1. Introduction
Adaptive-robust control [
1,
2,
3] is a strategy used to control processes with nonlinear dynamics, as it guarantees reference tracking and rejection of disruption by reidentifying the process model and controller each time performance degradation is detected. It requires little a priori knowledge of the process and is best suited for situations where information about system dynamics is difficult to obtain or processes are subject to various types of disruptions. However, process identification and controller tuning in close loops can be difficult to implement correctly, and the mathematical complexities may lead the control system to miss the real-time sampling deadline for fast processes. In case of processes that are exposed to a many different types of disturbances repeatedly, a combination of multimodel [
1,
4] and adaptive robust control can be used to avoid reidentification of nominal models and tuning of robust controllers. Similar to adaptive and robust philosophies, multimodel control is an approach to dealing with perturbations and changes in the operating circumstances.
Instead of trying to tune algorithms or reidentify nominal models, multimodel control stores precalculated nominal models and controllers that match various working regimes. When perturbations occur, the change in the working regime is detected through switching algorithms. The correct controller and model to use for a specific working regime is determined through the computation of a switching criterion [
5,
6,
7].
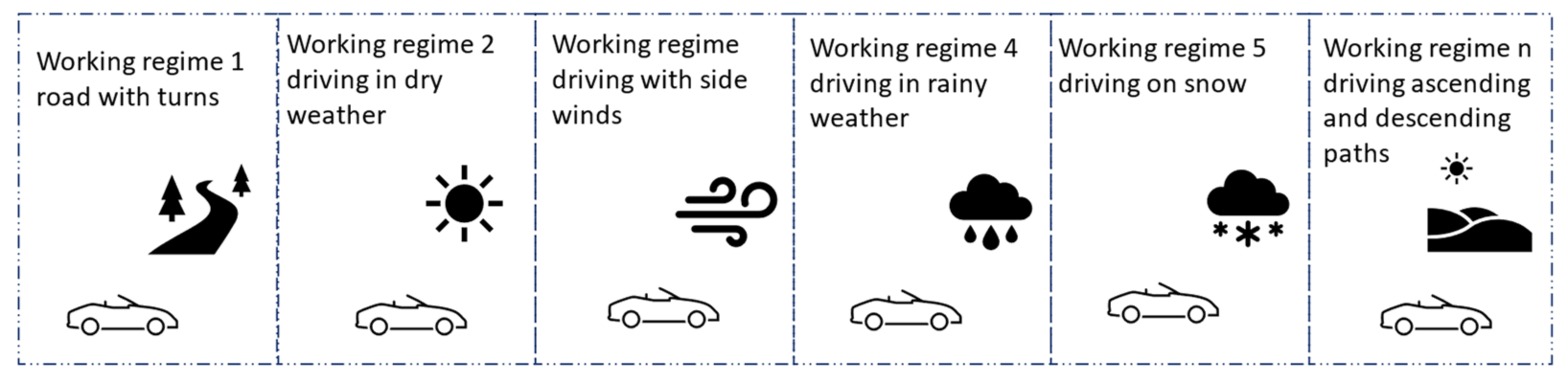
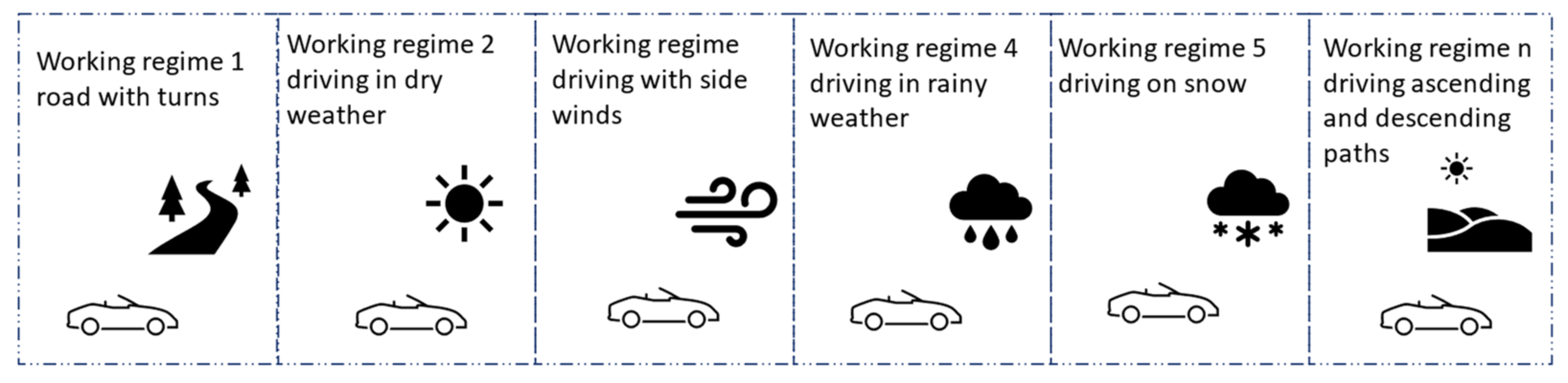
This control scheme works very well with systems that have many working regimes yet repetitive behavior. These are encountered in vehicles. One possible example is a vehicle’s suspension system, for a particular wheel. Depending on the speed, angle of movement, type of road pavement, temperature, car weight, and its weight distribution, the system behaves differently, with a different model for each working regime. Most cars tend to follow the same routes throughout their lifetime, so the repetitive nature of the perturbations is also met, as shown in
Figure 1. Another example are the components of the steering system in a plane or shuttle, such as the ailerons on wings. As the plane flies through changing atmospheric conditions and executes maneuvers, the working regime of an aileron changes, accounting for multiple possible models during a single flight trip.
