
Customizable Vector Acceleration in Extreme-Edge Computing: A RISC-V Software/Hardware Architecture Study on VGG-16 Implementation

 , ,
, ,
Abstract
1. Introduction
- We report the quantitative evidence of the trade-offs in vector co-processor design and configuration targeting simple edge-computing soft-cores;
- We present details on the small custom RISC-V compliant instruction extension sufficient to support typical vector operations in a tiny soft-core;
- We present a complete yet very simple library of intrinsic functions to support application development, and we discuss the full detail of source code exploiting the co-processor instructions in each VGG-16 layer execution;
- We give insights into the open-source Klessydra processor core microarchitecture.
2. Related Works
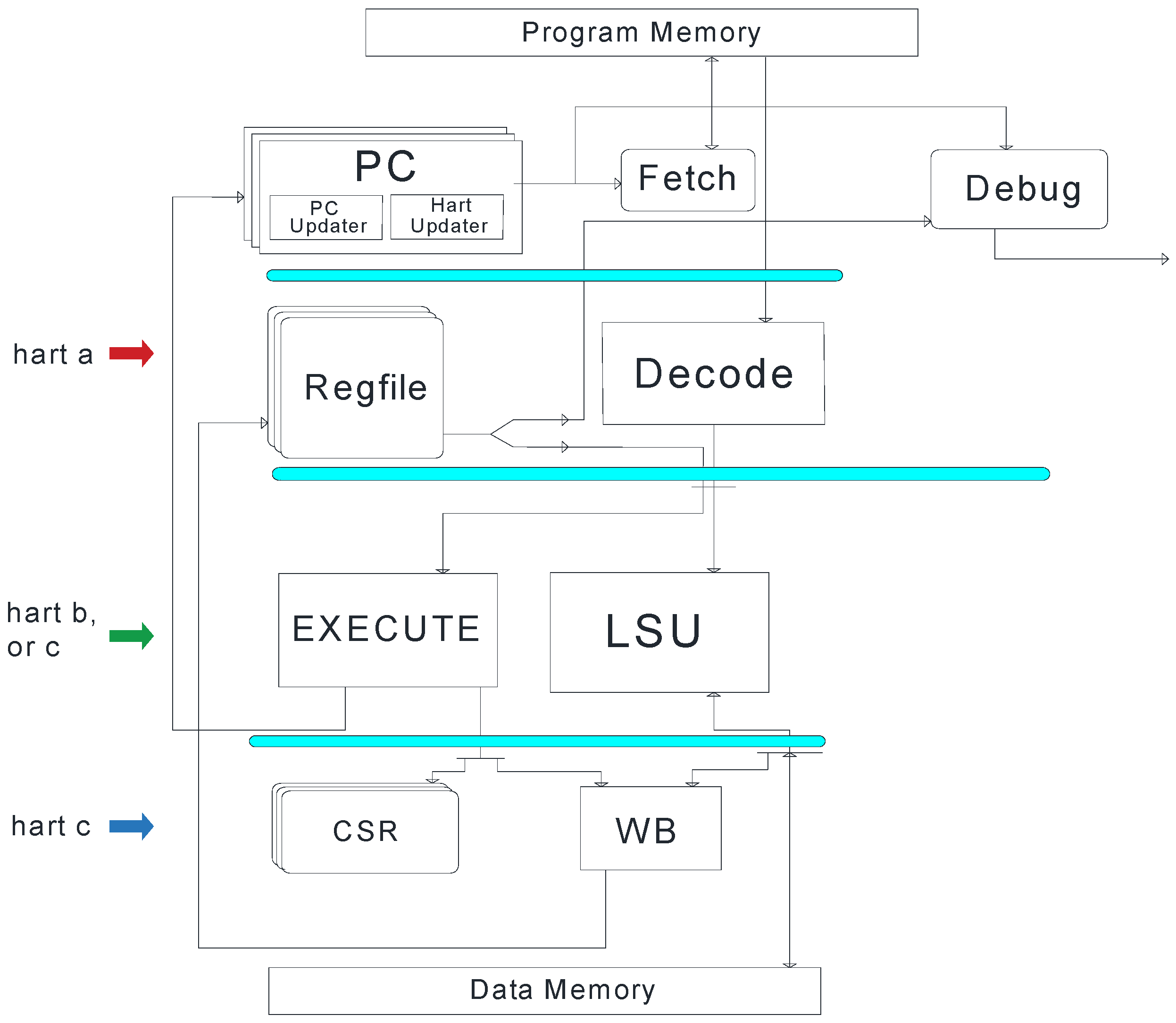
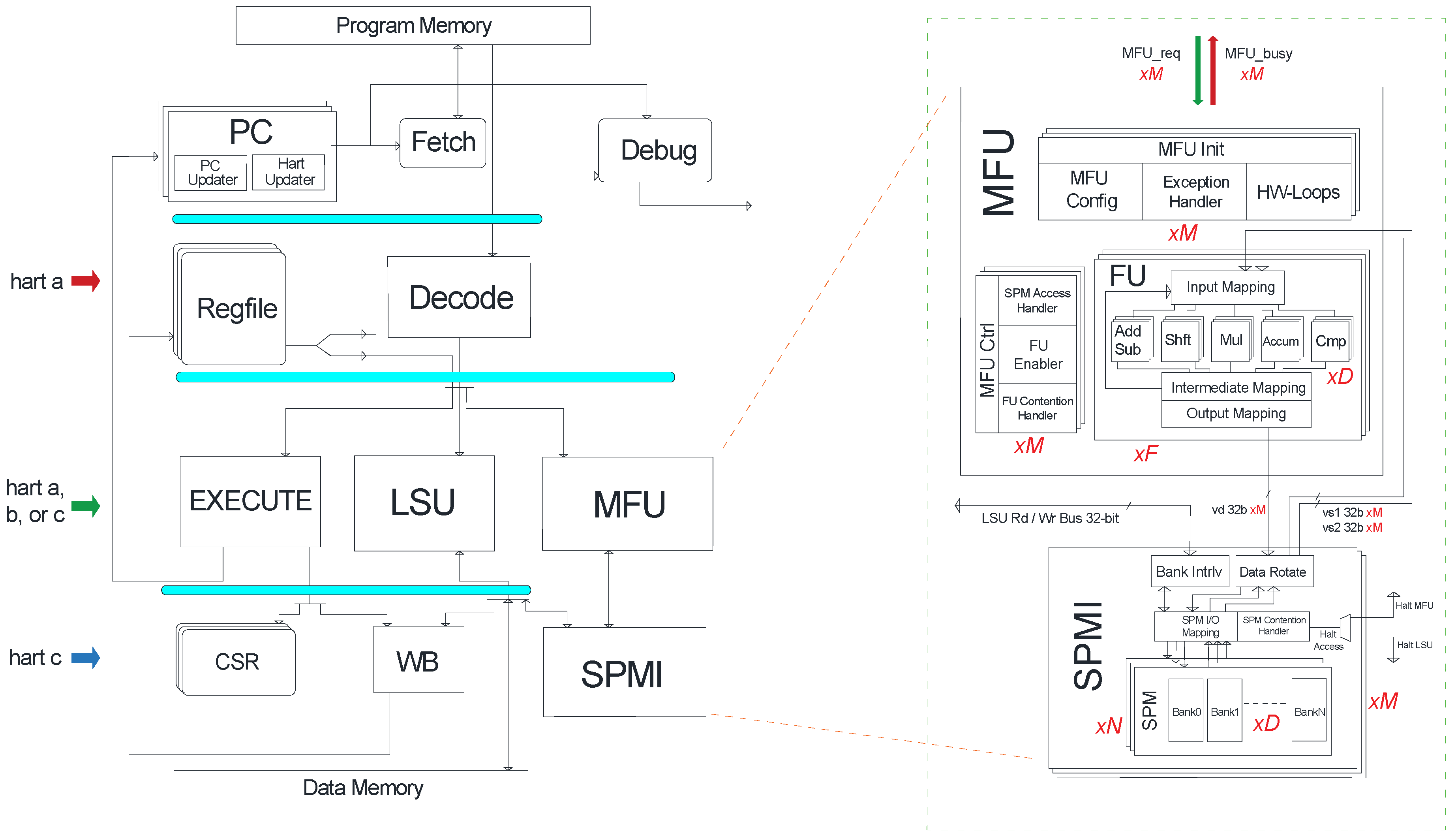
3. The Klessydra T1 Customizable Architecture
3.1. Hardware Microarchitecture
- Thread-Shared coprocessor: All harts in the core share a single MFU/SPM subsystem. Harts in this scheme are required to execute an infinite jump when trying to access the MFU when its busy. In this approach, instruction level parallelism is limited to occur only between coprocessor instructions writing to the SPM and non-coprocessor instructions writing to the main memory or register file. To mitigate the delays on a hart executing an infinite jump, the coprocessor here may exploit pure data level parallelism (DLP) acceleration, by SIMD execution.
