
Numerical Evaluation on Parametric Choices Influencing Segmentation Results in Radiology Images—A Multi-Dataset Study

 , ,
, , 
Abstract
1. Introduction
- We tested different combinations of parameters for organ segmentation on CT modality, including liver, cardiac and pancreas.
- Analysis of incremental performance while using these combinations were carried out.
- We present persistent results on the pre-trained CNN models using the proposed combinations, which convincingly provide better performance on multi-dataset segmentation on CT images.
2. Related Works
3. Materials and Methods
3.1. Convolutional Neural Networks
3.2. Weight Initialization
3.2.1. LeCun Initialization
3.2.2. Xavier Initialization
3.2.3. He Initialization
3.2.4. Random Normal Initialization
3.3. Optimizers
3.3.1. RMSprop
3.3.2. Adam
3.4. Loss Functions
3.4.1. Softmax-Cross Entropy Loss
3.4.2. Dice Loss
3.5. Activation Functions
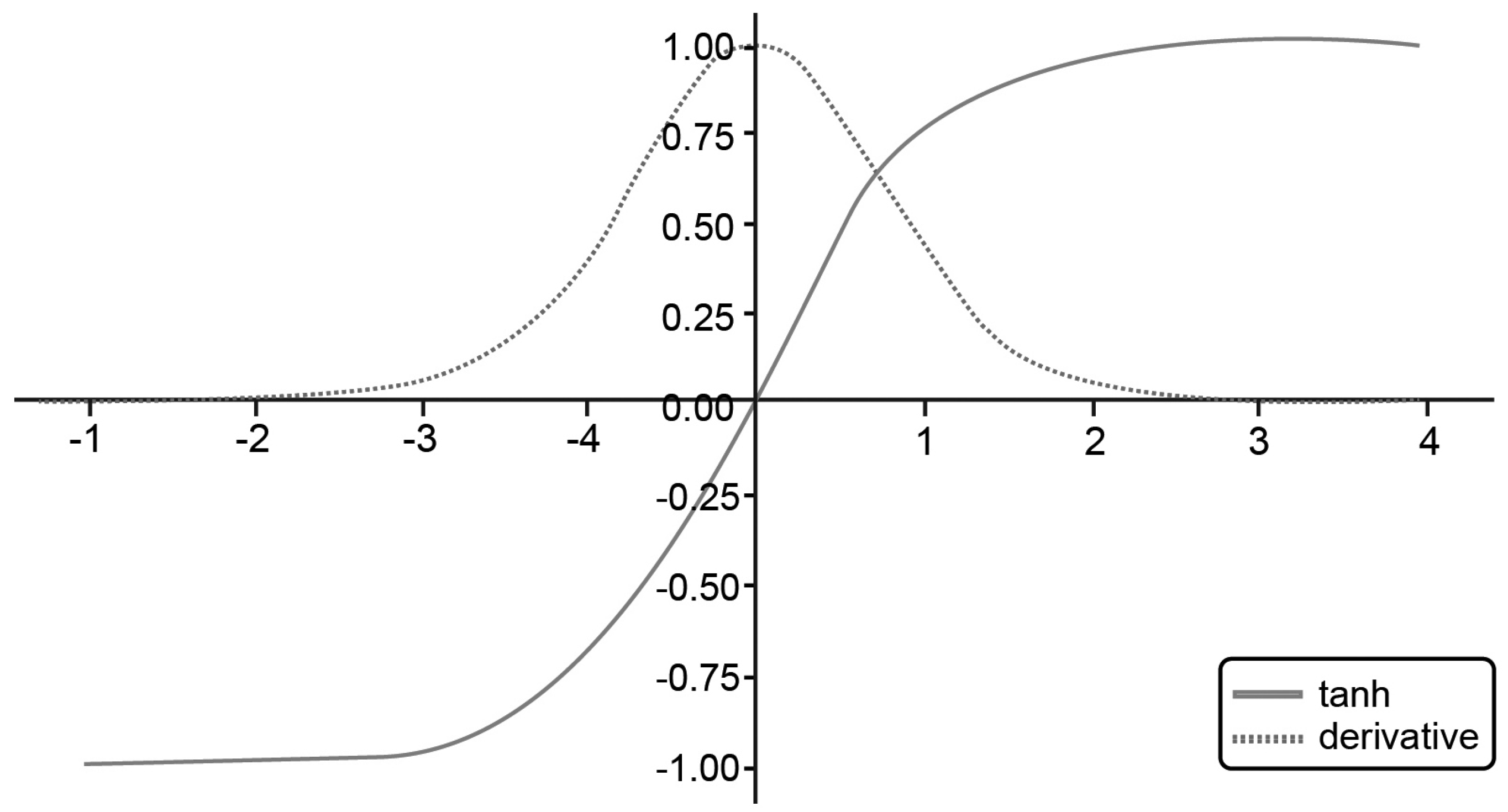
3.5.1. Tanh Activation Function
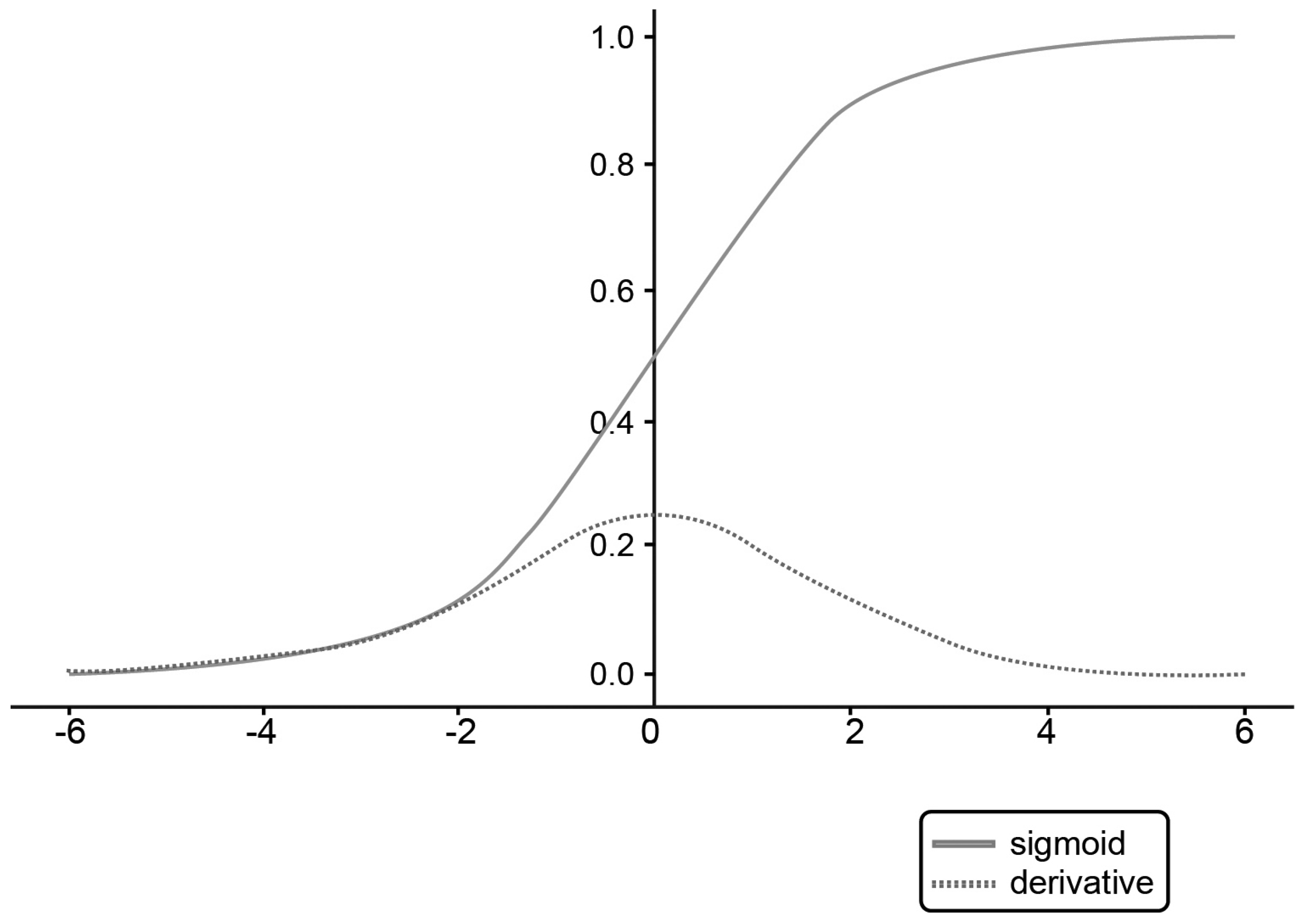
3.5.2. Sigmoid Activation Function
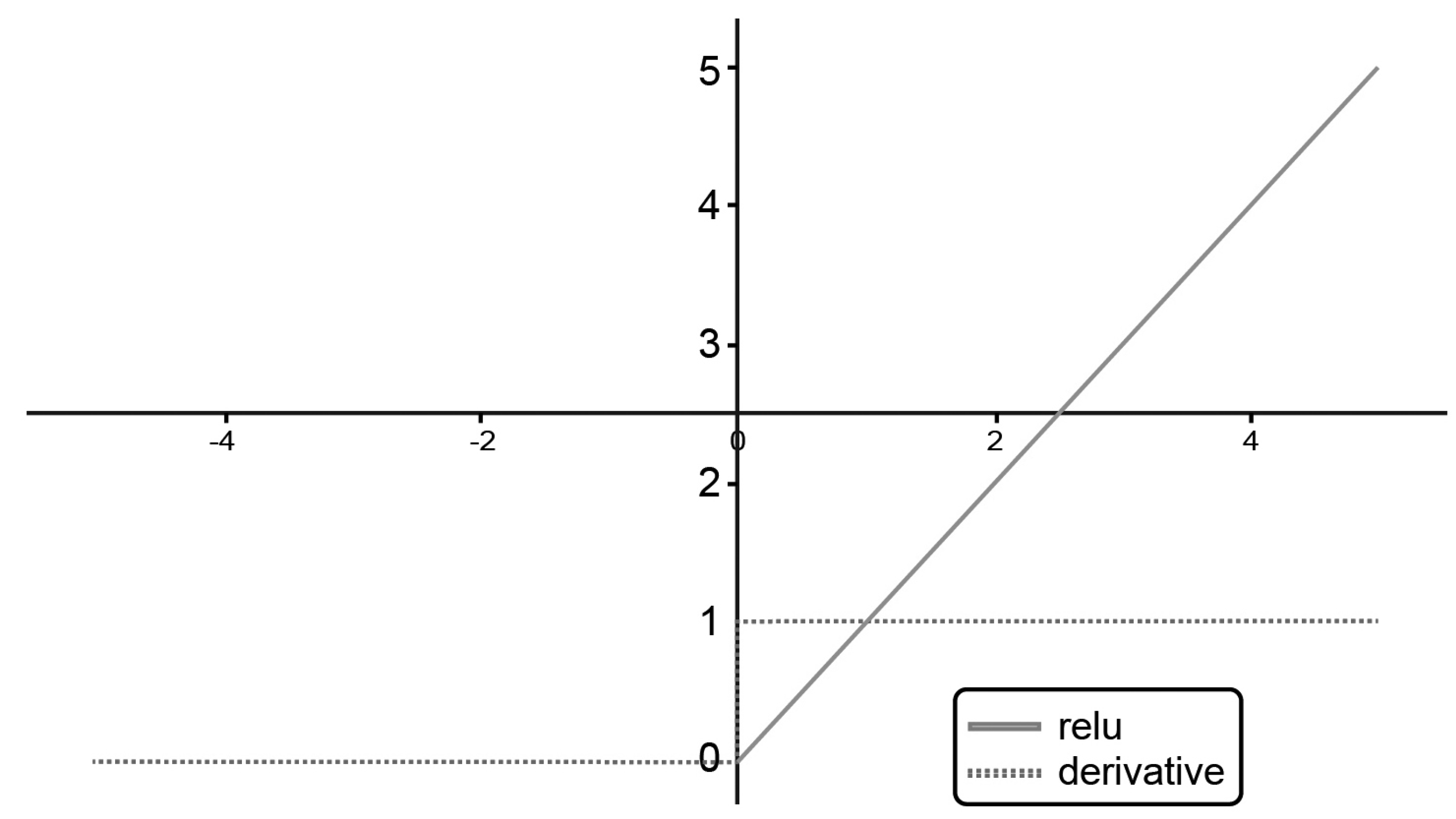
3.5.3. ReLU Activation Function
3.6. Dataset
3.6.1. Liver—LiTS
3.6.2. Medical Segmentation Decathlon
3.7. Experiment 1
3.8. Experiment 2
3.9. Segmentation Evaluation Methods
3.9.1. Dice Coefficient (DICE)
3.9.2. Hausdorff Distance (HD)
3.9.3. Average Hausdorff Distance (AVD)
3.9.4. Mahalanobis Distance (MHD)
3.9.5. Mutual Information (MI)
3.9.6. Variation of Information (VOI)
3.9.7. Area under ROC Curve (AUC)
3.9.8. Volumetric Similarity (VS)