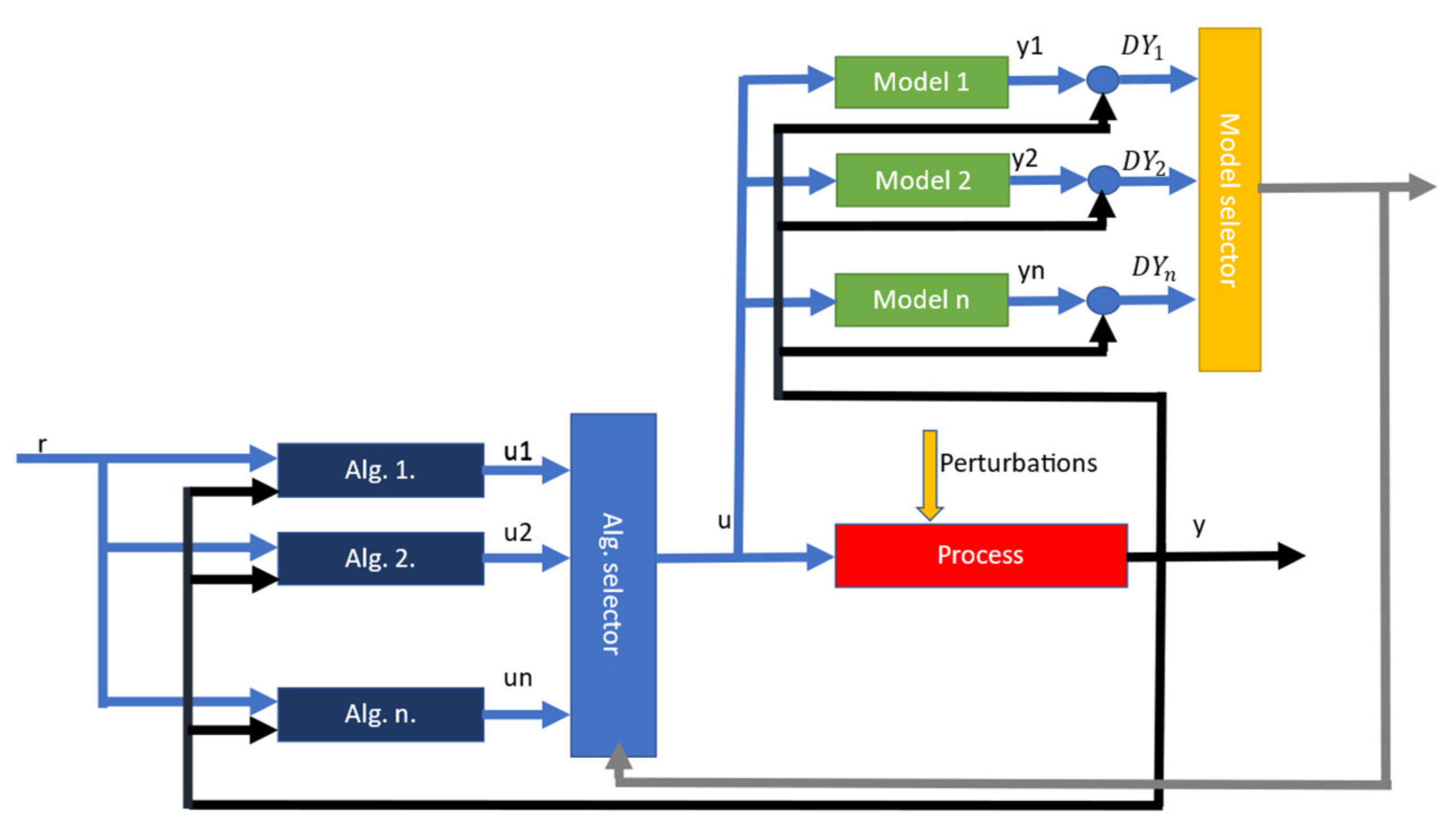
The detailed working model of the multimodel control scheme is shown in
Figure 2. When the process is exposed to perturbations, either parametric or structural, the output value y changes. This output value y is then fed into the model selector block, along with the command value u. For each model in the model selector block, an output value yn is computed using the commands and the output errors of the real process. Finally,
,
,
, and
are used to compute a switching criterion. Based on the switching criterion, a model that best matches the real process is chosen. The switching criterion is usually based on the delta between the real process output value
and the output value
of the nominal model [
5]. With the model determined, the appropriate control algorithm is chosen from the algorithm selector block, which is then finally used to issue commands to the real process.
The multimodel part consists of a knowledge base containing previously identified nominal models and their robust controllers, matching various working regimes that are subject to different types of perturbations. Switching between the current nominal model and robust controller to one in the cache is decided by calculating a switching criterion [
5], and only occurs when performance degradation is detected, a difference from the classical multimodel control philosophy, where the model switch can occur at every sampling time. If the knowledge base grows, it becomes difficult for the classical iterative approaches to compute the switching criterion for each cached nominal model and still hit the real time sampling deadline, especially when dealing with fast systems.
