
Using Machine Learning to Detect Events on the Basis of Bengali and Banglish Facebook Posts


 ,
, 
 and
and
Abstract
:1. Introduction
2. Literature Review
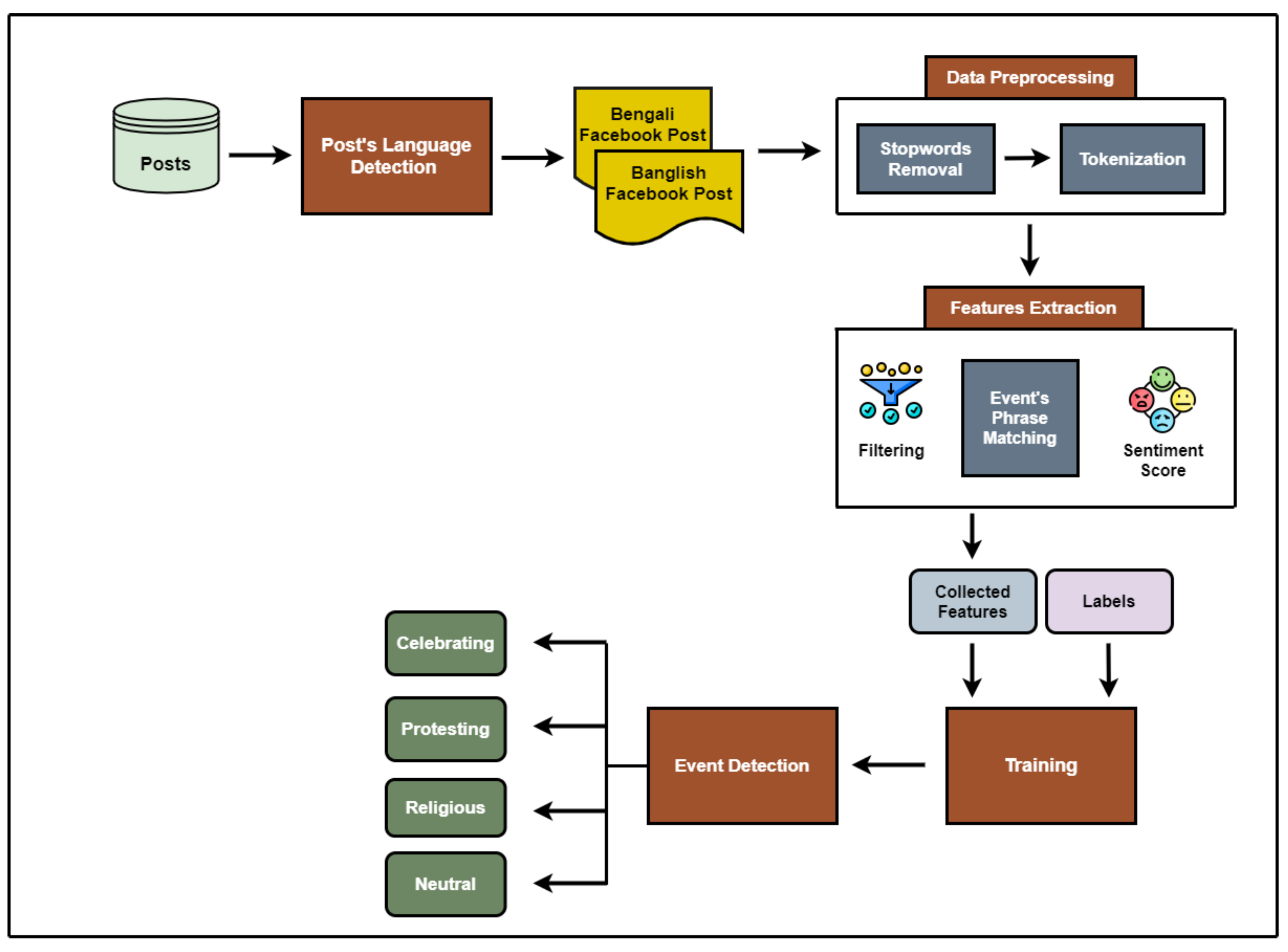
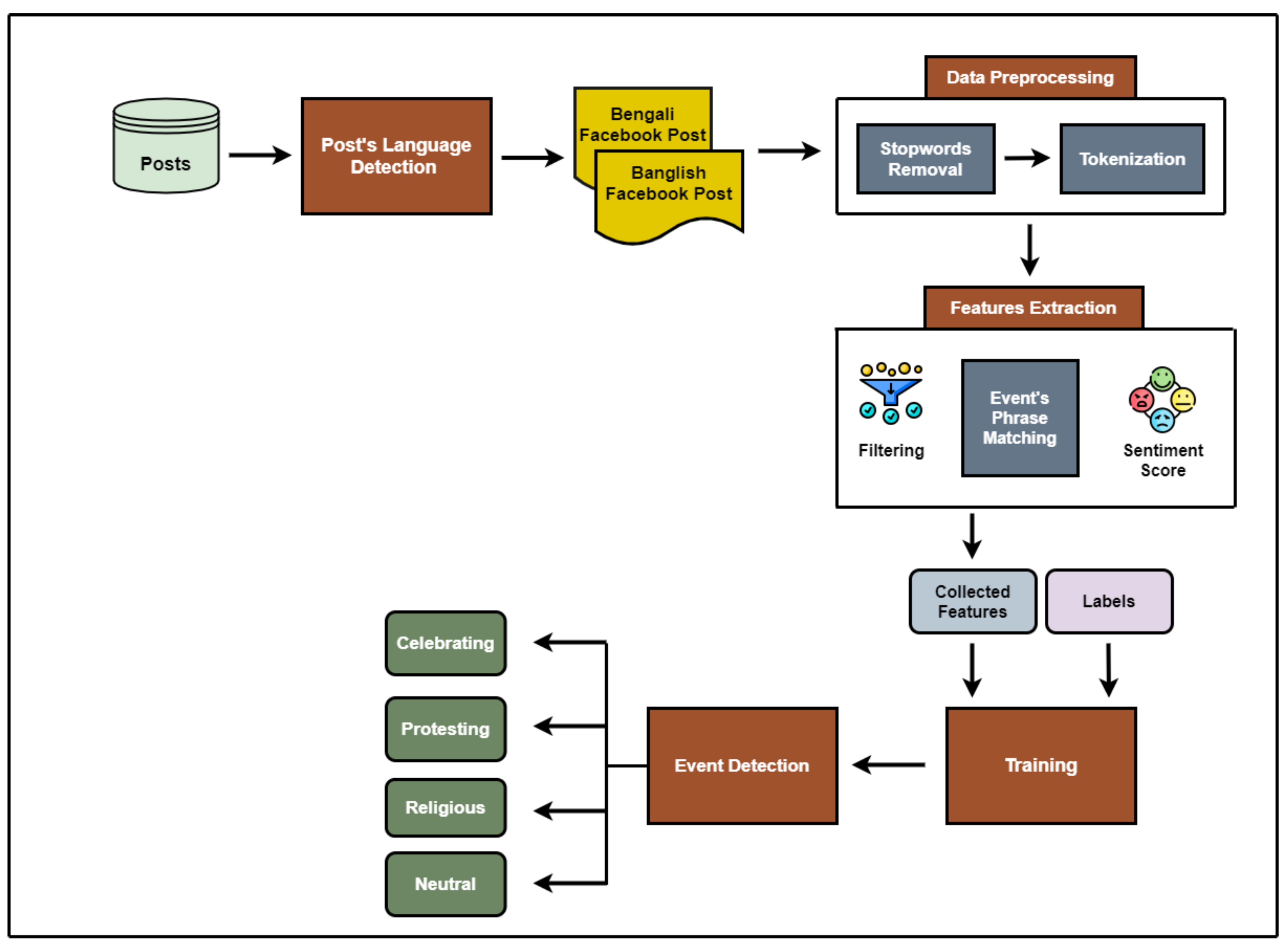
3. Proposed Model
| Algorithm 1. Event Detection |
 |
3.1. Data Collection
3.2. Language Detection
| Algorithm 2. Language Detection |
 |
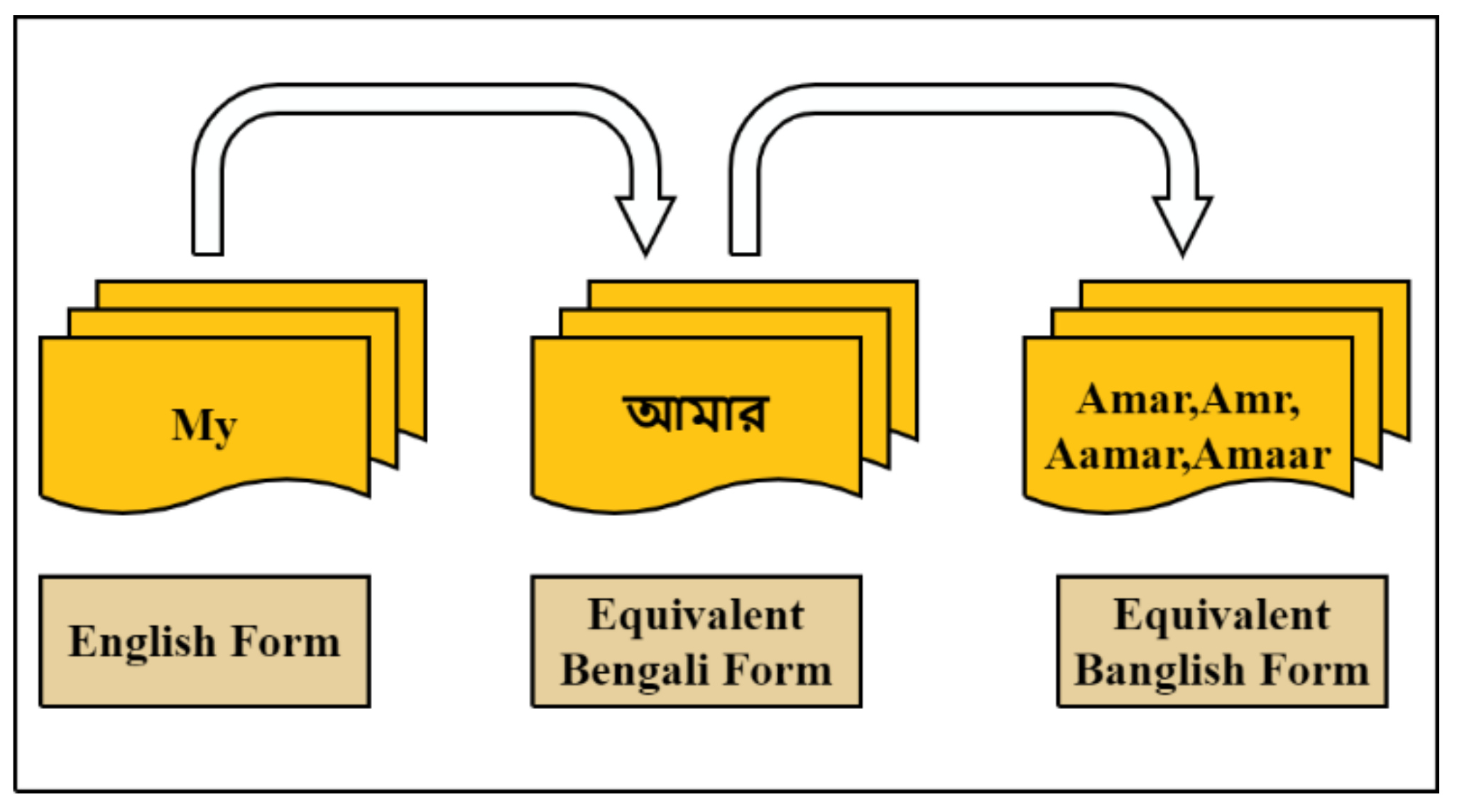
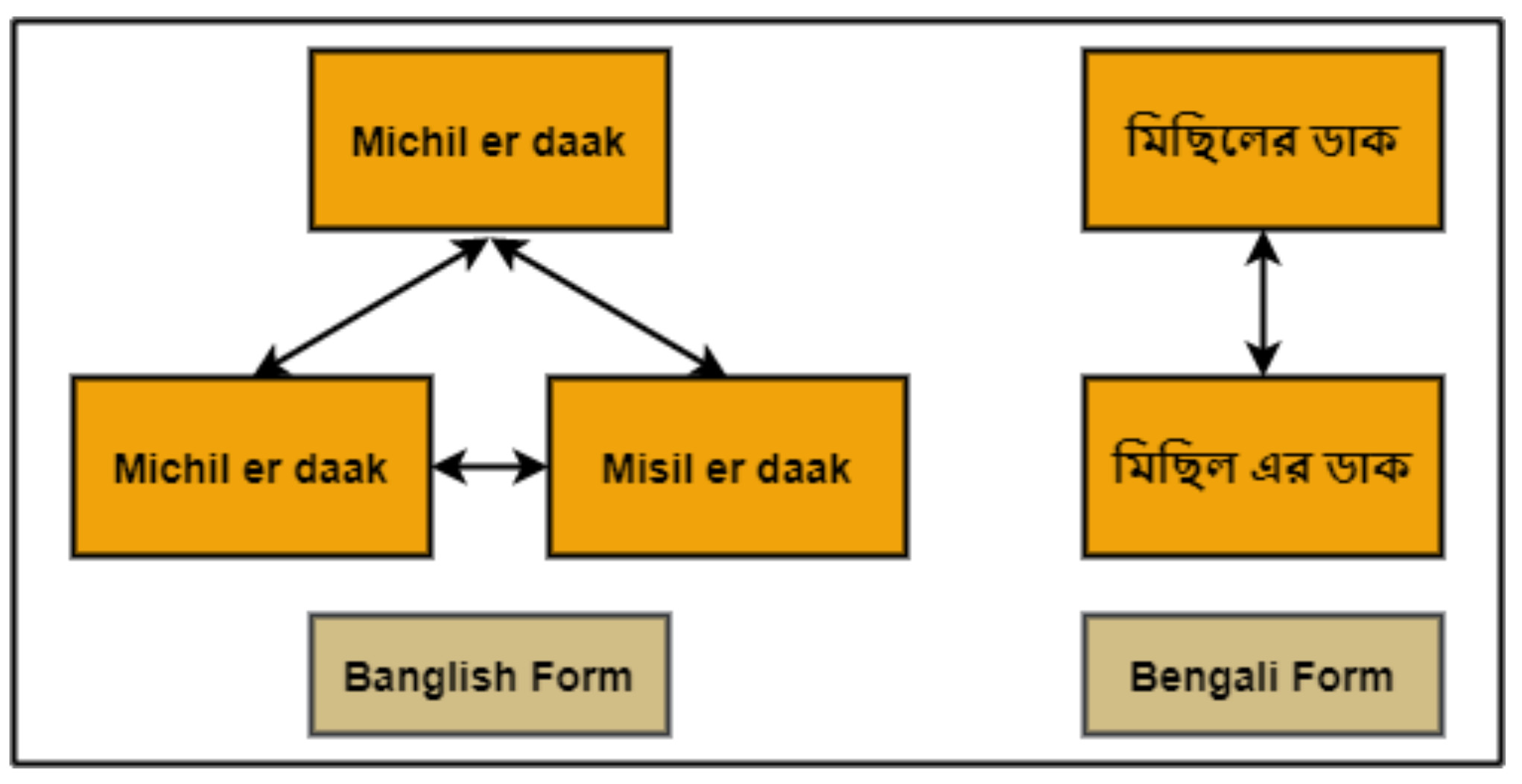
