd International Conference on Green High Performance Computing (ICGHPC), Nagercoil, India, 26–27 February 2016; pp. 1–8. [Google Scholar]
- Lym, S.; Lee, D.; O’Connor, M.; Chatterjee, N.; Erez, M. DeLTA: GPU Performance Model for Deep Learning Applications with In-Depth Memory System Traffic Analysis. In Proceedings of the 2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Madison, WI, USA, 24–26 March 2019; pp. 293–303. [Google Scholar]
- Joardar, B.K.; Nitthilan, K.J.; Janardhan, R.D.; Li, H.; Pande, P.P.; Chakrabarty, K. GRAMARCH: A GPU-ReRAM based Heterogeneous Architecture for Neural Image Segmentation. In Proceedings of the 2020 Design, Automation & Test in Europe Conference & Exhi-bition (DATE), Grenoble, France, 9–13 March 2020; pp. 228–233. [Google Scholar]
- Joardar, B.K.; Doppa, J.R.; Pande, P.P.; Li, H.; Chakrabarty, K. AccuReD: High Accuracy Training of CNNs on ReRAM/GPU Heterogeneous 3D Architecture. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2020. [Google Scholar] [CrossRef]
- Oyama, Y.; Nomura, A.; Sato, I.; Nishimura, H.; Tamatsu, Y.; Matsuoka, S. Predicting statistics of asynchronous SGD parameters for a large-scale distributed deep learning system on GPU supercomputers. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 66–75. [Google Scholar]
- Shriram, S.B.; Garg, A.; Kulkarni, P. Dynamic Memory Management for GPU-Based Training of Deep Neural Networks. In Proceedings of the 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Rio de Janeiro, Brazil, 20–24 May 2019; pp. 200–209. [Google Scholar]
- Khomenko, V.; Shyshkov, O.; Radyvonenko, O.; Bokhan, K. Accelerating recurrent neural network training using sequence bucketing and multi-GPU data parallelization. In Proceedings of the 2016 IEEE First International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 23–27 August 2016; pp. 100–103. [Google Scholar]
- Zhan, J.; Zhang, J. Pipe-Torch: Pipeline-Based Distributed Deep Learning in a GPU Cluster with Heterogeneous Net-working. In Proceedings of the 2019 Seventh Internetional Conference on Advanced Cloud and Big Data (CBD), Suzhou, China, 21–22 September 2019; pp. 55–60. [Google Scholar]
- Kim, Y.; Choi, H.; Lee, J.; Kim, J.-S.; Jei, H.; Roh, H. Efficient Large-Scale Deep Learning Framework for Heterogeneous Multi-GPU Cluster. In Proceedings of the 2019 IEEE 4th International Workshops on Foundations and Applications of Self* Systems (FAS*W), Umeå, Sweden, 16–20 June 2019; pp. 176–181. [Google Scholar] [CrossRef]
- Chen, C.-F.R.; Lee, G.G.C.; Xia, Y.; Lin, W.S.; Suzumura, T.; Lin, C.-Y. Efficient Multi-training Framework of Image Deep Learning on GPU Cluster. In Proceedings of the 2015 IEEE International Symposium on Multimedia (ISM), Miami, FL, USA, 14–16 December 2015; pp. 489–494. [Google Scholar] [CrossRef]
- Chen, G.; He, S.; Meng, H.; Huang, K. PhoneBit: Efficient GPU-Accelerated Binary Neural Network Inference Engine for Mobile Phones. In Proceedings of the 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020; pp. 786–791. [Google Scholar]
- Nurvitadhi, E.; Sheffield, D.; Sim, J.; Mishra, A.; Venkatesh, G.; Marr, D. Accelerating binarized neural networks: Comparison of FPGA, CPU, GPU, and ASIC. In Proceedings of the 2016 International Conference on Field-Programmable Technology (FPT), Xi’an, China, 7–9 December 2016; pp. 77–84. [Google Scholar]
