
Reliability Aware Multiple Path Installation in Software-Defined Networking



Abstract
:1. Introduction
2. Related Work
3. System Model
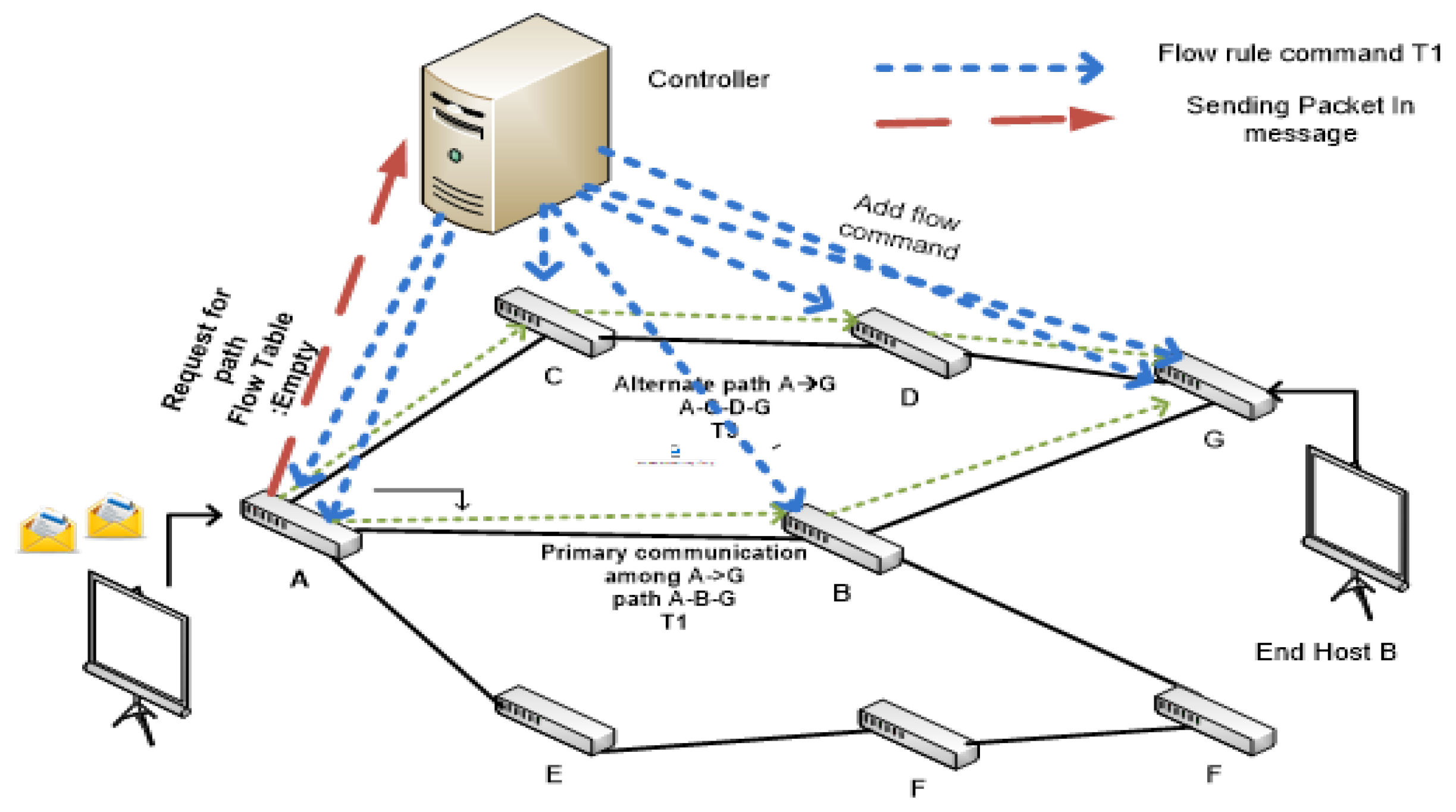
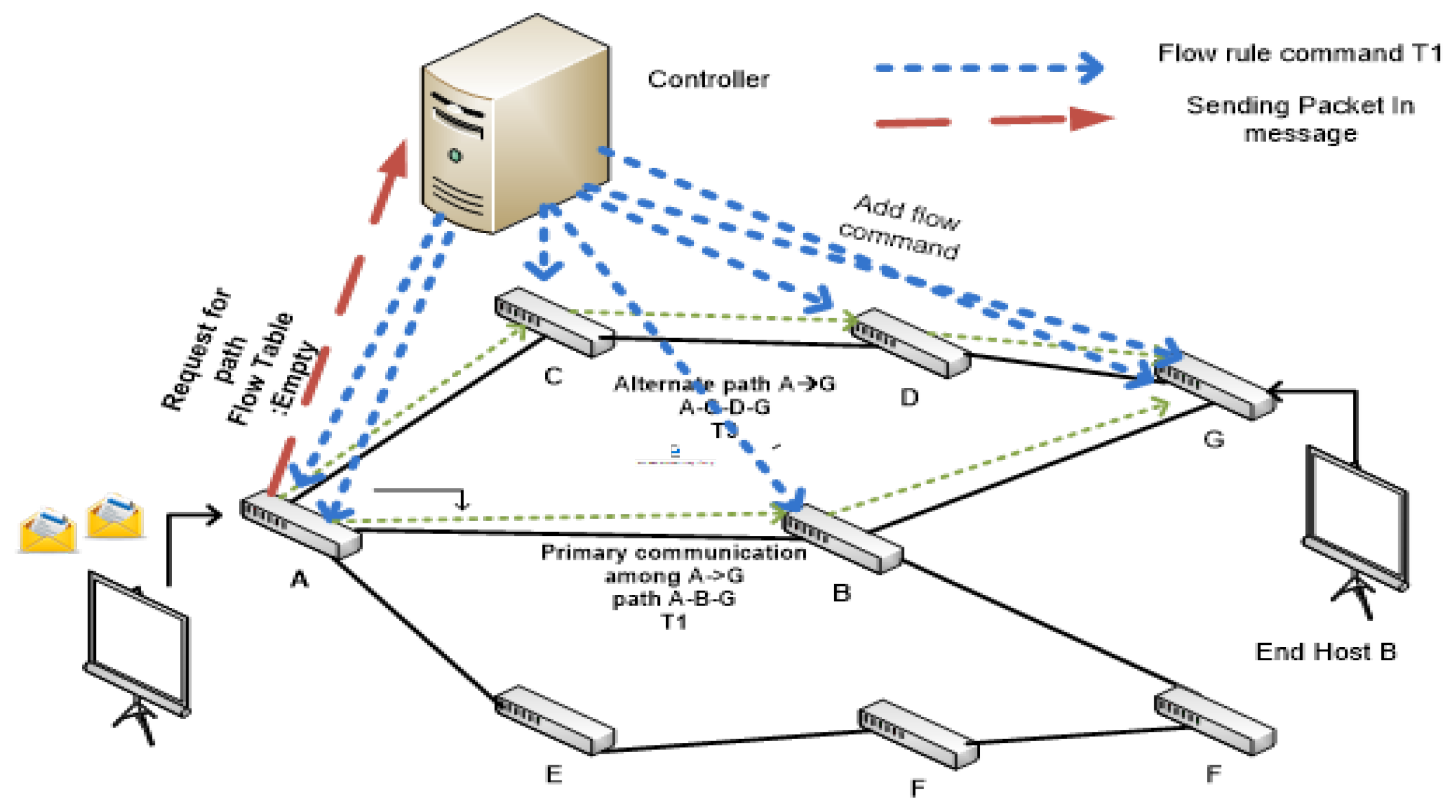
4. Proposed Approach
4.1. Phase A: Bootstrapping Process
4.2. Phase B: Graph Composition Process
| Algorithm 1: GC (C) |
| Input: C /*C is a controller*/ Initialize undirected Graph = G /*V is a set of , D is a set of switches */ /*L is a set of Links and its theirs attributes*/ Procedure Activate (C(event_publisher, event_subscriber)) Procedure Data_Plane (link_event, Publisher): C_handler (link_event, Subscriber) Return devices_map (D, , ) Procedure Data_Plane (end_user_event, Publisher): C_handler (end_user_event , Subscriber) return end_user_map (V, , ) UPDATE G |
4.3. Phase C: Path Computation and Flow Rule Installation Process
| Algorithm 2: CP(P,R, , D) |
| Input: P, R, /*P is an arrival packet*/ /*R is flow rule entry*/ /*D is the switch receiving P*/ /* is ACL table*/ if P ∈ R then  /*returns and */ |
4.3.1. Reliability Computation Process
4.3.2. RAF Path Computation
4.3.3. Distance-Based RAF (DRAF) Path Computation
4.3.4. Flow Installation Process
5. Simulations Setup
5.1. Mininet Emulator
5.2. POX Controller
5.3. OpenFlow API
5.4. Link Failure Process
5.5. Network Topology
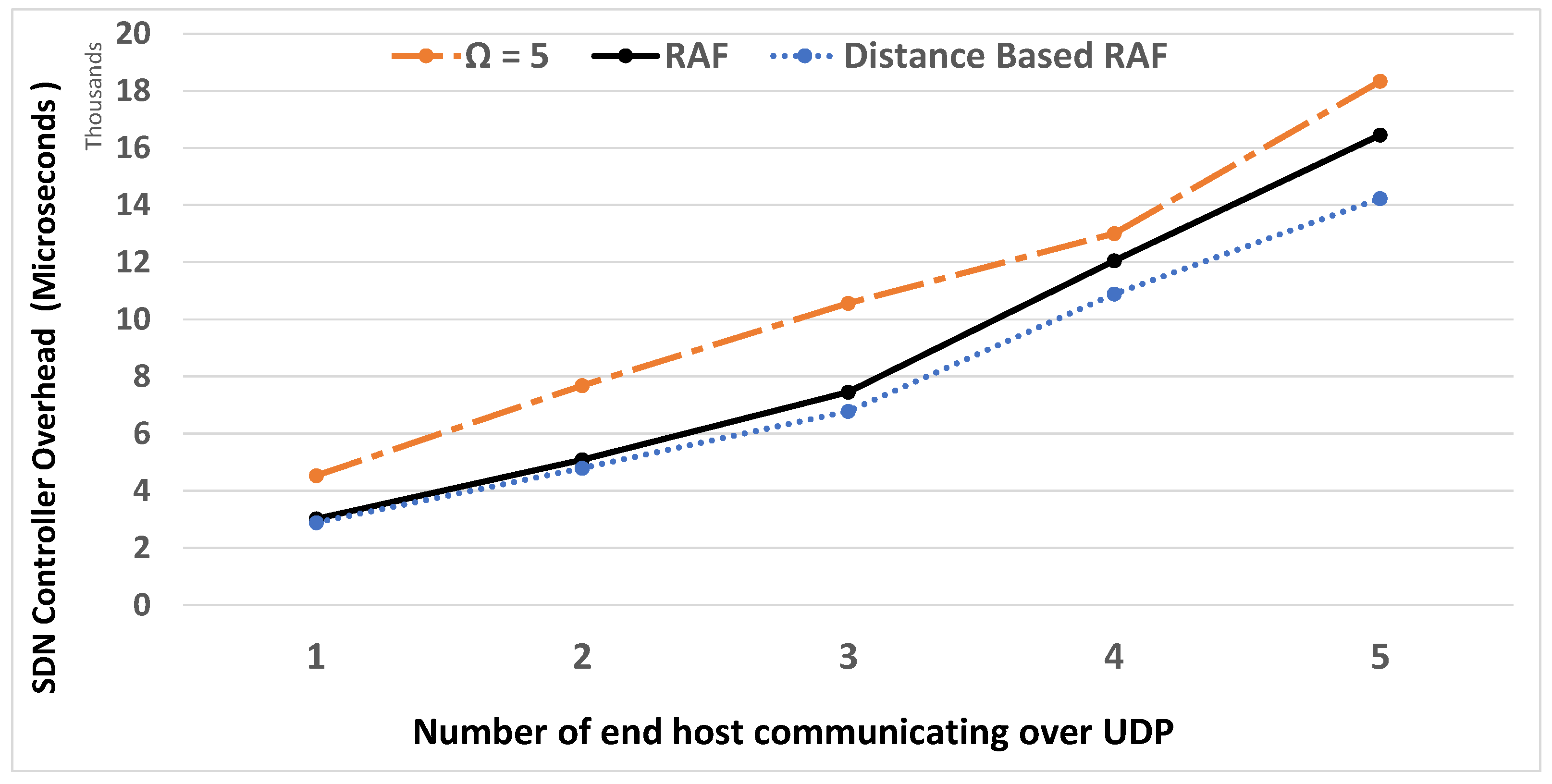
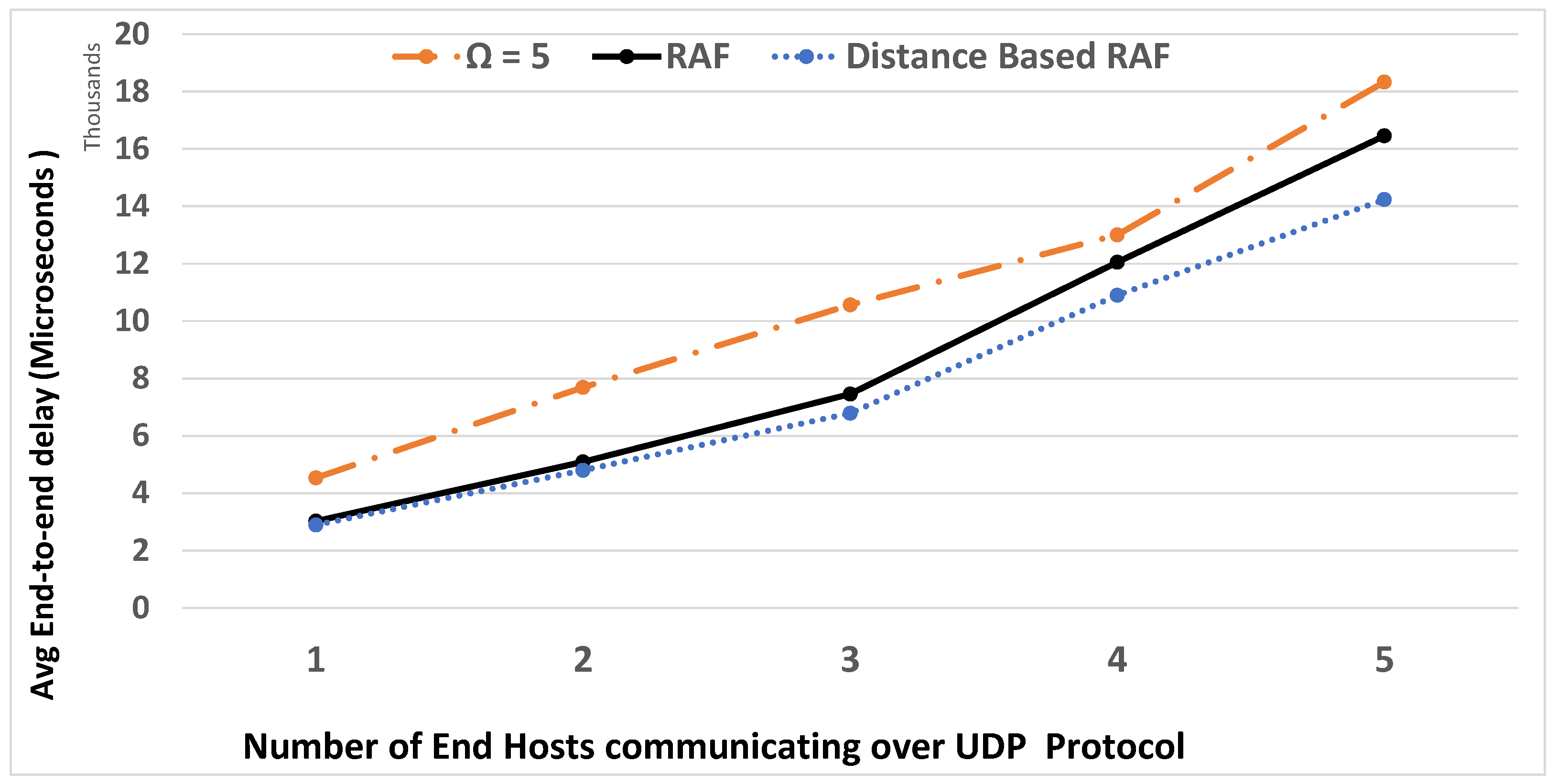
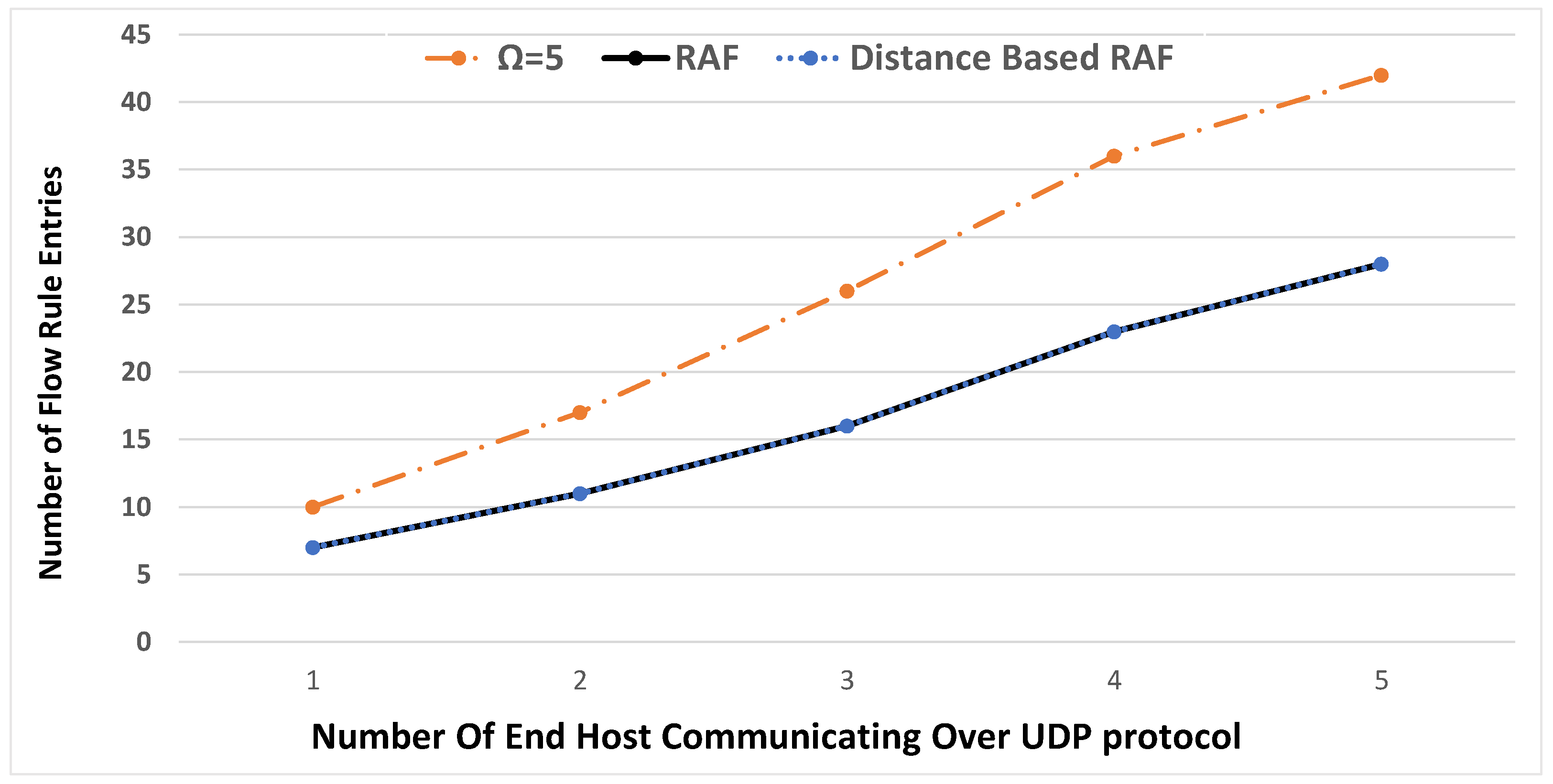
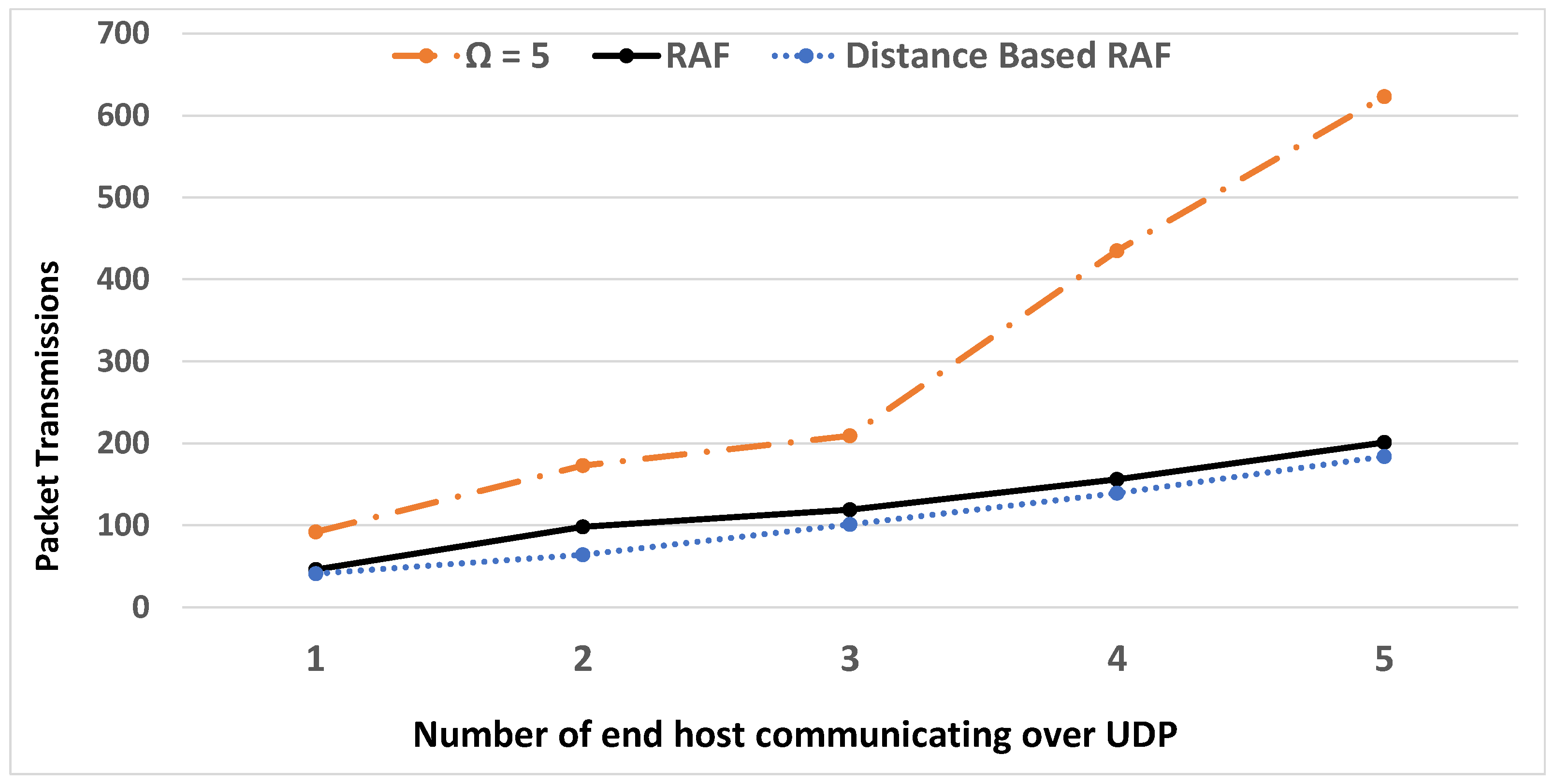
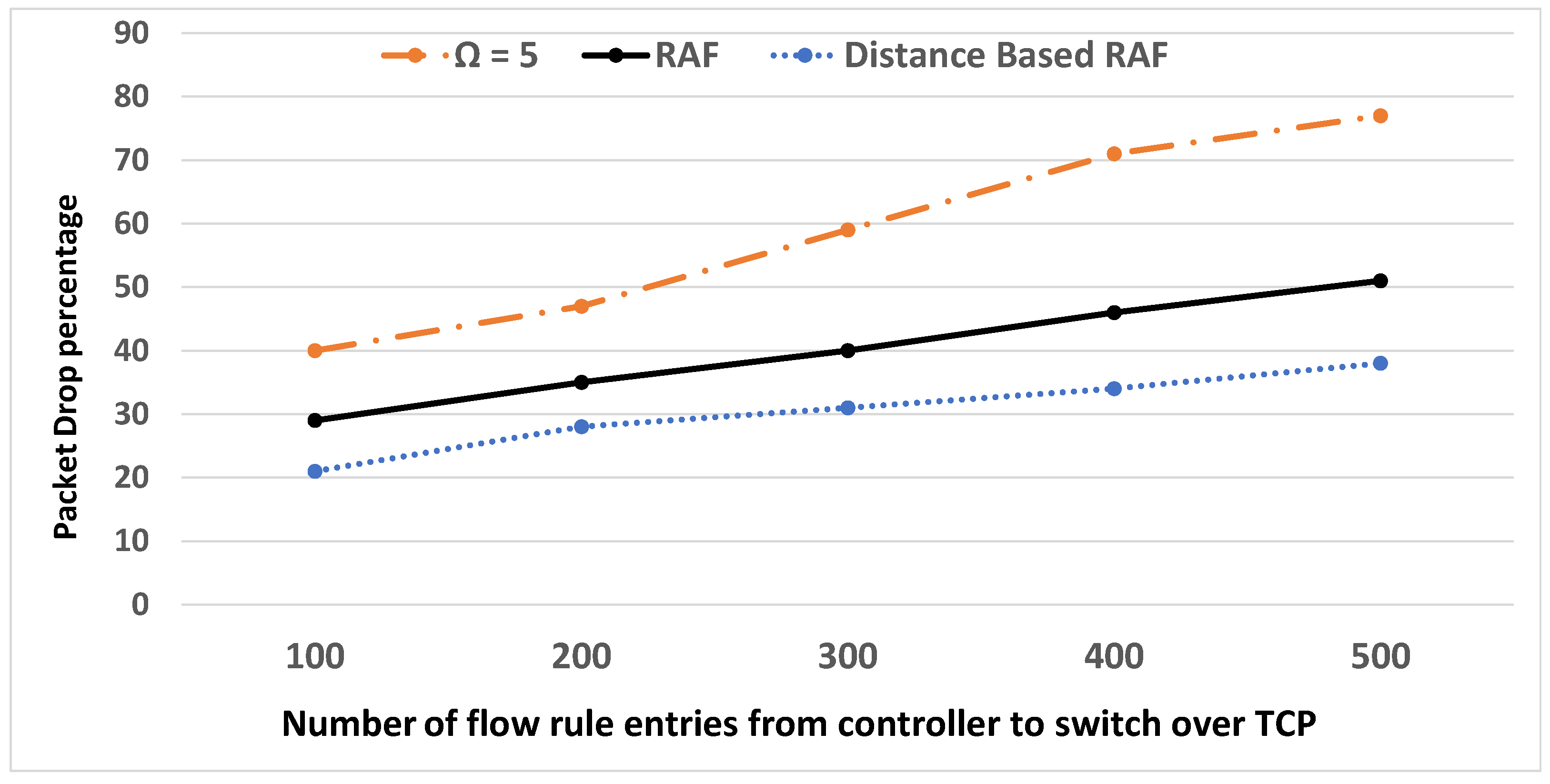
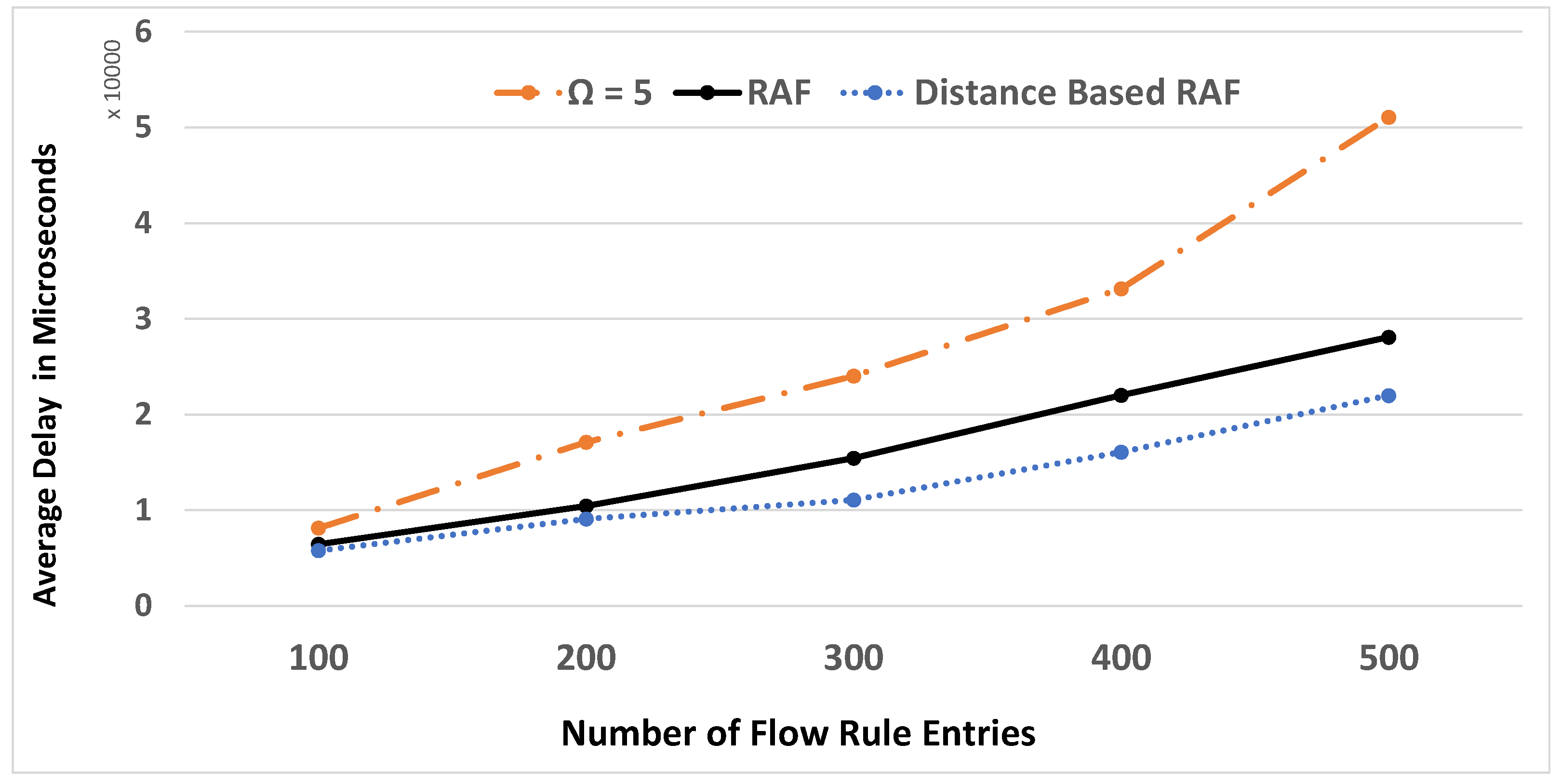
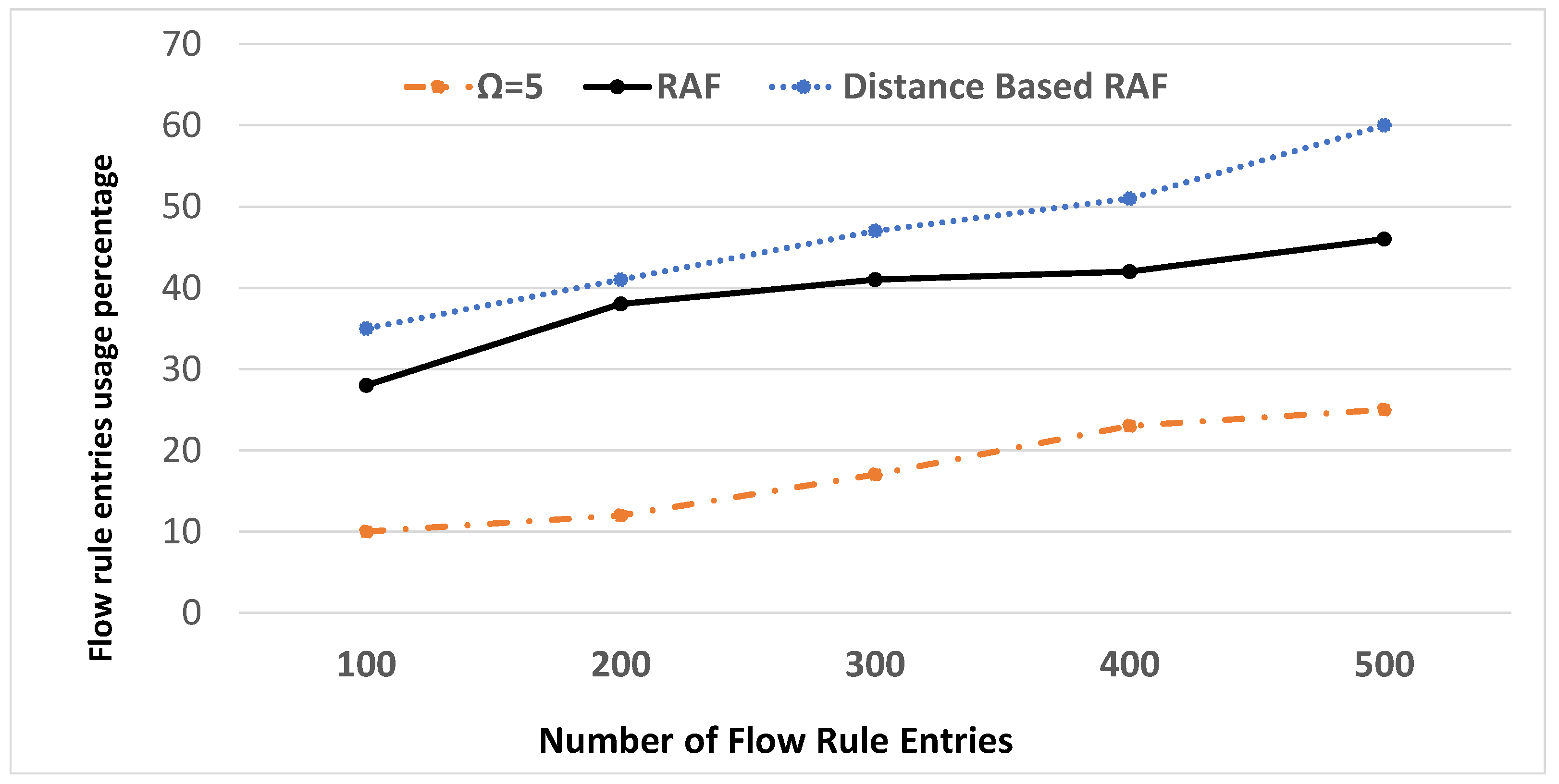
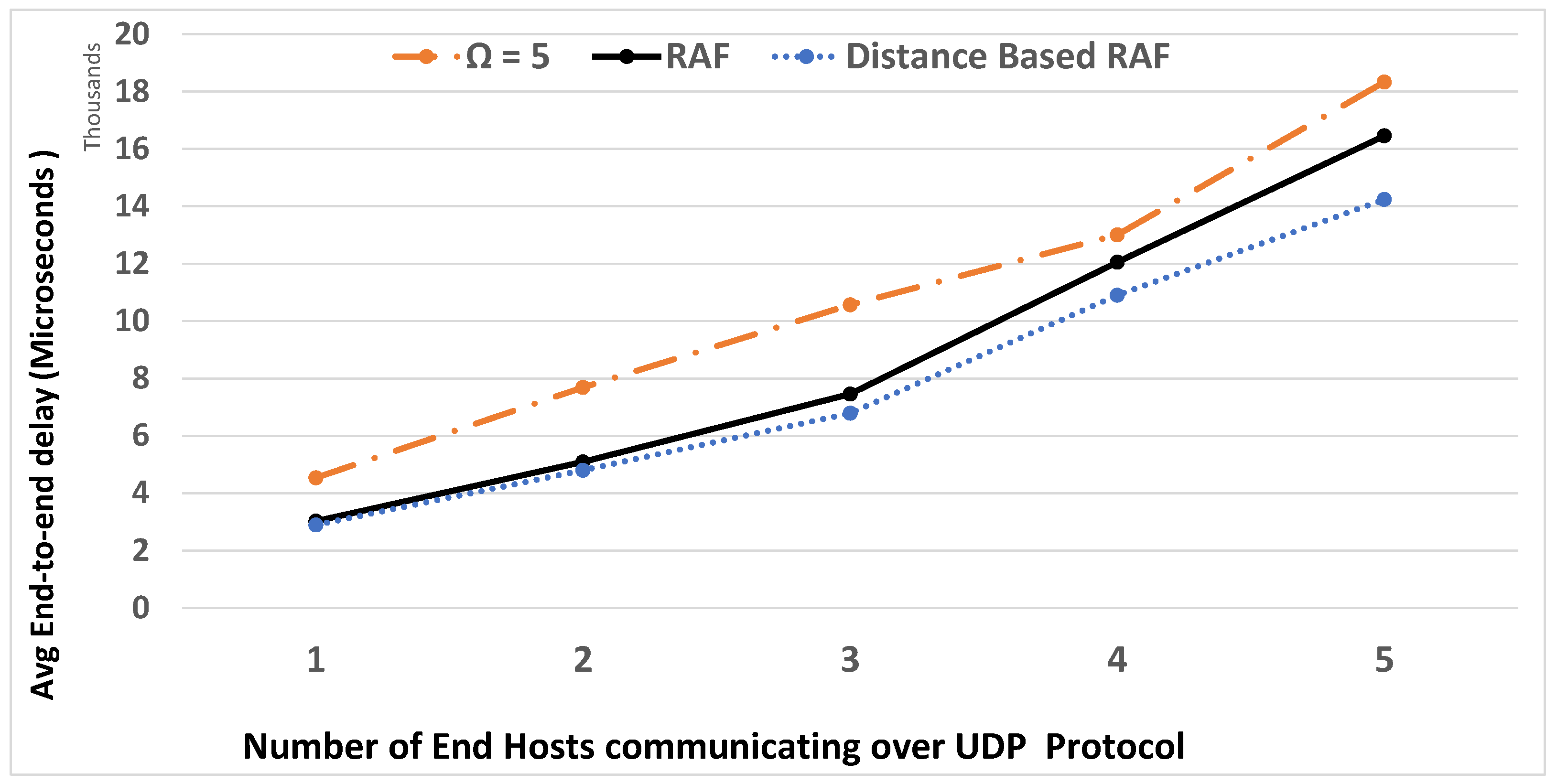
6. Experimental Results
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kim, H.; Feamster, N. Improving network management with software defined networking. IEEE Commun. Mag. 2013, 51, 114–119. [Google Scholar] [CrossRef]
- Chica, J.C.C.; Imbachi, J.C.; Botero, J.F. Security in SDN: A comprehensive survey. J. Netw. Comput. Appl. 2020, 159, 102595. [Google Scholar] [CrossRef]
- Sambo, N. Locally automated restoration in SDN disaggregated networks. IEEE/SA J. Opt. Commun. Netw. 2020, 12, C23–C30. [Google Scholar] [CrossRef]
