
Perceptual and Semantic Processing in Cognitive Robots


Abstract
:1. Introduction
2. Related Work
3. Problem Formulation
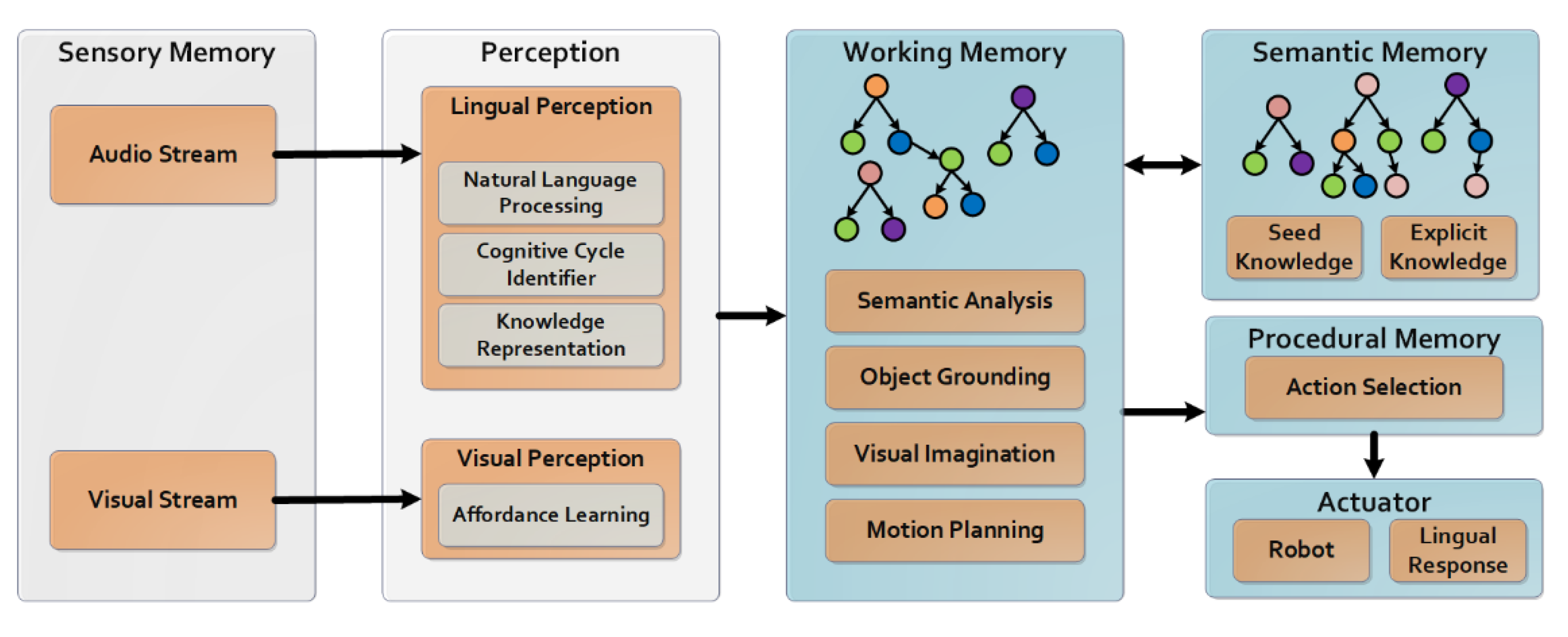
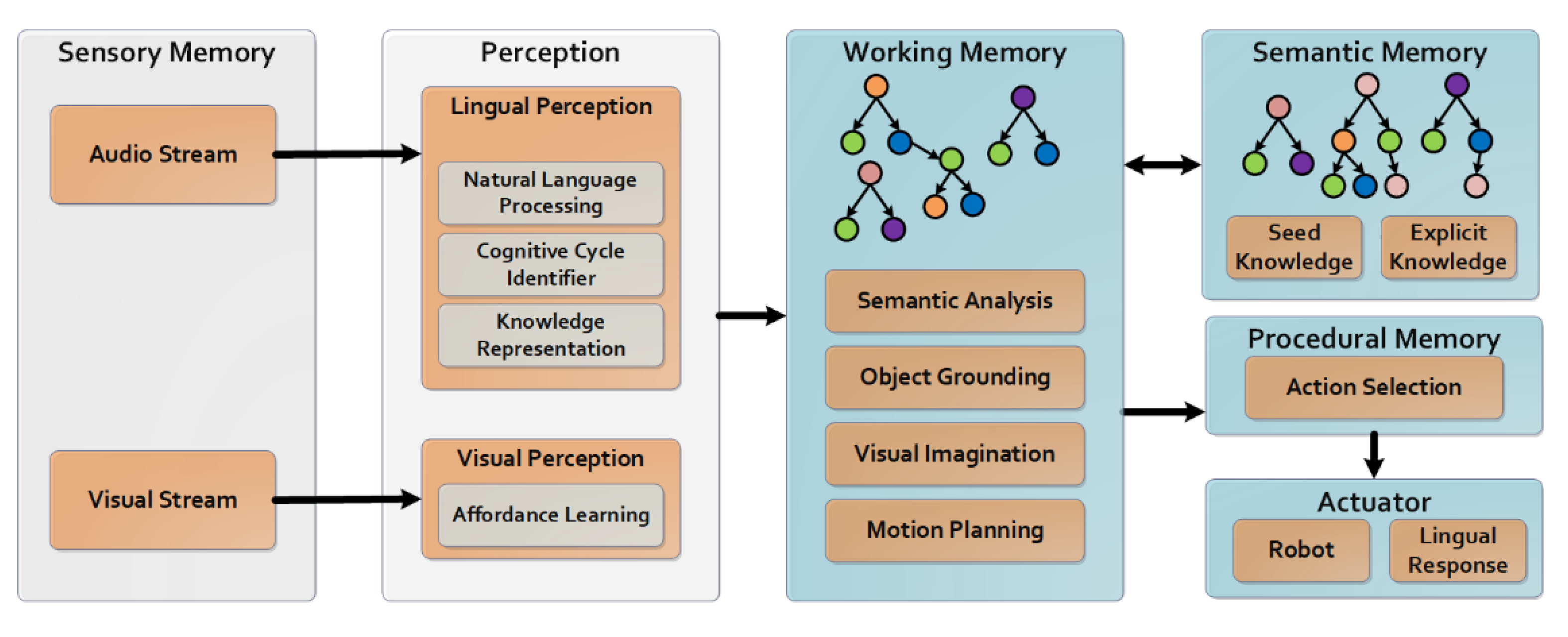
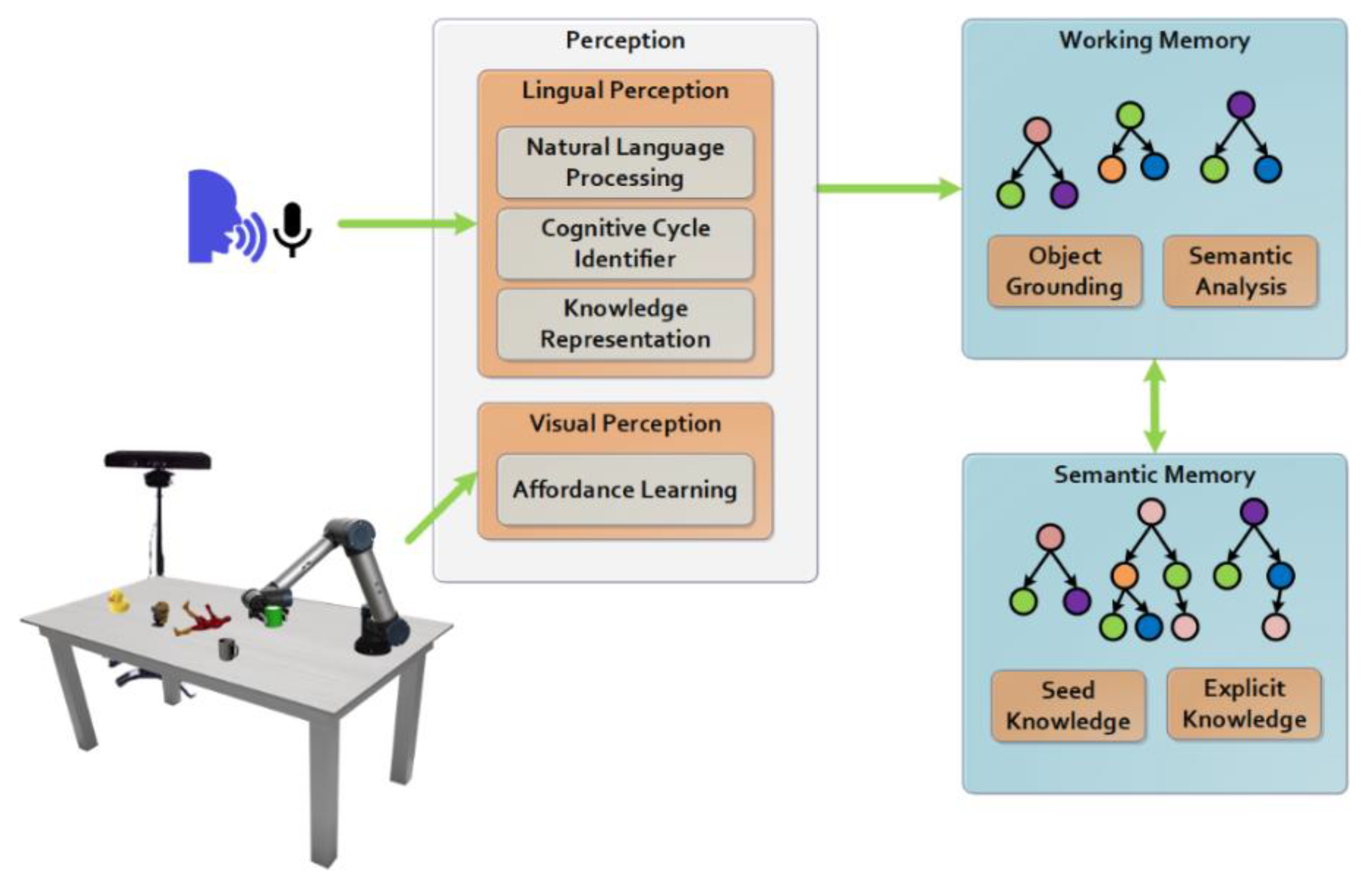
4. Methodology
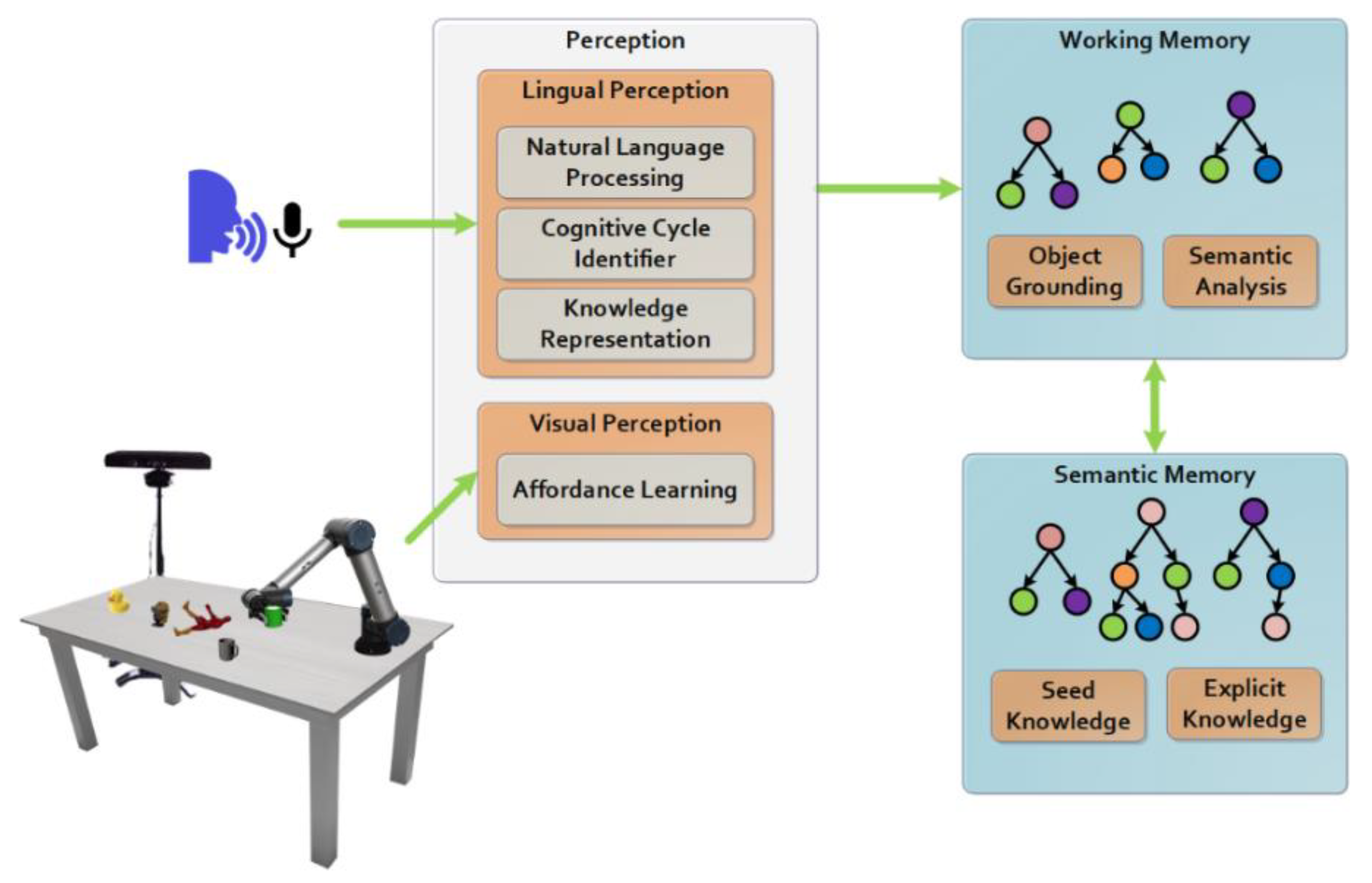
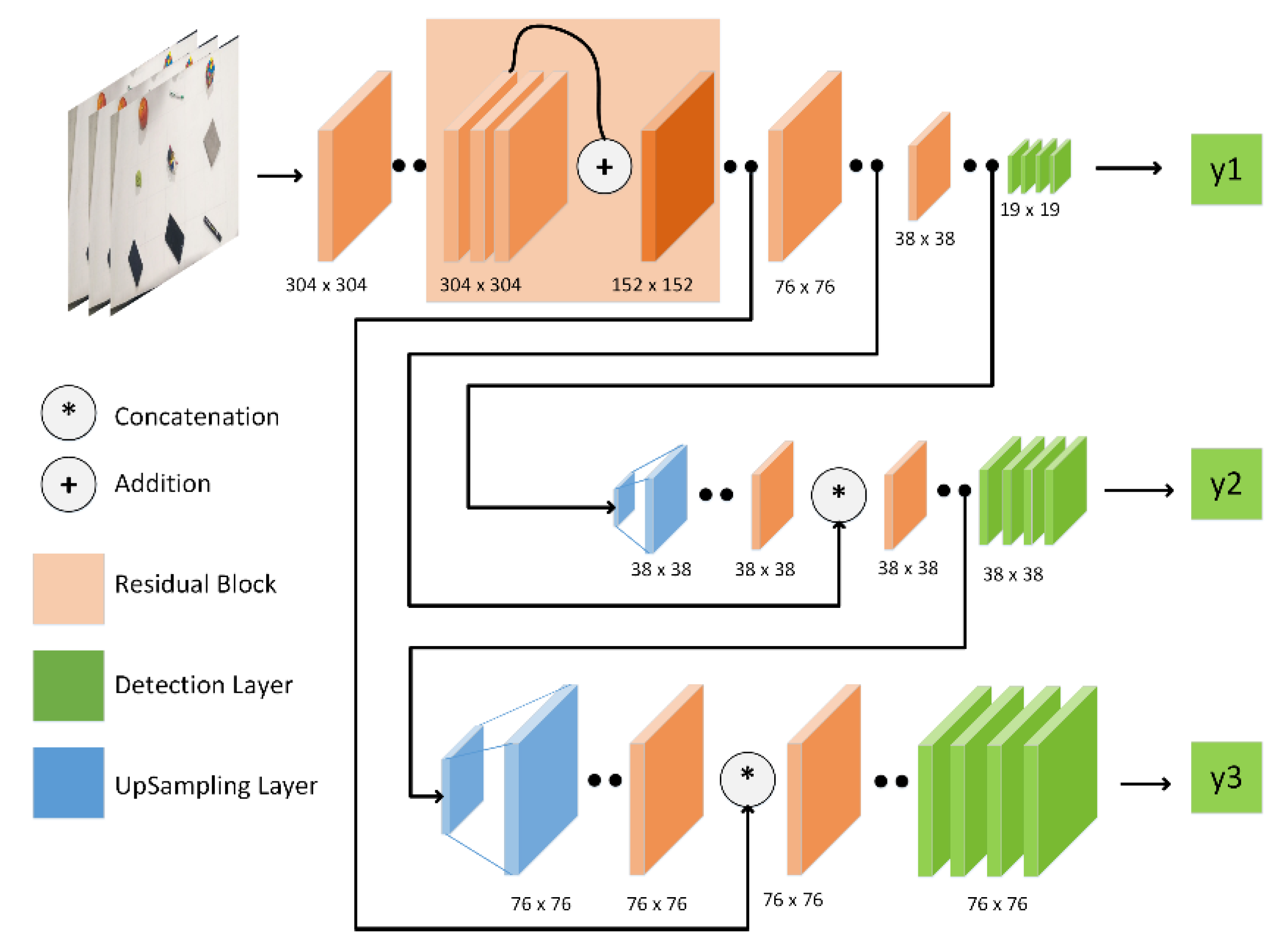
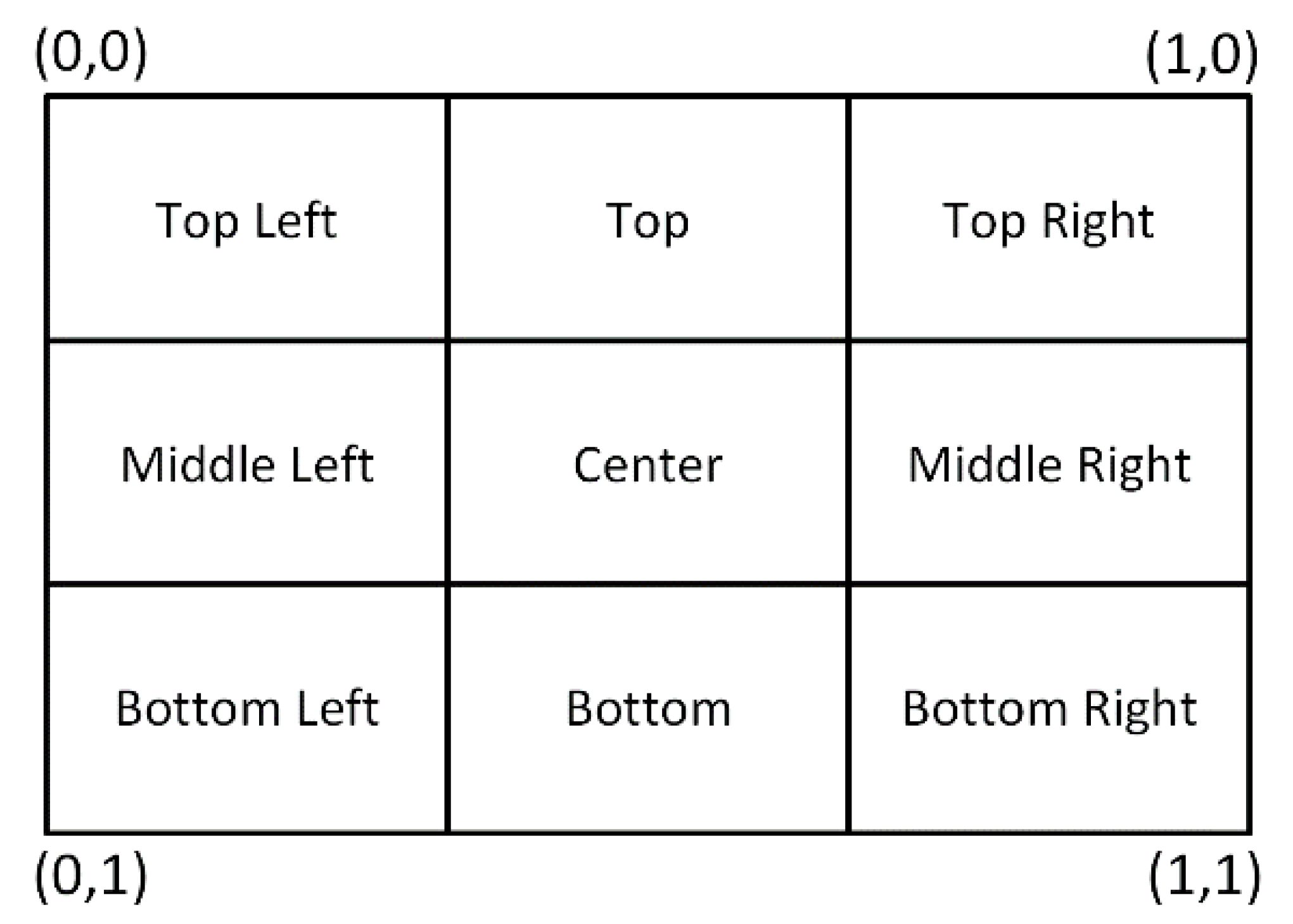
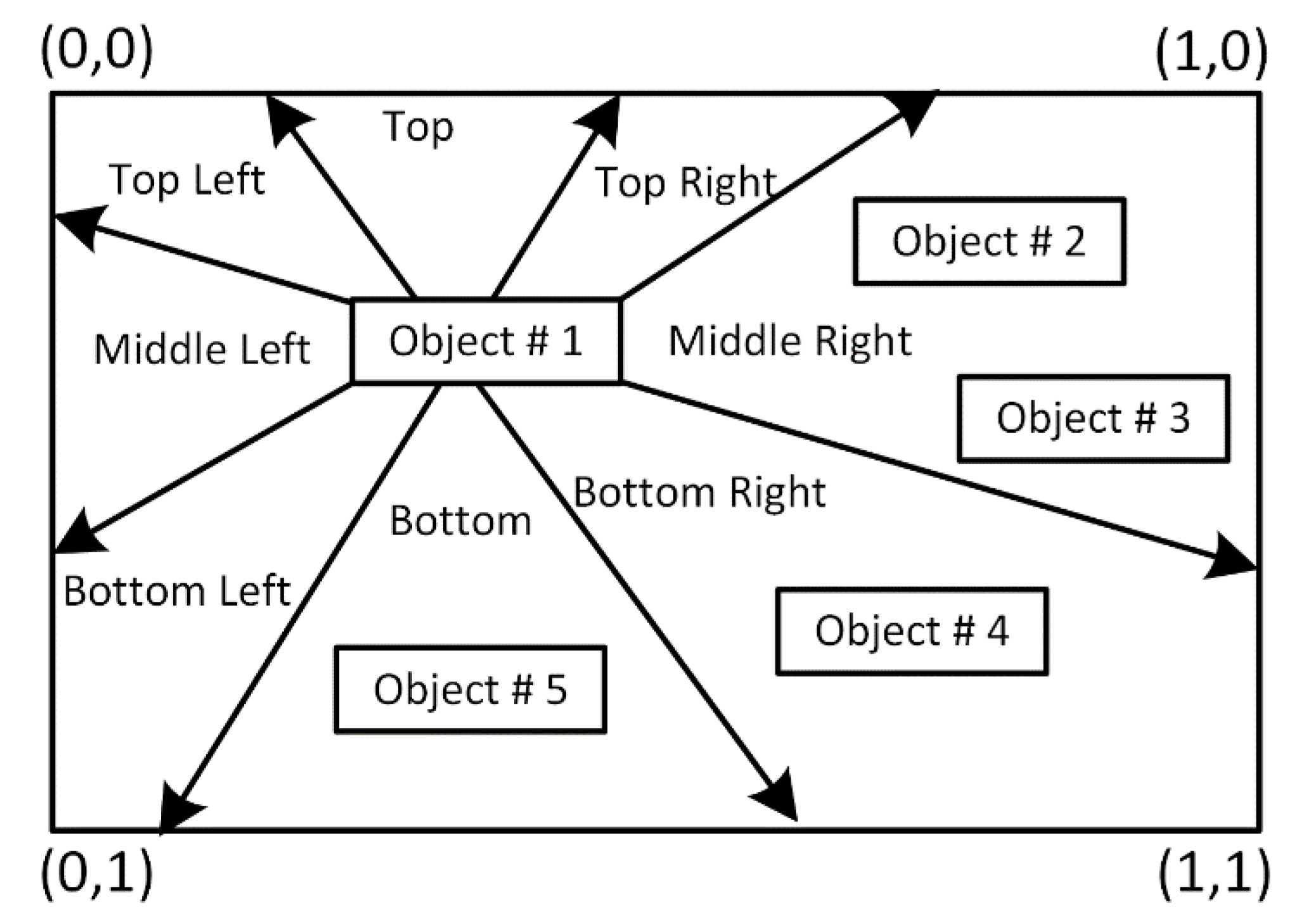
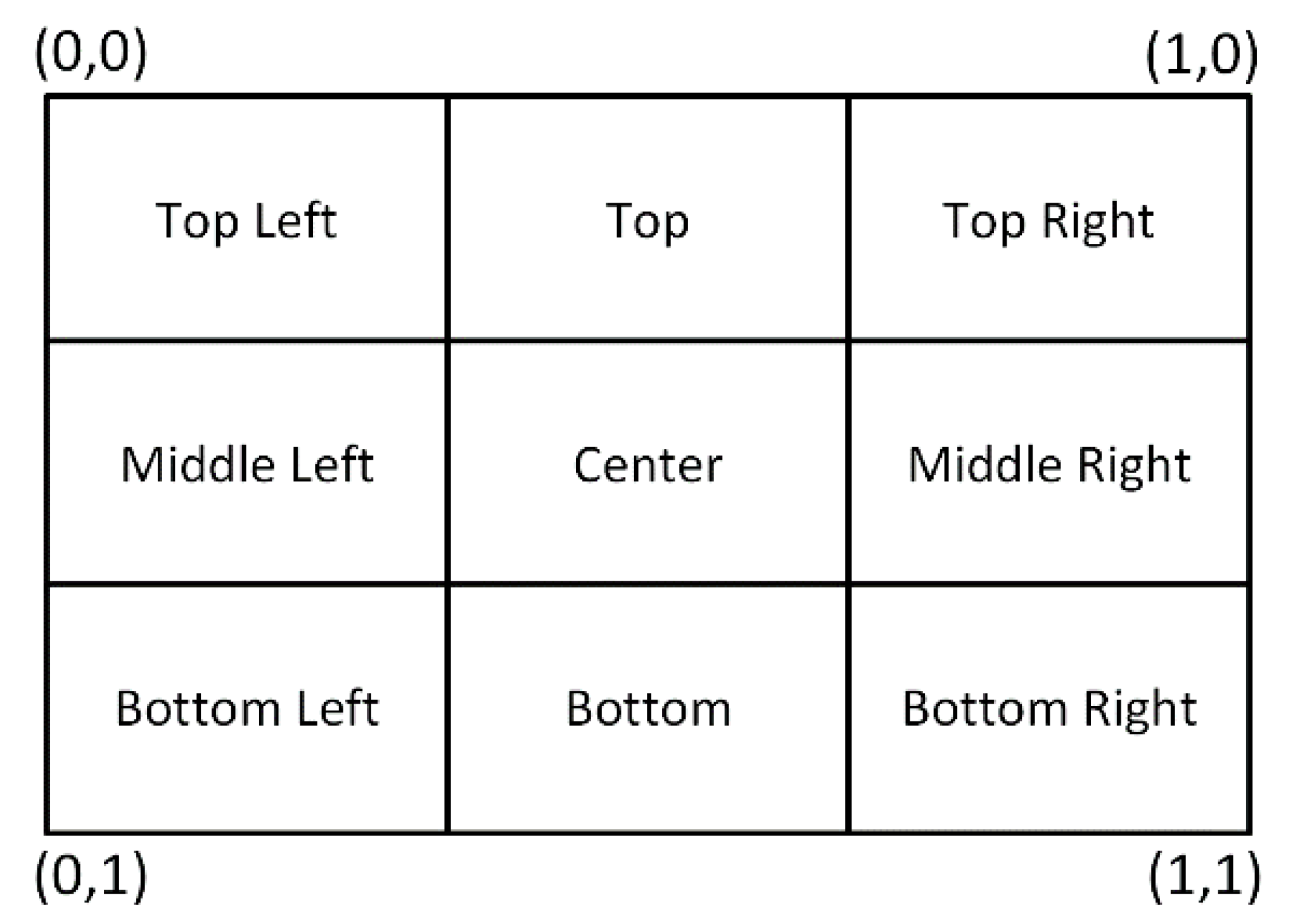
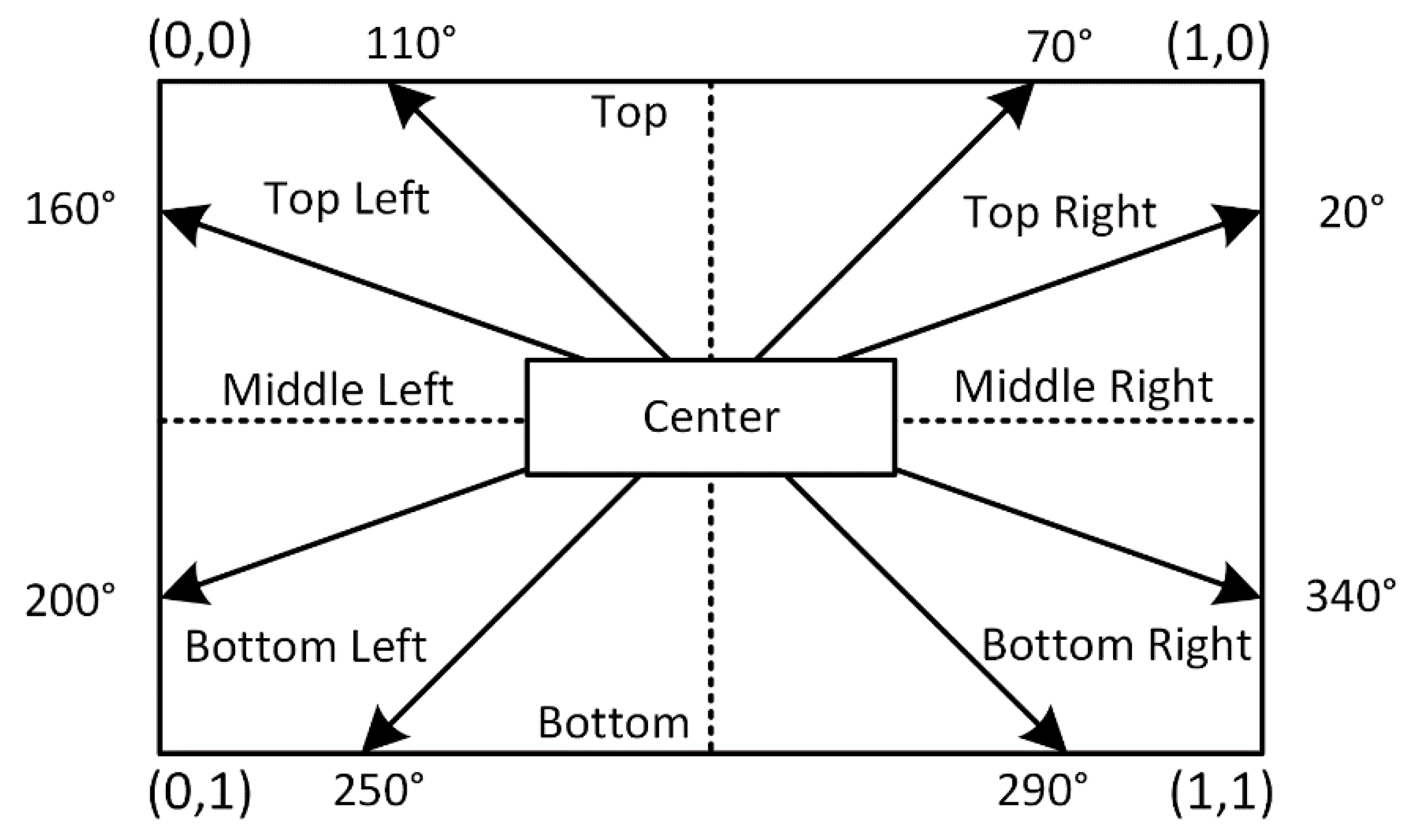
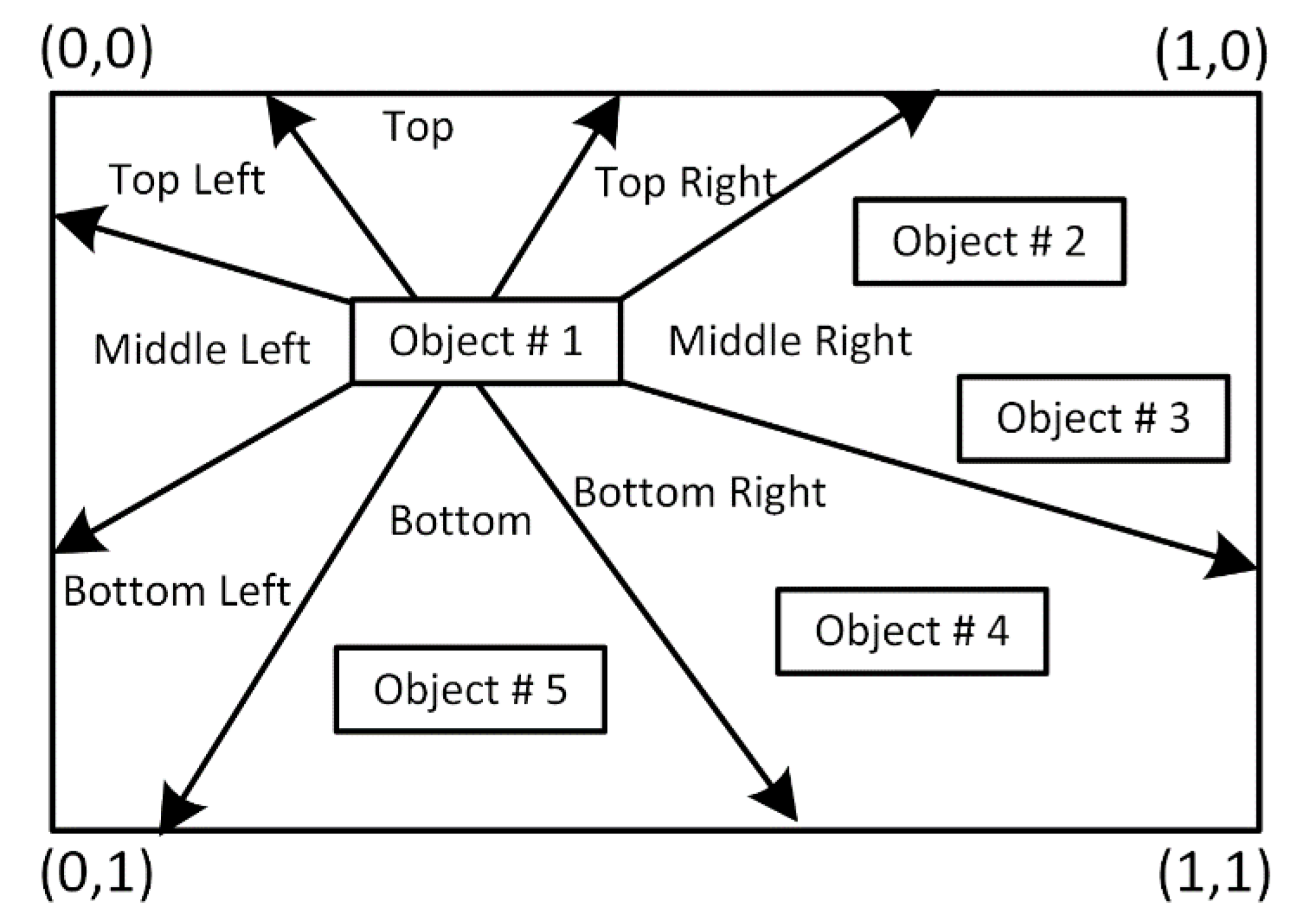
4.1. Visual Perception
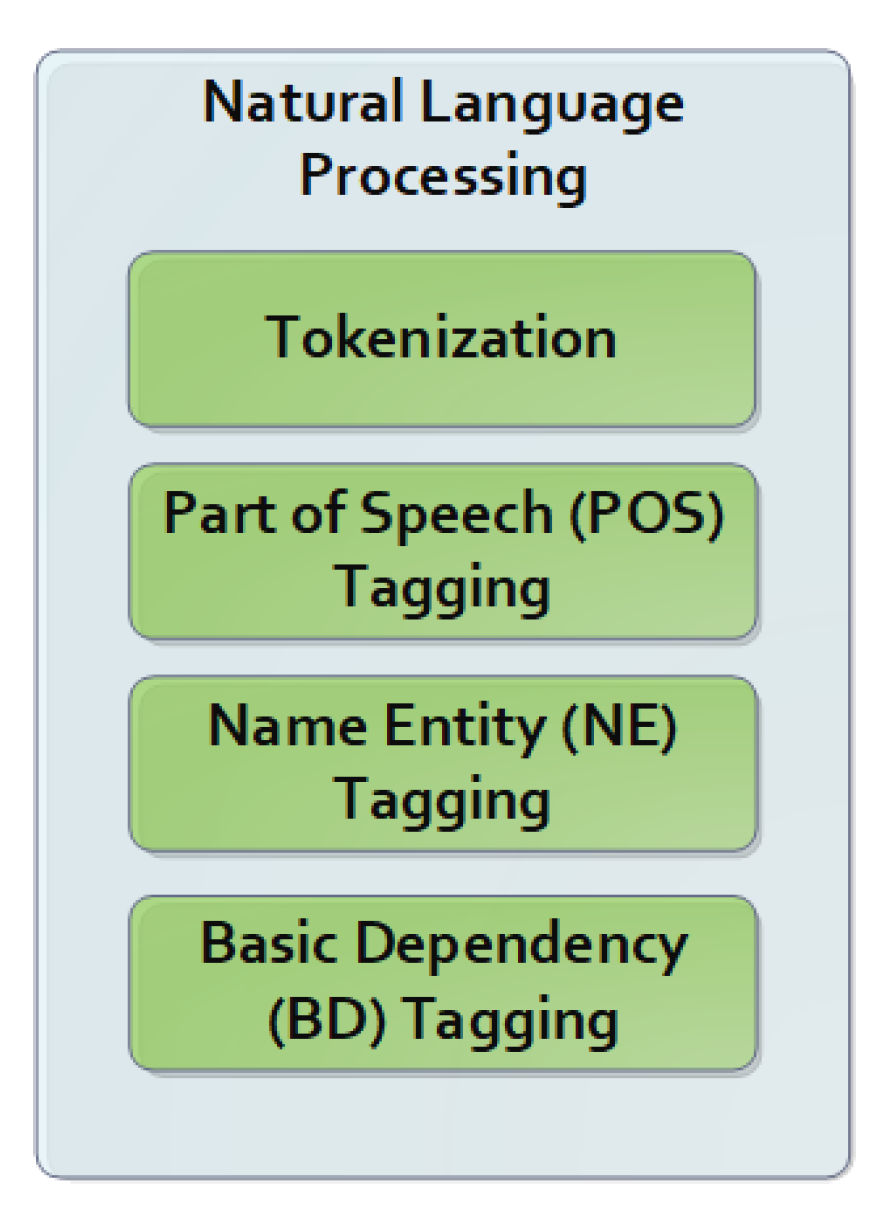
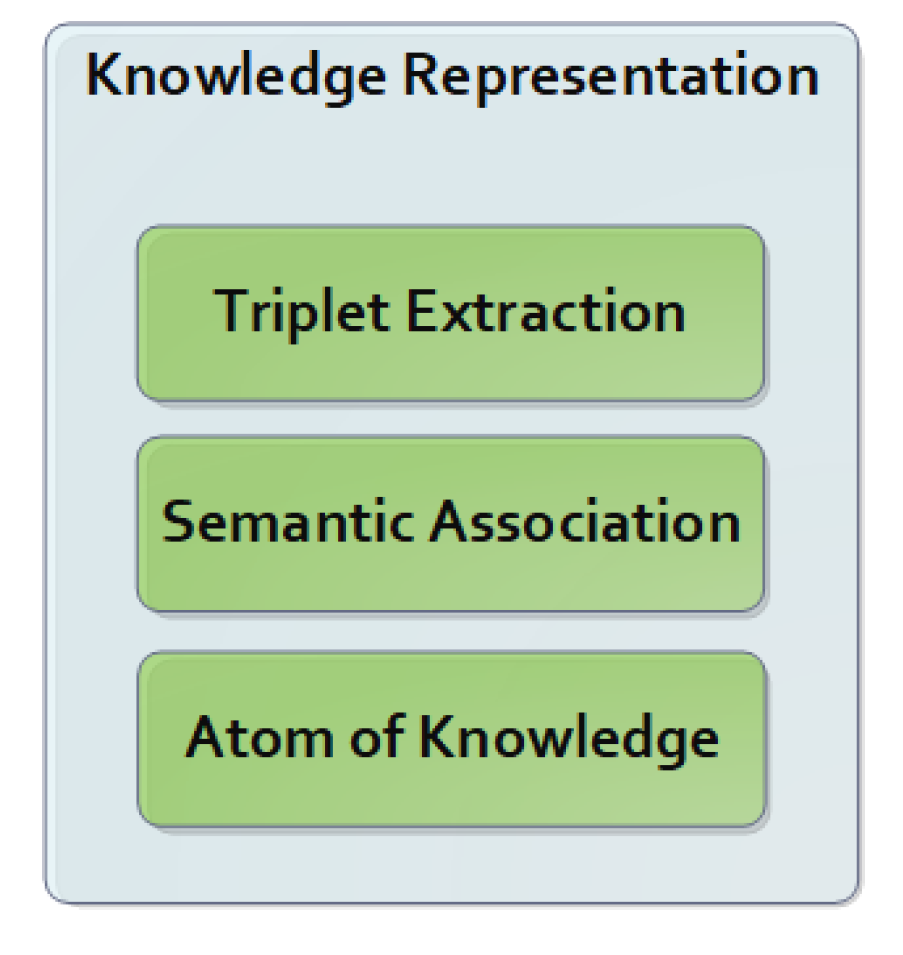
4.2. Lingual Perception
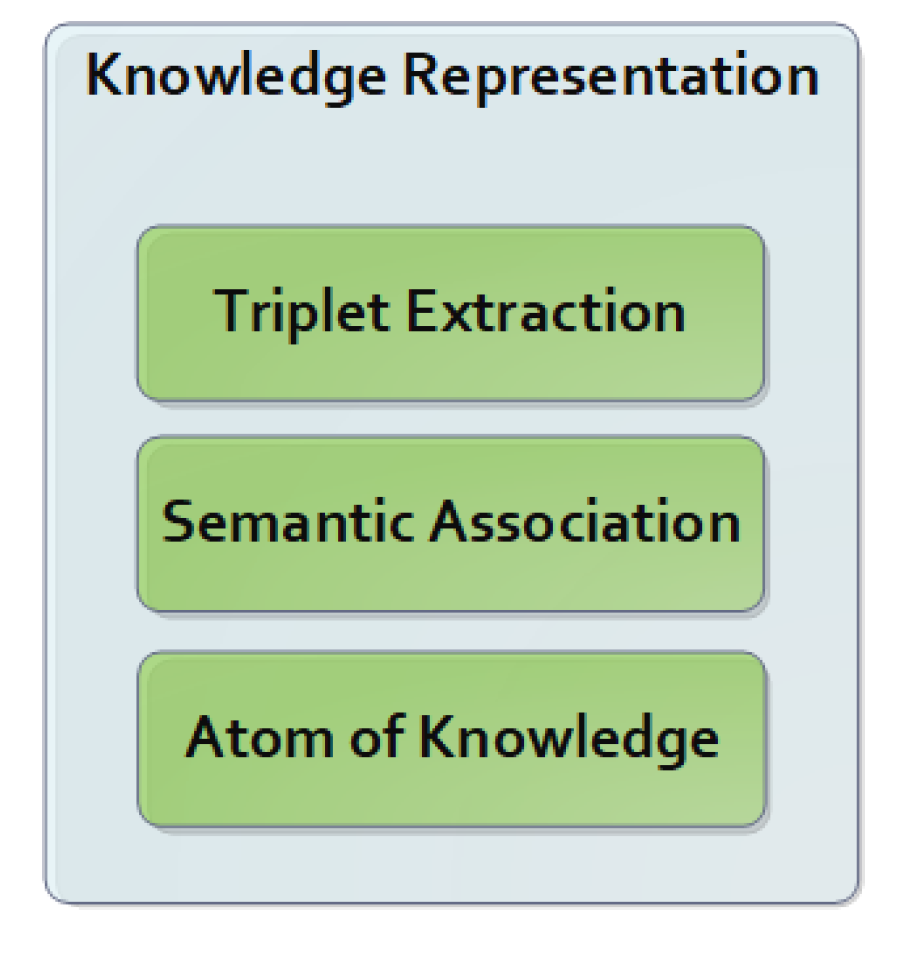
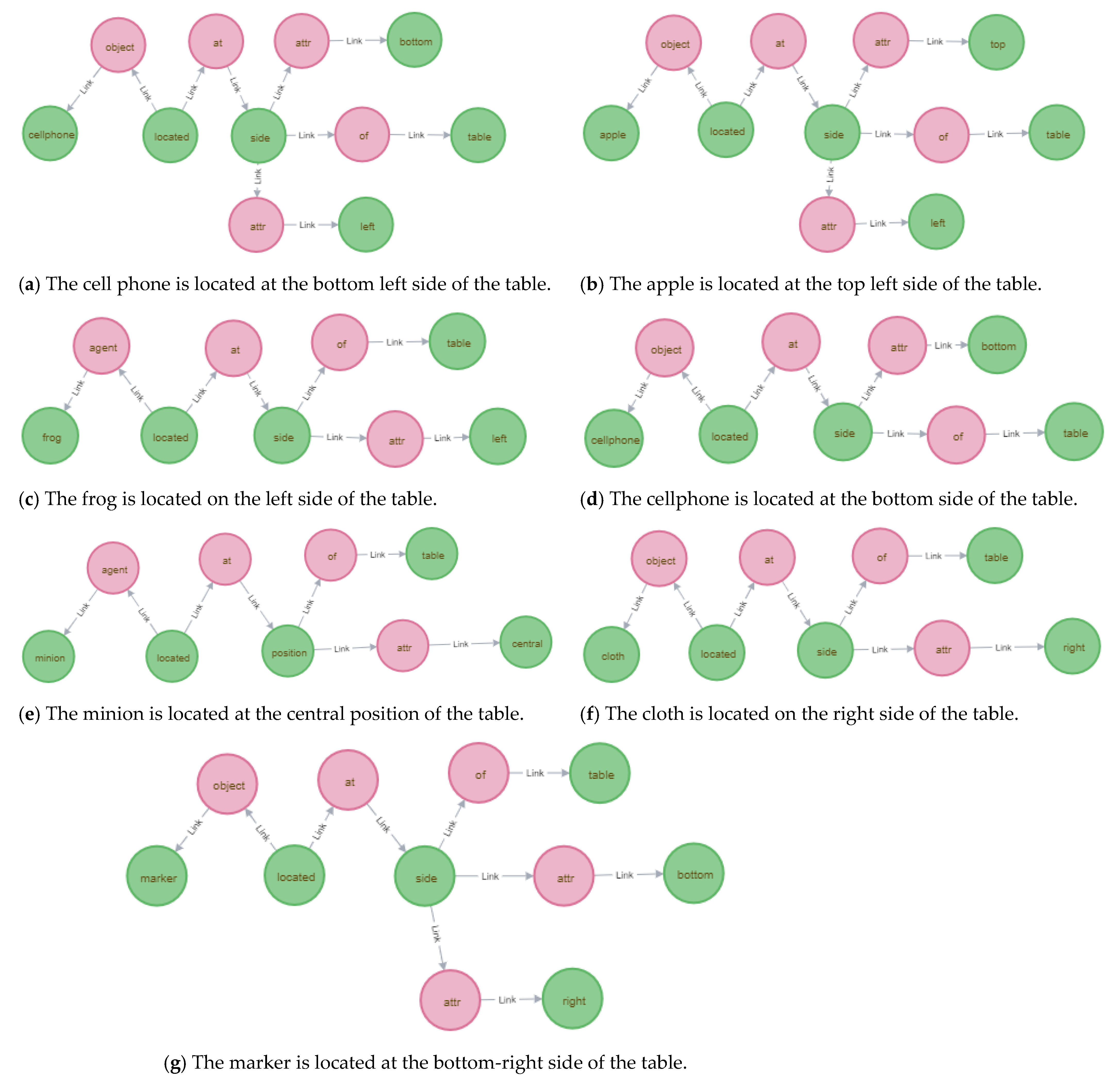
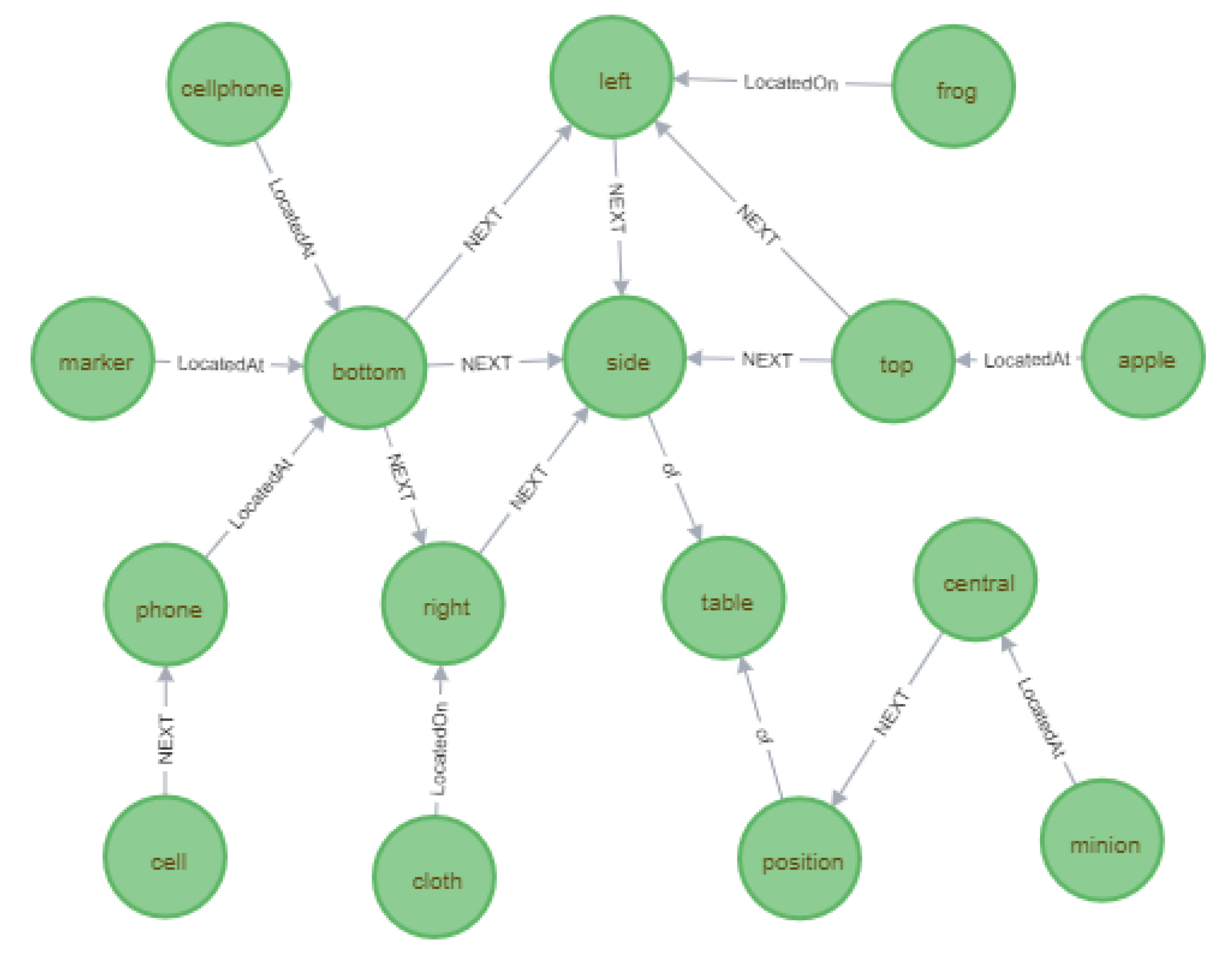
4.3. Semantic Memory
4.4. Working Memory
5. Results
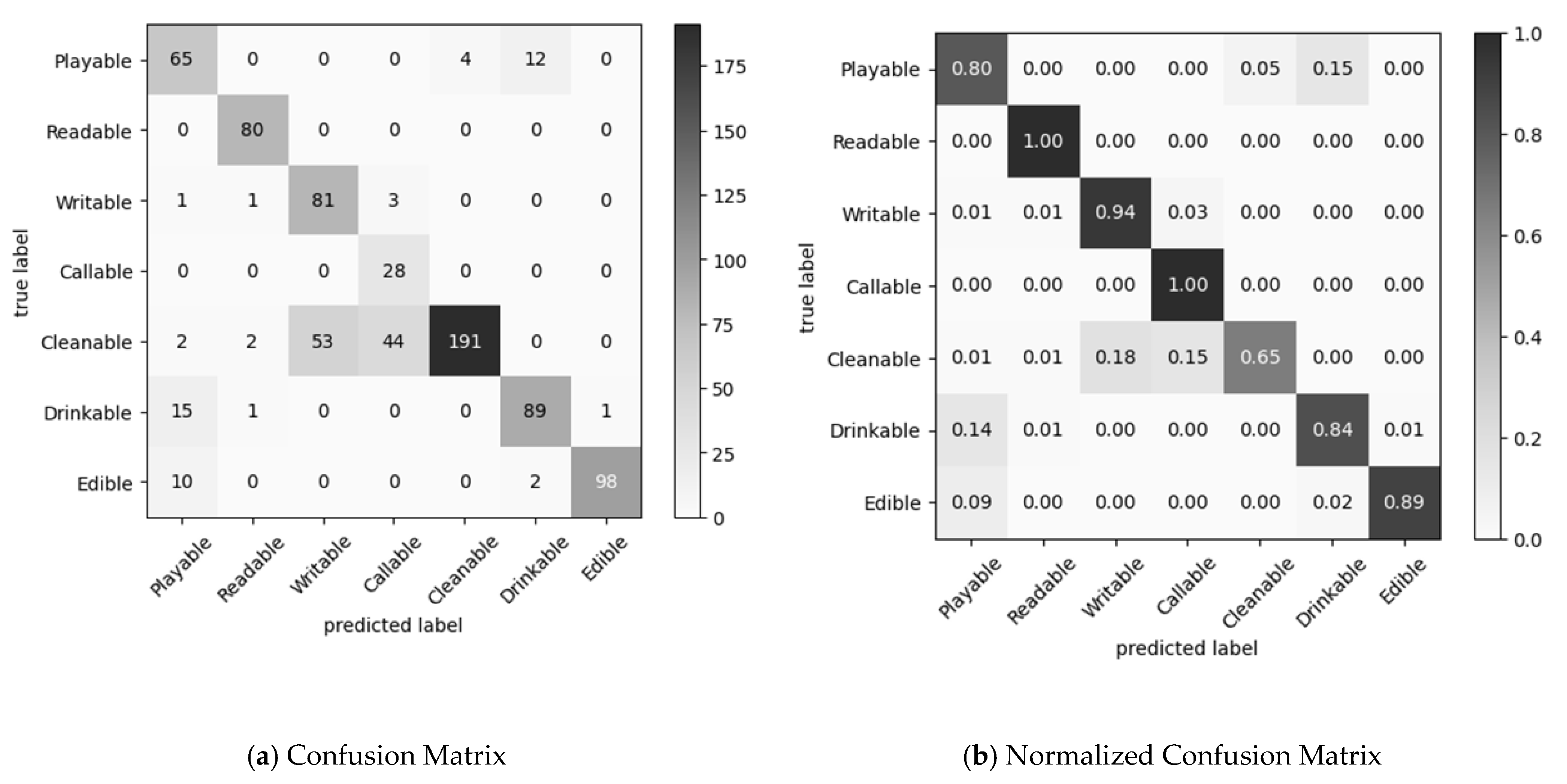
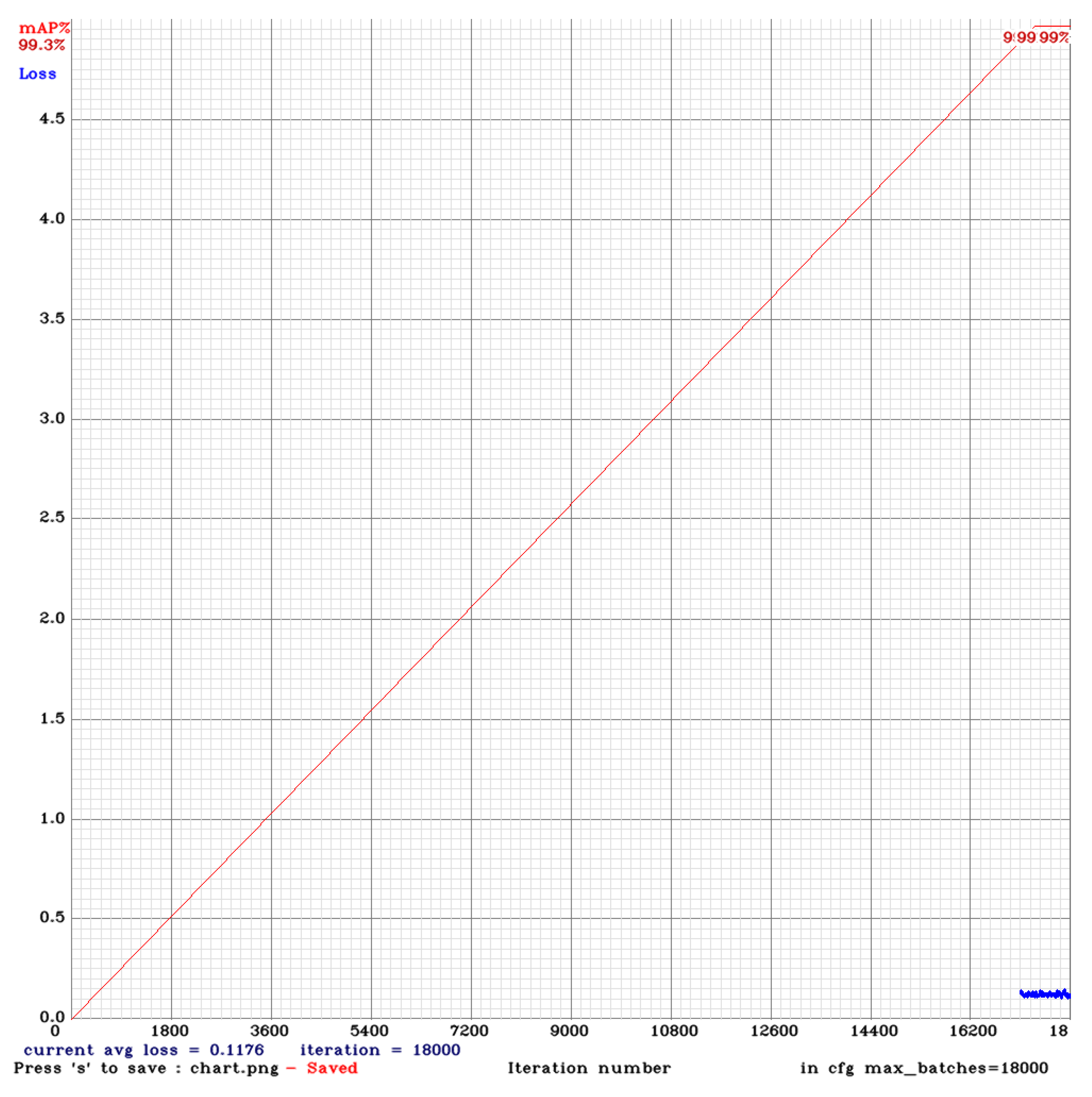
5.1. Visual Perception
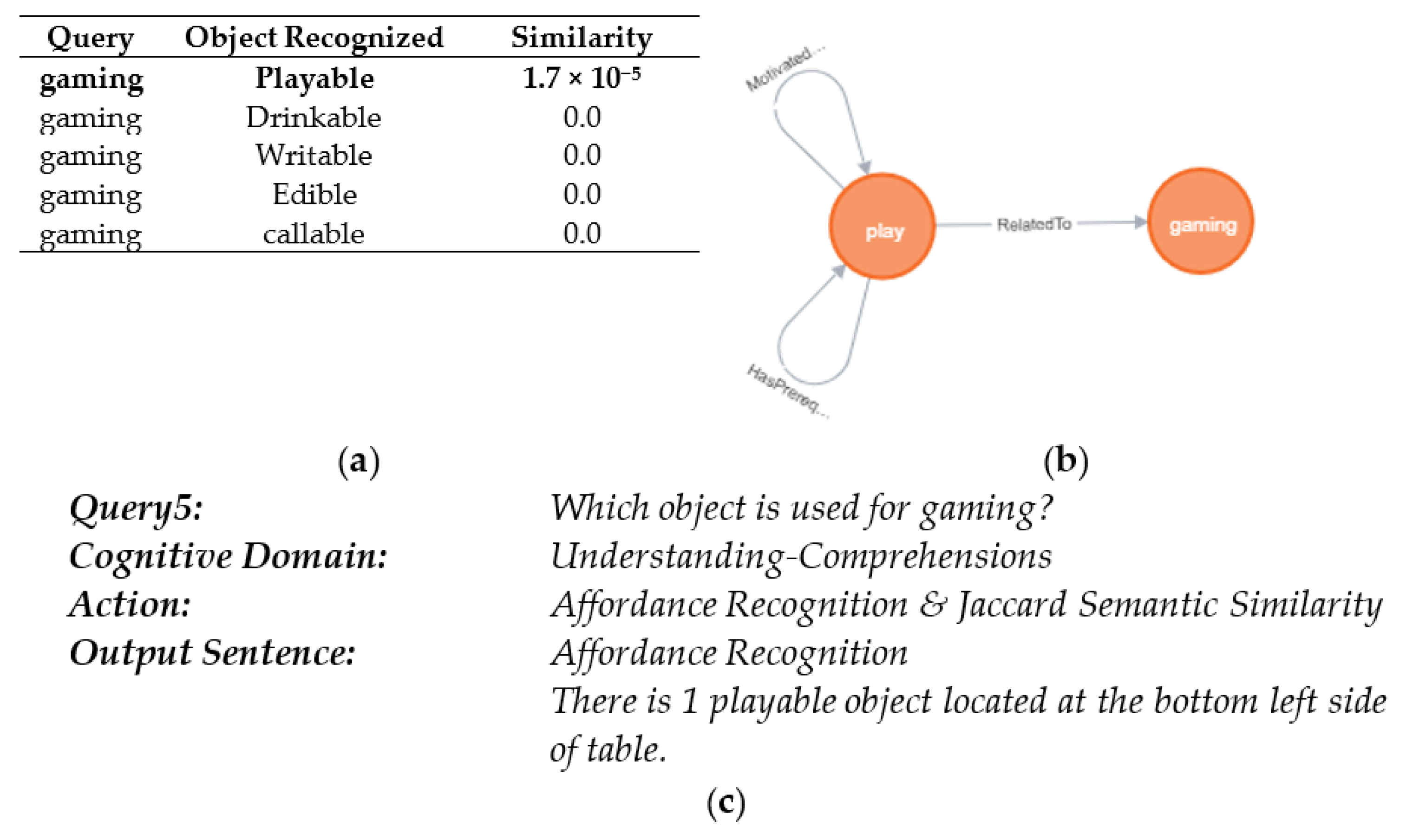
5.2. Lingual Perception and Object Grounding
5.3. Cognitive Cycle Identifier
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type | Layer | Filters | Concatenation | Size/Strd(dil) | Output | ||
|---|---|---|---|---|---|---|---|
| 0 | Convolutional | conv | 32 | 3 × 3/ 1 | 608 × 608 × 32 | ||
| 1 | conv | 64 | 3 × 3/ 2 | 304 × 304 × 64 | |||
| 2 | conv | 32 | 1 × 1/ 1 | 304 × 304 × 32 | |||
| 3 | conv | 64 | 3 × 3/ 1 | 304 × 304 × 64 | |||
| 4 | Residual | Shortcut Layer | 304 × 304 × 64 | ||||
| 5 | Convolutional | conv | 128 | 3 × 3/ 2 | 152 × 152 × 128 | ||
| 2 × | conv | 64 | 1 × 1/ 1 | 152 × 152 × 64 | |||
| conv | 128 | 3 × 3/ 1 | 152 × 152 × 128 | ||||
| 11 | Residual | Shortcut Layer | 152 × 152 × 128 | ||||
| 12 | Convolutional | conv | 256 | 3 × 3/ 2 | 76 × 76 × 256 | ||
| 8 × | conv | 128 | 1 × 1/ 1 | 76 × 76 × 128 | |||
| conv | 256 | 3 × 3/ 1 | 76 × 76 × 256 | ||||
| 36 | Residual | Shortcut Layer | 76 × 76 × 256 | ||||
| 37 | Convolutional | conv | 512 | 3 × 3/ 2 | 38 × 38 × 512 | ||
| 8 × | conv | 256 | 1 × 1/ 1 | 38 × 38 × 256 | |||
| conv | 512 | 3 × 3/ 1 | 38 × 38 × 512 | ||||
| 61 | Residual | Shortcut Layer | 38 × 38 × 512 | ||||
| 62 | Convolutional | conv | 1024 | 3 × 3/ 2 | 19 × 19 × 1024 | ||
| 4 × | conv | 512 | 1 × 1/ 1 | 19 × 19 × 512 | |||
| conv | 1024 | 3 × 3/ 1 | 19 × 19 × 1024 | ||||
| 74 | Residual | Shortcut Layer | 19 × 19 × 1024 | ||||
| 3 × | Convolutional | conv | 512 | 1 × 1/ 1 | 19 × 19 × 512 | ||
| 80 | conv | 1024 | 3 × 3/ 1 | 19 × 19 × 1024 | |||
| 81 | conv | 39 | 1 × 1/ 1 | 19 × 19 × 39 | |||
| 82 | Detection | yolo | |||||
| 83 | route | 79 | -> | ||||
