
Random Forest Similarity Maps: A Scalable Visual Representation for Global and Local Interpretation




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
2.1. General Explainability Strategies
2.2. Visualization for Interpreting Models
2.3. Random Forest Visualization
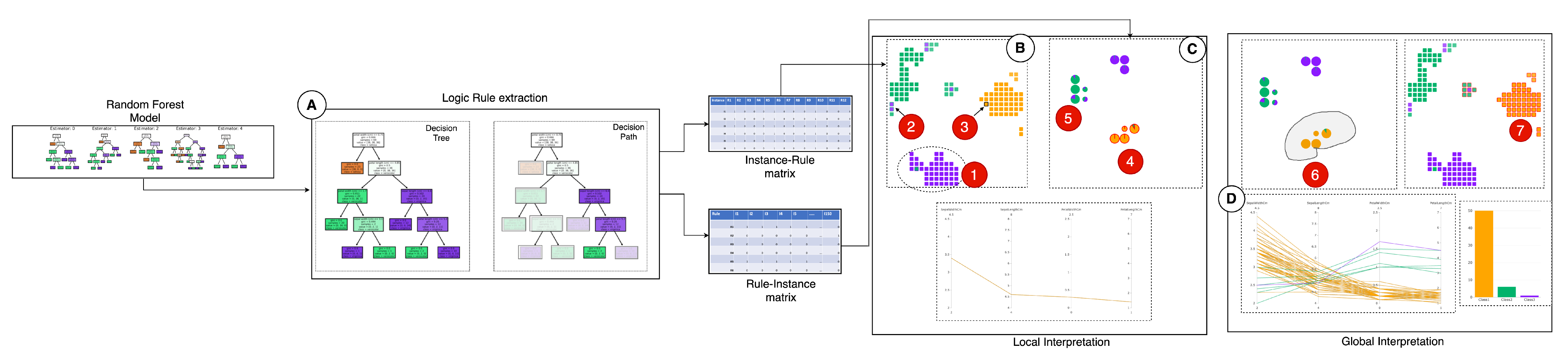
3. Random Forest Similarity Map
3.1. Background
3.2. Design Goals
- G1
- Global interpretation. An RF model is a collection of trees. One of the best ways to interpret the ensemble model’s inner working mechanism is to allow users to understand what knowledge the overall model has learned [15]. After the RF model training, the model presents an overview of the relationships between the data instances and the various decision paths, given a target class label. These relationships between decision paths and data instances mirror the RF model’s working mechanism at a granular level and help users comprehend the generic knowledge (valid for most of the instances) or specific knowledge (valid for only a few instances) learned by the model. Therefore, it simplifies the model’s complex nature and presents the knowledge learned (whether generic or specific), helping to understand how the overall RF models decisions. By enabling the interpretation of the knowledge learned by an RF model, we aim to explain the model globally.
- G2
- Local interpretation by preserving the global context. Local interpretation describes the reasons behind a specific decision for a particular instance [25]. In most RF models, local interpretation usually involves presenting the decision paths used to classify an instance [14]. However, to perform better local interpretation, preservation of the global context of the forest is essential so users can compare the used logic rules in the forest and answer questions such as—‘Are the decisions made from the most certain logic rules?’, ‘Does these rules have a good amount of data support (coverage) as compared to others?’. Being able to answer these questions not only helps users develop trust in their local explanation but also allows them to retain the local faithfulness [49] on unseen instances. Local interpretation also means allowing users to find out hidden patterns from the dataset or a specific set of examples and deduce further explanations based on them [15].
- G3
- Comparative analysis of RF models. Another design goal is the ability to have a comparative analysis between two or more RF models to assist model developers in selecting reliable models [50]. An RF model is built using various parameters such as the number of trees, splitting criteria, maximum depth of a tree, and the maximum number of features to be considered during a split. These factors are very imperative and influence the overall prediction capability of a model [42]. By visualizing and comparing RF models built using different properties, we can interpret their functioning and shed light on hidden patterns. For example, enabling the analysis of what happens to a model when we do not limit the tree depth.
3.3. Analytical Tasks
- T1
- Analyzing structure and properties of decision paths. The decision path in every RF model tree provides a way to understand the final predicted class. Hence, the analysis of the structural differences between various logic rules is imperative to uncover the black-box nature of an ensemble model (G1). For instance, how do we know which group of rules among the forest classifies samples as a particular class? Have they learned anything generic from the training data? We aim to provide users with an answer to these questions through our technique. Besides analyzing structural similarities between logic rules, it is also essential to know about the properties such as a rule’s class probabilities (certainty) and how much training data support a decision path has concerning its predicted class (rule coverage). High coverage and certain logic rules are the important ones in the model as they are valid for most of the instances (generic knowledge) and essential to the RF committee [14].
- T2
- Visualizing the forest. Visualizing an entire forest of trees is a challenging task, and its complexity increases with the number of trees used in an RF model. To support the case of understanding the working mechanism of complex ensemble models with certain number of trees (G1), it is essential to provide a way to visualize the entire forest. Visualizing the forest also helps users understand where a decision path is located within the forest and how these decision paths are related to one another [44]. Hence, to summarize the structure and understand various decision paths that form an RF model, visualizing the entire forest is non-trivial.
