
Feature-Based Interpretation of the Deep Neural Network


Abstract
:1. Introduction
2. Related Works
2.1. Rule Extraction from Neural Networks
2.2. Neural Networks Explanation
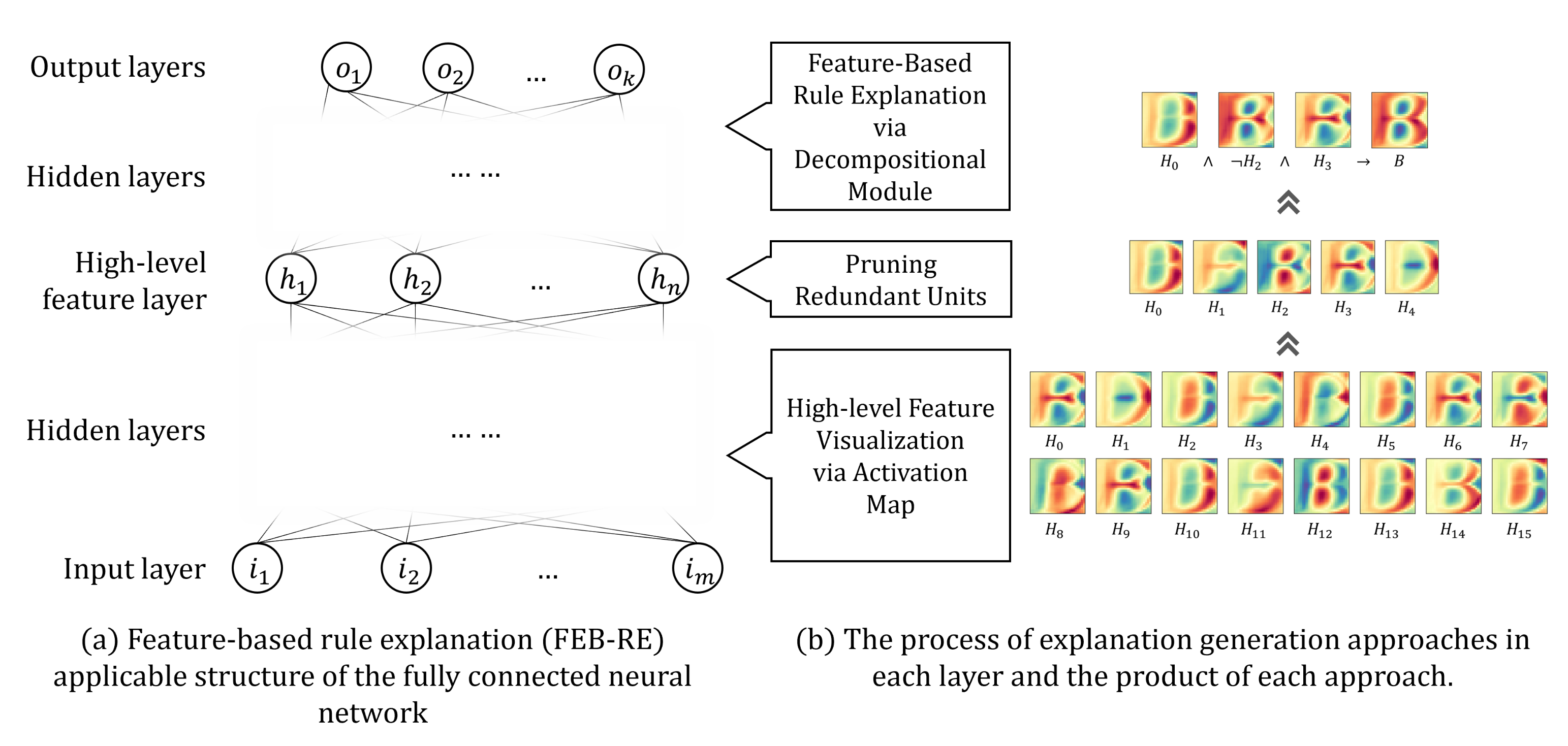
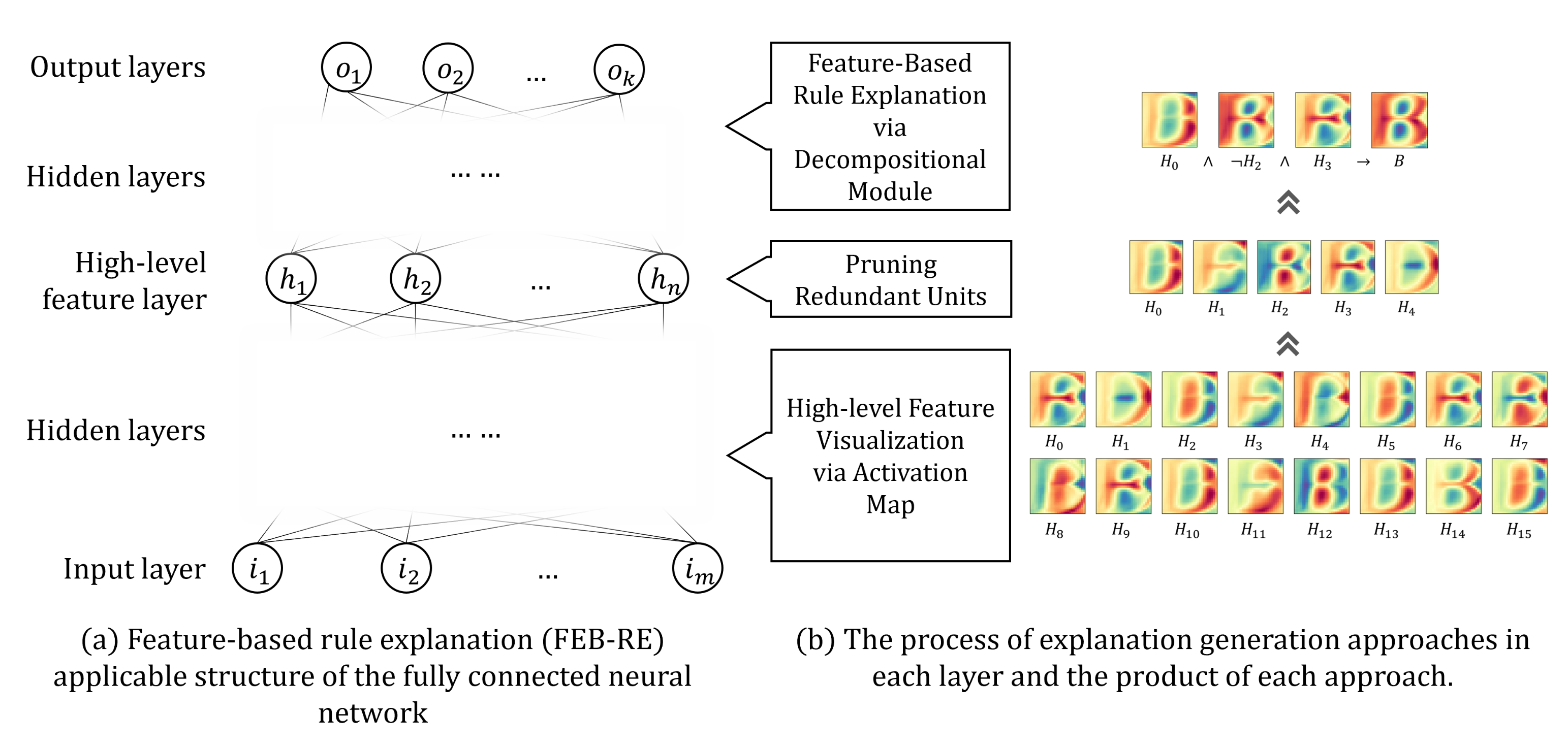
