1. Introduction
Over the past several decades, disparity estimation is a problem in stereo vision, which has been investigated, and is still an active research topic in the field of computer vision [
1]. It is a fundamental technology for the next-generation of network services to synthesize virtual viewpoints, including 3DTV, multiview video, free-view video, and virtual reality operations.
Stereo matching is an important vision problem that estimates the disparities in a given stereo image pair. Many stereo matching techniques have been proposed, which could be categorized as either global or local methods [
2]. The global methods produce more accurate disparity maps, which are typically derived from an energy minimization framework that allows for the express integration of disparity smoothness constraints, and are thus able to regularize the solution in weakly textured areas. However, as a result of minimization, they use an iterative strategy or graph cuts, which require a high computing cost. These methods are often quite slow, and thus unsuitable for processing a large amount of data. In contrast, local methods compute the disparity value by optimizing a matching cost, which compares the candidate target pixels and reference pixels while simultaneously considering the neighboring pixel information in a support window [
3]. Local methods, which are typically built upon the winner-takes-all (WTA) framework [
4,
5,
6], have the lowest computational costs and are suitable for implementation on parallel graphics processers. In the WTA framework, local stereo methods consider a range of disparity hypotheses and compute a cost volume using various pixel-wise dissimilarity metrics between the reference image and the matched image at every considered disparity value. The final disparities are selected from the cost volume by going through its values and selecting the disparities associated with the minimum matching costs for every pixel of the reference image. Hence, considering the computational cost, we used a local method with the WTA strategy in this study.
Adaptive-weight methods, iteratively updated support windows, and support weights [
4,
6,
7] have been used to find a support window and support weight for each pixel, while fixing the shape and size of a local support window. Although these methods can obtain excellent results using adaptive-weight algorithms, pixel-wise support weight computation is very time-consuming. De-Maeztu et al. [
8] proposed a local stereo matching algorithm inspired by anisotropic diffusion to reduce the computational requirements. However, the results were similar to those of the adaptive-weight method. Kowalczuk et al. [
6] combined temporal and spatial cost aggregations to improve the accuracy of stereo matching in video clips using iterative support weights.
Richardt et al. [
9] extended the dual-cross-bilateral grid method to the time dimension by applying a filter to the temporally adjacent depth images to smooth out the depth change, and presented its real-time performance using the adaptive support weights algorithm [
4]. However, the results were less accurate than those of the adaptive-weight algorithm [
4].
Vretos and Daras [
10] used a temporal window to calculate the disparity and enforce its temporal consistency on outliers, where the color remains within a certain distribution. This method used a range of frames to calculate the disparity at a pixel for a frame. However, object occlusion and motion will affect the determination of frame interval and disparity calculation in the specific temporal window. This causes the loss of disparity values of some object boundaries. Liu et al. [
11] proposed a spatiotemporal consistency enhancement method based on a guided filter in the spatial domain to reduce noises and inconsistent pixels, along with an adaptive filter in the temporal domain to improve the temporal consistency. Although this method could reduce noises and transient errors, the disparity maps were blurred after performing these filtering operations.
Jung et al. [
12] proposed a boundary-preserving stereo matching method to improve the fidelity of error disparities. This approach used segmentation-based disparity estimation, and the classification information of the certain and uncertain regions was used to adjust the disparity map in the support window. The initial disparity maps were obtained using the segmentation method. However, the noises and occlusion will disturb the segmentation process and reduce the initial disparity quality.
Me et al. [
13] used a four-mode census transform stereo matching method to improve the matching quality. This method used bidirectional constraint dynamic programming and relative confidence plane fitting. In a census window, the matching cost is determined by computing the Hamming distance of two bit strings. However, the matching cost computation in the window-based census transform is sensitive to all of the pixels in the window and noises, which will reduce the matching accuracy.
Zhan et al. [
14] proposed an image-based stereo matching approach that used the combined matching cost and multistep disparity refinement to improve the local stereo matching algorithm. This method was used for image-guided and filter-based guidance images to enhance the raw stereo images and improve the existing local stereo matching algorithm. The final disparity map removed the outliers using the combined matching cost, which included the double-RGB gradient, census transform, image color information, and a sequence of refinement sets.