- T3
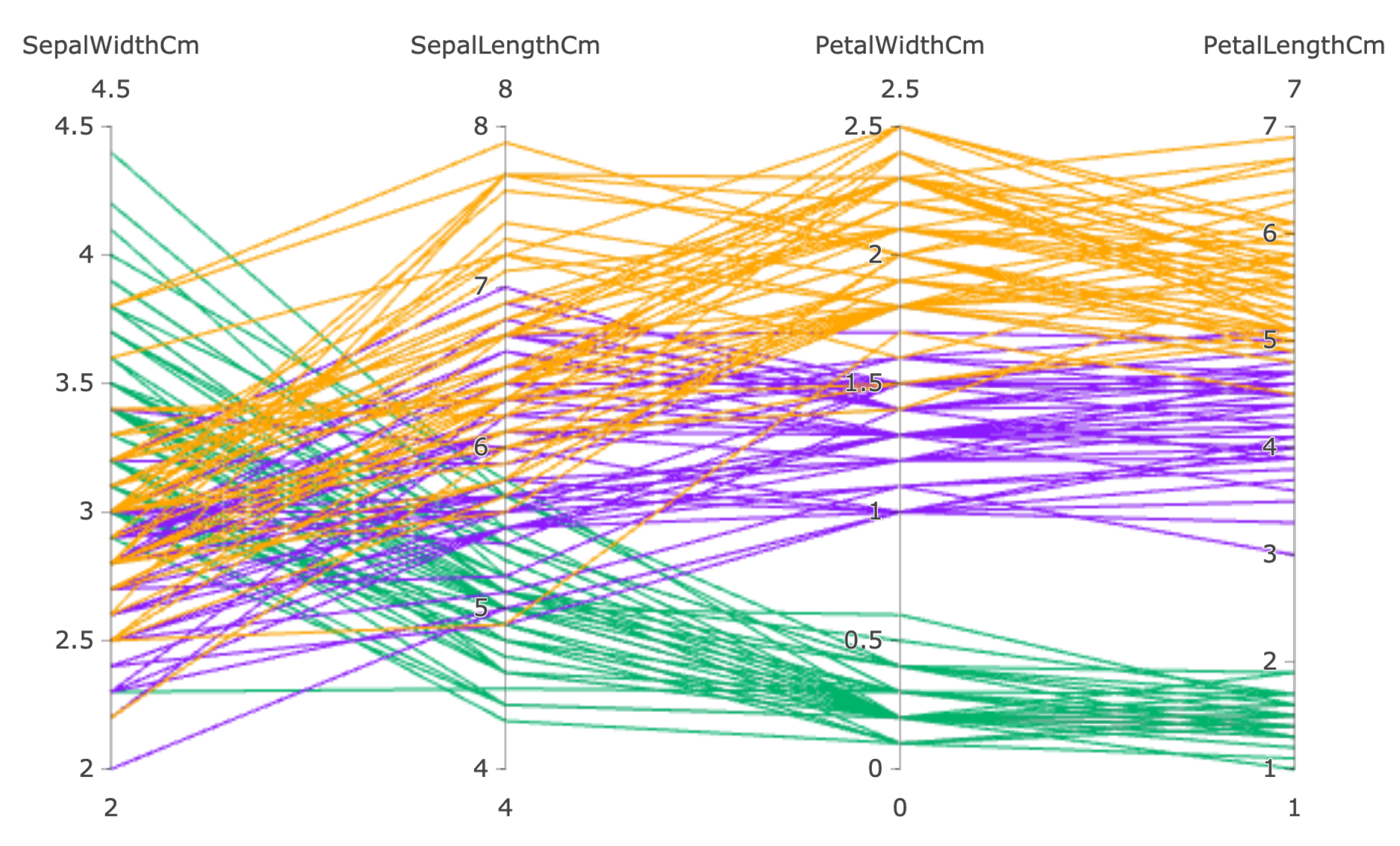
- Interpreting class separation among instances. The primary goal of any ML classification problem is to separate the data instances into their respective classes. By establishing a clear decision boundary between the classes, we can validate the model’s accuracy, understand its inner working mechanism (G1), and allow for the improvement of models through comparative analysis (G3) [42]. Thus, providing a visual metaphor to understand the class separation between the instances in a dataset is crucial.
