
Linked-Object Dynamic Offloading (LODO) for the Cooperation of Data and Tasks on Edge Computing Environment


Abstract
:1. Introduction
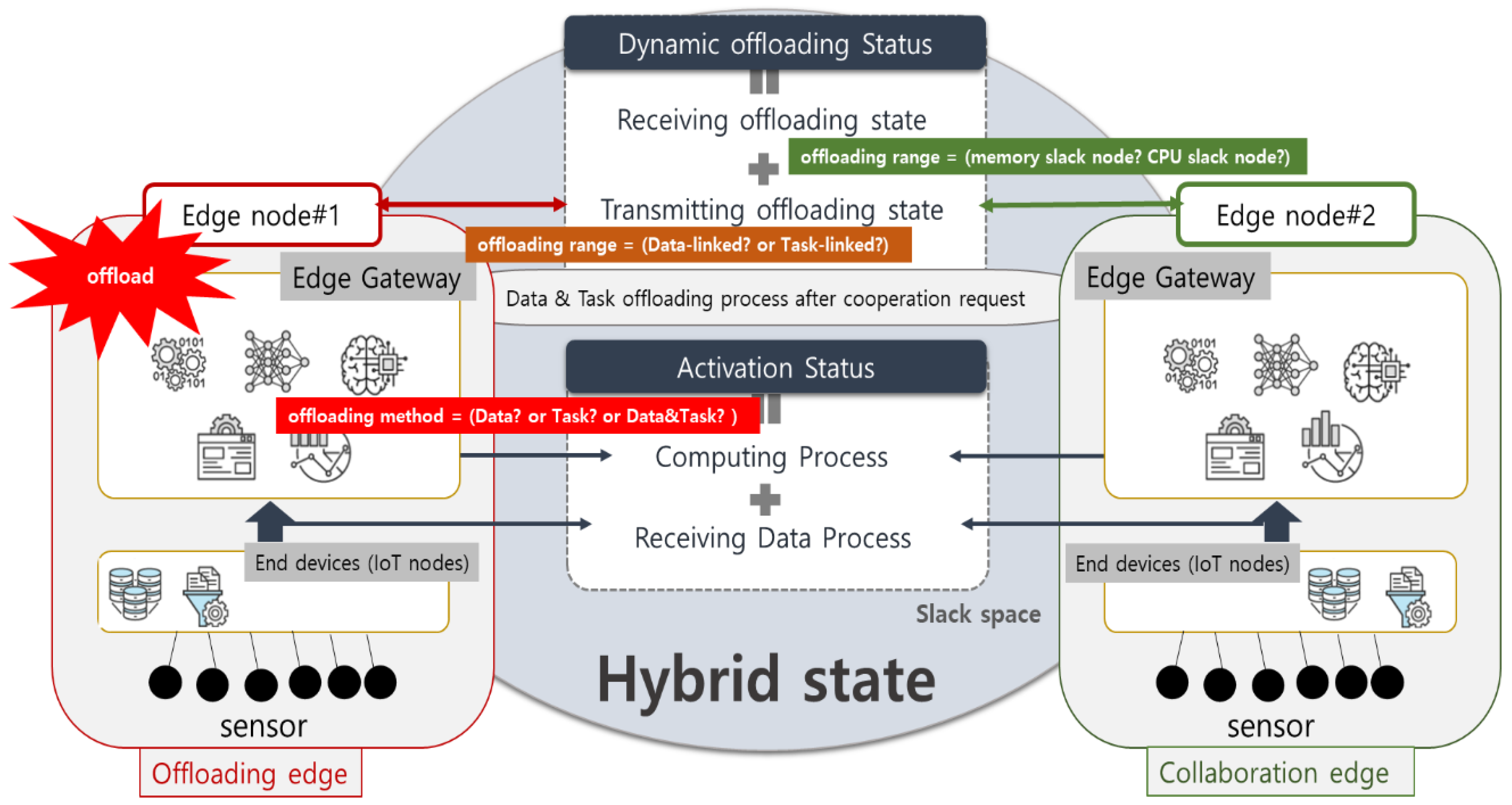
- We propose a Dynamic offloading method (DOM) with hybrid states that contains the resource requirements of offloading tasks and real-time resource availability information of each edge node. According to the current computational task execution state, the hybrid state is formed based on information related to all edge nodes (e.g., compute, storage, and network state). The edge computing reasonably offloaded the task to suitable edge nodes according to the hybrid state.