Yang et al. [
7] proposed a dynamic scene-based local stereo-matching algorithm that integrated a cost filter with motion flow in dynamic video clips. This method used the motion flow to calculate a suitable support weight for estimating the disparity and obtained an accurate stereo-matching result. However, a problem with occlusion will generate discontinuities in some objects. Thus, using the motion flow may produce an incorrect matching when the object was rotated, making it impossible to obtain a suitable weight. Some stereo matching algorithms based on the modified cost aggregation have been reported [
15,
16,
17,
18,
19,
20].
Although the stereo matching method provides excellent matching results for the two image pairs, there are still some complicated problems with stereo matching, such as object occlusion and flickering artifacts. Object occlusion, where there are no corresponding pixels to be captured, is a serious problem that could cause the stereo matching algorithm to be ineffective at finding the correct pixels. Thus, it will produce incorrect disparity values in the occluded regions. In addition, the problem of flickering artifacts usually occurs in disparity sequences generated by a stereo matching method as a result of inconsistent disparity maps. These flickers will significantly reduce the subjective quality of a video clip. Simultaneously, the incorrect disparity values would cause visual discomfort in the human eye, especially when they are used for synthesizing a virtual view in depth-image-based rendering (DIBR). To address this issue, we propose a strategy based on the spatiotemporal domain to reduce the inconsistent disparities and to refine the disparity map in a video clip. The main contribution of our proposed method is to improve the inconsistent disparities and reduce flickering errors in the estimated disparity sequences for the synthesized video. The advantages of this method are as follows. First, the outliers can be detected and removed using the superpixel-based segmentation method. Second, the disparity refinement is achieved using our proposed technique in the temporal and spatial domains. In the temporal domain, we propose the method to improve the cost aggregation based on segmentation, color difference, and disparity difference and then to refine the outliers in frames. In the spatial domain, the rest of disparity errors of each frame can be further refined based on refinement within superpixel bounds, propagation mechanism, and filtering. Finally, our proposed method is easy to implement and an efficient technique.
3. Proposed Method
This section describes the proposed method, which includes simple linear iterative clustering (SLIC) segmentation and merging, and temporal and spatial refinements.
Figure 3 illustrates the flowchart of the proposed system. The procedures are described in detail in the following subsections.
3.1. Outlier Detection Based on Disparity Variation
The initial disparity of each pixel according to the map calculated by the cross-based local stereo matching [
5] contains many outliers. In order to detect these outliers, we here use the consistency of the disparity variation under the same cluster to label the inconsistent pixels in the current frame. These inconsistent pixels are marked as outliers. Due to the disparity variation, one cluster may include many disparity values, which will cause inconsistent disparity values within the same cluster. Hence, we estimate the variation of the disparity values in the same cluster to detect the inconsistent pixels. First, all of the pixels in the disparity map are given different initial labels. Given a pixel
with label
, for every pixel
, a constraint is enforced on its labeling as follows.
where
is the cluster containing pixel
p,
denotes the disparity corresponding to a pixel, and
is a threshold. The symbol
denotes the absolute value. In a cluster, there exist many pixels, there might be different labels. In that cluster, the pixels with the label shown most frequently denote as a target. In the target, the disparity shown most frequently denotes the correct disparity. This value is found from those pixels with the same label shown most frequently. Additionally, the rest of the pixels are denoted as the outliers of the cluster.
However, the leftmost or rightmost disparities of the disparity sequences may cause serious disparity errors because they do not have related information in the left or right image. Thus, these pixels have zero values. In other words, the corresponding region at the leftmost or rightmost of the disparity map cannot be matched. Hence, the disparity value is zero, which indicates an error. We use the following procedures to detect the disparity errors positioned at the leftmost or rightmost of the disparity sequences. First, we detect segmented regions that include disparities with a value of zero in the leftmost or rightmost region. Then, we use the characteristic of a disparity variation from an endpoint to inner point and compute the average disparity of the segmented region. If the average disparity is less than a threshold ( = 4), this segmented region is labeled as having disparity error. After performing the above procedures, the disparity errors generated at the leftmost or rightmost of a disparity map can be reduced.
The detected outliers are recorded on the disparity map for the left view, as shown in
Figure 4. In
Figure 4, the red points are the outliers. In other words, these outliers are regarded as disparity error points on the disparity map with the left view and must be refined.
