
Blockchain-Based Reputation Systems: Implementation Challenges and Mitigation


Abstract
1. Introduction
- Survey current research difficulties in DLT-based RMSs and its enabling technologies. Highlighting some of the common pitfalls in designing and implementing a reputation system that is based on DLT.
- Provide insight into the challenges that are faced with recommendations and solutions to avoid the respective pitfalls. We discuss in detail the nature of the difficulties of merging a DLT with a reputation system.
- Analyze the effect of utilizing a fraction of service feedbacks to provide an accurate reputation with minimal feedbacks. We produce simulations that show that truncating the available feedbacks to a certain level will still maintain the reputation level. This is possible by taking the temporal behavior change into account.
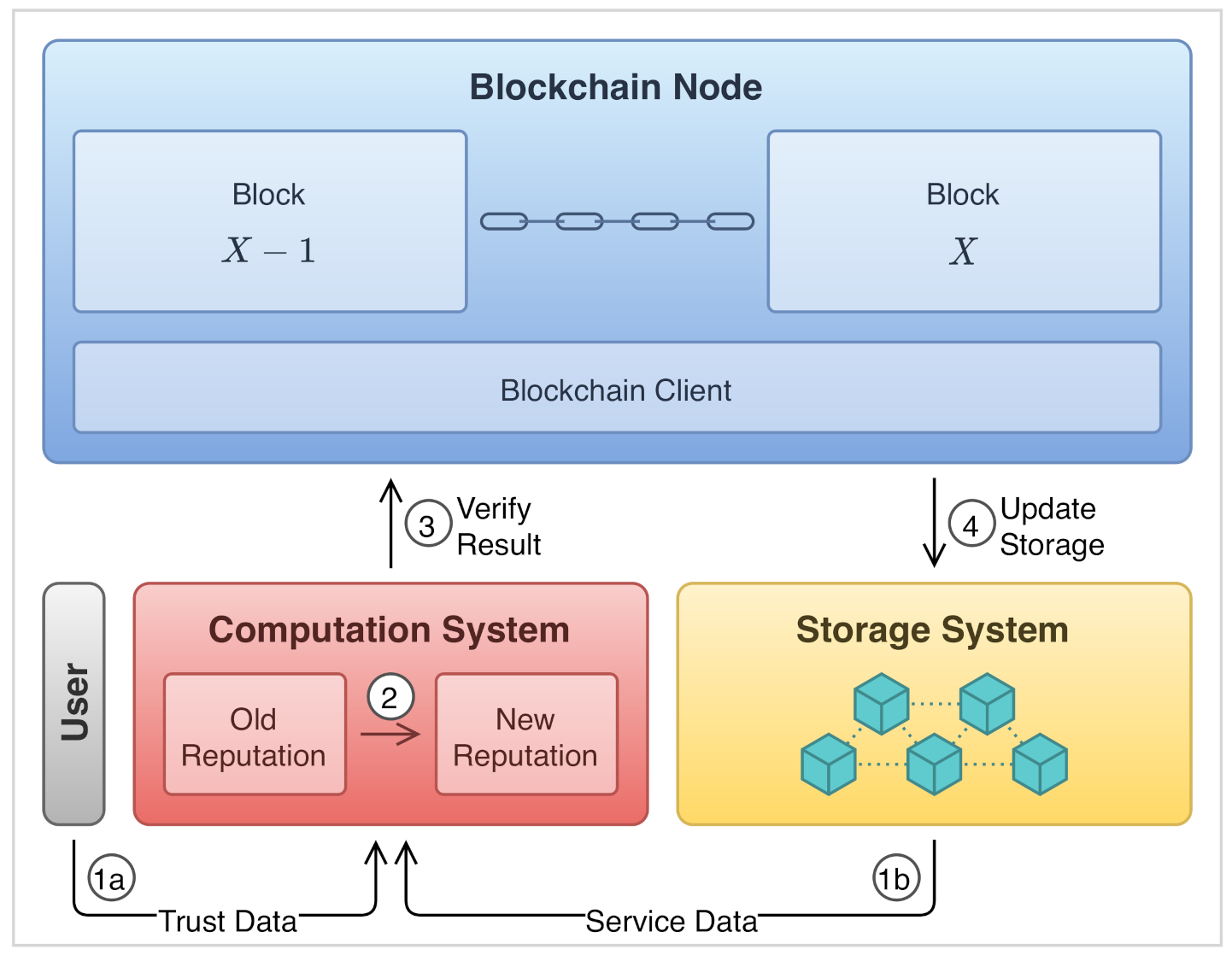
2. On-Chain and Off-Chain Tradeoffs
2.1. Consensus Computation
2.2. Data Management
2.3. Integrity and Reliability
2.4. The Case of Reputation Systems
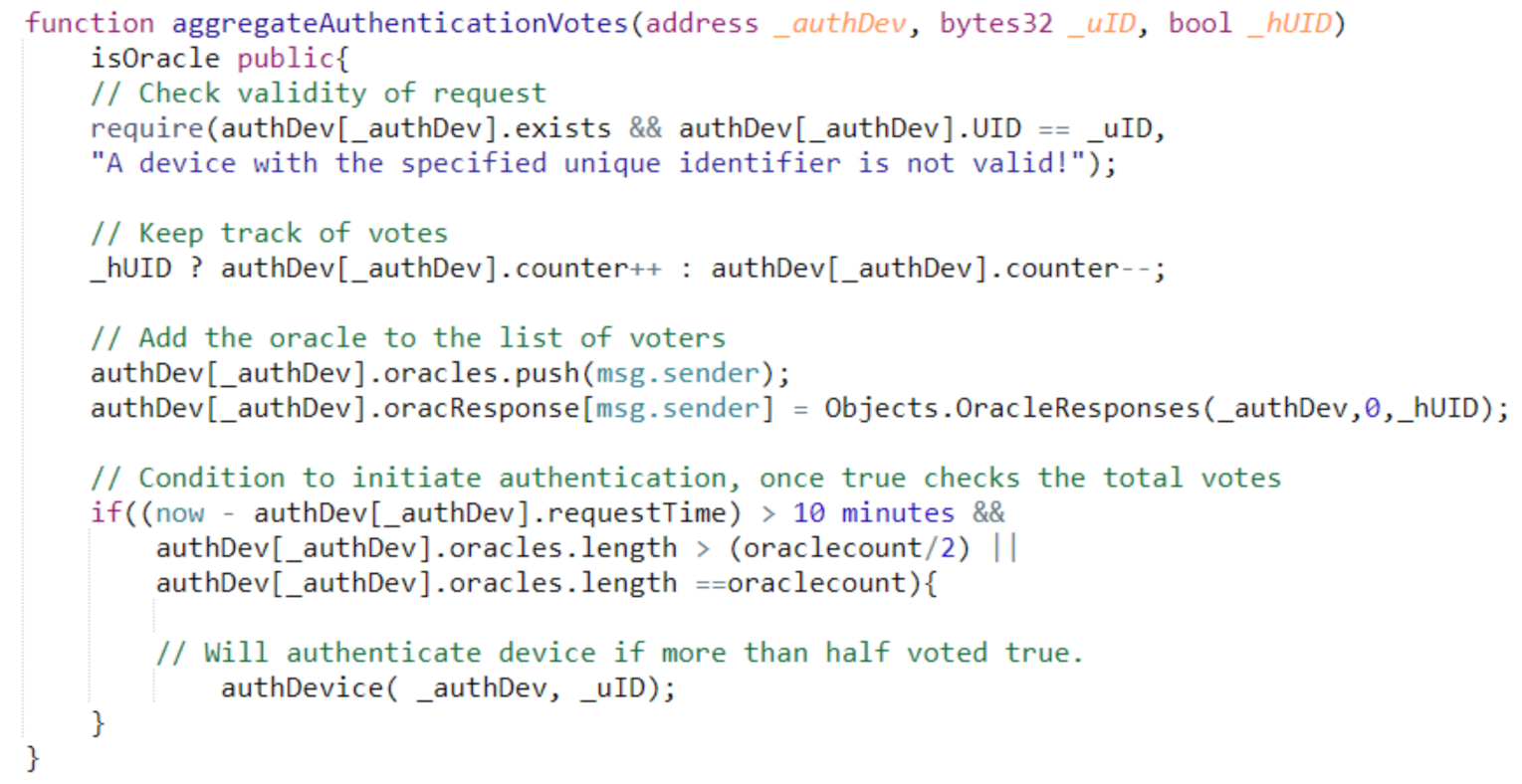
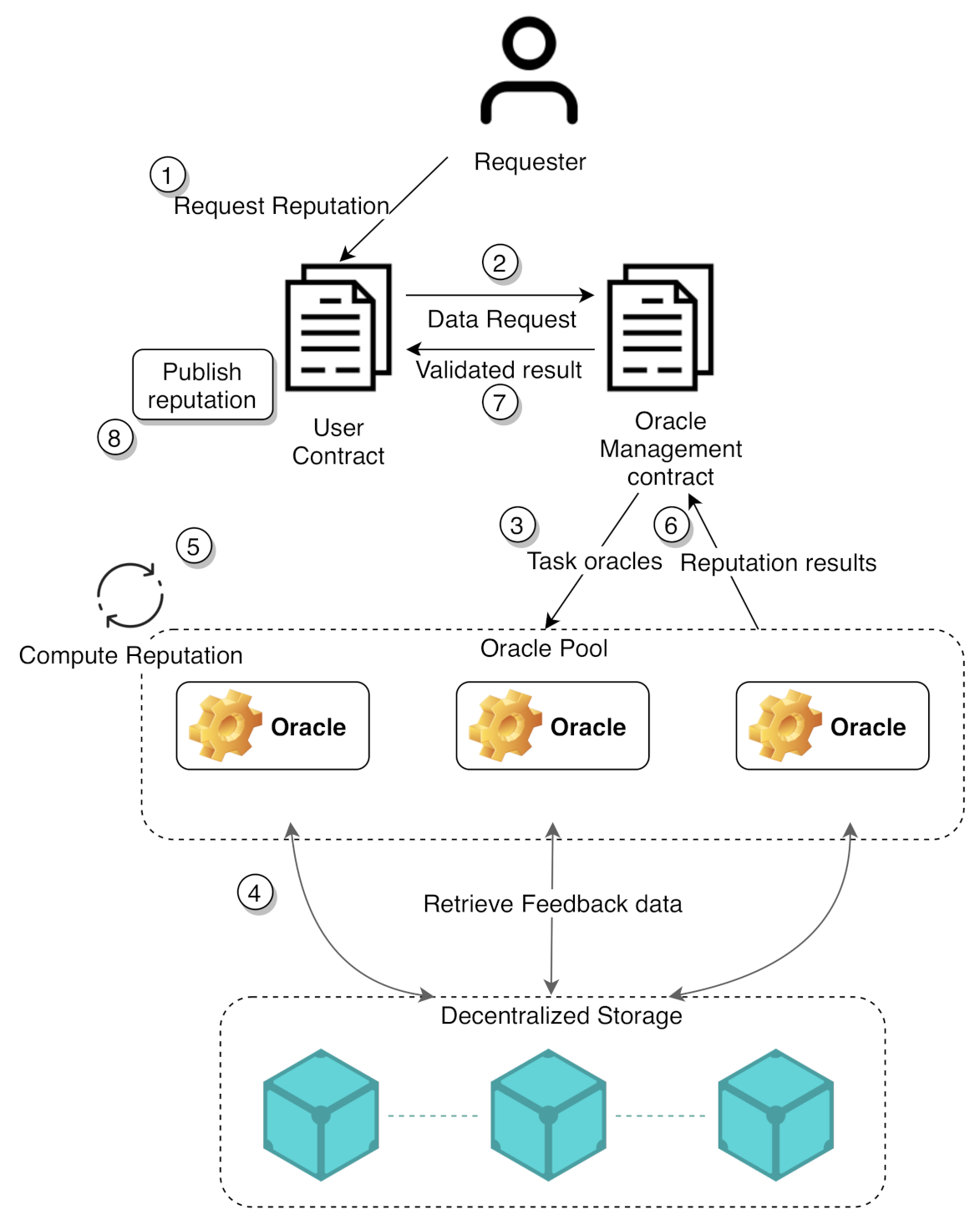
3. External Interaction Issues
3.1. Enabling External Interaction
3.2. Establishing Trust
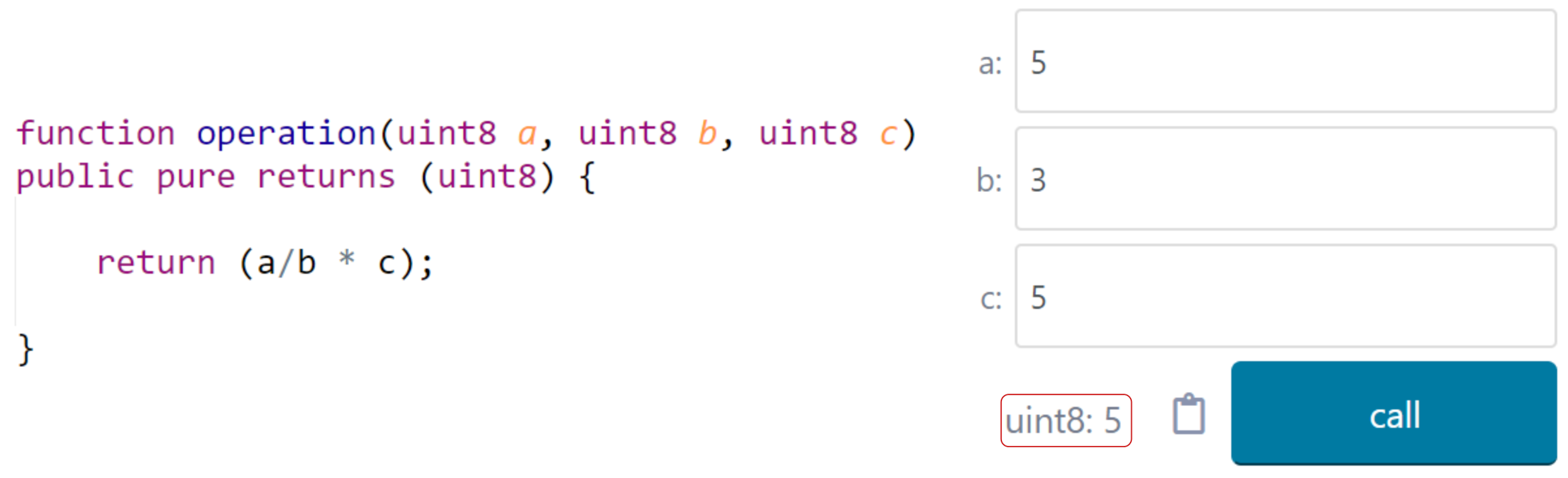
4. The Requirement of Deterministic Results
4.1. The Rationale of Determinism
4.2. The Impact on Smart Contract Operations
5. Time Management in the Context of Smart Contracts
Temporal Adaptability in Reputation
- The equation is recursive and does not require the aggregation of past feedbacks to generate the new reputation, but it is computed only while using the currently provided feedback.
- Time is explicitly incorporated by utilizing the smart contract supported Unix Epoch clock.
- A simple linear equation is used as opposed to a complex non-linear equation, in order to accommodate for the smart contract computation capabilities in a practical manner.
