
No-Reference Video Quality Assessment Based on Benford’s Law and Perceptual Features


Abstract
1. Introduction
1.1. Contributions
1.2. Structure
2. Related Work
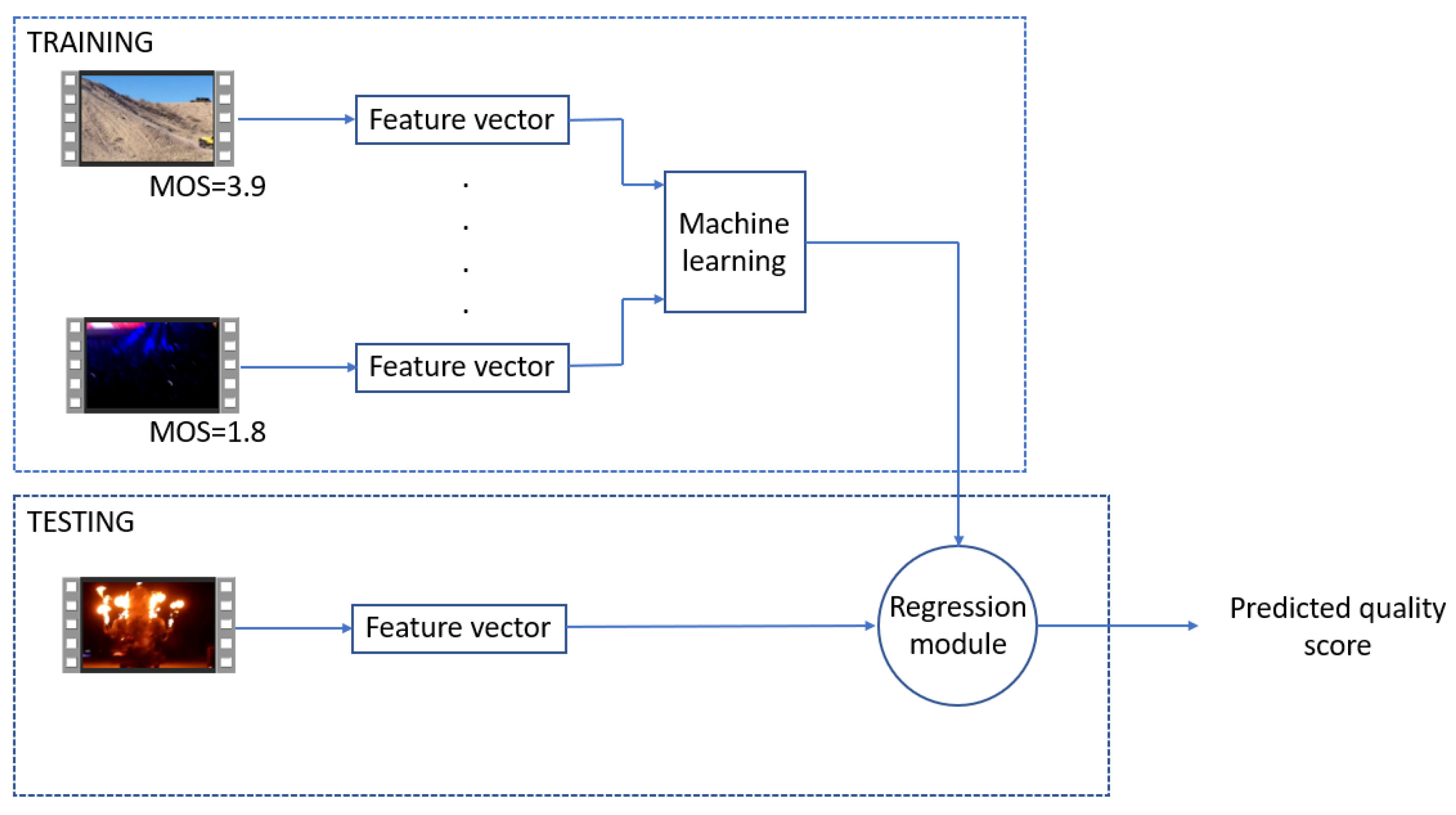
3. Proposed Method
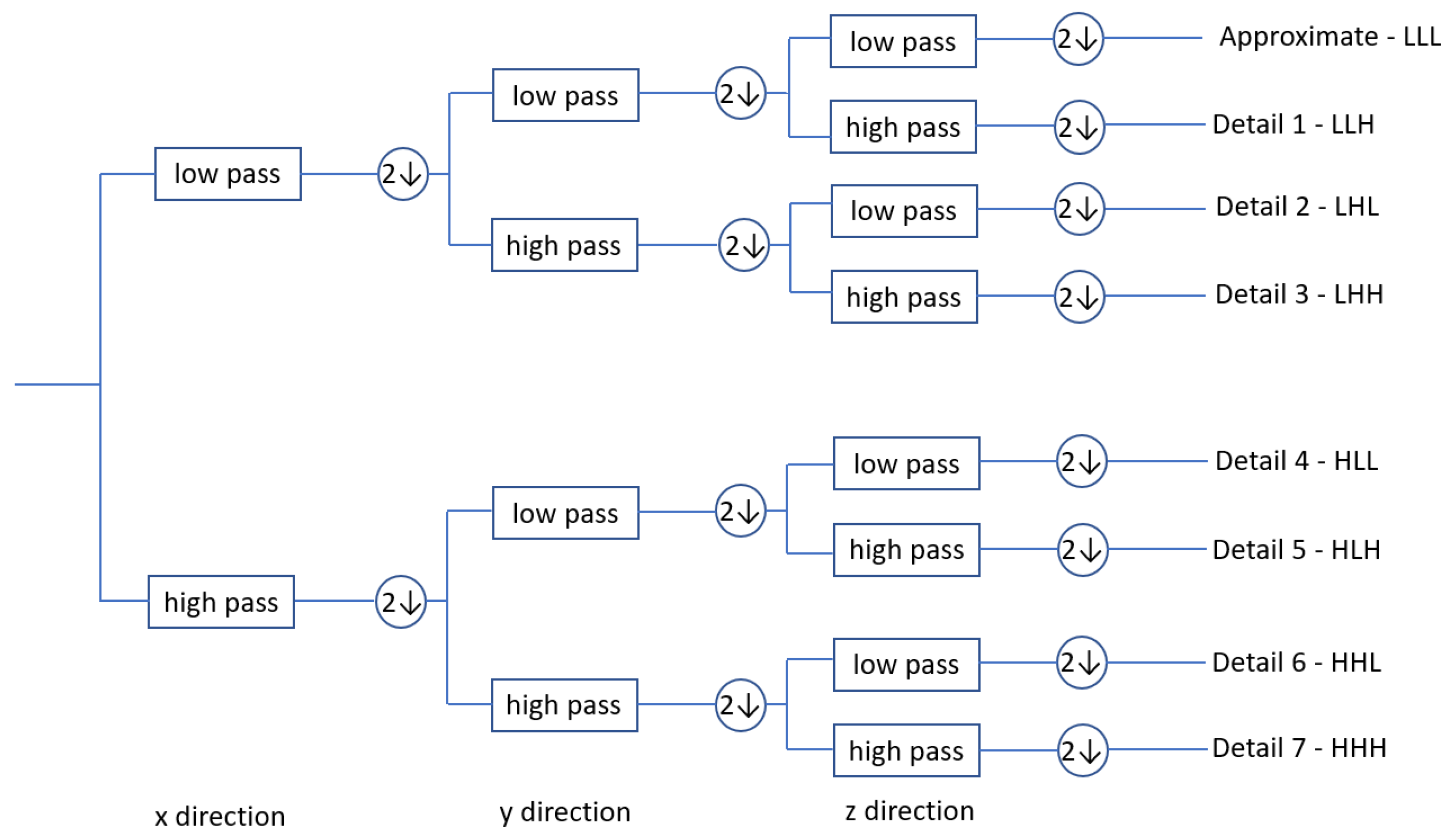
3.1. FDD-Based Features
3.2. Perceptual Features
- 1.
- Blur: This is the shape and area in an image that cannot be seen clearly because no distinct outline is present or an object is moving fast. Artifacts generated by blur usually result in the loss of details. Hereby, the amount of blur in an image heavily influences humans’ quality perception. Due its low computational costs, we adopted the approach of Crété-Roffet et al. [49] to quantify the amount of blur in an image, which is based on the comparison between variations of adjacent pixels after low-pass filtering;
- 2.
- Colorfulness: There are more studies that suggest colorfulness as an important factor for human visual quality perception [48,50,51]. In our study, Hasler and Suesstrunk’s model [52] was applied to measure colorfulness. Let’ us denote with R, G, and B the red, green, and blue channels of an RGB image, respectively. Two matrices are derived for the color channels: and . Next, colorfulness is defined as:where and stand for the variance and mean of their respective matrices. A video sequence’s colorfulness is considered as the average value of individual frames’ colorfulness;
- 3.
- Contrast: Perceptual image quality is strongly influenced by contrast, since humans’ ability to distinguish objects from each other in an image heavily depends on it [53]. In [16], Matkovic et al.’s [54] global contrast factor (GCF) model was applied to quantify image contrast. However, GCF’s computational cost is large, which makes it not feasible to measure a video sequence’s contrast. That is why we adopted here the root-mean-squared (RMS) contrast for measuring the contrast of a video frame. RMS contrast is defined as the standard deviation of the pixel intensities [55]:where stands for the ith, jth pixel intensity of a 2D grayscale image I with size . A video sequence’s contrast is considered as the average value of the video frames’ contrast;
- 4.
- Dark channel feature: He et al. [56] investigated the properties of fog-free natural images. It was found that dark pixels are those pixels whose intensity values are close to zero at least in one color channel within an image patch [57]. Based on this, a dark channel is defined as:where denotes the intensity of a color channel (R, G, or B) and is an image patch centered on x. Based on the above definition, the dark channel feature of an image is given as:where S stands for the area of the input image. A video sequence’s is considered as the average value of the individual video frames’ ;
