
Multi-Supervised Encoder-Decoder for Image Forgery Localization



Abstract
:1. Introduction
- We propose a Multi-Supervised Encoder–Decoder (MSED) to model high-scale contextual manipulated information and then conduct pixel-wise classification. As far as we know, we are the first to employ the semantic segmentation network for image forgery localization.
- A multi-supervised module is designed to guide the training process and optimize the network performance.
- Experiments on four benchmarks demonstrate that MSED achieves better performance compared to the state-of-the-art works without any pre-training process, which demonstrates the effectiveness of our proposed method.
2. Related Work
2.1. Image Forgery Localization
2.2. CNN-Based Image Semantic Segmentation
3. Materials and Methods
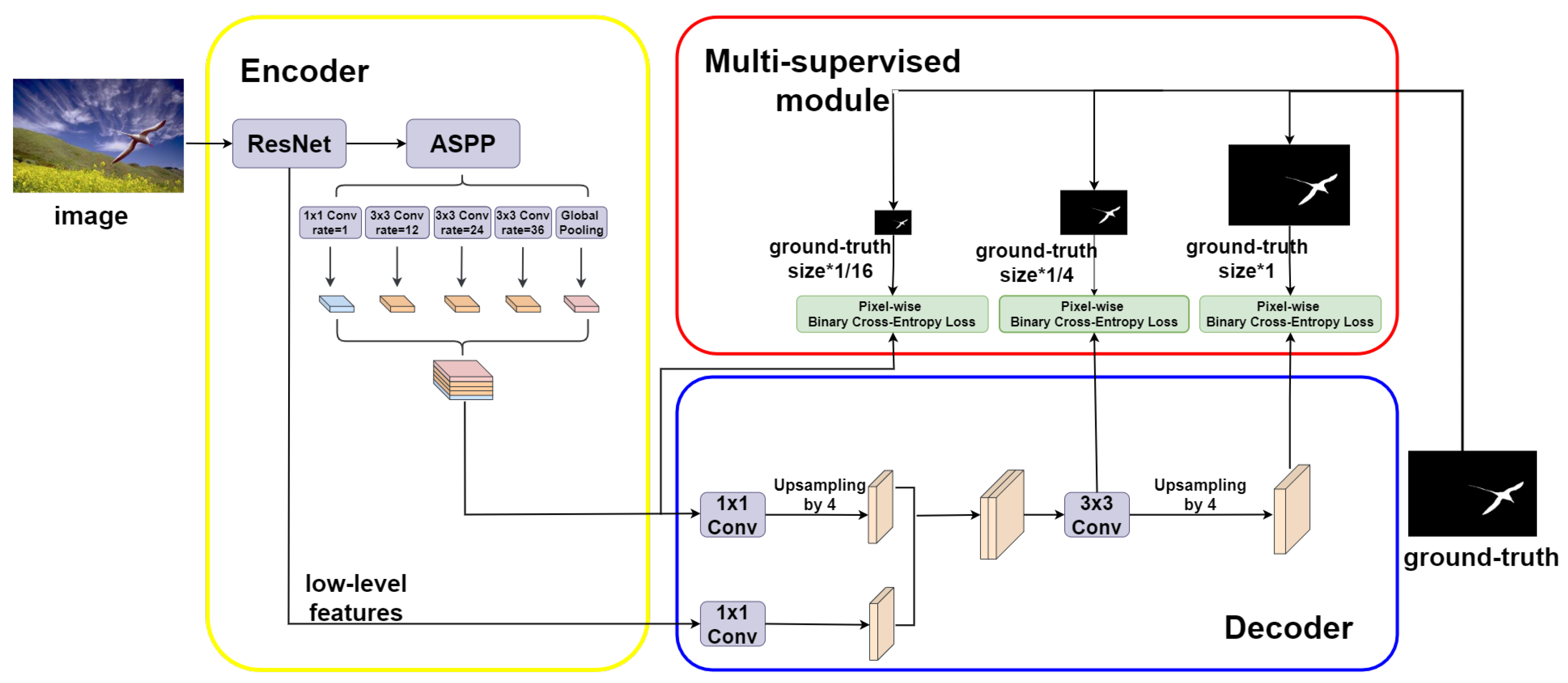
3.1. The Overall Structure of MSED
- (i)
- It improves boundary delineation;
- (ii)
- It reduces the number of parameters enabling end-to-end training.