- We propose a linked-object algorithm that, according to offloading task status, provides two cooperation offloading options. If the computing power of an edge node cannot meet the task requirements, performing the task-linked option. When the edge node’s memory/storage computing resource is not more available, executing the data-linked option. Each of these options helps solve the problem of load imbalance among computing nodes.
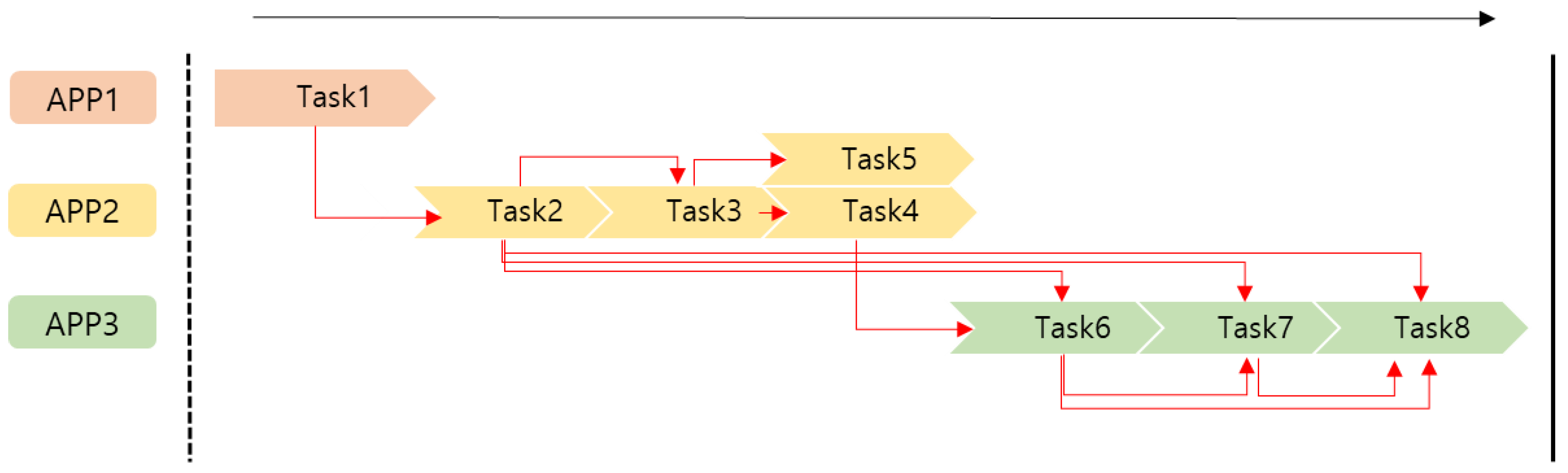
- We also investigate the application of forest fire that requires real-time sensing data and various time-critical tasks. For example, real-time data (such as temperature, humidity, wind, slope, and others) is necessary to predict the possibility of forest fires moving to other areas and the diffusion speed. If the task processing time is a large percentage of the total time, thus resulting in a processing delay of other tasks. Moreover, the total service time may become unacceptable when performing large tasks at the close but slow (low computing power) edge nodes. In this case, the LODO algorithm can offload computation tasks to suitable edge node according to the real-time computing resources status of the edge nodes.