- Thread-Dedicated coprocessor: Each hart is appointed a full MFU/SPM subsystem, eliminating inter-hart coprocessor contention and allowing inter-coprocessor parallel execution. Stalls can only happen if the next instruction of the same hart that is using the MFU requests an MFU operation. DLP by SIMD execution can still be exploited in this approach, but also thread level parallelism (TLP) by fully symmetric MIMD execution, allowing execution of multiple vector instructions in parallel.
- Thread-Dedicated SPMIs with a Shared MFU: The harts here maintain a dedicated SPM address space, yet they share the functional units in the MFU. This scheme still allows inter-hart parallel execution of coprocessor instructions, provided they use different internal functional units (FU) of the MFU (e.g., adder, multiplier). Harts that request a busy internal unit in the MFU will be stalled, and their access will be serialized until the contended unit becomes free, while harts that request a free functional unit can work in parallel with the other active harts in the MFU. DLP by SIMD execution can still be exploited in this approach, but also TLP by heterogeneous MIMD execution.
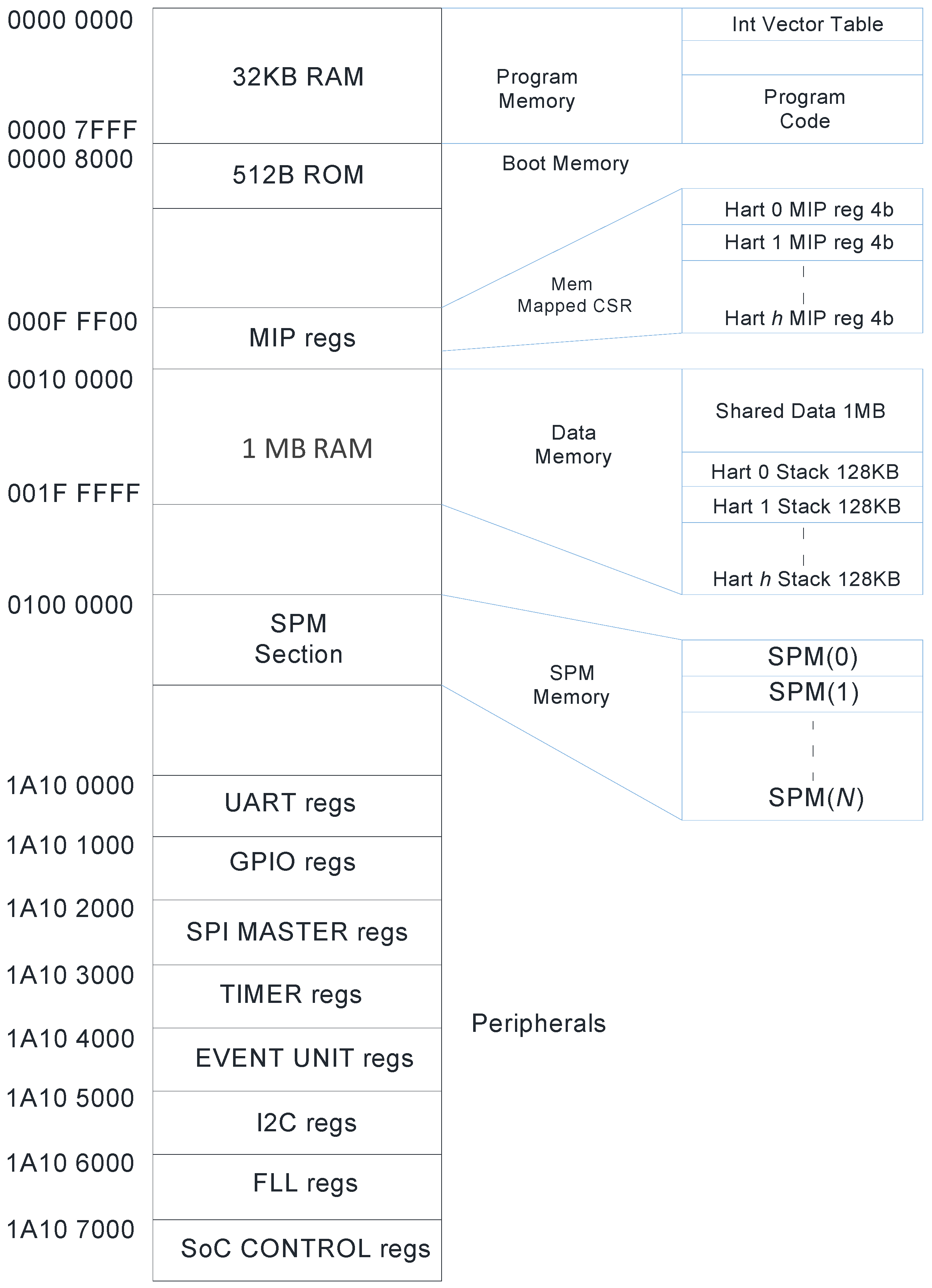
3.2. Programming Paradigm
4. VGG-16 Implementation on Klessydra T1
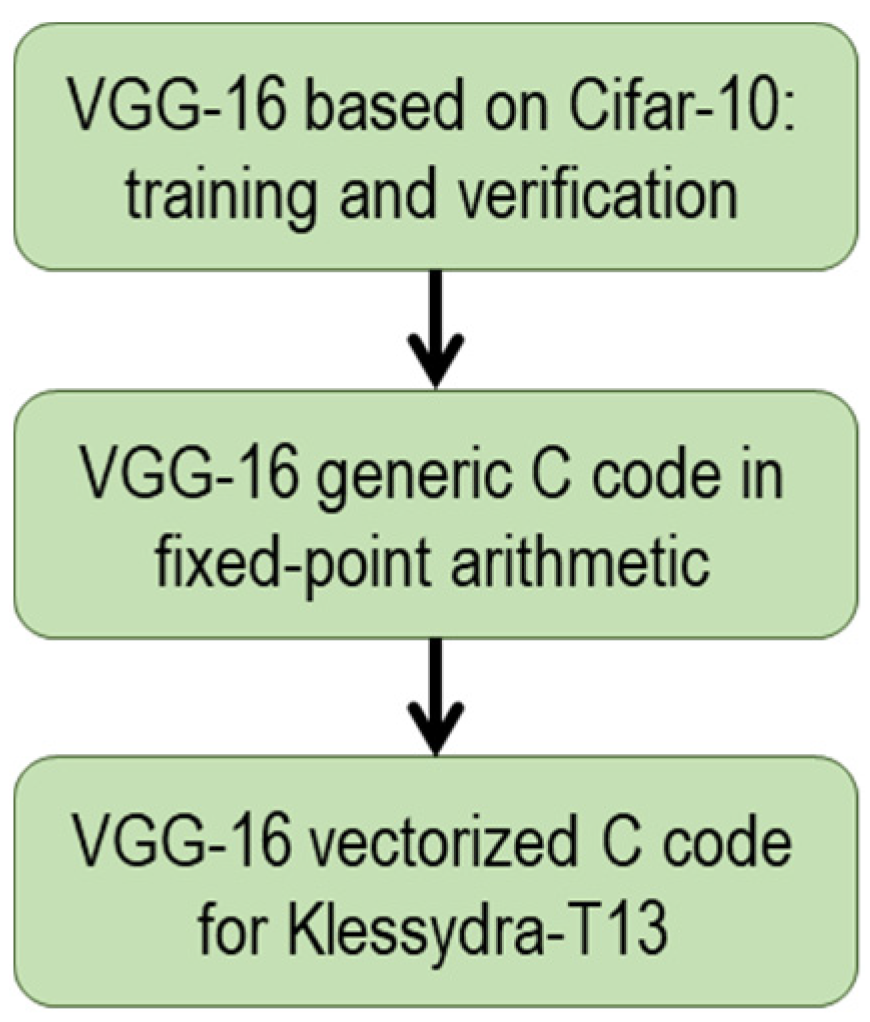
4.1. Implementation Workflow
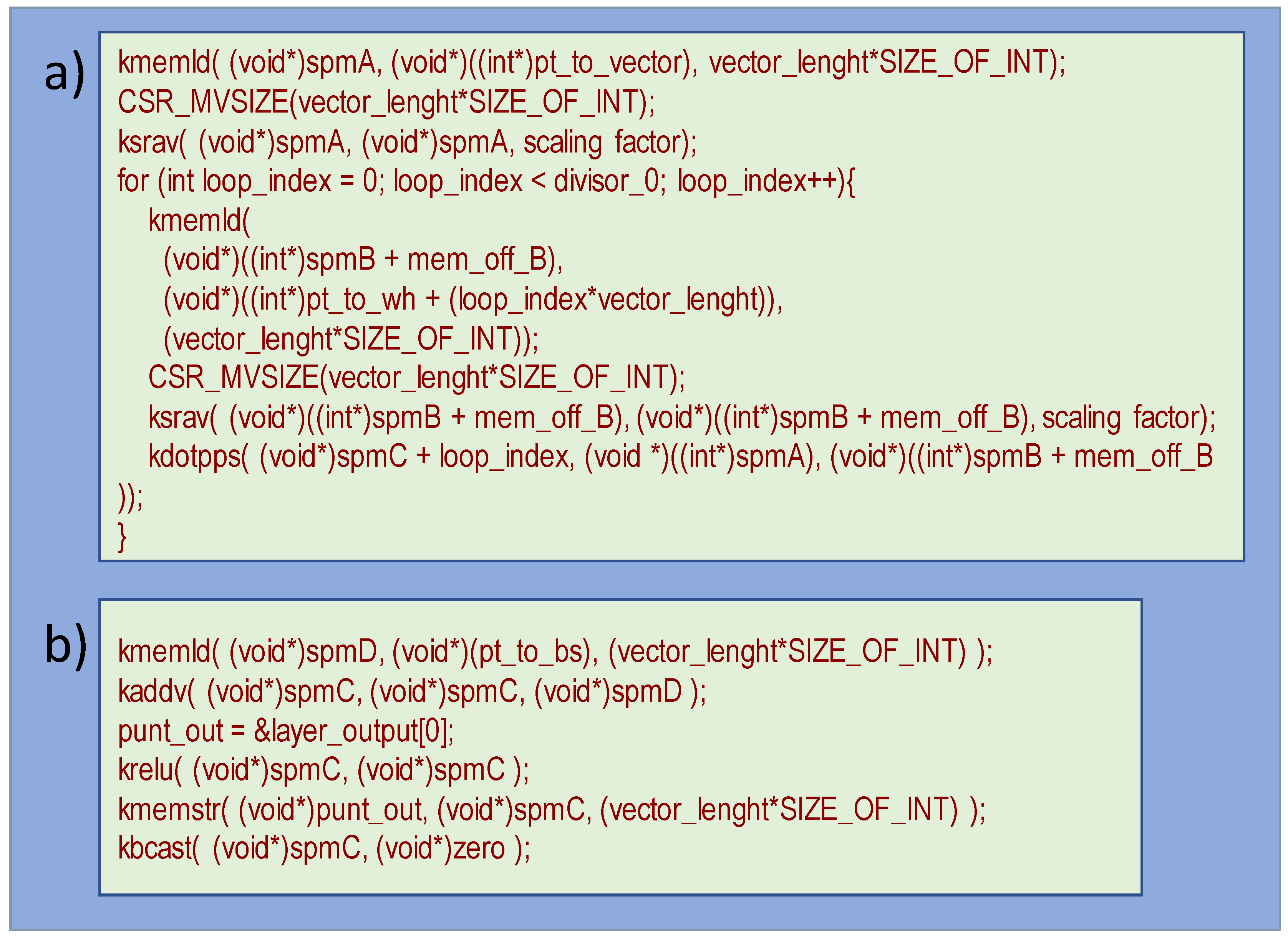
4.2. Generic Fixed-Point C Code Porting
4.3. Vectorized C Code Implementation
5. Performance and Power Analysis
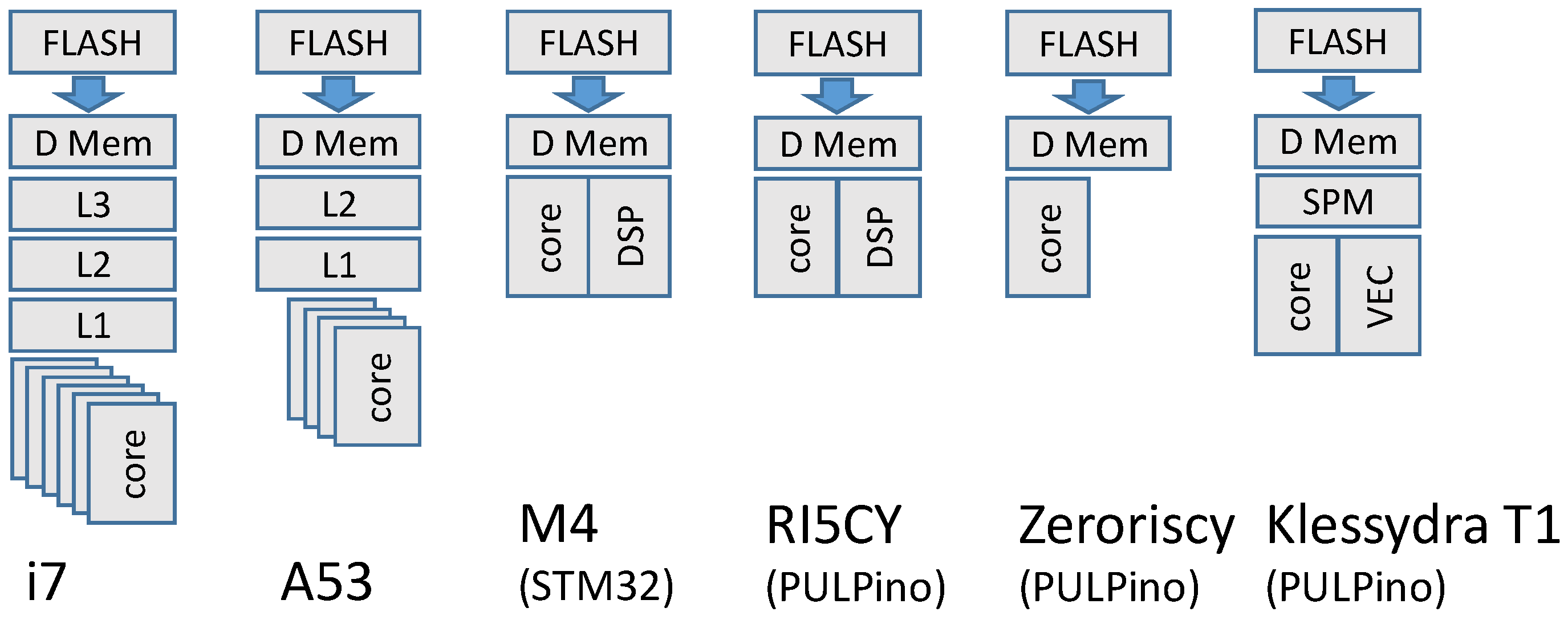
5.1. Setup
- An FPGA board featuring a soft-processor comprised of the extended PULPino platform equipped with the DSP-accelerated RI5CY core, reaching 65 MHz clock frequency;
- An FPGA board featuring a soft-processor comprised of the extended PULPino platform equipped with a Zeroriscy core [29], reaching 77 MHz clock frequency;
- An STM32 single board computer featuring an 84 MHz ARM Cortex M4 core with DSP extension, 96 KB data memory;
- A Raspberry-PI 3b+ single board computer featuring a 1.4 GHz ARM Cortex A53 quad-core CPU, 16 KB L1 cache and 512 KB L2 cache, 1 GB LPDDR2 main memory;
- An x86 single board computer featuring a 3 GHz exa-core, 12-thread i7 CPU, 384 KB L1 cache, 1.5 MB L2 cache, 9 MB LLC, 8 GB DDR4 main memory.
