1. Introduction
In the last few decades, digital technology has transformed educational practices. This process continues to evolve with technology-driven digitalization fostering a completely new philosophy for both teaching and learning. Advancements in computer technology and human-computer interaction (HCI) applications have enabled digitally driven educational resources to go far beyond the mere digitization of the learning process. CAPT systems belong to the relatively new domain of technology and education, which is why there are still many open issues. However, from the perspective of our current understanding we hold that focusing on computer-assisted pronunciation teaching is beneficial to language education as it helps to involve the very basic cognitive mechanisms of language acquisition. In this work we describe our efforts to pursue this process because
… pronunciation is not simply a fascinating object of inquiry, but one that permeates all spheres of human life, lying at the core of oral language expression and embodying the way in which the speaker and hearer work together to produce and understand each other… [
1].
Language learning has greatly benefitted from global technological advancement. With the appearance of mobile personalized devices, the extensive use of visual perception in conjunction to the audial input has become easier to implement. Online apps enable learners to use their mobile phones to improve their language skills in and outside classes. Apps that are not mobile-friendly are likely to be shunned by learners, particularly those whose primary porthole to the Internet is through their mobile device. From a technological perspective, mobile-first approach and user-friendly interface favoring networking in both technical and communication senses facilitate the building of highly accessible apps aimed at improving pronunciation anytime and anywhere [
2].
Native speaker pronunciation models have dominated English language teaching for many years. However, there is now increasing acceptance of world Englishes and non-standard pronunciation (i.e., not adhering to Anglophonic norms), stemming from the three concentric circle model proposed by Kachru [
3]. His model places historical and sociolinguistic bases of varieties of English, such as American and British English, in the inner circle surrounded by the outer circle of countries that use English as a
lingua franca, such as India and Kenya, while the expanding circle comprises countries that use English as medium to communicate internationally. With fewer users of English in the inner circle than the other two circles, there is debate over the appropriacy of native-speaker models. The trend to focus on intelligibility originated in the 1990s. Those arguing against native-speaker models note that intelligibility should be paramount. In recent years, the prevailing approach holds that intelligibility is more important than replicating native-speaker models [
4,
5,
6,
7]. Rightly or wrongly the goal of many learners of English is to emulate native-speaker models of pronunciation. This may be due to its perceived status and pragmatic value [
8].
Intonation patterns that do not conform to Anglocentric expectations (i.e., native speaker norms) are more likely to affect a native speaking hearer’s judgement of the attitude of the speaker rather than causing misunderstanding over the content of the message. For example, inappropriate pitch trajectories in English, such as using low pitch displacement for requests, are likely to be interpreted as rude by native speakers [
9]. Rhythm is used by native speakers to focus attention on certain key words and so when non-Anglocentric patterns are used, the comprehensibility of the message drops, forcing empathetic native speakers to concentrate intensively to decode the message. The intonation contour also indicates the pragmatic status of contextualized information as either given (known) or new (unknown) [
10,
11,
12]. Specifically, Halliday noted that new information is marked by tonic pitch movement [
13,
14]. This enables speakers to convey new information with more clarity [
15], reducing the burden on listeners to work out the words to which more attention should be paid. Communication competence in a foreign language and the ability to understand foreign language in its natural setting is much affected by the speaker’s level of pronunciation [
16].
Most language teachers focus learners on a particular aspect of pronunciation and then provide opportunities for them to practise [
17]. This approach follows the noticing hypothesis [
18], which states that noticing is a necessary precursor to learning. The effects of different attentional states and contexts with their pedagogical implications have been further examined in [
19] where the relation between the attention state and the stimuli were shown to vary with context. The complexity of phonological problems combined with simultaneously teaching learners with different phonological problems exacerbates the difficulty for classroom teachers to provide personalised feedback, particularly for those who teach large classes [
20].
The ideal solution is one that could present feedback to learners in their preferred form, e.g., graphical, textual or audio feedback. Graphical feedback requires learners to identify the key differences themselves. A feature that provides specific actionable advice in text form on differences between target language and learner performance by comparing the pitch waves could enhance the usability. Some learners prefer to hear than read, and so providing that option would be well received by auditory learners.
The CAPT system in focus is StudyIntonation [
21,
22,
23]. The practical purpose of the StudyIntonation project is twofold: first, to develop and assess a technology-driven language learning environment including a course toolkit with end-user mobile and web-based applications; and second, to develop tools for speech annotation and semantic analysis based on intonation patterns and digital signal processing algorithms. There has been significant advances in segmental pronunciation training. A framework proposed in [
24] detects mispronunciations and maps each case to a a phone-dependent decision tree where it can be interpreted and communicated to the second language learners in terms of the path from a leaf node to the root node. Similar systems, which address teaching segmental and prosodic speech phenomena, have been developed for different languages and groups of learners. Systems which are most similar to StudyIntonation in terms of architecture and functionality were developed for suprasegmental training in English [
25], for children with profound hearing loss to learn Hungarian [
26], and for Italian adults learning English as a foreign language [
27]. This study, in particular, exemplifies and explains the technological impact on CAPT development. These and many more CAPT systems adopt a common approach, which is based on speech processing, segmentation and forced alignment to obtain some numerically and graphically interpretable data for a set of pronunciation features [
28]. The individual systems or solutions differ in their choice of pronunciation aspects to train and scoring policy: a conventional approach is the simultaneous visual display of model and learner’s rhythm and intonation and the scoring performed as per Pearson and/or Spearman correlation or dynamic time warping (DTW). Even very powerful CAPT tools are still lacking explicit feedback for acquisition and assessment of foreign language suprasegmentals [
29].
Intonation contour and rhythmic portrait of a phrase provide learners with a better understanding of how they follow the recorded patterns of native speakers. However, such graphs do not presume innate corrective or instructive value. Conventional score-based approach cannot tell the second language learners why their mispronunciations occur and how to correct them. Consequently, adequate metrics to estimate learning progress and prosody production should be combined with CAPT development, while giving more intuitive and instructive feedback. Time-frequency and cepstrum prosody features, which are fairly well suited to the purpose of automatic classification, are impractical to grasp synchronization and coupling effects during learner interaction with a CAPT system. That is why the approach based on non-linear dynamics theory, in particular, recurrence quantification analysis (RQA) and cross RQA (CRQA) may contribute to the adequacy of provided feedback.