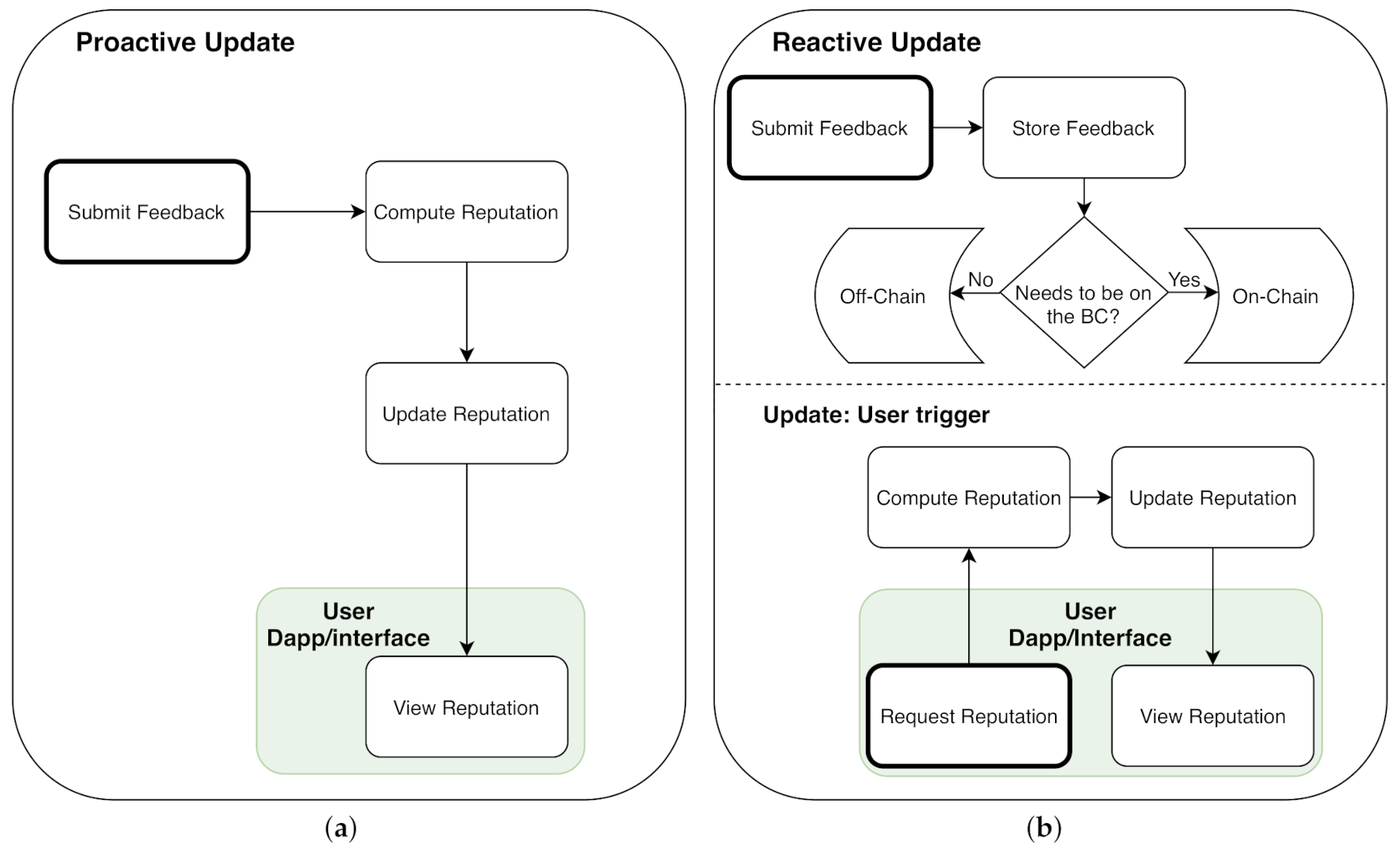
6. The Impact on Reputation Update
6.1. Proactive Updates
6.2. Reactive Updates
6.3. Delay
7. Reducing Smart Contract Storage Requirements
7.1. Simulation
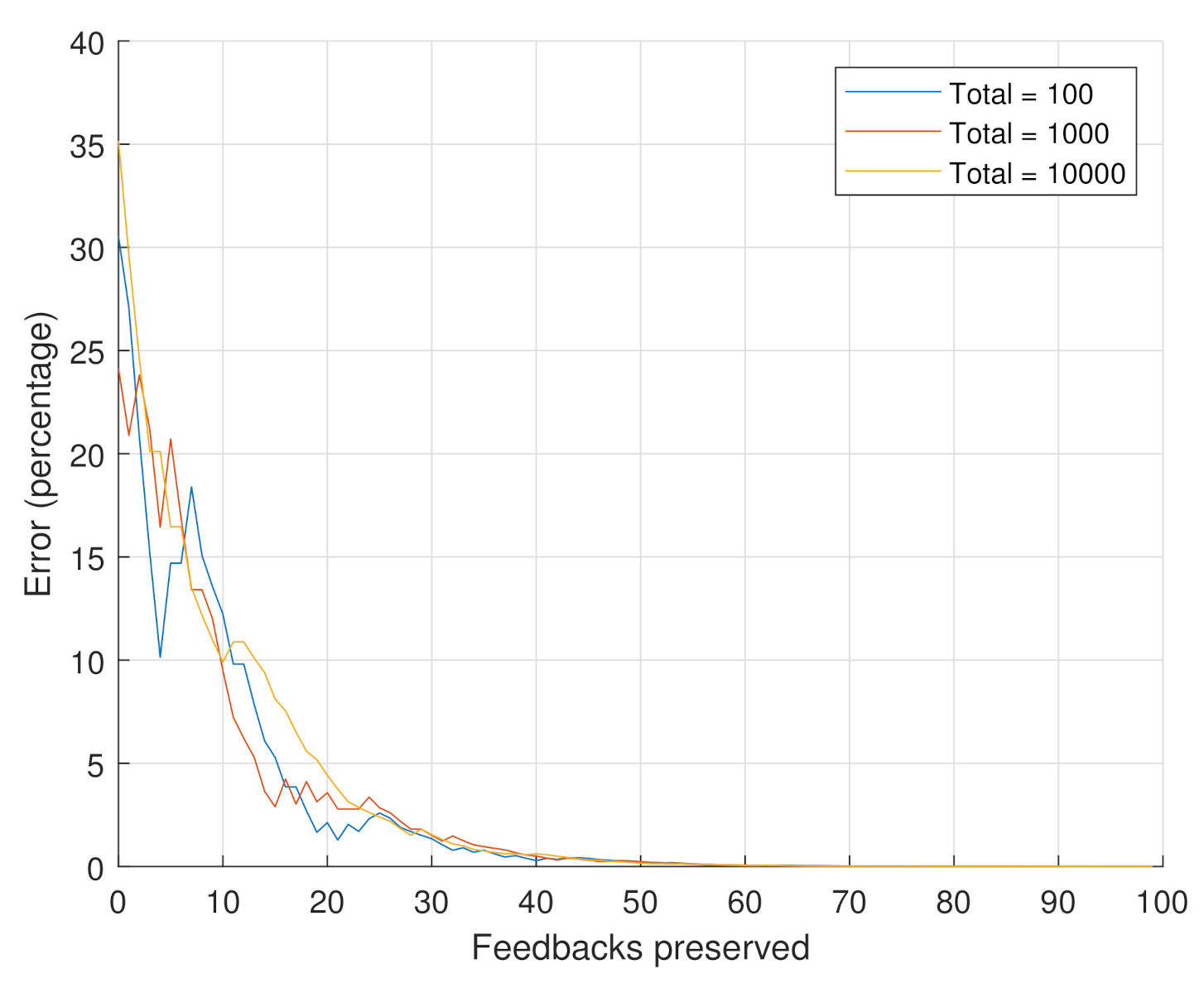
- Scenario 1: the goal of this scenario is to assess the impact of the number of considered feedbacks on the reputation value. In this scenario, we consider the feedbacks regarding a specific product. The number of total feedbacks is set to the following values . From the 10,000 feedbacks, the 100 and 1000 feedbacks are chosen as the oldest 100 and 1000 feedbacks, respectively. These may represent the evolution of the feedbacks that are received over time. The reputation values are computed while using Equation (4). Equation (6) is used in order to compute the percentage error incurred if we only consider a specific number of recent feedbacks (i.e., truncated reputation) out of the total number of feedbacks (i.e., original reputation). The weights of Equation (4) were held constant at .