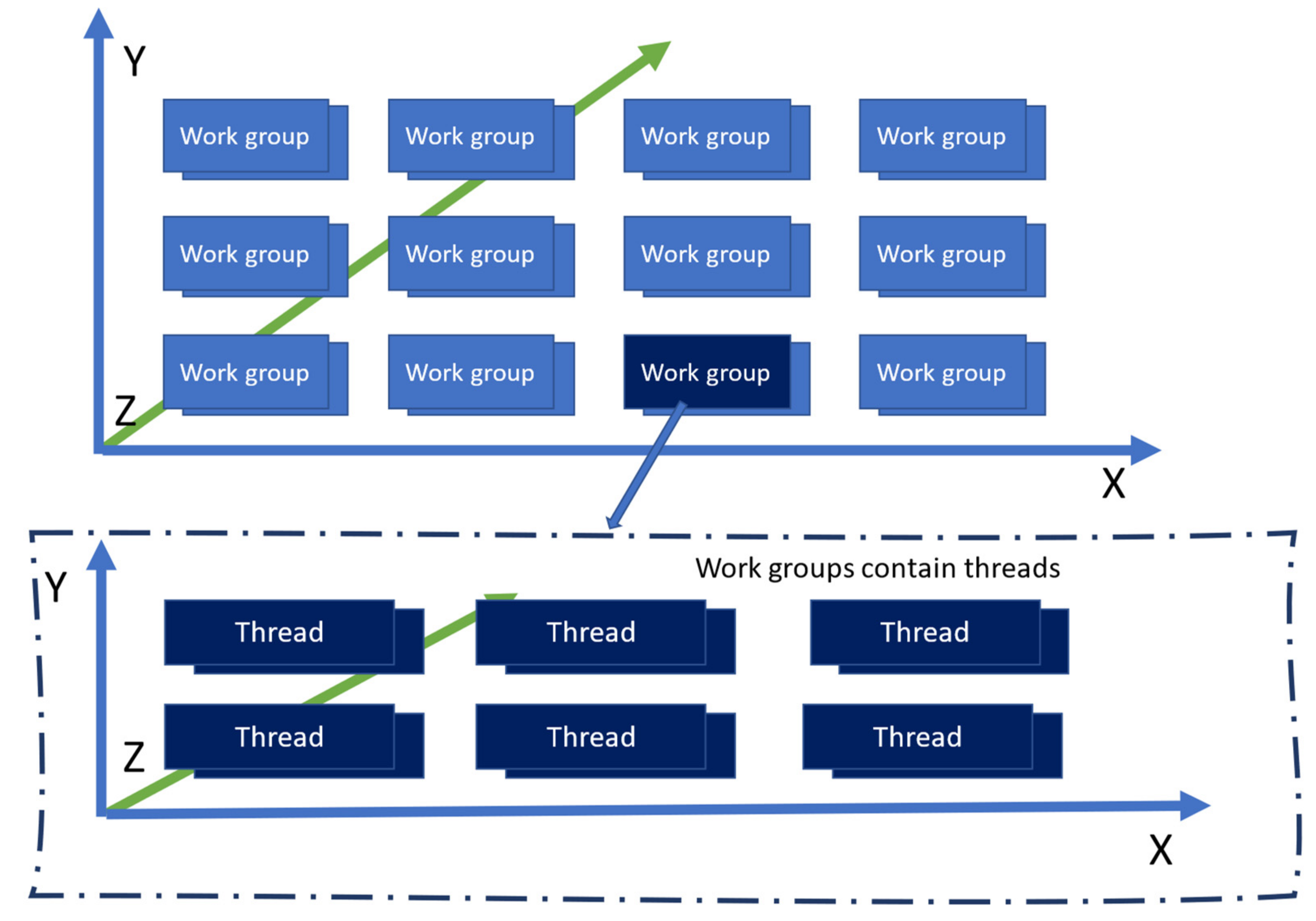
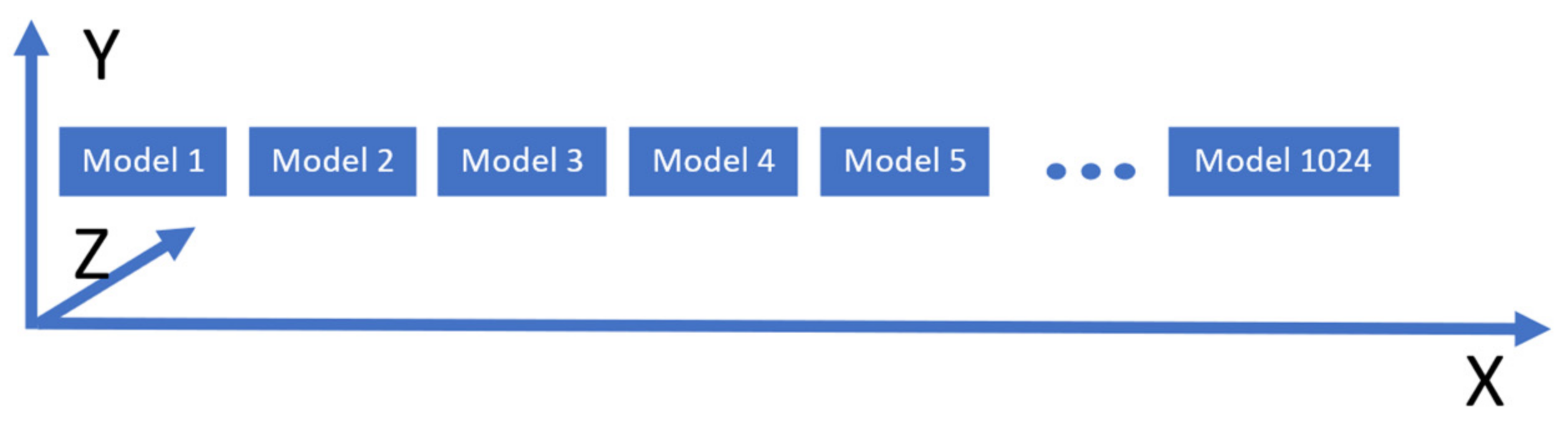
This article presents a novel approach to fixing the large knowledge base problem, by employing a graphics processing unit (GPU) to perform the calculation of the switching criterion in highly parallelized manner [
8]. As part of this new approach, the mathematical algorithms that simulate the evolution of processes (calculation of transfer function outputs in discrete form and controller command computation) have been adapted to make full use of the particularities of the GPU hardware. A software simulation was developed to showcase the results. The software can be easily modified to work with real systems.