3.2. Disparity Refinement in Temporal Domain
After detecting the outliers, we can determine the outliers in each frame within a video clip. When the camera or captured objects in the scene involve slow motion, the disparity of an object cannot show a dramatic change in a short period of time. In addition, an occlusion will cause a disparity with a great change in the background, which will result in disparity errors. However, a dramatic change may be caused by the appearance of another object. Hence, this approach will refine these disparity errors, whether they are caused by the appearance of another object or an occlusion.
These errors must be removed and refined in the disparity map. In our approach, the refining procedures are divided into two phases: refining in the temporal domain and in the spatial domain. The system design uses an object-based strategy.
We combine the segmentation information, region movement, color difference, and disparity difference to achieve the refinement in the temporal domain at this stage. We simply use the previous frame and its corresponding information to perform the refinement. The details of the procedures at this stage are described in the following.
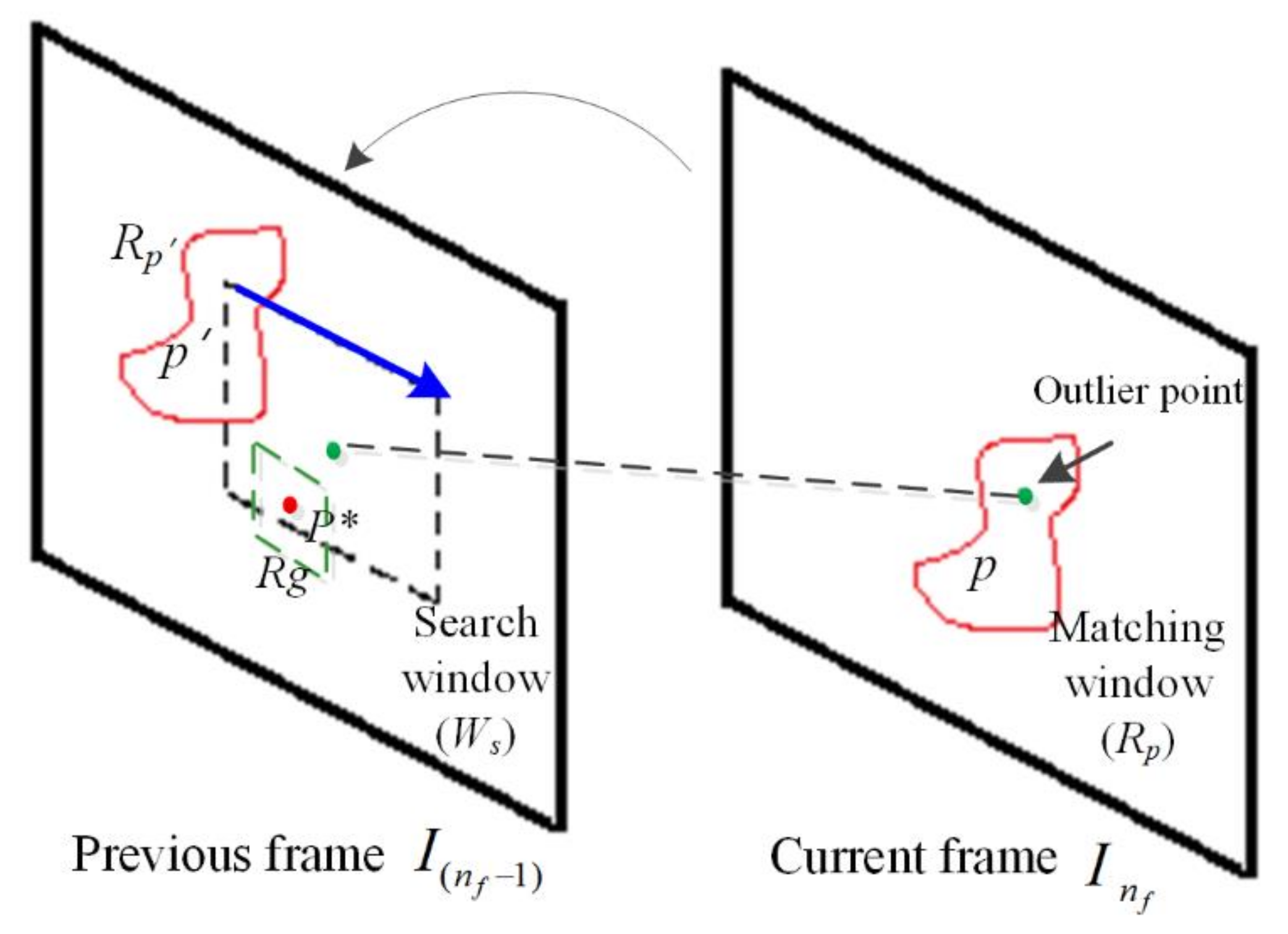
3.2.1. Searching for Matching Point in Previous Frame
First, we need to search for the matching positions in the previous frame corresponding to the outliers in the current frame. Assuming that a given pixel,
p, is in the current frame (at time
t),
, with
where
denotes a cluster as a result of the SLIC segmentation and merging, the candidate pixel,
, is from a given search window of 11 × 11 pixels in the previous fame denoted by
, i.e.,
, with its matching window to
denoted by
, the best matching point,
, in the previous frame (at time
t−1)
, to pixel
p of the current frame,
, is defined as follows,
where the cost function,
, is composed of color matching,
, and disparity matching cost,
, and is defined as
is a weighting parameter,
symbol “card(●)” denotes the cardinality operator,
and
are indexes to matching windows in frames
and
, respectively.