- T4
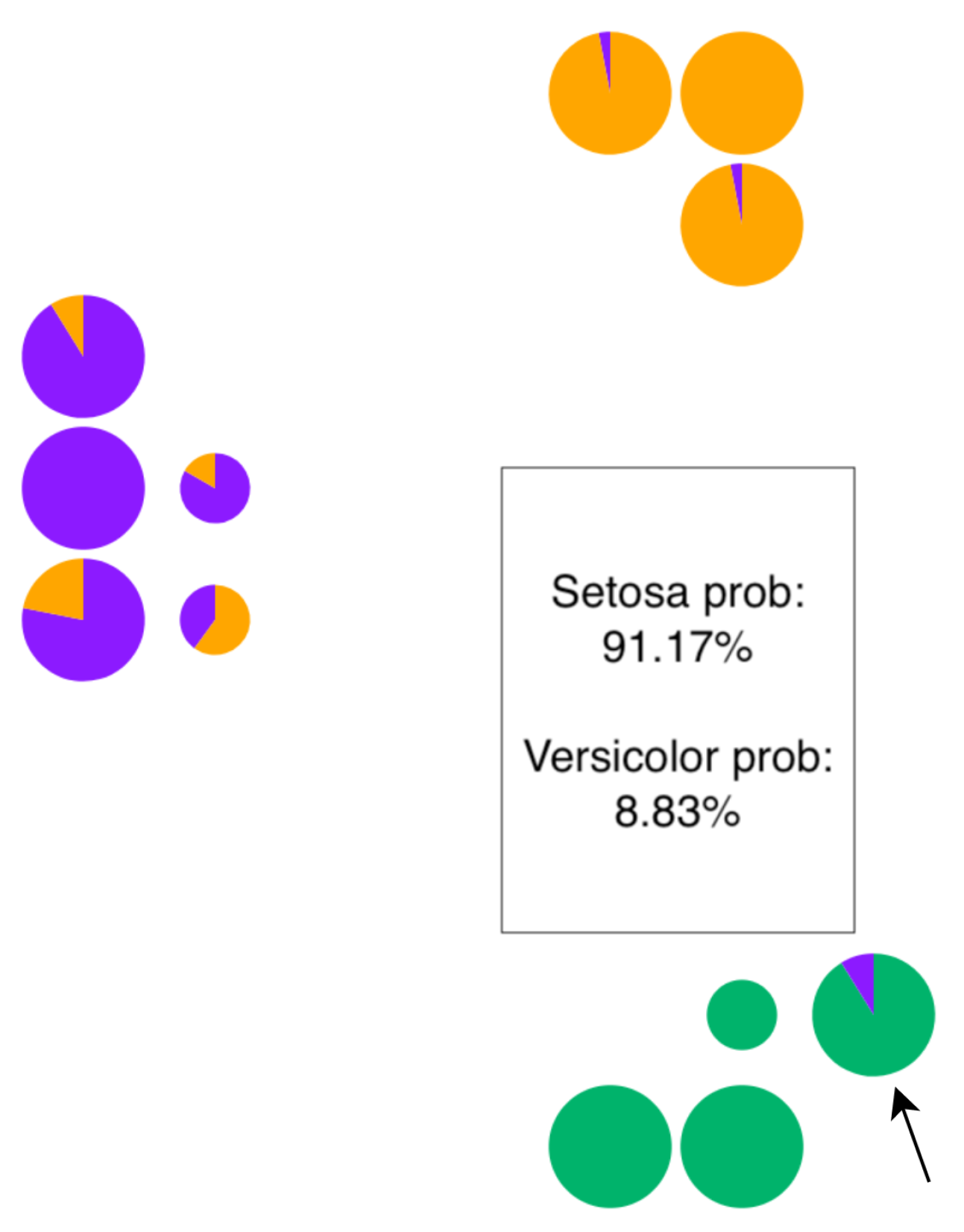
- Knowledge used by the model to make a prediction. To understand the prediction of a single instance or a group of instances, it is necessary to know what knowledge was used by the model [13], i.e., which logic rules were used to classify an instance. Although local interpretation methods allow users to know what rules (decision path) were applied to a sample [14,15], there is a lack in interpreting the knowledge learned from the entire forest of logic rules visually, preserving the global context (G2). The ability to inspect local instances while having a visual cue of the used rules from the forest allows users to perform in-depth interpretation, and it provides insights on the voting process for that instance.
- T5
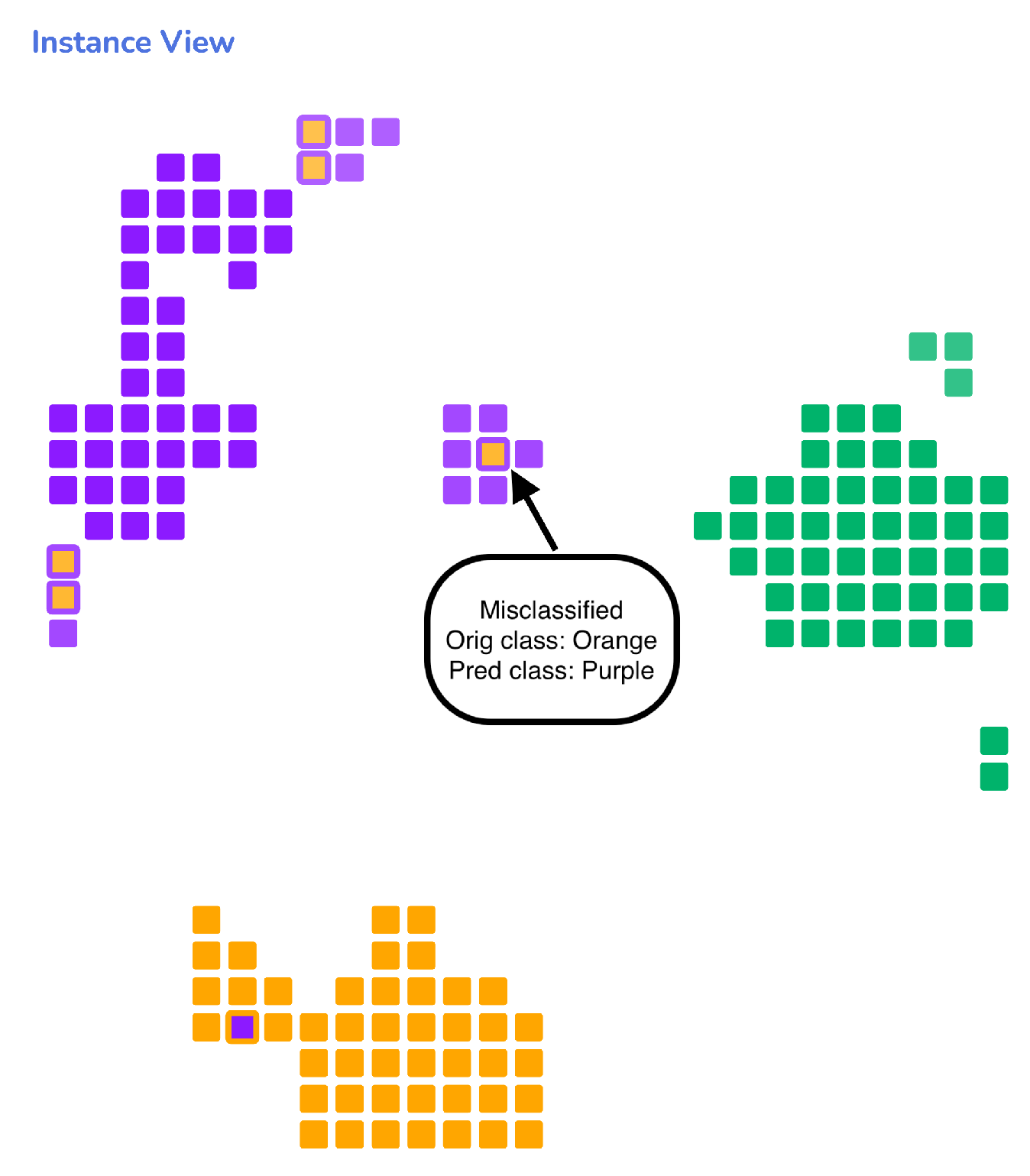
- Understanding the instances. Analyzing the structure of instances in a dataset helps provide intuition into specific hidden patterns that can, in turn, assist in understanding the way an RF model works on similar types of instances (G3). For example, by analyzing the within-class overlaps among samples in a dataset, we can interpret class errors made by the model in a classification problem and build user trust in the model. Additionally, understanding similarities or differences between a group of instances can help the user develop reasoning on how the RF model sees every instance and how it differentiates them.
- T6
- Performing model diagnosis. To develop an understanding of RF model performance, i.e., how properly the model can separate the classes, ML model experts and developers often need to drill down and analyze specific aspects, such as detecting the mistakes made by a model using confusion matrices [51] and visually comparing multiple confusion matrices [52]. Although confusion matrices are easy to use, they become challenging to interpret when the number of classes increases in a multi-class classification problem [42]. By having the ability to visualize the patterns formed among the logic rules in a model and compare it with other models (G3), users can develop their confidence in the models’ overall functioning and select the model that produces the desired result.
3.4. Overview
3.5. Visualization Design Preliminaries
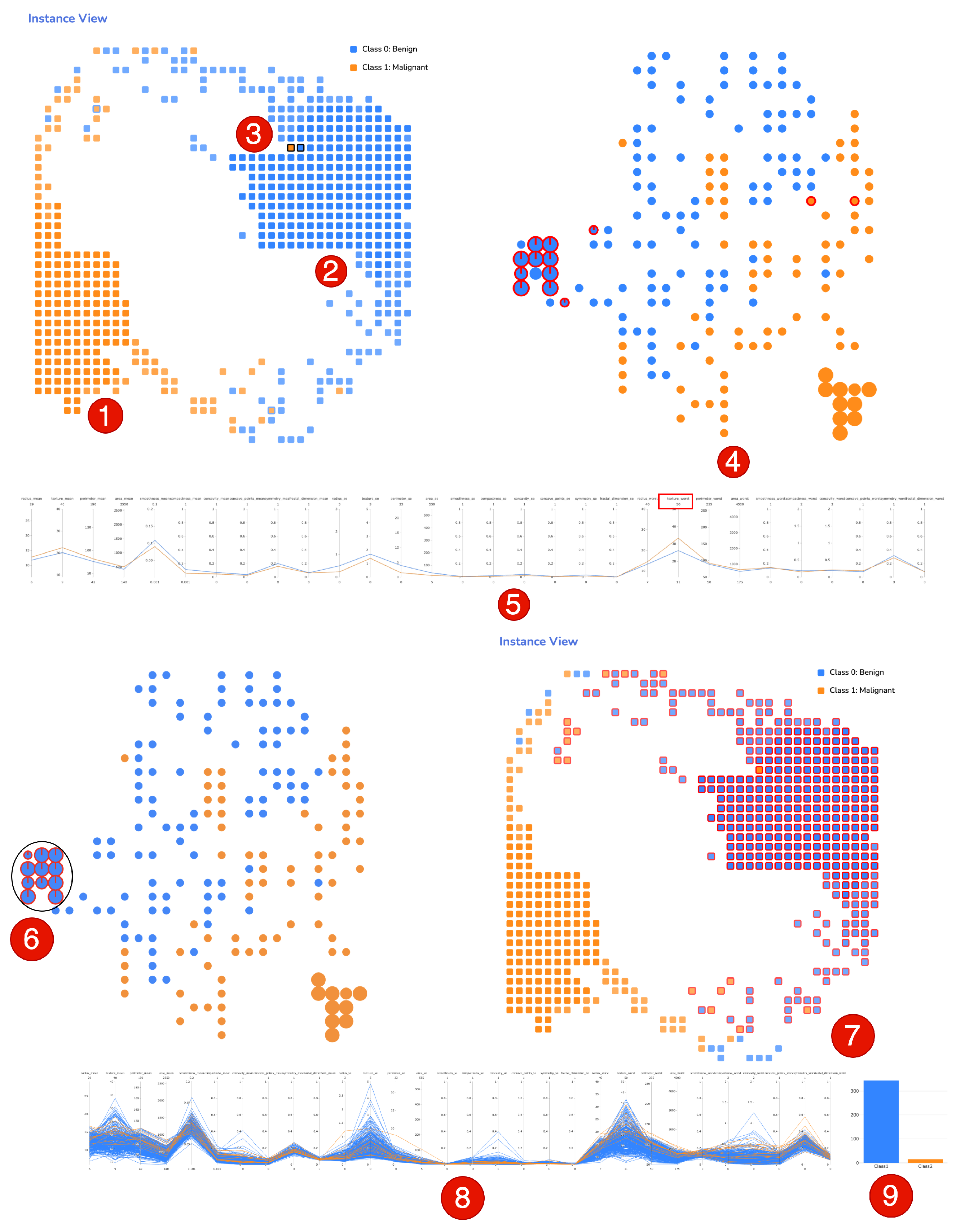
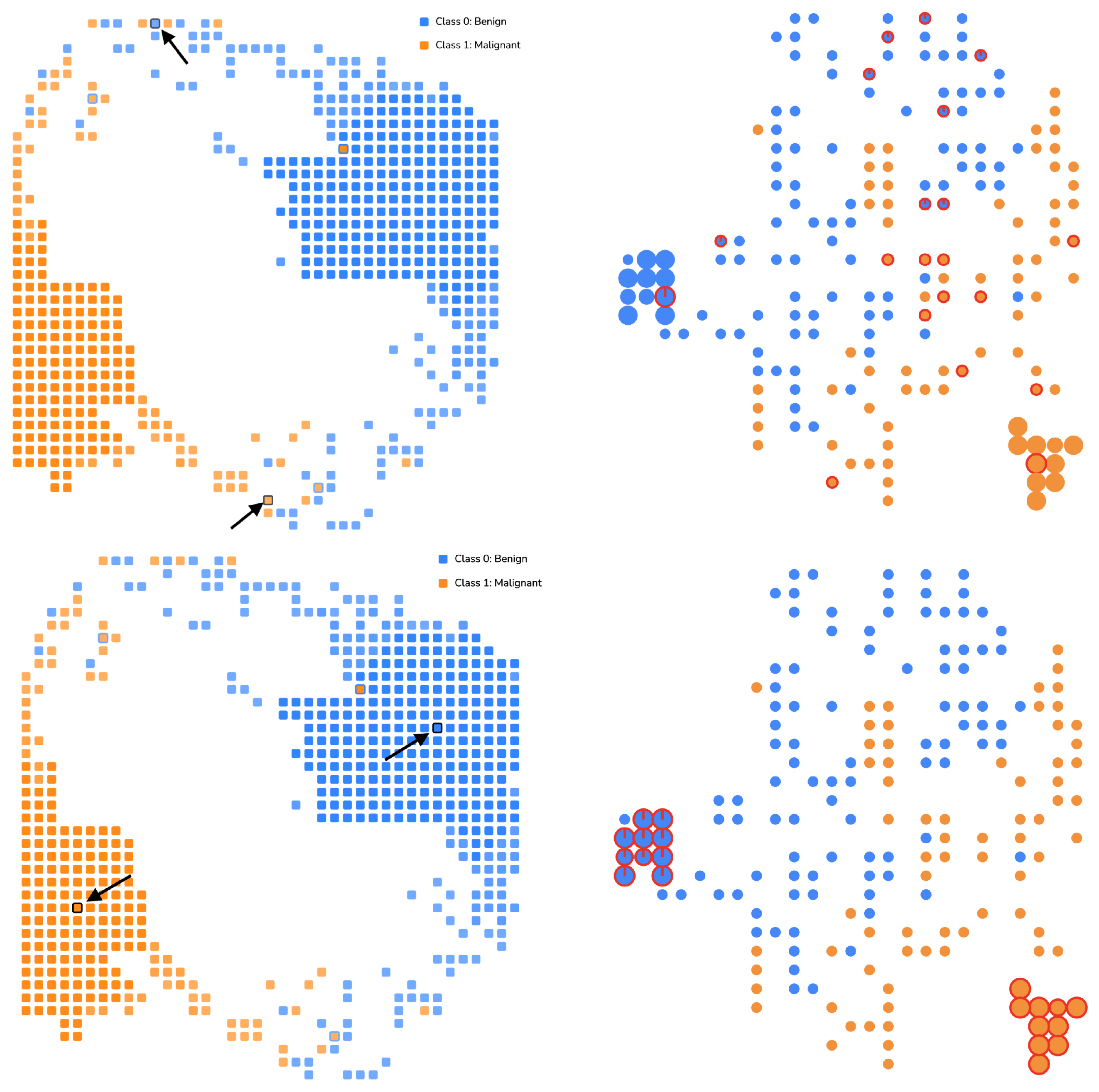
3.6. Instances View
3.7. Forest View