- Tu, Y.; Sadiq, S.; Tao, Y.; Shyu, M.L.; Chen, S.C. A Power Efficient Neural Network Implementation on Heterogeneous FPGA and GPU Devices. In Proceedings of the 2019 IEEE 20th International Conference Information Reuse and Integration for Data Science (IRI), Los Angeles, CA, USA, 30 July–1 August 2019; pp. 193–199. [Google Scholar]
- Chen, Z.; Quan, W.; Wen, M.; Fang, J.; Yu, J.; Zhang, C.; Luo, L. Deep Learning Research and Development Platform: Characterizing and Scheduling with QoS Guarantees on GPU Clusters. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 34–50. [Google Scholar] [CrossRef]
- Dryden, N.; Maruyama, N.; Moon, T.; Benson, T.; Yoo, A.; Snir, M.; Van Essen, B. Aluminum: An Asynchronous, GPU-Aware Communication Library Optimized for Large-Scale Training of Deep Neural Networks on HPC Systems. In Proceedings of the 2018 IEEE/ACM Machine Learning in HPC Environments (MLHPC), Dallas, TX, USA, 11–16 November 2018; pp. 1–13. [Google Scholar]
- Chu, C.-H.; Lu, X.; Awan, A.A.; Subramoni, H.; Hashmi, J.; Elton, B.; Panda, D.K. Efficient and Scalable Multi-Source Streaming Broadcast on GPU Clusters for Deep Learning. In Proceedings of the 2017 46th International Conference on Parallel Processing (ICPP), Bristol, UK, 14–17 August 2017; pp. 161–170. [Google Scholar]
- Banerjee, D.S.; Hamidouche, K.; Panda, D.K. Re-Designing CNTK Deep Learning Framework on Modern GPU Enabled Clusters. In Proceedings of the 2016 IEEE International Conference on Cloud Computing Technology and Science (CloudCom), Luxembourg City, Luxembourg, 12–15 December 2016; pp. 144–151. [Google Scholar]
- Ogayar-Anguita, C.J.; Rueda-Ruiz, A.J.; Segura-Sánchez, R.J.; Díaz-Medina, M.; García-Fernández, Á.L. A GPU-Based Framework for Generating Implicit Datasets of Voxelized Polygonal Models for the Training of 3D Convolutional Neural Networks. IEEE Access 2020, 8, 12675–12687. [Google Scholar] [CrossRef]
- Li, S.; Dou, Y.; Lv, Q.; Wang, Q.; Niu, X.; Yang, K. Optimized GPU acceleration algorithm of convolutional neural net-works for target detection. In Proceedings of the 2016 IEEE 18th International Conference High Performance Computing and Communications, Sydney, NSW, Australia, 12–14 December 2016; pp. 224–230. [Google Scholar]
- Chen, G.; Meng, H.; Liang, Y.; Huang, K. GPU-Accelerated Real-Time Stereo Estimation with Binary Neural Network. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 2896–2907. [Google Scholar] [CrossRef]
- Gong, T.; Fan, T.; Guo, J.; Cai, Z. Gpu-based parallel optimization and embedded system application of immune convolutional neural network. In Proceedings of the 2015 International Workshop Artificial Immune Systems (AIS), Taormina, Italy, 17–18 July 2015; pp. 1–8. [Google Scholar]
- Saypadith, S.; Aramvith, S. Real-Time Multiple Face Recognition using Deep Learning on Embedded GPU System. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; pp. 1318–1324. [Google Scholar]
- Xu, J.; Wang, B.; Li, J.; Hu, C.; Pan, J. Deep learning application based on embedded GPU. In Proceedings of the 2017 First International Conference on Electronics Instrumentation & Information Systems (EIIS), Harbin, China, 3–5 June 2017; pp. 1–4. [Google Scholar]