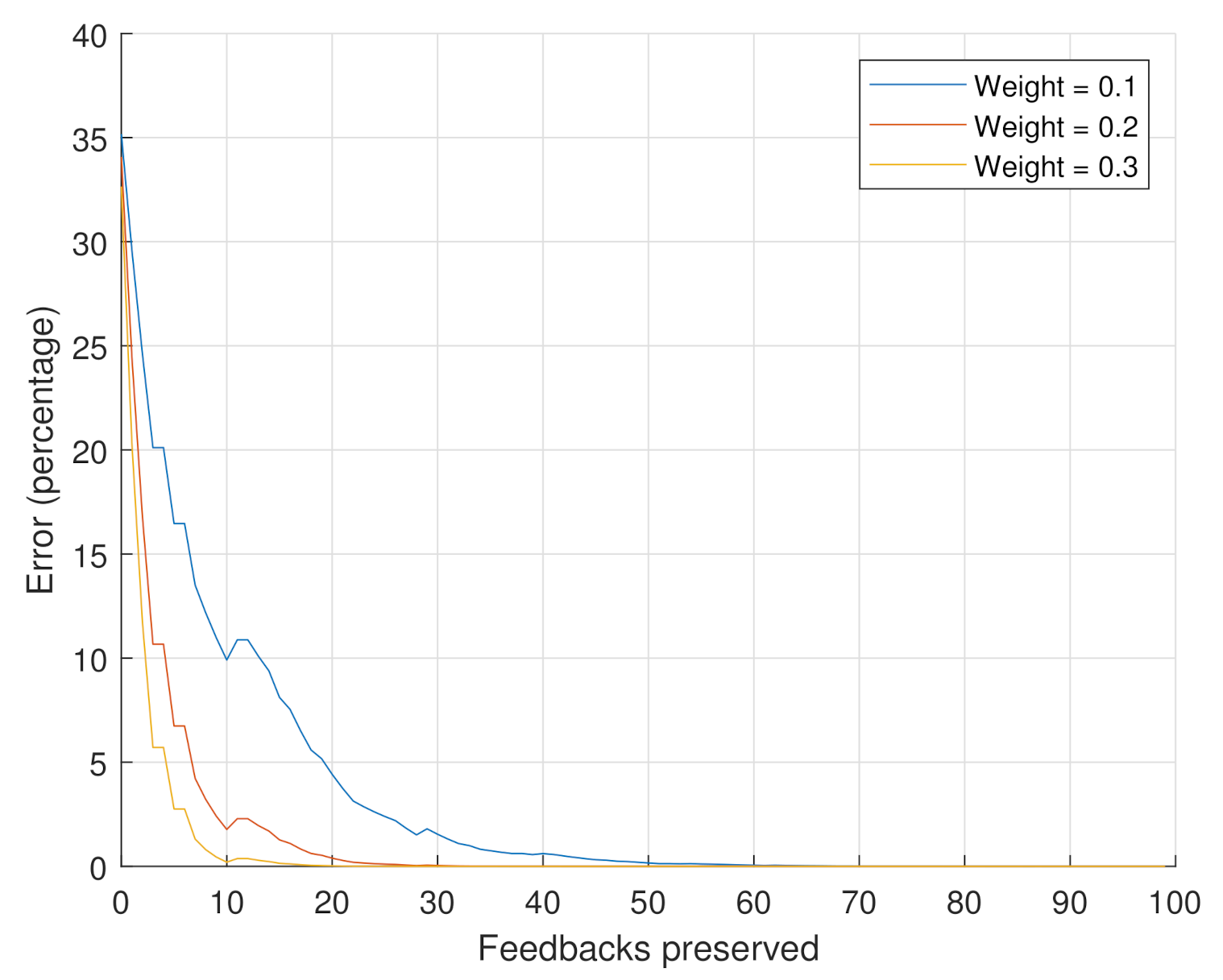
- Scenario 2: the goal of this scenario is to assess the impact of the weights on the reputation value. The number of considered feedbacks is set to 10,000. The considered weight values are .