- 5.
- Entropy: The entropy of a digital image is a feature that gives information about the average content in an image. The concept of the entropy of a signal in general is very old. Namely, it comes from Shannon’s theory of communication [58]. The entropy of a 2D grayscale image is given as:where stands for the empirical distribution of grayscale values in image I. The entropy of a video sequence is defined as the average of the video frames’ entropy;
- 6.
- Mean of phase congruency: Phase congruency (PC) characterizes a digital image in the frequency domain. Phase congruency is given by the following equation:where corresponds to the energy of signal x and can be given as:where is the Fourier transform of signal x and denotes the nth Fourier amplitude of signal x. To incorporate noise compensation, Kovesi [59] modified the above definition of PC by adding weights for the frequency spread:where is the weight function of the frequency spread, stands for the floor function, T is an estimation of the noise level, and is a small constant to avoid division by zero. Moreover, denotes the nth Fourier component at x and can be expressed as:where is the average phase at x. For a video sequence, the video frames’ mean PC values are averaged to obtain a perceptual feature;
- 7.
- Spatial information: The gradient magnitude maps of each video frame were determined with the help of a Sobel filter, and the standard deviations of each Sobel map were taken. The spatial information of a video sequence is the average of the Sobel maps’ standard deviations;
- 8.
- Temporal information: This characterizes the amount of temporal changes in a given video sequence [21]. In this study, the temporal information of a video sequence was considered as the mean of the pixelwise frame differences’ standard deviations;
- 9.
- Natural image quality evaluator (NIQE): The NIQE [60] measures the distance between the natural scene statistics-based features extracted from an image and certain ideal features. In the case of the NIQE, the features are modeled as multidimensional Gaussian distributions. Specifically, the value given by the NIQE can be considered as the degree of deviation from naturalness of a digital image. In this study, the naturalness of a video sequence is characterized by the average of the video frames’ NIQE values.