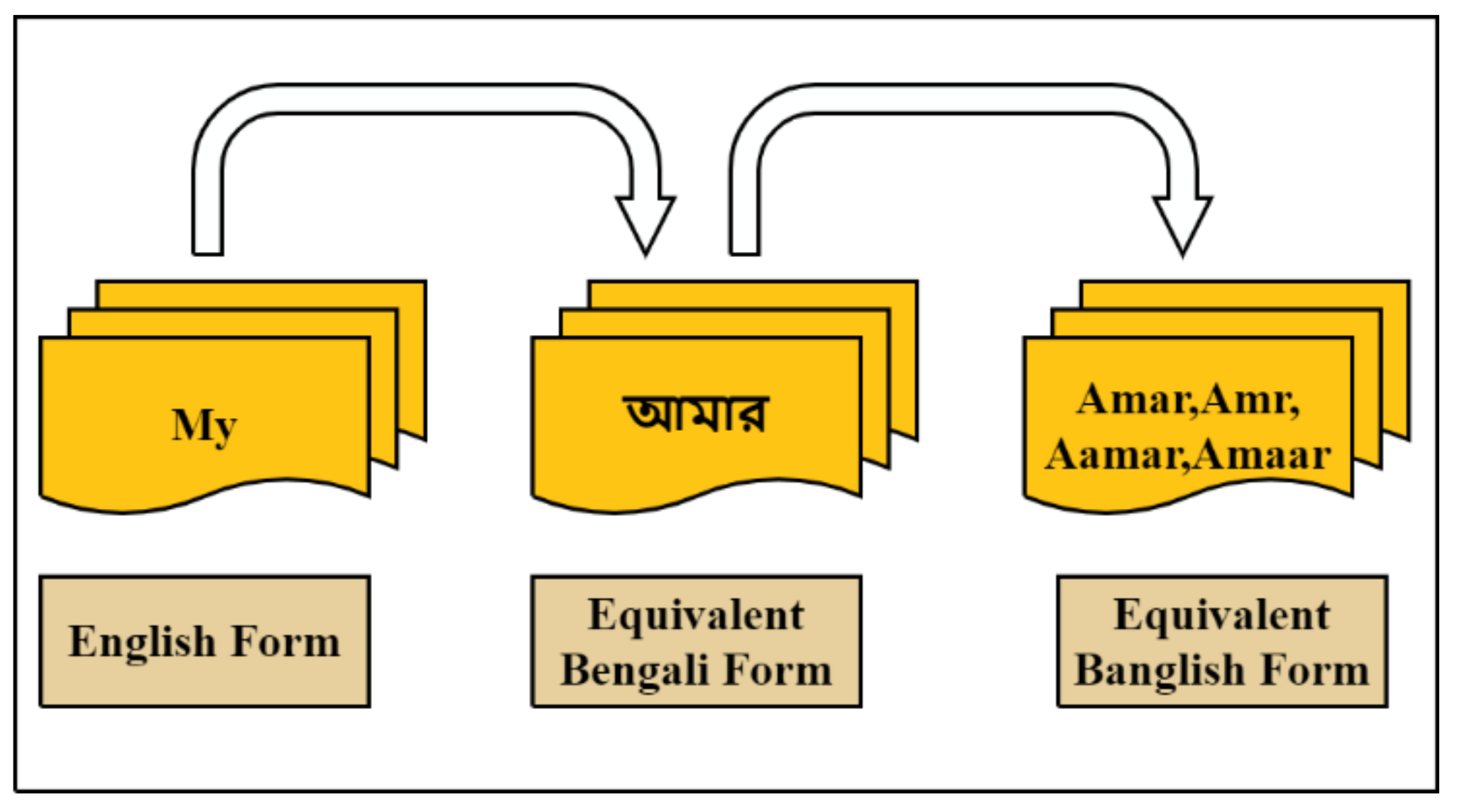
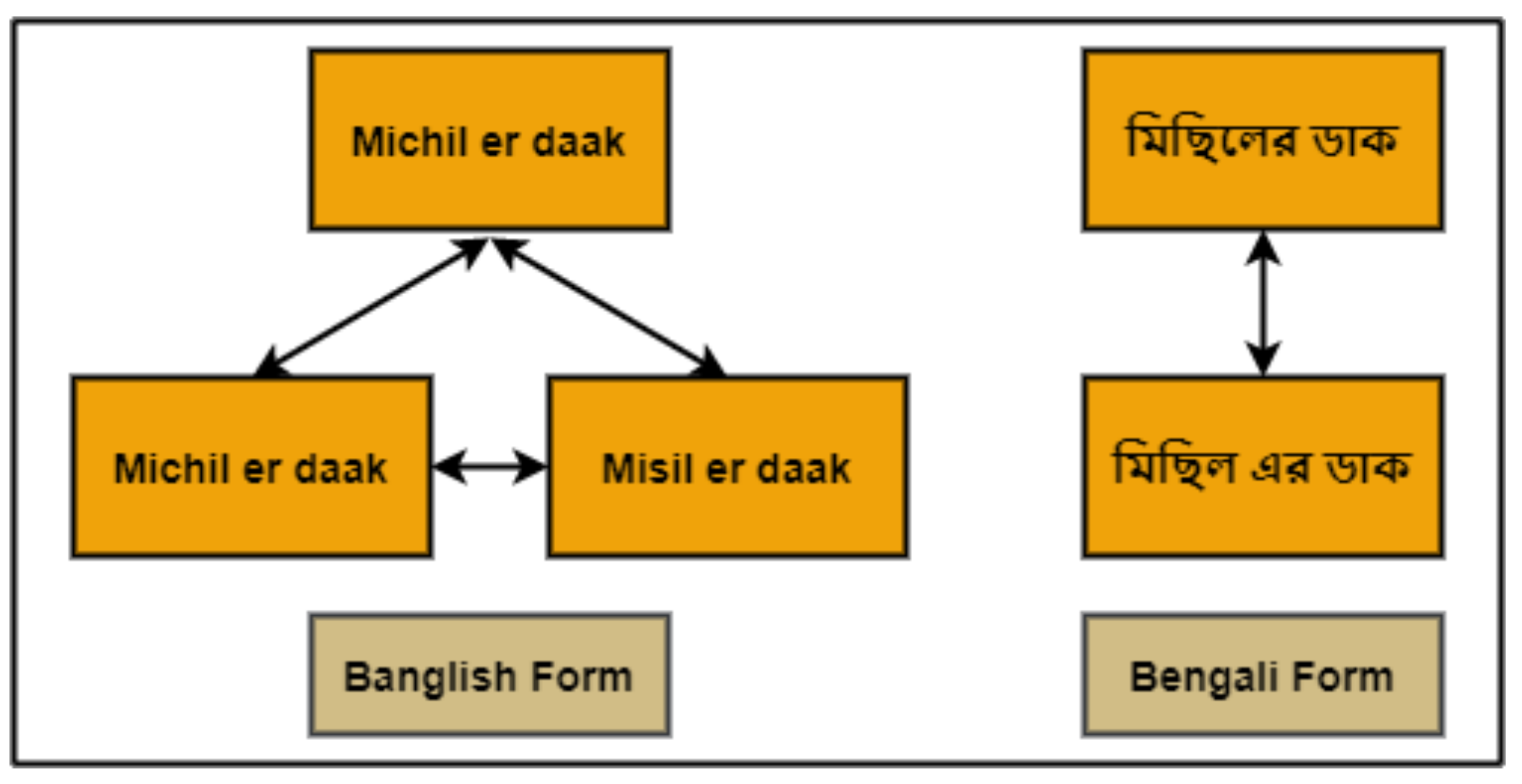
3.3. Data Pre-Processing
3.4. Feature Extraction
3.4.1. Filtering
| Algorithm 3. Filtering of Words and Phrases |
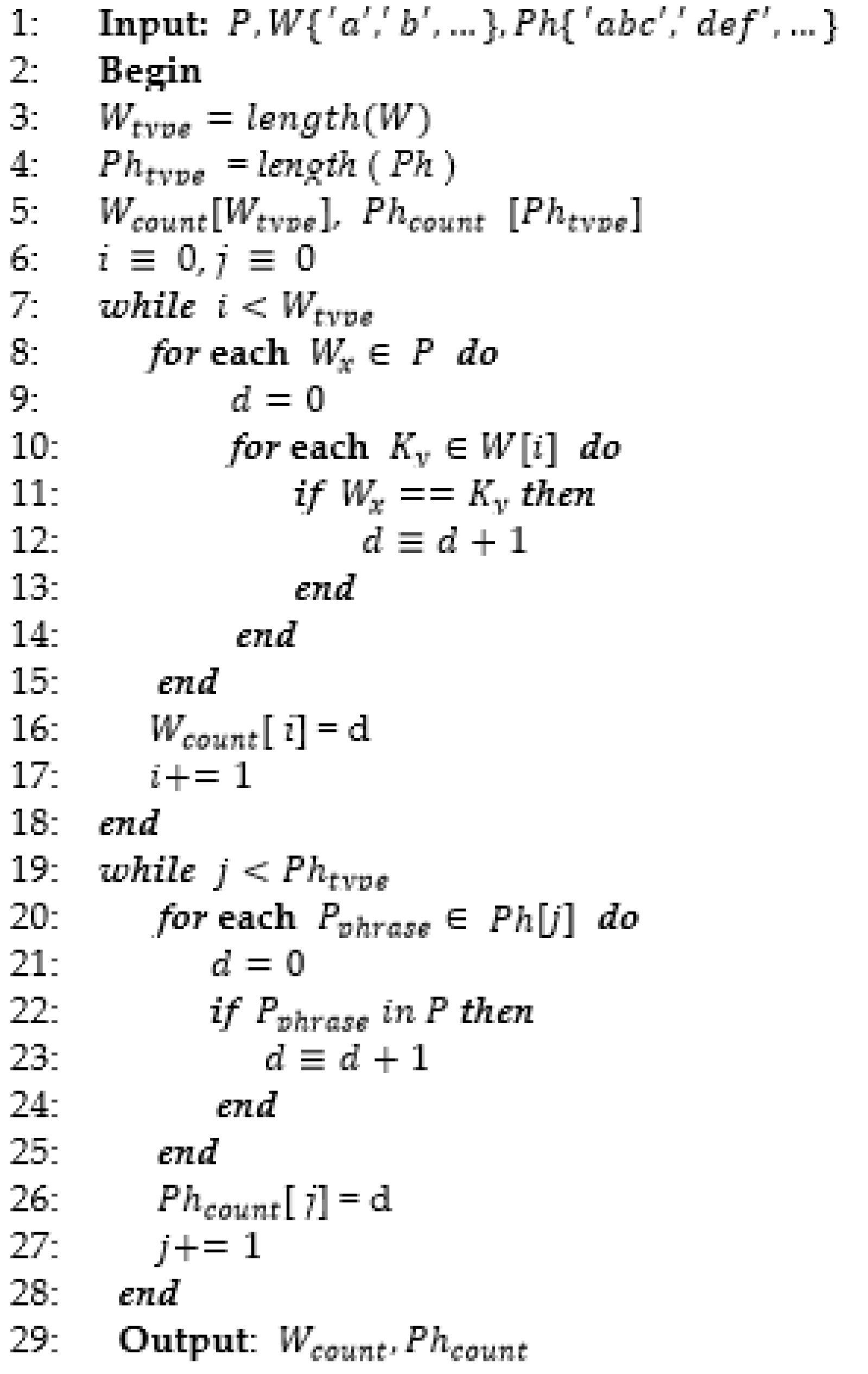 |
3.4.2. Phrase Matching of Specific Event
3.4.3. Sentiment Analysis
3.5. Model Training and Detection
4. Performance Evaluation
4.1. Performance Metrics
4.2. Used Datasets
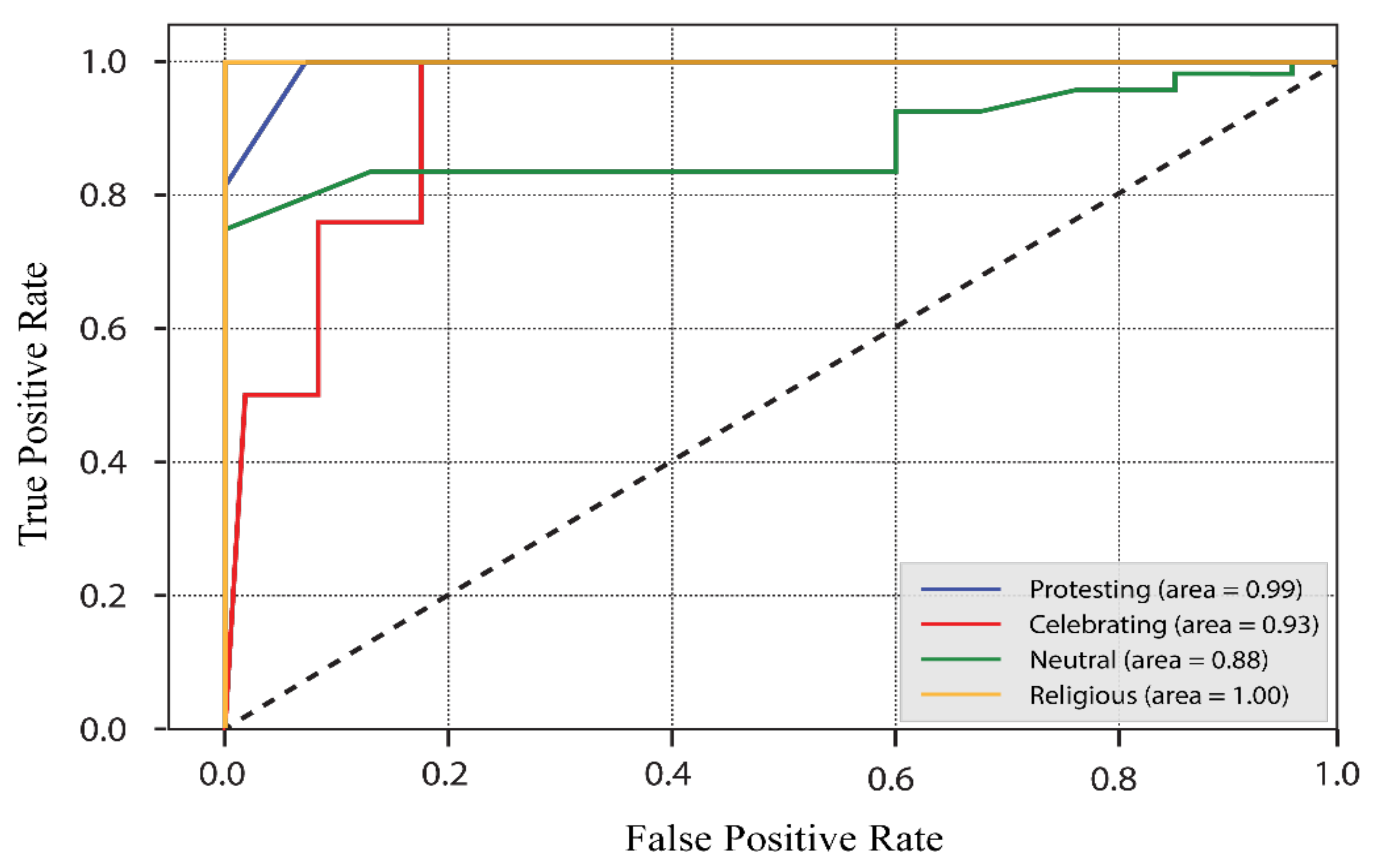
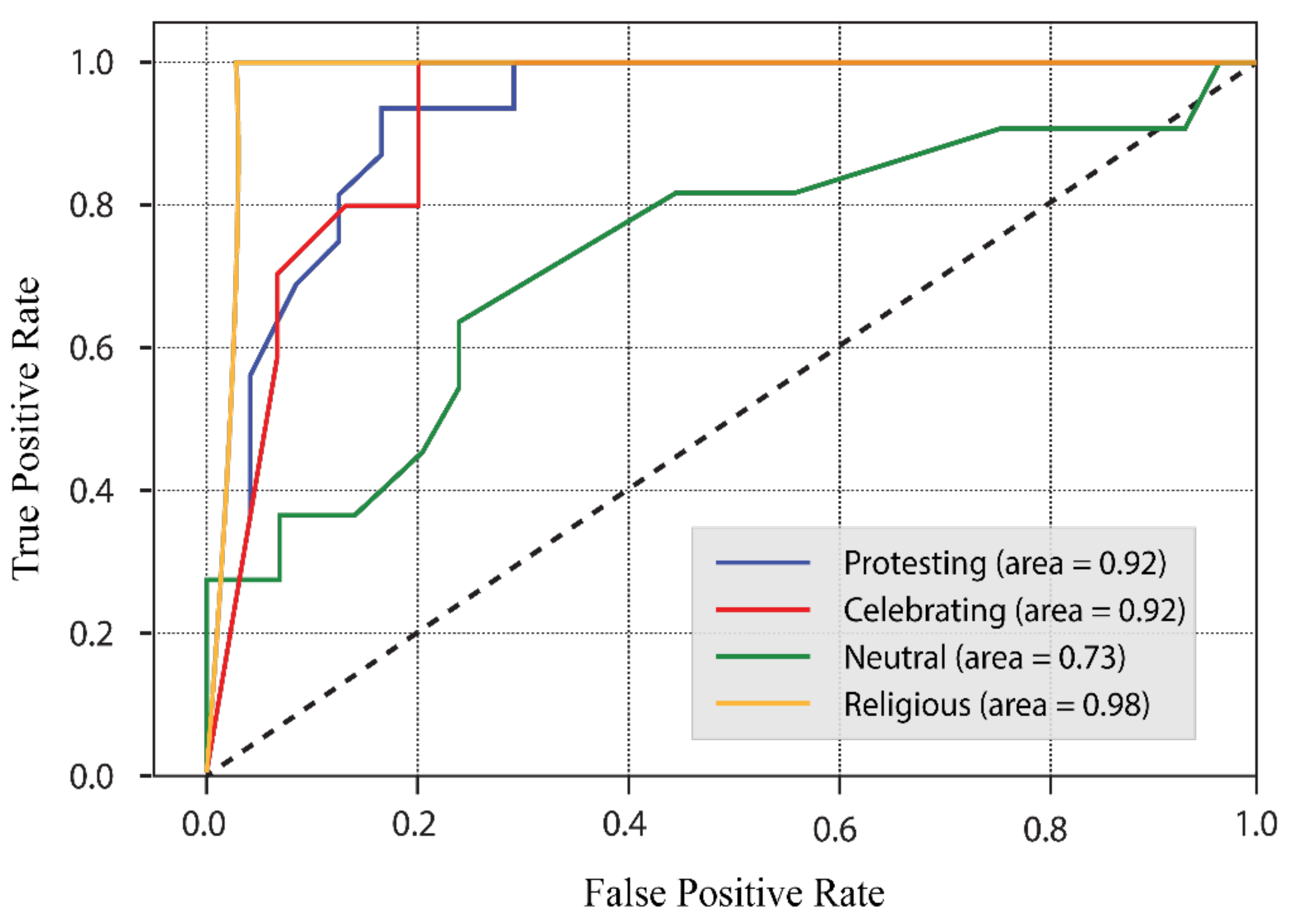
