
Algorithmic Structures for Realizing Short-Length Circular Convolutions with Reduced Complexity



Abstract
:1. Introduction
2. Preliminary Remarks
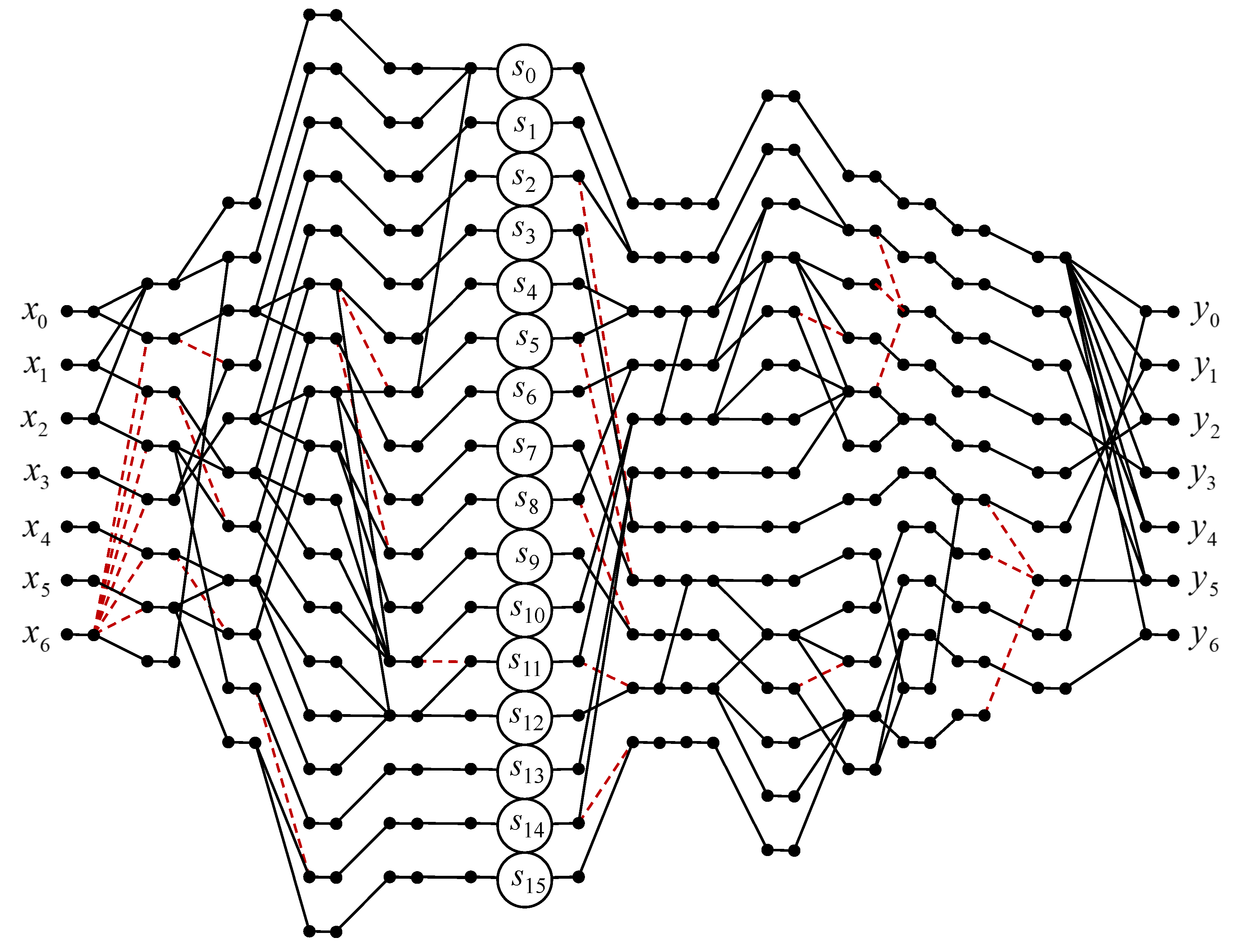
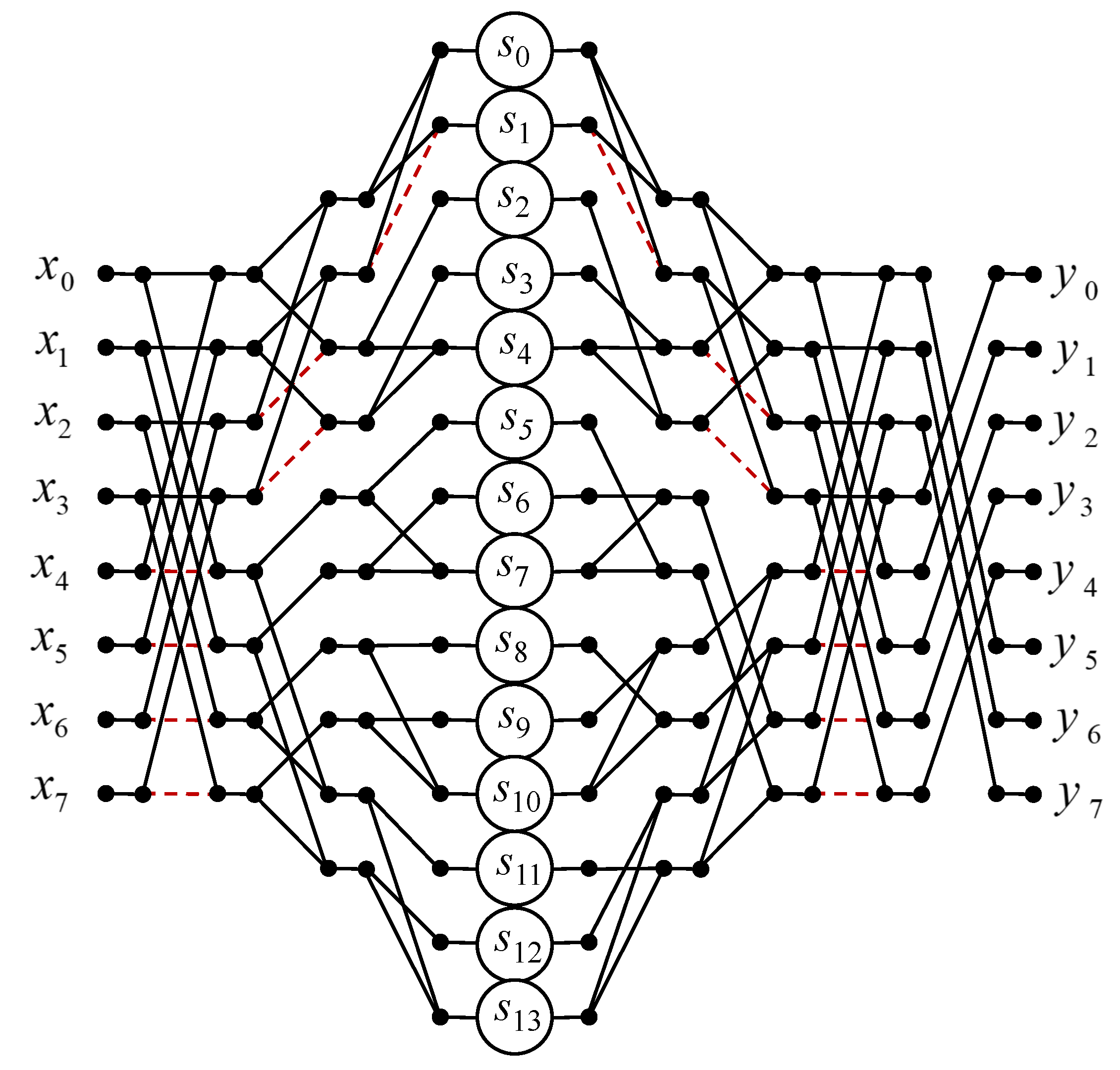
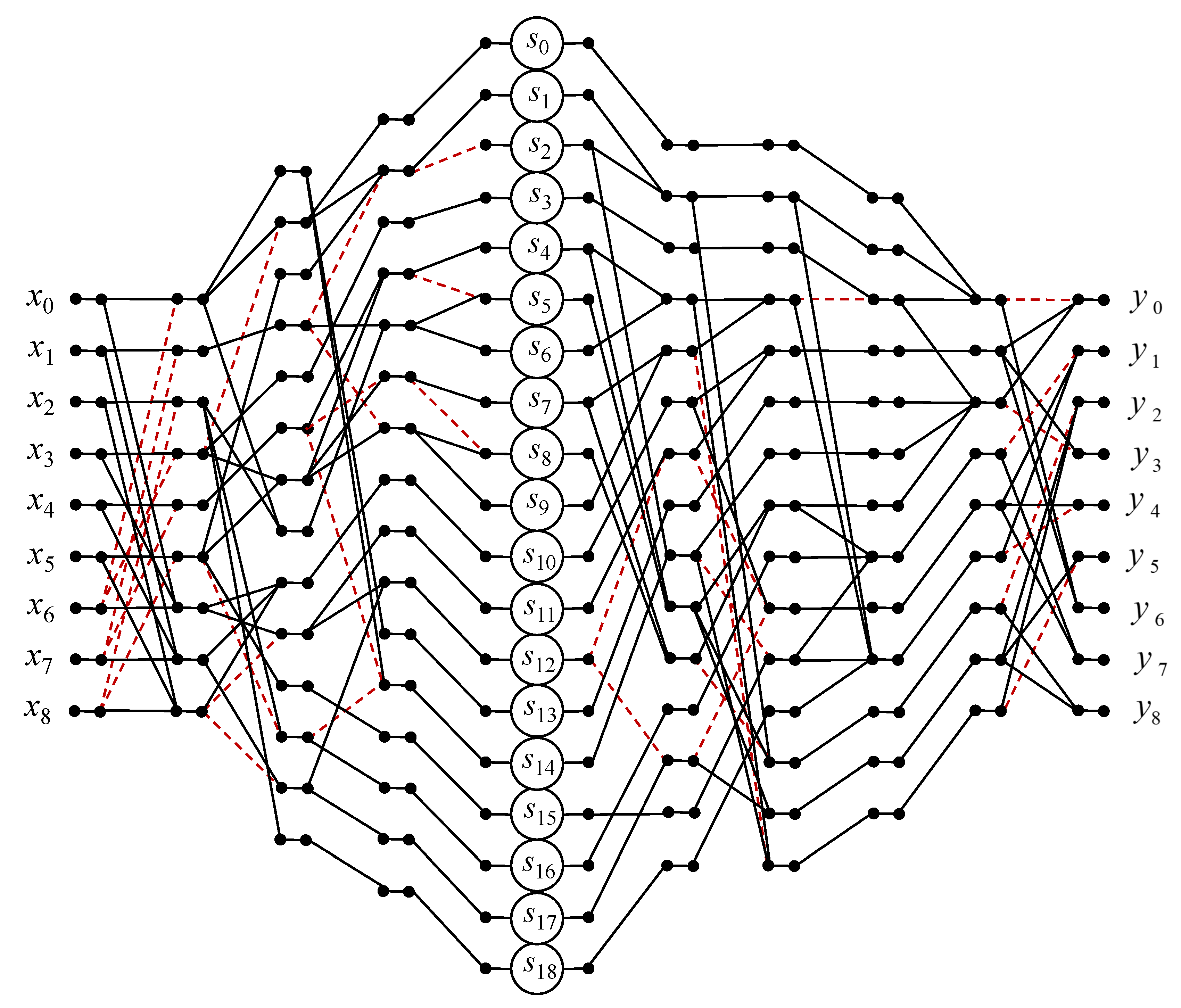
3. Algorithms for Short-Length Circular Convolution
3.1. Circular Convolution for
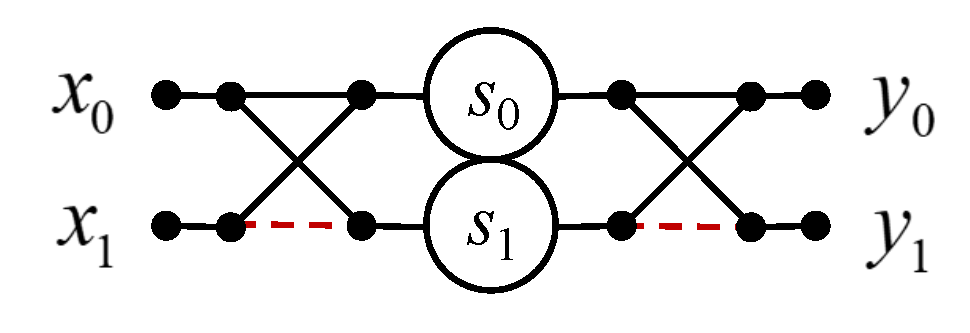
3.2. Circular Convolution for
3.3. Circular Convolution for
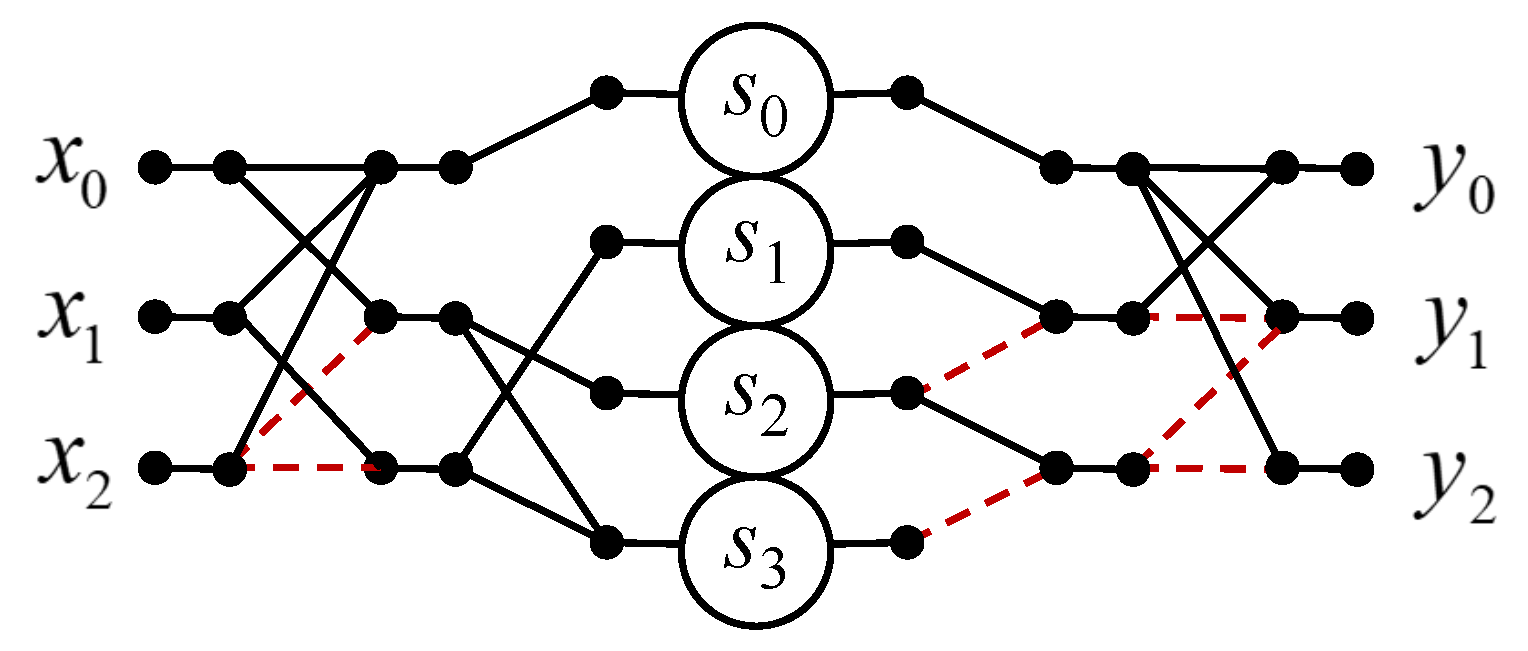
3.4. Circular Convolution for
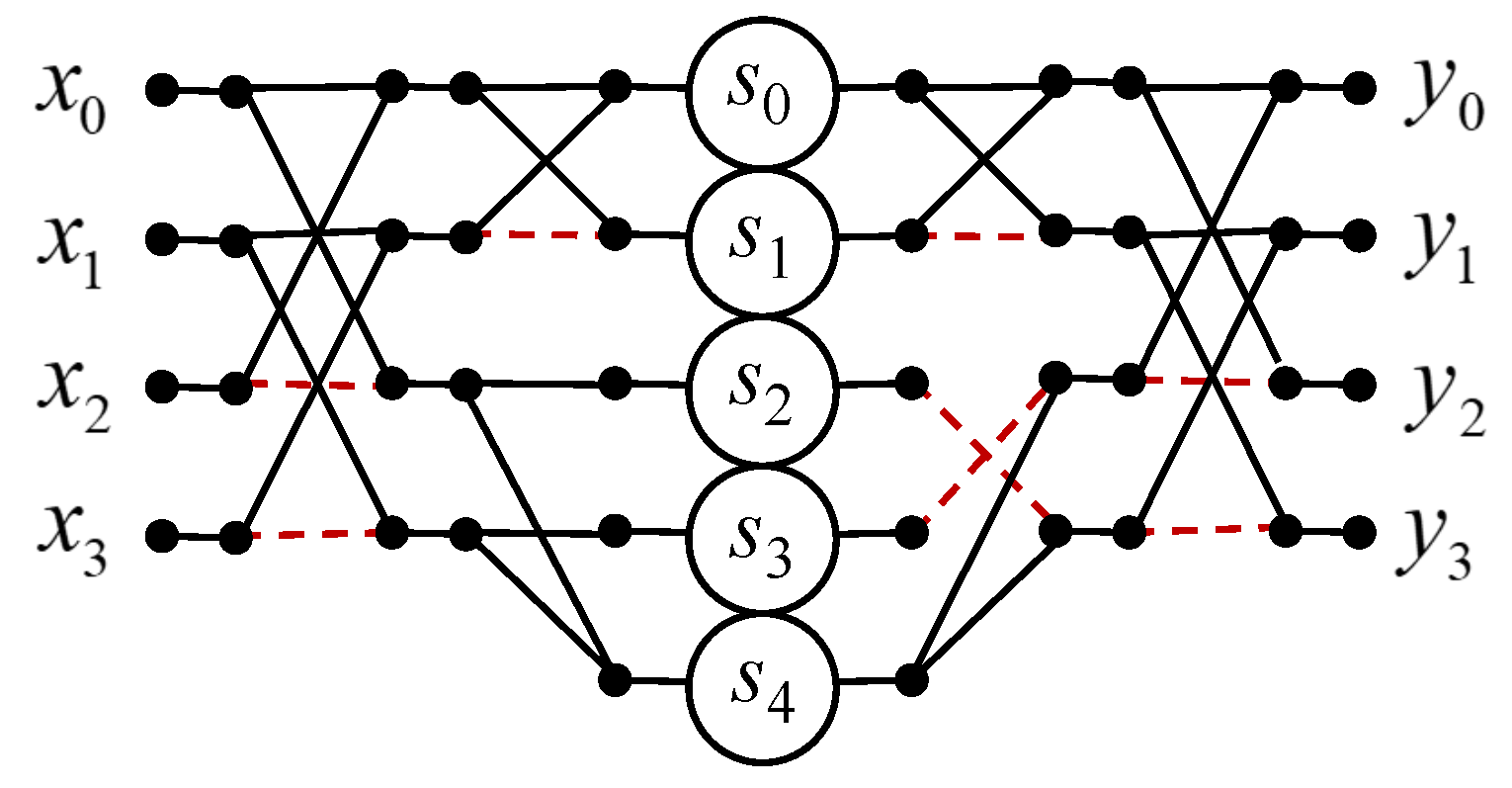
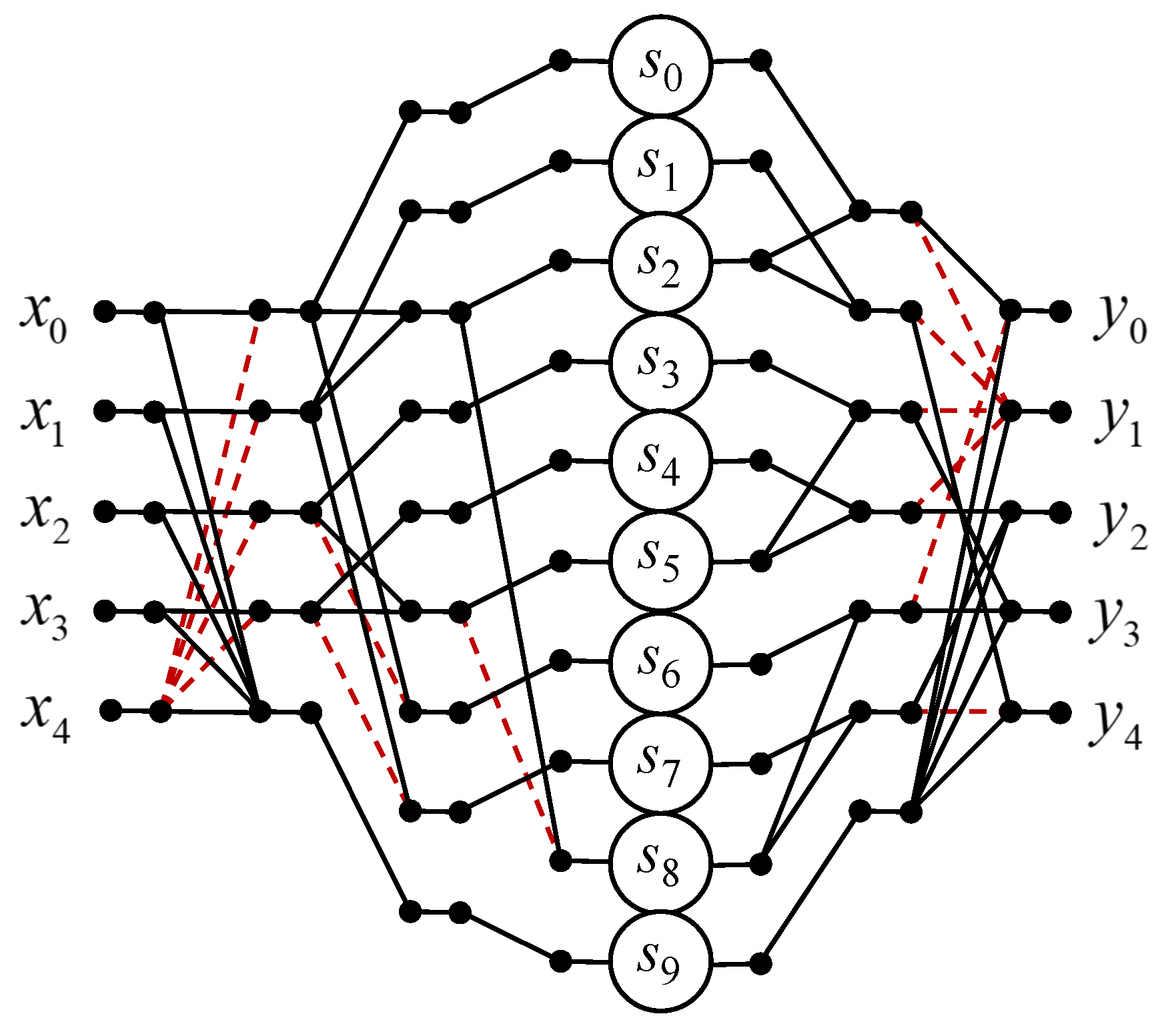
3.5. Circular Convolution for
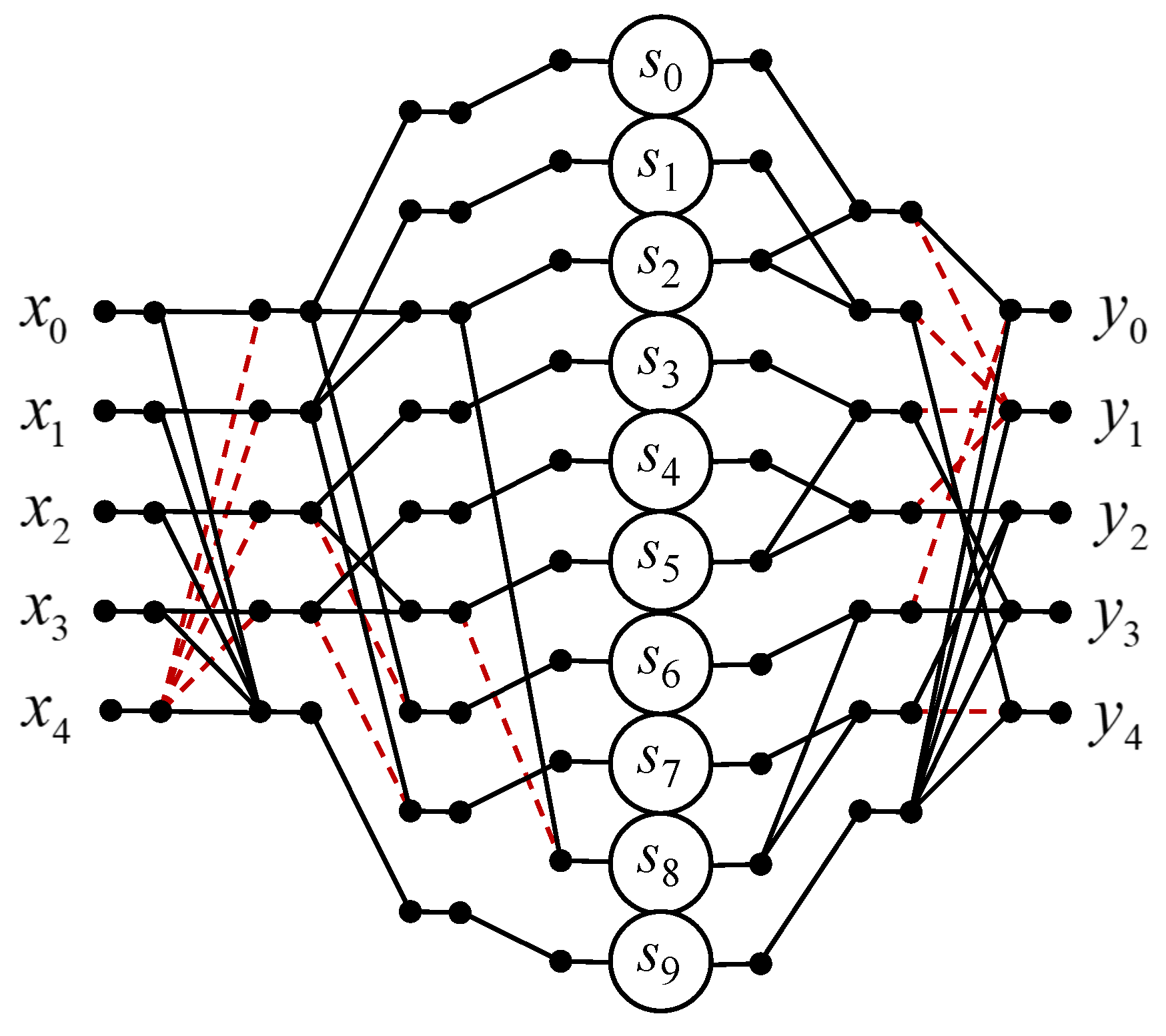
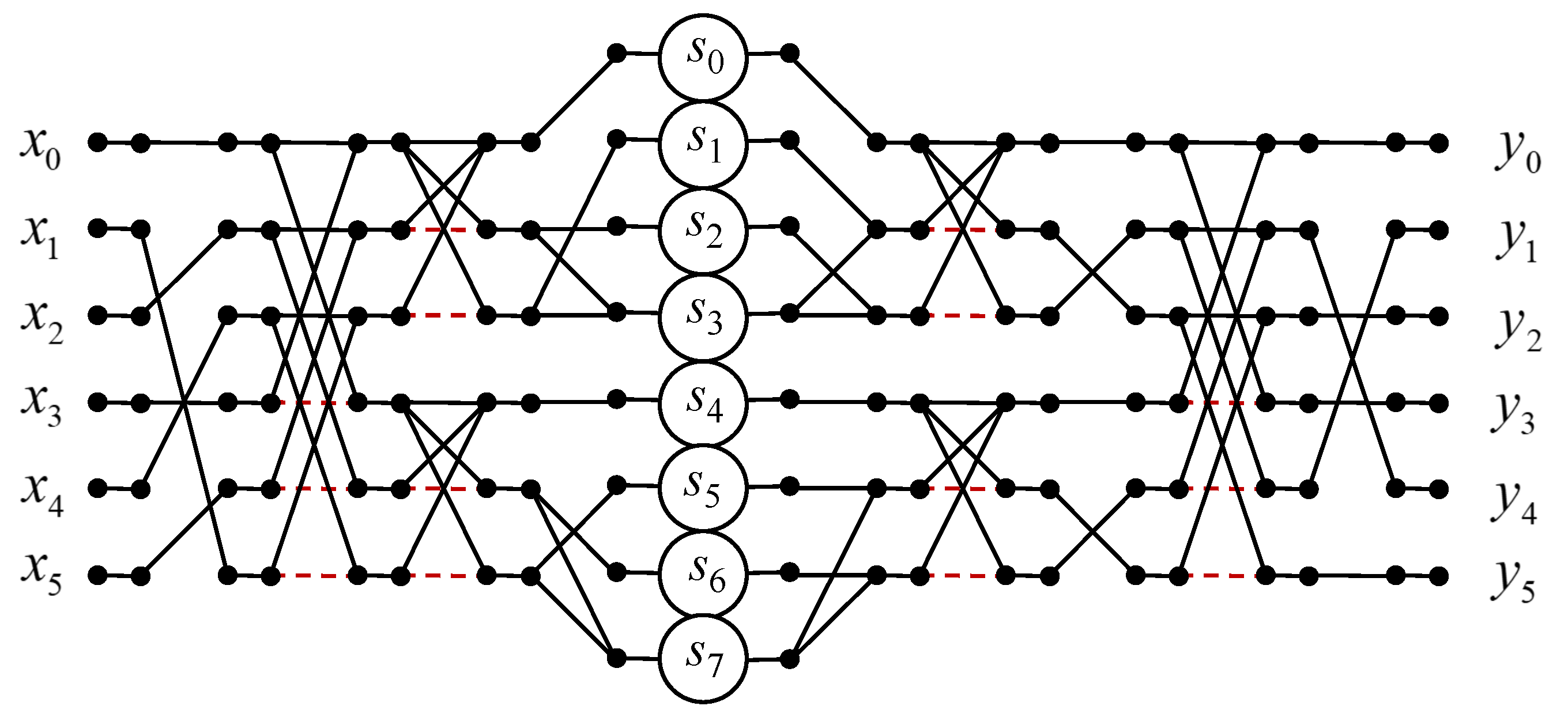
3.6. Circular Convolution for
3.7. Circular Convolution for
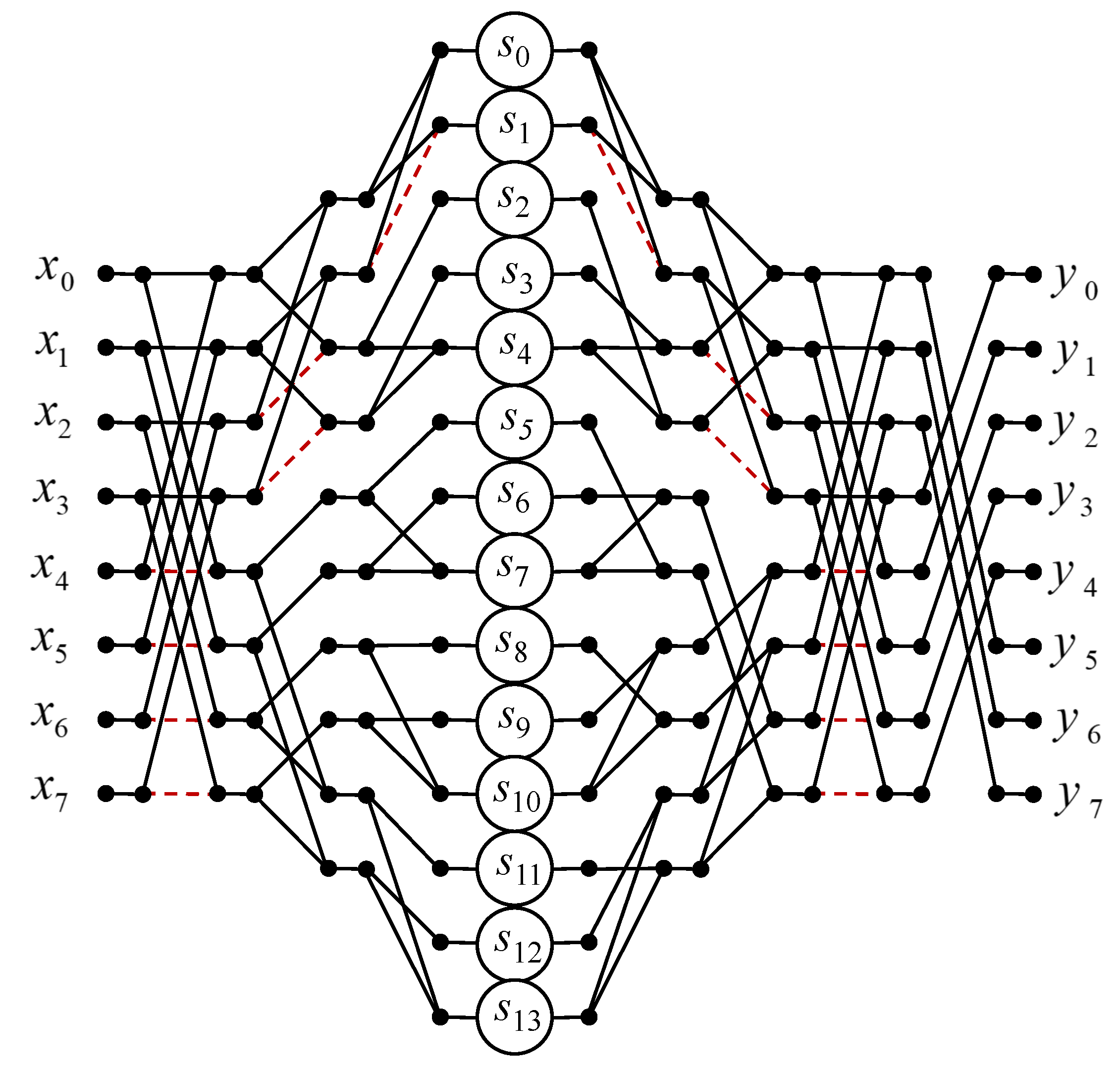
3.8. Circular Convolution for
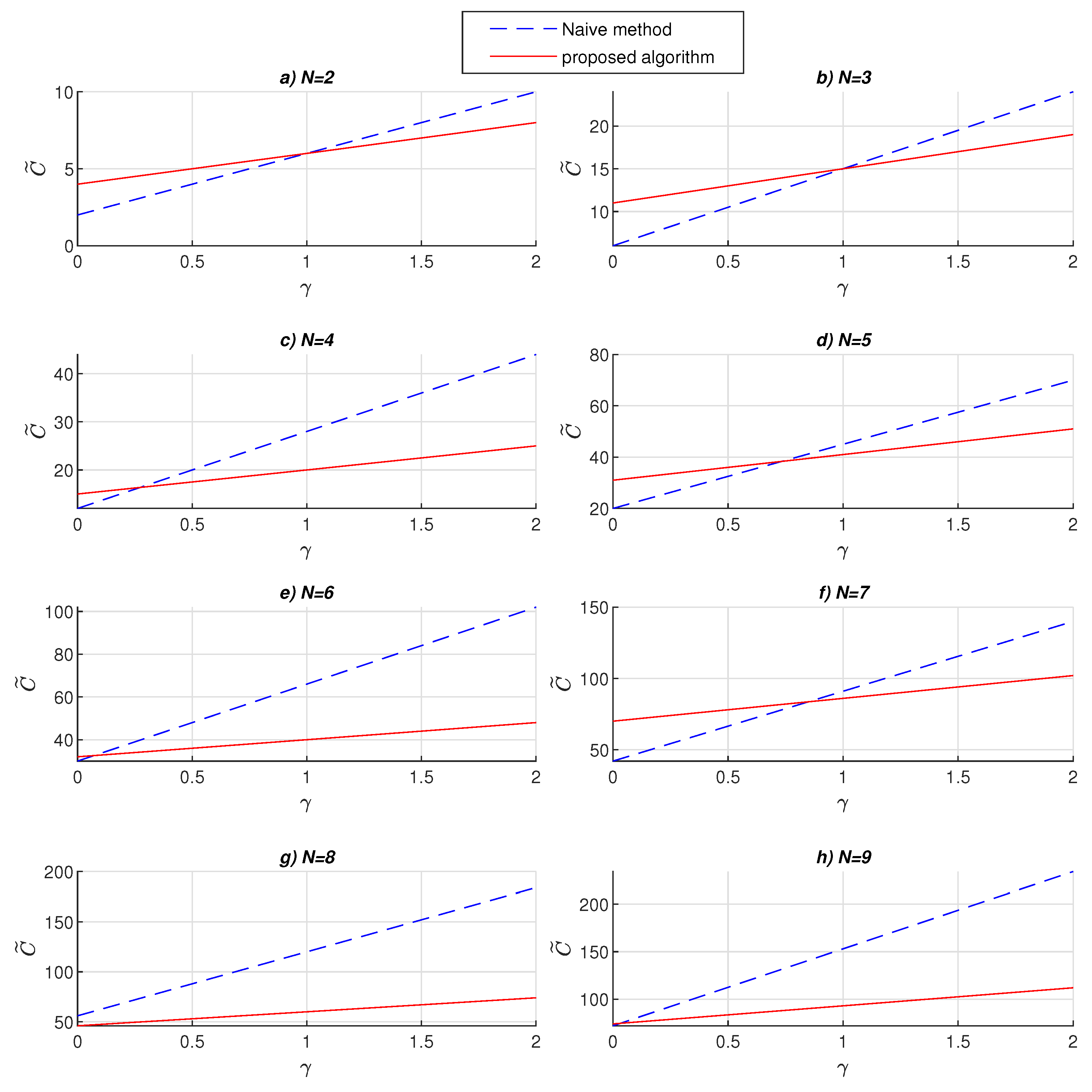
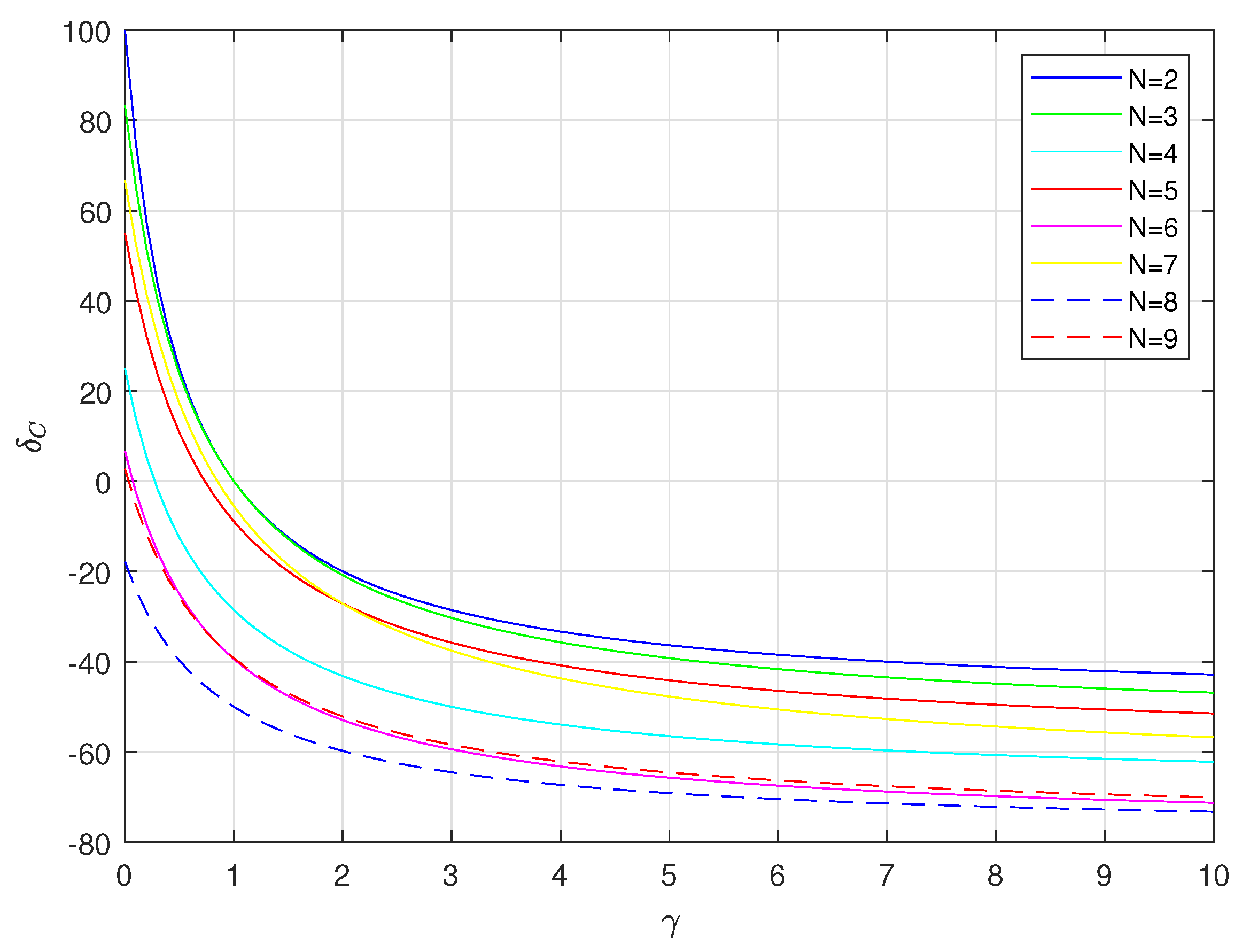
