A GAN-Based Video Intra Coding

Abstract
1. Introduction
2. Related Work
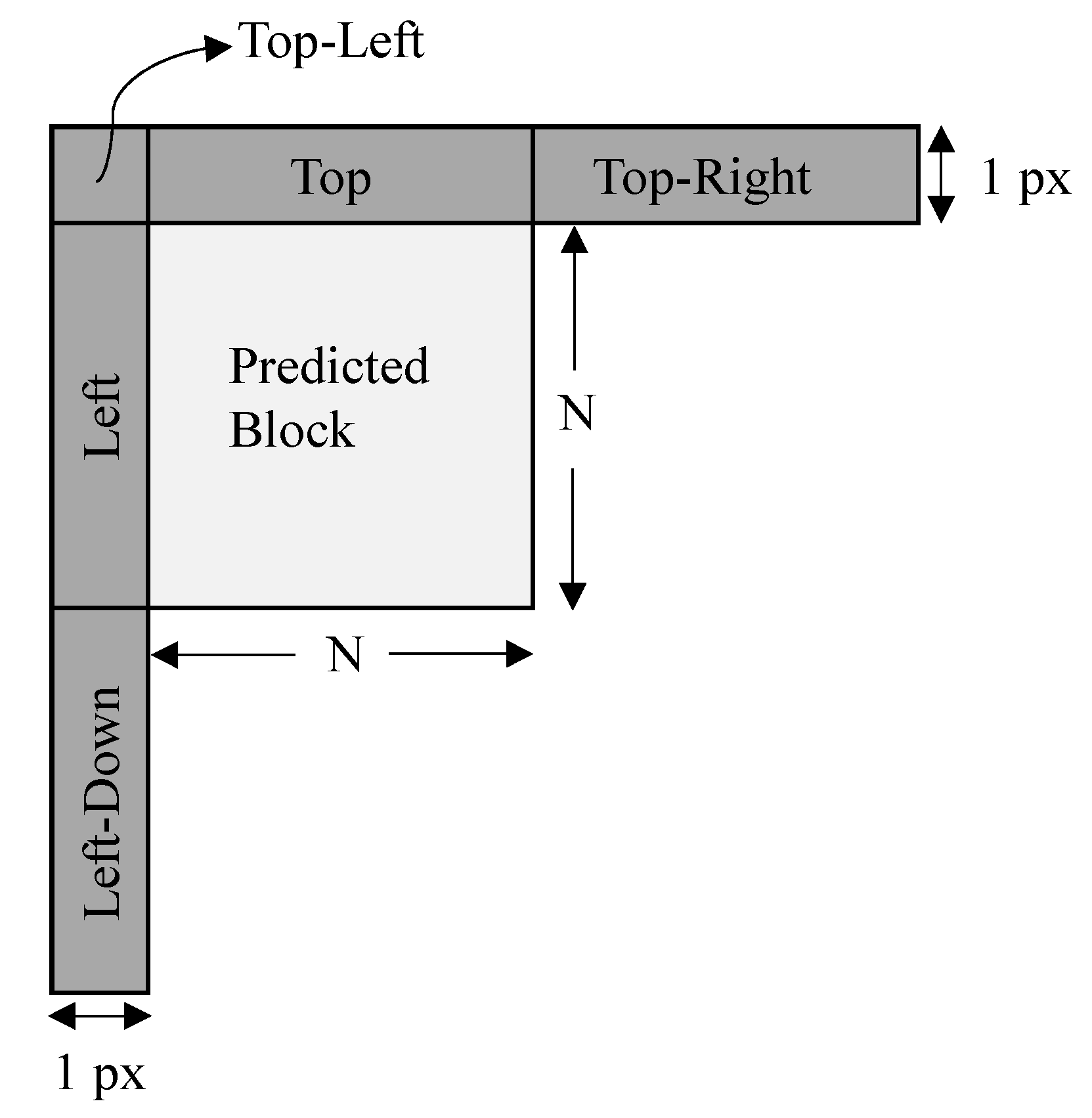
2.1. Intra Coding in Video Compression Framework
2.2. Neural Network-Based Video Coding
3. The Proposed Method
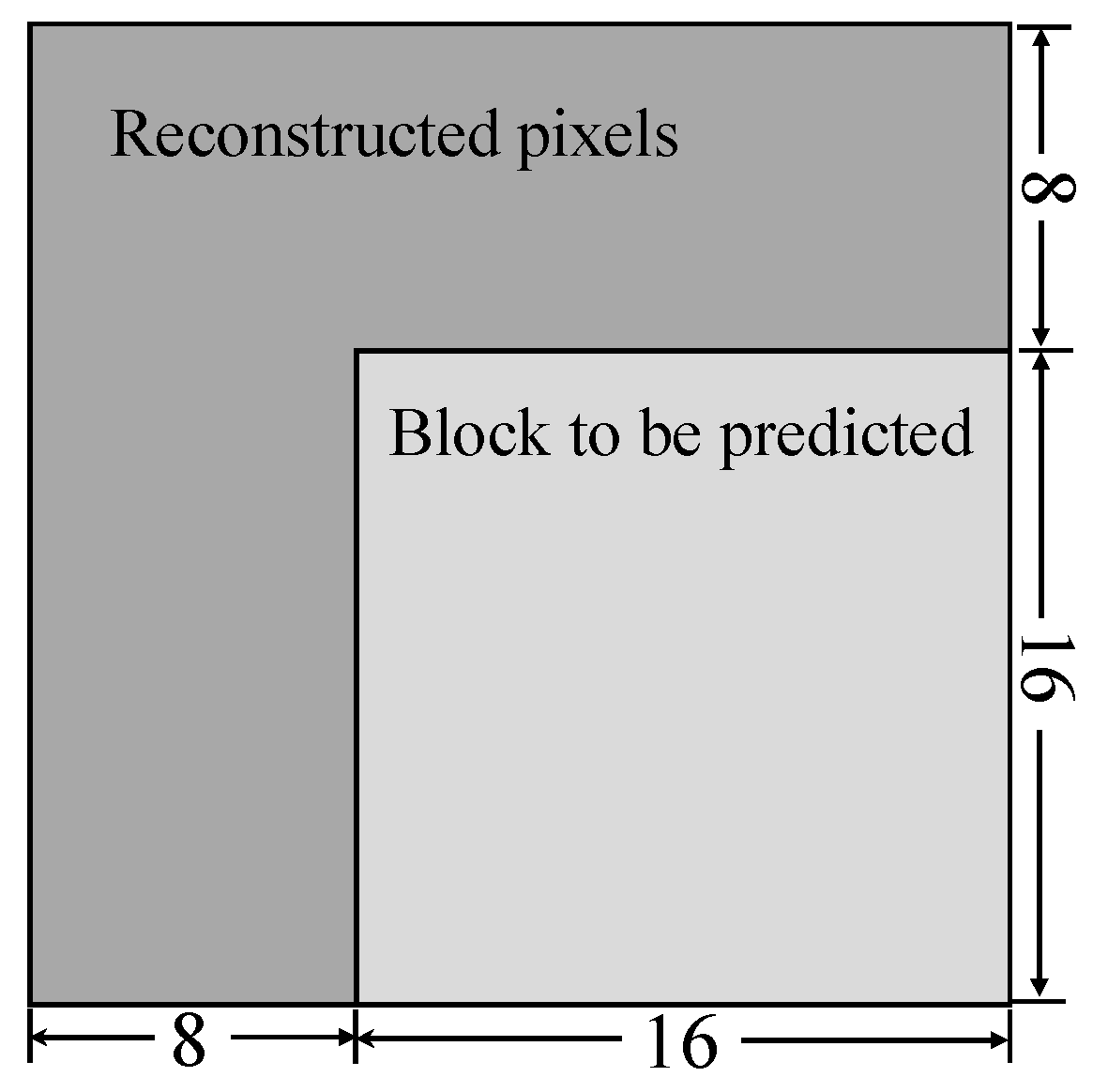
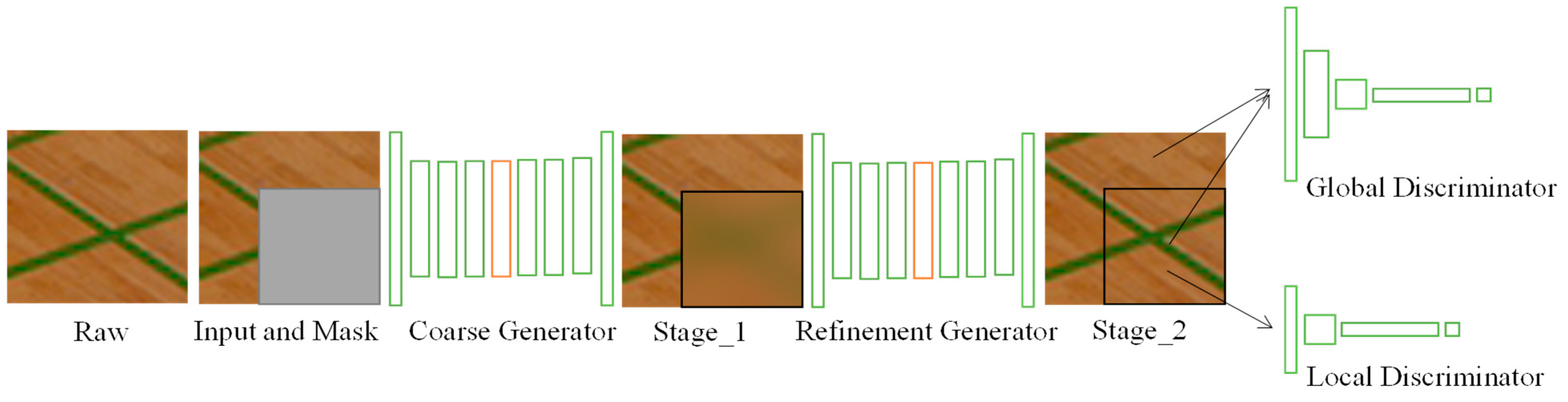
3.1. Network Architecture
3.2. Loss Function
3.3. Training Strategy
| Algorithm 1. Training Process of Generative Adversarial Networks. |
| 1: while generator is not converged do |
| 2: for i = 1, …, k do |
| 3: Fetch batch data x from raw pictures. |
| 4: Sample masks m for x. |
| 5: Corrupt inputs . |
| 6: Get predictions . |
| 7: Sample and . |
| 8: Update both discriminators with , and . |
| 9: end for |
| 10: Fetch batch data x from raw pictures. |
| 11: Sample masks m for x. |
| 12: Update generator with loss and adversarial discriminators losses. |
| 13: end while |
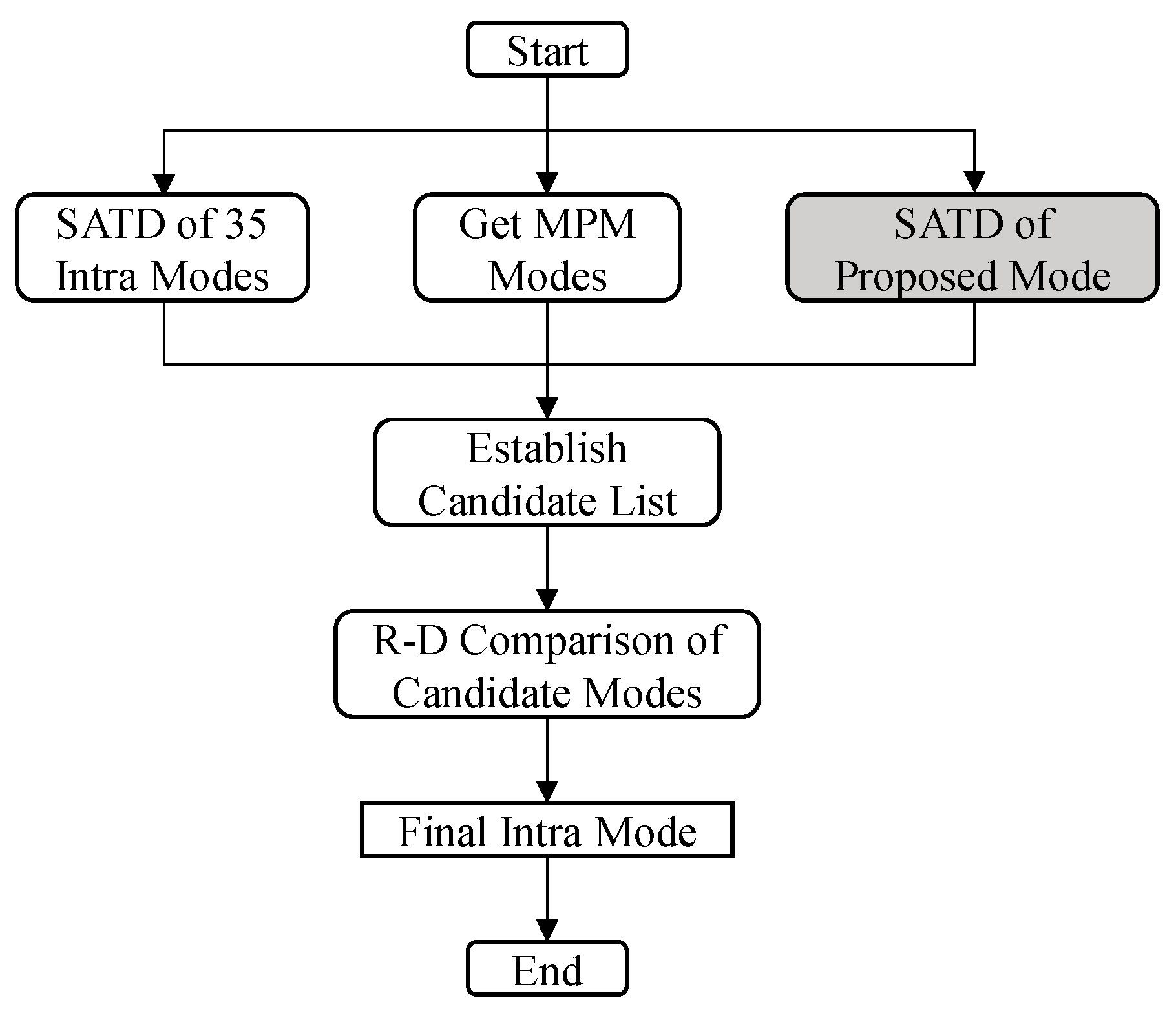
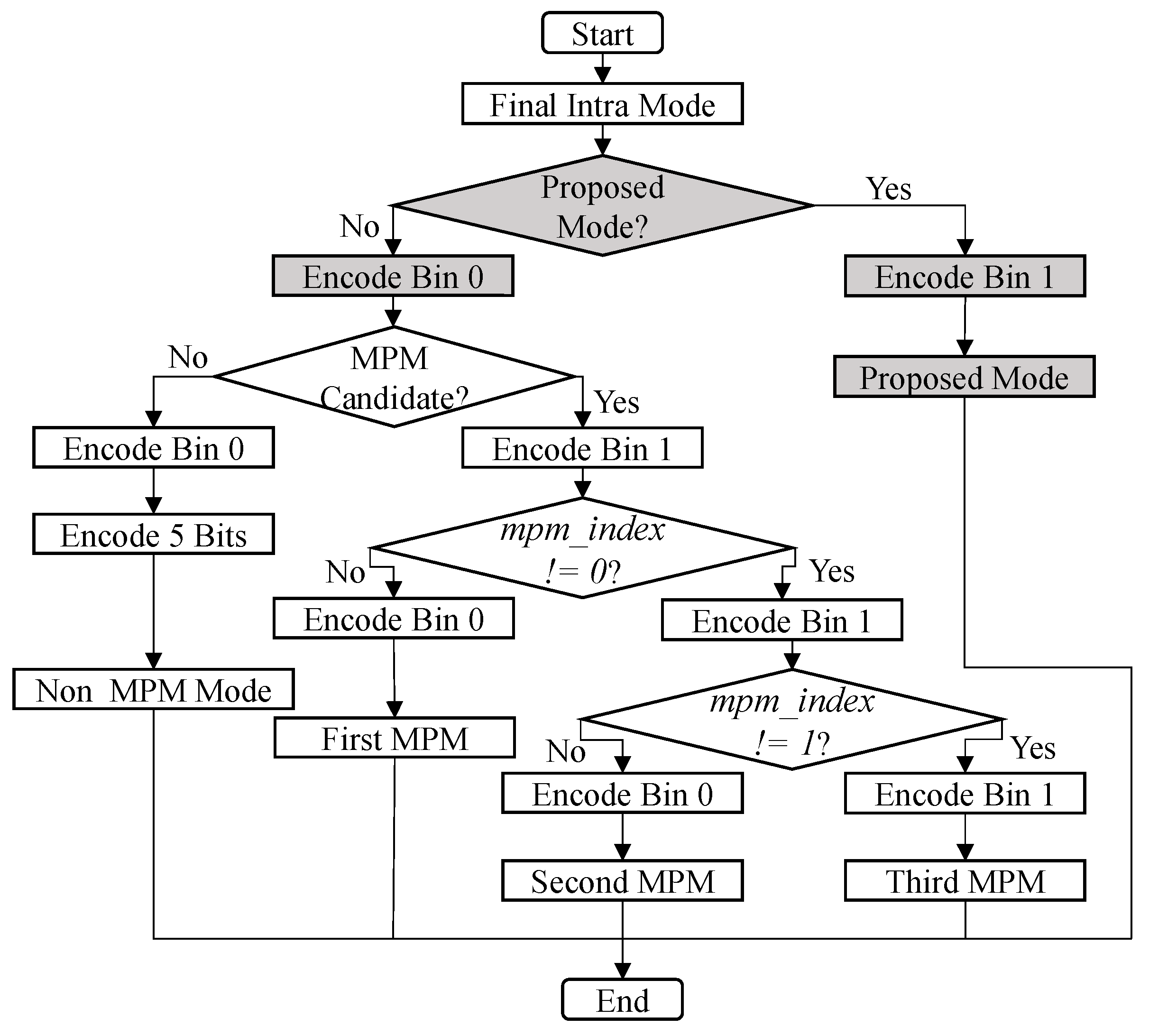
3.4. Integration of Proposed Method into HEVC
4. Experimental Results
4.1. Experimental Settings
4.2. Coding Performance of the Proposal
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kalampogia, A.; Koutsakis, P. H.264 and H.265 Video Bandwidth Prediction. IEEE Trans. Multimed. 2018, 20, 171–182. [Google Scholar] [CrossRef]