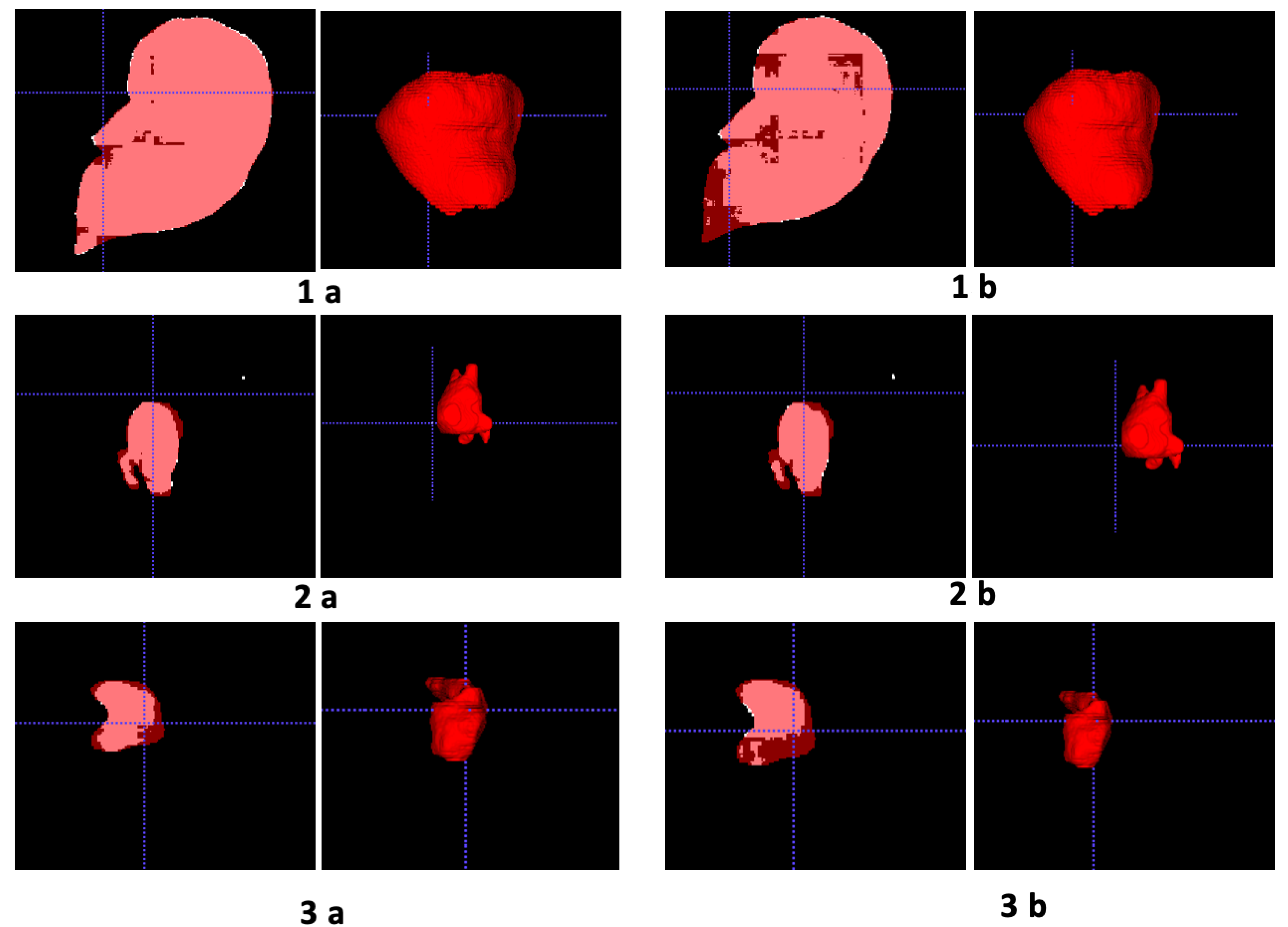
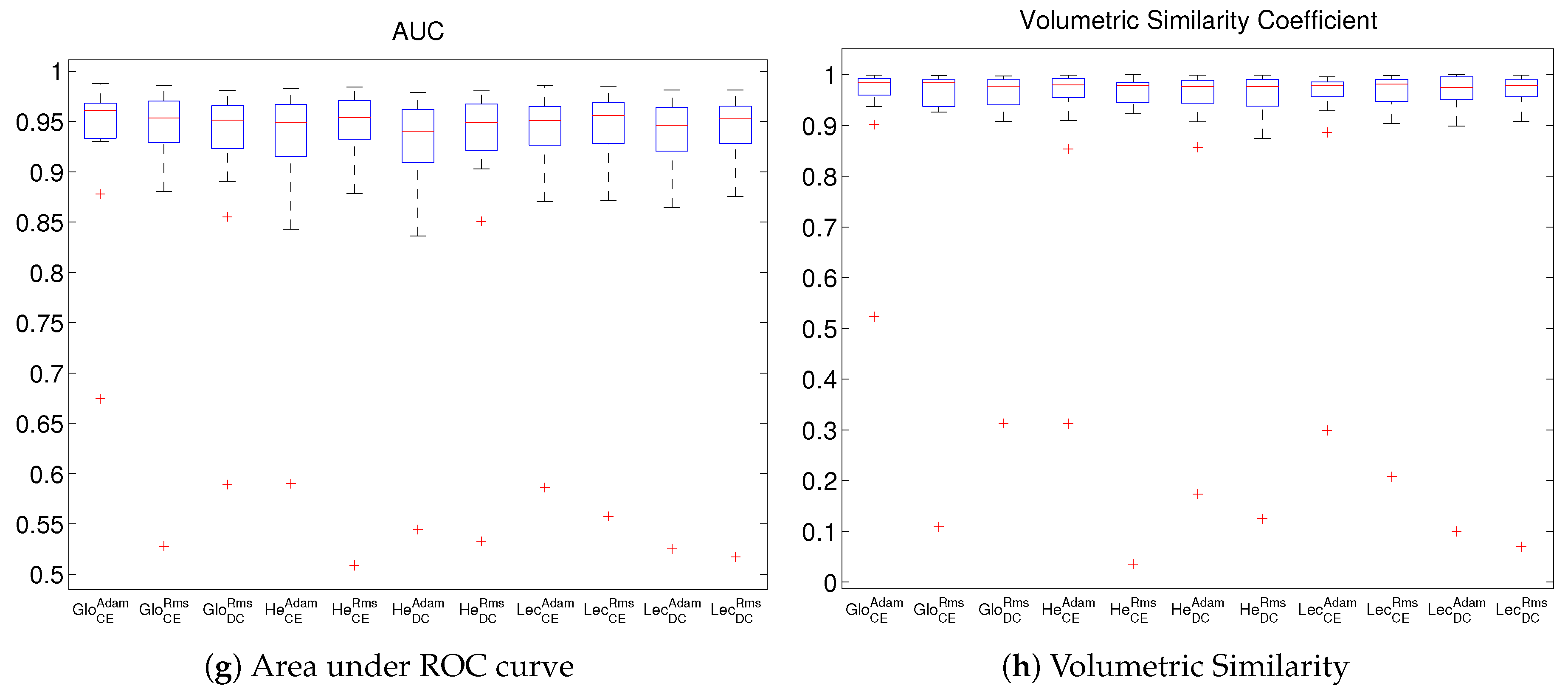
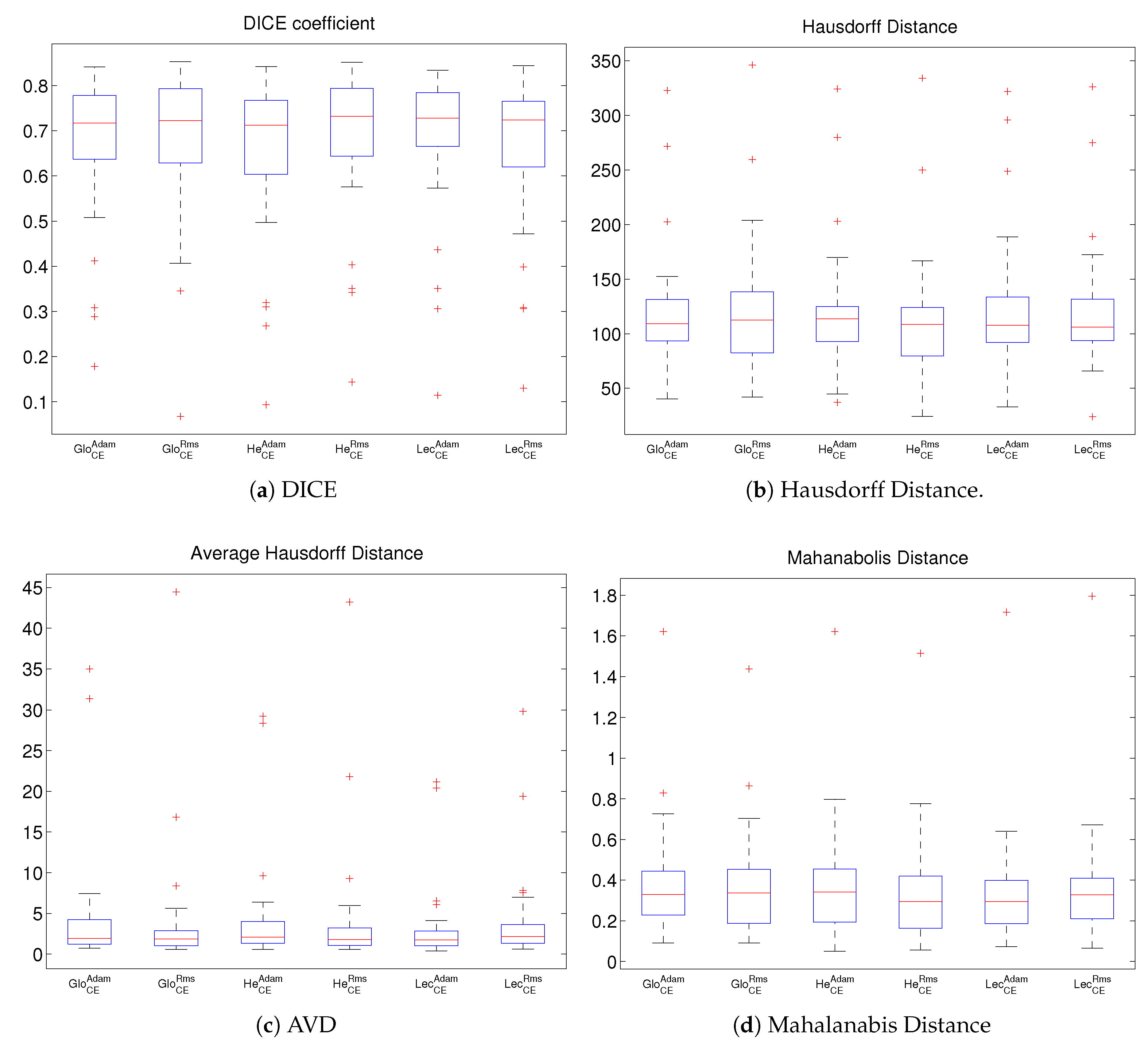
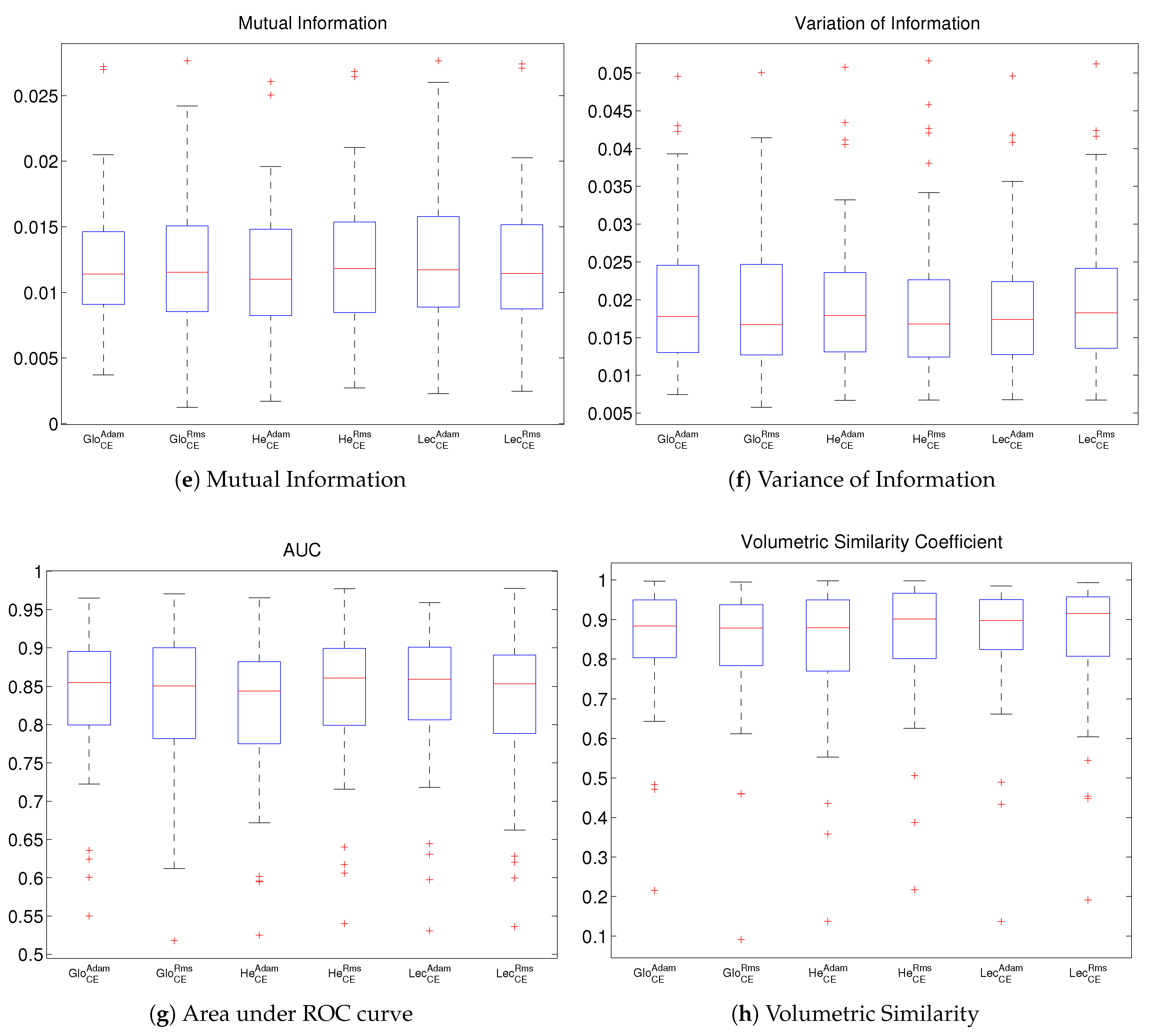
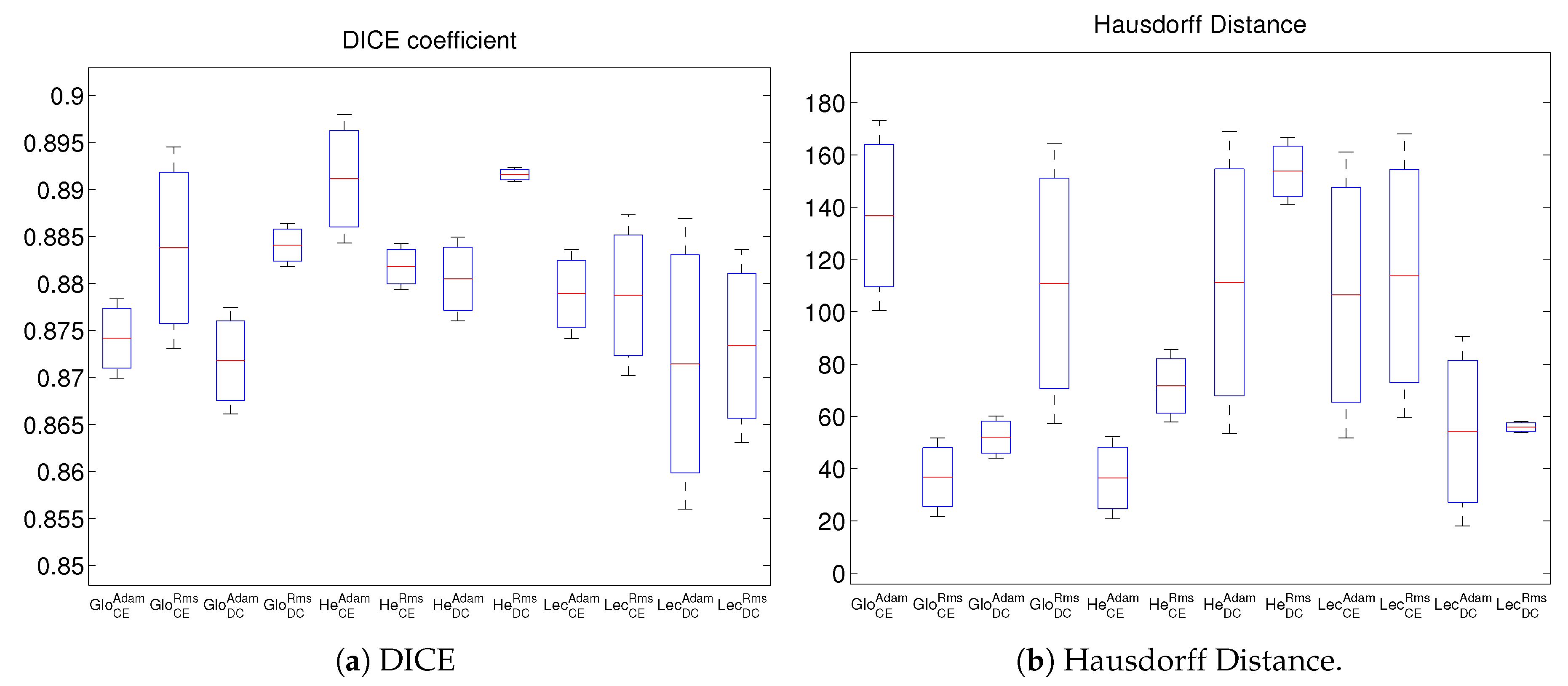
4. Experimental Results and Discussion
Comparison and Discussion of Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Different Parameters and Abbreviations

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
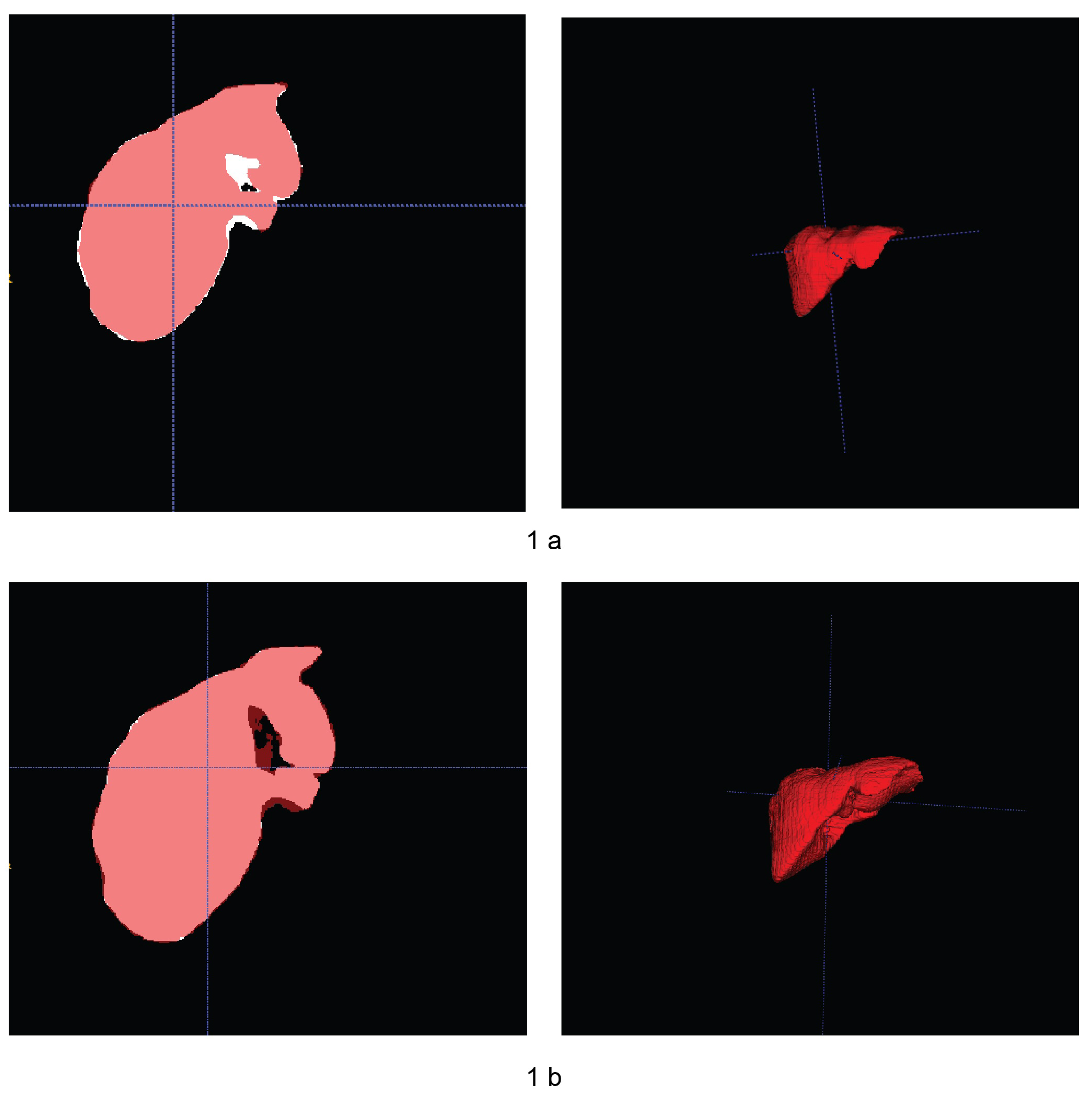{kind=link}
{kind=link}
{kind=link}
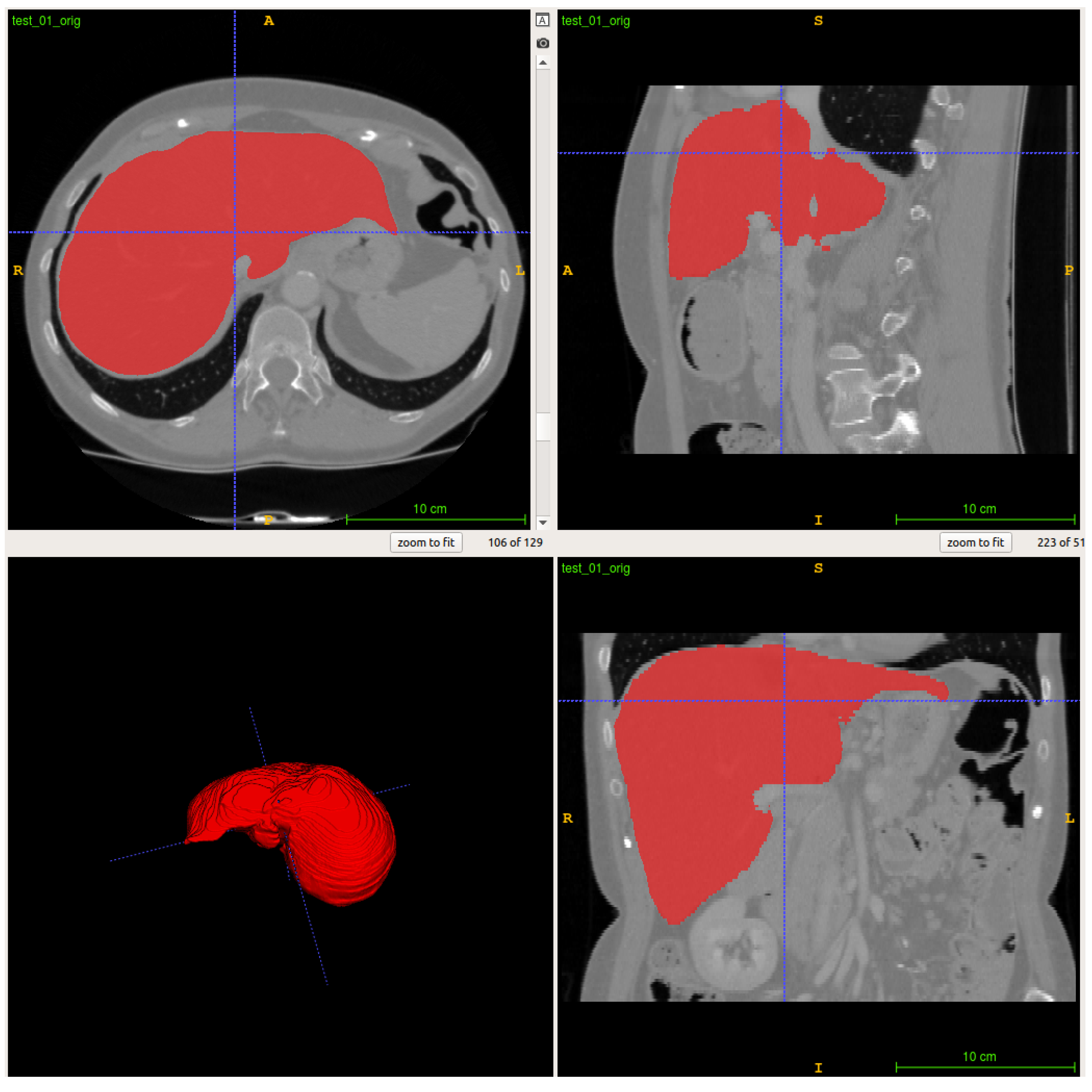
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Weight Initialization | Activation Function | Loss Function | Optimizer |
|---|---|---|---|
| Xavier or Glorot (Glo) | Tanh (tanh) | Cross Entropy (CE) | Adam (Adam) |
| He Initialization (He) | ReLU (relu) | Dice loss (DC) | RMSprop (Rms) |
| LeCun (Le) | Sigmoid (sigm) | ||
| Random Normal (RandNorm) |
References
- Galloway, R.L.; Herrell, S.D.; Miga, M.I. Image-guided abdominal surgery and therapy delivery. J. Healthc. Eng. 2012, 3, 203–228. [Google Scholar] [CrossRef]
- Warfield, S.K.; Jolesz, F.A.; Kikinis, R. Real-time image segmentation for image-guided surgery. In Proceedings of the 1998 ACM/IEEE Conference on Supercomputing (SC’98), Orlando, FL, USA, 7–13 November 1998; p. 42. [Google Scholar]
- Grimson, W.E.L.; Leventon, M.E.; Faugeras, O.D.; Wells, W.; Mirmehdi, M.; Thomas, B. Computer Vision Methods for Image Guided Surgery. In Proceedings of the BMVC, Bristol, UK, 11–14 September 2000; pp. 1–12. [Google Scholar]