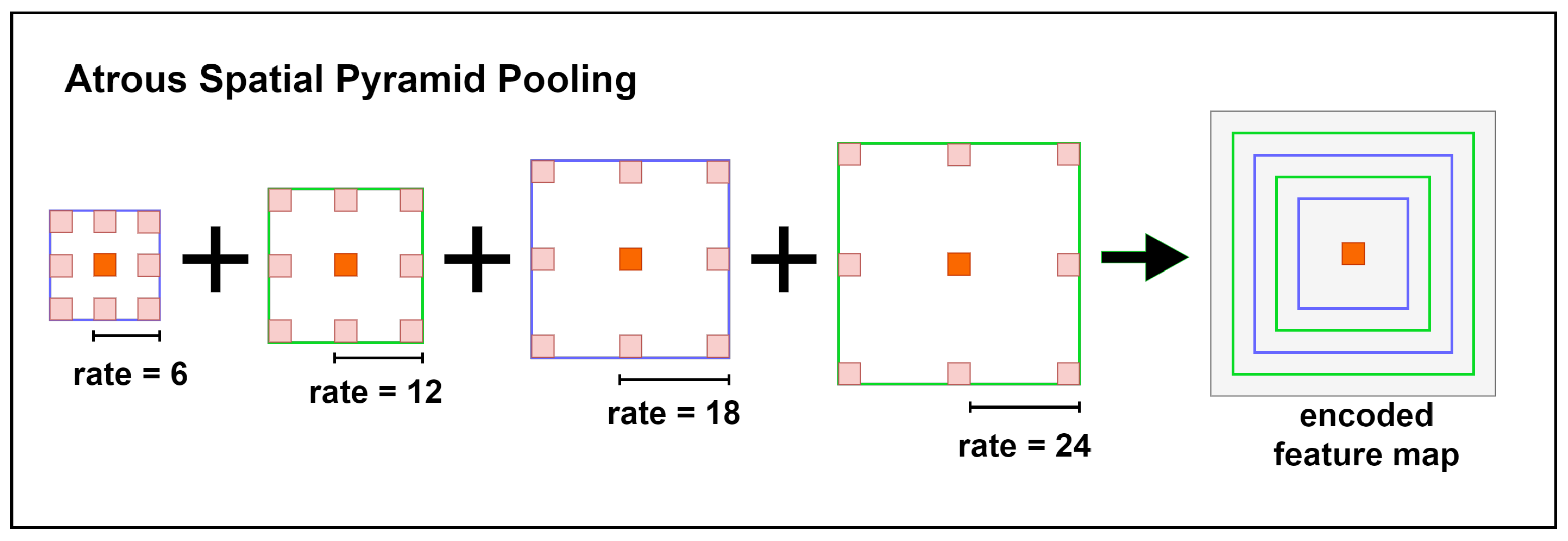
3.2. Encoder of Atrous Convolution
3.3. Decoder of Upsampling
3.4. Multi-Supervised Module
4. Results
4.1. Datasets
- CASIA [1] provides spliced and copy-moved images with binary ground-truth masks. We use CASIA 2.0 for training and CASIA 1.0 for evaluation. CASIA 1.0 contains 921 samples, while CASIA 2.0 includes 5123 samples. They also apply image enhancement techniques such as filtering and blurring to post-process the samples.
- NIST16 [39] is a standard image manipulation dataset that contains three tampered techniques, including splicing, copy-move, and removal. They provide 564 manipulated images and corresponding binary ground-truth masks. Samples of NIST16 are post-processed to hide visible traces.
- Columbia [40] contains 180 splicing forged images with provided edge masks. We transform the edge masks into binary ground-truth masks, in which 1 denotes manipulated pixels, while 0 represents authentic pixels.
- Coverage [25] is a copy-move forgery dataset that only contains 100 samples with corresponding binary masks. It copies objects to another similar region to before in order to conceal the manipulated artifacts.
4.2. Experimental Details
4.3. Evaluation Metrics
4.4. Evaluation and Comparisons
4.4.1. Baseline Models
- ELA: An error level analysis method [13] which aims to apply different JPEG compression qualities to find the compression error difference between tampered regions and authentic regions.
- NOI1: A noise inconsistency-based method detecting changes in noise level to capture manipulated information [16].
- CFA1: A Camera Filter Array (CFA) pattern estimation method [10] which approximates the CFA patterns using nearby pixels and then produces the tampering probability for each pixel.
- J-LSTM: An LSTM-based network [31] jointly training patch-level tampered edge classification and pixel-level tampered region segmentation.
- RGB-N: Bilinear pooling of RGB stream [2] and noise stream for manipulation classification.
- ManTra: An LSTM-based local anomaly detection network [3] which formulates the forgery localization problem as a local anomaly detection problem and captures the local anomaly.
- SPAN: A Spatial Pyramid Attention Network (SPAN) [4] which models the relationship between image patches at multiple scales by constructing a pyramid of local self-attention blocks.