Other approaches so far have avoided the large knowledge base issue by limiting the number of “fixed” models and initializing an adaptive model from the initial fixed model and performing continuous tuning [
9,
10]. This approach is accurate but slow and is therefore unsuitable for fast processes. The proposed approach is coarse but very fast and will be better suited for fast and slow processes alike.
The paper will first present the mathematical basis of the simulation, followed by a brief explanation on how GPUs were used in the application, and finally some simulation results. The simulation results will show that the algorithms work correctly. Although the point of the research is to deal with large numbers of models, the simulation will only show four models, to better explain how it works.
3. Results
To test the efficiency of the control scheme, a small knowledge base was used, and no dynamic filling added (as would be required for adaptive control integration). This will keep the knowledge base size constant, with three models, and the real plant would switch between them, to simulate its exposure to various types of perturbances. The switching criterion used to select the proper model is defined in (21) [
5,
23].
where
is the difference between the output of the nominal model and the output of the real plant.
[1],
[2],
[3]
represent the previous values of
, and
and
are constants chosen by the designer of the system, depending on the particularities of the models. The transfer function of the real plant, which is also the initial nominal model used in the simulation is shown in (21)
The knowledge base is prefilled with the models described in Equations (23)–(25)
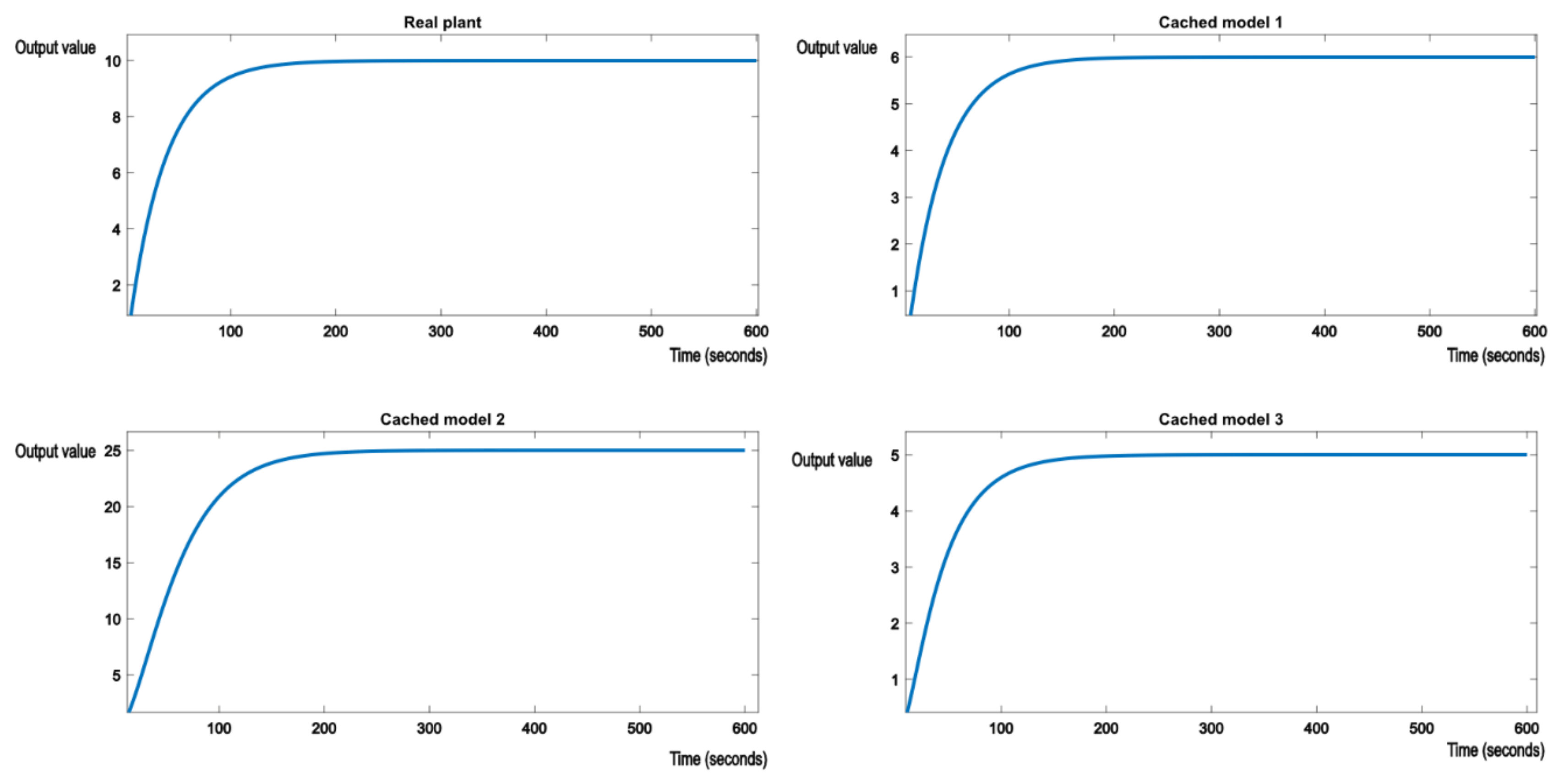
The system reference will be set to 10. It is expected that when the switch occurs from one model to another, after a brief hysteresis period, the proper nominal model, which best matches the real plant from Equations (23)–(25), will have its output stabilized around the reference value of 10.