4. Implementation Complexity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Loulou, A.; Yli-Kaakinen, J.; Renfors, M. Efficient fast-convolution based implementation of 5G waveform processing using circular convolution decomposition. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–7. [Google Scholar]
- Loulou, A.; Yli-Kaakinen, J.; Renfors, M. Advanced low-complexity multicarrier schemes using fast-convolution processing and circular convolution decomposition. IEEE Trans. Signal Process. 2019, 67, 2304–2319. [Google Scholar] [CrossRef]
- Mathieu, M.; Henaff, M.; LeCun, Y. Fast training of convolutional networks through ffts. arXiv 2013, arXiv:1312.5851. [Google Scholar]
- Lin, S.; Liu, N.; Nazemi, M.; Li, H.; Ding, C.; Wang, Y.; Pedram, M. FFT-based deep learning deployment in embedded systems. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 1045–1050. [Google Scholar]
- Abtahi, T.; Shea, C.; Kulkarni, A.; Mohsenin, T. Accelerating convolutional neural network with fft on embedded hardware. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 1737–1749. [Google Scholar] [CrossRef]
- Burrus, S.C.; Parks, T.W. DFT/FFT and Convolution Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 1985. [Google Scholar]
- Blahut, R.E. Fast Algorithms for Signal Processing; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- McClellen, J.H.; Rader, C.M. Number Theory in Digital Signal Processing; Professional Technical Reference; Prentice Hall: Hoboken, NJ, USA, 1979. [Google Scholar]
- Tolimieri, R.; An, M.; Lu, C. Algorithms for Discrete Fourier Transform and Convolution; Springer: Berlin/Heidelberg, Germany, 1989. [Google Scholar]
- Berg, L.; Nussbaumer, H. Fast Fourier Transform and Convolution Algorithms. Z. Angew. Math. Mech. 1982, 62, 282. [Google Scholar] [CrossRef]
- Garg, H.K. Digital Signal Processing Algorithms: Number Theory, Convolution, Fast Fourier Transforms, and Applications; Routledge: London, UK, 2017. [Google Scholar]
- Bi, G.; Zeng, Y. Transforms and Fast Algorithms for Signal Analysis and Representations; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Selesnick, I.W.; Burrus, C.S. Extending Winograd’s small convolution algorithm to