| 84 | Convolutional | conv | 256 | 1 × 1/ 1 | 19 × 19 × 256 | ||
| 85 | Upsampling | upsample | 2x | 38 × 38 × 256 | |||
| 86 | route: 85 -> 61 | 85 | 61 | 38 × 38 × 768 | |||
| 3 × | Convolutional | conv | 256 | 1 × 1/ 1 | 38 × 38 × 256 | ||
| 92 | conv | 512 | 3 × 3/ 1 | 38 × 38 × 512 | |||
| 93 | conv | 39 | 1 × 1/ 1 | 38 × 38 × 39 | |||
| 94 | Detection | yolo | |||||
| 95 | route | 91 | -> | ||||
| 96 | Convolutional | conv | 128 | 1 × 1/ 1 | 38 × 38 × 128 | ||
| 97 | Upsampling | upsample | 2 x | 76 × 76 × 128 | |||
| 98 | route: 97 -> 36 | 97 | 36 | 76 × 76 × 384 | |||
| 3 × | Convolutional | conv | 128 | 1 × 1/ 1 | 76 × 76 × 128 | ||
| 104 | conv | 256 | 3 × 3/ 1 | 76 × 76 × 256 | |||
| 105 | conv | 39 | 1 × 1/ 1 | 76 × 76 × 39 | |||
| 106 | Detection | yolo |
References
- Dubba, K.S.R.; Oliveira, M.R.d.; Lim, G.H.; Kasaei, H.; Lopes, L.S.; Tome, A.; Cohn, A.G. Grounding Language in Perception for Scene Conceptualization in Autonomous Robots. In Proceedings of the AAAI 2014 Spring Symposium, Palo Alto, CA, USA, 24–26 March 2014. [Google Scholar]
- Kotseruba, I.; Tsotsos, J.K. 40 years of cognitive architectures: Core cognitive abilities and practical applications. Artif. Intell. Rev. 2020, 53, 17–94. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, M.; Lopes, L.S.; Lim, G.H.; Kasaei, S.H.; Tomé, A.M.; Chauhan, A. 3D object perception and perceptual learning in the RACE project. Robot. Auton. Syst. 2016, 75, 614–626. [Google Scholar] [CrossRef]
- Oliveira, M.; Lim, G.H.; Lopes, L.S.; Kasaei, S.H.; Tomé, A.M.; Chauhan, A. A perceptual memory system for grounding semantic representations in intelligent service robots. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2014; pp. 2216–2223. [Google Scholar]
- Lopes, M.; Melo, F.S.; Montesano, L. Affordance-based imitation learning in robots. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 30 November 2006; IEEE: New York, NY, USA, 2007; pp. 1015–1021. [Google Scholar]
- Mi, J.; Tang, S.; Deng, Z.; Goerner, M.; Zhang, J. Object affordance based multimodal fusion for natural Human-Robot interaction. Cogn. Syst. Res. 2019, 54, 128–137. [Google Scholar] [CrossRef]
- Sowa, J.F. The Cognitive Cycle. In Proceedings of the 2015 Federated Conference on Computer Science and Information Systems (FedCSIS), Lodz, Poland, 13–16 September 2015; IEEE: New York, NY, USA, 2015; Volume 5, pp. 11–16. [Google Scholar]
- McCall, R.J. Fundamental Motivation and Perception for a Systems-Level Cognitive Architecture. Ph.D. Thesis, The University of Memphis, Memphis, TN, USA, 2014. [Google Scholar]
