
Investigation of Input Modalities Based on a Spatial Region Array for Hand-Gesture Interfaces

Abstract
:1. Introduction
1.1. Gesture Recognition
1.2. Interaction Based on a Spatial Region
1.3. Interaction of Visually Impaired Individuals
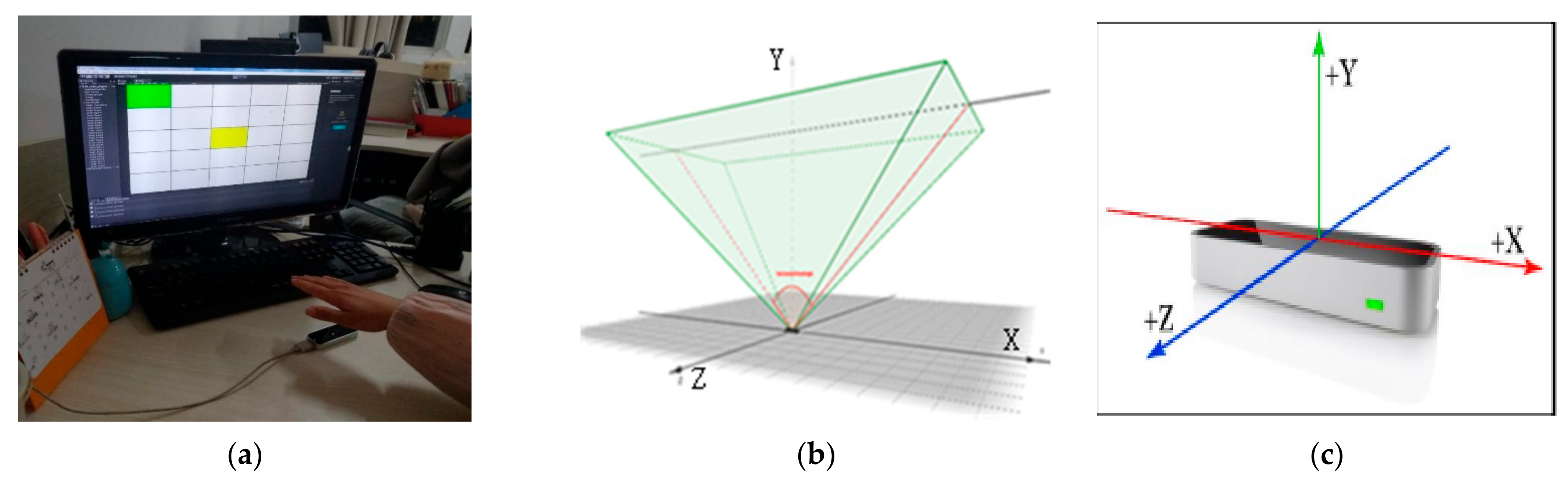
2. Materials and Methods
2.1. Pilot Study
- Finding the physical limits of the common operational spatial region in the vertical and horizontal direction and setting this region as a study object.
- Finding the threshold of the target size levels when the users accomplish the target selection tasks under the visual and non-visual scenarios.
- Finding the relationship between the target regions when the users accomplish the target select operations under the visual and non-visual scenarios.
2.1.1. Participants
2.1.2. Task & Procedure
2.1.3. Result
- It improves understanding the users and their controllability of space by identifying the common spatial region of users and the thresholds of target size and position.
- We proposed two interaction techniques and four interaction strategies concerning the target size and position in the spatial region.