denotes the pixel level disparity matching cost and is defined, for
,
, by
denotes the number of points that possess correct disparities in the matching windows in frames
and
, and is defined by
with
identifying pixels with correct disparities in candidate matching region and defined as
where
denotes the disparity of point
p in the current frame,
, whether there is an error or not. Additionally,
denotes the disparity of point
p in the previous frame,
, whether there is an error or not. Hence,
means that the disparity of point
p is correct, and the disparity of point
p in the previous frame is correct. According to Equation (3), the best matching point in the previous frame corresponding to the outlier in the current frame can be obtained.
Figure 5 shows the profile of the matching operation.
Afterward, we further compute and record the displacement of the coordinates of the matching point. The displacement of the coordinates of
p and
p* is computed as follows:
Based on the displacement information, we can more rapidly obtain the matching points of other outliers within the same segmented region. This is because they are clustered in the same region.
Hence, if we search for other matching points in the previous frame corresponding to any disparity errors in the same segmented region for the current frame, we can decide whether the displacement information belonging to the same cluster is recorded or not. Based on the displacement information, it is easier and quicker to find the matching point corresponding to the disparity error.
3.2.2. Disparity Refinement of Outliers
In terms of disparity refinement, based on the matching result in the previous process, we can obtain the matching point corresponding to the outlier. However, this matching point may not have the correct disparity. In order to avoid matching the error disparity, we use the color difference between point
p in the current frame
I and the neighborhood pixels of matching point
p* in the previous frame
to select the appropriate matching point. The selection of the appropriate matching point is computed using Equations (11) and (12):
where
Rg is a 3 × 3 region with center point
p*, as shown in
Figure 5.
After the computation using Equation (11), we further determine whether the disparity of point
k is right or not, and then compute the color difference between point
k and point
p. In order to maintain temporal consistency for the pixels in the temporal sequence, a threshold (
) is used to estimate whether the colors of the pixels remain within a certain distribution. When the color difference is less than a threshold (
) and the disparity of point
k is correct, the disparity error will be replaced by the disparity of point
k. The disparity refinement of the outliers in the temporal domain is expressed as follows:
where
and
denote the disparities of pixel
p and pixel
k, respectively.
denotes the disparity of point
k at time
t-1, whether there is an error or not. Hence,
means that the disparity of pixel
k is correct. At the same time, the color difference between pixel
p at time
t and pixel
k at time
t-1 is less than a threshold (
). Thus, the disparity of pixel
p in the current frame is replaced by the disparity of pixel
k.
After refining the disparities of the outliers at time t in the temporal domain, the refined current frame will be reused for the refinement in the next frame. In other words, the correct disparities for the object in the current frame can propagate to the following frames and be used to refine the same object under the specified camera lens motion.
3.3. Disparity Refinement in Spatial Domain
After performing the refinement in the temporal domain, a large number of the disparity errors were refined. However, some errors still exist in the temporal sequence. Hence, the rest of the errors will be refined in the spatial domain.