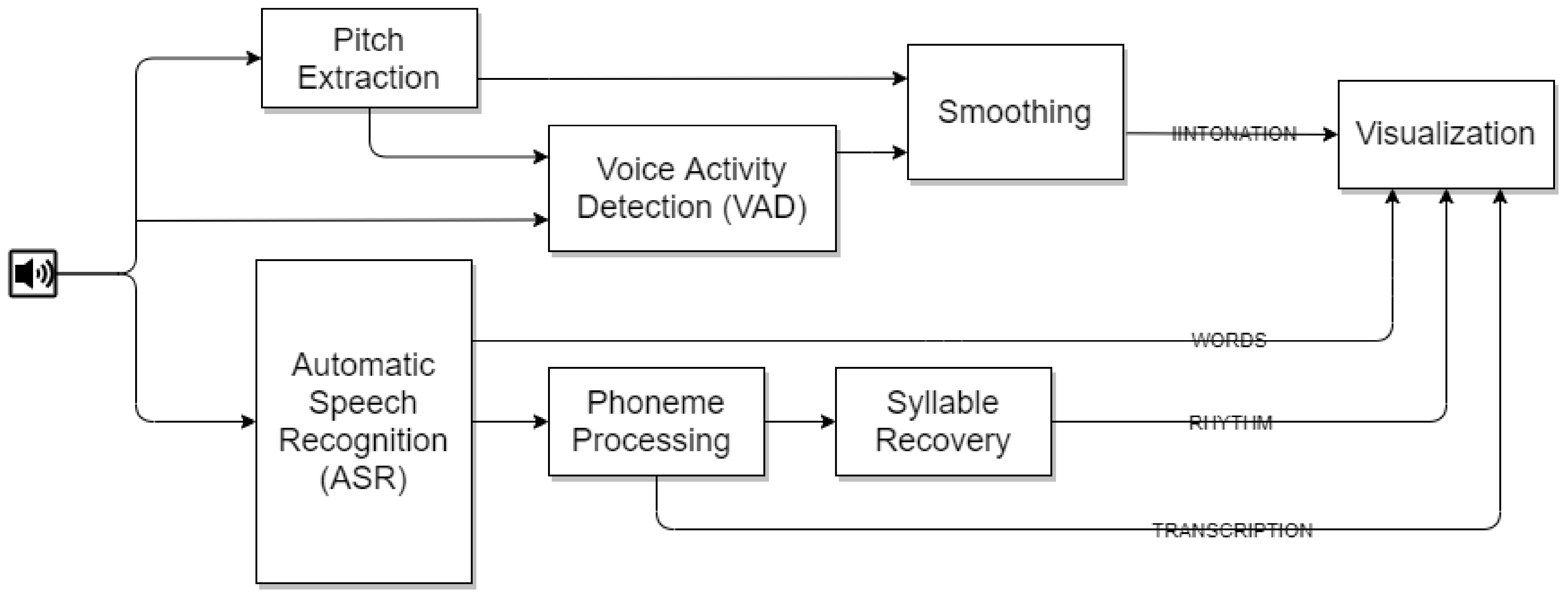
In this work we applied voice activity detection (VAD) before pitch processing and instrumented StudyIntonation with a third-party automatic speech recognition (ASR) system. ASR internal data obtained at intermediary stages of speech to text conversion provide phonetic transcriptions of the input utterances of both the model and learner. The rhythmic pattern is retrieved from phonemes and their duration and energy. Transcription and phrasal rhythm are visualized alongside with phrasal intonation shown by pitch curves. CAPT courseware is reorganized to represent each task as a hierarchical phonological structure which contains an intonation curve, a rhythmic pattern (based on energy and duration of syllables) and IPA transcription. The validity of dynamic time-warping (DTW), which is currently applied to determine the prosodic similarity between models and learners was estimated over native and non-native speakers corpora using IViE stimuli. DTW results were compared and contrasted against CRQA metrics which measured synchronization and coupling parameters in the course of CAPT operation between model and learner; and were, thus, shown to add to the accuracy of learner performance evaluation through the experiments with two automatic binary classifiers.
Our research questions are aimed at clarification of the (1) ASR system and ASR speech model applicability within a mobile CAPT system; (2) ASR system internal data consistency to represent phonological events for teaching purposes; and (3) CRQA impact to learner performance evaluation.
The remainder of this paper is structured as follows.
Section 2 is a review of the literature relevant to the cross-disciplinary research of CAPT system design,
Section 3 provides an overview of speech processing methods which extend the existing prototype functionality (voice activity detection; phoneme, syllable, and rhythm retrieval algorithms). Our approach to conjoin different phonological aspects of pronunciation within the learning content of the CAPT system is also described.
Section 4 contains the CAPT system signal processing software core design and presents the stages of its experimental assessment with reference phonological corpora and during target user group try-outs.
Section 5 discusses the major implications of our research. Specifically, the accuracy of phonological content processing; the aspects of joint training of segmentals and suprasegmentals; the typical feedback issues which arise in the CAPT systems; and, finally, some directions for future work based on theories drawn from cognitive linguistics and second language acquisition.
2. Literature Review
Pronunciation teaching exploits the potential of speech processing to individualize and adapt the learning of pronunciation. The underlying idea is to build CAPT systems which are able to automatically identify the differences between learner production and a model, and provide an appropriate user feedback. Comparing speech sample to an ideal reference is acknowledged to be a more consistent basis for scoring instead of general statistical values such as mean, standard deviation or probability density distribution of learner’s speech records [
25,
26,
30]. Immediate actionable feedback is paramount [
7,
31,
32]. Learner analysis of feedback can significantly improve pronunciation and has been used on various pronunciation features (e.g., segmentals [
33,
34]; suprasegmentals [
26,
35]; vowels [
36]).
CAPT systems frequently include signal processing algorithms and automated speech recognition (ASR), coupled with specific software for learning management, teacher-student communication, scheduling, grading, etc [
37]. Based on the importance of the system-building technology incorporated, the existing CAPT systems can be grouped into four classes namely: visual simulation, game playing, comparative phonetics approach, and artificial neural network/machine learning [
28]. ASR incorporating neural networks, probabilistic classifiers and decision making schemes, such as GMM, HMM and SVM, is one of the most effective technologies for CAPT design. Yet, some discrete precautions should be taken to apply ASR in a controlled CAPT environment [
38]. A case in point is the unsuitability of ASR for automatic evaluation of learner input. Instead, ASR algorithms are harnessed in CAPT to obtain the significant acoustic correlates of speech to create a variety of pronunciation learning content, contextualized in a particular speech situation [
38]. Pronunciation teaching covers both segmental and suprasegmental aspects of speech. In natural speech, tonal and temporal prosodic properties are co-produced [
39]; and, therefore, to characterize and evaluate non-native pronunciation, modern CAPT systems should have the means to collectively represent both segmentals and suprasegmentals [
27]. Segmental (phonemic and syllabic) activities work out the correct pronunciation of single phonemes and co-articulation of phonemes into higher phonological units. Suprasegmental (prosodic) pronunciation exercises embrace word and phrasal levels. Segmental features (phonemes) are represented nominally and temporally, while suprasegmental features (intonation, stress, accent, rhythm, etc.) have a large scale of representations including pitch curves, spectrograms and labelling based on a specific prosodic labelling notation (e.g., ToBI [
40], IViE [
41]). The usability of CAPT tools increases if they are able to display the features of natural connected speech such as elision, assimilation, deletion, juncture, etc. [
42].
At word level the following pronunciation aspects can be trained:
- -
stress positioning;
- -
stressed/unstressed syllables effects, e.g., vowel reduction; and
- -
tone movement.
Respectively, at phrasal level the learners might observe:
- -
sentence accent placement;
- -
rhythmic pattern production; and
- -
phrasal intonation movements related to communicative functions.