- Wiegand, T.; Sullivan, G.J.; Bjontegaard, G.; Luthra, A. Overview of the H.264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Ohm, J.-R.; Han, W.-J.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Chen, J.; Ye, Y.; Kim, S. Algorithm description for Versatile Video Coding and Test Model 10 (VTM 10 10); Doc. JVET-S2002. In Proceedings of the Teleconference (Online) Meeting, 24 June–1 July 2020. [Google Scholar]
- Pfaff, J.; Stallenberg, B.; Scahfer, M.; Merkle, P.; Helle, P.; Hinz, T.; Schwarz, H.; Marpe, D.; Wiegand, T. CE3: Affine linear weighted intra prediction (CE3-4.1, CE3-4.2). In Proceedings of the Meeting Report of the 14th Meeting of the Joint Video Experts Team (JVET), Geneva, Switzerland, 19–27 March 2019. [Google Scholar]
- Li, J.; Li, B.; Xu, J.; Xiong, R. Intra prediction using multiple reference lines for video coding. In Proceedings of the 2017 Data Compression Conference (DCC), Snowbird, UT, USA, 4–7 April 2017; pp. 221–230. [Google Scholar]
- Xu, X.; Liu, S.; Chuang, T.-D.; Huang, Y.-W.; Lei, S.; Rapaka, K.; Pang, C.; Seregin, V.; Wang, Y.-K.; Karczewicz, M. Intra Block Copy in HEVC Screen Content Coding Extensions. IEEE J. Emerg. Sel. Top. Circuits Syst. 2016, 6, 409–419. [Google Scholar] [CrossRef]
- Xu, J.; Joshi, R.; Cohen, R.A. Overview of the Emerging HEVC Screen Content Coding Extension. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 50–62. [Google Scholar] [CrossRef]
- Tan, T.K.; Boon, C.S.; Suzuki, Y. Intra prediction by template matching. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; pp. 1693–1696. [Google Scholar]