3. Experiment 1: Visual Scenario
3.1. Participants & Apparatus
3.2. Task & Procedure
3.3. Results
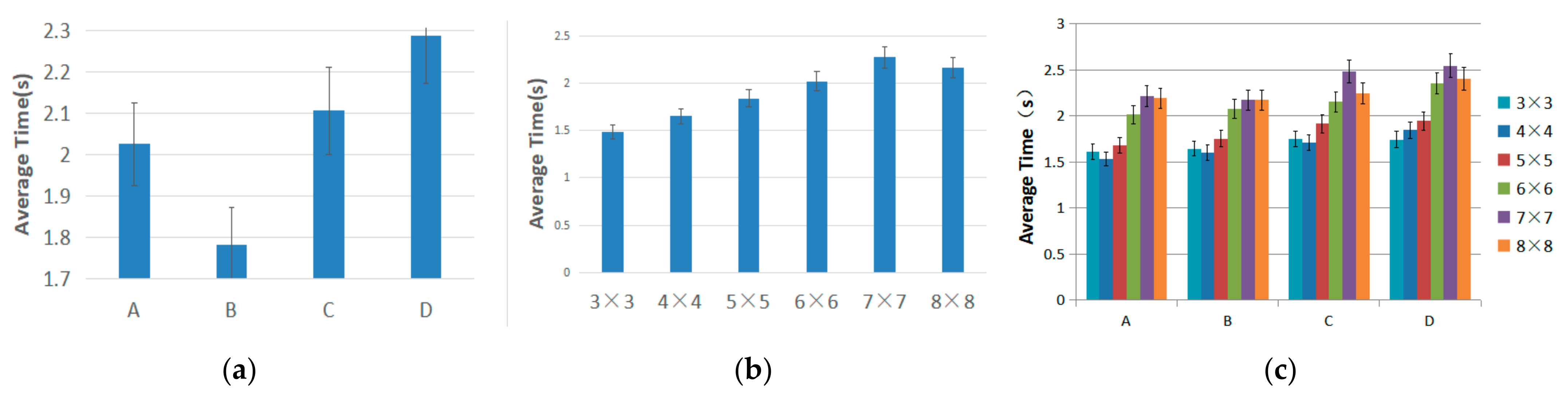
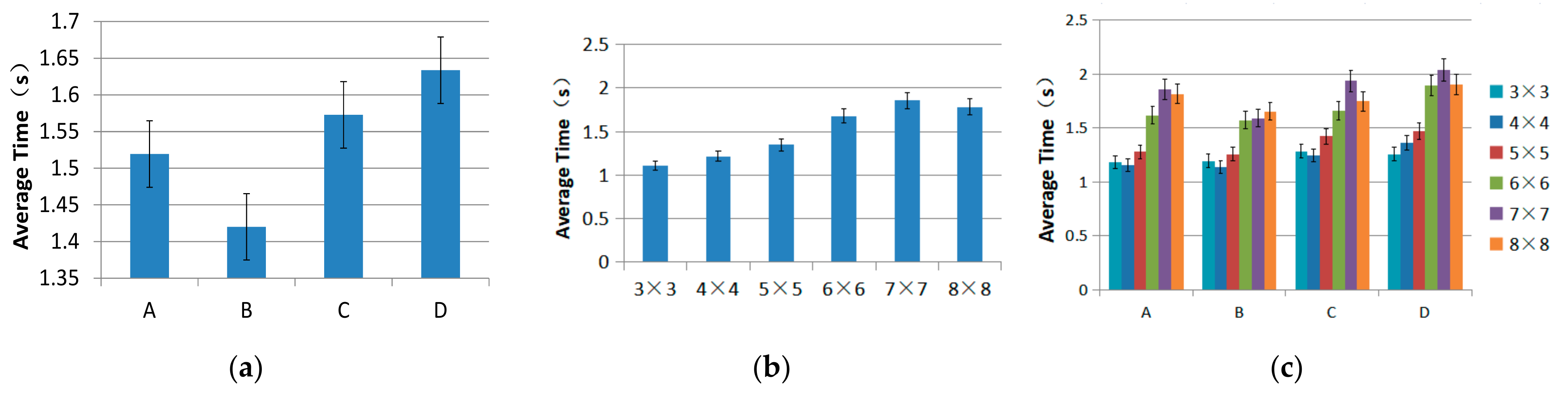
3.3.1. Selection Time
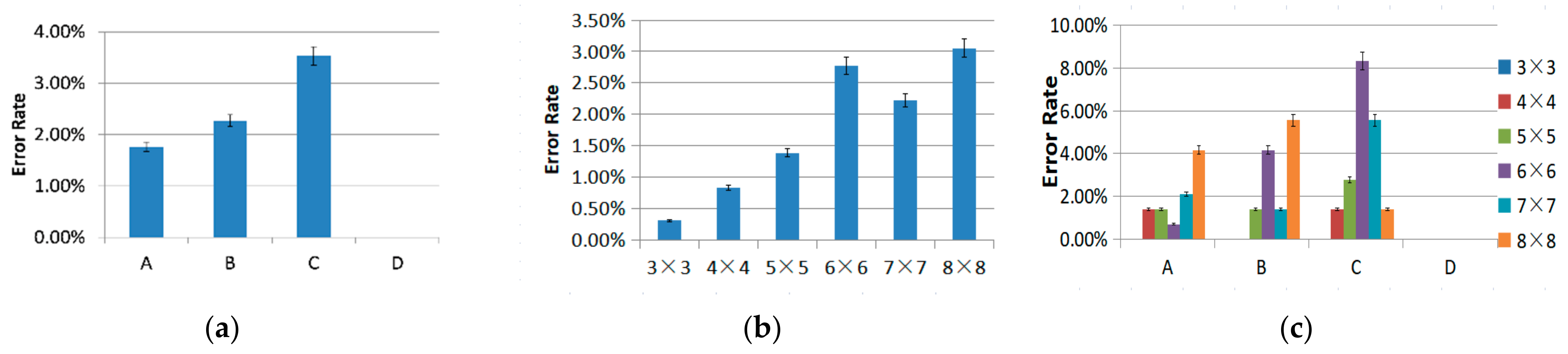
3.3.2. Selection Error Rate
3.4. Comparative Experiment 1
3.4.1. Selection Time
3.4.2. Selection Error Rate
4. Experiment 2: Non-Visual Scenario
4.1. Participants & Apparatus
4.2. Task & Procedure
4.3. Results
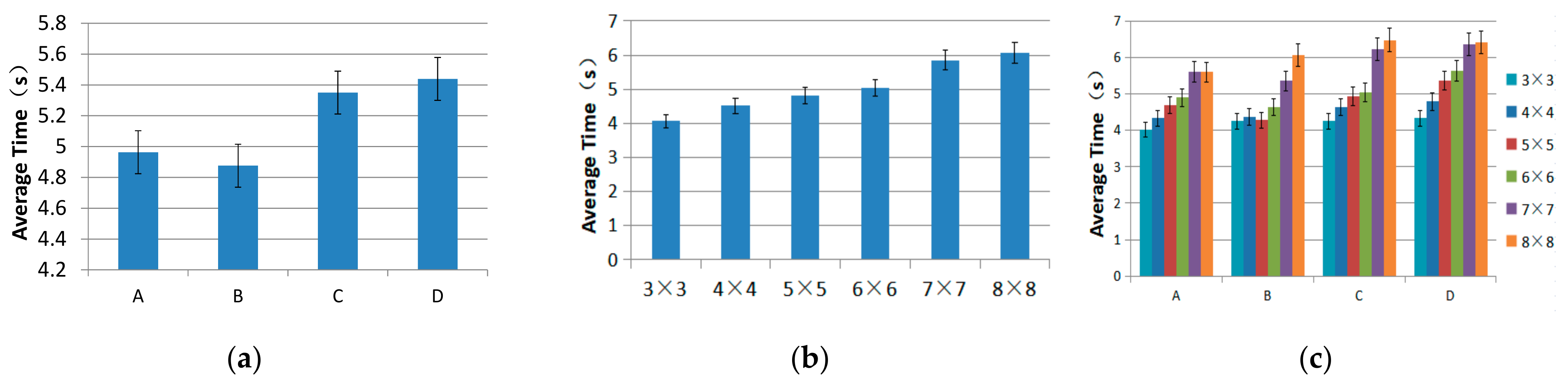