Contrasting the exercises as phonemic/prosodic as well as the definition of prosody purely in terms of suprasegmentals is a question under discussion so far, because prosodic and phonemic effects can naturally co-occur. When prosody is expressed through suprasegmental features one can also observe the specific segmental effects. For example, tone movement within a word shapes the acoustic parameters that influence voicing or articulation [
43]. Helping learners understand how segmentals and suprasegmentals collectively work to convey the non-verbal speech payload is one of the most valuable pedagogical contributions of CAPT.
A visual display of the fundamental frequency
(which is the main acoustical correlate of stress and intonation) combined with audio feedback (such as it is demonstrated in
Figure 1b) is generally helpful. However, the feasibility of visual feedback increases if the learner’s
contour is displayed not only along with a native model, but with possible formalized interpretation of the difference between the model and the learner. Searching for objective and reliable ways to tailor instantaneous corrective feedback about the prosodic similarity between the model and the learner’s pitch input remains one of the most problematic issues of CAPT development and operation [
29].
The problem of prosodic similarity evaluation arises within multiple research areas including automatic tone classification [
44] and proficiency assessment [
45]. Although in [
46] it was shown that the difference between two given pitch contours may be perfectly grasped by Pearson correlation coefficient (PCC) and Root Mean Square (RMS), in the last two decades, prosodic similarities were successfully evaluated using dynamic time warping (DTW). In [
47], DTW was shown to be effective at capturing the similar intonation patterns being tempo invariant and, therefore, more robust than Euclidean distance. DTW combines the prosodic contour alignment with the ability to operate with prosodic feature vectors containing not only
, but the whole feature sets, which can be extracted within a specific system. There is also evidence to that learner performance might be quantified by synchronization dynamics between model and learner achieved gradually in the course of learning. Accordingly, the applicable metrics may be constructed using cross recurrence quantification metrics (CRQA metrics) [
48,
49]. The effects of prosodic synchronization have been observed and described by CRQA metrics in several cases of emotion recognition [
50] and the analysis of informal and business conversations [
51].
Though speech recognition techniques (which are regularly discussed in the literature, e.g., in [
52,
53]) are beyond the scope of this paper, some state-of-the-art approaches of speech recognition may enhance the accuracy of user speech processing in real time. As such, using deep neural networks for recognition of learner speech might provide a sufficiently accurate result to be used to echo learner’s speech input and can be displayed along with the other visuals. The problem of background noise during live sound recording, which is partially solved in the present work by voice activity detection, can be tackled as per the separation of interfering background based on neural algorithms [
54].
3. Methods
3.1. Voice Activity Detection (VAD)
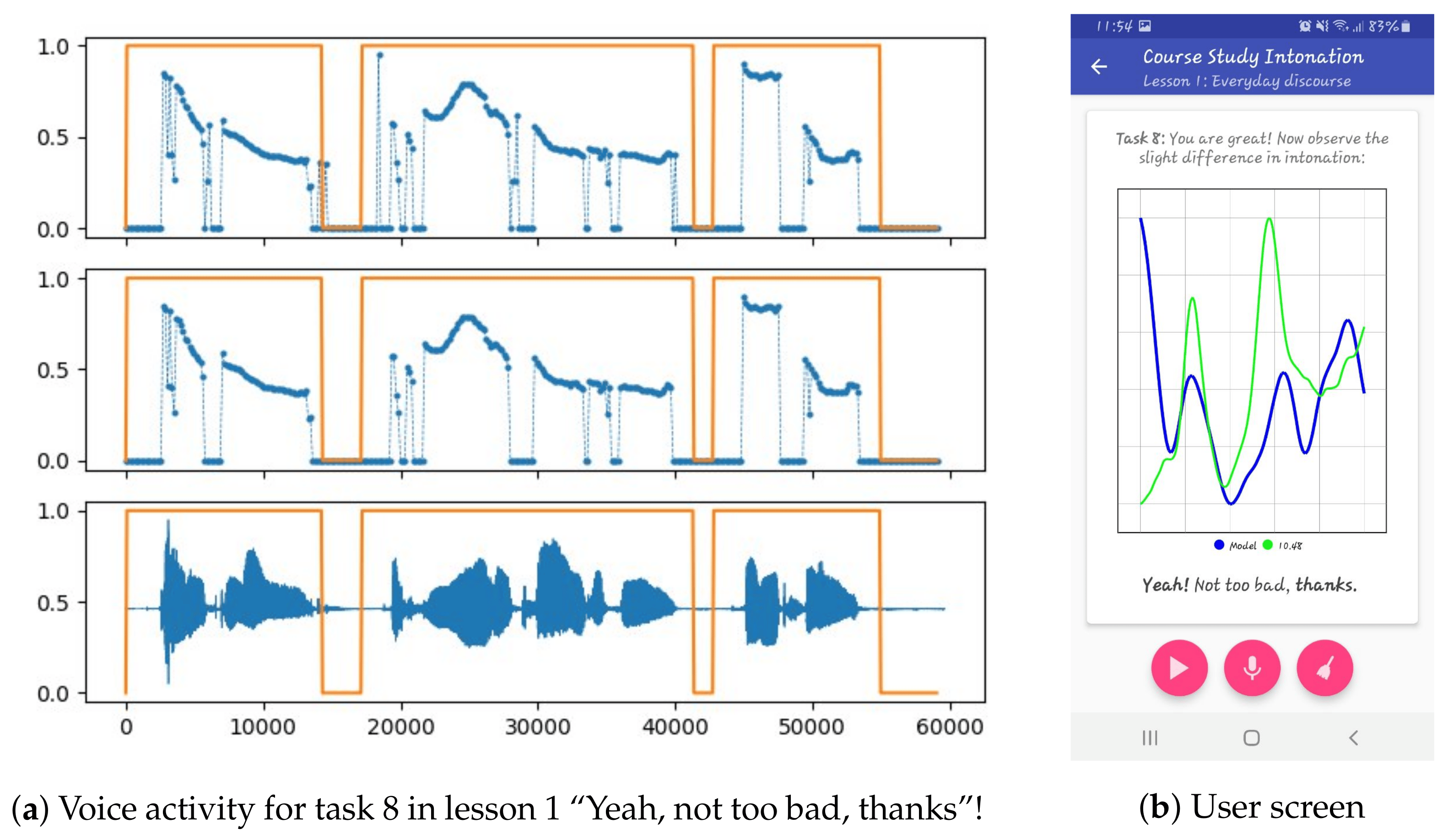
Visual feedback for intonation has become possible due to fundamental frequency (pitch) extraction which is a conventional operation in acoustic signal processing. Pitch detection algorithms output the pitches as three vectors of
(timestamps),
(pitch values) and
(confidence). However, the detection noise, clouds and discontinuities of pitch points, and sporadic prominences make the raw pitch series almost indiscernible by the human eye and unsuitable to be visualized “as is”. Pitch detection, filtering, approximation and smoothing are standard processing stages to obtain a pitch curve adapted for teaching purposes. When live speech recording for pitch extraction is assumed, a conventional practice is to apply some VAD to raw pitch readings before the other signal conditioning stages. To remove possible recording imperfections, VAD was incorporated into StudyIntonation DSPCore. VAD was implemented via a three-step algorithm as per [
55] with
logmmse [
56] applied at the speech enhancement stage. In
Figure 1a, the upper plot shows the raw pitch after preliminary thresholding in a range between 75 Hz and 500 Hz and at a confidence of 0.5. The plot in the middle shows the pitch curve after VAD. The last plot is speech signal in time. The rectangle areas on all plots mark the signal intervals where voice has been detected. Pitch samples outside voiced segments are suppressed, the background noise before and after the utterance as well as hesitation pauses are excluded. The mobile app GUI is shown in
Figure 1b.