- Zhang, H.; Wang, J.; Zhong, G.; Liang, F.; Cao, J.; Wang, X.; Du, X. Rotational weighted averaged template matching for intra prediction. In Proceedings of the 2019 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Bangkok, Thailand, 11–14 November 2019; pp. 373–376. [Google Scholar]
- Yokoyama, R.; Tahara, M.; Takeuchi, M.; Heming, S.U.N.; Matsuo, Y.; Katto, J. CNN based optimal intra prediction mode estimation in video coding. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 4–6 January 2020; pp. 1–2. [Google Scholar]
- Santamaria, M.; Blasi, S.; Izquierdo, E.; Mrak, M. Analytic simplification of neural network based intra-prediction modes for video compression. In Proceedings of the 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), London, UK, 6–10 July 2020; pp. 1–4. [Google Scholar]
- Chen, Z.; Shi, J.; Li, W. Learned Fast HEVC Intra Coding. IEEE Trans. Image Process. 2020, 29, 5431–5446. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Sun, H.; Katto, J.; Zeng, X.; Fan, Y. Fast qtmt partition decision algorithm in vvc intra coding based on variance and gradient. In Proceedings of the 2019 IEEE International Conference on Visual Communications and Image Processing (VCIP), Sydney, Australia, 1–4 December 2019; pp. 1–4. [Google Scholar]
- Li, J.; Li, B.; Xu, J.; Xiong, R. Intra prediction using fully connected network for video coding. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1–5. [Google Scholar]