- Mas–Machuca, C.; Musumeci, F.; Vizarreta, P.; Pezaros, D.; Jouët, S.; Tornatore, M.; Hmaity, A.; Liyanage, M.; Gurtov, A.; Braeken, A. Reliable Control and Data Planes for Softwarized Networks. In Guide to Disaster-Resilient Communication Networks; Springer: Cham, Switzerland, 2020; pp. 243–270. [Google Scholar]
- Scott, C.; Wundsam, A.; Raghavan, B.; Panda, A.; Or, A.; Lai, J.; Huang, E.; Liu, Z.; El-Hassany, A.; Whitlock, S.; et al. Troubleshooting blackbox SDN control software with minimal causal sequences. In Proceedings of the 2014 ACM Conference on SIGCOMM, Chicago, IL, USA, 18 August 2014. [Google Scholar]
- Duliński, Z.; Rzym, G.; Chołda, P. MPLS-based reduction of flow table entries in SDN switches supporting multipath transmission. Comput. Commun. 2020, 151, 365–385. [Google Scholar] [CrossRef] [Green Version]
- Qiu, K.; Yuan, J.; Zhao, J.; Wang, X.; Secci, S.; Fu, X. Fastrule: Efficient flow entry updates for tcam-based openflow switches. IEEE J. Sel. Areas Commun. 2019, 37, 484–498. [Google Scholar] [CrossRef] [Green Version]
- Thorat, P.; Jeon, S.; Choo, H. Enhanced local detouring mechanisms for rapid and lightweight failure recovery in OpenFlow networks. Comput. Commun. 2017, 108, 78–93. [Google Scholar] [CrossRef]
- Thorat, P.; Singh, S.; Bhat, A.; Narasimhan, V.L.; Jain, G. SDN-Enabled IoT: Ensuring Reliability in IoT Networks through Software Defined Networks. In Towards Cognitive IoT Networks; Springer: Cham, Switzerland, 2020; pp. 33–53. [Google Scholar]
- Wang, L.; Yao, L.; Xu, Z.; Wu, G.; Obaidat, M.S. CFR: A cooperative link failure recovery scheme in software-defined networks. Int. J. Commun. Syst. 2018, 31, e3560. [Google Scholar] [CrossRef]
- Güner, S.; Gür, G.; Alagöz, F. Proactive controller assignment schemes in SDN for fast recovery. In Proceedings of the 2020 International Conference on Information Networking (ICOIN), Barcelona, Spain, 7–10 January 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 136–141. [Google Scholar]
- Das, R.K.; Pohrmen, F.H.; Maji, A.K.; Saha, G. FT-SDN: A fault-tolerant distributed architecture for software defined network. Wirel. Pers. Commun. 2020, 114, 1045–1066. [Google Scholar] [CrossRef]
