
Design and Implementation of Programmable Data Plane Supporting Multiple Data Types


Abstract
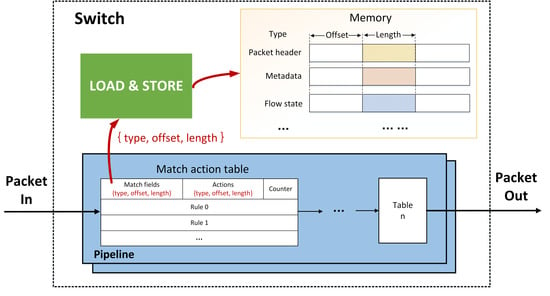
:
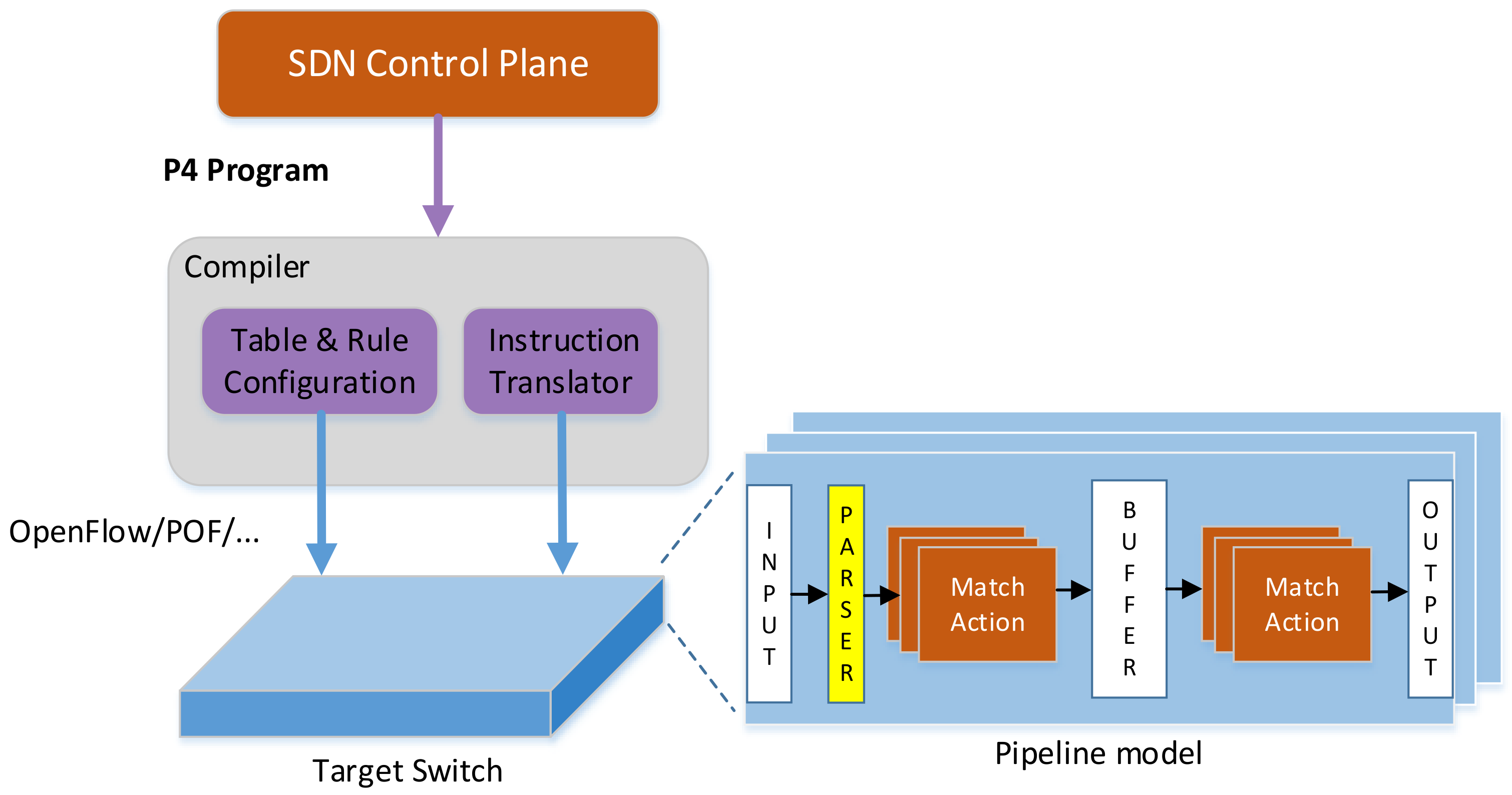
1. Introduction
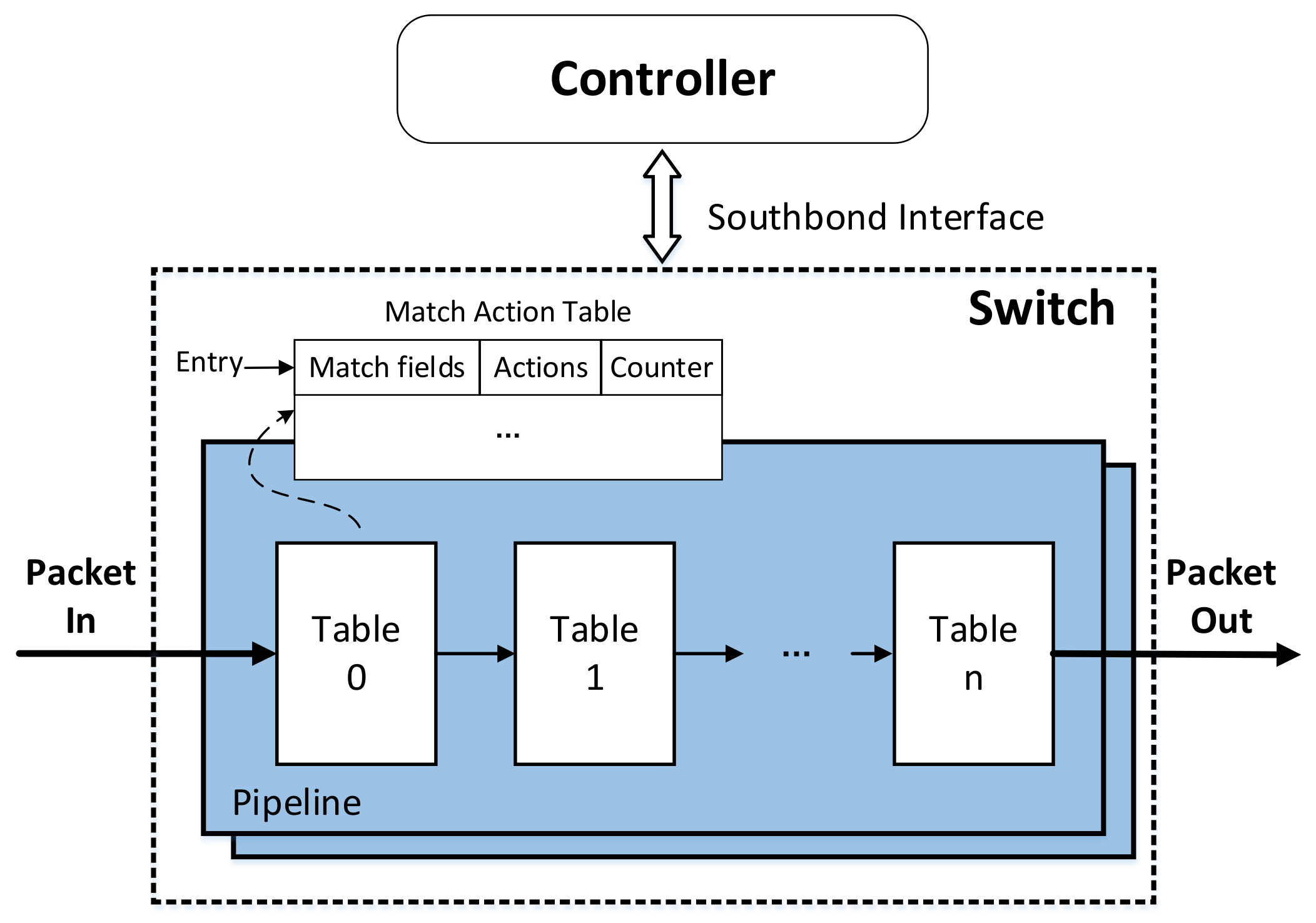
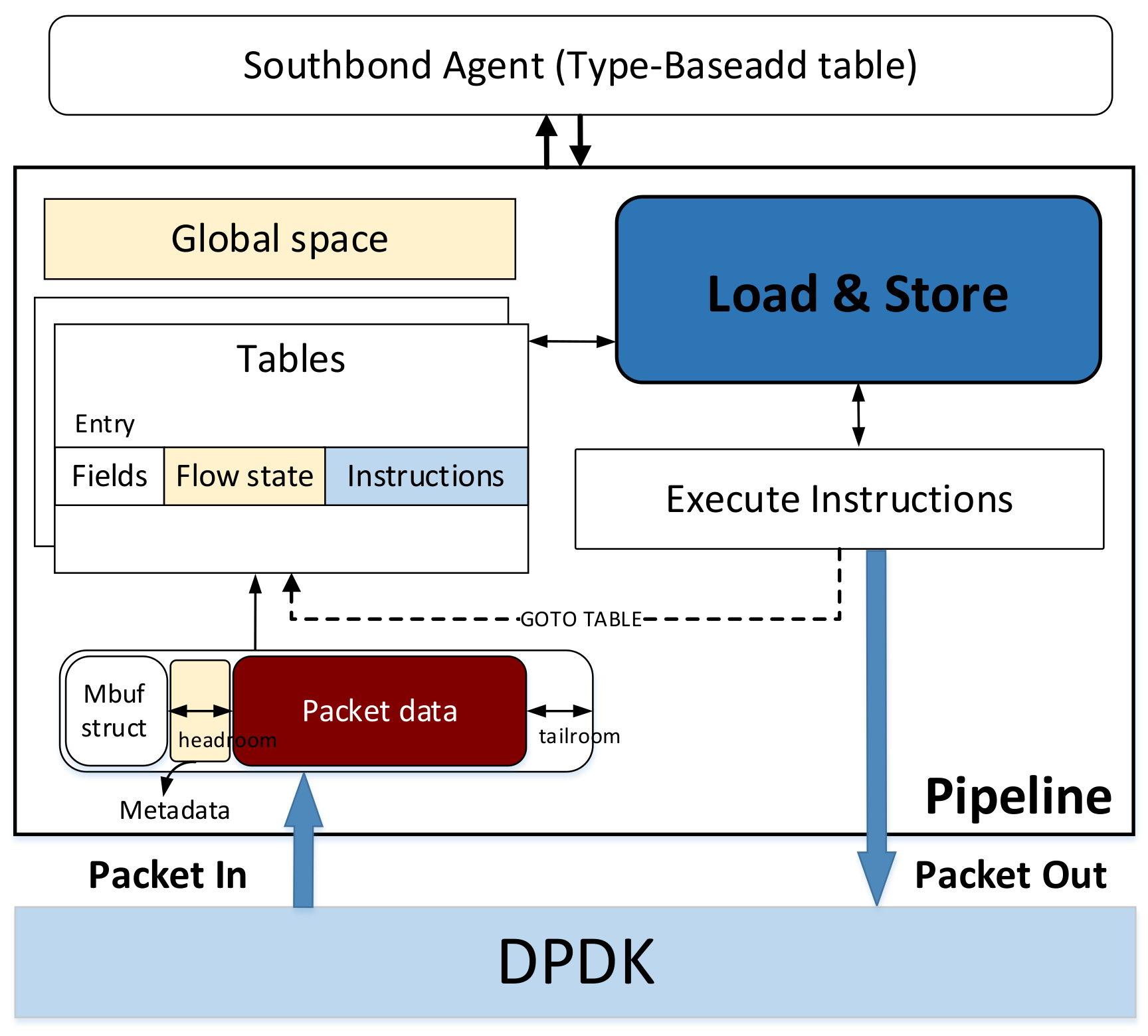
2. Match-Action Model
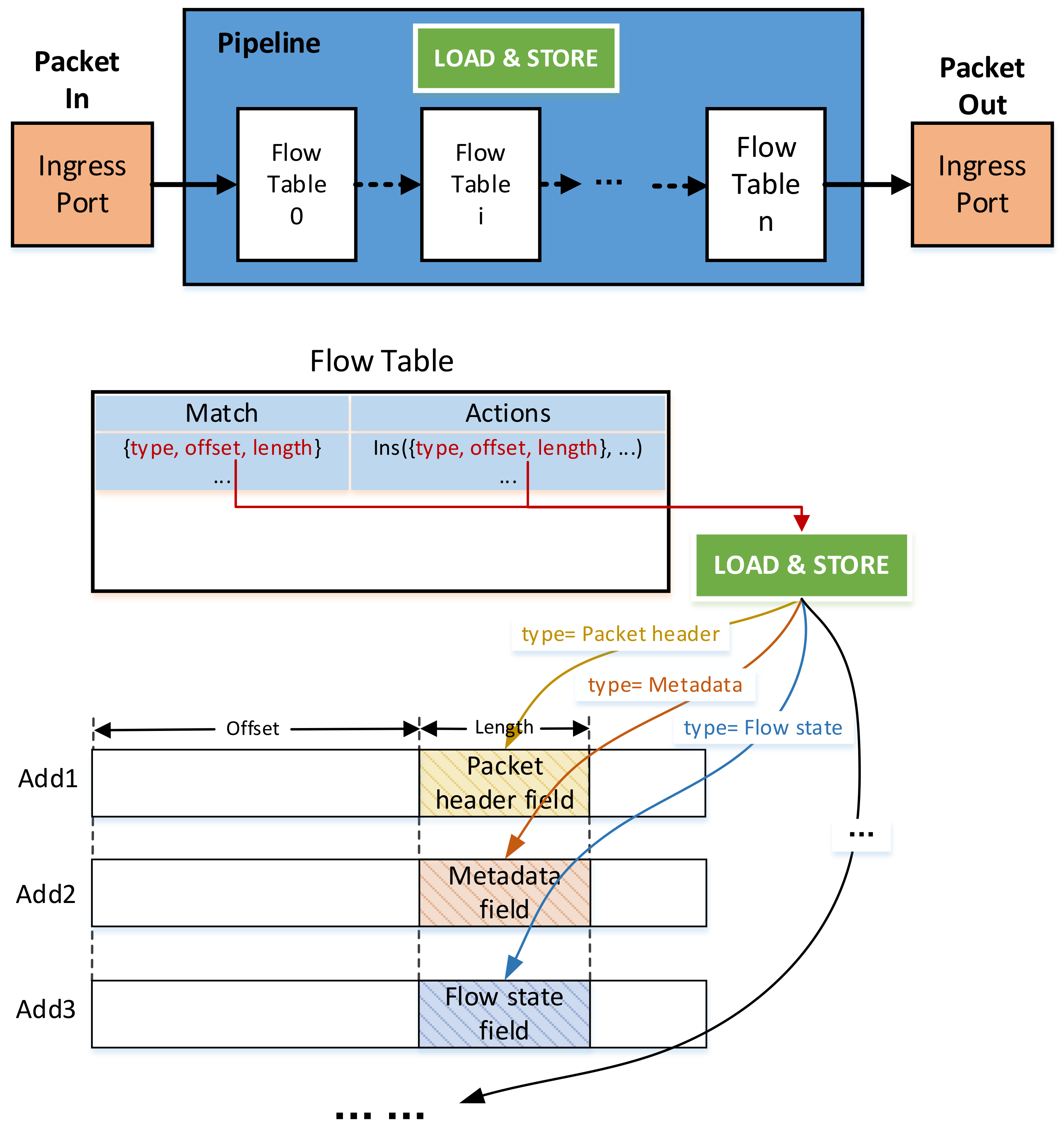
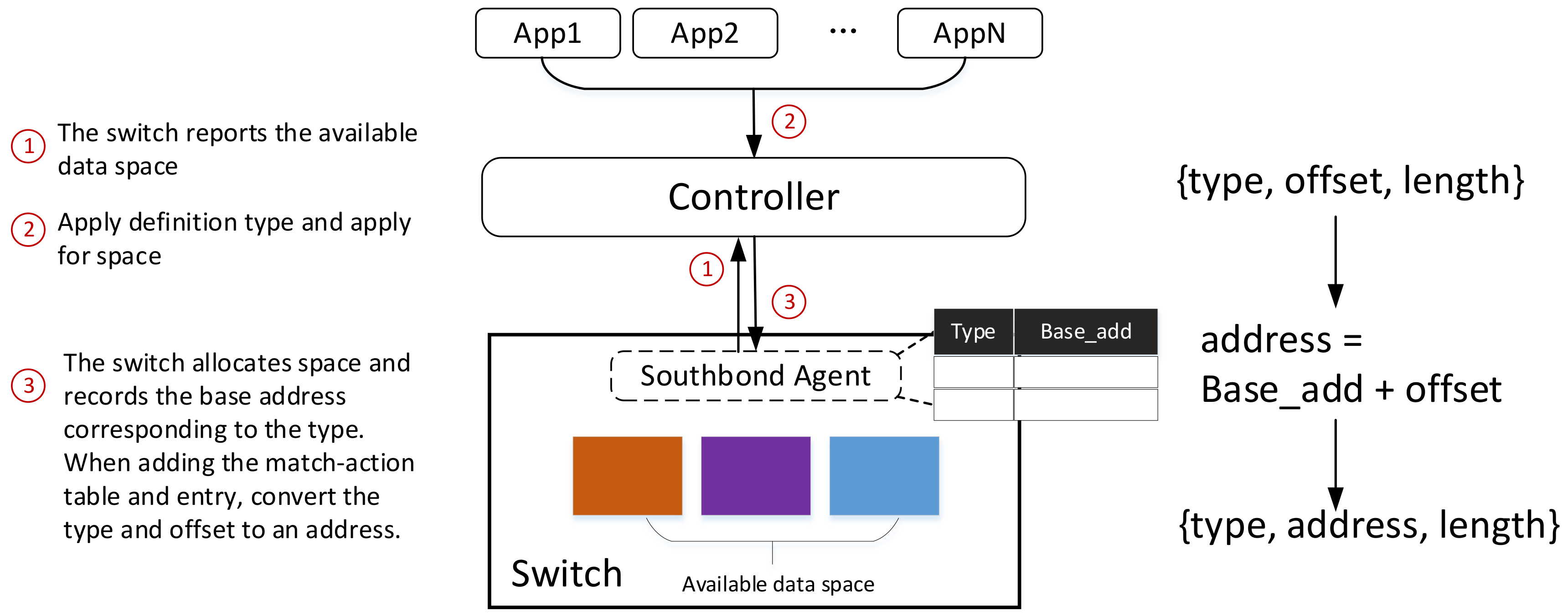
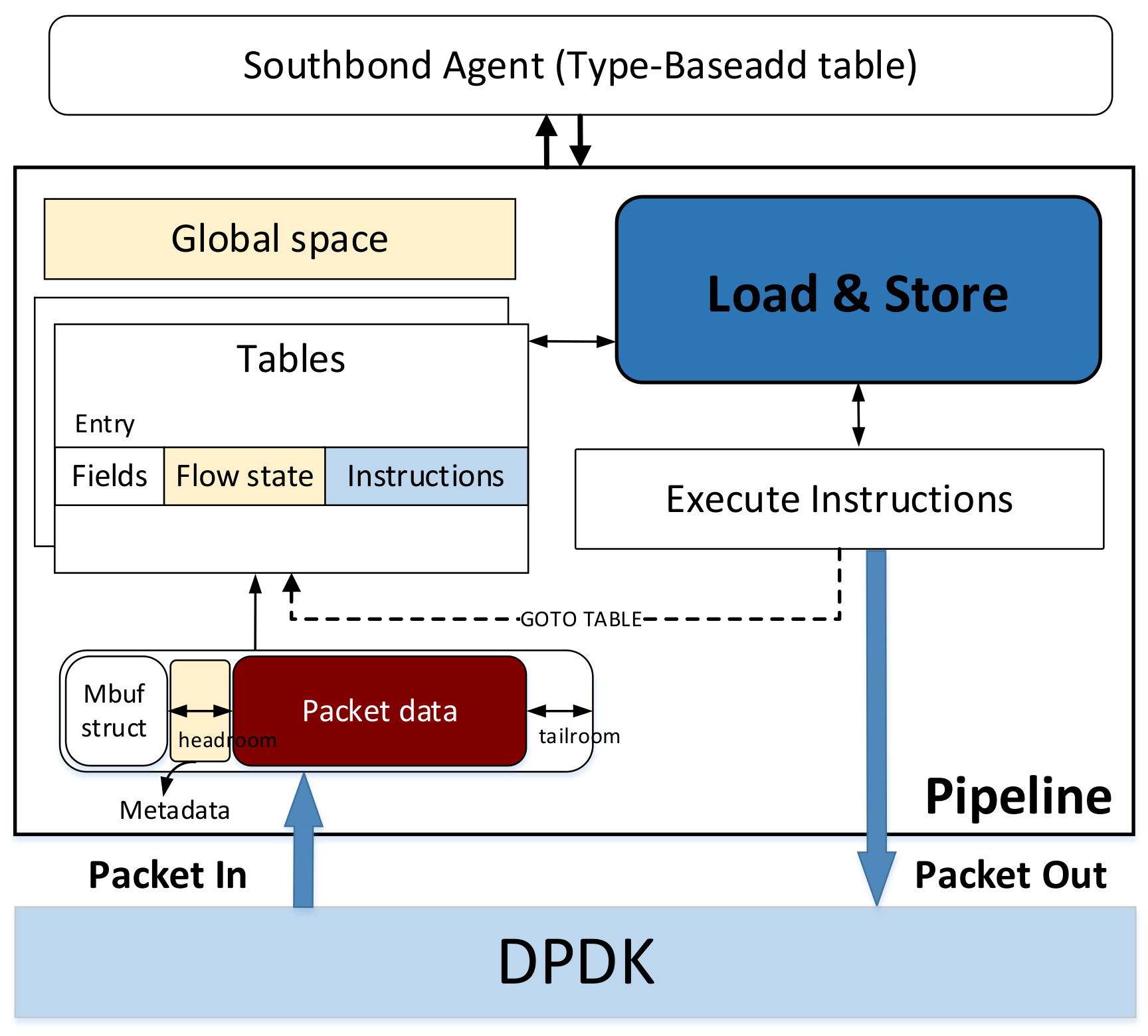
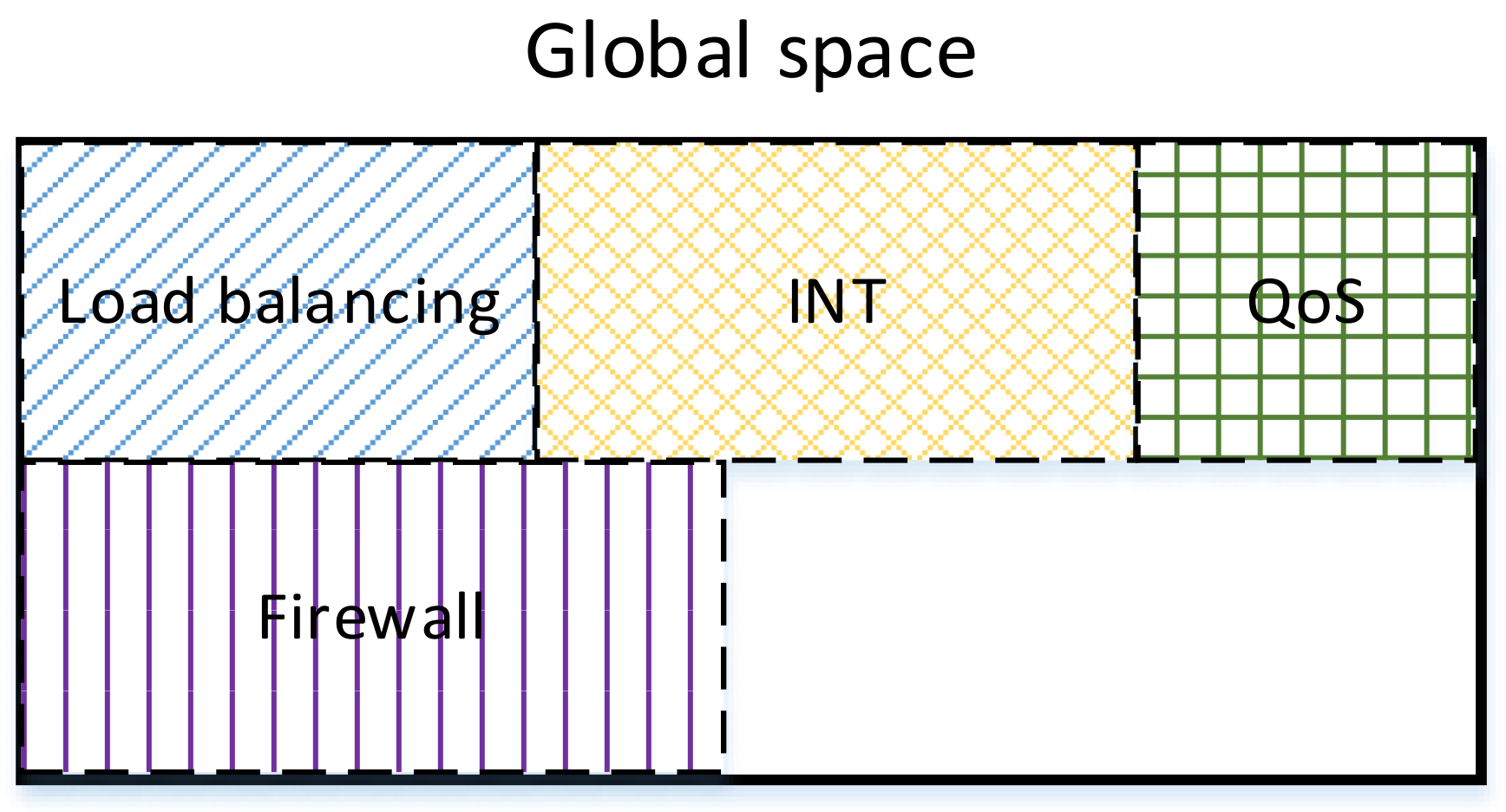
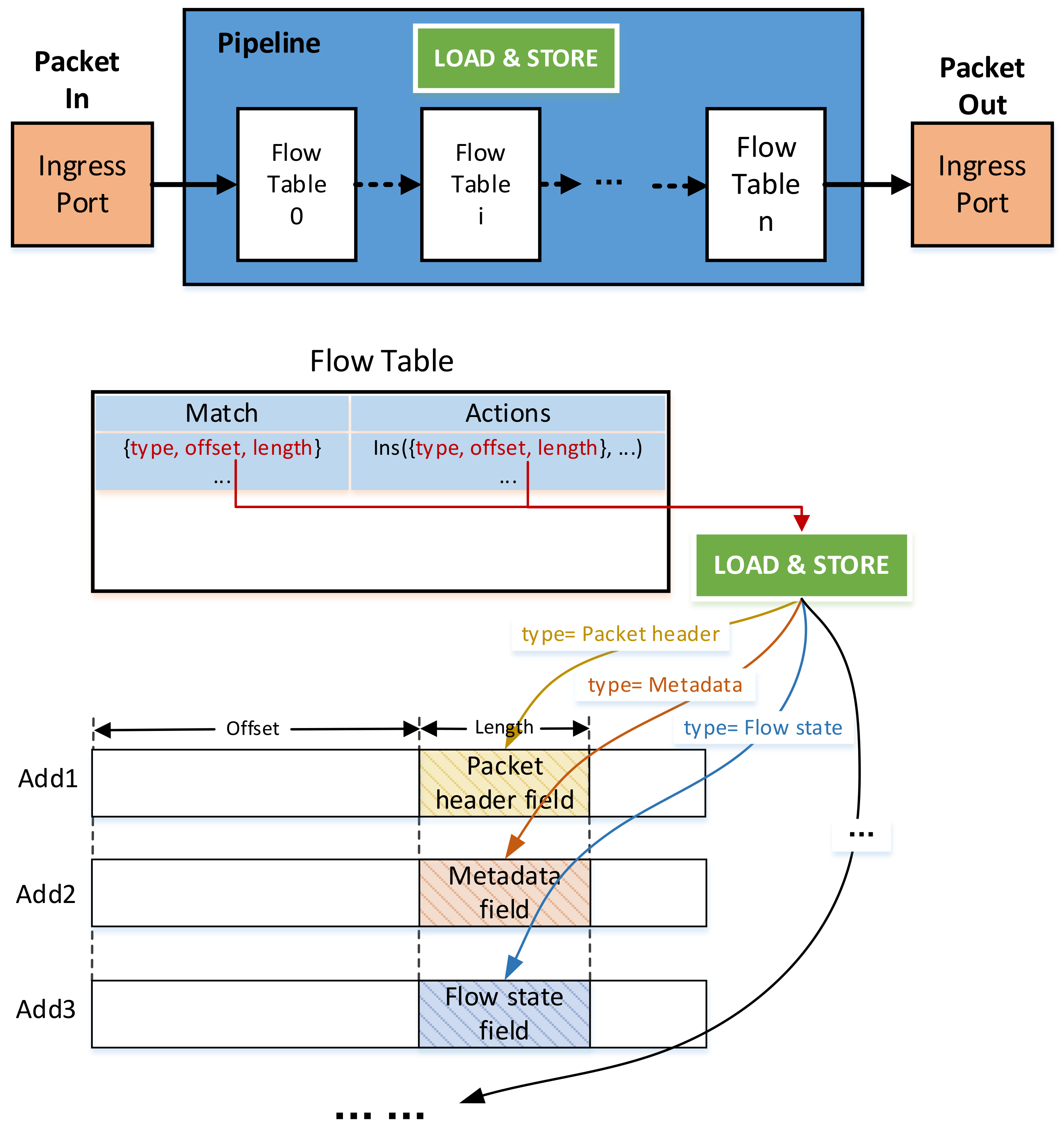
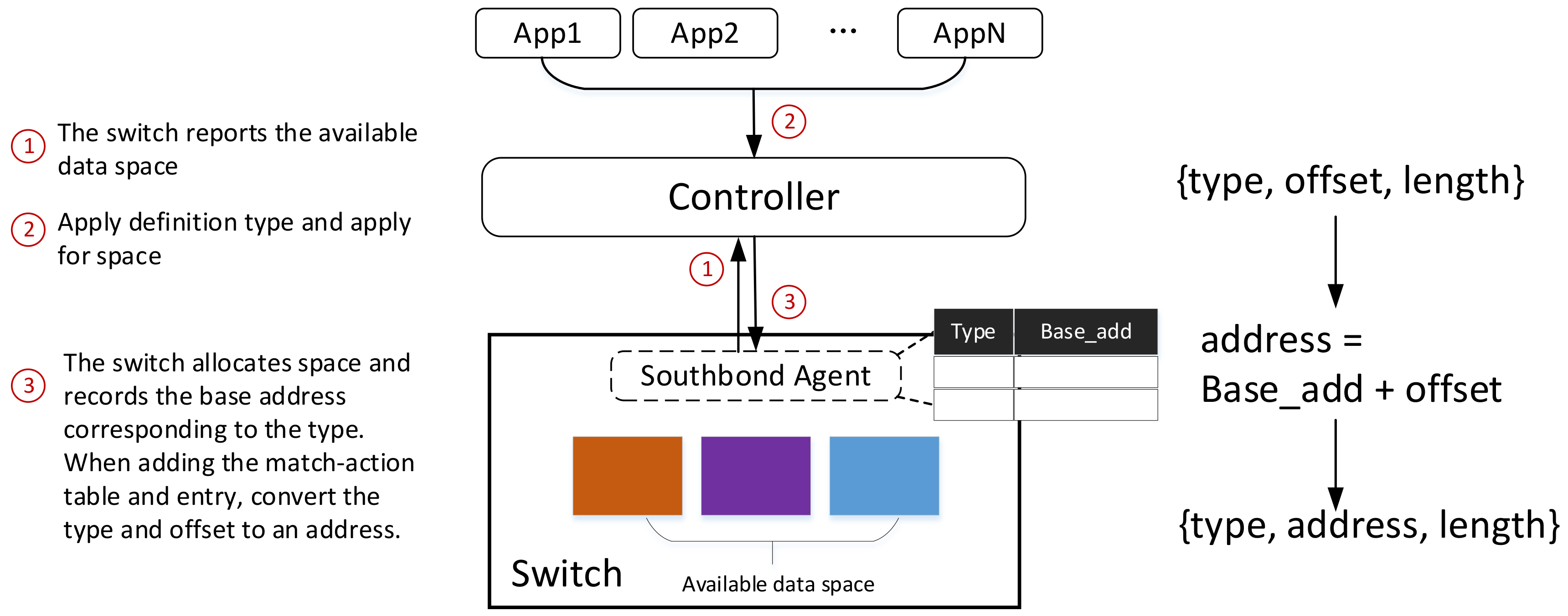
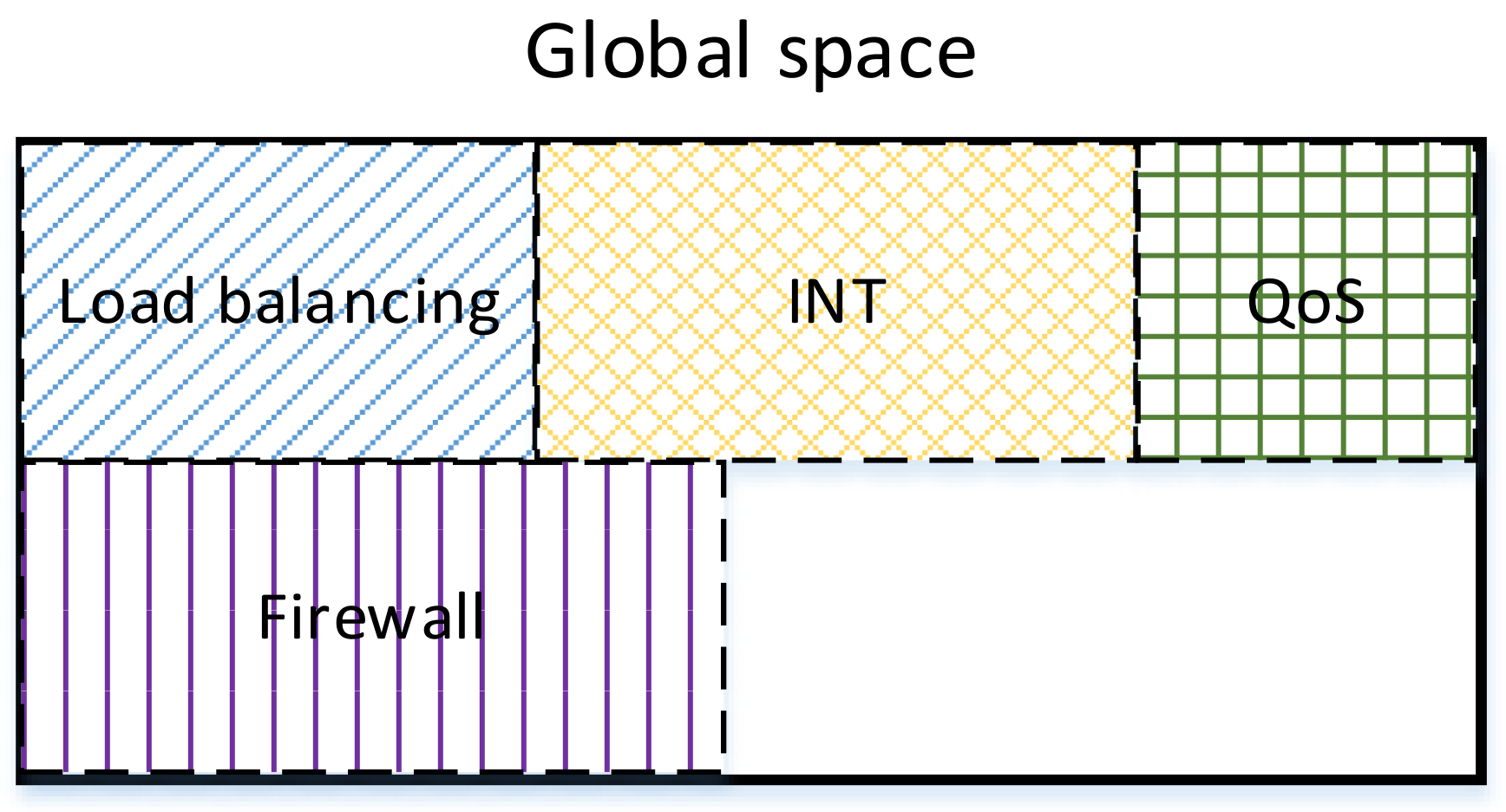
3. Data Type and Data Location
| Algorithm 1. Loading and storing data using {type, offset, length} in pipeline |
| Input: packet, match entry, instructions Output: packet’ 1. p_add = base address of the packet header 2. m_add = base address of the packet metadata 3. f_add = base address of the flow state 4. function load (type, offset, length): 5. if type is packet header: 