3.8. Feature View
4. Results and Evaluation
4.1. Usage Scenario 1: Breast Cancer Diagnostic
4.2. Usage Scenario 2: Election Votes
4.3. User Study
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- McInerney, J.; Lacker, B.; Hansen, S.; Higley, K.; Bouchard, H.; Gruson, A.; Mehrotra, R. Explore, exploit, and explain: Personalizing explainable recommendations with bandits. In Proceedings of the RecSys 2018—12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2 October 2018; pp. 31–39. [Google Scholar] [CrossRef]
- Luz, C.F.; Vollmer, M.; Decruyenaere, J.; Nijsten, M.W.; Glasner, C.; Sinha, B. Machine learning in infection management using routine electronic health records: Tools, techniques, and reporting of future technologies. Clin. Microbiol. Infect. 2020, 26, 1291–1299. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kotsiantis, S.B.; Zaharakis, I.D.; Pintelas, P.E. Machine learning: A review of classification and combining techniques. Artif. Intell. Rev. 2006, 26, 159–190. [Google Scholar] [CrossRef]
- Yang, B.S.; Di, X.; Han, T. Random forests classifier for machine fault diagnosis. J. Mech. Sci. Technol. 2008, 22, 1716–1725. [Google Scholar] [CrossRef]
- Cai, J.D.; Yan, R.W. Fault Diagnosis of Power Electronic Circuit Based on Random Forests Algorithm. In Proceedings of the 2009 Fifth International Conference on Natural Computation, Tianjin, China, 14–16 August 2009; Volume 2, pp. 214–217. [Google Scholar] [CrossRef]
- Domb, M.; Bonchek-Dokow, E.; Leshem, G. Lightweight adaptive Random-Forest for IoT rule generation and execution. J. Inf. Secur. Appl. 2017, 34, 218–224. [Google Scholar] [CrossRef]
- Caruana, R.; Lou, Y.; Gehrke, J.; Koch, P.; Sturm, M.; Elhadad, N. Intelligible Models for HealthCare; Association for Computing Machinery: Sydney, Australia, 2015; pp. 1721–1730. [Google Scholar] [CrossRef]
- Angwin, J.; Larson, J.; Mattu, S.; Kirchner, L. Machine Bias, 23 May 2016. Available online: https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing (accessed on 1 November 2021).
- Goodman, B.; Flaxman, S. European union regulations on algorithmic decision making and a “right to explanation”. AI Mag. 2017, 38, 50–57. [Google Scholar] [CrossRef] [Green Version]