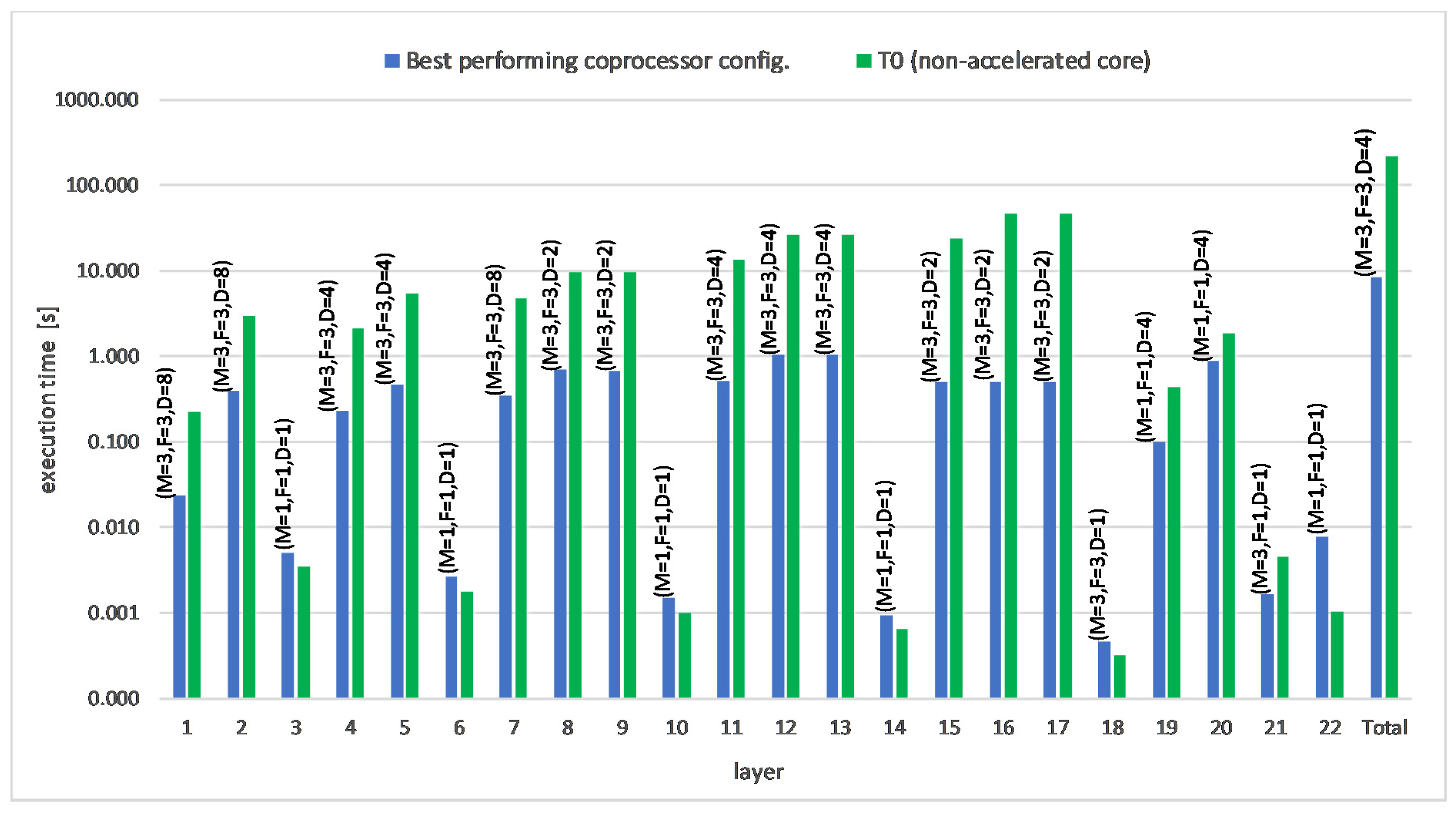
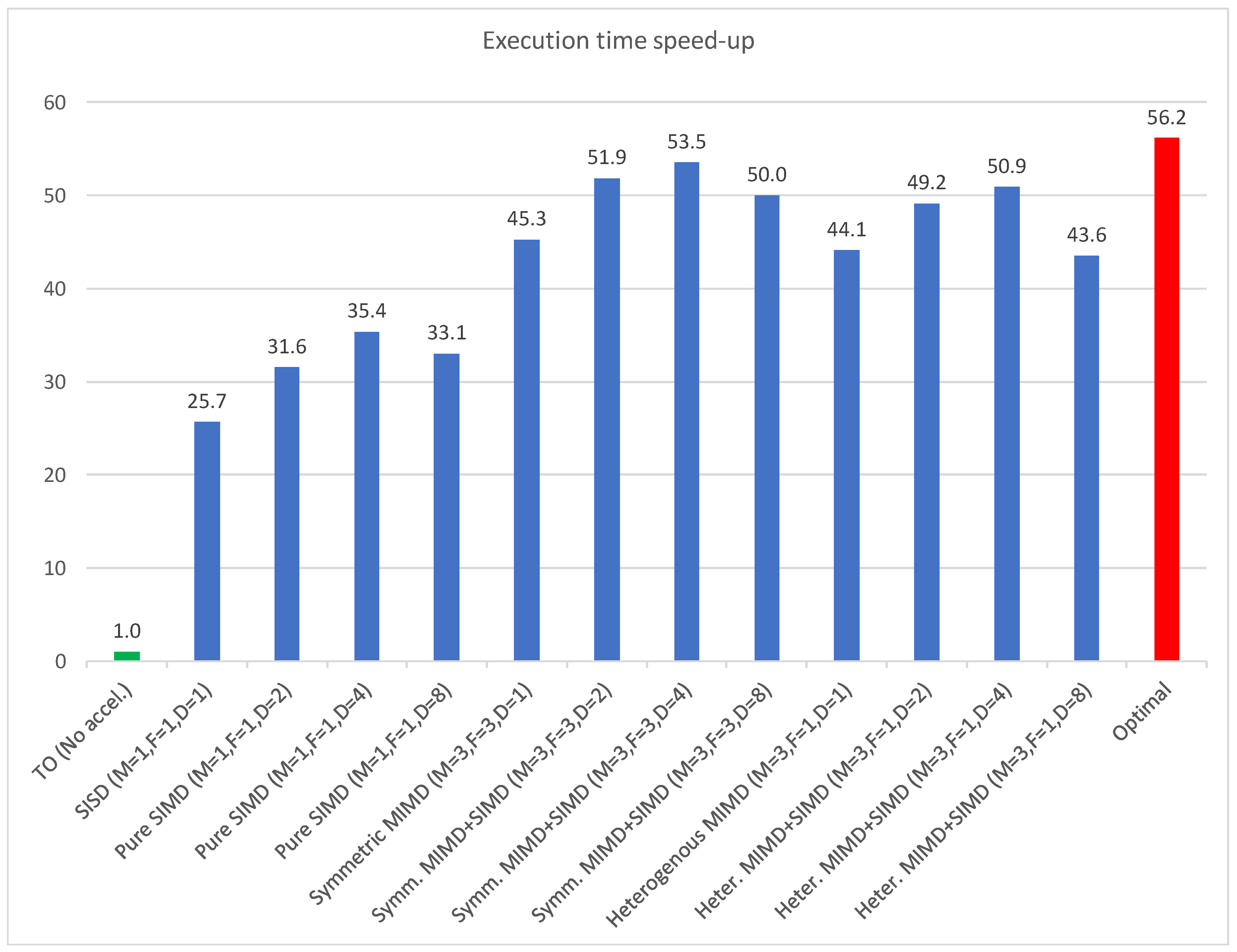
5.2. Results
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Samie, F.; Bauer, L.; Henkel, J. From Cloud Down to Things: An Overview of Machine Learning in Internet of Things. IEEE Internet Things J. 2019, 4662, 1. [Google Scholar] [CrossRef]
- European Processor Intiative (EPI). EU H2020 Research and Innovation Programme GA No 826647. Available online: https://www.european-processor-initiative.eu/project/epi/ (accessed on 26 January 2021).