- Appuhamy, E.J.G.S.; Madhusanka, B. Development of a GPU-Based Human Emotion Recognition Robot Eye for Service Robot by Using Convolutional Neural Network. In Proceedings of the 2018 IEEE/ACIS 17th International Conference on Computer and Information Science (ICIS), Singapore, 6–8 June 2018; pp. 433–438. [Google Scholar]
- Kain, E.; Wildenstein, D.; Pineda, A.C. Embedded GPU Cluster Computing Framework for Inference of Convolutional Neural Networks. In Proceedings of the 2019 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 24–26 September 2019; pp. 1–7. [Google Scholar]
- Campos, V.; Sastre, F.; Yagues, M.; Torres, J.; Giró-I-Nieto, X. Scaling a Convolutional Neural Network for Classification of Adjective Noun Pairs with TensorFlow on GPU Clusters. In Proceedings of the 2017 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID), Madrid, Spain, 14–17 May 2017; pp. 677–682. [Google Scholar]
- Dong, X.; Yang, Y. Searching for a Robust Neural Architecture in Four GPU Hours. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1761–1770. [Google Scholar]
- dos Santos, F.F.; Draghetti, L.; Weigel, L.; Carro, L.; Navaux, P.; Rech, P. Evaluation and mitigation of soft-errors in neu-ral network-based object detection in three gpu architectures. In Proceedings of the 2017 47th Annual IEEE/IFIP International Conference Dependable Systems and Networks Workshops (DSN-W), Denver, CO, USA, 26–29 June 2017; pp. 169–176. [Google Scholar]
- Zhang, C.; Weingartner, S.; Moeller, S.; Ugurbil, K.; Akcakaya, M. Fast GPU Implementation of a Scan-Specific Deep Learning Reconstruction for Accelerated Magnetic Resonance Imaging. In Proceedings of the 2018 IEEE International Conference on Electro/Information Technology (EIT), Rochester, MI, USA, 3–5 May 2018; Volume 2018, pp. 399–403. [Google Scholar]
- 38. Ziabari, A.; Ye, D.H.; Srivastava, S.; Sauer, K.D.; Thibault, J.-B.; Bouman, C.A. 2.5 D deep learning for CT image reconstruction using a multi-GPU implementation. In Proceedings of the 2018 52nd Asilomar Conference Signals, Systems, and Computers, Pacific Grove, CA, USA, 28–31 October 2018; pp. 2044–2049. [Google Scholar]
- Bijoy, M.B.; Shilimkar, V.; Jayaraj, P.B. Detecting Cervix Type Using Deep learning and GPU. In Proceedings of the 2018 IEEE Region 10 Humanitarian Technology Conference (R10-HTC), Malambe, Sri Lanka, 6–8 December 2018; pp. 1–6. [Google Scholar]
- Moharir, M.; Sachin, M.U.; Nagaraj, R.; Samiksha, M.; Rao, S. Identification of asphyxia in newborns using gpu for deep learning. In Proceedings of the 2017 2nd International Conference for Convergence in Technology (I2CT), Mumbai, India, 7–9 April 2017; pp. 236–239. [Google Scholar]
- Guerreiro, J.; Ilić, A.; Roma, N.; Tomás, P. GPU Static Modeling Using PTX and Deep Structured Learning. IEEE Access 2019, 7, 159150–159161. [Google Scholar] [CrossRef]
- Jhu, C.-F.; Liu, P.; Wu, J.-J. Data Pinning and Back Propagation Memory Optimization for Deep Learning on GPU. In Proceedings of the 2018 Sixth International Symposium on Computing and Networking (CANDAR), Takayama, Japan, 23–27 November 2018; pp. 19–28. [Google Scholar] [CrossRef]