4. Experimental Results and Analysis
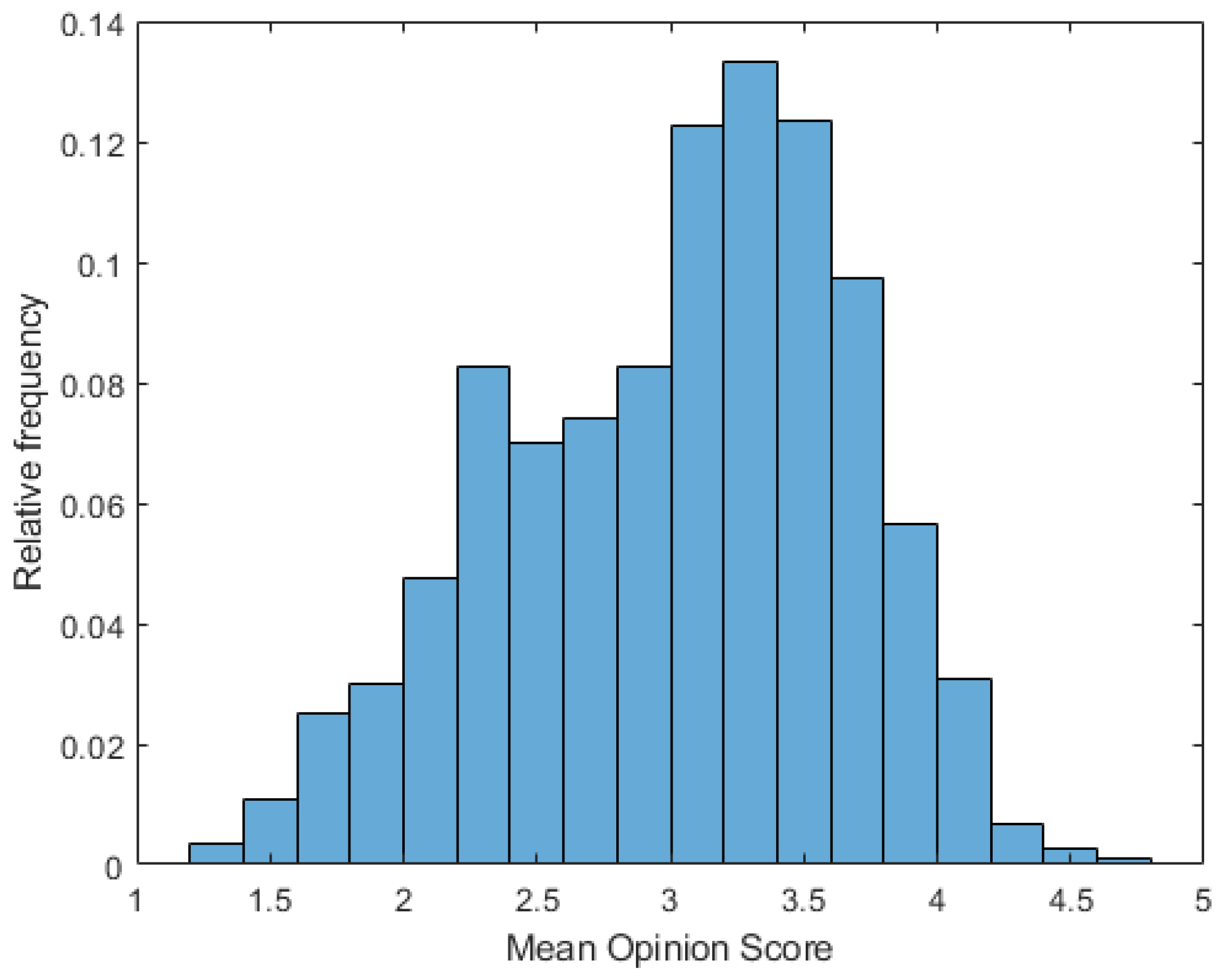
4.1. Databases
4.2. Evaluation Metrics
4.3. Evaluation Environment and Implementation Details
4.4. Parameter Study
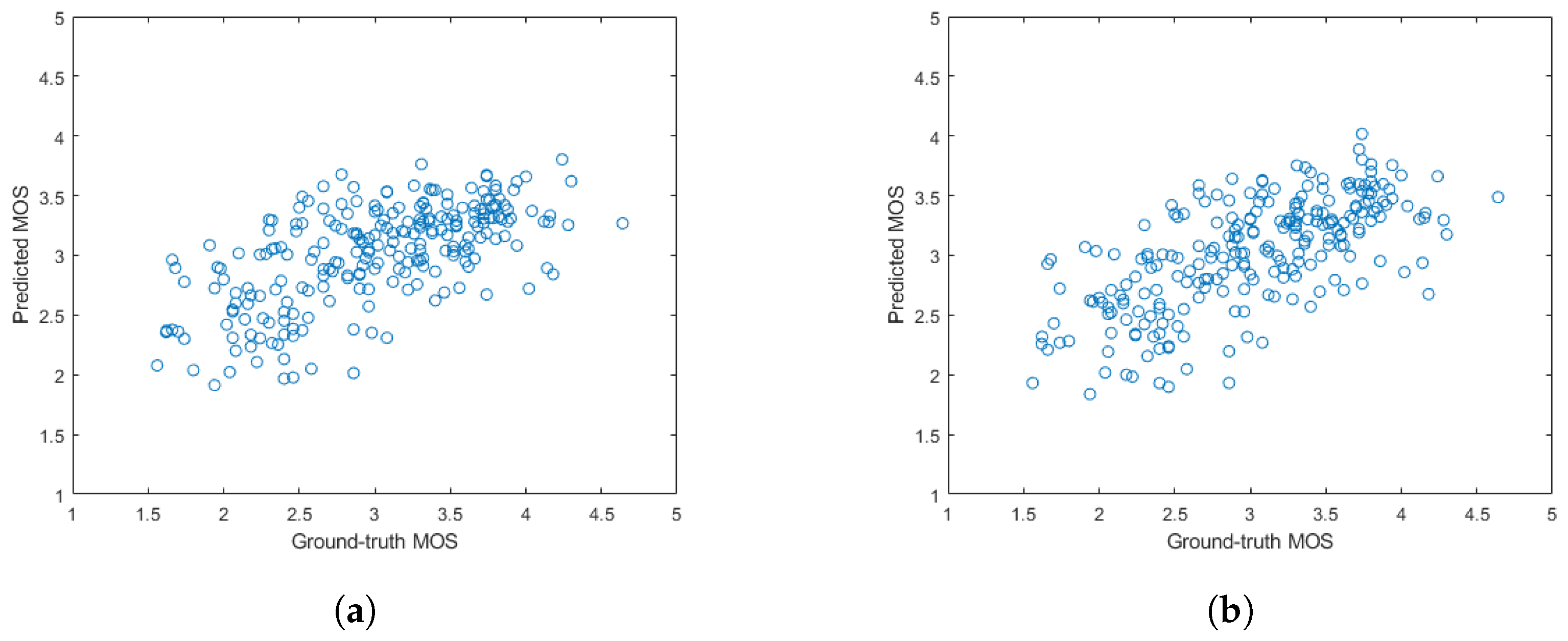
4.5. Comparison to the State-of-the-Art
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 3D | three-dimensional |
| BTR | binary tree regression |
| C | contrast |
| CF | colorfulness |
| DCF | dark channel feature |
| DCT | discrete cosine transform |
| DFT | discrete Fourier transform |
| DSLR | digital single-lens reflex |
| DWT | discrete wavelet transform |
| FDD | first-digit distribution |
| FR | full-reference |
| FR-VQA | full-reference video quality assessment |
| GCF | global contrast factor |
| GPR | Gaussian process regression |
| HOSVD | higher-order singular-value decomposition |
| JPEG | Joint Photographic Experts Group |
| LIVE | Laboratory for Image and Video Engineering |
| MOS | mean opinion score |
| MPEG | Moving Picture Experts Group |
| MSCN | mean subtracted and contrast normalized |
| NIQE | natural image quality evaluator |
| NR | no-reference |
| NR-VQA | no-reference video quality assessment |
| PC | phase congruency |
| PLCC | Pearson’s linear correlation coefficient |
| RBF | radial basis function |
| RFR | random forest regression |
| RMS | root mean square |
| RR | reduced-reference |
| RR-VQA | reduced-reference video quality assessment |
| SI | spatial information |
| SROCC | Spearman’s rank-order correlation coefficient |
| SVR | support vector regressor |
| TI | temporal information |
| VQA | video quality assessment |
| VQC | video quality challenge |
| YFCC100M | Yahoo Flickr Creative Commons 100 Million |
References
- Index, C.V.N. Cisco visual networking index: Forecast and methodology 2015–2020. In White Paper; CISCO: San Jose, CA, USA, 2015. [Google Scholar]
- Forecast, G. Cisco visual networking index: Global mobile data traffic forecast update, 2017–2022. Update 2019, 2017, 2022. [Google Scholar]
- Benford, F. The law of anomalous numbers. Proc. Am. Philos. Soc. 1938, 78, 551–572. [Google Scholar]
- Fewster, R.M. A simple explanation of Benford’s Law. Am. Stat. 2009, 63, 26–32. [Google Scholar] [CrossRef]
- Özer, G.; Babacan, B. Benford’s Law and Digital Analysis: Application on Turkish Banking Sector. Bus. Econ. Res. J. 2013, 4, 29–41. [Google Scholar] [CrossRef][Green Version]
- Hüllemann, S.; Schüpfer, G.; Mauch, J. Application of Benford’s law: A valuable tool for detecting scientific papers with fabricated data? Der Anaesthesist 2017, 66, 795–802. [Google Scholar] [CrossRef] [PubMed]
- Nye, J.; Moul, C. The political economy of numbers: On the application of Benford’s law to international macroeconomic statistics. BE J. Macroecon. 2007, 7, 1–14. [Google Scholar] [CrossRef]
- Gonzalez-Garcia, M.J.; Pastor, M.G.C. Benford’s Law and Macroeconomic Data Quality; International Monetary Fund: Washington, DC, USA, 2009. [Google Scholar]
- Rauch, B.; Göttsche, M.; Brähler, G.; Kronfeld, T. Deficit versus social statistics: Empirical evidence for the effectiveness of Benford’s law. Appl. Econ. Lett. 2014, 21, 147–151. [Google Scholar] [CrossRef]
- Jolion, J.M. Images and Benford’s law. J. Math. Imaging Vis. 2001, 14, 73–81. [Google Scholar]
- Pérez-González, F.; Heileman, G.L.; Abdallah, C.T. A generalization of Benford’s law and its application to images. In Proceedings of the 2007 European Control Conference (ECC), Kos, Greece, 2–5 July 2007; pp. 3613–3619. [Google Scholar]
- Pérez-González, F.; Heileman, G.L.; Abdallah, C.T. Benford’s law in image processing. In Proceedings of the 2007 IEEE International Conference on Image Processing, San Antonio, TX, USA, 16–19 September 2007; Volume 1, pp. 405–408. [Google Scholar]
- Fu, D.; Shi, Y.Q.; Su, W. A generalized Benford’s law for JPEG coefficients and its applications in image forensics. In Security, Steganography, and Watermarking of Multimedia Contents IX; International Society for Optics and Photonics: Bellingham, WA, USA, 2007; Volume 6505, p. 65051L. [Google Scholar]