- RISC-V. Instruction Set Specifications. Available online: https://riscv.org/specifications/ (accessed on 26 January 2021).
- Cheikh, A.; Sordillo, S.; Mastrandrea, A.; Menichelli, F.; Scotti, G.; Olivieri, M. Klessydra-T: Designing Vector Coprocessors for Multi-Threaded Edge-Computing Cores. IEEE Micro 2021, 1. [Google Scholar] [CrossRef]
- Gautschi, M.; Schiavone, P.; Traber, A.; Loi, I.; Pullini, A.; Rossi, D.; Flamand, E.; Gürkaynak, F.; Benini, L. Near-threshold RISC-V core with DSP extensions for scalable IoT endpoint devices. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2017, 25, 2700–2713. [Google Scholar] [CrossRef]
- Seo, S.; Dreslinski, R.G.; Woh, M.; Chakrabarti, C.; Mahlke, S.; Mudge, T. Diet SODA: A power-efficient processor for digital cameras. In Proceedings of the 16th ACM/IEEE International Symposium on Low Power Electronics and Design, Austin, TX, USA, 18–20 August 2010; pp. 79–84. [Google Scholar]
- Chen, Y.H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J. Solid-State Circuits 2016, 52, 127–138. [Google Scholar] [CrossRef]
- Moini, S.; Alizadeh, B.; Emad, M.; Ebrahimpour, R. A resource-limited hardware accelerator for convolutional neural networks in embedded vision applications. IEEE Trans. Circuits Syst. II Express Briefs 2017, 64, 1217–1221. [Google Scholar] [CrossRef]
- Conti, F.; Benini, L. A ultra-low-energy convolution engine for fast brain-inspired vision in multicore clusters. In Proceedings of the IEEE Design, Automation and Test in Europe Conference and Exhibition (DATE), Grenoble, France, 9–13 March 2015; pp. 683–688. [Google Scholar]
- Meloni, P.; Deriu, G.; Conti, F.; Loi, I.; Raffo, L.; Benini, L. Curbing the roofline: A scalable and flexible architecture for CNNs on FPGA. In Proceedings of the ACM International Conference on Computing Frontiers, Como, Italy, 16–18 May 2016; pp. 376–383. [Google Scholar]
- Wu, N.; Jiang, T.; Zhang, L.; Zhou, F.; Ge, F. A Reconfigurable Convolutional Neural Network-Accelerated Coprocessor Based on RISC-V Instruction Set. Electronics 2020, 9, 1005. [Google Scholar] [CrossRef]
- Watanabe, D.; Yano, Y.; Izumi, S.; Kawaguchi, H.; Takeuchi, K.; Hiramoto, T.; Iwai, S.; Murakata, M.; Yoshimoto, M. An Architectural Study for Inference Coprocessor Core at the Edge in IoT Sensing. In Proceedings of the 2nd IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), Genoa, Italy, 23–25 March 2020; pp. 305–309. [Google Scholar]
- Wu, Y.; Wang, J.J.; Qian, K.; Liu, Y.; Guo, R.; Hu, S.G.; Yu, Q.; Chen, T.P.; Liu, Y.; Rong, L. An energy-efficient deep convolutional neural networks coprocessor for multi-object detection. Microelectron. J. 2020, 98, 104737. [Google Scholar] [CrossRef]
- Chang, M.C.; Pan, Z.G.; Chen, J.L. Hardware accelerator for boosting convolution computation in image classification applications. In Proceedings of the 2017 IEEE 6th Global Conference on Consumer Electronics (GCCE), Nagoya, Japan, 24–27 October 2017; pp. 1–2. [Google Scholar]
- Lima, P.; Vieira, C.; Reis, J.; Almeida, A.; Silveira, J.; Goerl, R.; Marcon, C. Optimizing RISC-V ISA Usage by Sharing Coprocessors on MPSoC. In Proceedings of the 2020 IEEE Latin-American Test Symposium (LATS), Maceio, Brazil, 30 March–2 April 2020; pp. 1–5. [Google Scholar]
- Du, L.; Du, Y.; Li, Y.; Su, J.; Kuan, Y.C.; Liu, C.C.; Chang, M.C.F. A reconfigurable streaming deep convolutional neural network accelerator for Internet of Things. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 65, 198–208. [Google Scholar] [CrossRef]
- Olivieri, M.; Cheikh, A.; Cerutti, G.; Mastrandrea, A.; Menichelli, F. Investigation on the optimal pipeline organization in RISC-V multi-threaded soft processor cores. In 2017 New Generation of CAS (NGCAS); IEEE: New York, NY, USA, 2017; pp. 45–48. [Google Scholar]
- Cheikh, A.; Sordillo, S.; Mastrandrea, A.; Menichelli, F.; Olivieri, M. Efficient Mathematical Accelerator Design Coupled with an Interleaved Multi-threading RISC-V Microprocessor. In Proceedings of the International Conference on Applications in Electronics Pervading Industry, Environment and Society, Pisa, Italy, 11–13 September 2019; Springer: Cham, Switzerland, 2019; pp. 529–539. [Google Scholar]
- Lattner, C. RISC-V Vector Extension Intrinsic Support. Available online: https://www.sifive.com/blog/risc-v-vector-extension-intrinsic-support (accessed on 26 January 2021).