3. Feature-Based Rule Explanation
- Training a fully connected neural network using datasets.
- Defining one of the hidden layers to analyze the high-level features as a high-level feature layer. We assume that each hidden unit of the high-level feature layer has learned one high-level feature. After that obtaining the input units (low-level features) that activate the high-level feature unit.
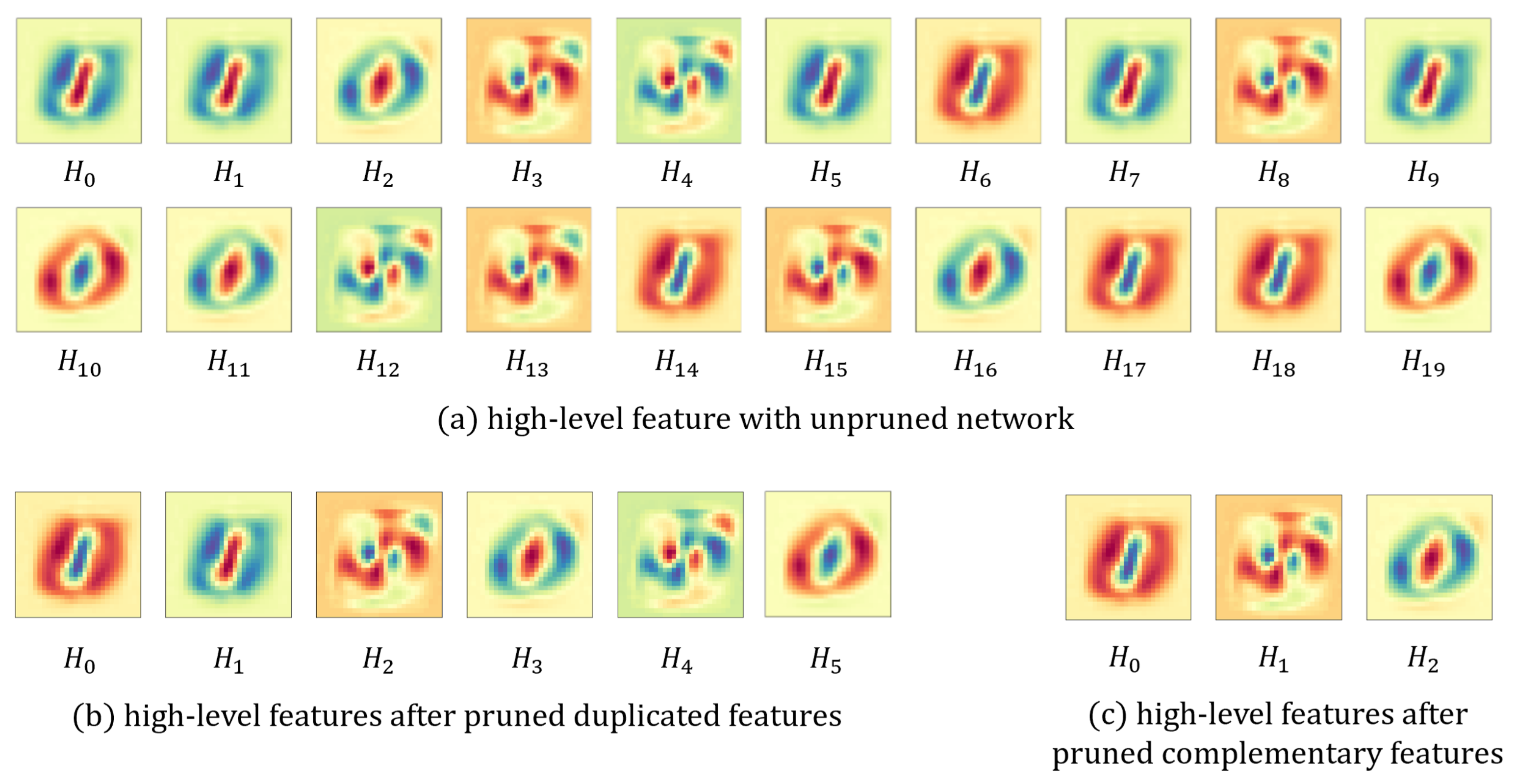
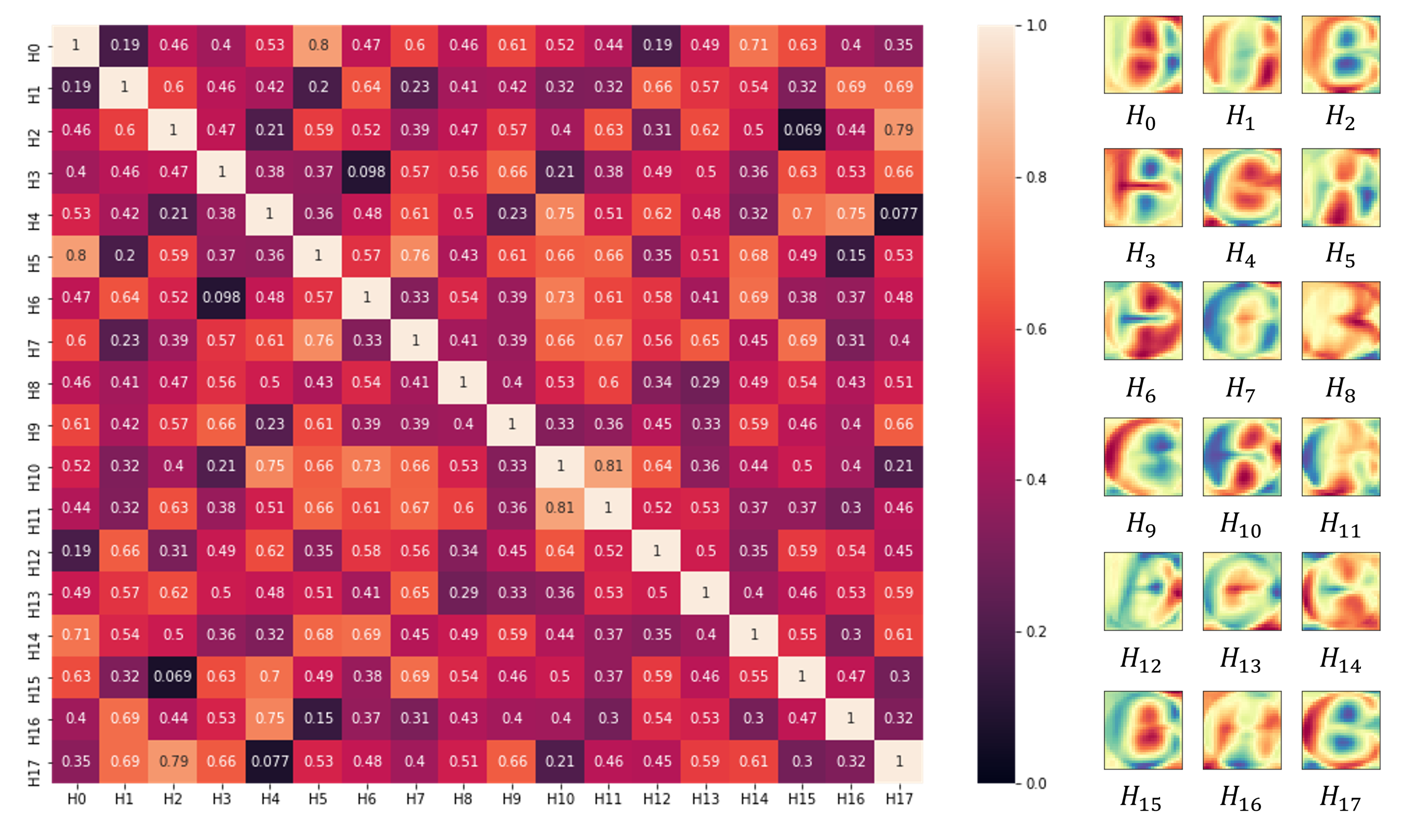
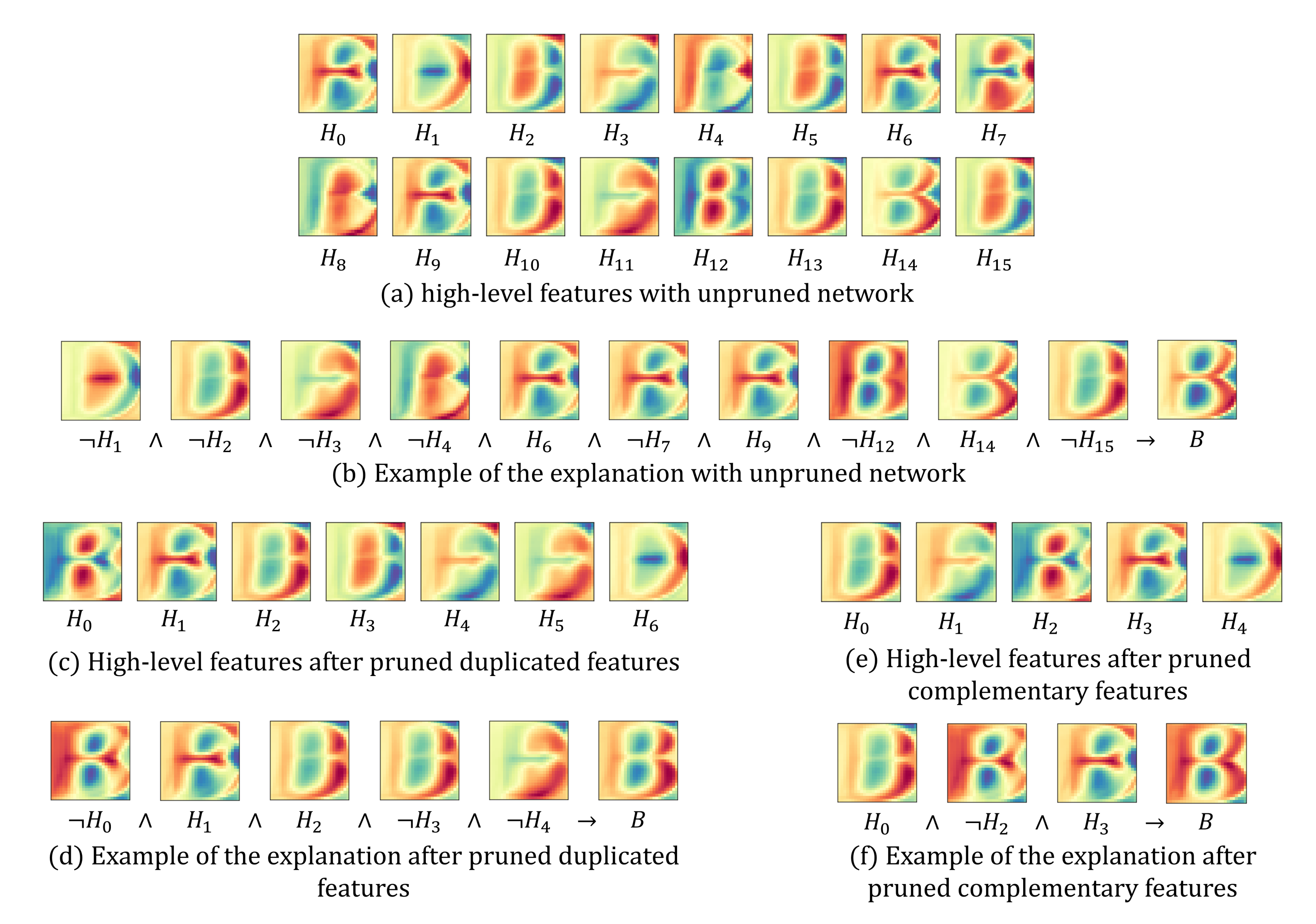