- Almadani, B.; Beg, A.; Mahmoud, A. Dsf: A distributed sdn control planeframework for the east/west interface. IEEE Access 2021, 9, 26735–26754. [Google Scholar] [CrossRef]
- Li, B.; Deng, X.; Deng, Y. Mobile-edge computing-based delay minimiza-tion controller placement in sdn-iov. Comput. Netw. 2021, 193, 108049. [Google Scholar] [CrossRef]
- Pontes, D.F.T.; Caetano, M.F.; Filho, G.P.R.; Granville, L.Z.; Marotta, M.A. On the transition of legacy networks to sdn-an analysison the impact of deployment time, number, and location of controllers. In Proceedings of the 2021 IFIP/IEEE International Symposium on Integrated NetworkManagement (IM), Bordeaux, France, 17–21 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 367–375. [Google Scholar]
- Malik, A.; de Fréin, R.; Aziz, B. Rapid restoration techniques for software-defined networks. Appl. Sci. 2020, 10, 3411. [Google Scholar] [CrossRef]
- Malik, A.; Aziz, B.; Adda, M.; Ke, C.H. Smart routing: Towards proactive fault handling of software-defined networks. Comput. Netw. 2020, 170, 107104. [Google Scholar] [CrossRef] [Green Version]
- Malik, A.; Aziz, B.; Bader-El-Den, M. Finding most reliable paths for software defined networks. In Proceedings of the 2017 13th International Wireless Communications and Mobile Computing Conference (IWCMC), Valencia, Spain, 26–30 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1309–1314. [Google Scholar]
- Yang, Z.; Yeung, K.L. Sdn candidate selection in hybrid ip/sdn networks for single link failure protection. IEEE/ACM Trans. Netw. 2020, 28, 312–321. [Google Scholar] [CrossRef]
- Shojaee, M.; Neves, M.; Haque, I. SafeGuard: Congestion and Memory-aware Failure Recovery in SD-WAN. In Proceedings of the 2020 16th International Conference on Network and Service Management (CNSM), Izmir, Turkey, 2–6 November 2020; pp. 1–7. [Google Scholar]
- Aljohani, S.L.; Alenazi, M.J. Mpresisdn: Multipath resilient routing scheme for sdn-enabled smart cities networks. Appl. Sci. 2021, 11, 1900. [Google Scholar] [CrossRef]
- Cascone, C.; Sanvito, D.; Pollini, L.; Capone, A.; Sanso, B. Fast failure detection and recovery in SDN with stateful data plane. Int. J. Netw. Manag. 2017, 27, e1957. [Google Scholar] [CrossRef]