- Chatzimparmpas, A.; Martins, R.M.; Jusufi, I.; Kerren, A. A survey of surveys on the use of visualization for interpreting machine learning models. Inf. Vis. 2020, 19, 207–233. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.D.; Ho, T.B.; Shimodaira, H. A visualization tool for interactive learning of large decision trees. In Proceedings of the International Conference on Tools with Artificial Intelligence, ICTAI, Vancouver, BC, Canada, 5 November 2000; pp. 28–35. [Google Scholar] [CrossRef]
- Kohavi, R. The power of decision tables. In Machine Learning: ECML-95; Lavrac, N., Wrobel, S., Eds.; Springer: Berlin/Heidelberg, Germany, 1995; pp. 174–189. [Google Scholar]
- Ming, Y.; Qu, H.; Bertini, E. RuleMatrix: Visualizing and Understanding Classifiers with Rules. IEEE Trans. Vis. Comput. Graph. 2019, 25, 342–352. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Popolin Neto, M.; Paulovich, F.V. Explainable Matrix—Visualization for Global and Local Interpretability of Random Forest Classification Ensembles. IEEE Trans. Vis. Comput. Graph. 2020, 27, 1427–1437. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Wu, Y.; Lee, D.L.; Cui, W. IForest: Interpreting Random Forests via Visual Analytics. IEEE Trans. Vis. Comput. Graph. 2019, 25, 407–416. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Espadoto, M.; Martins, R.M.; Kerren, A.; Hirata, N.S.T.; Telea, A.C. Toward a Quantitative Survey of Dimension Reduction Techniques. IEEE Trans. Vis. Comput. Graph. 2021, 27, 2153–2173. [Google Scholar] [CrossRef] [PubMed]
- Nonato, L.G.; Aupetit, M. Multidimensional Projection for Visual Analytics: Linking Techniques with Distortions, Tasks, and Layout Enrichment. IEEE Trans. Vis. Comput. Graph. 2019, 25, 2650–2673. [Google Scholar] [CrossRef] [PubMed]
- Kahng, M.; Andrews, P.Y.; Kalro, A.; Chau, D.H.P. ActiVis: Visual Exploration of Industry-Scale Deep Neural Network Models. IEEE Trans. Vis. Comput. Graph. 2018, 24, 88–97. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hohman, F.; Park, H.; Robinson, C.; Polo Chau, D.H. Summit: Scaling Deep Learning Interpretability by Visualizing Activation and Attribution Summarizations. IEEE Trans. Vis. Comput. Graph. 2020, 26, 1096–1106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martens, D.; Baesens, B.B.; Van Gestel, T. Decompositional Rule Extraction from Support Vector Machines by Active Learning. IEEE Trans. Knowl. Data Eng. 2009, 21, 178–191. [Google Scholar] [CrossRef]