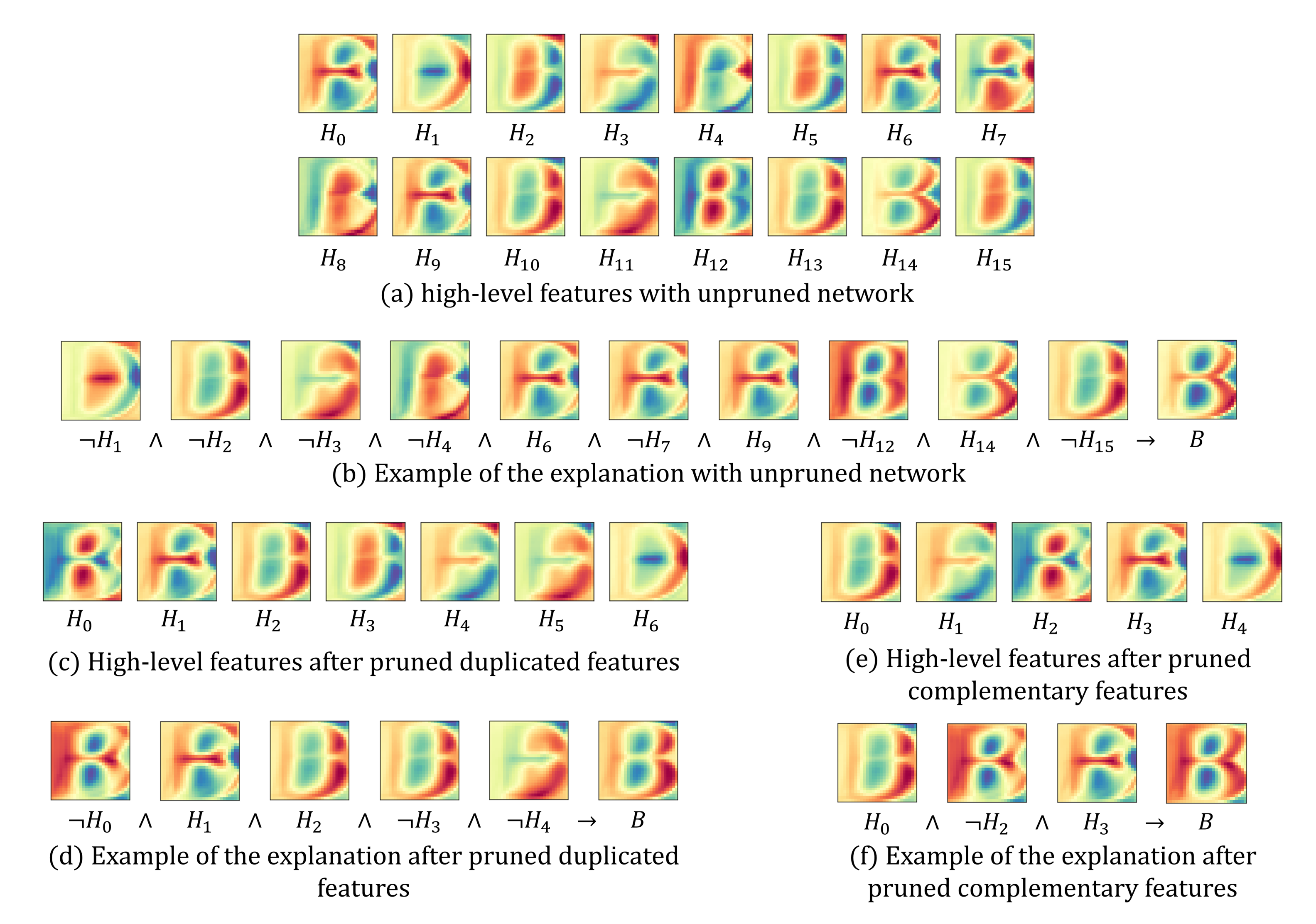
- Applying network pruning to the high-level feature layer. If there are unnecessary units in the layer, it becomes an obstacle to generating a concise explanation of the network and also increases the computation cost.