6. data_add = p_add + offset 7. else if type is metadata: 8. data_add = m_add + offset 9. else if type is f_add: 10. data_add = f_add + offset 11. else 12. data_add = offset 13. get the data using data_add and length 14 return data 15. function store (type, offset, length, result): 16. if type is packet header: 17. data_add = p_add + offset 18. else if type is metadata: 19. data_add = m_add + offset 20. else if type is f_add: 21. data_add = f_add + offset 22. else 23. data_add = offset 24. store result in data_add |
4. Implementation and Evaluation
4.1. Implementation
4.2. Evaluation
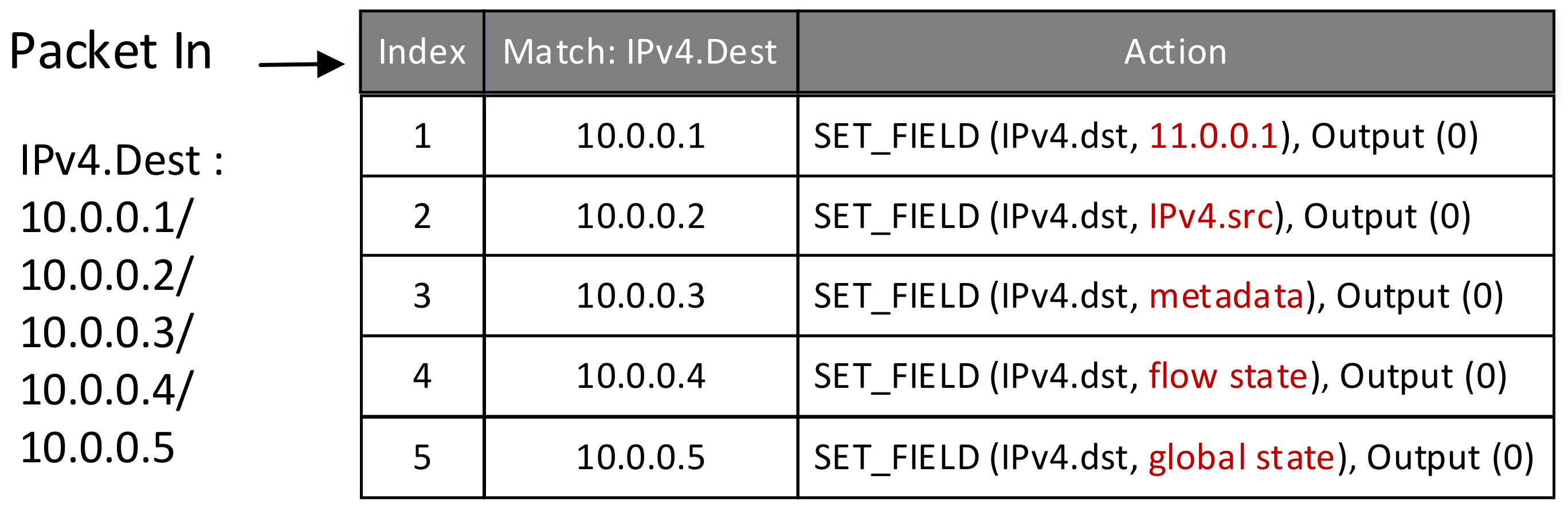
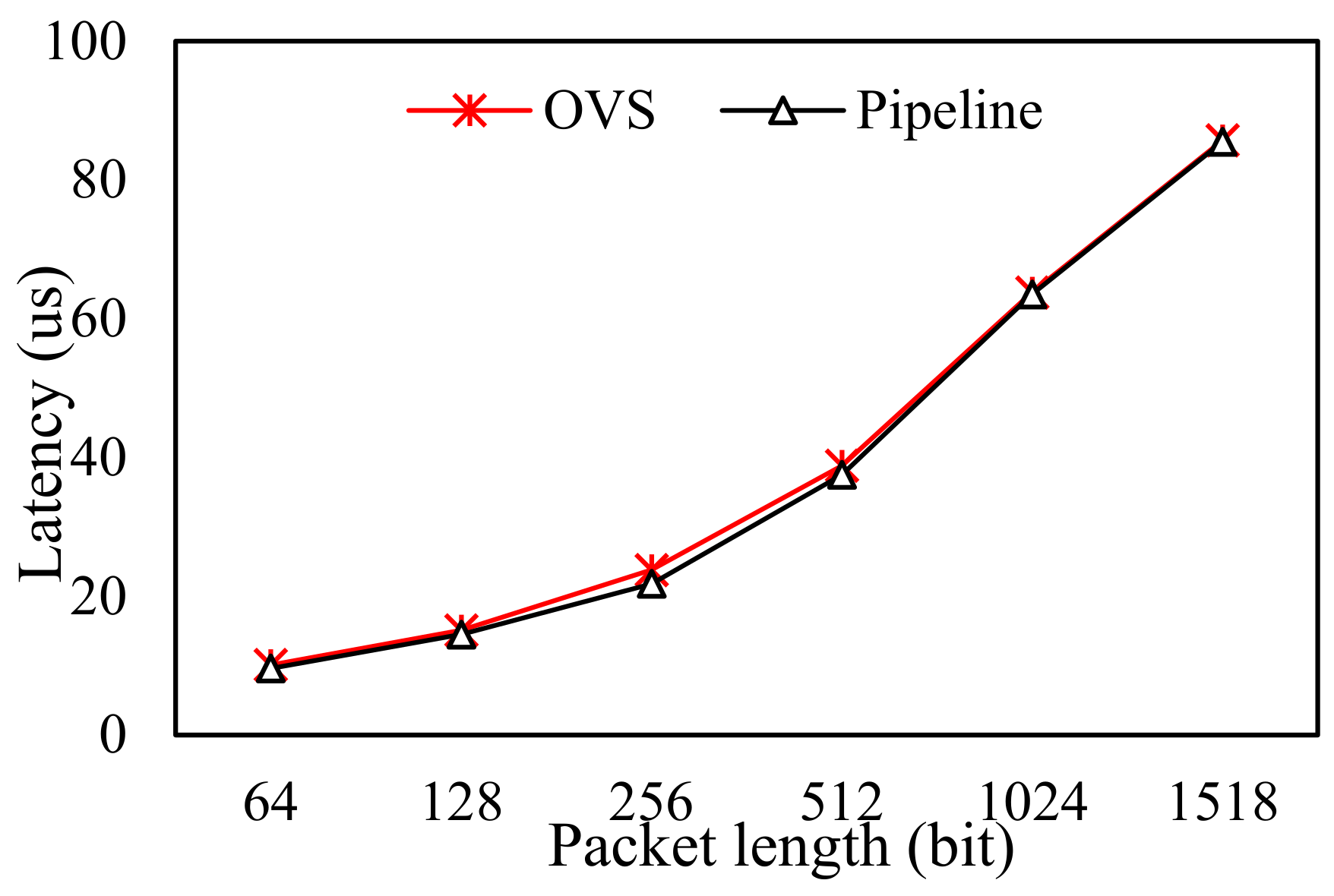
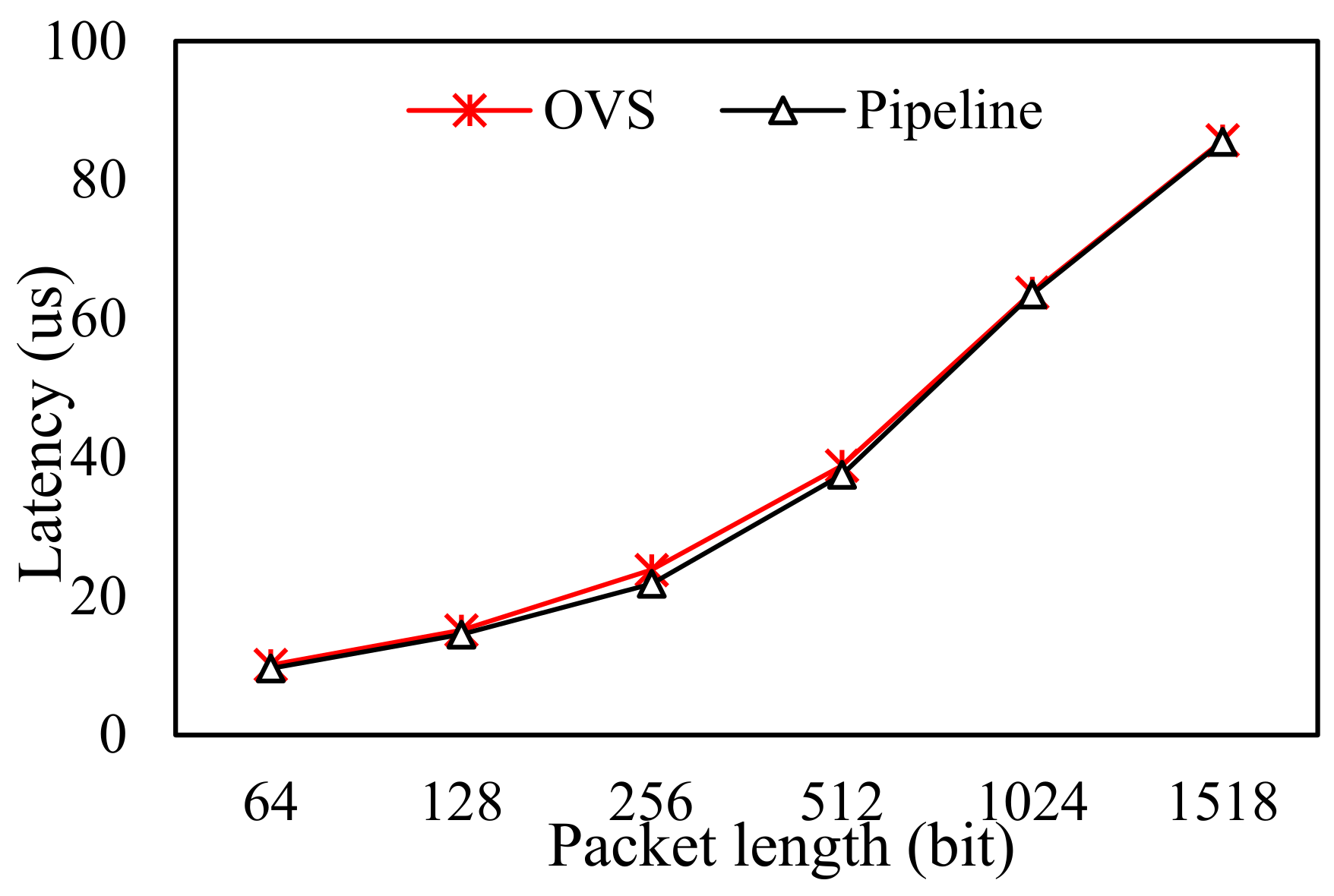
4.2.1. The Impact of Data Type on Forwarding Performance
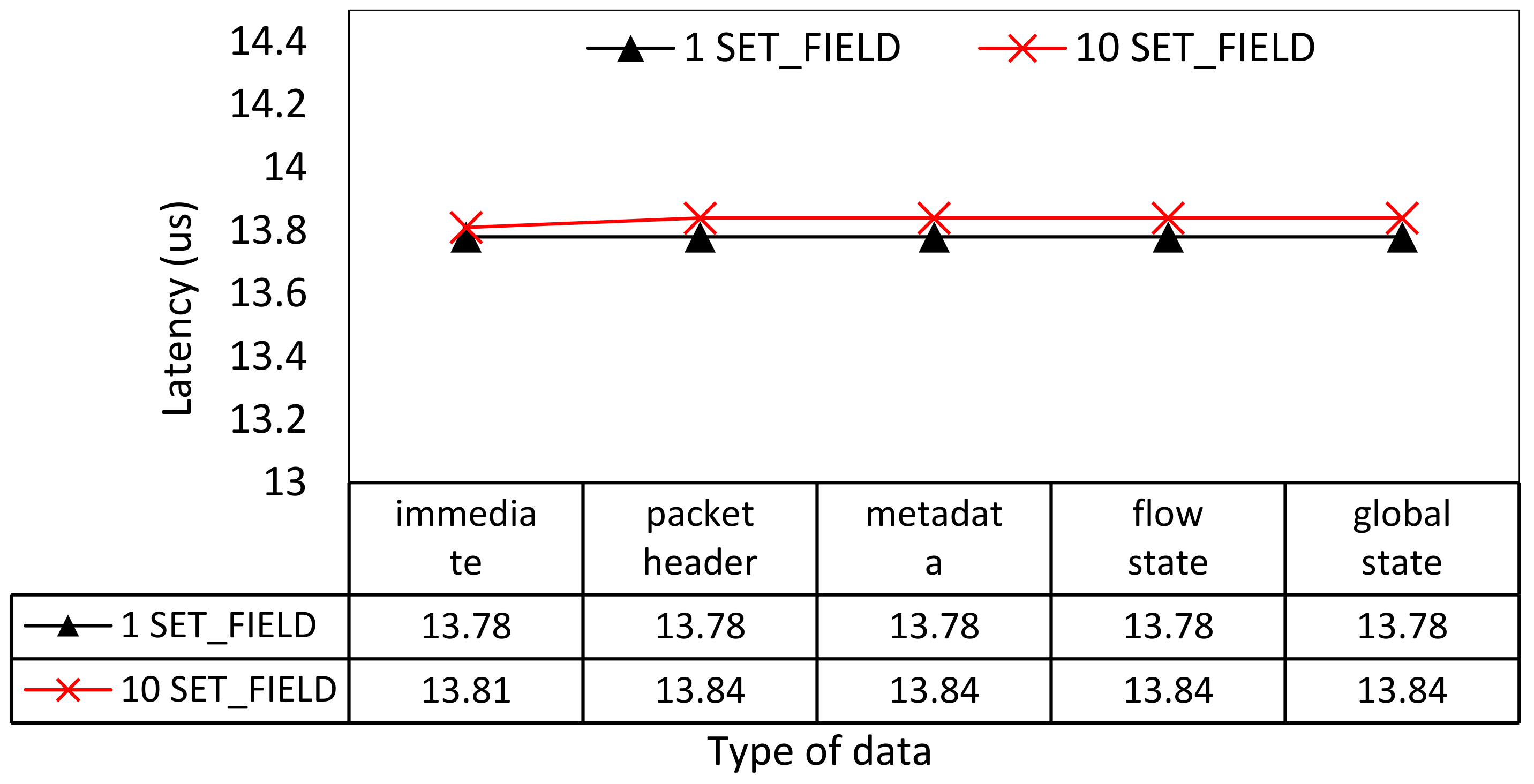
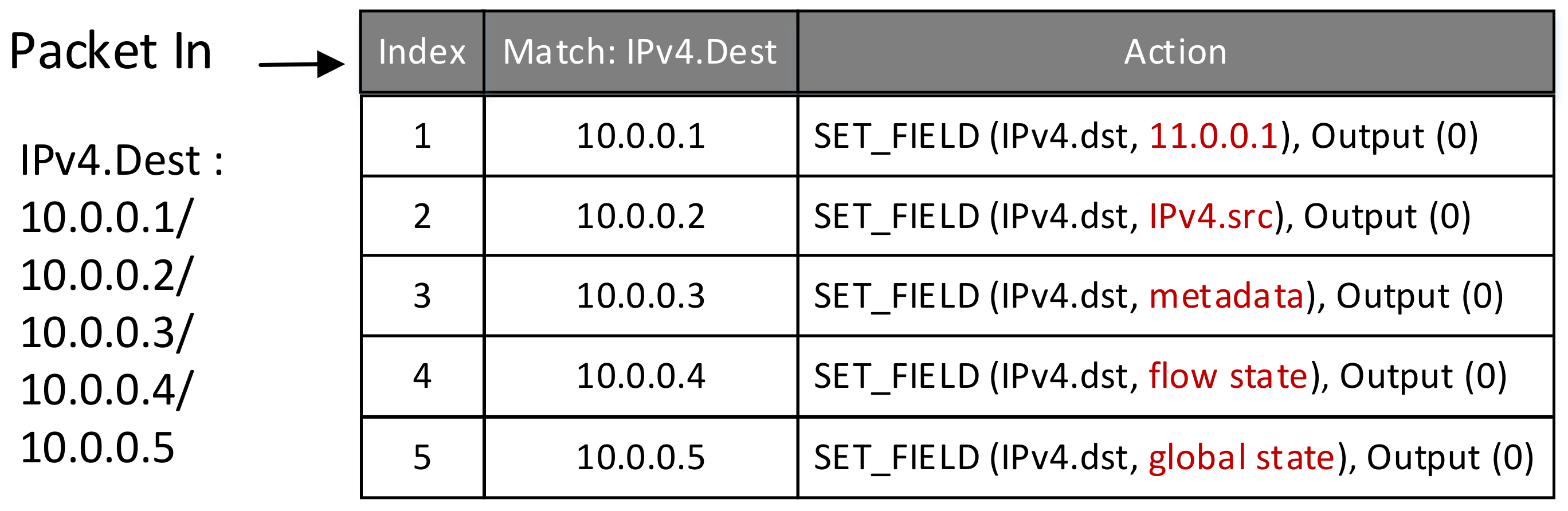
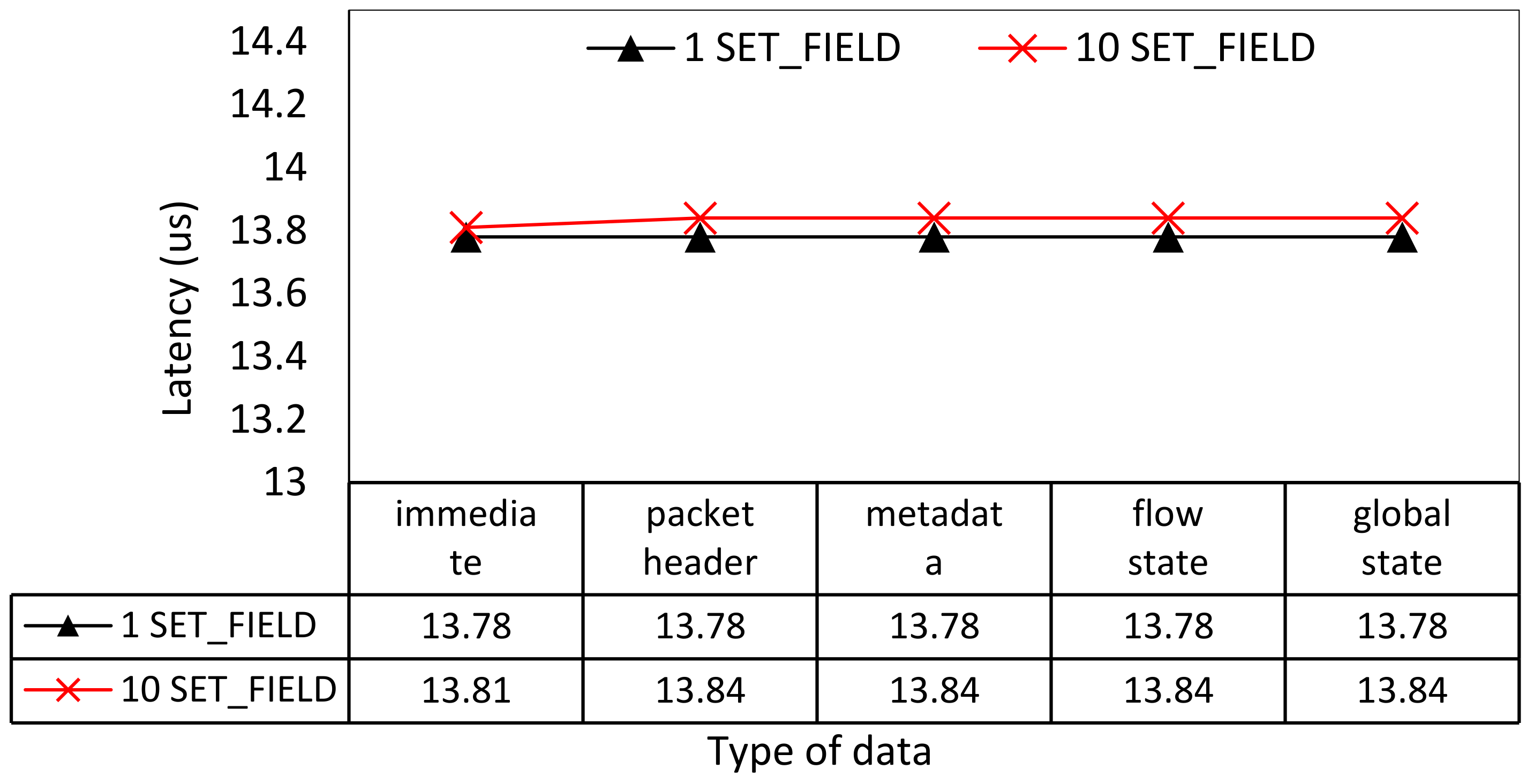
4.2.2. The Performance of Loading and Storing Data