3.2. Prosodic Similarity Evaluation
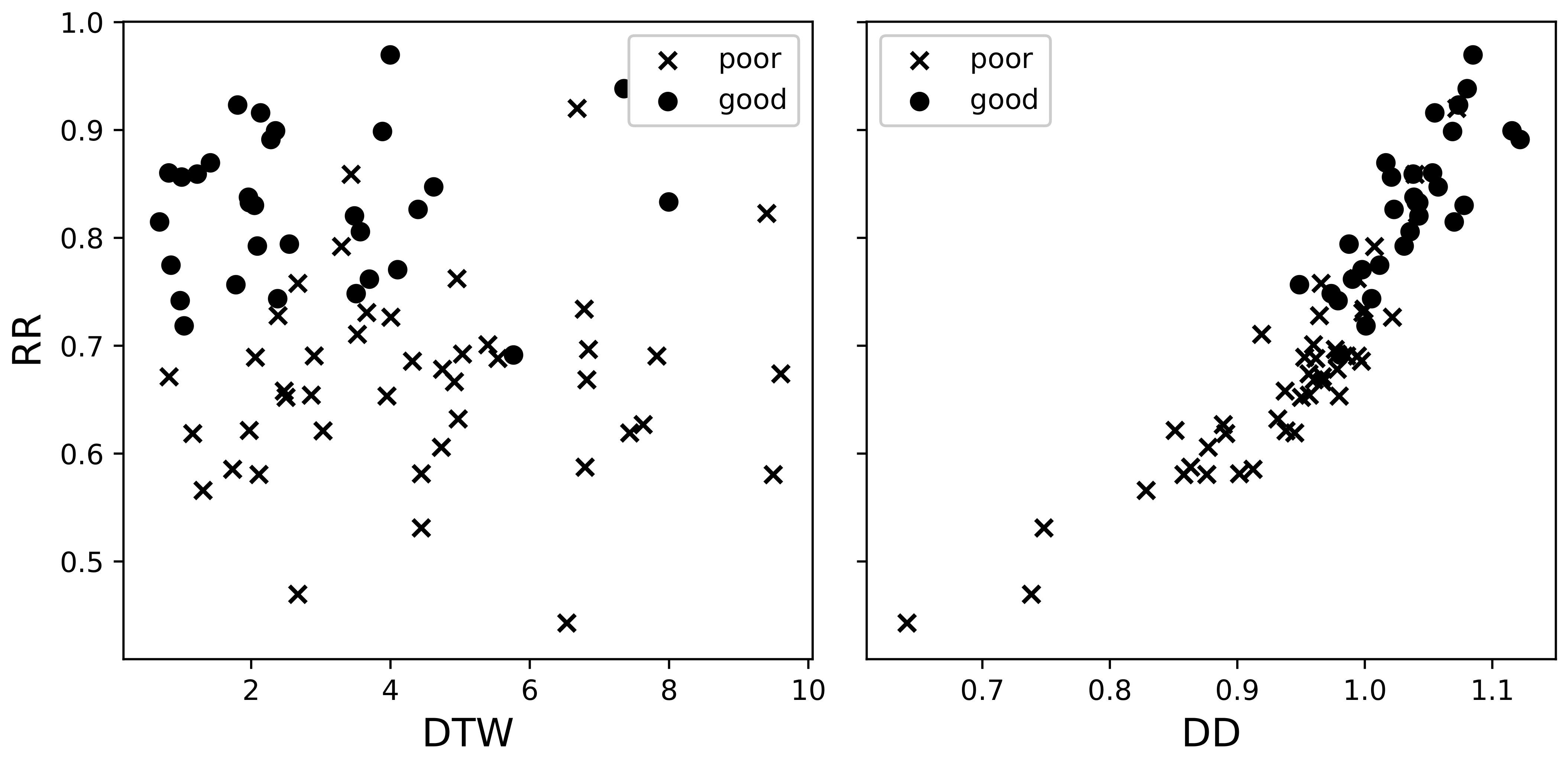
In its application to the domain of learner’s speech production evaluation, DTW accounts for prosodic similarity tolerably well. There are, however, two inherent limitations: firstly, DTW score is static and produces only an instant snap-shot of learner’s performance; and secondly, it is too holistic and general: the DTW score gives only one numerical value to a learner, and this value is hardly interpretable in terms of what to undertake to succeed or improve. On the other hand, the effects of synchronization and coupling that may be provided with the help of CRQA are more promising for constructing and representing more comprehensible CAPT feedback.
As soon as the learner is expected to synchronize the prosodic characteristics to a certain extent with the model, CRQA metrics might provide an insight into learning dynamics or, at least, have stronger correlation with “good” or “bad” attempts of a learner. Consequently, it might be reasonable to examine whether synchronization phenomenon occurs, register CRQA metrics and apply them collectively with DTW.
Natural processes can reveal recurrent behavior, e.g., periodicities and quasi-regular cycles [
48]. Recurrence of states, meaning the states converging to become arbitrary close after sometime, is a fundamental property of deterministic dynamical systems and is typical for nonlinear or chaotic systems [
57,
58]. Recurrences in the dynamics of a dynamical system can be visualised by the recurrence plot (RP), which represents the times at which the states
recur.
Recurrence of a state at time
i at another time
j is plotted on a two-dimensional squared matrix
R with dots, where both axes represent time:
where
N is the number of considered states of a model
and a learner
;
is a threshold distance;
is the Heaviside function.
To quantify the recurrence inside a system a set of recurrence variables may be defined [
48]. In the present study two are used: recurrence rate (
) and percent determinism (
).
is a measure of the relative density of recurrence points; it is related to the correlation sum:
describes the density of RP line structures.
is calculated via
—the histogram of the lengths of RP diagonal structures:
Hence,
is defined as the fraction of recurrence points that form the diagonal lines:
is connected with correlation between model and learner, while
values show to what extent the learners production of a given task is stable.
