
Complex-Valued Pix2pix—Deep Neural Network for Nonlinear Electromagnetic Inverse Scattering



Abstract
1. Introduction
- (Stage I) An initial guess of the contrast
- (Stage IIc) Obtain a better contrast estimation through a custom deep learning network.
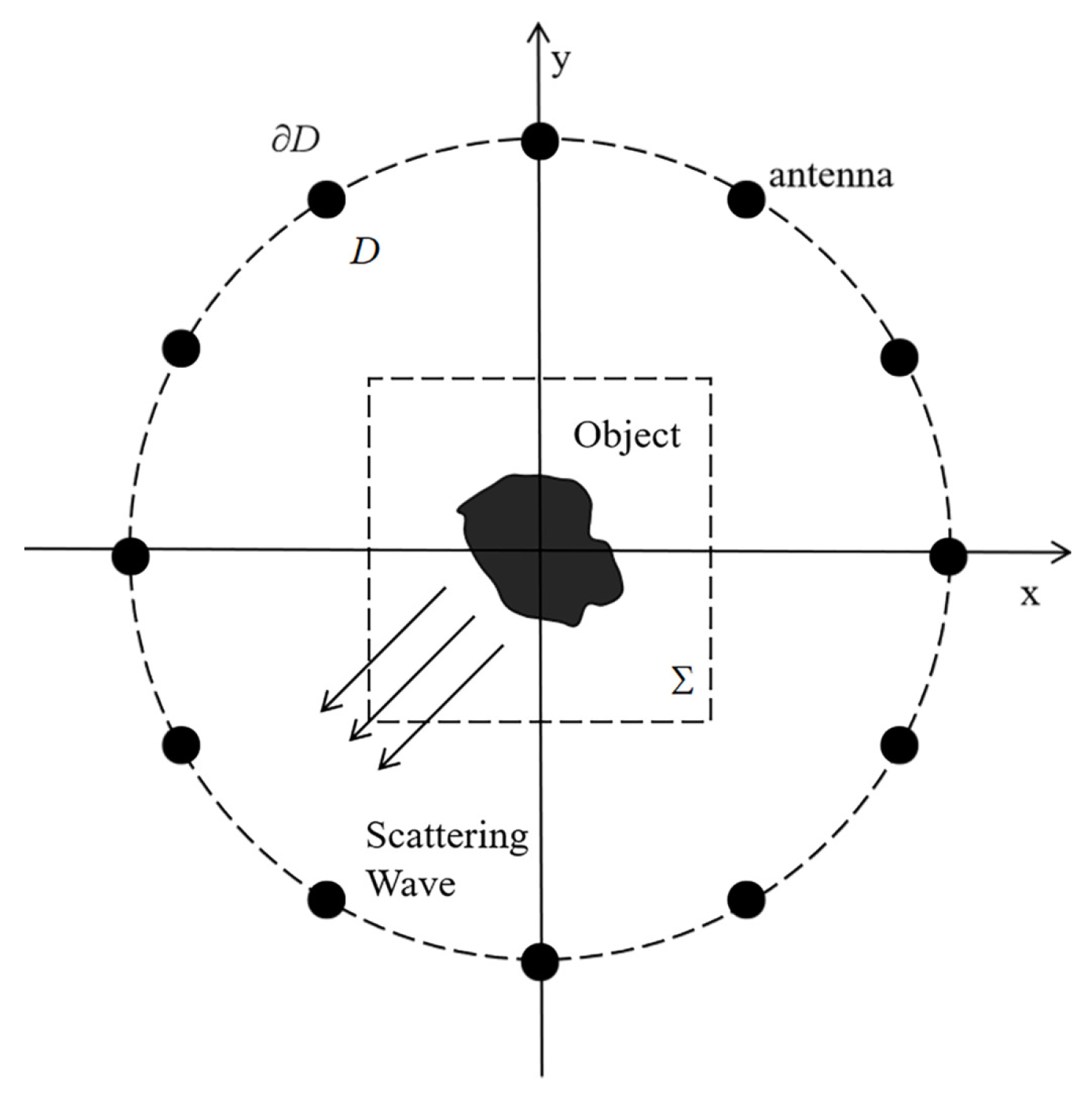
2. Problem Statement
3. Methods
3.1. Motivation
3.2. Initial Guess (Stage-I)
3.3. Comparison with Related Schemes
4. Implementation Details of the Network
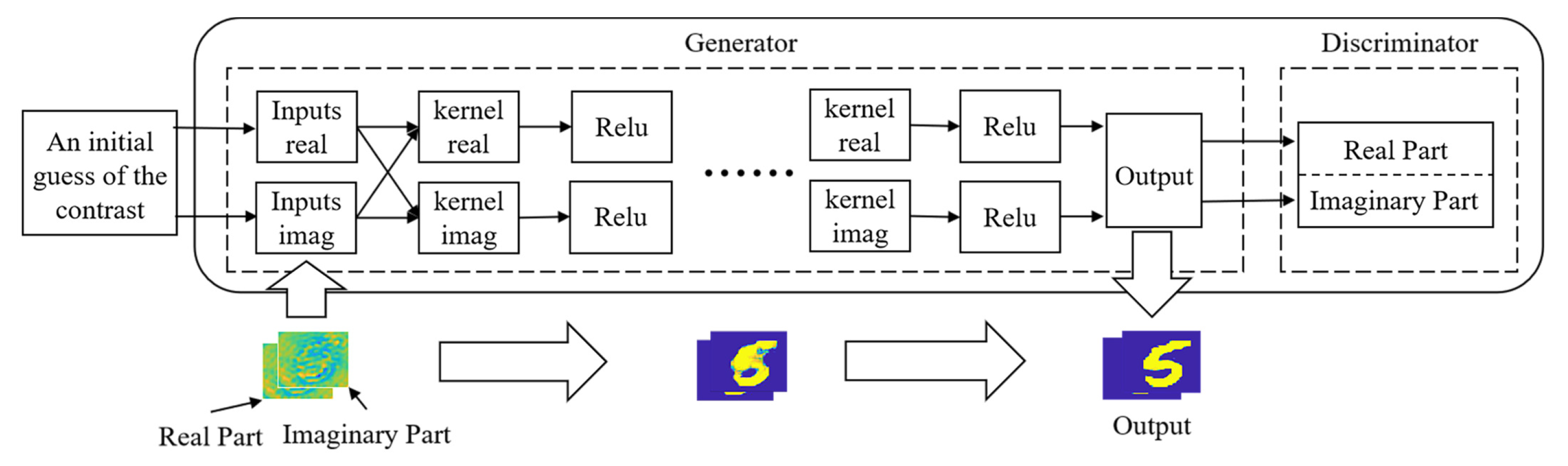
4.1. Structure and Core Idea of CVP2P
4.2. CVP2P Loss Function
4.3. CVP2P: Network Training
- (1)
- In the first step, the initial contrasts are divided into the real part and the imaginary part as the input of the generator. And then both parts are convolved with the corresponding filters according to Equation (10) to obtain a set of feature matrices. Note that the output of cCNN has the same size as its input. In other words, the size of the feature matrix remains constant in entire training process.
- (2)
- In the second step, these feature matrices undergo a nonlinear activation function to obtain a sparse outcome. Then the result is used as the input of the next layer to repeat above operation. Generally speaking, it is assumed that the relative permittivity is not smaller than 1 and the conductivity is non-negative. Therefore, the real part of the contrast is positive and the imaginary part of the contrast is negative. If we use the activation function of ReLu, we should apply the ReLu function to the complex conjugate of the contrast.
- (3)
- In the third step, the output of the final cCNN is sent to the corresponding discriminator for discrimination.