4.2.3. The Performance Impact of Separate Data Loading and Storage Modules
4.2.4. The Performance Impact of Data Location Conversion
5. Related Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Masoudi, R.; Ghaffari, A. Software defined networks: A survey. J. Netw. Comput. Appl. 2016, 67, 1–25. [Google Scholar] [CrossRef]
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parelkar, G.; Peterson, L.; Rexford, J.; Shenker, S.; Turner, J. OpenFlow: Enabling innovation in campus networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- Tan, L.; Su, W.; Zhang, W.; Lv, J.; Zhang, Z.; Miao, J.; Liu, X.; Li, N. In-band Network Telemetry: A Survey. Comput. Netw. 2021, 186, 107763. [Google Scholar] [CrossRef]
- Bera, S.; Misra, S.; Vasilakos, A.V. Software-Defined Networking for Internet of Things: A Survey. IEEE Internet Things J. 2017, 4, 1994–2008. [Google Scholar] [CrossRef]
- Khan, W.Z.; Ahmed, E.; Hakak, S.; Yaqoob, I.; Ahmed, A. Edge computing: A survey. Future Gener. Comput. Syst. 2019, 97, 219–235. [Google Scholar] [CrossRef]
- Eum, S.Y.; Jibiki, M.; Murata, M.; Asaeda, H.; Nishinaga, N. A design of an ICN architecture within the framework of SDN. In Proceedings of the 2015 Seventh International Conference on Ubiquitous and Future Networks, Sapporo, Japan, 7–10 July 2015; pp. 141–146. [Google Scholar] [CrossRef]
- Bianchi, G.; Capone, A.; Bonola, M.; Cascone, C. Public Review for OpenState: Programming Platform-independent Stateful OpenFlow Applications Inside the Switch. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 44–51. [Google Scholar] [CrossRef]
- Krongbaramee, P.; Somchit, Y. Implementation of SDN Stateful Firewall on Data Plane using Open vSwitch. In Proceedings of the 15th International Joint Conference on Computer Science and Software Engineering (JCSSE 2018), Nakhonpathom, Thailand, 11–13 July 2018. [Google Scholar] [CrossRef]