- Paraense, A.L.; Raizer, K.; de Paula, S.M.; Rohmer, E.; Gudwin, R.R. The cognitive systems toolkit and the CST reference cognitive architecture. Biol. Inspired Cogn. Archit. 2016, 17, 32–48. [Google Scholar] [CrossRef]
- Blanco, B.; Fajardo, J.O.; Liberal, F. Design of Cognitive Cycles in 5G Networks. In Collaboration in A Hyperconnected World; Springer Science and Business Media LLC: London, UK, 2016; pp. 697–708. [Google Scholar]
- Madl, T.; Baars, B.J.; Franklin, S. The Timing of the Cognitive Cycle. PLoS ONE 2011, 6, e14803. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krathwoh, D. A Revision of Bloom’s Taxonomy: An Overview. Theory Pract. 2002, 41, 213–264. [Google Scholar]
- Qazi, W.M.; Bukhari, S.T.S.; Ware, J.A.; Athar, A. NiHA: A Conscious Agent. In Proceedings of the COGNITIVE 2018, The Tenth International Conference on Advanced Cognitive Technologies and Applications, Barcelona, Spain, 18–22 February 2018; pp. 78–87. [Google Scholar]
- Marques, H.G. Architectures for Embodied Imagination. Neurocomputing 2009, 72, 743–759. [Google Scholar] [CrossRef]
- Samsonovich, A.V. On a roadmap for the BICA Challenge. Biol. Inspired Cogn. Archit. 2012, 1, 100–107. [Google Scholar] [CrossRef]
- Breux, Y.; Druon, S.; Zapata, R. From Perception to Semantics: An Environment Representation Model Based on Human-Robot Interactions. In Proceedings of the 2018 27th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Nanjing and Tai’an, China, 27–31 August 2018; IEEE: New York, NY, USA, 2018; pp. 672–677. [Google Scholar] [CrossRef]
- Bornstein, M.H.; Gibson, J.J. The Ecological Approach to Visual Perception. J. Aesthet. Art Crit. 1980, 39, 203. [Google Scholar] [CrossRef]
- Cruz, F.; Magg, S.; Weber, C.; Wermter, S. Training Agents With Interactive Reinforcement Learning and Contextual Affordances. IEEE Trans. Cogn. Dev. Syst. 2016, 8, 271–284. [Google Scholar] [CrossRef]
- Min, H.; Yi, C.; Luo, R.; Zhu, J.; Bi, S. Affordance Research in Developmental Robotics: A Survey. IEEE Trans. Cogn. Dev. Syst. 2016, 8, 237–255. [Google Scholar] [CrossRef]
- Kjellström, H.; Romero, J.; Kragić, D. Visual object-action recognition: Inferring object affordances from human demonstration. Comput. Vis. Image Underst. 2011, 115, 81–90. [Google Scholar] [CrossRef]
- Thomaz, A.L.; Cakmak, M. Learning about objects with human teachers. In Proceedings of the 2009 4th ACM/IEEE International Conference on Human-Robot Interaction (HRI), San Diego, CA, USA, 11–13 March 2009; IEEE: New York, NY, USA, 2009; pp. 15–22. [Google Scholar]
- Wang, C.; Hindriks, K.V.; Babuška, R. Robot learning and use of affordances in goal-directed tasks. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2013; pp. 2288–2294. [Google Scholar]