5. Numerical and Experimental Results
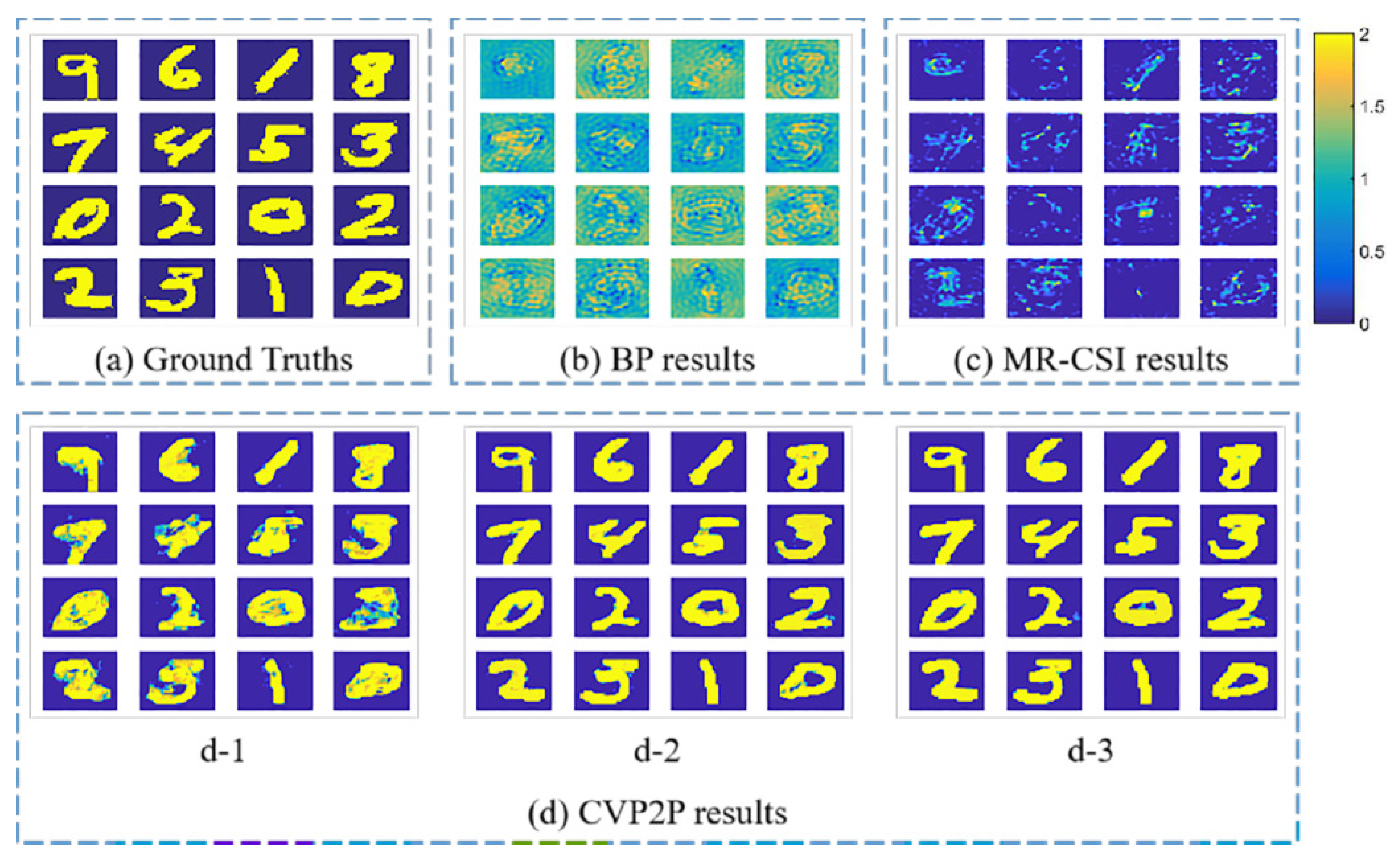
5.1. Training and Testing over MNIST Dataset
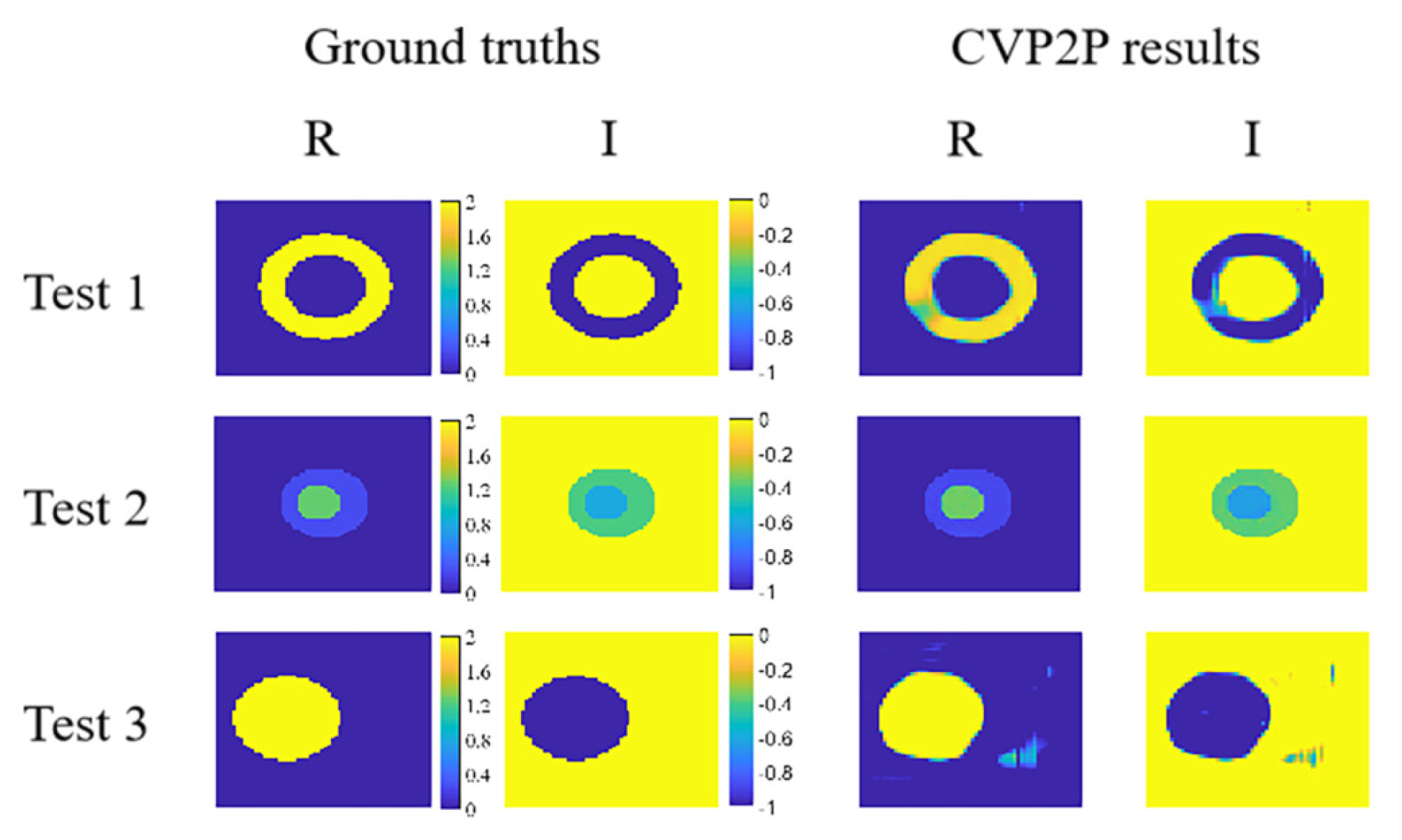
5.2. Testing over Letter Targets with Trained Networks
5.3. Tests with Lossy Scatterers
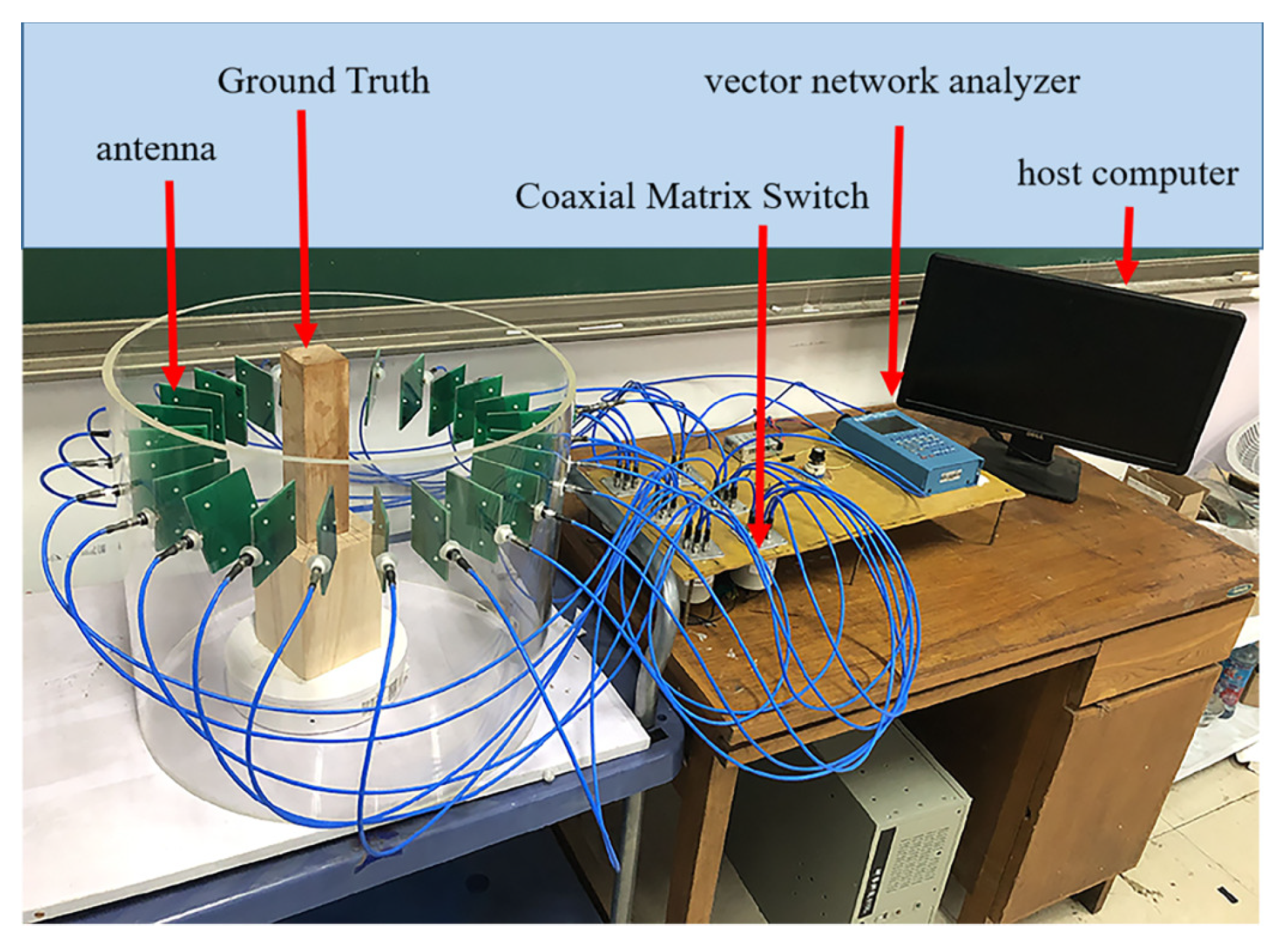
5.4. Testing Pre-Trained Networks by Experimental Data
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| GAN | Generative Adversarial Network |
| Pix2pix | Image-to-Image Translation with Conditional Adversarial Nets |
References
- Kofman, W.; Herique, A.; Barbin, Y.; Barriot, J.P.; Ciarletti, V.; Clifford, S.; Edenhofer, P.; Elachi, C.; Eyraud, C.; Goutail, J.P. Properties of the 67P/Churyumov-Gerasimenko interior revealed by CONSERT radar. Science 2015, 349, 6247. [Google Scholar] [CrossRef] [PubMed]
- Redo-Sanchez, A.; Heshmat, B.; Aghasi, A.; Naqvi, S.; Zhang, M.; Romberg, J.; Raskar, R. Terahertz time-gated spectral imaging for content extraction through layered structures. Nat. Commun. 2016, 7, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Colton, D.; Kress, R. Inverse Acoustic and Electromagnetic Scattering Theory; Springer Science and Business Media: Berlin, Germany, 2012; p. 93. [Google Scholar]
- Maire, G.; Drsek, F.; Girard, J.; Giovannini, H.; Talneau, A.; Konan, D.; Belkebir, K.; Chaumet, P.C.; Sentenac, A. Experimental Demonstration of Quantitative Imaging beyond Abbe’s Limit with Optical Diffraction Tomography. Phys. Rev. Lett. 2009, 102, 213905. [Google Scholar] [CrossRef] [PubMed]
- Meaney, P.M.; Fanning, M.W. A clinical prototype for active microwave imaging of the breast. IEEE Trans. Microw. Theory Tech. 2000, 48, 1841–1853. [Google Scholar]
- Haeberle, O.; Belkebir, K.; Giovaninni, H.; Sentenac, A. Tomographic diffractive microscopy: Basics, techniques and perspectives. J. Mod. Opt. 2010, 57, 686–699. [Google Scholar] [CrossRef]
- Kak, A.C.; Slaney, M. Principles of Computerized Tomographic Imaging; SIAM Press: Philadelphia, PA, USA, 2001; pp. 203–274. [Google Scholar]