- Stephens, B.; Cox, A.L.; Rixner, S. Scalable multi-failure fast failover via forwarding table compression. In Proceedings of the Symposium on SDN Research, Santa Clara, CA, USA, 14–15 March 2016. [Google Scholar]
- Lin, Y.D.; Teng, H.Y.; Hsu, C.R.; Liao, C.C.; Lai, Y.C. Fast failover and switchover for link failures and congestion in software defined networks. In Proceedings of the IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 23–27 May 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Kim, H.; Schlansker, M.; Santos, J.R.; Tourrilhes, J.; Turner, Y.; Feamster, N. Coronet: Fault tolerance for software defined networks. In Proceedings of the 20th IEEE International Conference on Network Protocols (ICNP), Austin, TX, USA, 30 October–2 November 2012; IEEE: Piscataway, NJ, USA, 2012. [Google Scholar]
- Ochoa-Aday, L.; Cervelló-Pastor, C.; Fernández-Fernández, A. Self-healing and SDN: Bridging the gap. Digit. Commun. Netw. 2020, 6, 354–368. [Google Scholar] [CrossRef]
- Panev, S.; Latkoski, P. SDN-based failure detection and recovery mechanism for 5G core networks. Trans. Emerg. Telecommun. Technol. 2020, 31, e3721. [Google Scholar] [CrossRef]
- Said, S.B.H.; Cousin, B.; Lahoud, S. Software Defined Networking (SDN) for reliable user connectivity in 5G Networks. In Proceedings of the 2017 IEEE Conference on Network Softwarization (NetSoft), Bologna, Italy, 3–7 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar]
- Lopez-Pajares, D.; Alvarez-Horcajo, J.; Rojas, E.; Asadujjaman, A.S.M.; Martinez-Yelmo, I. Amaru: Plug and play resilient in-band control for SDN. IEEE Access 2019, 7, 123202–123218. [Google Scholar] [CrossRef]
- Asadujjaman, A.S.M.; Rojas, E.; Alam, M.S.; Majumdar, S. Fast control channel recovery for resilient in-band OpenFlow networks. In Proceedings of the 2018 4th IEEE Conference on Network Softwarization and Workshops (NetSoft), Montreal, QC, Canada, 25–29 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 19–27. [Google Scholar]