- Alizadeh, M.; Edsall, T.; Dharmapurikar, S.; Vaidyanathan, R.; Chu, K.; Fingerhut, A.; Lam, V.T.; Matus, F.; Pan, R.; Yadav, N.; et al. CONGA: Distributed congestion-aware load balancing for datacenters. Comput. Commun. Rev. 2015, 44, 503–514. [Google Scholar] [CrossRef]
- Lotfimahyari, I.; Sviridov, G.; Giaccone, P.; Bianco, A. Data-Plane-Assisted State Replication With Network Function Virtualization. IEEE Syst. J. 2021, 1–12. [Google Scholar] [CrossRef]
- Yang, G.; Yoo, Y.; Kang, M.; Jin, H.; Yoo, C. Bandwidth Isolation Guarantee for SDN Virtual Networks. In Proceedings of the IEEE Annual Joint Conference: INFOCOM, IEEE Computer and Communications Societies, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar]
- Yang, G.; Yoo, Y.; Kang, M.; Jin, H.; Yoo, C. Accurate and Efficient Monitoring for Virtualized SDN in Clouds. IEEE Trans. Cloud Comput. 2021. [Google Scholar] [CrossRef]
- Yoo, Y.; Yang, G.; Kang, M.; Yoo, C. Adaptive Control Channel Traffic Shaping for Virtualized SDN in Clouds. In Proceedings of the 2020 IEEE 13th International Conference on Cloud Computing (CLOUD), Beijing, China, 19–23 October 2020; pp. 22–24. [Google Scholar]
