3.1. The Architecture of the Used HRNet
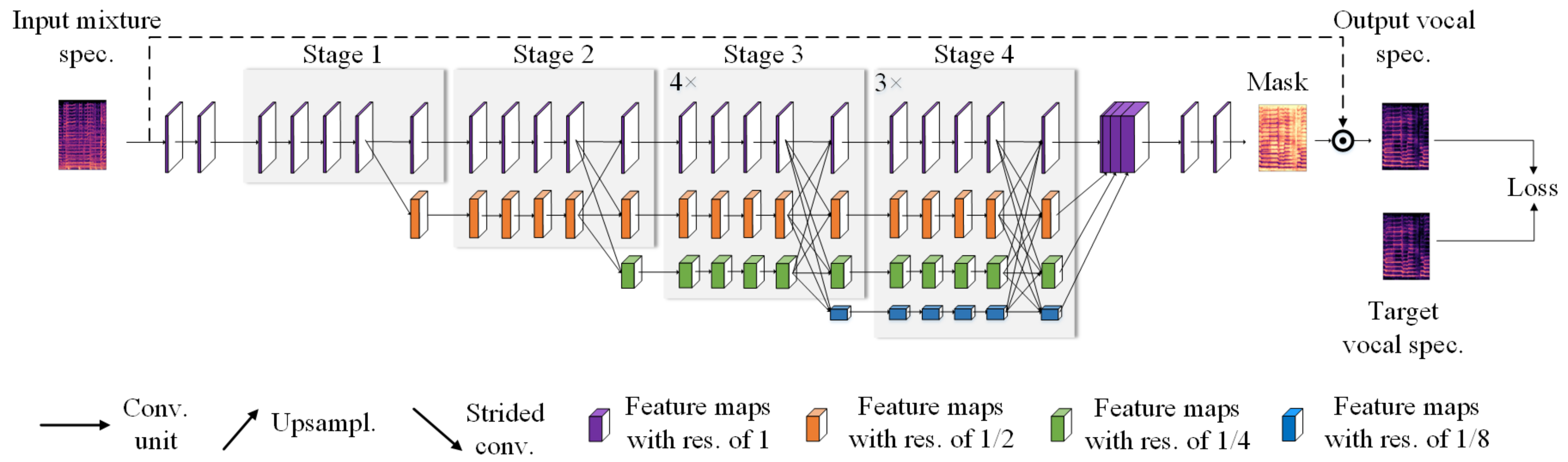
The architecture of the used HRNet is illustrated in
Figure 2. It takes a magnitude spectrogram as the input and feeds the input into two 3 × 3 convolutional layers with a stride of 1. Unlike [
14], we do not decrease the resolution here, for we want to preserve the high resolution of the input throughout the whole process.
Subsequently, four stages constitute the main body. In the first stage, there are 4 residual units, each of which, the same as the ResNet-50 [
24], is established by a bottleneck with a width (the number of channels) of 16. A 3 × 3 convolutional layer with a stride of 1 follows to transfer high-resolution representation into the second stage. The second, third, and fourth stages contain 1, 4, and 3 modules described below, respectively.
