1. Introduction
Autonomy underwater has until recently been limited to use-cases where localization and navigation can be based on sensors which exhibit positional drifts such as Doppler Velocity Logs (DVLs), compasses and IMUs. Such inaccurate localization methods are not suitable for intervention, inspection and maintenance use-cases where accurate localization is key. Underwater optical (3D) imaging has opened up possibilities for providing high-density information of the AUV surroundings, which is an enabler for accurate detection and 6DoF localization of objects. 6DoF localization refers to estimating a transformation that maps an object from object to camera coordinate system (three degrees for translation and rotation). In terrestrial applications, deep learning on 3D images has revolutionized detection and localization [
1]. However, its application and performance for object detection and localization on underwater imagery has not been explored to the same degree. In this paper, we propose a deep learning based network for 6DoF localization of known objects using underwater 3D range-gated images.
There are a range of 2D and 3D vision systems that can be used to solve a wide range of applications on ROVs and AUVs. However, water turbidity, absorption and scattering or colour distortion often limits the use of standard 2D and 3D vision systems as a solution to the problem of vision-based subsea object detection and pose estimation. Numerous optical 3D vision systems have been proposed for the purpose of subsea object detection, such as structured light and stereo-vision [
2]. Stereo-vision has the advantage of being a relatively simple and cost-effective approach for underwater 3D object detection. However, such approaches tend to struggle with limited viewing distance and water turbidity, which smear out the image details that are used for object detection and pose estimation. To improve the chances of detecting subsea objects and estimate object pose more precisely, this paper proposes to equip ROVs and AUV with a range-gated 3D camera (Utofia), which is described in detail in [
3]. The advantage of the 3D range-gated camera is the combination of depth resolution, field of view, real-time 3D acquisition (10 Hz), and its resistance to turbidity makes it ideal for real-time subsea object detection, localization and pose estimation.
From an algorithmic perspective, 3D vision-based pose estimation approaches focus on matching an extracted region of interest in an image or point cloud with a template CAD model to estimate the 6D pose [
4]. Although such approaches achieve good 6D pose estimation accuracy, the computational complexity increases linearly with the number of objects. Furthermore, they require an object segmentation algorithm for cropping object of interest as a pre-processing step and compute 6D pose for each object individually. Therefore, such approaches are not well suited for multi-object 6D pose estimation due to runtime limitations. In this paper, we propose a deep learning model that takes 3D data which does not encounter these issues. The proposed deep learning model is able to detect and estimate 6D-pose estimation under different turbidity in an end-to-end fashion using 3D data.
Next, we review existing methods related to the topic of deep learning for object detection and pose estimation for 3D data. Our review here is intended to highlight the broad approaches of existing 6D pose estimation algorithms for underwater and terrestrial applications, and to provide appropriate background for our work.
Terrestrial 6D pose estimation: Based on the sensor, 6D pose estimation can be roughly divided into two groups: 2D vision and 3D vision based 6D pose estimation. 2D vision based approaches rely on 2D image data to predict 6D pose. PoseCNN [
5] proposes a two stage process. The first stage extracts feature maps with different resolutions from the input image. This stage is the backbone of the network since the extracted features are shared across all the tasks performed by the network. The second stage consists of embedding the high-dimensional feature maps generated by the first stage into low-dimensional, task specific features. Then, the network performs three different tasks that lead to the 6D pose estimation, i.e., semantic labelling, 3D translation estimation, and 3D rotation. Using iterative closest point(ICP) as a refinement phase PoseCNN makes their 6D pose estimation accurate. In [
6], a method named CosyPose was proposed, which uses multiple views to reconstruct a scene composed of multiple objects to estimate 6D pose in three stages. In the first stage, for each view, initial object candidates are estimated separately. In the second stage, the object candidates are matched across views to recover a single consistent scene. In the third stage, object pose hypotheses across different views are jointly refined to minimize multi-view reprojection error. Bukschat et al. [
7] proposed a single stage approach, EfficientPose architecture that extends EfficientDet [
8] for 6D pose estimation by adding translation and iterative refining rotation subnetworks. In general, 2D vision based approaches are less robust for 6D pose estimation due to geometric information are partly lost due to projection, and different keypoints in 3D space may be overlapped and hard to be distinguished after projection to 2D space. On the other hand, 3D vision based approaches work on RGBD or point cloud data. Wang et al. proposed [
9] a DenseFusion method for 6D pose estimation. DenseFusion first performs image segmentation of object of interest and computes 6D pose in two stage process. In the first stage, image and geometric features are extracted by passing through a two stream network using cropped image data and point cloud, respectively. In the second stage, the RGB colours and point cloud from the depth map are encoded into embedding and fused at each corresponding pixel. The pose predictor produces a pose estimate for each pixel and the predictions are voted to generate the final 6D pose prediction of the object. In addition, it finally refines the result in an iterative procedure. In [
10], PVN3D is proposed which also has a two-stage pipeline. PVN3D extends a 2D key points to 3D key points detection followed by a pose parameters fitting module. They used a least-square fitting algorithm to the predicted keypoints to estimate 6DoF pose parameters.