- Obtaining a ruleset to activate the output layer using the pruned high-level features based on the decompositional approach. The generated explanation reveals how the entire neural network works by if-then rulesets through visualized high-level features.
3.1. Neural Network Structure
3.2. High-Level Feature Visualization via an Activation Map
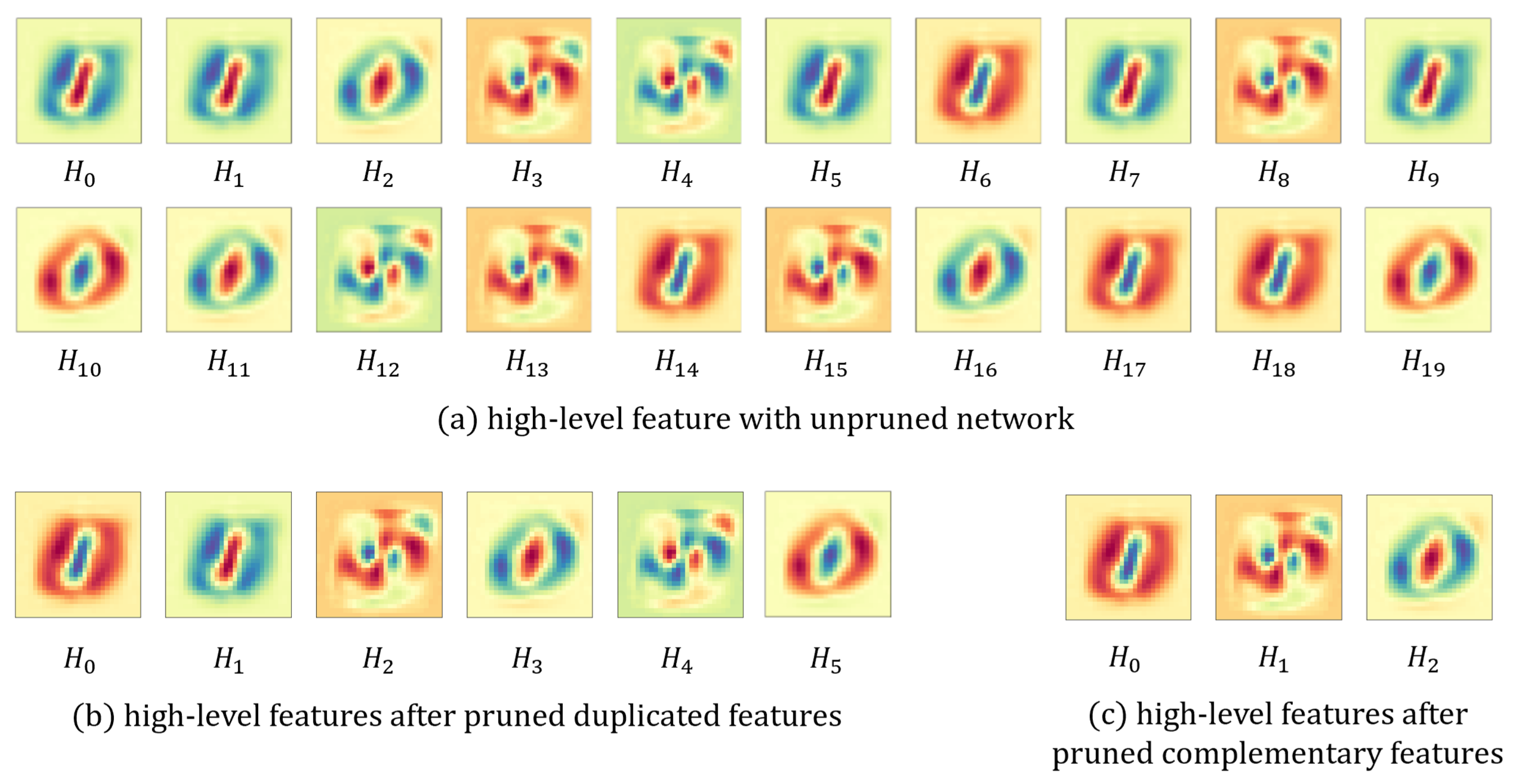
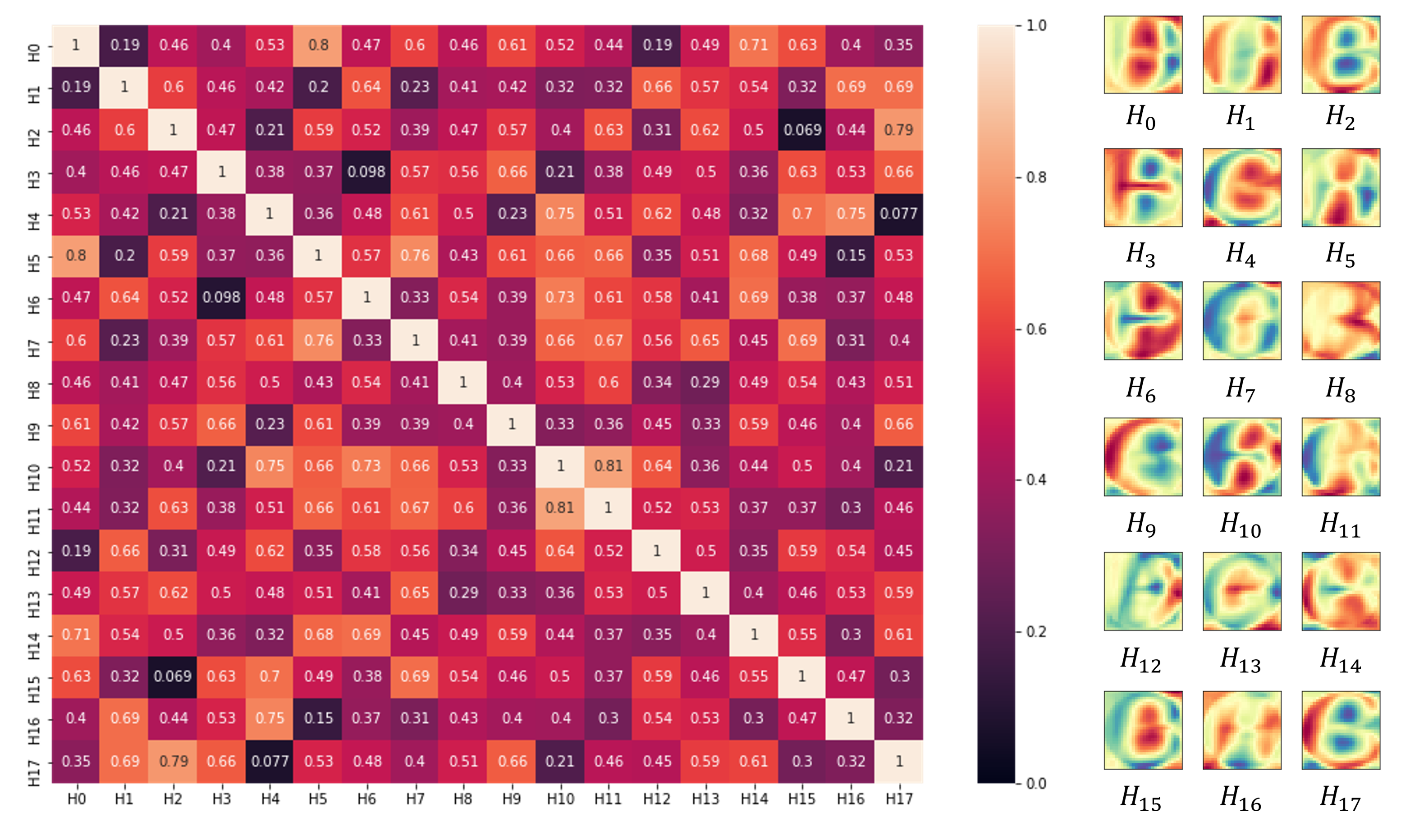
3.3. Pruning Redundant Units
3.4. Feature-Based Rule Explanation via the Decompositional Module
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Metrics
5. Results
5.1. Effects of Pruning Network
5.2. Quantitative Analysis of Explanation
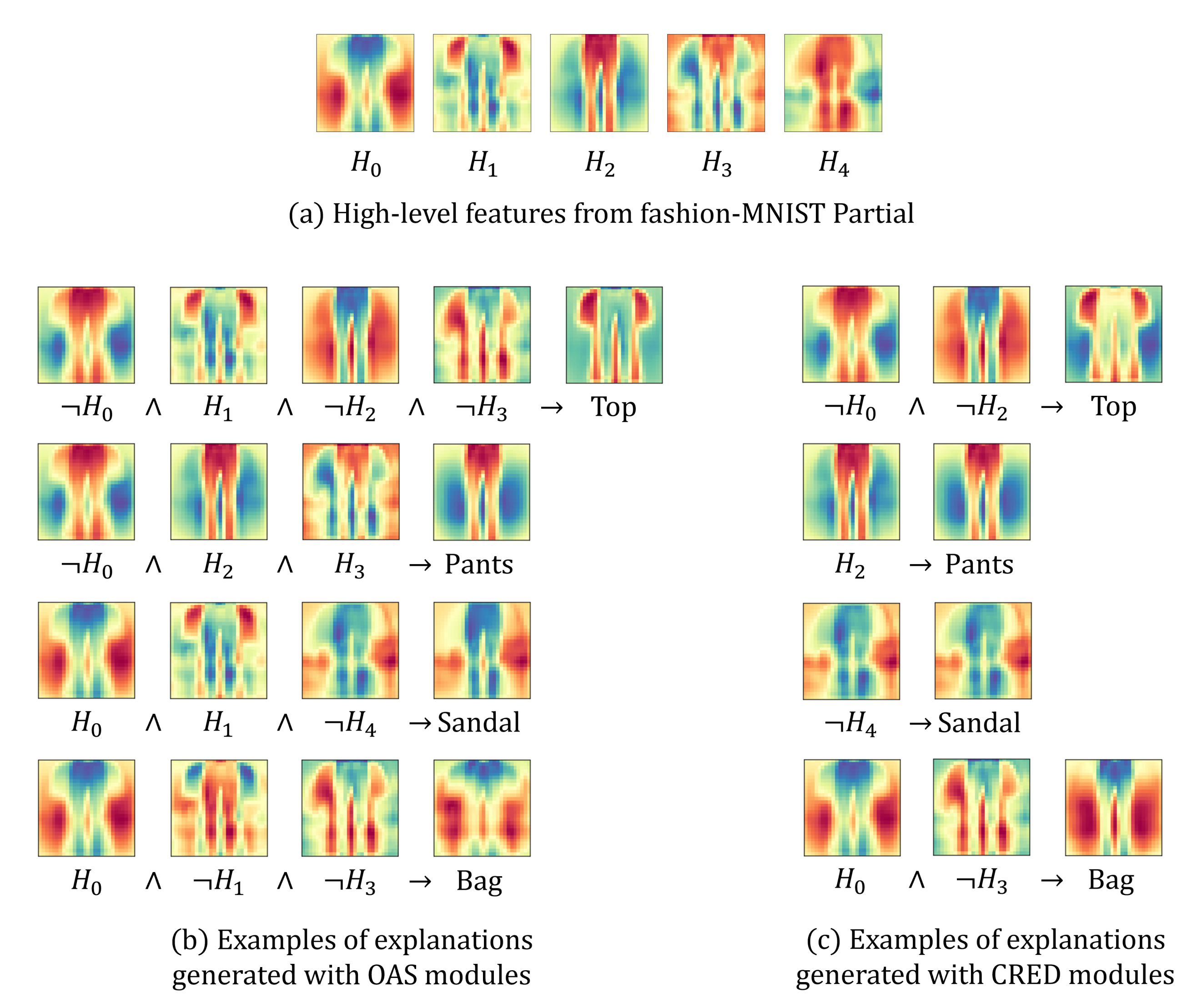
5.3. Qualitative Analysis of Explanation
5.4. Comparison of OAS and CRED
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| XAI | Explainable Artificial Intelligence |
| DNF | Disjunctive Normal Form |
| OAS | Ordered-Attribute Search |
| CRED | Continuous/discrete Rule Extractor via Decision tree induction |
| FEB-RE | Feature-based Rule Explanation |
| ReLU | Rectified Linear Unit |
| ELU | Exponential Linear Unit |
Appendix A. Explanations on Full Dataset

References
- Hinton, G.E.; Sejnowski, T.J. Learning and relearning in Boltzmann machines. Parallel Distrib. Process. Explor. Microstruct. Cogn. 1986, 1, 2. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Marcus, G. Deep learning: A critical appraisal. arXiv 2018, arXiv:1801.00631. [Google Scholar]
- Andrews, R.; Diederich, J.; Tickle, A.B. Survey and critique of techniques for extracting rules from trained artificial neural networks. Knowl.-Based Syst. 1995, 8, 373–389. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. (CSUR) 2018, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Buhrmester, V.; Münch, D.; Arens, M. Analysis of explainers of black box deep neural networks for computer vision: A survey. arXiv 2019, arXiv:1911.12116. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June 2016; pp. 2921–2929. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; PMLR: Lille, France, 2015; pp. 2048–2057. [Google Scholar]
- Hailesilassie, T. Rule extraction algorithm for deep neural networks: A review. arXiv 2016, arXiv:1610.05267. [Google Scholar]
- Taha, I.A.; Ghosh, J. Symbolic interpretation of artificial neural networks. IEEE Trans. Knowl. Data Eng. 1999, 11, 448–463. [Google Scholar] [CrossRef]
- Thrun, S. Extracting rules from artificial neural networks with distributed representations. Adv. Neural Inf. Process. Syst. 1995, 7, 505–512. [Google Scholar]
- Fu, L. Rule generation from neural networks. IEEE Trans. Syst. Man Cybern. 1994, 24, 1114–1124. [Google Scholar]
- Kim, H. Computationally efficient heuristics for if-then rule extraction from feed-forward neural networks. In Proceedings of the International Conference on Discovery Science, Kyoto, Japan, 4–6 December 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 170–182. [Google Scholar]
- Sato, M.; Tsukimoto, H. Rule extraction from neural networks via decision tree induction. In Proceedings of the IJCNN’01. International Joint Conference on Neural Networks. Proceedings (Cat. No. 01CH37222), Washington, DC, USA, 15–19 July 2001; Volume 3, pp. 1870–1875. [Google Scholar]
- Lee, H.; Kim, H. Uncertainty of Rules Extracted from Artificial Neural Networks. Appl. Artif. Intell. 2021, 35, 1–16. [Google Scholar] [CrossRef]
- Zilke, J.R.; Mencía, E.L.; Janssen, F. Deepred–rule extraction from deep neural networks. In Proceedings of the International Conference on Discovery Science, Bari, Italy, 19–21 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 457–473. [Google Scholar]