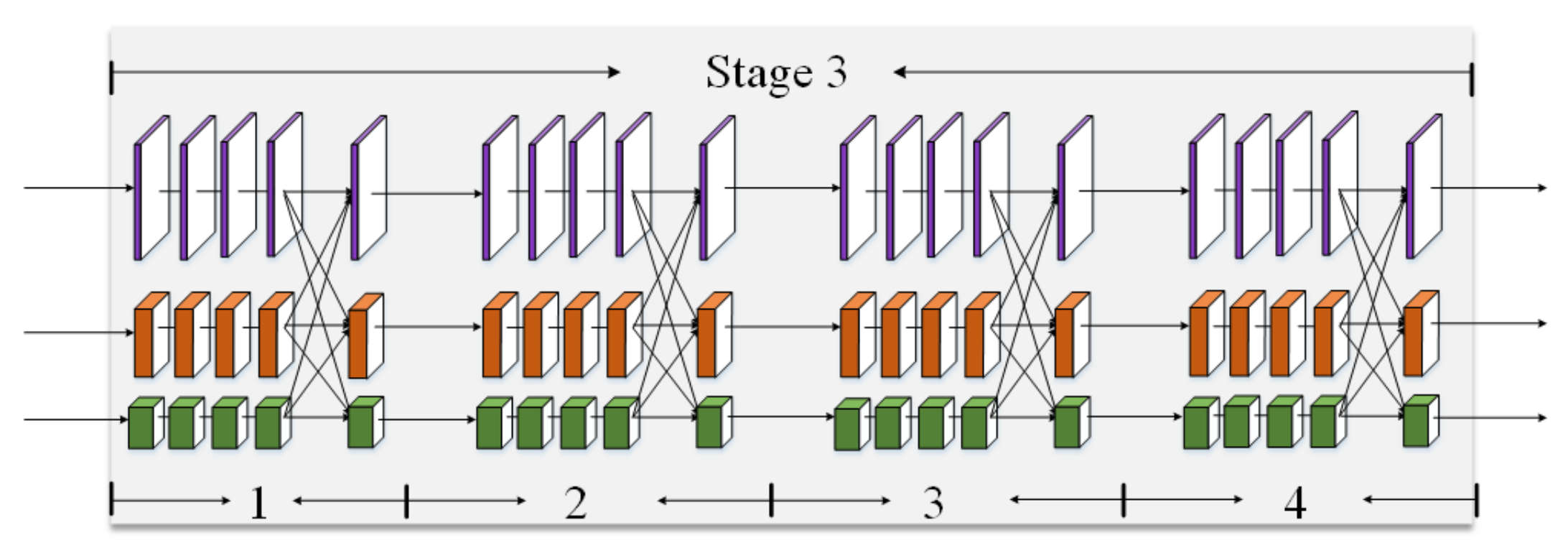
Figure 3 provides the third stage where 4 modules are stacked in series.
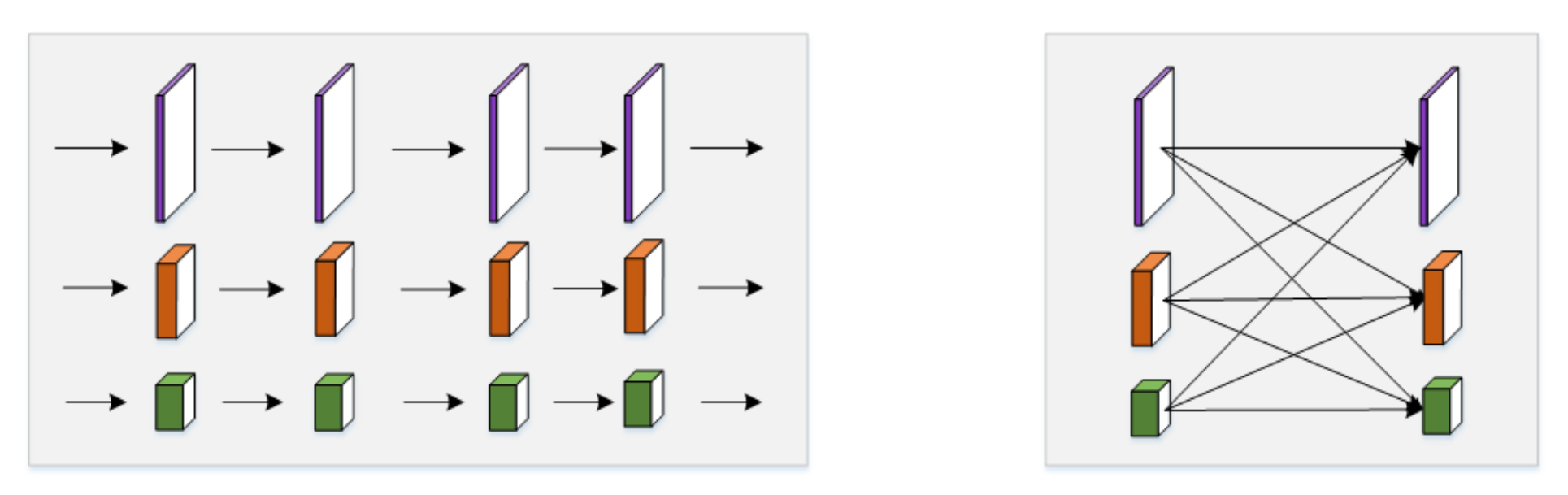
In each module, there are two parts: parallel multi-resolution convolutions (as shown in
Figure 4-left) and multi-resolution fusion (as shown in
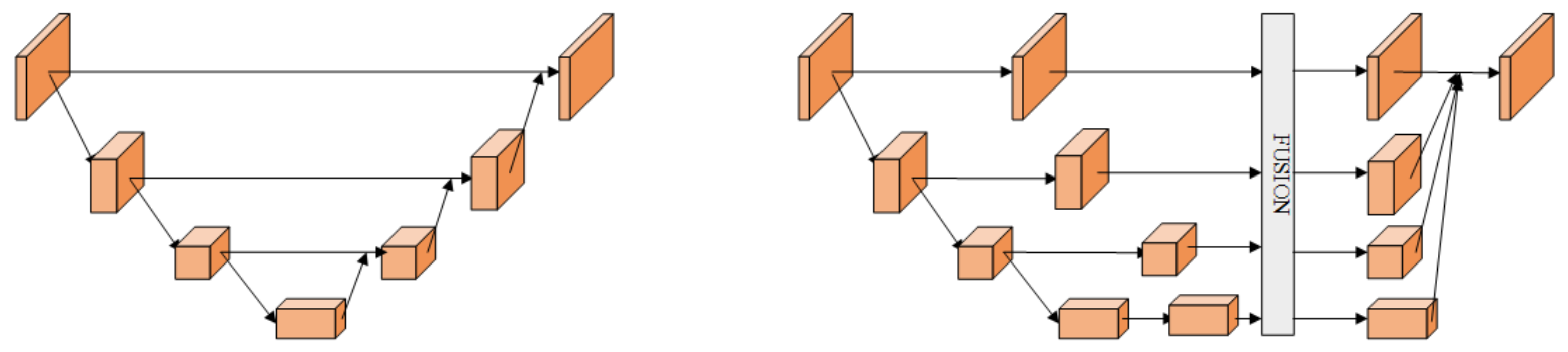
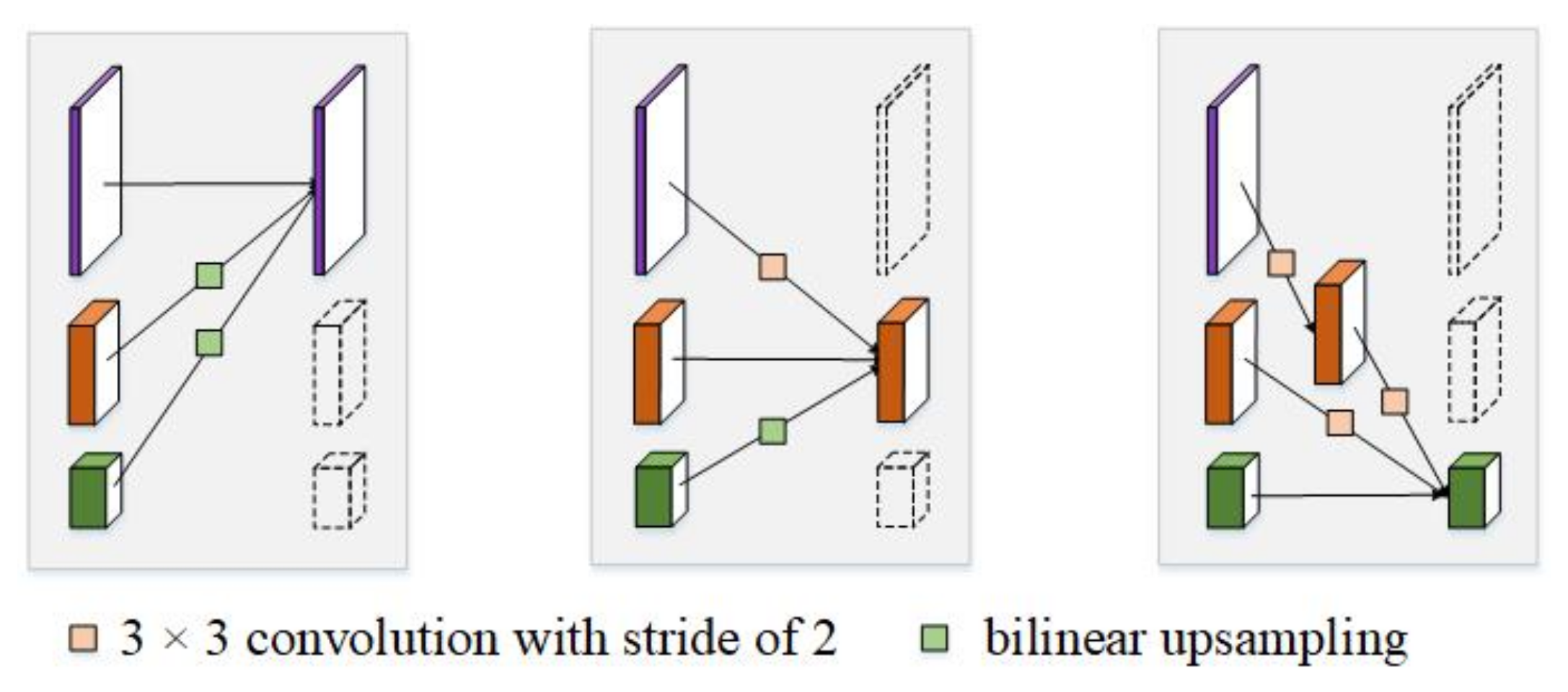
Figure 4-right). In the first part, the branches with different resolutions are connected in parallel. In each branch, there are 4 basic blocks. Each basic block comprises of two 3 × 3 convolutional layers, a batch normalization (BN) layer, and rectified linear units (ReLU). In the second part of each module, the branches with different resolutions are fused to exchange information. Specifically, the low-to-high process which increases the resolution is done by simply using bilinear upsampling, and the high-to-low process which decreases the resolution is done by using several strided convolutions (3 × 3 convolutional layers with a stride of 2). The number of strided convolutions required is determined by the resolution of the input feature maps and that of the target feature maps. If the resolution decreases from
a to
b (
a >
b|
a,
b∈ [1, 1/2, 1/4, 1/8]),
N (