- Andriotis, P.; Oikonomou, G.; Tryfonas, T. JPEG steganography detection with Benford’s Law. Digit. Investig. 2013, 9, 246–257. [Google Scholar] [CrossRef]
- Varga, D. Analysis of Benford’s Law for No-Reference Quality Assessment of Natural, Screen-Content, and Synthetic Images. Electronics 2021, 10, 2378. [Google Scholar] [CrossRef]
- Varga, D. No-reference image quality assessment based on the fusion of statistical and perceptual features. J. Imaging 2020, 6, 75. [Google Scholar] [CrossRef]
- Hosu, V.; Lin, H.; Saupe, D. Expertise screening in crowdsourcing image quality. In Proceedings of the 2018 Tenth International Conference on Quality of Multimedia Experience (QoMEX), Sardinia, Italy, 29–31 May 2018; pp. 1–6. [Google Scholar]
- Hoßfeld, T.; Keimel, C.; Hirth, M.; Gardlo, B.; Habigt, J.; Diepold, K.; Tran-Gia, P. Best practices for QoE crowdtesting: QoE assessment with crowdsourcing. IEEE Trans. Multimed. 2013, 16, 541–558. [Google Scholar] [CrossRef]
- ITU-R. Methodology for the Subjective Assessment of the Quality of Television Pictures; Recommendation ITU-R BT; International Telecommunication Union: Geneva, Switzerland, 2012; pp. 500–513. [Google Scholar]
- International Telecommunication Union. Methods for the Subjective Assessment of Video Quality Audio Quality and Audiovisual Quality of Internet Video and Distribution Quality Television in Any Environment; Series P: Terminals And Subjective and Objective Assessment Methods; International Telecommunication Union: Geneva, Switzerland, 2016. [Google Scholar]
- ITU-T RECOMMENDATION. Subjective Video Quality Assessment Methods for Multimedia Applications; International Telecommunication Union: Geneva, Switzerland, 1999. [Google Scholar]
- Hosu, V.; Hahn, F.; Jenadeleh, M.; Lin, H.; Men, H.; Szirányi, T.; Li, S.; Saupe, D. The Konstanz natural video database (KoNViD-1k). In Proceedings of the 2017 Ninth International Conference on Quality of Multimedia Experience (QoMEX), Erfurt, Germany, 29 May–2 June 2017; pp. 1–6. [Google Scholar]
- Sinno, Z.; Bovik, A.C. Large-scale study of perceptual video quality. IEEE Trans. Image Process. 2018, 28, 612–627. [Google Scholar] [CrossRef]
- Winkler, S. Analysis of public image and video databases for quality assessment. IEEE J. Sel. Top. Signal Process. 2012, 6, 616–625. [Google Scholar] [CrossRef]
- Okarma, K. Image and video quality assessment with the use of various verification databases. In Proceedings of the New Electrical and Electronic Technologies and their Industrial Implementation, Zakopane, Poland, 18–21 June 2013; Volume 142. [Google Scholar]
- Xu, L.; Lin, W.; Kuo, C.C.J. Visual Quality Assessment by Machine Learning; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Winkler, S.; Mohandas, P. The evolution of video quality measurement: From PSNR to hybrid metrics. IEEE Trans. Broadcast. 2008, 54, 660–668. [Google Scholar] [CrossRef]
- Argyropoulos, S.; Raake, A.; Garcia, M.N.; List, P. No-reference video quality assessment for SD and HD H. 264/AVC sequences based on continuous estimates of packet loss visibility. In Proceedings of the 2011 Third International Workshop on Quality of Multimedia Experience, Mechelen, Belgium, 7–9 September 2011; pp. 31–36. [Google Scholar]
- Keimel, C.; Habigt, J.; Klimpke, M.; Diepold, K. Design of no-reference video quality metrics with multiway partial least squares regression. In Proceedings of the 2011 Third International Workshop on Quality of Multimedia Experience, Mechelen, Belgium, 7–9 September 2011; pp. 49–54. [Google Scholar]
- Chen, Z.; Wu, D. Prediction of transmission distortion for wireless video communication: Analysis. IEEE Trans. Image Process. 2011, 21, 1123–1137. [Google Scholar] [CrossRef]