- Li, J.; Li, B.; Xu, J.; Xiong, R.; Gao, W. Fully Connected Network-Based Intra Prediction for Image Coding. IEEE Trans. Image Process. 2018, 27, 3236–3247. [Google Scholar] [CrossRef] [PubMed]
- Cui, W.; Zhang, T.; Zhang, S.; Jiang, F.; Zuo, W.; Zhao, D. Convolutional neural networks based intra prediction for hevc. In Proceedings of the 2017 Data Compression Conference (DCC), Snowbird, UT, USA, 4–7 April 2017; p. 436. [Google Scholar]
- Hu, Y.; Yang, W.; Xia, S.; Cheng, W.H.; Liu, J. Enhanced intra prediction with recurrent neural network in video coding. In Proceedings of the 2018 Data Compression Conference, Snowbird, UT, USA, 27–30 March 2018; p. 413. [Google Scholar]
- Hu, Y.; Yang, W.; Xia, S.; Liu, J. Optimized spatial recurrent network for intra prediction in video coding. In Proceedings of the 2018 IEEE Visual Communications and Image Processing Conference (VCIP), Taichung, Taiwan, 9–12 December 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Luo, W.; Kwong, S.; Zhang, Y.; Wang, S.; Wang, X. Generative adversarial network-based intra prediction for video coding. IEEE Trans. Multimed. 2020, 22, 45–58. [Google Scholar] [CrossRef]
- Schiopu, I.; Huang, H.; Munteanu, A. CNN-Based intra-prediction for lossless hevc. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1816–1828. [Google Scholar] [CrossRef]