3.3. Phoneme Processing and Transcription
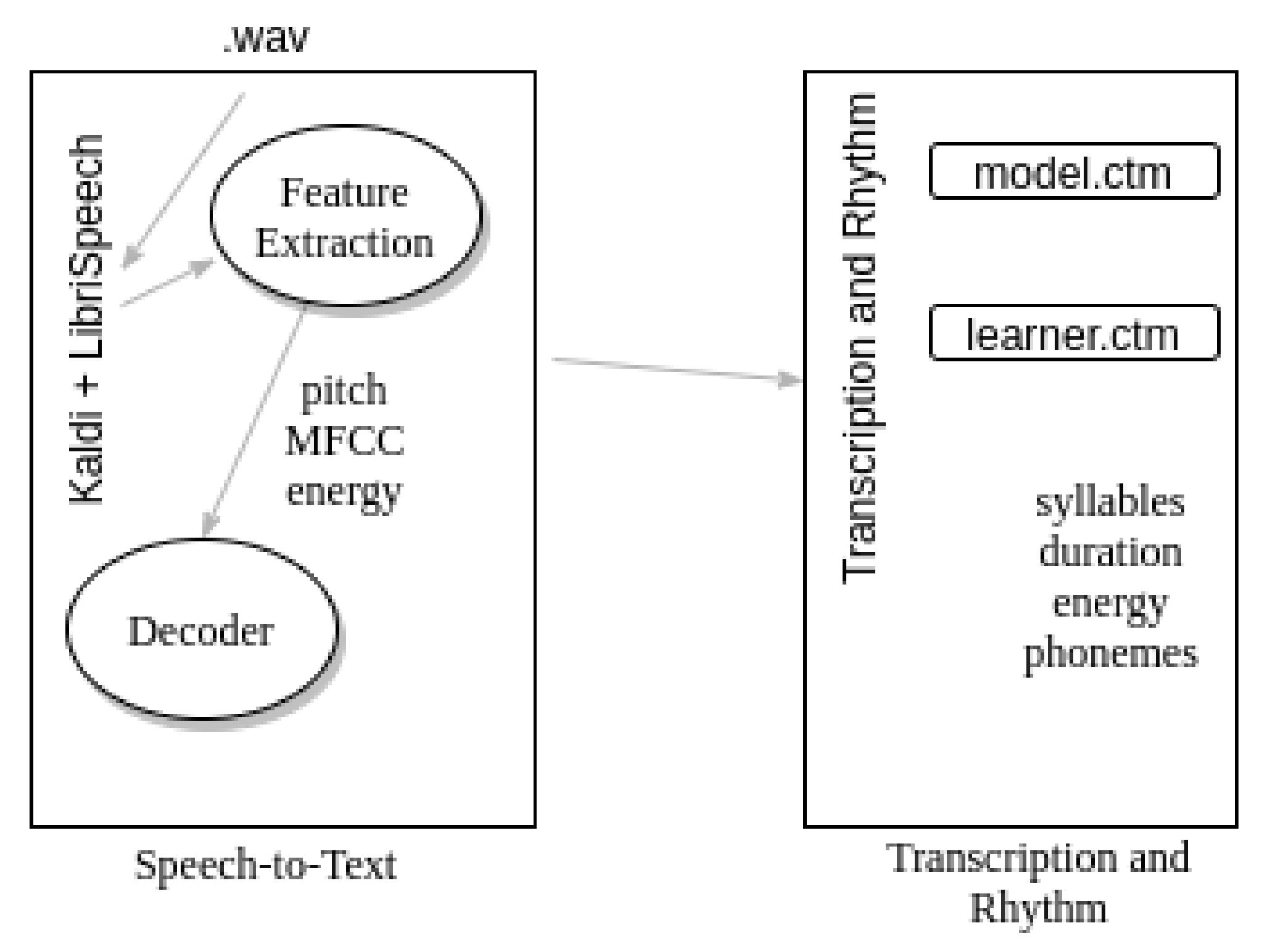
Phoneme and rhythm processing are performed by the automatic speech recognition component of DSPCore which incorporates the
Kaldi ASR tool with the pretrained
LibriSpeech ASR model. Kaldi [
59] is a full-fledged open source speech recognition tool, where the results might be obtained at any intermediary stage of speech to text processing. At the moment, there is a wide variety of ASR models, suitable for use in the Kaldi library. For English speech recognition, the most popular ASR models are
ASpIRE Chain Model and
LibriSpeech ASR. These models were compared in terms of vocabulary size and recognition accuracy. The ASpIRE Chain Model Dictionary contains 42,154 words, while the LibriSpeech Dictionary contains only 20,006 words, but has a lower error rate (8.92% against 15.50% for the ASpIRE Chain Model). The LibriSpeech model was chosen for the mobile platform to use with Kaldi ASR due to its compactness and lower error rate.
The incoming audio signal is split into equal frames of 20 ms to 40 ms, since the sound becomes less homogeneous at a longer duration with a respective decrease in accuracy of the allocated characteristics. The frame length is set to a Kaldi optimal value of 25 ms with a frame offset of 10 ms. Acoustic signal features including mel-frequency cepstral coefficients (MFCC), frame energy and pitch readings are extracted independently for each frame (
Figure 2). The decoding graph was built using the pretrained LibriSpeech ASR model. The essence of this stage is the construction of the
graph, which is a composition of the graphs H, C, L, G:
Graph H contains the definition of HMM. The input symbols are parameters of the transition matrix. Output symbols are context-dependent phonemes, namely a window of phonemes with an indication of the length of this window and the location of the central element.
Graph C illustrates context dependence. The input symbols are context-dependent phonemes, the output symbols of this graph are phonemes.
Graph L is a dictionary whose input symbols are phonemes and output symbols are words.
Graph G is the graph encoding the grammar of the language model.
Having a decoding graph and acoustic model as well as the extracted features of the incoming audio frames, Kaldi performs lattice definitions, which form an array of phoneme sets indicating the probabilities that the selected set of phonemes matches the speech signal. Accordingly, after obtaining the lattice, the most probable phoneme is selected from the sets of phonemes. Finally, the following information about each speech frame is generated and stored in a .ctm file:
the unique audio recording identifier
channel number (as all audio recordings are single-channel, the channel number is 1)
timestamps of the beginning of phonemes in seconds
phoneme duration in seconds
unique phoneme identifier
Using the LibriSpeech phoneme list, the strings of the .ctm file are matched with the corresponding phoneme unique identifier.
3.4. Rhythmic Pattern Retrieval
Kaldi output transcription of text at the phonemic level was further used for splitting the source text into syllables, finding their lengths, highlighting pauses and constructing the rhythm. The set of phonemes in the LibriSpeech model has 4 postfixes: “B” (beginning), “I” (internal), “E”(ending), and “S” (single). This feature of LibriSpeech phonemes allows individual words from a sequence of phonemes to be selected and split into syllables.