- Cavalcante, M.; Schuiki, F.; Zaruba, F.; Schaffner, M.; Benini, L. Ara: A 1-GHz+ Scalable and Energy-Efficient RISC-V Vector Processor with Multiprecision Floating-Point Support in 22-nm FD-SOI. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2020, 28, 530–543. [Google Scholar] [CrossRef]
- Chen, C.; Xiang, X.; Liu, C.; Shang, Y.; Guo, R.; Liu, D.; Lu, Y.; Hao, Z.; Luo, J.; Chen, Z.; et al. Xuantie-910: A Commercial Multi-Core 12-Stage Pipeline Out-of-Order 64-bit High Performance RISC-V Processor with Vector Extension: Industrial Product. In Proceedings of the 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 30 May–3 June 2020; pp. 52–64. [Google Scholar]
- Wright, J.C.; Schmidt, C.; Keller, B.; Dabbelt, D.P.; Kwak, J.; Iyer, V.; Mehta, N.; Chiu, P.-F.; Bailey, S.; Asanovic, K.; et al. A Dual-Core RISC-V Vector Processor with On-Chip Fine-Grain Power Management in 28-nm FD-SOI. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2020, 28, 2721–2725. [Google Scholar] [CrossRef]
- Kimura, Y.; Kikuchi, T.; Ootsu, K.; Yokota, T. Proposal of Scalable Vector Extension for Embedded RISC-V Soft-Core Processor. In Proceedings of the 7th International Symposium on Computing and Networking Workshops (CANDARW), Nagasaki, Japan, 26–29 November 2019; pp. 435–439. [Google Scholar]
- Johns, M.; Kazmierski, T.J. A Minimal RISC-V Vector Processor for Embedded Systems. In Proceedings of the 2020 Forum for Specification and Design Languages (FDL), Kiel, Germany, 15–17 September 2020. [Google Scholar]
- Traber, A.; Gautschi, M. PULPino: Datasheet; ETH: Zurich, Switzerland; University of Bologna: Bologna, Italy, 2017; Available online: https://pulp-platform.org/docs/pulpino_datasheet.pdf (accessed on 26 January 2021).
- Blasi, L.; Vigli, F.; Cheikh, A.; Mastrandrea, A.; Menichelli, F.; Olivieri, M. A RISC-V Fault-Tolerant Microcontroller Core Architecture Based on a Hardware Thread Full/Partial Protection and a Thread-Controlled Watch-Dog Timer. In Proceedings of the International Conference on Applications in Electronics Pervading Industry, Environment and Society, Pisa, Italy, 11–13 September 2019; Springer: Cham, Switzerland, 2019; pp. 505–511. [Google Scholar]
- Cheikh, A.; Cerutti, G.; Mastrandrea, A.; Menichelli, F.; Olivieri, M. The microarchitecture of a multi-threaded RISC-V compliant processing core family for IoT end-nodes. In Proceedings of the International Conference on Applications in Electronics Pervading Industry, Environment and Society, Rome, Italy, 21–22 September 2017; Springer: Cham, Switzerland, 2017; pp. 89–97. [Google Scholar]
- Genesys 2 Kintex-7 FPGA Development Board. Available online: https://reference.digilentinc.com/reference/programmable-logic/genesys-2/start?redirect=1 (accessed on 26 January 2021).
- Schiavone, P.D.; Conti, F.; Rossi, D.; Gautschi, M.; Pullini, A.; Flamand, E.; Benini, L. Slow and steady wins the race? A comparison of ultra-low-power risc-v cores for internet-of-things applications. In Proceedings of the 27th International Symposium on Power and Timing Modeling, Optimization and Simulation (PATMOS), Thessaloniki, Greece, 25–27 September 2017; pp. 1–8. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| M (Number of SPMI Units) | F (Number of FUs) | D (Number of Lanes in Each FU) | Execution Paradigm |