- Pandremmenou, K.; Shahid, M.; Kondi, L.P.; Lövström, B. A no-reference bitstream-based perceptual model for video quality estimation of videos affected by coding artifacts and packet losses. In Human Vision and Electronic Imaging XX; International Society for Optics and Photonics: Bellingham, WA, USA, 2015; Volume 9394, p. 93941F. [Google Scholar]
- Saad, M.A.; Bovik, A.C.; Charrier, C. Blind prediction of natural video quality. IEEE Trans. Image Process. 2014, 23, 1352–1365. [Google Scholar] [CrossRef] [PubMed]
- Zhu, K.; Li, C.; Asari, V.; Saupe, D. No-reference video quality assessment based on artifact measurement and statistical analysis. IEEE Trans. Circuits Syst. Video Technol. 2014, 25, 533–546. [Google Scholar] [CrossRef]
- Dendi, S.V.R.; Channappayya, S.S. No-reference video quality assessment using natural spatiotemporal scene statistics. IEEE Trans. Image Process. 2020, 29, 5612–5624. [Google Scholar] [CrossRef]
- Ebenezer, J.P.; Shang, Z.; Wu, Y.; Wei, H.; Bovik, A.C. No-reference video quality assessment using space-time chips. In Proceedings of the 2020 IEEE 22nd International Workshop on Multimedia Signal Processing (MMSP), Tampere, Finland, 21–24 September 2020; pp. 1–6. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ren, Y.; Yu, X.; Chen, J.; Li, T.H.; Li, G. Deep image spatial transformation for person image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7690–7699. [Google Scholar]
- Li, Y.; Po, L.M.; Cheung, C.H.; Xu, X.; Feng, L.; Yuan, F.; Cheung, K.W. No-reference video quality assessment with 3D shearlet transform and convolutional neural networks. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 1044–1057. [Google Scholar] [CrossRef]
- Ahn, S.; Lee, S. Deep blind video quality assessment based on temporal human perception. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 619–623. [Google Scholar]
- Li, D.; Jiang, T.; Jiang, M. Unified quality assessment of in-the-wild videos with mixed datasets training. Int. J. Comput. Vis. 2021, 129, 1238–1257. [Google Scholar] [CrossRef]
- Aqrawi, A.A.; Boe, T.H.; Barros, S. Detecting salt domes using a dip guided 3D Sobel seismic attribute. In SEG Technical Program Expanded Abstracts 2011; Society of Exploration Geophysicists: Tulsa, OK, USA, 2011; pp. 1014–1018. [Google Scholar]
- Weeks, M.; Bayoumi, M. 3D discrete wavelet transform architectures. In Proceedings of the 1998 IEEE International Symposium on Circuits and Systems (Cat. No. 98CH36187), ISCAS’98, Monterey, CA, USA, 31 May–3 June 1998; Volume 4, pp. 57–60. [Google Scholar]
- Heideman, M.T.; Johnson, D.H.; Burrus, C.S. Gauss and the history of the fast Fourier transform. Arch. Hist. Exact Sci. 1985, 34, 265–277. [Google Scholar] [CrossRef]
- Baranyi, P.; Varlaki, P.; Szeidl, L.; Yam, Y. Definition of the HOSVD based canonical form of polytopic dynamic models. In Proceedings of the 2006 IEEE International Conference on Mechatronics, Budapest, Hungary, 3–5 July 2006; pp. 660–665. [Google Scholar]
- Tucker, L.R. The extension of factor analysis to three-dimensional matrices. Contrib. Math. Psychol. 1964, 110119. [Google Scholar]
- De Lathauwer, L.; De Moor, B.; Vandewalle, J. A multilinear singular value decomposition. SIAM J. Matrix Anal. Appl. 2000, 21, 1253–1278. [Google Scholar] [CrossRef]
- Jenadeleh, M. Blind Image and Video Quality Assessment. Ph.D. Thesis, University of Konstanz, Konstanz, Germany, 2018. [Google Scholar]
- Crete, F.; Dolmiere, T.; Ladret, P.; Nicolas, M. The blur effect: Perception and estimation with a new no-reference perceptual blur metric. In Human Vision and Electronic Imaging XII; International Society for Optics and Photonics: Bellingham, WA, USA, 2007; Volume 6492, p. 64920I. [Google Scholar]
- de Ridder, H. Naturalness and image quality: Saturation and lightness variation in color images of natural scenes. J. Imaging Sci. Technol. 1996, 40, 487–493. [Google Scholar]