2. Dynamic Offloading Method (DOM) with Hybrid States
2.1. Expression of Hybrid States on Edge Node
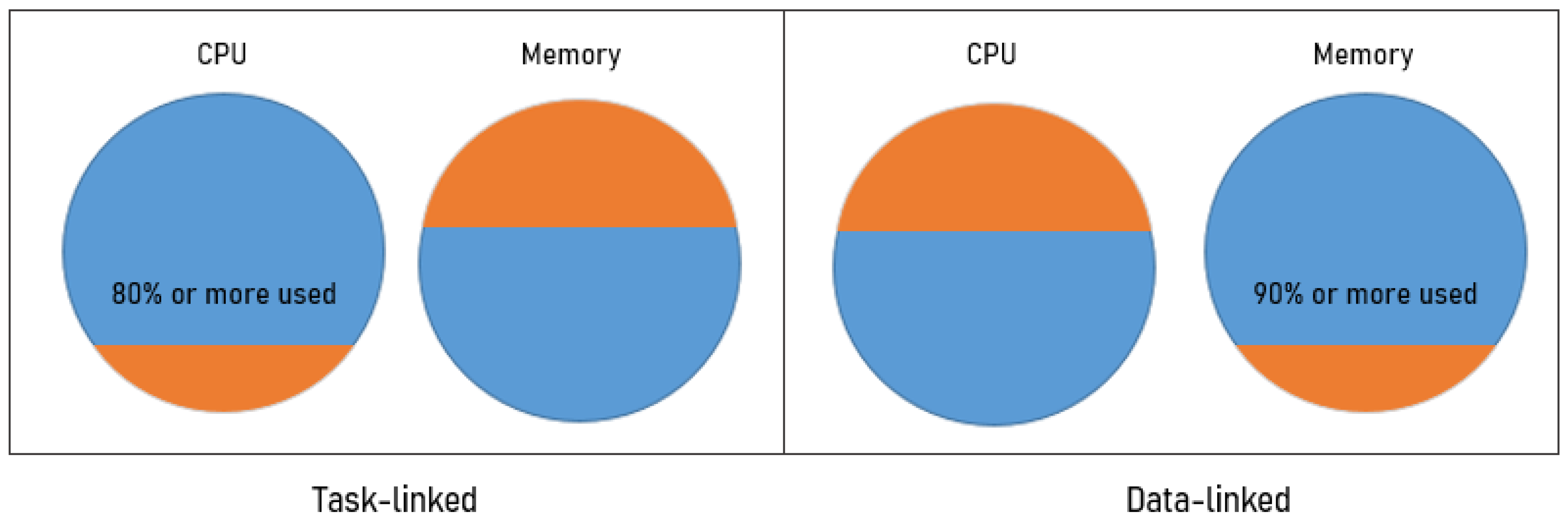
2.2. Definition of Assigning an Offloading Range
3. LODO (Linked-Object Dynamic Offloading) Algorithm
3.1. Data-Linked Algorithm
| Algorithm 1 Data-linked offloading | |
| Input: Next Execution, Data Dependency Group Output: Offloading Group, Collaboration Edge Node, TotalMemory | |
| 1 | Step 1: Overload detection and determination of cause. |
| 2 | IF Status of EN = Out of memory problem ## result of activation state |
| 3 | NextExecution = Data-linkedOffloading |
| 4 | OffloadingApply = True |
| 5 | ELSE |
| 6 | OffloadingApply = False |
| 7 | Step 2) Calculate group capabilities based on data |
| 8 | FOR I = 1 to length(data dependency group) |
| 9 | = data dependency group |
| 10 | GroupList(Data_list, Total_memory) = |
| 11 | END FOR |
| 12 | Step 3) Perform offloading after extracting possible groups based on collaboration nodes |
| 13 | WHILE OffloadingApply |
| 14 | FOR j = 1 to k |
| 15 | IF g_j(Total_memory) ≤ Collaboration_EN(Slack Memory) − (100-threshold) |
| 16 | possiblelist = (Data_list, Total_memory |
| 17 | END FOR |
| 18 | DO max(possiblelist) offloading to Colaboration_EN |
| 19 | IF EN(slack_memory) ≤ threshold |
| 20 | OffloadingApply = False |
| 21 | RETURN {possible list, collaboration edge node, Total_memory, Total_energy} |
3.2. Task-Linked Algorithm
| Algorithm 2 Task-Linked offloading | |
| Input: NextExecution, Task Dependency Group Output: Offloading Group, Total Time(EndPoint) | |
| 1 | Step 1) Overload detection and determination of the cause. |
| 2 | IF Status of EN = Out of CPU problem |
| 3 | NextExecution = Task-linkedOffloading |
| 4 | OffloadingApply = True |
| 5 | ELSE |
| 6 | OffloadingApply = False |
| 7 | Step 2) Calculate group capabilities based on task |
| 8 | FOR I = 1 to length(task dependency group) |
| 9 | = task dependency group |
| 10 | GroupList(Task_list, Total_CPU) = |
| 11 | END FOR |
| 12 | Step 3) Perform offloading after extracting possible groups based on collaboration nodes |
| 13 | WHILE OffloadingApply |
| FOR j = 1 to k | |
| IF g_j(Total_Time) ≤ Collaboration_EN(Slack space) − (100-threshold) | |
| possiblelist = (Task_list, Total_Time) | |
| END FOR | |
| DO max(possiblelist) offloading to Collaboration_EN | |
| IF EN(slack_space) ≤ threshold | |
| OffloadingApply = False | |
| RETURN{possiblelist, collaboration edge node, Total_CPU, Total_time} | |
4. Scenario and Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- El-Sayed, H.; Sankar, S.; Prasad, M.; Puthal, D.; Gupta, A.; Mohanty, M.; Lin, C.-T. Edge of Things: The big picture on the Integration of Edge, IoT and the cloud in a distributed computing environment. IEEE Access 2018, 6, 1706–1711. [Google Scholar] [CrossRef]