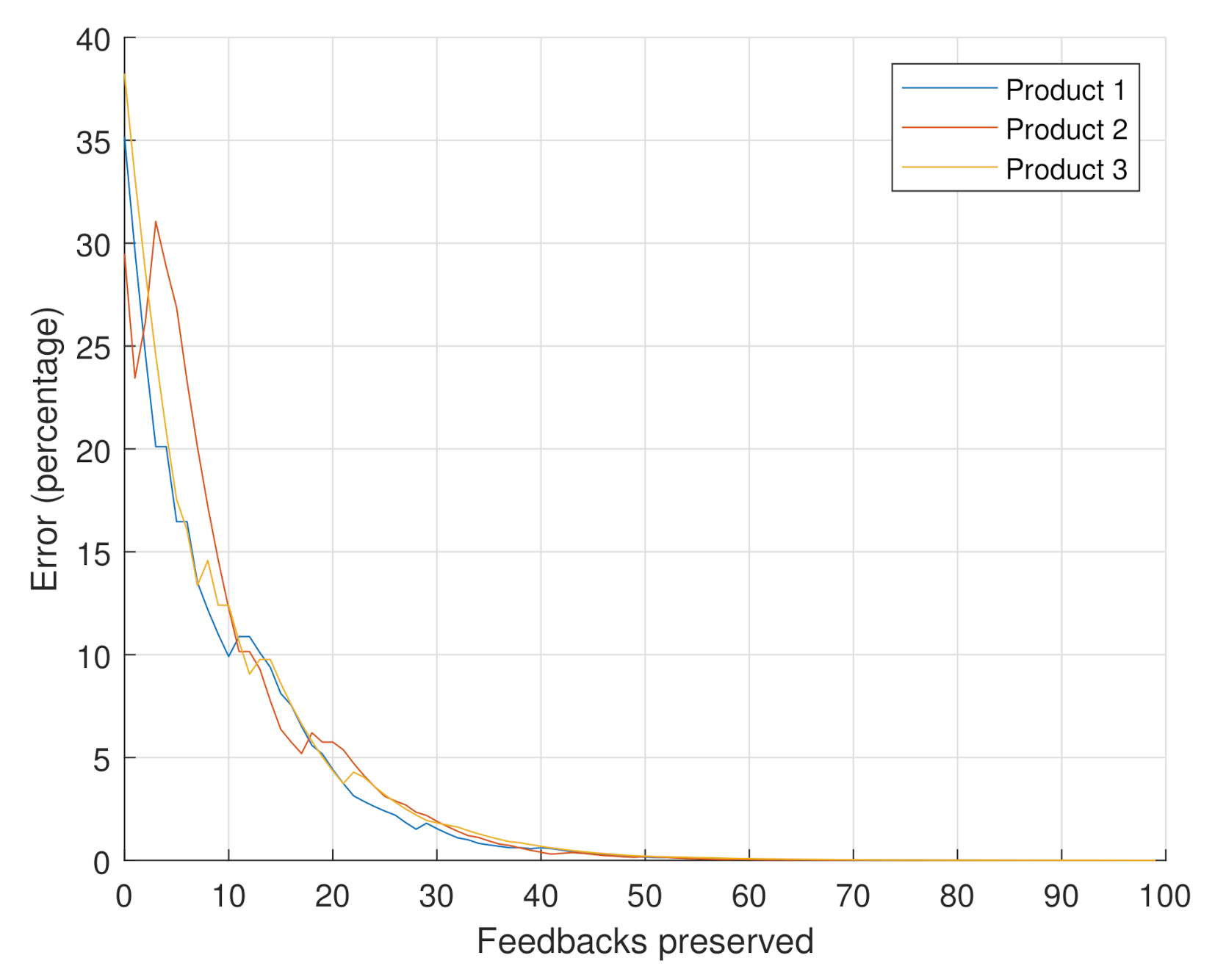
- Scenario 3: the goal of this scenario is to confirm that the behavior of the error with respect to the number of considered feedbacks is the same for any product. Three instant videos were randomly selected from the Amazon dataset. The total number of feedbacks was set to 10,000 as in the previous scenario, and the weight was similar to Scenario 1, being at .
7.2. Analysis
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| BFT | Byzantine Fault Tolerance |
| DL | Distributed Ledger |
| DLT | Distributed Ledger Technology |
| PoS | Proof-of-Stake |
| PoW | Proof-of-Work |
| RMS | Reputation Management System |
References
- Mekouar, L.; Iraqi, Y.; Boutaba, R. Reputation-Based Trust Management in Peer-to-Peer Systems: Taxonomy and Anatomy. In Handbook of Peer-to-Peer Networking; Springer: Berlin/Heidelberg, Germany, 2010; pp. 689–732. [Google Scholar]
- Ruan, Y.; Durresi, A. A Survey of Trust Management Systems for Online Social Communities—Trust Modeling, Trust Inference and Attacks. Knowl.-Based Syst. 2016, 106, 150–163. [Google Scholar] [CrossRef]
- Belotti, M.; Božić, N.; Pujolle, G.; Secci, S. A Vademecum on Blockchain Technologies: When, Which, and How. IEEE Commun. Surv. Tutor. 2019, 21, 3796–3838. [Google Scholar] [CrossRef]
- Bellini, E.; Iraqi, Y.; Damiani, E. Blockchain-Based Distributed Trust and Reputation Management Systems: A Survey. IEEE Access 2020, 8, 21127–21151. [Google Scholar] [CrossRef]
- Dennis, R.; Owen, G. Rep on the Block: A Next Generation Reputation System Based on the Blockchain. In Proceedings of the 2015 10th International Conference for Internet Technology and Secured Transactions (ICITST), London, UK, 14–16 December 2015; pp. 131–138. [Google Scholar] [CrossRef]
- Careem, M.A.A.; Dutta, A. SenseChain: Blockchain Based Reputation System for Distributed Spectrum Enforcement. In Proceedings of the 2019 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Newark, NJ, USA, 11–14 November 2019; pp. 1–10. [Google Scholar]
- Lu, Z.; Wang, Q.; Qu, G.; Liu, Z. Bars: A Blockchain-Based Anonymous Reputation System for Trust Management in VANETS. In Proceedings of the 2018 17th IEEE International Conference On Trust, Security And Privacy In Computing And Communications/12th IEEE International Conference On Big Data Science And Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018; pp. 98–103. [Google Scholar]
- Dorigo, M. Blockchain Technology for Robot Swarms: A Shared Knowledge and Reputation Management System for Collective Estimation. In Proceedings of the Swarm Intelligence: 11th International Conference, ANTS 2018, Rome, Italy, 29–31 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11172, p. 425. [Google Scholar]
- Smith, T.D. The Blockchain Litmus Test. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 2299–2308. [Google Scholar]
- Why New Off-Chain Storage Is Required for Blockchains Document Version 4.1. Technical Report. Available online: https://www.ibm.com/downloads/cas/RXOVXAPM (accessed on 17 September 2020).