- MSED (Ours): An encoder–decoder focusing on the spatial semantic manipulated information by atrous convolution with an additional multi-supervised module in the training process.
4.4.2. Comparisons
4.5. Qualitative Result
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Dong, J.; Wang, W.; Tan, T. CASIA Image Tampering Detection Evaluation Database. In Proceedings of the 2013 IEEE China Summit and International Conference on Signal and Information Processing, Beijing, China, 6–10 July 2013; pp. 422–426. [Google Scholar] [CrossRef]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Learning Rich Features for Image Manipulation Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1053–1061. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; AbdAlmageed, W.; Natarajan, P. ManTra-Net: Manipulation Tracing Network for Detection and Localization of Image Forgeries with Anomalous Features. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9535–9544. [Google Scholar] [CrossRef]
- Hu, X.; Zhang, Z.; Jiang, Z.; Chaudhuri, S.; Yang, Z.; Nevatia, R. SPAN: Spatial Pyramid Attention Network forImage Manipulation Localization. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Islam, A.; Long, C.; Basharat, A.; Hoogs, A. DOA-GAN: Dual-Order Attentive Generative Adversarial Network for Image Copy-Move Forgery Detection and Localization. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 4675–4684. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Bunk, J.; Bappy, J.H.; Mohammed, T.M.; Nataraj, L.; Flenner, A.; Manjunath, B.S.; Chandrasekaran, S.; Roy-Chowdhury, A.K.; Peterson, L. Detection and Localization of Image Forgeries Using Resampling Features and Deep Learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1881–1889. [Google Scholar] [CrossRef] [Green Version]
- Ferrara, P.; Bianchi, T.; De Rosa, A.; Piva, A. Image Forgery Localization via Fine-Grained Analysis of CFA Artifacts. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1566–1577. [Google Scholar] [CrossRef] [Green Version]
- Alattar, A.M.; Memon, N.D.; Heitzenrater, C.D.; Goljan, M.; Fridrich, J. CFA-aware features for steganalysis of color images. Proc. SPIE Int. Soc. Opt. Eng. 2015, 9409, 94090V. [Google Scholar]
- Dirik, A.E.; Memon, N. Image tamper detection based on demosaicing artifacts. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 1497–1500. [Google Scholar] [CrossRef]
- Krawetz, N. A picture’s worth. Hacker Factor Solut. 2007, 6, 2. [Google Scholar]
- Amerini, I.; Uricchio, T.; Ballan, L.; Caldelli, R. Localization of JPEG double compression through multi-domain convolutional neural networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Park, J.; Cho, D.; Ahn, W.; Lee, H.K. Double JPEG Detection in Mixed JPEG Quality Factors Using Deep Convolutional Neural Network. In Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Mahdian, B.; Saic, S. Using noise inconsistencies for blind image forensics. Image Vis. Comput. 2009, 27, 1497–1503. [Google Scholar] [CrossRef]
- Cozzolino, D.; Poggi, G.; Verdoliva, L. Splicebuster: A new blind image splicing detector. In Proceedings of the 2015 IEEE International Workshop on Information Forensics and Security (WIFS), Roma, Italy, 16–19 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Mccloskey, S.; Chen, C.; Yu, J. Focus Manipulation Detection via Photometric Histogram Analysis. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Bianchi, T.; De Rosa, A.; Piva, A. Improved DCT coefficient analysis for forgery localization in JPEG images. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011. [Google Scholar]
- Huh, M.; Liu, A.; Owens, A.; Efros, A.A. Fighting Fake News: Image Splice Detection via Learned Self-Consistency. In Proceedings of the Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Rao, Y.; Ni, J. A deep learning approach to detection of splicing and copy-move forgeries in images. In Proceedings of the 2016 IEEE International Workshop on Information Forensics and Security (WIFS), Abu Dhabi, United Arab Emirates, 4–7 December 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Kniaz, V.V.; Knyaz, V.A.; Remondino, F. The Point Where Reality Meets Fantasy: Mixed Adversarial Generators for Image Splice Detection. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 215–226. [Google Scholar]
- Salloum, R.; Ren, Y.; Kuo, C.C.J. Image Splicing Localization Using A Multi-Task Fully Convolutional Network (MFCN). J. Vis. Commun. Image Represent. 2017, 51, 201–209. [Google Scholar] [CrossRef] [Green Version]