3.3.1. Refinement within Superpixel Bounds
Based on the SLIC segmentation and merging, we will search the correct disparities to refine the rest disparities of error values using pixel-based processing of each frame. We compute the color differences between the pixels with the disparity error and the candidate pixels with the correct disparities, which are segmented into the same cluster. The disparity of a pixel with a minimum color difference is used to replace the disparity error of a pixel.
In order to refine the rest of the disparity errors in the spatial domain, first, given a pixel,
p, of disparity image in a segmented region
, i.e.,
, and a 37 × 37 search region denoted by
, a truth table for the candidate pixels representing correct disparity within the search region
can be formulated for
,
where
denotes that the disparity of pixel
j is error.
denotes that the disparity of pixel
j is correct.
is a threshold for the color difference between point
p and point
j. Based on the segmentation process, if any two pixels in the spatial domain are segmented into the same cluster, and the color difference between these two pixels is less than a threshold, these points will act as the candidate pixels for refining.
Next, the best candidate pixel among all of the candidate pixels denoted by
is selected as follows:
and disparity value at
p is replaced by that at
b as follows,
Based on Equation (14), we can obtain the best pixel b, and the disparity of pixel p is replaced by the disparity of pixel b.
3.3.2. Propagation from Horizontal Lines
After performing the disparity refinement of the outliers in the spatial domain and temporal domain, the boundaries of objects may look uneven, a few outliers may not have been corrected, or spatial noises exist in the frame. Thus, we use the following procedures to process the rest of the outliers.
The recovering procedures are described as follows. We use the propagation method in the horizontal direction for an outlier to further recover the disparity error. Assume that pixel
p is an outlier. We search for pixels with the correct disparities along the left arm and right arm for equal distances. This search procedure ends when the first correct disparity derived from the left arm or right arm is obtained. Then, we compute the color differences between the outlier and these pixels within the two arms and obtain the maximum color difference for the two arms. The maximum color difference for the two arms is computed as follows:
where
denotes all of the pixels from pixel
p to pixel
i on the left arm, and
denotes all of the pixels from pixel
p to pixel
i on the right arm.
Figure 6 shows an example of the profile of the color difference computation in the horizontal direction. From
Figure 6, it is clear that the pixels on the left arm may belong to the same cluster because their color variation is small. In contrast, the color variation on the right arm is extreme, which may denote the edge of an object or noises. Hence, we compute the maximum color difference within the search interval for the left arm and right arm using Equation (16).
In addition, if the correct disparity only appears on the right arm or left arm under equal distances, the disparity of the outlier is directly replaced by this correct disparity.
Next, we take the pixel with the minimum color difference using Equations (16) and (17) to obtain a reliable disparity. The disparity of this outlier
p is determined and replaced by
3.3.3. Filtering
After performing the above procedures, in order to obtain good visual quality of the refined disparity maps, we finally use a median filter with a size of 9 × 9 to modify the refined disparity maps based on the results of all the above steps. This result after performing filtering can present the best refining disparity maps.
3.4. Summary of Procedures
Temporal domain:
Input: Video clip
Output: A refined disparity map in the temporal domain
Step (1) Create the initial disparity maps using a local cross-based stereo matching method [
5].
Step (2) Detect the outliers for the initial disparity maps under our proposed method.
Step (3) Check whether the displacement information in the segmented region is recorded or not. If it is recorded, the matching point in the previous frame corresponding to an outlier in the current frame can be found using the displacement information, and go to Step (6), else go to Step (4).
Step (4) Search for the matching region and matching point p* in the previous frame for these outliers based on the segmented region, color difference, and disparity difference using Equations (5) and (6); compute the aggregated cost using Equation (4); use Equation (3) to find p*.
Step (5) Compute and record the displacement information of the matching pair using Equation (10).
Step (6) Replace the disparity value of an outlier by computing the color difference between the outlier in the current frame and the neighborhood points of the matching point in the previous frame based on Equations (11) and (12).
Step (7) Repeat Steps (3)–(6), until all of the frames in the video clip are done.
Spatial domain:
Input: The refined disparity maps of a video clip obtained by the processing in the temporal domain
Output: The final refined disparity maps
Step (1) Search for the rest of the disparity errors.
Step (2) Select all of the candidate pixels in the search region () based on the color difference using Equation (13).