- Muqaddas, A.S.; Sviridov, G.; Giaccone, P.; Bianco, A. Optimal State Replication in Stateful Data Planes. IEEE J. Sel. Areas Commun. 2020, 38, 1388–1400. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Li, G.; Wang, S.; Liu, C.; Chen, A.; Hu, H.; Gu, G.; Li, Q.; Xu, M.; Wu, J. Poseidon: Mitigating Volumetric DDoS Attacks with Programmable Switches. In Proceedings of the 27th Network and Distributed System Security Symposium (NDSS 2020), San Diego, CA, USA, 23–26 February 2020. [Google Scholar] [CrossRef]
- Mahrach, S.; Haqiq, A. DDoS flooding attack mitigation in software defined networks. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 693–700. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Xu, H.; Qian, C.; Ge, J.; Liu, J.; Huang, H. PrePass: Load balancing with data plane resource constraints using commodity SDN switches. Comput. Netw. 2020, 178, 107339. [Google Scholar] [CrossRef]
- Wang, H.; Xu, H.; Huang, L.; Wang, J.; Yang, X. Load-balancing routing in software defined networks with multiple controllers. Comput. Netw. 2018, 141, 82–91. [Google Scholar] [CrossRef]
- Benet, C.H.; Kassler, A.J.; Benson, T.; Pongracz, G. MP-HULA: Multipath Transport Aware Load Balancing Using Programmable Data Planes. In Proceedings of the 2018 Morning Workshop on In-Network Computing (NetCompute ’18), New York, NY, USA, 20 August 2018. [Google Scholar] [CrossRef]
- Olteanu, V.; Agache, A.; Voinescu, A.; Raiciu, C. Stateless Datacenter Load-balancing with Beamer. In Proceedings of the 15th USENIX Symposium on Networked Systems Design and Implementation, Renton, WA, USA, 9–11 April 2018. [Google Scholar]
- Turkovic, B.; Oostenbrink, J.; Kuipers, J. Detecting Heavy Hitters in the Data-Plane. 2019. Available online: http://arxiv.org/abs/1902.06993 (accessed on 23 August 2021).
