
Improving Deep Object Detection Algorithms for Game Scenes



Abstract
:1. Introduction
- We built a dataset of game scenes collected from eight games.
- We presented a framework for improving the performance of object detection algorithms on game scenes by retraining them using game scene datasets.
- We tested whether the augmented images using image abstraction and stylization schemes can improve the performance of the object detection algorithms on game scenes.
2. Related Work
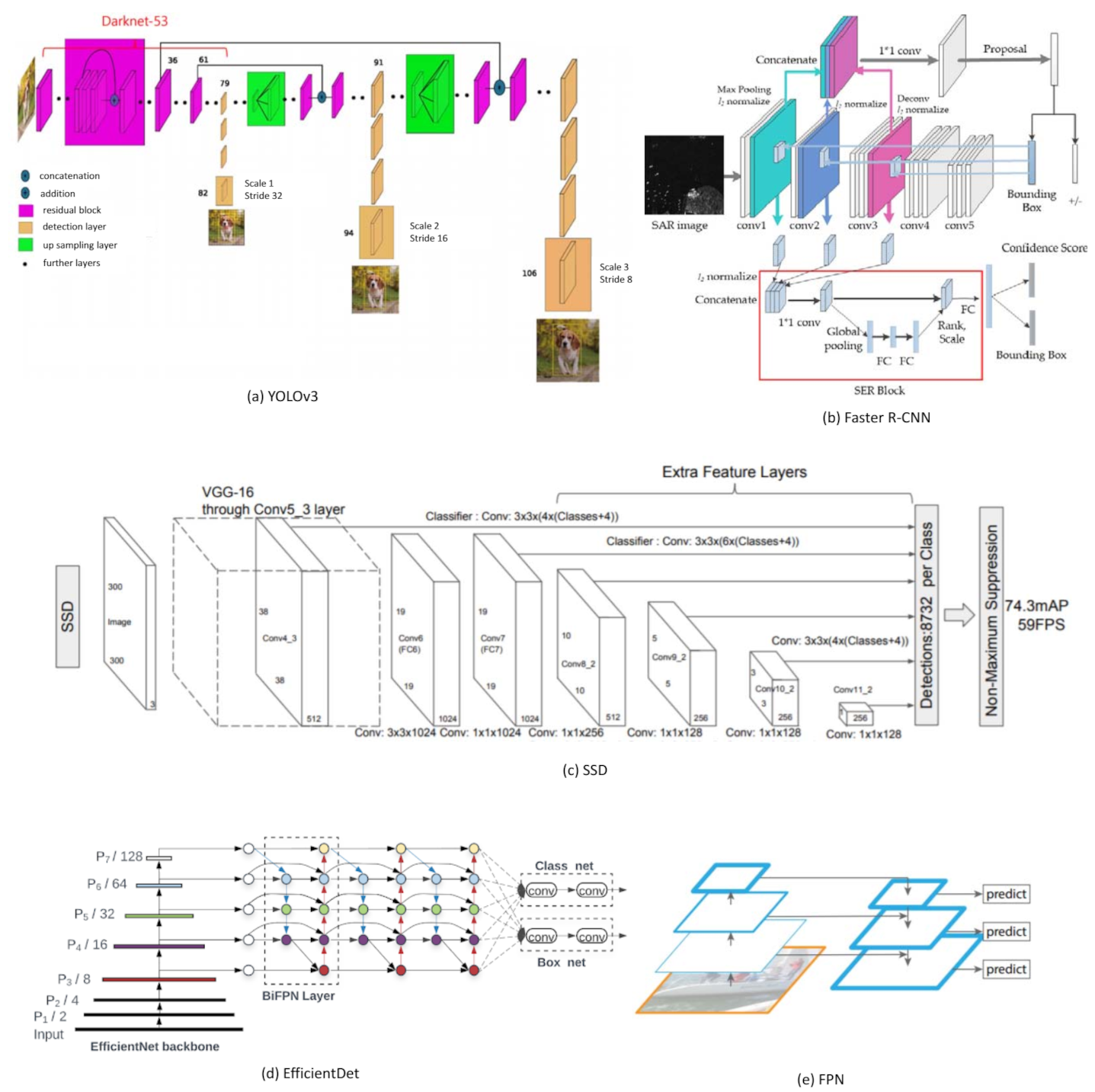
2.1. Deep Object Detection Approaches
2.2. Object Detection in a Game
3. Collecting Materials
3.1. Selected Deep Object Detection Algorithms
3.2. Selected Games
4. Training and Results
4.1. Training
4.2. Results
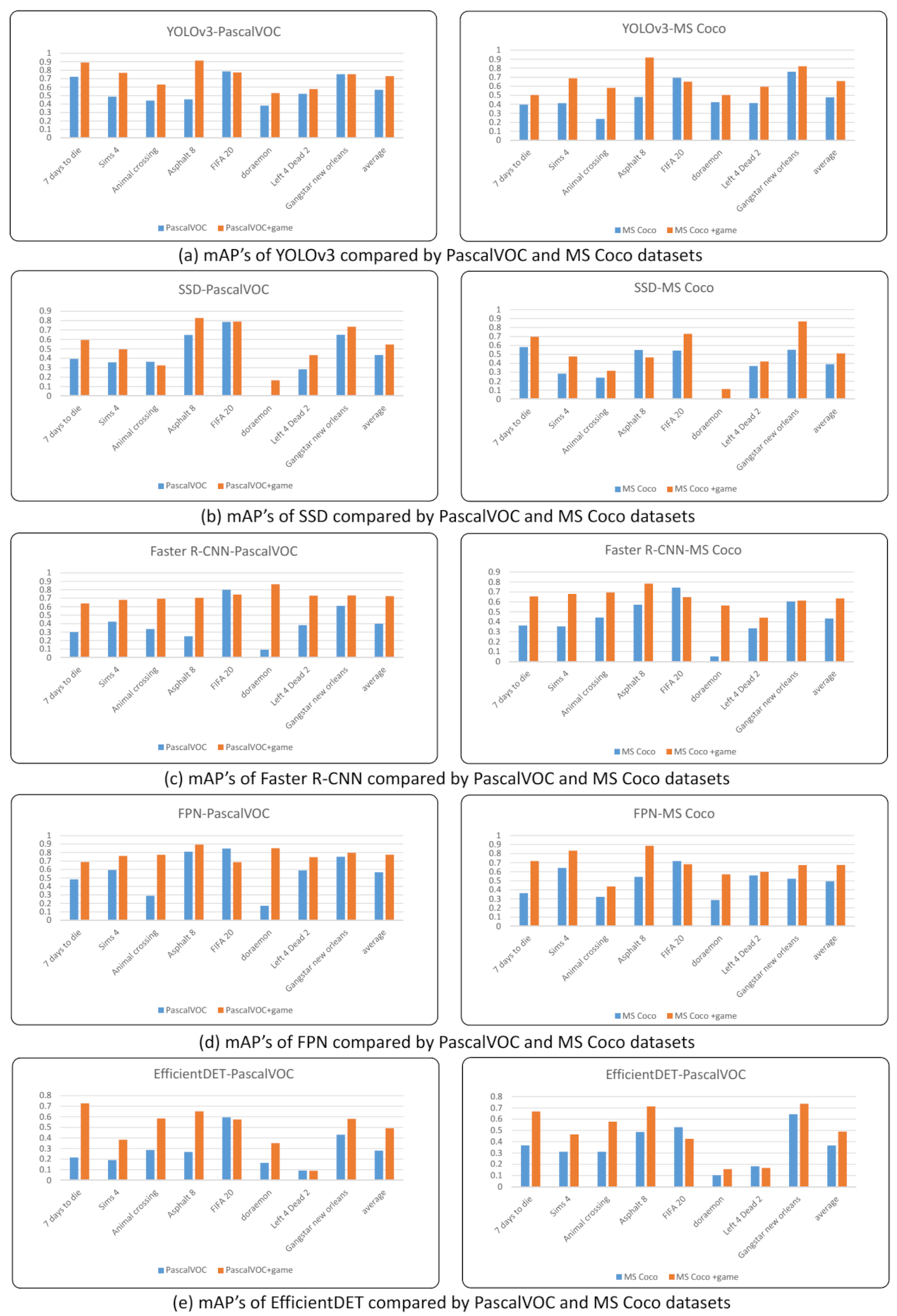
4.2.1. Measuring and Comparing Recognition Performance Using mAP