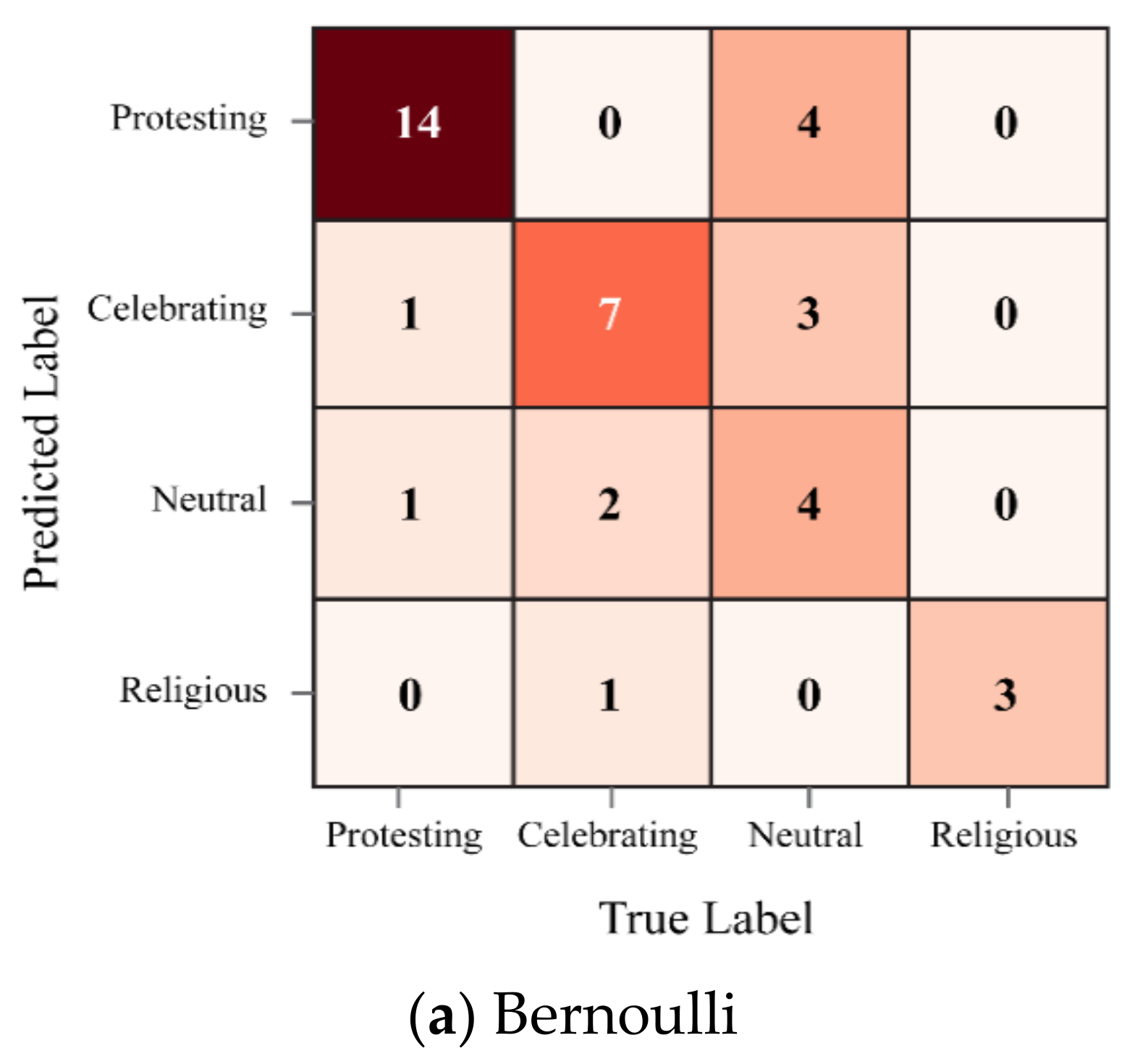
4.3. Experimental Results
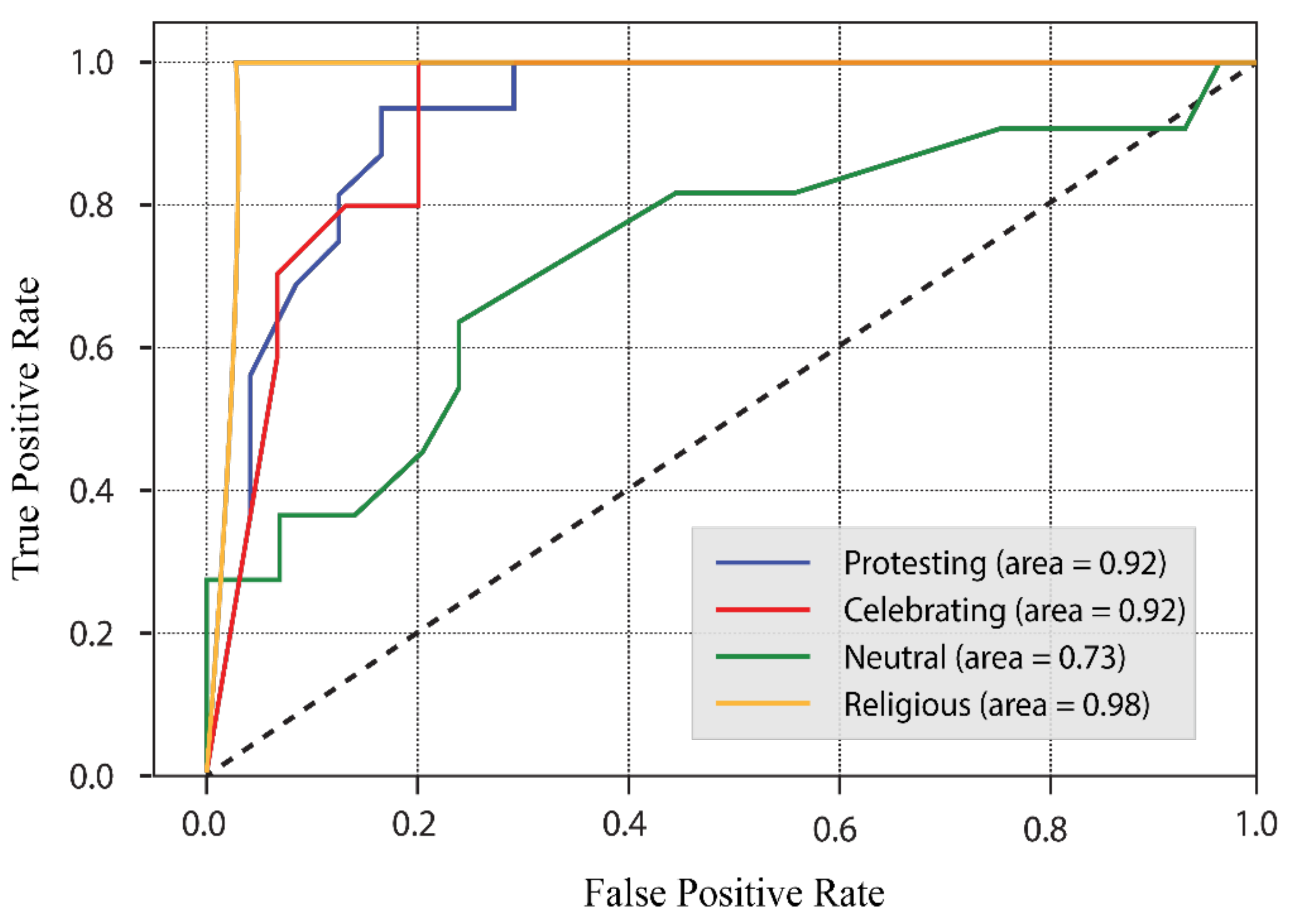
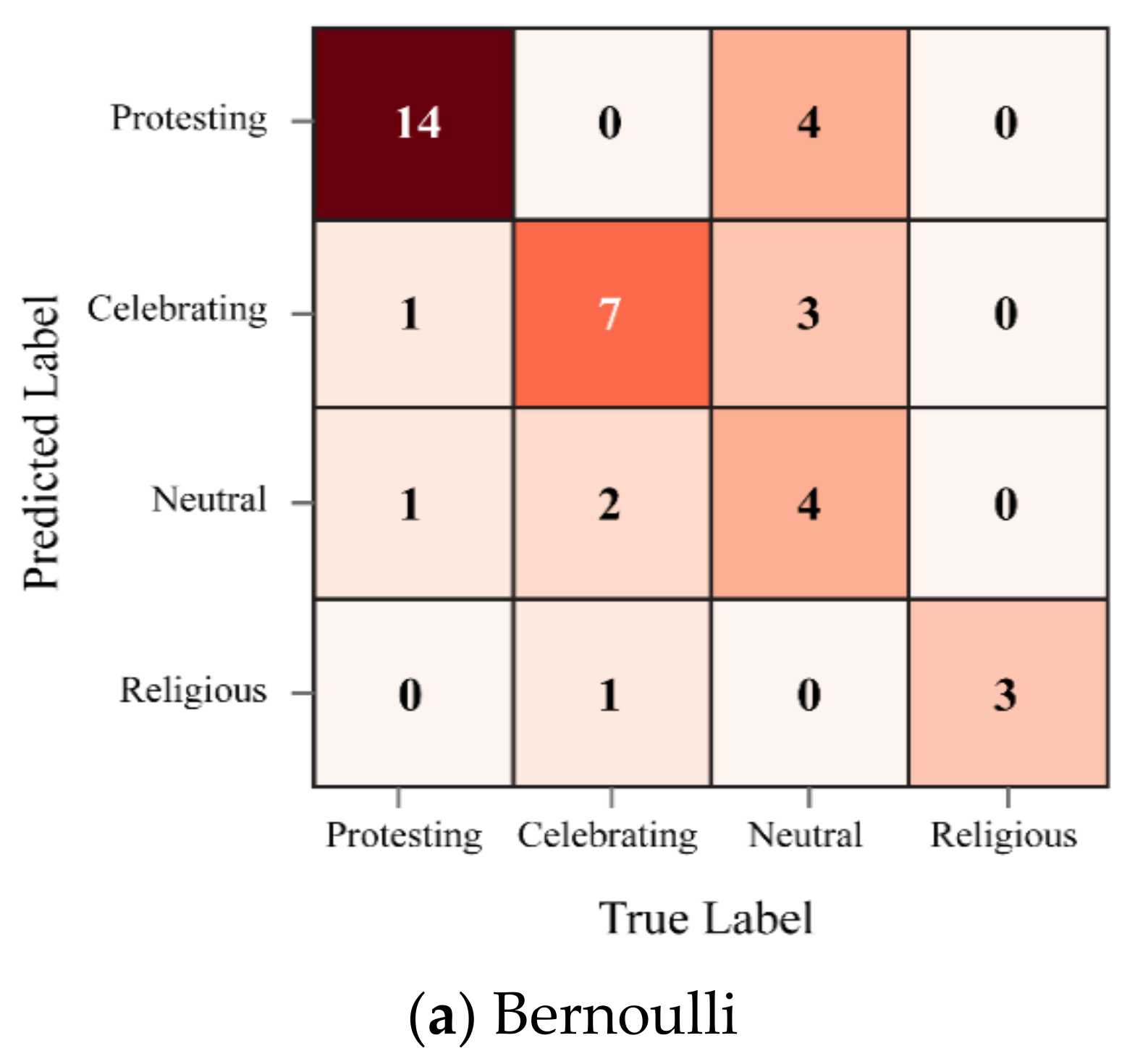
4.3.1. Results of Our Model’s Assessment of Bengali-Language Posts
4.3.2. Results of Our Model’s Assessment of Banglish-Form Posts
5. Conclusions, Limitations and Future Scope
5.1. Conclusions
5.2. Existing Limitations and Future Scope
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AVG | Average |
| AUC | Area Under Curve |
| BNB | Bernoulli Naive Bayes |
| CRF | Conditional Random Field |
| DT | Decision Tree |
| FPR | False Positive Rate |
| FNR | False Negative Rate |
| HITS | Hypertext Induced Topic Search |
| LSTM | Long Short-Term Memory |
| LDA | Latent Dirichlet Allocation |
| LSH | Locality Sensitive Hashing |
| MLP | Multi-Layer Perceptron |
| MTL | Multi-Task Learning |
| MC | Microblog Clique |
| NB | Naive Bayes |
| NER | Name Entity Recognition |
| PWE | Personal Wellness Events |
| ROC | Receiver Operating Characteristics |
| SVM | Support Vector Machine |
| TD-HITS | Topic Decision HITS |
| TPR | True Positive Rate |
| TNR | True Negative Rate |
| TS-LDA | Three Step LDA |
| VADER | Valence Aware Dictionary and Sentiment Reasoner |
References
- Taylor, D.B. The New York Times. Available online: https://web.archive.org/web/20200602235547/https://www.nytimes.com/article/george-floyd-protests-timeline.html (accessed on 8 May 2021).