|---|---|---|---|
| 1 | 1 | 1 | SISD |
| 1 | 1 | 2, 4, 8 | Pure SIMD |
| 3 | 3 | 1 | Symmetric MIMD |
| 3 | 3 | 2, 4, 8 | Symmetric MIMD + SIMD |
| 3 | 1 | 1 | Heterogenous MIMD |
| 3 | 1 | 2, 4, 8 | Heterogenous MIMD + SIMD |
| Assembly Syntax—(r) Denotes Memory Addressing via Register r | Function Declaration | Short Description |
|---|---|---|
| kmemld (rd), (rs1), (rs2) | kmemld((void*) rd, (void*) rs1, (int) rs2) | load vector into scratchpad region |
| kmemstr (rd), (rs1), (rs2) | kmemstr((void*) rd, (void*) rs1, (int) rs2) | store vector into main memory |
| kaddv (rd), (rs1), (rs2) | kaddv((void*) rd, (void*) rs1, (void*) rs2) | adds vectors in scratchpad region |
| ksubv (rd), (rs1), (rs2) | ksubv((void*) rd, (void*) rs1, (void*) rs2) | subtract vectors in scratchpad region |
| kvmul (rd), (rs1), (rs2) | kvmul((void*) rd, (void*) rs1, (void*) rs2) | multiply vectors in scratchpad region |
| kvred (rd), (rs1) | kvred((void*) rd, (void*) rs1) | reduce vector by addition |
| kdotp (rd), (rs1), (rs2) | kdotp((void*) rd, (void*) rs1, (void*) rs2) | vector dot product into register |
| ksvaddsc (rd), (rs1), (rs2) | ksvaddsc((void*) rd, (void*) rs1, (void*) rs2) | add vector + scalar into scratchpad |
| ksvaddrf (rd), (rs1), rs2 | ksvaddrf((void*) rd, (void*) rs1, (int) rs2) | add vector + scalar into register |
| ksvmulsc (rd), (rs1), (rs2) | ksvmulsc((void*) rd, (void*) rs1, (void*) rs2) | multiply vector + scalar into scratchpad |
| ksvmulrf (rd), (rs1), rs2 | ksvmulrf((void*) rd, (void*) rs1, (int) rs2) | multiply vector + scalar into register |
| kdotpps (rd), (rs1), (rs2) | kdotpps((void*) rd, (void*) rs1, (void*) rs2) | vector dot product and post scaling |
| ksrlv (rd), (rs1), rs2 | ksrlv((void*) rd, (void*) rs1, (int) rs2) | vector logic shift within scratchpad |
| ksrav (rd), (rs1), rs2 | ksrav((void*) rd, (void*) rs1, (int) rs2) | vector arithmetic shift within scratchpad |
| krelu (rd), (rs1) | krelu((void*) rd, (void*) rs1) | vector ReLu within scratchpad |
| kvslt (rd), (rs1), (rs2) | kvslt((void*) rd, (void*) rs1, (void*) rs2) | compare vectors and create mask vector |
| ksvslt (rd), (rs1), rs2 | ksvslt((void*) rd, (void*) rs1, (int) rs2) | compare vector-scalar and create mask |
| kvcp (rd), (rs1) | ksrlv((void*) rd, (void*) rs1) | copy vector within scratchpad region |
| csr MVSIZE, rs1 | mvsize((int) rs1) | vector length setting |
| csr MVTYPE, rs1 | mvtype((int) rs1) | element width setting (8, 16, 32 bits) |
| csr MPSCLFAC, rs1 | mpsclfac((int) rs1) | post scaling factor (kdotpps instruction) |
| Layer Number | Computation Type | Matrix Size |
|---|---|---|
| 1 | Convolution | 32 × 32 |
| 2 | Convolution | 32 × 32 |
| 3 | Max Pool | 16 × 16 |
| 4 | Convolution | 16 × 16 |
| 5 | Convolution | 16 × 16 |
| 6 | Max Pool | 8 × 8 |
| 7 | Convolution | 8 × 8 |
| 8 | Convolution | 8 × 8 |
| 9 | Convolution | 8 × 8 |
| 10 | Max Pool | 4 × 4 |
| 11 | Convolution | 4 × 4 |
| 12 | Convolution | 4 × 4 |
| 13 | Convolution | 4 × 4 |
| 14 | Max Pool | 2 × 2 |
| 15 | Convolution | 2 × 2 |
| 16 | Convolution | 2 × 2 |