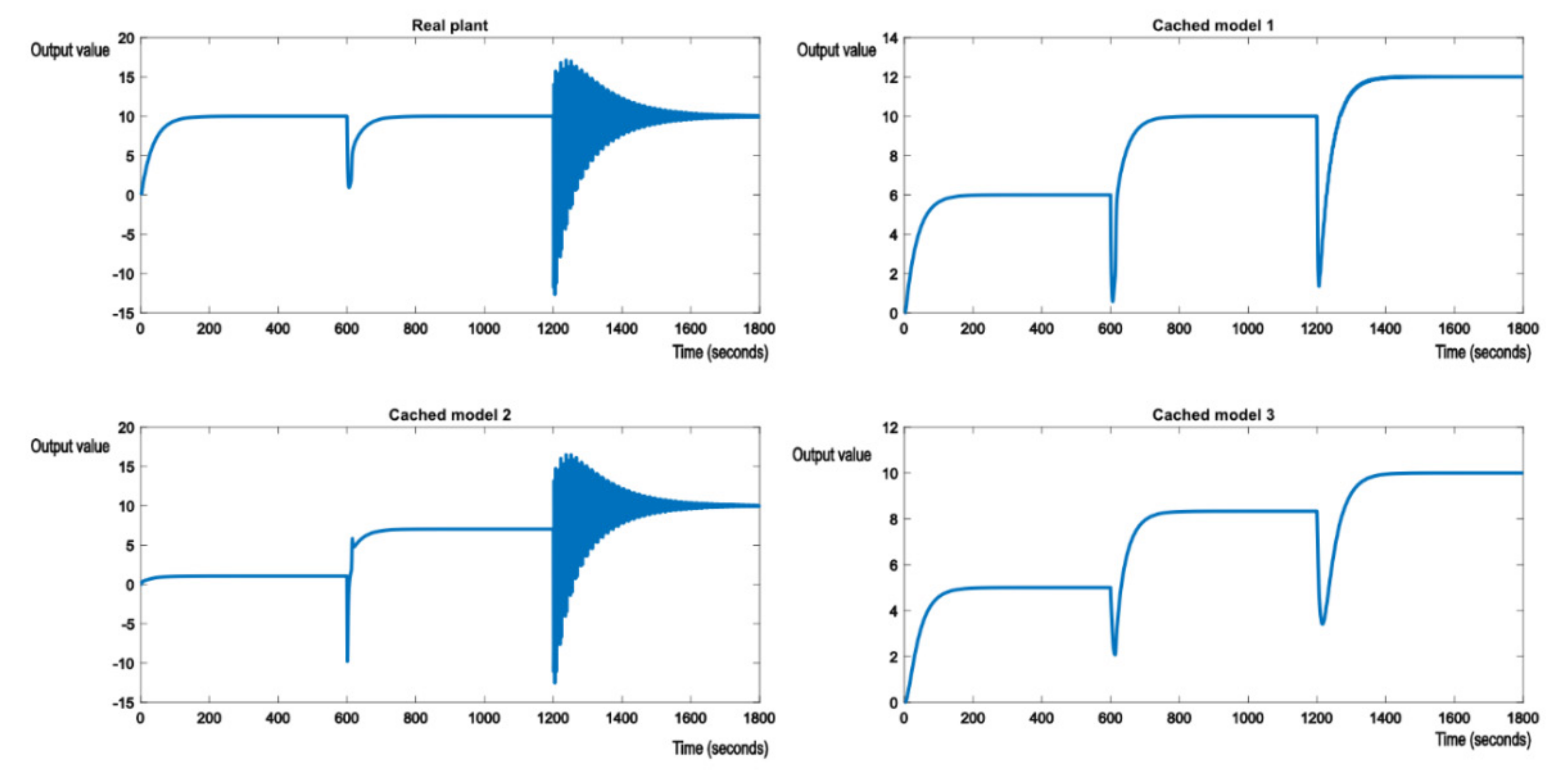
Figure 6 shows the initial evolution of the real plant and nominal models. Real plant tracks the reference value of 10 without any errors.
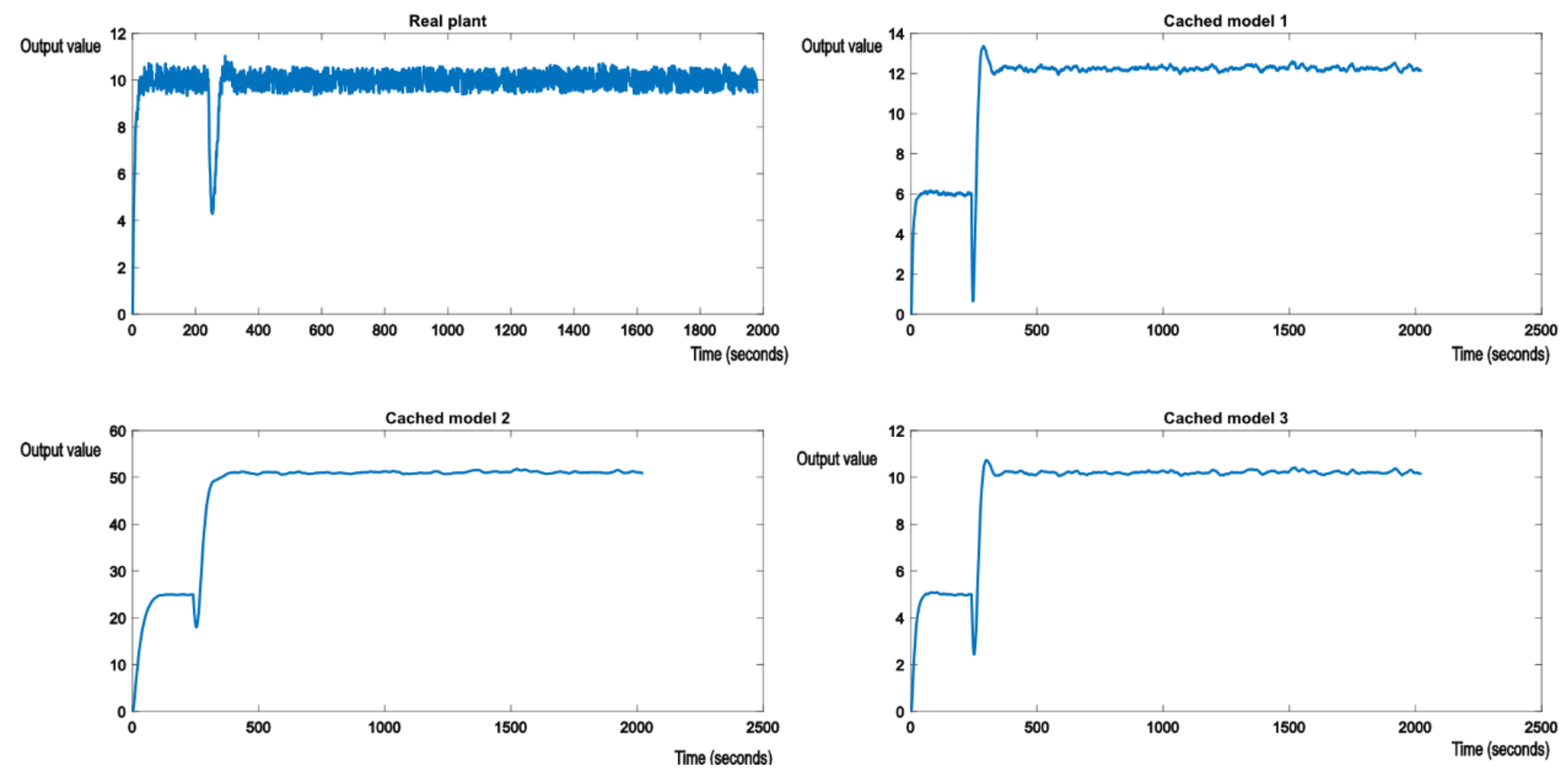
The real plan is then exposed to parametric perturbations, switching the real plant model to something like the model described in (24). For example, if our real plant would be the suspension system in a car, a sudden perturbation would be caused by degrading weather conditions. The supervisor will detect the degradation in performance and will proceed to look for a model in the knowledge base that will offer better performance. The evolution is shown in
Figure 7.
Figure 7 shows that the switching logic is working as expected and allows the system to maintain the required performance. It can also