- Nguyen, A.; Kanoulas, D.; Muratore, L.; Caldwell, D.G.; Tsagarakis, N.G. Translating Videos to Commands for Robotic Manipulation with Deep Recurrent Neural Networks. 2017. Available online: https://www.researchgate.net/publication/320180040_Translating_Videos_to_Commands_for_Robotic_Manipulation_with_Deep_Recurrent_Neural_Networks (accessed on 17 September 2018).
- Myers, A.; Teo, C.L.; Fermuller, C.; Aloimonos, Y. Affordance detection of tool parts from geometric features. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; IEEE: New York, NY, USA, 2015; pp. 1374–1381. [Google Scholar]
- Moldovan, B.; Raedt, L.D. Occluded object search by relational affordances. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 7 June 2014; IEEE: New York, NY, USA, 2014; pp. 169–174. [Google Scholar]
- Nguyen, A.; Kanoulas, D.; Caldwell, D.G.; Tsagarakis, N.G. Object-based affordances detection with Convolutional Neural Networks and dense Conditional Random Fields. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; IEEE: New York, NY, USA, 2017; pp. 5908–5915. [Google Scholar]
- Antunes, A.; Jamone, L.; Saponaro, G.; Bernardino, A.; Ventura, R. From human instructions to robot actions: Formulation of goals, affordances and probabilistic planning. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA); Institute of Electrical and Electronics Engineers (IEEE), Stockholm, Sweden, 16–21 May 2016; IEEE: New York, NY, USA, 2016; pp. 5449–5454. [Google Scholar]
- Tenorth, M.; Beetz, M. Representations for robot knowledge in the KnowRob framework. Artif. Intell. 2017, 247, 151–169. [Google Scholar] [CrossRef]
- Roy, D.; Hsiao, K.-Y.; Mavridis, N. Mental Imagery for a Conversational Robot. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2004, 34, 1374–1383. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson Education, Inc.: Upper Saddle River, NJ, USA, 1994. [Google Scholar]
- Madl, T.; Franklin, S.; Chen, K.; Trappl, R. A computational cognitive framework of spatial memory in brains and robots. Cogn. Syst. Res. 2018, 47, 147–172. [Google Scholar] [CrossRef] [Green Version]
- Shaw, D.B. Robots as Art and Automation. Sci. Cult. 2018, 27, 283–295. [Google Scholar] [CrossRef]
- Victores, J.G. Robot Imagination System; Universidad Carlos III de Madrid: Madrid, Spain, 2014. [Google Scholar]
- Diana, M.; De La Croix, J.-P.; Egerstedt, M. Deformable-medium affordances for interacting with multi-robot systems. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2013; pp. 5252–5257. [Google Scholar]