- Robinson, K. Council on Foreign Relations. Available online: https://www.cfr.org/article/arab-spring-ten-years-whats-legacy-uprisings (accessed on 2 April 2021).
- The Economist. Available online: https://www.economist.com/asia/2018/04/21/protests-in-bangladesh-put-an-end-to-a-corrupt-quota-system (accessed on 20 March 2021).
- Firstplot. Available online: https://www.firstpost.com/world/students-end-protests-on-road-safety-in-bangladesh-after-nine-days-education-ministry-to-hold-meet-tomorrow-4913421.html (accessed on 27 March 2021).
- Anantharam, P.; Barnaghi, P.; Thirunarayan, K.; Sheth, A. Extracting city traffic events from social streams. ACM Trans. Intell. Syst. Technol. 2015, 6, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Alomari, E.; Mehmood, R.; Katib, I. Sentiment analysis of Arabic tweets for road traffic congestion and event detection. In Smart Infrastructure and Applications; Springer: Cham, Switzerland, 2020; pp. 37–54. [Google Scholar] [CrossRef]
- Imran, M.; Elbassuoni, S.; Castillo, C.; Diaz, F.; Meier, P. Practical extraction of disaster-relevant information from social media. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1021–1024. [Google Scholar] [CrossRef] [Green Version]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes twitter users: Real-time event detection by social sensors. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 851–860. [Google Scholar] [CrossRef]
- Fathima, P.N.; George, A. Event detection and text summary by disaster warning. Int. Res. J. Eng. Technol. 2019, 6, 2510–2513. [Google Scholar]
- Ristea, A.; Al Boni, M.; Resch, B.; Gerber, M.S.; Leitner, M. Spatial crime distribution and prediction for sporting events using social media. Int. J. Geogr. Inf. Sci. 2020, 34, 1708–1739. [Google Scholar] [CrossRef] [Green Version]
- Fedoryszak, M.; Frederick, B.; Rajaram, V.; Zhong, C. Real-time event detection on social data streams. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2774–2782. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, Z.; Varshney, D.; Ekbal, A.; Bhattacharyya, P. Multi-Lingual Event Identification in Disaster Domain; Indian Institute of Technology Patna: Bihta, India, 2019. [Google Scholar]
- Shi, K.; Gong, C.; Lu, H.; Zhu, Y.; Niu, Z. Wide-grained capsule network with sentence-level feature to detect meteorological event in social network. Future Gener. Comput. Syst. 2020, 102, 323–332. [Google Scholar] [CrossRef]
- Ali, D.; Missen, M.M.S.; Husnain, M. Multiclass Event Classification from Text. Sci. Program. 2021, 2021, 6660651. [Google Scholar] [CrossRef]
- Choi, D.; Park, S.; Ham, D.; Lim, H.; Bok, K.; Yoo, J. Local Event Detection Scheme by Analyzing Relevant Documents in Social Networks. Appl. Sci. 2021, 11, 577. [Google Scholar] [CrossRef]
- Alomari, E.; Katib, I.; Mehmood, R. Iktishaf: A big data road-traffic event detection tool using Twitter and spark machine learning. Mob. Netw. Appl. 2020, 1–16. [Google Scholar] [CrossRef]
- Jain, A.; Kasiviswanathan, G.; Huang, R. Towards accurate event detection in social media: A weakly supervised approach for learning implicit event indicators. In Proceedings of the 2nd Workshop on Noisy User-Generated Text (WNUT), Osaka, Japan, 11 December 2016; pp. 70–77. [Google Scholar]
- Alsaedi, N.; Burnap, P. Arabic event detection in social media. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Cairo, Egypt, 14–20 April 2015; Springer: Cham, Switzerland, 2015; pp. 384–401. [Google Scholar] [CrossRef]
- Suma, S.; Mehmood, R.; Albeshri, A. Automatic event detection in smart cities using big data analytics. In Proceedings of the International Conference on Smart Cities, Infrastructure, Technologies and Applications, Jeddah, Saudi Arabia, 27–29 November 2017; Springer: Cham, Switzerland, 2017; pp. 111–122. [Google Scholar] [CrossRef]
- Cui, W.; Wang, P.; Du, Y.; Chen, X.; Guo, D.; Li, J.; Zhou, Y. An algorithm for event detection based on social media data. Neurocomputing 2017, 254, 53–58. [Google Scholar] [CrossRef]
- Gao, Y.; Zhao, S.; Yang, Y.; Chua, T.S. Multimedia social event detection in microblog. In Proceedings of the International Conference on Multimedia Modeling, Sydney, NSW, Australia, 5–7 January 2015; Springer: Cham, Switzerland, 2015; pp. 269–281. [Google Scholar] [CrossRef]
- StatCounter GlobalStats. Available online: https://gs.statcounter.com/social-media-stats/all/bangladesh (accessed on 1 March 2021).
- Statista. Available online: https://www.statista.com/statistics/268136/top-15-countries-based-on-number-of-facebook-users/ (accessed on 25 January 2021).
- Mumu, T.F.; Munni, I.J.; Das, A.K. Depressed people detection from bangla social media status using lstm and cnn approach. J. Eng. Adv. 2021, 2, 41–47. [Google Scholar] [CrossRef]
- Das, A.K.; Al Asif, A.; Paul, A.; Hossain, M.N. Bangla hate speech detection on social media using attention-based recurrent neural network. J. Intell. Syst. 2021, 30, 578–591. [Google Scholar] [CrossRef]
- Rozen, A. Twitter Blog. Available online: https://blog.twitter.com/official/en_us/topics/product/2017/tweetingmadeeasier.html (accessed on 25 March 2021).