- Di Donato, L.; Bevacqua, M.T.; Crocco, L.; Isernia, T. Inverse Scattering Via Virtual Experiments and Contrast Source Regularization. IEEE Trans. Antennas Propag. 2015, 63, 1669–1677. [Google Scholar] [CrossRef]
- Di Donato, L.; Palmeri, R.; Sorbello, G.; Isernia, T.; Crocco, L. A New Linear Distorted-Wave Inversion Method for Microwave Imaging via Virtual Experiments. IEEE Trans. Microw. Theory Tech. 2016, 64, 2478–2488. [Google Scholar] [CrossRef]
- Palmeri, R.; Bevacqua, M.T.; Crocco, L.; Isernia, T.; Di Donato, L. Microwave Imaging via Distorted Iterated Virtual Experiments. IEEE Trans. Antennas Propag. 2017, 65, 829–838. [Google Scholar] [CrossRef]
- Waller, L.; Tian, L. Computational imaging: Machine learning for 3D microscopy. Nature 2015, 523, 416–417. [Google Scholar] [CrossRef] [PubMed]
- Chew, W.C.; Wang, Y.M. Reconstruction of two-dimensional permittivity distribution using the distorted Born iterative method. IEEE Trans. Med Imaging 1990, 9, 218–225. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Wang, L.G.; Ding, J.; Liu, P.K.; Xia, M.Y.; Cui, T.J. A Probabilistic Model for the Nonlinear Electromagnetic Inverse Scattering: TM Case. IEEE Trans. Antennas Propag. 2017, 65, 5984–5991. [Google Scholar] [CrossRef]
- Chen, X. Subspace-based optimization method for solving inverse-scattering problems. IEEE Trans. Geosci. Remote Sens. 2009, 48, 42–49. [Google Scholar] [CrossRef]
- Zhong, Y.; Chen, X. Twofold subspace-based optimization method for solving inverse scattering problems. Inverse Probl. 2009, 25, 085003. [Google Scholar] [CrossRef]
- Zhong, Y.; Chen, X. An FFT Twofold Subspace-Based Optimization Method for Solving Electromagnetic Inverse Scattering Problems. IEEE Trans. Antennas Propag. 2011, 59, 914–927. [Google Scholar] [CrossRef]
- Zhong, Y.; Lambert, M.; Lesselier, D.; Chen, X. A New Integral Equation Method to Solve Highly Nonlinear Inverse Scattering Problems. IEEE Trans. Antennas Propag. 2016, 64, 1788–1799. [Google Scholar] [CrossRef]
- Oliveri, G.; Zhong, Y.; Chen, X.; Massa, A. Multiresolution subspace-based optimization method for inverse scattering problems. J. Opt. Soc. Am. Opt. Image Sci. Vis. 2011, 28, 2057–2069. [Google Scholar] [CrossRef]