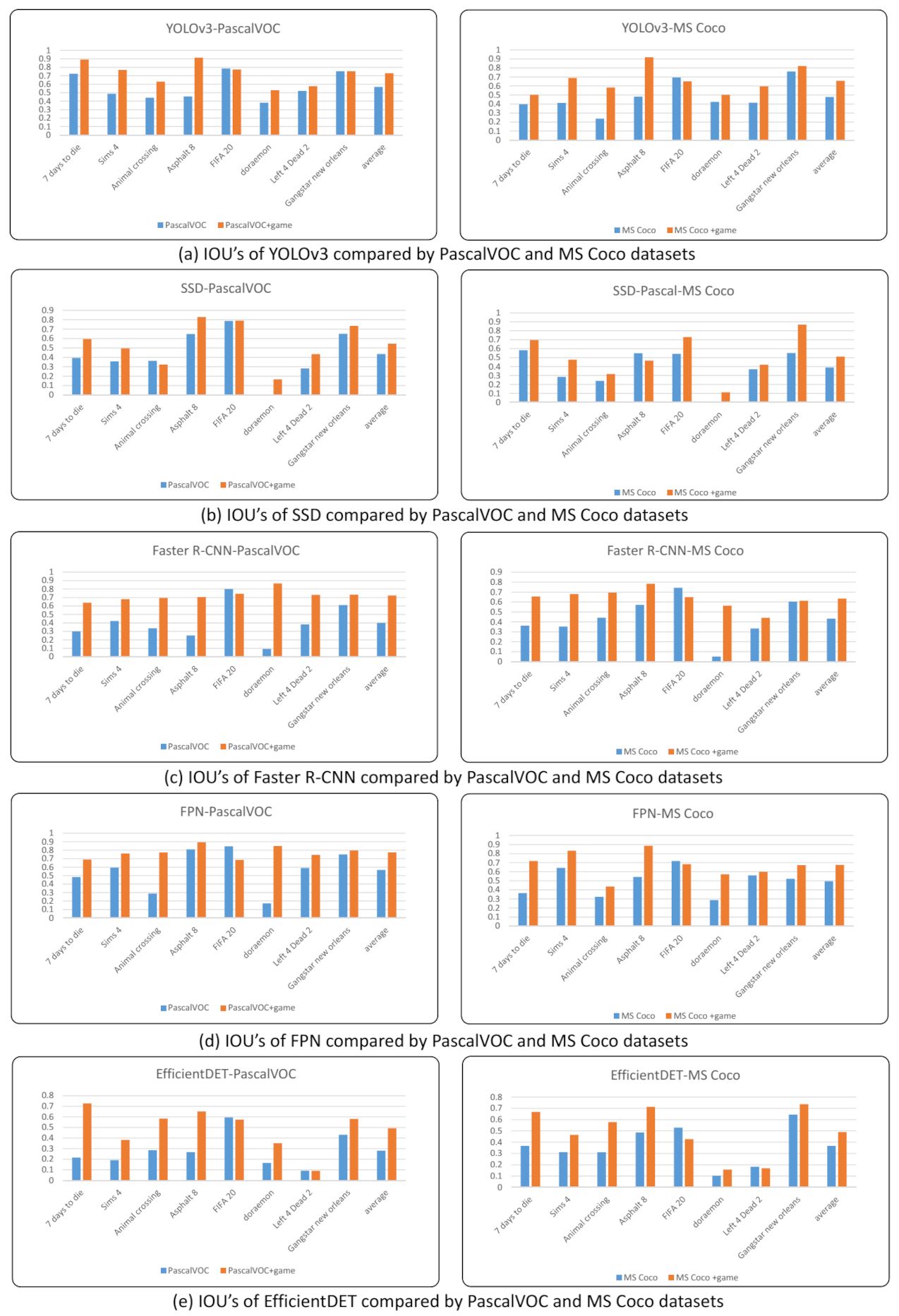
4.2.2. Measuring and Comparing Localization Performance Using IoU
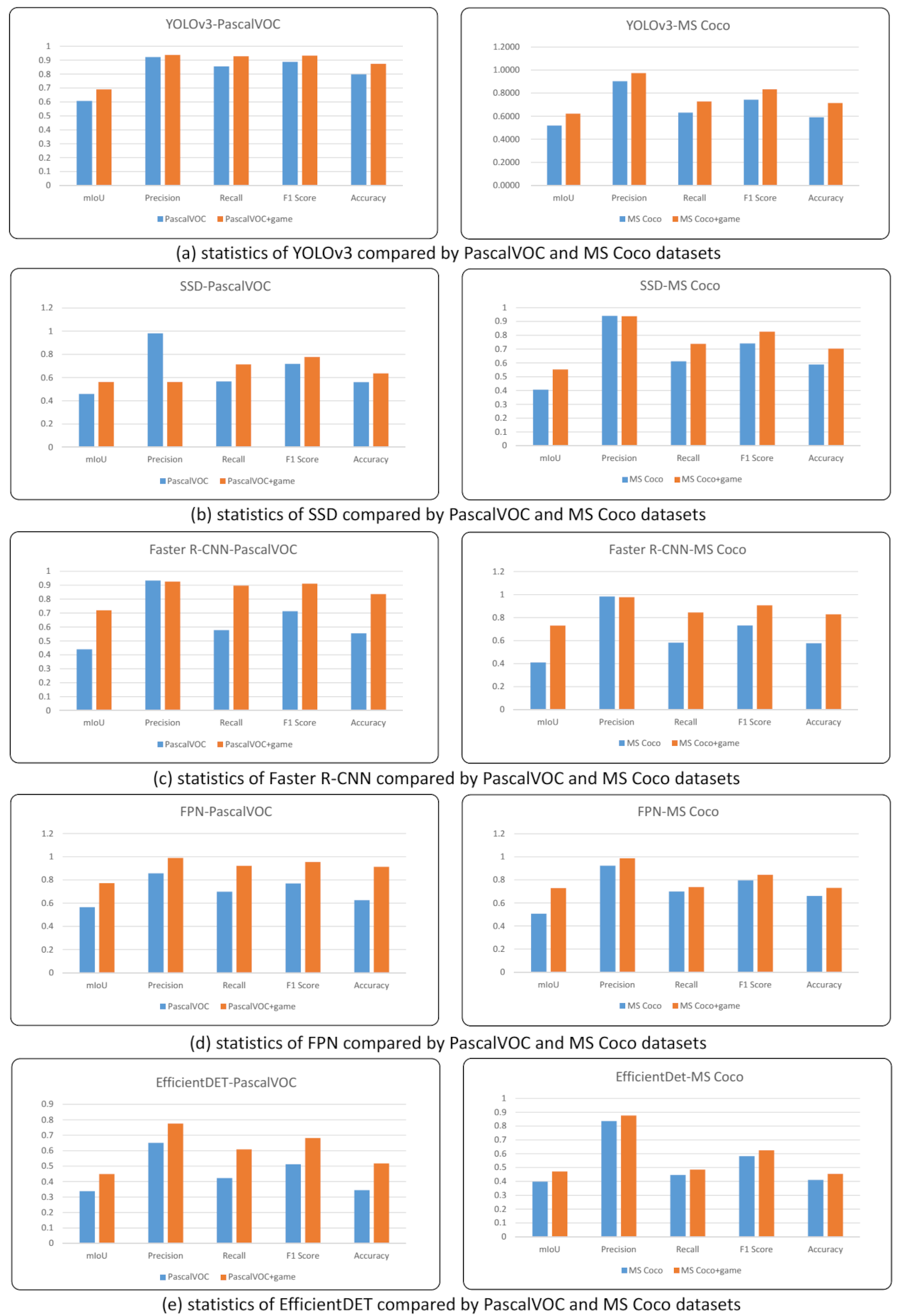
4.2.3. Measuring and Comparing Various Statistics
5. Analysis
- RQ1
- Does our strategy to retrain existing object detection algorithms with game scenes improve mAP?
- RQ2
- Does our strategy to retrain existing object detection algorithms with game scenes improve IoU?