- Fallon, M.; Kuindersma, S.; Karumanchi, S.; Antone, M.; Schneider, T.; Dai, H.; D’Arpino, C.P.; Deits, R.; DiCicco, M.; Fourie, D.; et al. An Architecture for Online Affordance-based Perception and Whole-body Planning. J. Field Robot. 2014, 32, 229–254. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Ren, S.; Lin, Y. Object–object interaction affordance learning. Robot. Auton. Syst. 2014, 62, 487–496. [Google Scholar] [CrossRef]
- Hart, S.; Dinh, P.; Hambuchen, K. The Affordance Template ROS package for robot task programming. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 26 2015; IEEE: New York, NY, USA, 2015; pp. 6227–6234. [Google Scholar]
- Gago, J.J.; Victores, J.G.; Balaguer, C. Sign Language Representation by TEO Humanoid Robot: End-User Interest, Comprehension and Satisfaction. Electronics 2019, 8, 57. [Google Scholar] [CrossRef] [Green Version]
- Pandey, A.K.; Alami, R. Affordance graph: A framework to encode perspective taking and effort based affordances for day-to-day human-robot interaction. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems; Institute of Electrical and Electronics Engineers (IEEE), Tokyo, Japan, 3–7 November 2013; IEEE: New York, NY, USA, 2013; pp. 2180–2187. [Google Scholar]
- Bukhari, S.T.S.; Qazi, W.M.; Intelligent Machines & Robotics Group, COMSATS University Islamabad, Lahore Campus. Affordance Dataset. 2019. Available online: https://github.com/stsbukhari/Dataset-Affordance (accessed on 8 September 2021).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings CVPR IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 18–20 June 1996; IEEE: New York, NY, USA, 2016; pp. 779–788. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Taylor, A.; Marcus, M.; Santorini, B. The Penn Treebank: An Overview. Treebanks 2003, 20, 5–22. [Google Scholar]
- Yahya, A.A.; Osman, A.; Taleb, A.; Alattab, A.A. Analyzing the Cognitive Level of Classroom Questions Using Machine Learning Techniques. Procedia-Soc. Behav. Sci. 2013, 97, 587–595. [Google Scholar] [CrossRef] [Green Version]
- Sowa, J.F. Semantic Networks. In Encyclopedia of Cognitive Science; American Cancer Society: Chicago, IL, USA, 2006. [Google Scholar]
- Sowa, J.F. Conceptual graphs as a universal knowledge representation. Comput. Math. Appl. 1992, 23, 75–93. [Google Scholar] [CrossRef] [Green Version]
- Do, T.-T.; Nguyen, A.; Reid, I. AffordanceNet: An End-to-End Deep Learning Approach for Object Affordance Detection. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; IEEE: New York, NY, USA, 2018; pp. 1–5. [Google Scholar]