- Van den Berg, P.M.; Abubakar, A. Contrast source inversion method: State of art. Prog. Electromagn. Res. 2001, 34, 189–218. [Google Scholar] [CrossRef]
- Li, L.; Zheng, H.; Li, F. Two-Dimensional Contrast Source Inversion Method With Phaseless Data: TM Case. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1719–1736. [Google Scholar]
- Guo, L.; Zhong, M.; Song, G.; Yang, S.; Gong, L. Incremental distorted multiplicative regularized contrast source inversion for inhomogeneous background: The case of TM data. Electromagnetics 2020, 40, 1–17. [Google Scholar]
- Rocca, P.; Benedetti, M.; Donelli, M.; Franceschini, D.; Massa, A. Evolutionary optimization as applied to inverse scattering problems. Inverse Probl. 2009, 25, 123003. [Google Scholar] [CrossRef]
- Rocca, P.; Oliveri, G.; Massa, A. Differential evolution as applied to electromagnetics. IEEE Antennas Propag. Mag. 2011, 53, 38–49. [Google Scholar] [CrossRef]
- Pastorino, M. Stochastic optimization methods applied to microwave imaging: A review. IEEE Trans. Antennas Propag. 2007, 55, 538–548. [Google Scholar] [CrossRef]
- Pu, W.; Wang, X.; Yang, J. Video SAR Imaging Based on Low-Rank Tensor Recovery. IEEE Trans. Neural Networks Learn. Syst. 2020. [Google Scholar] [CrossRef] [PubMed]
- Jian, F.; Zong, B.X.; Zhang, B.C.; Hong, W.; Wu, Y. Fast compressed sensing SAR imaging based on approximated observation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 352–363. [Google Scholar] [CrossRef]
- Pu, W.; Wu, J. OSRanP: A Novel Way for Radar Imaging Utilizing Joint Sparsity and Low-Rankness. IEEE Trans. Comput. Imaging 2020, 6, 868–882. [Google Scholar] [CrossRef]
- Alver, M.B.; Saleem, A.; Cetin, M. A Novel Plug-and-Play SAR Reconstruction Framework Using Deep Priors. In Proceedings of the 2019 IEEE Radar Conference (RadarConf), Boston, MA, USA, 22–26 April 2019; pp. 1–6. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Couriville, A. Couriville. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; pp. 10–13. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. arXiv 2014, arXiv:1406.2283. [Google Scholar]