5.1. Analysis of mAP Improvement
5.1.1. t-Test
5.1.2. Cohen’s d
5.2. Analysis on the Improvement of IoU
5.2.1. t-Test
5.2.2. Cohen’s d
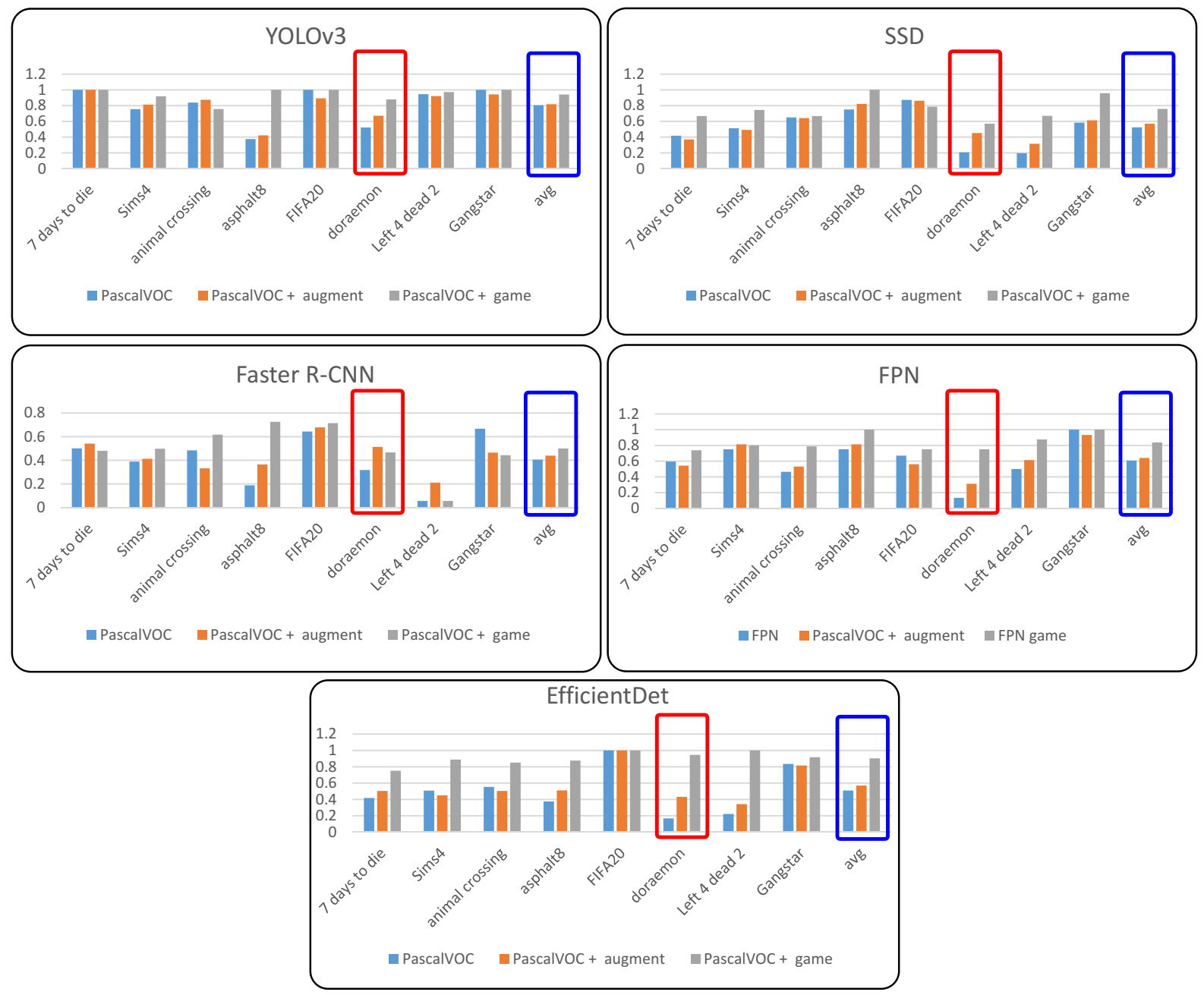
5.3. Training with Augmented Dataset
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Appendix A










References
- Redmon, J.; Farhardi, A. YOLOv3: An Incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A. SSD: Single shot multiBox detector. In Proceedings of the ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Everingham, M.; van Gool, L.; Williams, C.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Eslami, S.A.; van Gool, L.; Williams, C.; Winn, J.; Zisserman, A. The Pascal Visual Object Chasses Challenges: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C. Microsoft COCO: Common Objects in Context. In Proceedings of the ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2014), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girschick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV 2015), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Utsumi, O.; Miura, K.; Ide, I.; Sakai, S.; Tanaka, H. An object detection method for describing soccer games from video. In Proceedings of the IEEE International Conference on Multimedia and Expo, Lausanne, Switzerland, 26–29 August 2002; pp. 45–48. [Google Scholar]
- Chen, Z.; Yi, D. The Game Imitation: Deep Supervised Convolutional Networks for Quick Video Game AI. arXiv 2017, arXiv:1702.05663. [Google Scholar]
- Sundareson, P. Parallel image pre-processing for in-game object classification. In Proceedings of the IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Bengaluru, India, 5–7 October 2017; pp. 115–116. [Google Scholar]
- Venkatesh, A. Object Tracking in Games Using Convolutional Neutral Networks. Master’s Thesis, California Polytechnic State University, San Luis Obispo, CA, USA, 2018. [Google Scholar]
- Liu, S.; Zheng, B.; Zhao, Y.; Guo, B. Game robot’s vision based on faster R-CNN. In Proceedings of the Chinese Automation Congress (CAC) 2018, Xi’an, China, 30 November–2 December 2018; pp. 2472–2476. [Google Scholar]
- Chen, Y.; Huang, W.; He, S.; Sun, Y. A Long-time multi-object tracking method for football game analysis. In Proceedings of the Photonics & Electromagnetics Research Symposium-Fall 2019, Xiamen, China, 17–20 December 2019; pp. 440–442. [Google Scholar]
- Tolmacheva, A.; Ogurcov, D.; Dorrer, M. Puck tracking system for aerohockey game with YOLO2. J. Phys. Conf. Ser. 2019, 1399. [Google Scholar] [CrossRef] [Green Version]
- Yao, W.; Sun, Z.; Chen, X. Understanding video content: Efficient hero detection and recognition for the game Honor of Kings. arXiv 2019, arXiv:1907.07854. [Google Scholar]
- Spijkerman, R.; van der Haar, D. Video footage highlight detection in Formula 1 through vehicle recognition with faster R-CNN trained on game footage. In Proceedings of the International Conference on Computer Vision and Graphics 2020, Warsaw, Poland, 14–16 September 2020; pp. 176–187. [Google Scholar]
- Kim, K.; Kim, S.; Shchur, D. A UAS-based work zone safety monitoring system by integrating internal traffic control plan (ITCP) and automated object detection in game engine environment. Autom. Constr. 2021, 128. [Google Scholar] [CrossRef]
- YOLO in Game Object Detection. 2019. Available online: https://forum.unity.com/threads/yolo-in-game-object-detection-deep-learning.643240/ (accessed on 10 March 2019).