Underwater 6D pose estimation: The results of previous object pose estimation mostly focus on terrestrial environments and optical vision based 6D pose estimation has not been widely used in underwater scenarios. In [
11], to deal with lack of underwater dataset, they generated a synthetic underwater dataset for pose estimation and object detection task. The pose estimation is done in two stages. Firstly, Mask R-CNN [
12] is used to detect object of interest. Secondly, the cropped object is passed through a second network for pose estimation using Euler angle representation. Miguel et al. [
13] proposed to use PointNet [
14] to recognize pipes and valves in 3D RGB point cloud information provided by a stereo camera. However, the authors do not consider realistic cases such as water turbidity. In Nielsen et al. [
15], a PoseNet architecture [
16], which regresses both position and orientation simultaneously, is explored for underwater application. Their approach takes RGB image as input and considers a single turbidity and a single object subsea connector that is connected to a metal stick.
In contrast to earlier works, the proposed model is a single stage network for fast and efficient underwater object detection and 6D pose estimation using 3D data. Furthermore, the proposed model is able to estimate 6D pose under seven different turbidity levels with 91.03% mAP and average pose deviation of 2.59. To summarize, the main contributions of this work are as follows:
The use of 3D range-gated camera for underwater 6D for efficient pose estimation.
A single stage end-to-end sub-sea object detection and 6D pose estimation deep learning model that runs 16 frames per second with 91.03% mAP and average deviation in rotation (2.59), and translation ( cm) as compared to the ground truth data over test turbidities.
Ground truth data generation setup for efficient data collection for training deep learning models and a labelled dataset containing six underwater objects such as valves, fish-tails etc. with a total of 30 K frames.
This paper is structured as follows.
Section 2 describes experimental setup for data acquisition and automated data labelling procedure.
Section 3 describes the study methodology to estimate object pose using 3D vision data.
Section 4 presents and analyses the results with discussion on dataset bias analysis.