- Cao, J.S.W.; Xu, Z.; Ponce, J. Learning a convolutional neural network for non-uniform motion blur removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 769–777. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef]
- Liu, D.; Wang, Z.; Wen, B.; Yang, J.; Han, W.; Huang, T.S. Robust Single Image Super-Resolution via Deep Netw. Sparse Prior. IEEE Trans. Image Process. 2016, 25, 3194–3207. [Google Scholar] [CrossRef] [PubMed]
- Kalinin, S.V.; Sumpter, B.G.; Archibald, R.K. Archibald. Big-deep-smart data imaging for guiding materials design. Nat. Mater. 2015, 14, 973–980. [Google Scholar] [CrossRef]
- Mousavi, A.; Baraniuk, R. Learning to Invert: Signal Recovery via Deep Convolutional Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Kulkarni, K.; Lohit, S.; Turaga, P.; Kerviche, R.; Ashok, A. ReconNet: Non-Iterative Reconstruction of Images from Compressively Sensed Measurements. In Proceedings of the 2016 IEEE Conference on Computer Vision And Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 449–458. [Google Scholar]
- Kraus, O.Z.; Grys, B.T.; Ba, J.; Chong, Y.; Frey, B.J.; Boone, C.; Andrews, B.J. Automated analysis of high-content microscopy data with deep learning. Mol. Syst. Biol. 2017, 13, 924. [Google Scholar] [CrossRef]
- Zhang, Q.; Kong, Q.; Zhang, C.; You, S.; Wei, H.; Sun, R.; Li, L. A new road extraction method using Sentinel-1 SAR images based on the deep fully convolutional neural network. Eur. J. Remote Sens. 2019, 52, 572–582. [Google Scholar] [CrossRef]
- Han, Y.; Yoo, J.; Ye, J.C. Deep residual Learning for Compressed sensing CT Reconstruction via Persistent Homology Analysis. arXiv 2016, arXiv:1611.06391. [Google Scholar]
- Jin, K.H.; McCann, M.T.; Froustey, E.; Unser, M. “Deep Convolutional Neural Network for Inverse Problems in Imaging. IEEE Trans. Image Process. 2017, 26, 4509–4522. [Google Scholar] [CrossRef]