- Cui, H.; Zhang, H.; Ganger, G.R.; Gibbons, P.B.; Xing, E.P. Geeps: Scalable deep learning on distributed gpus with a gpu specialized parameter server. In Proceedings of the Eleventh European Conference on Computer Systems, London, UK, 18–21 April 2016; pp. 4:1–4:16. [Google Scholar]
- Fukushi, M.; Kanbara, Y. A GPU Implementation Method of Deep Neural Networks Based on Data Swapping. In Proceedings of the 2019 IEEE International Conference on Consumer Electronics—Taiwan (ICCE-TW), Yilan, Taiwan, 20–22 May 2019; pp. 1–2. [Google Scholar]
- Kim, Y.; Lee, J.; Kim, J.-S.; Jei, H.; Roh, H. Efficient Multi-GPU Memory Management for Deep Learning Acceleration. In Proceedings of the 2018 IEEE 3rd International Workshops on Foundations and Applications of Self* Systems (FAS*W), Trento, Italy, 3–7 September 2018; pp. 37–43. [Google Scholar] [CrossRef]
- Ito, Y.; Matsumiya, R.; Endo, T. ooc_cuDNN: Accommodating convolutional neural networks over GPU memory capacity. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 183–192. [Google Scholar]
- Rizvi, S.T.H.; Cabodi, G.; Francini, G. GPU-only unified ConvMM layer for neural classifiers. In Proceedings of the 2017 4th International Conference on Control, Decision and Information Technologies (CoDIT), Barcelona, Spain, 5–7 April 2017; pp. 0539–0543. [Google Scholar]
- Malik, A.; Lu, M.; Wang, N.; Lin, Y.; Yoo, S. Detailed Performance Analysis of Distributed Tensorflow on a GPU Cluster using Deep Learning Algorithms. In Proceedings of the 2018 New York Scientific Data Summit (NYSDS), Upton, NY, USA, 6–8 August 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Thanasekhar, B.; Gomathy, N.; Shwetha, B.; Sumithra, A. Fault and Delay Tolerance in Deep Learning Framework under GPU. In Proceedings of the 2019 11th International Conference on Advanced Computing (ICoAC), Chennai, India, 18–20 December 2019; pp. 139–146. [Google Scholar]
- Raniah, Z.; Shaziya, H. GPU-based empirical evaluation of activation functions in convolutional neural networks. In Proceedings of the 2018 2nd International Conference Inventive Systems and Control (ICISC), Coimbatore, India, 19–20 January 2018; pp. 769–773. [Google Scholar]
- Lin, Y.; Jiang, Z.; Gu, J.; Li, W.; Dhar, S.; Ren, H.; Khailany, B.; Pan, D.Z. DREAMPlace: Deep Learning Toolkit-Enabled GPU Acceleration for Modern VLSI Placement. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2020. [Google Scholar] [CrossRef]
- Chen, C.; Li, K.; Ouyang, A.; Tang, Z.; Li, K. GPU-Accelerated Parallel Hierarchical Extreme Learning Machine on Flink for Big Data. IEEE Trans. Syst. Man, Cybern. Syst. 2017, 47, 2740–2753. [Google Scholar] [CrossRef]
- Li, P.; Luo, Y.; Zhang, N.; Cao, Y. Heterospark: A heterogeneous cpu/gpu spark platform for machine learning algorithms. In Proceedings of the 2015 IEEE International Conference on Networking, Architecture and Storage (NAS), Boston, MA, USA, 6–7 August 2015; pp. 347–348. [Google Scholar]
- Sun, T.; Wang, H.; Shen, Y.; Wu, J. Accelerating support vector machine learning with GPU-based mapreduce. In Proceedings of the 2015 IEEE International Conference Systems, Man, and Cybernetics, Kowloon, China, 9–12 October 2015; pp. 876–881. [Google Scholar]
- She, X.; Long, Y.; Mukhopadhyay, S. Fast and Low-Precision Learning in GPU-Accelerated Spiking Neural Network. In Proceedings of the 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE), Florence, Italy, 25–29 March 2019; pp. 450–455. [Google Scholar]