- Sharma, S.; Colle, D.; Pickavet, M. Enabling Fast Failure Recovery in OpenFlow networks using RouteFlow. In Proceedings of the 2020 IEEE International Symposium on Local and Metropolitan Area Networks (LANMAN), Orlando, FL, USA, 13–15 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Tomovic, S.; Radusinovic, I. A new traffic engineering approach for QoS provisioning and failure recovery in SDN-based ISP networks. In Proceedings of the 23rd International Scientific-Professional Conference on Information Technology (IT), Žabljak, Montenegro, 19–24 February 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Adami, D.; Giordano, S.; Pagano, M.; Santinelli, N. Class-based traffic recovery with load balancing in software-defined networks. In Proceedings of the IEEE Globecom Workshops (GC Wkshps), Austin, TX, USA, 8–12 December 2014; IEEE: Piscataway, NJ, USA, 2014. [Google Scholar]
- Rehman, A.U.; Aguiar, R.L.; Barraca, J.P. Fault-tolerance in the scope of software-defined networking (sdn). IEEE Access 2019, 7, 124474–124490. [Google Scholar] [CrossRef]
- Tajiki, M.M.; Shojafar, M.; Akbari, B.; Salsano, S.; Conti, M.; Singhal, M. Joint failure recovery, fault prevention, and energy-efficient resource management for real-time SFC in fog-supported SDN. Comput. Netw. 2019, 162, 106850. [Google Scholar] [CrossRef] [Green Version]
- Muthumanikandan, V.; Valliyammai, C. Link failure recovery using shortest path fast rerouting technique in SDN. Wirel. Pers. Commun. 2017, 97, 2475–2495. [Google Scholar] [CrossRef]
- Ghannami, A.; Shao, C. Efficient fast recovery mechanism in software-defined networks: Multipath routing approach. In Proceedings of the 11th International Conference for Internet Technology and Secured Transactions (ICITST), Barcelona, Spain, 5–7 December 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Ali, J.; Lee, G.M.; Roh, B.H.; Ryu, D.K.; Park, G. Software-Defined Networking Approaches for Link Failure Recovery: A Survey. Sustainability 2020, 12, 4255. [Google Scholar] [CrossRef]
- Tomassilli, A.; Di Lena, G.; Giroire, F.; Tahiri, I.; Saucez, D.; Pérennes, S.; Turletti, T.; Sadykov, R.; Vanderbeck, F.; Lac, C. Design of robust programmable networks with bandwidth-optimal failure recovery scheme. Comput. Netw. 2021, 192, 108043. [Google Scholar] [CrossRef]
- Kiadehi, K.B.; Rahmani, A.M.; Molahosseini, A.S. A fault-tolerant architecture for internet-of-things based on software-defined networks. Telecommun. Syst. 2021, 77, 155–169. [Google Scholar] [CrossRef]