- Li, X.; Qin, Y.; Zhou, H.; Cheng, Y.; Zhang, Z.; Ai, Z. Intelligent Rapid adaptive offloading algorithm for computational services in dynamic internet of things system. Sensors 2019, 19, 3423. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Premsankar, G.; Di Francesco, M.; Taleb, T. Edge computing for the Internet of Things: A case study. IEEE Internet Things J. 2018, 5, 1275–1284. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Pan, J.; Esposito, F.; Calyam, P.; Yang, Z.; Mohapatra, P. Edge cloud offloading algorithms: Issues, methods, and perspectives. ACM Comput. Surv. 2019, 52, 2. [Google Scholar] [CrossRef]
- Yousefpour, A.; Fung, C.; Nguyen, T.; Kadiyala, K.; Jalali, F.; Niakanlahiji, A.; Kong, J.; Jue, J.P. All one needs to know about fog computing and related edge computing paradigms: A complete survey. J. Syst. Archit. 2019, 98, 289–330. [Google Scholar] [CrossRef]
- Cui, Y.; Ma, X.; Wang, H.; Stojmenovic, I.; Liu, J. A survey of energy efficient wireless transmission and modeling in mobile cloud computing. Mobile Netw. Appl. 2013, 18, 148–155. [Google Scholar] [CrossRef]
- Mehrabi, M.; You, D.; Latzko, V.; Salah, H.; Reisslein, M.; Fitzek, F.H.P. Device-enhanced MEC: Multi-access edge computing (MEC) aided by end device computation and caching: A survey. IEEE Access 2019, 7, 166079–166108. [Google Scholar] [CrossRef]
- Kai, C.; Zhou, H.; Yi, Y.; Huang, W. Collaborative Cloud-Edge-End Task Offloading in Mobile-Edge Computing Networks With Limited Communication Capability. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 624–634. [Google Scholar] [CrossRef]
- Huang, W.; Huang, Y.; He, S.; Yang, L. Cloud and edge multicast beamforming for cache-enabled ultra-dense networks. IEEE Trans. Veh. Technol. 2020, 69, 3481–3485. [Google Scholar] [CrossRef]
- Ren, J.; Yu, G.; Cai, Y.; He, Y. Latency optimization for resource allocation in mobile-edge computation offloading. IEEE Trans. Wireless Commun. 2018, 17, 5506–5519. [Google Scholar] [CrossRef] [Green Version]
- Kao, Y.; Krishnamachari, B.; Ra, M.; Bai, F. Hermes: Latency optimal task assignment for resource-constrained mobile computing. IEEE Trans. Mobile Comput. 2017, 16, 3056–3069. [Google Scholar] [CrossRef]
- Auluck, N.; Azim, A.; Fizza, K. Improving the schedulability of real-time tasks using fog computing. IEEE Trans. Serv. Comput. 2019. [Google Scholar] [CrossRef]
- Li, H.; Ota, K.; Dong, M. Learning IoT in edge: Deep learning for the Internet of Things with edge computing. IEEE Netw. 2018, 32, 96–101. [Google Scholar] [CrossRef] [Green Version]
- Tran, T.X.; Pompili, D. Joint task offloading and resource allocation for multi-server mobile-edge computing networks. IEEE Trans. Veh. Technol. 2019, 68, 856–868. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Li, Q.; Gong, Y.; Zhang, K. Computation Offloading and Resource Allocation for Cloud Assisted Mobile Edge Computing in Vehicular Networks. IEEE Trans. Veh. Technol. 2019, 68, 7944–7956. [Google Scholar] [CrossRef]
- Mao, S.; Leng, S.; Zhang, Y. Joint communication and computation resource optimization for NOMA-assisted mobile edge computing. In Proceedings of the IEEE International Conference Communication (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Haber, E.; Nguyen, T.M.; Assi, C.; Ajib, W. Macro-cell assisted task offloading in MEC-based heterogeneous networks with wireless backhaul. IEEE Trans. Netw. Serv. Manag. 2019, 16, 1754–1767. [Google Scholar] [CrossRef]