- Sharmin, S.; Chakma, D. Attention-based convolutional neural network for Bangla sentiment analysis. AI Soc. 2021, 36, 381–396. [Google Scholar] [CrossRef]
- Rahman, M.; Haque, S.; Saurav, Z.R. Identifying and categorizing opinions expressed in bangla sentences using deep learning technique. Int. J. Comput. Appl. 2020, 975, 8887. [Google Scholar] [CrossRef]
- Alam, T.; Khan, A.; Alam, F. Bangla Text Classification using Transformers. arXiv 2020, arXiv:2011.04446. [Google Scholar]
- Dey, N.; Mredula, M.S.; Sakib, M.N.; Islam, M.N.; Rahman, M.S. A Machine Learning Approach to Predict Events by Analyzing Bengali Facebook Posts. In Proceedings of the International Conference on Trends in Computational and Cognitive Engineering, Dhaka, Bangladesh, 17–18 December 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 133–143. [Google Scholar]
- Chen, G.; Kong, Q.; Mao, W. Online event detection and tracking in social media based on neural similarity metric learning. In Proceedings of the 2017 IEEE International Conference on Intelligence and Security Informatics (ISI), Beijing, China, 22–24 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 182–184. [Google Scholar] [CrossRef]
- Bekoulis, G.; Deleu, J.; Demeester, T.; Develder, C. Sub-event detection from twitter streams as a sequence labeling problem. arXiv 2019, arXiv:1903.05396. [Google Scholar]
- Aldhaheri, A.; Lee, J. Event detection on large social media using temporal analysis. In Proceedings of the 2017 IEEE 7th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 9−11 January 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Nourbakhsh, A.; Shah, S.; Liu, X. Real-time novel event detection from social media. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1129–1139. [Google Scholar] [CrossRef]
- Kannan, J.; Shanavas, A.M.; Swaminathan, S. Sportsbuzzer: Detecting events at real time in twitter using incremental clustering. Trans. Mach. Learn. Artif. Intell. 2018, 6, 1. [Google Scholar]
- Feng, X.; Zhang, S.; Liang, W.; Liu, J. Efficient location-based event detection in social text streams. In Proceedings of the International Conference on Intelligent Science and Big Data Engineering, Suzhou, China, 14–16 June 2015; Springer: Cham, Switzerland, 2015; pp. 213–222. [Google Scholar] [CrossRef]
- Arachie, C.; Gaur, M.; Anzaroot, S.; Groves, W.; Zhang, K.; Jaimes, A. Unsupervised detection of sub-events in large scale disasters. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 354–361. [Google Scholar] [CrossRef]
- Pekar, V.; Binner, J.; Najafi, H.; Hale, C.; Schmidt, V. Early detection of heterogeneous disaster events using social media. J. Assoc. Inf. Sci. Technol. 2020, 71, 43–54. [Google Scholar] [CrossRef]
- Akbari, M.; Hu, X.; Liqiang, N.; Chua, T.S. From tweets to wellness: Wellness event detection from twitter streams. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Panagiotou, N.; Katakis, I.; Gunopulos, D. Detecting events in online social networks: Definitions, trends and challenges. In Solving Large Scale Learning Tasks. Challenges and Algorithms; Springer: Cham, Switzerland, 2016; pp. 42–84. [Google Scholar] [CrossRef]
- Kolya, A.K.; Ekbal, A.; Bandyopadhyay, S. A simple approach for Monolingual Event Tracking system in Bengali. In Proceedings of the 2009 Eighth International Symposium on Natural Language Processing, Bangkok, Thailand, 20–22 October 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 48–53. [Google Scholar] [CrossRef]
- Zhao, S.; Gao, Y.; Ding, G.; Chua, T.S. Real-time multimedia social event detection in microblog. IEEE Trans. Cybern. 2017, 48, 3218–3231. [Google Scholar] [CrossRef] [PubMed]
- Shi, L.; Wu, Y.; Liu, L.; Sun, X.; Jiang, L. Event detection and identification of influential spreaders in social media data streams. Big Data Min. Anal. 2018, 1, 34–46. [Google Scholar] [CrossRef]
- Nurwidyantoro, A.; Winarko, E. Event detection in social media: A survey. In Proceedings of the International Conference on ICT for Smart Society, Jakarta, Indonesia, 13–14 June 2013; IEEE: Piscaaway, NJ, USA, 2013; pp. 1–5. [Google Scholar] [CrossRef]
- Zarrinkalam, F.; Bagheri, E. Event identification in social networks. Encycl. Semant. Comput. Robot. Intell. 2017, 1, 1630002. [Google Scholar] [CrossRef] [Green Version]
- Dou, W.; Wang, X.; Ribarsky, W.; Zhou, M. Event detection in social media data. In Proceedings of the IEEE VisWeek Workshop on Interactive Visual Text Analytics-Task Driven Analytics of Social Media Content, Seattle, WA, USA, 14–19 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 971–980. [Google Scholar]
- Said, N.; Ahmad, K.; Riegler, M.; Pogorelov, K.; Hassan, L.; Ahmad, N.; Conci, N. Natural disasters detection in social media and satellite imagery: A survey. Multimed. Tools Appl. 2019, 78, 31267–31302. [Google Scholar] [CrossRef] [Green Version]
- Saeed, Z.; Abbasi, R.A.; Maqbool, O.; Sadaf, A.; Razzak, I.; Daud, A.; Aljohani, N.R.; Xu, G. What’s happening around the world? A survey and framework on event detection techniques on twitter. J. Grid Comput. 2019, 17, 279–312. [Google Scholar] [CrossRef] [Green Version]
- Yu, M.; Bambacus, M.; Cervone, G.; Clarke, K.; Duffy, D.; Huang, Q.; Li, J.; Li, W.; Li, Z.; Liu, Q.; et al. Spatiotemporal event detection: A review. Int. J. Digit. Earth 2020, 13, 1339–1365. [Google Scholar] [CrossRef] [Green Version]
- Zhou, D.; Huang, J.; Schölkopf, B. Learning with hypergraphs: Clustering, classification, and embedding. Adv. Neural Inf. Process. Syst. 2006, 19, 1601–1608. [Google Scholar]
- Akaike, H. Information theory and an extension of the maximum likelihood principle. In Selected Papers of Hirotugu Akaike; Springer: New York, NY, USA, 1998; pp. 199–213. [Google Scholar]
- Pypi. Available online: https://pypi.org/project/langdetect/?fbclid=IwAR17pzcUCVFUaWi7PMLHOiD7pqjYhX7rew_DTxSLXXFBKJdGmes6V3qooyU (accessed on 2 January 2021).
- Hutto, C.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; IEEE: Piscataway, NJ, USA, 2014; Volume 8. [Google Scholar]
- GitHub. Available online: https://github.com/porimol/bnbphoneticparser?fbclid=IwAR2bXVZioSZyVaijKoIXE8srOEtyhycFmcaTsL88zWnprNhbrRXY4J2NxpY (accessed on 5 January 2021).
- QuantInsti. Available online: https://blog.quantinsti.com/vader-sentiment/#:~:text=Compound\%20VADER\%20scores\%20for\%20analyzing,1\%20(most\%20extreme\%20positive) (accessed on 10 March 2021).
- Analytics Vidhya. Available online: https://www.analyticsvidhya.com/blog/2017/09/naive-bayes-explained/ (accessed on 12 August 2021).
- Rodríguez-Fdez, I.; Canosa, A.; Mucientes, M.; Bugarín, A. STAC: A web platform for the comparison of algorithms using statistical tests. In Proceedings of the 2015 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Istanbul, Turkey, 2–5 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–8. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Papers with Publishing Year | Method | Objective | Used Language | Used Data | Dissimilarity from Our Work |
|---|---|---|---|---|---|
| Ref. [9] “Event detection and text summary by disaster warning”, 2019. | LDA | -Proposed a user interest-based model. -Their model outputs a brief summary of the microblogging comments. | - | - | -Examined only Twitter data. -Only summarized comments of microblog data. -Discarded some tweet attributes (i.e., embedded URL) while computing. |
| Ref. [11] “Real-time event detection on social data streams”, 2019. | Clustering algorithm | -Handled event progress over time. -Estimated both online and offline performance. | -English | - | -Analyzed only Twitter data. -Their dataset only consisted of English tweets. |
| Ref. [18] “Arabic event detection in social media”, 2015. | NB and online clustering scheme | -Recognized disruptive events from Arabic tweets. | -Arabic | -1.7 million tweets | -Adopted only the Arabic language while ignoring local languages used in tweeting. -Detected only disruptive events while ignoring other types of events. |
| Ref. [24] “Depressed People Detection from Bangla Social Media Status using LSTM and CNN Approach”, 2021. | Hybrid CNN-LSTM | -Utilized a hybrid algorithm. -Detected depressed people. | -Bangla | -7163. | -Only the Bangla language was considered. -The dataset was still in the update stage. |
| Ref. [25] “Bangla hate speech detection on social media using attention-based recurrent neural network”, 2021. | LSTM and GRU (hybrid) model El | -Disclosed Bangla hate speech. -Classified news comments into seven categories. | -Bangla | - | -Experimented only with Bangla language. -Analyzed only news comments rather than whole posts. |
| Ref. [27] “Attention-based convolutional neural network for Bangla sentiment analysis”, 2021. | CNN | -Effectively incorporated attention mechanism. -Analyzed Bangla sentiment from comments and reviews. | -Bangla | -2979 reviews and comments | -Did not occupy semantic meanings of individual words. -Could not bypass word-sense ambiguity. |
| Ref. [28] “Identifying and Categorizing Opinions Expressed in Bangla Sentences using Deep Learning Technique”, 2020. | Deep learning networks (CNN and LSTM) | -Categorized sports news comments based on their sentiment. -Explored four types of sentiments: happiness, sadness, advice, annoyance. | -Bangla | -2492 sentences | -Only employed the Bangla language. -Utilized news comments only. |