- Zhou, Z.; Xue-Chang, Z.; Si-Ming, Z.; Hua-Fei, X.; Yue-Ding, S. Semi-automatic Liver Segmentation in CT Images through Intensity Separation and Region Growing. Procedia Comput. Sci. 2018, 131, 220–225. [Google Scholar] [CrossRef]
- Hesamian, M.H.; Jia, W.; He, X.; Kennedy, P. Deep Learning Techniques for Medical Image Segmentation: Achievements and Challenges. J. Digit. Imaging 2019, 32. [Google Scholar] [CrossRef] [PubMed]
- Roth, H.R.; Shen, C.; Oda, H.; Oda, M.; Hayashi, Y.; Misawa, K.; Mori, K. Deep learning and its application to medical image segmentation. Med. Imaging Technol. 2018, 36, 63–71. [Google Scholar]
- Talbi, E.G. Optimization of Deep Neural Networks: A Survey and Unified Taxonomy. 2020. Available online: https://hal.inria.fr/hal-02570804v2 (accessed on 8 December 2020).
- Christ, P.F.; Elshaer, M.E.A.; Ettlinger, F.; Tatavarty, S.; Bickel, M.; Bilic, P.; Rempfler, M.; Armbruster, M.; Hofmann, F.; D’Anastasi, M.; et al. Automatic liver and lesion segmentation in CT using cascaded fully convolutional neural networks and 3D conditional random fields. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 415–423. [Google Scholar]
- Shen, D.; Wu, G.; Suk, H.I. Deep Learning in Medical Image Analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef] [PubMed]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Zhu, W.; Huang, Y.; Zeng, L.; Chen, X.; Liu, Y.; Qian, Z.; Du, N.; Fan, W.; Xie, X. AnatomyNet: Deep learning for fast and fully automated whole-volume segmentation of head and neck anatomy. Med. Phys. 2019, 46, 576–589. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 IEEE Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Aguirre, D. A Novel Set of Weight Initialization Techniques for Deep Learning Architectures. Ph.D. Thesis, The University of Texas at El Paso, El Paso, TX, USA, 2019. [Google Scholar]
- Hosseini, H.; Xiao, B.; Jaiswal, M.; Poovendran, R. On the limitation of convolutional neural networks in recognizing negative images. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 352–358. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1139–1147. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Mishkin, D.; Matas, J. All you need is a good init. arXiv 2015, arXiv:1511.06422. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for activation functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Zaid, G.; Bossuet, L.; Habrard, A.; Venelli, A. Methodology for Efficient CNN Architectures in Profiling Attacks. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2019, 2020, 1–36. [Google Scholar] [CrossRef]
- Janocha, K.; Czarnecki, W. On loss functions for deep neural networks in classification. Schedae Inform. 2016, 25. Available online: https://arxiv.org/abs/1702.05659 (accessed on 10 September 2020). [CrossRef]
- Dewa, C.K. Suitable CNN Weight Initialization and Activation Function for Javanese Vowels Classification. Procedia Comput. Sci. 2018, 144, 124–132. [Google Scholar] [CrossRef]
- Breuel, T.M. The Effects of Hyperparameters on SGD Training of Neural Networks. arXiv 2015, arXiv:1508.02788. [Google Scholar]