- Naveros, F.; Luque, N.R.; Garrido, J.A.; Carrillo, R.R.; Anguita, M.; Ros, E. A Spiking Neural Simulator Integrating Event-Driven and Time-Driven Computation Schemes Using Parallel CPU-GPU Co-Processing: A Case Study. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 1567–1574. [Google Scholar] [CrossRef]
- Yazdanbakhsh, A.; Park, J.; Sharma, H.; Lotfi-Kamran, P.; Esmaeilzadeh, H. Neural acceleration for gpu throughput proces-sors. In Proceedings of the 48th International Symposium Microarchitecture, Columbus, OH, USA, 12–16 October 2019; pp. 482–493. [Google Scholar]
- Xu, H.; Emani, M.; Lin, P.-H.; Hu, L.; Liao, C. Machine Learning Guided Optimal Use of GPU Unified Memory. In Proceedings of the 2019 IEEE/ACM Workshop on Memory Centric High Performance Computing (MCHPC), Denver, CO, USA, 18 November 2019; pp. 64–70. [Google Scholar]
- Vooturi, D.T.; Kothapalli, K. Efficient Sparse Neural Networks Using Regularized Multi Block Sparsity Pattern on a GPU. In Proceedings of the 2019 IEEE 26th International Conference on High Performance Computing, Data, and Analytics (HiPC), Hyderabad, India, 17–20 December 2019; pp. 215–224. [Google Scholar]
- Dogaru, R.; Dogaru, I. Optimization of GPU and CPU acceleration for neural networks layers implemented in python. In Proceedings of the 2017 5th International Symposium on Electrical and Electronics Engineering (ISEEE), Galati, Romania, 20–22 October 2017; pp. 1–6. [Google Scholar]
- Mei, S.; He, M.; Shen, Z. Optimizing Hopfield Neural Network for Spectral Mixture Unmixing on GPU Platform. IEEE Geosci. Remote Sens. Lett. 2013, 11, 818–822. [Google Scholar] [CrossRef]
- Huang, Y.; Guo, B.; Shen, Y. GPU Energy Consumption Optimization with a Global-Based Neural Network Method. IEEE Access 2019, 7, 64303–64314. [Google Scholar] [CrossRef]
- Li, J.; Guo, B.; Shen, Y.; Li, D.; Wang, J.; Huang, Y.; Li, Q. GPU-memory coordinated energy saving approach based on extreme learning machine. In Proceedings of the 2015 IEEE 17th International Conference on High Performance Computing and Communications, New York, NY, USA, 24–26 August 2015; pp. 827–830. [Google Scholar]
- O’Leary, G.; Taras, I.; Stuart, D.M.; Koerner, J.; Groppe, D.M.; Valiante, T.A.; Genov, R. GPU—Accelerated Parameter Selection for Neural Connectivity Analysis Devices. In Proceedings of the 2018 IEEE Biomedical Circuits and Systems Conference (BioCAS), Cleveland, OH, USA, 17–19 October 2018; pp. 1–4. [Google Scholar]
- Mujahid, T.; Rahman, A.U.; Khan, M.M. GPU-accelerated multivariate empirical mode decomposition for massive neural data processing. IEEE Access 2017, 5, 8691–8701. [Google Scholar] [CrossRef]
- Neofytou, A.; Chatzikonstantis, G.; Magkanaris, I.; Smaragdos, G.; Strydis, C.; Soudris, D. GPU Implementation of Neural-Network Simulations Based on Adaptive-Exponential Models. In Proceedings of the 2019 IEEE 19th International Conference on Bioinformatics and Bioengineering (BIBE), Athens, Greece, 28–30 October 2019; pp. 339–343. [Google Scholar]
- Hacker, C.; Aizenberg, I.; Wilson, J. GPU simulator of multilayer neural network based on multi-valued neurons. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 4125–4132. [Google Scholar]