- Myers, A. From Form to Function: Detecting the Affordance of Tool Parts using Geometric Features and Material Cues. Ph.D. Thesis, University of Maryland, College Park, MD, USA, 2016. [Google Scholar]
- Jiang, Y.; Koppula, H.; Saxena, A.; Saxena, A. Hallucinated Humans as the Hidden Context for Labeling 3D Scenes. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 18–20 June 1996; IEEE: New York, NY, USA, 2013; pp. 2993–3000. [Google Scholar]
- Koppula, H.S.; Jain, A.; Saxena, A. Anticipatory Planning for Human-Robot Teams. In Experimental Robotics; Springer: Berlin/Heidelberg, Germany, 2016; pp. 453–470. [Google Scholar]
- Baleia, J.; Santana, P.; Barata, J. On Exploiting Haptic Cues for Self-Supervised Learning of Depth-Based Robot Navigation Affordances. J. Intell. Robot. Syst. 2015, 80, 455–474. [Google Scholar] [CrossRef] [Green Version]
- Chu, F.-J.; Xu, R.; Vela, P.A. Learning Affordance Segmentation for Real-World Robotic Manipulation via Synthetic Images. IEEE Robot. Autom. Lett. 2019, 4, 1140–1147. [Google Scholar] [CrossRef]





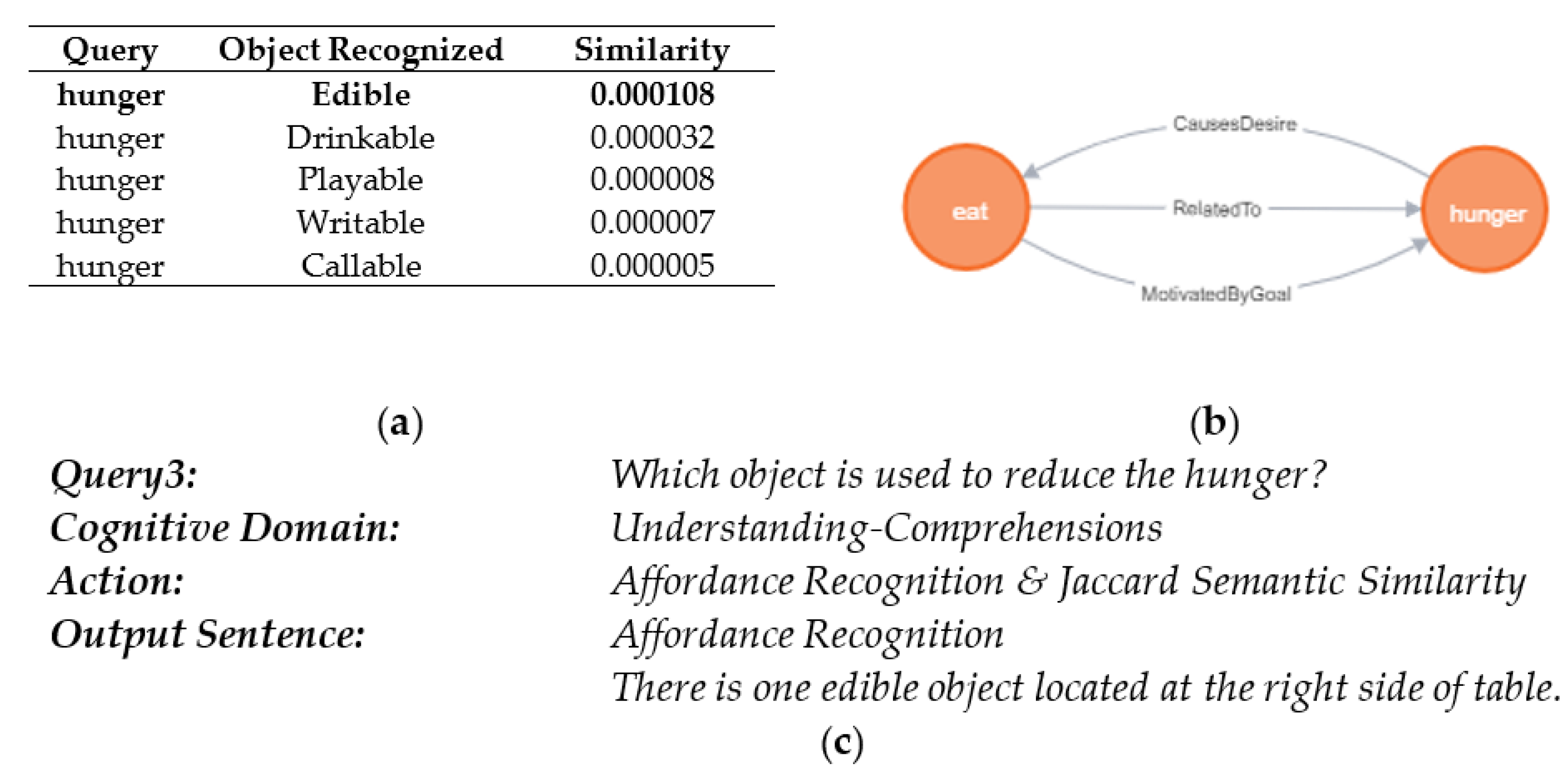
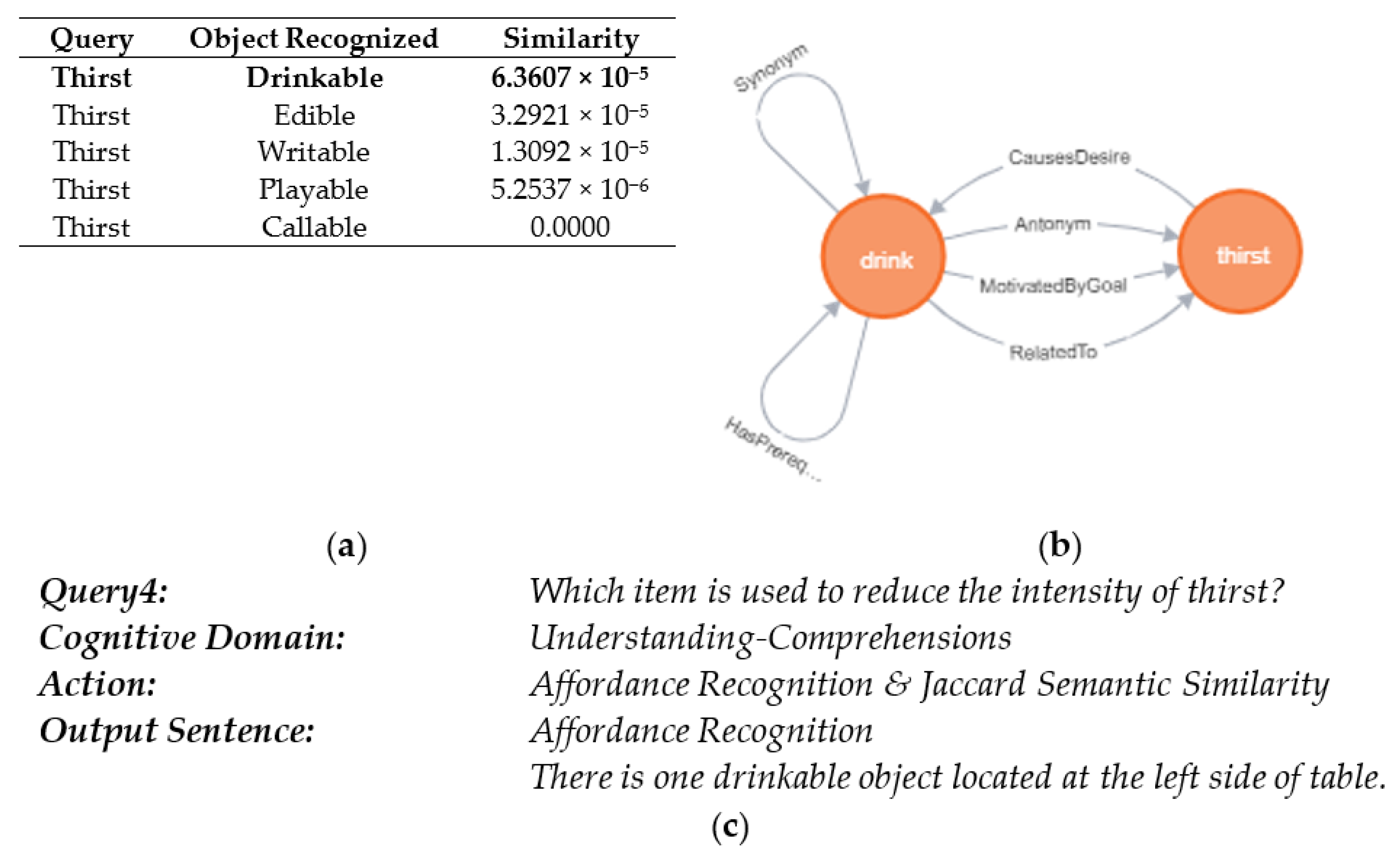
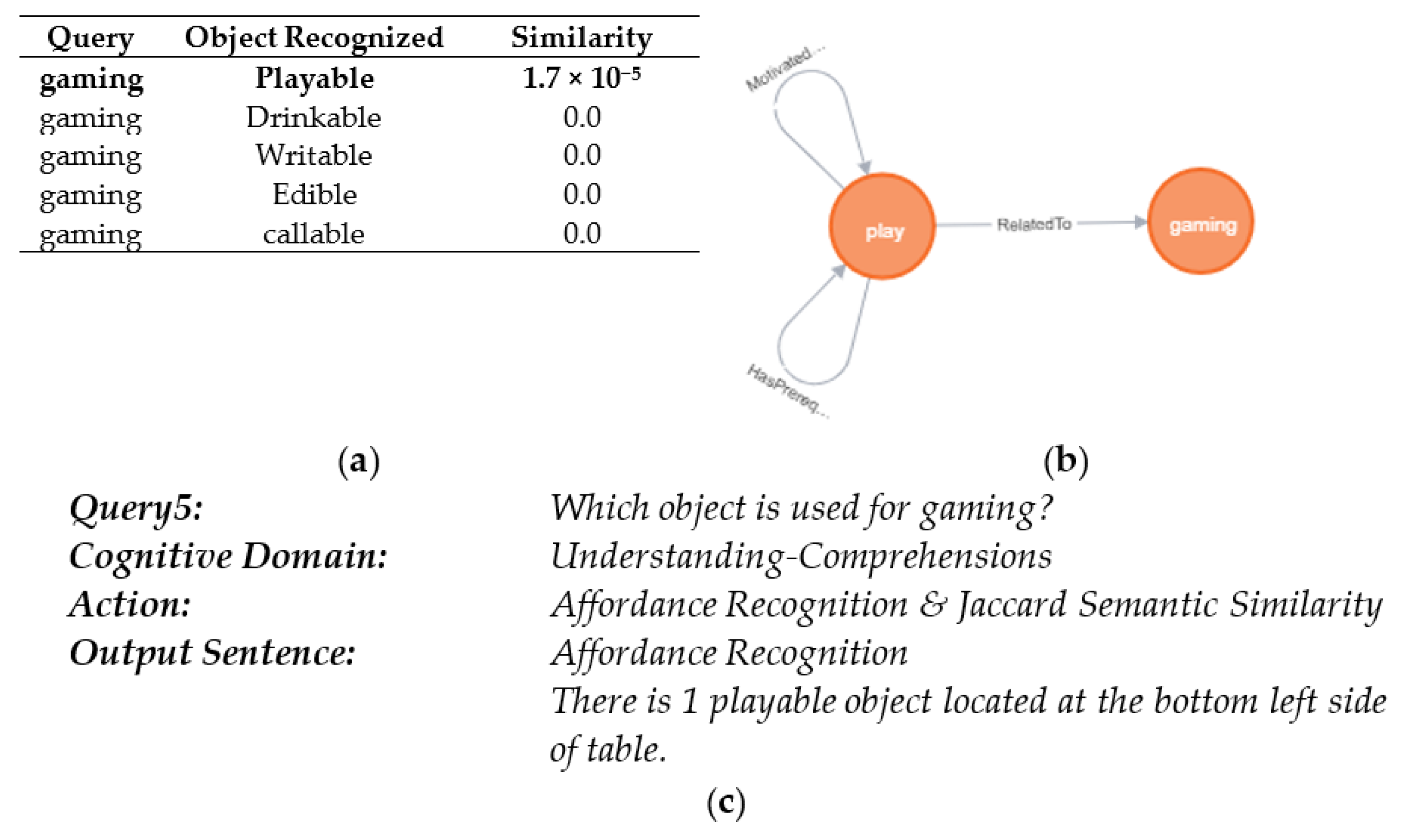
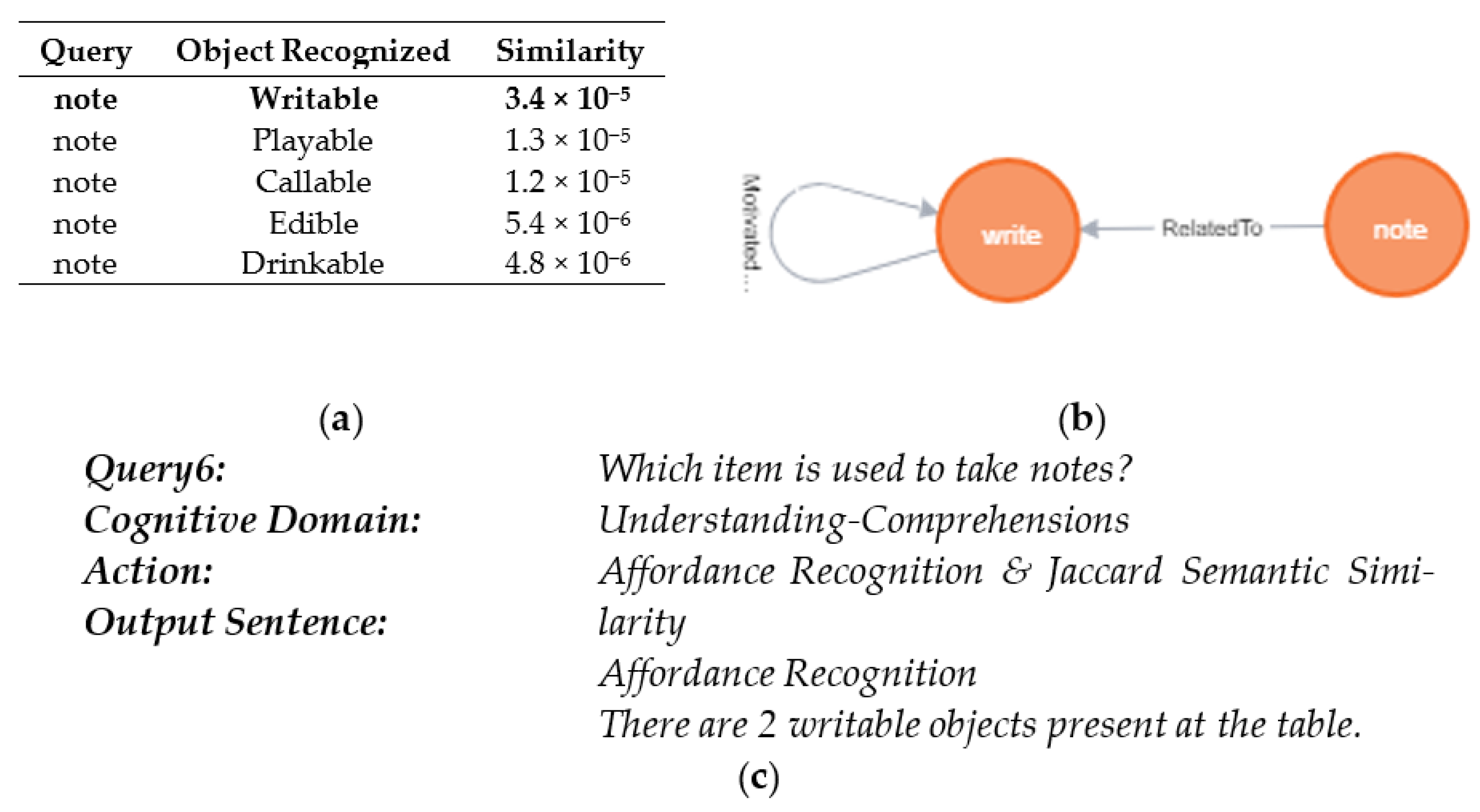
| Work | Platform | Task | Perception | Data Source | Control Structure | Grounding | Affordance Dataset | Knowledge Base/Ontology | Evaluation Metric/Method |
|---|---|---|---|---|---|---|---|---|---|
| [20] | N/A | Object Manipulation | Visual | Demonstration | No | No | 6 Categories/330 Views | No | Accuracy |
| [3] | PR2 | Object Manipulation | Visual | Interaction | RACE | 10 Categories /339 Views | Semantic Memory | Accuracy | |
| [33] | Toe | Object Manipulation | Visual | Labels | Robot Imagination System | Yes | Geometric Shapes | No | Token Test |
| [38] | Toe | Object Manipulation | Visual | Labels | Yes | 10 Classes/30 Sign Symbols | No | Accuracy | |
| [34] | Khepera III | Navigation | Visual | Labels | Multi-robot Control System | No | N/A | No | N/A |
| [39] | PR2 | Action Prediction | Visuo-Spatial | Interaction | N/A | N/A | Graph | N/A | |
| [35] | Atlas | Manipulation /Navigation | Visual | Labels | Yes | No | 8 Classes | N/A | N/A |
| [27] | iCub | Object Manipulation | Visual | Heuristic | Yes | Yes | N/A | Semantic Memory | N/A |
| [21] | Bioloid | Object Manipulation | Visual | Labels | C5M | No | 5 Classes/4 Affordance Classes | N/A | Accuracy |
| [22] | NAO | Action Prediction/Navigation | Visual | Labels/Trail & Error | Yes | No | 8 Action Classes | N/A | Accuracy |
| [18] | iCub | Object Manipulation | Visual | Heuristic | No | Yes | N/A | N/A | Accuracy |
| [23] | N/A | Action Prediction | Visual | Heuristic/Labels | No | No | 9 Classes/10 Object Categories | N/A | Weighted F Measure |