- Wang, Y.; Fan, X.; Jia, C.; Zhao, D.; Gao, W. Neural Network Based Inter Prediction for HEVC. In 2018 IEEE International Conference on Multimedia and Expo (ICME); Institute of Electrical and Electronics Engineers (IEEE): San Diego, CA, USA, 2018; pp. 1–6. [Google Scholar]
- Park, W.-S.; Kim, M. CNN-based in-loop filtering for coding efficiency improvement. In Proceedings of the 2016 IEEE 12th Image, Video, and Multidimensional Signal Processing Workshop (IVMSP), Bordeaux, France, 11–12 July 2016. [Google Scholar]
- Lee, Y.-W.; Kim, J.-H.; Choi, Y.-J.; Kim, B.-G. CNN-based approach for visual quality improvement on HEVC. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 12–15 January 2018. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5892–5900. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); Institute of Electrical and Electronics Engineers (IEEE): Las Vegas, NV, USA, 2016; pp. 2536–2544. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Rippel, O.; Nair, S.; Lew, C.; Branson, S.; Anderson, A.; Bourdev, L. Learned video compression. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Chen, T.; Liu, H.; Shen, Q.; Yue, T.; Cao, X.; Ma, Z. DeepCoder: A deep neural network based video compression. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017. [Google Scholar]