- Quinlan, J.R. Generating Production Rules from Decision Trees. In Proceedings of the 10th International Joint Conference on Artificial Intelligence, Milan, Italy, 23–28 August 1987; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1987. IJCAI’87. Volume 1, pp. 304–307. [Google Scholar]
- Zhang, Y.; Wallace, B. A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification. arXiv 2015, arXiv:1510.03820. [Google Scholar]
- Cortez, P.; Embrechts, M.J. Opening black box Data Mining models using Sensitivity Analysis. In Proceedings of the IEEE SSCI 2011: Symposium Series on Computational Intelligence—CIDM 2011: 2011 IEEE Symposium on Computational Intelligence and Data Mining, Paris, France, 11–15 April 2011; pp. 341–348. [Google Scholar] [CrossRef] [Green Version]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Humbird, K.D.; Peterson, J.L.; Mcclarren, R.G. Deep Neural Network Initialization With Decision Trees. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1286–1295. [Google Scholar] [CrossRef] [Green Version]
- Letham, B.; Rudin, C.; McCormick, T.H.; Madigan, D. Interpretable classifiers using rules and bayesian analysis: Building a better stroke prediction model. Ann. Appl. Stat. 2015, 9, 1350–1371. [Google Scholar] [CrossRef]
- Mashayekhi, M.; Gras, R. Rule Extraction from Random Forest: The RF+HC Methods. In Advances in Artificial Intelligence; Barbosa, D., Milios, E., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 223–237. [Google Scholar]
- Valenzuela-Escárcega, M.A.; Nagesh, A.; Surdeanu, M. Lightly-supervised Representation Learning with Global Interpretability. arXiv 2018, arXiv:1805.11545. [Google Scholar]
- Yang, C.; Rangarajan, A.; Ranka, S. Global Model Interpretation Via Recursive Partitioning. In Proceedings of the 20th International Conference on High Performance Computing and Communications, IEEE 16th International Conference on Smart City and IEEE 4th International Conference on Data Science and Systems, HPCC/SmartCity/DSS 2018, Exeter, UK, 28–30 June 2018; pp. 1563–1570. [Google Scholar] [CrossRef] [Green Version]
- Linsley, D.; Shiebler, D.; Eberhardt, S.; Serre, T. Learning what and where to attend. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Model-Agnostic Interpretability of Machine Learning. arXiv 2016, arXiv:1606.05386. [Google Scholar]