- List of Video Game Genres. Available online: https://en.wikipedia.org/wiki/List_of_video_game_genres (accessed on 17 September 2021).
- 7 Days to Die. Available online: https://7daystodie.com/ (accessed on 5 August 2013).
- Left 4 Dead 2. Available online: https://www.l4d.com/blog/ (accessed on 17 November 2009).
- Gangstar New Orleans. Available online: https://www.gameloft.com/en/game/gangstar-new-orleans/ (accessed on 7 February 2017).
- Sims4. Available online: https://www.ea.com/games/the-sims/the-sims-4 (accessed on 2 September 2014).
- Animal Crossing. Available online: https://animal-crossing.com/ (accessed on 14 April 2001).
- Doraemon. Available online: https://store.steampowered.com/app/965230/DORAEMON_STORY_OF_SEASONS/ (accessed on 13 June 2019).
- Asphalt 8. Available online: https://www.gameloft.com/asphalt8/ (accessed on 22 August 2013).
- FIFA 20. Available online: https://www.ea.com/games/fifa/fifa-20 (accessed on 24 September 2019).
- Huang, S.; Ramanan, D. Expecting the Unexpected: Training Detectors for Unusual Pedestrians with Adversarial Imposters. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 2243–2252. [Google Scholar]
- Chan, Z.; Ouyang, W.; Liu, T.; Tao, D. A Shape Transformation-based Dataset Augmentation Framework for Pedestrian Detection. Int. J. Comput. Vis. 2021, 129, 1121–1138. [Google Scholar] [CrossRef]
- Kang, H.; Lee, S.; Chui, C. Flow-based image abstraction. IEEE Trans. Vis. Comp. Graph. 2009, 15, 62–76. [Google Scholar] [CrossRef] [PubMed]
- Winnemoller, H.; Olsen, S.; Gooch, B. Real-time video abstraction. ACM Trans. Graph. 2006, 25, 1221–1226. [Google Scholar] [CrossRef]
- Kim, J.; Kim, M.; Kang, H.; Lee, K. U-gat-it: Unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | YOLOv3 [1] | Faster R-CNN [2] | SSD [3] | FPN [4] | EfficientDet [5] |
|---|---|---|---|---|---|
| Time required for retraining the algorithms | 9.5 | 8.1 | 9.1 | 9.4 | 8.5 |
| Algorithm | YOLOv3 | SSD | Faster R-CNN | FPN | EfficientDet | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game |
| 7 Days to Die | 1.0 | 1.0 | 0.4167 | 0.6667 | 0.5 | 0.4792 | 0.5940 | 0.7376 | 0.4167 | 0.75 |
| Sims4 | 0.7556 | 0.9182 | 0.5118 | 0.7452 | 0.3885 | 0.4973 | 0.75 | 0.8 | 0.5092 | 0.8878 |
| Animal Crossing | 0.8389 | 0.7567 | 0.65 | 0.6667 | 0.4833 | 0.6167 | 0.4636 | 0.7882 | 0.5524 | 0.85 |
| Asphalt8 | 0.375 | 1.0 | 0.75 | 1.0 | 0.1875 | 0.725 | 0.75 | 1 | 0.375 | 0.875 |
| FIFA 20 | 1.0 | 1.0 | 0.8725 | 0.7857 | 0.6428 | 0.7143 | 0.6694 | 0.75 | 1.0 | 1.0 |
| Doraemon | 0.5222 | 0.8778 | 0.2056 | 0.57 | 0.3167 | 0.4667 | 0.1333 | 0.875 | 0.1667 | 0.9444 |
| Left 4 Dead 2 | 0.9444 | 0.9724 | 0.1944 | 0.67 | 0.056 | 0.215 | 0.5 | 0.875 | 0.2222 | 1.0 |
| Gangstar | 1.0 | 1.0 | 0.5833 | 0.9583 | 0.6667 | 0.4431 | 1 | 1 | 0.8333 | 0.9167 |
| Average | 0.8045 | 0.9406 | 0.5230 | 0.7578 | 0.4051 | 0.4973 | 0.6076 | 0.8376 | 0.5092 | 0.9029 |
| Algorithm | YOLOv3 | SSD | Faster R-CNN | FPN | EfficientDet | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | MS | MS + Game | MS | MS + Game | MS | MS + Game | MS | MS + Game | MS | MS + Game |
| 7 Days to Die | 0.88 | 0.9 | 0.75 | 1 | 0.7457 | 0.8 | 0.5 | 0.8 | 0.4792 | 0.9 |
| Sims4 | 0.3511 | 0.7984 | 0.45 | 0.5961 | 0.5643 | 0.725 | 0.6697 | 0.8361 | 0.75 | 1 |
| Animal Crossing | 0.6731 | 0.8030 | 0.6694 | 0.7576 | 0.4636 | 0.639 | 0.4337 | 0.8394 | 0.5758 | 0.875 |