) strided convolutions are required. Finally, the target feature maps of each branch are calculated by summation of the results of the up/downsampling process.
Figure 5 illustrates the details of low-to-high process and high-to-low process in multi-resolution fusion.
Moreover, at the end of each stage, except the fourth stage, a 3 × 3 convolutional layer with a stride of 2 is used to decrease the resolution to start a new branch. On the whole, from top to bottom, the resolution of four branches is decreased by half (1, 1/2, 1/4, and 1/8) each time and the number of channels is accordingly doubled (16, 32, 64, and 128).
After four stages, four feature maps with a resolution of 1, 1/2, 1/4, and 1/8 are generated, respectively. To obtain the soft mask for the target signal, the feature maps with the resolution of 1/2, 1/4, and 1/8 are rescaled to the feature maps with a resolution of 1 by using bilinear upsampling without changing the number of their channels, as shown in
Figure 6. Finally, we concatenate these four high-resolution feature maps and use two 1 × 1 convolutional layers with a stride of 1 to produce the target mask.
3.2. Training Details of SVS
The input of the HRNet were magnitude spectrograms calculated from mixture audio by Short-Time Fourier Transform (STFT) with a window size of 1024 and a hop size of 512. The mixture audio was downsampled into 16 kHz to speed up processing. For training the network with mini-batches, the input spectrograms were divided into fixed-length segments of 64 frames, nearly 2 s long.
The HRNet was supervised by the magnitude spectrograms of vocals corresponding to the input mixture audio. It outputted the soft masks for the vocals. Then we multiplied the output soft masks with the input mixture spectrograms to obtain the estimated vocal spectrograms.
Following [
11], the loss function was calculated by the
norm of the difference between the estimated vocal spectrogram and the target vocal spectrogram, defined as
where
X indicates the input mixture spectrogram,
represents the output mask from the HRNet taking the
X as the input,
Y means the target vocal spectrogram, and ⊙ is element-wise multiplication of two matrices. The
norm of a matrix is calculated by the sum of the absolute values of all elements.
The ADAM optimizer was used to minimize the loss function. The learning rate was set to 0.0001 and batch size 5. During inference, given a mixture audio signal, we first used the trained HRNet to obtain the estimated vocal spectrograms and then combined them with the phase of the corresponding input mixture to reconstruct the vocal signals.