| Ref. [29] “Bangla Text Classification using Transformers”, 2020. | Multilingual BERT and XLM-RoBERTa | -Explored different transformer models for classifying text. -Conducted work in the domain of sentiment analysis, news categorization, emotion detection, and authorship distribution. | -Bangla | -Youtube comment dataset (15,686) -News comment sentiment dataset (13,802) -Authorship attriution dataset (14,047) -News classification dataset (11,284) | -Dataset consisted of Bangla articles only. |
| Ref. [31] “Online event detection and tracking in social media based on neural similarity metric learning”, 2017. | NN | -Distinguished and traced events. -Utilized memory module. | - | -9,563,979 tweets | -Conducted their experiment only with Twitter data. |
| Ref. [32] “Sub-event detection from twitter streams as a sequence labeling problem”, 2019. | Long Short Term Memory (LSTM), MLP | -Detected the existence and type of sub event. -Basically, focused on the chronological relation of the tweets. | - | -2 M | -Used Twitter data. |
| Ref. [33] “Event detection on large social media using temporal Analysis”, 2017. | Neural Network (NN) | -Proposed a temporal approach of event detection. -Also detected the complexity of social media chains. | - | -17 GB | -Worked with Twitter data only. -Did not consider Bengali or Banglish posts. |
| Ref. [34] “Real-time novel event detection from social media”, 2017. | Clustering algorithm | -Focused on improving event detection performance. -Also identified temporal information. | -English | -120 million tweets collected (finally 100 k from them were used) | -Used only Twitter data. |
| Ref. [35] “Sportsbuzzer: detecting events at real time in twitter using incremental clustering”, 2018. | LSH | -Identified events from cricket domain. -Used event lexicon for identification of event. | - | -Tweets of 44 games with a file size of over 6 GB | -Detected sports event. -Exploited Twitter data. |
| Ref. [36] “Efficient location-based event detection in social text streams”, 2015. | LSH and SVM classifier | -Proposed a location-based event detection method. -Considered message content along with its time. | - | -257,872 messages | -Collected microblogs only from Sina Weibo. |
| Ref. [42] “Real-time multimedia social event detection in microblog”, 2018. | Hypergraph cut method [50] and transfer cut method [51] | -Considered the correlation among data. -Generated an intermediate semantic level. | - | -3 million microblogs | -Dataset consisted of microblogs from Sina Weibo. -Considered neither the Bengali nor Banglish languages. |
| Common Event’s Words | Celebrating Event’s Words | Protesting Event’s Words | Religious Event’s Words |
|---|---|---|---|
| ঘটেছ (happening),ঘটবে (will happen), সমাবেশ (assembly), জমায়েত (gathering),সমাগম (gathering), সভা (meeting) | আনন্দমেলা (funfair), অনুষ্ঠান (ceremony), বিয়ে (marriage), পুনঃমিলনী (reunion), মেলা (fair) | মিছিল (procession), মানববন্ধন (human chain), বিক্ষোভ (demonstrato), সংঘর্ষ (conflct), হামলা (attack), আন্দোলন (protest) | ওয়াজ (waaz), মাহফিল (religious concert), নামাজ (prayer), দাফন (burial), জানাযা (funeral), পূজা (worship) |
| Ghotche, ghotbe, shomabesh, jomayet, shomagom, shova | Anondomela, onusthan, biye, punomiloni, mela | Michil, manobbondhon, bikkhov, shongghorsho, hamla, andolon | Waaz, mahfil, namaz, dafon, janaza, puja |
| Celebrating Event’s Phrases | Protesting Event’s Phrases | Religious Event’s Phrases |
|---|---|---|
| জন্মবার্ষিকীর অনুষ্ঠান (birthday celebration), বিজয়মিছিল চলছে (victory process is going on), মিলনমেলা চলছে (The reunion is going on), আয়োজিত হবে (will be organized),জমকালো র্যালি হবে (will be splendid rally) | উত্তাল অবস্থা তৈরী (created turbulent condition), মিছিলের আহবান (call of procession), আন্দোলনের ডাক (call of movement), রাজপথে নামতে হবে (have to take the highway), প্রতিবাদ সভা হবে (will be a protest meeting) | ওয়াজ মহফিল অনুষ্ঠিত হবে (waaz mahfil will be held), জানাজা হবে (will be zanaja), দাফন করা হবে (will be buried), পূজা হবে (will be worship) |
| Jonmobarshikir onusthan, bijoymichil cholche, milonmela cholche, aayojit hbe, jomkalo rally hbe | Uttal obostha toiri, michiler ahoban, andoloner dak, rajpothe namte hbe, protibad shobha hbe | Owaaz mahfil onusthito hbe, janaza hbe, dafon kora hbe, puja hbe |
| Method | Event Type | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|---|
| BNB | Celebrating | 0.50 | 0.50 | 0.50 | 0.9041 |
| Protesting | 0.83 | 1.00 | 0.91 | ||
| Religious | 1.00 | 1.00 | 1.00 | ||
| Neutral | 0.96 | 0.90 | 0.92 | ||
| SVM | Celebrating | 0.50 | 0.50 | 0.50 | 0.8767 |
| Protesting | 0.83 | 1.00 | 0.91 | ||
| Religious | 1.00 | 0.67 | 0.80 | ||
| Neutral | 0.91 | 0.90 | 0.91 | ||
| DT | Celebrating | 0.60 | 0.75 | 0.67 | 0.8761 |
| Protesting | 079 | 1.00 | 0.88 | ||
| Religious | 1.00 | 0.67 | 0.80 | ||
| Neutral | 0.93 | 0.88 | 0.90 |
| Method | Protesting | Celebrating | Religious | Neutral | ||||
|---|---|---|---|---|---|---|---|---|
| True Protesting | False Protesting | True Celebratig | False Celebratig | True Religious | False Religious | True Neutral | False Neutral | |
| BNB | 1.00 | 0.00 | 0.50 | 0.50 | 0.89 | 0.11 | 1.00 | 0.00 |
| SVM | 1.00 | 0.00 | 0.50 | 0.50 | 0.89 | 0.11 | 0.67 | 0.33 |
| DT | 1.00 | 0.00 | 0.75 | 0.25 | 0.87 | 0.13 | 0.67 | 0.33 |
| Method | Standard Deviation | ||||
|---|---|---|---|---|---|
| BNB | SVM | DT | BNB | SVM | DT |
| 0.9041 | 0.8767 | 0.8904 | 0.027707 | 0.023926 | 0.024082 |
| 0.8767 | 0.8904 | 0.8904 | |||
| 0.8904 | 0.8493 | 0.8904 | |||
| 0.8630 | 0.8630 | 0.8767 | |||
| 0.8082 | 0.8219 | 0.8356 | |||
| 0.9041 | 0.8767 | 0.8767 | |||
| 0.8493 | 0.8630 | 0.8630 | |||
| 0.8767 | 0.8630 | 0.8767 | |||
| 0.8904 | 0.8767 | 0.8356 | |||
| 0.89041 | 0.9178 | 0.9178 | |||
| 0.8753 | 0.8698 | 0.8753 | Average | ||
| Author Name with Reference | F-Score |
|---|---|
| Sakaki et al. [8] | 73.69 |
| Alomari et al. [16] | 83 |
| Alsaedi et al. [18] | 80.24 |
| Dey et al. [30] | 82.5 |
| Our approach | 92 |
| Method | Event Type | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|---|
| BNB | Celebrating | 0.64 | 0.70 | 0.67 | 0.70 |
| Protesting | 0.78 | 0.88 | 0.82 | ||
| Religious | 0.75 | 1.00 | 0.86 | ||
| Neutral | 0.57 | 0.36 | 0.44 | ||
| SVM | Celebrating | 0.60 | 0.60 | 0.60 | 0.65 |
| Protesting | 0.85 | 0.69 | 0.75 | ||
| Religious | 0.75 | 1.00 | 0.86 | ||
| Neutral | 0.46 | 0.55 | 0.50 | ||
| DT | Celebrating | 0.54 | 0.70 | 0.61 | 0.67 |
| Protesting | 0.79 | 0.94 | 0.86 | ||
| Religious | 0.75 | 1.00 | 0.86 | ||
| Neutral | 0.50 | 0.18 | 0.27 |
| Method | Protesting | Celebrating | Religious | Neutral | ||||
|---|---|---|---|---|---|---|---|---|
| True Protesting | False Protesting | True Celebrating | False Celebrating | True Religious | False Religious | True Neutral | False Neutral | |
| BNB | 0.87 | 0.13 | 0.70 | 0.30 | 1.00 | 0.00 | 0.38 | 0.62 |
| SVM | 0.69 | 0.31 | 0.60 | 0.40 | 1.00 | 0.00 | 0.55 | 0.45 |
| DT | 0.93 | 0.07 | 0.70 | 0.30 | 1.00 | 0.00 | 0.19 | 0.81 |
| Method | Standard Deviation | ||||
|---|---|---|---|---|---|
| BNB | SVM | DT | BNB | SVM | DT |
| 0.675 | 0.675 | 0.65 | 0.06 | 0.061033 | 0.070755 |
| 0.7 | 0.675 | 0.675 | |||
| 0.725 | 0.675 | 0.65 | |||
| 0.75 | 0.725 | 0.75 | |||
| 0.65 | 0.625 | 0.625 | |||
| 0.8 | 0.725 | 0.725 | |||
| 0.775 | 0.75 | 0.675 | |||
| 0.85 | 0.825 | 0.85 | |||
| 0.7 | 0.675 | 0.625 | |||
| 0.675 | 0.6 | 0.6 | |||
| 0.73 | 0.69 | 0.68 | Average | ||
| Datasets | ANOVA between Cases Test | Bonferroni-Dunn Test | |||||
|---|---|---|---|---|---|---|---|
| Statistic | p-Value | Result | Compare | Statistic | p-Value | Result | |
| Bengali | 0.02392 | 0.97639 | H0 is accepted | NB vs. SVM | 0.18943 | 1.00000 | H0 is accepted |
| SVM vs. DT | 0.18940 | 1.00000 | H0 is accepted | ||||
| NB vs. DT | 0.00003 | 1.00000 | H0 is accepted | ||||
| Banglish | −0.23622 | 1.00000 | H0 is accepted | NB vs. SVM | 0.48853 | 0.94368 | H0 is accepted |
| SVM vs. DT | 0.17447 | 1.00000 | H0 is accepted | ||||
| NB vs. DT | 0.66300 | 0.76943 | H0 is accepted | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dey, N.; Rahman, M.S.; Mredula, M.S.; Hosen, A.S.M.S.; Ra, I.-H. Using Machine Learning to Detect Events on the Basis of Bengali and Banglish Facebook Posts. Electronics 2021, 10, 2367. https://doi.org/10.3390/electronics10192367
Dey N, Rahman MS, Mredula MS, Hosen ASMS, Ra I-H. Using Machine Learning to Detect Events on the Basis of Bengali and Banglish Facebook Posts. Electronics. 2021; 10(19):2367. https://doi.org/10.3390/electronics10192367
Chicago/Turabian StyleDey, Noyon, Md. Sazzadur Rahman, Motahara Sabah Mredula, A. S. M. Sanwar Hosen, and In-Ho Ra. 2021. "Using Machine Learning to Detect Events on the Basis of Bengali and Banglish Facebook Posts" Electronics 10, no. 19: 2367. https://doi.org/10.3390/electronics10192367
APA StyleDey, N., Rahman, M. S., Mredula, M. S., Hosen, A. S. M. S., & Ra, I.-H. (2021). Using Machine Learning to Detect Events on the Basis of Bengali and Banglish Facebook Posts. Electronics, 10(19), 2367. https://doi.org/10.3390/electronics10192367