| Asphalt8 | 0.7781 | 1 | 0.75 | 1 | 0.6964 | 0.875 | 0.6786 | 0.875 | 0.7143 | 1 |
| FIFA 20 | 0.8712 | 0.9286 | 0.748 | 1 | 0.8571 | 0.7857 | 1 | 1 | 0.8571 | 1 |
| Doraemon | 0.3871 | 0.7202 | 0 | 0.5523 | 0.2762 | 0.526 | 0.1333 | 0.6667 | 0.4 | 0.8 |
| Left 4 Dead 2 | 0.6153 | 0.9218 | 0.5833 | 0.814 | 0.2857 | 0.4464 | 0.875 | 1 | 0.875 | 0.875 |
| Gangstar | 0.8914 | 1 | 0.4431 | 0.9583 | 0.9135 | 0.9689 | 0.579 | 0.875 | 1 | 0.8571 |
| Average | 0.6809 | 0.8840 | 0.54923 | 0.8348 | 0.6003 | 0.7208 | 0.6087 | 0.8615 | 0.7064 | 0.9134 |
| Algorithm | YOLOv3 | SSD | Faster R-CNN | FPN | EfficientDet | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game |
| 7 Days to Die | 0.7237 | 0.7889 | 0.3938 | 0.6944 | 0.3010 | 0.6389 | 0.4831 | 0.6891 | 0.3887 | 0.5566 |
| Sims4 | 0.5148 | 0.6373 | 0.3576 | 0.5955 | 0.4234 | 0.6805 | 0.5934 | 0.7605 | 0.1911 | 0.4830 |
| Animal Crossing | 0.5001 | 0.6810 | 0.3632 | 0.3545 | 0.3369 | 0.6949 | 0.2891 | 0.7732 | 0.3985 | 0.5974 |
| Asphalt8 | 0.5560 | 0.7941 | 0.6482 | 0.8289 | 0.2516 | 0.7057 | 0.8099 | 0.8946 | 0.3506 | 0.6062 |
| FIFA 20 | 0.7857 | 0.7741 | 0.7870 | 0.8500 | 0.8005 | 0.7445 | 0.8472 | 0.6860 | 0.5950 | 0.5752 |
| Doraemon | 0.3818 | 0.6303 | 0.1664 | 0.6231 | 0.0927 | 0.8656 | 0.1719 | 0.8507 | 0.1644 | 0.4516 |
| Left 4 Dead 2 | 0.5214 | 0.6769 | 0.2828 | 0.6345 | 0.3825 | 0.7308 | 0.5894 | 0.7454 | 0.0917 | 0.0905 |
| Gangstar | 0.7536 | 0.8033 | 0.6503 | 0.7352 | 0.6113 | 0.7334 | 0.7503 | 0.7966 | 0.4308 | 0.4751 |
| Average | 0.5689 | 0.7299 | 0.4354 | 0.5462 | 0.3999 | 0.7243 | 0.2803 | 0.4935 | 0.5668 | 0.7745 |
| Algorithm | YOLOv3 | SSD | Faster R-CNN | FPN | EfficientDet | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | MS | MS + Game | MS | MS + Game | MS | MS + Game | MS | MS + Game | MS | MS + Game |
| 7 Days to Die | 0.3972 | 0.5024 | 0.5823 | 0.6964 | 0.3624 | 0.6551 | 0.3672 | 0.6691 | 0.3643 | 0.7183 |
| Sims4 | 0.4129 | 0.6891 | 0.2852 | 0.4767 | 0.3531 | 0.6805 | 0.3114 | 0.4648 | 0.6419 | 0.8419 |
| Animal Crossing | 0.2382 | 0.5830 | 0.2403 | 0.3174 | 0.4427 | 0.6949 | 0.3109 | 0.5789 | 0.3234 | 0.4371 |
| Asphalt8 | 0.4817 | 0.9184 | 0.5495 | 0.4665 | 0.5717 | 0.7832 | 0.4858 | 0.7133 | 0.5428 | 0.8873 |
| FIFA 20 | 0.6942 | 0.6516 | 0.5424 | 0.7304 | 0.7435 | 0.6486 | 0.5299 | 0.4262 | 0.7177 | 0.6830 |
| Doraemon | 0.4242 | 0.5027 | 0 | 0.1132 | 0.0513 | 0.5632 | 0.1031 | 0.1574 | 0.2873 | 0.5719 |
| Left 4 Dead 2 | 0.4144 | 0.5956 | 0.3706 | 0.4209 | 0.3337 | 0.4408 | 0.1824 | 0.1684 | 0.5588 | 0.5985 |
| Gangstar | 0.7611 | 0.8215 | 0.5515 | 0.8694 | 0.6043 | 0.6125 | 0.6448 | 0.7374 | 0.5224 | 0.6730 |
| Average | 0.4779 | 0.6580 | 0.3902 | 0.5114 | 0.4328 | 0.6349 | 0.3669 | 0.4894 | 0.4948 | 0.6751 |
| Algorithm | YOLOv3 | SSD | Faster R-CNN | FPN | EfficientDet | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game |
| average IoU | 0.5689 | 0.7299 | 0.4354 | 0.5462 | 0.3999 | 0.7243 | 0.2803 | 0.4934 | 0.3263 | 0.4795 |
| precision | 0.9222 | 0.9375 | 0.9821 | 0.5627 | 0.9333 | 0.9255 | 0.8571 | 0.9896 | 0.6508 | 0.7763 |
| recall | 0.8557 | 0.9278 | 0.5670 | 0.7143 | 0.5773 | 0.8969 | 0.6990 | 0.9223 | 0.4227 | 0.6082 |
| F1 score | 0.8877 | 0.9326 | 0.7190 | 0.7778 | 0.7134 | 0.9110 | 0.7701 | 0.9548 | 0.5125 | 0.6821 |
| accuracy | 0.7981 | 0.8738 | 0.5612 | 0.6364 | 0.5545 | 0.8365 | 0.6261 | 0.9135 | 0.3445 | 0.5175 |