- Cozzolino, D.; Poggi, G.; Verdoliva, L. Efficient Dense-Field Copy–Move Forgery Detection. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2284–2297. [Google Scholar] [CrossRef]
- Wen, B.; Zhu, Y.; Subramanian, R.; Ng, T.T.; Winkler, S. COVERAGE—A novel database for copy-move forgery detection. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Yue, W.; Abd-Almageed, W.; Natarajan, P. Image Copy-Move Forgery Detection via an End-to-End Deep Neural Network. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- Wu, Y.; Abdalmageed, W.; Natarajan, P. BusterNet: Detecting Copy-Move Image Forgery with Source/Target Localization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhu, X.; Qian, Y.; Zhao, X.; Sun, B.; Sun, Y. A deep learning approach to patch-based image inpainting forensics. Signal Process. Image Commun. 2018, 67, 90–99. [Google Scholar] [CrossRef]
- Bayar, B.; Stamm, M. A Deep Learning Approach to Universal Image Manipulation Detection Using a New Convolutional Layer. In Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security, Vigo, Galicia, Spain, 20–22 June 2016; pp. 5–10. [Google Scholar] [CrossRef]
- Bayar, B.; Stamm, M.C. Constrained Convolutional Neural Networks: A New Approach Towards General Purpose Image Manipulation Detection. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2691–2706. [Google Scholar] [CrossRef]
- Bappy, J.H.; Roy-Chowdhury, A.K.; Bunk, J.; Nataraj, L.; Manjunath, B.S. Exploiting Spatial Structure for Localizing Manipulated Image Regions. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4980–4989. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Papandreou, G.; Kokkinos, I. Untangling Local and Global Deformations in Deep Convolutional Networks for Image Classification and Sliding Window Detection. arXiv 2014, arXiv:1412.0296. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. arXiv 2016, arXiv:1506.02025. [Google Scholar]
- NIST: Nist Nimble 2016 Datasets. 2016. Available online: https://www.nist.gov/itl/iad/mig/ (accessed on 13 June 2016).
- Hsu, Y.-F.; Chang, S.-F. Detecting Image Splicing Using Geometry Invariants and Camera Characteristics Consistency. In Proceedings of the IEEE International Conference on Multimedia and Expo, Seattle, WA, USA, 26 December 2006. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Wu, Y.; Abd-Almageed, W.; Natarajan, P. Deep Matching and Validation Network: An End-to-End Solution to Constrained Image Splicing Localization and Detection. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1480–1502. [Google Scholar] [CrossRef]
- Gloe, T.; Bohme, R. The Dresden Image Database for Benchmarking Digital Image Forensics. J. Digit. Forensic Pract. 2010, 3, 150–159. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | NIST16 | CASIA | Coverage | Columbia | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AUC | AUC | AUC | AUC | |||||||
| ELA [13] | × | × | 23.6 | 42.9 | 21.4 | 61.3 | 22.2 | 58.3 | 47.0 | 58.1 |
| NOI1 [16] | × | × | 28.5 | 48.7 | 26.3 | 61.2 | 26.9 | 58.7 | 57.4 | 54.6 |
| CFA1 [10] | × | × | 17.4 | 50.1 | 20.7 | 52.2 | 19.0 | 48.5 | 46.7 | 72.0 |
| J-LSTM [31] | √ | √ | - | 76.4 | - | - | - | 61.4 | - | - |
| ManTra [3] | √ | √ | - | 79.5 | - | 81.7 | - | 81.9 | - | 82.4 |
| RGB-N [2] | √ | √ | 72.2 | 93.7 | 40.8 | 79.5 | 43.7 | 81.7 | 69.7 | 85.8 |
| SPAN (1) [4] | √ | × | 29.0 | 83.6 | 33.6 | 81.4 | 53.5 | 91.2 | 81.5 | 93.6 |
| SPAN (2) [4] | √ | √ | 58.2 | 96.1 | 38.2 | 83.8 | 55.8 | 93.7 | - | - |
| MSED (Ours) | × | × | 96.0 | 96.2 | 74.7 | 67.8 | 95.1 | 96.1 | 94.6 | 94.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, C.; Zhou, J.; Li, Q. Multi-Supervised Encoder-Decoder for Image Forgery Localization. Electronics 2021, 10, 2255. https://doi.org/10.3390/electronics10182255
Yu C, Zhou J, Li Q. Multi-Supervised Encoder-Decoder for Image Forgery Localization. Electronics. 2021; 10(18):2255. https://doi.org/10.3390/electronics10182255
Chicago/Turabian StyleYu, Chunfang, Jizhe Zhou, and Qin Li. 2021. "Multi-Supervised Encoder-Decoder for Image Forgery Localization" Electronics 10, no. 18: 2255. https://doi.org/10.3390/electronics10182255
APA StyleYu, C., Zhou, J., & Li, Q. (2021). Multi-Supervised Encoder-Decoder for Image Forgery Localization. Electronics, 10(18), 2255. https://doi.org/10.3390/electronics10182255