- Mohammadi, R.; Javidan, R. EFSUTE: A novel efficient and survivable traffic engineering for software defined networks. J. Reliab. Intell. Environ. 2021, 1–14. [Google Scholar] [CrossRef]
- Lee, S.S.; Li, K.-Y.; Chan, K.Y.; Lai, G.-H.; Chung, Y.C. Software-based fast failure recovery for resilient OpenFlow networks. In Proceedings of the 7th International Workshop on Reliable Networks Design and Modeling (RNDM), Munich, Germany, 5–7 October 2015; pp. 194–200. [Google Scholar]
- Raeisi, B.; Giorgetti, A. Software-based fast failure recovery in load balanced SDN-based datacenter networks. In Proceedings of the 2016 6th International Conference on Information Communication and Management (ICICM), Hertfordshire, UK, 29–31 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 95–99. [Google Scholar]
- Kuźniar, M.; Perešíni, P.; Vasić, N.; Canini, M.; Kostić, D. Automatic failure recovery for software-defined networks. In Proceedings of the Second ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking, Hong Kong, China, 16 August 2013. [Google Scholar]
- Yamansavascilar, B.; Baktir, A.C.; Ozgovde, A.; Ersoy, C. Fault tolerance in SDN data plane considering network and application based metrics. J. Netw. Comput. Appl. 2020, 170, 102780. [Google Scholar] [CrossRef]
- Chu, C.Y.; Xi, K.; Luo, M.; Chao, H.J. Congestion-aware single link failure recovery in hybrid SDN networks. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), Hong Kong, China, 26 April–1 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1086–1094. [Google Scholar]
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. In-band control, queuing, and failure recovery functionalities for OpenFlow. IEEE Netw. 2016, 30, 106–112. [Google Scholar] [CrossRef] [Green Version]
- Bianchi, G.; Bonola, M.; Capone, A.; Cascone, C. OpenState: Programming platform-independent stateful openflow applications inside the switch. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 44–51. [Google Scholar] [CrossRef]
- Hussain, M.; Shah, N.; Tahir, A. Graph-based policy change detection and implementation in SDN. Electronics 2019, 8, 1136. [Google Scholar] [CrossRef] [Green Version]