- Schilling, F. The Effect of Batch Normalization on Deep Convolutional Neural Networks. 2016. Available online: https://www.semanticscholar.org/paper/The-Effect-of-Batch-Normalization-on-Deep-Neural-Schilling/f2f96b1d293d143304038ee77cde7296b6843932 (accessed on 10 August 2020).
- Bertrand, H. Hyper-Parameter Optimization in Deep Learning and Transfer Learning: Applications to Medical Imaging. Ph.D. Thesis, Université Paris-Saclay, Saint-Aubin, France, 2019. [Google Scholar]
- Pasi, K.G.; Naik, S.R. Effect of parameter variations on accuracy of Convolutional Neural Network. In Proceedings of the 2016 International Conference on Computing, Analytics and Security Trends (CAST), Pune, India, 19–21 December 2016; pp. 398–403. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Y.; Song, Y.; Rong, X. The Influence of the Activation Function in a Convolution Neural Network Model of Facial Expression Recognition. Appl. Sci. 2020, 10, 1897. [Google Scholar] [CrossRef]
- Koutsoukas, A.; Monaghan, K.; Li, X.; Huan, J. Deep-learning: Investigating deep neural networks hyper-parameters and comparison of performance to shallow methods for modeling bioactivity data. J. Cheminform. 2017, 9. [Google Scholar] [CrossRef] [PubMed]
- Baydilli, Y.; Atila, U. Understanding effects of hyper-parameters on learning: A comparative analysis. In Proceedings of the International Conference on Advanced Technologies, Computer Engineering and Science, Safranbolu, Turkey, 11–13 May 2018. [Google Scholar]
- Luo, S. Review on the methods of automatic liver segmentation from abdominal images. J. Comput. Commun. 2014, 2, 1. [Google Scholar] [CrossRef][Green Version]