3. Methods
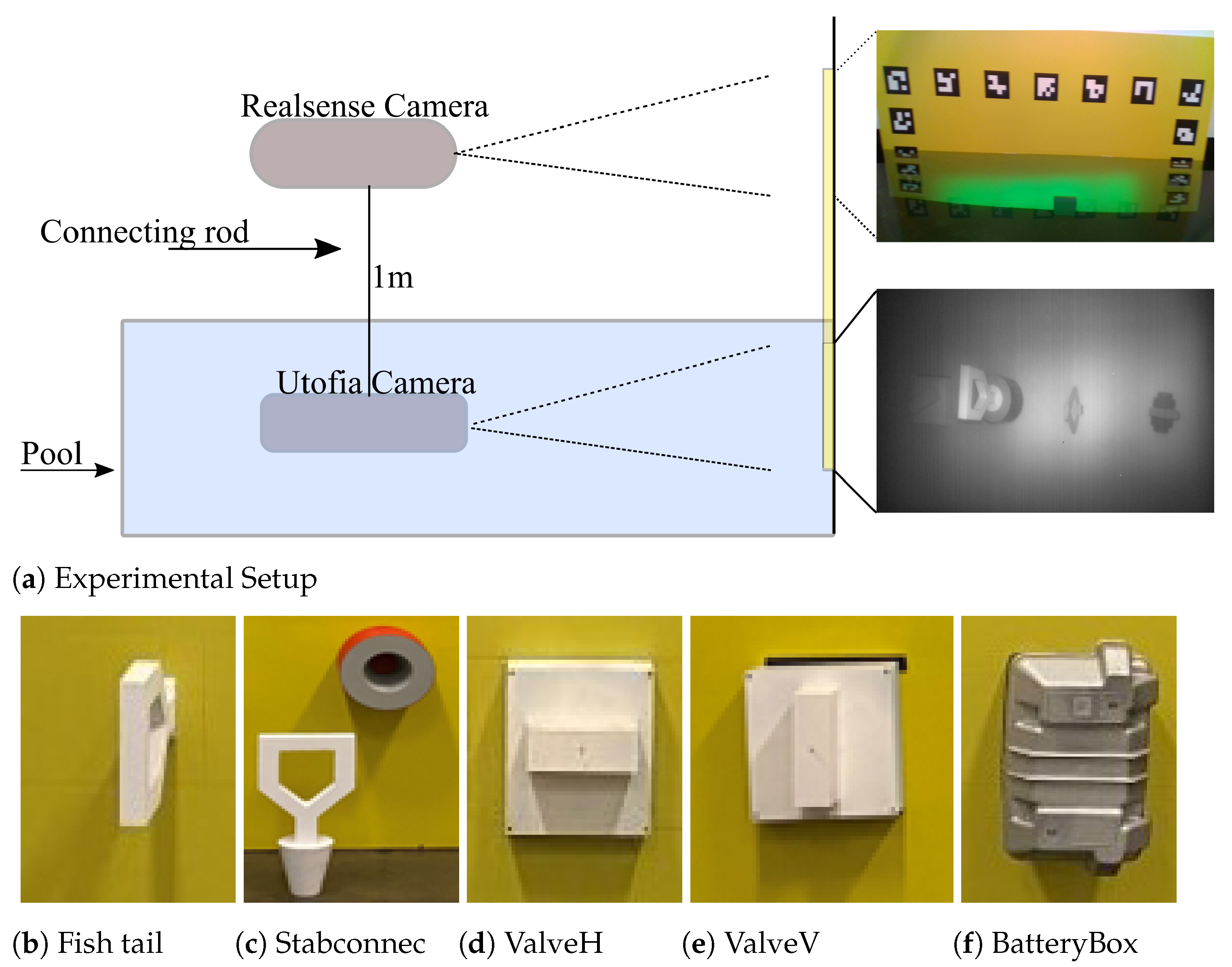
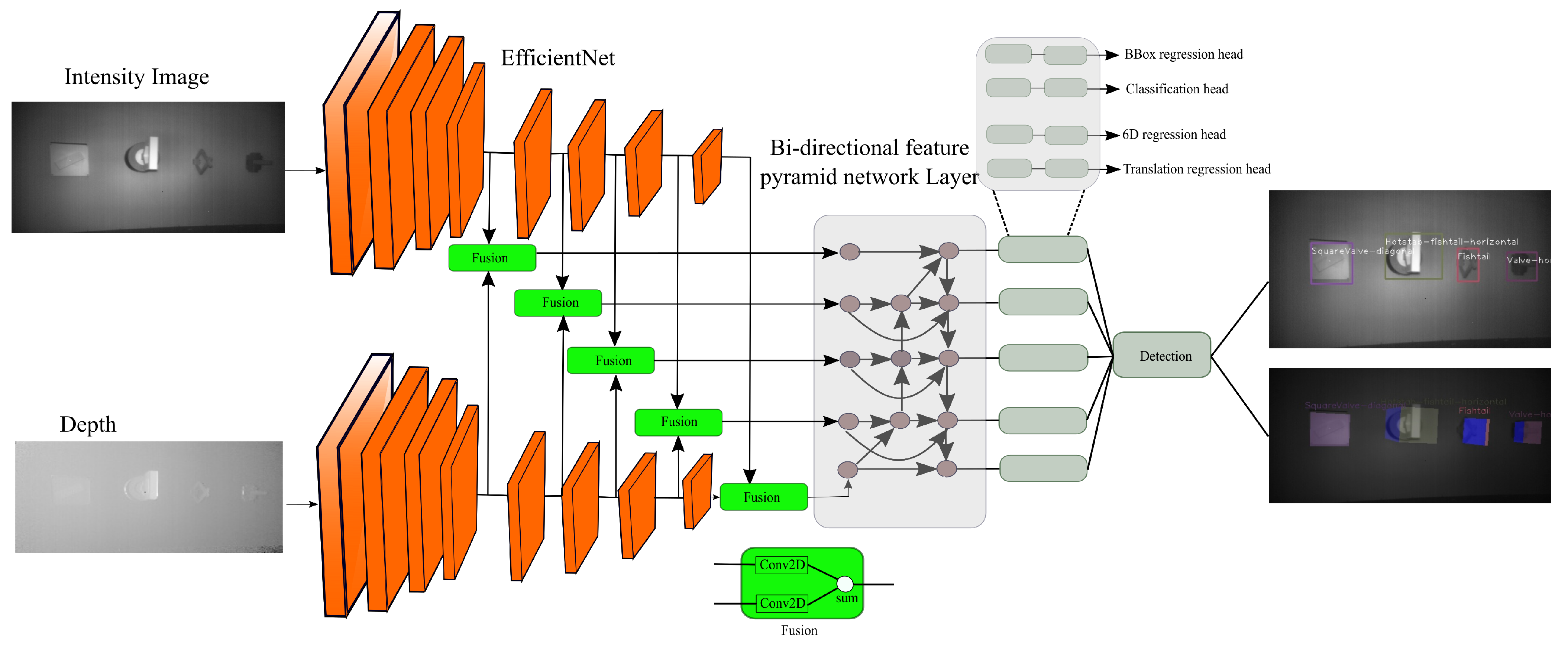
The proposed pipeline shown in (
Figure 4) is divided into 4 sub-tasks that combined can solve the task of object 6D pose estimation. Class and box prediction sub-networks handle detecting objects with 3D data while handling multiple object categories and instances. The class and box prediction sub-networks follow EfficientDet architecture [
8] using the EfficientNet base network [
20]. Rotation and translation prediction sub-networks estimate the rigid transformation (3D rotation
and a translation
) that transforms an object from a world coordinate system to the camera world coordinate system. The features from intensity and depth network stream are merged and passed to a bidirectional feature pyramid network layer (BiFPN) [
8]. BiFPN leveraged a convolutional neural network (CNN) to extract bidirectional feature maps at different resolutions.
3.1. Rotation Sub-Network
The rotation sub-network takes in BiFPN feature maps and predicts a rotation vector in a continuous 6D representation [
21], which has been shown to lead to a more stable CNN training than quaternions. The sub-network architecture is similar to class and box prediction sub-networks, except that sigmoid activation is replaced with SiLU activation function [
22], which provides a better gradient flow. The last conv layer of rotation sub-network have dimension of
, where
is the number of anchor boxes. The orthogonal properties of rotation matrices are enforced by the network by using the Gram–Schmidt orthogonalization procedure Equation (
1). Given the rotation sub-network outputs
the 3D rotation matrix is reconstructed as
as follows:
3.2. Translation Sub-Network
The network architecture for the translation sub-network follows similar architecture as the rotation sub-network and predicts the 3D translation vector
such that
is the coordinate of the object origin in the camera coordinate system. Rather than regressing the
directly, the sub-network estimates the centre pixel coordinate offset from the anchor box centre and the normalized distance
. This reformulation has been shown to make bounding box regression task easier to learn [
23]. The centre pixels,
is the centre of the projected 3D object on image coordinate [
5]. Given the sub-network estimate for
in the image, the normalized distance
and the camera intrinsic parameters, the 3D translation vector
can be recovered following the perspective camera model as:
with the 2D projection of centre of the 3D object
, focal lengths of the camera
and principal point
. Here, the principal point is the point where the optical axis intersects the image plane.