- Sinha, A.; Lee, J.; Li, S.; Barbastathis, G. Lensless computational imaging through deep learning. Optica 2017, 4, 1117–1125. [Google Scholar] [CrossRef]
- Kamilov, U.S.; Papadopoulos, I.N.; Shoreh, M.H.; Goy, A.; Vonesch, C.; Unser, M.; Pasaltis, D. Learning approach to optical tomography. Optica 2015, 2, 517–522. [Google Scholar] [CrossRef]
- Li, L.; Wang, L.G.; Teixeira, F.L.; Liu, C.; Nehorai, A.; Cui, T.J. DeepNIS: Deep Neural Network for Nonlinear Electromagnetic Inverse Scattering. IEEE Trans. Antennas Propag. 2019, 67, 1819–1825. [Google Scholar] [CrossRef]
- Marashdeh, Q.; Warsito, W.; Fan, L.-S.; Teixeira, F.L. Nonlinear forward problem solution for electrical capacitance tomography using feed forward neural network. IEEE Sens. J. 2006, 6, 441–449. [Google Scholar] [CrossRef]
- Marashdeh, Q.; Warsito, W.; Fan, L.-S.; Teixeira, F.L. A nonlinear image reconstruction technique for ECT using combined neural network approach. Meas. Sci. Technol. 2006, 17, 2097–2103. [Google Scholar] [CrossRef]
- Sanghvi, Y.; Kalepu, Y.; Khankhoje, U.K. Embedding Deep Learning in Inverse Scattering Problems. IEEE Trans. Comput. Imaging 2020, 6, 46–56. [Google Scholar] [CrossRef]
- Wei, Z.; Chen, X. Deep-Learning Schemes for Full-Wave Nonlinear Inverse Scattering Problems. IEEE Trans. Geosci. Remote. Sens. 2019, 57, 1849–1860. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 1 July 2017; pp. 5967–5976. [Google Scholar]
- Lecun, Y.; Bottou, L. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Goodfellow, J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Adv. Neural Inf. Process. Syst. 2014, 3, 2672–2680. [Google Scholar] [CrossRef]
- Catedra, M.F.; Torres, R.P.; Basterrechea, J.; Gago, E. The CG-FFT Method: Application of Signal Processing Techniques to Electromagnetics; Artech House: Boston, MA, USA, 1995; pp. 78–89. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2017, arXiv:1412:6980. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ground Truths for Testing | BP | MR-CSI | CVP2P |
|---|---|---|---|
 | 9.837 | 11.67 | 20.94 |
 | 9.92 | 10.68 | 20.34 |
 | 10.95 | 12.58 | 21.57 |