be seen that the shock of the perturbation is forwarded to the nominal models in the cache, as the output errors of the real system are passed as parameters to the GPU shader. As expected, cached model 3, which matches the transfer function (25), stabilizes at the reference value, along with the real plant. At this point, the optimal controller of (25) is also applied to the real plant, to achieve best possible performance. This is felt in the evolution of the other two cached models, which change their output values to 12 and 50.
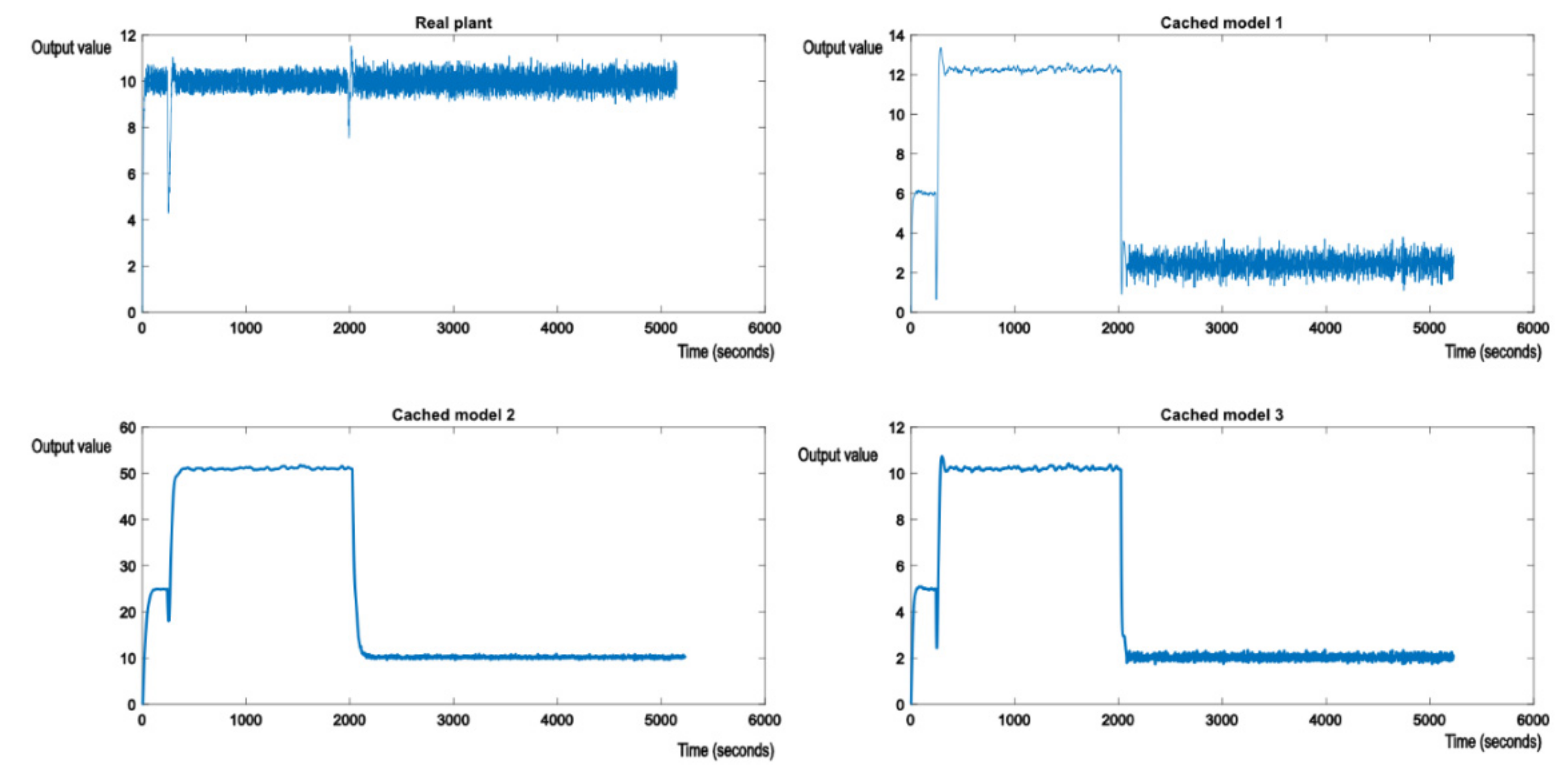
Figure 8 shows another switch in the perturbation, this time to something like the nominal model (24). The behavior is very much the same. Cached model 2, which matches model (24), stabilizes to the reference value of 10, along with the real plant.