longer lengths. In Proceedings of the IEEE International Symposium on Circuits and Systems-ISCAS’94, London, UK, 30 May–2 June 1994; Volume 2, pp. 449–452. [Google Scholar]
- Stasinski, R. Extending sizes of effective convolution algorithms. Electron. Lett. 1990, 26, 1602–1604. [Google Scholar] [CrossRef]
- Karas, P.; Svoboda, D. Algorithms for efficient computation of convolution. In Design and Architectures for Digital Signal Processing; IntechOpen: London, UK, 2013; pp. 179–208. [Google Scholar]
- Mohammad, K.; Agaian, S. Efficient FPGA implementation of convolution. In Proceedings of the 2009 IEEE International Conference on Systems, Man and Cybernetics, San Antonio, TX, USA, 11–14 October 2009; pp. 3478–3483. [Google Scholar]
- Duhamel, P.; Vetterli, M. Cyclic convolution of real sequences: Hartley versus fourier and new schemes. In Proceedings of the ICASSP’86. IEEE International Conference on Acoustics, Speech, and Signal Processing, Tokyo, Japan, 7–11 April 1986; Volume 11, pp. 229–232. [Google Scholar]
- Duhamel, P.; Vetterli, M. Improved Fourier and Hartley transform algorithms: Application to cyclic convolution of real data. IEEE Trans. Acoust. Speech Signal Process. 1987, 35, 818–824. [Google Scholar] [CrossRef] [Green Version]
- Meher, P.; Panda, G. Fast Computation of Circular Convolution of Real Valued Data using Prime Factor Fast Hartley Transform Algorithm. IEEE J. Res. 1995, 41, 261–264. [Google Scholar] [CrossRef]
- Reju, V.G.; Koh, S.N.; Soon, Y. Convolution using discrete sine and cosine transforms. IEEE Signal Process. Lett. 2007, 14, 445–448. [Google Scholar] [CrossRef]
- Cheng, C.; Parhi, K.K. Hardware efficient fast DCT based on novel cyclic convolution structures. IEEE Trans. Signal Process. 2006, 54, 4419–4434. [Google Scholar] [CrossRef]
- Chan, Y.H.; Siu, W.C. General approach for the realization of DCT/IDCT using convolutions. Signal Process. 1994, 37, 357–363. [Google Scholar] [CrossRef]
- Hunt, B. A matrix theory proof of the discrete convolution theorem. IEEE Trans. Audio Electroacoust. 1971, 19, 285–288. [Google Scholar] [CrossRef]