- Palus, H. Colorfulness of the image: Definition, computation, and properties. In Lightmetry and Light and Optics in Biomedicine 2004; International Society for Optics and Photonics: Bellingham, WA, USA, 2006; Volume 6158, p. 615805. [Google Scholar]
- Hasler, D.; Suesstrunk, S.E. Measuring colorfulness in natural images. In Human Vision and Electronic Imaging VIII; International Society for Optics and Photonics: Bellingham, WA, USA, 2003; Volume 5007, pp. 87–95. [Google Scholar]
- Segler, D.; Pettitt, G.; van Kessel, P. The importance of contrast and its effect on image quality. SMPTE Motion Imaging J. 2002, 111, 533–540. [Google Scholar] [CrossRef]
- Matkovic, K.; Neumann, L.; Neumann, A.; Psik, T.; Purgathofer, W. Global Contrast Factor-a New Approach to Image Contrast; The Eurographics Association: Geneve, Switzerland, 2005; pp. 159–167. [Google Scholar]
- Peli, E. Contrast in complex images. JOSA A 1990, 7, 2032–2040. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Lee, S.; Yun, S.; Nam, J.H.; Won, C.S.; Jung, S.W. A review on dark channel prior based image dehazing algorithms. EURASIP J. Image Video Process. 2016, 2016, 1–23. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Kovesi, P. Phase congruency detects corners and edges. In Proceedings of the Australian Pattern Recognition Society Conference, DICTA, Sydney, Australia, 10–12 December 2003; Volume 2003. [Google Scholar]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Thomee, B.; Shamma, D.A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Borth, D.; Li, L.J. YFCC100M: The new data in multimedia research. Commun. ACM 2016, 59, 64–73. [Google Scholar] [CrossRef]
- Saupe, D.; Hahn, F.; Hosu, V.; Zingman, I.; Rana, M.; Li, S. Crowd workers proven useful: A comparative study of subjective video quality assessment. In Proceedings of the 8th International Conference on Quality of Multimedia Experience, QoMEX 2016, Lisbon, Portugal, 6–8 June 2016. [Google Scholar]
- Rohaly, A.M.; Corriveau, P.J.; Libert, J.M.; Webster, A.A.; Baroncini, V.; Beerends, J.; Blin, J.L.; Contin, L.; Hamada, T.; Harrison, D.; et al. Video quality experts group: Current results and future directions. In Visual Communications and Image Processing 2000; International Society for Optics and Photonics: Bellingham, WA, USA, 2000; Volume 4067, pp. 742–753. [Google Scholar]
- Mittal, A. Natural Scene Statistics-Based Blind Visual Quality Assessment in the Spatial Domain. Ph.D. Thesis, The University of Texas at Austin, Austin, TX, USA, 2013. [Google Scholar]
- Mittal, A.; Saad, M.A.; Bovik, A.C. A completely blind video integrity oracle. IEEE Trans. Image Process. 2015, 25, 289–300. [Google Scholar] [CrossRef] [PubMed]
- Men, H.; Lin, H.; Saupe, D. Spatiotemporal feature combination model for no-reference video quality assessment. In Proceedings of the 2018 Tenth international conference on quality of multimedia experience (QoMEX), Sardinia, Italy, 29–31 May 2018; pp. 1–3. [Google Scholar]
- Yan, P.; Mou, X. No-reference video quality assessment based on perceptual features extracted from multi-directional video spatiotemporal slices images. In Optoelectronic Imaging and Multimedia Technology V; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10817, p. 108171D. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.309 | 0.183 | 0.121 | 0.096 | 0.093 | 0.059 | 0.052 | 0.046 | 0.041 | 0.004 | |
| 0.313 | 0.180 | 0.121 | 0.099 | 0.089 | 0.059 | 0.050 | 0.046 | 0.043 | 0.004 | |
| 0.316 | 0.180 | 0.121 | 0.099 | 0.090 | 0.058 | 0.049 | 0.045 | 0.043 | 0.004 | |
| 0.322 | 0.177 | 0.118 | 0.098 | 0.096 | 0.056 | 0.046 | 0.043 | 0.043 | 0.008 | |
| 0.331 | 0.173 | 0.114 | 0.098 | 0.102 | 0.054 | 0.043 | 0.042 | 0.044 | 0.014 | |
| Benford’s law | 0.301 | 0.176 | 0.125 | 0.097 | 0.079 | 0.067 | 0.058 | 0.051 | 0.046 | 0 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.308 | 0.184 | 0.119 | 0.096 | 0.096 | 0.059 | 0.052 | 0.046 | 0.041 | 0.005 | |
| 0.308 | 0.186 | 0.120 | 0.098 | 0.092 | 0.059 | 0.050 | 0.045 | 0.042 | 0.005 | |