Cached model 3, no longer offering best performance, degrades along with cached model 1 to output value 2. Similar behavior will be observed with a switch to model (24). If the output value measurement is polluted by a white noise, it can be removed through filtering. In the following examples, a moving average filter with window size 4 was applied to even out the measurement noise. This means the values of CM and CP from (1) will be applied on mean of the last four output values read.
Figure 9 shows the effect of perturbations applied to the real plant by altering its model to match (25). This is the same case as shown in
Figure 7, but with white noise affecting the measurement of the system output.
As expected, nominal model 3 from the cache will now have its value gravitating around the reference value, but not quite matching it, due to the white noise polluting the output measurements of the real plant (but at a much lower intensity). The analogue of
Figure 8 with measurement noise is shown in
Figure 10.
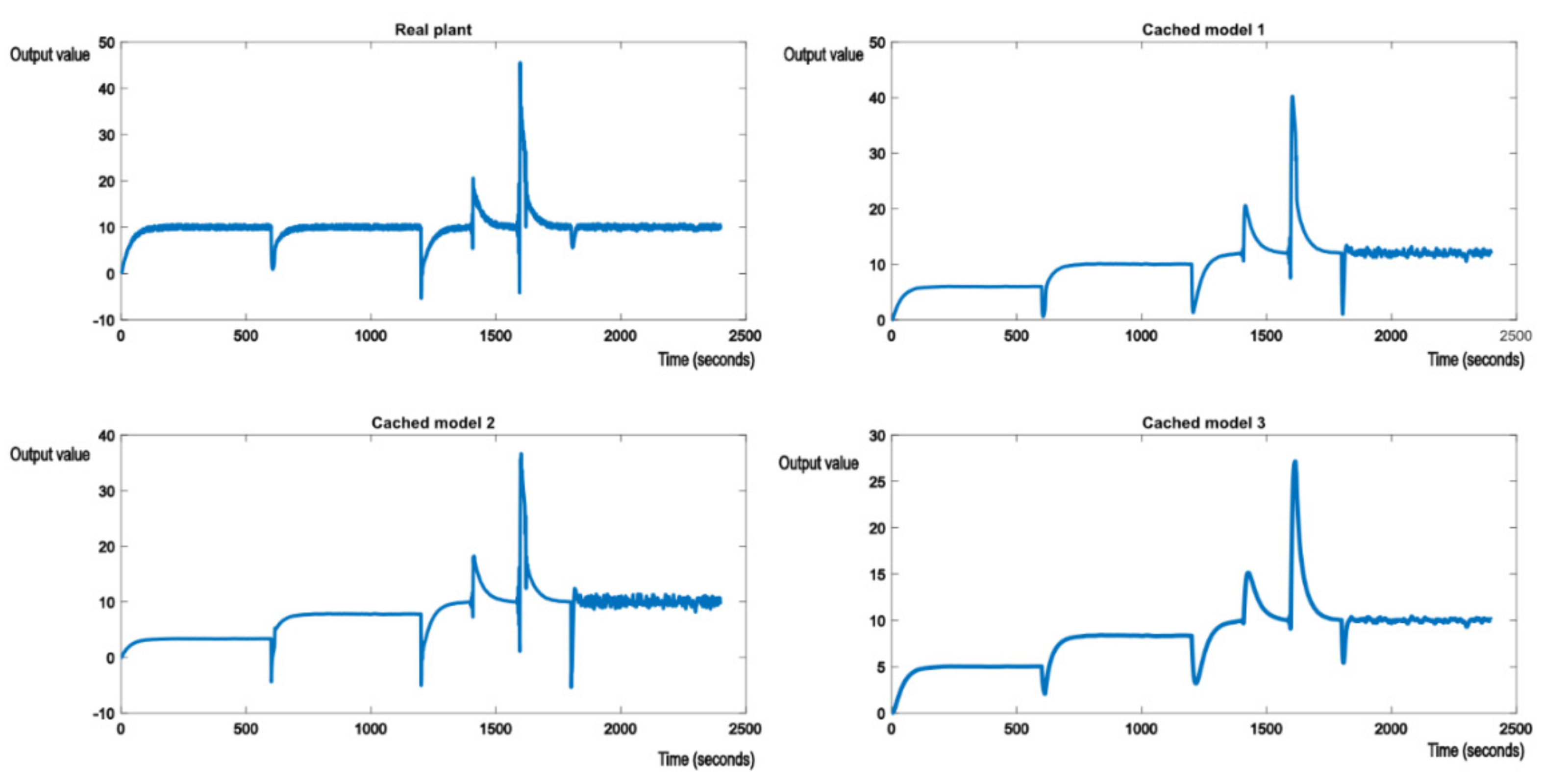
Simulating structural perturbances is achieved by having some second order systems in the nominal model knowledge base. To keep the same low number of models, the second model, cached model 2, will be replaced with various second order transfer functions.