- Lundervold, A.S.; Lundervold, A. An overview of deep learning in medical imaging focusing on MRI. Z. für Med. Phys. 2019, 29, 102–127. [Google Scholar] [CrossRef]
- Singh, S.P.; Wang, L.; Gupta, S.; Goli, H.; Padmanabhan, P.; Gulyás, B. 3D Deep Learning on Medical Images: A Review. arXiv 2020, arXiv:2004.00218. [Google Scholar] [CrossRef]
- Taha, A.A.; Hanbury, A. Metrics for evaluating 3D medical image segmentation: Analysis, selection, and tool. BMC Med. Imaging 2015, 15, 29. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Orr, G.; Müller, K.R. Efficient BackProp. In Neural Networks: Tricks of the Trade. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7700. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Setti Ballas, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Saxe, A.; Koh, P.W.; Chen, Z.; Bhand, M.; Suresh, B.; Ng, A.Y. On random weights and unsupervised feature learning. In Proceedings of the International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2010. [Google Scholar]
- Igel, C.; Hüsken, M. Improving the Rprop Learning Algorithm. In Proceedings of the Second International ICSC Symposium on Neural Computation (NC 2000), Berlin, Germany, 23–26 May 2000. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Shaw, S. A Comparative Study of Activation Functions. 2014. Available online: https://wandb.ai/shweta/Activation%20Functions/reports/A-Comparative-Study-of-Activation-Functions–VmlldzoxMDQwOTQ (accessed on 20 August 2020).