| [24] | N/A | Object Manipulation | Visual | Labels | No | No | 7 Classes/105 Objects | N/A | Recognition Accuracy |
| [36] | Fanuc | Object Manipulation | Visual | Labels | Yes | No | 13 Classes | N/A | Accuracy |
| [25] | N/A | Action Prediction | Visual | Labels | No | No | 13 Classes/6 Action Affordances | N/A | Accuracy |
| [37] | Valkyrie | Object Manipulation | Visual | Labels | Yes | No | N/A | N/A | N/A |
| [28] | PR2 | Object Manipulation | Visual | Labels | Yes | No | N/A | KnowRob | N/A |
| [26] | Walk man | Action Prediction | Visual | Labels | No | No | 10 Object Classes/ 9 Affordance Classes | No | Weighted F Measure |
| [16] | Wheeled Robot | Object Manipulation | Visual/Auditory | Labels | Yes | Yes | N/A | Knowledge Graph | N/A |
| Ours | UR5 | Grasping/Object Manipulation | Visual/Auditory | Labels/Heuristic | NiHA | Yes | 7 Affordance Classes | Semantic Memory | F1 Measure/Semantic Similarity |
| ConceptNet to Semantic Memory | ||||
|---|---|---|---|---|
| Items | Original Terms | Attached to | Adopted Terms | Attached to |
| Unit of Knowledge | Edge or Assertion | ConceptNet | Concept Node | Graph-Based Ontology |
| Attributes | Fields | Assertions | Properties | Nodes/Edges |
| Attribute_1 | Uri | Assertion | conceptUri | Node |
| Attribute_2 | rel | Assertion | RelationShip Type | Edge |
| Attribute_3 | start (Concept) | Assertion | Concept Node | Node |
| Attribute_4 | end (Concept) | Assertion | Concept Node | Node |
| Attribute_5 | weight | Assertion | weight | Edge |
| Attribute_6 | sources | Assertion | - | - |
| Attribute_7 | license | Assertion | - | - |
| Attribute_8 | dataset | Assertion | dataset | Edge |
| Attribute_9 | surfaceText | Assertion | Name | Node |
| - | - | pos (Extracted frm Uri) | Node | |
| - | - | Id (Extracted frm Uri) | Node | |
| <id> (Graph Index) | Node/Edge | |||
| WordNet to Semantic Memory | ||
|---|---|---|
| Items | Adopted Terms | Attached to |
| Hyponym | IsA | Edge |
| Hypernym | IsA | Edge |
| Member Homonym | PartOf | Edge |
| Substance Holonym | PartOf | Edge |
| Part Holonym | PartOf | Edge |
| Member Meronym | PartOf | Edge |
| Substance Meronym | PartOf | Edge |
| Part Meronym | PartOf | Edge |
| Topic Domain | Domain | Edge |
| Region Domain | Domain | Edge |
| Usage Domain | Domain | Edge |
| Attribute | Attribute | Edge |
| Entailment | Entailment | Edge |
| Causes | Causes | Edge |
| Also See | AlsoSee | Edge |
| Verb Group | VerbGroup | Edge |
| Similar To | SimilarTo | Edge |
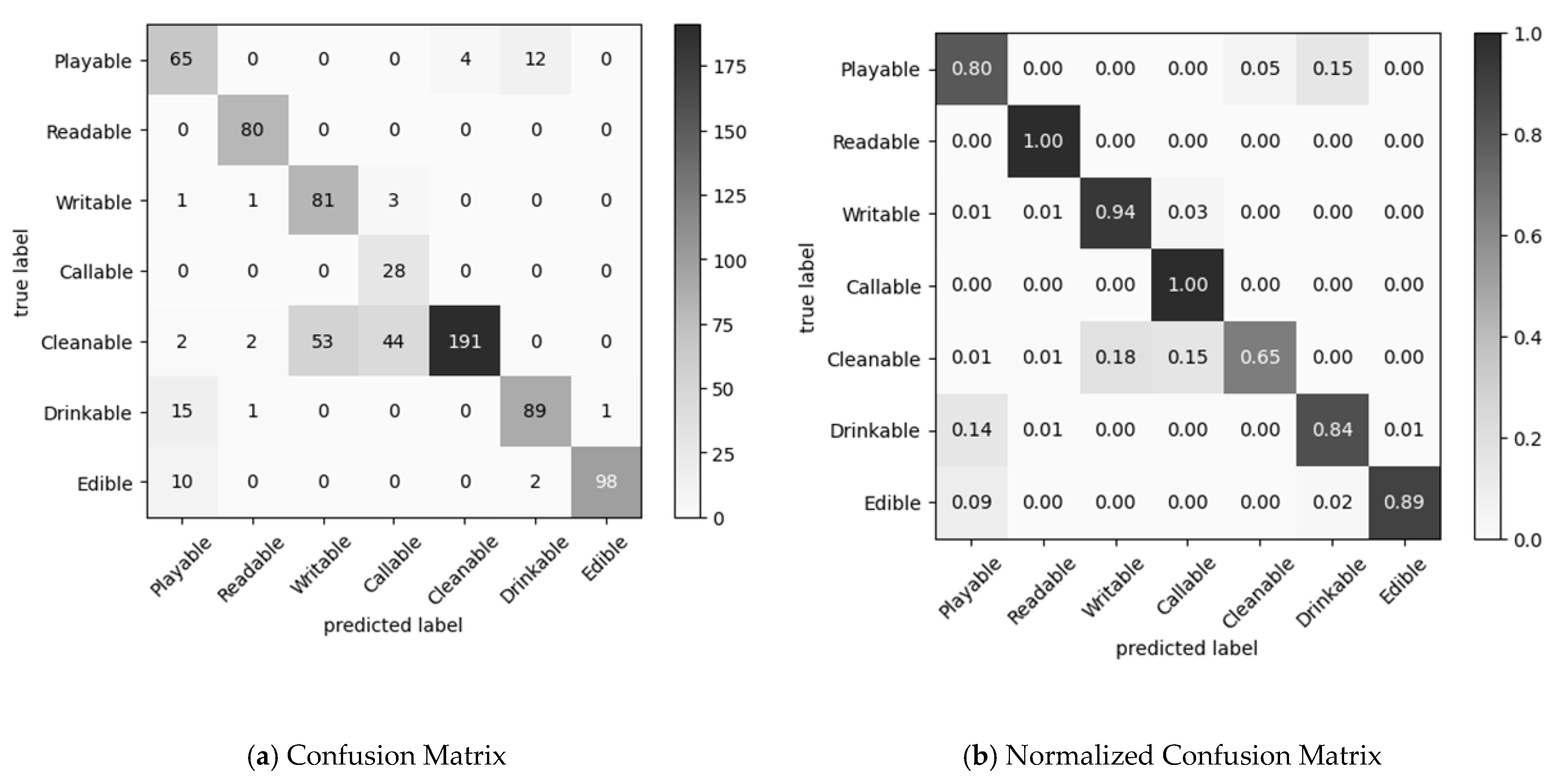