- Lee, E.H.; Kim, H. Bottom-up Approach of Rule Rewriting in Neural Network Rule Extraction. In Proceedings of the Korea Information Processing Society Conference; Korea Information Processing Society: Seoul, Korea, 2018; pp. 916–919. [Google Scholar]
- Setiono, R.; Leow, W.K. FERNN: An algorithm for fast extraction of rules from neural networks. Appl. Intell. 2000, 12, 15–25. [Google Scholar] [CrossRef]
- Lu, H.; Setiono, R.; Liu, H. Effective data mining using neural networks. IEEE Trans. Knowl. Data Eng. 1996, 8, 957–961. [Google Scholar]
- Shahroudnejad, A. A survey on understanding, visualizations, and explanation of deep neural networks. arXiv 2021, arXiv:2102.01792. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tsukimoto, H. Extracting rules from trained neural networks. IEEE Trans. Neural Netw. 2000, 11, 377–389. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Freedman, D.; Pisani, R.; Purves, R. Statistics; WW Norton & Company: New York, NY, USA, 2007. [Google Scholar]
- Augasta, M.G.; Kathirvalavakumar, T. Reverse engineering the neural networks for rule extraction in classification problems. Neural Process. Lett. 2012, 35, 131–150. [Google Scholar] [CrossRef]
- Towell, G.G.; Shavlik, J.W. Extracting refined rules from knowledge-based neural networks. Mach. Learn. 1993, 13, 71–101. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Cortes, C. MNIST Handwritten Digit Database. 2010. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 3 September 2021).
- Bulatov, Y. Notmnist Dataset. Google (Books/OCR). 2011. Available online: http://yaroslavvb.blogspot.it/2011/09/notmnist-dataset.html (accessed on 3 September 2021).