3.3. Encoder-Decoder Network
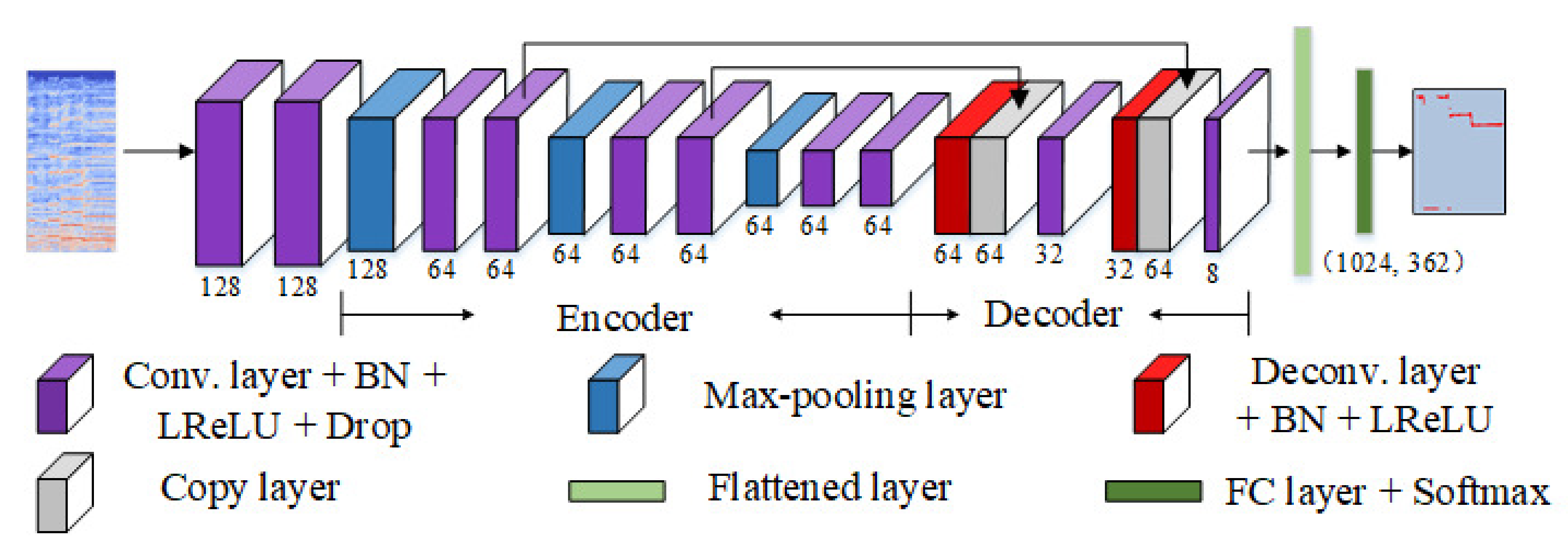
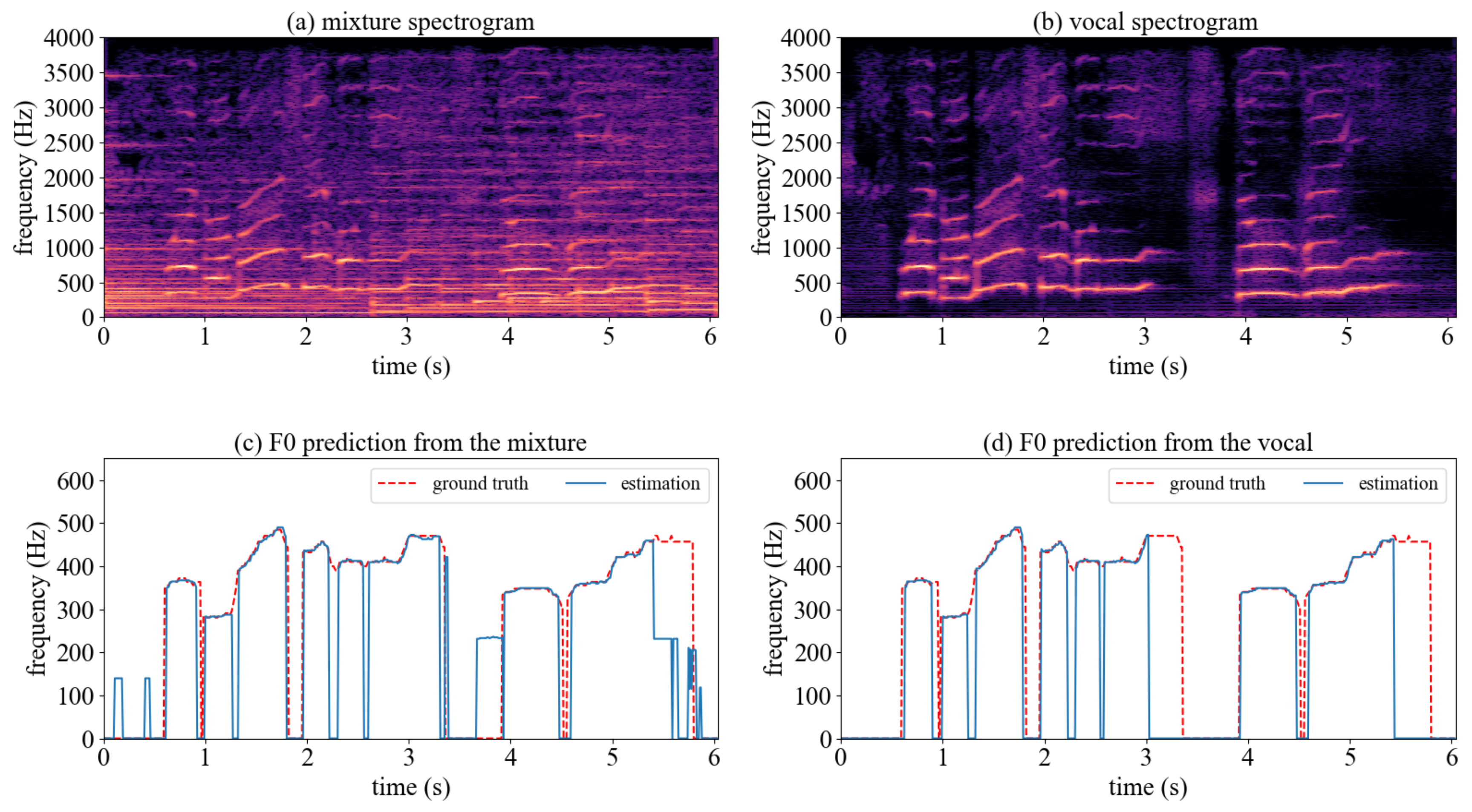
In this section, an encoder-decoder network is designed to estimate F0 values. As shown in
Figure 7, it takes a magnitude spectrogram as the input and begins with two 3 × 3 convolutional layers with a stride of 1 and a width of 128.
Three encoder blocks are then built. Each one contains a max-pooling layer with a stride of 4, a 7 × 7 convolutional layer with a stride of 1 and a width of 64, and a 5 × 5 convolutional layer with a stride of 1 and a width of 64 in order. The max-pooling layer in each block is only conducted on the frequency axis, hence all feature maps preserve the input size on the time axis. Also, each convolutional layer is followed by a BN layer, leaky ReLU with leakiness 0.01, and a dropout layer with 50%.
Next, two decoder blocks are constructed. Each one consists of a 7 × 7 deconvolutional layer with a stride of 4 without changing channel number, and a 5 × 5 convolutional layer with a stride of 1. We also add skip connections at the convolutional layers with the same resolution in the encoder and decoder to strengthen the representation of decoder blocks. Each convolutional/deconvolutional layer is followed by a BN layer and leaky ReLU with leakiness 0.01.
The feature maps outputted from the last decoder block are then flattened on the frequency axis. At this point, each frame is represented by a 1024-dimensional feature vector. Finally, these feature vectors are fed into the FC layer with a softmax function to estimate F0 values frame by frame.
3.4. Training Details of VME
The input of the encoder-decoder network was the magnitude spectrogram of an audio signal calculated by STFT with a window size of 1024 and a hop size of 80. The sampling rate was set to 8 kHz and the input spectrograms were divided into fixed-length segments of 20 frames, nearly 0.2 s long. Following [
7], the pitch frequency range we considered in this paper was from 73.41 Hz (MIDI Number 38) to 987.77 Hz (MIDI Number 83) with a resolution of 1/8 semitone, hence the total pitch class number was 362, including an unvoiced class.
The ADAM optimizer was used to minimize the loss function calculated from cross entropy. The initial learning rate was set to 0.0015 and batch size 16. After each epoch of training, the learning rate was reset to 98% of its previous one.
During inference, given an audio signal, the trained encoder-decoder network outputted the posterior distribution of each class against a total of 362 classes frame by frame. The frequency bin with the maximum value per frame was selected and directly converted into frequency as follows:
where
bin means the selected frequency bin with maximal activation of each frame.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}