- Wang, Z.; Simoncelli, E.; Bovik, A. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of wasserstein GANs. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wilson, K.; Snavely, N. Robust Global Translations with 1DSfM. In Computer Vision–ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 61–75. [Google Scholar]
- Dumas, T.; Roumy, A.; Guillemot, C. Context-Adaptive Neural Network-Based Prediction for Image Compression. IEEE Trans. Image Process. 2019, 29, 679–693. [Google Scholar] [CrossRef] [PubMed]
- The HM Reference Software for HEVC Development, Version 16.15. Available online: https://vcgit.hhi.fraunhofer.de/jct-vc/HM/-/tree/HM-16.15 (accessed on 20 November 2020).
- Sharman, K.; Suehring, K. Common Test Conditions for HM, JCTVC-Z1100. In Proceedings of the 26th JVET Meeting, Geneva, Switzerland, 12–20 January 2017. [Google Scholar]
- Bjontegaard, G. VCEG-M33: Calculation of average PSNR differences between RDcurves. In Proceedings of the ITU-T VEGC Thirteenth Meeting, Austin TX, USA, 2–4 April 2001. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Kernel | Dilation | Stride | Outputs |
|---|---|---|---|---|
| Conv. | 5 × 5 | 1 | 1 × 1 | 32 |
| Conv. | 3 × 3 | 2 × 2 | 64 | |
| Conv. | 1 × 1 | |||
| Conv. | 128 | |||
| Dilated Conv. | 2 | |||
| Conv. | 1 | |||
| Conv. | 64 | |||
| Conv. | 32 | |||
| Deconv. | 1/2 × 1/2 | 16 | ||
| Conv. | 1 × 1 | 1 |
| Type | Outputs |
|---|---|
| Conv. | 64 |
| Conv. | 128 |
| Flatten. | 2048 |
| FC. | 1 |
| Type | Outputs |
|---|---|
| Conv. | 64 |
| Conv. | 128 |