- Phaudphut, C.; So-In, C.; Phusomsai, W. A parallel probabilistic neural network ECG recognition architecture over GPU platforms. In Proceedings of the 2016 13th International Joint Conference on Computer Science and Software Engineering (JCSSE), Khon Kaen, Thailand, 13–15 July 2016; pp. 1–7. [Google Scholar]
- Mayerich, D.; Kwon, J.; Panchal, A.; Keyser, J.; Choe, Y. Fast cell detection in high-throughput imagery using GPU-accelerated machine learning. In Proceedings of the 2011 IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Chicago, IL, USA, 30 March–2 April 2011; pp. 719–723. [Google Scholar] [CrossRef]
- Liu, Z.; Murakami, T.; Kawamura, S.; Yoshida, H. Parallel Implementation of Chaos Neural Networks for an Embedded GPU. In Proceedings of the 2019 IEEE 10th International Conference on Awareness Science and Technology (iCAST), Morioka, Japan, 23–25 October 2019; pp. 1–6. [Google Scholar]
- Van, N.T.T.; Thinh, T.N. Accelerating Anomaly-Based IDS Using Neural Network on GPU. In Proceedings of the 2015 International Conference on Advanced Computing and Applications (ACOMP), Ho Chi Minh City, Vietnam, 23–25 November 2015; pp. 67–74. [Google Scholar]
- Hamer, M.; Widmer, L.; D’andrea, R. Fast generation of collision-free trajectories for robot swarms using GPU acceleration. IEEE Access 2018, 7, 6679–6690. [Google Scholar] [CrossRef]
- Moreira, R.D.S.; Ebecken, N.F.F.; Affiliation, N.F.F.E. GWVT: A GPU maritime vessel tracker based on the wisard weightless neural network. Nav. Eng. J. 2017, 129, 109–116. [Google Scholar] [CrossRef]
- Gavali, P.; Banu, J. Bird Species Identification using Deep Learning on GPU platform. In Proceedings of the 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE), Vellore, India, 24–25 February 2020; pp. 1–6. [Google Scholar]











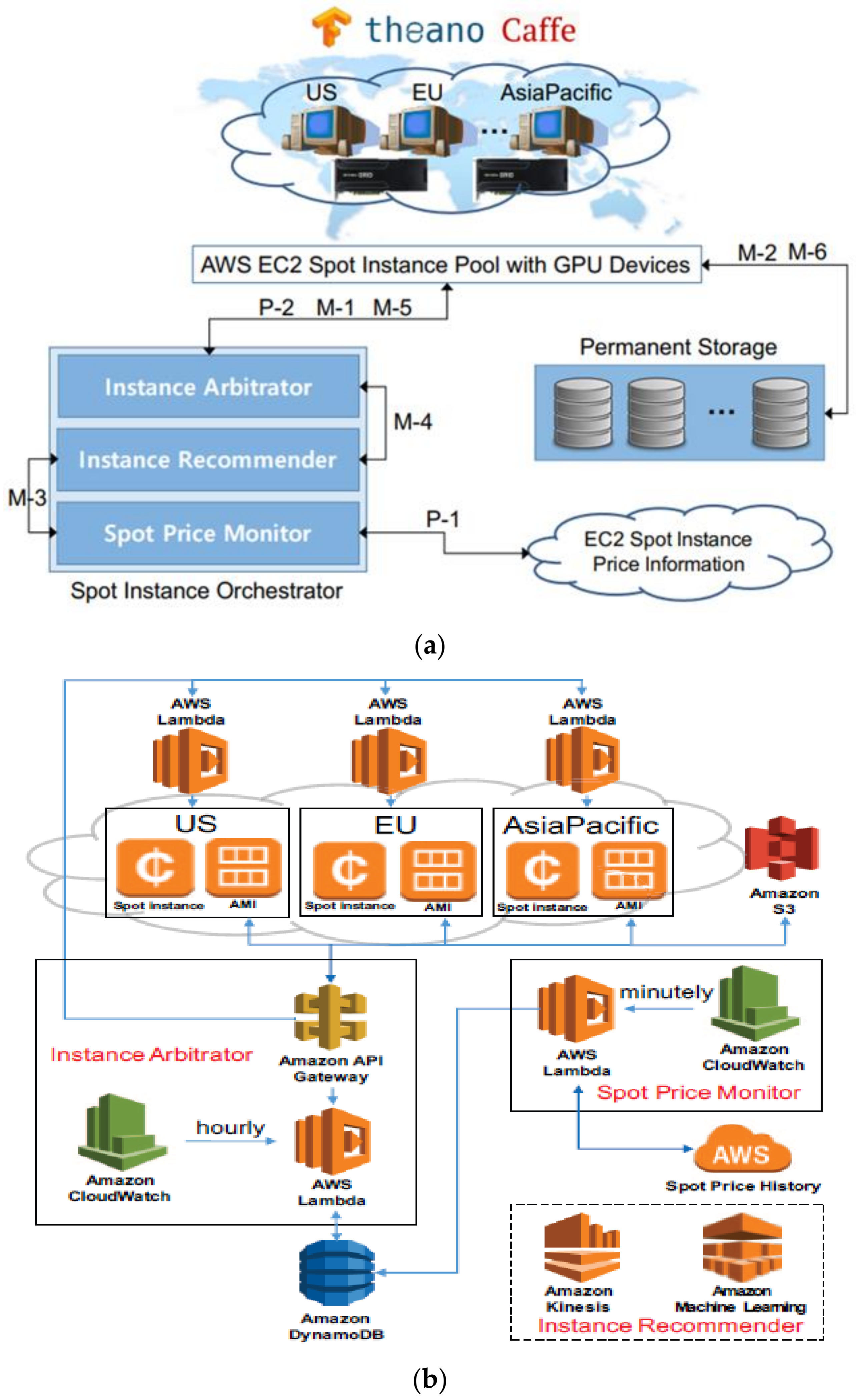{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification Descriptor | References |
|---|---|
| GPU-based Deep Learning Technologies for EI | |
| Architecture framework and strategy | [11,12,13,14,15,16,17,18,19,20,21,22,23,24,25] |
| Scheduling and communication | [26,27,28,29] |
| Image processing and computer vision | [30,31,32,33,34,35,36,37,38,39,40] |
| Medical or health | [41,42,43,44] |
| Modeling or prediction | [45,46,47,48,49,50,51] |
| Convolution or performance analysis | [6,52,53,54] |
| VLSI placement | [55] |
| GPU-based Machine Learning Technologies for EI | |
| Architecture platform | [56,57,58,59,60,61,62,63,64,65] |
| Applications | [66,67,68,69,70,71,72,73,74,75,76,77] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ang, L.M.; Seng, K.P. GPU-Based Embedded Intelligence Architectures and Applications. Electronics 2021, 10, 952. https://doi.org/10.3390/electronics10080952
Ang LM, Seng KP. GPU-Based Embedded Intelligence Architectures and Applications. Electronics. 2021; 10(8):952. https://doi.org/10.3390/electronics10080952
Chicago/Turabian StyleAng, Li Minn, and Kah Phooi Seng. 2021. "GPU-Based Embedded Intelligence Architectures and Applications" Electronics 10, no. 8: 952. https://doi.org/10.3390/electronics10080952
APA StyleAng, L. M., & Seng, K. P. (2021). GPU-Based Embedded Intelligence Architectures and Applications. Electronics, 10(8), 952. https://doi.org/10.3390/electronics10080952