 | 10.25 | 9.837 | 20.07 |
 | 10.57 | 10.64 | 20.3 |
 | 9.702 | 10.88 | 19.27 |
 | 9.567 | 10.56 | 20.38 |
 | 9.614 | 9.725 | 19.42 |
 | 9.665 | 9.885 | 19.65 |
 | 10.46 | 11.736 | 20.59 |
 | 9.556 | 9.323 | 19.13 |
 | 9.925 | 9.756 | 19.15 |
 | 9.724 | 10.37 | 20.22 |
 | 10.02 | 10.37 | 18.4 |
 | 10.7 | 14.04 | 21.61 |
 | 9.951 | 10.23 | 20.12 |
| Ground Truths for Testing | BP | MR-CSI | CVP2P |
|---|---|---|---|
 | 0.666 | 0.714 | 0.972 |
 | 0.641 | 0.661 | 0.968 |
 | 0.747 | 0.758 | 0.975 |
 | 0.672 | 0.594 | 0.967 |
 | 0.718 | 0.642 | 0.967 |
 | 0.646 | 0.667 | 0.958 |
 | 0.637 | 0.639 | 0.968 |
 | 0.632 | 0.576 | 0.962 |
 | 0.628 | 0.585 | 0.963 |
 | 0.707 | 0.724 | 0.969 |
 | 0.599 | 0.551 | 0.96 |
 | 0.644 | 0.589 | 0.959 |
 | 0.622 | 0.616 | 0.967 |
 | 0.666 | 0.627 | 0.951 |
 | 0.732 | 0.838 | 0.973 |
 | 0.670 | 0.618 | 0.966 |
| Ground Truths for Testing | BP | MR-CSI | CVP2P |
|---|---|---|---|
 | 0.648 | 0.829 | 0.943 |
 | 0.448 | 0.857 | 0.976 |
 | 0.694 | 0.861 | 0.963 |
 | 0.697 | 0.76 | 0.975 |
 | 0.634 | 0.783 | 0.914 |
 | 0.685 | 0.756 | 0.956 |
| Ground Truths for Testing | BP | MR-CSI | CVP2P |
|---|---|---|---|
| R | 0.966 | 0.986 | 0.979 |
| I | 0.956 | 0.970 | 0.968 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, L.; Song, G.; Wu, H. Complex-Valued Pix2pix—Deep Neural Network for Nonlinear Electromagnetic Inverse Scattering. Electronics 2021, 10, 752. https://doi.org/10.3390/electronics10060752
Guo L, Song G, Wu H. Complex-Valued Pix2pix—Deep Neural Network for Nonlinear Electromagnetic Inverse Scattering. Electronics. 2021; 10(6):752. https://doi.org/10.3390/electronics10060752
Chicago/Turabian StyleGuo, Liang, Guanfeng Song, and Hongsheng Wu. 2021. "Complex-Valued Pix2pix—Deep Neural Network for Nonlinear Electromagnetic Inverse Scattering" Electronics 10, no. 6: 752. https://doi.org/10.3390/electronics10060752
APA StyleGuo, L., Song, G., & Wu, H. (2021). Complex-Valued Pix2pix—Deep Neural Network for Nonlinear Electromagnetic Inverse Scattering. Electronics, 10(6), 752. https://doi.org/10.3390/electronics10060752