| Conv. | 128 |
| Flatten. | 1152 |
| FC. | 1 |
| Sequence | Stage_1 | Stage_2 | |
|---|---|---|---|
| Class B | Kimono | −1.5% | −2.0% |
| ParkScene | −1.1% | −1.3% | |
| Cactus | −1.4% | −1.6% | |
| BasketballDrive | −0.9% | −1.8% | |
| BQTerrace | −1.2% | −1.5% | |
| Class C | BasketballDrill | −1.1% | −1.0% |
| BQMall | −1.5% | −2.0% | |
| PartyScene | −1.1% | −1.4% | |
| RaceHorses | −1.0% | −1.3% | |
| Class D | BasketballPass | −0.8% | −1.1% |
| BQSquare | −0.8% | −0.9% | |
| BlowingBubbles | −1.0% | −1.6% | |
| RaceHorses | −1.1% | −1.4% | |
| Class E | FourPeople | −1.6% | −2.1% |
| Johnny | −1.6% | −2.3% | |
| KristenAndSara | −1.1% | −1.9% | |
| Average | −1.2% | −1.6% | |
| Sequence | FC [15] | CNN [17] | RNN [18] | RNN [19] | Stage_1 | Stage_2 | |
|---|---|---|---|---|---|---|---|
| Class B | Kimono | −3.2% | −0.2% | - | −2.8% | −1.6% | −1.9% |
| ParkScene | −1.1% | −0.8% | - | −1.7% | −1.8% | −1.9% | |
| Cactus | −0.9% | −0.8% | - | −1.2% | −1.7% | −1.9% | |
| BasketballDrive | −0.9% | −0.6% | - | −1.0% | −2.1% | −2.3% | |
| BQTerrace | −0.5% | −0.8% | - | −1.0% | −1.3% | −1.4% | |
| Average of Class B | −1.3% | −0.8% | −0.2% | −1.5% | −1.7% | −1.9% | |
| Class C | BasketballDrill | −0.3% | −0.5% | - | −1.0% | −1.0% | −0.9% |
| BQMall | −0.3% | −0.6% | - | −0.8% | −1.4% | −1.6% | |
| PartyScene | −0.4% | −0.5% | - | −1.0% | −1.5% | −1.7% | |
| RaceHorses | −0.8% | −0.7% | - | −1.1% | −1.5% | −1.8% | |