- Caprolu, M.; Raponi, S.; Pietro, R.D. FORTRESS: An efficient and distributed firewall for stateful data plane SDN. Secur. Commun. Netw. 2019, 2019, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Cascone, C.; Sanvito, D.; Pollini, L.; Capone, A.; Sansò, B. Fast failure detection and recovery in SDN with stateful data plane. Int. J. Netw. Manag. 2017, 27, 1–32. [Google Scholar] [CrossRef]
- Liao, Y.; Tsai, S.C. Fast failover with hierarchical disjoint paths in SDN. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–7. [Google Scholar]
- Zhu, S.; Bi, J.; Sun, C.; Wu, C.X.; Hu, H. SDPA: Enhancing stateful forwarding for software-defined networking. In Proceedings of the IEEE 23rd International Conference on Network Protocols (ICNP), San Francisco, CA, USA, 10–13 November 2015; pp. 323–333. [Google Scholar] [CrossRef]
- Bonola, M.; Bifulco, R.; Petrucci, L.; Pontarelli, S.; Tulumello, A.; Bianchi, G. Implementing advanced network functions with stateful programmable data planes. In Proceedings of the 2017 IEEE International Symposium on Local and Metropolitan Area Networks (LANMAN), Osaka, Japan, 12–14 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- OpenFlow Switch Specifications Version 1.0, Open Network Fundation. Available online: https://www.opennetworking.org/wpcontent/uploads/2013/04/openflow-spec-v1.0.0.pdf (accessed on 23 August 2021).
- DPDK. Available online: https://www.dpdk.org/ (accessed on 23 August 2021).
- Song, H. Protocol-oblivious forwarding: Unleash the power of SDN through a future-proof forwarding plane. In Proceedings of the Second ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking, Hong Kong, China, 16 August 2013; pp. 127–132. [Google Scholar] [CrossRef]
- Moshref, M.; Bhargava, A.; Gupta, A.; Yu, M.; Govindan, R. Flow-level state transition as a new switch primitive for SDN. In Proceedings of the Third Workshop on Hot Topics in Software Defined Networking, Chicago, IL, USA, 22 August 2014; pp. 61–66. [Google Scholar] [CrossRef]
- Pontarelli, S.; Bifulco, R.; Bonola, M.; Cascone, C.; Spaziani, M.; Bruschi, V. Flowblaze: Stateful packet processing in hardware. In Proceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation, Boston, MA, USA, 26–28 February 2019; pp. 531–547. [Google Scholar]
- Bosshart, P.; Daly, D.; Gibb, G.; Izzard, M.; McKeown, N.; Rexford, J.; Schlesinger, C.; Talayco, D.; Vahdat, A.; Varghese, G.; et al. P4: Programming protocol-independent packet processors. Comput. Commun. Rev. 2014, 44, 87–95. [Google Scholar] [CrossRef]
- Amin, R.; Shah, N.; Mehmood, W. Enforcing optimal ACL policies using K-partite graph in hybrid SDN. Electronics 2019, 8, 604. [Google Scholar] [CrossRef] [Green Version]
- Open vSwitch v2.8.5. Available online: https://www.openvswitch.org/releases/openvswitch-2.8.5.tar.gz (accessed on 23 August 2021).
- Bosshart, P.; Gibb, G.; Kim, H.; Varghese, G.; McKeown, N.; Izzard, M.; Mujica, F.; Horowitz, M. Forwarding metamorphosis: Fast programmable match-action processing in hardware for SDN. Comput. Commun. Rev. 2013, 43, 99–110. [Google Scholar] [CrossRef]
- P4 v1.0. Available online: https://p4lang.github.io/p4-spec/p4–14/v1.0.4/tex/p4.pdf (accessed on 23 August 2021).
- P4 v1.2.2. Available online: https://p4lang.github.io/p4-spec/docs/P4–16-working-spec.html (accessed on 23 August 2021).
- Zhang, X.; Cui, L.; Wei, K.; Tso, F.; Ji, Y.; Jia, W. A survey on stateful data plane in software defined networks. Comput. Netw. 2021, 184, 107597. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Application | Requirement | Ref. | Date |
|---|---|---|---|
| Urban mobility tracking | Copy the status information of the mobile terminal in the 5G network | [10] | 2021 |
| Bandwidth isolation | Collect physical network information (e.g., total and remaining link capacity) | [11] | 2021 |
| Network monitoring | Collect statistics (e.g., number of packets per flow entry) | [12,13] | 2021 |
| Flow size counter | Report to the controller after the completion of collecting the size of flow in data plane | [14] | 2020 |
| Distributed Denial of Service (DDoS) detection | Switches count the features of the background traffic to detect potential attacks | [15,16] | 2020 |
| Load balancing | Switches share network traffic with multiple links | [9,17,18,19,20] | 2020 |
| Heavy-hitter detection | Save a counter for every flow | [21] | 2019 |
| Stateful firewalls | Switch filters unsolicited inbound TCP connections without any outboard flow | [8,22] | 2019 |
| Link failover | Switches save backup path and monitor link’s status | [23,24] | 2018 |
| Domain Name System (DNS) detection | Assign a counter to keep track of all the resolved IP addresses for clients | [25] | 2017 |
| Synchronize Sequence Numbers (SYN) flood detection | Switches maintain a counter for every flow to detect SYN-Flood | [25] | 2017 |
| Network Address Transform (NAT) | Track the status of each flow in the NAT switch | [26] | 2017 |
| Implementation | Match Ability | Action Ability |
|---|---|---|
| OpenFlow | Specific protocol field | Instruction and protocol tightly coupled |
| POF, P4 switch | All protocol fields | Instructions support processing limited types of data (packet field, metadata, register) |
| Our method | All protocol fields and various types of network states | Instruction compatible multi-types of data processing |
| Category | Instructions |
|---|---|
| Field editing | set_field, insert_field, del_field, calculate_checksum, add, sub, srl, sll, and, or, xor, nor, not |
| Forwarding | goto_table, output, flood |
| Branch | jump, compare |
| Entry | add_entry, del_entry, set_entry |
| Central Processing Unit (CPU) | Intel Xeon CPU E7–4809 v4 @2.10 GHz |
|---|---|
| Caches | 32 k L1i and L1d, 256 KB L2, 20 MB L3 |
| Memory | 128 G DDR3 @ 1333 MHz, 4-channels |
| Network Interface Controller (NIC) | Intel XL710, PCI Express 3.0/x8, 4*10 Gb Intel I350, PCI Express 3.0/x8, 4*1 Gb |
| DPDK | v19.11 |
| Length (bit) | LOAD (ns) | STORE (ns) |
|---|---|---|
| 7 | 3.4 | 5.82 |
| 16 | 2.2 | 1.92 |
| 21 | 3.99 | 7.85 |
| 32 | 2.62 | 2.25 |
| 43 | 5.52 | 9.3 |
| 64 | 2.85 | 2.91 |
| Action | Field Type | Cycles | Action | Filed Type | Cycles | Action | Filed Type | Cycles |
|---|---|---|---|---|---|---|---|---|
| set_field | f, imm | 7 | sll | f, f | 18 | nor | f, f | 16 |
| set_field | f, f | 13 | srl | f, imm | 12 | calculate_checksum | f, f | 67 |
| add_field | f, imm | 5 | srl | f, f | 18 | not | f, imm_64 | 10 |
| add_field | f, f | 11 | and | f, imm | 10 | not | f, f | 16 |
| del_field | f | 14 | and | f, f | 16 | compare | f, f | 10 |
| add | f, imm | 10 | or | f, imm | 10 | compare | f, f | 16 |
| add | f, f | 16 | or | f, f | 16 | add_entry | f, f | 75,800 |
| sub | f, imm | 10 | xor | f, imm | 10 | set_entry | f, f | 76,410 |
| sub | f, f | 16 | xor | f, f | 16 | del_entry | f, f | 45,830 |
| sll | f, imm | 12 | nor | f, imm | 10 |
| Transfer the Data Location | Number of FLOW_MOD Processed/s |
|---|---|
| YES | 8624 |
| NO | 8624 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jing, L.; Chen, X.; Wang, J. Design and Implementation of Programmable Data Plane Supporting Multiple Data Types. Electronics 2021, 10, 2639. https://doi.org/10.3390/electronics10212639
Jing L, Chen X, Wang J. Design and Implementation of Programmable Data Plane Supporting Multiple Data Types. Electronics. 2021; 10(21):2639. https://doi.org/10.3390/electronics10212639
Chicago/Turabian StyleJing, Linan, Xiao Chen, and Jinlin Wang. 2021. "Design and Implementation of Programmable Data Plane Supporting Multiple Data Types" Electronics 10, no. 21: 2639. https://doi.org/10.3390/electronics10212639
APA StyleJing, L., Chen, X., & Wang, J. (2021). Design and Implementation of Programmable Data Plane Supporting Multiple Data Types. Electronics, 10(21), 2639. https://doi.org/10.3390/electronics10212639