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Quinlan, J.R. C4. 5: Programs for Machine Learning; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Vedaldi, A.; Soatto, S. Quick shift and kernel methods for mode seeking. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 705–718. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train Instance | Test Instance | Features | Categories |
|---|---|---|---|---|
| MNIST partial | 23,937 | 3981 | 784 (28 × 28) | 4 |
| MNIST Full | 60,000 | 10,000 | 784 (28 × 28) | 10 |
| notMNIST partial | 5992 | 1498 | 784 (28 × 28) | 4 |
| notMNIST Full | 18,724 | 3744 | 784 (28 × 28) | 10 |
| Fashion-MNIST partial | 24,000 | 4000 | 784 (28 × 28) | 4 |
| Fashion-MNIST Full | 60,000 | 10,000 | 784 (28 × 28) | 10 |
| Dataset | MNIST Full | notMNIST Full | Fashion-MINST Full | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Threshold | # of features | Training accuracy | Test accuracy | # of features | Training accuracy | Test accuracy | # of features | Training accuracy | Test accuracy |
| unpruned | 50 | 99.70 | 97.90 | 50 | 98.10 | 97.36 | 50 | 93.32 | 88.98 |
| 0.95 | 34 | 99.69 | 96.81 | 31 | 97.77 | 97.08 | 38 | 90.5 | 86.91 |
| 0.9 | 18 | 97.68 | 95.6 | 18 | 96.77 | 95.86 | 20 | 86.97 | 83.56 |
| 0.85 | 15 | 97.46 | 95.17 | 14 | 96.32 | 94.75 | 17 | 86.26 | 82.87 |
| 0.8 | 13 | 97.21 | 94.67 | 12 | 95.35 | 94.4 | 15 | 84.66 | 81.59 |
| 0.75 | 10 | 95.74 | 92.35 | 10 | 93.16 | 91.32 | 12 | 82.02 | 79.29 |
| Dataset | Model | # of High- Level Features | Training Accuracy | Test Accuracy | # of Exps |
|---|---|---|---|---|---|
| MNIST Full | unpruned | 50 | 99.70 | 97.90 | - |
| pruned duplicate | 18 | 97.68 | 95.60 | 335 | |
| pruned complement | 16 | 92.18 | 90.68 | 78 | |
| pruned+retrained | 16 | 99.72 | 97.75 | 70 | |
| notMNIST Full | unpruned | 50 | 98.10 | 97.36 | - |
| pruned duplicate | 18 | 96.77 | 95.86 | 737 | |
| pruned complement | 15 | 91.18 | 90.65 | 103 | |
| pruned+retrained | 15 | 97.65 | 96.26 | 75 | |
| Fashion- MNIST Full | unpruned | 50 | 93.32 | 88.98 | - |
| pruned duplicate | 20 | 86.97 | 83.56 | 3368 | |
| pruned complement | 16 | 80.91 | 79.14 | 223 | |
| pruned+retrained | 16 | 92.77 | 88.27 | 165 |
| Dataset | Model | Accuracy | Fidelity | Average Coverage | # of Exps |
|---|---|---|---|---|---|
| MNIST Partial | original NN | 99.96 | - | - | - |
| FEB-RE+OAS | 99.65 | 99.67 | 23.13 | 29 | |
| FEB-RE+CRED | 99.96 | 99.97 | 31.97 | 16 | |
| MNIST Full | original NN | 99.70 | - | - | - |
| FEB-RE+OAS | 98.20 | 98.19 | 8.08 | 70 | |
| FEB-RE+CRED | 99.77 | 99.78 | 10.79 | 38 | |
| notMNIST Partial | original NN | 99.24 | - | - | - |
| FEB-RE+OAS | 98.71 | 98.89 | 24.43 | 28 | |
| FEB-RE+CRED | 99.43 | 99.23 | 25.35 | 14 | |
| notMNIST Full | original NN | 98.10 | - | - | - |
| FEB-RE+OAS | 97.65 | 97.89 | 9.19 | 75 | |
| FEB-RE+CRED | 99.25 | 97.14 | 8.03 | 42 | |
| Fashion-MNIST Partial | original NN | 99.77 | - | - | - |
| FEB-RE+OAS | 97.59 | 97.60 | 22.98 | 26 | |
| FEB-RE+CRED | 99.69 | 99.98 | 24.97 | 14 | |
| Fashion-MNIST Full | original NN | 93.32 | - | - | - |
| FEB-RE+OAS | 92.77 | 92.92 | 8.86 | 165 | |
| FEB-RE+CRED | 94.54 | 95.06 | 11.45 | 52 |
| Dataset | ||||||
|---|---|---|---|---|---|---|
| Model | MNIST | MNIST | notMNIST | notMNIST | Fashion- | Fashion- |
| Full | Partial | Full | Partial | MNIST Full | MNIST Partial | |
| FEB-RE+OAS | 91.46 | 95.84 | 95.11 | 98.20 | 84.97 | 92.30 |
| FEB-RE+CRED | 48.79 | 69.64 | 64.59 | 73.99 | 43.72 | 67.86 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, E.-H.; Kim, H. Feature-Based Interpretation of the Deep Neural Network. Electronics 2021, 10, 2687. https://doi.org/10.3390/electronics10212687
Lee E-H, Kim H. Feature-Based Interpretation of the Deep Neural Network. Electronics. 2021; 10(21):2687. https://doi.org/10.3390/electronics10212687
Chicago/Turabian StyleLee, Eun-Hun, and Hyeoncheol Kim. 2021. "Feature-Based Interpretation of the Deep Neural Network" Electronics 10, no. 21: 2687. https://doi.org/10.3390/electronics10212687
APA StyleLee, E.-H., & Kim, H. (2021). Feature-Based Interpretation of the Deep Neural Network. Electronics, 10(21), 2687. https://doi.org/10.3390/electronics10212687