4.3.1. Selection Time
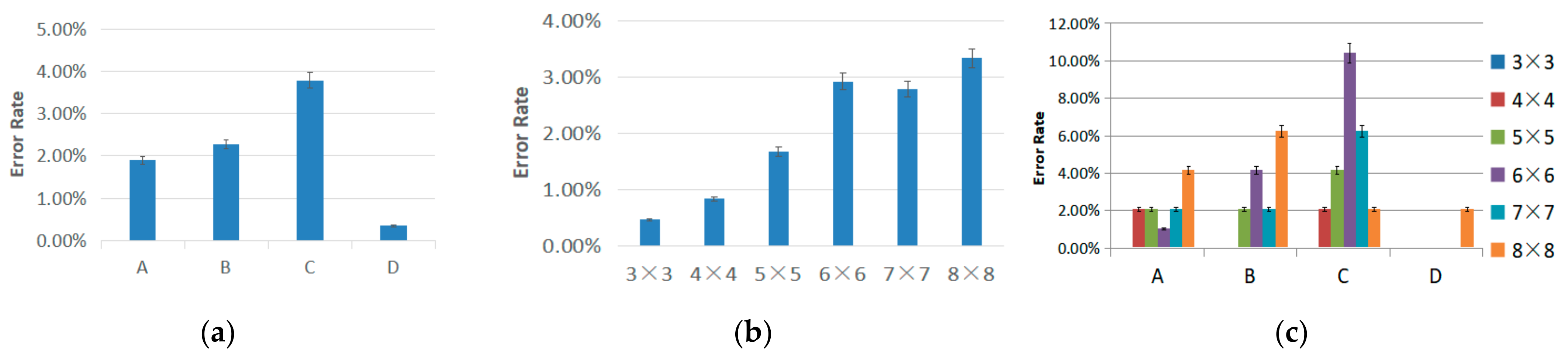
4.3.2. Selection Error Rate
4.4. Comparative Experiment 2
4.4.1. Selection Time
4.4.2. Selection Error Rate
5. Discussion & Conclusions
- Common operational range. As a result of the pilot study, the horizontal range of the common operational range was the interval of (−152, +152), and the vertical range was the interval of (80, 320), which means that the rectangle’s length was 304 mm, and the width was 240 mm.