| Algorithm | YOLOv3 | SSD | Faster R-CNN | FPN | EfficientDet | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | MS | MS + Game | MS | MS + Game | MS | MS + Game | MS | MS + Game | MS | MS + Game |
| average IoU | 0.4779 | 0.6580 | 0.3902 | 0.5114 | 0.4328 | 0.6349 | 0.3669 | 0.4894 | 0.4948 | 0.6751 |
| precision | 0.9028 | 0.9740 | 0.9403 | 0.9383 | 0.9836 | 0.9775 | 0.9231 | 0.9870 | 0.8364 | 0.8772 |
| recall | 0.6311 | 0.7282 | 0.6117 | 0.7379 | 0.5825 | 0.8447 | 0.6990 | 0.7379 | 0.4466 | 0.4854 |
| F1 score | 0.7429 | 0.8333 | 0.7412 | 0.8261 | 0.7317 | 0.9062 | 0.7956 | 0.8444 | 0.5823 | 0.6250 |
| accuracy | 0.5909 | 0.7143 | 0.5888 | 0.7037 | 0.5769 | 0.8286 | 0.6606 | 0.7308 | 0.4107 | 0.4545 |
| Algorithm | YOLOv3 | SSD | Faster R-CNN | FPN | EfficientDet | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game |
| average mAP | 0.8045 | 0.9182 | 0.5118 | 0.7452 | 0.3885 | 0.4973 | 0.6076 | 0.8376 | 0.5092 | 0.8878 |
| std. dev. | 0.2396 | 0.1057 | 0.2457 | 0.1562 | 0.2196 | 0.2114 | 0.2552 | 0.1091 | 0.2864 | 0.0959 |
| p | 0.2476 | 0.0397 | 0.3301 | 0.0437 | 0.0063 | |||||
| Not | Distinguished | Not | Distinguished | Distinguished | ||||||
| Not | Not | Not | Not | Distinguished | ||||||
| Algorithm | YOLOv3 | SSD | Faster R-CNN | FPN | EfficientDet | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | MS | MS + Game | MS | MS + Game | MS | MS + Game | MS | MS + Game | MS | MS + Game |
| average mAP | 0.6809 | 0.8840 | 0.5492 | 0.8348 | 0.6003 | 0.7208 | 0.7064 | 0.9134 | 0.6087 | 0.8615 |
| std. dev. | 0.2168 | 0.1009 | 0.2559 | 0.1853 | 0.2445 | 0.1756 | 0.2076 | 0.0771 | 0.2678 | 0.1079 |
| p | 0.0372 | 0.0228 | 0.2768 | 0.0352 | 0.0268 | |||||
| Distinguished | Distinguished | Not | Distinguished | Distinguished | ||||||
| Not | Not | Not | Not | Not | ||||||
| Algorithm | YOLOv3 | SSD | Faster R-CNN | FPN | EfficientDet | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game |
| average mAP | 0.8045 | 0.9182 | 0.5118 | 0.7452 | 0.3885 | 0.4973 | 0.6076 | 0.8376 | 0.5092 | 0.8878 |
| std. dev. | 0.1883 | 0.2326 | 0.2743 | 0.2157 | 0.2237 | |||||
| Cohen’s d | 0.8681 | 1.6031 | 2.5073 | 1.0278 | 0.7136 | |||||
| Effect size | Large | Large | Large | Large | >medium | |||||
| Algorithm | YOLOv3 | SSD | Faster R-CNN | FPN | EfficientDet | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | MS | MS + Game | MS | MS + Game | MS | MS + Game | MS | MS + Game | MS | MS + Game |
| average mAP | 0.6809 | 0.8840 | 0.5492 | 0.8348 | 0.6003 | 0.7208 | 0.7064 | 0.9134 | 0.6087 | 0.8615 |
| std. dev. | 0.1941 | 0.2614 | 0.2148 | 0.1853 | 0.2365 | |||||
| Cohen’s d | 1.0461 | 1.0924 | 1.0689 | 1.1171 | 0.5606 | |||||
| Effect size | Large | Large | Large | Large | >medium | |||||
| Algorithm | YOLOv3 | SSD | Faster R-CNN | FPN | EfficientDet | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game |
| average IoU | 0.5689 | 0.7299 | 0.4356 | 0.5462 | 0.3999 | 0.7243 | 0.5668 | 0.7745 | 0.2803 | 0.4935 |
| std. dev. | 0.1594 | 0.1398 | 0.2509 | 0.2348 | 0.2191 | 0.0665 | 0.2428 | 0.0726 | 0.1616 | 0.2064 |
| p | 0.0497 | 0.0377 | 0.0039 | 0.0490 | 0.0373 | |||||
| Distinguished | Distinguished | Distinguished | Distinguished | Distinguished | ||||||
| Not | Not | Distinguished | Not | Not | ||||||