- De Oliveira, R.L.S.; Schweitzer, C.M.; Shinoda, A.A.; Prete, L.R. Using mininet for emulation and prototyping software-defined networks. In Proceedings of the 2014 IEEE Colombian Conference on Communications and Computing (COLCOM), Bogota, Colombia, 4–6 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–6. [Google Scholar]
- Kaur, S.; Singh, J.; Ghumman, N.S. Network programmability using POX controller. Proc. Int. Conf. Commun. Comput. Syst. (ICCCS) 2014, 138, 134–138. [Google Scholar]
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.; Peterson, L.; Rexford, J.; Turner, J. OpenFlow: Enabling innovation in campus networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- Komajwar, S.; Korkmaz, T. SPRM: Source Path Routing Model and Link Failure Handling in Software Defined Networks. IEEE Trans. Netw. Serv. Manag. 2021, 18, 2873–2887. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Procedure | Network Infrastructure | Recovery Approach | Control Channel Connectivity | Number of Controllers |
|---|---|---|---|---|---|
| CIP, CDP [8] | FF, indirect group, VLAN-based Flow Aggregation | OpenFlow Networks | proactive | out-of-band | single |
| LIm, ICoD [9] | FF, indirect group, VLAN-based aggregation | Internet of Things | proactive, reactive | out-of-band | single |
| CFR [10] | FF, VLAN-based flow rule aggregation | OpenFlow Networks | proactive, reactive | out-of-band | single |
| [42] | Probing, in-band control tree | OpenFlow Network | reactive | out-of-band, in-band | single |
| [43] | Probing, OpenFow group utility | SDN-enabled data centers | reactive | in-band | single |
| AFRO [44] | Control Channel Event Recording, Shadow Controller | OpenFlow Networks | reactive | in-band | multiple |
| PREF-CP [11] | Controller load aware genetic algorithm | OpenFlow Networks | proactive | out-of-band | multiple |
| FT-SDN [12] | State Replication Method, Network Information Base, control channel synchronization | OpenFlow Networks | reactive | out-of-band | multiple |
| [16] | Network Node, communication path community segmentation | Large OpenFlow Network Topologies | reactive | out-of-band | single |