- Zheng, Z.; Xie, S.; Dai, H.; Chen, X.; Wang, H. An Overview of Blockchain Technology: Architecture, Consensus, and Future Trends. In Proceedings of the 2017 IEEE International Congress on Big Data (BigData Congress), Honolulu, HI, USA, 25–30 June 2017; pp. 557–564. [Google Scholar]
- Zhou, Q.; Huang, H.; Zheng, Z.; Bian, J. Solutions to Scalability of Blockchain: A Survey. IEEE Access 2020, 8, 16440–16455. [Google Scholar] [CrossRef]
- Göbel, J.; Krzesinski, A.E. Increased Block Size and Bitcoin Blockchain Dynamics. In Proceedings of the 2017 27th International Telecommunication Networks and Applications Conference (ITNAC), Melbourne, VIC, Australia, 22–24 November 2017; pp. 1–6. [Google Scholar]
- Eberhardt, J.; Heiss, J. Off-Chaining Models and Approaches to Off-Chain Computations. In Proceedings of the 2ndWorkshop on Scalable and Resilient Infrastructures for Distributed Ledgers; Association for Computing Machinery, SERIAL’18, New York, NY, USA, 10–14 December 2018; pp. 7–12. [Google Scholar] [CrossRef]
- Bitcoin Blocks-Size. Available online: https://www.blockchain.com/charts/blocks-size (accessed on 14 November 2020).
- Acharjamayum, I.; Patgiri, R.; Devi, D. Blockchain: A Tale of Peer to Peer Security. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 609–617. [Google Scholar]
- Bitansky, N.; Canetti, R.; Chiesa, A.; Goldwasser, S.; Lin, H.; Rubinstein, A.; Tromer, E. The Hunting of the SNARK. J. Cryptol. 2017, 30, 989–1066. [Google Scholar] [CrossRef]
- Bünz, B.; Bootle, J.; Boneh, D.; Poelstra, A.; Wuille, P.; Maxwell, G. Bulletproofs: Short Proofs for Confidential Transactions and More. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 315–334. [Google Scholar]
- Konda, C.; Connor, M.; Westland, D.; Drouot, Q.; Brody, P. Nightfall. Available online: https://img.learnblockchain.cn/pdf/nightfall-v1.pdf (accessed on 17 September 2020).
- Zheng, Z.; Xie, S.; Dai, H.N.; Chen, W.; Chen, X.; Weng, J.; Imran, M. An Overview on Smart Contracts: Challenges, Advances and Platforms. Future Gener. Comput. Syst. 2020, 105, 475–491. [Google Scholar] [CrossRef]
- Szabo, N. Smart Contracts. Phonetic Sciences. Available online: https://www.fon.hum.uva.nl/rob/Courses/InformationInSpeech/CDROM/Literature/LOTwinterschool2006/szabo.best.vwh.net/smart.contracts.html (accessed on 14 November 2020).
- Beniiche, A. A Study of Blockchain Oracles. arXiv 2020, arXiv:2004.07140. [Google Scholar]
- Provable. Blockchain Oracle Service, Enabling Data-Rich Smart Contracts. Available online: https://provable.xyz/ (accessed on 14 November 2020).
- Ellis, S.; Juels, A.; Nazarov, S. ChainLink: A Decentralized Oracle Network. White Paper. Available online: https://link.smartcontract.com/whitepaper (accessed on 17 September 2020).
- Swarm. Swarm 0.5 Documentation. Available online: https://swarm-guide.readthedocs.io/en/latest/introduction.html (accessed on 14 November 2020).
- Benet, J. IPFS-Content Addressed, Versioned, P2P File System. arXiv 2014, arXiv:1407.3561. [Google Scholar]
- Yaga, D.; Mell, P.; Roby, N.; Scarfone, K. Blockchain Technology Overview. arXiv 2019, arXiv:1906.11078. [Google Scholar]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. Technical Report. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 17 September 2020).
- Chainlink. Generate Random Numbers for Smart Contracts Using Chainlink VRF. Available online: https://docs.chain.link/docs/chainlink-vrf (accessed on 14 November 2020).
- Sanchez-Stern, A.; Panchekha, P.; Lerner, S.; Tatlock, Z. Finding Root Causes of Floating Point Error. In Proceedings of the 39th ACM SIGPLAN Conference on Programming Language Design and Implementation, Philadelphia, PA, USA, 18–22 June 2018; pp. 256–269. [Google Scholar]
- OpenZeppelin. OpenZeppelin-Contracts-SafeMath. Available online: https://github.com/OpenZeppelin/openzeppelin-contracts/blob/master/contracts/math/SafeMath.sol (accessed on 19 November 2020).