- Bilic, P.; Christ, P.F.; Vorontsov, E.; Chlebus, G.; Chen, H.; Dou, Q.; Fu, C.W.; Han, X.; Heng, P.A.; Hesser, J.; et al. The Liver Tumor Segmentation Benchmark (LiTS). arXiv 2019, arXiv:1901.04056.2019. [Google Scholar]
- Simpson, A.L.; Antonelli, M.; Bakas, S.; Bilello, M.; Farahani, K.; van Ginneken, B.; Kopp-Schneider, A.; Landman, B.A.; Litjens, G.J.S.; Menze, B.H.; et al. A large annotated medical image dataset for the development and evaluation of segmentation algorithms. arXiv 2019, arXiv:1902.09063. [Google Scholar]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The multimodal brain tumor image segmentation benchmark (BRATS). IEEE Trans. Med. Imaging 2014, 34, 1993–2024. [Google Scholar] [CrossRef]
- McLachlan, G.J. Mahalanobis distance. Resonance 1999, 4, 20–26. [Google Scholar] [CrossRef]
- Russakoff, D.B.; Tomasi, C.; Rohlfing, T.; Maurer, C.R. Image similarity using mutual information of regions. In Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 596–607. [Google Scholar]
- Meilă, M. Comparing clusterings by the variation of information. In Learning Theory and Kernel Machines; Springer: Berlin/Heidelberg, Germany, 2003; pp. 173–187. [Google Scholar]
- Powers, D. Evaluation: From Precision, Recall and F-Factor to ROC, Informedness, Markedness & Correlation. Mach. Learn. Technol. 2008, 2. Available online: https://www.researchgate.net/publication/228529307_Evaluation_From_Precision_Recall_and_F-Factor_to_ROC_Informedness_Markedness_Correlation (accessed on 15 September 2020).
- Cárdenes, R.; de Luis-García, R.; Bach-Cuadra, M. A multidimensional segmentation evaluation for medical image data. Comput. Methods Programs Biomed. 2009, 96, 108–124. [Google Scholar] [CrossRef] [PubMed]
- Yushkevich, P.A.; Piven, J.; Cody Hazlett, H.; Gimpel Smith, R.; Ho, S.; Gee, J.C.; Gerig, G. User-Guided 3D Active Contour Segmentation of Anatomical Structures: Significantly Improved Efficiency and Reliability. Neuroimage 2006, 31, 1116–1128. [Google Scholar] [CrossRef] [PubMed]
- Radiuk, P. Applying 3D U-Net Architecture to the Task of Multi-Organ Segmentation in Computed Tomography. Appl. Comput. Syst. 2020, 25, 43–50. [Google Scholar] [CrossRef]
- Huang, C.; Han, H.; Yao, Q.; Zhu, S.; Zhou, S.K. 3D U2-Net: A 3D Universal U-Net for Multi-Domain Medical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Datta, L. A Survey on Activation Functions and their relation with Xavier and He Normal Initialization. arXiv 2020, arXiv:2004.06632. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 8 October 2020).













| Configuration | DICE | HD | AVD | MHD | MI | VOI | AUC | VS |
|---|---|---|---|---|---|---|---|---|
| GloCEAdam | 0.897 ± 0.100 | 291.24 ± 93.73 | 2.553 ± 3.02 | 0.163 ± 0.153 | 0.138 ± 0.076 | 0.071 ± 0.057 | 0.938 ± 0.069 | 0.952 ± 0.107 |
| GloCERms | 0.870 ± 0.191 | 298.39 ± 96.38 | 3.62 ± 4.15 | 0.200 ± 0.194 | 0.133 ± 0.078 | 0.076 ± 0.066 | 0.929 ± 0.101 | 0.927 ± 0.200 |
| GloDCRms | 0.866 ± 0.147 | 316.81 ± 74.69 | 4.33 ± 4.75 | 0.213 ± 0.156 | 0.131 ± 0.076 | 0.082 ± 0.062 | 0.925 ± 0.087 | 0.936 ± 0.153 |
| HeCEAdam | 0.871 ± 0.146 | 293.74 ± 95.25 | 2.88 ± 2.96 | 0.183 ± 0.160 | 0.131 ± 0.074 | 0.081 ± 0.065 | 0.923 ± 0.087 | 0.937 ± 0.155 |
| HeCERms | 0.863 ± 0.205 | 295.67 ± 96.23 | 4.24 ± 4.68 | 0.232 ± 0.261 | 0.132 ± 0.079 | 0.078 ± 0.063 | 0.929 ± 0.105 | 0.923 ± 0.216 |
| HeDCAdam | 0.858 ± 0.177 | 294.17 ± 77.70 | 3.60 ± 4.00 | 0.208 ± 0.236 | 0.129 ± 0.077 | 0.082 ± 0.065 | 0.916 ± 0.097 | 0.925 ± 0.185 |
| HeDCRms | 0.860 ± 0.185 | 297.14 ± 101.46 | 3.82 ± 4.03 | 0.203 ± 0.173 | 0.129 ± 0.076 | 0.082 ± 0.066 | 0.921 ± 0.099 | 0.924 ± 0.196 |
| LecCEAdam | 0.883 ± 0.148 | 287.11 ± 89.97 | 2.40 ± 2.73 | 0.160 ± 0.150 | 0.134 ± 0.078 | 0.073 ± 0.062 | 0.929 ± 0.087 | 0.935 ± 0.156 |
| LecCERms | 0.873 ± 0.168 | 295.23 ± 99.38 | 3.47 ± 4.10 | 0.210 ± 0.220 | 0.133 ± 0.078 | 0.076 ± 0.062 | 0.928 ± 0.094 | 0.934 ± 0.177 |
| LecDCAdam | 0.860 ± 0.191 | 302.52 ± 95.88 | 3.80 ± 4.01 | 0.214 ± 0.217 | 0.130 ± 0.078 | 0.081 ± 0.064 | 0.921 ± 0.100 | 0.928 ± 0.202 |
| LecDCRms | 0.867 ± 0.199 | 311.64 ± 76.32 | 3.54 ± 4.23 | 0.204 ± 0.226 | 0.133 ± 0.080 | 0.076 ± 0.062 | 0.926 ± 0.102 | 0.927 ± 0.209 |
| Configuration | DICE | HD | AVD | MHD | MI | VOI | AUC | VS |
|---|---|---|---|---|---|---|---|---|
| GloCEAdam | 0.874 ± 0.006 | 136.84 ± 51.41 | 0.374 ± 0.078 | 0.132 ± 0.005 | 0.025 ± 0.004 | 0.014 ± 0.003 | 0.916 ± 0.002 | 0.948 ± 0.014 |
| GloCERms | 0.884 ± 0.015 | 36.76 ± 21.20 | 0.310 ± 0.021 | 0.084 ± 0.007 | 0.026 ± 0.003 | 0.013 ± 0.004 | 0.921 ± 0.007 | 0.951 ± 0.001 |
| GloDCAdam | 0.872 ± 0.008 | 52.04 ± 11.46 | 0.658 ± 0.367 | 0.174 ± 0.096 | 0.025 ± 0.004 | 0.015 ± 0.002 | 0.919 ± 0.005 | 0.961 ± 0.004 |
| GloDCRms | 0.884 ± 0.003 | 110.88 ± 75.91 | 0.494 ± 0.168 | 0.146 ± 0.055 | 0.026 ± 0.004 | 0.014 ± 0.003 | 0.792 ± 0.005 | 0.964 ± 0.019 |