| RPR-DT, RPR-LB [19] | SDN candidate selection | hybrid SDN network | proactive | out-of-band | single |
| SafeGuard [20] | MILP | SD-WAN, FF | proactive | out-of-band | single |
| SPIDER [22] | Open-State, FSM | SDN | proactive | topology independent | single |
| MpresiSDN [21] | Open-State, FSM | SDN | proactive | topology independent | single |
| Smart Routing [17] | Fault Tolerance Algorithms, prediction | SDN | proactive | out-of-band | single |
| Fast failover and switchover [24] | FF, Port monitoring | SDN | proactive, reactive | out-of-band | single |
| CORONET [25] | VLAN growing algorithm | SDN | Proactive | out-of-band | single |
| [28] | OF supported state modification methods | SDN enabled 5G network infrastructure | reactive | out-of-band | single |
| DPQoAP [45] | Dynamic Adaptive Streaming over HTTP (DASH), FF | SDN | proactive, reactive | our-of-band | single |
| [46] | IP tunneling protocol | hybrid SDN | reactive | out-of-band | single |
| Amaru [29] | Recursive BFS, Mac Labeling | hybrid SDN | proactive | in-band | single |
| [30] | communication channel division, logical ring based failure identification | SDN | proactive | in-band | single |
| [47] | control and data traffic queuing, Bidirectional Forwarding Detection (BFD) | SDN | proactive, reactive | in-band | single |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raza, S.M.; Ahvar, S.; Amin, R.; Hussain, M. Reliability Aware Multiple Path Installation in Software-Defined Networking. Electronics 2021, 10, 2820. https://doi.org/10.3390/electronics10222820
Raza SM, Ahvar S, Amin R, Hussain M. Reliability Aware Multiple Path Installation in Software-Defined Networking. Electronics. 2021; 10(22):2820. https://doi.org/10.3390/electronics10222820
Chicago/Turabian StyleRaza, Syed Mohsan, Shohreh Ahvar, Rashid Amin, and Mudassar Hussain. 2021. "Reliability Aware Multiple Path Installation in Software-Defined Networking" Electronics 10, no. 22: 2820. https://doi.org/10.3390/electronics10222820
APA StyleRaza, S. M., Ahvar, S., Amin, R., & Hussain, M. (2021). Reliability Aware Multiple Path Installation in Software-Defined Networking. Electronics, 10(22), 2820. https://doi.org/10.3390/electronics10222820