- Cariow, A.; Paplinski, J.P. Some algorithms for computing short-length linear convolution. Electronics 2020, 9, 2115. [Google Scholar] [CrossRef]
- Adámek, K.; Dimoudi, S.; Giles, M.; Armour, W. GPU fast convolution via the overlap-and-save method in shared memory. ACM Trans. Archit. Code Optim. (TACO) 2020, 17, 1–20. [Google Scholar] [CrossRef]
- Narasimha, M.J. Modified overlap-add and overlap-save convolution algorithms for real signals. IEEE Signal Process. Lett. 2006, 13, 669–671. [Google Scholar] [CrossRef]
- Huang, T.S. Two-dimensional digital signal processing II. Transforms and median filters. In Two-Dimensional Digital Signal Processing II. Transforms and Median Filters; Topics in Applied Physics; Springer: Berlin/Heidelberg, Germany, 1981; Volume 43. [Google Scholar]
- Parhi, K.K. VLSI Digital Signal Processing Systems: Design and Implementation; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Ju, C.; Solomonik, E. Derivation and Analysis of Fast Bilinear Algorithms for Convolution. arXiv 2019, arXiv:1910.13367. [Google Scholar] [CrossRef]
- Regalia, P.A.; Sanjit, M.K. Kronecker products, unitary matrices and signal processing applications. SIAM Rev. 1989, 31, 586–613. [Google Scholar] [CrossRef]
- Granata, J.; Conner, M.; Tolimieri, R. The tensor product: A mathematical programming language for FFTs and other fast DSP operations. IEEE Signal Process. Mag. 1992, 9, 40–48. [Google Scholar] [CrossRef]
- Saha, P.; Banerjee, A.; Dandapat, A.; Bhattacharyya, P. ASIC implementation of high speed processor for calculating discrete fourier transformation using circular convolution technique. WSEAS Trans. Circuits Syst. 2011, 10, 278–288. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Length N | Number of Arithmetical Blocks (Multipliers—“×” and Adders—“+”) | Implementation Normalized Cost Estimate | |||||
|---|---|---|---|---|---|---|---|
| Naive Method | Proposed Solutions | ||||||
| 0 | “×” | “+” | “×” | “+” | Naive Method | Proposed Solutions | |
| 2 | 4 | 2 | 2 | 4 | |||
| 3 | 9 | 6 | 4 | 11 | |||
| 4 | 16 | 12 | 5 | 15 | |||
| 5 | 25 | 20 | 10 | 31 | |||
| 6 | 36 | 30 | 8 | 32 | |||
| 7 | 49 | 42 | 16 | 70 | |||
| 8 | 64 | 56 | 14 | 46 | |||
| 9 | 81 | 72 | 19 | 73 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cariow, A.; Paplinski, J.P. Algorithmic Structures for Realizing Short-Length Circular Convolutions with Reduced Complexity. Electronics 2021, 10, 2800. https://doi.org/10.3390/electronics10222800
Cariow A, Paplinski JP. Algorithmic Structures for Realizing Short-Length Circular Convolutions with Reduced Complexity. Electronics. 2021; 10(22):2800. https://doi.org/10.3390/electronics10222800
Chicago/Turabian StyleCariow, Aleksandr, and Janusz P. Paplinski. 2021. "Algorithmic Structures for Realizing Short-Length Circular Convolutions with Reduced Complexity" Electronics 10, no. 22: 2800. https://doi.org/10.3390/electronics10222800
APA StyleCariow, A., & Paplinski, J. P. (2021). Algorithmic Structures for Realizing Short-Length Circular Convolutions with Reduced Complexity. Electronics, 10(22), 2800. https://doi.org/10.3390/electronics10222800