- Tan, S.; Caruana, R.; Hooker, G.; Lou, Y. Distill-and-Compare: Auditing Black-Box Models Using Transparent Model Distillation. In Proceedings of the AIES 2018—2018 AAAI/ACM Conference on AI, Ethics, and Society, Orleans, LA, USA, 2–3 February 2018; pp. 303–310. [Google Scholar] [CrossRef] [Green Version]
- Rauber, P.E.; Fadel, S.G.; Falcão, A.X.; Telea, A.C. Visualizing the Hidden Activity of Artificial Neural Networks. IEEE Trans. Vis. Comput. Graph. 2017, 23, 101–110. [Google Scholar] [CrossRef]
- Di Castro, F.; Bertini, E. Surrogate decision tree visualization interpreting and visualizing black-box classification models with surrogate decision tree. CEUR Workshop Proc. 2019, 2327. Available online: http://ceur-ws.org/Vol-2327/IUI19WS-ExSS2019-15.pdf (accessed on 1 November 2021).
- Alsallakh, B.; Hanbury, A.; Hauser, H.; Miksch, S.; Rauber, A. Visual methods for analyzing probabilistic classification data. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1703–1712. [Google Scholar] [CrossRef]
- Ren, D.; Amershi, S.; Lee, B.; Suh, J.; Williams, J.D. Squares: Supporting Interactive Performance Analysis for Multiclass Classifiers. IEEE Trans. Vis. Comput. Graph. 2017, 23, 61–70. [Google Scholar] [CrossRef] [PubMed]
- Amershi, S.; Chickering, M.; Drucker, S.M.; Lee, B.; Simard, P.; Suh, J. Modeltracker: Redesigning performance analysis tools for machine learning. In Proceedings of the Conference on Human Factors in Computing Systems—Proceedings, Seoul, Korea, 18–23 April 2015; pp. 337–346. [Google Scholar] [CrossRef]
- Zahavy, T.; Zrihem, N.B.; Mannor, S. Graying the black box: Understanding DQNs. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 4, pp. 2809–2822. [Google Scholar]
- Cantareira, G.D.; Etemad, E.; Paulovich, F.V. Exploring neural network hidden layer activity using vector fields†. Information 2020, 11, 426. [Google Scholar] [CrossRef]
- Rauber, P.E.; Falcaõ, A.X.; Telea, A.C. Projections as visual aids for classification system design. Inf. Vis. 2018, 17, 282–305. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hänsch, R.; Wiesner, P.; Wendler, S.; Hellwich, O. Colorful trees: Visualizing random forests for analysis and interpretation. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision, WACV 2019, Waikoloa, HI, USA, 7 March 2019; pp. 294–302. [Google Scholar] [CrossRef]
- Breiman, L. WALD Lecture II. Looking Inside the Black Box. 2002, p. 34. Available online: https://www.stat.berkeley.edu/users/breiman/wald2002-2.pdf (accessed on 1 November 2021).