Step (3) Compute the minimum color difference and obtain the best candidate pixel based on Equations (14) and (15). Then, the disparity of the candidate pixel is used to replace the disparity of the error point.
Step (4) Process the rest of the outliers using Equations (16) and (17).
Step (5) Repeat Steps (1)–(4), until the disparity errors for all the frames are recovered.
Step (6) Use a median filter to improve the results of Step (5).
5. Conclusions
This paper proposed an efficient spatiotemporal stereo matching with disparity refinement method based on SLIC segmentation. Based on the segmentation information, the disparity errors in the disparity map are first detected. Next, we search for the matching region in the previous frame based on the segmented region. Then, based on the motion information of the matching region in the previous frame, we can find the correct disparities. The disparity refinement is performed using our proposed technique in the temporal and spatial domains. Finally, in order to obtain a more comfortable visual perception, a median filter is used on the refined disparity maps.
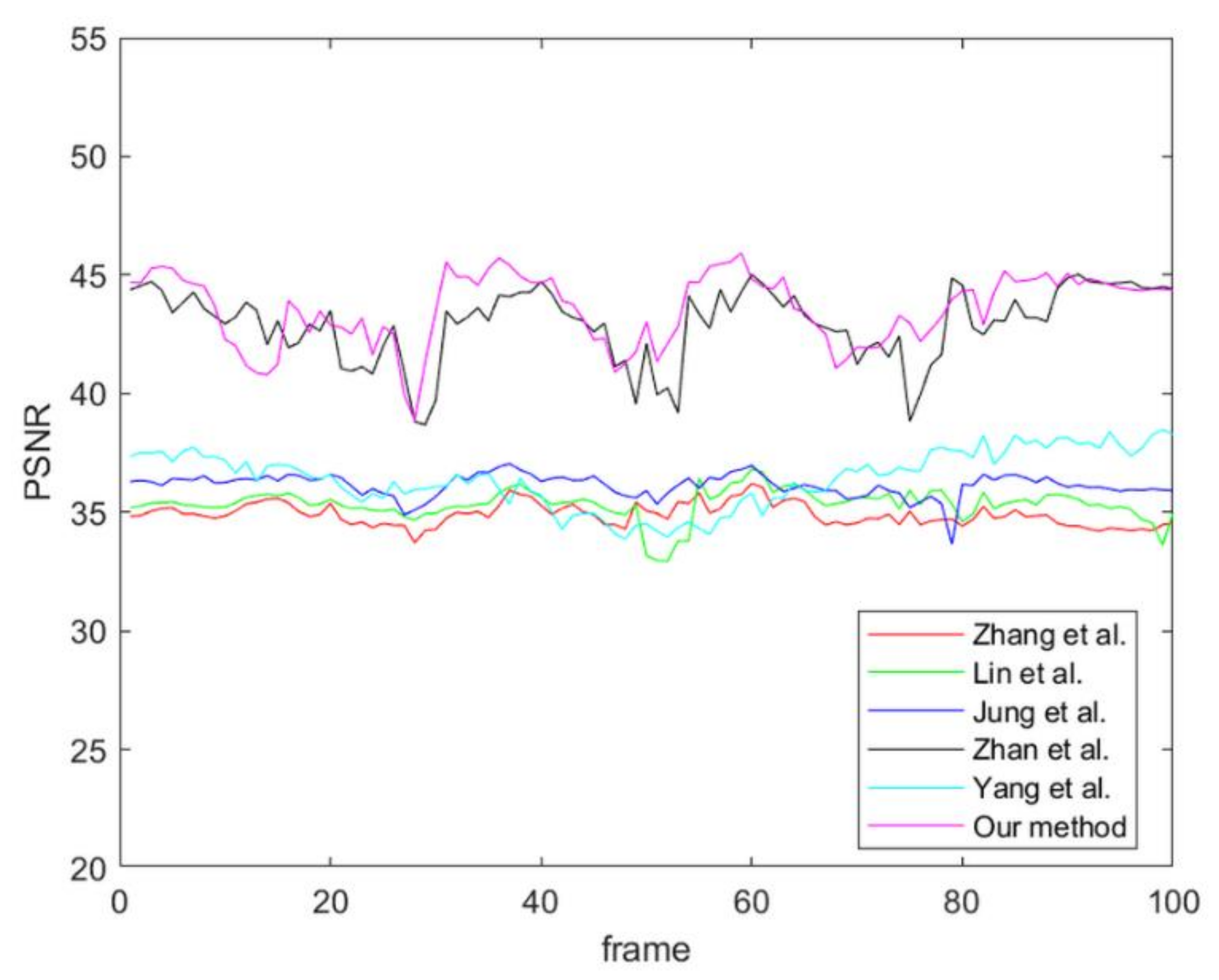