- Hossain, M.D.; Sultana, T.; Nguyen, V.; Nguyen, T.D.; Huynh, L.N.; Huh, E.N. Fuzzy Based Collaborative Task Offloading Scheme in the Densely Deployed Small-Cell Networks with Multi-Access Edge Computing. Appl. Sci. 2020, 10, 3115. [Google Scholar] [CrossRef]
- Ren, J.; Yu, G.; Cai, Y.; He, Y. Collaborative cloud and edge computing for latency minimization. IEEE Trans. Veh. Technol. 2019, 68, 5031–5044. [Google Scholar] [CrossRef]
- Kang, J.; Kim, S.; Kim, J.; Sung, N.; Yoon, Y. Dynamic Offloading Model for Distributed Collaboration in Edge Computing: A Use Case on Forest Fires Management. Appl. Sci. 2020, 10, 2334. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Wu, J.; Chen, L.; Jiang, G.; Lam, S.K. Collaborative task offloading with computation result reusing for mobile edge computing. Comput. J. 2019, 62, 1450–1462. [Google Scholar] [CrossRef]
- Zhang, D.; Ma, Y.; Zheng, C.; Zhang, Y.; Hu, X.H.; Wang, D. Cooperative-competitive task allocation in edge computing for delay-sensitive social sensing. In Proceedings of the 2018 IEEE/ACM Symposium on Edge Computing (SEC), Seattle, WA, USA, 25–27 October 2018; pp. 243–259. [Google Scholar]
- Ning, Z.; Dong, P.; Kong, X.; Xia, F. A cooperative partial computation offloading scheme for mobile edge computing enabled Internet of Things. IEEE Internet Things J. 2018, 6, 4804–4814. [Google Scholar] [CrossRef]
- Yang, L.; Dai, Z.; Li, K. An offloading strategy based on cloud and edge computing for industrial Internet. In Proceedings of the 2019 IEEE 21st International Conference on High Performance Computing and Communications, IEEE 17th International Conference on Smart City, IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Zhangjiajie, China, 10–12 August 2019. [Google Scholar]
- He, B.; Bi, S.; Xing, H.; Lin, X. Collaborative computation offloading in wireless powered mobile-edge computing systems. In Proceedings of the 2019 IEEE Globecom Workshops (GC Wkshps), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–7. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Application | Task | Data | Output |
|---|---|---|---|
| APP1. Fire Probability Prediction | Task 1. Fire probability and probability prediction | temperatures (data1), | Forest fire Probability |
| humidity (data2), | |||
| fuel (data3), | |||
| mount.terrain (data4), weather (data5), | (data13) | ||
| fuel (data3), | |||
| for geography (data6) | |||
| APP2. Diffusion Range Prediction | Task 2. Diffusion rate | fuel (data3), | Diffusion rate |
| mount.terrain (data4), | |||
| weather (data5), | (data9) | ||
| for geography (data6) | |||
| Task 3. Forest fire intensity | diffusion rate (data9) | Fire intensity | |
| (data10) | |||
| Task 4. Flame height, | fire intensity (data10) | Fire type | |
| Fire type prediction | (data14) | ||
| Task 5. Fire direction, | temperatures (data1), | End | |
| Diffusion area prediction | humidity (data2), | ||
| for.geography (data6), | |||
| wind speed (data7), | |||
| fire intensity (data10) | |||
| APP3. Diffusion Location Prediction | Task 6. Flame length | fire type (data14), | Flame length (data11) |