| Algorithm | YOLOv3 | SSD | Faster R-CNN | FPN | EfficientDet | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | MS | MS + Game | MS | MS + Game | MS | MS + Game | MS | MS + Game | MS | MS + Game |
| average IoU | 0.4779 | 0.6580 | 0.3902 | 0.5114 | 0.4329 | 0.6439 | 0.3669 | 0.4894 | 0.4948 | 0.6751 |
| std. dev. | 0.1699 | 0.1480 | 0.2062 | 0.2443 | 0.2111 | 0.1011 | 0.1804 | 0.2298 | 0.1549 | 0.1438 |
| p | 0.0403 | 0.3021 | 0.0348 | 0.2554 | 0.0301 | |||||
| Distinguished | Not | Distinguished | Not | Distinguished | ||||||
| Not | Not | Not | Not | Not | ||||||
| Algorithm | YOLOv3 | SSD | Faster R-CNN | FPN | EfficientDet | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game | Pascal | Pascal + Game |
| average IoU | 0.5689 | 0.7299 | 0.4356 | 0.5462 | 0.3999 | 0.7243 | 0.5668 | 0.7745 | 0.2803 | 0.4935 |
| std. dev. | 0.1670 | 0.2416 | 0.2291 | 0.2037 | 0.2102 | |||||
| Cohen’s d | 0.9641 | 0.4586 | 1.4153 | 1.020 | 0.0142 | |||||
| Effect size | Large | >small | Large | Large | Large | |||||
| Algorithm | YOLOv3 | SSD | Faster R-CNN | FPN | EfficientDet | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | MS | MS + Game | MS | MS + Game | MS | MS + Game | MS | MS + Game | MS | MS + Game |
| average IoU | 0.4779 | 0.6580 | 0.3902 | 0.5114 | 0.4329 | 0.6439 | 0.3669 | 0.4894 | 0.4948 | 0.6751 |
| std. dev. | 0.1798 | 0.2272 | 0.1909 | 0.1718 | 0.2094 | |||||
| Cohen’s d | 1.0011 | 0.5332 | 1.0581 | 1.0494 | 0.5849 | |||||
| Effect size | Large | >medium | Large | >medium | Large | |||||
| Algorithm | YOLOv3 | SSD | Faster R-CNN | FPN | EfficientDet | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Pascal | Pascal + Augment | Pascal | Pascal + Augment | Pascal | Pascal + Augment | Pascal | Pascal + Augment | Pascal | Pascal + Augment |
| 7 Days to Die | 1.0 | 1.0 | 0.4167 | 0.3705 | 0.5 | 0.5413 | 0.5940 | 0.5415 | 0.4167 | 0.5035 |
| Sims4 | 0.7556 | 0.8125 | 0.5118 | 0.4915 | 0.3885 | 0.4124 | 0.75 | 0.8125 | 0.5092 | 0.4501 |
| Animal Crossing | 0.8389 | 0.8735 | 0.65 | 0.6413 | 0.4833 | 0.3314 | 0.4636 | 0.5315 | 0.5524 | 0.5035 |
| Asphalt8 | 0.375 | 0.4214 | 0.75 | 0.8215 | 0.1875 | 0.3641 | 0.75 | 0.8125 | 0.375 | 0.5102 |
| FIFA 20 | 1.0 | 0.8921 | 0.8725 | 0.8613 | 0.6428 | 0.6784 | 0.6694 | 0.5603 | 1.0 | 1.0 |
| Doraemon | 0.5222 | 0.6712 | 0.2056 | 0.4510 | 0.3167 | 0.5124 | 0.1333 | 0.3125 | 0.1667 | 0.4315 |
| Left 4 Dead 2 | 0.9444 | 0.9214 | 0.1944 | 0.315 | 0.056 | 0.2105 | 0.5 | 0.6124 | 0.2222 | 0.3415 |
| Gangstar | 1.0 | 0.9416 | 0.5833 | 0.6135 | 0.6667 | 0.4641 | 1 | 0.9315 | 0.8333 | 0.8145 |
| Average | 0.8045 | 0.8168 | 0.5230 | 0.5707 | 0.4051 | 0.4288 | 0.6076 | 0.6394 | 0.5092 | 0.5693 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, M.; Yang, H.; Min, K. Improving Deep Object Detection Algorithms for Game Scenes. Electronics 2021, 10, 2527. https://doi.org/10.3390/electronics10202527
Jung M, Yang H, Min K. Improving Deep Object Detection Algorithms for Game Scenes. Electronics. 2021; 10(20):2527. https://doi.org/10.3390/electronics10202527
Chicago/Turabian StyleJung, Minji, Heekyung Yang, and Kyungha Min. 2021. "Improving Deep Object Detection Algorithms for Game Scenes" Electronics 10, no. 20: 2527. https://doi.org/10.3390/electronics10202527
APA StyleJung, M., Yang, H., & Min, K. (2021). Improving Deep Object Detection Algorithms for Game Scenes. Electronics, 10(20), 2527. https://doi.org/10.3390/electronics10202527