| 0.313 | 0.183 | 0.120 | 0.098 | 0.093 | 0.058 | 0.048 | 0.044 | 0.042 | 0.006 | |
| 0.322 | 0.178 | 0.116 | 0.097 | 0.101 | 0.055 | 0.046 | 0.042 | 0.042 | 0.011 | |
| 0.328 | 0.173 | 0.113 | 0.098 | 0.108 | 0.053 | 0.044 | 0.041 | 0.043 | 0.016 | |
| Benford’s law | 0.301 | 0.176 | 0.125 | 0.097 | 0.079 | 0.067 | 0.058 | 0.051 | 0.046 | 0 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.294 | 0.187 | 0.152 | 0.077 | 0.040 | 0.044 | 0.142 | 0.033 | 0.032 | 0.097 | |
| 0.306 | 0.156 | 0.186 | 0.068 | 0.045 | 0.046 | 0.139 | 0.029 | 0.026 | 0.114 | |
| 0.306 | 0.154 | 0.193 | 0.066 | 0.039 | 0.045 | 0.146 | 0.027 | 0.024 | 0.139 | |
| 0.289 | 0.157 | 0.198 | 0.070 | 0.038 | 0.053 | 0.150 | 0.025 | 0.020 | 0.148 | |
| 0.280 | 0.158 | 0.200 | 0.077 | 0.036 | 0.059 | 0.149 | 0.023 | 0.016 | 0.156 | |
| Benford’s law | 0.301 | 0.176 | 0.125 | 0.097 | 0.079 | 0.067 | 0.058 | 0.051 | 0.046 | 0 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.266 | 0.144 | 0.196 | 0.067 | 0.056 | 0.033 | 0.184 | 0.039 | 0.017 | 0.191 | |
| 0.257 | 0.134 | 0.259 | 0.066 | 0.052 | 0.030 | 0.158 | 0.032 | 0.012 | 0.233 | |
| 0.243 | 0.127 | 0.288 | 0.065 | 0.048 | 0.030 | 0.161 | 0.032 | 0.011 | 0.281 | |
| 0.244 | 0.112 | 0.312 | 0.051 | 0.048 | 0.027 | 0.157 | 0.040 | 0.009 | 0.327 | |
| 0.235 | 0.099 | 0.337 | 0.046 | 0.048 | 0.028 | 0.154 | 0.044 | 0.009 | 0.370 | |
| Benford’s law | 0.301 | 0.176 | 0.125 | 0.097 | 0.079 | 0.067 | 0.058 | 0.051 | 0.046 | 0 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.306 | 0.170 | 0.120 | 0.095 | 0.079 | 0.069 | 0.060 | 0.053 | 0.048 | ||
| 0.302 | 0.173 | 0.123 | 0.097 | 0.080 | 0.068 | 0.059 | 0.052 | 0.047 | ||
| 0.294 | 0.172 | 0.125 | 0.100 | 0.082 | 0.069 | 0.060 | 0.052 | 0.046 | ||
| 0.288 | 0.172 | 0.128 | 0.102 | 0.084 | 0.070 | 0.060 | 0.052 | 0.045 | 0.001 | |
| 0.287 | 0.177 | 0.131 | 0.102 | 0.083 | 0.068 | 0.058 | 0.050 | 0.044 | 0.0011 | |
| Benford’s law | 0.301 | 0.176 | 0.125 | 0.097 | 0.079 | 0.067 | 0.058 | 0.051 | 0.046 | 0 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.305 | 0.174 | 0.123 | 0.096 | 0.079 | 0.067 | 0.059 | 0.052 | 0.047 | ||
| 0.302 | 0.175 | 0.124 | 0.097 | 0.079 | 0.067 | 0.059 | 0.052 | 0.046 | ||
| 0.298 | 0.174 | 0.125 | 0.098 | 0.081 | 0.068 | 0.059 | 0.052 | 0.046 | ||
| 0.295 | 0.174 | 0.126 | 0.099 | 0.081 | 0.069 | 0.059 | 0.052 | 0.046 | ||
| 0.294 | 0.176 | 0.128 | 0.100 | 0.081 | 0.068 | 0.058 | 0.051 | 0.045 | ||
| Benford’s law | 0.301 | 0.176 | 0.125 | 0.097 | 0.079 | 0.067 | 0.058 | 0.051 | 0.046 | 0 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.303 | 0.175 | 0.124 | 0.096 | 0.079 | 0.067 | 0.058 | 0.052 | 0.046 | ||
| 0.300 | 0.174 | 0.125 | 0.097 | 0.080 | 0.068 | 0.059 | 0.052 | 0.046 | ||
| 0.297 | 0.174 | 0.125 | 0.098 | 0.081 | 0.068 | 0.059 | 0.052 | 0.046 | ||
| 0.295 | 0.175 | 0.125 | 0.098 | 0.081 | 0.068 | 0.058 | 0.051 | 0.045 | ||
| 0.295 | 0.177 | 0.128 | 0.099 | 0.081 | 0.068 | 0.058 | 0.051 | 0.045 | ||
| Benford’s law | 0.301 | 0.176 | 0.125 | 0.097 | 0.079 | 0.067 | 0.058 | 0.051 | 0.046 | 0 |
| Blur | CF | Contrast | DCF | Entropy | PC | SI | TI | NIQE | |
|---|---|---|---|---|---|---|---|---|---|
| 0.309 | 0.229 | 0.211 | 0.197 | 7.027 | 0.019 | 83.478 | 0.034 | 3.745 | |
| 0.371 | 0.196 | 0.223 | 0.244 | 7.103 | 0.017 | 70.850 | 0.067 | 3.802 | |
| 0.423 | 0.193 | 0.226 | 0.223 | 6.800 | 0.013 | 59.306 | 0.081 | 4.163 | |
| 0.458 | 0.198 | 0.188 | 0.153 | 6.260 | 0.007 | 42.072 | 0.077 | 4.888 | |
| 0.451 | 0.213 | 0.158 | 0.098 | 5.577 | 0.007 | 34.056 | 0.081 | 5.356 |
| Attribute | KoNViD-1k [22] | LIVE VQC [23] |
|---|---|---|
| Year | 2017 | 2018 |
| No. of sequences | 1200 | 585 |
| No. of scenes | 1200 | 585 |
| No. of devices | N/A | 101 |
| Device types | DSLR | smartphone |
| Distortion type | authentic | authentic |
| Duration | ∼8 s | ∼10 s |
| Resolution | – | |
| Frame rate | 30 | N/A |
| Format | MPEG-4 | N/A |
| Rating per video | 50 | 200 |