- Threshold of target size levels. For a sighted person, the threshold target size was the 5 × 5 level, whose length was 60.8 mm, and the width was 48 mm. For a visually impaired individual, the threshold target size was the 4 × 4 level, whose length was 76 mm, and the width was 60 mm.
- Target region thresholds. For a sighted individual, the threshold target regions were region B with the shortest selection time, and region D with the lowest selection error rate. There was a significant difference between regions B and D. For a visually impaired individual, the threshold target region with the shortest selection time was region B. There were no significant differences in the error rate of target selection among all the levels.
- For visual scenarios, Region D (the bottom-right corner) is not recommended when high speed in selecting a target is needed. However, due to its lower error rate, region D remains a good alternative for scenes with higher requirements for a correct rate.
- For visual scenarios, the 6 × 6 level (50.7 mm × 40 mm) is not recommended because both its error rate and the average time were high. We recommend the 5 × 5 level (60.8 mm × 48 mm) after considering the selection time and error rate.
- For non-visual scenarios, we recommend region B (the upper-right corner) after considering the selection time and error rate. Another reason is that region B costs the least time and error rate when selecting targets.
- For non-visual scenarios, we recommend the 4 × 4 level (76 mm × 60 mm) after considering the selection time and error rate because it served as the threshold.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lee, M.; Bae, J. Deep learning based real-time recognition of dynamic finger gestures using a data glove. IEEE Access 2020, 8, 219923–219933. [Google Scholar] [CrossRef]
- Marin, G.; Dominio, F.; Zanuttigh, P. Hand gesture recognition with leap motion and Kinect devices. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014. [Google Scholar]
- Chatterjee, I.; Xiao, R.; Harrison, C. Gaze+gesture: Expressive, precise and targeted free-space interactions. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction (ICMI ′15), Association for Computing Machinery, New York, NY, USA, 9–13 November 2015; pp. 131–138. [Google Scholar]
- Chalasani, T.; Smolic, A. Simultaneous segmentation and recognition: Towards more accurate ego gesture recognition. In Proceedings of the 2019 IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Martinez, J.; Griffiths, D.; Biscione, V.; Georgiou, O.; Carter, T. Touchless haptic feedback for supernatural VR Experiences. In Proceedings of the 25th IEEE Conference on Virtual Reality and 3D User Interfaces, VR 2018-Proceedings, Tuebingen/Reutlingen, Germany, 18–22 March 2018. [Google Scholar]
- Park, J.; Jin, Y.; Cho, S.; Sung, Y.; Cho, K. Advanced machine learning for gesture learning and recognition based on intelligent big data of heterogeneous sensors. Symmetry 2019, 11, 929. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Yang, Z.; Zhang, G.; Wu, C.; Zhang, L. XGest: Enabling Cross-Label gesture recognition with RF signals. ACM Trans Sens. Netw. TOSN 2021, 17, 1–23. [Google Scholar] [CrossRef]
- Liu, M.; Nancel, M.; Vogel, D. Gunslinger: Subtle arms-down mid-air interaction. In Proceedings of the 28th Annual ACM Symposium on User Interface Software & Technology (UIST ′15), Association for Computing Machinery, New York, NY, USA, 9 August 2015; pp. 63–71. [Google Scholar]