3.3. Loss
To regress the 6D pose, we use Equation (
3) as a loss function during the training. This loss function is similar to that of DenseFusion and EfficientPose [
7,
9], except that loss is computed for the 3D bounding box coordinates:
where,
denotes the
ith corner of the 3D bounding box points from the objects 3D model,
is the ground truth pose, where
is the rotation matrix of the object and
is the translation. Furthermore, to handle symmetric objects in the rotation sub-network we used PoseLoss [
5], which measures the average squared distance between points on the correct model pose:
the complete transformation loss function
is given by:
3.4. Data Pre-Processing and Training
The dataset is divided into a training and test set; the training set contains all K images from turbidity 0, 2, 4, 5, and 7, while K images from turbidity 1, 3, and 6 is used for the test set. Our capturing setup configuration is stationary such that orientation of objects, ordering of objects, positioning is the same. This could result in the learning algorithm to memorize the configuration rather than learning the actual pose leading to overfitting the training data. To circumvent this problem we have introduced pre-processing step and random augmentation. First, the depth image is smoothed with median filter of size (5, 5) as a pre-processing step to improve object detection. Both intensity and depth image values are normalized between 0 and 1. Second, ground truth rotation matrix is augmented by applying random rotation (0 to 360) and scale (0.7 to 1.3). Random noise is added for objects that lie on the image boundary or partially visible after augmentation with a probability of 0.5. Finally, the intensity and depth images are resized to () and padded with zeros to a fixed size of ().
We trained the network for 100 epochs, using mini-batches of 16 images, and observed that the loss converged after approximately 50 epochs. The network outputs four parameters for each object and the final loss function has the following form.
For all of our experiments we set
and
. These values were found empirically. The first term is classification (focal) loss and we used
and
, while the second term is the bounding box regression loss. The last term is the transformation loss Equation (
6).
4. Results and Discussions
The performance of the network under different turbidities is evaluated based on the Relative Translation Error (RTE) and Relative Rotation Error (RRE) metrics that measures the deviations between the predicted and and ground truth pose as defined in [
24]. Furthermore, mean Average Precision [
25] (mAP) is computed by taking the average of precision over all the objects at 0.5 IoU (Intersection over union). Given the ground truth rotation
and translation
of each object, the RTE and RRE are defined as follows:
where
and
denote the estimated translation vector and translation matrix, respectively.
Table 1 lists the AP, RTE, RRE of the proposed model for the turbidities in the test dataset. Looking at the metrics presented for each class, the level of difficulty for object detection and pose estimation underwater varies with turbidity and the size of object of interest. It is important to note that most of the objects considered in our experiment are symmetric which is known to be more challenging than non-symmetric objects [
16]. Overall, the proposed method is able to localize and estimate objects with 6D poses in a single shot without the need of further post-processing or refinement step. To the best of our knowledge, our approach is the first holistic method achieving competitive performance on varying turbidity with multiple objects for sub-sea application [
13,
14,
15]. To visualize the estimated pose on the test dataset, we project the eight corners of the 3D bounding box of the predicted object with the estimated rotation and translation vector and visualize them in
Figure 5. The last row shows some of failure cases where it fails to detect objects with limited view and turbidity.
4.1. Evaluation on Intensity, Depth and Fusion Data
We investigate pose estimation performance under different turbidities to shed more light on the proposed model, to objectively evaluate the contribution of intensity, depth and fusion networks against the test datasets, and evaluate the performance in terms of the mAP, RTE and RRE. To this end, we devised prediction performance comparison models, namely, Intensity-Only, Depth-Only, and Fusion. In the Intensity-Only model, the pose estimation network is a single stream network with only intensity image as an input. The intensity image is single channel (gray scale) with a size of
. The designed EfficientNet encoder takes an input of size
; therefore, the intensity image is padded with zeros to a fixed size of
. In the Depth-Only model, the input to the network is only depth image. Similar to the intensity, the depth image is a single channel of
depth values normalized to [0,1]. The depth image is padded with zeros to a fixed size of
similar to intensity image. In the fusion model, both intensity and depth data are fused as discussed in
Section 3 and shown in
Figure 4. Both intensity and depth images are passed through two EfficientNet encoders. The features from both encoders are fused at different resolution and passed to BiFPN. For all our experiments hyperparameters such as learning rate, batch size, data augmentation remain the same as described in
Section 3.4.