| True Positive | False Positive | False Negative | True Negative | Precision | Recall | F1 Score | |
|---|---|---|---|---|---|---|---|
| Playable | 65 | 28 | 16 | 674 | 0.699 | 0.802 | 0.747 |
| Readable | 80 | 4 | 0 | 699 | 0.952 | 1.000 | 0.976 |
| Writeable | 81 | 53 | 5 | 644 | 0.604 | 0.942 | 0.736 |
| Callable | 28 | 47 | 0 | 708 | 0.373 | 1.000 | 0.544 |
| Cleanable | 191 | 4 | 101 | 487 | 0.979 | 0.654 | 0.784 |
| Drinkable | 89 | 14 | 17 | 663 | 0.864 | 0.840 | 0.852 |
| Edible | 98 | 1 | 12 | 672 | 0.990 | 0.891 | 0.938 |
| Average | 0.78 | 0.87 | 0.80 |
| Work | Affordance/Objects | Robotic Task | Size of Dataset | Evaluation Metrics |
|---|---|---|---|---|
| [47] | 9 Classes/10 Object Categories | Action Prediction | 8835 RGB Images | Weighted F Score = 73.35 |
| [48] | 7 Classes/105 Objects | Object Manipulation | 30,000 RGB-D Image Pairs | Recognition Accuracy = 95.0% |
| [6] | 7 Classes/42 Objects | Object Grasp | 8960 RGB Images | Recognition Accuracy = 100% |
| [49] | 28 Homes/24 Offices/17 Classes | Action Prediction | 550 RGB-D Views | Max Precision = 88.40 |
| [50] | 17 Classes | Action Prediction | 250 RGB-D Videos | Time Saving Accuracy |
| [51] | 9 Objects | Object Manipulation | RGB-D Images | Confidence Level |
| [52] | 7 Classes/17 Categories/105 Objects | Object Manipulation | 28k+ RGB-D Images | Weighted F Measure |
| Ours | 7 Classes/26 Objects (Originally 8 Classes/30 Objects) | Object Grasp | 7622 (Originally 8538) RGB Images | Average F Score = 0.80 |
| Human Cues | Video |
|---|---|
| I am feeling thirsty | https://youtu.be/A16Q0Od7vg4 (Accessed on 8 September 2021) |
| I am hungry, I need something to eat. | https://youtu.be/YJe9CCo1z-M (Accessed on 8 September 2021) |
| Give me anything to play a video game. | https://youtu.be/R46WCwMzryc (Accessed on 8 September 2021) |
| I am hungry (unsuccessful) | https://youtu.be/f2vJswBkpZs (Accessed on 8 September 2021) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bukhari, S.T.S.; Qazi, W.M. Perceptual and Semantic Processing in Cognitive Robots. Electronics 2021, 10, 2216. https://doi.org/10.3390/electronics10182216
Bukhari STS, Qazi WM. Perceptual and Semantic Processing in Cognitive Robots. Electronics. 2021; 10(18):2216. https://doi.org/10.3390/electronics10182216
Chicago/Turabian StyleBukhari, Syed Tanweer Shah, and Wajahat Mahmood Qazi. 2021. "Perceptual and Semantic Processing in Cognitive Robots" Electronics 10, no. 18: 2216. https://doi.org/10.3390/electronics10182216
APA StyleBukhari, S. T. S., & Qazi, W. M. (2021). Perceptual and Semantic Processing in Cognitive Robots. Electronics, 10(18), 2216. https://doi.org/10.3390/electronics10182216