- Zaiţi, I.A.; Pentiuc, S.G.; Vatavu, R.D. On free-hand TV control: Experimental results on user-elicited gestures with leap motion. Pers. Ubiquitous Comput. 2015, 5, 821–838. [Google Scholar] [CrossRef]
- Sa-Nguannarm, P.; Senavongse, W.; Charoenpong, T.; Kiatsoontorn, K. Hand movement recognition by using a touchless sensor for controlling images in operating room. In Proceedings of the 2018 International Electrical Engineering Congress (iEECON), Krabi, Thailand, 7–9 March 2018. [Google Scholar]
- Liu, C. Leveraging physical human actions in large interaction spaces. In Proceedings of the Adjunct Publication of the 27th Annual ACM Symposium on User Interface software and Technology (UIST ′14 Adjunct), Association for Computing Machinery, New York, NY, USA, 5–8 October 2014; pp. 9–12. [Google Scholar]
- Aslan, I.; Krischkowsky, A.; Meschtscherjakov, A.; Wuchse, M.; Tscheligi, M. A leap for touch: Proximity sensitive touch targets in cars. In Proceedings of the 7th International Conference on Automotive User Interfaces and Interactive Vehicular Applications (AutomotiveUI ′15), Association for Computing Machinery, New York, NY, USA, 1–3 September 2015; pp. 39–46. [Google Scholar]
- Feng, J.; Shengping, Z.; Shen, W.; Yang, G.; Debin, Z. Multi-Layered gesture recognition with kinect. J. Mach. Learn. Res. 2015, 1, 227–254. [Google Scholar]
- Spindler, M.; Stellmach, S.; Dachselt, R. PaperLens: Advanced magic lens interaction above the tabletop. In Proceedings of the ACM International Conference on Interactive Tabletops and Surfaces (ITS ′09), Association for Computing Machinery, New York, NY, USA, 23–25 November 2009; pp. 69–76. [Google Scholar]
- Cockburn, A.; Quinn, P.; Gutwin, C.; Ramos, G.; Looser, J. Air pointing: Design and evaluation of spatial target acquisition with and without visual feedback. Int. J. Hum. Comput. Stud. 2011, 6, 401–414. [Google Scholar] [CrossRef]
- Gareth, Y.; Hamish, M.; Daniel, G.; Elliot, P.; Robert, B.; Orestis, G. Designing mid-air haptic gesture controlled user interfaces for cars. ACM Hum.-Comput. Interact. 2020, 4, 1–23. [Google Scholar]
- Spindler, M.; Schuessler, M.; Martsch, M.; Dachselt, R. Pinch-Drag-Flick vs. spatial input: Rethinking zoom & pan on mobile displays. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ′14), Association for Computing Machinery, New York, NY, USA, 26 April–1 May 2014; pp. 1113–1122. [Google Scholar]
- Jingyu, C.; Victoria, K.; Alan, M.; Elias, G.; David, H.; Joseph, T. A momentum-conserving implicit material point method for surface tension with contact angles and spatial gradients. ACM Trans. Graph. 2021, 4, 1–16. [Google Scholar]
- Lee, M.; Kwahk, J.; Han, S.H.; Lee, H. Relative pointing interface: A gesture interaction method based on the ability to divide space. Int. J. Ind. Ergon. 2020, 75, 02878. [Google Scholar] [CrossRef]
- Cha, Y.; Myung, R. Extended Fitts’ law for 3D pointing tasks using 3D target arrangements. Int. J. Ind. Ergon. 2013, 4, 350–355. [Google Scholar] [CrossRef]
- Brand, D.; Meschtscherjakov, A.; Büchele, K. Pointing at the HUD: Gesture interaction using a leap motion. In Proceedings of the 8th International Conference on Automotive User Interfaces and Interactive Vehicular Applications (AutomotiveUI ‘16 Adjunct), Association for Computing Machinery, New York, NY, USA, 24–26 October 2016; pp. 167–172. [Google Scholar]
- Davis, M.M.; Gabbard, J.L.; Bowman, D.A.; Gracanin, D. Depth-Based 3D gesture multi-level radial menu for virtual object manipulation. In Proceedings of the 2016 IEEE Virtual Reality (VR), Greenville, SC, USA, 19–23 March 2016. [Google Scholar]