Table 2,
Table 3 and
Table 4 summarize the 2D object detection and pose estimation performances for intensity only, depth only and fusion networks. The results demonstrate that the object detection and rotation estimation performance improved when fusing the intensity and depth image subnetworks. Furthermore, it can be concluded that the rotation error can be reduced optimally by
on average over all turbidities by combining the intensity and the depth subnetworks. However, the translation error is reduced by 0.36 cm as compared to using only depth. In summary, the 2D and rotation predictions obtained by fusing depth and intensity subnetworks are found to be complementary, and the fusion model can obtain more accurate 6D pose estimation.
4.2. Dataset Bias Analysis
We further analyse the capture bias problem [
26] (generalization beyond the training domain) in order to explore the limitation and performance of the proposed approach as well as the dataset. The capture bias is related to how the images are acquired both in terms of turbidity and of the collector preferences for point of view, lighting, etc.
Table 1 shows the proposed approach is able to generalize to novel turbidity that is not in the training dataset. Compared to related works [
13,
14,
15], the proposed model is robust to different turbidity levels. In regard to preference for view point,
Figure 6 shows the variation of rotation error with respect to ground truth euler angles of each object along X, Y and Z axis.
The ground truth mean rotation angle of the test dataset distribution is shown in the right side Y axis of
Figure 6. We observe that the rotation error varies with a span of dataset capturing setup more in high turbidity. This is expected in that, in high turbid cases 6D pose estimation requires large amount of data for a better generalization. Overall, the proposed model is able to generalize in high turbidity cases with mAP score above 90% as show in
Table 1.
4.3. Discussion
The ability to detect and localize objects underwater is a crucial step for subsea inspection, maintenance and repair operations. The results presented earlier in this section revealed that the pose estimation errors exhibit variation in performance with object size, data capture bias and turbidity. Large objects such as battery box are easy to detect as compared to small objects (
) AP. Increasing capturing device image resolution as well as models input resolution could help boost the performance. Using 3D vision reduces the rotation and translation error by
and
mm, respectively, as compared to 2D vision. However, the rotation sub-network is benefited more from 3D vision than translation sub-network. This is due to the fact that there is a small deviation between object location in the intensity and depth images during fast movement of the capturing setup. Performance drop on high turbidity water could be mitigated by including high turbidity examples for training the network (i.e., we used turbidity 0, 2, 4, 5, and 7 for training and turbidity 1, 3 and 6 for testing). Lastly, dataset capture bias related to view point selection in 3D pose estimation could also impact the performance of the proposed method.
Figure 6 shows that the rotation values are not evenly represented in the datasets. This is seen in conjunction with turbidity values and prediction error in the rotation. It appears that, the largest errors of the pose estimates occur in the high turbidity and with less represented pose values in the training dataset. In practical settings, such issues need to be addressed if one is to build a system that works outside of well calibrated laboratory setups and datasets. Data capture bias can emanate from automated data labelling process. Recall from
Section 2.1 that the process of labelling the datasets was automated and based on real-sense camera detected Aruco markers mapped by a time-stamp to the locations in the images of the Utofia camera. The transformation between the two cameras could result in small drift depending on the speed of capturing setup, which in turn results in miss-aligned bounding boxes. It is uncertain how these incorrect pose labels affect the performance of the network. It is also possible that there will be outliers in the training/test dataset with small bounding box and pose deviation. Moreover, such deviation in the test set could affect the results as the network will not predict the corresponding incorrect values. However, for the training and test data, we have filtered frames with large displacement and trained only clean version of the dataset (using only frames were the capturing setup is relatively stationary). We have checked visually that such deviations occur in a few samples out of thousands in the training sets, and should therefore not have a too big impact.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}