| wind speed (data7), | |||
| diffusion rate (data9) | |||
| Task 7. Non-combustible material lift height calculation | temperatures (data1), | Flame height (data12) | |
| humidity (data2), | |||
| mount.terrain (data4), | |||
| for.geography (data6), | |||
| wind speed (data7), | |||
| wind direction (data8), | |||
| diffusion rate (data9) | |||
| Task 8. Distance for non-combustible mater. Fireworks Landing Position Prediction | wind speed (data7), | End | |
| wind direction (data8), | |||
| diffusion rate (data9), | |||
| flame length (data11), | |||
| flame height (data12) |
| Task | Acquire Memory |
|---|---|
| Task8 | data12 |
| Task8, Task7 | data12, data11, data8 |
| Task8, Task7, Task5 Task6 | data12, data11, data8, data7 |
| Task8, Task7, Task3, Task6 | data12, data11, data8, data9 |
| Task8, Task7, Task4, Task5 | data12, data11, data8, data10 |
| Task | Number of Moves | |
|---|---|---|
| 1 | Task2 | 2 |
| Task3 | 2 | |
| Task4 | 2 | |
| Task5 | 2 | |
| Task6 | 3 | |
| Task7 | 3 | |
| Task8 | 4 | |
| 2 | Task2-Task3 | 2 |
| Task3-Task4 | 2 | |
| Task3-Task5 | 2 | |
| Task4-Task6 | 3 | |
| Task6-Task7 | 3 | |
| Task7-Task8 | 3 | |
| 3 | Task2-Task3-Task4 | 2 |
| Task2-Task3-Task5 | 2 | |
| Task3-Task4-Task6 | 2 | |
| Task4-Task6-Task7 | 3 | |
| Task6-Task7-Task8 | 3 | |
| 4 | Task2-Task3-Task4-Task6 | 2 |
| Task2-Task3-Task4-Task5 | 3 | |
| Task3-Task4-Task6-Task7 | 2 | |
| Task3-Task4-Task5-Task6 | 3 | |
| Task4-Task6-Task7-Task8 | 3 | |
| Task4-Task5-Task6-Task7 | 4 | |
| 5 | Task2-Task3-Task4-Task5-Task6 | 3 |
| Task3-Task4-Task5-Task6-Task7 | 3 | |
| Task4-Task5-Task6-Task7-Task8 | 4 | |
| 6 | Task2-Task3-Task4-Task5-Task6-Task7 | 3 |
| Task3-Task4-Task5-Task6-Task7-Task8 | 3 | |
| 7 | Task2-Task3-Task4-Task5-Task6-Task7-Task8 | 3 |
| All Group | Data-Linked Algorithm Group | Task-Linked Algorithm Group | |
|---|---|---|---|
| Offloading Transmission (Memory) | 1,199,392 (Kb) | 1,574,156 (Kb) | 921,015.1 (Kb) |
| Offloading Performance(CPU) | 5.72 (GHz) | 8.67 (GHz) | 4.19 (GHz) |
| Percentage of memory available | 45,332.69 (3.78%) | 212,775.5 (8.15%) | 30,394.8 (3.30%) |
| The average number of moves | 3.72 | 3.55 | 2.63 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.; Kang, J.; Yoon, Y. Linked-Object Dynamic Offloading (LODO) for the Cooperation of Data and Tasks on Edge Computing Environment. Electronics 2021, 10, 2156. https://doi.org/10.3390/electronics10172156
Kim S, Kang J, Yoon Y. Linked-Object Dynamic Offloading (LODO) for the Cooperation of Data and Tasks on Edge Computing Environment. Electronics. 2021; 10(17):2156. https://doi.org/10.3390/electronics10172156
Chicago/Turabian StyleKim, Svetlana, Jieun Kang, and YongIk Yoon. 2021. "Linked-Object Dynamic Offloading (LODO) for the Cooperation of Data and Tasks on Edge Computing Environment" Electronics 10, no. 17: 2156. https://doi.org/10.3390/electronics10172156
APA StyleKim, S., Kang, J., & Yoon, Y. (2021). Linked-Object Dynamic Offloading (LODO) for the Cooperation of Data and Tasks on Edge Computing Environment. Electronics, 10(17), 2156. https://doi.org/10.3390/electronics10172156