For most English words, the number of syllables is equivalent to the number of vowel phonemes. This rule will be used further since due to phonological peculiarities of the English language there is no single algorithm for syllable splitting. Two possible ways could be using a dictionary of English words with manual syllabic segmentation or exploiting language properties that allow automatic segmentation with a certain error percentage. Syllabic segmentation is based on the information about word boundaries and vowels in a word, and also adhere to the rule of maximum number of consonants at the beginning of a syllable [
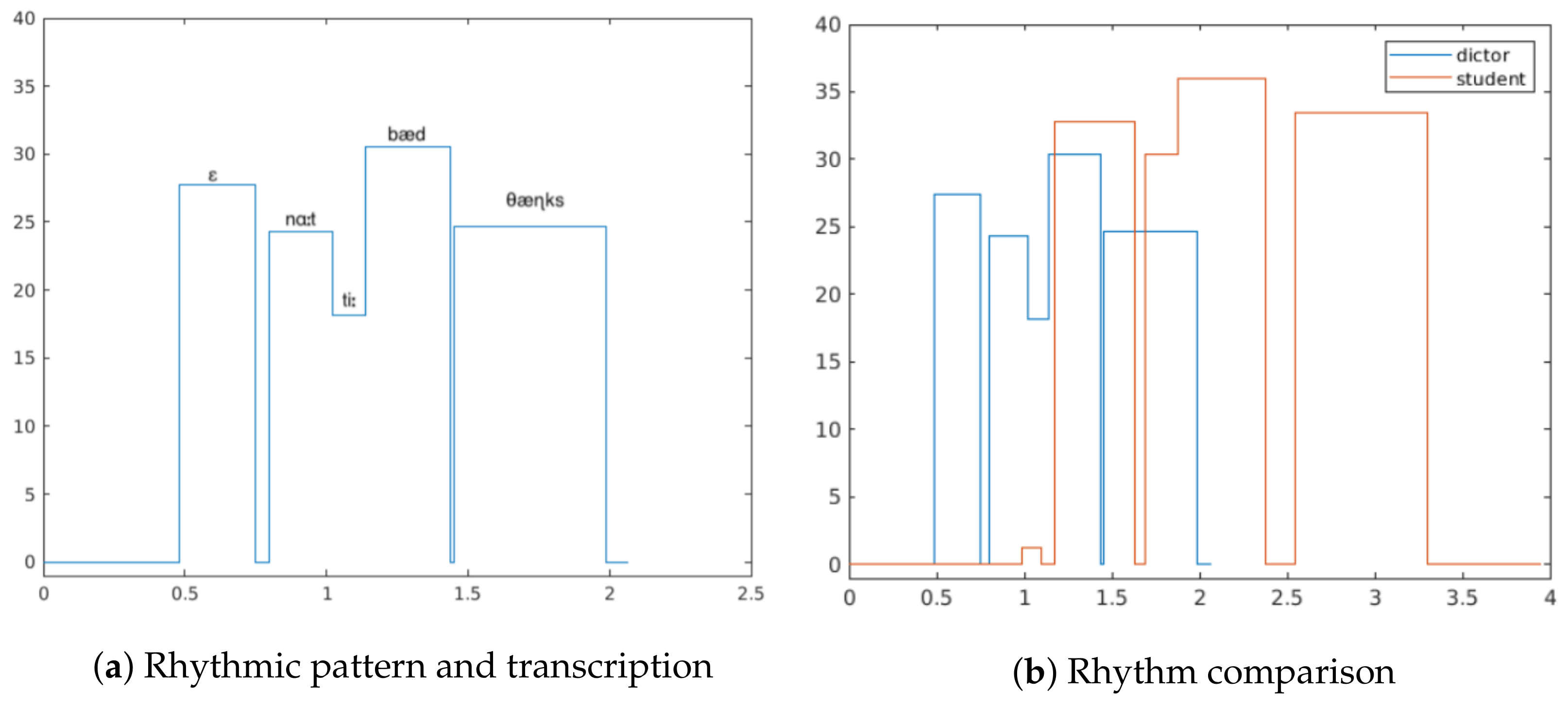
38]. This method achieved segmentation accuracy of 93%. It is possible to increase the accuracy by adding manually selected words that do not lend themselves to the common rule. At this stage, it is also necessary to take into account the pauses between syllables and syllable duration for the subsequent rhythmic pattern retrieval. We store the data of syllables and pauses in the following data structure: data type; syllable or pause; duration; start time; maximum energy on a data interval; and an array of phonemes included. In the case of a pause the maximum energy is taken to be zero, and the array of phonemes contains the phoneme, defining silence, labeled SIL in LibriSpeech. The duration of a syllable or pause is calculated as the sum of all phoneme durations of a syllable. Relative start time is assumed as the start time of the first phoneme in the syllable.
The maximum energy is calculated using MFCC obtained for all frames of the audio signal (
Section 3.3). Accordingly, to find the maximum energy, it is necessary to conjoin the frames related to a given syllable and take the maximum entry of the frame energy in this area. Knowing the start and end timestamps of a syllable, one can get the first frame containing the beginning of the syllable and the last frame containing the last phoneme. This operation is linear to the number of syllable frames. The obtained syllable characteristics are used to mark the stressed and unstressed syllables. It is also worth noting that LibriSpeech uses AB notation to represent phonemes, for this reason, before writing the results in json format it is necessary to carry out the conversion of phonemes to IPA1 notation. All this information (
Table 1,
Figure 3a,b) is used to construct visualization and feedback on rhythm, which can be displayed either jointly with phonetic transcription or separately in the form of energy/duration rectangular patterns (
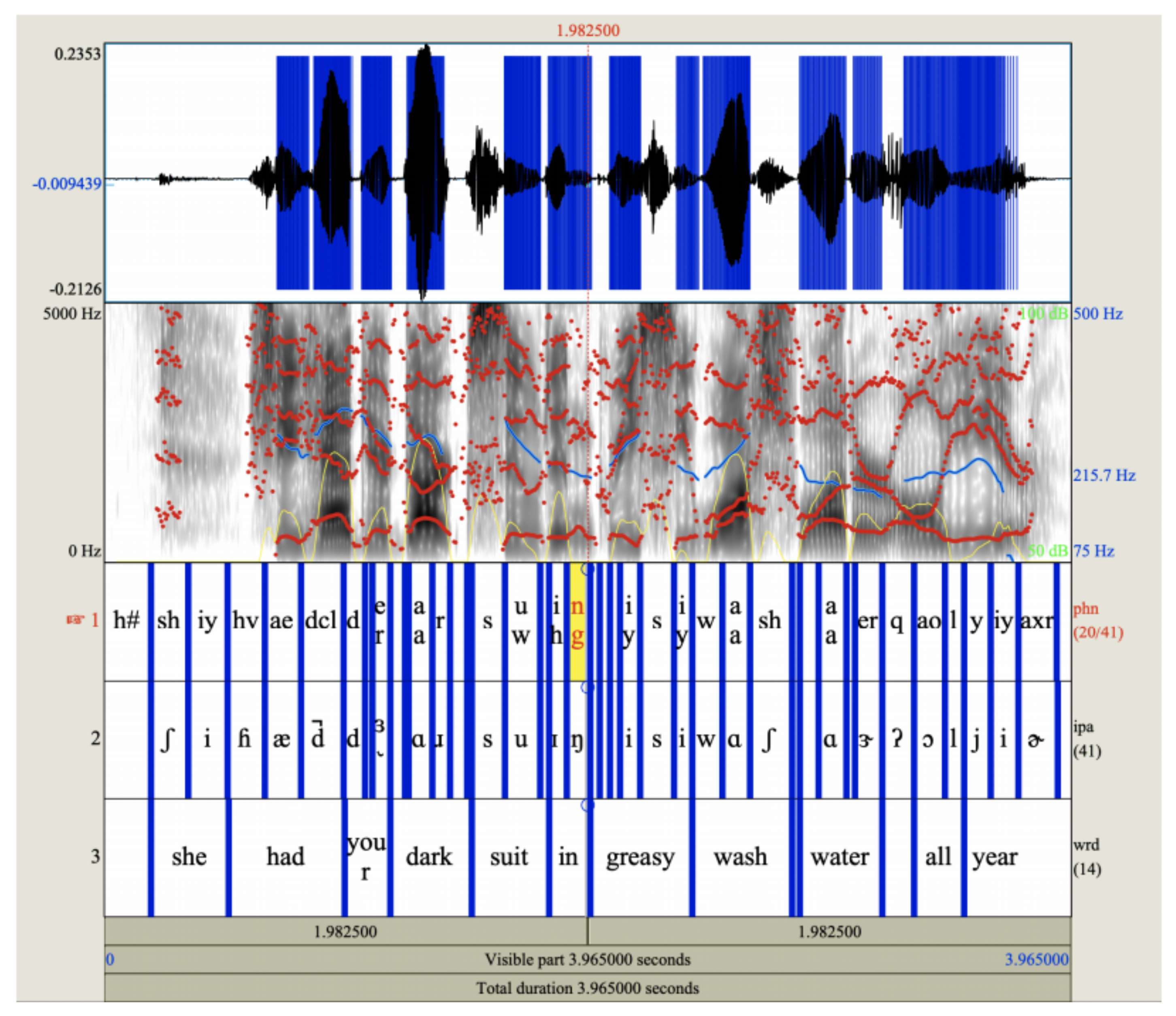
Figure 4a,b). In case, when transcription and rhythm are addressed separately, the former might be visualized as aligned orthographic and phonetic phrases (
Figure 5). Technically, all ASR-based features are implemented as the following C++ software components:
Transcription API
Transcription Recognizer
Transcription Analyzer
Syllable Builder
3.5. Content Structure
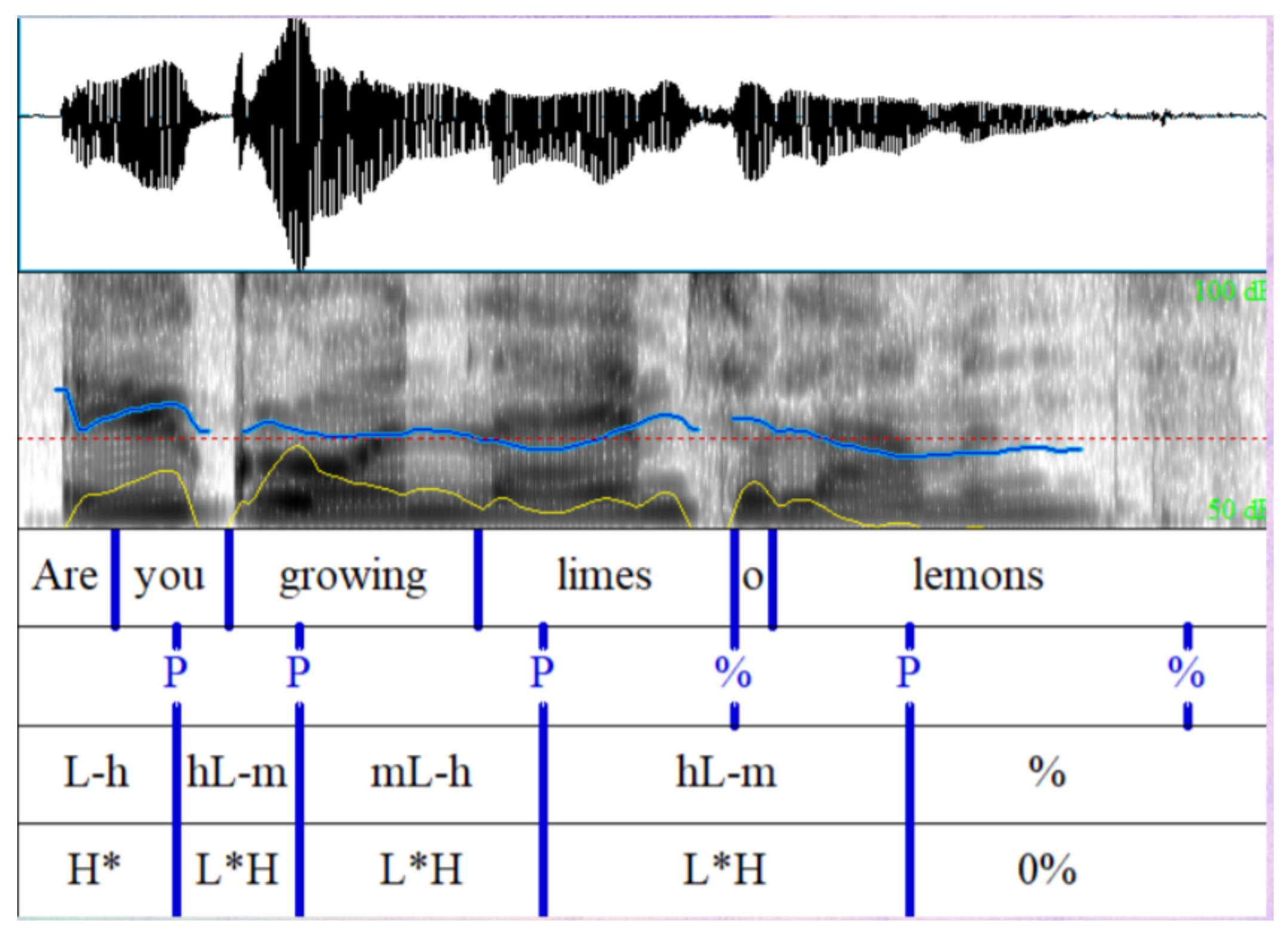
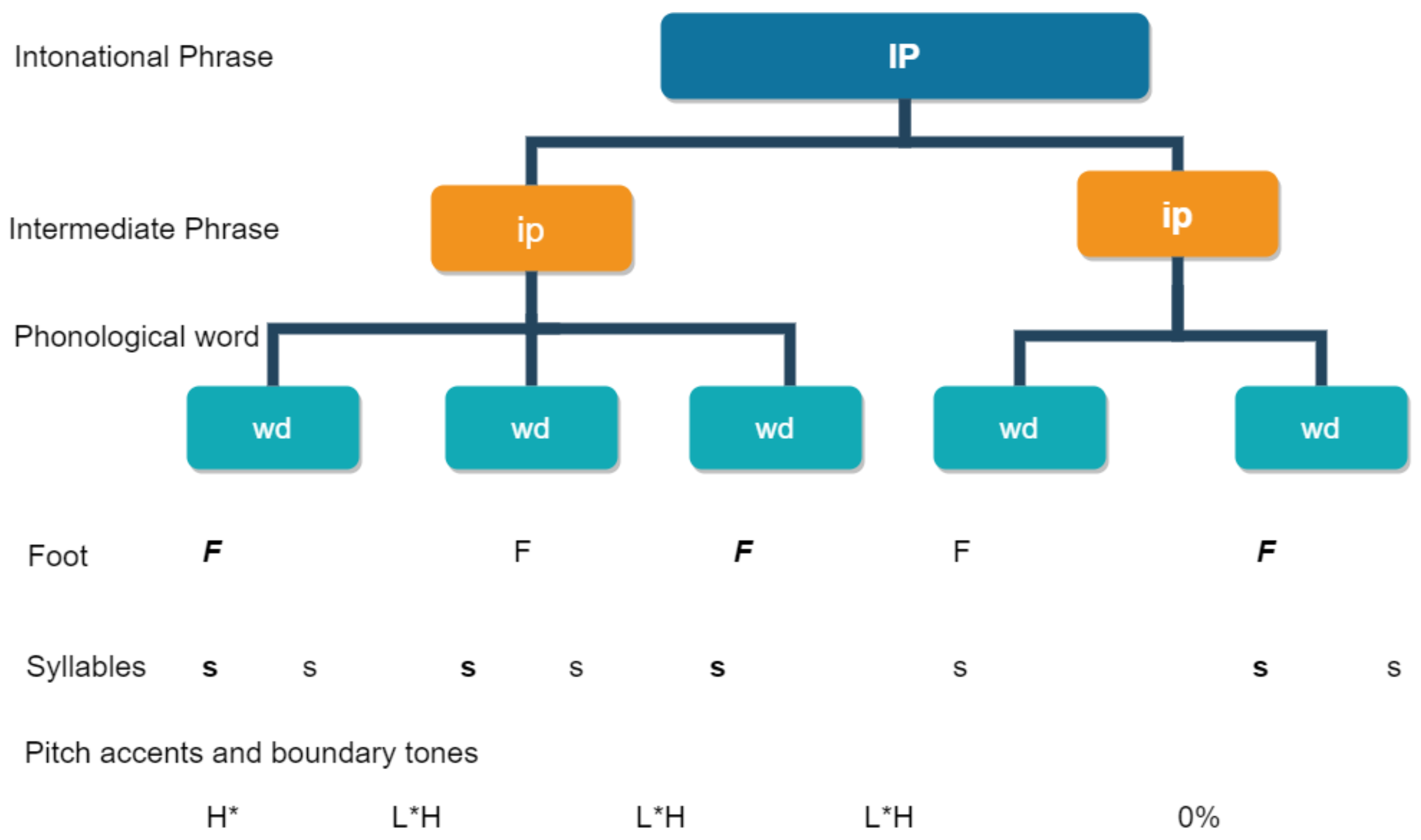
StudyIntonation courseware is organized using a hierarchical phonological structure to display the distribution of suprasegmental features and how they consequently influence the timing of phones and syllables; thus, defining variation in their phonetic implementation. For example, the fundamental frequency F0 in English is a correlate of phrasal prominence and associates with pitch accent increased duration which is a consistent correlate of stress.