| MOS range | 1.0–5.0 | 0.0–100.0 |
| Computer model | STRIX Z270H Gaming |
| CPU | Intel(R) Core(TM) i7-7700K CPU 4.20 GHz (8 cores) |
| Memory | 15 GB |
| GPU | Nvidia GeForce GTX 1080 |
| Feature Vector | Linear SVR | RBF-SVR | GPR | BTR | RFR |
|---|---|---|---|---|---|
| FDD of X directional gradient magnitudes | 0.402 | 0.419 | 0.432 | 0.223 | 0.218 |
| FDD of Y directional gradient magnitudes | 0.436 | 0.409 | 0.486 | 0.213 | 0.238 |
| FDD of Z directional gradient magnitudes | 0.394 | 0.359 | 0.386 | 0.206 | 0.183 |
| FDD of HLL wavelet coefficients | 0.320 | 0.302 | 0.347 | 0.152 | 0.171 |
| FDD of LHL wavelet coefficients | 0.279 | 0.382 | 0.412 | 0.201 | 0.202 |
| FDD of HHL wavelet coefficients | 0.425 | 0.493 | 0.503 | 0.323 | 0.328 |
| FDD of LLH wavelet coefficients | 0.338 | 0.387 | 0.414 | 0.220 | 0.237 |
| FDD of HLH wavelet coefficients | 0.347 | 0.394 | 0.421 | 0.237 | 0.250 |
| FDD of LHH wavelet coefficients | 0.316 | 0.412 | 0.428 | 0.229 | 0.246 |
| FDD of HHH wavelet coefficients | 0.449 | 0.479 | 0.498 | 0.323 | 0.304 |
| FDD of 3D DFT coefficients | 0.136 | 0.218 | 0.203 | 0.092 | 0.090 |
| FDD of 3D DCT coefficients | 0.135 | 0.190 | 0.207 | 0.132 | 0.092 |
| FDD of higher-order singular values | 0.156 | 0.117 | 0.144 | 0.097 | 0.091 |
| Perceptual features | 0.626 | 0.675 | 0.686 | 0.488 | 0.502 |
| All FDDs | 0.617 | 0.588 | 0.640 | 0.363 | 0.401 |
| All FDDs + Perceptual | 0.676 | 0.661 | 0.711 | 0.472 | 0.52 |
| Method | PLCC | SROCC |
|---|---|---|
| NVIE [64] | 0.404 | 0.333 |
| V.BLIINDS [32] | 0.661 | 0.694 |
| VIIDEO [65] | 0.301 | 0.299 |
| 3D-MSCN [34] | 0.401 | 0.370 |
| ST-Gabor [34] | 0.639 | 0.628 |
| 3D-MSCN + ST-Gabor [34] | 0.653 | 0.640 |
| FC Model [66] | 0.492 | 0.472 |
| STFC Model [66] | 0.639 | 0.606 |
| STS-SVR [67] | 0.680 | 0.673 |
| STS-MLP [67] | 0.407 | 0.420 |
| ChipQA [35] | 0.697 | 0.694 |
| FDD-VQA | 0.654 | 0.640 |
| FDD + Perceptual-VQA | 0.716 | 0.711 |
| Method | PLCC | SROCC |
|---|---|---|
| NVIE [64] | 0.447 | 0.459 |
| V.BLIINDS [32] | 0.690 | 0.703 |
| VIIDEO [65] | −0.006 | −0.034 |
| 3D-MSCN [34] | 0.502 | 0.510 |
| ST-Gabor [34] | 0.591 | 0.599 |
| 3D-MSCN + ST-Gabor [34] | 0.675 | 0.677 |
| FC Model [66] | - | - |
| STFC Model [66] | - | - |
| STS-SVR [67] | - | - |
| STS-MLP [67] | - | - |
| ChipQA [35] | 0.669 | 0.697 |
| FDD-VQA | 0.623 | 0.630 |
| FDD + Perceptual-VQA | 0.694 | 0.705 |
| NVIE | V.BLIINDS | VIIDEO | 3D-MSCN | ST-Gabor | 3D-MSCN + ST-Gabor | FDD + Perceptual-VQA | |
|---|---|---|---|---|---|---|---|
| NVIE | - | 1 | |||||
| V.BLIINDS | 1 | - | 1 | 1 | 1 | 1 | |
| VIIDEO | - | ||||||
| 3D-MSCN | 1 | 1 | - | ||||
| ST-Gabor | 1 | 1 | 1 | - | |||
| 3D-MSCN + ST-Gabor | 1 | 1 | 1 | 1 | - | ||
| FDD + Perceptual-VQA | 1 | 1 | 1 | 1 | 1 | 1 | - |
| NVIE | V.BLIINDS | VIIDEO | 3D-MSCN | ST-Gabor | 3D-MSCN + ST-Gabor | FDD + Perceptual-VQA | |
|---|---|---|---|---|---|---|---|
| NVIE | - | 1 | |||||
| V.BLIINDS | 1 | - | 1 | 1 | 1 | 1 | 0 |
| VIIDEO | - | ||||||
| 3D-MSCN | 1 | 1 | 1 | - | |||
| ST-Gabor | 1 | 1 | 1 | - | |||
| 3D-MSCN + ST-Gabor | 1 | 1 | 1 | 1 | - | ||
| FDD + Perceptual-VQA | 1 | 0 | 1 | 1 | 1 | 1 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Varga, D. No-Reference Video Quality Assessment Based on Benford’s Law and Perceptual Features. Electronics 2021, 10, 2768. https://doi.org/10.3390/electronics10222768
Varga D. No-Reference Video Quality Assessment Based on Benford’s Law and Perceptual Features. Electronics. 2021; 10(22):2768. https://doi.org/10.3390/electronics10222768
Chicago/Turabian StyleVarga, Domonkos. 2021. "No-Reference Video Quality Assessment Based on Benford’s Law and Perceptual Features" Electronics 10, no. 22: 2768. https://doi.org/10.3390/electronics10222768
APA StyleVarga, D. (2021). No-Reference Video Quality Assessment Based on Benford’s Law and Perceptual Features. Electronics, 10(22), 2768. https://doi.org/10.3390/electronics10222768