- Lau, K. Random Forest Ensemble Visualization. 2014. Available online: https://www.cs.ubc.ca/~tmm/courses/547-14/projects/ken/report.pdf (accessed on 1 November 2021).
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Loyola-González, O.; Medina-Pérez, M.A.; Choo, K.K.R. A Review of Supervised Classification based on Contrast Patterns: Applications, Trends, and Challenges. J. Grid Comput. 2020, 18, 797–845. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, LA, USA, 2–7 February 2018; McIlraith, S.A., Weinberger, K.Q., Eds.; AAAI Press: Palo Alto, CA, USA, 2018; pp. 1527–1535. [Google Scholar]
- Li, Y.; Fujiwara, T.; Choi, Y.K.; Kim, K.K.; Ma, K.L. A visual analytics system for multi-model comparison on clinical data predictions. Vis. Inform. 2020, 4, 122–131. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Talbot, J.; Lee, B.; Kapoor, A.; Tan, D.S. EnsembleMatrix: Interactive Visualization to Support Machine Learning with Multiple Classifiers. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 4–9 April 2009; Association for Computing Machinery: New York, NY, USA, 2009. CHI ’09. pp. 1283–1292. [Google Scholar] [CrossRef]
- Liao, Q.V.; Gruen, D.; Miller, S. Questioning the AI: Informing Design Practices for Explainable AI User Experiences. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; Association for Computing Machinery: New York, NY, USA, 2020. CHI ’20. pp. 1–15. [Google Scholar] [CrossRef]
- Bostock, M.; Ogievetsky, V.H.J. D3: Data-Driven Documents. IEEE Trans. Vis. Comput. Graph. 1997, 7, 2–3. [Google Scholar] [CrossRef]
- Plotly. Plotly Parallel Coordinate. Available online: https://plotly.com/javascript/parallel-coordinates-plot/ (accessed on 1 November 2021).
- Breiman, L.; Cutler, A. Manual–Setting Up, Using, and Understanding Random Forests V4.0 2003. Available online: https://www.stat.berkeley.edu/~breiman/Using_random_forests_V3.1.pdf (accessed on 1 November 2021).
- Hilasaca, G.M.; Marcílio, W.E., Jr.; Eler, D.M.; Martins, R.M.; Paulovich, F.V. Overlap Removal in Dimensionality Reduction Scatterplot Layouts. arXiv 2021, arXiv:1903.06262. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics; Springer: New York, NY, USA, 2001. [Google Scholar]
- Louppe, G. Understanding Random Forests: From Theory to Practice. arXiv 2014, arXiv:1407.7502. [Google Scholar]
- Torgerson, W.S. Multidimensional scaling: I. Theory and method. Psychometrika 1952, 17, 401–419. [Google Scholar] [CrossRef]
- Kruskal, J.B. Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis. Psychometrika 1964, 29, 1–27. [Google Scholar] [CrossRef]
- Choi, S.S.; Cha, S.H.; Tappert, C.C. A survey of binary similarity and distance measures. J. Syst. Cybern. Inform. 2010, 8, 43–48. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2020, arXiv:1802.03426. [Google Scholar]
- Inselberg, A. The plane with parallel coordinates. Vis. Comput. 1985, 1, 69–91. [Google Scholar] [CrossRef]
- Wolberg, W.; Street, W.; Mangasarian, O. Nuclear feature extraction for breast tumor diagnosis. Int. Soc. Opt. Photonics 1993, 1905, 861–870. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mazumdar, D.; Neto, M.P.; Paulovich, F.V. Random Forest Similarity Maps: A Scalable Visual Representation for Global and Local Interpretation. Electronics 2021, 10, 2862. https://doi.org/10.3390/electronics10222862
Mazumdar D, Neto MP, Paulovich FV. Random Forest Similarity Maps: A Scalable Visual Representation for Global and Local Interpretation. Electronics. 2021; 10(22):2862. https://doi.org/10.3390/electronics10222862
Chicago/Turabian StyleMazumdar, Dipankar, Mário Popolin Neto, and Fernando V. Paulovich. 2021. "Random Forest Similarity Maps: A Scalable Visual Representation for Global and Local Interpretation" Electronics 10, no. 22: 2862. https://doi.org/10.3390/electronics10222862
APA StyleMazumdar, D., Neto, M. P., & Paulovich, F. V. (2021). Random Forest Similarity Maps: A Scalable Visual Representation for Global and Local Interpretation. Electronics, 10(22), 2862. https://doi.org/10.3390/electronics10222862