According to [
43], the phonological representation is layered (
Figure 6), and the elements at a lower level combine to form higher level prosodic constituents such as words and phrases (
Figure 7). Using this hierarchical approach, prosody is represented in terms of boundaries that mark the edges and prominences such as stress and accent which are assigned to an element within the prosodic constituent at a given level [
43].
5. Discussion
The field of second language (L2) acquisition has seen an increasing interest in pronunciation research and its application to language teaching with the help of present day technology based on signal processing algorithms. Particularly, an idea to make use of visual input to extend the audio perception process has become easier to implement using mobile personalized solutions harnessing the power of modern portable devices which have become much more than simply communication tools. It has led to language learning environments which widely incorporate speech technologies [
5], visualization and personalizing based on mobile software and hardware designs [
19,
61], which include our own efforts [
21,
22,
62].
Many language teachers use transcription and various methods of notation to show how a sentence should be pronounced. The complexity of notation ranges from simple directional arrows or pitch waves to marking multiple suprasegmental features. Transcription often takes the form of English phonemics popularized by [
63]. This involves students learning IPA symbols and leads them to acquire a skill of phonetic reading, which consequently corrects some habitual mistakes, e.g., voiced ð and voiceless θ mispronunciation or weak form elimination. Using transcription, connected speech events can be explained, the connected speech phenomena of a model speech may be displayed and the difference between phonemes of a model and a learner may garner hints on how to speak in a foreign language more naturally.
During assessment, DSPCore allowed inaccuracies in the construction of phonetic transcription of colloquial speech. To the best of our knowledge, the cause of these inaccuracies stems from the ASR model used (e.g., Librispeech), which is trained on audio-books performed by professional actors. These texts are assumed to be recorded in Standard British English. That explains why their phonetic transcription is more consistent with the transcription of the text itself rather than with colloquial speech (
Table 2). This is also shown by a relatively good accuracy of phrase No. 2 (
), in which there was a minimum amount of elision of sounds from all the phrases given. For the case when connected speech effects are the CAPT goal, another ASR model instead of Librispeech for ASR decoder training should be chosen or designed deliberately to recognize and transcribe connected speech.
For teaching purposes, when the content is formed with model utterances, carefully pronounced in Standard British English [