Similar tests have been conducted to demonstrate the behavior of the control system.
Figure 11 shows the switch from the initial nominal model to cached model 1 (a parametric disturbance) to cached model 2 (a structural disturbance). The control scheme behaves as expected. First, nominal model 1 tracks the reference value, then when the structural perturbation occurs, the appropriate cached model 2 tracks the reference, signaling which model and controller was chosen by the control structure. In this case, the second order system behaves similarly to a first order system, because its poles lay on the real axis and have no imaginary components.
However, the closer the poles get to the imaginary axis, the more unstable the system becomes when doing the switch. For the following nominal model, shown in (27)
The system will show oscillations when switching, as shown in
Figure 12. This occurs because the poles of (27),
, are close to the imaginary axis, and this is known to make the system unstable, on top of the systemic shock caused by switching and disturbances. This leads to strong oscillations the moment the perturbation occurs and eventually oscillations around the reference value. Unlike oscillations caused by noisy measurements, these cannot be trivially removed using simple filters.
When dealing with noisy measurements of the output error, the MA filter is still good in case of structural perturbances, as shown in
Figure 13. Additionally,
Figure 13 shows a series of switches between various types of models, Equations (23), (25) and (26).
As far as performance is concerned, GPUs are designed to deal with large data sets. Depending on the technical specifications, a GPU can handle thousands of parallel computations of the switching criterion without performance degradations. This allows the control system to provide real time responses even for real plants that work in extremely varied working conditions.
Table 1 shows the time taken to finish the shader invocation with an increasing number of nominal models in the knowledge base. Using GPUs is therefore best in situations where the potential number of nominal models is high. Because performance is strictly tied to hardware, we can observe that execution times do not have a linear increase. For 100 and 1000 models, the execution time does not grow in a linear fashion, with only a slightly 2× increase in execution time for a 10× increase in the number of models. Things take a turn for the worse at 10,000 models copying of structured data from GPU memory to CPU memory.
4. Discussion
The premises of the research were to show that GPUs and compute shaders can be used in real time systems control. The adaptive robust multimodel control philosophy is a perfect place to apply such technologies, as the parallel nature of the GPU hardware makes it extremely easy to handle many nominal models in the knowledge base, perhaps hundreds or even thousands of nominal models, and compute the value of the switching criterion for each of them in a single shader invocation. As seen in the results section, this approach works for both parametric and structural perturbations.
It was possible to use a single shader implementation for both first and second order transfer functions. Second order transfer functions can be combined to achieve higher order functions, but it may no longer be possible to use the same shader declaration for higher order functions.
Unlike traditional programming, shaders are supposed to be simple and not contain much branching logic or iterative functions. Branching logic is supported through various instructions such as if, for, and while, but it is notoriously expensive, and many have unforeseen side effects. The recommendation is to not use branching logic unless it is unavoidable. Iterative functions are usually replaced by the parallel nature of the GPU. Implementing a universal solution for all possible kinds of models is therefore possible but remains as a future research topic on the matter.
The choice of models that form the knowledge base also has a significant impact on the behavior of this control scheme. As physical processes can be represented by several transfer functions, it is possible that the chosen model from the knowledge base will not always be the expected one. If its robust controller provides decent performance, then it will be deemed good enough by the supervisor. This is because the robustness margin from (1) creates a zone of stability around nominal models, and any other model that fits in that zone will be a good match for the robust controller (although maybe not optimal). This can be adjusted by using a different criterion for detecting performance degradation.
Another important aspect regarding the choice of models is stability. The results show that poorly dumped or undumped models will introduce instability, and this instability is further augmented by the shock of switching. This control scheme is therefore not suitable for handling such models, but this is not related to the use of GPUs.
Output measurement noise was filtered out using a moving average filter. This worked very well, as seen in the results section, but it may not always be the best choice. Assuming more information is known about the system and the type of disturbances it may encounter, other time domain filters like band pass biquad filters or other time domain IIR filters may be used for removing the noise.
The potential applicability of compute shaders in real time control is extensive. Most modern vehicles now come equipped with GPU hardware, as infotainment systems or state of the art car status systems no longer use mechanical knobs or gauges but use high resolution displays and touchscreens to show information to drivers, sometimes even in 3D. This requires powerful GPU hardware that can keep up with real time considerations. The GPUs can potentially be used to keep track of the many electronic control units in modern cars and act as powerful supervisors over the good functioning of cars. Future research will explore the usability of compute shaders in fault detection and recovery.
As performance scales very well with a large number of models in the knowledge base, the GPU approach makes it possible to use multimodel control with a large knowledge base for fast systems, where the sampling period imposes a hard limit on the number of models, as traditional CPUs will have limited scalability due to a lower number of cores.
5. Conclusions
This article presented the use of graphics processing units in real time adaptive robust multimodel control, which is best suited for processes that may encounter repetitive types of parametric or structural perturbances. The multimodel aspect of this implementation is based on a knowledge base of previously discovered nominal models and their robust controllers. Graphics processing units are designed to deal with massive parallel computations and are extremely proficient at dealing with large knowledge bases, containing hundreds or thousands of models matching various types of perturbances that the real process may encounter during its function. The knowledge base can be filled in advance, depending on the knowledge on the functional environment of the plant, or it can be combined with an adaptive closed loop identification algorithm that discovers new working models for the plant and fills in the knowledge base in real time.
The results section showed how the control scheme would behave when dealing with parametric and structural perturbances, both with and without output measurement noise. The algorithms performed as expected, showing that graphics processing units and compute shaders can be used in real time control.
Future research will focus on implementing the control model on physical systems and implementing more of the adaptive-robust control scheme using the GPU. This includes implementing the PID tuning algorithms and system identification procedures on the GPU, thus removing the dependency on third party software, such as MATLAB.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}