| Average of Class C | −0.5% | −0.6% | −0.2% | −1.0% | −1.4% | −1.5% | |
| Class D | BasketballPass | −0.4% | −0.4% | - | −0.8% | −1.1% | −1.3% |
| BQSquare | −0.2% | −0.1% | - | −0.6% | −0.8% | −0.8% | |
| BlowingBubbles | −0.6% | −0.7% | - | −1.0% | −1.2% | −1.3% | |
| RaceHorses | −0.6% | −0.7% | - | −1.1% | −2.0% | −2.3% | |
| Average of Class D | −0.5% | −0.5% | −0.1% | −0.9% | −1.3% | −1.4% | |
| Class E | FourPeople | −0.8% | −0.3% | - | −2.2% | −1.5% | −1.6% |
| Johnny | −1.0% | −1.0% | - | −1.5% | −1.7% | −2.3% | |
| KristenAndSara | −0.8% | −0.8% | - | −1.3% | −1.2% | −1.8% | |
| Average of Class E | −0.9% | −0.7% | −0.8% | −1.7% | −1.4% | −1.9% | |
| Overall Average | −0.8% | −0.7% | −0.3% | −1.3% | −1.4% | −1.7% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, G.; Wang, J.; Hu, J.; Liang, F. A GAN-Based Video Intra Coding. Electronics 2021, 10, 132. https://doi.org/10.3390/electronics10020132
Zhong G, Wang J, Hu J, Liang F. A GAN-Based Video Intra Coding. Electronics. 2021; 10(2):132. https://doi.org/10.3390/electronics10020132
Chicago/Turabian StyleZhong, Guangyu, Jun Wang, Jiyuan Hu, and Fan Liang. 2021. "A GAN-Based Video Intra Coding" Electronics 10, no. 2: 132. https://doi.org/10.3390/electronics10020132
APA StyleZhong, G., Wang, J., Hu, J., & Liang, F. (2021). A GAN-Based Video Intra Coding. Electronics, 10(2), 132. https://doi.org/10.3390/electronics10020132