26] and under the assumption that the learner does not produce connected speech phenomena such as elision, etc., we can conclude that DSPCore works sufficiently well for recognition and, hopefully, is able to provide actionable feedback. CAPT systems such as StudyIntonation supporting individual work of students with technology-enriched learning environments which extensively use the multimedia capabilities of portable devices are often considered to be a natural components of the distance learning process. However, distance learning has its own quirks. One problem commonly faced while implementing a CAPT system is how to establish a relevant and adequate feedback mechanism [
29]. This “feedback issue” is manifold. First and most important, the feedback is required so that both the teacher and the learner are able to identify and evaluate the segmental and suprasegmental errors. Second, the feedback is required to evaluate the current progress and to suggest steps for improvement in the system. Third, the teachers are often interested in getting a kind of behavioral feedback from their students including their interests, involvement or engagement (as distance learning tools may lack good ways to deliver such kind of feedback). Finally, there are also usability aspects.
Although StudyIntonation enables provisioning the feedback in the form of visuals and some numeric scores, there are still open issues in our design such as (1) metric adequacy and sensitivity to phonemic, rhythmic and intonational distortions; (2) feedback limitations when learners are not verbally instructed what to do to improve; (3) rigid interface when the graphs are not interactive; and (4) the effect of context which produces multiple prosodic portraits of the same phrase which are difficult to be displayed simultaneously [
62]. Mobile CAPT tools are supposed to be used in an unsupervised environment, when the interpretation of pronunciation errors cannot be performed by a human teacher, thus an adequate, unbiased and helpful automatic feedback is desirable. Therefore, we need some sensible metrics to be extracted from the speech, which could be effectively classified. Many studies have demonstrated that communicative interactions share features with complex dynamic systems. In our case, CRQA scores of recurrence rate and percentage of determinism were shown to increase the binary classification accuracy by nearly 20% in case of joint application with DTW scores. The computational complexity of DTW [
47] and CRQA [
48] is proportional to several samples in
N, which in the worst case is ≈
. The results of StudyIntonation technological and didactic assessment using Henrichsen criteria [
64] is provided in [
65].
The user tryouts showed that despite the correct match between the spoken phonemes of the learner and those of the model, the rhythm and intonation of a learner did not approach the rhythm and intonation of the model. It proves that suprasegmentals are more difficult to be trained. This can be understood as an argument in favour of joint training of phonetic, rhythmic and intonational features towards accurate suprasegmental usage which is acknowledged as a key linguistic component of multimodal communication [
66]. As pronunciation learning is no longer understood as blind copying or shadowing of input stimuli but is acknowledged to be cognitively refracted by innate language faculty; cognitive linguistics and embodied cognitive science might be of help to gain insight into human cognition processes of language and speech; which, in turn, might lead to more effective ways of pronunciation teaching and learning.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}