- Ethereum Homestead 0.1 Documentation. Account Types, Gas, and Transactions. Available online: https://ethdocs.org/en/latest/contracts-and-transactions/account-types-gas-and-transactions.html (accessed on 14 November 2020).
- ABDK-Consulting. Abdk-Consulting/Abdk-Libraries-Solidity. Available online: https://github.com/abdk-consulting/abdk-libraries-solidity (accessed on 14 November 2020).
- BANKEX. Solidity-Float-Point-Calculation. Available online: https://github.com/BankEx/solidity-float-point-calculation (accessed on 14 November 2020).
- Compound-Finance. Compound-Protocol/Exponential.sol. Available online: https://github.com/compound-finance/compound-protocol/blob/v2.6/contracts/Exponential.sol (accessed on 14 November 2020).
- Cement Meta-Stable Coin. CementDAO/Fixidity. Available online: https://github.com/CementDAO/Fixidity (accessed on 14 November 2020).
- Buterin, V. A Next-Generation Smart Contract and Decentralized Application Platform. White Paper. Available online: https://blockchainlab.com/pdf/Ethereum_white_paper-a_next_generation_smart_contract_and_decentralized_application_platform-vitalik-buterin.pdf (accessed on 17 September 2020).
- Unix Manual, First Edition. Unix Programmer’s Manual. Available online: https://www.bell-labs.com/usr/dmr/www/1stEdman.html (accessed on 14 November 2020).
- Jøsang, A.; Hird, S.; Faccer, E. Simulating the Effect of Reputation Systems on e-Markets. In Proceedings of the International Conference on Trust Management, Crete, Greece, 28–30 May 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 179–194. [Google Scholar]
- Mu, P.; Chang, M. Time-Decay-Based Reputation Method for Buyers Making Decisions in Online Shopping. In Proceedings of the 9th International Conference on Electronic Business, Macau, China, 30 November–4 December 2009; pp. 855–863. [Google Scholar]
- Alswailim, M.A.; Hassanein, H.S.; Zulkernine, M. A Reputation System to Evaluate Participants for Participatory Sensing. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016; pp. 1–6. [Google Scholar]
- Huynh, T.D.; Jennings, N.R.; Shadbolt, N.R. An Integrated Trust and Reputation Model for Open Multi-Agent Systems. Auton. Agents-Multi-Agent Syst. 2006, 13, 119–154. [Google Scholar] [CrossRef]
- Michiardi, P.; Molva, R. Core: A Collaborative Reputation Mechanism to Enforce Node Cooperation in Mobile Ad Hoc Networks. In Advanced Communications and Multimedia Security; Springer: Berlin/Heidelberg, Germany, 2002; pp. 107–121. [Google Scholar]
- Ayday, E.; Lee, H.; Fekri, F. An Iterative Algorithm for Trust and Reputation Management. In Proceedings of the 2009 IEEE International Symposium on Information Theory, Seoul, Korea, 28 June–3 July 2009; pp. 2051–2055. [Google Scholar]
- Xu, Z.; Martin, P.; Powley, W.; Zulkernine, F. Reputation-Enhanced QoS-Based Web Services Discovery. In Proceedings of the IEEE International Conference on Web Services (ICWS 2007), Salt Lake City, UT, USA, 9–13 July 2007; pp. 249–256. [Google Scholar]
- Wishart, R.; Robinson, R.; Indulska, J.; Jøsang, A. SuperstringRep: Reputation-Enhanced Service Discovery. In Proceedings of the Twenty-eighth Australasian conference on Computer Science, Newcastle, NSW, Australia, 31 January–3 February 2005; Volume 38, pp. 49–57. [Google Scholar]
- Josang, A.; Haller, J. Dirichlet Reputation Systems. In Proceedings of the Second International Conference on Availability, Reliability and Security (ARES’07), Vienna, Austria, 10–13 April 2007; pp. 112–119. [Google Scholar]
- Margaris, D.; Vassilakis, C. Pruning and Aging for User Histories in Collaborative Filtering. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–8. [Google Scholar]
- Kiayias, A.; Russell, A.; David, B.; Oliynykov, R. Ouroboros: A Provably Secure Proof-of-Stake Blockchain Protocol. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 20–24 August 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 357–388. [Google Scholar]
- Josang, A.; Ismail, R. The Beta Reputation System. In Proceedings of the 15th Bled Electronic Commerce Conference, Bled, Slovenia, 17–19 June 2002; Volume 5, pp. 2502–2511. [Google Scholar]
- He, R.; McAuley, J. Ups and Downs: Modeling the Visual Evolution of Fashion Trends with One-Class Collaborative Filtering. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 May 2016; pp. 507–517. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gas Cost | Ether | USD ($) | Storage Size (Bytes) | |
|---|---|---|---|---|
| reputationComputation( ) | 28,676 | 0.0011 | 0.6565 | 126 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Battah, A.; Iraqi, Y.; Damiani, E. Blockchain-Based Reputation Systems: Implementation Challenges and Mitigation. Electronics 2021, 10, 289. https://doi.org/10.3390/electronics10030289
Battah A, Iraqi Y, Damiani E. Blockchain-Based Reputation Systems: Implementation Challenges and Mitigation. Electronics. 2021; 10(3):289. https://doi.org/10.3390/electronics10030289
Chicago/Turabian StyleBattah, Ammar, Youssef Iraqi, and Ernesto Damiani. 2021. "Blockchain-Based Reputation Systems: Implementation Challenges and Mitigation" Electronics 10, no. 3: 289. https://doi.org/10.3390/electronics10030289
APA StyleBattah, A., Iraqi, Y., & Damiani, E. (2021). Blockchain-Based Reputation Systems: Implementation Challenges and Mitigation. Electronics, 10(3), 289. https://doi.org/10.3390/electronics10030289