| HeCEAdam | 0.891 ± 0.010 | 36.44 ± 22.20 | 0.311 ± 0.013 | 0.101 ± 0.019 | 0.026 ± 0.004 | 0.013 ± 0.003 | 0.927 ± 0.001 | 0.957 ± 0.008 |
| HeCERms | 0.882 ± 0.003 | 71.70 ± 19.61 | 0.360 ± 0.015 | 0.143 ± 0.015 | 0.026 ± 0.004 | 0.014 ± 0.003 | 0.921 ± 0.010 | 0.954 ± 0.028 |
| HeDCAdam | 0.881 ± 0.006 | 111.29 ± 81.84 | 0.359 ± 0.101 | 0.115 ± 0.031 | 0.026 ± 0.004 | 0.014 ± 0.003 | 0.922 ± 0.003 | 0.957 ± 0.015 |
| HeDCRms | 0.892 ± 0.001 | 153.89 ± 18.03 | 0.310 ± 0.012 | 0.117 ± 0.050 | 0.026 ± 0.004 | 0.013 ± 0.002 | 0.929 ± 0.006 | 0.961 ± 0.013 |
| LecCEAdam | 0.879 ± 0.007 | 106.52 ± 77.41 | 0.375 ± 0.107 | 0.101 ± 0.003 | 0.026 ± 0.004 | 0.014 ± 0.003 | 0.919 ± 0.002 | 0.951 ± 0.015 |
| LecCERms | 0.879 ± 0.012 | 113.72 ± 76.83 | 0.568 ± 0.346 | 0.155 ± 0.074 | 0.026 ± 0.005 | 0.014 ± 0.002 | 0.918 ± 0.017 | 0.949 ± 0.028 |
| LecDCAdam | 0.871 ± 0.022 | 54.26 ± 51.20 | 0.414 ± 0.149 | 0.142 ± 0.095 | 0.025 ± 0.005 | 0.014 ± 0.001 | 0.914 ± 0.022 | 0.946 ± 0.030 |
| LecDCRms | 0.873 ± 0.014 | 55.87 ± 3.03 | 0.341 ± 0.051 | 0.145 ± 0.066 | 0.025 ± 0.005 | 0.014 ± 0.002 | 0.911 ± 0.019 | 0.936 ± 0.033 |
| Configuration | DICE | HD | AVD | MHD | MI | VOI | AUC | VS |
|---|---|---|---|---|---|---|---|---|
| GloCEAdam | 0.679 ± 0.148 | 117.03 ± 50.96 | 4.02 ± 6.83 | 0.382 ± 0.262 | 0.012 ± 0.005 | 0.020 ± 0.010 | 0.834 ± 0.098 | 0.848 ± 0.159 |
| GloCERms | 0.681 ± 0.156 | 119.79 ± 56.51 | 3.49 ± 7.03 | 0.370 ± 0.251 | 0.012 ± 0.005 | 0.020 ± 0.010 | 0.827 ± 0.099 | 0.834 ± 0.173 |
| HeCEAdam | 0.659 ± 0.165 | 117.58 ± 51.82 | 3.89 ± 5.94 | 0.372 ± 0.266 | 0.012 ± 0.005 | 0.020 ± 0.010 | 0.814 ± 0.104 | 0.826 ± 0.187 |
| HeCERms | 0.686 ± 0.156 | 111.14 ± 52.88 | 3.623 ± 7.14 | 0.339 ± 0.257 | 0.013 ± 0.005 | 0.020 ± 0.011 | 0.836 ± 0.099 | 0.849 ± 0.168 |
| LecCEAdam | 0.691 ± 0.148 | 121.52 ± 57.92 | 2.97 ± 4.25 | 0.325 ± 0.264 | 0.013 ± 0.006 | 0.019 ± 0.009 | 0.837 ± 0.097 | 0.848 ± 0.168 |
| LecCERms | 0.672 ± 0.156 | 117.91 ± 50.82 | 3.74 ± 5.23 | 0.357 ± 0.274 | 0.012 ± 0.005 | 0.020 ± 0.010 | 0.825 ± 0.102 | 0.845 ± 0.171 |
| Configuration | DICE | HD | AVD | MHD | MI | VOI | AUC | VS |
|---|---|---|---|---|---|---|---|---|
| Glotanh | 0.921 ± 0.034 | 474.95 ± 131.44 | 1.32 ± 2.08 | 0.302 ± 0.179 | 0.124 ± 0.048 | 0.056 ± 0.050 | 0.969 ± 0.026 | 0.962 ± 0.031 |
| RandNormrelu | 0.853 ± 0.063 | 499.38 ± 92.03 | 2.30 ± 1.92 | 0.507 ± 0.190 | 0.113 ± 0.030 | 0.093 ± 0.078 | 0.951 ± 0.053 | 0.906 ± 0.067 |
| Hesigm | 0.857 ± 0.063 | 511.43 ± 92.94 | 2.40 ± 2.43 | 0.515 ± 0.201 | 0.110 ± 0.034 | 0.087 ± 0.072 | 0.952 ± 0.047 | 0.913 ± 0.061 |
| Configuration | DICE | HD | AVD | MHD | MI | VOI | AUC | VS |
|---|---|---|---|---|---|---|---|---|
| GloCERms | ✓ | ✓ | ✓ | |||||
| GloDCRms | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| HeCEAdam | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| HeCERms | ✓ | ✓ | ✓ | |||||
| HeDCAdam | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| HeDCRms | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| LecCEAdam | ✓ | ✓ | ||||||
| LecCERms | ✓ | ✓ | ✓ | ✓ | ||||
| LecDCAdam | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| LecDCRms | ✓ | ✓ | ✓ | ✓ |
| Configuration | DICE | HD | AVD | MHD | MI | VOI | AUC | VS |
|---|---|---|---|---|---|---|---|---|
| GloCEAdam | ✓ | ✓ | ✓ | ✓ | ||||
| GloCERms | ✓ | ✓ | ✓ | ✓ | ||||
| HeCEAdam | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| HeCERms | ✓ | |||||||
| LecCERms | ✓ | ✓ | ✓ | ✓ |
| Configuration | DICE | HD | AVD | MHD | MI | VOI | AUC | VS |
|---|---|---|---|---|---|---|---|---|
| RandNormrelu | 4.43 | 6.74 | 4.14 | 1.05 | 4.36 | 6.82 | 1.36 | 2.83 |
| Hesigm | 9.75 | 5.97 | 1.36 | 1.12 | 1.42 | 2.61 | 4.71 | 1.45 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prasad, P.J.R.; Survarachakan, S.; Khan, Z.A.; Lindseth, F.; Elle, O.J.; Albregtsen, F.; Kumar, R.P. Numerical Evaluation on Parametric Choices Influencing Segmentation Results in Radiology Images—A Multi-Dataset Study. Electronics 2021, 10, 431. https://doi.org/10.3390/electronics10040431
Prasad PJR, Survarachakan S, Khan ZA, Lindseth F, Elle OJ, Albregtsen F, Kumar RP. Numerical Evaluation on Parametric Choices Influencing Segmentation Results in Radiology Images—A Multi-Dataset Study. Electronics. 2021; 10(4):431. https://doi.org/10.3390/electronics10040431
Chicago/Turabian StylePrasad, Pravda Jith Ray, Shanmugapriya Survarachakan, Zohaib Amjad Khan, Frank Lindseth, Ole Jakob Elle, Fritz Albregtsen, and Rahul Prasanna Kumar. 2021. "Numerical Evaluation on Parametric Choices Influencing Segmentation Results in Radiology Images—A Multi-Dataset Study" Electronics 10, no. 4: 431. https://doi.org/10.3390/electronics10040431
APA StylePrasad, P. J. R., Survarachakan, S., Khan, Z. A., Lindseth, F., Elle, O. J., Albregtsen, F., & Kumar, R. P. (2021). Numerical Evaluation on Parametric Choices Influencing Segmentation Results in Radiology Images—A Multi-Dataset Study. Electronics, 10(4), 431. https://doi.org/10.3390/electronics10040431