- Schinazi, V.; Thrash, T.; Chebat, D. Spatial navigation by congenitally blind individuals. In Wiley Interdisciplinary Reviews: Cognitive Science; Wiley & Sons: New York, NY, USA, 2016. [Google Scholar]
- Abidin, A.H.Z.; Xie, H.; Wong, K.W. Touch screen with audio feedback: Content analysis and the effect of spatial ability on blind people’s sense of position of web pages. In Proceedings of the 2013 International Conference on Research and Innovation in Information Systems (ICRIIS), Kuala Lumpur, Malaysia, 27–28 November 2013. [Google Scholar]
- Muniandy, M.; Sulaiman, S. Touch sensation as part of multimedia design elements to improve computer accessibility for the blind users. In Proceedings of the 2017 International Conference on Research and Innovation in Information Systems (ICRIIS), Langkawi, Malaysia, 16–17 July 2017. [Google Scholar]
- Khambadkar, V.; Folmer, E. GIST: A gestural interface for remote nonvisual spatial perception. In Proceedings of the 26th Annual ACM Symposium on User Interface Software and Technology (UIST ′13), Association for Computing Machinery, New York, NY, USA, 8–11 October 2013; pp. 301–310. [Google Scholar]
- Khurana, R.; McIsaac, D.; Lockerman, E.; Mankoff, J. Nonvisual interaction techniques at the keyboard surface. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems (CHI ′18). Association for Computing Machinery, New York, NY, USA, 21–26 April 2018; pp. 1–12. [Google Scholar]
- Wahab, M.; Mohamed, A.; Sukor, A.; Teng, O. Text reader for visually impaired person. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2021. [Google Scholar]
- Jinmo, K. VIVR: Presence of immersive interaction for visual Impairment virtual reality. IEEE Access 2020, 8, 196151–196159. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | A | B | C | D |
|---|---|---|---|---|
| Position | Upper Left | Upper Right | Bottom Left | Bottom Right |
| Level | 3 × 3 | 4 × 4 | 5 × 5 | 6 × 6 | 7 × 7 | 8 × 8 |
|---|---|---|---|---|---|---|
| Size (mm) | 101.33 × 80 | 76 × 60 | 60.8 × 48 | 50.7 × 40 | 43.43 × 34.29 | 38 × 30 |
| Longest Time | Shortest Time | Time Threshold | Highest Error Rate | Lowest Error Rate | Error Threshold | Proposal | |
|---|---|---|---|---|---|---|---|
| Size | 43.43 × 34.29 | 60.8 × 48 | 60.8 × 48 | 38 × 30 | 101.33 × 80 | 60.8 × 48 | 60.8 × 48 |
| Region | D | B | / | C | D | / | D |
| Longest Time | Shortest Time | Time Threshold | Highest Error Rate | Lowest Error Rate | Error Threshold | Proposal | |
|---|---|---|---|---|---|---|---|
| Size | 38 × 30 | 50.7 × 40 | 50.7 × 40 | 38 × 30 | 101.33 × 80 | 76 × 60 | 76 × 60 |
| Region | D | B | / | C | B | / | D |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Han, Y.; Zhou, Y.; Zhang, X.; Yin, J.; Wang, S. Investigation of Input Modalities Based on a Spatial Region Array for Hand-Gesture Interfaces. Electronics 2021, 10, 3078. https://doi.org/10.3390/electronics10243078
Wu H, Han Y, Zhou Y, Zhang X, Yin J, Wang S. Investigation of Input Modalities Based on a Spatial Region Array for Hand-Gesture Interfaces. Electronics. 2021; 10(24):3078. https://doi.org/10.3390/electronics10243078
Chicago/Turabian StyleWu, Huanwei, Yi Han, Yanyin Zhou, Xiangliang Zhang, Jibin Yin, and Shuoyu Wang. 2021. "Investigation of Input Modalities Based on a Spatial Region Array for Hand-Gesture Interfaces" Electronics 10, no. 24: 3078. https://doi.org/10.3390/electronics10243078
APA StyleWu, H., Han, Y., Zhou, Y., Zhang, X., Yin, J., & Wang, S. (2021). Investigation of Input Modalities Based on a Spatial Region Array for Hand-Gesture Interfaces. Electronics, 10(24), 3078. https://doi.org/10.3390/electronics10243078