| 17 | Convolution | 2 × 2 |
| 18 | Max Pool | 1 × 1 |
| 19 | Fully connected | 512 × 512 |
| 20 | Fully connected | 4096 × 4096 |
| 21 | Fully connected | 4096 × 4096 |
| 22 | Softmax | 10 |
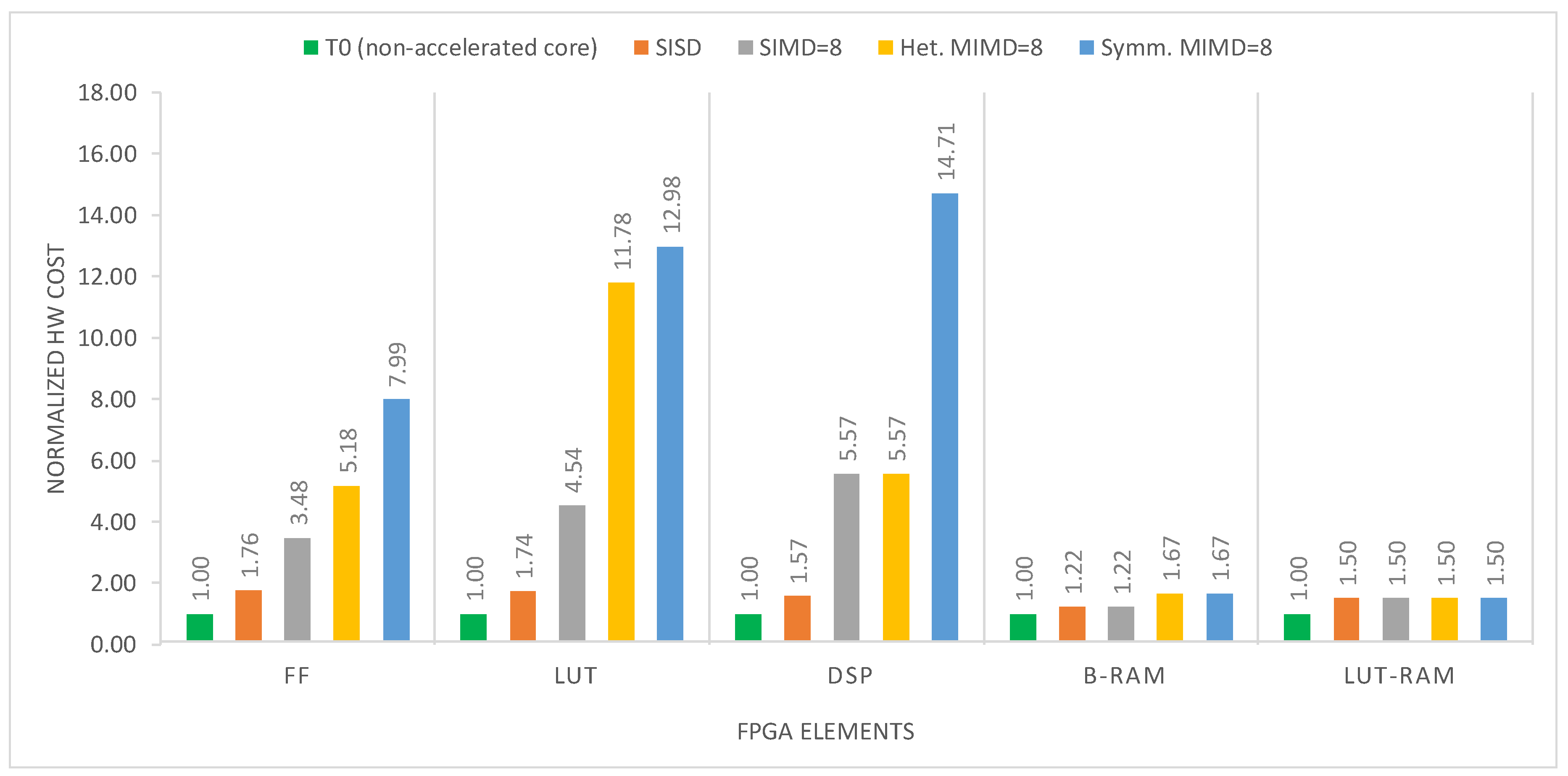
| Configuration | Hardware Utilization | Top Freq. [MHz] | ||||
|---|---|---|---|---|---|---|
| FF | LUT | DSP | B-RAM | LUT-RAM | ||
| SISD (M = 1, F = 1, D = 1) | 2482 | 7083 | 11 | 88 | 264 | 132.1 |
| Pure SIMD (M = 1, F = 1, D = 2) | 2664 | 9010 | 15 | 88 | 264 | 127.0 |
| Pure SIMD (M = 1, F = 1, D = 4) | 3510 | 11,678 | 23 | 88 | 264 | 125.5 |
| Pure SIMD (M = 1, F = 1, D = 8) | 4904 | 18,531 | 39 | 88 | 264 | 112.6 |
| Symmetric MIMD (M = 3, F = 3, D = 1) | 3509 | 10,701 | 19 | 120 | 264 | 114.2 |
| Symmetric MIMD+SIMD (M = 3, F = 3, D = 2) | 4659 | 16,556 | 31 | 120 | 264 | 113.9 |
| Symmetric MIMD+SIMD (M = 3, F = 3, D = 4) | 6746 | 27,485 | 55 | 120 | 264 | 108.9 |
| Symmetric MIMD+SIMD (M = 3, F = 3, D = 8) | 11,253 | 52,930 | 103 | 120 | 264 | 96.3 |
| Heterogenous MIMD (M = 3, F = 1, D = 1) | 3025 | 10,655 | 11 | 120 | 264 | 119.9 |
| Heterogenous MIMD+SIMD (M = 3, F = 1, D = 2) | 3741 | 17,161 | 15 | 120 | 264 | 115.7 |
| Heterogenous MIMD+SIMD (M = 3, F = 1, D = 4) | 4767 | 25,535 | 23 | 120 | 264 | 110.4 |
| Heterogenous MIMD+SIMD (M = 3, F = 1, D = 8) | 7303 | 48,066 | 39 | 120 | 264 | 91.5 |
| T0 (No accl) | 1409 | 4079 | 7 | 72 | 176 | 194.6 |
| RI5CY | 1307 | 6351 | 6 | 72 | 0 | 65.1 |
| Zeroriscy | 1605 | 2834 | 1 | 72 | 0 | 77.2 |
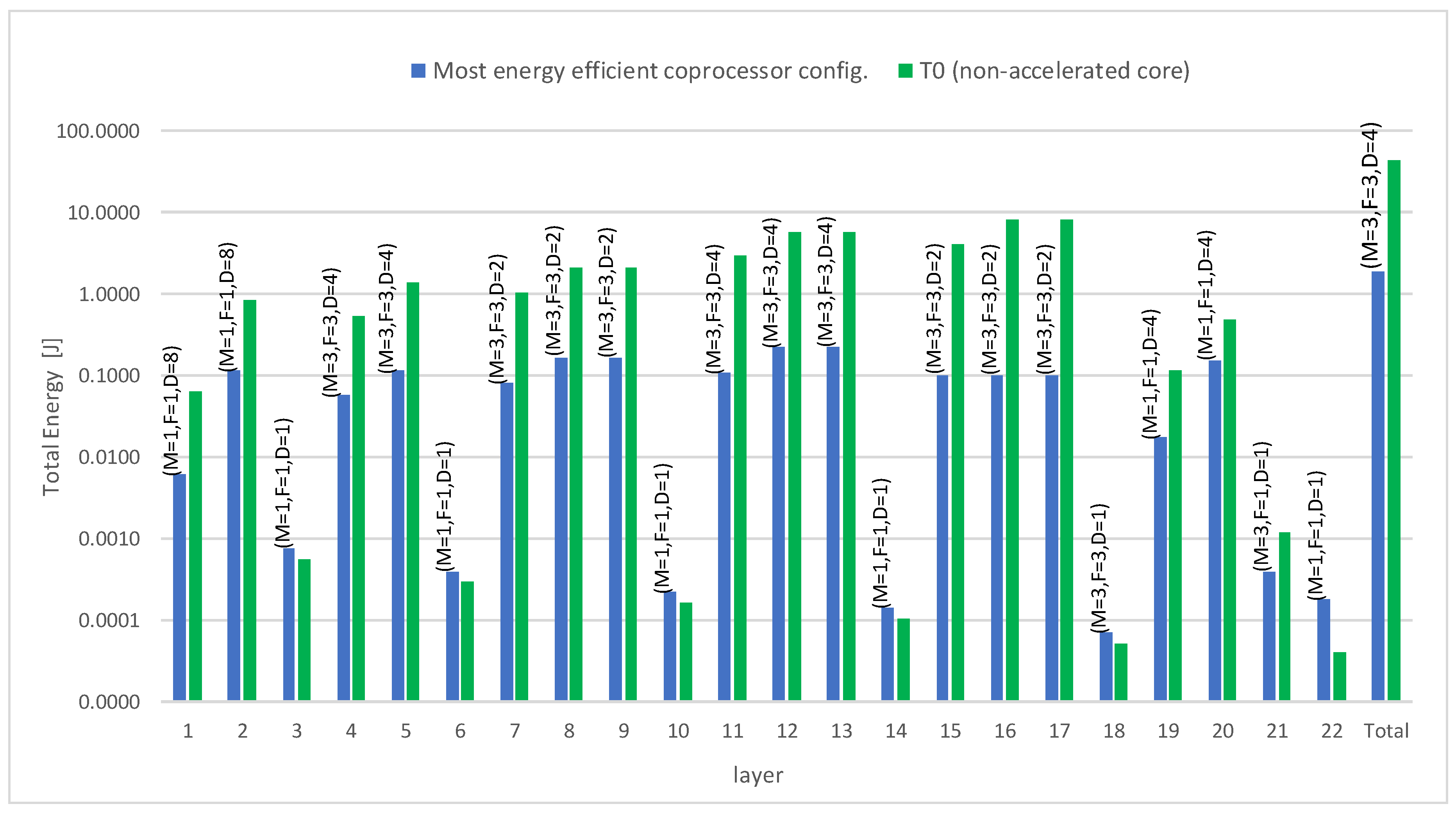
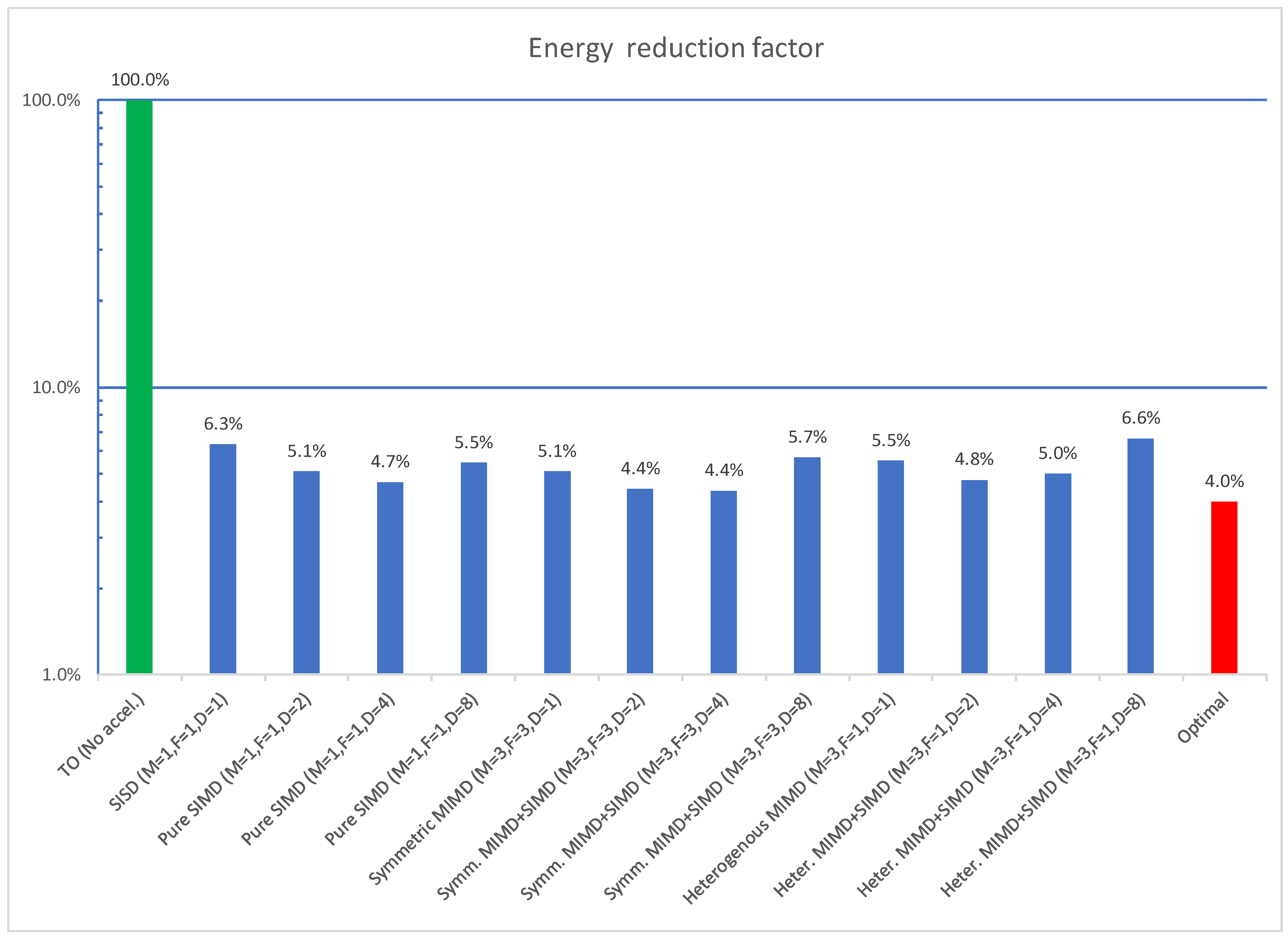
| Processor | Time [s] | Energy [J] | Energy per op [pJ/op] |
|---|---|---|---|
| Core i7 PC board | 0.08 | 2.90 | 21 |
| Cortex A53 Raspberry Pi 3 | 0.89 | 2.32 | 17 |
| Cortex M4 STM32 | 117.78 | 7.77 | 55 |
| RI5CY PULPino on FPGA | 444.30 | 40.06 | 285 |
| Zeroriscy PULPino on FPGA | 548.04 | 38.90 | 277 |
| Klessydra-T1 PULPino on FPGA | 7.91 | 1.74 | 12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sordillo, S.; Cheikh, A.; Mastrandrea, A.; Menichelli, F.; Olivieri, M. Customizable Vector Acceleration in Extreme-Edge Computing: A RISC-V Software/Hardware Architecture Study on VGG-16 Implementation. Electronics 2021, 10, 518. https://doi.org/10.3390/electronics10040518
Sordillo S, Cheikh A, Mastrandrea A, Menichelli F, Olivieri M. Customizable Vector Acceleration in Extreme-Edge Computing: A RISC-V Software/Hardware Architecture Study on VGG-16 Implementation. Electronics. 2021; 10(4):518. https://doi.org/10.3390/electronics10040518
Chicago/Turabian StyleSordillo, Stefano, Abdallah Cheikh, Antonio Mastrandrea, Francesco Menichelli, and Mauro Olivieri. 2021. "Customizable Vector Acceleration in Extreme-Edge Computing: A RISC-V Software/Hardware Architecture Study on VGG-16 Implementation" Electronics 10, no. 4: 518. https://doi.org/10.3390/electronics10040518
APA StyleSordillo, S., Cheikh, A., Mastrandrea, A., Menichelli, F., & Olivieri, M. (2021). Customizable Vector Acceleration in Extreme-Edge Computing: A RISC-V Software/Hardware Architecture Study on VGG-16 Implementation. Electronics, 10(4), 518. https://doi.org/10.3390/electronics10040518