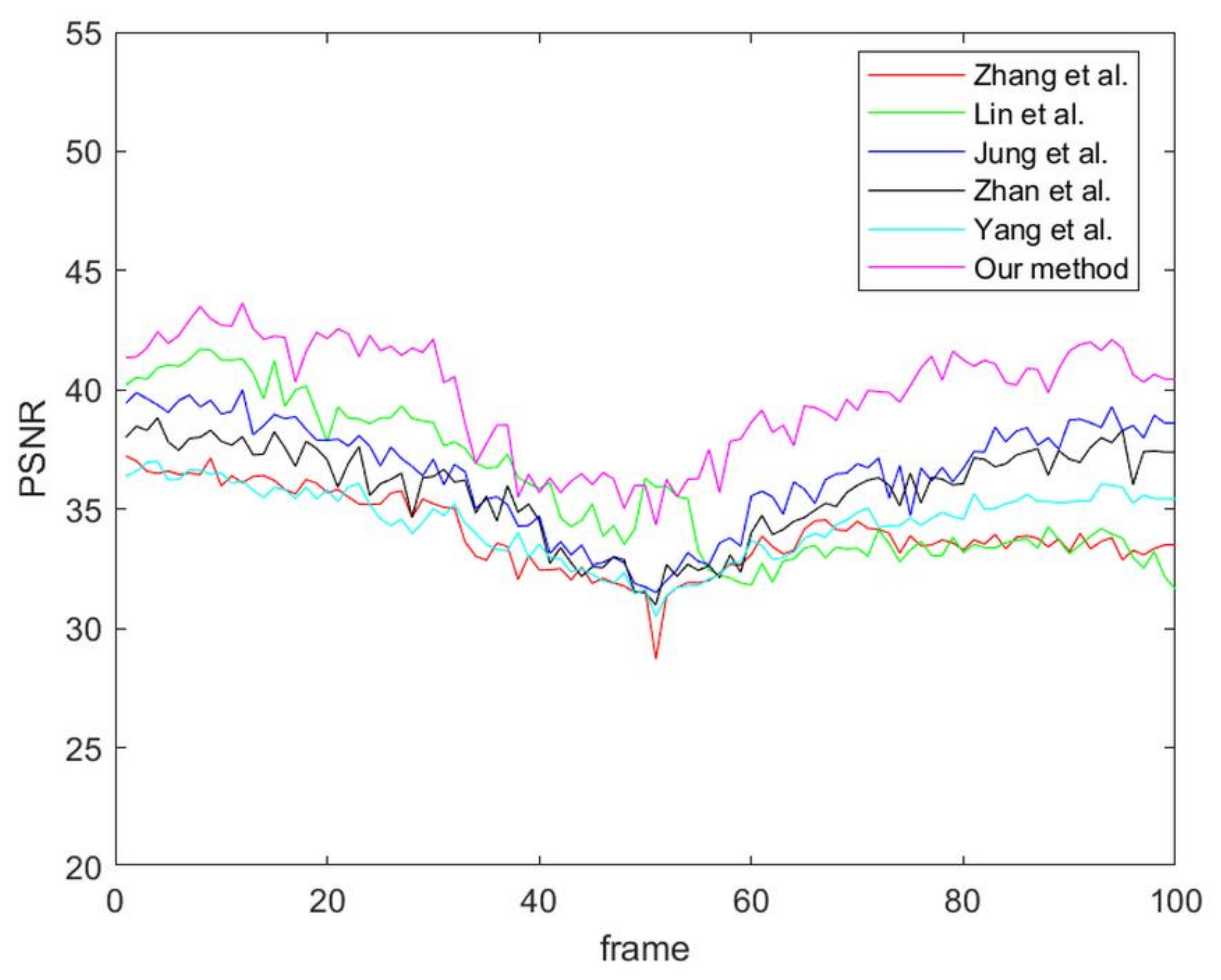
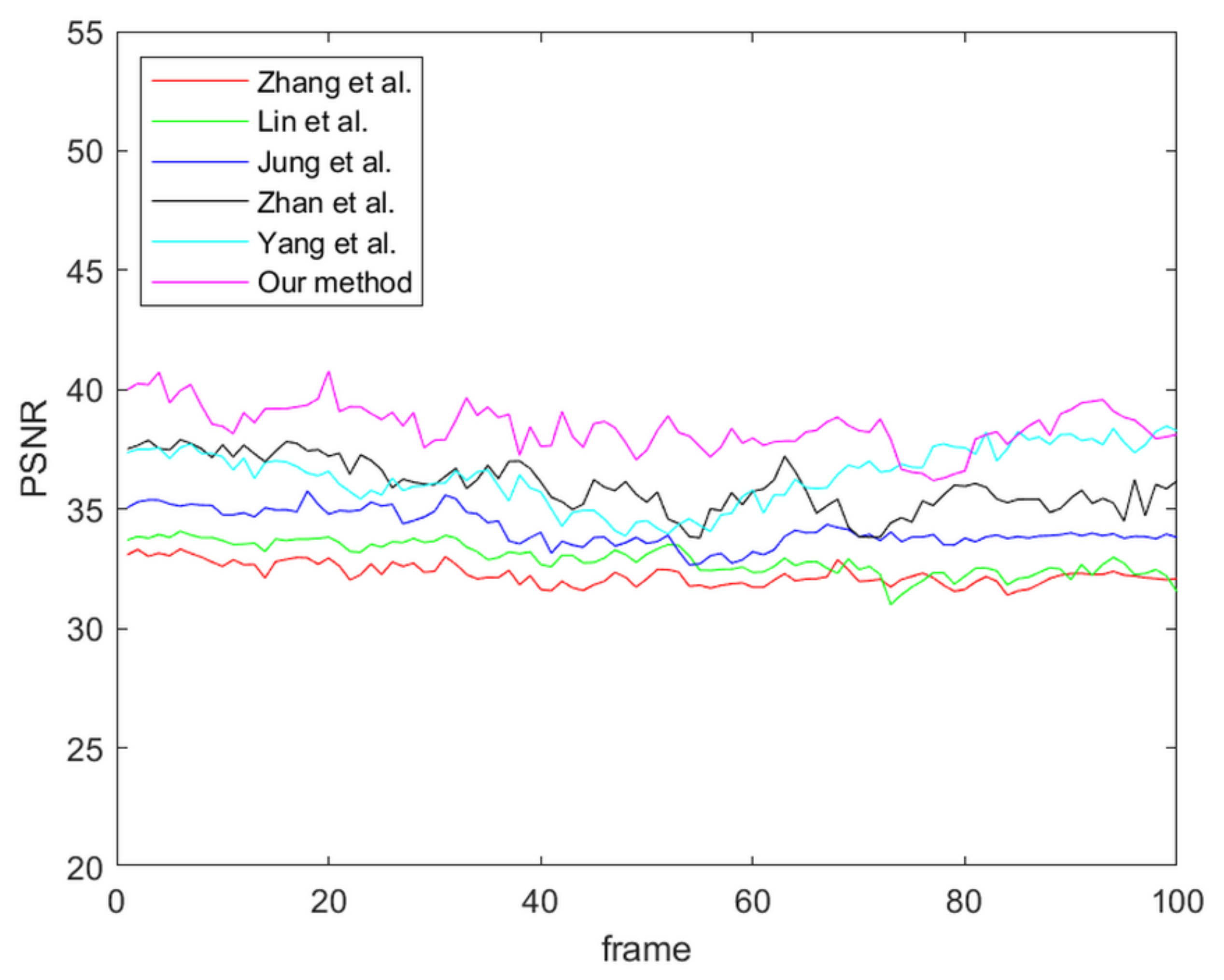
As previously presented in the experimental results, it is clear that the proposed method can efficiently improve the disparity quality and present a smooth disparity map for a video clip. However, the current system cannot search for the correct matching point to refine in the temporal domain refinement if the variation of the object aspect is too abrupt. Processing the variation of the object aspect in the temporal domain will be a major focus of future research.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}